| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:GOLGA4-MLH1 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: GOLGA4-MLH1 | FusionPDB ID: 33904 | FusionGDB2.0 ID: 33904 | Hgene | Tgene | Gene symbol | GOLGA4 | MLH1 | Gene ID | 2803 | 4292 |
| Gene name | golgin A4 | mutL homolog 1 | |
| Synonyms | CRPF46|GCP2|GOLG|MU-RMS-40.18|p230 | COCA2|FCC2|HNPCC|HNPCC2|hMLH1 | |
| Cytomap | 3p22.2 | 3p22.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | golgin subfamily A member 4256 kDa golgin72.1 proteincentrosome-related protein F46golgi autoantigen, golgin subfamily a, 4golgin-240golgin-245protein 72.1trans-Golgi p230 | DNA mismatch repair protein Mlh1mutL homolog 1, colon cancer, nonpolyposis type 2 | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | Q13439 | P40692 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000435830, ENST00000356847, ENST00000361924, ENST00000444882, | ENST00000231790, ENST00000435176, ENST00000455445, ENST00000458205, ENST00000536378, ENST00000539477, ENST00000492474, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 24 X 16 X 11=4224 | 8 X 18 X 5=720 |
| # samples | 27 | 20 | |
| ** MAII score | log2(27/4224*10)=-3.96757852230762 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(20/720*10)=-1.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: GOLGA4 [Title/Abstract] AND MLH1 [Title/Abstract] AND fusion [Title/Abstract] An interstitial deletion at 3p21.3 results in the genetic fusion of MLH1 and ITGA9 in a Lynch syndrome family (pmid: 19188145) | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | GOLGA4(37370584)-MLH1(37089010), # samples:2 GOLGA4(37343823)-MLH1(37058997), # samples:2 GOLGA4(37360685)-MLH1(37061801), # samples:2 MLH1(37050396)-GOLGA4(37376544), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | GOLGA4-MLH1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. GOLGA4-MLH1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. GOLGA4-MLH1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. GOLGA4-MLH1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. MLH1-GOLGA4 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. MLH1-GOLGA4 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. GOLGA4-MLH1 seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. GOLGA4-MLH1 seems lost the major protein functional domain in Tgene partner, which is a tumor suppressor due to the frame-shifted ORF. MLH1-GOLGA4 seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. MLH1-GOLGA4 seems lost the major protein functional domain in Hgene partner, which is a tumor suppressor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | GOLGA4 | GO:0043001 | Golgi to plasma membrane protein transport | 15265687 |
| Hgene | GOLGA4 | GO:0045773 | positive regulation of axon extension | 22705394 |
| Fusion gene breakpoints across GOLGA4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
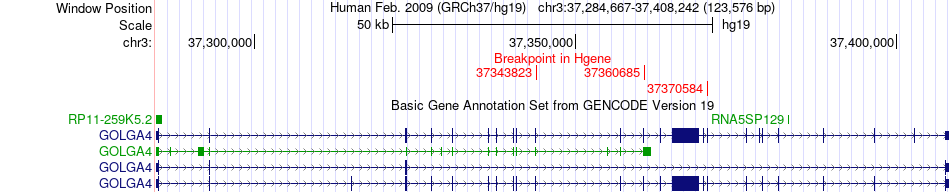 |
| Fusion gene breakpoints across MLH1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
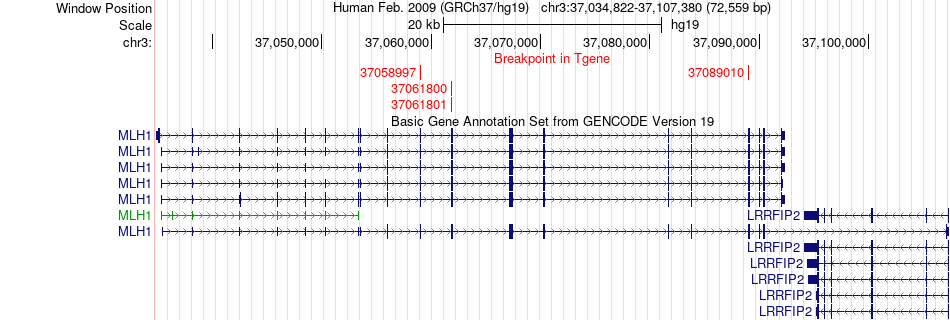 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-BH-A0B9-01A | GOLGA4 | chr3 | 37370584 | - | MLH1 | chr3 | 37089010 | + |
| ChimerDB4 | BRCA | TCGA-BH-A0B9-01A | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + |
| ChimerDB4 | PRAD | TCGA-EJ-A46G-01A | GOLGA4 | chr3 | 37343823 | - | MLH1 | chr3 | 37058997 | + |
| ChimerDB4 | PRAD | TCGA-EJ-A46G | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + |
| ChimerDB4 | STAD | TCGA-BR-A4QI-01A | GOLGA4 | chr3 | 37360685 | - | MLH1 | chr3 | 37061801 | + |
| ChimerDB4 | STAD | TCGA-BR-A4QI-01A | GOLGA4 | chr3 | 37360685 | + | MLH1 | chr3 | 37061801 | + |
| ChimerDB4 | STAD | TCGA-BR-A4QI | GOLGA4 | chr3 | 37360685 | + | MLH1 | chr3 | 37061800 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000361924 | GOLGA4 | chr3 | 37370584 | + | ENST00000536378 | MLH1 | chr3 | 37089010 | + | 7211 | 6566 | 374 | 6940 | 2188 |
| ENST00000361924 | GOLGA4 | chr3 | 37370584 | + | ENST00000231790 | MLH1 | chr3 | 37089010 | + | 7371 | 6566 | 374 | 7105 | 2243 |
| ENST00000361924 | GOLGA4 | chr3 | 37370584 | + | ENST00000458205 | MLH1 | chr3 | 37089010 | + | 7299 | 6566 | 374 | 7105 | 2243 |
| ENST00000361924 | GOLGA4 | chr3 | 37370584 | + | ENST00000539477 | MLH1 | chr3 | 37089010 | + | 7295 | 6566 | 374 | 7105 | 2243 |
| ENST00000361924 | GOLGA4 | chr3 | 37370584 | + | ENST00000455445 | MLH1 | chr3 | 37089010 | + | 7159 | 6566 | 374 | 7105 | 2243 |
| ENST00000361924 | GOLGA4 | chr3 | 37370584 | + | ENST00000435176 | MLH1 | chr3 | 37089010 | + | 7297 | 6566 | 374 | 7105 | 2243 |
| ENST00000356847 | GOLGA4 | chr3 | 37370584 | + | ENST00000536378 | MLH1 | chr3 | 37089010 | + | 7202 | 6557 | 299 | 6931 | 2210 |
| ENST00000356847 | GOLGA4 | chr3 | 37370584 | + | ENST00000231790 | MLH1 | chr3 | 37089010 | + | 7362 | 6557 | 299 | 7096 | 2265 |
| ENST00000356847 | GOLGA4 | chr3 | 37370584 | + | ENST00000458205 | MLH1 | chr3 | 37089010 | + | 7290 | 6557 | 299 | 7096 | 2265 |
| ENST00000356847 | GOLGA4 | chr3 | 37370584 | + | ENST00000539477 | MLH1 | chr3 | 37089010 | + | 7286 | 6557 | 299 | 7096 | 2265 |
| ENST00000356847 | GOLGA4 | chr3 | 37370584 | + | ENST00000455445 | MLH1 | chr3 | 37089010 | + | 7150 | 6557 | 299 | 7096 | 2265 |
| ENST00000356847 | GOLGA4 | chr3 | 37370584 | + | ENST00000435176 | MLH1 | chr3 | 37089010 | + | 7288 | 6557 | 299 | 7096 | 2265 |
| ENST00000361924 | GOLGA4 | chr3 | 37343823 | + | ENST00000536378 | MLH1 | chr3 | 37058997 | + | 3194 | 1608 | 374 | 2923 | 849 |
| ENST00000361924 | GOLGA4 | chr3 | 37343823 | + | ENST00000231790 | MLH1 | chr3 | 37058997 | + | 3354 | 1608 | 374 | 3088 | 904 |
| ENST00000361924 | GOLGA4 | chr3 | 37343823 | + | ENST00000458205 | MLH1 | chr3 | 37058997 | + | 3282 | 1608 | 374 | 3088 | 904 |
| ENST00000361924 | GOLGA4 | chr3 | 37343823 | + | ENST00000539477 | MLH1 | chr3 | 37058997 | + | 3278 | 1608 | 374 | 3088 | 904 |
| ENST00000361924 | GOLGA4 | chr3 | 37343823 | + | ENST00000455445 | MLH1 | chr3 | 37058997 | + | 3142 | 1608 | 374 | 3088 | 904 |
| ENST00000361924 | GOLGA4 | chr3 | 37343823 | + | ENST00000435176 | MLH1 | chr3 | 37058997 | + | 3280 | 1608 | 374 | 3088 | 904 |
| ENST00000356847 | GOLGA4 | chr3 | 37343823 | + | ENST00000536378 | MLH1 | chr3 | 37058997 | + | 3185 | 1599 | 299 | 2914 | 871 |
| ENST00000356847 | GOLGA4 | chr3 | 37343823 | + | ENST00000231790 | MLH1 | chr3 | 37058997 | + | 3345 | 1599 | 299 | 3079 | 926 |
| ENST00000356847 | GOLGA4 | chr3 | 37343823 | + | ENST00000458205 | MLH1 | chr3 | 37058997 | + | 3273 | 1599 | 299 | 3079 | 926 |
| ENST00000356847 | GOLGA4 | chr3 | 37343823 | + | ENST00000539477 | MLH1 | chr3 | 37058997 | + | 3269 | 1599 | 299 | 3079 | 926 |
| ENST00000356847 | GOLGA4 | chr3 | 37343823 | + | ENST00000455445 | MLH1 | chr3 | 37058997 | + | 3133 | 1599 | 299 | 3079 | 926 |
| ENST00000356847 | GOLGA4 | chr3 | 37343823 | + | ENST00000435176 | MLH1 | chr3 | 37058997 | + | 3271 | 1599 | 299 | 3079 | 926 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000361924 | ENST00000536378 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.006049119 | 0.99395084 |
| ENST00000361924 | ENST00000231790 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.003566246 | 0.99643373 |
| ENST00000361924 | ENST00000458205 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.003832263 | 0.9961677 |
| ENST00000361924 | ENST00000539477 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.003853235 | 0.9961468 |
| ENST00000361924 | ENST00000455445 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.004602227 | 0.99539775 |
| ENST00000361924 | ENST00000435176 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.003859314 | 0.99614066 |
| ENST00000356847 | ENST00000536378 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.006042724 | 0.9939573 |
| ENST00000356847 | ENST00000231790 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.003534591 | 0.99646544 |
| ENST00000356847 | ENST00000458205 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.003797337 | 0.99620265 |
| ENST00000356847 | ENST00000539477 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.003817712 | 0.99618226 |
| ENST00000356847 | ENST00000455445 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.004595975 | 0.995404 |
| ENST00000356847 | ENST00000435176 | GOLGA4 | chr3 | 37370584 | + | MLH1 | chr3 | 37089010 | + | 0.003824235 | 0.99617577 |
| ENST00000361924 | ENST00000536378 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.004909623 | 0.99509037 |
| ENST00000361924 | ENST00000231790 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.001505231 | 0.99849474 |
| ENST00000361924 | ENST00000458205 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.00180432 | 0.9981957 |
| ENST00000361924 | ENST00000539477 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.001832405 | 0.9981675 |
| ENST00000361924 | ENST00000455445 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.003150999 | 0.996849 |
| ENST00000361924 | ENST00000435176 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.00184663 | 0.9981534 |
| ENST00000356847 | ENST00000536378 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.005112992 | 0.99488705 |
| ENST00000356847 | ENST00000231790 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.001656868 | 0.9983431 |
| ENST00000356847 | ENST00000458205 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.001977768 | 0.9980222 |
| ENST00000356847 | ENST00000539477 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.002013255 | 0.9979868 |
| ENST00000356847 | ENST00000455445 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.003416389 | 0.9965836 |
| ENST00000356847 | ENST00000435176 | GOLGA4 | chr3 | 37343823 | + | MLH1 | chr3 | 37058997 | + | 0.002023718 | 0.99797624 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >33904_33904_1_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000356847_MLH1_chr3_37058997_ENST00000231790_length(amino acids)=926AA_BP=433 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVY AAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSS TSGSSDKVYAHQMVRTDSREQKLDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSE KRGPTSSNPRKRHREDSDVEMVEDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLL NTTKLSEELFYQILIYDFANFGVLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLP LLIDNYVPPLEGLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILP -------------------------------------------------------------- >33904_33904_2_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000356847_MLH1_chr3_37058997_ENST00000435176_length(amino acids)=926AA_BP=433 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVY AAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSS TSGSSDKVYAHQMVRTDSREQKLDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSE KRGPTSSNPRKRHREDSDVEMVEDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLL NTTKLSEELFYQILIYDFANFGVLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLP LLIDNYVPPLEGLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILP -------------------------------------------------------------- >33904_33904_3_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000356847_MLH1_chr3_37058997_ENST00000455445_length(amino acids)=926AA_BP=433 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVY AAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSS TSGSSDKVYAHQMVRTDSREQKLDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSE KRGPTSSNPRKRHREDSDVEMVEDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLL NTTKLSEELFYQILIYDFANFGVLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLP LLIDNYVPPLEGLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILP -------------------------------------------------------------- >33904_33904_4_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000356847_MLH1_chr3_37058997_ENST00000458205_length(amino acids)=926AA_BP=433 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVY AAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSS TSGSSDKVYAHQMVRTDSREQKLDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSE KRGPTSSNPRKRHREDSDVEMVEDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLL NTTKLSEELFYQILIYDFANFGVLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLP LLIDNYVPPLEGLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILP -------------------------------------------------------------- >33904_33904_5_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000356847_MLH1_chr3_37058997_ENST00000536378_length(amino acids)=871AA_BP=433 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVY AAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSS TSGSSDKVYAHQMVRTDSREQKLDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSE KRGPTSSNPRKRHREDSDVEMVEDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLL NTTKLSEELFYQILIYDFANFGVLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLP -------------------------------------------------------------- >33904_33904_6_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000356847_MLH1_chr3_37058997_ENST00000539477_length(amino acids)=926AA_BP=433 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVY AAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSS TSGSSDKVYAHQMVRTDSREQKLDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSE KRGPTSSNPRKRHREDSDVEMVEDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLL NTTKLSEELFYQILIYDFANFGVLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLP LLIDNYVPPLEGLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILP -------------------------------------------------------------- >33904_33904_7_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000361924_MLH1_chr3_37058997_ENST00000231790_length(amino acids)=904AA_BP=411 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVYAAYLPKNTHPFLYLSLEISPQN VDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSSTSGSSDKVYAHQMVRTDSREQK LDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSEKRGPTSSNPRKRHREDSDVEMV EDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLLNTTKLSEELFYQILIYDFANFG VLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLAT EVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNILQLANLPDLYKV -------------------------------------------------------------- >33904_33904_8_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000361924_MLH1_chr3_37058997_ENST00000435176_length(amino acids)=904AA_BP=411 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVYAAYLPKNTHPFLYLSLEISPQN VDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSSTSGSSDKVYAHQMVRTDSREQK LDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSEKRGPTSSNPRKRHREDSDVEMV EDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLLNTTKLSEELFYQILIYDFANFG VLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLAT EVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNILQLANLPDLYKV -------------------------------------------------------------- >33904_33904_9_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000361924_MLH1_chr3_37058997_ENST00000455445_length(amino acids)=904AA_BP=411 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVYAAYLPKNTHPFLYLSLEISPQN VDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSSTSGSSDKVYAHQMVRTDSREQK LDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSEKRGPTSSNPRKRHREDSDVEMV EDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLLNTTKLSEELFYQILIYDFANFG VLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLAT EVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNILQLANLPDLYKV -------------------------------------------------------------- >33904_33904_10_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000361924_MLH1_chr3_37058997_ENST00000458205_length(amino acids)=904AA_BP=411 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVYAAYLPKNTHPFLYLSLEISPQN VDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSSTSGSSDKVYAHQMVRTDSREQK LDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSEKRGPTSSNPRKRHREDSDVEMV EDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLLNTTKLSEELFYQILIYDFANFG VLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLAT EVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNILQLANLPDLYKV -------------------------------------------------------------- >33904_33904_11_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000361924_MLH1_chr3_37058997_ENST00000536378_length(amino acids)=849AA_BP=411 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVYAAYLPKNTHPFLYLSLEISPQN VDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSSTSGSSDKVYAHQMVRTDSREQK LDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSEKRGPTSSNPRKRHREDSDVEMV EDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLLNTTKLSEELFYQILIYDFANFG VLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLAT -------------------------------------------------------------- >33904_33904_12_GOLGA4-MLH1_GOLGA4_chr3_37343823_ENST00000361924_MLH1_chr3_37058997_ENST00000539477_length(amino acids)=904AA_BP=411 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVYAAYLPKNTHPFLYLSLEISPQN VDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSSTSGSSDKVYAHQMVRTDSREQK LDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSEKRGPTSSNPRKRHREDSDVEMV EDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLLNTTKLSEELFYQILIYDFANFG VLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLAT EVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNILQLANLPDLYKV -------------------------------------------------------------- >33904_33904_13_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000356847_MLH1_chr3_37089010_ENST00000231790_length(amino acids)=2265AA_BP=2086 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEE ARRKLKAEMDEQIKTIEKTSEEERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKS QSEYLKISQEKEQQESLALEELELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVM VEKHKTELESLKHQQDALWTEKLQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLK ARHKLEEELSVLKDQTDKMKQELEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKR SEGELQQASAKLDVFQSYQSATHEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEME QKVKSLTQVYESKLEDGNKEQEQTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQE TLKKKLLDQEAKLKKELENTALELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEEL QEIHEIQLQEKEQEVAELKQKILLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLK ENTFLQEQLVELKMLAEEDKRKVSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINI SSSKTNAILSRISHCQHRTTKVKEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGG NQQQAASEKESCITQLKKELSENINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLS FKVDTLSKEKISALEQVDDWSNKFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSK MEKKESNLETELKSQTARIMELEDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMK AELETKKKELEHVNLSVKSKEEELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREV HILEEKLKSVESSQSETLIVPRSAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLI KLEHAEAKQHEDQSMIGHLQEELEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKE VHRVEMEELTSKYEKLQALQQMDGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRK EHQQELEILKKEYDQEREEKIKQEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEK DDDLKRTAKRYEEILDEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLE GLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNIL -------------------------------------------------------------- >33904_33904_14_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000356847_MLH1_chr3_37089010_ENST00000435176_length(amino acids)=2265AA_BP=2086 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEE ARRKLKAEMDEQIKTIEKTSEEERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKS QSEYLKISQEKEQQESLALEELELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVM VEKHKTELESLKHQQDALWTEKLQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLK ARHKLEEELSVLKDQTDKMKQELEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKR SEGELQQASAKLDVFQSYQSATHEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEME QKVKSLTQVYESKLEDGNKEQEQTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQE TLKKKLLDQEAKLKKELENTALELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEEL QEIHEIQLQEKEQEVAELKQKILLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLK ENTFLQEQLVELKMLAEEDKRKVSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINI SSSKTNAILSRISHCQHRTTKVKEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGG NQQQAASEKESCITQLKKELSENINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLS FKVDTLSKEKISALEQVDDWSNKFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSK MEKKESNLETELKSQTARIMELEDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMK AELETKKKELEHVNLSVKSKEEELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREV HILEEKLKSVESSQSETLIVPRSAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLI KLEHAEAKQHEDQSMIGHLQEELEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKE VHRVEMEELTSKYEKLQALQQMDGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRK EHQQELEILKKEYDQEREEKIKQEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEK DDDLKRTAKRYEEILDEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLE GLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNIL -------------------------------------------------------------- >33904_33904_15_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000356847_MLH1_chr3_37089010_ENST00000455445_length(amino acids)=2265AA_BP=2086 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEE ARRKLKAEMDEQIKTIEKTSEEERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKS QSEYLKISQEKEQQESLALEELELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVM VEKHKTELESLKHQQDALWTEKLQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLK ARHKLEEELSVLKDQTDKMKQELEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKR SEGELQQASAKLDVFQSYQSATHEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEME QKVKSLTQVYESKLEDGNKEQEQTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQE TLKKKLLDQEAKLKKELENTALELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEEL QEIHEIQLQEKEQEVAELKQKILLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLK ENTFLQEQLVELKMLAEEDKRKVSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINI SSSKTNAILSRISHCQHRTTKVKEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGG NQQQAASEKESCITQLKKELSENINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLS FKVDTLSKEKISALEQVDDWSNKFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSK MEKKESNLETELKSQTARIMELEDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMK AELETKKKELEHVNLSVKSKEEELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREV HILEEKLKSVESSQSETLIVPRSAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLI KLEHAEAKQHEDQSMIGHLQEELEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKE VHRVEMEELTSKYEKLQALQQMDGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRK EHQQELEILKKEYDQEREEKIKQEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEK DDDLKRTAKRYEEILDEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLE GLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNIL -------------------------------------------------------------- >33904_33904_16_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000356847_MLH1_chr3_37089010_ENST00000458205_length(amino acids)=2265AA_BP=2086 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEE ARRKLKAEMDEQIKTIEKTSEEERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKS QSEYLKISQEKEQQESLALEELELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVM VEKHKTELESLKHQQDALWTEKLQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLK ARHKLEEELSVLKDQTDKMKQELEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKR SEGELQQASAKLDVFQSYQSATHEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEME QKVKSLTQVYESKLEDGNKEQEQTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQE TLKKKLLDQEAKLKKELENTALELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEEL QEIHEIQLQEKEQEVAELKQKILLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLK ENTFLQEQLVELKMLAEEDKRKVSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINI SSSKTNAILSRISHCQHRTTKVKEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGG NQQQAASEKESCITQLKKELSENINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLS FKVDTLSKEKISALEQVDDWSNKFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSK MEKKESNLETELKSQTARIMELEDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMK AELETKKKELEHVNLSVKSKEEELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREV HILEEKLKSVESSQSETLIVPRSAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLI KLEHAEAKQHEDQSMIGHLQEELEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKE VHRVEMEELTSKYEKLQALQQMDGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRK EHQQELEILKKEYDQEREEKIKQEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEK DDDLKRTAKRYEEILDEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLE GLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNIL -------------------------------------------------------------- >33904_33904_17_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000356847_MLH1_chr3_37089010_ENST00000536378_length(amino acids)=2210AA_BP=2086 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEE ARRKLKAEMDEQIKTIEKTSEEERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKS QSEYLKISQEKEQQESLALEELELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVM VEKHKTELESLKHQQDALWTEKLQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLK ARHKLEEELSVLKDQTDKMKQELEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKR SEGELQQASAKLDVFQSYQSATHEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEME QKVKSLTQVYESKLEDGNKEQEQTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQE TLKKKLLDQEAKLKKELENTALELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEEL QEIHEIQLQEKEQEVAELKQKILLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLK ENTFLQEQLVELKMLAEEDKRKVSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINI SSSKTNAILSRISHCQHRTTKVKEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGG NQQQAASEKESCITQLKKELSENINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLS FKVDTLSKEKISALEQVDDWSNKFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSK MEKKESNLETELKSQTARIMELEDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMK AELETKKKELEHVNLSVKSKEEELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREV HILEEKLKSVESSQSETLIVPRSAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLI KLEHAEAKQHEDQSMIGHLQEELEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKE VHRVEMEELTSKYEKLQALQQMDGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRK EHQQELEILKKEYDQEREEKIKQEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEK DDDLKRTAKRYEEILDEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLE -------------------------------------------------------------- >33904_33904_18_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000356847_MLH1_chr3_37089010_ENST00000539477_length(amino acids)=2265AA_BP=2086 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEE ARRKLKAEMDEQIKTIEKTSEEERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKS QSEYLKISQEKEQQESLALEELELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVM VEKHKTELESLKHQQDALWTEKLQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLK ARHKLEEELSVLKDQTDKMKQELEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKR SEGELQQASAKLDVFQSYQSATHEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEME QKVKSLTQVYESKLEDGNKEQEQTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQE TLKKKLLDQEAKLKKELENTALELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEEL QEIHEIQLQEKEQEVAELKQKILLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLK ENTFLQEQLVELKMLAEEDKRKVSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINI SSSKTNAILSRISHCQHRTTKVKEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGG NQQQAASEKESCITQLKKELSENINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLS FKVDTLSKEKISALEQVDDWSNKFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSK MEKKESNLETELKSQTARIMELEDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMK AELETKKKELEHVNLSVKSKEEELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREV HILEEKLKSVESSQSETLIVPRSAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLI KLEHAEAKQHEDQSMIGHLQEELEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKE VHRVEMEELTSKYEKLQALQQMDGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRK EHQQELEILKKEYDQEREEKIKQEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEK DDDLKRTAKRYEEILDEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLE GLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILPPKHFTEDGNIL -------------------------------------------------------------- >33904_33904_19_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000361924_MLH1_chr3_37089010_ENST00000231790_length(amino acids)=2243AA_BP=2064 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEEARRKLKAEMDEQIKTIEKTSEE ERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKSQSEYLKISQEKEQQESLALEEL ELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVMVEKHKTELESLKHQQDALWTEK LQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLKARHKLEEELSVLKDQTDKMKQE LEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKRSEGELQQASAKLDVFQSYQSAT HEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEMEQKVKSLTQVYESKLEDGNKEQE QTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQETLKKKLLDQEAKLKKELENTAL ELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEELQEIHEIQLQEKEQEVAELKQKI LLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLKENTFLQEQLVELKMLAEEDKRK VSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINISSSKTNAILSRISHCQHRTTKV KEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGGNQQQAASEKESCITQLKKELSE NINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLSFKVDTLSKEKISALEQVDDWSN KFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSKMEKKESNLETELKSQTARIMEL EDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMKAELETKKKELEHVNLSVKSKEE ELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREVHILEEKLKSVESSQSETLIVPR SAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLIKLEHAEAKQHEDQSMIGHLQEE LEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKEVHRVEMEELTSKYEKLQALQQM DGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRKEHQQELEILKKEYDQEREEKIK QEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEKDDDLKRTAKRYEEILDEPAPLF DLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLATEVNWDEEKECF -------------------------------------------------------------- >33904_33904_20_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000361924_MLH1_chr3_37089010_ENST00000435176_length(amino acids)=2243AA_BP=2064 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEEARRKLKAEMDEQIKTIEKTSEE ERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKSQSEYLKISQEKEQQESLALEEL ELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVMVEKHKTELESLKHQQDALWTEK LQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLKARHKLEEELSVLKDQTDKMKQE LEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKRSEGELQQASAKLDVFQSYQSAT HEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEMEQKVKSLTQVYESKLEDGNKEQE QTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQETLKKKLLDQEAKLKKELENTAL ELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEELQEIHEIQLQEKEQEVAELKQKI LLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLKENTFLQEQLVELKMLAEEDKRK VSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINISSSKTNAILSRISHCQHRTTKV KEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGGNQQQAASEKESCITQLKKELSE NINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLSFKVDTLSKEKISALEQVDDWSN KFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSKMEKKESNLETELKSQTARIMEL EDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMKAELETKKKELEHVNLSVKSKEE ELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREVHILEEKLKSVESSQSETLIVPR SAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLIKLEHAEAKQHEDQSMIGHLQEE LEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKEVHRVEMEELTSKYEKLQALQQM DGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRKEHQQELEILKKEYDQEREEKIK QEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEKDDDLKRTAKRYEEILDEPAPLF DLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLATEVNWDEEKECF -------------------------------------------------------------- >33904_33904_21_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000361924_MLH1_chr3_37089010_ENST00000455445_length(amino acids)=2243AA_BP=2064 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEEARRKLKAEMDEQIKTIEKTSEE ERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKSQSEYLKISQEKEQQESLALEEL ELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVMVEKHKTELESLKHQQDALWTEK LQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLKARHKLEEELSVLKDQTDKMKQE LEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKRSEGELQQASAKLDVFQSYQSAT HEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEMEQKVKSLTQVYESKLEDGNKEQE QTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQETLKKKLLDQEAKLKKELENTAL ELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEELQEIHEIQLQEKEQEVAELKQKI LLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLKENTFLQEQLVELKMLAEEDKRK VSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINISSSKTNAILSRISHCQHRTTKV KEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGGNQQQAASEKESCITQLKKELSE NINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLSFKVDTLSKEKISALEQVDDWSN KFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSKMEKKESNLETELKSQTARIMEL EDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMKAELETKKKELEHVNLSVKSKEE ELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREVHILEEKLKSVESSQSETLIVPR SAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLIKLEHAEAKQHEDQSMIGHLQEE LEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKEVHRVEMEELTSKYEKLQALQQM DGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRKEHQQELEILKKEYDQEREEKIK QEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEKDDDLKRTAKRYEEILDEPAPLF DLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLATEVNWDEEKECF -------------------------------------------------------------- >33904_33904_22_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000361924_MLH1_chr3_37089010_ENST00000458205_length(amino acids)=2243AA_BP=2064 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEEARRKLKAEMDEQIKTIEKTSEE ERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKSQSEYLKISQEKEQQESLALEEL ELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVMVEKHKTELESLKHQQDALWTEK LQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLKARHKLEEELSVLKDQTDKMKQE LEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKRSEGELQQASAKLDVFQSYQSAT HEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEMEQKVKSLTQVYESKLEDGNKEQE QTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQETLKKKLLDQEAKLKKELENTAL ELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEELQEIHEIQLQEKEQEVAELKQKI LLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLKENTFLQEQLVELKMLAEEDKRK VSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINISSSKTNAILSRISHCQHRTTKV KEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGGNQQQAASEKESCITQLKKELSE NINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLSFKVDTLSKEKISALEQVDDWSN KFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSKMEKKESNLETELKSQTARIMEL EDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMKAELETKKKELEHVNLSVKSKEE ELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREVHILEEKLKSVESSQSETLIVPR SAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLIKLEHAEAKQHEDQSMIGHLQEE LEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKEVHRVEMEELTSKYEKLQALQQM DGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRKEHQQELEILKKEYDQEREEKIK QEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEKDDDLKRTAKRYEEILDEPAPLF DLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLATEVNWDEEKECF -------------------------------------------------------------- >33904_33904_23_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000361924_MLH1_chr3_37089010_ENST00000536378_length(amino acids)=2188AA_BP=2064 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEEARRKLKAEMDEQIKTIEKTSEE ERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKSQSEYLKISQEKEQQESLALEEL ELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVMVEKHKTELESLKHQQDALWTEK LQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLKARHKLEEELSVLKDQTDKMKQE LEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKRSEGELQQASAKLDVFQSYQSAT HEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEMEQKVKSLTQVYESKLEDGNKEQE QTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQETLKKKLLDQEAKLKKELENTAL ELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEELQEIHEIQLQEKEQEVAELKQKI LLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLKENTFLQEQLVELKMLAEEDKRK VSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINISSSKTNAILSRISHCQHRTTKV KEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGGNQQQAASEKESCITQLKKELSE NINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLSFKVDTLSKEKISALEQVDDWSN KFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSKMEKKESNLETELKSQTARIMEL EDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMKAELETKKKELEHVNLSVKSKEE ELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREVHILEEKLKSVESSQSETLIVPR SAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLIKLEHAEAKQHEDQSMIGHLQEE LEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKEVHRVEMEELTSKYEKLQALQQM DGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRKEHQQELEILKKEYDQEREEKIK QEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEKDDDLKRTAKRYEEILDEPAPLF DLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLATEVNWDEEKECF -------------------------------------------------------------- >33904_33904_24_GOLGA4-MLH1_GOLGA4_chr3_37370584_ENST00000361924_MLH1_chr3_37089010_ENST00000539477_length(amino acids)=2243AA_BP=2064 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRESGDTQSFAQKLQLRVPSVESLFRSPIKESLFRSSSK ESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYSELVTAYQMLQREKKKLQGILSQ SQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPLPQLEPQAEVFTKEENPESDGEP VVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHMAEKTKLITQLRDAKNLIEQLEQ DKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERAAFEELEKALSTAQKTEEARRKLKAEMDEQIKTIEKTSEE ERISLQQELSRVKQEVVDVMKKSSEEQIAKLQKLHEKELARKEQELTKKLQTREREFQEQMKVALEKSQSEYLKISQEKEQQESLALEEL ELQKKAILTESENKLRDLQQEAETYRTRILELESSLEKSLQENKNQSKDLAVHLEAEKNKHNKEITVMVEKHKTELESLKHQQDALWTEK LQVLKQQYQTEMEKLREKCEQEKETLLKDKEIIFQAHIEEMNEKTLEKLDVKQTELESLSSELSEVLKARHKLEEELSVLKDQTDKMKQE LEAKMDEQKNHHQQQVDSIIKEHEVSIQRTEKALKDQINQLELLLKERDKHLKEHQAHVENLEADIKRSEGELQQASAKLDVFQSYQSAT HEQTKAYEEQLAQLQQKLLDLETERILLTKQVAEVEAQKKDVCTELDAHKIQVQDLMQQLEKQNSEMEQKVKSLTQVYESKLEDGNKEQE QTKQILVEKENMILQMREGQKKEIEILTQKLSAKEDSIHILNEEYETKFKNQEKKMEKVKQKAKEMQETLKKKLLDQEAKLKKELENTAL ELSQKEKQFNAKMLEMAQANSAGISDAVSRLETNQKEQIESLTEVHRRELNDVISIWEKKLNQQAEELQEIHEIQLQEKEQEVAELKQKI LLFGCEKEEMNKEITWLKEEGVKQDTTLNELQEQLKQKSAHVNSLAQDETKLKAHLEKLEVDLNKSLKENTFLQEQLVELKMLAEEDKRK VSELTSKLKTTDEEFQSLKSSHEKSNKSLEDKSLEFKKLSEELAIQLDICCKKTEALLEAKTNELINISSSKTNAILSRISHCQHRTTKV KEALLIKTCTVSELEAQLRQLTEEQNTLNISFQQATHQLEEKENQIKSMKADIESLVTEKEALQKEGGNQQQAASEKESCITQLKKELSE NINAVTLMKEELKEKKVEISSLSKQLTDLNVQLQNSISLSEKEAAISSLRKQYDEEKCELLDQVQDLSFKVDTLSKEKISALEQVDDWSN KFSEWKKKAQSRFTQHQNTVKELQIQLELKSKEAYEKDEQINLLKEELDQQNKRFDCLKGEMEDDKSKMEKKESNLETELKSQTARIMEL EDHITQKTIEIESLNEVLKNYNQQKDIEHKELVQKLQHFQELGEEKDNRVKEAEEKILTLENQVYSMKAELETKKKELEHVNLSVKSKEE ELKALEDRLESESAAKLAELKRKAEQKIAAIKKQLLSQMEEKEEQYKKGTESHLSELNTKLQEREREVHILEEKLKSVESSQSETLIVPR SAKNVAAYTEQEEADSQGCVQKTYEEKISVLQRNLTEKEKLLQRVGQEKEETVSSHFEMRCQYQERLIKLEHAEAKQHEDQSMIGHLQEE LEEKNKKYSLIVAQHVEKEGGKNNIQAKQNLENVFDDVQKTLQEKELTCQILEQKIKELDSCLVRQKEVHRVEMEELTSKYEKLQALQQM DGRNKPTELLEENTEEKSKSHLVQPKLLSNMEAQHNDLEFKLAGAEREKQKLGKEIVRLQKDLRMLRKEHQQELEILKKEYDQEREEKIK QEQEDLELKHNSTLKQLMREFNTQLAQKEQELEMTIKETINKAQEVEAELLESHQEETNQLLKKIAEKDDDLKRTAKRYEEILDEPAPLF DLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLPLLIDNYVPPLEGLPIFILRLATEVNWDEEKECF -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:37370584/chr3:37089010) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GOLGA4 | MLH1 |
| FUNCTION: Involved in vesicular trafficking at the Golgi apparatus level. May play a role in delivery of transport vesicles containing GPI-linked proteins from the trans-Golgi network through its interaction with MACF1. Involved in endosome-to-Golgi trafficking (PubMed:29084197). {ECO:0000269|PubMed:15265687, ECO:0000269|PubMed:29084197}. | FUNCTION: Heterodimerizes with PMS2 to form MutL alpha, a component of the post-replicative DNA mismatch repair system (MMR). DNA repair is initiated by MutS alpha (MSH2-MSH6) or MutS beta (MSH2-MSH3) binding to a dsDNA mismatch, then MutL alpha is recruited to the heteroduplex. Assembly of the MutL-MutS-heteroduplex ternary complex in presence of RFC and PCNA is sufficient to activate endonuclease activity of PMS2. It introduces single-strand breaks near the mismatch and thus generates new entry points for the exonuclease EXO1 to degrade the strand containing the mismatch. DNA methylation would prevent cleavage and therefore assure that only the newly mutated DNA strand is going to be corrected. MutL alpha (MLH1-PMS2) interacts physically with the clamp loader subunits of DNA polymerase III, suggesting that it may play a role to recruit the DNA polymerase III to the site of the MMR. Also implicated in DNA damage signaling, a process which induces cell cycle arrest and can lead to apoptosis in case of major DNA damages. Heterodimerizes with MLH3 to form MutL gamma which plays a role in meiosis. {ECO:0000269|PubMed:16873062, ECO:0000269|PubMed:18206974, ECO:0000269|PubMed:20020535, ECO:0000269|PubMed:21120944, ECO:0000269|PubMed:9311737}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000455445 | 8 | 19 | 100_104 | 22.333333333333332 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000455445 | 8 | 19 | 82_84 | 22.333333333333332 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000458205 | 9 | 20 | 100_104 | 22.333333333333332 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000458205 | 9 | 20 | 82_84 | 22.333333333333332 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000539477 | 7 | 18 | 100_104 | 22.333333333333332 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000539477 | 7 | 18 | 82_84 | 22.333333333333332 | 516.0 | Nucleotide binding | ATP |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GOLGA4 | chr3:37343823 | chr3:37058997 | ENST00000356847 | + | 11 | 23 | 133_2185 | 433.3333333333333 | 2244.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GOLGA4 | chr3:37343823 | chr3:37058997 | ENST00000361924 | + | 10 | 24 | 133_2185 | 411.3333333333333 | 2306.3333333333335 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GOLGA4 | chr3:37370584 | chr3:37089010 | ENST00000356847 | + | 17 | 23 | 133_2185 | 2086.0 | 2244.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GOLGA4 | chr3:37370584 | chr3:37089010 | ENST00000361924 | + | 16 | 24 | 133_2185 | 2064.0 | 2306.3333333333335 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GOLGA4 | chr3:37343823 | chr3:37058997 | ENST00000356847 | + | 11 | 23 | 252_2096 | 433.3333333333333 | 2244.0 | Compositional bias | Note=Glu-rich |
| Hgene | GOLGA4 | chr3:37343823 | chr3:37058997 | ENST00000361924 | + | 10 | 24 | 252_2096 | 411.3333333333333 | 2306.3333333333335 | Compositional bias | Note=Glu-rich |
| Hgene | GOLGA4 | chr3:37370584 | chr3:37089010 | ENST00000356847 | + | 17 | 23 | 252_2096 | 2086.0 | 2244.0 | Compositional bias | Note=Glu-rich |
| Hgene | GOLGA4 | chr3:37370584 | chr3:37089010 | ENST00000361924 | + | 16 | 24 | 252_2096 | 2064.0 | 2306.3333333333335 | Compositional bias | Note=Glu-rich |
| Hgene | GOLGA4 | chr3:37343823 | chr3:37058997 | ENST00000356847 | + | 11 | 23 | 2168_2215 | 433.3333333333333 | 2244.0 | Domain | GRIP |
| Hgene | GOLGA4 | chr3:37343823 | chr3:37058997 | ENST00000361924 | + | 10 | 24 | 2168_2215 | 411.3333333333333 | 2306.3333333333335 | Domain | GRIP |
| Hgene | GOLGA4 | chr3:37370584 | chr3:37089010 | ENST00000356847 | + | 17 | 23 | 2168_2215 | 2086.0 | 2244.0 | Domain | GRIP |
| Hgene | GOLGA4 | chr3:37370584 | chr3:37089010 | ENST00000361924 | + | 16 | 24 | 2168_2215 | 2064.0 | 2306.3333333333335 | Domain | GRIP |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000231790 | 8 | 19 | 100_104 | 263.3333333333333 | 757.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000231790 | 8 | 19 | 82_84 | 263.3333333333333 | 757.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000435176 | 8 | 19 | 100_104 | 165.33333333333334 | 659.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37343823 | chr3:37058997 | ENST00000435176 | 8 | 19 | 82_84 | 165.33333333333334 | 659.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000231790 | 14 | 19 | 100_104 | 577.0 | 757.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000231790 | 14 | 19 | 82_84 | 577.0 | 757.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000435176 | 14 | 19 | 100_104 | 479.0 | 659.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000435176 | 14 | 19 | 82_84 | 479.0 | 659.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000455445 | 14 | 19 | 100_104 | 336.0 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000455445 | 14 | 19 | 82_84 | 336.0 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000458205 | 15 | 20 | 100_104 | 336.0 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000458205 | 15 | 20 | 82_84 | 336.0 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000539477 | 13 | 18 | 100_104 | 336.0 | 516.0 | Nucleotide binding | ATP | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000539477 | 13 | 18 | 82_84 | 336.0 | 516.0 | Nucleotide binding | ATP |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file >>>1718_GOLGA4_37343823_MLH1_37058997_ranked_0.pdb | GOLGA4 | 37343823 | 37343823 | ENST00000435176 | MLH1 | chr3 | 37058997 | + | MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNRENASTHASKSPDSVNGSEPSIPQSGDTQSFAQKLQLR VPSVESLFRSPIKESLFRSSSKESLVRTSSRESLNRLDLDSSTASFDPPSDMDSEAEDLVGNSDSLNKEQLIQRLRRMERSLSSYRGKYS ELVTAYQMLQREKKKLQGILSQSQDKSLRRIAELREELQMDQQAKKHLQEEFDASLEEKDQYISVLQTQVSLLKQRLRNGPMNVDVLKPL PQLEPQAEVFTKEENPESDGEPVVEDGTSVKTLETLQQRVKRQENLLKRCKETIQSHKEQCTLLTSEKEALQEQLDERLQELEKIKDLHM AEKTKLITQLRDAKNLIEQLEQDKGMVIAETKRQMHETLEMKEEEIAQLRSRIKQMTTQGEELREQKEKSERADRLVESTSLRKAIETVY AAYLPKNTHPFLYLSLEISPQNVDVNVHPTKHEVHFLHEESILERVQQHIESKLLGSNSSRMYFTQTLLPGLAGPSGEMVKSTTSLTSSS TSGSSDKVYAHQMVRTDSREQKLDAFLQPLSKPLSSQPQAIVTEDKTDISSGRARQQDEEMLELPAPAEVAAKNQSLEGDTTKGTSEMSE KRGPTSSNPRKRHREDSDVEMVEDDSRKEMTAACTPRRRIINLTSVLSLQEEINEQGHEVLREMLHNHSFVGCVNPQWALAQHQTKLYLL NTTKLSEELFYQILIYDFANFGVLRLSEPAPLFDLAMLALDSPESGWTEEDGPKEGLAEYIVEFLKKKAEMLADYFSLEIDEEGNLIGLP LLIDNYVPPLEGLPIFILRLATEVNWDEEKECFESLSKECAMFYSIRKQYISEESTLSGQQSEVPGSIPNSWKWTVEHIVYKALRSHILP | 926 |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
GOLGA4_pLDDT.png  |
MLH1_pLDDT.png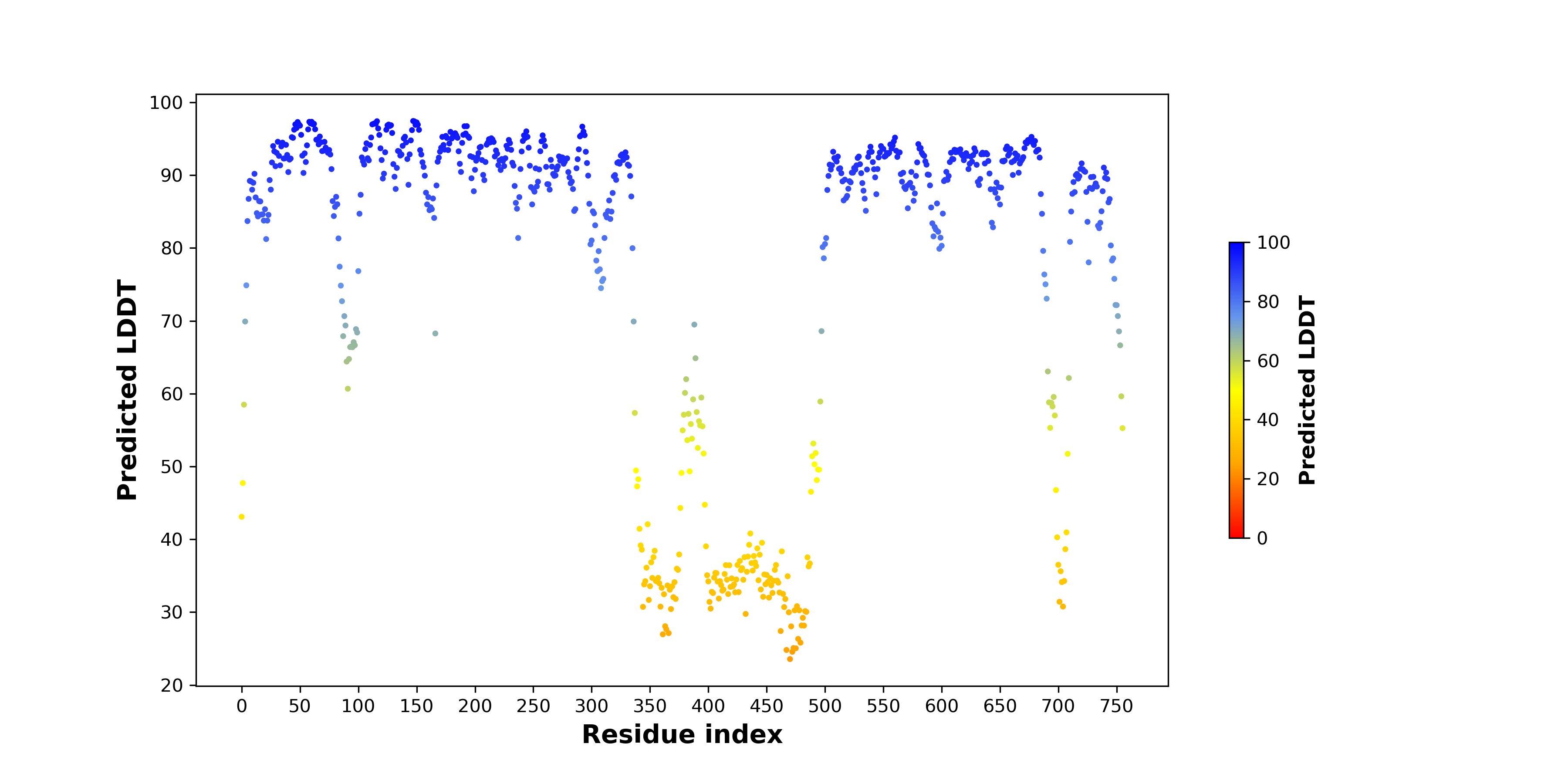  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
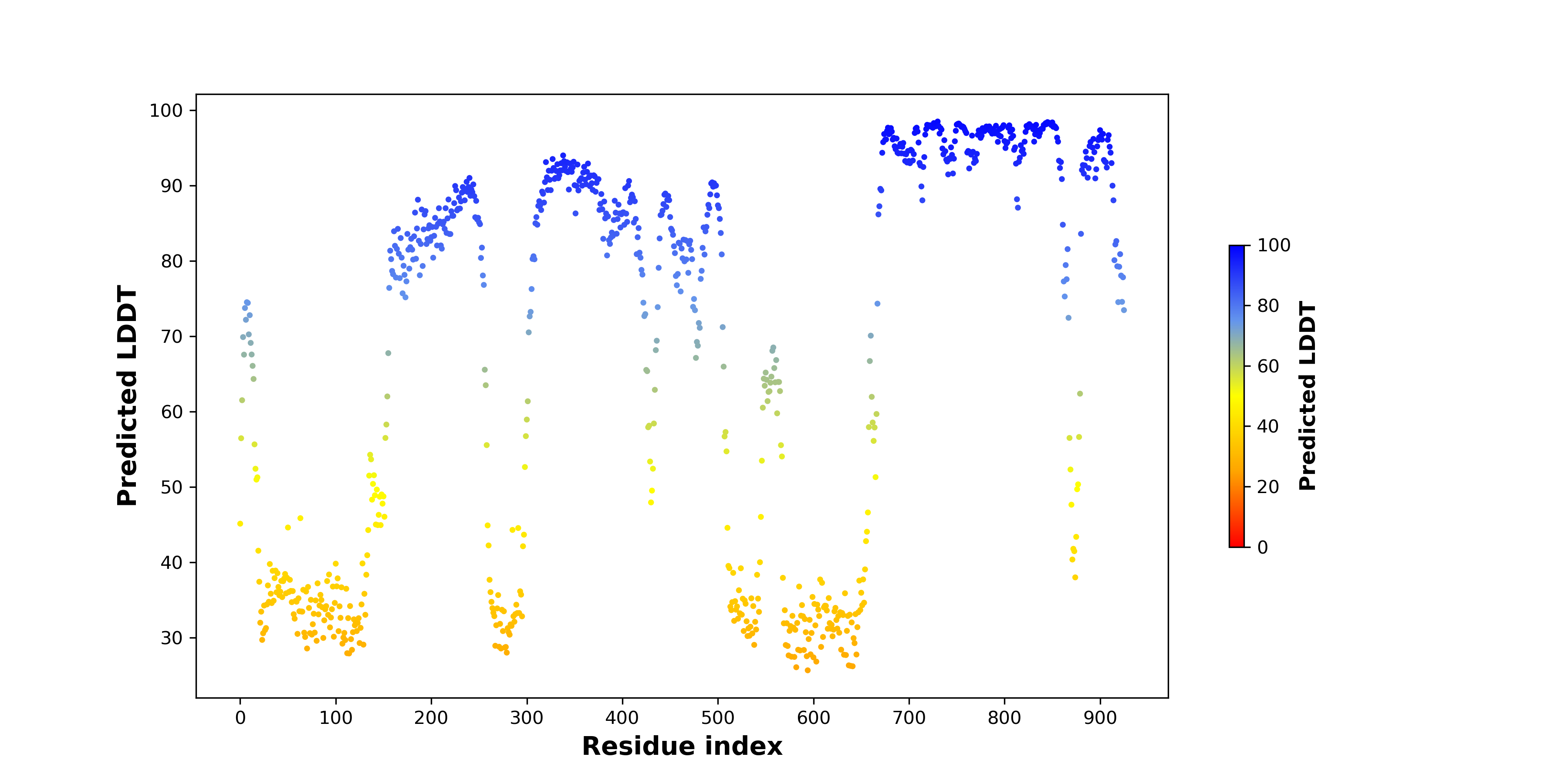 |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| GOLGA4 | |
| MLH1 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000231790 | 14 | 19 | 410_650 | 577.0 | 757.0 | EXO1 | |
| Tgene | MLH1 | chr3:37370584 | chr3:37089010 | ENST00000435176 | 14 | 19 | 410_650 | 479.0 | 659.0 | EXO1 |
Top |
Related Drugs to GOLGA4-MLH1 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to GOLGA4-MLH1 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies