| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:COL6A2-FUS |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: COL6A2-FUS | FusionPDB ID: 18435 | FusionGDB2.0 ID: 18435 | Hgene | Tgene | Gene symbol | COL6A2 | FUS | Gene ID | 1292 | 2521 |
| Gene name | collagen type VI alpha 2 chain | FUS RNA binding protein | |
| Synonyms | BTHLM1|PP3610|UCMD1 | ALS6|ETM4|FUS1|HNRNPP2|POMP75|TLS | |
| Cytomap | 21q22.3 | 16p11.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | collagen alpha-2(VI) chaincollagen VI, alpha-2 polypeptidecollagen, type VI, alpha 2epididymis secretory sperm binding proteinhuman mRNA for collagen VI alpha-2 C-terminal globular domain | RNA-binding protein FUS75 kDa DNA-pairing proteinfus-like proteinfused in sarcomafusion gene in myxoid liposarcomaheterogeneous nuclear ribonucleoprotein P2oncogene FUSoncogene TLStranslocated in liposarcoma protein | |
| Modification date | 20200328 | 20200329 | |
| UniProtAcc | P12110 | P35637 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000300527, ENST00000310645, ENST00000357838, ENST00000397763, ENST00000409416, ENST00000460886, | ENST00000474990, ENST00000254108, ENST00000380244, ENST00000568685, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 13 X 9 X 8=936 | 20 X 13 X 10=2600 |
| # samples | 13 | 22 | |
| ** MAII score | log2(13/936*10)=-2.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(22/2600*10)=-3.56293619439116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: COL6A2 [Title/Abstract] AND FUS [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | COL6A2(47546455)-FUS(31199645), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | COL6A2-FUS seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. COL6A2-FUS seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. COL6A2-FUS seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. COL6A2-FUS seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | FUS | GO:0006355 | regulation of transcription, DNA-templated | 26124092 |
| Tgene | FUS | GO:0006357 | regulation of transcription by RNA polymerase II | 25453086 |
| Tgene | FUS | GO:0008380 | RNA splicing | 26124092 |
| Tgene | FUS | GO:0043484 | regulation of RNA splicing | 25453086|27731383 |
| Tgene | FUS | GO:0048255 | mRNA stabilization | 27378374 |
| Tgene | FUS | GO:0051260 | protein homooligomerization | 25453086 |
| Tgene | FUS | GO:1905168 | positive regulation of double-strand break repair via homologous recombination | 10567410 |
| Fusion gene breakpoints across COL6A2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
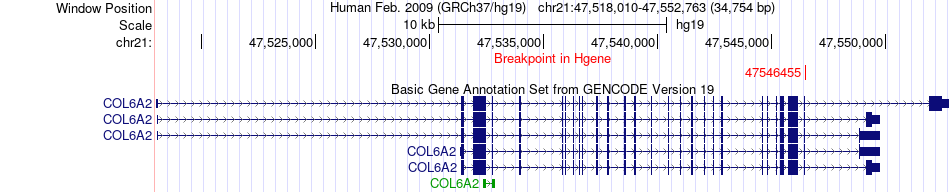 |
| Fusion gene breakpoints across FUS (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-FC-7961 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000300527 | COL6A2 | chr21 | 47546455 | + | ENST00000254108 | FUS | chr16 | 31199645 | + | 3715 | 2565 | 17 | 3346 | 1109 |
| ENST00000300527 | COL6A2 | chr21 | 47546455 | + | ENST00000380244 | FUS | chr16 | 31199645 | + | 3511 | 2565 | 17 | 3346 | 1109 |
| ENST00000300527 | COL6A2 | chr21 | 47546455 | + | ENST00000568685 | FUS | chr16 | 31199645 | + | 3487 | 2565 | 17 | 3349 | 1110 |
| ENST00000310645 | COL6A2 | chr21 | 47546455 | + | ENST00000254108 | FUS | chr16 | 31199645 | + | 3693 | 2543 | 82 | 3324 | 1080 |
| ENST00000310645 | COL6A2 | chr21 | 47546455 | + | ENST00000380244 | FUS | chr16 | 31199645 | + | 3489 | 2543 | 82 | 3324 | 1080 |
| ENST00000310645 | COL6A2 | chr21 | 47546455 | + | ENST00000568685 | FUS | chr16 | 31199645 | + | 3465 | 2543 | 82 | 3327 | 1081 |
| ENST00000357838 | COL6A2 | chr21 | 47546455 | + | ENST00000254108 | FUS | chr16 | 31199645 | + | 3693 | 2543 | 82 | 3324 | 1080 |
| ENST00000357838 | COL6A2 | chr21 | 47546455 | + | ENST00000380244 | FUS | chr16 | 31199645 | + | 3489 | 2543 | 82 | 3324 | 1080 |
| ENST00000357838 | COL6A2 | chr21 | 47546455 | + | ENST00000568685 | FUS | chr16 | 31199645 | + | 3465 | 2543 | 82 | 3327 | 1081 |
| ENST00000409416 | COL6A2 | chr21 | 47546455 | + | ENST00000254108 | FUS | chr16 | 31199645 | + | 3674 | 2524 | 0 | 3305 | 1101 |
| ENST00000409416 | COL6A2 | chr21 | 47546455 | + | ENST00000380244 | FUS | chr16 | 31199645 | + | 3470 | 2524 | 0 | 3305 | 1101 |
| ENST00000409416 | COL6A2 | chr21 | 47546455 | + | ENST00000568685 | FUS | chr16 | 31199645 | + | 3446 | 2524 | 0 | 3308 | 1102 |
| ENST00000397763 | COL6A2 | chr21 | 47546455 | + | ENST00000254108 | FUS | chr16 | 31199645 | + | 3638 | 2488 | 27 | 3269 | 1080 |
| ENST00000397763 | COL6A2 | chr21 | 47546455 | + | ENST00000380244 | FUS | chr16 | 31199645 | + | 3434 | 2488 | 27 | 3269 | 1080 |
| ENST00000397763 | COL6A2 | chr21 | 47546455 | + | ENST00000568685 | FUS | chr16 | 31199645 | + | 3410 | 2488 | 27 | 3272 | 1081 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000300527 | ENST00000254108 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000907059 | 0.99909294 |
| ENST00000300527 | ENST00000380244 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.001006905 | 0.9989931 |
| ENST00000300527 | ENST00000568685 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000959199 | 0.9990408 |
| ENST00000310645 | ENST00000254108 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000901891 | 0.9990982 |
| ENST00000310645 | ENST00000380244 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.001005827 | 0.9989942 |
| ENST00000310645 | ENST00000568685 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000954204 | 0.9990458 |
| ENST00000357838 | ENST00000254108 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000901891 | 0.9990982 |
| ENST00000357838 | ENST00000380244 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.001005827 | 0.9989942 |
| ENST00000357838 | ENST00000568685 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000954204 | 0.9990458 |
| ENST00000409416 | ENST00000254108 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000880113 | 0.99911994 |
| ENST00000409416 | ENST00000380244 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000976531 | 0.99902344 |
| ENST00000409416 | ENST00000568685 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000939693 | 0.99906033 |
| ENST00000397763 | ENST00000254108 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000845627 | 0.9991543 |
| ENST00000397763 | ENST00000380244 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000939097 | 0.9990609 |
| ENST00000397763 | ENST00000568685 | COL6A2 | chr21 | 47546455 | + | FUS | chr16 | 31199645 | + | 0.000906848 | 0.9990932 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >18435_18435_1_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000300527_FUS_chr16_31199645_ENST00000254108_length(amino acids)=1109AA_BP=965 MLLTRRPRLGPSGAEPPRDQDFRATGAAKMLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQS PTDILLFHMKQFVPQFISQLQNEFYLDQVALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSK GTVHFAVVITDGHVTGSPCGGIKLQAERAREEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHE AYGECYKVSCLEIPGPSGPKGYRGQKGAKGNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDG QKGKLGRIGPPGCKGDPGNRGPDGYPGEAGSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKG EPGRRGDPGTKGSPGSDGPKGEKGDPGPEGPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPG RPGFSYPGPRGAPGEKGEPGPRGPEGGRGDFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRET CGCCDCEKRCGALDVVFVIDSSESIGYTNFTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAV KNLEWIAGGTWTPSALKFAYDRLIKESRRQKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQ QVRNMTLFSDLVAEKFIDDMEDVLCPDPQIVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKT GQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGR GGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGG -------------------------------------------------------------- >18435_18435_2_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000300527_FUS_chr16_31199645_ENST00000380244_length(amino acids)=1109AA_BP=965 MLLTRRPRLGPSGAEPPRDQDFRATGAAKMLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQS PTDILLFHMKQFVPQFISQLQNEFYLDQVALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSK GTVHFAVVITDGHVTGSPCGGIKLQAERAREEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHE AYGECYKVSCLEIPGPSGPKGYRGQKGAKGNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDG QKGKLGRIGPPGCKGDPGNRGPDGYPGEAGSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKG EPGRRGDPGTKGSPGSDGPKGEKGDPGPEGPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPG RPGFSYPGPRGAPGEKGEPGPRGPEGGRGDFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRET CGCCDCEKRCGALDVVFVIDSSESIGYTNFTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAV KNLEWIAGGTWTPSALKFAYDRLIKESRRQKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQ QVRNMTLFSDLVAEKFIDDMEDVLCPDPQIVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKT GQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGR GGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGG -------------------------------------------------------------- >18435_18435_3_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000300527_FUS_chr16_31199645_ENST00000568685_length(amino acids)=1110AA_BP=966 MLLTRRPRLGPSGAEPPRDQDFRATGAAKMLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQS PTDILLFHMKQFVPQFISQLQNEFYLDQVALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSK GTVHFAVVITDGHVTGSPCGGIKLQAERAREEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHE AYGECYKVSCLEIPGPSGPKGYRGQKGAKGNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDG QKGKLGRIGPPGCKGDPGNRGPDGYPGEAGSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKG EPGRRGDPGTKGSPGSDGPKGEKGDPGPEGPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPG RPGFSYPGPRGAPGEKGEPGPRGPEGGRGDFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRET CGCCDCEKRCGALDVVFVIDSSESIGYTNFTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAV KNLEWIAGGTWTPSALKFAYDRLIKESRRQKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQ QVRNMTLFSDLVAEKFIDDMEDVLCPDPQIVCPDLPCQTGPRDQGSRHDSAEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKK TGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGG RGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRG -------------------------------------------------------------- >18435_18435_4_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000310645_FUS_chr16_31199645_ENST00000254108_length(amino acids)=1080AA_BP=936 MLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFHMKQFVPQFISQLQNEFYLDQV ALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVVITDGHVTGSPCGGIKLQAERA REEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKVSCLEIPGPSGPKGYRGQKGAK GNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRIGPPGCKGDPGNRGPDGYPGEA GSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDPGTKGSPGSDGPKGEKGDPGPE GPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPGPRGAPGEKGEPGPRGPEGGRG DFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEKRCGALDVVFVIDSSESIGYTN FTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAGGTWTPSALKFAYDRLIKESRR QKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLFSDLVAEKFIDDMEDVLCPDPQ IVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPS AKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENM NFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGEHRQDRRERPY -------------------------------------------------------------- >18435_18435_5_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000310645_FUS_chr16_31199645_ENST00000380244_length(amino acids)=1080AA_BP=936 MLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFHMKQFVPQFISQLQNEFYLDQV ALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVVITDGHVTGSPCGGIKLQAERA REEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKVSCLEIPGPSGPKGYRGQKGAK GNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRIGPPGCKGDPGNRGPDGYPGEA GSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDPGTKGSPGSDGPKGEKGDPGPE GPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPGPRGAPGEKGEPGPRGPEGGRG DFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEKRCGALDVVFVIDSSESIGYTN FTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAGGTWTPSALKFAYDRLIKESRR QKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLFSDLVAEKFIDDMEDVLCPDPQ IVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPS AKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENM NFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGEHRQDRRERPY -------------------------------------------------------------- >18435_18435_6_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000310645_FUS_chr16_31199645_ENST00000568685_length(amino acids)=1081AA_BP=937 MLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFHMKQFVPQFISQLQNEFYLDQV ALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVVITDGHVTGSPCGGIKLQAERA REEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKVSCLEIPGPSGPKGYRGQKGAK GNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRIGPPGCKGDPGNRGPDGYPGEA GSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDPGTKGSPGSDGPKGEKGDPGPE GPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPGPRGAPGEKGEPGPRGPEGGRG DFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEKRCGALDVVFVIDSSESIGYTN FTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAGGTWTPSALKFAYDRLIKESRR QKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLFSDLVAEKFIDDMEDVLCPDPQ IVCPDLPCQTGPRDQGSRHDSAEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPP SAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCEN MNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGEHRQDRRERP -------------------------------------------------------------- >18435_18435_7_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000357838_FUS_chr16_31199645_ENST00000254108_length(amino acids)=1080AA_BP=936 MLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFHMKQFVPQFISQLQNEFYLDQV ALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVVITDGHVTGSPCGGIKLQAERA REEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKVSCLEIPGPSGPKGYRGQKGAK GNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRIGPPGCKGDPGNRGPDGYPGEA GSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDPGTKGSPGSDGPKGEKGDPGPE GPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPGPRGAPGEKGEPGPRGPEGGRG DFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEKRCGALDVVFVIDSSESIGYTN FTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAGGTWTPSALKFAYDRLIKESRR QKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLFSDLVAEKFIDDMEDVLCPDPQ IVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPS AKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENM NFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGEHRQDRRERPY -------------------------------------------------------------- >18435_18435_8_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000357838_FUS_chr16_31199645_ENST00000380244_length(amino acids)=1080AA_BP=936 MLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFHMKQFVPQFISQLQNEFYLDQV ALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVVITDGHVTGSPCGGIKLQAERA REEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKVSCLEIPGPSGPKGYRGQKGAK GNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRIGPPGCKGDPGNRGPDGYPGEA GSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDPGTKGSPGSDGPKGEKGDPGPE GPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPGPRGAPGEKGEPGPRGPEGGRG DFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEKRCGALDVVFVIDSSESIGYTN FTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAGGTWTPSALKFAYDRLIKESRR QKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLFSDLVAEKFIDDMEDVLCPDPQ IVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPS AKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENM NFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGEHRQDRRERPY -------------------------------------------------------------- >18435_18435_9_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000357838_FUS_chr16_31199645_ENST00000568685_length(amino acids)=1081AA_BP=937 MLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFHMKQFVPQFISQLQNEFYLDQV ALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVVITDGHVTGSPCGGIKLQAERA REEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKVSCLEIPGPSGPKGYRGQKGAK GNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRIGPPGCKGDPGNRGPDGYPGEA GSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDPGTKGSPGSDGPKGEKGDPGPE GPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPGPRGAPGEKGEPGPRGPEGGRG DFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEKRCGALDVVFVIDSSESIGYTN FTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAGGTWTPSALKFAYDRLIKESRR QKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLFSDLVAEKFIDDMEDVLCPDPQ IVCPDLPCQTGPRDQGSRHDSAEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPP SAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCEN MNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGEHRQDRRERP -------------------------------------------------------------- >18435_18435_10_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000397763_FUS_chr16_31199645_ENST00000254108_length(amino acids)=1080AA_BP=936 MLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFHMKQFVPQFISQLQNEFYLDQV ALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVVITDGHVTGSPCGGIKLQAERA REEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKVSCLEIPGPSGPKGYRGQKGAK GNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRIGPPGCKGDPGNRGPDGYPGEA GSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDPGTKGSPGSDGPKGEKGDPGPE GPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPGPRGAPGEKGEPGPRGPEGGRG DFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEKRCGALDVVFVIDSSESIGYTN FTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAGGTWTPSALKFAYDRLIKESRR QKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLFSDLVAEKFIDDMEDVLCPDPQ IVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPS AKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENM NFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGEHRQDRRERPY -------------------------------------------------------------- >18435_18435_11_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000397763_FUS_chr16_31199645_ENST00000380244_length(amino acids)=1080AA_BP=936 MLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFHMKQFVPQFISQLQNEFYLDQV ALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVVITDGHVTGSPCGGIKLQAERA REEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKVSCLEIPGPSGPKGYRGQKGAK GNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRIGPPGCKGDPGNRGPDGYPGEA GSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDPGTKGSPGSDGPKGEKGDPGPE GPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPGPRGAPGEKGEPGPRGPEGGRG DFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEKRCGALDVVFVIDSSESIGYTN FTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAGGTWTPSALKFAYDRLIKESRR QKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLFSDLVAEKFIDDMEDVLCPDPQ IVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPS AKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENM NFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGEHRQDRRERPY -------------------------------------------------------------- >18435_18435_12_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000397763_FUS_chr16_31199645_ENST00000568685_length(amino acids)=1081AA_BP=937 MLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFHMKQFVPQFISQLQNEFYLDQV ALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVVITDGHVTGSPCGGIKLQAERA REEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKVSCLEIPGPSGPKGYRGQKGAK GNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRIGPPGCKGDPGNRGPDGYPGEA GSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDPGTKGSPGSDGPKGEKGDPGPE GPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPGPRGAPGEKGEPGPRGPEGGRG DFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEKRCGALDVVFVIDSSESIGYTN FTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAGGTWTPSALKFAYDRLIKESRR QKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLFSDLVAEKFIDDMEDVLCPDPQ IVCPDLPCQTGPRDQGSRHDSAEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPP SAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCEN MNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGEHRQDRRERP -------------------------------------------------------------- >18435_18435_13_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000409416_FUS_chr16_31199645_ENST00000254108_length(amino acids)=1101AA_BP=957 LGVSERPPPLLQDFRATGAAKMLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFH MKQFVPQFISQLQNEFYLDQVALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVV ITDGHVTGSPCGGIKLQAERAREEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKV SCLEIPGPSGPKGYRGQKGAKGNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRI GPPGCKGDPGNRGPDGYPGEAGSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDP GTKGSPGSDGPKGEKGDPGPEGPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPG PRGAPGEKGEPGPRGPEGGRGDFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEK RCGALDVVFVIDSSESIGYTNFTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAG GTWTPSALKFAYDRLIKESRRQKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLF SDLVAEKFIDDMEDVLCPDPQIVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLY TDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGG GGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGG -------------------------------------------------------------- >18435_18435_14_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000409416_FUS_chr16_31199645_ENST00000380244_length(amino acids)=1101AA_BP=957 LGVSERPPPLLQDFRATGAAKMLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFH MKQFVPQFISQLQNEFYLDQVALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVV ITDGHVTGSPCGGIKLQAERAREEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKV SCLEIPGPSGPKGYRGQKGAKGNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRI GPPGCKGDPGNRGPDGYPGEAGSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDP GTKGSPGSDGPKGEKGDPGPEGPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPG PRGAPGEKGEPGPRGPEGGRGDFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEK RCGALDVVFVIDSSESIGYTNFTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAG GTWTPSALKFAYDRLIKESRRQKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLF SDLVAEKFIDDMEDVLCPDPQIVCPDLPCQTGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLY TDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGG GGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGG -------------------------------------------------------------- >18435_18435_15_COL6A2-FUS_COL6A2_chr21_47546455_ENST00000409416_FUS_chr16_31199645_ENST00000568685_length(amino acids)=1102AA_BP=958 LGVSERPPPLLQDFRATGAAKMLQGTCSVLLLWGILGAIQAQQQEVISPDTTERNNNCPEKTDCPIHVYFVLDTSESVTMQSPTDILLFH MKQFVPQFISQLQNEFYLDQVALSWRYGGLHFSDQVEVFSPPGSDRASFIKNLQGISSFRRGTFTDCALANMTEQIRQDRSKGTVHFAVV ITDGHVTGSPCGGIKLQAERAREEGIRLFAVAPNQNLKEQGLRDIASTPHELYRNDYATMLPDSTEIDQDTINRIIKVMKHEAYGECYKV SCLEIPGPSGPKGYRGQKGAKGNMGEPGEPGQKGRQGDPGIEGPIGFPGPKGVPGFKGEKGEFGADGRKGAPGLAGKNGTDGQKGKLGRI GPPGCKGDPGNRGPDGYPGEAGSPGERGDQGGKGDPGRPGRRGPPGEIGAKGSKGYQGNSGAPGSPGVKGAKGGPGPRGPKGEPGRRGDP GTKGSPGSDGPKGEKGDPGPEGPRGLAGEVGNKGAKGDRGLPGPRGPQGALGEPGKQGSRGDPGDAGPRGDSGQPGPKGDPGRPGFSYPG PRGAPGEKGEPGPRGPEGGRGDFGLKGEPGRKGEKGEPADPGPPGEPGPRGPRGVPGPEGEPGPPGDPGLTECDVMTYVRETCGCCDCEK RCGALDVVFVIDSSESIGYTNFTLEKNFVINVVNRLGAIAKDPKSETGTRVGVVQYSHEGTFEAIQLDDERIDSLSSFKEAVKNLEWIAG GTWTPSALKFAYDRLIKESRRQKTRVFAVVITDGRHDPRDDDLNLRALCDRDVTVTAIGIGDMFHEKHESENLYSIACDKPQQVRNMTLF SDLVAEKFIDDMEDVLCPDPQIVCPDLPCQTGPRDQGSRHDSAEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINL YTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGG GGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRG -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr21:47546455/chr16:31199645) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| COL6A2 | FUS |
| FUNCTION: Collagen VI acts as a cell-binding protein. | FUNCTION: DNA/RNA-binding protein that plays a role in various cellular processes such as transcription regulation, RNA splicing, RNA transport, DNA repair and damage response (PubMed:27731383). Binds to nascent pre-mRNAs and acts as a molecular mediator between RNA polymerase II and U1 small nuclear ribonucleoprotein thereby coupling transcription and splicing (PubMed:26124092). Binds also its own pre-mRNA and autoregulates its expression; this autoregulation mechanism is mediated by non-sense-mediated decay (PubMed:24204307). Plays a role in DNA repair mechanisms by promoting D-loop formation and homologous recombination during DNA double-strand break repair (PubMed:10567410). In neuronal cells, plays crucial roles in dendritic spine formation and stability, RNA transport, mRNA stability and synaptic homeostasis (By similarity). {ECO:0000250|UniProtKB:P56959, ECO:0000269|PubMed:10567410, ECO:0000269|PubMed:24204307, ECO:0000269|PubMed:26124092, ECO:0000269|PubMed:27731383}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 46_234 | 820.3333333333334 | 1020.0 | Domain | VWFA 1 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 615_805 | 820.3333333333334 | 1020.0 | Domain | VWFA 2 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 46_234 | 820.3333333333334 | 829.0 | Domain | VWFA 1 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 615_805 | 820.3333333333334 | 829.0 | Domain | VWFA 2 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 46_234 | 820.3333333333334 | 919.0 | Domain | VWFA 1 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 615_805 | 820.3333333333334 | 919.0 | Domain | VWFA 2 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 46_234 | 820.3333333333334 | 919.0 | Domain | VWFA 1 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 615_805 | 820.3333333333334 | 919.0 | Domain | VWFA 2 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 46_234 | 820.3333333333334 | 829.0 | Domain | VWFA 1 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 615_805 | 820.3333333333334 | 829.0 | Domain | VWFA 2 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 366_368 | 820.3333333333334 | 1020.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 426_428 | 820.3333333333334 | 1020.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 489_491 | 820.3333333333334 | 1020.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 498_500 | 820.3333333333334 | 1020.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 539_541 | 820.3333333333334 | 1020.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 366_368 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 426_428 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 489_491 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 498_500 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 539_541 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 366_368 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 426_428 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 489_491 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 498_500 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 539_541 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 366_368 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 426_428 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 489_491 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 498_500 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 539_541 | 820.3333333333334 | 919.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 366_368 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 426_428 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 489_491 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 498_500 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 539_541 | 820.3333333333334 | 829.0 | Motif | Cell attachment site |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 21_256 | 820.3333333333334 | 1020.0 | Region | Note=Nonhelical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 257_590 | 820.3333333333334 | 1020.0 | Region | Note=Triple-helical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 21_256 | 820.3333333333334 | 829.0 | Region | Note=Nonhelical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 257_590 | 820.3333333333334 | 829.0 | Region | Note=Triple-helical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 21_256 | 820.3333333333334 | 919.0 | Region | Note=Nonhelical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 257_590 | 820.3333333333334 | 919.0 | Region | Note=Triple-helical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 21_256 | 820.3333333333334 | 919.0 | Region | Note=Nonhelical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 257_590 | 820.3333333333334 | 919.0 | Region | Note=Triple-helical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 21_256 | 820.3333333333334 | 829.0 | Region | Note=Nonhelical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 257_590 | 820.3333333333334 | 829.0 | Region | Note=Triple-helical region |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000254108 | 6 | 15 | 371_526 | 266.3333333333333 | 527.0 | Compositional bias | Note=Arg/Gly-rich | |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000380244 | 6 | 15 | 371_526 | 265.3333333333333 | 526.0 | Compositional bias | Note=Arg/Gly-rich | |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000254108 | 6 | 15 | 285_371 | 266.3333333333333 | 527.0 | Domain | RRM | |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000380244 | 6 | 15 | 285_371 | 265.3333333333333 | 526.0 | Domain | RRM | |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000254108 | 6 | 15 | 422_453 | 266.3333333333333 | 527.0 | Zinc finger | RanBP2-type | |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000380244 | 6 | 15 | 422_453 | 265.3333333333333 | 526.0 | Zinc finger | RanBP2-type |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 833_1014 | 820.3333333333334 | 1020.0 | Domain | VWFA 3 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 833_1014 | 820.3333333333334 | 829.0 | Domain | VWFA 3 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 833_1014 | 820.3333333333334 | 919.0 | Domain | VWFA 3 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 833_1014 | 820.3333333333334 | 919.0 | Domain | VWFA 3 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 833_1014 | 820.3333333333334 | 829.0 | Domain | VWFA 3 |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000300527 | + | 27 | 28 | 591_1019 | 820.3333333333334 | 1020.0 | Region | Note=Nonhelical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000310645 | + | 27 | 28 | 591_1019 | 820.3333333333334 | 829.0 | Region | Note=Nonhelical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000357838 | + | 27 | 28 | 591_1019 | 820.3333333333334 | 919.0 | Region | Note=Nonhelical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000397763 | + | 26 | 27 | 591_1019 | 820.3333333333334 | 919.0 | Region | Note=Nonhelical region |
| Hgene | COL6A2 | chr21:47546455 | chr16:31199645 | ENST00000409416 | + | 26 | 27 | 591_1019 | 820.3333333333334 | 829.0 | Region | Note=Nonhelical region |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000254108 | 6 | 15 | 166_267 | 266.3333333333333 | 527.0 | Compositional bias | Note=Gly-rich | |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000254108 | 6 | 15 | 1_165 | 266.3333333333333 | 527.0 | Compositional bias | Note=Gln/Gly/Ser/Tyr-rich | |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000380244 | 6 | 15 | 166_267 | 265.3333333333333 | 526.0 | Compositional bias | Note=Gly-rich | |
| Tgene | FUS | chr21:47546455 | chr16:31199645 | ENST00000380244 | 6 | 15 | 1_165 | 265.3333333333333 | 526.0 | Compositional bias | Note=Gln/Gly/Ser/Tyr-rich |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| FUS | EIF6, USF2, PRMT1, PTBP2, SRRM1, SPI1, YBX1, ILF3, SF1, SRSF10, THRA, RXRA, RELA, OTUB1, ZMYM2, SARNP, TARDBP, Mapk13, DGCR8, Pds5a, Shoc2, Ccdc15, PCM1, SF3A2, SIRT7, SQSTM1, TDRD3, CUL3, CUL4A, CUL4B, CUL5, CUL2, CDK2, CUL1, COPS5, COPS6, DCUN1D1, CAND1, NEDD8, ARHGEF28, PA2G4, UBE2I, ATXN1L, GRB2, PIK3R2, HNRNPA3, NONO, EEF1A1, DYNC1H1, GSE1, MBD3, MRPS18B, SAP30BP, RPLP1, ESR1, FN1, VCAM1, TP63, IL7R, UBL4A, ITGA4, CTNNB1, ECM32, NAM8, SBP1, SKO1, VHR1, UPF1, LMNA, EWSR1, RBMX, PSMB7, ESRRA, MDH1, TAF15, SRSF9, SAFB2, TNIP1, KHDRBS3, NKD2, MAX, PARK2, SUV39H1, WBP4, HNRNPU, LARS, rev, RPA3, RPA2, RPA1, WWOX, HSPA5, VCP, SFPQ, YWHAZ, YWHAQ, PFN1, FASN, PGK1, CKB, ENO1, LDHB, PAICS, PHGDH, LDHA, GAPDH, PKM, ATXN2L, MTHFD1, ACACA, CA2, ALDOA, GPI, PYCRL, PFKL, PGM1, ABCA1, HPRT1, PM20D2, TKT, UBA1, PSMD12, CDH4, ANXA2P2, GNAS, PLCE1, TRPM4, SLC1A5, UBAP2, UBAP2L, LYZ, CKAP4, YPEL1, HIST4H4, H3F3A, H3F3B, HIST2H2BE, DDX42, HNRNPD, SYNCRIP, DHX40, SF3A1, SF3B3, SF3B4, SERBP1, FANCM, RAD54B, PCNA, PHB, TP73, RPL18, RPL9, RPS9, TBPL1, TRIP4, DNAJC10, SAE1, DLD, GOT2, ATP5A1, GSTP1, HARS2, SLC25A3, KPNA2, RAB7A, SPATA6, UACA, STATH, ANXA5, MAP3K3, UBC, TUBB, CFL1, TUBA1A, ACTB, HNRNPF, HNRNPH1, DHX15, CPSF6, SF3A3, HNRNPK, PSPC1, HNRNPL, RPS5, RPS8, RPL12, RPN2, EEF2, EEF1G, HSP90AA1, CCT5, CCT6A, HSP90AB1, CCT2, CCT4, HSP90B1, CCT3, CCT7, CCT8, HSPA8, PPIL4, TCP1, PDIA3, PPIA, SSBP1, GLUD1, ATP5B, HSPA9, ERAL1, TUFM, HSPD1, PYCR1, MDH2, ABCF2, KPNB1, PRDX1, ERP44, F7, ALB, ARMC6, ADCK5, CCDC88A, GPR101, ITK, DGKA, SLC22A11, HERC6, TUBA1B, MTSS1L, CEP112, COL18A1, SEC13, NAP1L1, SNRPD2, NCAPG2, RBBP4, FLJ22447, LSM12, NUDT21, DDX1, C14orf166, DDX5, HIVEP3, NCOA6, RAVER1, TCEB1, TXNL4B, TTI2, GEN1, RPL14, RPS14, NPM1, RPL11, RPL4, EIF4A1, PCBP2, ST13, NSDHL, MTAP, MAT2A, AHCY, OAT, BCS1L, SLC25A5, TIMM50, MYH10, GOLIM4, CSE1L, RAN, KLHL40, KLHL5, IGKV1-5, C6, GIMAP8, CDC5L, CEP78, DBF4B, AMOT, FAM71F1, MFGE8, FAM98A, C11orf70, RTCB, UFL1, LRRIQ4, NUPR1, CUL7, OBSL1, EZH2, SUZ12, BMI1, ABL1, CHEK1, SIK2, SRPK1, DBR1, LUZP4, UPF2, UPF3A, FAM58A, YEATS4, RPS6KB2, HNRNPA1, HSP104, FBXW11, ACAT1, ARMC1, C2orf49, DDX17, DNAJC7, EIF4H, AURKA, PTBP1, TOMM34, TXLNA, UFD1L, HNRNPDL, MEF2D, NAA50, NPLOC4, PFKP, PICALM, TARS, NTRK1, SCARNA22, TCF7L2, KIF22, EMC2, MATR3, MCM2, SNW1, RC3H1, EGFR, TRAF6, CRBN, KCTD6, RPS27, PSRC1, SMCO3, CYLD, TRIM25, BRCA1, HDAC6, WDR77, PCBP1, PPIE, YAP1, EFTUD2, AAR2, PIH1D1, NKX2-1, CHD3, CHD4, TNF, HEXIM1, MEPCE, LARP7, RUNX1, PPT1, CTDSPL2, AGR2, RECQL4, CDK9, ARID1A, SMARCA4, SMARCD1, DDIT3, SMARCC2, SMARCC1, SS18, SMARCB1, FLI1, TP53BP1, MDC1, METTL3, METTL14, KIAA1429, RC3H2, ATG16L1, LINC00470, AKT1, ACTC1, RBX1, MYC, MAPT, HIV2gp4, HIV2gp3, NR2C2, UBQLN2, HDAC2, ZFYVE21, XRCC6, DYNLT1, HIST1H4A, SNRNP70, SNRPA, SRSF1, SNRPB, SNRPC, SNRPD1, SNRPD3, RNU1-1, FUS, TRIM28, HNRNPA2B1, HNRNPR, PPP1R10, ILF2, DHX9, PABPC1, DDX3X, SRSF7, HNRNPM, HNRNPUL1, PABPC4, SF3B1, LARP1, PBRM1, THRAP3, MOV10, FAM120A, SKIV2L2, TOX, POLR2A, ELAVL1, SF3B2, STRBP, WDR82, HNRNPCL1, CCNT1, RBM14, U2SURP, DDX20, HIST1H1C, NUMA1, CCBL2, ZFR, ACIN1, CDC73, DDX23, SLTM, SRRT, IGF2BP3, ZC3H18, PRRC2A, HNRNPUL2, THOC1, AKAP8, BCLAF1, SRSF3, CHERP, INTS12, PAF1, PNN, PPFIA1, RBM10, SNRNP200, TOE1, TRA2B, HNRNPC, HNRNPA0, PPP1CC, CCAR1, DDX21, HNRNPAB, INTS6, POLR2B, PRPF6, RALY, RBM25, RBM7, SAFB, THOC5, XRN2, EBNA1BP2, HSPA1A, RBM39, STRAP, TRA2A, YBX3, ZCCHC8, GPATCH8, SMN1, SRSF5, CTR9, EIF4A3, GNL3, HNRNPH3, HP1BP3, NCBP1, PRPF19, RBM17, RRP9, THOC2, ZC3HAV1, EXOSC10, GEMIN6, XAB2, HSPB1, PABPN1, CAPRIN1, CCAR2, GEMIN4, INTS4, KHDRBS1, PLRG1, PRMT5, SRSF6, ZNF326, ADAR, ARID2, GEMIN5, PHF10, PURB, SMU1, TOX4, AQR, ITFG1, ARAF, BIRC3, NFX1, VPS15, VPS34, VPS38, VPS8, PEP3, VPS21, CDC48, UBX3, BRE5, UBP3, SOX2, EP300, CMTR1, ARIH2, PLEKHA4, PINK1, PRMT8, FANCD2, MIRLET7A1, MIRLET7A2, MIRLET7A3, MIRLET7B, MIRLET7C, MIRLET7D, MIRLET7E, MIRLET7F1, MIRLET7F2, MIRLET7G, MIRLET7I, MIR98, MIR1-1, MIR1-2, MIR7-1, MIR7-2, MIR7-3, MIR9-1, MIR9-2, MIR9-3, MIR10B, MIR15A, MIR15B, MIR16-1, MIR16-2, MIR17, MIR18A, MIR18B, MIR19A, MIR19B1, MIR19B2, MIR20A, MIR20B, MIR21, MIR25, MIR29A, MIR29B1, MIR29B2, MIR29C, MIR31, MIR34A, MIR34B, MIR34C, MIR92A1, MIR92A2, MIR93, MIR106A, MIR106B, MIR107, MIR122, MIR128-1, MIR128-2, MIR138-1, MIR138-2, MIR140, MIR141, MIR143, MIR145, MIR155, MIR199A1, MIR199A2, MIR200A, MIR200B, MIR200C, MIR205, MIR206, MIR214, MIR221, MIR222, MIR363, MIR429, MIR451A, ADAMTS9-AS2, MDM2, OPTN, PRKD1, HVCN1, CELF1, FUBP3, DUX4, DUX4L9, CIT, CHMP4B, ECT2, KIF14, KIF20A, KIF23, PRC1, MKI67, BRD4, NINL, RBM45, UCHL1, Apc2, FBP1, LGALS9, WDR76, EIF3F, CREBBP, vpr, RNF4, OGT, CD274, SPOP, DDRGK1, TP53, DDX39B, HIST1H2BG, USP15, FZR1, WDR5, NUDCD2, CPSF1, NUP43, BTF3, BSG, S, RCHY1, NBR1, BACH2, PDE4B, SIRT6, |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| COL6A2 | |
| FUS | 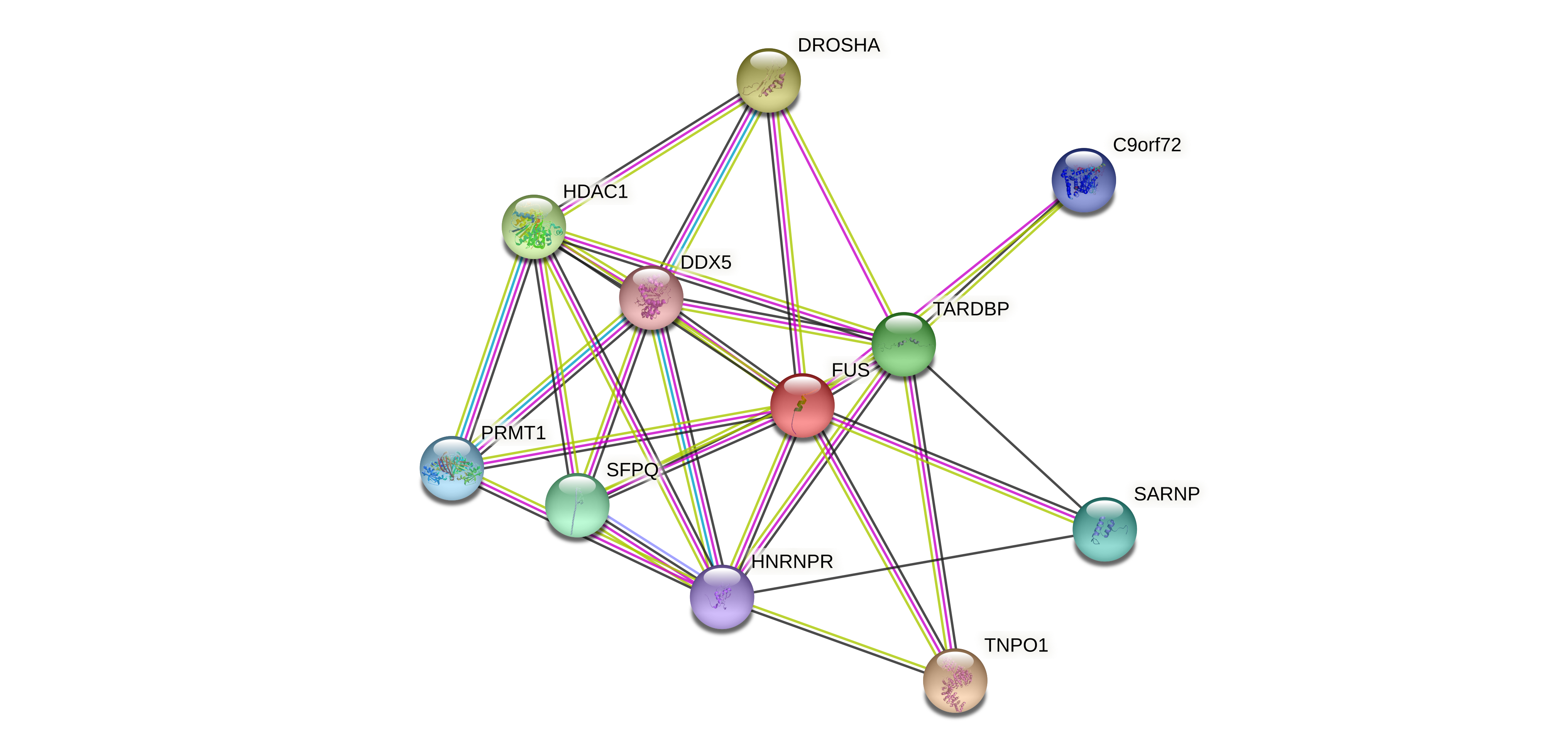 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to COL6A2-FUS |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to COL6A2-FUS |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | FUS | C1842675 | AMYOTROPHIC LATERAL SCLEROSIS 6 (disorder) | 5 | UNIPROT |
| Tgene | FUS | C3468114 | Juvenile amyotrophic lateral sclerosis | 5 | ORPHANET |
| Tgene | FUS | C0002736 | Amyotrophic Lateral Sclerosis | 2 | CTD_human;ORPHANET |
| Tgene | FUS | C0206634 | Liposarcoma, Myxoid | 2 | CTD_human;ORPHANET |
| Tgene | FUS | C0393554 | Amyotrophic Lateral Sclerosis With Dementia | 1 | CTD_human |
| Tgene | FUS | C0497327 | Dementia | 1 | GENOMICS_ENGLAND |
| Tgene | FUS | C0543859 | Amyotrophic Lateral Sclerosis, Guam Form | 1 | CTD_human |
| Tgene | FUS | C3539195 | TREMOR, HEREDITARY ESSENTIAL, 4 | 1 | CTD_human;UNIPROT |
| Tgene | FUS | C3888102 | Frontotemporal Dementia With Motor Neuron Disease | 1 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies