| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:LGR6-NAV1 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: LGR6-NAV1 | FusionPDB ID: 44597 | FusionGDB2.0 ID: 44597 | Hgene | Tgene | Gene symbol | LGR6 | NAV1 | Gene ID | 59352 | 89796 |
| Gene name | leucine rich repeat containing G protein-coupled receptor 6 | neuron navigator 1 | |
| Synonyms | GPCR|VTS20631 | POMFIL3|STEERIN1|UNC53H1 | |
| Cytomap | 1q32.1 | 1q32.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | leucine-rich repeat-containing G-protein coupled receptor 6gonadotropin receptor | neuron navigator 1pore membrane and/or filament interacting like protein 3unc-53 homolog 1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9HBX8 | Q8NEY1 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000255432, ENST00000367278, ENST00000439764, ENST00000308543, | ENST00000469130, ENST00000295624, ENST00000367295, ENST00000367296, ENST00000367297, ENST00000367300, ENST00000367302, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 4 X 2 X 3=24 | 10 X 10 X 4=400 |
| # samples | 8 | 12 | |
| ** MAII score | log2(8/24*10)=1.73696559416621 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(12/400*10)=-1.73696559416621 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: LGR6 [Title/Abstract] AND NAV1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | LGR6(202205121)-NAV1(201749549), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | LGR6-NAV1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. LGR6-NAV1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. LGR6-NAV1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. LGR6-NAV1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | LGR6 | GO:0030177 | positive regulation of Wnt signaling pathway | 22615920 |
| Hgene | LGR6 | GO:0030335 | positive regulation of cell migration | 22615920 |
| Fusion gene breakpoints across LGR6 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NAV1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
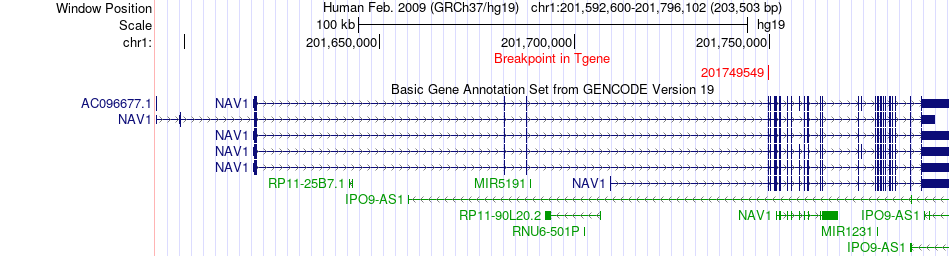 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCEC | TCGA-AJ-A3BF-01A | LGR6 | chr1 | 202205121 | - | NAV1 | chr1 | 201749549 | + |
| ChimerDB4 | UCEC | TCGA-AJ-A3BF-01A | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000367278 | LGR6 | chr1 | 202205121 | + | ENST00000367302 | NAV1 | chr1 | 201749549 | + | 8157 | 517 | 89 | 4744 | 1551 |
| ENST00000367278 | LGR6 | chr1 | 202205121 | + | ENST00000367296 | NAV1 | chr1 | 201749549 | + | 11962 | 517 | 89 | 4924 | 1611 |
| ENST00000367278 | LGR6 | chr1 | 202205121 | + | ENST00000295624 | NAV1 | chr1 | 201749549 | + | 11958 | 517 | 89 | 4915 | 1608 |
| ENST00000367278 | LGR6 | chr1 | 202205121 | + | ENST00000367297 | NAV1 | chr1 | 201749549 | + | 11943 | 517 | 89 | 4900 | 1603 |
| ENST00000367278 | LGR6 | chr1 | 202205121 | + | ENST00000367300 | NAV1 | chr1 | 201749549 | + | 11787 | 517 | 89 | 4744 | 1551 |
| ENST00000367278 | LGR6 | chr1 | 202205121 | + | ENST00000367295 | NAV1 | chr1 | 201749549 | + | 11953 | 517 | 89 | 4915 | 1608 |
| ENST00000255432 | LGR6 | chr1 | 202205121 | + | ENST00000367302 | NAV1 | chr1 | 201749549 | + | 7996 | 356 | 6 | 4583 | 1525 |
| ENST00000255432 | LGR6 | chr1 | 202205121 | + | ENST00000367296 | NAV1 | chr1 | 201749549 | + | 11801 | 356 | 6 | 4763 | 1585 |
| ENST00000255432 | LGR6 | chr1 | 202205121 | + | ENST00000295624 | NAV1 | chr1 | 201749549 | + | 11797 | 356 | 6 | 4754 | 1582 |
| ENST00000255432 | LGR6 | chr1 | 202205121 | + | ENST00000367297 | NAV1 | chr1 | 201749549 | + | 11782 | 356 | 6 | 4739 | 1577 |
| ENST00000255432 | LGR6 | chr1 | 202205121 | + | ENST00000367300 | NAV1 | chr1 | 201749549 | + | 11626 | 356 | 6 | 4583 | 1525 |
| ENST00000255432 | LGR6 | chr1 | 202205121 | + | ENST00000367295 | NAV1 | chr1 | 201749549 | + | 11792 | 356 | 6 | 4754 | 1582 |
| ENST00000439764 | LGR6 | chr1 | 202205121 | + | ENST00000367302 | NAV1 | chr1 | 201749549 | + | 7939 | 299 | 0 | 4526 | 1508 |
| ENST00000439764 | LGR6 | chr1 | 202205121 | + | ENST00000367296 | NAV1 | chr1 | 201749549 | + | 11744 | 299 | 0 | 4706 | 1568 |
| ENST00000439764 | LGR6 | chr1 | 202205121 | + | ENST00000295624 | NAV1 | chr1 | 201749549 | + | 11740 | 299 | 0 | 4697 | 1565 |
| ENST00000439764 | LGR6 | chr1 | 202205121 | + | ENST00000367297 | NAV1 | chr1 | 201749549 | + | 11725 | 299 | 0 | 4682 | 1560 |
| ENST00000439764 | LGR6 | chr1 | 202205121 | + | ENST00000367300 | NAV1 | chr1 | 201749549 | + | 11569 | 299 | 0 | 4526 | 1508 |
| ENST00000439764 | LGR6 | chr1 | 202205121 | + | ENST00000367295 | NAV1 | chr1 | 201749549 | + | 11735 | 299 | 0 | 4697 | 1565 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000367278 | ENST00000367302 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.002000424 | 0.9979996 |
| ENST00000367278 | ENST00000367296 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000810687 | 0.9991893 |
| ENST00000367278 | ENST00000295624 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.00071953 | 0.9992805 |
| ENST00000367278 | ENST00000367297 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.00084264 | 0.9991573 |
| ENST00000367278 | ENST00000367300 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000698043 | 0.9993019 |
| ENST00000367278 | ENST00000367295 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000719098 | 0.99928087 |
| ENST00000255432 | ENST00000367302 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.001637981 | 0.998362 |
| ENST00000255432 | ENST00000367296 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000679584 | 0.9993204 |
| ENST00000255432 | ENST00000295624 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000596607 | 0.99940336 |
| ENST00000255432 | ENST00000367297 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000702019 | 0.999298 |
| ENST00000255432 | ENST00000367300 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000581446 | 0.9994186 |
| ENST00000255432 | ENST00000367295 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000596772 | 0.99940324 |
| ENST00000439764 | ENST00000367302 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.001554827 | 0.9984452 |
| ENST00000439764 | ENST00000367296 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000638031 | 0.99936193 |
| ENST00000439764 | ENST00000295624 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000560278 | 0.99943966 |
| ENST00000439764 | ENST00000367297 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000659608 | 0.99934036 |
| ENST00000439764 | ENST00000367300 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000544927 | 0.99945503 |
| ENST00000439764 | ENST00000367295 | LGR6 | chr1 | 202205121 | + | NAV1 | chr1 | 201749549 | + | 0.000560553 | 0.9994394 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >44597_44597_1_LGR6-NAV1_LGR6_chr1_202205121_ENST00000255432_NAV1_chr1_201749549_ENST00000295624_length(amino acids)=1582AA_BP=117 MCLTDAPNAEAPERRLWCKGKPTGQGMGRPRLTLVCQVSIIISARDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSL KILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSW FSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKAT DKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVS NSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAK AKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSA SGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEEL TWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVSPTAATTPRITRS NSIPTHEAAFELYSGSQMGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSAEERMQSEQIRKLRRELESSQEKVATLTS QLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSIT SHSSIGSSKDADAKKKKKKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTEGPA HPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVP GSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQV FKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHRRLV LSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNGALT CKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEKHST SDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPHSIA -------------------------------------------------------------- >44597_44597_2_LGR6-NAV1_LGR6_chr1_202205121_ENST00000255432_NAV1_chr1_201749549_ENST00000367295_length(amino acids)=1582AA_BP=117 MCLTDAPNAEAPERRLWCKGKPTGQGMGRPRLTLVCQVSIIISARDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSL KILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSW FSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKAT DKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVS NSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAK AKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSA SGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEEL TWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVSPTAATTPRITRS NSIPTHEAAFELYSGSQMGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSAEERMQSEQIRKLRRELESSQEKVATLTS QLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSIT SHSSIGSSKDADAKKKKKKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTEGPA HPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVP GSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQV FKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHRRLV LSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNGALT CKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEKHST SDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPHSIA -------------------------------------------------------------- >44597_44597_3_LGR6-NAV1_LGR6_chr1_202205121_ENST00000255432_NAV1_chr1_201749549_ENST00000367296_length(amino acids)=1585AA_BP=117 MCLTDAPNAEAPERRLWCKGKPTGQGMGRPRLTLVCQVSIIISARDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSL KILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSW FSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKAT DKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVS NSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAK AKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSA SGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEEL TWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVSPTAATTPRITRS NSIPTHEAAFELYSGSQMGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSAEERMQSEQIRKLRRELESSQEKVATLTS QLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSIT SHSSIGSSKDADAKKKKKKSWVYELRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTE GPAHPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPG QVPGSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAV FQVFKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHR RLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNG ALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEK HSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPH -------------------------------------------------------------- >44597_44597_4_LGR6-NAV1_LGR6_chr1_202205121_ENST00000255432_NAV1_chr1_201749549_ENST00000367297_length(amino acids)=1577AA_BP=117 MCLTDAPNAEAPERRLWCKGKPTGQGMGRPRLTLVCQVSIIISARDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSL KILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSW FSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKAT DKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVS NSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAK AKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSA SGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEEL TWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVSPTAATTPRITRS NSIPTHEAAFELYSGSQMGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSQIRKLRRELESSQEKVATLTSQLSANANL VAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSITSHSSIGSS KDADAKKKKKKSWVYELRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPH TRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSAL SSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYI SKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPS GTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNGALTCKYHK CPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLI GPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPHSIASPPED -------------------------------------------------------------- >44597_44597_5_LGR6-NAV1_LGR6_chr1_202205121_ENST00000255432_NAV1_chr1_201749549_ENST00000367300_length(amino acids)=1525AA_BP=117 MCLTDAPNAEAPERRLWCKGKPTGQGMGRPRLTLVCQVSIIISARDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSL KILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSW FSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKAT DKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVS NSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAK AKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSA SGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEEL TWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVHGSVLSLASSASS TYSSAEERMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAV IQGALNASETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPS SPKLQHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETM HNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHI IKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGL KEKCVDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQI DRETGIGDVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESD SDINANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPV -------------------------------------------------------------- >44597_44597_6_LGR6-NAV1_LGR6_chr1_202205121_ENST00000255432_NAV1_chr1_201749549_ENST00000367302_length(amino acids)=1525AA_BP=117 MCLTDAPNAEAPERRLWCKGKPTGQGMGRPRLTLVCQVSIIISARDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSL KILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSW FSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKAT DKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVS NSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAK AKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSA SGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEEL TWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVHGSVLSLASSASS TYSSAEERMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAV IQGALNASETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPS SPKLQHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETM HNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHI IKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGL KEKCVDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQI DRETGIGDVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESD SDINANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPV -------------------------------------------------------------- >44597_44597_7_LGR6-NAV1_LGR6_chr1_202205121_ENST00000367278_NAV1_chr1_201749549_ENST00000295624_length(amino acids)=1608AA_BP=143 MPSPPGLRALWLCAALCASRRAGGAPQPGPGPTACPAPCHCQEDGIMLSADCSELGLSAVPGDLDPLTAYLDLSMNNLTELQPGLFHHLR FLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPT ASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPP VAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSA TLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLK EPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNS NSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPS AFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALP MSLSAKGQLTNIVSPTAATTPRITRSNSIPTHEAAFELYSGSQMGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSAEE RMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNA SETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHG STETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEV DLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQ QEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDS LVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIG DVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANK EELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTL -------------------------------------------------------------- >44597_44597_8_LGR6-NAV1_LGR6_chr1_202205121_ENST00000367278_NAV1_chr1_201749549_ENST00000367295_length(amino acids)=1608AA_BP=143 MPSPPGLRALWLCAALCASRRAGGAPQPGPGPTACPAPCHCQEDGIMLSADCSELGLSAVPGDLDPLTAYLDLSMNNLTELQPGLFHHLR FLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPT ASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPP VAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSA TLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLK EPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNS NSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPS AFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALP MSLSAKGQLTNIVSPTAATTPRITRSNSIPTHEAAFELYSGSQMGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSAEE RMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNA SETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHG STETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEV DLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQ QEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDS LVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIG DVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANK EELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTL -------------------------------------------------------------- >44597_44597_9_LGR6-NAV1_LGR6_chr1_202205121_ENST00000367278_NAV1_chr1_201749549_ENST00000367296_length(amino acids)=1611AA_BP=143 MPSPPGLRALWLCAALCASRRAGGAPQPGPGPTACPAPCHCQEDGIMLSADCSELGLSAVPGDLDPLTAYLDLSMNNLTELQPGLFHHLR FLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPT ASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPP VAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSA TLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLK EPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNS NSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPS AFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALP MSLSAKGQLTNIVSPTAATTPRITRSNSIPTHEAAFELYSGSQMGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSAEE RMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNA SETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWVYELRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKL QHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQ LEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGD LKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKC VDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRET GIGDVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDIN ANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVR -------------------------------------------------------------- >44597_44597_10_LGR6-NAV1_LGR6_chr1_202205121_ENST00000367278_NAV1_chr1_201749549_ENST00000367297_length(amino acids)=1603AA_BP=143 MPSPPGLRALWLCAALCASRRAGGAPQPGPGPTACPAPCHCQEDGIMLSADCSELGLSAVPGDLDPLTAYLDLSMNNLTELQPGLFHHLR FLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPT ASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPP VAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSA TLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLK EPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNS NSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPS AFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALP MSLSAKGQLTNIVSPTAATTPRITRSNSIPTHEAAFELYSGSQMGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSQIR KLRRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKEL RIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWVYELRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETA SPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKA ENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFL GCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFET LIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLV ILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLR VLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSA -------------------------------------------------------------- >44597_44597_11_LGR6-NAV1_LGR6_chr1_202205121_ENST00000367278_NAV1_chr1_201749549_ENST00000367300_length(amino acids)=1551AA_BP=143 MPSPPGLRALWLCAALCASRRAGGAPQPGPGPTACPAPCHCQEDGIMLSADCSELGLSAVPGDLDPLTAYLDLSMNNLTELQPGLFHHLR FLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPT ASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPP VAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSA TLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLK EPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNS NSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPS AFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALP MSLSAKGQLTNIVHGSVLSLASSASSTYSSAEERMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAE EKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWLRSSFNKAFS IKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWE KEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSP MDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKR VLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEG IVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRM LTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNS IIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPHSIASPPEDRTVKDSTPSSLDSDPLMAMLLKLQEA -------------------------------------------------------------- >44597_44597_12_LGR6-NAV1_LGR6_chr1_202205121_ENST00000367278_NAV1_chr1_201749549_ENST00000367302_length(amino acids)=1551AA_BP=143 MPSPPGLRALWLCAALCASRRAGGAPQPGPGPTACPAPCHCQEDGIMLSADCSELGLSAVPGDLDPLTAYLDLSMNNLTELQPGLFHHLR FLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEALWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPT ASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSGSLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPP VAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSSDAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSA TLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQYRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLK EPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIGSPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNS NSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPILNINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPS AFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRDRNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALP MSLSAKGQLTNIVHGSVLSLASSASSTYSSAEERMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAE EKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWLRSSFNKAFS IKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWE KEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSP MDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKR VLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEG IVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRM LTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNS IIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPHSIASPPEDRTVKDSTPSSLDSDPLMAMLLKLQEA -------------------------------------------------------------- >44597_44597_13_LGR6-NAV1_LGR6_chr1_202205121_ENST00000439764_NAV1_chr1_201749549_ENST00000295624_length(amino acids)=1565AA_BP=100 MRLEGEGRSARAGQNLSRAGSARRGAPRDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEA LWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSG SLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSS DAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQ YRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIG SPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPIL NINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRD RNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVSPTAATTPRITRSNSIPTHEAAFELYSGSQ MGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSAEERMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLV NMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKK KKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEP EKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALT HSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLS TESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLA EYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPV KMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGI EDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPHSIASPPEDRTVKDSTPSSLD -------------------------------------------------------------- >44597_44597_14_LGR6-NAV1_LGR6_chr1_202205121_ENST00000439764_NAV1_chr1_201749549_ENST00000367295_length(amino acids)=1565AA_BP=100 MRLEGEGRSARAGQNLSRAGSARRGAPRDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEA LWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSG SLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSS DAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQ YRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIG SPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPIL NINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRD RNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVSPTAATTPRITRSNSIPTHEAAFELYSGSQ MGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSAEERMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLV NMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKK KKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEP EKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALT HSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLS TESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLA EYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPV KMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGI EDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPHSIASPPEDRTVKDSTPSSLD -------------------------------------------------------------- >44597_44597_15_LGR6-NAV1_LGR6_chr1_202205121_ENST00000439764_NAV1_chr1_201749549_ENST00000367296_length(amino acids)=1568AA_BP=100 MRLEGEGRSARAGQNLSRAGSARRGAPRDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEA LWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSG SLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSS DAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQ YRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIG SPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPIL NINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRD RNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVSPTAATTPRITRSNSIPTHEAAFELYSGSQ MGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSAEERMQSEQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLV NMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKK KKSWVYELRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEE EEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGL ALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTL GLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTN RLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTN QPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCP IGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPHSIASPPEDRTVKDSTPS -------------------------------------------------------------- >44597_44597_16_LGR6-NAV1_LGR6_chr1_202205121_ENST00000439764_NAV1_chr1_201749549_ENST00000367297_length(amino acids)=1560AA_BP=100 MRLEGEGRSARAGQNLSRAGSARRGAPRDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEA LWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSG SLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSS DAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQ YRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIG SPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPIL NINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRD RNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVSPTAATTPRITRSNSIPTHEAAFELYSGSQ MGSTLSLAERPKGMIRSGSFRDPTDDVHGSVLSLASSASSTYSSQIRKLRRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRH LAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRIKRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWVYEL RSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIKSSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEV SELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRLKVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGP SLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKVSGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIH GYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKPMMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVE RSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDDLSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPN HGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWVPKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRT WFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQSKLYHLPPPTVGPHSIASPPEDRTVKDSTPSSLDSDPLM -------------------------------------------------------------- >44597_44597_17_LGR6-NAV1_LGR6_chr1_202205121_ENST00000439764_NAV1_chr1_201749549_ENST00000367300_length(amino acids)=1508AA_BP=100 MRLEGEGRSARAGQNLSRAGSARRGAPRDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEA LWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSG SLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSS DAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQ YRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIG SPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPIL NINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRD RNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVHGSVLSLASSASSTYSSAEERMQSEQIRKL RRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRI KRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIK SSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRL KVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKV SGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKP MMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDD LSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWV PKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQS -------------------------------------------------------------- >44597_44597_18_LGR6-NAV1_LGR6_chr1_202205121_ENST00000439764_NAV1_chr1_201749549_ENST00000367302_length(amino acids)=1508AA_BP=100 MRLEGEGRSARAGQNLSRAGSARRGAPRDLSMNNLTELQPGLFHHLRFLEELRLSGNHLSHIPGQAFSGLYSLKILMLQNNQLGGIPAEA LWELPSLQSLWDESSSISSGLSDASDNLSSEEFNASSSLNSLPSTPTASRRNSTIVLRTDSEKRSLAESGLSWFSESEEKAPKKLEYDSG SLKMEPGTSKWRRERPESCDDSSKGGELKKPISLGHPGSLKKGKTPPVAVTSPITHTAQSALKVAGKPEGKATDKGKLAVKNTGLQRSSS DAGRDRLSDAKKPPSGIARPSTSGSFGYKKPPPATGTATVMQTGGSATLSKIQKSSGIPVKPVNGRKTSLDVSNSAEPGFLAPGARSNIQ YRSLPRPAKSSSMSVTGGRGGPRPVSSSIDPSLLSTKQGGLTPSRLKEPTKVASGRTTPAPVNQTDREKEKAKAKAVALDSDNISLKSIG SPESTPKNQASHPTATKLAELPPTPLRATAKSFVKPPSLANLDKVNSNSLDLPSSSDTTHASKVPDLHATSSASGGPLPSCFTPSPAPIL NINSASFSQGLELMSGFSVPKETRMYPKLSGLHRSMESLQMPMSLPSAFPSSTPVPTPPAPPAAPTEEETEELTWSGSPRAGQLDSNQRD RNTLPKKGLRYQLQSQEETKERRHSHTIGGLPESDDQSELPSPPALPMSLSAKGQLTNIVHGSVLSLASSASSTYSSAEERMQSEQIRKL RRELESSQEKVATLTSQLSANANLVAAFEQSLVNMTSRLRHLAETAEEKDTELLDLRETIDFLKKKNSEAQAVIQGALNASETTPKELRI KRQNSSDSISSLNSITSHSSIGSSKDADAKKKKKKSWLRSSFNKAFSIKKGPKSASSYSDIEEIATPDSSAPSSPKLQHGSTETASPSIK SSTSSSVGTDVTEGPAHPAPHTRLFHANEEEEPEKKEVSELRSELWEKEMKLTDIRLEALNSAHQLDQLRETMHNMQLEVDLLKAENDRL KVAPGPSSGSTPGQVPGSSALSSPRRSLGLALTHSFGPSLADTDLSPMDGISTCGPKEEVTLRVVVRMPPQHIIKGDLKQQEFFLGCSKV SGKVDWKMLDEAVFQVFKDYISKMDPASTLGLSTESIHGYSISHVKRVLDAEPPEMPPCRRGVNNISVSLKGLKEKCVDSLVFETLIPKP MMQHYISLLLKHRRLVLSGPSGTGKTYLTNRLAEYLVERSGREVTEGIVSTFNMHQQSCKDLQLYLSNLANQIDRETGIGDVPLVILLDD LSEAGSISELVNGALTCKYHKCPYIIGTTNQPVKMTPNHGLHLSFRMLTFSNNVEPANGFLVRYLRRKLVESDSDINANKEELLRVLDWV PKLWYHLHTFLEKHSTSDFLIGPCFFLSCPIGIEDFRTWFIDLWNNSIIPYLQEGAKDGIKVHGQKAAWEDPVEWVRDTLPWPSAQQDQS -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:202205121/chr1:201749549) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| LGR6 | NAV1 |
| FUNCTION: Receptor for R-spondins that potentiates the canonical Wnt signaling pathway and acts as a marker of multipotent stem cells in the epidermis. Upon binding to R-spondins (RSPO1, RSPO2, RSPO3 or RSPO4), associates with phosphorylated LRP6 and frizzled receptors that are activated by extracellular Wnt receptors, triggering the canonical Wnt signaling pathway to increase expression of target genes. In contrast to classical G-protein coupled receptors, does not activate heterotrimeric G-proteins to transduce the signal. May act as a tumor suppressor. {ECO:0000269|PubMed:21727895, ECO:0000269|PubMed:22615920}. | FUNCTION: May be involved in neuronal migration. {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 26_66 | 90.66666666666667 | 916.0 | Domain | Note=LRRNT |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 26_66 | 142.66666666666666 | 968.0 | Domain | Note=LRRNT |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 26_66 | 99.66666666666667 | 829.0 | Domain | Note=LRRNT |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 115_136 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 2 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 91_112 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 1 |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000295624 | 2 | 29 | 1072_1163 | 408.6666666666667 | 1875.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000295624 | 2 | 29 | 1303_1362 | 408.6666666666667 | 1875.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000295624 | 2 | 29 | 731_756 | 408.6666666666667 | 1875.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367295 | 0 | 27 | 1072_1163 | 17.666666666666668 | 1484.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367295 | 0 | 27 | 1303_1362 | 17.666666666666668 | 1484.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367295 | 0 | 27 | 255_280 | 17.666666666666668 | 1484.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367295 | 0 | 27 | 731_756 | 17.666666666666668 | 1484.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367296 | 2 | 30 | 1072_1163 | 408.6666666666667 | 1878.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367296 | 2 | 30 | 1303_1362 | 408.6666666666667 | 1878.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367296 | 2 | 30 | 731_756 | 408.6666666666667 | 1878.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367297 | 2 | 29 | 1072_1163 | 408.6666666666667 | 1870.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367297 | 2 | 29 | 1303_1362 | 408.6666666666667 | 1870.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367297 | 2 | 29 | 731_756 | 408.6666666666667 | 1870.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367300 | 2 | 28 | 1072_1163 | 408.6666666666667 | 1818.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367300 | 2 | 28 | 1303_1362 | 408.6666666666667 | 1818.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367300 | 2 | 28 | 731_756 | 408.6666666666667 | 1818.0 | Coiled coil | Ontology_term=ECO:0000255 |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 952_955 | 90.66666666666667 | 916.0 | Compositional bias | Note=Poly-Gly |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 952_955 | 142.66666666666666 | 968.0 | Compositional bias | Note=Poly-Gly |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 952_955 | 99.66666666666667 | 829.0 | Compositional bias | Note=Poly-Gly |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 115_136 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 2 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 139_160 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 3 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 163_186 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 4 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 187_208 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 5 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 211_232 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 6 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 235_256 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 7 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 258_279 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 8 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 282_303 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 9 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 306_328 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 10 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 329_350 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 11 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 353_374 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 12 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 375_396 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 13 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 399_420 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 14 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 423_443 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 15 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 91_112 | 90.66666666666667 | 916.0 | Repeat | Note=LRR 1 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 139_160 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 3 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 163_186 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 4 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 187_208 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 5 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 211_232 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 6 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 235_256 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 7 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 258_279 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 8 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 282_303 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 9 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 306_328 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 10 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 329_350 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 11 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 353_374 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 12 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 375_396 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 13 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 399_420 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 14 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 423_443 | 142.66666666666666 | 968.0 | Repeat | Note=LRR 15 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 115_136 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 2 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 139_160 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 3 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 163_186 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 4 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 187_208 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 5 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 211_232 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 6 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 235_256 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 7 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 258_279 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 8 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 282_303 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 9 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 306_328 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 10 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 329_350 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 11 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 353_374 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 12 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 375_396 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 13 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 399_420 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 14 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 423_443 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 15 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 91_112 | 99.66666666666667 | 829.0 | Repeat | Note=LRR 1 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 25_567 | 90.66666666666667 | 916.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 589_598 | 90.66666666666667 | 916.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 620_644 | 90.66666666666667 | 916.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 666_687 | 90.66666666666667 | 916.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 709_727 | 90.66666666666667 | 916.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 749_774 | 90.66666666666667 | 916.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 796_809 | 90.66666666666667 | 916.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 831_967 | 90.66666666666667 | 916.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 25_567 | 142.66666666666666 | 968.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 589_598 | 142.66666666666666 | 968.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 620_644 | 142.66666666666666 | 968.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 666_687 | 142.66666666666666 | 968.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 709_727 | 142.66666666666666 | 968.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 749_774 | 142.66666666666666 | 968.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 796_809 | 142.66666666666666 | 968.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 831_967 | 142.66666666666666 | 968.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 25_567 | 99.66666666666667 | 829.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 589_598 | 99.66666666666667 | 829.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 620_644 | 99.66666666666667 | 829.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 666_687 | 99.66666666666667 | 829.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 709_727 | 99.66666666666667 | 829.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 749_774 | 99.66666666666667 | 829.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 796_809 | 99.66666666666667 | 829.0 | Topological domain | Extracellular |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 831_967 | 99.66666666666667 | 829.0 | Topological domain | Cytoplasmic |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 568_588 | 90.66666666666667 | 916.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 599_619 | 90.66666666666667 | 916.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 645_665 | 90.66666666666667 | 916.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 688_708 | 90.66666666666667 | 916.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 728_748 | 90.66666666666667 | 916.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 775_795 | 90.66666666666667 | 916.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000255432 | + | 4 | 18 | 810_830 | 90.66666666666667 | 916.0 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 568_588 | 142.66666666666666 | 968.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 599_619 | 142.66666666666666 | 968.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 645_665 | 142.66666666666666 | 968.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 688_708 | 142.66666666666666 | 968.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 728_748 | 142.66666666666666 | 968.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 775_795 | 142.66666666666666 | 968.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000367278 | + | 4 | 18 | 810_830 | 142.66666666666666 | 968.0 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 568_588 | 99.66666666666667 | 829.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 599_619 | 99.66666666666667 | 829.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 645_665 | 99.66666666666667 | 829.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 688_708 | 99.66666666666667 | 829.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 728_748 | 99.66666666666667 | 829.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 775_795 | 99.66666666666667 | 829.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | LGR6 | chr1:202205121 | chr1:201749549 | ENST00000439764 | + | 4 | 16 | 810_830 | 99.66666666666667 | 829.0 | Transmembrane | Helical%3B Name%3D7 |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000295624 | 2 | 29 | 255_280 | 408.6666666666667 | 1875.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367296 | 2 | 30 | 255_280 | 408.6666666666667 | 1878.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367297 | 2 | 29 | 255_280 | 408.6666666666667 | 1870.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NAV1 | chr1:202205121 | chr1:201749549 | ENST00000367300 | 2 | 28 | 255_280 | 408.6666666666667 | 1818.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| LGR6 | |
| NAV1 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to LGR6-NAV1 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to LGR6-NAV1 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies