| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:FGFR1-BCR |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: FGFR1-BCR | FusionPDB ID: 30240 | FusionGDB2.0 ID: 30240 | Hgene | Tgene | Gene symbol | FGFR1 | BCR | Gene ID | 2260 | 613 |
| Gene name | fibroblast growth factor receptor 1 | BCR activator of RhoGEF and GTPase | |
| Synonyms | BFGFR|CD331|CEK|ECCL|FGFBR|FGFR-1|FLG|FLT-2|FLT2|HBGFR|HH2|HRTFDS|KAL2|N-SAM|OGD|bFGF-R-1 | ALL|BCR1|CML|D22S11|D22S662|PHL | |
| Cytomap | 8p11.23 | 22q11.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | fibroblast growth factor receptor 1FGFR1/PLAG1 fusionFMS-like tyrosine kinase 2basic fibroblast growth factor receptor 1fms-related tyrosine kinase 2heparin-binding growth factor receptorhydroxyaryl-protein kinaseproto-oncogene c-Fgr | breakpoint cluster region proteinBCR, RhoGEF and GTPase activating proteinBCR/FGFR1 chimera proteinFGFR1/BCR chimera proteinbreakpoint cluster regionrenal carcinoma antigen NY-REN-26 | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | Q9NVK5 | P11274 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000326324, ENST00000335922, ENST00000341462, ENST00000356207, ENST00000397091, ENST00000397103, ENST00000397108, ENST00000397113, ENST00000425967, ENST00000447712, ENST00000532791, ENST00000496629, | ENST00000398512, ENST00000436990, ENST00000305877, ENST00000359540, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 17 X 24 X 9=3672 | 15 X 58 X 7=6090 |
| # samples | 20 | 61 | |
| ** MAII score | log2(20/3672*10)=-4.19849415363908 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(61/6090*10)=-3.31956108034345 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: FGFR1 [Title/Abstract] AND BCR [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | BCR(23603730)-FGFR1(38275904), # samples:2 FGFR1(38277056)-BCR(23610592), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | FGFR1-BCR seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. FGFR1-BCR seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. FGFR1-BCR seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. FGFR1-BCR seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. FGFR1-BCR seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. FGFR1-BCR seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. FGFR1-BCR seems lost the major protein functional domain in Hgene partner, which is a kinase due to the frame-shifted ORF. FGFR1-BCR seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. FGFR1-BCR seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. FGFR1-BCR seems lost the major protein functional domain in Tgene partner, which is a kinase due to the frame-shifted ORF. FGFR1-BCR seems lost the major protein functional domain in Tgene partner, which is a tumor suppressor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | FGFR1 | GO:0008284 | positive regulation of cell proliferation | 8663044 |
| Hgene | FGFR1 | GO:0008543 | fibroblast growth factor receptor signaling pathway | 8663044 |
| Hgene | FGFR1 | GO:0010863 | positive regulation of phospholipase C activity | 18480409 |
| Hgene | FGFR1 | GO:0018108 | peptidyl-tyrosine phosphorylation | 8622701|18480409 |
| Hgene | FGFR1 | GO:0043406 | positive regulation of MAP kinase activity | 8622701|18480409 |
| Hgene | FGFR1 | GO:0046777 | protein autophosphorylation | 8622701 |
| Hgene | FGFR1 | GO:2000546 | positive regulation of endothelial cell chemotaxis to fibroblast growth factor | 21885851 |
| Tgene | BCR | GO:0090630 | activation of GTPase activity | 7479768 |
| Fusion gene breakpoints across FGFR1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
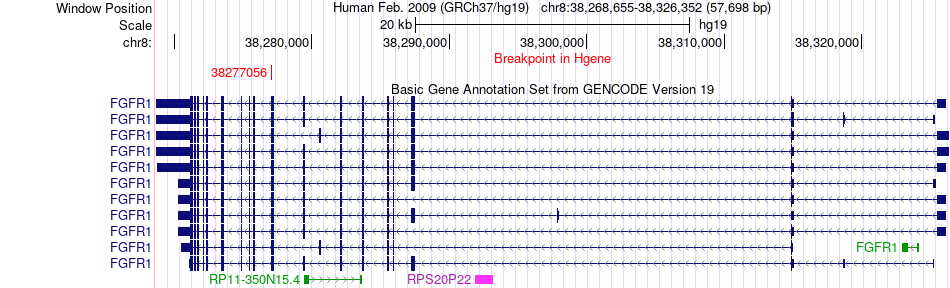 |
| Fusion gene breakpoints across BCR (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChiTaRS5.0 | N/A | AB742171 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + |
| ChiTaRS5.0 | N/A | AJ298917 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000397091 | FGFR1 | chr8 | 38277056 | - | ENST00000305877 | BCR | chr22 | 23610592 | + | 6606 | 2027 | 368 | 4090 | 1240 |
| ENST00000397091 | FGFR1 | chr8 | 38277056 | - | ENST00000359540 | BCR | chr22 | 23610592 | + | 4387 | 2027 | 368 | 3958 | 1196 |
| ENST00000447712 | FGFR1 | chr8 | 38277056 | - | ENST00000305877 | BCR | chr22 | 23610592 | + | 6805 | 2226 | 561 | 4289 | 1242 |
| ENST00000447712 | FGFR1 | chr8 | 38277056 | - | ENST00000359540 | BCR | chr22 | 23610592 | + | 4586 | 2226 | 561 | 4157 | 1198 |
| ENST00000341462 | FGFR1 | chr8 | 38277056 | - | ENST00000305877 | BCR | chr22 | 23610592 | + | 6805 | 2226 | 561 | 4289 | 1242 |
| ENST00000341462 | FGFR1 | chr8 | 38277056 | - | ENST00000359540 | BCR | chr22 | 23610592 | + | 4586 | 2226 | 561 | 4157 | 1198 |
| ENST00000532791 | FGFR1 | chr8 | 38277056 | - | ENST00000305877 | BCR | chr22 | 23610592 | + | 6587 | 2008 | 349 | 4071 | 1240 |
| ENST00000532791 | FGFR1 | chr8 | 38277056 | - | ENST00000359540 | BCR | chr22 | 23610592 | + | 4368 | 2008 | 349 | 3939 | 1196 |
| ENST00000397113 | FGFR1 | chr8 | 38277056 | - | ENST00000305877 | BCR | chr22 | 23610592 | + | 6174 | 1595 | 131 | 3658 | 1175 |
| ENST00000397113 | FGFR1 | chr8 | 38277056 | - | ENST00000359540 | BCR | chr22 | 23610592 | + | 3955 | 1595 | 131 | 3526 | 1131 |
| ENST00000356207 | FGFR1 | chr8 | 38277056 | - | ENST00000305877 | BCR | chr22 | 23610592 | + | 6320 | 1741 | 343 | 3804 | 1153 |
| ENST00000356207 | FGFR1 | chr8 | 38277056 | - | ENST00000359540 | BCR | chr22 | 23610592 | + | 4101 | 1741 | 343 | 3672 | 1109 |
| ENST00000326324 | FGFR1 | chr8 | 38277056 | - | ENST00000305877 | BCR | chr22 | 23610592 | + | 6314 | 1735 | 343 | 3798 | 1151 |
| ENST00000326324 | FGFR1 | chr8 | 38277056 | - | ENST00000359540 | BCR | chr22 | 23610592 | + | 4095 | 1735 | 343 | 3666 | 1107 |
| ENST00000397103 | FGFR1 | chr8 | 38277056 | - | ENST00000305877 | BCR | chr22 | 23610592 | + | 5653 | 1074 | 27 | 3137 | 1036 |
| ENST00000397103 | FGFR1 | chr8 | 38277056 | - | ENST00000359540 | BCR | chr22 | 23610592 | + | 3434 | 1074 | 27 | 3005 | 992 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000397091 | ENST00000305877 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.001132622 | 0.9988674 |
| ENST00000397091 | ENST00000359540 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.005665587 | 0.99433446 |
| ENST00000447712 | ENST00000305877 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.001551464 | 0.9984485 |
| ENST00000447712 | ENST00000359540 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.008129668 | 0.9918703 |
| ENST00000341462 | ENST00000305877 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.00143417 | 0.99856585 |
| ENST00000341462 | ENST00000359540 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.008032697 | 0.99196726 |
| ENST00000532791 | ENST00000305877 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.001624274 | 0.99837565 |
| ENST00000532791 | ENST00000359540 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.005706698 | 0.99429333 |
| ENST00000397113 | ENST00000305877 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.000654634 | 0.99934536 |
| ENST00000397113 | ENST00000359540 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.003898213 | 0.99610174 |
| ENST00000356207 | ENST00000305877 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.001034158 | 0.99896586 |
| ENST00000356207 | ENST00000359540 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.003342084 | 0.99665797 |
| ENST00000326324 | ENST00000305877 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.00100359 | 0.99899644 |
| ENST00000326324 | ENST00000359540 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.003369942 | 0.99663 |
| ENST00000397103 | ENST00000305877 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.000834885 | 0.9991652 |
| ENST00000397103 | ENST00000359540 | FGFR1 | chr8 | 38277056 | - | BCR | chr22 | 23610592 | + | 0.001243163 | 0.9987569 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >30240_30240_1_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000326324_BCR_chr22_23610592_ENST00000305877_length(amino acids)=1151AA_BP=464 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQDALPSSEDDDDDDDSSSEEKETD NTKPNPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVEN EYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKEME VLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMAV HKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHDL LKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQQ YDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSRN GKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNLY CTLEVDSFGYFVNKAKTRVYRDTAEPNWNEEFEIELEGSQTLRILCYEKCYNKTKIPKEDGESTDRLMGKGQVQLDPQALQDRDWQRTVI AMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNK DVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSL -------------------------------------------------------------- >30240_30240_2_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000326324_BCR_chr22_23610592_ENST00000359540_length(amino acids)=1107AA_BP=464 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQDALPSSEDDDDDDDSSSEEKETD NTKPNPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVEN EYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKEME VLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMAV HKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHDL LKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQQ YDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSRN GKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNLY CTLEVDSFGYFVNKAKTRVYRDTAEPNWNELDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRER SKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIAL SDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESKLPANPSQPITMTDSWSLEVMSQVQ -------------------------------------------------------------- >30240_30240_3_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000341462_BCR_chr22_23610592_ENST00000305877_length(amino acids)=1242AA_BP=555 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQAQPWGAPVEVESFLVHPGDLLQL RCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNVSVPIDALPSSEDDDDDDDSSSEEKE TDNTKPNPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIV ENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKHSGINSSDAE VLTLFNVTEAQSGEYVCKVSNYIGEANQSAWLTVTRPVLEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMA VHKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHD LLKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQ QYDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSR NGKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNL YCTLEVDSFGYFVNKAKTRVYRDTAEPNWNEEFEIELEGSQTLRILCYEKCYNKTKIPKEDGESTDRLMGKGQVQLDPQALQDRDWQRTV IAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNN KDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMS -------------------------------------------------------------- >30240_30240_4_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000341462_BCR_chr22_23610592_ENST00000359540_length(amino acids)=1198AA_BP=555 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQAQPWGAPVEVESFLVHPGDLLQL RCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNVSVPIDALPSSEDDDDDDDSSSEEKE TDNTKPNPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIV ENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKHSGINSSDAE VLTLFNVTEAQSGEYVCKVSNYIGEANQSAWLTVTRPVLEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMA VHKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHD LLKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQ QYDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSR NGKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNL YCTLEVDSFGYFVNKAKTRVYRDTAEPNWNELDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRE RSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIA LSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESKLPANPSQPITMTDSWSLEVMSQV -------------------------------------------------------------- >30240_30240_5_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000356207_BCR_chr22_23610592_ENST00000305877_length(amino acids)=1153AA_BP=466 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQDALPSSEDDDDDDDSSSEEKETD NTKPNRMPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIV ENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKE MEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQM AVHKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLH DLLKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKT QQYDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHS RNGKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSN LYCTLEVDSFGYFVNKAKTRVYRDTAEPNWNEEFEIELEGSQTLRILCYEKCYNKTKIPKEDGESTDRLMGKGQVQLDPQALQDRDWQRT VIAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVN NKDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKM -------------------------------------------------------------- >30240_30240_6_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000356207_BCR_chr22_23610592_ENST00000359540_length(amino acids)=1109AA_BP=466 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQDALPSSEDDDDDDDSSSEEKETD NTKPNRMPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIV ENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKE MEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQM AVHKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLH DLLKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKT QQYDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHS RNGKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSN LYCTLEVDSFGYFVNKAKTRVYRDTAEPNWNELDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKR ERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGI ALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESKLPANPSQPITMTDSWSLEVMSQ -------------------------------------------------------------- >30240_30240_7_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000397091_BCR_chr22_23610592_ENST00000305877_length(amino acids)=1240AA_BP=553 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQAQPWGAPVEVESFLVHPGDLLQL RCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNVSDALPSSEDDDDDDDSSSEEKETDN TKPNPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVENE YGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKEMEV LHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMAVH KLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHDLL KHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQQY DCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSRNG KSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNLYC TLEVDSFGYFVNKAKTRVYRDTAEPNWNEEFEIELEGSQTLRILCYEKCYNKTKIPKEDGESTDRLMGKGQVQLDPQALQDRDWQRTVIA MNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKD VSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLH -------------------------------------------------------------- >30240_30240_8_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000397091_BCR_chr22_23610592_ENST00000359540_length(amino acids)=1196AA_BP=553 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQAQPWGAPVEVESFLVHPGDLLQL RCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNVSDALPSSEDDDDDDDSSSEEKETDN TKPNPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVENE YGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKEMEV LHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMAVH KLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHDLL KHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQQY DCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSRNG KSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNLYC TLEVDSFGYFVNKAKTRVYRDTAEPNWNELDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERS KVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALS DPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESKLPANPSQPITMTDSWSLEVMSQVQV -------------------------------------------------------------- >30240_30240_9_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000397103_BCR_chr22_23610592_ENST00000305877_length(amino acids)=1036AA_BP=349 MSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQDALPSSEDDDDDDDSSSEEKETDNTKPNPVAPYWTSPEKMEKKLHAVPAA KTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGL PANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKHSGINSSDAEVLTLFNVTEAQSGEYVCKVSNYIGEANQS AWLTVTRPVAKALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMAVHKLAKSIPLRRQVTASQLGVYRAFV DNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHDLLKHTPASHPDHPLLQDALRISQNFL SSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQQYDCKWYIPLTDLSFQMVDELEAVPN IPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSRNGKSYTFLISSDYERAEWRENIREQQ KKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNLYCTLEVDSFGYFVNKAKTRVYRDTAE PNWNEEFEIELEGSQTLRILCYEKCYNKTKIPKEDGESTDRLMGKGQVQLDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSLKRMPS RKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKLYFREL PEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESKLPANP -------------------------------------------------------------- >30240_30240_10_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000397103_BCR_chr22_23610592_ENST00000359540_length(amino acids)=992AA_BP=349 MSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQDALPSSEDDDDDDDSSSEEKETDNTKPNPVAPYWTSPEKMEKKLHAVPAA KTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGL PANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKHSGINSSDAEVLTLFNVTEAQSGEYVCKVSNYIGEANQS AWLTVTRPVAKALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMAVHKLAKSIPLRRQVTASQLGVYRAFV DNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHDLLKHTPASHPDHPLLQDALRISQNFL SSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQQYDCKWYIPLTDLSFQMVDELEAVPN IPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSRNGKSYTFLISSDYERAEWRENIREQQ KKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNLYCTLEVDSFGYFVNKAKTRVYRDTAE PNWNELDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIY RVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTF LFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESKLPANPSQPITMTDSWSLEVMSQVQVLLYFLQLEAIPAPDSKRQSILFST -------------------------------------------------------------- >30240_30240_11_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000397113_BCR_chr22_23610592_ENST00000305877_length(amino acids)=1175AA_BP=488 MRPLPALVPPLFPPPNFSSNSRSGAGEAAAAPQVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLP EQAQPWGAPVEVESFLVHPGDLLQLRCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNV SDALPSSEDDDDDDDSSSEEKETDNTKPNPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRY ATWSIIMDSVVPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKI GPDNLPYVQILKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCM VGSVIVYKMKSGTKKSDFHSQMAVHKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTK NSLETLLYKPVDRVTRSTLVLHDLLKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLR HVFLFTDLLLCTKLKKQSGGKTQQYDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKK KLSEQESLLLLMSPSMAFRVHSRNGKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDES PGLYGFLNVIVHSATGFKQSSNLYCTLEVDSFGYFVNKAKTRVYRDTAEPNWNEEFEIELEGSQTLRILCYEKCYNKTKIPKEDGESTDR LMGKGQVQLDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEV GIYRVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANL LTFLFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESKLPANPSQPITMTDSWSLEVMSQVQVLLYFLQLEAIPAPDSKRQSIL -------------------------------------------------------------- >30240_30240_12_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000397113_BCR_chr22_23610592_ENST00000359540_length(amino acids)=1131AA_BP=488 MRPLPALVPPLFPPPNFSSNSRSGAGEAAAAPQVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLP EQAQPWGAPVEVESFLVHPGDLLQLRCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNV SDALPSSEDDDDDDDSSSEEKETDNTKPNPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRY ATWSIIMDSVVPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKI GPDNLPYVQILKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCM VGSVIVYKMKSGTKKSDFHSQMAVHKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTK NSLETLLYKPVDRVTRSTLVLHDLLKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLR HVFLFTDLLLCTKLKKQSGGKTQQYDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKK KLSEQESLLLLMSPSMAFRVHSRNGKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDES PGLYGFLNVIVHSATGFKQSSNLYCTLEVDSFGYFVNKAKTRVYRDTAEPNWNELDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSL KRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKL YFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESK -------------------------------------------------------------- >30240_30240_13_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000447712_BCR_chr22_23610592_ENST00000305877_length(amino acids)=1242AA_BP=555 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQAQPWGAPVEVESFLVHPGDLLQL RCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNVSDALPSSEDDDDDDDSSSEEKETDN TKPNRMPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVE NEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKEM EVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMA VHKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHD LLKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQ QYDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSR NGKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNL YCTLEVDSFGYFVNKAKTRVYRDTAEPNWNEEFEIELEGSQTLRILCYEKCYNKTKIPKEDGESTDRLMGKGQVQLDPQALQDRDWQRTV IAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNN KDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMS -------------------------------------------------------------- >30240_30240_14_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000447712_BCR_chr22_23610592_ENST00000359540_length(amino acids)=1198AA_BP=555 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQAQPWGAPVEVESFLVHPGDLLQL RCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNVSDALPSSEDDDDDDDSSSEEKETDN TKPNRMPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVE NEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKEM EVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMA VHKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHD LLKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQ QYDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSR NGKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNL YCTLEVDSFGYFVNKAKTRVYRDTAEPNWNELDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRE RSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIA LSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESKLPANPSQPITMTDSWSLEVMSQV -------------------------------------------------------------- >30240_30240_15_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000532791_BCR_chr22_23610592_ENST00000305877_length(amino acids)=1240AA_BP=552 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQAQPWGAPVEVESFLVHPGDLLQL RCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNVSDALPSSEDDDDDDDSSSEEKETDN TKPNRMPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVE NEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKEM EVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMA VHKLAKSIPLRRQASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHDLL KHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQQY DCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSRNG KSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNLYC TLEVDSFGYFVNKAKTRVYRDTAEPNWNEEFEIELEGSQTLRILCYEKCYNKTKIPKEDGESTDRLMGKGQVQLDPQALQDRDWQRTVIA MNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKD VSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLH -------------------------------------------------------------- >30240_30240_16_FGFR1-BCR_FGFR1_chr8_38277056_ENST00000532791_BCR_chr22_23610592_ENST00000359540_length(amino acids)=1196AA_BP=552 MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQAQPWGAPVEVESFLVHPGDLLQL RCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNVSDALPSSEDDDDDDDSSSEEKETDN TKPNRMPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVE NEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKEM EVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMA VHKLAKSIPLRRQASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHDLL KHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQQY DCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSRNG KSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNLYC TLEVDSFGYFVNKAKTRVYRDTAEPNWNELDPQALQDRDWQRTVIAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERS KVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNNKDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALS DPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMSLHNLATVFGPTLLRPSEKESKLPANPSQPITMTDSWSLEVMSQVQV -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:23603730/chr22:38275904) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| FGFR1 | BCR |
| FUNCTION: May be involved in wound healing pathway. {ECO:0000250}. | FUNCTION: Protein with a unique structure having two opposing regulatory activities toward small GTP-binding proteins. The C-terminus is a GTPase-activating protein (GAP) domain which stimulates GTP hydrolysis by RAC1, RAC2 and CDC42. Accelerates the intrinsic rate of GTP hydrolysis of RAC1 or CDC42, leading to down-regulation of the active GTP-bound form (PubMed:7479768, PubMed:1903516, PubMed:17116687). The central Dbl homology (DH) domain functions as guanine nucleotide exchange factor (GEF) that modulates the GTPases CDC42, RHOA and RAC1. Promotes the conversion of CDC42, RHOA and RAC1 from the GDP-bound to the GTP-bound form (PubMed:7479768, PubMed:23940119). The amino terminus contains an intrinsic kinase activity (PubMed:1657398). Functions as an important negative regulator of neuronal RAC1 activity (By similarity). Regulates macrophage functions such as CSF1-directed motility and phagocytosis through the modulation of RAC1 activity (PubMed:17116687). Plays a major role as a RHOA GEF in keratinocytes being involved in focal adhesion formation and keratinocyte differentiation (PubMed:23940119). {ECO:0000250|UniProtKB:Q6PAJ1, ECO:0000269|PubMed:1657398, ECO:0000269|PubMed:17116687, ECO:0000269|PubMed:1903516, ECO:0000269|PubMed:23940119, ECO:0000269|PubMed:7479768}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 158_246 | 337.0 | 732.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 25_119 | 337.0 | 732.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 158_246 | 418.0 | 813.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 255_357 | 418.0 | 813.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 25_119 | 418.0 | 813.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 158_246 | 339.0 | 734.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 25_119 | 339.0 | 734.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 158_246 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 255_357 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 25_119 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 158_246 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 255_357 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 25_119 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 158_246 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 255_357 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 25_119 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 158_246 | 459.0 | 854.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 255_357 | 459.0 | 854.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 25_119 | 459.0 | 854.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 158_246 | 428.0 | 823.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 255_357 | 428.0 | 823.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 25_119 | 428.0 | 823.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 158_246 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 255_357 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 25_119 | 426.0 | 821.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 160_177 | 337.0 | 732.0 | Region | Note=Heparin-binding |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 160_177 | 418.0 | 813.0 | Region | Note=Heparin-binding |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 160_177 | 339.0 | 734.0 | Region | Note=Heparin-binding |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 160_177 | 426.0 | 821.0 | Region | Note=Heparin-binding |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 160_177 | 426.0 | 821.0 | Region | Note=Heparin-binding |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 160_177 | 426.0 | 821.0 | Region | Note=Heparin-binding |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 160_177 | 459.0 | 854.0 | Region | Note=Heparin-binding |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 160_177 | 428.0 | 823.0 | Region | Note=Heparin-binding |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 160_177 | 426.0 | 821.0 | Region | Note=Heparin-binding |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 22_376 | 418.0 | 813.0 | Topological domain | Extracellular |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 22_376 | 426.0 | 821.0 | Topological domain | Extracellular |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 22_376 | 426.0 | 821.0 | Topological domain | Extracellular |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 22_376 | 426.0 | 821.0 | Topological domain | Extracellular |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 22_376 | 459.0 | 854.0 | Topological domain | Extracellular |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 22_376 | 428.0 | 823.0 | Topological domain | Extracellular |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 22_376 | 426.0 | 821.0 | Topological domain | Extracellular |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 377_397 | 418.0 | 813.0 | Transmembrane | Helical |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 377_397 | 426.0 | 821.0 | Transmembrane | Helical |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 377_397 | 426.0 | 821.0 | Transmembrane | Helical |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 377_397 | 426.0 | 821.0 | Transmembrane | Helical |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 377_397 | 459.0 | 854.0 | Transmembrane | Helical |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 377_397 | 428.0 | 823.0 | Transmembrane | Helical |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 377_397 | 426.0 | 821.0 | Transmembrane | Helical |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000305877 | 3 | 23 | 824_827 | 584.0 | 1272.0 | Compositional bias | Note=Poly-Leu | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000359540 | 3 | 22 | 824_827 | 584.0 | 1228.0 | Compositional bias | Note=Poly-Leu | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000305877 | 3 | 23 | 1054_1248 | 584.0 | 1272.0 | Domain | Rho-GAP | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000305877 | 3 | 23 | 708_866 | 584.0 | 1272.0 | Domain | PH | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000305877 | 3 | 23 | 893_1020 | 584.0 | 1272.0 | Domain | C2 | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000359540 | 3 | 22 | 1054_1248 | 584.0 | 1228.0 | Domain | Rho-GAP | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000359540 | 3 | 22 | 708_866 | 584.0 | 1228.0 | Domain | PH | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000359540 | 3 | 22 | 893_1020 | 584.0 | 1228.0 | Domain | C2 |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 255_357 | 337.0 | 732.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 478_767 | 337.0 | 732.0 | Domain | Protein kinase |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 478_767 | 418.0 | 813.0 | Domain | Protein kinase |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 255_357 | 339.0 | 734.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 478_767 | 339.0 | 734.0 | Domain | Protein kinase |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 478_767 | 426.0 | 821.0 | Domain | Protein kinase |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 478_767 | 426.0 | 821.0 | Domain | Protein kinase |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 478_767 | 426.0 | 821.0 | Domain | Protein kinase |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 478_767 | 459.0 | 854.0 | Domain | Protein kinase |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 478_767 | 428.0 | 823.0 | Domain | Protein kinase |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 478_767 | 426.0 | 821.0 | Domain | Protein kinase |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 484_490 | 337.0 | 732.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 562_564 | 337.0 | 732.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 484_490 | 418.0 | 813.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 562_564 | 418.0 | 813.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 484_490 | 339.0 | 734.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 562_564 | 339.0 | 734.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 484_490 | 426.0 | 821.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 562_564 | 426.0 | 821.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 484_490 | 426.0 | 821.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 562_564 | 426.0 | 821.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 484_490 | 426.0 | 821.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 562_564 | 426.0 | 821.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 484_490 | 459.0 | 854.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 562_564 | 459.0 | 854.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 484_490 | 428.0 | 823.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 562_564 | 428.0 | 823.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 484_490 | 426.0 | 821.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 562_564 | 426.0 | 821.0 | Nucleotide binding | Note=ATP |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 22_376 | 337.0 | 732.0 | Topological domain | Extracellular |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 398_822 | 337.0 | 732.0 | Topological domain | Cytoplasmic |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000335922 | - | 10 | 19 | 398_822 | 418.0 | 813.0 | Topological domain | Cytoplasmic |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 22_376 | 339.0 | 734.0 | Topological domain | Extracellular |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 398_822 | 339.0 | 734.0 | Topological domain | Cytoplasmic |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397091 | - | 9 | 18 | 398_822 | 426.0 | 821.0 | Topological domain | Cytoplasmic |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397108 | - | 10 | 19 | 398_822 | 426.0 | 821.0 | Topological domain | Cytoplasmic |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000397113 | - | 9 | 18 | 398_822 | 426.0 | 821.0 | Topological domain | Cytoplasmic |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000425967 | - | 10 | 19 | 398_822 | 459.0 | 854.0 | Topological domain | Cytoplasmic |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000447712 | - | 9 | 18 | 398_822 | 428.0 | 823.0 | Topological domain | Cytoplasmic |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000532791 | - | 9 | 18 | 398_822 | 426.0 | 821.0 | Topological domain | Cytoplasmic |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000326324 | - | 8 | 17 | 377_397 | 337.0 | 732.0 | Transmembrane | Helical |
| Hgene | FGFR1 | chr8:38277056 | chr22:23610592 | ENST00000356207 | - | 8 | 17 | 377_397 | 339.0 | 734.0 | Transmembrane | Helical |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000305877 | 3 | 23 | 498_691 | 584.0 | 1272.0 | Domain | DH | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000359540 | 3 | 22 | 498_691 | 584.0 | 1228.0 | Domain | DH | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000305877 | 3 | 23 | 197_385 | 584.0 | 1272.0 | Region | Note=Binding to ABL SH2-domain | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000305877 | 3 | 23 | 1_426 | 584.0 | 1272.0 | Region | Note=Kinase | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000359540 | 3 | 22 | 197_385 | 584.0 | 1228.0 | Region | Note=Binding to ABL SH2-domain | |
| Tgene | BCR | chr8:38277056 | chr22:23610592 | ENST00000359540 | 3 | 22 | 1_426 | 584.0 | 1228.0 | Region | Note=Kinase |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file >>>1957_FGFR1_38277056_BCR_23610592_ranked_0.pdb | FGFR1 | 38277056 | 38277056 | ENST00000359540 | BCR | chr22 | 23610592 | + | MRSGGGGHKVWRPRVADGSPPPAPPPGHQLRLHCSRPGWRRRAPSAAGSRAPAAELLRPRQDPNRARGRRAGAGDAGTRPLAQATADSPE AEPPRRARVSLKRRIELTVEYPWRCGALSPTSNCRTGMWSWKCLLFWAVLVTATLCTARPSPTLPEQAQPWGAPVEVESFLVHPGDLLQL RCRLRDDVQSINWLRDGVQLAESNRTRITGEEVEVQDSVPADSGLYACVTSSPSGSDTTYFSVNVSDALPSSEDDDDDDDSSSEEKETDN TKPNRMPVAPYWTSPEKMEKKLHAVPAAKTVKFKCPSSGTPNPTLRWLKNGKEFKPDHRIGGYKVRYATWSIIMDSVVPSDKGNYTCIVE NEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQILKTAGVNTTDKEM EVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKSGTKKSDFHSQMA VHKLAKSIPLRRQVTASQLGVYRAFVDNYGVAMEMAEKCCQANAQFAEISENLRARSNKDAKDPTTKNSLETLLYKPVDRVTRSTLVLHD LLKHTPASHPDHPLLQDALRISQNFLSSINEEITPRRQSMTVKKGEHRQLLKDSFMVELVEGARKLRHVFLFTDLLLCTKLKKQSGGKTQ QYDCKWYIPLTDLSFQMVDELEAVPNIPLVPDEELDALKIKISQIKNDIQREKRANKGSKATERLKKKLSEQESLLLLMSPSMAFRVHSR NGKSYTFLISSDYERAEWRENIREQQKKCFRSFSLTSVELQMLTNSCVKLQTVHSIPLTINKEDDESPGLYGFLNVIVHSATGFKQSSNL YCTLEVDSFGYFVNKAKTRVYRDTAEPNWNEEFEIELEGSQTLRILCYEKCYNKTKIPKEDGESTDRLMGKGQVQLDPQALQDRDWQRTV IAMNGIEVKLSVKFNSREFSLKRMPSRKQTGVFGVKIAVVTKRERSKVPYIVRQCVEEIERRGMEEVGIYRVSGVATDIQALKAAFDVNN KDVSVMMSEMDVNAIAGTLKLYFRELPEPLFTDEFYPNFAEGIALSDPVAKESCMLNLLLSLPEANLLTFLFLLDHLKRVAEKEAVNKMS | 1242 |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
FGFR1_pLDDT.png  |
BCR_pLDDT.png  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
 |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| BCR | MLLT4, HCK, PTPN6, FES, RB1, ERCC3, GRB2, ABL1, GAB2, HOXA9, CRKL, KIT, PIK3CG, IGSF21, TP53, UNC119, SOS1, PXN, RAC1, CDC42, RHOA, IL3, WDR48, TSG101, VPS28, INPP5D, MYC, HSP90AA1, HSPA8, HIF1A, CRK, GABRR1, CBL, LNX1, LRRK1, GRK5, UBASH3B, PIK3R2, SHC1, AP2M1, Grasp, CFTR, ERBB2IP, DOK1, PTGES3, HSPA4, HSPD1, UBC, CSNK2A2, STUB1, CCDC183, RSPH9, SEC13, Numb, NTRK1, CEP128, NINL, XPO1, Scai, PIK3R1, PDZK1, COMMD1, TULP3, JPH4, NAGK, USP15, SPAG9, MCM2, MCM4, WEE1, CSNK1A1, MCM6, TRIM25, RAD51, HNRNPL, EGLN3, ESR2, DPF2, RECQL4, EZR, KIAA1429, SCAI, HOOK3, PTPN3, PLK1, PLEKHA4, nsp12, nsp15, nsp2, ARHGEF39, HSCB, SAMD4B, SMG6, BRPF3, CECR2, SP110, TRIM66, AP2A1, CSNK2A1, DDX58, USP1, ACTR1A, ANK3, AP2B1, CEP135, CLTA, CTNNA1, DCTN2, MAPRE3, PFN1, RAB2A, RDX, RHOB, SQSTM1, VASP, ATG7, ATG10, ATG3, MAP4K1, NUDCD2, VPS33A, PSD4, SLA2, AGO4, DDR1, YWHAB, NAA10, YWHAH, YWHAG, SURF6, SYNC, CSNK2B, BACE2, GRAP2, |
| FGFR1 | FDPS, FRS3, NCAM1, FGF1, FGFR1, FRS2, PLCG1, FGF2, SHB, GRB14, BNIP2, KPNB1, CREBBP, STAT3, JAK2, SRC, NEDD4, PPP2R1B, FGF23, PTK6, ITK, NCK1, VAV1, HSP90AA1, ERBB3, CTPS2, CDK9, RPS6KA3, CDC20, TSPAN3, CEACAM21, IL20RB, LGALS8, TGFBR2, GINM1, DLK1, LTBR, TNFRSF10B, EVI2A, MREG, HEPACAM2, GOLGA7B, LDLRAD4, CRK, CTNNB1, CDH1, FGF8, SOS1, PIK3R1, PKM, FGF3, FGF5, FGF6, FGF9, FGF10, FGF17, CD44, RPS6KA1, SLA, PIK3R2, SH3BP2, NCK2, TENC1, RTN1, RTN3, PVRL1, EPHA4, YES1, L1CAM, TNK2, AKT1, PDP1, FGFR2, FAM8A1, TMEM30B, LRRN2, LITAF, C16orf58, ZDHHC11, IFNGR1, GAD1, FCGRT, IL27RA, RAET1E, SLC1A1, C14orf37, MANSC1, TPCN2, CD79B, SCN3B, C19orf45, HTR1A, FLRT1, KAL1, RASA1, CDH2, ZMYM2, FGF4, OPCML, SHC1, S100B, AGER, KLB, CDH11, TGFBR3, PTPN1, IL17RD, FBXO7, CRKL, RPN1, STOML2, DDOST, CANX, LMAN2, TMED9, RCN2, HSPA6, CDC37, HSPA2, ACTG1, ACTA1, PARD3, PGRMC1, PHGDH, ATP5B, VDAC1, VDAC2, SLC25A6, RUVBL2, RPA1, PLCG2, RAP1A, PHB, RAB1A, RAB5A, RAB8A, RAB4A, RAB14, RAB15, ARF4, RAB2B, RAB9A, COPA, SEC22B, TMEM109, STX12, CLPTM1, HSPA1L, DNAJC13, DNAJB1, TUBB4A, TUBA4A, AFAP1, TUBA1B, MTCH1, BAX, IMMT, GNB1, RAB7A, RAB11B, GAB1, PTPN11, RXRA, RARA, Nr4a2, H3F3A, Nr4a1, TH, UBC, SHE, Il17rd, PDGFRB, MFHAS1, PDK1, HEXIM1, LARP7, GNAI1, RIN1, ITGB3, KIAA1429, ERBB2, APEX1, ORF3a, ORF3b, CORO1C, HSP90AB3P, HSP90AB1, BAG2, MRPS7, MRPS31, MRPS14, P4HB, CDK1, HPX, ATP5O, LIMA1, TMOD3, CORO1B, ACTB, PLEC, RPL22L1, PPM1B, TBL2, DIMT1, SPATS2L, FARSB, HSD17B10, NUFIP2, TRMT10C, SND1, OBSCN, AIMP2, RARS, SRP19, POLRMT, MRPS2, MRPS26, BOLA2, ARGLU1, PFKFB3, MRPS6, CFL1, MRPS33, RPL22, KCTD5, HSPD1, EGFR, HULC, LDHA, MKRN2, DDX58, MLC1, IL3RA, IL32, AQP9, KCNE3, UGT1A7, GJA8, CLEC4A, AVPR1B, DEFB135, RNF149, C7orf34, EPB41L4A, CRLF2, DEFB109P1B, TBXA2R, NRSN1, OR1M1, IFNAR1, SYT2, CDH16, FBXO2, TSHR, MFI2, BCAN, CSNK1G2, CDHR4, CTSG, C1QTNF9B, PCDHA8, IZUMO1, CD8B, SFTPC, GREM2, DHFRL1, CD83, KCNC3, ANK1, PTPRN2, TMEM59, PCDHB7, P2RX4, |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| FGFR1 |  |
| BCR |  |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to FGFR1-BCR |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to FGFR1-BCR |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | FGFR1 | C1563720 | Kallmann Syndrome 2 (disorder) | 18 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Hgene | FGFR1 | C1845146 | Holoprosencephaly, Ectrodactyly, and Bilateral Cleft Lip-Palate | 6 | GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | FGFR1 | C0011570 | Mental Depression | 5 | PSYGENET |
| Hgene | FGFR1 | C0011581 | Depressive disorder | 5 | CTD_human;PSYGENET |
| Hgene | FGFR1 | C0220658 | Pfeiffer Syndrome | 5 | GENOMICS_ENGLAND;UNIPROT |
| Hgene | FGFR1 | C0432283 | Osteoglophonic dwarfism | 5 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | FGFR1 | C0041696 | Unipolar Depression | 4 | CTD_human;PSYGENET |
| Hgene | FGFR1 | C0406612 | Encephalocraniocutaneous lipomatosis | 4 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | FGFR1 | C0005586 | Bipolar Disorder | 3 | PSYGENET |
| Hgene | FGFR1 | C0795998 | JACKSON-WEISS SYNDROME | 3 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Hgene | FGFR1 | C1269683 | Major Depressive Disorder | 3 | PSYGENET |
| Hgene | FGFR1 | C0006142 | Malignant neoplasm of breast | 2 | CGI;CTD_human |
| Hgene | FGFR1 | C0007131 | Non-Small Cell Lung Carcinoma | 2 | CTD_human |
| Hgene | FGFR1 | C0007137 | Squamous cell carcinoma | 2 | CTD_human |
| Hgene | FGFR1 | C0027022 | Myeloproliferative disease | 2 | CTD_human |
| Hgene | FGFR1 | C0162809 | Kallmann Syndrome | 2 | CTD_human;ORPHANET |
| Hgene | FGFR1 | C0432122 | Interfrontal craniofaciosynostosis | 2 | GENOMICS_ENGLAND;UNIPROT |
| Hgene | FGFR1 | C0678222 | Breast Carcinoma | 2 | CGI;CTD_human |
| Hgene | FGFR1 | C1257931 | Mammary Neoplasms, Human | 2 | CTD_human |
| Hgene | FGFR1 | C1458155 | Mammary Neoplasms | 2 | CTD_human |
| Hgene | FGFR1 | C4704874 | Mammary Carcinoma, Human | 2 | CTD_human |
| Hgene | FGFR1 | C0004114 | Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0008924 | Cleft upper lip | 1 | CTD_human |
| Hgene | FGFR1 | C0008925 | Cleft Palate | 1 | CTD_human |
| Hgene | FGFR1 | C0010278 | Craniosynostosis | 1 | CTD_human;GENOMICS_ENGLAND |
| Hgene | FGFR1 | C0011573 | Endogenous depression | 1 | CTD_human |
| Hgene | FGFR1 | C0017638 | Glioma | 1 | CTD_human |
| Hgene | FGFR1 | C0018824 | Heart valve disease | 1 | CTD_human |
| Hgene | FGFR1 | C0024121 | Lung Neoplasms | 1 | CTD_human |
| Hgene | FGFR1 | C0025193 | Melancholia | 1 | CTD_human |
| Hgene | FGFR1 | C0036341 | Schizophrenia | 1 | CTD_human |
| Hgene | FGFR1 | C0085682 | Hypophosphatemia | 1 | GENOMICS_ENGLAND |
| Hgene | FGFR1 | C0086133 | Depressive Syndrome | 1 | CTD_human |
| Hgene | FGFR1 | C0149925 | Small cell carcinoma of lung | 1 | CTD_human |
| Hgene | FGFR1 | C0205768 | Subependymal Giant Cell Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0206726 | gliosarcoma | 1 | ORPHANET |
| Hgene | FGFR1 | C0242379 | Malignant neoplasm of lung | 1 | CTD_human |
| Hgene | FGFR1 | C0259783 | mixed gliomas | 1 | CTD_human |
| Hgene | FGFR1 | C0265535 | Trigonocephaly | 1 | CTD_human;ORPHANET |
| Hgene | FGFR1 | C0280783 | Juvenile Pilocytic Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0280785 | Diffuse Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0282126 | Depression, Neurotic | 1 | CTD_human |
| Hgene | FGFR1 | C0334579 | Anaplastic astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0334580 | Protoplasmic astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0334581 | Gemistocytic astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0334582 | Fibrillary Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0334583 | Pilocytic Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0334588 | Giant Cell Glioblastoma | 1 | ORPHANET |
| Hgene | FGFR1 | C0338070 | Childhood Cerebral Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0338503 | Septo-Optic Dysplasia | 1 | ORPHANET |
| Hgene | FGFR1 | C0342384 | Idiopathic hypogonadotropic hypogonadism | 1 | GENOMICS_ENGLAND |
| Hgene | FGFR1 | C0376634 | Craniofacial Abnormalities | 1 | CTD_human |
| Hgene | FGFR1 | C0431362 | Lobar Holoprosencephaly | 1 | ORPHANET |
| Hgene | FGFR1 | C0547065 | Mixed oligoastrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0555198 | Malignant Glioma | 1 | CTD_human |
| Hgene | FGFR1 | C0750935 | Cerebral Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0750936 | Intracranial Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C0751617 | Semilobar Holoprosencephaly | 1 | ORPHANET |
| Hgene | FGFR1 | C1519086 | Pilomyxoid astrocytoma | 1 | ORPHANET |
| Hgene | FGFR1 | C1704230 | Grade I Astrocytoma | 1 | CTD_human |
| Hgene | FGFR1 | C1837218 | Cleft palate, isolated | 1 | CTD_human |
| Hgene | FGFR1 | C1852406 | Cutis Gyrata Syndrome of Beare And Stevenson | 1 | GENOMICS_ENGLAND |
| Hgene | FGFR1 | C2931196 | Craniofacial dysostosis type 1 | 1 | GENOMICS_ENGLAND |
| Hgene | FGFR1 | C3150773 | CHROMOSOME 8p11 MYELOPROLIFERATIVE SYNDROME | 1 | ORPHANET |
| Tgene | BCR | C0005586 | Bipolar Disorder | 4 | PSYGENET |
| Tgene | BCR | C0023473 | Myeloid Leukemia, Chronic | 3 | CTD_human;ORPHANET |
| Tgene | BCR | C0005699 | Blast Phase | 1 | CTD_human |
| Tgene | BCR | C0006413 | Burkitt Lymphoma | 1 | ORPHANET |
| Tgene | BCR | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human |
| Tgene | BCR | C0027022 | Myeloproliferative disease | 1 | CTD_human |
| Tgene | BCR | C0027540 | Necrosis | 1 | CTD_human |
| Tgene | BCR | C0027659 | Neoplasms, Experimental | 1 | CTD_human |
| Tgene | BCR | C0041696 | Unipolar Depression | 1 | PSYGENET |
| Tgene | BCR | C1269683 | Major Depressive Disorder | 1 | PSYGENET |
| Tgene | BCR | C1292769 | Precursor B-cell lymphoblastic leukemia | 1 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies