| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:TP53BP1-PDGFRB |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: TP53BP1-PDGFRB | FusionPDB ID: 93185 | FusionGDB2.0 ID: 93185 | Hgene | Tgene | Gene symbol | TP53BP1 | PDGFRB | Gene ID | 7158 | 5159 |
| Gene name | tumor protein p53 binding protein 1 | platelet derived growth factor receptor beta | |
| Synonyms | 53BP1|TDRD30|p202|p53BP1 | CD140B|IBGC4|IMF1|JTK12|KOGS|PDGFR|PDGFR-1|PDGFR1|PENTT | |
| Cytomap | 15q15.3 | 5q32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | TP53-binding protein 1p53-binding protein 1tumor protein 53-binding protein, 1tumor suppressor p53-binding protein 1 | platelet-derived growth factor receptor betaActivated tyrosine kinase PDGFRBCD140 antigen-like family member BNDEL1-PDGFRBPDGF-R-betaPDGFR-betabeta-type platelet-derived growth factor receptorplatelet-derived growth factor receptor 1platelet-deriv | |
| Modification date | 20200322 | 20200329 | |
| UniProtAcc | Q12888 | P09619 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000263801, ENST00000382039, ENST00000382044, ENST00000450115, ENST00000605155, | ENST00000523456, ENST00000261799, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 11 X 12 X 7=924 | 28 X 26 X 6=4368 |
| # samples | 13 | 15 | |
| ** MAII score | log2(13/924*10)=-2.8293812283876 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(15/4368*10)=-4.86393845042397 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: TP53BP1 [Title/Abstract] AND PDGFRB [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | |||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | TP53BP1 | GO:0006303 | double-strand break repair via nonhomologous end joining | 23333306|23760478|28241136 |
| Hgene | TP53BP1 | GO:0006974 | cellular response to DNA damage stimulus | 17500065|28241136 |
| Hgene | TP53BP1 | GO:0045830 | positive regulation of isotype switching | 23345425 |
| Hgene | TP53BP1 | GO:0051260 | protein homooligomerization | 23345425 |
| Hgene | TP53BP1 | GO:2000042 | negative regulation of double-strand break repair via homologous recombination | 23333306|23345425 |
| Tgene | PDGFRB | GO:0007165 | signal transduction | 10821867 |
| Tgene | PDGFRB | GO:0010863 | positive regulation of phospholipase C activity | 1653029 |
| Tgene | PDGFRB | GO:0018108 | peptidyl-tyrosine phosphorylation | 1653029|2536956|2850496 |
| Tgene | PDGFRB | GO:0030335 | positive regulation of cell migration | 17470632 |
| Tgene | PDGFRB | GO:0032516 | positive regulation of phosphoprotein phosphatase activity | 7691811 |
| Tgene | PDGFRB | GO:0038091 | positive regulation of cell proliferation by VEGF-activated platelet derived growth factor receptor signaling pathway | 17470632 |
| Tgene | PDGFRB | GO:0043552 | positive regulation of phosphatidylinositol 3-kinase activity | 1314164 |
| Tgene | PDGFRB | GO:0046777 | protein autophosphorylation | 1314164|2536956|2850496 |
| Tgene | PDGFRB | GO:0048008 | platelet-derived growth factor receptor signaling pathway | 1314164|2536956 |
| Tgene | PDGFRB | GO:0060326 | cell chemotaxis | 2554309|17991872 |
| Fusion gene breakpoints across TP53BP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
| Fusion gene breakpoints across PDGFRB (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerKB3 | . | . | TP53BP1 | chr15 | 43707791 | - | PDGFRB | chr5 | 149506177 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000263801 | TP53BP1 | chr15 | 43707791 | - | ENST00000261799 | PDGFRB | chr5 | 149506177 | - | 8995 | 5327 | 253 | 7068 | 2271 |
| ENST00000382039 | TP53BP1 | chr15 | 43707791 | - | ENST00000261799 | PDGFRB | chr5 | 149506177 | - | 8669 | 5001 | 62 | 6742 | 2226 |
| ENST00000382044 | TP53BP1 | chr15 | 43707791 | - | ENST00000261799 | PDGFRB | chr5 | 149506177 | - | 8885 | 5217 | 128 | 6958 | 2276 |
| ENST00000450115 | TP53BP1 | chr15 | 43707791 | - | ENST00000261799 | PDGFRB | chr5 | 149506177 | - | 8841 | 5173 | 84 | 6914 | 2276 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >93185_93185_1_TP53BP1-PDGFRB_TP53BP1_chr15_43707791_ENST00000263801_PDGFRB_chr5_149506177_ENST00000261799_length(amino acids)=2271AA_BP=1690 MDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSRHLPNLQTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLKENKVA DPVDSSNLDTCGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKEKEEDTSGNTTHSLGAEDTASSQLGFGVLELSQSQD VEENTVPYEVDKEQLQSVTTNSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKDVHVVKEQNPPPARSEDMPFSPKASV AAMEAKEQLSAQELMESGLQIQKSPEPEVLSTQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLSGQRSLVQDSLSTNSS DLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTSVLSEEGGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPPGSLPI PSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEIEPKNSPEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHRIDEDG ENTQIEDTEPMSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRDDISILATGCKGREETVAEDVCIDLTCDSGSQAVPS PATRSEALSSVLDQEEAMEIKEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTETQSQGLCLQKEMPKKECSEAMEVET SVISIDSPQKLAILDQELEHKEQEAWEEATSEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIEPCAENRLDTKEEKSV EYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLRLDQELQQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSFCESSS ETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNYPESTIATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKLCLRMK LVSPETEASEESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQENEARSEDPPTTPIRGNLLHFPSSQGEEEKEKLEGD HTIRQSQQPMKPISPVKDPVSPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIERPSQNNIGIQTMECSLRVPETVSAA TQTIKNVCEQGTSTVDQNFGKQDATVQTERGSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIREVRTLVTRVITDVYYV DGTEVERKVTEETEEPIVECQECETEVSPSQTGGSSGDLGDISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTEPADFA LPSSRGGPGKLSPRKGVSQTGTPVCEEDGDAGLGIRQGGKAPVTPRGRGRRGRPPSRTTGTRETAVPGPLGIEDISPNLSPDDKSFSRVV PRVPDSTRRTDVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNSFVGLRVVAKWSSNGYFYSGKITRDVGAGKYKLLFDDGYECDVLGK DILLCDPIPLDTEVTALSEDEYFSAGVVKGHRKESGELYYSIEKEGQRKWYKRMAVILSLEQGNRLREQYGLGPYEAVTPLTKAADISLD NLVEGKRKRRSNVSSPATPTASSSSSTTPTRKITESPRASMGVLSGKRKLITSEEERSPAKRGRKSATVKPALPFKVVVISAILALVVLT IISLIILIMLWQKKPRYEIRWKVIESVSSDGHEYIYVDPMQLPYDSTWELPRDQLVLGRTLGSGAFGQVVEATAHGLSHSQATMKVAVKM LKSTARSSEKQALMSELKIMSHLGPHLNVVNLLGACTKGGPIYIITEYCRYGDLVDYLHRNKHTFLQHHSDKRRPPSAELYSNALPVGLP LPSHVSLTGESDGGYMDMSKDESVDYVPMLDMKGDVKYADIESSNYMAPYDNYVPSAPERTCRATLINESPVLSYMDLVGFSYQVANGME FLASKNCVHRDLAARNVLICEGKLVKICDFGLARDIMRDSNYISKGSTFLPLKWMAPESIFNSLYTTLSDVWSFGILLWEIFTLGGTPYP ELPMNEQFYNAIKRGYRMAQPAHASDEIYEIMQKCWEEKFEIRPPFSQLVLLLERLLGEGYKKKYQQVDEEFLRSDHPAILRSQARLPGF HGLRSPLDTSSVLYTAVQPNEGDNDYIIPLPDPKPEVADEGPLEGSPSLASSTLNEVNTSSTISCDSPLEPQDEPEPEPQLELQVEPEPE -------------------------------------------------------------- >93185_93185_2_TP53BP1-PDGFRB_TP53BP1_chr15_43707791_ENST00000382039_PDGFRB_chr5_149506177_ENST00000261799_length(amino acids)=2226AA_BP=1645 MPGEQMDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSRHLPNLQTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLK ENKVADPVDSSNLDTCGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKEKEEDTSGNTTHSLGAEDTASSQLGFGVLEL SQSQDVEENTVPYEVDKEQLQSVTTNSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKDVHVVKEQNPPPARSEDMPFS PKASVAAMEAKEQLSAQELMESGLQIQKSPEPEVLSTQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLSGQRSLVQDSL STNSSDLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTSVLSEEGGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPP GSLPIPSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEIEPKNSPEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHR IDEDGENTQIEDTEPMSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRDDISILATGCKGREETVAEDVCIDLTCDSGS QAVPSPATRSEALSSVLDQEEAMEIKEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTETQSQGLCLQKEMPKKECSEA MEVETSVISIDSPQKLAILDQELEHKEQEAWEEATSEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIEPCAENRLDTK EEKSVEYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLRLDQELQQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSF CESSSETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNYPESTIATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKL CLRMKLVSPETEASEESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQENEARSEDPPTTPIRGNLLHFPSSQGEEEKE KLEGDHTIRQSQQPMKPISPVKDPVSPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIERPSQNNIGIQTMECSLRVPE TVSAATQTIKNVCEQGTSTVDQNFGKQDATVQTERGSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIREVRTLVTRVIT DVYYVDGTEVERKVTEETEEPIVECQECETEVSPSQTGGSSGDLGDISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTE PADFALPSSRGGPGKLRETAVPGPLGIEDISPNLSPDDKSFSRVVPRVPDSTRRTDVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNS FVGLRVVAKWSSNGYFYSGKITRDVGAGKYKLLFDDGYECDVLGKDILLCDPIPLDTEVTALSEDEYFSAGVVKGHRKESGELYYSIEKE GQRKWYKRMAVILSLEQGNRLREQYGLGPYEAVTPLTKAADISLDNLVEGKRKRRSNVSSPATPTASSSSSTTPTRKITESPRASMGVLS GKRKLITSEEERSPAKRGRKSATVKPALPFKVVVISAILALVVLTIISLIILIMLWQKKPRYEIRWKVIESVSSDGHEYIYVDPMQLPYD STWELPRDQLVLGRTLGSGAFGQVVEATAHGLSHSQATMKVAVKMLKSTARSSEKQALMSELKIMSHLGPHLNVVNLLGACTKGGPIYII TEYCRYGDLVDYLHRNKHTFLQHHSDKRRPPSAELYSNALPVGLPLPSHVSLTGESDGGYMDMSKDESVDYVPMLDMKGDVKYADIESSN YMAPYDNYVPSAPERTCRATLINESPVLSYMDLVGFSYQVANGMEFLASKNCVHRDLAARNVLICEGKLVKICDFGLARDIMRDSNYISK GSTFLPLKWMAPESIFNSLYTTLSDVWSFGILLWEIFTLGGTPYPELPMNEQFYNAIKRGYRMAQPAHASDEIYEIMQKCWEEKFEIRPP FSQLVLLLERLLGEGYKKKYQQVDEEFLRSDHPAILRSQARLPGFHGLRSPLDTSSVLYTAVQPNEGDNDYIIPLPDPKPEVADEGPLEG -------------------------------------------------------------- >93185_93185_3_TP53BP1-PDGFRB_TP53BP1_chr15_43707791_ENST00000382044_PDGFRB_chr5_149506177_ENST00000261799_length(amino acids)=2276AA_BP=1695 MPGEQMDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSRHLPNLQTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLK ENKVADPVDSSNLDTCGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKEKEEDTSGNTTHSLGAEDTASSQLGFGVLEL SQSQDVEENTVPYEVDKEQLQSVTTNSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKDVHVVKEQNPPPARSEDMPFS PKASVAAMEAKEQLSAQELMESGLQIQKSPEPEVLSTQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLSGQRSLVQDSL STNSSDLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTSVLSEEGGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPP GSLPIPSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEIEPKNSPEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHR IDEDGENTQIEDTEPMSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRDDISILATGCKGREETVAEDVCIDLTCDSGS QAVPSPATRSEALSSVLDQEEAMEIKEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTETQSQGLCLQKEMPKKECSEA MEVETSVISIDSPQKLAILDQELEHKEQEAWEEATSEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIEPCAENRLDTK EEKSVEYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLRLDQELQQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSF CESSSETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNYPESTIATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKL CLRMKLVSPETEASEESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQENEARSEDPPTTPIRGNLLHFPSSQGEEEKE KLEGDHTIRQSQQPMKPISPVKDPVSPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIERPSQNNIGIQTMECSLRVPE TVSAATQTIKNVCEQGTSTVDQNFGKQDATVQTERGSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIREVRTLVTRVIT DVYYVDGTEVERKVTEETEEPIVECQECETEVSPSQTGGSSGDLGDISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTE PADFALPSSRGGPGKLSPRKGVSQTGTPVCEEDGDAGLGIRQGGKAPVTPRGRGRRGRPPSRTTGTRETAVPGPLGIEDISPNLSPDDKS FSRVVPRVPDSTRRTDVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNSFVGLRVVAKWSSNGYFYSGKITRDVGAGKYKLLFDDGYEC DVLGKDILLCDPIPLDTEVTALSEDEYFSAGVVKGHRKESGELYYSIEKEGQRKWYKRMAVILSLEQGNRLREQYGLGPYEAVTPLTKAA DISLDNLVEGKRKRRSNVSSPATPTASSSSSTTPTRKITESPRASMGVLSGKRKLITSEEERSPAKRGRKSATVKPALPFKVVVISAILA LVVLTIISLIILIMLWQKKPRYEIRWKVIESVSSDGHEYIYVDPMQLPYDSTWELPRDQLVLGRTLGSGAFGQVVEATAHGLSHSQATMK VAVKMLKSTARSSEKQALMSELKIMSHLGPHLNVVNLLGACTKGGPIYIITEYCRYGDLVDYLHRNKHTFLQHHSDKRRPPSAELYSNAL PVGLPLPSHVSLTGESDGGYMDMSKDESVDYVPMLDMKGDVKYADIESSNYMAPYDNYVPSAPERTCRATLINESPVLSYMDLVGFSYQV ANGMEFLASKNCVHRDLAARNVLICEGKLVKICDFGLARDIMRDSNYISKGSTFLPLKWMAPESIFNSLYTTLSDVWSFGILLWEIFTLG GTPYPELPMNEQFYNAIKRGYRMAQPAHASDEIYEIMQKCWEEKFEIRPPFSQLVLLLERLLGEGYKKKYQQVDEEFLRSDHPAILRSQA RLPGFHGLRSPLDTSSVLYTAVQPNEGDNDYIIPLPDPKPEVADEGPLEGSPSLASSTLNEVNTSSTISCDSPLEPQDEPEPEPQLELQV -------------------------------------------------------------- >93185_93185_4_TP53BP1-PDGFRB_TP53BP1_chr15_43707791_ENST00000450115_PDGFRB_chr5_149506177_ENST00000261799_length(amino acids)=2276AA_BP=1695 MPGEQMDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSRHLPNLQTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLK ENKVADPVDSSNLDTCGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKEKEEDTSGNTTHSLGAEDTASSQLGFGVLEL SQSQDVEENTVPYEVDKEQLQSVTTNSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKDVHVVKEQNPPPARSEDMPFS PKASVAAMEAKEQLSAQELMESGLQIQKSPEPEVLSTQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLSGQRSLVQDSL STNSSDLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTSVLSEEGGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPP GSLPIPSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEIEPKNSPEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHR IDEDGENTQIEDTEPMSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRDDISILATGCKGREETVAEDVCIDLTCDSGS QAVPSPATRSEALSSVLDQEEAMEIKEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTETQSQGLCLQKEMPKKECSEA MEVETSVISIDSPQKLAILDQELEHKEQEAWEEATSEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIEPCAENRLDTK EEKSVEYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLRLDQELQQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSF CESSSETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNYPESTIATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKL CLRMKLVSPETEASEESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQENEARSEDPPTTPIRGNLLHFPSSQGEEEKE KLEGDHTIRQSQQPMKPISPVKDPVSPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIERPSQNNIGIQTMECSLRVPE TVSAATQTIKNVCEQGTSTVDQNFGKQDATVQTERGSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIREVRTLVTRVIT DVYYVDGTEVERKVTEETEEPIVECQECETEVSPSQTGGSSGDLGDISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTE PADFALPSSRGGPGKLSPRKGVSQTGTPVCEEDGDAGLGIRQGGKAPVTPRGRGRRGRPPSRTTGTRETAVPGPLGIEDISPNLSPDDKS FSRVVPRVPDSTRRTDVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNSFVGLRVVAKWSSNGYFYSGKITRDVGAGKYKLLFDDGYEC DVLGKDILLCDPIPLDTEVTALSEDEYFSAGVVKGHRKESGELYYSIEKEGQRKWYKRMAVILSLEQGNRLREQYGLGPYEAVTPLTKAA DISLDNLVEGKRKRRSNVSSPATPTASSSSSTTPTRKITESPRASMGVLSGKRKLITSEEERSPAKRGRKSATVKPALPFKVVVISAILA LVVLTIISLIILIMLWQKKPRYEIRWKVIESVSSDGHEYIYVDPMQLPYDSTWELPRDQLVLGRTLGSGAFGQVVEATAHGLSHSQATMK VAVKMLKSTARSSEKQALMSELKIMSHLGPHLNVVNLLGACTKGGPIYIITEYCRYGDLVDYLHRNKHTFLQHHSDKRRPPSAELYSNAL PVGLPLPSHVSLTGESDGGYMDMSKDESVDYVPMLDMKGDVKYADIESSNYMAPYDNYVPSAPERTCRATLINESPVLSYMDLVGFSYQV ANGMEFLASKNCVHRDLAARNVLICEGKLVKICDFGLARDIMRDSNYISKGSTFLPLKWMAPESIFNSLYTTLSDVWSFGILLWEIFTLG GTPYPELPMNEQFYNAIKRGYRMAQPAHASDEIYEIMQKCWEEKFEIRPPFSQLVLLLERLLGEGYKKKYQQVDEEFLRSDHPAILRSQA RLPGFHGLRSPLDTSSVLYTAVQPNEGDNDYIIPLPDPKPEVADEGPLEGSPSLASSTLNEVNTSSTISCDSPLEPQDEPEPEPQLELQV -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr15:/chr5:) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| TP53BP1 | PDGFRB |
| FUNCTION: Double-strand break (DSB) repair protein involved in response to DNA damage, telomere dynamics and class-switch recombination (CSR) during antibody genesis (PubMed:12364621, PubMed:22553214, PubMed:23333306, PubMed:17190600, PubMed:21144835, PubMed:27153538, PubMed:28241136). Plays a key role in the repair of double-strand DNA breaks (DSBs) in response to DNA damage by promoting non-homologous end joining (NHEJ)-mediated repair of DSBs and specifically counteracting the function of the homologous recombination (HR) repair protein BRCA1 (PubMed:22553214, PubMed:23727112, PubMed:23333306, PubMed:27153538). In response to DSBs, phosphorylation by ATM promotes interaction with RIF1 and dissociation from NUDT16L1/TIRR, leading to recruitment to DSBs sites (PubMed:28241136). Recruited to DSBs sites by recognizing and binding histone H2A monoubiquitinated at 'Lys-15' (H2AK15Ub) and histone H4 dimethylated at 'Lys-20' (H4K20me2), two histone marks that are present at DSBs sites (PubMed:23760478, PubMed:27153538, PubMed:28241136, PubMed:17190600). Required for immunoglobulin class-switch recombination (CSR) during antibody genesis, a process that involves the generation of DNA DSBs (PubMed:23345425). Participates in the repair and the orientation of the broken DNA ends during CSR (By similarity). In contrast, it is not required for classic NHEJ and V(D)J recombination (By similarity). Promotes NHEJ of dysfunctional telomeres via interaction with PAXIP1 (PubMed:23727112). {ECO:0000250|UniProtKB:P70399, ECO:0000269|PubMed:12364621, ECO:0000269|PubMed:17190600, ECO:0000269|PubMed:21144835, ECO:0000269|PubMed:22553214, ECO:0000269|PubMed:23333306, ECO:0000269|PubMed:23345425, ECO:0000269|PubMed:23727112, ECO:0000269|PubMed:23760478, ECO:0000269|PubMed:27153538, ECO:0000269|PubMed:28241136}. | FUNCTION: Tyrosine-protein kinase that acts as cell-surface receptor for homodimeric PDGFB and PDGFD and for heterodimers formed by PDGFA and PDGFB, and plays an essential role in the regulation of embryonic development, cell proliferation, survival, differentiation, chemotaxis and migration. Plays an essential role in blood vessel development by promoting proliferation, migration and recruitment of pericytes and smooth muscle cells to endothelial cells. Plays a role in the migration of vascular smooth muscle cells and the formation of neointima at vascular injury sites. Required for normal development of the cardiovascular system. Required for normal recruitment of pericytes (mesangial cells) in the kidney glomerulus, and for normal formation of a branched network of capillaries in kidney glomeruli. Promotes rearrangement of the actin cytoskeleton and the formation of membrane ruffles. Binding of its cognate ligands - homodimeric PDGFB, heterodimers formed by PDGFA and PDGFB or homodimeric PDGFD -leads to the activation of several signaling cascades; the response depends on the nature of the bound ligand and is modulated by the formation of heterodimers between PDGFRA and PDGFRB. Phosphorylates PLCG1, PIK3R1, PTPN11, RASA1/GAP, CBL, SHC1 and NCK1. Activation of PLCG1 leads to the production of the cellular signaling molecules diacylglycerol and inositol 1,4,5-trisphosphate, mobilization of cytosolic Ca(2+) and the activation of protein kinase C. Phosphorylation of PIK3R1, the regulatory subunit of phosphatidylinositol 3-kinase, leads to the activation of the AKT1 signaling pathway. Phosphorylation of SHC1, or of the C-terminus of PTPN11, creates a binding site for GRB2, resulting in the activation of HRAS, RAF1 and down-stream MAP kinases, including MAPK1/ERK2 and/or MAPK3/ERK1. Promotes phosphorylation and activation of SRC family kinases. Promotes phosphorylation of PDCD6IP/ALIX and STAM. Receptor signaling is down-regulated by protein phosphatases that dephosphorylate the receptor and its down-stream effectors, and by rapid internalization of the activated receptor. {ECO:0000269|PubMed:11297552, ECO:0000269|PubMed:11331881, ECO:0000269|PubMed:1314164, ECO:0000269|PubMed:1396585, ECO:0000269|PubMed:1653029, ECO:0000269|PubMed:1709159, ECO:0000269|PubMed:1846866, ECO:0000269|PubMed:20494825, ECO:0000269|PubMed:20529858, ECO:0000269|PubMed:21098708, ECO:0000269|PubMed:21679854, ECO:0000269|PubMed:21733313, ECO:0000269|PubMed:2554309, ECO:0000269|PubMed:26599395, ECO:0000269|PubMed:2835772, ECO:0000269|PubMed:2850496, ECO:0000269|PubMed:7685273, ECO:0000269|PubMed:7691811, ECO:0000269|PubMed:7692233, ECO:0000269|PubMed:8195171}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file (1116) | TP53BP1 | chr15 | 43707791 | - | PDGFRB | chr5 | 149506177 | - | MPGEQMDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSR HLPNLQTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLKENKVADPVDS SNLDTCGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKE KEEDTSGNTTHSLGAEDTASSQLGFGVLELSQSQDVEENTVPYEVDKEQL QSVTTNSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKD VHVVKEQNPPPARSEDMPFSPKASVAAMEAKEQLSAQELMESGLQIQKSP EPEVLSTQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLS GQRSLVQDSLSTNSSDLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTS VLSEEGGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPP GSLPIPSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEI EPKNSPEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHRIDEDGENTQI EDTEPMSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRD DISILATGCKGREETVAEDVCIDLTCDSGSQAVPSPATRSEALSSVLDQE EAMEIKEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTE TQSQGLCLQKEMPKKECSEAMEVETSVISIDSPQKLAILDQELEHKEQEA WEEATSEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIE PCAENRLDTKEEKSVEYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLR LDQELQQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSF CESSSETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNY PESTIATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKLCLRMKLVSPE TEASEESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQE NEARSEDPPTTPIRGNLLHFPSSQGEEEKEKLEGDHTIRQSQQPMKPISP VKDPVSPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIE RPSQNNIGIQTMECSLRVPETVSAATQTIKNVCEQGTSTVDQNFGKQDAT VQTERGSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIRE VRTLVTRVITDVYYVDGTEVERKVTEETEEPIVECQECETEVSPSQTGGS SGDLGDISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTE PADFALPSSRGGPGKLRETAVPGPLGIEDISPNLSPDDKSFSRVVPRVPD STRRTDVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNSFVGLRVVAKW SSNGYFYSGKITRDVGAGKYKLLFDDGYECDVLGKDILLCDPIPLDTEVT ALSEDEYFSAGVVKGHRKESGELYYSIEKEGQRKWYKRMAVILSLEQGNR LREQYGLGPYEAVTPLTKAADISLDNLVEGKRKRRSNVSSPATPTASSSS STTPTRKITESPRASMGVLSGKRKLITSEEERSPAKRGRKSATVKPALPF KVVVISAILALVVLTIISLIILIMLWQKKPRYEIRWKVIESVSSDGHEYI YVDPMQLPYDSTWELPRDQLVLGRTLGSGAFGQVVEATAHGLSHSQATMK VAVKMLKSTARSSEKQALMSELKIMSHLGPHLNVVNLLGACTKGGPIYII TEYCRYGDLVDYLHRNKHTFLQHHSDKRRPPSAELYSNALPVGLPLPSHV SLTGESDGGYMDMSKDESVDYVPMLDMKGDVKYADIESSNYMAPYDNYVP SAPERTCRATLINESPVLSYMDLVGFSYQVANGMEFLASKNCVHRDLAAR NVLICEGKLVKICDFGLARDIMRDSNYISKGSTFLPLKWMAPESIFNSLY TTLSDVWSFGILLWEIFTLGGTPYPELPMNEQFYNAIKRGYRMAQPAHAS DEIYEIMQKCWEEKFEIRPPFSQLVLLLERLLGEGYKKKYQQVDEEFLRS DHPAILRSQARLPGFHGLRSPLDTSSVLYTAVQPNEGDNDYIIPLPDPKP EVADEGPLEGSPSLASSTLNEVNTSSTISCDSPLEPQDEPEPEPQLELQV | 2226 |
| PDB file (1121) | TP53BP1 | chr15 | 43707791 | - | PDGFRB | chr5 | 149506177 | - | MDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSRHLPNL QTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLKENKVADPVDSSNLDT CGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKEKEEDT SGNTTHSLGAEDTASSQLGFGVLELSQSQDVEENTVPYEVDKEQLQSVTT NSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKDVHVVK EQNPPPARSEDMPFSPKASVAAMEAKEQLSAQELMESGLQIQKSPEPEVL STQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLSGQRSL VQDSLSTNSSDLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTSVLSEE GGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPPGSLPI PSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEIEPKNS PEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHRIDEDGENTQIEDTEP MSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRDDISIL ATGCKGREETVAEDVCIDLTCDSGSQAVPSPATRSEALSSVLDQEEAMEI KEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTETQSQG LCLQKEMPKKECSEAMEVETSVISIDSPQKLAILDQELEHKEQEAWEEAT SEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIEPCAEN RLDTKEEKSVEYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLRLDQEL QQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSFCESSS ETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNYPESTI ATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKLCLRMKLVSPETEASE ESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQENEARS EDPPTTPIRGNLLHFPSSQGEEEKEKLEGDHTIRQSQQPMKPISPVKDPV SPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIERPSQN NIGIQTMECSLRVPETVSAATQTIKNVCEQGTSTVDQNFGKQDATVQTER GSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIREVRTLV TRVITDVYYVDGTEVERKVTEETEEPIVECQECETEVSPSQTGGSSGDLG DISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTEPADFA LPSSRGGPGKLSPRKGVSQTGTPVCEEDGDAGLGIRQGGKAPVTPRGRGR RGRPPSRTTGTRETAVPGPLGIEDISPNLSPDDKSFSRVVPRVPDSTRRT DVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNSFVGLRVVAKWSSNGY FYSGKITRDVGAGKYKLLFDDGYECDVLGKDILLCDPIPLDTEVTALSED EYFSAGVVKGHRKESGELYYSIEKEGQRKWYKRMAVILSLEQGNRLREQY GLGPYEAVTPLTKAADISLDNLVEGKRKRRSNVSSPATPTASSSSSTTPT RKITESPRASMGVLSGKRKLITSEEERSPAKRGRKSATVKPALPFKVVVI SAILALVVLTIISLIILIMLWQKKPRYEIRWKVIESVSSDGHEYIYVDPM QLPYDSTWELPRDQLVLGRTLGSGAFGQVVEATAHGLSHSQATMKVAVKM LKSTARSSEKQALMSELKIMSHLGPHLNVVNLLGACTKGGPIYIITEYCR YGDLVDYLHRNKHTFLQHHSDKRRPPSAELYSNALPVGLPLPSHVSLTGE SDGGYMDMSKDESVDYVPMLDMKGDVKYADIESSNYMAPYDNYVPSAPER TCRATLINESPVLSYMDLVGFSYQVANGMEFLASKNCVHRDLAARNVLIC EGKLVKICDFGLARDIMRDSNYISKGSTFLPLKWMAPESIFNSLYTTLSD VWSFGILLWEIFTLGGTPYPELPMNEQFYNAIKRGYRMAQPAHASDEIYE IMQKCWEEKFEIRPPFSQLVLLLERLLGEGYKKKYQQVDEEFLRSDHPAI LRSQARLPGFHGLRSPLDTSSVLYTAVQPNEGDNDYIIPLPDPKPEVADE GPLEGSPSLASSTLNEVNTSSTISCDSPLEPQDEPEPEPQLELQVEPEPE | 2271 |
| PDB file (1122) | TP53BP1 | chr15 | 43707791 | - | PDGFRB | chr5 | 149506177 | - | MPGEQMDPTGSQLDSDFSQQDTPCLIIEDSQPESQVLEDDSGSHFSMLSR HLPNLQTHKENPVLDVVSNPEQTAGEERGDGNSGFNEHLKENKVADPVDS SNLDTCGSISQVIEQLPQPNRTSSVLGMSVESAPAVEEEKGEELEQKEKE KEEDTSGNTTHSLGAEDTASSQLGFGVLELSQSQDVEENTVPYEVDKEQL QSVTTNSGYTRLSDVDANTAIKHEEQSNEDIPIAEQSSKDIPVTAQPSKD VHVVKEQNPPPARSEDMPFSPKASVAAMEAKEQLSAQELMESGLQIQKSP EPEVLSTQEDLFDQSNKTVSSDGCSTPSREEGGCSLASTPATTLHLLQLS GQRSLVQDSLSTNSSDLVAPSPDAFRSTPFIVPSSPTEQEGRQDKPMDTS VLSEEGGEPFQKKLQSGEPVELENPPLLPESTVSPQASTPISQSTPVFPP GSLPIPSQPQFSHDIFIPSPSLEEQSNDGKKDGDMHSSSLTVECSKTSEI EPKNSPEDLGLSLTGDSCKLMLSTSEYSQSPKMESLSSHRIDEDGENTQI EDTEPMSPVLNSKFVPAENDSILMNPAQDGEVQLSQNDDKTKGDDTDTRD DISILATGCKGREETVAEDVCIDLTCDSGSQAVPSPATRSEALSSVLDQE EAMEIKEHHPEEGSSGSEVEEIPETPCESQGEELKEENMESVPLHLSLTE TQSQGLCLQKEMPKKECSEAMEVETSVISIDSPQKLAILDQELEHKEQEA WEEATSEDSSVVIVDVKEPSPRVDVSCEPLEGVEKCSDSQSWEDIAPEIE PCAENRLDTKEEKSVEYEGDLKSGTAETEPVEQDSSQPSLPLVRADDPLR LDQELQQPQTQEKTSNSLTEDSKMANAKQLSSDAEAQKLGKPSAHASQSF CESSSETPFHFTLPKEGDIIPPLTGATPPLIGHLKLEPKRHSTPIGISNY PESTIATSDVMSESMVETHDPILGSGKGDSGAAPDVDDKLCLRMKLVSPE TEASEESLQFNLEKPATGERKNGSTAVAESVASPQKTMSVLSCICEARQE NEARSEDPPTTPIRGNLLHFPSSQGEEEKEKLEGDHTIRQSQQPMKPISP VKDPVSPASQKMVIQGPSSPQGEAMVTDVLEDQKEGRSTNKENPSKALIE RPSQNNIGIQTMECSLRVPETVSAATQTIKNVCEQGTSTVDQNFGKQDAT VQTERGSGEKPVSAPGDDTESLHSQGEEEFDMPQPPHGHVLHRHMRTIRE VRTLVTRVITDVYYVDGTEVERKVTEETEEPIVECQECETEVSPSQTGGS SGDLGDISSFSSKASSLHRTSSGTSLSAMHSSGSSGKGAGPLRGKTSGTE PADFALPSSRGGPGKLSPRKGVSQTGTPVCEEDGDAGLGIRQGGKAPVTP RGRGRRGRPPSRTTGTRETAVPGPLGIEDISPNLSPDDKSFSRVVPRVPD STRRTDVGAGALRRSDSPEIPFQAAAGPSDGLDASSPGNSFVGLRVVAKW SSNGYFYSGKITRDVGAGKYKLLFDDGYECDVLGKDILLCDPIPLDTEVT ALSEDEYFSAGVVKGHRKESGELYYSIEKEGQRKWYKRMAVILSLEQGNR LREQYGLGPYEAVTPLTKAADISLDNLVEGKRKRRSNVSSPATPTASSSS STTPTRKITESPRASMGVLSGKRKLITSEEERSPAKRGRKSATVKPALPF KVVVISAILALVVLTIISLIILIMLWQKKPRYEIRWKVIESVSSDGHEYI YVDPMQLPYDSTWELPRDQLVLGRTLGSGAFGQVVEATAHGLSHSQATMK VAVKMLKSTARSSEKQALMSELKIMSHLGPHLNVVNLLGACTKGGPIYII TEYCRYGDLVDYLHRNKHTFLQHHSDKRRPPSAELYSNALPVGLPLPSHV SLTGESDGGYMDMSKDESVDYVPMLDMKGDVKYADIESSNYMAPYDNYVP SAPERTCRATLINESPVLSYMDLVGFSYQVANGMEFLASKNCVHRDLAAR NVLICEGKLVKICDFGLARDIMRDSNYISKGSTFLPLKWMAPESIFNSLY TTLSDVWSFGILLWEIFTLGGTPYPELPMNEQFYNAIKRGYRMAQPAHAS DEIYEIMQKCWEEKFEIRPPFSQLVLLLERLLGEGYKKKYQQVDEEFLRS DHPAILRSQARLPGFHGLRSPLDTSSVLYTAVQPNEGDNDYIIPLPDPKP EVADEGPLEGSPSLASSTLNEVNTSSTISCDSPLEPQDEPEPEPQLELQV | 2276 |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
TP53BP1_pLDDT.png  |
PDGFRB_pLDDT.png  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
TP53BP1_PDGFRB_1116_pLDDT_and_active_sites.png (AA BP:) |
TP53BP1_PDGFRB_1116_violinplot.png (AA BP:)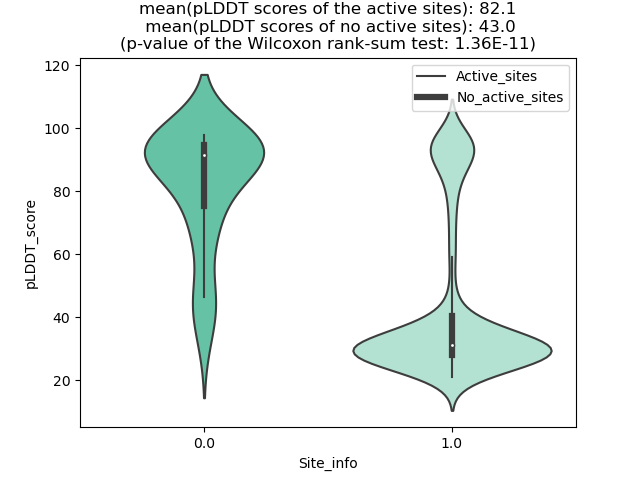 |
TP53BP1_PDGFRB_1121_pLDDT_and_active_sites.png (AA BP:) |
TP53BP1_PDGFRB_1121_violinplot.png (AA BP:)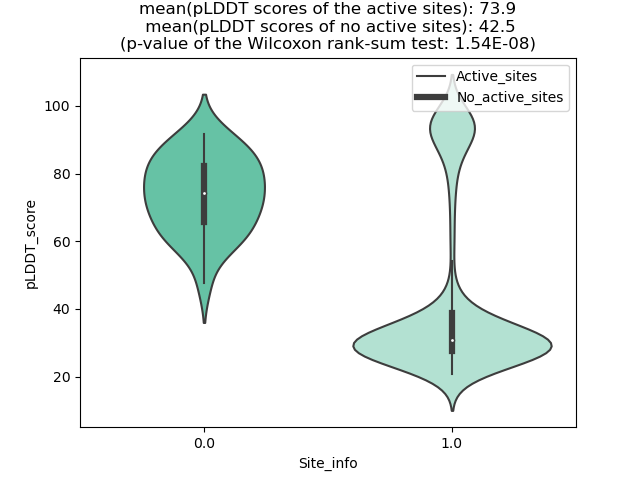 |
TP53BP1_PDGFRB_1122_pLDDT_and_active_sites.png (AA BP:)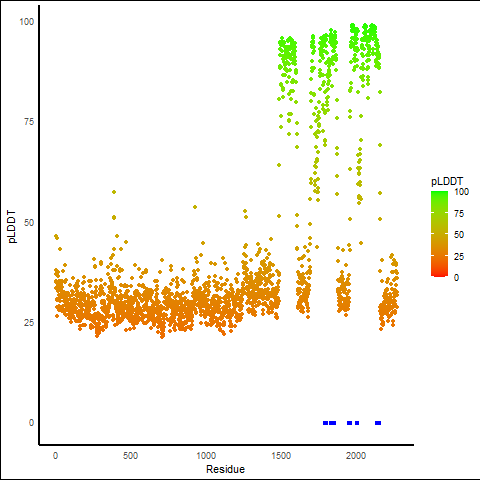 |
TP53BP1_PDGFRB_1122_violinplot.png (AA BP:) |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Potential Active Site Information |
| The potential binding sites of these fusion proteins were identified using SiteMap, a module of the Schrodinger suite. |
| Fusion AA seq ID in FusionPDB | Site score | Size | D score | Volume | Exposure | Enclosure | Contact | Phobic | Philic | Balance | Don/Acc | Residues |
| 1116 | 1.095 | 111 | 1.126 | 532.336 | 0.586 | 0.799 | 0.894 | 0.776 | 0.9 | 0.862 | 1.514 | Chain A: 1743,1745,1746,1749,1750,1782,1788,1802,1 803,1804,1805,1906,1907,1908,1909,1910,1911,1955,1 956,1959,1961,2093,2096,2097,2100,2101,2102,2103 |
| 1121 | 1.073 | 128 | 1.119 | 311.101 | 0.556 | 0.742 | 0.932 | 0.828 | 0.815 | 1.016 | 0.68 | Chain A: 1722,1724,1725,1726,1727,1728,1729,1730,1 732,1748,1749,1750,1776,1808,1811,1812,1815,1990,1 991,2011,2016,2027,2028,2029,2030,2031,2045 |
| 1122 | 1.098 | 123 | 1.138 | 466.823 | 0.544 | 0.788 | 0.936 | 1.092 | 0.843 | 1.296 | 0.521 | Chain A: 1793,1795,1796,1799,1800,1832,1838,1852,1 853,1854,1855,1956,1957,1958,1959,1961,2005,2006,2 009,2011,2143,2146,2147,2150,2151,2152,2153 |
Top |
Potentially Interacting Small Molecules through Virtual Screening |
| The FDA-approved small molecule library molecules were subjected to virtual screening using the Glide. |
| Fusion AA seq ID in FusionPDB | ZINC ID | DrugBank ID | Drug name | Docking score | Glide gscore |
Top |
| Drug information from DrugBank of the top 20 interacting small molecules. |
| ZINC ID | DrugBank ID | Drug name | Drug type | SMILES | Drug group |
Top |
Biochemical Features of Small Molecules |
| ADME (Absorption, Distribution, Metabolism, and Excretion) of drugs using QikProp(v3.9) |
| ZINC ID | mol_MW | dipole | SASA | FOSA | FISA | PISA | WPSA | volume | donorHB | accptHB | IP | Human Oral Absorption | Percent Human Oral Absorption | Rule Of Five | Rule Of Three |
Top |
Drug Toxicity Information |
| Toxicity information of individual drugs using eToxPred |
| ZINC ID | Smile | Surface Accessibility | Toxicity |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| TP53BP1 | TP53, RPA2, BLM, H2AFX, H2afx, PAXIP1, CHEK1, DYNLL1, ATM, DCLRE1A, NFKB1, RPA1, Trp53, E2F1, TFDP1, BRCA1, CHEK2, RAD18, USP28, UBE2I, PIAS4, RNF8, RNF168, MDC1, MCPH1, HDAC4, TP53I3, vpr, EP300, SETD8, Dynll1, HIST1H4A, HIST1H3A, ARAP1, NCOA3, SIRT7, COPS5, NEK1, NUP107, CCNT1, ACAA2, LIG4, ACR, PCNT, PSMD8, SDHB, SPAG9, GALNTL5, AAMP, CAPZA1, CAPZB, CDC27, CUX1, ARID3A, FASN, FLNA, XRCC6, KPNA1, KPNB1, KPNA3, MCM6, NUMA1, PCMT1, MAPK1, MAPK3, PSMC5, PTPN9, DPF2, RFC2, SAFB, SRSF1, SMARCD1, TMPO, TP73, TRPS1, DNAJC7, XRCC5, YWHAZ, DEK, HAT1, CDC23, CDC16, MTA2, ANAPC10, GNB2L1, PAICS, MYL12A, NUDC, STRAP, CBX3, CLASP2, RCOR1, SUN2, DHRS7B, CACYBP, ANAPC2, ANAPC4, ANAPC5, ANAPC7, PELO, UGGT1, BEND3, ANAPC1, ZBTB10, ANAPC16, FLCN, VCP, CDK1, CCNB1, PLK1, HIST2H4A, MEOX2, VAC14, UBE2L3, ENO1, SHMT2, MOV10, NXF1, MSL1, EED, SUMO2, KDM1A, THAP10, NUP50, POLR1C, SUB1, SMC6, Cenpf, Scai, FOXK1, FOXK2, UBC, TRIM28, PCGF1, DPPA4, NANOG, POU5F1, NFATC2, NUDT16L1, MRPS7, PRPF38A, BUB1, KAT8, LMNA, CFTR, TRIM14, RNF4, SPDL1, ESR2, UBE4A, EZH2, TNRC6A, RIF1, MYC, HIST1H2BB, CDK8, SFXN1, MGST3, COX4I1, PLGRKT, AURKAIP1, FUS, FAM175A, HUS1, BRCC3, UIMC1, TOPBP1, TP53BP1, ATR, BABAM1, BRE, RAD50, CDKN1A, ZEB1, NBN, RAD9A, MRE11A, RAD1, POT1, OBFC1, TINF2, MAD2L2, SETX, ARID1A, SLX4, CREBBP, ERCC4, ZNF207, GTF2H1, ATRIP, RECQL, ARID1B, RHNO1, HNRNPA2B1, ERCC1, RNF169, TERF1, ACD, TLK1, RECQL5, HNRNPUL1, GTF2H3, BARD1, WRNIP1, ERCC3, TERF2, CTC1, ATF3, SMC5, MUS81, JMJD1C, SMN1, BRCA2, MNAT1, C11orf30, ZNF827, NDNL2, SFPQ, USP34, GTF2H4, HMBOX1, USP3, PIAS3, NSMCE1, UBR5, PSPC1, PSMD14, CIRBP, NONO, BUB3, RAD52, MAU2, EP400, AEN, AKAP8L, ANXA11, ANXA7, API5, ASH2L, ASUN, EWSR1, BHLHE40, C18orf25, CABIN1, CARM1, KHSRP, SUMO1, CCDC101, CCNC, CD2BP2, CDK19, ZNF451, CPSF6, CPSF7, CSTF3, CXorf67, DAZAP1, DBR1, DDX20, DDX39B, DDX42, DDX46, DGCR8, DHX38, PML, DIS3, DNPEP, DPY30, ILF2, EGR1, ETV6, EXOSC5, FAM103A1, FAM98B, SMARCC1, SMARCC2, TRIM33, FBXO22, FUBP1, GEMIN4, GTF2IRD1, GTF3C1, GTF3C3, GTF3C4, GTF3C5, HEXIM1, HNRNPAB, HNRNPD, HNRNPDL, HSPA1A, IFI16, INTS9, KAT2A, ZBTB48, LSM3, LSM4, HIRA, SMARCB1, MBNL1, MDN1, MED1, MED10, MED12, MED13, MED13L, MED14, ILF3, MED15, MED17, MED18, MED20, SMARCE1, MED22, MED25, MED27, MED30, MED31, MED4, MED6, SF3B1, MED7, MED8, MED9, MORC3, MSANTD3, NELFB, NFIC, NOSIP, NR2C1, NR2C2, NSUN2, NUDT21, SMARCD2, OGT, PARN, PPM1G, PPP1R10, PPP1R8, PRAME, PRCC, PRR12, PSMC1, PSMC3, PSMC4, PSMD13, PSMD2, PSMD4, PSMD6, PSME3, PTGS2, RAD54L2, RBM10, RBM5, RFX1, RNGTT, RNMT, INTS3, SAGE1, SAP130, SETD1A, SIN3A, SLX4IP, SNAPC1, SP110, SRRT, SS18L1, TADA1, TADA3, TAF10, TAF15, TAF5L, TAF6L, TCEB2, TCF12, TEX10, THOC2, THOC7, TOPORS, TRIM22, TRMT1L, TRMT2A, TSPYL1, UPP1, VWA9, WDR26, WTAP, ZBTB2, ZBTB25, ZBTB9, ZC3H4, ZFC3H1, ZFR, ZHX2, ZNF316, ZNF609, ZZZ3, KIAA1429, KDM2A, E2F4, RBL1, RBL2, SIRT3, PPP5C, EXOC4, ACTC1, ESR1, C20orf196, RAD51, SCAI, MAP1LC3A, PELI1, ANKS1A, PITX1, POU6F2, BCL6, KLHDC7B, UBAP2, CREB5, CCDC120, OXER1, TLX3, HGS, C10orf55, CIC, NUDT16, PARP1, Arrb1, ARRB1, PTEN, DNAJB6, SLIT2, RPS21, CSNK1E, HIST1H1T, PIP4K2A, METTL1, BCKDK, SPRR2E, TMA16, LRPAP1, PHF6, DDX58, HIST1H2AB, SKA3, NAA40, DYNLL2, CDKN3, SLFN11, KIFAP3, BIRC5, TOP3B, CTSL, nsp15, nsp9, ORF7b, TOLLIP, SIRT6, Paxip1, MEF2A, SPOP, NPLOC4, RB1CC1, Kpna2, |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| TP53BP1 |  |
| PDGFRB |  |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to TP53BP1-PDGFRB |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to TP53BP1-PDGFRB |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | TP53BP1 | C0006142 | Malignant neoplasm of breast | 1 | CTD_human |
| Hgene | TP53BP1 | C0007102 | Malignant tumor of colon | 1 | CTD_human |
| Hgene | TP53BP1 | C0007131 | Non-Small Cell Lung Carcinoma | 1 | CTD_human |
| Hgene | TP53BP1 | C0009375 | Colonic Neoplasms | 1 | CTD_human |
| Hgene | TP53BP1 | C0017636 | Glioblastoma | 1 | CTD_human |
| Hgene | TP53BP1 | C0024232 | Lymphatic Metastasis | 1 | CTD_human |
| Hgene | TP53BP1 | C0334588 | Giant Cell Glioblastoma | 1 | CTD_human |
| Hgene | TP53BP1 | C0678222 | Breast Carcinoma | 1 | CTD_human |
| Hgene | TP53BP1 | C0919267 | ovarian neoplasm | 1 | CTD_human |
| Hgene | TP53BP1 | C1140680 | Malignant neoplasm of ovary | 1 | CTD_human |
| Hgene | TP53BP1 | C1257931 | Mammary Neoplasms, Human | 1 | CTD_human |
| Hgene | TP53BP1 | C1458155 | Mammary Neoplasms | 1 | CTD_human |
| Hgene | TP53BP1 | C1621958 | Glioblastoma Multiforme | 1 | CTD_human |
| Hgene | TP53BP1 | C4704874 | Mammary Carcinoma, Human | 1 | CTD_human |
| Tgene | PDGFRB | C3554321 | BASAL GANGLIA CALCIFICATION, IDIOPATHIC, 4 | 6 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Tgene | PDGFRB | C0393590 | Fahr's syndrome (disorder) | 3 | GENOMICS_ENGLAND;ORPHANET |
| Tgene | PDGFRB | C4225270 | Kosaki overgrowth syndrome | 3 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Tgene | PDGFRB | C4551572 | MYOFIBROMATOSIS, INFANTILE, 1 | 3 | GENOMICS_ENGLAND;UNIPROT |
| Tgene | PDGFRB | C0013421 | Dystonia | 2 | GENOMICS_ENGLAND |
| Tgene | PDGFRB | C0023480 | Leukemia, Myelomonocytic, Chronic | 2 | ORPHANET |
| Tgene | PDGFRB | C0023893 | Liver Cirrhosis, Experimental | 2 | CTD_human |
| Tgene | PDGFRB | C0036341 | Schizophrenia | 2 | PSYGENET |
| Tgene | PDGFRB | C0432284 | Infantile myofibromatosis | 2 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Tgene | PDGFRB | C0004782 | Basal Ganglia Diseases | 1 | CTD_human |
| Tgene | PDGFRB | C0006663 | Calcinosis | 1 | CTD_human |
| Tgene | PDGFRB | C0015371 | Extrapyramidal Disorders | 1 | CTD_human |
| Tgene | PDGFRB | C0036337 | Schizoaffective Disorder | 1 | PSYGENET |
| Tgene | PDGFRB | C0206648 | Myofibromatosis | 1 | GENOMICS_ENGLAND |
| Tgene | PDGFRB | C0263628 | Tumoral calcinosis | 1 | CTD_human |
| Tgene | PDGFRB | C0521174 | Microcalcification | 1 | CTD_human |
| Tgene | PDGFRB | C0750951 | Lenticulostriate Disorders | 1 | CTD_human |
| Tgene | PDGFRB | C1333046 | Myeloproliferative Neoplasm, Unclassifiable | 1 | ORPHANET |
| Tgene | PDGFRB | C1866182 | Penttinen-Aula syndrome | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Tgene | PDGFRB | C3472621 | Myeloid neoplasm with beta-type platelet-derived growth factor receptor gene rearrangement | 1 | ORPHANET |
| Tgene | PDGFRB | C3714756 | Intellectual Disability | 1 | GENOMICS_ENGLAND |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies