| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:EIF3L-TRIOBP |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: EIF3L-TRIOBP | FusionPDB ID: 25908 | FusionGDB2.0 ID: 25908 | Hgene | Tgene | Gene symbol | EIF3L | TRIOBP | Gene ID | 51386 | 11078 |
| Gene name | eukaryotic translation initiation factor 3 subunit L | TRIO and F-actin binding protein | |
| Synonyms | EIF3EIP|EIF3S11|EIF3S6IP|HSPC021|HSPC025|MSTP005 | DFNB28|HRIHFB2122|TAP68|TARA|dJ37E16.4 | |
| Cytomap | 22q13.1 | 22q13.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | eukaryotic translation initiation factor 3 subunit LeIEF associated protein HSPC021eukaryotic translation initiation factor 3 subunit 6-interacting proteineukaryotic translation initiation factor 3 subunit E-interacting protein | TRIO and F-actin-binding proteinprotein Taratara-like proteintrio-associated repeat on actin | |
| Modification date | 20200322 | 20200313 | |
| UniProtAcc | Q9Y262 | . | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000381683, ENST00000406934, ENST00000412331, ENST00000476955, | ENST00000403663, ENST00000407319, ENST00000406386, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 13 X 8 X 9=936 | 13 X 17 X 5=1105 |
| # samples | 18 | 19 | |
| ** MAII score | log2(18/936*10)=-2.37851162325373 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(19/1105*10)=-2.53997504594785 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: EIF3L [Title/Abstract] AND TRIOBP [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | EIF3L(38274178)-TRIOBP(38106434), # samples:2 EIF3L(38274178)-TRIOBP(38147779), # samples:2 EIF3L(38274178)-TRIOBP(38106433), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | EIF3L-TRIOBP seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. EIF3L-TRIOBP seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. EIF3L-TRIOBP seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. EIF3L-TRIOBP seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. EIF3L-TRIOBP seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. EIF3L-TRIOBP seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | EIF3L | GO:0006413 | translational initiation | 17581632 |
| Hgene | EIF3L | GO:0075525 | viral translational termination-reinitiation | 21347434 |
| Tgene | TRIOBP | GO:1900026 | positive regulation of substrate adhesion-dependent cell spreading | 11148140 |
| Fusion gene breakpoints across EIF3L (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TRIOBP (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-DK-AA6P-01A | EIF3L | chr22 | 38251651 | + | TRIOBP | chr22 | 38150884 | + |
| ChimerDB4 | ESCA | TCGA-L5-A4OS-01A | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38106434 | + |
| ChimerDB4 | ESCA | TCGA-L5-A4OS | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38106433 | + |
| ChimerDB4 | ESCA | TCGA-L5-A4OS | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38106434 | + |
| ChimerDB4 | ESCA | TCGA-L5-A4OS | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38119192 | + |
| ChimerDB4 | LUSC | TCGA-43-5668-01A | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + |
| ChimerDB4 | LUSC | TCGA-43-5668 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + |
| ChimerDB4 | LUSC | TCGA-43-5668 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000412331 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38106434 | + | 11917 | 2157 | 444 | 9140 | 2898 |
| ENST00000381683 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38106434 | + | 11224 | 1464 | 33 | 8447 | 2804 |
| ENST00000406934 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38106434 | + | 11756 | 1996 | 700 | 8979 | 2759 |
| ENST00000412331 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38147779 | + | 6709 | 2157 | 444 | 3932 | 1162 |
| ENST00000412331 | EIF3L | chr22 | 38274178 | + | ENST00000407319 | TRIOBP | chr22 | 38147779 | + | 4089 | 2157 | 444 | 3269 | 941 |
| ENST00000412331 | EIF3L | chr22 | 38274178 | + | ENST00000403663 | TRIOBP | chr22 | 38147779 | + | 4293 | 2157 | 444 | 3932 | 1162 |
| ENST00000381683 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38147779 | + | 6016 | 1464 | 33 | 3239 | 1068 |
| ENST00000381683 | EIF3L | chr22 | 38274178 | + | ENST00000407319 | TRIOBP | chr22 | 38147779 | + | 3396 | 1464 | 33 | 2576 | 847 |
| ENST00000381683 | EIF3L | chr22 | 38274178 | + | ENST00000403663 | TRIOBP | chr22 | 38147779 | + | 3600 | 1464 | 33 | 3239 | 1068 |
| ENST00000406934 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38147779 | + | 6548 | 1996 | 700 | 3771 | 1023 |
| ENST00000406934 | EIF3L | chr22 | 38274178 | + | ENST00000407319 | TRIOBP | chr22 | 38147779 | + | 3928 | 1996 | 700 | 3108 | 802 |
| ENST00000406934 | EIF3L | chr22 | 38274178 | + | ENST00000403663 | TRIOBP | chr22 | 38147779 | + | 4132 | 1996 | 700 | 3771 | 1023 |
| ENST00000412331 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38106433 | + | 11917 | 2157 | 444 | 9140 | 2898 |
| ENST00000381683 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38106433 | + | 11224 | 1464 | 33 | 8447 | 2804 |
| ENST00000406934 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38106433 | + | 11756 | 1996 | 700 | 8979 | 2759 |
| ENST00000412331 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38147778 | + | 6709 | 2157 | 444 | 3932 | 1162 |
| ENST00000412331 | EIF3L | chr22 | 38274178 | + | ENST00000407319 | TRIOBP | chr22 | 38147778 | + | 4089 | 2157 | 444 | 3269 | 941 |
| ENST00000412331 | EIF3L | chr22 | 38274178 | + | ENST00000403663 | TRIOBP | chr22 | 38147778 | + | 4293 | 2157 | 444 | 3932 | 1162 |
| ENST00000381683 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38147778 | + | 6016 | 1464 | 33 | 3239 | 1068 |
| ENST00000381683 | EIF3L | chr22 | 38274178 | + | ENST00000407319 | TRIOBP | chr22 | 38147778 | + | 3396 | 1464 | 33 | 2576 | 847 |
| ENST00000381683 | EIF3L | chr22 | 38274178 | + | ENST00000403663 | TRIOBP | chr22 | 38147778 | + | 3600 | 1464 | 33 | 3239 | 1068 |
| ENST00000406934 | EIF3L | chr22 | 38274178 | + | ENST00000406386 | TRIOBP | chr22 | 38147778 | + | 6548 | 1996 | 700 | 3771 | 1023 |
| ENST00000406934 | EIF3L | chr22 | 38274178 | + | ENST00000407319 | TRIOBP | chr22 | 38147778 | + | 3928 | 1996 | 700 | 3108 | 802 |
| ENST00000406934 | EIF3L | chr22 | 38274178 | + | ENST00000403663 | TRIOBP | chr22 | 38147778 | + | 4132 | 1996 | 700 | 3771 | 1023 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000412331 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38106434 | + | 0.005266005 | 0.99473405 |
| ENST00000381683 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38106434 | + | 0.003509875 | 0.99649006 |
| ENST00000406934 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38106434 | + | 0.007663807 | 0.9923362 |
| ENST00000412331 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + | 0.001873807 | 0.9981262 |
| ENST00000412331 | ENST00000407319 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + | 0.001017117 | 0.99898285 |
| ENST00000412331 | ENST00000403663 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + | 0.004200514 | 0.9957995 |
| ENST00000381683 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + | 0.001563313 | 0.9984366 |
| ENST00000381683 | ENST00000407319 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + | 0.001779435 | 0.9982205 |
| ENST00000381683 | ENST00000403663 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + | 0.004241605 | 0.99575835 |
| ENST00000406934 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + | 0.002091307 | 0.9979087 |
| ENST00000406934 | ENST00000407319 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + | 0.002386635 | 0.99761343 |
| ENST00000406934 | ENST00000403663 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147779 | + | 0.004297425 | 0.99570256 |
| ENST00000412331 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38106433 | + | 0.005266005 | 0.99473405 |
| ENST00000381683 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38106433 | + | 0.003509875 | 0.99649006 |
| ENST00000406934 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38106433 | + | 0.007663807 | 0.9923362 |
| ENST00000412331 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + | 0.001873807 | 0.9981262 |
| ENST00000412331 | ENST00000407319 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + | 0.001017117 | 0.99898285 |
| ENST00000412331 | ENST00000403663 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + | 0.004200514 | 0.9957995 |
| ENST00000381683 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + | 0.001563313 | 0.9984366 |
| ENST00000381683 | ENST00000407319 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + | 0.001779435 | 0.9982205 |
| ENST00000381683 | ENST00000403663 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + | 0.004241605 | 0.99575835 |
| ENST00000406934 | ENST00000406386 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + | 0.002091307 | 0.9979087 |
| ENST00000406934 | ENST00000407319 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + | 0.002386635 | 0.99761343 |
| ENST00000406934 | ENST00000403663 | EIF3L | chr22 | 38274178 | + | TRIOBP | chr22 | 38147778 | + | 0.004297425 | 0.99570256 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >25908_25908_1_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000381683_TRIOBP_chr22_38106433_ENST00000406386_length(amino acids)=2804AA_BP=761 MSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQTYQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYE IQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKELYYRHIYAKVSFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVL NVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYY VGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQV YEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMK NLVWTSGISALDGEFQSASEVDFYIDKELRSPSGAEVPYCDLPRCPPAPEDPLSASTSGCQSVVDPGLRPGPKRGPSPSAGLPEEGPTAA PRSRSRELEAVPYLEGLTTSLCGSCNEDPGSDPTSSPDSATPDDTSNSSSVDWDTVERQEEEAPSWDELAVMIPRRPREGPRADSSQRAP SLLTRSPVGGDAAGQKKEDTGGGGRSAGQHWARLRGESGLSLERHRSTLTQASSMTPHSGPRSTTSQASPAQRDTAQAASTREIPRASSP HRITQRDTSRASSTQQEISRASSTQQETSRASSTQEDTPRASSTQEDTPRASSTQWNTPRASSPSRSTQLDNPRTSSTQQDNPQTSFPTC TPQRENPRTPCVQQDDPRASSPNRTTQRENSRTSCAQRDNPKASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQRDNP RASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRAARDNPTT SCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNR TTQQDSPRTSCARRDDPRASSPNRTIQQENPRTSCALRDNPRASSPSRTIQQENPRTSCAQRDDPRASSPNRTTQQENPRTSCARRDNPR ASSRNRTIQRDNPRTSCAQRDNPRASSPNRTIQQENLRTSCTRQDNPRTSSPNRATRDNPRTSCAQRDNLRASSPIRATQQDNPRTCIQQ NIPRSSSTQQDNPKTSCTKRDNLRPTCTQRDRTQSFSFQRDNPGTSSSQCCTQKENLRPSSPHRSTQWNNPRNSSPHRTNKDIPWASFPL RPTQSDGPRTSSPSRSKQSEVPWASIALRPTQGDRPQTSSPSRPAQHDPPQSSFGPTQYNLPSRATSSSHNPGHQSTSRTSSPVYPAAYG APLTSPEPSQPPCAVCIGHRDAPRASSPPRYLQHDPFPFFPEPRAPESEPPHHEPPYIPPAVCIGHRDAPRASSPPRHTQFDPFPFLPDT SDAEHQCQSPQHEPLQLPAPVCIGYRDAPRASSPPRQAPEPSLLFQDLPRASTESLVPSMDSLHECPHIPTPVCIGHRDAPSFSSPPRQA PEPSLFFQDPPGTSMESLAPSTDSLHGSPVLIPQVCIGHRDAPRASSPPRHPPSDLAFLAPSPSPGSSGGSRGSAPPGETRHNLEREEYT VLADLPPPRRLAQRQPGPQAQCSSGGRTHSPGRAEVERLFGQERRKSEAAGAFQAQDEGRSQQPSQGQSQLLRRQSSPAPSRQVTMLPAK QAELTRRSQAEPPHPWSPEKRPEGDRQLQGSPLPPRTSARTPERELRTQRPLESGQAGPRQPLGVWQSQEEPPGSQGPHRHLERSWSSQE GGLGPGGWWGCGEPSLGAAKAPEGAWGGTSREYKESWGQPEAWEEKPTHELPRELGKRSPLTSPPENWGGPAESSQSWHSGTPTAVGWGA EGACPYPRGSERRPELDWRDLLGLLRAPGEGVWARVPSLDWEGLLELLQARLPRKDPAGHRDDLARALGPELGPPGTNDVPEQESHSQPE GWAEATPVNGHSPALQSQSPVQLPSPACTSTQWPKIKVTRGPATATLAGLEQTGPLGSRSTAKGPSLPELQFQPEEPEESEPSRGQDPLT DQKQADSADKRPAEGKAGSPLKGRLVTSWRMPGDRPTLFNPFLLSLGVLRWRRPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHW FVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSN KENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFE ATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEA WRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELS RELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGF IASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDELQMMQKDKRFTSGKYQDVYVELSHIKTRSEREIEQLKEHLRLAMA -------------------------------------------------------------- >25908_25908_2_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000381683_TRIOBP_chr22_38106434_ENST00000406386_length(amino acids)=2804AA_BP=761 MSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQTYQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYE IQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKELYYRHIYAKVSFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVL NVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYY VGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQV YEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMK NLVWTSGISALDGEFQSASEVDFYIDKELRSPSGAEVPYCDLPRCPPAPEDPLSASTSGCQSVVDPGLRPGPKRGPSPSAGLPEEGPTAA PRSRSRELEAVPYLEGLTTSLCGSCNEDPGSDPTSSPDSATPDDTSNSSSVDWDTVERQEEEAPSWDELAVMIPRRPREGPRADSSQRAP SLLTRSPVGGDAAGQKKEDTGGGGRSAGQHWARLRGESGLSLERHRSTLTQASSMTPHSGPRSTTSQASPAQRDTAQAASTREIPRASSP HRITQRDTSRASSTQQEISRASSTQQETSRASSTQEDTPRASSTQEDTPRASSTQWNTPRASSPSRSTQLDNPRTSSTQQDNPQTSFPTC TPQRENPRTPCVQQDDPRASSPNRTTQRENSRTSCAQRDNPKASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQRDNP RASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRAARDNPTT SCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNR TTQQDSPRTSCARRDDPRASSPNRTIQQENPRTSCALRDNPRASSPSRTIQQENPRTSCAQRDDPRASSPNRTTQQENPRTSCARRDNPR ASSRNRTIQRDNPRTSCAQRDNPRASSPNRTIQQENLRTSCTRQDNPRTSSPNRATRDNPRTSCAQRDNLRASSPIRATQQDNPRTCIQQ NIPRSSSTQQDNPKTSCTKRDNLRPTCTQRDRTQSFSFQRDNPGTSSSQCCTQKENLRPSSPHRSTQWNNPRNSSPHRTNKDIPWASFPL RPTQSDGPRTSSPSRSKQSEVPWASIALRPTQGDRPQTSSPSRPAQHDPPQSSFGPTQYNLPSRATSSSHNPGHQSTSRTSSPVYPAAYG APLTSPEPSQPPCAVCIGHRDAPRASSPPRYLQHDPFPFFPEPRAPESEPPHHEPPYIPPAVCIGHRDAPRASSPPRHTQFDPFPFLPDT SDAEHQCQSPQHEPLQLPAPVCIGYRDAPRASSPPRQAPEPSLLFQDLPRASTESLVPSMDSLHECPHIPTPVCIGHRDAPSFSSPPRQA PEPSLFFQDPPGTSMESLAPSTDSLHGSPVLIPQVCIGHRDAPRASSPPRHPPSDLAFLAPSPSPGSSGGSRGSAPPGETRHNLEREEYT VLADLPPPRRLAQRQPGPQAQCSSGGRTHSPGRAEVERLFGQERRKSEAAGAFQAQDEGRSQQPSQGQSQLLRRQSSPAPSRQVTMLPAK QAELTRRSQAEPPHPWSPEKRPEGDRQLQGSPLPPRTSARTPERELRTQRPLESGQAGPRQPLGVWQSQEEPPGSQGPHRHLERSWSSQE GGLGPGGWWGCGEPSLGAAKAPEGAWGGTSREYKESWGQPEAWEEKPTHELPRELGKRSPLTSPPENWGGPAESSQSWHSGTPTAVGWGA EGACPYPRGSERRPELDWRDLLGLLRAPGEGVWARVPSLDWEGLLELLQARLPRKDPAGHRDDLARALGPELGPPGTNDVPEQESHSQPE GWAEATPVNGHSPALQSQSPVQLPSPACTSTQWPKIKVTRGPATATLAGLEQTGPLGSRSTAKGPSLPELQFQPEEPEESEPSRGQDPLT DQKQADSADKRPAEGKAGSPLKGRLVTSWRMPGDRPTLFNPFLLSLGVLRWRRPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHW FVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSN KENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFE ATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEA WRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELS RELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGF IASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDELQMMQKDKRFTSGKYQDVYVELSHIKTRSEREIEQLKEHLRLAMA -------------------------------------------------------------- >25908_25908_3_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000381683_TRIOBP_chr22_38147778_ENST00000403663_length(amino acids)=1068AA_BP=477 MSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQTYQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYE IQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKELYYRHIYAKVSFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVL NVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYY VGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQV YEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMK NLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEI DLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEV ISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTED QQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYIS QEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEA LKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLR -------------------------------------------------------------- >25908_25908_4_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000381683_TRIOBP_chr22_38147778_ENST00000406386_length(amino acids)=1068AA_BP=477 MSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQTYQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYE IQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKELYYRHIYAKVSFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVL NVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYY VGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQV YEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMK NLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEI DLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEV ISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTED QQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYIS QEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEA LKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLR -------------------------------------------------------------- >25908_25908_5_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000381683_TRIOBP_chr22_38147778_ENST00000407319_length(amino acids)=847AA_BP=477 MSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQTYQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYE IQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKELYYRHIYAKVSFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVL NVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYY VGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQV YEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMK NLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEI DLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEV ISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTED QQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYIS -------------------------------------------------------------- >25908_25908_6_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000381683_TRIOBP_chr22_38147779_ENST00000403663_length(amino acids)=1068AA_BP=477 MSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQTYQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYE IQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKELYYRHIYAKVSFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVL NVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYY VGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQV YEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMK NLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEI DLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEV ISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTED QQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYIS QEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEA LKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLR -------------------------------------------------------------- >25908_25908_7_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000381683_TRIOBP_chr22_38147779_ENST00000406386_length(amino acids)=1068AA_BP=477 MSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQTYQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYE IQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKELYYRHIYAKVSFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVL NVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYY VGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQV YEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMK NLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEI DLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEV ISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTED QQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYIS QEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEA LKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLR -------------------------------------------------------------- >25908_25908_8_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000381683_TRIOBP_chr22_38147779_ENST00000407319_length(amino acids)=847AA_BP=477 MSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQTYQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYE IQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKELYYRHIYAKVSFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVL NVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYY VGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQV YEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMK NLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEI DLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEV ISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTED QQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYIS -------------------------------------------------------------- >25908_25908_9_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000406934_TRIOBP_chr22_38106433_ENST00000406386_length(amino acids)=2759AA_BP=716 MTRKCMSYRPVVSPVMSLTRRCMRSRTSMRTDAVFLILYKELYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWL WDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFS LVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQ NEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQ QAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMKNLVWTSGISALDGEFQSASEVDFYIDKELRSPSGAEVPYCDLPRC PPAPEDPLSASTSGCQSVVDPGLRPGPKRGPSPSAGLPEEGPTAAPRSRSRELEAVPYLEGLTTSLCGSCNEDPGSDPTSSPDSATPDDT SNSSSVDWDTVERQEEEAPSWDELAVMIPRRPREGPRADSSQRAPSLLTRSPVGGDAAGQKKEDTGGGGRSAGQHWARLRGESGLSLERH RSTLTQASSMTPHSGPRSTTSQASPAQRDTAQAASTREIPRASSPHRITQRDTSRASSTQQEISRASSTQQETSRASSTQEDTPRASSTQ EDTPRASSTQWNTPRASSPSRSTQLDNPRTSSTQQDNPQTSFPTCTPQRENPRTPCVQQDDPRASSPNRTTQRENSRTSCAQRDNPKASR TSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQ RDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRAARDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRATRD NPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRTTQQDSPRTSCARRDDPRASSPNRTIQQENPRTSCALRDNPRASS PSRTIQQENPRTSCAQRDDPRASSPNRTTQQENPRTSCARRDNPRASSRNRTIQRDNPRTSCAQRDNPRASSPNRTIQQENLRTSCTRQD NPRTSSPNRATRDNPRTSCAQRDNLRASSPIRATQQDNPRTCIQQNIPRSSSTQQDNPKTSCTKRDNLRPTCTQRDRTQSFSFQRDNPGT SSSQCCTQKENLRPSSPHRSTQWNNPRNSSPHRTNKDIPWASFPLRPTQSDGPRTSSPSRSKQSEVPWASIALRPTQGDRPQTSSPSRPA QHDPPQSSFGPTQYNLPSRATSSSHNPGHQSTSRTSSPVYPAAYGAPLTSPEPSQPPCAVCIGHRDAPRASSPPRYLQHDPFPFFPEPRA PESEPPHHEPPYIPPAVCIGHRDAPRASSPPRHTQFDPFPFLPDTSDAEHQCQSPQHEPLQLPAPVCIGYRDAPRASSPPRQAPEPSLLF QDLPRASTESLVPSMDSLHECPHIPTPVCIGHRDAPSFSSPPRQAPEPSLFFQDPPGTSMESLAPSTDSLHGSPVLIPQVCIGHRDAPRA SSPPRHPPSDLAFLAPSPSPGSSGGSRGSAPPGETRHNLEREEYTVLADLPPPRRLAQRQPGPQAQCSSGGRTHSPGRAEVERLFGQERR KSEAAGAFQAQDEGRSQQPSQGQSQLLRRQSSPAPSRQVTMLPAKQAELTRRSQAEPPHPWSPEKRPEGDRQLQGSPLPPRTSARTPERE LRTQRPLESGQAGPRQPLGVWQSQEEPPGSQGPHRHLERSWSSQEGGLGPGGWWGCGEPSLGAAKAPEGAWGGTSREYKESWGQPEAWEE KPTHELPRELGKRSPLTSPPENWGGPAESSQSWHSGTPTAVGWGAEGACPYPRGSERRPELDWRDLLGLLRAPGEGVWARVPSLDWEGLL ELLQARLPRKDPAGHRDDLARALGPELGPPGTNDVPEQESHSQPEGWAEATPVNGHSPALQSQSPVQLPSPACTSTQWPKIKVTRGPATA TLAGLEQTGPLGSRSTAKGPSLPELQFQPEEPEESEPSRGQDPLTDQKQADSADKRPAEGKAGSPLKGRLVTSWRMPGDRPTLFNPFLLS LGVLRWRRPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGF QIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYV ELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKL PLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVM EELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEI GALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDE -------------------------------------------------------------- >25908_25908_10_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000406934_TRIOBP_chr22_38106434_ENST00000406386_length(amino acids)=2759AA_BP=716 MTRKCMSYRPVVSPVMSLTRRCMRSRTSMRTDAVFLILYKELYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWL WDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFS LVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQ NEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQ QAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMKNLVWTSGISALDGEFQSASEVDFYIDKELRSPSGAEVPYCDLPRC PPAPEDPLSASTSGCQSVVDPGLRPGPKRGPSPSAGLPEEGPTAAPRSRSRELEAVPYLEGLTTSLCGSCNEDPGSDPTSSPDSATPDDT SNSSSVDWDTVERQEEEAPSWDELAVMIPRRPREGPRADSSQRAPSLLTRSPVGGDAAGQKKEDTGGGGRSAGQHWARLRGESGLSLERH RSTLTQASSMTPHSGPRSTTSQASPAQRDTAQAASTREIPRASSPHRITQRDTSRASSTQQEISRASSTQQETSRASSTQEDTPRASSTQ EDTPRASSTQWNTPRASSPSRSTQLDNPRTSSTQQDNPQTSFPTCTPQRENPRTPCVQQDDPRASSPNRTTQRENSRTSCAQRDNPKASR TSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQ RDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRAARDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRATRD NPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRTTQQDSPRTSCARRDDPRASSPNRTIQQENPRTSCALRDNPRASS PSRTIQQENPRTSCAQRDDPRASSPNRTTQQENPRTSCARRDNPRASSRNRTIQRDNPRTSCAQRDNPRASSPNRTIQQENLRTSCTRQD NPRTSSPNRATRDNPRTSCAQRDNLRASSPIRATQQDNPRTCIQQNIPRSSSTQQDNPKTSCTKRDNLRPTCTQRDRTQSFSFQRDNPGT SSSQCCTQKENLRPSSPHRSTQWNNPRNSSPHRTNKDIPWASFPLRPTQSDGPRTSSPSRSKQSEVPWASIALRPTQGDRPQTSSPSRPA QHDPPQSSFGPTQYNLPSRATSSSHNPGHQSTSRTSSPVYPAAYGAPLTSPEPSQPPCAVCIGHRDAPRASSPPRYLQHDPFPFFPEPRA PESEPPHHEPPYIPPAVCIGHRDAPRASSPPRHTQFDPFPFLPDTSDAEHQCQSPQHEPLQLPAPVCIGYRDAPRASSPPRQAPEPSLLF QDLPRASTESLVPSMDSLHECPHIPTPVCIGHRDAPSFSSPPRQAPEPSLFFQDPPGTSMESLAPSTDSLHGSPVLIPQVCIGHRDAPRA SSPPRHPPSDLAFLAPSPSPGSSGGSRGSAPPGETRHNLEREEYTVLADLPPPRRLAQRQPGPQAQCSSGGRTHSPGRAEVERLFGQERR KSEAAGAFQAQDEGRSQQPSQGQSQLLRRQSSPAPSRQVTMLPAKQAELTRRSQAEPPHPWSPEKRPEGDRQLQGSPLPPRTSARTPERE LRTQRPLESGQAGPRQPLGVWQSQEEPPGSQGPHRHLERSWSSQEGGLGPGGWWGCGEPSLGAAKAPEGAWGGTSREYKESWGQPEAWEE KPTHELPRELGKRSPLTSPPENWGGPAESSQSWHSGTPTAVGWGAEGACPYPRGSERRPELDWRDLLGLLRAPGEGVWARVPSLDWEGLL ELLQARLPRKDPAGHRDDLARALGPELGPPGTNDVPEQESHSQPEGWAEATPVNGHSPALQSQSPVQLPSPACTSTQWPKIKVTRGPATA TLAGLEQTGPLGSRSTAKGPSLPELQFQPEEPEESEPSRGQDPLTDQKQADSADKRPAEGKAGSPLKGRLVTSWRMPGDRPTLFNPFLLS LGVLRWRRPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGF QIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYV ELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKL PLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVM EELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEI GALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDE -------------------------------------------------------------- >25908_25908_11_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000406934_TRIOBP_chr22_38147778_ENST00000403663_length(amino acids)=1023AA_BP=432 MTRKCMSYRPVVSPVMSLTRRCMRSRTSMRTDAVFLILYKELYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWL WDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFS LVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQ NEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQ QAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPG EPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEAL RKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQ EELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPS DGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEET AATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLR HNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDELQMMQKDKRFTSGKYQDVYVELSHIK -------------------------------------------------------------- >25908_25908_12_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000406934_TRIOBP_chr22_38147778_ENST00000406386_length(amino acids)=1023AA_BP=432 MTRKCMSYRPVVSPVMSLTRRCMRSRTSMRTDAVFLILYKELYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWL WDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFS LVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQ NEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQ QAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPG EPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEAL RKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQ EELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPS DGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEET AATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLR HNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDELQMMQKDKRFTSGKYQDVYVELSHIK -------------------------------------------------------------- >25908_25908_13_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000406934_TRIOBP_chr22_38147778_ENST00000407319_length(amino acids)=802AA_BP=432 MTRKCMSYRPVVSPVMSLTRRCMRSRTSMRTDAVFLILYKELYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWL WDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFS LVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQ NEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQ QAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPG EPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEAL RKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQ EELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPS -------------------------------------------------------------- >25908_25908_14_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000406934_TRIOBP_chr22_38147779_ENST00000403663_length(amino acids)=1023AA_BP=432 MTRKCMSYRPVVSPVMSLTRRCMRSRTSMRTDAVFLILYKELYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWL WDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFS LVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQ NEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQ QAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPG EPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEAL RKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQ EELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPS DGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEET AATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLR HNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDELQMMQKDKRFTSGKYQDVYVELSHIK -------------------------------------------------------------- >25908_25908_15_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000406934_TRIOBP_chr22_38147779_ENST00000406386_length(amino acids)=1023AA_BP=432 MTRKCMSYRPVVSPVMSLTRRCMRSRTSMRTDAVFLILYKELYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWL WDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFS LVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQ NEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQ QAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPG EPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEAL RKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQ EELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPS DGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEET AATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLR HNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDELQMMQKDKRFTSGKYQDVYVELSHIK -------------------------------------------------------------- >25908_25908_16_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000406934_TRIOBP_chr22_38147779_ENST00000407319_length(amino acids)=802AA_BP=432 MTRKCMSYRPVVSPVMSLTRRCMRSRTSMRTDAVFLILYKELYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWL WDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNVHSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFS LVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVTTYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQ NEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKGDPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQ QAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFKHKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPG EPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEAL RKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQ EELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPS -------------------------------------------------------------- >25908_25908_17_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000412331_TRIOBP_chr22_38106433_ENST00000406386_length(amino acids)=2898AA_BP=855 MSQMARGLGKASGFPAGPSGAELPASGRRRGPLISLFPAVLASEAAMSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQT YQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYEIQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKE LYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWLWDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNV HSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVT TYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKG DPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFK HKMKNLVWTSGISALDGEFQSASEVDFYIDKELRSPSGAEVPYCDLPRCPPAPEDPLSASTSGCQSVVDPGLRPGPKRGPSPSAGLPEEG PTAAPRSRSRELEAVPYLEGLTTSLCGSCNEDPGSDPTSSPDSATPDDTSNSSSVDWDTVERQEEEAPSWDELAVMIPRRPREGPRADSS QRAPSLLTRSPVGGDAAGQKKEDTGGGGRSAGQHWARLRGESGLSLERHRSTLTQASSMTPHSGPRSTTSQASPAQRDTAQAASTREIPR ASSPHRITQRDTSRASSTQQEISRASSTQQETSRASSTQEDTPRASSTQEDTPRASSTQWNTPRASSPSRSTQLDNPRTSSTQQDNPQTS FPTCTPQRENPRTPCVQQDDPRASSPNRTTQRENSRTSCAQRDNPKASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQ RDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRAARD NPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRAS SPNRTTQQDSPRTSCARRDDPRASSPNRTIQQENPRTSCALRDNPRASSPSRTIQQENPRTSCAQRDDPRASSPNRTTQQENPRTSCARR DNPRASSRNRTIQRDNPRTSCAQRDNPRASSPNRTIQQENLRTSCTRQDNPRTSSPNRATRDNPRTSCAQRDNLRASSPIRATQQDNPRT CIQQNIPRSSSTQQDNPKTSCTKRDNLRPTCTQRDRTQSFSFQRDNPGTSSSQCCTQKENLRPSSPHRSTQWNNPRNSSPHRTNKDIPWA SFPLRPTQSDGPRTSSPSRSKQSEVPWASIALRPTQGDRPQTSSPSRPAQHDPPQSSFGPTQYNLPSRATSSSHNPGHQSTSRTSSPVYP AAYGAPLTSPEPSQPPCAVCIGHRDAPRASSPPRYLQHDPFPFFPEPRAPESEPPHHEPPYIPPAVCIGHRDAPRASSPPRHTQFDPFPF LPDTSDAEHQCQSPQHEPLQLPAPVCIGYRDAPRASSPPRQAPEPSLLFQDLPRASTESLVPSMDSLHECPHIPTPVCIGHRDAPSFSSP PRQAPEPSLFFQDPPGTSMESLAPSTDSLHGSPVLIPQVCIGHRDAPRASSPPRHPPSDLAFLAPSPSPGSSGGSRGSAPPGETRHNLER EEYTVLADLPPPRRLAQRQPGPQAQCSSGGRTHSPGRAEVERLFGQERRKSEAAGAFQAQDEGRSQQPSQGQSQLLRRQSSPAPSRQVTM LPAKQAELTRRSQAEPPHPWSPEKRPEGDRQLQGSPLPPRTSARTPERELRTQRPLESGQAGPRQPLGVWQSQEEPPGSQGPHRHLERSW SSQEGGLGPGGWWGCGEPSLGAAKAPEGAWGGTSREYKESWGQPEAWEEKPTHELPRELGKRSPLTSPPENWGGPAESSQSWHSGTPTAV GWGAEGACPYPRGSERRPELDWRDLLGLLRAPGEGVWARVPSLDWEGLLELLQARLPRKDPAGHRDDLARALGPELGPPGTNDVPEQESH SQPEGWAEATPVNGHSPALQSQSPVQLPSPACTSTQWPKIKVTRGPATATLAGLEQTGPLGSRSTAKGPSLPELQFQPEEPEESEPSRGQ DPLTDQKQADSADKRPAEGKAGSPLKGRLVTSWRMPGDRPTLFNPFLLSLGVLRWRRPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQW KKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKL SDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERR KWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRA QLEAWRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQ EELSRELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQ LRGFIASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDELQMMQKDKRFTSGKYQDVYVELSHIKTRSEREIEQLKEHLR -------------------------------------------------------------- >25908_25908_18_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000412331_TRIOBP_chr22_38106434_ENST00000406386_length(amino acids)=2898AA_BP=855 MSQMARGLGKASGFPAGPSGAELPASGRRRGPLISLFPAVLASEAAMSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQT YQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYEIQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKE LYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWLWDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNV HSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVT TYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKG DPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFK HKMKNLVWTSGISALDGEFQSASEVDFYIDKELRSPSGAEVPYCDLPRCPPAPEDPLSASTSGCQSVVDPGLRPGPKRGPSPSAGLPEEG PTAAPRSRSRELEAVPYLEGLTTSLCGSCNEDPGSDPTSSPDSATPDDTSNSSSVDWDTVERQEEEAPSWDELAVMIPRRPREGPRADSS QRAPSLLTRSPVGGDAAGQKKEDTGGGGRSAGQHWARLRGESGLSLERHRSTLTQASSMTPHSGPRSTTSQASPAQRDTAQAASTREIPR ASSPHRITQRDTSRASSTQQEISRASSTQQETSRASSTQEDTPRASSTQEDTPRASSTQWNTPRASSPSRSTQLDNPRTSSTQQDNPQTS FPTCTPQRENPRTPCVQQDDPRASSPNRTTQRENSRTSCAQRDNPKASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQ RDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPSRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRAARD NPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRASSPNRATRDNPTTSCAQRDNPRASRTSSPNRATRDNPRTSCAQRDNPRAS SPNRTTQQDSPRTSCARRDDPRASSPNRTIQQENPRTSCALRDNPRASSPSRTIQQENPRTSCAQRDDPRASSPNRTTQQENPRTSCARR DNPRASSRNRTIQRDNPRTSCAQRDNPRASSPNRTIQQENLRTSCTRQDNPRTSSPNRATRDNPRTSCAQRDNLRASSPIRATQQDNPRT CIQQNIPRSSSTQQDNPKTSCTKRDNLRPTCTQRDRTQSFSFQRDNPGTSSSQCCTQKENLRPSSPHRSTQWNNPRNSSPHRTNKDIPWA SFPLRPTQSDGPRTSSPSRSKQSEVPWASIALRPTQGDRPQTSSPSRPAQHDPPQSSFGPTQYNLPSRATSSSHNPGHQSTSRTSSPVYP AAYGAPLTSPEPSQPPCAVCIGHRDAPRASSPPRYLQHDPFPFFPEPRAPESEPPHHEPPYIPPAVCIGHRDAPRASSPPRHTQFDPFPF LPDTSDAEHQCQSPQHEPLQLPAPVCIGYRDAPRASSPPRQAPEPSLLFQDLPRASTESLVPSMDSLHECPHIPTPVCIGHRDAPSFSSP PRQAPEPSLFFQDPPGTSMESLAPSTDSLHGSPVLIPQVCIGHRDAPRASSPPRHPPSDLAFLAPSPSPGSSGGSRGSAPPGETRHNLER EEYTVLADLPPPRRLAQRQPGPQAQCSSGGRTHSPGRAEVERLFGQERRKSEAAGAFQAQDEGRSQQPSQGQSQLLRRQSSPAPSRQVTM LPAKQAELTRRSQAEPPHPWSPEKRPEGDRQLQGSPLPPRTSARTPERELRTQRPLESGQAGPRQPLGVWQSQEEPPGSQGPHRHLERSW SSQEGGLGPGGWWGCGEPSLGAAKAPEGAWGGTSREYKESWGQPEAWEEKPTHELPRELGKRSPLTSPPENWGGPAESSQSWHSGTPTAV GWGAEGACPYPRGSERRPELDWRDLLGLLRAPGEGVWARVPSLDWEGLLELLQARLPRKDPAGHRDDLARALGPELGPPGTNDVPEQESH SQPEGWAEATPVNGHSPALQSQSPVQLPSPACTSTQWPKIKVTRGPATATLAGLEQTGPLGSRSTAKGPSLPELQFQPEEPEESEPSRGQ DPLTDQKQADSADKRPAEGKAGSPLKGRLVTSWRMPGDRPTLFNPFLLSLGVLRWRRPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQW KKHWFVLTDSSLKYYRDSTAEEADELDGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKL SDSNKENALHSYSTQKGPLKAGEQRAGSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERR KWFEATDSRTPEVPAGEGPRRGLGAPLTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRA QLEAWRLQGEAPQSALRSQEDGHIPPGYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQ EELSRELSKTRSLQQGPDGLRKQHQSDVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQ LRGFIASQGMGNGCGRSNERSSCELEVLLRVKENELQYLKKEVQCLRDELQMMQKDKRFTSGKYQDVYVELSHIKTRSEREIEQLKEHLR -------------------------------------------------------------- >25908_25908_19_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000412331_TRIOBP_chr22_38147778_ENST00000403663_length(amino acids)=1162AA_BP=571 MSQMARGLGKASGFPAGPSGAELPASGRRRGPLISLFPAVLASEAAMSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQT YQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYEIQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKE LYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWLWDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNV HSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVT TYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKG DPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFK HKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADEL DGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRA GSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAP LTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPP GYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQS DVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELE -------------------------------------------------------------- >25908_25908_20_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000412331_TRIOBP_chr22_38147778_ENST00000406386_length(amino acids)=1162AA_BP=571 MSQMARGLGKASGFPAGPSGAELPASGRRRGPLISLFPAVLASEAAMSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQT YQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYEIQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKE LYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWLWDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNV HSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVT TYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKG DPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFK HKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADEL DGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRA GSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAP LTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPP GYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQS DVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELE -------------------------------------------------------------- >25908_25908_21_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000412331_TRIOBP_chr22_38147778_ENST00000407319_length(amino acids)=941AA_BP=571 MSQMARGLGKASGFPAGPSGAELPASGRRRGPLISLFPAVLASEAAMSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQT YQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYEIQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKE LYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWLWDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNV HSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVT TYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKG DPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFK HKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADEL DGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRA GSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAP LTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPP -------------------------------------------------------------- >25908_25908_22_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000412331_TRIOBP_chr22_38147779_ENST00000403663_length(amino acids)=1162AA_BP=571 MSQMARGLGKASGFPAGPSGAELPASGRRRGPLISLFPAVLASEAAMSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQT YQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYEIQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKE LYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWLWDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNV HSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVT TYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKG DPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFK HKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADEL DGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRA GSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAP LTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPP GYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQS DVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELE -------------------------------------------------------------- >25908_25908_23_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000412331_TRIOBP_chr22_38147779_ENST00000406386_length(amino acids)=1162AA_BP=571 MSQMARGLGKASGFPAGPSGAELPASGRRRGPLISLFPAVLASEAAMSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQT YQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYEIQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKE LYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWLWDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNV HSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVT TYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKG DPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFK HKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADEL DGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRA GSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAP LTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPP GYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQS DVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELE -------------------------------------------------------------- >25908_25908_24_EIF3L-TRIOBP_EIF3L_chr22_38274178_ENST00000412331_TRIOBP_chr22_38147779_ENST00000407319_length(amino acids)=941AA_BP=571 MSQMARGLGKASGFPAGPSGAELPASGRRRGPLISLFPAVLASEAAMSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQT YQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYEIQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKE LYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWLWDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNV HSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVT TYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKG DPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFK HKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADEL DGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRA GSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAP LTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPP -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:38274178/chr22:38106434) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| EIF3L | . |
| FUNCTION: Component of the eukaryotic translation initiation factor 3 (eIF-3) complex, which is required for several steps in the initiation of protein synthesis (PubMed:17581632, PubMed:25849773, PubMed:27462815). The eIF-3 complex associates with the 40S ribosome and facilitates the recruitment of eIF-1, eIF-1A, eIF-2:GTP:methionyl-tRNAi and eIF-5 to form the 43S pre-initiation complex (43S PIC). The eIF-3 complex stimulates mRNA recruitment to the 43S PIC and scanning of the mRNA for AUG recognition. The eIF-3 complex is also required for disassembly and recycling of post-termination ribosomal complexes and subsequently prevents premature joining of the 40S and 60S ribosomal subunits prior to initiation (PubMed:17581632). The eIF-3 complex specifically targets and initiates translation of a subset of mRNAs involved in cell proliferation, including cell cycling, differentiation and apoptosis, and uses different modes of RNA stem-loop binding to exert either translational activation or repression (PubMed:25849773). {ECO:0000255|HAMAP-Rule:MF_03011, ECO:0000269|PubMed:17581632, ECO:0000269|PubMed:25849773, ECO:0000269|PubMed:27462815}.; FUNCTION: (Microbial infection) In case of FCV infection, plays a role in the ribosomal termination-reinitiation event leading to the translation of VP2 (PubMed:18056426). {ECO:0000269|PubMed:18056426}. | FUNCTION: Might normally function as a transcriptional repressor. EWS-fusion-proteins (EFPS) may play a role in the tumorigenic process. They may disturb gene expression by mimicking, or interfering with the normal function of CTD-POLII within the transcription initiation complex. They may also contribute to an aberrant activation of the fusion protein target genes. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106433 | ENST00000406386 | 2 | 24 | 2062_2247 | 38.0 | 3262.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106433 | ENST00000406386 | 2 | 24 | 2281_2361 | 38.0 | 3262.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106433 | ENST00000407319 | 0 | 8 | 2062_2247 | 0 | 432.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106433 | ENST00000407319 | 0 | 8 | 2281_2361 | 0 | 432.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106434 | ENST00000406386 | 2 | 24 | 2062_2247 | 38.0 | 3262.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106434 | ENST00000406386 | 2 | 24 | 2281_2361 | 38.0 | 3262.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106434 | ENST00000407319 | 0 | 8 | 2062_2247 | 0 | 432.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106434 | ENST00000407319 | 0 | 8 | 2281_2361 | 0 | 432.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147778 | ENST00000406386 | 10 | 24 | 2062_2247 | 1774.0 | 3262.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147778 | ENST00000406386 | 10 | 24 | 2281_2361 | 1774.0 | 3262.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147778 | ENST00000407319 | 0 | 8 | 2062_2247 | 61.0 | 432.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147778 | ENST00000407319 | 0 | 8 | 2281_2361 | 61.0 | 432.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147779 | ENST00000406386 | 10 | 24 | 2062_2247 | 1774.0 | 3262.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147779 | ENST00000406386 | 10 | 24 | 2281_2361 | 1774.0 | 3262.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147779 | ENST00000407319 | 0 | 8 | 2062_2247 | 61.0 | 432.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147779 | ENST00000407319 | 0 | 8 | 2281_2361 | 61.0 | 432.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106433 | ENST00000406386 | 2 | 24 | 1778_1887 | 38.0 | 3262.0 | Domain | PH | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106433 | ENST00000407319 | 0 | 8 | 1778_1887 | 0 | 432.0 | Domain | PH | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106434 | ENST00000406386 | 2 | 24 | 1778_1887 | 38.0 | 3262.0 | Domain | PH | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38106434 | ENST00000407319 | 0 | 8 | 1778_1887 | 0 | 432.0 | Domain | PH | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147778 | ENST00000406386 | 10 | 24 | 1778_1887 | 1774.0 | 3262.0 | Domain | PH | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147778 | ENST00000407319 | 0 | 8 | 1778_1887 | 61.0 | 432.0 | Domain | PH | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147779 | ENST00000406386 | 10 | 24 | 1778_1887 | 1774.0 | 3262.0 | Domain | PH | |
| Tgene | TRIOBP | chr22:38274178 | chr22:38147779 | ENST00000407319 | 0 | 8 | 1778_1887 | 61.0 | 432.0 | Domain | PH |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EIF3L | chr22:38274178 | chr22:38106433 | ENST00000381683 | + | 9 | 11 | 331_537 | 477.0 | 517.0 | Domain | PCI |
| Hgene | EIF3L | chr22:38274178 | chr22:38106433 | ENST00000412331 | + | 11 | 13 | 331_537 | 525.0 | 565.0 | Domain | PCI |
| Hgene | EIF3L | chr22:38274178 | chr22:38106434 | ENST00000381683 | + | 9 | 11 | 331_537 | 477.0 | 517.0 | Domain | PCI |
| Hgene | EIF3L | chr22:38274178 | chr22:38106434 | ENST00000412331 | + | 11 | 13 | 331_537 | 525.0 | 565.0 | Domain | PCI |
| Hgene | EIF3L | chr22:38274178 | chr22:38147778 | ENST00000381683 | + | 9 | 11 | 331_537 | 477.0 | 517.0 | Domain | PCI |
| Hgene | EIF3L | chr22:38274178 | chr22:38147778 | ENST00000412331 | + | 11 | 13 | 331_537 | 525.0 | 565.0 | Domain | PCI |
| Hgene | EIF3L | chr22:38274178 | chr22:38147779 | ENST00000381683 | + | 9 | 11 | 331_537 | 477.0 | 517.0 | Domain | PCI |
| Hgene | EIF3L | chr22:38274178 | chr22:38147779 | ENST00000412331 | + | 11 | 13 | 331_537 | 525.0 | 565.0 | Domain | PCI |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file >>>1901_EIF3L_38274178_TRIOBP_38147779_ranked_0.pdb | EIF3L | 38274178 | 38274178 | ENST00000403663 | TRIOBP | chr22 | 38147779 | + | MSQMARGLGKASGFPAGPSGAELPASGRRRGPLISLFPAVLASEAAMSYPADDYESEAAYDPYAYPSDYDMHTGDPKQDLAYERQYEQQT YQVIPEVIKNFIQYFHKTVSDLIDQKVYELQASRVSSDVIDQKVYEIQDIYENSWTKLTERFFKNTPWPEAEAIAPQVGNDAVFLILYKE LYYRHIYAKVSGGPSLEQRFESYYNYCNLFNYILNADGPAPLELPNQWLWDIIDEFIYQFQSFSQYRCKTAKKSEEEIDFLRSNPKIWNV HSVLNVLHSLVDKSNINRQLEVYTSGGDPESVAGEYGRHSLYKMLGYFSLVGLLRLHSLLGDYYQAIKVLENIELNKKSMYSRVPECQVT TYYYVGFAYLMMRRYQDAIRVFANILLYIQRTKSMFQRTTYKYEMINKQNEQMHALLAIALTMYPMRIDESIHLQLREKYGDKMLRMQKG DPQVYEELFSYSCPKFLSPVVPNYDNVHPNYHKEPFLQQLKVFSDEVQQQAQLSTIRSFLKLYTTMPVAKLAGFLDLTEQEFRIQLLVFK HKMKNLVWTSGISALDGEFQSASEVDFYIDKPDLLNFKKGWMSILDEPGEPPSPSLTTTSTSQWKKHWFVLTDSSLKYYRDSTAEEADEL DGEIDLRSCTDVTEYAVQRNYGFQIHTKDAVYTLSAMTSGIRRNWIEALRKTVRPTSAPDVTKLSDSNKENALHSYSTQKGPLKAGEQRA GSEVISRGGPRKADGQRQALDYVELSPLTQASPQRARTPARTPDRLAKQEELERDLAQRSEERRKWFEATDSRTPEVPAGEGPRRGLGAP LTEDQQNRLSEEIEKKWQELEKLPLRENKRVPLTALLNQSRGERRGPPSDGHEALEKEVQALRAQLEAWRLQGEAPQSALRSQEDGHIPP GYISQEACERSLAEMESSHQQVMEELQRHHERELQRLQQEKEWLLAEETAATASAIEAMKKAYQEELSRELSKTRSLQQGPDGLRKQHQS DVEALKRELQVLSEQYSQKCLEIGALMRQAEEREHTLRRCQQEGQELLRHNQELHGRLSEEIDQLRGFIASQGMGNGCGRSNERSSCELE | 1162 |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
EIF3L_pLDDT.png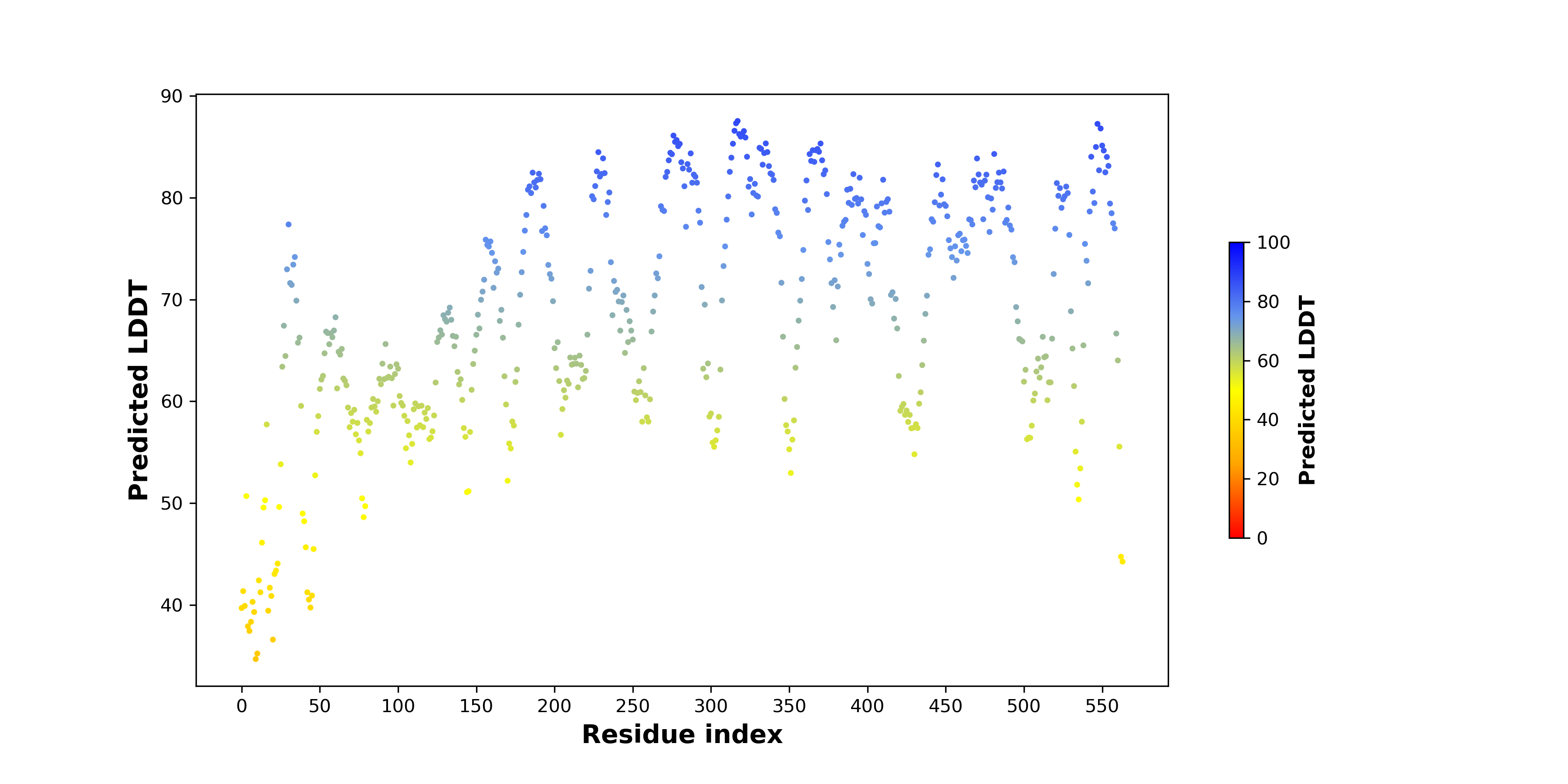  |
TRIOBP_pLDDT.png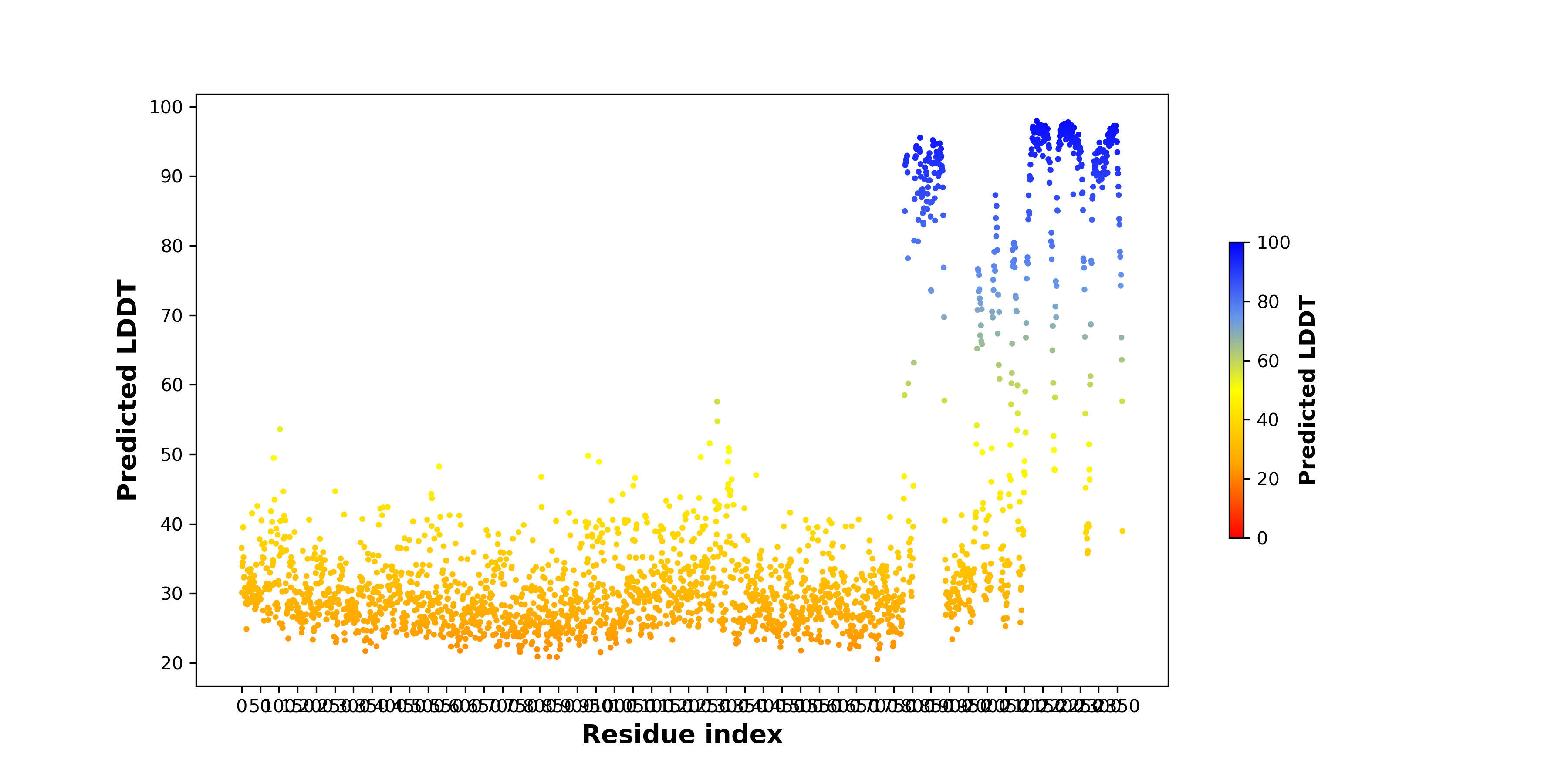  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
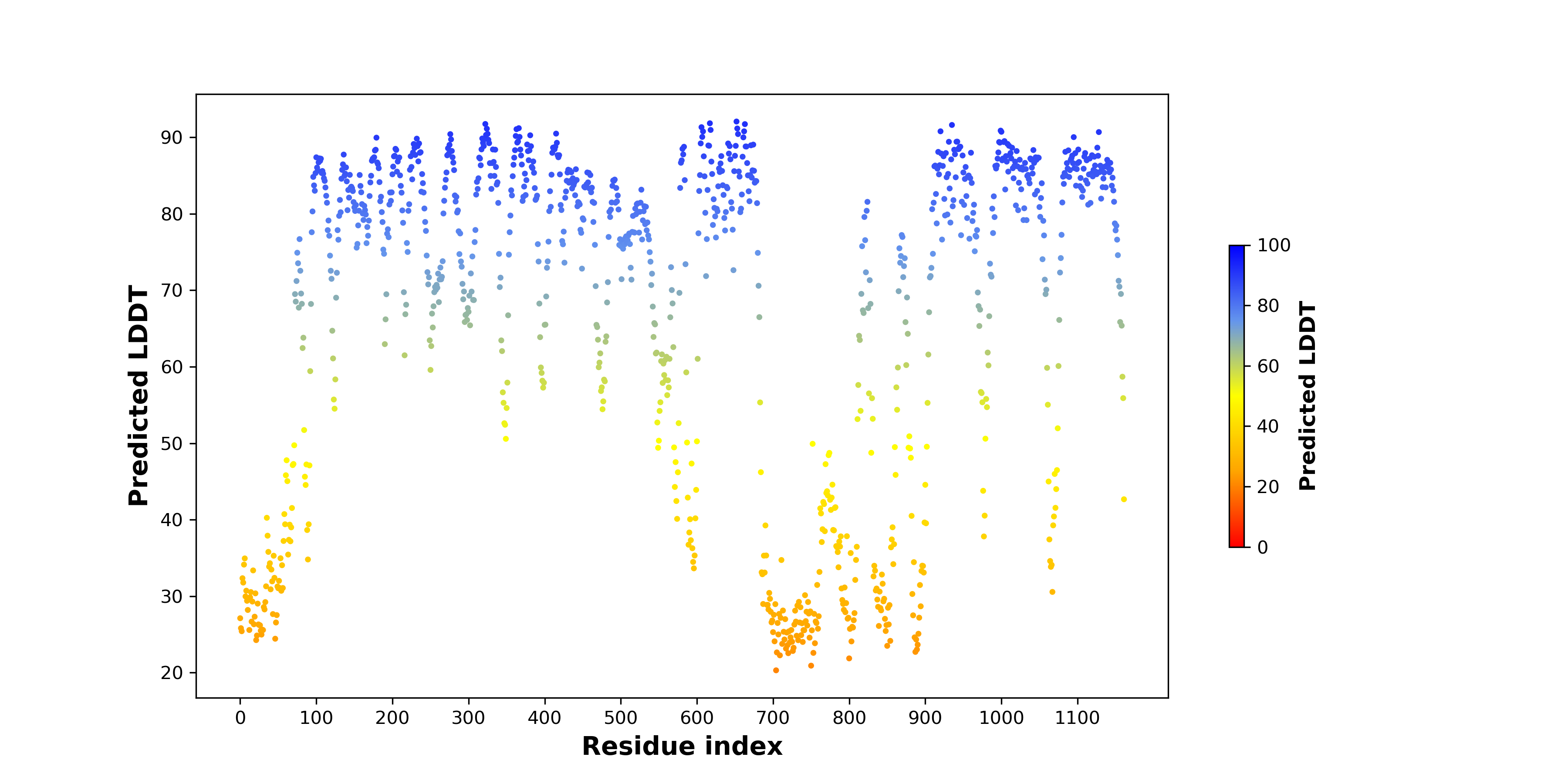 |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| EIF3L | |
| TRIOBP |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to EIF3L-TRIOBP |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to EIF3L-TRIOBP |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies