| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:KDM4C-ARMC2 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: KDM4C-ARMC2 | FusionPDB ID: 41826 | FusionGDB2.0 ID: 41826 | Hgene | Tgene | Gene symbol | KDM4C | ARMC2 | Gene ID | 23081 | 84071 |
| Gene name | lysine demethylase 4C | armadillo repeat containing 2 | |
| Synonyms | GASC1|JHDM3C|JMJD2C|TDRD14C | SPGF38|bA787I22.1 | |
| Cytomap | 9p24.1 | 6q21 | |
| Type of gene | protein-coding | protein-coding | |
| Description | lysine-specific demethylase 4CJmjC domain-containing histone demethylation protein 3Cgene amplified in squamous cell carcinoma 1 proteinjumonji domain-containing protein 2Clysine (K)-specific demethylase 4Ctudor domain containing 14C | armadillo repeat-containing protein 2 | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | Q9H3R0 | Q8NEN0 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000489243, ENST00000381306, ENST00000381309, ENST00000442236, ENST00000535193, ENST00000536108, ENST00000543771, ENST00000401787, ENST00000428870, | ENST00000368972, ENST00000392644, ENST00000481850, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 22 X 15 X 12=3960 | 15 X 15 X 7=1575 |
| # samples | 22 | 16 | |
| ** MAII score | log2(22/3960*10)=-4.16992500144231 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(16/1575*10)=-3.29920801838728 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: KDM4C [Title/Abstract] AND ARMC2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | KDM4C(6893232)-ARMC2(109220897), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | KDM4C-ARMC2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. KDM4C-ARMC2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. KDM4C-ARMC2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. KDM4C-ARMC2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. KDM4C-ARMC2 seems lost the major protein functional domain in Hgene partner, which is a epigenetic factor due to the frame-shifted ORF. KDM4C-ARMC2 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. KDM4C-ARMC2 seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | KDM4C | GO:0006357 | regulation of transcription by RNA polymerase II | 17277772 |
| Hgene | KDM4C | GO:0033169 | histone H3-K9 demethylation | 18066052|21914792 |
| Hgene | KDM4C | GO:0070544 | histone H3-K36 demethylation | 21914792 |
| Fusion gene breakpoints across KDM4C (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
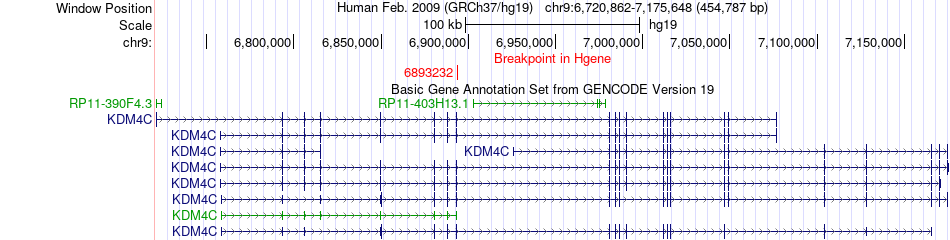 |
| Fusion gene breakpoints across ARMC2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-EW-A6S9-01A | KDM4C | chr9 | 6893232 | - | ARMC2 | chr6 | 109220897 | + |
| ChimerDB4 | BRCA | TCGA-EW-A6S9-01A | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109220897 | + |
| ChimerDB4 | BRCA | TCGA-EW-A6S9-01A | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000535193 | KDM4C | chr9 | 6893232 | + | ENST00000368972 | ARMC2 | chr6 | 109232102 | + | 2922 | 1073 | 83 | 2653 | 856 |
| ENST00000535193 | KDM4C | chr9 | 6893232 | + | ENST00000392644 | ARMC2 | chr6 | 109232102 | + | 3123 | 1073 | 83 | 2653 | 856 |
| ENST00000543771 | KDM4C | chr9 | 6893232 | + | ENST00000368972 | ARMC2 | chr6 | 109232102 | + | 3350 | 1501 | 448 | 3081 | 877 |
| ENST00000543771 | KDM4C | chr9 | 6893232 | + | ENST00000392644 | ARMC2 | chr6 | 109232102 | + | 3551 | 1501 | 448 | 3081 | 877 |
| ENST00000381306 | KDM4C | chr9 | 6893232 | + | ENST00000368972 | ARMC2 | chr6 | 109232102 | + | 3335 | 1486 | 433 | 3066 | 877 |
| ENST00000381306 | KDM4C | chr9 | 6893232 | + | ENST00000392644 | ARMC2 | chr6 | 109232102 | + | 3536 | 1486 | 433 | 3066 | 877 |
| ENST00000381309 | KDM4C | chr9 | 6893232 | + | ENST00000368972 | ARMC2 | chr6 | 109232102 | + | 3335 | 1486 | 433 | 3066 | 877 |
| ENST00000381309 | KDM4C | chr9 | 6893232 | + | ENST00000392644 | ARMC2 | chr6 | 109232102 | + | 3536 | 1486 | 433 | 3066 | 877 |
| ENST00000442236 | KDM4C | chr9 | 6893232 | + | ENST00000368972 | ARMC2 | chr6 | 109232102 | + | 2747 | 898 | 250 | 2478 | 742 |
| ENST00000442236 | KDM4C | chr9 | 6893232 | + | ENST00000392644 | ARMC2 | chr6 | 109232102 | + | 2948 | 898 | 250 | 2478 | 742 |
| ENST00000536108 | KDM4C | chr9 | 6893232 | + | ENST00000368972 | ARMC2 | chr6 | 109232102 | + | 2758 | 909 | 462 | 2489 | 675 |
| ENST00000536108 | KDM4C | chr9 | 6893232 | + | ENST00000392644 | ARMC2 | chr6 | 109232102 | + | 2959 | 909 | 462 | 2489 | 675 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000535193 | ENST00000368972 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000661255 | 0.9993387 |
| ENST00000535193 | ENST00000392644 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000527687 | 0.9994723 |
| ENST00000543771 | ENST00000368972 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000765948 | 0.9992341 |
| ENST00000543771 | ENST00000392644 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000577136 | 0.9994229 |
| ENST00000381306 | ENST00000368972 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000768031 | 0.99923193 |
| ENST00000381306 | ENST00000392644 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000577383 | 0.99942267 |
| ENST00000381309 | ENST00000368972 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000768031 | 0.99923193 |
| ENST00000381309 | ENST00000392644 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000577383 | 0.99942267 |
| ENST00000442236 | ENST00000368972 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000903068 | 0.999097 |
| ENST00000442236 | ENST00000392644 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000707474 | 0.9992925 |
| ENST00000536108 | ENST00000368972 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000983752 | 0.9990163 |
| ENST00000536108 | ENST00000392644 | KDM4C | chr9 | 6893232 | + | ARMC2 | chr6 | 109232102 | + | 0.000769811 | 0.99923015 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >41826_41826_1_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000381306_ARMC2_chr6_109232102_ENST00000368972_length(amino acids)=877AA_BP=351 MSPSAEQVSQISQISLGRRPLSSLPPPPSRALAPTRAPDTALTIMEVAEVESPLNPSCKIMTFRPSMEEFREFNKYLAYMESKGAHRAGL AKVIPPKEWKPRQCYDDIDNLLIPAPIQQMVTGQSGLFTQYNIQKKAMTVKEFRQLANSGKYCTPRYLDYEDLERKYWKNLTFVAPIYGA DINGSIYDEGVDEWNIARLNTVLDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQ GFFPSSSQGCDAFLRHKMTLISPSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLL NVCKLIFKISRNEKNDSLIQNDSILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTF LPNSGHLLVQVTATLRNLVDSSLVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQK KQDLVVRVVFILGNLTAKNNQAREQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGV GPVLAANPGIVGLLLTTLEYKSLDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVC DFIVQNNVHRFMMALLDAQHQDICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFG -------------------------------------------------------------- >41826_41826_2_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000381306_ARMC2_chr6_109232102_ENST00000392644_length(amino acids)=877AA_BP=351 MSPSAEQVSQISQISLGRRPLSSLPPPPSRALAPTRAPDTALTIMEVAEVESPLNPSCKIMTFRPSMEEFREFNKYLAYMESKGAHRAGL AKVIPPKEWKPRQCYDDIDNLLIPAPIQQMVTGQSGLFTQYNIQKKAMTVKEFRQLANSGKYCTPRYLDYEDLERKYWKNLTFVAPIYGA DINGSIYDEGVDEWNIARLNTVLDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQ GFFPSSSQGCDAFLRHKMTLISPSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLL NVCKLIFKISRNEKNDSLIQNDSILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTF LPNSGHLLVQVTATLRNLVDSSLVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQK KQDLVVRVVFILGNLTAKNNQAREQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGV GPVLAANPGIVGLLLTTLEYKSLDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVC DFIVQNNVHRFMMALLDAQHQDICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFG -------------------------------------------------------------- >41826_41826_3_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000381309_ARMC2_chr6_109232102_ENST00000368972_length(amino acids)=877AA_BP=351 MSPSAEQVSQISQISLGRRPLSSLPPPPSRALAPTRAPDTALTIMEVAEVESPLNPSCKIMTFRPSMEEFREFNKYLAYMESKGAHRAGL AKVIPPKEWKPRQCYDDIDNLLIPAPIQQMVTGQSGLFTQYNIQKKAMTVKEFRQLANSGKYCTPRYLDYEDLERKYWKNLTFVAPIYGA DINGSIYDEGVDEWNIARLNTVLDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQ GFFPSSSQGCDAFLRHKMTLISPSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLL NVCKLIFKISRNEKNDSLIQNDSILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTF LPNSGHLLVQVTATLRNLVDSSLVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQK KQDLVVRVVFILGNLTAKNNQAREQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGV GPVLAANPGIVGLLLTTLEYKSLDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVC DFIVQNNVHRFMMALLDAQHQDICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFG -------------------------------------------------------------- >41826_41826_4_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000381309_ARMC2_chr6_109232102_ENST00000392644_length(amino acids)=877AA_BP=351 MSPSAEQVSQISQISLGRRPLSSLPPPPSRALAPTRAPDTALTIMEVAEVESPLNPSCKIMTFRPSMEEFREFNKYLAYMESKGAHRAGL AKVIPPKEWKPRQCYDDIDNLLIPAPIQQMVTGQSGLFTQYNIQKKAMTVKEFRQLANSGKYCTPRYLDYEDLERKYWKNLTFVAPIYGA DINGSIYDEGVDEWNIARLNTVLDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQ GFFPSSSQGCDAFLRHKMTLISPSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLL NVCKLIFKISRNEKNDSLIQNDSILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTF LPNSGHLLVQVTATLRNLVDSSLVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQK KQDLVVRVVFILGNLTAKNNQAREQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGV GPVLAANPGIVGLLLTTLEYKSLDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVC DFIVQNNVHRFMMALLDAQHQDICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFG -------------------------------------------------------------- >41826_41826_5_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000442236_ARMC2_chr6_109232102_ENST00000368972_length(amino acids)=742AA_BP=216 MHTWSLKEPIVRVLQRYCTPRYLDYEDLERKYWKNLTFVAPIYGADINGSIYDEGVDEWNIARLNTVLDVVEEECGISIEGVNTPYLYFG MWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQGFFPSSSQGCDAFLRHKMTLISPSVLKKYGIPFDKITQEAGEFMI TFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLLNVCKLIFKISRNEKNDSLIQNDSILESLLEVLRSEDLQTNMEAFL YCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTFLPNSGHLLVQVTATLRNLVDSSLVRSKFLNISALPQLCTAMEQYK GDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQKKQDLVVRVVFILGNLTAKNNQAREQFSKEKGSIQTLLSLFQTFHQ LDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGVGPVLAANPGIVGLLLTTLEYKSLDDCEELVINATATINNLSYYQV KNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVCDFIVQNNVHRFMMALLDAQHQDICFSACGVLLNLTVDKDKRVILK EGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFGNEDTNTLLLLLSSFLDEELALDGSFDPDLKNYHKLHWETEFKPVA -------------------------------------------------------------- >41826_41826_6_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000442236_ARMC2_chr6_109232102_ENST00000392644_length(amino acids)=742AA_BP=216 MHTWSLKEPIVRVLQRYCTPRYLDYEDLERKYWKNLTFVAPIYGADINGSIYDEGVDEWNIARLNTVLDVVEEECGISIEGVNTPYLYFG MWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQGFFPSSSQGCDAFLRHKMTLISPSVLKKYGIPFDKITQEAGEFMI TFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLLNVCKLIFKISRNEKNDSLIQNDSILESLLEVLRSEDLQTNMEAFL YCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTFLPNSGHLLVQVTATLRNLVDSSLVRSKFLNISALPQLCTAMEQYK GDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQKKQDLVVRVVFILGNLTAKNNQAREQFSKEKGSIQTLLSLFQTFHQ LDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGVGPVLAANPGIVGLLLTTLEYKSLDDCEELVINATATINNLSYYQV KNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVCDFIVQNNVHRFMMALLDAQHQDICFSACGVLLNLTVDKDKRVILK EGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFGNEDTNTLLLLLSSFLDEELALDGSFDPDLKNYHKLHWETEFKPVA -------------------------------------------------------------- >41826_41826_7_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000535193_ARMC2_chr6_109232102_ENST00000368972_length(amino acids)=856AA_BP=330 MMKHYGLPWKRTEEAAADTALTIMEVAEVESPLNPSCKIMTFRPSMEEFREFNKYLAYMESKGAHRAGLAKVIPPKEWKPRQCYDDIDNL LIPAPIQQMVTGQSGLFTQYNIQKKAMTVKEFRQLANSGKYCTPRYLDYEDLERKYWKNLTFVAPIYGADINGSIYDEGVDEWNIARLNT VLDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQGFFPSSSQGCDAFLRHKMTLI SPSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLLNVCKLIFKISRNEKNDSLIQN DSILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTFLPNSGHLLVQVTATLRNLVDS SLVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQKKQDLVVRVVFILGNLTAKNNQ AREQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGVGPVLAANPGIVGLLLTTLEYK SLDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVCDFIVQNNVHRFMMALLDAQHQ DICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFGNEDTNTLLLLLSSFLDEELAL -------------------------------------------------------------- >41826_41826_8_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000535193_ARMC2_chr6_109232102_ENST00000392644_length(amino acids)=856AA_BP=330 MMKHYGLPWKRTEEAAADTALTIMEVAEVESPLNPSCKIMTFRPSMEEFREFNKYLAYMESKGAHRAGLAKVIPPKEWKPRQCYDDIDNL LIPAPIQQMVTGQSGLFTQYNIQKKAMTVKEFRQLANSGKYCTPRYLDYEDLERKYWKNLTFVAPIYGADINGSIYDEGVDEWNIARLNT VLDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQGFFPSSSQGCDAFLRHKMTLI SPSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLLNVCKLIFKISRNEKNDSLIQN DSILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTFLPNSGHLLVQVTATLRNLVDS SLVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQKKQDLVVRVVFILGNLTAKNNQ AREQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGVGPVLAANPGIVGLLLTTLEYK SLDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVCDFIVQNNVHRFMMALLDAQHQ DICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFGNEDTNTLLLLLSSFLDEELAL -------------------------------------------------------------- >41826_41826_9_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000536108_ARMC2_chr6_109232102_ENST00000368972_length(amino acids)=675AA_BP=149 MDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQGFFPSSSQGCDAFLRHKMTLIS PSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLLNVCKLIFKISRNEKNDSLIQND SILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTFLPNSGHLLVQVTATLRNLVDSS LVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQKKQDLVVRVVFILGNLTAKNNQA REQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGVGPVLAANPGIVGLLLTTLEYKS LDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVCDFIVQNNVHRFMMALLDAQHQD ICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFGNEDTNTLLLLLSSFLDEELALD -------------------------------------------------------------- >41826_41826_10_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000536108_ARMC2_chr6_109232102_ENST00000392644_length(amino acids)=675AA_BP=149 MDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQGFFPSSSQGCDAFLRHKMTLIS PSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLLNVCKLIFKISRNEKNDSLIQND SILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTFLPNSGHLLVQVTATLRNLVDSS LVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQKKQDLVVRVVFILGNLTAKNNQA REQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGVGPVLAANPGIVGLLLTTLEYKS LDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVCDFIVQNNVHRFMMALLDAQHQD ICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFGNEDTNTLLLLLSSFLDEELALD -------------------------------------------------------------- >41826_41826_11_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000543771_ARMC2_chr6_109232102_ENST00000368972_length(amino acids)=877AA_BP=351 MSPSAEQVSQISQISLGRRPLSSLPPPPSRALAPTRAPDTALTIMEVAEVESPLNPSCKIMTFRPSMEEFREFNKYLAYMESKGAHRAGL AKVIPPKEWKPRQCYDDIDNLLIPAPIQQMVTGQSGLFTQYNIQKKAMTVKEFRQLANSGKYCTPRYLDYEDLERKYWKNLTFVAPIYGA DINGSIYDEGVDEWNIARLNTVLDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQ GFFPSSSQGCDAFLRHKMTLISPSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLL NVCKLIFKISRNEKNDSLIQNDSILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTF LPNSGHLLVQVTATLRNLVDSSLVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQK KQDLVVRVVFILGNLTAKNNQAREQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGV GPVLAANPGIVGLLLTTLEYKSLDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVC DFIVQNNVHRFMMALLDAQHQDICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFG -------------------------------------------------------------- >41826_41826_12_KDM4C-ARMC2_KDM4C_chr9_6893232_ENST00000543771_ARMC2_chr6_109232102_ENST00000392644_length(amino acids)=877AA_BP=351 MSPSAEQVSQISQISLGRRPLSSLPPPPSRALAPTRAPDTALTIMEVAEVESPLNPSCKIMTFRPSMEEFREFNKYLAYMESKGAHRAGL AKVIPPKEWKPRQCYDDIDNLLIPAPIQQMVTGQSGLFTQYNIQKKAMTVKEFRQLANSGKYCTPRYLDYEDLERKYWKNLTFVAPIYGA DINGSIYDEGVDEWNIARLNTVLDVVEEECGISIEGVNTPYLYFGMWKTTFAWHTEDMDLYSINYLHFGEPKSWYAIPPEHGKRLERLAQ GFFPSSSQGCDAFLRHKMTLISPSVLKKYGIPFDKITQEAGEFMITFPYGYHAGFNHGFNCAESTNFATVRWIDYGKVAKLLKVSRKNLL NVCKLIFKISRNEKNDSLIQNDSILESLLEVLRSEDLQTNMEAFLYCMGSIKFISGNLGFLNEMISKGAVEILINLIKQINENIKKCGTF LPNSGHLLVQVTATLRNLVDSSLVRSKFLNISALPQLCTAMEQYKGDKDVCTNIARIFSKLTSYRDCCTALASYSRCYALFLNLINKYQK KQDLVVRVVFILGNLTAKNNQAREQFSKEKGSIQTLLSLFQTFHQLDLHSQKPVGQRGEQHRAQRPPSEAEDVLIKLTRVLANIAIHPGV GPVLAANPGIVGLLLTTLEYKSLDDCEELVINATATINNLSYYQVKNSIIQDKKLYIAELLLKLLVSNNMDGILEAVRVFGNLSQDHDVC DFIVQNNVHRFMMALLDAQHQDICFSACGVLLNLTVDKDKRVILKEGGGIKKLVDCLRDLGPTDWQLACLVCKTLWNFSENITNASSCFG -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:6893232/chr6:109220897) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| KDM4C | ARMC2 |
| FUNCTION: Histone demethylase that specifically demethylates 'Lys-9' and 'Lys-36' residues of histone H3, thereby playing a central role in histone code. Does not demethylate histone H3 'Lys-4', H3 'Lys-27' nor H4 'Lys-20'. Demethylates trimethylated H3 'Lys-9' and H3 'Lys-36' residue, while it has no activity on mono- and dimethylated residues. Demethylation of Lys residue generates formaldehyde and succinate. {ECO:0000269|PubMed:16603238, ECO:0000269|PubMed:28262558}. | FUNCTION: Required for sperm flagellum axoneme organization and function (By similarity). Involved in axonemal central pair complex assembly and/or stability (By similarity). {ECO:0000250|UniProtKB:Q3URY6}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381306 | + | 8 | 21 | 144_310 | 307.0 | 1048.0 | Domain | JmjC |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381306 | + | 8 | 21 | 16_58 | 307.0 | 1048.0 | Domain | JmjN |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381309 | + | 8 | 22 | 144_310 | 307.0 | 1057.0 | Domain | JmjC |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381309 | + | 8 | 22 | 16_58 | 307.0 | 1057.0 | Domain | JmjN |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000535193 | + | 8 | 18 | 144_310 | 329.0 | 836.0 | Domain | JmjC |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000535193 | + | 8 | 18 | 16_58 | 329.0 | 836.0 | Domain | JmjN |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000543771 | + | 8 | 18 | 144_310 | 307.0 | 814.0 | Domain | JmjC |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000543771 | + | 8 | 18 | 16_58 | 307.0 | 814.0 | Domain | JmjN |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 363_403 | 341.0 | 868.0 | Repeat | Note=ARM 3 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 408_449 | 341.0 | 868.0 | Repeat | Note=ARM 4 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 462_503 | 341.0 | 868.0 | Repeat | Note=ARM 5 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 506_547 | 341.0 | 868.0 | Repeat | Note=ARM 6 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 551_589 | 341.0 | 868.0 | Repeat | Note=ARM 7 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 591_616 | 341.0 | 868.0 | Repeat | Note=ARM 8 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 619_662 | 341.0 | 868.0 | Repeat | Note=ARM 9 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 664_705 | 341.0 | 868.0 | Repeat | Note=ARM 10 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 707_746 | 341.0 | 868.0 | Repeat | Note=ARM 11 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 748_790 | 341.0 | 868.0 | Repeat | Note=ARM 12 |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381306 | + | 8 | 21 | 877_934 | 307.0 | 1048.0 | Domain | Note=Tudor 1 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381306 | + | 8 | 21 | 935_991 | 307.0 | 1048.0 | Domain | Note=Tudor 2 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381309 | + | 8 | 22 | 877_934 | 307.0 | 1057.0 | Domain | Note=Tudor 1 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381309 | + | 8 | 22 | 935_991 | 307.0 | 1057.0 | Domain | Note=Tudor 2 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000535193 | + | 8 | 18 | 877_934 | 329.0 | 836.0 | Domain | Note=Tudor 1 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000535193 | + | 8 | 18 | 935_991 | 329.0 | 836.0 | Domain | Note=Tudor 2 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000543771 | + | 8 | 18 | 877_934 | 307.0 | 814.0 | Domain | Note=Tudor 1 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000543771 | + | 8 | 18 | 935_991 | 307.0 | 814.0 | Domain | Note=Tudor 2 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381306 | + | 8 | 21 | 689_747 | 307.0 | 1048.0 | Zinc finger | Note=PHD-type 1 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381306 | + | 8 | 21 | 752_785 | 307.0 | 1048.0 | Zinc finger | C2HC pre-PHD-type |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381306 | + | 8 | 21 | 808_865 | 307.0 | 1048.0 | Zinc finger | PHD-type 2 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381309 | + | 8 | 22 | 689_747 | 307.0 | 1057.0 | Zinc finger | Note=PHD-type 1 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381309 | + | 8 | 22 | 752_785 | 307.0 | 1057.0 | Zinc finger | C2HC pre-PHD-type |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000381309 | + | 8 | 22 | 808_865 | 307.0 | 1057.0 | Zinc finger | PHD-type 2 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000535193 | + | 8 | 18 | 689_747 | 329.0 | 836.0 | Zinc finger | Note=PHD-type 1 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000535193 | + | 8 | 18 | 752_785 | 329.0 | 836.0 | Zinc finger | C2HC pre-PHD-type |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000535193 | + | 8 | 18 | 808_865 | 329.0 | 836.0 | Zinc finger | PHD-type 2 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000543771 | + | 8 | 18 | 689_747 | 307.0 | 814.0 | Zinc finger | Note=PHD-type 1 |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000543771 | + | 8 | 18 | 752_785 | 307.0 | 814.0 | Zinc finger | C2HC pre-PHD-type |
| Hgene | KDM4C | chr9:6893232 | chr6:109232102 | ENST00000543771 | + | 8 | 18 | 808_865 | 307.0 | 814.0 | Zinc finger | PHD-type 2 |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 262_301 | 341.0 | 868.0 | Repeat | Note=ARM 1 | |
| Tgene | ARMC2 | chr9:6893232 | chr6:109232102 | ENST00000392644 | 7 | 18 | 304_344 | 341.0 | 868.0 | Repeat | Note=ARM 2 |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| KDM4C | |
| ARMC2 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to KDM4C-ARMC2 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to KDM4C-ARMC2 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies