| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:CUX1-THSD7A |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: CUX1-THSD7A | FusionPDB ID: 20745 | FusionGDB2.0 ID: 20745 | Hgene | Tgene | Gene symbol | CUX1 | THSD7A | Gene ID | 1523 | 221981 |
| Gene name | cut like homeobox 1 | thrombospondin type 1 domain containing 7A | |
| Synonyms | CASP|CDP|CDP/Cut|CDP1|COY1|CUTL1|CUX|Clox|Cux/CDP|GDDI|GOLIM6|Nbla10317|p100|p110|p200|p75 | - | |
| Cytomap | 7q22.1 | 7p21.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | protein CASPHomeobox protein cut-like 1CCAAT displacement proteinCUX1 gene Alternatively Spliced Productcut homologgolgi integral membrane protein 6homeobox protein cux-1putative protein product of Nbla10317 | thrombospondin type-1 domain-containing protein 7Athrombospondin, type I, domain containing 7A | |
| Modification date | 20200320 | 20200322 | |
| UniProtAcc | P39880 | . | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000560541, ENST00000292535, ENST00000292538, ENST00000360264, ENST00000393824, ENST00000425244, ENST00000437600, ENST00000546411, ENST00000547394, ENST00000549414, ENST00000550008, ENST00000556210, | ENST00000423059, ENST00000480061, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 32 X 26 X 13=10816 | 7 X 7 X 5=245 |
| # samples | 37 | 7 | |
| ** MAII score | log2(37/10816*10)=-4.86949797576587 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/245*10)=-1.8073549220576 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: CUX1 [Title/Abstract] AND THSD7A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | CUX1(101713697)-THSD7A(11676588), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | CUX1-THSD7A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CUX1-THSD7A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CUX1-THSD7A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CUX1-THSD7A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across CUX1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
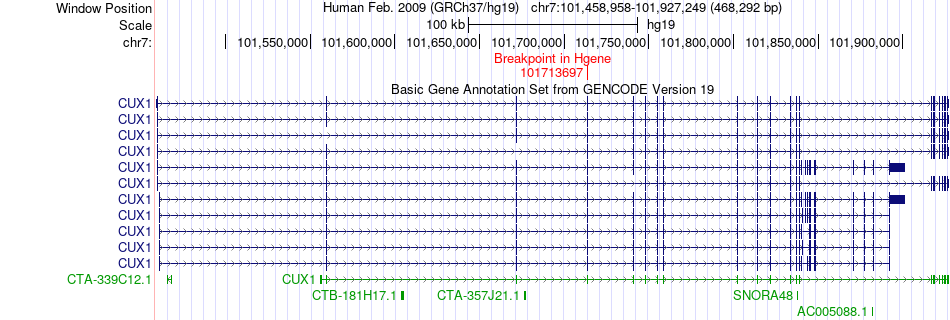 |
| Fusion gene breakpoints across THSD7A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
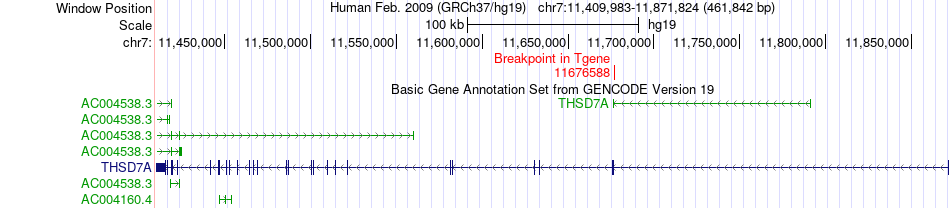 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-CV-6961-01A | CUX1 | chr7 | 101713697 | - | THSD7A | chr7 | 11676588 | - |
| ChimerDB4 | HNSC | TCGA-CV-6961-01A | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000437600 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10874 | 653 | 352 | 5436 | 1694 |
| ENST00000292538 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10548 | 327 | 26 | 5110 | 1694 |
| ENST00000393824 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10434 | 213 | 23 | 4996 | 1657 |
| ENST00000547394 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10496 | 275 | 22 | 5058 | 1678 |
| ENST00000360264 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10542 | 321 | 20 | 5104 | 1694 |
| ENST00000425244 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10532 | 311 | 10 | 5094 | 1694 |
| ENST00000292535 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10527 | 306 | 38 | 5089 | 1683 |
| ENST00000549414 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10489 | 268 | 0 | 5051 | 1683 |
| ENST00000556210 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10489 | 268 | 0 | 5051 | 1683 |
| ENST00000550008 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10489 | 268 | 0 | 5051 | 1683 |
| ENST00000546411 | CUX1 | chr7 | 101713697 | + | ENST00000423059 | THSD7A | chr7 | 11676588 | - | 10489 | 268 | 0 | 5051 | 1683 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000437600 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.00040224 | 0.9995977 |
| ENST00000292538 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000266156 | 0.99973387 |
| ENST00000393824 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000264938 | 0.99973506 |
| ENST00000547394 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000262052 | 0.9997379 |
| ENST00000360264 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000264637 | 0.9997353 |
| ENST00000425244 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000262179 | 0.9997378 |
| ENST00000292535 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000270461 | 0.9997296 |
| ENST00000549414 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000258994 | 0.999741 |
| ENST00000556210 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000258994 | 0.999741 |
| ENST00000550008 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000258994 | 0.999741 |
| ENST00000546411 | ENST00000423059 | CUX1 | chr7 | 101713697 | + | THSD7A | chr7 | 11676588 | - | 0.000258994 | 0.999741 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >20745_20745_1_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000292535_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1683AA_BP=89 MLCVAGARLKRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFLNVYKRLIDVPG PWGRCMGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKPLECIKGEEGIQ VREIACIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCPNLTEFQVCQSS PCEAEELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGYQTREVMCINKT GKAADLSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCLSQGDGVVPCAT YGWRTTEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQLCHIPCPTECE VSPWSAWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECGPGTQVQEVVCI NSDGEEVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSALQEVRSCNEHPC TVYHWQTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCIVTPYSDWTSCP SSCKEGDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGPGRQARAITCRK QDGGQAGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIETQYCPCDKYNAQ PVGNWSDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSNWSRCSKSCGSG VKVRSKWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNTADGPSEHVEDY LCDPEEMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYDYNVTDWSTCQL SEKAVCGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRTVTQPFQGDGRP CPSLMDQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVLEESCSQPCPGD CYLKDWSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWCQRSDGINVTGG CLVMSQPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPSSNPAGRGRTWF -------------------------------------------------------------- >20745_20745_2_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000292538_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1694AA_BP=100 MAANVGSMFQYWKRFDLQQLQRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFL NVYKRLIDVPGPWGRCMGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKP LECIKGEEGIQVREIACIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCP NLTEFQVCQSSPCEAEELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGY QTREVMCINKTGKAADLSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCL SQGDGVVPCATYGWRTTEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQ LCHIPCPTECEVSPWSAWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECG PGTQVQEVVCINSDGEEVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSAL QEVRSCNEHPCTVYHWQTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCI VTPYSDWTSCPSSCKEGDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGP GRQARAITCRKQDGGQAGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIET QYCPCDKYNAQPVGNWSDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSN WSRCSKSCGSGVKVRSKWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNT ADGPSEHVEDYLCDPEEMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYD YNVTDWSTCQLSEKAVCGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRT VTQPFQGDGRPCPSLMDQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVL EESCSQPCPGDCYLKDWSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWC QRSDGINVTGGCLVMSQPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPS -------------------------------------------------------------- >20745_20745_3_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000360264_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1694AA_BP=100 MAANVGSMFQYWKRFDLQQLQRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFL NVYKRLIDVPGPWGRCMGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKP LECIKGEEGIQVREIACIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCP NLTEFQVCQSSPCEAEELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGY QTREVMCINKTGKAADLSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCL SQGDGVVPCATYGWRTTEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQ LCHIPCPTECEVSPWSAWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECG PGTQVQEVVCINSDGEEVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSAL QEVRSCNEHPCTVYHWQTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCI VTPYSDWTSCPSSCKEGDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGP GRQARAITCRKQDGGQAGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIET QYCPCDKYNAQPVGNWSDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSN WSRCSKSCGSGVKVRSKWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNT ADGPSEHVEDYLCDPEEMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYD YNVTDWSTCQLSEKAVCGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRT VTQPFQGDGRPCPSLMDQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVL EESCSQPCPGDCYLKDWSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWC QRSDGINVTGGCLVMSQPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPS -------------------------------------------------------------- >20745_20745_4_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000393824_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1657AA_BP=63 MAANVGSMFQYWKRFDLQQLQDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFLNVYKRLIDVPGPWGRCMGDECGPGGIQTRAVWCAHVE GWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKPLECIKGEEGIQVREIACIQKDKDIPAEDIICEYFEPK PLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCPNLTEFQVCQSSPCEAEELRYSLHVGPWSTCSMPHSRQ VRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGYQTREVMCINKTGKAADLSFCQQEKLPMTFQSCVITKE CQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCLSQGDGVVPCATYGWRTTEWTECRVDPLLSQQDKRRGN QTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQLCHIPCPTECEVSPWSAWGPCTYENCNDQQGKKGFKL RKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECGPGTQVQEVVCINSDGEEVDRQLCRDAIFPIPVACDAP CPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSALQEVRSCNEHPCTVYHWQTGPWGQCIEDTSVSSFNTTT TWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCIVTPYSDWTSCPSSCKEGDSSIRKQSRHRVIIQLPANG GRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGPGRQARAITCRKQDGGQAGIHECLQYAGPVPALTQACQ IPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIETQYCPCDKYNAQPVGNWSDCILPEGKVEVLLGMKVQGD IKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSNWSRCSKSCGSGVKVRSKWLREKPYNGGRPCPKLDHVN QAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNTADGPSEHVEDYLCDPEEMPLGSRVCKLPCPEDCVISE WGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYDYNVTDWSTCQLSEKAVCGNGIKTRMLDCVRSDGKSVD LKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRTVTQPFQGDGRPCPSLMDQSKPCPVKPCYRWQYGQWSP CQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVLEESCSQPCPGDCYLKDWSSWSLCQLTCVNGEDLGFGG IQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWCQRSDGINVTGGCLVMSQPDADRSCNPPCSQPHSYCSE TKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPSSNPAGRGRTWFLQPFGPDGRLKTWVYGVAAGAFVLLI -------------------------------------------------------------- >20745_20745_5_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000425244_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1694AA_BP=100 MAANVGSMFQYWKRFDLQQLQRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFL NVYKRLIDVPGPWGRCMGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKP LECIKGEEGIQVREIACIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCP NLTEFQVCQSSPCEAEELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGY QTREVMCINKTGKAADLSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCL SQGDGVVPCATYGWRTTEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQ LCHIPCPTECEVSPWSAWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECG PGTQVQEVVCINSDGEEVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSAL QEVRSCNEHPCTVYHWQTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCI VTPYSDWTSCPSSCKEGDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGP GRQARAITCRKQDGGQAGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIET QYCPCDKYNAQPVGNWSDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSN WSRCSKSCGSGVKVRSKWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNT ADGPSEHVEDYLCDPEEMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYD YNVTDWSTCQLSEKAVCGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRT VTQPFQGDGRPCPSLMDQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVL EESCSQPCPGDCYLKDWSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWC QRSDGINVTGGCLVMSQPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPS -------------------------------------------------------------- >20745_20745_6_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000437600_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1694AA_BP=100 MAANVGSMFQYWKRFDLQQLQRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFL NVYKRLIDVPGPWGRCMGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKP LECIKGEEGIQVREIACIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCP NLTEFQVCQSSPCEAEELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGY QTREVMCINKTGKAADLSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCL SQGDGVVPCATYGWRTTEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQ LCHIPCPTECEVSPWSAWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECG PGTQVQEVVCINSDGEEVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSAL QEVRSCNEHPCTVYHWQTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCI VTPYSDWTSCPSSCKEGDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGP GRQARAITCRKQDGGQAGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIET QYCPCDKYNAQPVGNWSDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSN WSRCSKSCGSGVKVRSKWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNT ADGPSEHVEDYLCDPEEMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYD YNVTDWSTCQLSEKAVCGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRT VTQPFQGDGRPCPSLMDQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVL EESCSQPCPGDCYLKDWSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWC QRSDGINVTGGCLVMSQPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPS -------------------------------------------------------------- >20745_20745_7_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000546411_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1683AA_BP=89 MLCVAGARLKRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFLNVYKRLIDVPG PWGRCMGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKPLECIKGEEGIQ VREIACIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCPNLTEFQVCQSS PCEAEELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGYQTREVMCINKT GKAADLSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCLSQGDGVVPCAT YGWRTTEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQLCHIPCPTECE VSPWSAWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECGPGTQVQEVVCI NSDGEEVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSALQEVRSCNEHPC TVYHWQTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCIVTPYSDWTSCP SSCKEGDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGPGRQARAITCRK QDGGQAGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIETQYCPCDKYNAQ PVGNWSDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSNWSRCSKSCGSG VKVRSKWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNTADGPSEHVEDY LCDPEEMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYDYNVTDWSTCQL SEKAVCGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRTVTQPFQGDGRP CPSLMDQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVLEESCSQPCPGD CYLKDWSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWCQRSDGINVTGG CLVMSQPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPSSNPAGRGRTWF -------------------------------------------------------------- >20745_20745_8_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000547394_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1678AA_BP=84 MAANVGSMFQYWKRFDLQQLQRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEIDALSKRSKEAEAAFLNVYKRLIDVPGPWGRC MGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKPLECIKGEEGIQVREIA CIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCPNLTEFQVCQSSPCEAE ELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGYQTREVMCINKTGKAAD LSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCLSQGDGVVPCATYGWRT TEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQLCHIPCPTECEVSPWS AWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECGPGTQVQEVVCINSDGE EVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSALQEVRSCNEHPCTVYHW QTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCIVTPYSDWTSCPSSCKE GDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGPGRQARAITCRKQDGGQ AGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIETQYCPCDKYNAQPVGNW SDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSNWSRCSKSCGSGVKVRS KWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNTADGPSEHVEDYLCDPE EMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYDYNVTDWSTCQLSEKAV CGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRTVTQPFQGDGRPCPSLM DQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVLEESCSQPCPGDCYLKD WSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWCQRSDGINVTGGCLVMS QPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPSSNPAGRGRTWFLQPFG -------------------------------------------------------------- >20745_20745_9_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000549414_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1683AA_BP=89 MLCVAGARLKRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFLNVYKRLIDVPG PWGRCMGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKPLECIKGEEGIQ VREIACIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCPNLTEFQVCQSS PCEAEELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGYQTREVMCINKT GKAADLSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCLSQGDGVVPCAT YGWRTTEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQLCHIPCPTECE VSPWSAWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECGPGTQVQEVVCI NSDGEEVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSALQEVRSCNEHPC TVYHWQTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCIVTPYSDWTSCP SSCKEGDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGPGRQARAITCRK QDGGQAGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIETQYCPCDKYNAQ PVGNWSDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSNWSRCSKSCGSG VKVRSKWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNTADGPSEHVEDY LCDPEEMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYDYNVTDWSTCQL SEKAVCGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRTVTQPFQGDGRP CPSLMDQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVLEESCSQPCPGD CYLKDWSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWCQRSDGINVTGG CLVMSQPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPSSNPAGRGRTWF -------------------------------------------------------------- >20745_20745_10_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000550008_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1683AA_BP=89 MLCVAGARLKRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFLNVYKRLIDVPG PWGRCMGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKPLECIKGEEGIQ VREIACIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCPNLTEFQVCQSS PCEAEELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGYQTREVMCINKT GKAADLSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCLSQGDGVVPCAT YGWRTTEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQLCHIPCPTECE VSPWSAWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECGPGTQVQEVVCI NSDGEEVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSALQEVRSCNEHPC TVYHWQTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCIVTPYSDWTSCP SSCKEGDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGPGRQARAITCRK QDGGQAGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIETQYCPCDKYNAQ PVGNWSDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSNWSRCSKSCGSG VKVRSKWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNTADGPSEHVEDY LCDPEEMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYDYNVTDWSTCQL SEKAVCGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRTVTQPFQGDGRP CPSLMDQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVLEESCSQPCPGD CYLKDWSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWCQRSDGINVTGG CLVMSQPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPSSNPAGRGRTWF -------------------------------------------------------------- >20745_20745_11_CUX1-THSD7A_CUX1_chr7_101713697_ENST00000556210_THSD7A_chr7_11676588_ENST00000423059_length(amino acids)=1683AA_BP=89 MLCVAGARLKRELDATATVLANRQDESEQSRKRLIEQSREFKKNTPEDLRKQVAPLLKSFQGEIDALSKRSKEAEAAFLNVYKRLIDVPG PWGRCMGDECGPGGIQTRAVWCAHVEGWTTLHTNCKQAERPNNQQNCFKVCDWHKELYDWRLGPWNQCQPVISKSLEKPLECIKGEEGIQ VREIACIQKDKDIPAEDIICEYFEPKPLLEQACLIPCQQDCIVSEFSAWSECSKTCGSGLQHRTRHVVAPPQFGGSGCPNLTEFQVCQSS PCEAEELRYSLHVGPWSTCSMPHSRQVRQARRRGKNKEREKDRSKGVKDPEARELIKKKRNRNRQNRQENKYWDIQIGYQTREVMCINKT GKAADLSFCQQEKLPMTFQSCVITKECQVSEWSEWSPCSKTCHDMVSPAGTRVRTRTIRQFPIGSEKECPEFEEKEPCLSQGDGVVPCAT YGWRTTEWTECRVDPLLSQQDKRRGNQTALCGGGIQTREVYCVQANENLLSQLSTHKNKEASKPMDLKLCTGPIPNTTQLCHIPCPTECE VSPWSAWGPCTYENCNDQQGKKGFKLRKRRITNEPTGGSGVTGNCPHLLEAIPCEEPACYDWKAVRLGNCEPDNGKECGPGTQVQEVVCI NSDGEEVDRQLCRDAIFPIPVACDAPCPKDCVLSTWSTWSSCSHTCSGKTTEGKQIRARSILAYAGEEGGIRCPNSSALQEVRSCNEHPC TVYHWQTGPWGQCIEDTSVSSFNTTTTWNGEASCSVGMQTRKVICVRVNVGQVGPKKCPESLRPETVRPCLLPCKKDCIVTPYSDWTSCP SSCKEGDSSIRKQSRHRVIIQLPANGGRDCTDPLYEEKACEAPQACQSYRWKTHKWRRCQLVPWSVQQDSPGAQEGCGPGRQARAITCRK QDGGQAGIHECLQYAGPVPALTQACQIPCQDDCQLTSWSKFSSCNGDCGAVRTRKRTLVGKSKKKEKCKNSHLYPLIETQYCPCDKYNAQ PVGNWSDCILPEGKVEVLLGMKVQGDIKECGQGYRYQAMACYDQNGRLVETSRCNSHGYIEEACIIPCPSDCKLSEWSNWSRCSKSCGSG VKVRSKWLREKPYNGGRPCPKLDHVNQAQVYEVVPCHSDCNQYLWVTEPWSICKVTFVNMRENCGEGVQTRKVRCMQNTADGPSEHVEDY LCDPEEMPLGSRVCKLPCPEDCVISEWGPWTQCVLPCNQSSFRQRSADPIRQPADEGRSCPNAVEKEPCNLNKNCYHYDYNVTDWSTCQL SEKAVCGNGIKTRMLDCVRSDGKSVDLKYCEALGLEKNWQMNTSCMVECPVNCQLSDWSPWSECSQTCGLTGKMIRRRTVTQPFQGDGRP CPSLMDQSKPCPVKPCYRWQYGQWSPCQVQEAQCGEGTRTRNISCVVSDGSADDFSKVVDEEFCADIELIIDGNKNMVLEESCSQPCPGD CYLKDWSSWSLCQLTCVNGEDLGFGGIQVRSRPVIIQELENQHLCPEQMLETKSCYDGQCYEYKWMASAWKGSSRTVWCQRSDGINVTGG CLVMSQPDADRSCNPPCSQPHSYCSETKTCHCEEGYTEVMSSNSTLEQCTLIPVVVLPTMEDKRGDVKTSRAVHPTQPSSNPAGRGRTWF -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:101713697/chr7:11676588) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CUX1 | . |
| FUNCTION: Transcription factor involved in the control of neuronal differentiation in the brain. Regulates dendrite development and branching, and dendritic spine formation in cortical layers II-III. Also involved in the control of synaptogenesis. In addition, it has probably a broad role in mammalian development as a repressor of developmentally regulated gene expression. May act by preventing binding of positively-activing CCAAT factors to promoters. Component of nf-munr repressor; binds to the matrix attachment regions (MARs) (5' and 3') of the immunoglobulin heavy chain enhancer. Represses T-cell receptor (TCR) beta enhancer function by binding to MARbeta, an ATC-rich DNA sequence located upstream of the TCR beta enhancer. Binds to the TH enhancer; may require the basic helix-loop-helix protein TCF4 as a coactivator. {ECO:0000250|UniProtKB:P53564}.; FUNCTION: [CDP/Cux p110]: Plays a role in cell cycle progression, in particular at the G1/S transition. As cells progress into S phase, a fraction of CUX1 molecules is proteolytically processed into N-terminally truncated proteins of 110 kDa. While CUX1 only transiently binds to DNA and carries the CCAAT-displacement activity, CDP/Cux p110 makes a stable interaction with DNA and stimulates expression of genes such as POLA1. {ECO:0000269|PubMed:15099520}. | FUNCTION: Might normally function as a transcriptional repressor. EWS-fusion-proteins (EFPS) may play a role in the tumorigenic process. They may disturb gene expression by mimicking, or interfering with the normal function of CTD-POLII within the transcription initiation complex. They may also contribute to an aberrant activation of the fusion protein target genes. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 267_315 | 63.333333333333336 | 1658.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 1035_1095 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 13 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 1096_1163 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 14 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 1166_1220 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 15 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 120_192 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 2 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 1221_1284 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 16 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 1286_1341 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 17 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 1342_1412 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 18 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 1414_1475 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 19 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 194_247 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 3 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 360_416 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 4 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 423_510 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 5 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 512_574 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 6 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 634_695 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 7 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 696_769 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 8 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 771_831 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 9 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 832_904 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 10 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 906_959 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 11 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 960_1033 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 12 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 1629_1657 | 63.333333333333336 | 1658.0 | Topological domain | Cytoplasmic | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 1608_1628 | 63.333333333333336 | 1658.0 | Transmembrane | Helical |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292535 | + | 4 | 24 | 56_407 | 89.33333333333333 | 1506.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292538 | + | 4 | 23 | 502_556 | 100.33333333333333 | 679.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292538 | + | 4 | 23 | 67_450 | 100.33333333333333 | 679.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000360264 | + | 4 | 24 | 56_407 | 100.33333333333333 | 1517.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000393824 | + | 3 | 22 | 502_556 | 63.333333333333336 | 640.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000393824 | + | 3 | 22 | 67_450 | 63.333333333333336 | 640.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000425244 | + | 4 | 22 | 56_407 | 100.33333333333333 | 633.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000437600 | + | 4 | 23 | 502_556 | 100.33333333333333 | 677.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000437600 | + | 4 | 23 | 67_450 | 100.33333333333333 | 677.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000546411 | + | 4 | 24 | 56_407 | 89.33333333333333 | 1404.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000547394 | + | 3 | 22 | 502_556 | 84.33333333333333 | 663.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000547394 | + | 3 | 22 | 67_450 | 84.33333333333333 | 663.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000549414 | + | 4 | 23 | 56_407 | 89.33333333333333 | 1484.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000550008 | + | 4 | 22 | 56_407 | 89.33333333333333 | 1450.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000556210 | + | 4 | 22 | 56_407 | 89.33333333333333 | 1348.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292535 | + | 4 | 24 | 1406_1438 | 89.33333333333333 | 1506.0 | Compositional bias | Note=Ala-rich |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000360264 | + | 4 | 24 | 1406_1438 | 100.33333333333333 | 1517.0 | Compositional bias | Note=Ala-rich |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000425244 | + | 4 | 22 | 1406_1438 | 100.33333333333333 | 633.0 | Compositional bias | Note=Ala-rich |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000546411 | + | 4 | 24 | 1406_1438 | 89.33333333333333 | 1404.0 | Compositional bias | Note=Ala-rich |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000549414 | + | 4 | 23 | 1406_1438 | 89.33333333333333 | 1484.0 | Compositional bias | Note=Ala-rich |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000550008 | + | 4 | 22 | 1406_1438 | 89.33333333333333 | 1450.0 | Compositional bias | Note=Ala-rich |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000556210 | + | 4 | 22 | 1406_1438 | 89.33333333333333 | 1348.0 | Compositional bias | Note=Ala-rich |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292535 | + | 4 | 24 | 1117_1204 | 89.33333333333333 | 1506.0 | DNA binding | CUT 3 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292535 | + | 4 | 24 | 1244_1303 | 89.33333333333333 | 1506.0 | DNA binding | Homeobox |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292535 | + | 4 | 24 | 542_629 | 89.33333333333333 | 1506.0 | DNA binding | CUT 1 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292535 | + | 4 | 24 | 934_1021 | 89.33333333333333 | 1506.0 | DNA binding | CUT 2 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000360264 | + | 4 | 24 | 1117_1204 | 100.33333333333333 | 1517.0 | DNA binding | CUT 3 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000360264 | + | 4 | 24 | 1244_1303 | 100.33333333333333 | 1517.0 | DNA binding | Homeobox |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000360264 | + | 4 | 24 | 542_629 | 100.33333333333333 | 1517.0 | DNA binding | CUT 1 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000360264 | + | 4 | 24 | 934_1021 | 100.33333333333333 | 1517.0 | DNA binding | CUT 2 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000425244 | + | 4 | 22 | 1117_1204 | 100.33333333333333 | 633.0 | DNA binding | CUT 3 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000425244 | + | 4 | 22 | 1244_1303 | 100.33333333333333 | 633.0 | DNA binding | Homeobox |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000425244 | + | 4 | 22 | 542_629 | 100.33333333333333 | 633.0 | DNA binding | CUT 1 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000425244 | + | 4 | 22 | 934_1021 | 100.33333333333333 | 633.0 | DNA binding | CUT 2 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000546411 | + | 4 | 24 | 1117_1204 | 89.33333333333333 | 1404.0 | DNA binding | CUT 3 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000546411 | + | 4 | 24 | 1244_1303 | 89.33333333333333 | 1404.0 | DNA binding | Homeobox |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000546411 | + | 4 | 24 | 542_629 | 89.33333333333333 | 1404.0 | DNA binding | CUT 1 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000546411 | + | 4 | 24 | 934_1021 | 89.33333333333333 | 1404.0 | DNA binding | CUT 2 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000549414 | + | 4 | 23 | 1117_1204 | 89.33333333333333 | 1484.0 | DNA binding | CUT 3 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000549414 | + | 4 | 23 | 1244_1303 | 89.33333333333333 | 1484.0 | DNA binding | Homeobox |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000549414 | + | 4 | 23 | 542_629 | 89.33333333333333 | 1484.0 | DNA binding | CUT 1 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000549414 | + | 4 | 23 | 934_1021 | 89.33333333333333 | 1484.0 | DNA binding | CUT 2 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000550008 | + | 4 | 22 | 1117_1204 | 89.33333333333333 | 1450.0 | DNA binding | CUT 3 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000550008 | + | 4 | 22 | 1244_1303 | 89.33333333333333 | 1450.0 | DNA binding | Homeobox |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000550008 | + | 4 | 22 | 542_629 | 89.33333333333333 | 1450.0 | DNA binding | CUT 1 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000550008 | + | 4 | 22 | 934_1021 | 89.33333333333333 | 1450.0 | DNA binding | CUT 2 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000556210 | + | 4 | 22 | 1117_1204 | 89.33333333333333 | 1348.0 | DNA binding | CUT 3 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000556210 | + | 4 | 22 | 1244_1303 | 89.33333333333333 | 1348.0 | DNA binding | Homeobox |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000556210 | + | 4 | 22 | 542_629 | 89.33333333333333 | 1348.0 | DNA binding | CUT 1 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000556210 | + | 4 | 22 | 934_1021 | 89.33333333333333 | 1348.0 | DNA binding | CUT 2 |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292538 | + | 4 | 23 | 1_619 | 100.33333333333333 | 679.0 | Topological domain | Cytoplasmic |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292538 | + | 4 | 23 | 641_678 | 100.33333333333333 | 679.0 | Topological domain | Lumenal |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000393824 | + | 3 | 22 | 1_619 | 63.333333333333336 | 640.0 | Topological domain | Cytoplasmic |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000393824 | + | 3 | 22 | 641_678 | 63.333333333333336 | 640.0 | Topological domain | Lumenal |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000437600 | + | 4 | 23 | 1_619 | 100.33333333333333 | 677.0 | Topological domain | Cytoplasmic |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000437600 | + | 4 | 23 | 641_678 | 100.33333333333333 | 677.0 | Topological domain | Lumenal |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000547394 | + | 3 | 22 | 1_619 | 84.33333333333333 | 663.0 | Topological domain | Cytoplasmic |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000547394 | + | 3 | 22 | 641_678 | 84.33333333333333 | 663.0 | Topological domain | Lumenal |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000292538 | + | 4 | 23 | 620_640 | 100.33333333333333 | 679.0 | Transmembrane | Helical%3B Anchor for type IV membrane protein |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000393824 | + | 3 | 22 | 620_640 | 63.333333333333336 | 640.0 | Transmembrane | Helical%3B Anchor for type IV membrane protein |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000437600 | + | 4 | 23 | 620_640 | 100.33333333333333 | 677.0 | Transmembrane | Helical%3B Anchor for type IV membrane protein |
| Hgene | CUX1 | chr7:101713697 | chr7:11676588 | ENST00000547394 | + | 3 | 22 | 620_640 | 84.33333333333333 | 663.0 | Transmembrane | Helical%3B Anchor for type IV membrane protein |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 57_116 | 63.333333333333336 | 1658.0 | Domain | TSP type-1 1 | |
| Tgene | THSD7A | chr7:101713697 | chr7:11676588 | ENST00000423059 | 0 | 28 | 48_1607 | 63.333333333333336 | 1658.0 | Topological domain | Extracellular |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| CUX1 | |
| THSD7A |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to CUX1-THSD7A |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to CUX1-THSD7A |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies