| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:ERC1-ROS1 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: ERC1-ROS1 | FusionPDB ID: 27280 | FusionGDB2.0 ID: 27280 | Hgene | Tgene | Gene symbol | ERC1 | ROS1 | Gene ID | 23085 | 6098 |
| Gene name | ELKS/RAB6-interacting/CAST family member 1 | ROS proto-oncogene 1, receptor tyrosine kinase | |
| Synonyms | Cast2|ELKS|ERC-1|RAB6IP2 | MCF3|ROS|c-ros-1 | |
| Cytomap | 12p13.33 | 6q22.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | ELKS/Rab6-interacting/CAST family member 1RAB6 interacting protein 2 | proto-oncogene tyrosine-protein kinase ROSROS proto-oncogene 1 , receptor tyrosine kinasec-ros oncogene 1 , receptor tyrosine kinaseproto-oncogene c-Ros-1transmembrane tyrosine-specific protein kinasev-ros avian UR2 sarcoma virus oncogene homolog 1 | |
| Modification date | 20200313 | 20200314 | |
| UniProtAcc | Q8IUD2 | P08922 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000536573, ENST00000355446, ENST00000360905, ENST00000397203, ENST00000543086, ENST00000546231, ENST00000589028, | ENST00000368507, ENST00000368508, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 32 X 23 X 16=11776 | 18 X 20 X 5=1800 |
| # samples | 38 | 20 | |
| ** MAII score | log2(38/11776*10)=-4.95370634772607 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(20/1800*10)=-3.16992500144231 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: ERC1 [Title/Abstract] AND ROS1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | |||
| Anticipated loss of major functional domain due to fusion event. | ERC1-ROS1 seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. ERC1-ROS1 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. ERC1-ROS1 seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. ERC1-ROS1 seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. ERC1-ROS1 seems lost the major protein functional domain in Tgene partner, which is a kinase due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ERC1 | GO:0007252 | I-kappaB phosphorylation | 15218148 |
| Tgene | ROS1 | GO:0001558 | regulation of cell growth | 16885344 |
| Tgene | ROS1 | GO:0006468 | protein phosphorylation | 16885344 |
| Tgene | ROS1 | GO:0032006 | regulation of TOR signaling | 16885344 |
| Fusion gene breakpoints across ERC1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
| Fusion gene breakpoints across ROS1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerKB3 | . | . | ERC1 | chr12 | 1292587 | + | ROS1 | chr6 | 117641193 | - |
| ChimerKB3 | . | . | ERC1 | chr12 | 1299218 | + | ROS1 | chr6 | 117641193 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000543086 | ERC1 | chr12 | 1299218 | + | ENST00000368508 | ROS1 | chr6 | 117641193 | - | 3997 | 2538 | 271 | 3804 | 1177 |
| ENST00000543086 | ERC1 | chr12 | 1299218 | + | ENST00000368507 | ROS1 | chr6 | 117641193 | - | 3997 | 2538 | 271 | 3804 | 1177 |
| ENST00000546231 | ERC1 | chr12 | 1299218 | + | ENST00000368508 | ROS1 | chr6 | 117641193 | - | 4338 | 2879 | 528 | 4145 | 1205 |
| ENST00000546231 | ERC1 | chr12 | 1299218 | + | ENST00000368507 | ROS1 | chr6 | 117641193 | - | 4338 | 2879 | 528 | 4145 | 1205 |
| ENST00000397203 | ERC1 | chr12 | 1299218 | + | ENST00000368508 | ROS1 | chr6 | 117641193 | - | 4216 | 2757 | 406 | 4023 | 1205 |
| ENST00000397203 | ERC1 | chr12 | 1299218 | + | ENST00000368507 | ROS1 | chr6 | 117641193 | - | 4216 | 2757 | 406 | 4023 | 1205 |
| ENST00000360905 | ERC1 | chr12 | 1299218 | + | ENST00000368508 | ROS1 | chr6 | 117641193 | - | 3991 | 2532 | 181 | 3798 | 1205 |
| ENST00000360905 | ERC1 | chr12 | 1299218 | + | ENST00000368507 | ROS1 | chr6 | 117641193 | - | 3991 | 2532 | 181 | 3798 | 1205 |
| ENST00000589028 | ERC1 | chr12 | 1299218 | + | ENST00000368508 | ROS1 | chr6 | 117641193 | - | 3967 | 2508 | 157 | 3774 | 1205 |
| ENST00000589028 | ERC1 | chr12 | 1299218 | + | ENST00000368507 | ROS1 | chr6 | 117641193 | - | 3967 | 2508 | 157 | 3774 | 1205 |
| ENST00000355446 | ERC1 | chr12 | 1299218 | + | ENST00000368508 | ROS1 | chr6 | 117641193 | - | 3942 | 2483 | 132 | 3749 | 1205 |
| ENST00000355446 | ERC1 | chr12 | 1299218 | + | ENST00000368507 | ROS1 | chr6 | 117641193 | - | 3942 | 2483 | 132 | 3749 | 1205 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >27280_27280_1_ERC1-ROS1_ERC1_chr12_1299218_ENST00000355446_ROS1_chr6_117641193_ENST00000368507_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- >27280_27280_2_ERC1-ROS1_ERC1_chr12_1299218_ENST00000355446_ROS1_chr6_117641193_ENST00000368508_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- >27280_27280_3_ERC1-ROS1_ERC1_chr12_1299218_ENST00000360905_ROS1_chr6_117641193_ENST00000368507_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- >27280_27280_4_ERC1-ROS1_ERC1_chr12_1299218_ENST00000360905_ROS1_chr6_117641193_ENST00000368508_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- >27280_27280_5_ERC1-ROS1_ERC1_chr12_1299218_ENST00000397203_ROS1_chr6_117641193_ENST00000368507_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- >27280_27280_6_ERC1-ROS1_ERC1_chr12_1299218_ENST00000397203_ROS1_chr6_117641193_ENST00000368508_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- >27280_27280_7_ERC1-ROS1_ERC1_chr12_1299218_ENST00000543086_ROS1_chr6_117641193_ENST00000368507_length(amino acids)=1177AA_BP=755 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKIGQVKQELSRK DTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNKKTKQIQDMAEEKGTQAGEIHDLKDMLDV KERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIERLKEQRDRDEREKQEEIDNYKKDLKDLK EKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKAHEAALEARASPEMSDRIQHLEREITRYK DESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLGSGAFGEVYEGTAVDILGVGSGEIKVAVK TLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKARMATFYGPLLTLVDLVDLCVDISKGCVYL ERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPESLMDGIFTTQSDVWSFGILIWEILTLGHQ PYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFFLNSIYKSRDEANNSGVINESFEGEDGDV ICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHADKDFCQEKQVAYCPSGKPEGLNYACLTHS -------------------------------------------------------------- >27280_27280_8_ERC1-ROS1_ERC1_chr12_1299218_ENST00000543086_ROS1_chr6_117641193_ENST00000368508_length(amino acids)=1177AA_BP=755 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKIGQVKQELSRK DTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNKKTKQIQDMAEEKGTQAGEIHDLKDMLDV KERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIERLKEQRDRDEREKQEEIDNYKKDLKDLK EKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKAHEAALEARASPEMSDRIQHLEREITRYK DESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLGSGAFGEVYEGTAVDILGVGSGEIKVAVK TLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKARMATFYGPLLTLVDLVDLCVDISKGCVYL ERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPESLMDGIFTTQSDVWSFGILIWEILTLGHQ PYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFFLNSIYKSRDEANNSGVINESFEGEDGDV ICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHADKDFCQEKQVAYCPSGKPEGLNYACLTHS -------------------------------------------------------------- >27280_27280_9_ERC1-ROS1_ERC1_chr12_1299218_ENST00000546231_ROS1_chr6_117641193_ENST00000368507_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- >27280_27280_10_ERC1-ROS1_ERC1_chr12_1299218_ENST00000546231_ROS1_chr6_117641193_ENST00000368508_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- >27280_27280_11_ERC1-ROS1_ERC1_chr12_1299218_ENST00000589028_ROS1_chr6_117641193_ENST00000368507_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- >27280_27280_12_ERC1-ROS1_ERC1_chr12_1299218_ENST00000589028_ROS1_chr6_117641193_ENST00000368508_length(amino acids)=1205AA_BP=783 MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGSGKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMT LGRSGGRLPYGVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNTIMDLQTQLKEVLRENDLLRKDVEVKESKLS SSMNSIKTFWSPELKKERALRKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDSSSRTGEPCVAELTEENFQRL HAEHERQAKELFLLRKTLEEMELRIETQKQTLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLLEQKEKENSML REEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRDLEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNK KTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERTIE RLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKA HEAALEARASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPREKLTLRLLLG SGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPES LMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRNFF LNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHAD -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:/chr6:) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ERC1 | ROS1 |
| FUNCTION: Regulatory subunit of the IKK complex. Probably recruits IkappaBalpha/NFKBIA to the complex. May be involved in the organization of the cytomatrix at the nerve terminals active zone (CAZ) which regulates neurotransmitter release. May be involved in vesicle trafficking at the CAZ. May be involved in Rab-6 regulated endosomes to Golgi transport. {ECO:0000269|PubMed:15218148}. | FUNCTION: Orphan receptor tyrosine kinase (RTK) that plays a role in epithelial cell differentiation and regionalization of the proximal epididymal epithelium. May activate several downstream signaling pathways related to cell differentiation, proliferation, growth and survival including the PI3 kinase-mTOR signaling pathway. Mediates the phosphorylation of PTPN11, an activator of this pathway. May also phosphorylate and activate the transcription factor STAT3 to control anchorage-independent cell growth. Mediates the phosphorylation and the activation of VAV3, a guanine nucleotide exchange factor regulating cell morphology. May activate other downstream signaling proteins including AKT1, MAPK1, MAPK3, IRS1 and PLCG2. {ECO:0000269|PubMed:11094073, ECO:0000269|PubMed:16885344}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file (840) >>>840.pdbFusion protein BP residue: 755 CIF file (840) >>>840.cif | ERC1 | chr12 | 1299218 | + | ROS1 | chr6 | 117641193 | - | MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGS GKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMTLGRSGGRLPY GVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNT IMDLQTQLKEVLRENDLLRKDVEVKESKLSSSMNSIKTFWSPELKKERAL RKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDS SSRTGEPCVAELTEENFQRLHAEHERQAKELFLLRKTLEEMELRIETQKQ TLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLL EQKEKENSMLREEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRD LEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKIGQVKQELSRK DTELLALQTKLETLTNQFSDSKQHIEVLKESLTAKEQRAAILQTEVDALR LRLEEKETMLNKKTKQIQDMAEEKGTQAGEIHDLKDMLDVKERKVNVLQK KIENLQEQLRDKEKQMSSLKERVKSLQADTTNTDTALTTLEEALAEKERT IERLKEQRDRDEREKQEEIDNYKKDLKDLKEKVSLLQGDLSEKEASLLDL KEHASSLASSGLKKDSRLKTLEIALEQKKEECLKMESQLKKAHEAALEAR ASPEMSDRIQHLEREITRYKDESSKAQAEVDRLLEILKEVENEKNDKDKK IAELESTLPTQEEIENLPAFPREKLTLRLLLGSGAFGEVYEGTAVDILGV GSGEIKVAVKTLKKGSTDQEKIEFLKEAHLMSKFNHPNILKQLGVCLLNE PQYIILELMEGGDLLTYLRKARMATFYGPLLTLVDLVDLCVDISKGCVYL ERMHFIHRDLAARNCLVSVKDYTSPRIVKIGDFGLARDIYKNDYYRKRGE GLLPVRWMAPESLMDGIFTTQSDVWSFGILIWEILTLGHQPYPAHSNLDV LNYVQTGGRLEPPRNCPDDLWNLMTQCWAQEPDQRPTFHRIQDQLQLFRN FFLNSIYKSRDEANNSGVINESFEGEDGDVICLNSDDIMPVALMETKNRE GLNYMVLATECGQGEEKSEGPLGSQESESCGLRKEEKEPHADKDFCQEKQ | 1177 |
| 3D view using mol* of 840 (AA BP:755) | ||||||||||
 | ||||||||||
| PDB file (854) >>>854.pdbFusion protein BP residue: 783 CIF file (854) >>>854.cif | ERC1 | chr12 | 1299218 | + | ROS1 | chr6 | 117641193 | - | MYGSARSVGKVEPSSQSPGRSPRLPRSPRLGHRRTNSTGGSSGSSVGGGS GKTLSMENIQSLNAAYATSGPMYLSDHENVGSETPKSTMTLGRSGGRLPY GVRMTAMGSSPNIASSGVASDTIAFGEHHLPPVSMASTVPHSLRQARDNT IMDLQTQLKEVLRENDLLRKDVEVKESKLSSSMNSIKTFWSPELKKERAL RKDEASKITIWKEQYRVVQEENQHMQMTIQALQDELRIQRDLNQLFQQDS SSRTGEPCVAELTEENFQRLHAEHERQAKELFLLRKTLEEMELRIETQKQ TLNARDESIKKLLEMLQSKGLSAKATEEDHERTRRLAEAEMHVHHLESLL EQKEKENSMLREEMHRRFENAPDSAKTKALQTVIEMKDSKISSMERGLRD LEEEIQMLKSNGALSTEEREEEMKQMEVYRSHSKFMKNKVEQLKEELSSK EAQWEELKKKAAGLQAEIGQVKQELSRKDTELLALQTKLETLTNQFSDSK QHIEVLKESLTAKEQRAAILQTEVDALRLRLEEKETMLNKKTKQIQDMAE EKGTQAGEIHDLKDMLDVKERKVNVLQKKIENLQEQLRDKEKQMSSLKER VKSLQADTTNTDTALTTLEEALAEKERTIERLKEQRDRDEREKQEEIDNY KKDLKDLKEKVSLLQGDLSEKEASLLDLKEHASSLASSGLKKDSRLKTLE IALEQKKEECLKMESQLKKAHEAALEARASPEMSDRIQHLEREITRYKDE SSKAQAEVDRLLEILKEVENEKNDKDKKIAELESTLPTQEEIENLPAFPR EKLTLRLLLGSGAFGEVYEGTAVDILGVGSGEIKVAVKTLKKGSTDQEKI EFLKEAHLMSKFNHPNILKQLGVCLLNEPQYIILELMEGGDLLTYLRKAR MATFYGPLLTLVDLVDLCVDISKGCVYLERMHFIHRDLAARNCLVSVKDY TSPRIVKIGDFGLARDIYKNDYYRKRGEGLLPVRWMAPESLMDGIFTTQS DVWSFGILIWEILTLGHQPYPAHSNLDVLNYVQTGGRLEPPRNCPDDLWN LMTQCWAQEPDQRPTFHRIQDQLQLFRNFFLNSIYKSRDEANNSGVINES FEGEDGDVICLNSDDIMPVALMETKNREGLNYMVLATECGQGEEKSEGPL GSQESESCGLRKEEKEPHADKDFCQEKQVAYCPSGKPEGLNYACLTHSGY | 1205 |
| 3D view using mol* of 854 (AA BP:783) | ||||||||||
| ||||||||||
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
ERC1_pLDDT.png  |
ROS1_pLDDT.png  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
ERC1_ROS1_840_pLDDT.png (AA BP:755)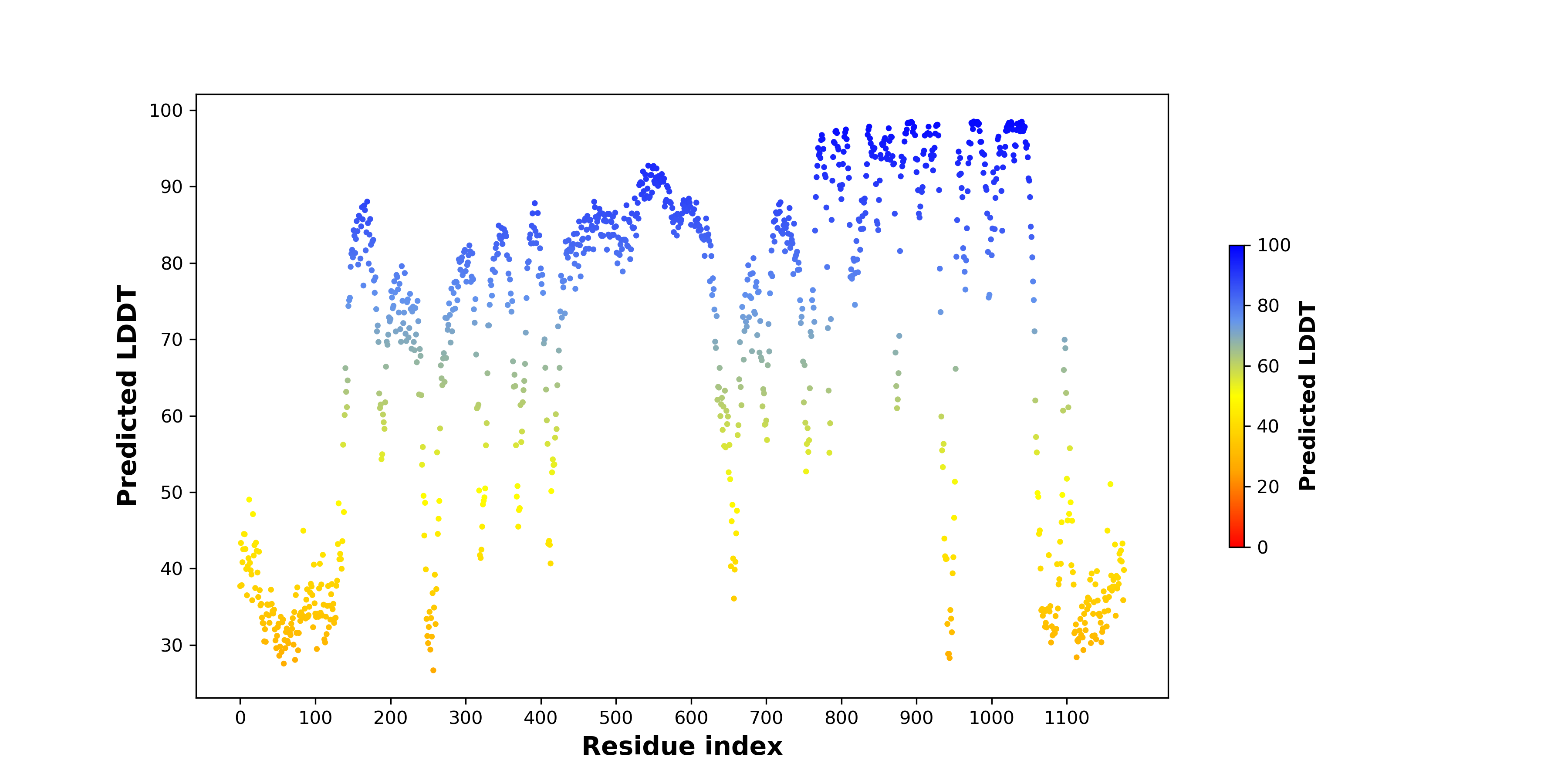 |
ERC1_ROS1_840_pLDDT_and_active_sites.png (AA BP:755)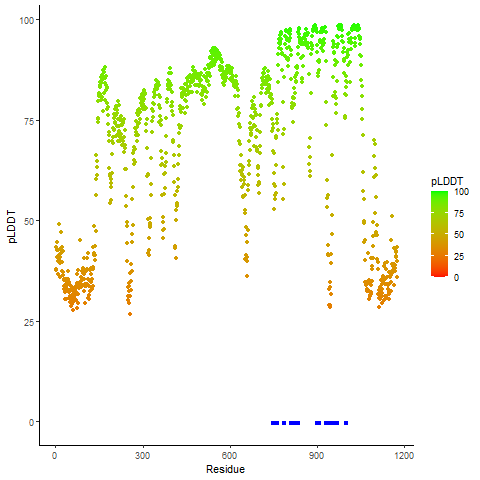 |
ERC1_ROS1_840_violinplot.png (AA BP:755)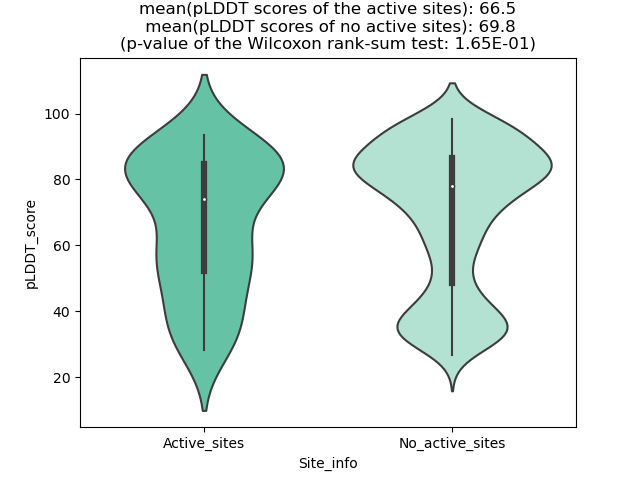 |
ERC1_ROS1_854_pLDDT.png (AA BP:783)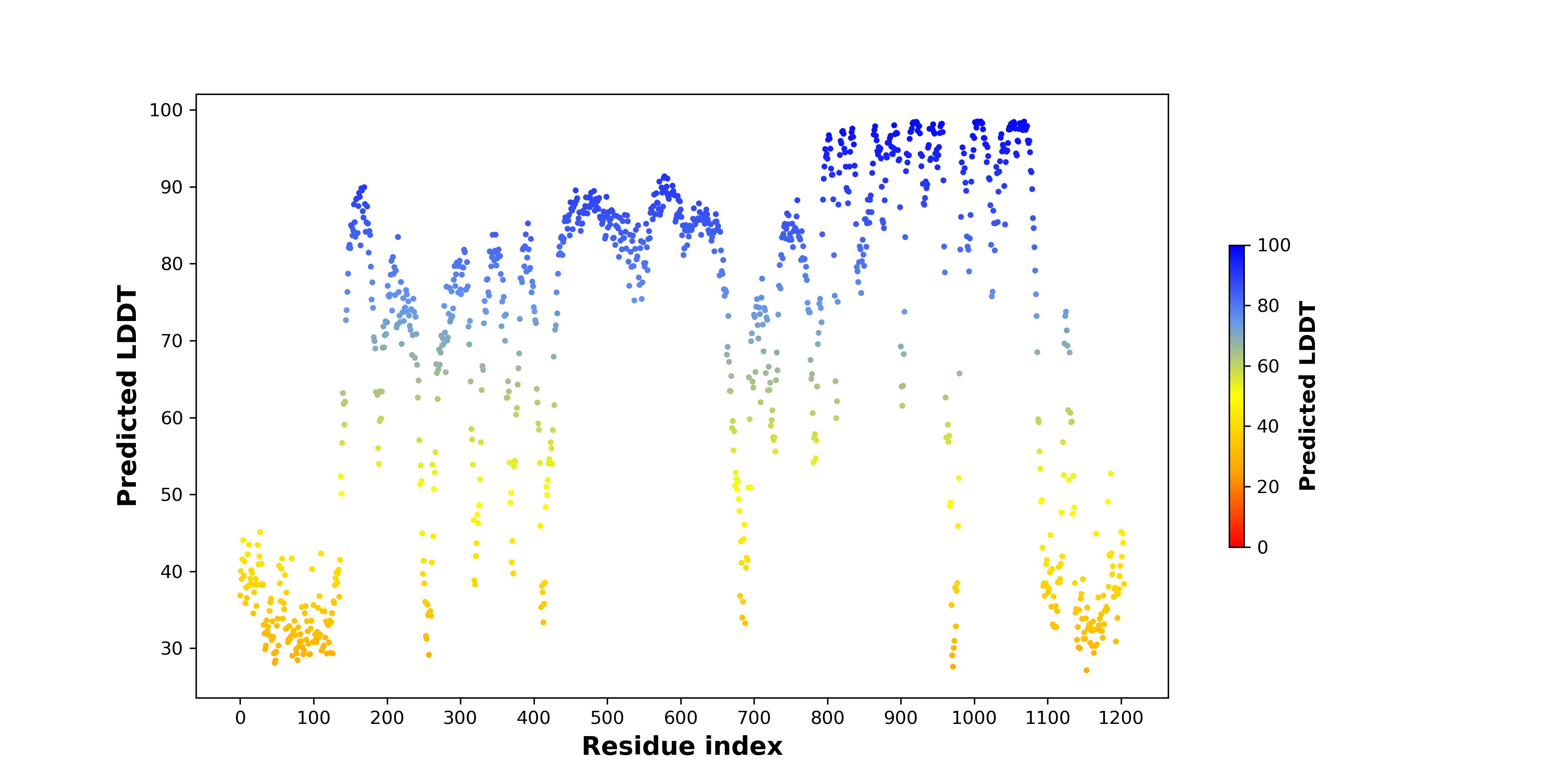 |
ERC1_ROS1_854_pLDDT_and_active_sites.png (AA BP:783)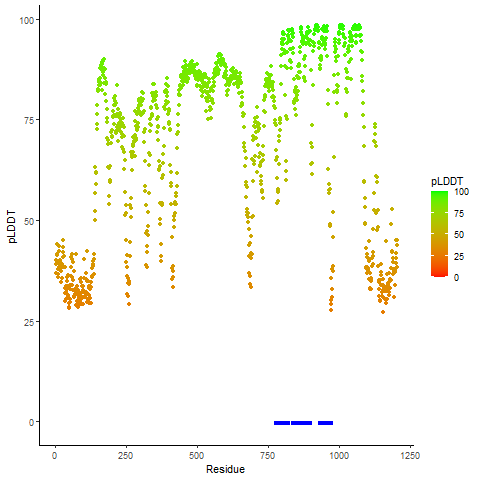 |
ERC1_ROS1_854_violinplot.png (AA BP:783)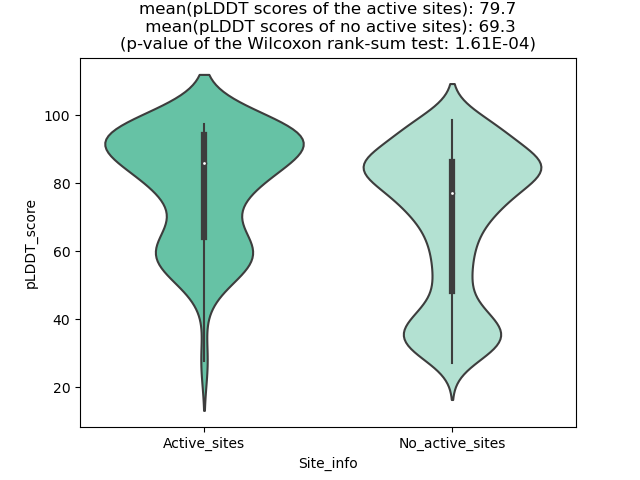 |
Top |
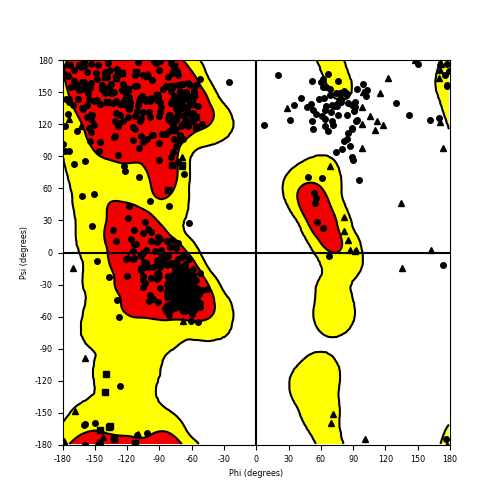
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
| ERC1_ROS1_840.png |
 |
Top |
Potential Active Site Information |
| The potential binding sites of these fusion proteins were identified using SiteMap, a module of the Schrodinger suite. |
| Fusion AA seq ID in FusionPDB | Site score | Size | D score | Volume | Exposure | Enclosure | Contact | Phobic | Philic | Balance | Don/Acc | Residues |
| 840 | 1.0184 | 392 | 1.0425 | 1036.889 | 0.5044 | 0.7129 | 0.956 | 0.8663 | 0.9976 | 0.8683 | 1.0777 | Chain A: 750,753,754,756,757,758,759,763,786,810,8 19,820,822,823,824,826,827,829,830,833,834,902,903 ,904,905,906,908,932,933,934,935,936,937,938,939,9 41,942,943,944,945,946,947,948,949,950,951,952,953 ,955,958,962,963,965,966,968,1001 |
| 854 | 1.021 | 297 | 1.042 | 903.119 | 0.548 | 0.722 | 0.957 | 0.814 | 1.014 | 0.803 | 0.986 | Chain A: 779,782,783,784,785,786,787,788,791,807,8 09,810,811,812,813,814,817,819,836,838,847,848,850 ,851,854,855,857,858,859,861,868,884,885,886,887,8 88,889,890,891,894,895,898,933,934,935,936,941,942 ,944,948,950,959,960,961,962,963,964,965,966,967,9 68,972 |
Top |
Potentially Interacting Small Molecules through Virtual Screening |
| The FDA-approved small molecule library molecules were subjected to virtual screening using the Glide. |
| Fusion AA seq ID in FusionPDB | ZINC ID | DrugBank ID | Drug name | Docking score | Glide gscore |
Top |
| Drug information from DrugBank of the top 20 interacting small molecules. |
| ZINC ID | DrugBank ID | Drug name | Drug type | SMILES | Drug group |
Top |
Biochemical Features of Small Molecules |
| ADME (Absorption, Distribution, Metabolism, and Excretion) of drugs using QikProp(v3.9) |
| ZINC ID | mol_MW | dipole | SASA | FOSA | FISA | PISA | WPSA | volume | donorHB | accptHB | IP | Human Oral Absorption | Percent Human Oral Absorption | Rule Of Five | Rule Of Three |
Top |
Drug Toxicity Information |
| Toxicity information of individual drugs using eToxPred |
| ZINC ID | Smile | Surface Accessibility | Toxicity |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| ERC1 | YWHAG, TWF2, RAB6A, RAB6B, KBTBD7, IKBKB, MAP3K7, IKBKG, XIAP, ITSN2, RAD23A, SH3KBP1, CHUK, NFKBIA, CUL3, APP, ATP6V0D1, NCBP1, WDR4, ERC2, MYC, PAN2, CDK19, MAPK4, CDK20, LATS2, STK4, GFOD1, ADPRHL2, SNX2, MED4, EWSR1, SRPK2, OFD1, PCM1, CEP104, CEP162, CEP152, CEP128, CEP135, CEP89, CNTRL, FBF1, NINL, NIN, SCLT1, SASS6, DVL2, SLC16A6, KIF23, MAPRE1, RACGAP1, CHST15, PPP1R21, Actb, Cd2ap, Kif4, Myh9, Ckap5, MACROD1, PCGF1, NANOG, POU5F1, NHLRC2, CDH1, EYA4, TSHB, SPERT, TRIM25, BRCA1, LNX1, EFTUD2, MYO6, AGR2, KIAA1429, FLCN, DNAJC5, GBF1, DYNC1I2, BICD1, BICD2, APEX1, DYRK1A, nsp13, LMBR1L, PLEKHA4, CYLD, DUSP1, RASSF8, nsp16, nsp7, CIT, ANLN, KIF14, TRIM33, nsp13ab, nsp16ab, SEC62, ORF6, MKRN3, ACTR3, AGPS, AMOT, ANAPC2, CYP2C9, DCTN2, ERGIC2, GOLGA1, IMPDH2, KDM1A, KRT18, KRT19, KRT8, NDC80, NEFM, PEX14, PFN1, PXN, SEPT10, SYNE3, TMOD1, NAA40, VPS33A, NUP62, FTL, DES, YWHAQ, SERF2, YWHAB, ING1, CEP112, MFAP4, C15orf59, YWHAH, PIPSL, KRT38, KRT37, ATG16L1, TBC1D32, E, ATRX, |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| ERC1 |  |
| ROS1 |  |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to ERC1-ROS1 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to ERC1-ROS1 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| ERC1 | ROS1 | Lung Adenocarcinoma | MyCancerGenome | |
| ERC1 | ROS1 | Dedifferentiated Liposarcoma | MyCancerGenome | |
| ERC1 | ROS1 | Breast Invasive Ductal Carcinoma | MyCancerGenome | |
| ERC1 | ROS1 | Anaplastic Ganglioglioma | MyCancerGenome | |
| ERC1 | ROS1 | Cancer Of Unknown Primary | MyCancerGenome |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ERC1 | C0238463 | Papillary thyroid carcinoma | 1 | ORPHANET |
| Hgene | ERC1 | C4749581 | Distal monosomy 12p | 1 | ORPHANET |
| Tgene | ROS1 | C0007131 | Non-Small Cell Lung Carcinoma | 4 | CTD_human |
| Tgene | ROS1 | C0017638 | Glioma | 1 | CTD_human |
| Tgene | ROS1 | C0025202 | melanoma | 1 | CTD_human |
| Tgene | ROS1 | C0152013 | Adenocarcinoma of lung (disorder) | 1 | CGI;CTD_human |
| Tgene | ROS1 | C0259783 | mixed gliomas | 1 | CTD_human |
| Tgene | ROS1 | C0555198 | Malignant Glioma | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies