| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:FDFT1-CASK |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: FDFT1-CASK | FusionPDB ID: 30039 | FusionGDB2.0 ID: 30039 | Hgene | Tgene | Gene symbol | FDFT1 | CASK | Gene ID | 2222 | 8573 |
| Gene name | farnesyl-diphosphate farnesyltransferase 1 | calcium/calmodulin dependent serine protein kinase | |
| Synonyms | DGPT|ERG9|SQS|SQSD|SS | CAGH39|CAMGUK|CMG|FGS4|LIN2|MICPCH|MRXSNA|TNRC8|hCASK | |
| Cytomap | 8p23.1 | Xp11.4 | |
| Type of gene | protein-coding | protein-coding | |
| Description | squalene synthaseFPP:FPP farnesyltransferasepresqualene-di-diphosphate synthasesqualene synthetase | peripheral plasma membrane protein CASKcalcium/calmodulin-dependent serin protein kinasecalcium/calmodulin-dependent serine protein kinase (MAGUK family)calcium/calmodulin-dependent serine protein kinase membrane-associated guanylate kinaseprotein lin | |
| Modification date | 20200320 | 20200327 | |
| UniProtAcc | P37268 | Q8WXE0 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000220584, ENST00000525777, ENST00000525900, ENST00000528643, ENST00000528812, ENST00000530664, ENST00000538689, ENST00000443614, ENST00000446331, | ENST00000378154, ENST00000472704, ENST00000318588, ENST00000361962, ENST00000378158, ENST00000378163, ENST00000378166, ENST00000421587, ENST00000442742, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 16 X 12 X 9=1728 | 15 X 14 X 9=1890 |
| # samples | 20 | 17 | |
| ** MAII score | log2(20/1728*10)=-3.11103131238874 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(17/1890*10)=-3.47477958297073 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: FDFT1 [Title/Abstract] AND CASK [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | FDFT1(11679387)-CASK(41530783), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | FDFT1-CASK seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. FDFT1-CASK seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. FDFT1-CASK seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. FDFT1-CASK seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CASK | GO:0010839 | negative regulation of keratinocyte proliferation | 18664494 |
| Fusion gene breakpoints across FDFT1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
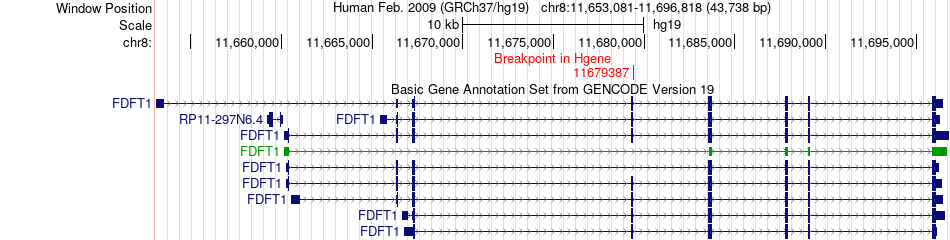 |
| Fusion gene breakpoints across CASK (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
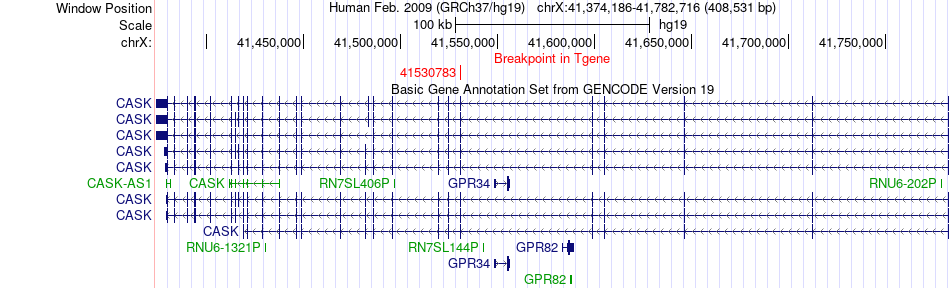 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-HU-A4H2 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000538689 | FDFT1 | chr8 | 11679387 | + | ENST00000421587 | CASK | chrX | 41530783 | - | 8601 | 850 | 376 | 3114 | 912 |
| ENST00000538689 | FDFT1 | chr8 | 11679387 | + | ENST00000318588 | CASK | chrX | 41530783 | - | 8673 | 850 | 376 | 3186 | 936 |
| ENST00000538689 | FDFT1 | chr8 | 11679387 | + | ENST00000361962 | CASK | chrX | 41530783 | - | 8637 | 850 | 376 | 3150 | 924 |
| ENST00000538689 | FDFT1 | chr8 | 11679387 | + | ENST00000378163 | CASK | chrX | 41530783 | - | 4357 | 850 | 376 | 3201 | 941 |
| ENST00000538689 | FDFT1 | chr8 | 11679387 | + | ENST00000378158 | CASK | chrX | 41530783 | - | 3918 | 850 | 376 | 3150 | 924 |
| ENST00000538689 | FDFT1 | chr8 | 11679387 | + | ENST00000378166 | CASK | chrX | 41530783 | - | 3517 | 850 | 376 | 3186 | 936 |
| ENST00000538689 | FDFT1 | chr8 | 11679387 | + | ENST00000442742 | CASK | chrX | 41530783 | - | 3202 | 850 | 376 | 3117 | 913 |
| ENST00000220584 | FDFT1 | chr8 | 11679387 | + | ENST00000421587 | CASK | chrX | 41530783 | - | 8483 | 732 | 222 | 2996 | 924 |
| ENST00000220584 | FDFT1 | chr8 | 11679387 | + | ENST00000318588 | CASK | chrX | 41530783 | - | 8555 | 732 | 222 | 3068 | 948 |
| ENST00000220584 | FDFT1 | chr8 | 11679387 | + | ENST00000361962 | CASK | chrX | 41530783 | - | 8519 | 732 | 222 | 3032 | 936 |
| ENST00000220584 | FDFT1 | chr8 | 11679387 | + | ENST00000378163 | CASK | chrX | 41530783 | - | 4239 | 732 | 222 | 3083 | 953 |
| ENST00000220584 | FDFT1 | chr8 | 11679387 | + | ENST00000378158 | CASK | chrX | 41530783 | - | 3800 | 732 | 222 | 3032 | 936 |
| ENST00000220584 | FDFT1 | chr8 | 11679387 | + | ENST00000378166 | CASK | chrX | 41530783 | - | 3399 | 732 | 222 | 3068 | 948 |
| ENST00000220584 | FDFT1 | chr8 | 11679387 | + | ENST00000442742 | CASK | chrX | 41530783 | - | 3084 | 732 | 222 | 2999 | 925 |
| ENST00000525900 | FDFT1 | chr8 | 11679387 | + | ENST00000421587 | CASK | chrX | 41530783 | - | 8307 | 556 | 67 | 2820 | 917 |
| ENST00000525900 | FDFT1 | chr8 | 11679387 | + | ENST00000318588 | CASK | chrX | 41530783 | - | 8379 | 556 | 67 | 2892 | 941 |
| ENST00000525900 | FDFT1 | chr8 | 11679387 | + | ENST00000361962 | CASK | chrX | 41530783 | - | 8343 | 556 | 67 | 2856 | 929 |
| ENST00000525900 | FDFT1 | chr8 | 11679387 | + | ENST00000378163 | CASK | chrX | 41530783 | - | 4063 | 556 | 67 | 2907 | 946 |
| ENST00000525900 | FDFT1 | chr8 | 11679387 | + | ENST00000378158 | CASK | chrX | 41530783 | - | 3624 | 556 | 67 | 2856 | 929 |
| ENST00000525900 | FDFT1 | chr8 | 11679387 | + | ENST00000378166 | CASK | chrX | 41530783 | - | 3223 | 556 | 67 | 2892 | 941 |
| ENST00000525900 | FDFT1 | chr8 | 11679387 | + | ENST00000442742 | CASK | chrX | 41530783 | - | 2908 | 556 | 67 | 2823 | 918 |
| ENST00000528812 | FDFT1 | chr8 | 11679387 | + | ENST00000421587 | CASK | chrX | 41530783 | - | 8669 | 918 | 525 | 3182 | 885 |
| ENST00000528812 | FDFT1 | chr8 | 11679387 | + | ENST00000318588 | CASK | chrX | 41530783 | - | 8741 | 918 | 525 | 3254 | 909 |
| ENST00000528812 | FDFT1 | chr8 | 11679387 | + | ENST00000361962 | CASK | chrX | 41530783 | - | 8705 | 918 | 525 | 3218 | 897 |
| ENST00000528812 | FDFT1 | chr8 | 11679387 | + | ENST00000378163 | CASK | chrX | 41530783 | - | 4425 | 918 | 525 | 3269 | 914 |
| ENST00000528812 | FDFT1 | chr8 | 11679387 | + | ENST00000378158 | CASK | chrX | 41530783 | - | 3986 | 918 | 525 | 3218 | 897 |
| ENST00000528812 | FDFT1 | chr8 | 11679387 | + | ENST00000378166 | CASK | chrX | 41530783 | - | 3585 | 918 | 525 | 3254 | 909 |
| ENST00000528812 | FDFT1 | chr8 | 11679387 | + | ENST00000442742 | CASK | chrX | 41530783 | - | 3270 | 918 | 525 | 3185 | 886 |
| ENST00000530664 | FDFT1 | chr8 | 11679387 | + | ENST00000421587 | CASK | chrX | 41530783 | - | 8537 | 786 | 345 | 3050 | 901 |
| ENST00000530664 | FDFT1 | chr8 | 11679387 | + | ENST00000318588 | CASK | chrX | 41530783 | - | 8609 | 786 | 345 | 3122 | 925 |
| ENST00000530664 | FDFT1 | chr8 | 11679387 | + | ENST00000361962 | CASK | chrX | 41530783 | - | 8573 | 786 | 345 | 3086 | 913 |
| ENST00000530664 | FDFT1 | chr8 | 11679387 | + | ENST00000378163 | CASK | chrX | 41530783 | - | 4293 | 786 | 345 | 3137 | 930 |
| ENST00000530664 | FDFT1 | chr8 | 11679387 | + | ENST00000378158 | CASK | chrX | 41530783 | - | 3854 | 786 | 345 | 3086 | 913 |
| ENST00000530664 | FDFT1 | chr8 | 11679387 | + | ENST00000378166 | CASK | chrX | 41530783 | - | 3453 | 786 | 345 | 3122 | 925 |
| ENST00000530664 | FDFT1 | chr8 | 11679387 | + | ENST00000442742 | CASK | chrX | 41530783 | - | 3138 | 786 | 345 | 3053 | 902 |
| ENST00000528643 | FDFT1 | chr8 | 11679387 | + | ENST00000421587 | CASK | chrX | 41530783 | - | 8411 | 660 | 369 | 2924 | 851 |
| ENST00000528643 | FDFT1 | chr8 | 11679387 | + | ENST00000318588 | CASK | chrX | 41530783 | - | 8483 | 660 | 369 | 2996 | 875 |
| ENST00000528643 | FDFT1 | chr8 | 11679387 | + | ENST00000361962 | CASK | chrX | 41530783 | - | 8447 | 660 | 369 | 2960 | 863 |
| ENST00000528643 | FDFT1 | chr8 | 11679387 | + | ENST00000378163 | CASK | chrX | 41530783 | - | 4167 | 660 | 369 | 3011 | 880 |
| ENST00000528643 | FDFT1 | chr8 | 11679387 | + | ENST00000378158 | CASK | chrX | 41530783 | - | 3728 | 660 | 369 | 2960 | 863 |
| ENST00000528643 | FDFT1 | chr8 | 11679387 | + | ENST00000378166 | CASK | chrX | 41530783 | - | 3327 | 660 | 369 | 2996 | 875 |
| ENST00000528643 | FDFT1 | chr8 | 11679387 | + | ENST00000442742 | CASK | chrX | 41530783 | - | 3012 | 660 | 369 | 2927 | 852 |
| ENST00000525777 | FDFT1 | chr8 | 11679387 | + | ENST00000421587 | CASK | chrX | 41530783 | - | 8475 | 724 | 433 | 2988 | 851 |
| ENST00000525777 | FDFT1 | chr8 | 11679387 | + | ENST00000318588 | CASK | chrX | 41530783 | - | 8547 | 724 | 433 | 3060 | 875 |
| ENST00000525777 | FDFT1 | chr8 | 11679387 | + | ENST00000361962 | CASK | chrX | 41530783 | - | 8511 | 724 | 433 | 3024 | 863 |
| ENST00000525777 | FDFT1 | chr8 | 11679387 | + | ENST00000378163 | CASK | chrX | 41530783 | - | 4231 | 724 | 433 | 3075 | 880 |
| ENST00000525777 | FDFT1 | chr8 | 11679387 | + | ENST00000378158 | CASK | chrX | 41530783 | - | 3792 | 724 | 433 | 3024 | 863 |
| ENST00000525777 | FDFT1 | chr8 | 11679387 | + | ENST00000378166 | CASK | chrX | 41530783 | - | 3391 | 724 | 433 | 3060 | 875 |
| ENST00000525777 | FDFT1 | chr8 | 11679387 | + | ENST00000442742 | CASK | chrX | 41530783 | - | 3076 | 724 | 433 | 2991 | 852 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000538689 | ENST00000421587 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000265918 | 0.9997341 |
| ENST00000538689 | ENST00000318588 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000180312 | 0.9998197 |
| ENST00000538689 | ENST00000361962 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000200109 | 0.9997999 |
| ENST00000538689 | ENST00000378163 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000276932 | 0.999723 |
| ENST00000538689 | ENST00000378158 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000469787 | 0.9995302 |
| ENST00000538689 | ENST00000378166 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.001127156 | 0.9988728 |
| ENST00000538689 | ENST00000442742 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.002473055 | 0.99752694 |
| ENST00000220584 | ENST00000421587 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000409652 | 0.99959034 |
| ENST00000220584 | ENST00000318588 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000398295 | 0.9996018 |
| ENST00000220584 | ENST00000361962 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000410856 | 0.99958915 |
| ENST00000220584 | ENST00000378163 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.00049162 | 0.9995084 |
| ENST00000220584 | ENST00000378158 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000805747 | 0.9991942 |
| ENST00000220584 | ENST00000378166 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.002022659 | 0.9979773 |
| ENST00000220584 | ENST00000442742 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.004473877 | 0.99552613 |
| ENST00000525900 | ENST00000421587 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000203069 | 0.9997969 |
| ENST00000525900 | ENST00000318588 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000187235 | 0.9998128 |
| ENST00000525900 | ENST00000361962 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000190759 | 0.9998092 |
| ENST00000525900 | ENST00000378163 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000200332 | 0.99979967 |
| ENST00000525900 | ENST00000378158 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.00039457 | 0.9996055 |
| ENST00000525900 | ENST00000378166 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.00107248 | 0.99892753 |
| ENST00000525900 | ENST00000442742 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.002260215 | 0.9977398 |
| ENST00000528812 | ENST00000421587 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.00025656 | 0.9997434 |
| ENST00000528812 | ENST00000318588 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000173876 | 0.99982613 |
| ENST00000528812 | ENST00000361962 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000192883 | 0.9998072 |
| ENST00000528812 | ENST00000378163 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000227999 | 0.999772 |
| ENST00000528812 | ENST00000378158 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000392552 | 0.9996075 |
| ENST00000528812 | ENST00000378166 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000857985 | 0.99914205 |
| ENST00000528812 | ENST00000442742 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.001555782 | 0.99844426 |
| ENST00000530664 | ENST00000421587 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000260098 | 0.99973994 |
| ENST00000530664 | ENST00000318588 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000176841 | 0.99982315 |
| ENST00000530664 | ENST00000361962 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000195746 | 0.9998043 |
| ENST00000530664 | ENST00000378163 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000251072 | 0.9997489 |
| ENST00000530664 | ENST00000378158 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000457208 | 0.99954283 |
| ENST00000530664 | ENST00000378166 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.001066203 | 0.99893373 |
| ENST00000530664 | ENST00000442742 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.00245672 | 0.99754333 |
| ENST00000528643 | ENST00000421587 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000577396 | 0.99942267 |
| ENST00000528643 | ENST00000318588 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000486332 | 0.9995136 |
| ENST00000528643 | ENST00000361962 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000518384 | 0.9994816 |
| ENST00000528643 | ENST00000378163 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000535834 | 0.9994642 |
| ENST00000528643 | ENST00000378158 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000862677 | 0.9991373 |
| ENST00000528643 | ENST00000378166 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.001923173 | 0.9980768 |
| ENST00000528643 | ENST00000442742 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.003334714 | 0.9966653 |
| ENST00000525777 | ENST00000421587 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000494646 | 0.9995054 |
| ENST00000525777 | ENST00000318588 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000415979 | 0.999584 |
| ENST00000525777 | ENST00000361962 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000442754 | 0.9995572 |
| ENST00000525777 | ENST00000378163 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000387335 | 0.99961275 |
| ENST00000525777 | ENST00000378158 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.000576834 | 0.99942315 |
| ENST00000525777 | ENST00000378166 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.001051873 | 0.99894816 |
| ENST00000525777 | ENST00000442742 | FDFT1 | chr8 | 11679387 | + | CASK | chrX | 41530783 | - | 0.001915926 | 0.99808407 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >30039_30039_1_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000220584_CASK_chrX_41530783_ENST00000318588_length(amino acids)=948AA_BP=170 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV EKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKE NSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWS HISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSE DPTSSVLLIVSRAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENN DAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHC IVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSD LPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQE QQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNY YFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKE -------------------------------------------------------------- >30039_30039_2_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000220584_CASK_chrX_41530783_ENST00000361962_length(amino acids)=936AA_BP=170 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV EKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKE NSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWS HISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSE DPTSSVLLIVSRAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENN DAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHC IVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSI YVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKK KQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDI SNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYF -------------------------------------------------------------- >30039_30039_3_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000220584_CASK_chrX_41530783_ENST00000378158_length(amino acids)=936AA_BP=170 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV EKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKE NSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWS HISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSE DPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENN DAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHC IVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSI YVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKK KQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDI SNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYF -------------------------------------------------------------- >30039_30039_4_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000220584_CASK_chrX_41530783_ENST00000378163_length(amino acids)=953AA_BP=170 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV EKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKE NSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWS HISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSE DPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENN DAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHC IVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSD LPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQE QQASCTWFGKKKKQYKDKYLAKHNAVFDQLDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEE NGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQ -------------------------------------------------------------- >30039_30039_5_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000220584_CASK_chrX_41530783_ENST00000378166_length(amino acids)=948AA_BP=170 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV EKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKE NSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWS HISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSE DPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENN DAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHC IVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSD LPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQE QQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNY YFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKE -------------------------------------------------------------- >30039_30039_6_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000220584_CASK_chrX_41530783_ENST00000421587_length(amino acids)=924AA_BP=170 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV EKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKE NSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWS HISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSE DPTSSGAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELK RILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIM HGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPAKDDLIP CKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNAVFDQ LDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHE DAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDET -------------------------------------------------------------- >30039_30039_7_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000220584_CASK_chrX_41530783_ENST00000442742_length(amino acids)=925AA_BP=170 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV EKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKE NSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWS HISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSE DPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENN DAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHC IVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPA KDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKH NADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSH EDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDE -------------------------------------------------------------- >30039_30039_8_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525777_CASK_chrX_41530783_ENST00000318588_length(amino acids)=875AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSVLLIVSRAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPE LQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPI PHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPT -------------------------------------------------------------- >30039_30039_9_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525777_CASK_chrX_41530783_ENST00000361962_length(amino acids)=863AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSVLLIVSRAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAME KTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEE NGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQ -------------------------------------------------------------- >30039_30039_10_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525777_CASK_chrX_41530783_ENST00000378158_length(amino acids)=863AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAME KTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEE NGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQ -------------------------------------------------------------- >30039_30039_11_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525777_CASK_chrX_41530783_ENST00000378163_length(amino acids)=880AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPE LQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNAVFDQLDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDR FAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVF -------------------------------------------------------------- >30039_30039_12_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525777_CASK_chrX_41530783_ENST00000378166_length(amino acids)=875AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPE LQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPI PHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPT -------------------------------------------------------------- >30039_30039_13_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525777_CASK_chrX_41530783_ENST00000421587_length(amino acids)=851AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEV LEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMG ITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQI YVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKK KQYKDKYLAKHNAVFDQLDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQ MMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRT -------------------------------------------------------------- >30039_30039_14_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525777_CASK_chrX_41530783_ENST00000442742_length(amino acids)=852AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQ PKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCT WFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHD QMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQR -------------------------------------------------------------- >30039_30039_15_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525900_CASK_chrX_41530783_ENST00000318588_length(amino acids)=941AA_BP=163 MEFVKCLGHPEEFYNLVRFRIGGKRKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLL HNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKL GGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAK DLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSVL LIVSRAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKR ILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMH GGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQP KGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTW FGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQ MMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRT -------------------------------------------------------------- >30039_30039_16_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525900_CASK_chrX_41530783_ENST00000361962_length(amino acids)=929AA_BP=163 MEFVKCLGHPEEFYNLVRFRIGGKRKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLL HNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKL GGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAK DLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSVL LIVSRAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKR ILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMH GGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSIYVRAQFE YDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKY LAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLE YGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINN -------------------------------------------------------------- >30039_30039_17_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525900_CASK_chrX_41530783_ENST00000378158_length(amino acids)=929AA_BP=163 MEFVKCLGHPEEFYNLVRFRIGGKRKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLL HNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKL GGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAK DLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGL LAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKR ILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMH GGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSIYVRAQFE YDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKY LAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLE YGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINN -------------------------------------------------------------- >30039_30039_18_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525900_CASK_chrX_41530783_ENST00000378163_length(amino acids)=946AA_BP=163 MEFVKCLGHPEEFYNLVRFRIGGKRKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLL HNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKL GGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAK DLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGL LAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKR ILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMH GGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQP KGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTW FGKKKKQYKDKYLAKHNAVFDQLDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYF VSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESD -------------------------------------------------------------- >30039_30039_19_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525900_CASK_chrX_41530783_ENST00000378166_length(amino acids)=941AA_BP=163 MEFVKCLGHPEEFYNLVRFRIGGKRKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLL HNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKL GGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAK DLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGL LAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKR ILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMH GGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQP KGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTW FGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQ MMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRT -------------------------------------------------------------- >30039_30039_20_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525900_CASK_chrX_41530783_ENST00000421587_length(amino acids)=917AA_BP=163 MEFVKCLGHPEEFYNLVRFRIGGKRKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLL HNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKL GGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAK DLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGA VSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPH FMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHR QGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIR FRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNAVFDQLDLVTYE EVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTK LETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEA -------------------------------------------------------------- >30039_30039_21_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000525900_CASK_chrX_41530783_ENST00000442742_length(amino acids)=918AA_BP=163 MEFVKCLGHPEEFYNLVRFRIGGKRKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLL HNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKL GGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAK DLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGL LAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKR ILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMH GGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPC KEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTY EEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGT KLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEE -------------------------------------------------------------- >30039_30039_22_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528643_CASK_chrX_41530783_ENST00000318588_length(amino acids)=875AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSVLLIVSRAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPE LQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPI PHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPT -------------------------------------------------------------- >30039_30039_23_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528643_CASK_chrX_41530783_ENST00000361962_length(amino acids)=863AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSVLLIVSRAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAME KTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEE NGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQ -------------------------------------------------------------- >30039_30039_24_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528643_CASK_chrX_41530783_ENST00000378158_length(amino acids)=863AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAME KTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEE NGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQ -------------------------------------------------------------- >30039_30039_25_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528643_CASK_chrX_41530783_ENST00000378163_length(amino acids)=880AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPE LQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNAVFDQLDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDR FAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVF -------------------------------------------------------------- >30039_30039_26_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528643_CASK_chrX_41530783_ENST00000378166_length(amino acids)=875AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTS RQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPE LQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPI PHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPT -------------------------------------------------------------- >30039_30039_27_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528643_CASK_chrX_41530783_ENST00000421587_length(amino acids)=851AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEV LEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMG ITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQI YVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKK KQYKDKYLAKHNAVFDQLDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQ MMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRT -------------------------------------------------------------- >30039_30039_28_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528643_CASK_chrX_41530783_ENST00000442742_length(amino acids)=852AA_BP=97 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT SEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERL FEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHK FNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAV QRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKN TDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQ PKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCT WFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHD QMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQR -------------------------------------------------------------- >30039_30039_29_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528812_CASK_chrX_41530783_ENST00000318588_length(amino acids)=909AA_BP=131 MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTIS LEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVK REPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRY AYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSVLLIVSRAVSQVLDSLEEIHALTDCSEKDLDFLH SVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPP PTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQL QKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRV GDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAF KRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIH EQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEAVELVCTAP -------------------------------------------------------------- >30039_30039_30_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528812_CASK_chrX_41530783_ENST00000361962_length(amino acids)=897AA_BP=131 MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTIS LEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVK REPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRY AYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSVLLIVSRAVSQVLDSLEEIHALTDCSEKDLDFLH SVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPP PTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQL QKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDH NWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHG VGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEP -------------------------------------------------------------- >30039_30039_31_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528812_CASK_chrX_41530783_ENST00000378158_length(amino acids)=897AA_BP=131 MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTIS LEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVK REPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRY AYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLH SVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPP PTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQL QKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDH NWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHG VGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEP -------------------------------------------------------------- >30039_30039_32_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528812_CASK_chrX_41530783_ENST00000378163_length(amino acids)=914AA_BP=131 MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTIS LEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVK REPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRY AYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLH SVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPP PTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQL QKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRV GDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNAVFDQLDLVTYEEVV KLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLET IRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEAVEL -------------------------------------------------------------- >30039_30039_33_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528812_CASK_chrX_41530783_ENST00000378166_length(amino acids)=909AA_BP=131 MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTIS LEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVK REPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRY AYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLH SVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPP PTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQL QKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRV GDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAF KRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIH EQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEAVELVCTAP -------------------------------------------------------------- >30039_30039_34_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528812_CASK_chrX_41530783_ENST00000421587_length(amino acids)=885AA_BP=131 MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTIS LEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVK REPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRY AYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGAVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQ HLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPPPTSPYL NGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQLQKMLRE MRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGL IPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNAVFDQLDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLIT KHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFA -------------------------------------------------------------- >30039_30039_35_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000528812_CASK_chrX_41530783_ENST00000442742_length(amino acids)=886AA_BP=131 MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTIS LEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVAGGRVGTPHFMAPEVVK REPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERITVYEALNHPWLKERDRY AYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEEIHALTDCSEKDLDFLH SVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVYSDEALRVTPP PTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGISVANQTVEQL QKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSK NGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLI TKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEF -------------------------------------------------------------- >30039_30039_36_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000530664_CASK_chrX_41530783_ENST00000318588_length(amino acids)=925AA_BP=147 MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME SKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVA GGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERIT VYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSVLLIVSRAVSQVLDSLEE IHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDV VAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEI REINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPA KDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKH NADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSH EDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDE -------------------------------------------------------------- >30039_30039_37_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000530664_CASK_chrX_41530783_ENST00000361962_length(amino acids)=913AA_BP=147 MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME SKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVA GGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERIT VYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSVLLIVSRAVSQVLDSLEE IHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDV VAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEI REINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSIYVRAQFEYDPAKDDLIPCKEAGI RFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVK LPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETI RKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEAVELV -------------------------------------------------------------- >30039_30039_38_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000530664_CASK_chrX_41530783_ENST00000378158_length(amino acids)=913AA_BP=147 MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME SKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVA GGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERIT VYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEE IHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDV VAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEI REINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSIYVRAQFEYDPAKDDLIPCKEAGI RFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVK LPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETI RKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEAVELV -------------------------------------------------------------- >30039_30039_39_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000530664_CASK_chrX_41530783_ENST00000378163_length(amino acids)=930AA_BP=147 MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME SKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVA GGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERIT VYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEE IHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDV VAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEI REINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPA KDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKH NAVFDQLDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYL EYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIIN -------------------------------------------------------------- >30039_30039_40_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000530664_CASK_chrX_41530783_ENST00000378166_length(amino acids)=925AA_BP=147 MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME SKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVA GGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERIT VYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEE IHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDV VAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEI REINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQPKGRQIYVRAQFEYDPA KDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKH NADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSH EDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDE -------------------------------------------------------------- >30039_30039_41_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000530664_CASK_chrX_41530783_ENST00000421587_length(amino acids)=901AA_BP=147 MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME SKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVA GGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERIT VYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGAVSQVLDSLEEIHALTD CSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDVVAHEVY SDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEIREINGI SVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHN WWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNAVFDQLDLVTYEEVVKLPAFKRKTLVLL GAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAIL DVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEAVELVCTAPQWVPVSWV -------------------------------------------------------------- >30039_30039_42_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000530664_CASK_chrX_41530783_ENST00000442742_length(amino acids)=902AA_BP=147 MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME SKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGVAIQLGESGLVA GGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRRMLMLDPAERIT VYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAERAVSQVLDSLEE IHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALLQTHDV VAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLHVGDEI REINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQII SKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVL LGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAI LDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEAVELVCTAPQWVPVSW -------------------------------------------------------------- >30039_30039_43_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000538689_CASK_chrX_41530783_ENST00000318588_length(amino acids)=936AA_BP=158 MKSVRPRTNQFRTHLDSTDSKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHS FLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGV AIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRR MLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSVLLIVSR AVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQP HFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIH RQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQPKGRQI YVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKK KQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDI SNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYF -------------------------------------------------------------- >30039_30039_44_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000538689_CASK_chrX_41530783_ENST00000361962_length(amino acids)=924AA_BP=158 MKSVRPRTNQFRTHLDSTDSKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHS FLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGV AIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRR MLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSVLLIVSR AVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQP HFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIH RQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSIYVRAQFEYDPAK DDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHN ADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHE DAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDET -------------------------------------------------------------- >30039_30039_45_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000538689_CASK_chrX_41530783_ENST00000378158_length(amino acids)=924AA_BP=158 MKSVRPRTNQFRTHLDSTDSKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHS FLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGV AIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRR MLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAER AVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQP HFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIH RQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSIYVRAQFEYDPAK DDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHN ADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHE DAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDET -------------------------------------------------------------- >30039_30039_46_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000538689_CASK_chrX_41530783_ENST00000378163_length(amino acids)=941AA_BP=158 MKSVRPRTNQFRTHLDSTDSKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHS FLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGV AIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRR MLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAER AVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQP HFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIH RQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQPKGRQI YVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKK KQYKDKYLAKHNAVFDQLDLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQ MMQDISNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRT -------------------------------------------------------------- >30039_30039_47_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000538689_CASK_chrX_41530783_ENST00000378166_length(amino acids)=936AA_BP=158 MKSVRPRTNQFRTHLDSTDSKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHS FLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGV AIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRR MLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAER AVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQP HFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIH RQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCERDSPSTSRQSPANGHSSTNNSVSDLPSTTQPKGRQI YVRAQFEYDPAKDDLIPCKEAGIRFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKK KQYKDKYLAKHNADLVTYEEVVKLPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDI SNNEYLEYGSHEDAMYGTKLETIRKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYF -------------------------------------------------------------- >30039_30039_48_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000538689_CASK_chrX_41530783_ENST00000421587_length(amino acids)=912AA_BP=158 MKSVRPRTNQFRTHLDSTDSKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHS FLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGV AIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRR MLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGAVSQVL DSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQPHFMALL QTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIHRQGTLH VGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGIRFRVGD IIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNAVFDQLDLVTYEEVVKL PAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETIR KIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEAVELVC -------------------------------------------------------------- >30039_30039_49_FDFT1-CASK_FDFT1_chr8_11679387_ENST00000538689_CASK_chrX_41530783_ENST00000442742_length(amino acids)=913AA_BP=158 MKSVRPRTNQFRTHLDSTDSKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHS FLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKPHCVLLASKENSAPVKLGGFGV AIQLGESGLVAGGRVGTPHFMAPEVVKREPYGKPVDVWGCGVILFILLSGCLPFYGTKERLFEGIIKGKYKMNPRQWSHISESAKDLVRR MLMLDPAERITVYEALNHPWLKERDRYAYKIHLPETVEQLRKFNARRKLKGAVLAAVSSHKFNSFYGDPPEELPDFSEDPTSSGLLAAER AVSQVLDSLEEIHALTDCSEKDLDFLHSVFQDQHLHTLLDLYDKINTKSSPQIRNPPSDAVQRAKEVLEEISCYPENNDAKELKRILTQP HFMALLQTHDVVAHEVYSDEALRVTPPPTSPYLNGDSPESANGDMDMENVTRVRLVQFQKNTDEPMGITLKMNELNHCIVARIMHGGMIH RQGTLHVGDEIREINGISVANQTVEQLQKMLREMRGSITFKIVPSYRTQSSSCEDLPSTTQPKGRQIYVRAQFEYDPAKDDLIPCKEAGI RFRVGDIIQIISKDDHNWWQGKLENSKNGTAGLIPSPELQEWRVACIAMEKTKQEQQASCTWFGKKKKQYKDKYLAKHNADLVTYEEVVK LPAFKRKTLVLLGAHGVGRRHIKNTLITKHPDRFAYPIPHTTRPPKKDEENGKNYYFVSHDQMMQDISNNEYLEYGSHEDAMYGTKLETI RKIHEQGLIAILDVEPQALKVLRTAEFAPFVVFIAAPTITPGLNEDESLQRLQKESDILQRTYAHYFDLTIINNEIDETIRHLEEAVELV -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:11679387/chrX:41530783) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| FDFT1 | CASK |
| FUNCTION: Catalyzes the condensation of 2 farnesyl pyrophosphate (FPP) moieties to form squalene. Proceeds in two distinct steps. In the first half-reaction, two molecules of FPP react to form the stable presqualene diphosphate intermediate (PSQPP), with concomitant release of a proton and a molecule of inorganic diphosphate. In the second half-reaction, PSQPP undergoes heterolysis, isomerization, and reduction with NADPH or NADH to form squalene. It is the first committed enzyme of the sterol biosynthesis pathway. {ECO:0000269|PubMed:10896663, ECO:0000269|PubMed:24531458}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378158 | 4 | 26 | 343_398 | 143.0 | 910.0 | Domain | L27 1 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378158 | 4 | 26 | 402_455 | 143.0 | 910.0 | Domain | L27 2 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378158 | 4 | 26 | 489_564 | 143.0 | 910.0 | Domain | PDZ | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378158 | 4 | 26 | 612_682 | 143.0 | 910.0 | Domain | SH3 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378158 | 4 | 26 | 739_911 | 143.0 | 910.0 | Domain | Guanylate kinase-like | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378163 | 4 | 27 | 343_398 | 143.0 | 927.0 | Domain | L27 1 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378163 | 4 | 27 | 402_455 | 143.0 | 927.0 | Domain | L27 2 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378163 | 4 | 27 | 489_564 | 143.0 | 927.0 | Domain | PDZ | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378163 | 4 | 27 | 612_682 | 143.0 | 927.0 | Domain | SH3 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378163 | 4 | 27 | 739_911 | 143.0 | 927.0 | Domain | Guanylate kinase-like | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378166 | 4 | 27 | 343_398 | 143.0 | 922.0 | Domain | L27 1 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378166 | 4 | 27 | 402_455 | 143.0 | 922.0 | Domain | L27 2 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378166 | 4 | 27 | 489_564 | 143.0 | 922.0 | Domain | PDZ | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378166 | 4 | 27 | 612_682 | 143.0 | 922.0 | Domain | SH3 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378166 | 4 | 27 | 739_911 | 143.0 | 922.0 | Domain | Guanylate kinase-like | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000421587 | 4 | 25 | 343_398 | 143.0 | 898.0 | Domain | L27 1 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000421587 | 4 | 25 | 402_455 | 143.0 | 898.0 | Domain | L27 2 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000421587 | 4 | 25 | 489_564 | 143.0 | 898.0 | Domain | PDZ | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000421587 | 4 | 25 | 612_682 | 143.0 | 898.0 | Domain | SH3 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000421587 | 4 | 25 | 739_911 | 143.0 | 898.0 | Domain | Guanylate kinase-like | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000442742 | 4 | 26 | 343_398 | 143.0 | 899.0 | Domain | L27 1 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000442742 | 4 | 26 | 402_455 | 143.0 | 899.0 | Domain | L27 2 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000442742 | 4 | 26 | 489_564 | 143.0 | 899.0 | Domain | PDZ | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000442742 | 4 | 26 | 612_682 | 143.0 | 899.0 | Domain | SH3 | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000442742 | 4 | 26 | 739_911 | 143.0 | 899.0 | Domain | Guanylate kinase-like | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378158 | 4 | 26 | 305_315 | 143.0 | 910.0 | Region | Note=Calmodulin-binding | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378163 | 4 | 27 | 305_315 | 143.0 | 927.0 | Region | Note=Calmodulin-binding | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378166 | 4 | 27 | 305_315 | 143.0 | 922.0 | Region | Note=Calmodulin-binding | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000421587 | 4 | 25 | 305_315 | 143.0 | 898.0 | Region | Note=Calmodulin-binding | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000442742 | 4 | 26 | 305_315 | 143.0 | 899.0 | Region | Note=Calmodulin-binding |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | FDFT1 | chr8:11679387 | chrX:41530783 | ENST00000220584 | + | 4 | 8 | 284_304 | 170.0 | 418.0 | Transmembrane | Helical |
| Hgene | FDFT1 | chr8:11679387 | chrX:41530783 | ENST00000220584 | + | 4 | 8 | 384_404 | 170.0 | 418.0 | Transmembrane | Helical |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378158 | 4 | 26 | 12_276 | 143.0 | 910.0 | Domain | Protein kinase | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378163 | 4 | 27 | 12_276 | 143.0 | 927.0 | Domain | Protein kinase | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378166 | 4 | 27 | 12_276 | 143.0 | 922.0 | Domain | Protein kinase | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000421587 | 4 | 25 | 12_276 | 143.0 | 898.0 | Domain | Protein kinase | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000442742 | 4 | 26 | 12_276 | 143.0 | 899.0 | Domain | Protein kinase | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378158 | 4 | 26 | 18_26 | 143.0 | 910.0 | Nucleotide binding | ATP | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378163 | 4 | 27 | 18_26 | 143.0 | 927.0 | Nucleotide binding | ATP | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000378166 | 4 | 27 | 18_26 | 143.0 | 922.0 | Nucleotide binding | ATP | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000421587 | 4 | 25 | 18_26 | 143.0 | 898.0 | Nucleotide binding | ATP | |
| Tgene | CASK | chr8:11679387 | chrX:41530783 | ENST00000442742 | 4 | 26 | 18_26 | 143.0 | 899.0 | Nucleotide binding | ATP |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| FDFT1 | |
| CASK |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to FDFT1-CASK |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to FDFT1-CASK |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies