| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:ASPSCR1-TFE3 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: ASPSCR1-TFE3 | FusionPDB ID: 7235 | FusionGDB2.0 ID: 7235 | Hgene | Tgene | Gene symbol | ASPSCR1 | TFE3 | Gene ID | 79058 | 7030 |
| Gene name | ASPSCR1 tether for SLC2A4, UBX domain containing | transcription factor binding to IGHM enhancer 3 | |
| Synonyms | ASPCR1|ASPL|ASPS|RCC17|TUG|UBXD9|UBXN9 | RCCP2|RCCX1|TFEA|bHLHe33 | |
| Cytomap | 17q25.3 | Xp11.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | tether containing UBX domain for GLUT4ASPSCR1, UBX domain containing tether for SLC2A4UBX domain protein 9UBX domain-containing protein 9alveolar soft part sarcoma chromosomal region candidate gene 1 proteinalveolar soft part sarcoma chromosome regio | transcription factor E3class E basic helix-loop-helix protein 33transcription factor E family, member Atranscription factor for IgH enhancertranscription factor for immunoglobulin heavy-chain enhancer 3 | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | Q9BZE9 | P19532 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000306729, ENST00000306739, ENST00000580534, ENST00000581647, ENST00000582404, | ENST00000487451, ENST00000315869, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 9 X 6 X 8=432 | 14 X 15 X 6=1260 |
| # samples | 12 | 15 | |
| ** MAII score | log2(12/432*10)=-1.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(15/1260*10)=-3.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: ASPSCR1 [Title/Abstract] AND TFE3 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | ASPSCR1(79954722)-TFE3(48895640), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ASPSCR1-TFE3 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ASPSCR1-TFE3 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ASPSCR1-TFE3 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ASPSCR1-TFE3 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. TFE3-ASPSCR1 seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. TFE3-ASPSCR1 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. TFE3-ASPSCR1 seems lost the major protein functional domain in Hgene partner, which is a transcription factor due to the frame-shifted ORF. TFE3-ASPSCR1 seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. TFE3-ASPSCR1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across ASPSCR1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TFE3 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | alveolar soft part sarcoma renal cell carcinoma | AY034077 | ASPSCR1 | chr17 | 79954722 | TFE3 | chrX | 48891659 | ||
| ChimerKB3 | . | . | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891659 | - |
| ChimerKB3 | . | . | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891766 | - |
| ChimerKB3 | . | . | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895639 | - |
| ChimerKB3 | . | . | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895967 | - |
| ChimerKB4 | . | . | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895639 | - |
| ChiTaRS5.0 | N/A | AY034077 | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891767 | - |
| ChiTaRS5.0 | N/A | AY034078 | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895640 | - |
| ChiTaRS5.0 | N/A | HI518913 | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895640 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000306729 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48891659 | - | 3193 | 1030 | 97 | 1473 | 458 |
| ENST00000306739 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48891659 | - | 3193 | 1030 | 97 | 1473 | 458 |
| ENST00000580534 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48891659 | - | 3053 | 890 | 164 | 1333 | 389 |
| ENST00000306729 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48891766 | - | 3300 | 1030 | 97 | 1872 | 591 |
| ENST00000306739 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48891766 | - | 3300 | 1030 | 97 | 1872 | 591 |
| ENST00000580534 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48891766 | - | 3160 | 890 | 164 | 1732 | 522 |
| ENST00000306729 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48895639 | - | 3405 | 1030 | 97 | 1977 | 626 |
| ENST00000306739 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48895639 | - | 3405 | 1030 | 97 | 1977 | 626 |
| ENST00000580534 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48895639 | - | 3265 | 890 | 164 | 1837 | 557 |
| ENST00000306729 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48895967 | - | 3651 | 1030 | 97 | 2223 | 708 |
| ENST00000306739 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48895967 | - | 3651 | 1030 | 97 | 2223 | 708 |
| ENST00000580534 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48895967 | - | 3511 | 890 | 164 | 2083 | 639 |
| ENST00000306729 | ASPSCR1 | chr17 | 79954722 | ENST00000315869 | TFE3 | chrX | 48891659 | 3193 | 1030 | 97 | 1473 | 458 | ||
| ENST00000306739 | ASPSCR1 | chr17 | 79954722 | ENST00000315869 | TFE3 | chrX | 48891659 | 3193 | 1030 | 97 | 1473 | 458 | ||
| ENST00000580534 | ASPSCR1 | chr17 | 79954722 | ENST00000315869 | TFE3 | chrX | 48891659 | 3053 | 890 | 164 | 1333 | 389 | ||
| ENST00000306729 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48891767 | - | 3300 | 1030 | 97 | 1872 | 591 |
| ENST00000306739 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48891767 | - | 3300 | 1030 | 97 | 1872 | 591 |
| ENST00000580534 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48891767 | - | 3160 | 890 | 164 | 1732 | 522 |
| ENST00000306729 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48895640 | - | 3405 | 1030 | 97 | 1977 | 626 |
| ENST00000306739 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48895640 | - | 3405 | 1030 | 97 | 1977 | 626 |
| ENST00000580534 | ASPSCR1 | chr17 | 79954722 | + | ENST00000315869 | TFE3 | chrX | 48895640 | - | 3265 | 890 | 164 | 1837 | 557 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000306729 | ENST00000315869 | ASPSCR1 | chr17 | 79954722 | TFE3 | chrX | 48891659 | 0.07848231 | 0.9215177 | ||
| ENST00000306739 | ENST00000315869 | ASPSCR1 | chr17 | 79954722 | TFE3 | chrX | 48891659 | 0.07848231 | 0.9215177 | ||
| ENST00000580534 | ENST00000315869 | ASPSCR1 | chr17 | 79954722 | TFE3 | chrX | 48891659 | 0.087091014 | 0.91290903 | ||
| ENST00000306729 | ENST00000315869 | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891767 | - | 0.046352573 | 0.95364743 |
| ENST00000306739 | ENST00000315869 | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891767 | - | 0.046352573 | 0.95364743 |
| ENST00000580534 | ENST00000315869 | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891767 | - | 0.050309557 | 0.94969046 |
| ENST00000306729 | ENST00000315869 | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895640 | - | 0.028840447 | 0.9711595 |
| ENST00000306739 | ENST00000315869 | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895640 | - | 0.028840447 | 0.9711595 |
| ENST00000580534 | ENST00000315869 | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895640 | - | 0.03831428 | 0.9616858 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >7235_7235_1_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306729_TFE3_chrX_48891659_ENST00000315869_length(amino acids)=458AA_BP= MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATF HVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGLSGGALSPLRAASDPLLSSVSPAVSKASSRRS -------------------------------------------------------------- >7235_7235_2_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306729_TFE3_chrX_48891766_ENST00000315869_length(amino acids)=591AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERLPVSGNLLDVYSSQGVATPAITVSNSCPAELPNIKREISETEAKALLKE RQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQRSLEQANRSLQLRIQELELQA QIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDI -------------------------------------------------------------- >7235_7235_3_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306729_TFE3_chrX_48891767_ENST00000315869_length(amino acids)=591AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERLPVSGNLLDVYSSQGVATPAITVSNSCPAELPNIKREISETEAKALLKE RQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQRSLEQANRSLQLRIQELELQA QIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDI -------------------------------------------------------------- >7235_7235_4_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306729_TFE3_chrX_48895639_ENST00000315869_length(amino acids)=626AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERIDDVIDEIISLESSYNDEMLSYLPGGTTGLQLPSTLPVSGNLLDVYSSQ GVATPAITVSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKL QKEQQRSKDLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPH -------------------------------------------------------------- >7235_7235_5_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306729_TFE3_chrX_48895640_ENST00000315869_length(amino acids)=626AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERIDDVIDEIISLESSYNDEMLSYLPGGTTGLQLPSTLPVSGNLLDVYSSQ GVATPAITVSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKL QKEQQRSKDLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPH -------------------------------------------------------------- >7235_7235_6_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306729_TFE3_chrX_48895967_ENST00000315869_length(amino acids)=708AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERVQTHLENPTRYHLQQARRQQVKQYLSTTLGPKLASQALTPPPGPASAQP LPAPEAAHTTGPTGSAPNSPMALLTIGSSSEKEIDDVIDEIISLESSYNDEMLSYLPGGTTGLQLPSTLPVSGNLLDVYSSQGVATPAIT VSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSK DLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPS -------------------------------------------------------------- >7235_7235_7_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306739_TFE3_chrX_48891659_ENST00000315869_length(amino acids)=458AA_BP= MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATF HVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGLSGGALSPLRAASDPLLSSVSPAVSKASSRRS -------------------------------------------------------------- >7235_7235_8_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306739_TFE3_chrX_48891766_ENST00000315869_length(amino acids)=591AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERLPVSGNLLDVYSSQGVATPAITVSNSCPAELPNIKREISETEAKALLKE RQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQRSLEQANRSLQLRIQELELQA QIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDI -------------------------------------------------------------- >7235_7235_9_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306739_TFE3_chrX_48891767_ENST00000315869_length(amino acids)=591AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERLPVSGNLLDVYSSQGVATPAITVSNSCPAELPNIKREISETEAKALLKE RQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQRSLEQANRSLQLRIQELELQA QIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDI -------------------------------------------------------------- >7235_7235_10_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306739_TFE3_chrX_48895639_ENST00000315869_length(amino acids)=626AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERIDDVIDEIISLESSYNDEMLSYLPGGTTGLQLPSTLPVSGNLLDVYSSQ GVATPAITVSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKL QKEQQRSKDLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPH -------------------------------------------------------------- >7235_7235_11_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306739_TFE3_chrX_48895640_ENST00000315869_length(amino acids)=626AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERIDDVIDEIISLESSYNDEMLSYLPGGTTGLQLPSTLPVSGNLLDVYSSQ GVATPAITVSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKL QKEQQRSKDLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPH -------------------------------------------------------------- >7235_7235_12_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000306739_TFE3_chrX_48895967_ENST00000315869_length(amino acids)=708AA_BP=311 MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEYDLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPEN MVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIRFVMKCYDPVGK TPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKLP KSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERVQTHLENPTRYHLQQARRQQVKQYLSTTLGPKLASQALTPPPGPASAQP LPAPEAAHTTGPTGSAPNSPMALLTIGSSSEKEIDDVIDEIISLESSYNDEMLSYLPGGTTGLQLPSTLPVSGNLLDVYSSQGVATPAIT VSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSK DLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPS -------------------------------------------------------------- >7235_7235_13_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000580534_TFE3_chrX_48891659_ENST00000315869_length(amino acids)=389AA_BP= MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSL GLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGG QRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERELELQAQIHGLPVPPTPGLLSLATTSAS DSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGLSGGALSPLRA -------------------------------------------------------------- >7235_7235_14_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000580534_TFE3_chrX_48891766_ENST00000315869_length(amino acids)=522AA_BP=242 MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSL GLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGG QRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERLPVSGNLLDVYSSQGVATPAITVSNSCP AELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQ RSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDL -------------------------------------------------------------- >7235_7235_15_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000580534_TFE3_chrX_48891767_ENST00000315869_length(amino acids)=522AA_BP=242 MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSL GLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGG QRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERLPVSGNLLDVYSSQGVATPAITVSNSCP AELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQ RSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDL -------------------------------------------------------------- >7235_7235_16_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000580534_TFE3_chrX_48895639_ENST00000315869_length(amino acids)=557AA_BP=242 MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSL GLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGG QRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERIDDVIDEIISLESSYNDEMLSYLPGGTT GLQLPSTLPVSGNLLDVYSSQGVATPAITVSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSD PEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEE EGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGLSGGALSPLRAASDPLLSSVSPA -------------------------------------------------------------- >7235_7235_17_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000580534_TFE3_chrX_48895640_ENST00000315869_length(amino acids)=557AA_BP=242 MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSL GLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGG QRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERIDDVIDEIISLESSYNDEMLSYLPGGTT GLQLPSTLPVSGNLLDVYSSQGVATPAITVSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSD PEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEE EGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGLSGGALSPLRAASDPLLSSVSPA -------------------------------------------------------------- >7235_7235_18_ASPSCR1-TFE3_ASPSCR1_chr17_79954722_ENST00000580534_TFE3_chrX_48895967_ENST00000315869_length(amino acids)=639AA_BP=242 MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSL GLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGG QRLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERVQTHLENPTRYHLQQARRQQVKQYLSTT LGPKLASQALTPPPGPASAQPLPAPEAAHTTGPTGSAPNSPMALLTIGSSSEKEIDDVIDEIISLESSYNDEMLSYLPGGTTGLQLPSTL PVSGNLLDVYSSQGVATPAITVSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKG TILKASVDYIRKLQKEQQRSKDLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAAT FHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGLSGGALSPLRAASDPLLSSVSPAVSKASSRR -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:79954722/chrX:48895640) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ASPSCR1 | TFE3 |
| FUNCTION: Tethering protein that sequesters GLUT4-containing vesicles in the cytoplasm in the absence of insulin. Modulates the amount of GLUT4 that is available at the cell surface (By similarity). Enhances VCP methylation catalyzed by VCPKMT. {ECO:0000250, ECO:0000269|PubMed:23349634}. | FUNCTION: Transcription factor that acts as a master regulator of lysosomal biogenesis and immune response (PubMed:2338243, PubMed:29146937, PubMed:30733432, PubMed:31672913). Specifically recognizes and binds E-box sequences (5'-CANNTG-3'); efficient DNA-binding requires dimerization with itself or with another MiT/TFE family member such as TFEB or MITF (By similarity). Involved in the cellular response to amino acid availability by acting downstream of MTOR: in the presence of nutrients, TFE3 phosphorylation by MTOR promotes its cytosolic retention and subsequent inactivation (PubMed:31672913). Upon starvation or lysosomal stress, inhibition of MTOR induces TFE3 dephosphorylation, resulting in nuclear localization and transcription factor activity (PubMed:31672913). In association with TFEB, activates the expression of CD40L in T-cells, thereby playing a role in T-cell-dependent antibody responses in activated CD4(+) T-cells and thymus-dependent humoral immunity (By similarity). Specifically recognizes the MUE3 box, a subset of E-boxes, present in the immunoglobulin enhancer (PubMed:2338243). It also binds very well to a USF/MLTF site (PubMed:2338243). May regulate lysosomal positioning in response to nutrient deprivation by promoting the expression of PIP4P1 (PubMed:29146937). Acts as a positive regulator of browning of adipose tissue by promoting expression of target genes; mTOR-dependent phosphorylation promotes cytoplasmic retention of TFE3 and inhibits browning of adipose tissue (By similarity). Maintains the pluripotent state of embryonic stem cells by promoting the expression of genes such as ESRRB; mTOR-dependent nuclear exclusion promotes exit from pluripotency (By similarity). Required to maintain the naive pluripotent state of hematopoietic stem cell; mTOR-dependent cytoplasmic retention of TFE3 promotes the exit of hematopoietic stem cell from pluripotency (PubMed:30733432). {ECO:0000250|UniProtKB:Q64092, ECO:0000269|PubMed:2338243, ECO:0000269|PubMed:29146937, ECO:0000269|PubMed:30733432, ECO:0000269|PubMed:31672913}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | TFE3 | chr17:79954722 | chrX:48891767 | ENST00000315869 | 4 | 10 | 346_399 | 295.0 | 576.0 | Domain | bHLH | |
| Tgene | TFE3 | chr17:79954722 | chrX:48895640 | ENST00000315869 | 3 | 10 | 346_399 | 260.0 | 576.0 | Domain | bHLH | |
| Tgene | TFE3 | chr17:79954722 | chrX:48891767 | ENST00000315869 | 4 | 10 | 409_430 | 295.0 | 576.0 | Region | Note=Leucine-zipper | |
| Tgene | TFE3 | chr17:79954722 | chrX:48895640 | ENST00000315869 | 3 | 10 | 260_271 | 260.0 | 576.0 | Region | Strong transcription activation domain | |
| Tgene | TFE3 | chr17:79954722 | chrX:48895640 | ENST00000315869 | 3 | 10 | 409_430 | 260.0 | 576.0 | Region | Note=Leucine-zipper |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48891767 | ENST00000306729 | + | 7 | 17 | 386_462 | 311.0 | 648.0 | Domain | UBX |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48891767 | ENST00000306739 | + | 7 | 16 | 386_462 | 311.0 | 554.0 | Domain | UBX |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48891767 | ENST00000580534 | + | 6 | 15 | 386_462 | 234.0 | 502.0 | Domain | UBX |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48895640 | ENST00000306729 | + | 7 | 17 | 386_462 | 311.0 | 648.0 | Domain | UBX |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48895640 | ENST00000306739 | + | 7 | 16 | 386_462 | 311.0 | 554.0 | Domain | UBX |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48895640 | ENST00000580534 | + | 6 | 15 | 386_462 | 234.0 | 502.0 | Domain | UBX |
| Tgene | TFE3 | chr17:79954722 | chrX:48891767 | ENST00000315869 | 4 | 10 | 260_271 | 295.0 | 576.0 | Region | Strong transcription activation domain |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file (144) >>>144.pdbFusion protein BP residue: CIF file (144) >>>144.cif | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891659 | - | MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLS HFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIR FVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDAD TSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKL PKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERELELQAQI HGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQN APHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGL | 389 |
| 3D view using mol* of 144 (AA BP:) | ||||||||||
 | ||||||||||
| PDB file (230) >>>230.pdbFusion protein BP residue: CIF file (230) >>>230.cif | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891659 | - | MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEY DLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPENMVRIALQLDD GSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAA LRGTTLQSLGLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPL PLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQ RLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERE RDPQQEQERERELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIE EEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPF HLGLEDILMEEEEGVVGGLSGGALSPLRAASDPLLSSVSPAVSKASSRRS | 458 |
| 3D view using mol* of 230 (AA BP:) | ||||||||||
| ||||||||||
| PDB file (342) >>>342.pdbFusion protein BP residue: 242 CIF file (342) >>>342.cif | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891766 | - | MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLS HFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIR FVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDAD TSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKL PKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERLPVSGNLL DVYSSQGVATPAITVSNSCPAELPNIKREISETEAKALLKERQKKDNHNL IERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQ QRSKDLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATT SASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDL HFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGLSGGALSPLRAASDPLLS | 522 |
| 3D view using mol* of 342 (AA BP:242) | ||||||||||
| ||||||||||
| PDB file (402) >>>402.pdbFusion protein BP residue: 242 CIF file (402) >>>402.cif | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895639 | - | MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLS HFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIR FVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDAD TSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKL PKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERIDDVIDEI ISLESSYNDEMLSYLPGGTTGLQLPSTLPVSGNLLDVYSSQGVATPAITV SNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIKE LGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQRSLEQ ANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEE EGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFH LGLEDILMEEEEGVVGGLSGGALSPLRAASDPLLSSVSPAVSKASSRRSS | 557 |
| 3D view using mol* of 402 (AA BP:242) | ||||||||||
| ||||||||||
| PDB file (456) >>>456.pdbFusion protein BP residue: 311 CIF file (456) >>>456.cif | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48891766 | - | MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEY DLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPENMVRIALQLDD GSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAA LRGTTLQSLGLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPL PLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQ RLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERE RDPQQEQERERLPVSGNLLDVYSSQGVATPAITVSNSCPAELPNIKREIS ETEAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWN KGTILKASVDYIRKLQKEQQRSKDLESRQRSLEQANRSLQLRIQELELQA QIHGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPA QNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVG | 591 |
| 3D view using mol* of 456 (AA BP:311) | ||||||||||
| ||||||||||
| PDB file (498) >>>498.pdbFusion protein BP residue: 311 CIF file (498) >>>498.cif | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895639 | - | MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEY DLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPENMVRIALQLDD GSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAA LRGTTLQSLGLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPL PLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQ RLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERE RDPQQEQERERIDDVIDEIISLESSYNDEMLSYLPGGTTGLQLPSTLPVS GNLLDVYSSQGVATPAITVSNSCPAELPNIKREISETEAKALLKERQKKD NHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKGTILKASVDYIRKL QKEQQRSKDLESRQRSLEQANRSLQLRIQELELQAQIHGLPVPPTPGLLS LATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQNAPHQQPPAPPSDA LLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGLSGGALSPLRAASD | 626 |
| 3D view using mol* of 498 (AA BP:311) | ||||||||||
| ||||||||||
| PDB file (510) >>>510.pdbFusion protein BP residue: 242 CIF file (510) >>>510.cif | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895967 | - | MPNNAKLEMVPASRSREGPENMVRIALQLDDGSRLQDSFCSGQTLWELLS HFPQIRECLQHPGGATPVCVYTRDEVTGEAALRGTTLQSLGLTGGSATIR FVMKCYDPVGKTPGSLGSSASAGQAAASAPLPLESGELSRGDLSRPEDAD TSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQRLGGPPGPTRPLTSSSAKL PKSLSSPGGPSKPKKSKSGQDPQQEQEQERERDPQQEQERERVQTHLENP TRYHLQQARRQQVKQYLSTTLGPKLASQALTPPPGPASAQPLPAPEAAHT TGPTGSAPNSPMALLTIGSSSEKEIDDVIDEIISLESSYNDEMLSYLPGG TTGLQLPSTLPVSGNLLDVYSSQGVATPAITVSNSCPAELPNIKREISET EAKALLKERQKKDNHNLIERRRRFNINDRIKELGTLIPKSSDPEMRWNKG TILKASVDYIRKLQKEQQRSKDLESRQRSLEQANRSLQLRIQELELQAQI HGLPVPPTPGLLSLATTSASDSLKPEQLDIEEEGRPGAATFHVGGGPAQN APHQQPPAPPSDALLDLHFPSDHLGDLGDPFHLGLEDILMEEEEGVVGGL | 639 |
| 3D view using mol* of 510 (AA BP:242) | ||||||||||
| ||||||||||
| PDB file (582) >>>582.pdbFusion protein BP residue: 311 CIF file (582) >>>582.cif | ASPSCR1 | chr17 | 79954722 | + | TFE3 | chrX | 48895967 | - | MAAPAGGGGSAVSVLAPNGRRHTVKVTPSTVLLQVLEDTCRRQDFNPCEY DLKFQRSVLDLSLQWRFANLPNNAKLEMVPASRSREGPENMVRIALQLDD GSRLQDSFCSGQTLWELLSHFPQIRECLQHPGGATPVCVYTRDEVTGEAA LRGTTLQSLGLTGGSATIRFVMKCYDPVGKTPGSLGSSASAGQAAASAPL PLESGELSRGDLSRPEDADTSGPCCEHTQEKQSTRAPAAAPFVPFSGGGQ RLGGPPGPTRPLTSSSAKLPKSLSSPGGPSKPKKSKSGQDPQQEQEQERE RDPQQEQERERVQTHLENPTRYHLQQARRQQVKQYLSTTLGPKLASQALT PPPGPASAQPLPAPEAAHTTGPTGSAPNSPMALLTIGSSSEKEIDDVIDE IISLESSYNDEMLSYLPGGTTGLQLPSTLPVSGNLLDVYSSQGVATPAIT VSNSCPAELPNIKREISETEAKALLKERQKKDNHNLIERRRRFNINDRIK ELGTLIPKSSDPEMRWNKGTILKASVDYIRKLQKEQQRSKDLESRQRSLE QANRSLQLRIQELELQAQIHGLPVPPTPGLLSLATTSASDSLKPEQLDIE EEGRPGAATFHVGGGPAQNAPHQQPPAPPSDALLDLHFPSDHLGDLGDPF HLGLEDILMEEEEGVVGGLSGGALSPLRAASDPLLSSVSPAVSKASSRRS | 708 |
| 3D view using mol* of 582 (AA BP:311) | ||||||||||
| ||||||||||
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
ASPSCR1_pLDDT.png  |
TFE3_pLDDT.png  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
ASPSCR1_TFE3_144_PAE.png (AA BP:) |
ASPSCR1_TFE3_144_pLDDT.png (AA BP:)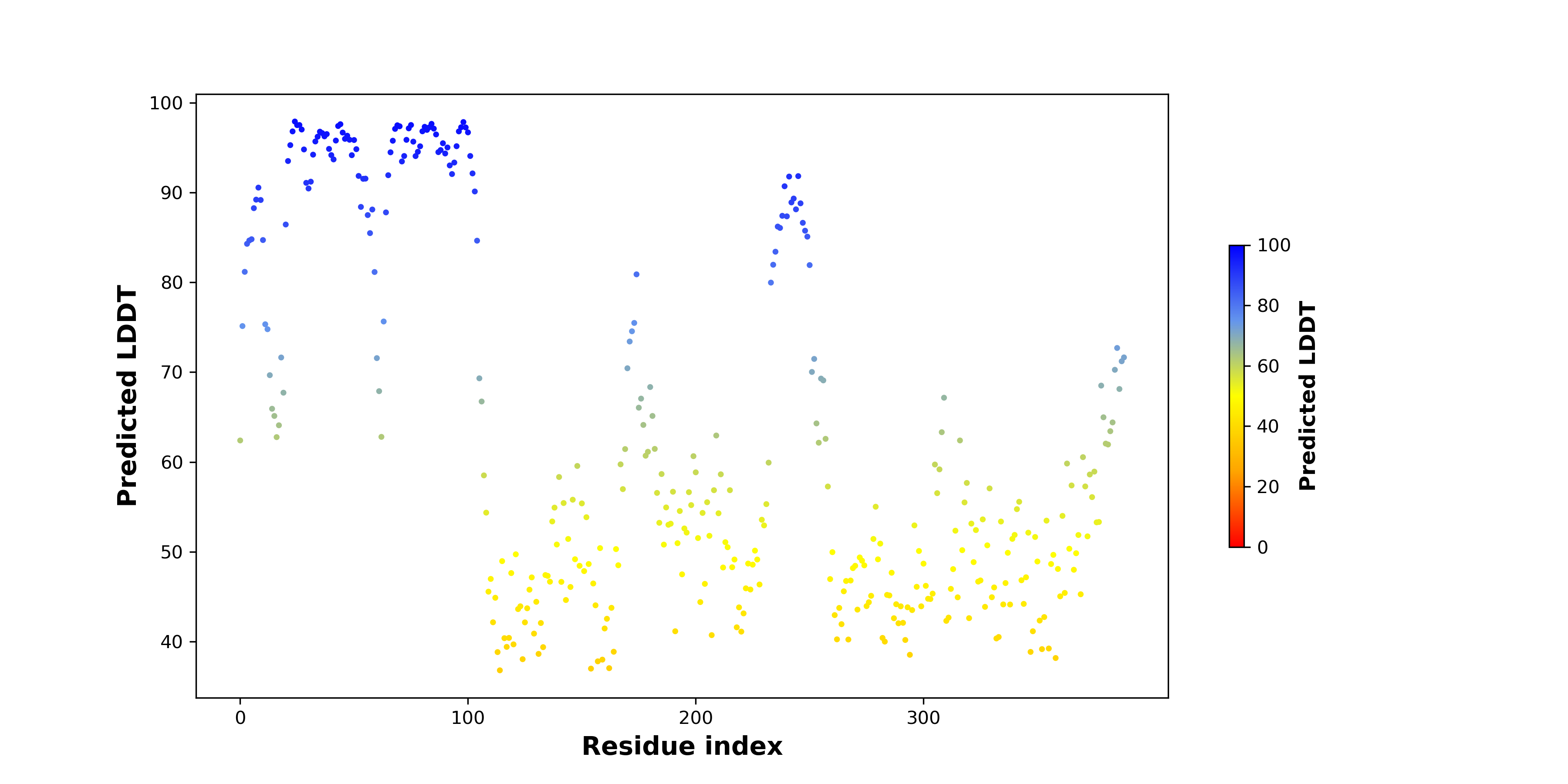 |
ASPSCR1_TFE3_144_pLDDT_and_active_sites.png (AA BP:) |
ASPSCR1_TFE3_144_violinplot.png (AA BP:)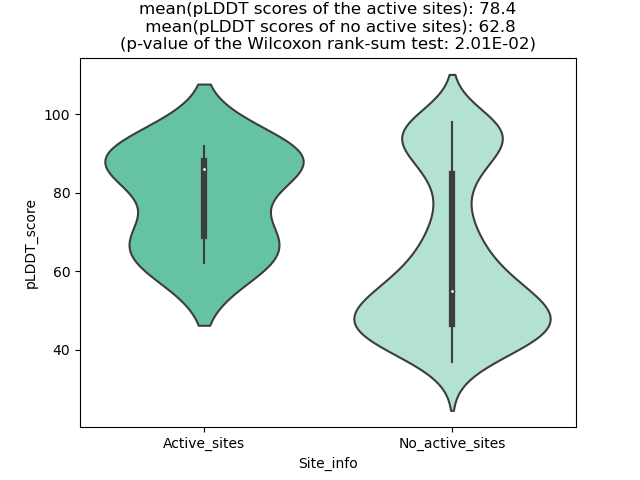 |
ASPSCR1_TFE3_230_PAE.png (AA BP:)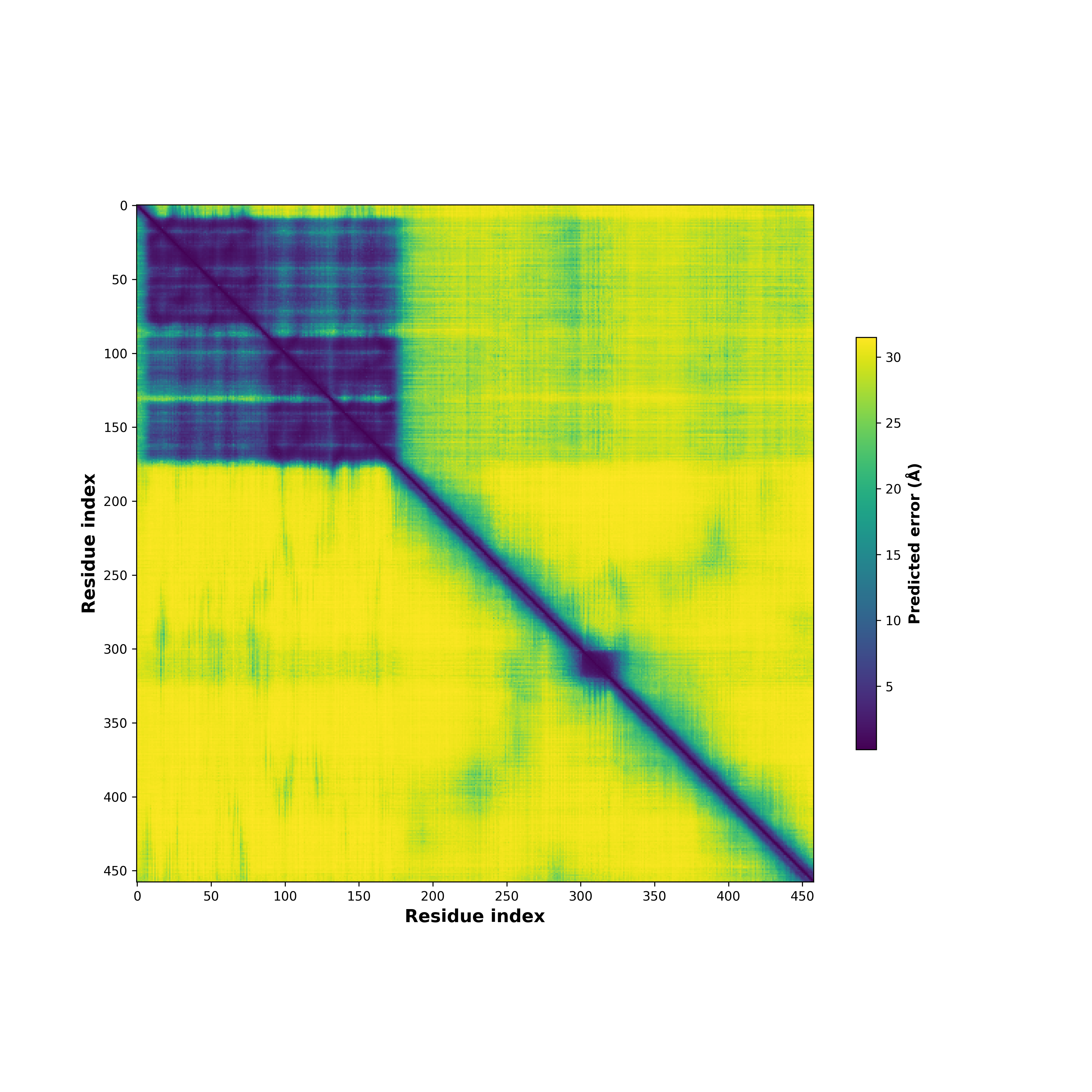 |
ASPSCR1_TFE3_230_pLDDT.png (AA BP:)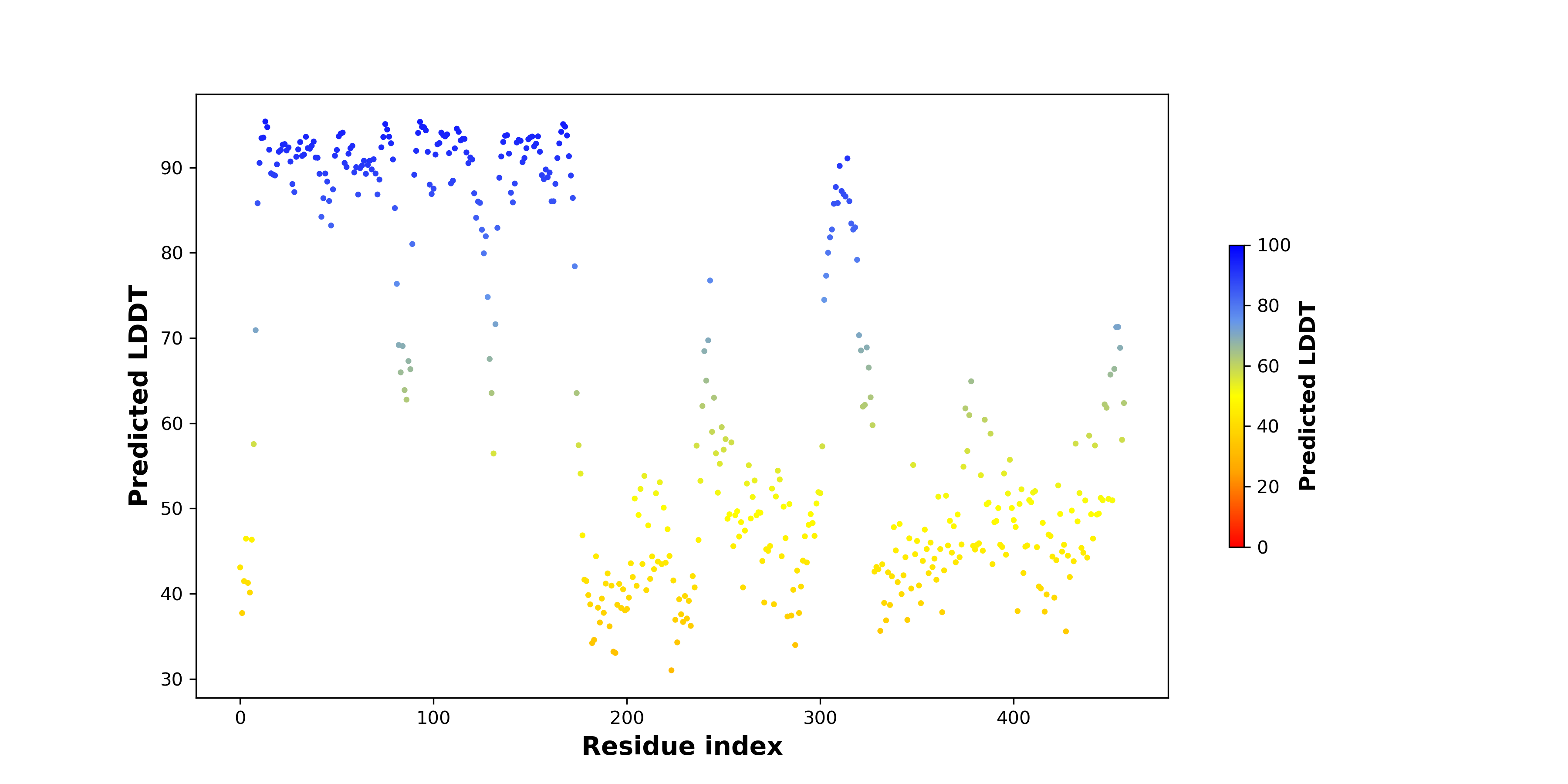 |
ASPSCR1_TFE3_230_pLDDT_and_active_sites.png (AA BP:) |
ASPSCR1_TFE3_230_violinplot.png (AA BP:) |
ASPSCR1_TFE3_342_pLDDT.png (AA BP:242) |
ASPSCR1_TFE3_342_pLDDT_and_active_sites.png (AA BP:242) |
ASPSCR1_TFE3_342_violinplot.png (AA BP:242) |
ASPSCR1_TFE3_402_pLDDT.png (AA BP:242)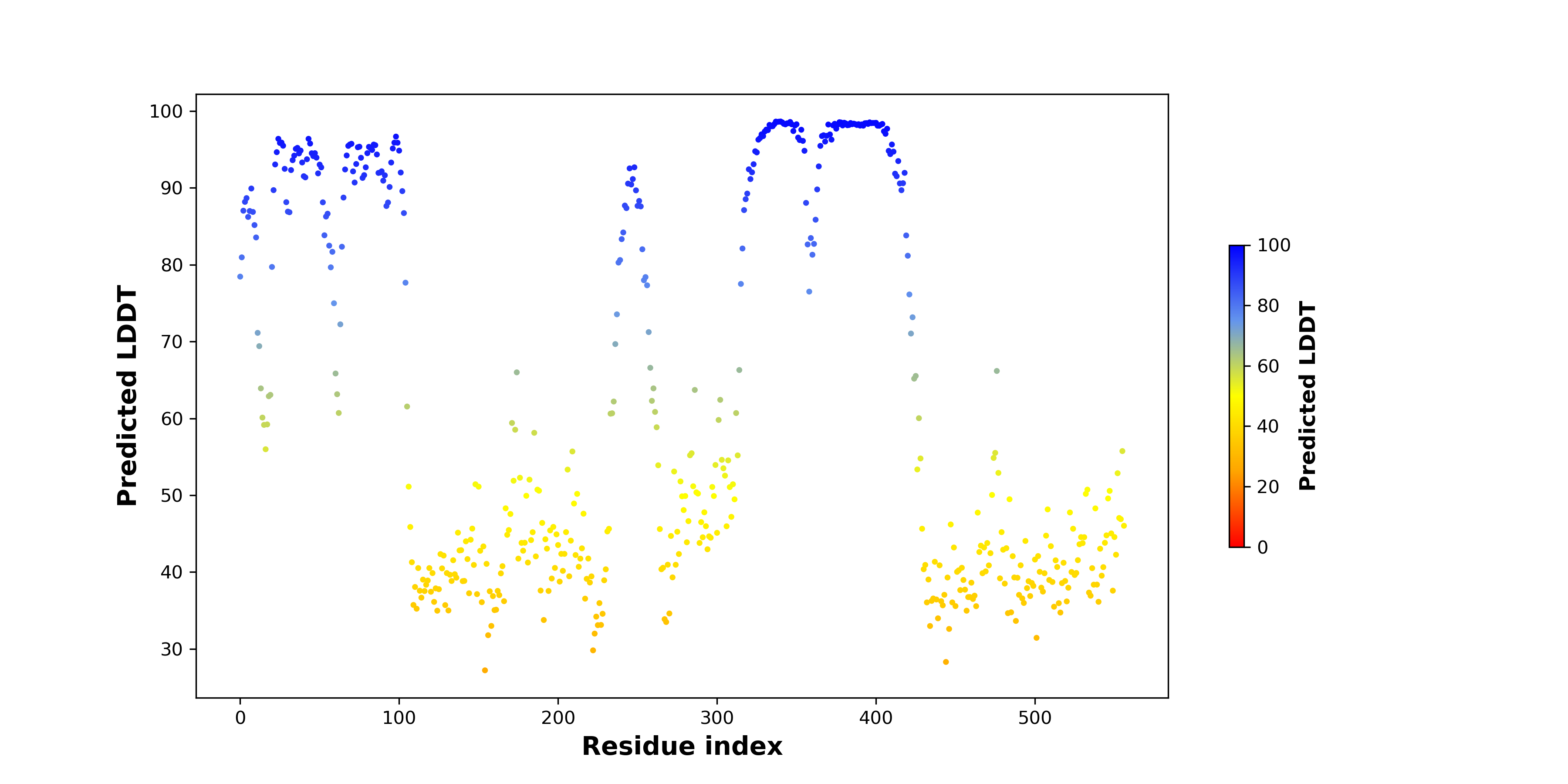 |
ASPSCR1_TFE3_402_pLDDT_and_active_sites.png (AA BP:242)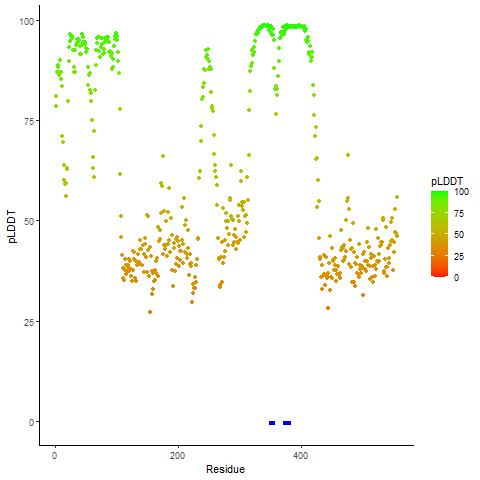 |
ASPSCR1_TFE3_402_violinplot.png (AA BP:242)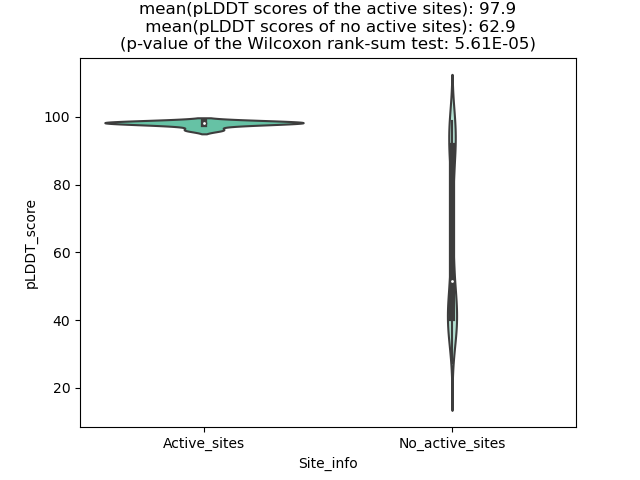 |
ASPSCR1_TFE3_456_pLDDT.png (AA BP:311) |
ASPSCR1_TFE3_456_pLDDT_and_active_sites.png (AA BP:311) |
ASPSCR1_TFE3_456_violinplot.png (AA BP:311)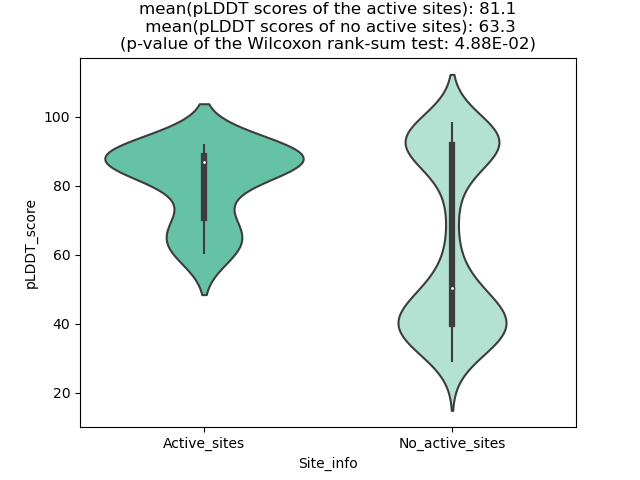 |
ASPSCR1_TFE3_498_pLDDT.png (AA BP:311)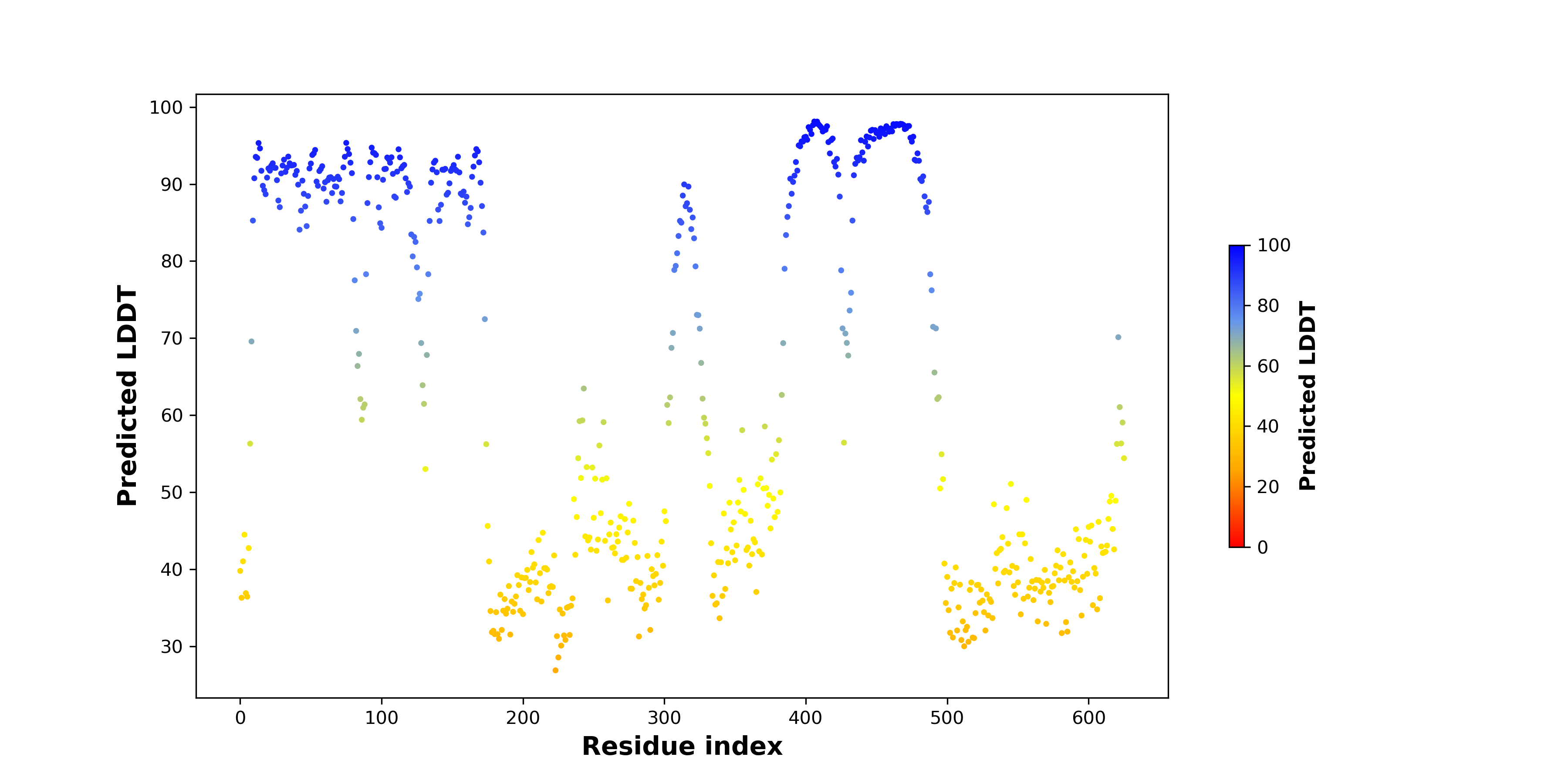 |
ASPSCR1_TFE3_498_pLDDT_and_active_sites.png (AA BP:311) |
ASPSCR1_TFE3_498_violinplot.png (AA BP:311) |
ASPSCR1_TFE3_510_pLDDT.png (AA BP:242) |
ASPSCR1_TFE3_510_pLDDT_and_active_sites.png (AA BP:242) |
ASPSCR1_TFE3_510_violinplot.png (AA BP:242) |
ASPSCR1_TFE3_582_pLDDT.png (AA BP:311)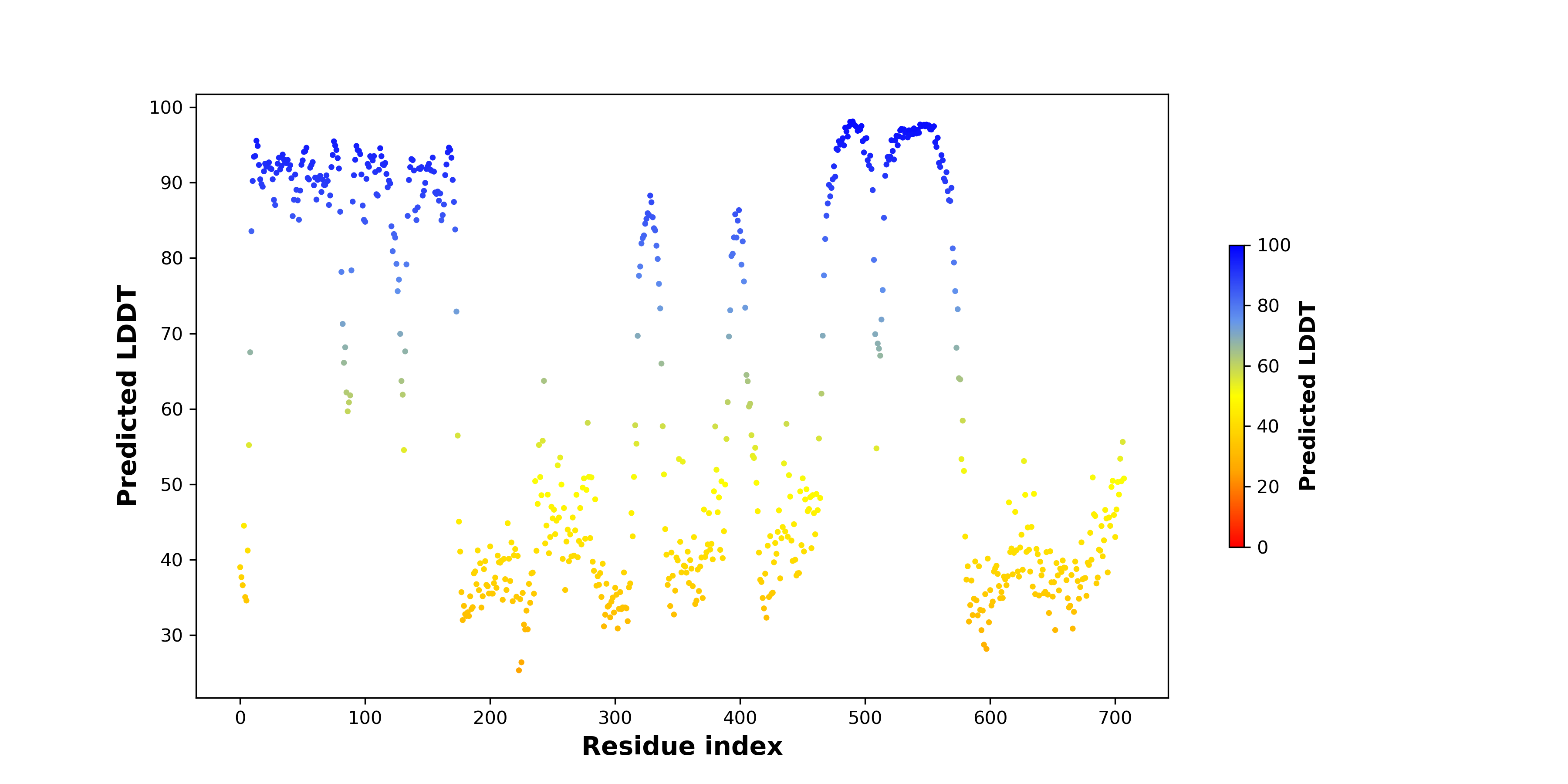 |
ASPSCR1_TFE3_582_pLDDT_and_active_sites.png (AA BP:311) |
ASPSCR1_TFE3_582_violinplot.png (AA BP:311) |
Top |
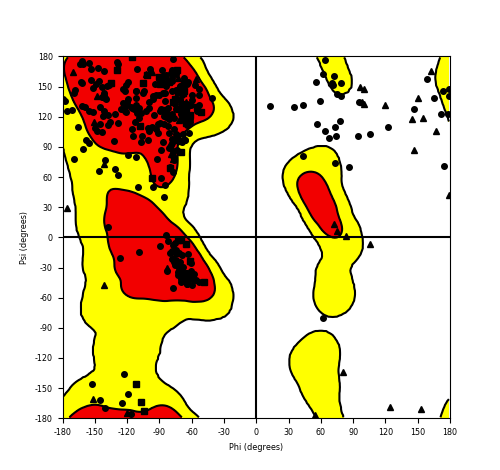
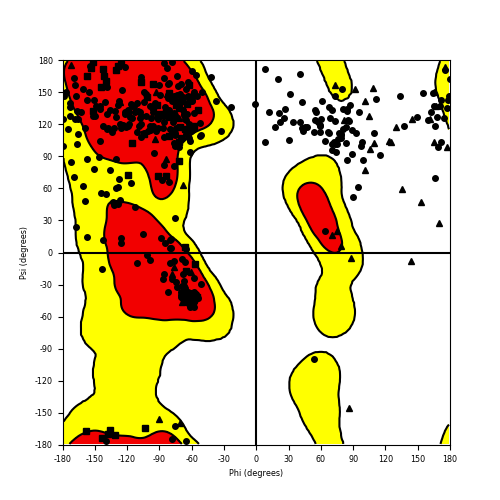
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
| ASPSCR1_TFE3_144.png |
 |
| ASPSCR1_TFE3_230.png |
 |
| ASPSCR1_TFE3_342.png |
 |
| ASPSCR1_TFE3_402.png |
 |
| ASPSCR1_TFE3_456.png |
 |
| ASPSCR1_TFE3_498.png |
 |
| ASPSCR1_TFE3_510.png |
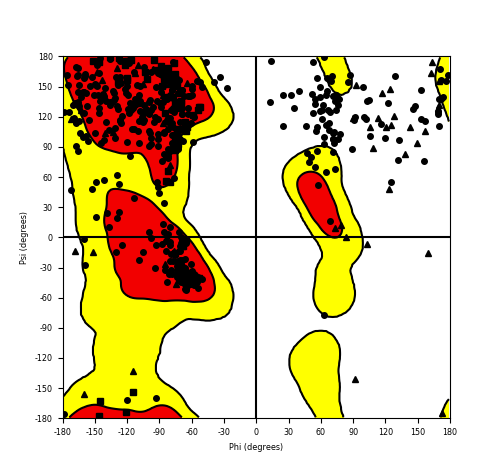 |
| ASPSCR1_TFE3_582.png |
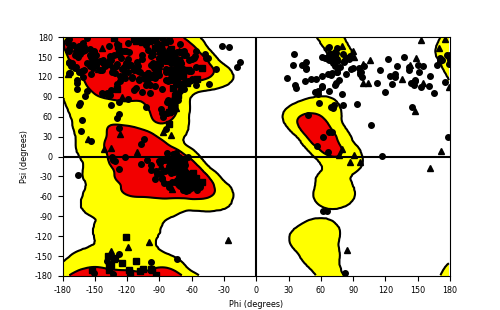 |
Top |
Potential Active Site Information |
| The potential binding sites of these fusion proteins were identified using SiteMap, a module of the Schrodinger suite. |
| Fusion AA seq ID in FusionPDB | Site score | Size | D score | Volume | Exposure | Enclosure | Contact | Phobic | Philic | Balance | Don/Acc | Residues |
| 144 | 0.661 | 31 | 0.677 | 62.769 | 0.728 | 0.515 | 0.635 | 0.823 | 0.477 | 1.726 | 5.012 | Chain A: 238,241,242,244,245,255,256,257,258 |
| 230 | 0.69 | 33 | 0.56 | 79.919 | 0.571 | 0.7 | 0.961 | 0.145 | 1.229 | 0.118 | 1.572 | Chain A: 60,61,62,83,84,85,89,90,162,163 |
| 342 | 0.753 | 59 | 0.735 | 143.717 | 0.678 | 0.579 | 0.877 | 0.342 | 1.025 | 0.334 | 0.631 | Chain A: 368,371,372,375,378,379,382,386,387,388,3 89,390,391,392,393,394,395,396,397,398 |
| 402 | 0.697 | 21 | 0.742 | 26.068 | 0.596 | 0.565 | 0.685 | 3.272 | 0.087 | 37.579 | 0.761 | Chain A: 351,354,355,374,377,378,381 |
| 456 | 0.8399 | 70 | 0.82 | 170.471 | 0.6154 | 0.6377 | 0.8413 | 0.2813 | 1.0709 | 0.2627 | 0.8686 | Chain A: 33,47,48,60,61,62,83,84,85,86,87,89,90,91 ,109,110,111,157,162,163,164 |
| 498 | 0.973 | 107 | 1.006 | 300.811 | 0.701 | 0.637 | 0.759 | 0.268 | 0.971 | 0.276 | 0.797 | Chain A: 29,30,31,33,34,37,47,48,60,61,62,64,83,84 ,85,86,87,89,90,110,111,143,155,157,158,159,162,16 3,164 |
| 510 | 0.607 | 23 | 0.554 | 92.267 | 0.713 | 0.616 | 0.813 | 0.676 | 0.817 | 0.827 | 1.581 | Chain A: 492,495,499,505,506,507,508,509,510,511,5 12 |
| 582 | 0.911 | 78 | 0.744 | 173.215 | 0.549 | 0.693 | 0.981 | 0.121 | 1.541 | 0.078 | 0.811 | Chain A: 33,60,61,62,83,84,85,86,87,89,90,91,110,1 11,157,162,163,164 |
Top |
Potentially Interacting Small Molecules through Virtual Screening |
| The FDA-approved small molecule library molecules were subjected to virtual screening using the Glide. |
| Fusion AA seq ID in FusionPDB | ZINC ID | DrugBank ID | Drug name | Docking score | Glide gscore |
Top |
| Drug information from DrugBank of the top 20 interacting small molecules. |
| ZINC ID | DrugBank ID | Drug name | Drug type | SMILES | Drug group |
Top |
Biochemical Features of Small Molecules |
| ADME (Absorption, Distribution, Metabolism, and Excretion) of drugs using QikProp(v3.9) |
| ZINC ID | mol_MW | dipole | SASA | FOSA | FISA | PISA | WPSA | volume | donorHB | accptHB | IP | Human Oral Absorption | Percent Human Oral Absorption | Rule Of Five | Rule Of Three |
Top |
Drug Toxicity Information |
| Toxicity information of individual drugs using eToxPred |
| ZINC ID | Smile | Surface Accessibility | Toxicity |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| ASPSCR1 | UBC, VCP, ALPP, NPLOC4, UFD1L, VCPIP1, PHAX, NEDD4, HHV8GK18_gp81, UBXN6, APP, VCPKMT, DCAF11, KRT31, TCF4, TACC3, ADAMTSL4, KRTAP10-8, NOTCH2NL, EZH2, GAPDH, GLUL, UBXN2B, HPD, MAT1A, NSF, AGL, BANF1, DERA, YTHDF1, YTHDF2, NTRK1, UBXN2A, UBXN7, NSFL1C, UBXN10, FAF1, KCTD3, FAM136A, SHKBP1, HAO2, ASNA1, HK1, HACL1, SERPINB2, GLTP, FADS1, HNRNPL, CUL1, USP25, CLK2, KRTAP1-1, INCA1, PINK1, PPIB, DDX58, GOPC, PREX1, EFTUD2, XAF1, NDOR1, URGCP, FTL, SEPHS1, MAN2C1, PIPSL, SLC12A9, |
| TFE3 | AKR1B1, CLTC, PHB2, ACLY, CUL2, EPRS, PFAS, VARS, NEDD8, RPL38, TRIM28, EIF3A, RPA3, E2F3, SMARCE1, MITF, TFE3, SMAD3, SMAD4, TFEC, EWSR1, XPO1, TFEB, Arrb2, TARDBP, HIST1H4A, LAMTOR3, nsp2, nsp7, AIM2, NR3C1, DDX58, YWHAG, YWHAQ, HDAC5, BTF3, nsp16, IRF8, KLF12, KLF16, KLF3, KLF5, KLF8, SOX2, TLX3, VSX1, |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| ASPSCR1 |  |
| TFE3 |  |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48891767 | ENST00000306729 | + | 7 | 17 | 317_380 | 311.0 | 648.0 | GLUT4 |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48891767 | ENST00000306739 | + | 7 | 16 | 317_380 | 311.0 | 554.0 | GLUT4 |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48891767 | ENST00000580534 | + | 6 | 15 | 317_380 | 234.0 | 502.0 | GLUT4 |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48895640 | ENST00000306729 | + | 7 | 17 | 317_380 | 311.0 | 648.0 | GLUT4 |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48895640 | ENST00000306739 | + | 7 | 16 | 317_380 | 311.0 | 554.0 | GLUT4 |
| Hgene | ASPSCR1 | chr17:79954722 | chrX:48895640 | ENST00000580534 | + | 6 | 15 | 317_380 | 234.0 | 502.0 | GLUT4 |
Top |
Related Drugs to ASPSCR1-TFE3 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to ASPSCR1-TFE3 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| ASPSCR1 | TFE3 | Alveolar Soft Part Sarcoma | MyCancerGenome | |
| ASPSCR1 | TFE3 | Translocation-Associated Renal Cell Carcinoma | MyCancerGenome | |
| ASPSCR1 | TFE3 | Large Cell Neuroendocrine Carcinoma | MyCancerGenome | |
| ASPSCR1 | TFE3 | Renal Cell Carcinoma | MyCancerGenome |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ASPSCR1 | C4518356 | MiT family translocation renal cell carcinoma | 3 | ORPHANET |
| Hgene | ASPSCR1 | C0206657 | Alveolar Soft Part Sarcoma | 1 | CTD_human;ORPHANET |
| Tgene | TFE3 | C4518356 | MiT family translocation renal cell carcinoma | 2 | ORPHANET |
| Tgene | TFE3 | C0206657 | Alveolar Soft Part Sarcoma | 1 | ORPHANET |
| Tgene | TFE3 | C0206732 | Epithelioid hemangioendothelioma | 1 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies