| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:DDX58-KDM4C |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: DDX58-KDM4C | FusionPDB ID: 22058 | FusionGDB2.0 ID: 22058 | Hgene | Tgene | Gene symbol | DDX58 | KDM4C | Gene ID | 23586 | 23081 |
| Gene name | DExD/H-box helicase 58 | lysine demethylase 4C | |
| Synonyms | RIG-I|RIG1|RIGI|RLR-1|SGMRT2 | GASC1|JHDM3C|JMJD2C|TDRD14C | |
| Cytomap | 9p21.1 | 9p24.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | probable ATP-dependent RNA helicase DDX58DEAD (Asp-Glu-Ala-Asp) box polypeptide 58DEAD box protein 58DEAD/H (Asp-Glu-Ala-Asp/His) box polypeptideRNA helicase RIG-Iretinoic acid-inducible gene 1 proteinretinoic acid-inducible gene I protein | lysine-specific demethylase 4CJmjC domain-containing histone demethylation protein 3Cgene amplified in squamous cell carcinoma 1 proteinjumonji domain-containing protein 2Clysine (K)-specific demethylase 4Ctudor domain containing 14C | |
| Modification date | 20200329 | 20200329 | |
| UniProtAcc | O95786 | Q9H3R0 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000379868, ENST00000379882, ENST00000379883, ENST00000542096, ENST00000545044, | ENST00000401787, ENST00000428870, ENST00000489243, ENST00000536108, ENST00000381306, ENST00000381309, ENST00000442236, ENST00000535193, ENST00000543771, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 7 X 7 X 6=294 | 22 X 22 X 7=3388 |
| # samples | 9 | 26 | |
| ** MAII score | log2(9/294*10)=-1.70781924850669 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(26/3388*10)=-3.70385034630374 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: DDX58 [Title/Abstract] AND KDM4C [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | DDX58(32491298)-KDM4C(7011697), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | DDX58-KDM4C seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DDX58-KDM4C seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DDX58-KDM4C seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. DDX58-KDM4C seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. DDX58-KDM4C seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. DDX58-KDM4C seems lost the major protein functional domain in Hgene partner, which is a tumor suppressor due to the frame-shifted ORF. DDX58-KDM4C seems lost the major protein functional domain in Tgene partner, which is a epigenetic factor due to the frame-shifted ORF. DDX58-KDM4C seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. DDX58-KDM4C seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | DDX58 | GO:0009597 | detection of virus | 17079289 |
| Hgene | DDX58 | GO:0010628 | positive regulation of gene expression | 24409285 |
| Hgene | DDX58 | GO:0030334 | regulation of cell migration | 19122199 |
| Hgene | DDX58 | GO:0032725 | positive regulation of granulocyte macrophage colony-stimulating factor production | 24409285 |
| Hgene | DDX58 | GO:0032727 | positive regulation of interferon-alpha production | 19576794 |
| Hgene | DDX58 | GO:0032728 | positive regulation of interferon-beta production | 17079289 |
| Hgene | DDX58 | GO:0032755 | positive regulation of interleukin-6 production | 24409285 |
| Hgene | DDX58 | GO:0032757 | positive regulation of interleukin-8 production | 24409285 |
| Hgene | DDX58 | GO:0039529 | RIG-I signaling pathway | 28469175 |
| Hgene | DDX58 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 17079289 |
| Hgene | DDX58 | GO:0051091 | positive regulation of DNA-binding transcription factor activity | 17079289 |
| Hgene | DDX58 | GO:0051607 | defense response to virus | 21478870 |
| Tgene | KDM4C | GO:0006357 | regulation of transcription by RNA polymerase II | 17277772 |
| Tgene | KDM4C | GO:0033169 | histone H3-K9 demethylation | 18066052|21914792 |
| Tgene | KDM4C | GO:0070544 | histone H3-K36 demethylation | 21914792 |
| Fusion gene breakpoints across DDX58 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across KDM4C (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
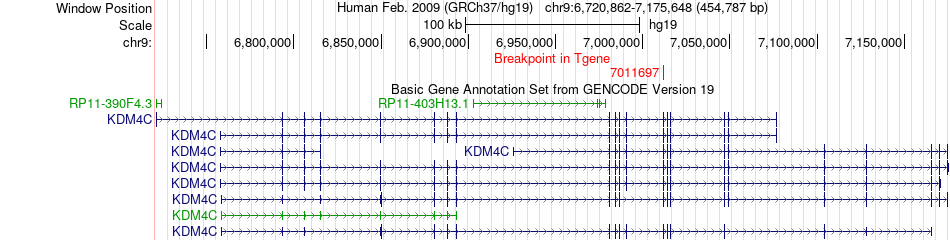 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 5381N | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000379882 | DDX58 | chr9 | 32491298 | - | ENST00000535193 | KDM4C | chr9 | 7011697 | + | 2181 | 714 | 140 | 1369 | 409 |
| ENST00000379882 | DDX58 | chr9 | 32491298 | - | ENST00000543771 | KDM4C | chr9 | 7011697 | + | 2181 | 714 | 140 | 1369 | 409 |
| ENST00000379882 | DDX58 | chr9 | 32491298 | - | ENST00000381306 | KDM4C | chr9 | 7011697 | + | 2964 | 714 | 140 | 2071 | 643 |
| ENST00000379882 | DDX58 | chr9 | 32491298 | - | ENST00000381309 | KDM4C | chr9 | 7011697 | + | 3018 | 714 | 140 | 2098 | 652 |
| ENST00000379882 | DDX58 | chr9 | 32491298 | - | ENST00000442236 | KDM4C | chr9 | 7011697 | + | 2194 | 714 | 140 | 2098 | 652 |
| ENST00000379868 | DDX58 | chr9 | 32491298 | - | ENST00000535193 | KDM4C | chr9 | 7011697 | + | 2052 | 585 | 503 | 1240 | 245 |
| ENST00000379868 | DDX58 | chr9 | 32491298 | - | ENST00000543771 | KDM4C | chr9 | 7011697 | + | 2052 | 585 | 503 | 1240 | 245 |
| ENST00000379868 | DDX58 | chr9 | 32491298 | - | ENST00000381306 | KDM4C | chr9 | 7011697 | + | 2835 | 585 | 503 | 1942 | 479 |
| ENST00000379868 | DDX58 | chr9 | 32491298 | - | ENST00000381309 | KDM4C | chr9 | 7011697 | + | 2889 | 585 | 503 | 1969 | 488 |
| ENST00000379868 | DDX58 | chr9 | 32491298 | - | ENST00000442236 | KDM4C | chr9 | 7011697 | + | 2065 | 585 | 503 | 1969 | 488 |
| ENST00000379883 | DDX58 | chr9 | 32491298 | - | ENST00000535193 | KDM4C | chr9 | 7011697 | + | 2316 | 849 | 140 | 1504 | 454 |
| ENST00000379883 | DDX58 | chr9 | 32491298 | - | ENST00000543771 | KDM4C | chr9 | 7011697 | + | 2316 | 849 | 140 | 1504 | 454 |
| ENST00000379883 | DDX58 | chr9 | 32491298 | - | ENST00000381306 | KDM4C | chr9 | 7011697 | + | 3099 | 849 | 140 | 2206 | 688 |
| ENST00000379883 | DDX58 | chr9 | 32491298 | - | ENST00000381309 | KDM4C | chr9 | 7011697 | + | 3153 | 849 | 140 | 2233 | 697 |
| ENST00000379883 | DDX58 | chr9 | 32491298 | - | ENST00000442236 | KDM4C | chr9 | 7011697 | + | 2329 | 849 | 140 | 2233 | 697 |
| ENST00000545044 | DDX58 | chr9 | 32491298 | - | ENST00000535193 | KDM4C | chr9 | 7011697 | + | 2039 | 572 | 490 | 1227 | 245 |
| ENST00000545044 | DDX58 | chr9 | 32491298 | - | ENST00000543771 | KDM4C | chr9 | 7011697 | + | 2039 | 572 | 490 | 1227 | 245 |
| ENST00000545044 | DDX58 | chr9 | 32491298 | - | ENST00000381306 | KDM4C | chr9 | 7011697 | + | 2822 | 572 | 490 | 1929 | 479 |
| ENST00000545044 | DDX58 | chr9 | 32491298 | - | ENST00000381309 | KDM4C | chr9 | 7011697 | + | 2876 | 572 | 490 | 1956 | 488 |
| ENST00000545044 | DDX58 | chr9 | 32491298 | - | ENST00000442236 | KDM4C | chr9 | 7011697 | + | 2052 | 572 | 490 | 1956 | 488 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000379882 | ENST00000535193 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000728893 | 0.9992711 |
| ENST00000379882 | ENST00000543771 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000728893 | 0.9992711 |
| ENST00000379882 | ENST00000381306 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000707539 | 0.9992925 |
| ENST00000379882 | ENST00000381309 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000635852 | 0.9993642 |
| ENST00000379882 | ENST00000442236 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.00201176 | 0.9979882 |
| ENST00000379868 | ENST00000535193 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.002467773 | 0.99753225 |
| ENST00000379868 | ENST00000543771 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.002467773 | 0.99753225 |
| ENST00000379868 | ENST00000381306 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000440304 | 0.9995597 |
| ENST00000379868 | ENST00000381309 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000427295 | 0.9995727 |
| ENST00000379868 | ENST00000442236 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.001629433 | 0.9983706 |
| ENST00000379883 | ENST00000535193 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000638131 | 0.99936193 |
| ENST00000379883 | ENST00000543771 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000638131 | 0.99936193 |
| ENST00000379883 | ENST00000381306 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000698357 | 0.9993017 |
| ENST00000379883 | ENST00000381309 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000606096 | 0.99939394 |
| ENST00000379883 | ENST00000442236 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.002155503 | 0.99784446 |
| ENST00000545044 | ENST00000535193 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.002474541 | 0.9975255 |
| ENST00000545044 | ENST00000543771 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.002474541 | 0.9975255 |
| ENST00000545044 | ENST00000381306 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.000432125 | 0.9995679 |
| ENST00000545044 | ENST00000381309 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.00041817 | 0.9995819 |
| ENST00000545044 | ENST00000442236 | DDX58 | chr9 | 32491298 | - | KDM4C | chr9 | 7011697 | + | 0.00156753 | 0.99843246 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >22058_22058_1_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379868_KDM4C_chr9_7011697_ENST00000381306_length(amino acids)=479AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR NAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLKCIFCRHRVKRVSGACIQCSYGRCPASFHV TCAHAAGVLMEPDDWPYVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRVMAVTSQTFYEVMFDDGSFSRDTFPEDIVS RDCLKLGPPAEGEVVQVKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEELPKRVKARFVSAGRCHLGTCQVNSLSSPH -------------------------------------------------------------- >22058_22058_2_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379868_KDM4C_chr9_7011697_ENST00000381309_length(amino acids)=488AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR NAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLKCIFCRHRVKRVSGACIQCSYGRCPASFHV TCAHAAGVLMEPDDWPYVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRVMAVTSQTFYEVMFDDGSFSRDTFPEDIVS RDCLKLGPPAEGEVVQVKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEELPKRVKARFSTASDMRFEDTFYGADIIQG -------------------------------------------------------------- >22058_22058_3_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379868_KDM4C_chr9_7011697_ENST00000442236_length(amino acids)=488AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR NAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLKCIFCRHRVKRVSGACIQCSYGRCPASFHV TCAHAAGVLMEPDDWPYVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRVMAVTSQTFYEVMFDDGSFSRDTFPEDIVS RDCLKLGPPAEGEVVQVKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEELPKRVKARFSTASDMRFEDTFYGADIIQG -------------------------------------------------------------- >22058_22058_4_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379868_KDM4C_chr9_7011697_ENST00000535193_length(amino acids)=245AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR -------------------------------------------------------------- >22058_22058_5_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379868_KDM4C_chr9_7011697_ENST00000543771_length(amino acids)=245AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR -------------------------------------------------------------- >22058_22058_6_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379882_KDM4C_chr9_7011697_ENST00000381306_length(amino acids)=643AA_BP=189 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREGYSGLYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSE CLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLALEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPEC QNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDE VVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGA LKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLKCIFCRHRVKRVSGACIQCSYGRCPASFHVTCAHAAGVLMEPDDWP YVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRVMAVTSQTFYEVMFDDGSFSRDTFPEDIVSRDCLKLGPPAEGEVVQ VKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEELPKRVKARFVSAGRCHLGTCQVNSLSSPHVSQAQQETYLGFWINS -------------------------------------------------------------- >22058_22058_7_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379882_KDM4C_chr9_7011697_ENST00000381309_length(amino acids)=652AA_BP=189 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREGYSGLYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSE CLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLALEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPEC QNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDE VVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGA LKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLKCIFCRHRVKRVSGACIQCSYGRCPASFHVTCAHAAGVLMEPDDWP YVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRVMAVTSQTFYEVMFDDGSFSRDTFPEDIVSRDCLKLGPPAEGEVVQ VKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEELPKRVKARFSTASDMRFEDTFYGADIIQGERKRQRVLSSRFKNEY -------------------------------------------------------------- >22058_22058_8_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379882_KDM4C_chr9_7011697_ENST00000442236_length(amino acids)=652AA_BP=189 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREGYSGLYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSE CLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLALEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPEC QNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDE VVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGA LKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLKCIFCRHRVKRVSGACIQCSYGRCPASFHVTCAHAAGVLMEPDDWP YVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRVMAVTSQTFYEVMFDDGSFSRDTFPEDIVSRDCLKLGPPAEGEVVQ VKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEELPKRVKARFSTASDMRFEDTFYGADIIQGERKRQRVLSSRFKNEY -------------------------------------------------------------- >22058_22058_9_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379882_KDM4C_chr9_7011697_ENST00000535193_length(amino acids)=409AA_BP=189 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREGYSGLYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSE CLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLALEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPEC QNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDE VVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGA -------------------------------------------------------------- >22058_22058_10_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379882_KDM4C_chr9_7011697_ENST00000543771_length(amino acids)=409AA_BP=189 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREGYSGLYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSE CLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLALEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPEC QNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDE VVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGA -------------------------------------------------------------- >22058_22058_11_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379883_KDM4C_chr9_7011697_ENST00000381306_length(amino acids)=688AA_BP=234 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREEEVQYIQAEKNNKGPMEAATLFLKFLLELQEEGWFRGFLDALDHAGYSG LYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSECLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLA LEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFA AEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCA KCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLK CIFCRHRVKRVSGACIQCSYGRCPASFHVTCAHAAGVLMEPDDWPYVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRV MAVTSQTFYEVMFDDGSFSRDTFPEDIVSRDCLKLGPPAEGEVVQVKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEE -------------------------------------------------------------- >22058_22058_12_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379883_KDM4C_chr9_7011697_ENST00000381309_length(amino acids)=697AA_BP=234 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREEEVQYIQAEKNNKGPMEAATLFLKFLLELQEEGWFRGFLDALDHAGYSG LYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSECLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLA LEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFA AEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCA KCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLK CIFCRHRVKRVSGACIQCSYGRCPASFHVTCAHAAGVLMEPDDWPYVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRV MAVTSQTFYEVMFDDGSFSRDTFPEDIVSRDCLKLGPPAEGEVVQVKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEE -------------------------------------------------------------- >22058_22058_13_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379883_KDM4C_chr9_7011697_ENST00000442236_length(amino acids)=697AA_BP=234 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREEEVQYIQAEKNNKGPMEAATLFLKFLLELQEEGWFRGFLDALDHAGYSG LYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSECLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLA LEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFA AEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCA KCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLK CIFCRHRVKRVSGACIQCSYGRCPASFHVTCAHAAGVLMEPDDWPYVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRV MAVTSQTFYEVMFDDGSFSRDTFPEDIVSRDCLKLGPPAEGEVVQVKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEE -------------------------------------------------------------- >22058_22058_14_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379883_KDM4C_chr9_7011697_ENST00000535193_length(amino acids)=454AA_BP=234 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREEEVQYIQAEKNNKGPMEAATLFLKFLLELQEEGWFRGFLDALDHAGYSG LYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSECLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLA LEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFA AEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCA KCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLG -------------------------------------------------------------- >22058_22058_15_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000379883_KDM4C_chr9_7011697_ENST00000543771_length(amino acids)=454AA_BP=234 MQAEAGMTTEQRRSLQAFQDYIRKTLDPTYILSYMAPWFREEEVQYIQAEKNNKGPMEAATLFLKFLLELQEEGWFRGFLDALDHAGYSG LYEAIESWDFKKIEKLEEYRLLLKRLQPEFKTRIIPTDIISDLSECLINQECEEILQICSTKGMMAGAEKLVECLLRSDKENWPKTLKLA LEKERNKFSELWIVEKGIKDVETEDLEDKMETSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFA AEQEYNATVARMKPHCAICTLLMPYHKPDSSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCA KCCVRVHASCYGIPSHEICDGWLCARCKRNAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLG -------------------------------------------------------------- >22058_22058_16_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000545044_KDM4C_chr9_7011697_ENST00000381306_length(amino acids)=479AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR NAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLKCIFCRHRVKRVSGACIQCSYGRCPASFHV TCAHAAGVLMEPDDWPYVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRVMAVTSQTFYEVMFDDGSFSRDTFPEDIVS RDCLKLGPPAEGEVVQVKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEELPKRVKARFVSAGRCHLGTCQVNSLSSPH -------------------------------------------------------------- >22058_22058_17_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000545044_KDM4C_chr9_7011697_ENST00000381309_length(amino acids)=488AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR NAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLKCIFCRHRVKRVSGACIQCSYGRCPASFHV TCAHAAGVLMEPDDWPYVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRVMAVTSQTFYEVMFDDGSFSRDTFPEDIVS RDCLKLGPPAEGEVVQVKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEELPKRVKARFSTASDMRFEDTFYGADIIQG -------------------------------------------------------------- >22058_22058_18_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000545044_KDM4C_chr9_7011697_ENST00000442236_length(amino acids)=488AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR NAWTAECCLCNLRGGALKQTKNNKWAHVMCAVAVPEVRFTNVPERTQIDVGRIPLQRLKLKCIFCRHRVKRVSGACIQCSYGRCPASFHV TCAHAAGVLMEPDDWPYVVNITCFRHKVNPNVKSKACEKVISVGQTVITKHRNTRYYSCRVMAVTSQTFYEVMFDDGSFSRDTFPEDIVS RDCLKLGPPAEGEVVQVKWPDGKLYGAKYFGSNIAHMYQVEFEDGSQIAMKREDIYTLDEELPKRVKARFSTASDMRFEDTFYGADIIQG -------------------------------------------------------------- >22058_22058_19_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000545044_KDM4C_chr9_7011697_ENST00000535193_length(amino acids)=245AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR -------------------------------------------------------------- >22058_22058_20_DDX58-KDM4C_DDX58_chr9_32491298_ENST00000545044_KDM4C_chr9_7011697_ENST00000543771_length(amino acids)=245AA_BP=25 METSDIQIFYQEDPECQNLSENSCPPSELPEVLSIEEEVEETESWAKPLIHLWQTKSPNFAAEQEYNATVARMKPHCAICTLLMPYHKPD SSNEENDARWETKLDEVVTSEGKTKPLIPEMCFIYSEENIEYSPPNAFLEEDGTSLLISCAKCCVRVHASCYGIPSHEICDGWLCARCKR -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:32491298/chr9:7011697) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DDX58 | KDM4C |
| FUNCTION: Innate immune receptor that senses cytoplasmic viral nucleic acids and activates a downstream signaling cascade leading to the production of type I interferons and proinflammatory cytokines. Forms a ribonucleoprotein complex with viral RNAs on which it homooligomerizes to form filaments. The homooligomerization allows the recruitment of RNF135 an E3 ubiquitin-protein ligase that activates and amplifies the RIG-I-mediated antiviral signaling in an RNA length-dependent manner through ubiquitination-dependent and -independent mechanisms (PubMed:28469175, PubMed:31006531). Upon activation, associates with mitochondria antiviral signaling protein (MAVS/IPS1) that activates the IKK-related kinases TBK1 and IKBKE which in turn phosphorylate the interferon regulatory factors IRF3 and IRF7, activating transcription of antiviral immunological genes including the IFN-alpha and IFN-beta interferons (PubMed:28469175, PubMed:31006531). Ligands include 5'-triphosphorylated ssRNAs and dsRNAs but also short dsRNAs (<1 kb in length). In addition to the 5'-triphosphate moiety, blunt-end base pairing at the 5'-end of the RNA is very essential. Overhangs at the non-triphosphorylated end of the dsRNA RNA have no major impact on its activity. A 3'overhang at the 5'triphosphate end decreases and any 5'overhang at the 5' triphosphate end abolishes its activity. Detects both positive and negative strand RNA viruses including members of the families Paramyxoviridae: Human respiratory syncytial virus and measles virus (MeV), Rhabdoviridae: vesicular stomatitis virus (VSV), Orthomyxoviridae: influenza A and B virus, Flaviviridae: Japanese encephalitis virus (JEV), hepatitis C virus (HCV), dengue virus (DENV) and west Nile virus (WNV). It also detects rotaviruses and reoviruses. Also involved in antiviral signaling in response to viruses containing a dsDNA genome such as Epstein-Barr virus (EBV). Detects dsRNA produced from non-self dsDNA by RNA polymerase III, such as Epstein-Barr virus-encoded RNAs (EBERs). May play important roles in granulocyte production and differentiation, bacterial phagocytosis and in the regulation of cell migration. {ECO:0000269|PubMed:15208624, ECO:0000269|PubMed:15708988, ECO:0000269|PubMed:16125763, ECO:0000269|PubMed:16127453, ECO:0000269|PubMed:16153868, ECO:0000269|PubMed:17190814, ECO:0000269|PubMed:18636086, ECO:0000269|PubMed:19122199, ECO:0000269|PubMed:19211564, ECO:0000269|PubMed:19576794, ECO:0000269|PubMed:19609254, ECO:0000269|PubMed:19631370, ECO:0000269|PubMed:21742966, ECO:0000269|PubMed:28469175, ECO:0000269|PubMed:29117565, ECO:0000269|PubMed:31006531}. | FUNCTION: Histone demethylase that specifically demethylates 'Lys-9' and 'Lys-36' residues of histone H3, thereby playing a central role in histone code. Does not demethylate histone H3 'Lys-4', H3 'Lys-27' nor H4 'Lys-20'. Demethylates trimethylated H3 'Lys-9' and H3 'Lys-36' residue, while it has no activity on mono- and dimethylated residues. Demethylation of Lys residue generates formaldehyde and succinate. {ECO:0000269|PubMed:16603238, ECO:0000269|PubMed:28262558}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379882 | - | 4 | 17 | 1_87 | 185.33333333333334 | 881.0 | Domain | Note=CARD 1 |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379882 | - | 4 | 17 | 92_172 | 185.33333333333334 | 881.0 | Domain | Note=CARD 2 |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379883 | - | 5 | 18 | 1_87 | 230.33333333333334 | 926.0 | Domain | Note=CARD 1 |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379883 | - | 5 | 18 | 92_172 | 230.33333333333334 | 926.0 | Domain | Note=CARD 2 |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381306 | 11 | 21 | 877_934 | 595.3333333333334 | 1048.0 | Domain | Note=Tudor 1 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381306 | 11 | 21 | 935_991 | 595.3333333333334 | 1048.0 | Domain | Note=Tudor 2 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381309 | 11 | 22 | 877_934 | 595.3333333333334 | 1057.0 | Domain | Note=Tudor 1 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381309 | 11 | 22 | 935_991 | 595.3333333333334 | 1057.0 | Domain | Note=Tudor 2 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000535193 | 11 | 18 | 877_934 | 617.3333333333334 | 836.0 | Domain | Note=Tudor 1 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000535193 | 11 | 18 | 935_991 | 617.3333333333334 | 836.0 | Domain | Note=Tudor 2 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000543771 | 11 | 18 | 877_934 | 595.3333333333334 | 814.0 | Domain | Note=Tudor 1 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000543771 | 11 | 18 | 935_991 | 595.3333333333334 | 814.0 | Domain | Note=Tudor 2 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381306 | 11 | 21 | 689_747 | 595.3333333333334 | 1048.0 | Zinc finger | Note=PHD-type 1 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381306 | 11 | 21 | 752_785 | 595.3333333333334 | 1048.0 | Zinc finger | C2HC pre-PHD-type | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381306 | 11 | 21 | 808_865 | 595.3333333333334 | 1048.0 | Zinc finger | PHD-type 2 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381309 | 11 | 22 | 689_747 | 595.3333333333334 | 1057.0 | Zinc finger | Note=PHD-type 1 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381309 | 11 | 22 | 752_785 | 595.3333333333334 | 1057.0 | Zinc finger | C2HC pre-PHD-type | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381309 | 11 | 22 | 808_865 | 595.3333333333334 | 1057.0 | Zinc finger | PHD-type 2 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000535193 | 11 | 18 | 689_747 | 617.3333333333334 | 836.0 | Zinc finger | Note=PHD-type 1 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000535193 | 11 | 18 | 752_785 | 617.3333333333334 | 836.0 | Zinc finger | C2HC pre-PHD-type | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000535193 | 11 | 18 | 808_865 | 617.3333333333334 | 836.0 | Zinc finger | PHD-type 2 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000543771 | 11 | 18 | 689_747 | 595.3333333333334 | 814.0 | Zinc finger | Note=PHD-type 1 | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000543771 | 11 | 18 | 752_785 | 595.3333333333334 | 814.0 | Zinc finger | C2HC pre-PHD-type | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000543771 | 11 | 18 | 808_865 | 595.3333333333334 | 814.0 | Zinc finger | PHD-type 2 |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379882 | - | 4 | 17 | 251_430 | 185.33333333333334 | 881.0 | Domain | Helicase ATP-binding |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379882 | - | 4 | 17 | 610_776 | 185.33333333333334 | 881.0 | Domain | Helicase C-terminal |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379882 | - | 4 | 17 | 794_925 | 185.33333333333334 | 881.0 | Domain | RLR CTR |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379883 | - | 5 | 18 | 251_430 | 230.33333333333334 | 926.0 | Domain | Helicase ATP-binding |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379883 | - | 5 | 18 | 610_776 | 230.33333333333334 | 926.0 | Domain | Helicase C-terminal |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379883 | - | 5 | 18 | 794_925 | 230.33333333333334 | 926.0 | Domain | RLR CTR |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379882 | - | 4 | 17 | 372_375 | 185.33333333333334 | 881.0 | Motif | Note=DECH box |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379883 | - | 5 | 18 | 372_375 | 230.33333333333334 | 926.0 | Motif | Note=DECH box |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379882 | - | 4 | 17 | 264_271 | 185.33333333333334 | 881.0 | Nucleotide binding | ATP |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379883 | - | 5 | 18 | 264_271 | 230.33333333333334 | 926.0 | Nucleotide binding | ATP |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381306 | 11 | 21 | 144_310 | 595.3333333333334 | 1048.0 | Domain | JmjC | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381306 | 11 | 21 | 16_58 | 595.3333333333334 | 1048.0 | Domain | JmjN | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381309 | 11 | 22 | 144_310 | 595.3333333333334 | 1057.0 | Domain | JmjC | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000381309 | 11 | 22 | 16_58 | 595.3333333333334 | 1057.0 | Domain | JmjN | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000535193 | 11 | 18 | 144_310 | 617.3333333333334 | 836.0 | Domain | JmjC | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000535193 | 11 | 18 | 16_58 | 617.3333333333334 | 836.0 | Domain | JmjN | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000543771 | 11 | 18 | 144_310 | 595.3333333333334 | 814.0 | Domain | JmjC | |
| Tgene | KDM4C | chr9:32491298 | chr9:7011697 | ENST00000543771 | 11 | 18 | 16_58 | 595.3333333333334 | 814.0 | Domain | JmjN |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| DDX58 | |
| KDM4C |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379882 | - | 4 | 17 | 218_925 | 185.33333333333334 | 881.0 | ZC3HAV1 |
| Hgene | DDX58 | chr9:32491298 | chr9:7011697 | ENST00000379883 | - | 5 | 18 | 218_925 | 230.33333333333334 | 926.0 | ZC3HAV1 |
Top |
Related Drugs to DDX58-KDM4C |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to DDX58-KDM4C |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies