| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:MYO1B-ABCC4 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: MYO1B-ABCC4 | FusionPDB ID: 56619 | FusionGDB2.0 ID: 56619 | Hgene | Tgene | Gene symbol | MYO1B | ABCC4 | Gene ID | 4430 | 10257 |
| Gene name | myosin IB | ATP binding cassette subfamily C member 4 | |
| Synonyms | MMI-alpha|MMIa|MYH-1c|myr1 | MOAT-B|MOATB|MRP4 | |
| Cytomap | 2q32.3 | 13q32.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | unconventional myosin-IbMYO1B variant proteinmyosin-I alpha | multidrug resistance-associated protein 4MRP/cMOAT-related ABC transporterbA464I2.1 (ATP-binding cassette, sub-family C (CFTR/MRP), member 4)canalicular multispecific organic anion transporter (ABC superfamily)multi-specific organic anion transporter | |
| Modification date | 20200315 | 20200313 | |
| UniProtAcc | O43795 | O15439 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000304164, ENST00000339514, ENST00000392316, ENST00000392318, ENST00000439065, ENST00000496992, | ENST00000538287, ENST00000431522, ENST00000474158, ENST00000536256, ENST00000376887, ENST00000412704, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 13 X 10 X 6=780 | 20 X 18 X 5=1800 |
| # samples | 16 | 21 | |
| ** MAII score | log2(16/780*10)=-2.28540221886225 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(21/1800*10)=-3.09953567355091 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: MYO1B [Title/Abstract] AND ABCC4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | MYO1B(192261223)-ABCC4(95887088), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | MYO1B-ABCC4 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. MYO1B-ABCC4 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. MYO1B-ABCC4 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. MYO1B-ABCC4 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | ABCC4 | GO:0032310 | prostaglandin secretion | 25173977 |
| Fusion gene breakpoints across MYO1B (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
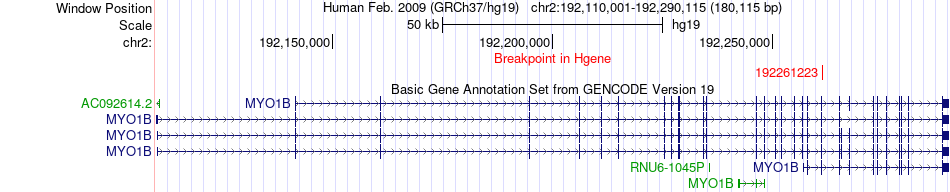 |
| Fusion gene breakpoints across ABCC4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-HC-7211-01A | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000339514 | MYO1B | chr2 | 192261223 | - | ENST00000412704 | ABCC4 | chr13 | 95887088 | - | 7932 | 2655 | 126 | 6185 | 2019 |
| ENST00000339514 | MYO1B | chr2 | 192261223 | - | ENST00000376887 | ABCC4 | chr13 | 95887088 | - | 8071 | 2655 | 126 | 6326 | 2066 |
| ENST00000392318 | MYO1B | chr2 | 192261223 | - | ENST00000412704 | ABCC4 | chr13 | 95887088 | - | 7819 | 2542 | 13 | 6072 | 2019 |
| ENST00000392318 | MYO1B | chr2 | 192261223 | - | ENST00000376887 | ABCC4 | chr13 | 95887088 | - | 7958 | 2542 | 13 | 6213 | 2066 |
| ENST00000304164 | MYO1B | chr2 | 192261223 | - | ENST00000412704 | ABCC4 | chr13 | 95887088 | - | 7665 | 2388 | 84 | 5918 | 1944 |
| ENST00000304164 | MYO1B | chr2 | 192261223 | - | ENST00000376887 | ABCC4 | chr13 | 95887088 | - | 7804 | 2388 | 84 | 6059 | 1991 |
| ENST00000392316 | MYO1B | chr2 | 192261223 | - | ENST00000412704 | ABCC4 | chr13 | 95887088 | - | 7583 | 2306 | 2 | 5836 | 1944 |
| ENST00000392316 | MYO1B | chr2 | 192261223 | - | ENST00000376887 | ABCC4 | chr13 | 95887088 | - | 7722 | 2306 | 2 | 5977 | 1991 |
| ENST00000439065 | MYO1B | chr2 | 192261223 | - | ENST00000412704 | ABCC4 | chr13 | 95887088 | - | 5564 | 287 | 86 | 3817 | 1243 |
| ENST00000439065 | MYO1B | chr2 | 192261223 | - | ENST00000376887 | ABCC4 | chr13 | 95887088 | - | 5703 | 287 | 86 | 3958 | 1290 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000339514 | ENST00000412704 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.000478843 | 0.99952114 |
| ENST00000339514 | ENST00000376887 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.000401081 | 0.9995989 |
| ENST00000392318 | ENST00000412704 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.000414584 | 0.99958545 |
| ENST00000392318 | ENST00000376887 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.00034731 | 0.99965274 |
| ENST00000304164 | ENST00000412704 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.000318723 | 0.99968135 |
| ENST00000304164 | ENST00000376887 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.000267506 | 0.99973243 |
| ENST00000392316 | ENST00000412704 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.000292046 | 0.9997079 |
| ENST00000392316 | ENST00000376887 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.000245128 | 0.99975485 |
| ENST00000439065 | ENST00000412704 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.000293329 | 0.9997067 |
| ENST00000439065 | ENST00000376887 | MYO1B | chr2 | 192261223 | - | ABCC4 | chr13 | 95887088 | - | 0.000246092 | 0.9997539 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >56619_56619_1_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000304164_ABCC4_chr13_95887088_ENST00000376887_length(amino acids)=1991AA_BP=768 METMAKMEVKTSLLDNMIGVGDMVLLEPLNEETFINNLKKRFDHSEIYTYIGSVVISVNPYRSLPIYSPEKVEEYRNRNFYELSPHIFAL SDEAYRSLRDQDKDQCILITGESGAGKTEASKLVMSYVAAVCGKGAEVNQVKEQLLQSNPVLEAFGNAKTVRNDNSSRFGKYMDIEFDFK GDPLGGVISNYLLEKSRVVKQPRGERNFHVFYQLLSGASEELLNKLKLERDFSRYNYLSLDSAKVNGVDDAANFRTVRNAMQIVGFMDHE AESVLAVVAAVLKLGNIEFKPESRVNGLDESKIKDKNELKEICELTGIDQSVLERAFSFRTVEAKQEKVSTTLNVAQAYYARDALAKNLY SRLFSWLVNRINESIKAQTKVRKKVMGVLDIYGFEIFEDNSFEQFIINYCNEKLQQIFIELTLKEEQEEYIREDIEWTHIDYFNNAIICD LIENNTNGILAMLDEECLRPGTVTDETFLEKLNQVCATHQHFESRMSKCSRFLNDTSLPHSCFRIQHYAGKVLYQVEGFVDKNNDLLYRD LSQAMWKASHALIKSLFPEGNPAKINLKRPPTAGSQFKASVATLMKNLQTKNPNYIRCIKPNDKKAAHIFNEALVCHQIRYLGLLENVRV RRAGYAFRQAYEPCLERYKMLCKQTWPHWKGPARSGVEVLFNELEIPVEEYSFGRSKIFIRNPRTLFKLEDLRKQRLEDLATLIQKIYRG WKCRTHFLLMKKSQIVIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDPMDSVALNTAYAYATVLTFC TLILAILHHLYFYHVQCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFLWAGPLQAIAVTALLWMEIG ISCLAGMAVLIILLPLQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKKEISKILRSSCLRGMNLASF FSASKIIVFVTFTTYVLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEISQRNRQLPSDGKKMVHVQD FTAFWDKASETPTLQGLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVFSGTLRSNILFGKKYEKERY EKVIKACALKKDLQLLEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFELCICQILHEKITILVTHQL QYLKAASQILILKDGKMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSSRPSLKDGALESQDTENVPV TLSEENRSEGKVGFQAYKNYFRAGAHWIVFIFLILLNTAAQVAYVLQDWWLSYWANKQSMLNVTVNGGGNVTEKLDLNWYLGIYSGLTVA TVLFGIARSLLVFYVLVNSSQTLHNKMFESILKAPVLFFDRNPIGRILNRFSKDIGHLDDLLPLTFLDFIQTLLQVVGVVSVAVAVIPWI AIPLVPLGIIFIFLRRYFLETSRDVKRLESTTRSPVFSHLSSSLQGLWTIRAYKAEERCQELFDAHQDLHSEAWFLFLTTSRWFAVRLDA ICAMFVIIVAFGSLILAKTLDAGQVGLALSYALTLMGMFQWCVRQSAEVENMMISVERVIEYTDLEKEAPWEYQKRPPPAWPHEGVIIFD NVNFMYSPGGPLVLKHLTALIKSQEKVGIVGRTGAGKSSLISALFRLSEPEGKIWIDKILTTEIGLHDLRKKMSIIPQEPVLFTGTMRKN LDPFNEHTDEELWNALQEVQLKETIEDLPGKMDTELAESGSNFSVGQRQLVCLARAILRKNQILIIDEATANVDPRTDELIQKKIREKFA HCTVLTIAHRLNTIIDSDKIMVLDSGRLKEYDEPYVLLQNKESLFYKMVQQLGKAEAAALTETAKQVYFKRNYPHIGHTDHMVTNTSNGQ -------------------------------------------------------------- >56619_56619_2_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000304164_ABCC4_chr13_95887088_ENST00000412704_length(amino acids)=1944AA_BP=768 METMAKMEVKTSLLDNMIGVGDMVLLEPLNEETFINNLKKRFDHSEIYTYIGSVVISVNPYRSLPIYSPEKVEEYRNRNFYELSPHIFAL SDEAYRSLRDQDKDQCILITGESGAGKTEASKLVMSYVAAVCGKGAEVNQVKEQLLQSNPVLEAFGNAKTVRNDNSSRFGKYMDIEFDFK GDPLGGVISNYLLEKSRVVKQPRGERNFHVFYQLLSGASEELLNKLKLERDFSRYNYLSLDSAKVNGVDDAANFRTVRNAMQIVGFMDHE AESVLAVVAAVLKLGNIEFKPESRVNGLDESKIKDKNELKEICELTGIDQSVLERAFSFRTVEAKQEKVSTTLNVAQAYYARDALAKNLY SRLFSWLVNRINESIKAQTKVRKKVMGVLDIYGFEIFEDNSFEQFIINYCNEKLQQIFIELTLKEEQEEYIREDIEWTHIDYFNNAIICD LIENNTNGILAMLDEECLRPGTVTDETFLEKLNQVCATHQHFESRMSKCSRFLNDTSLPHSCFRIQHYAGKVLYQVEGFVDKNNDLLYRD LSQAMWKASHALIKSLFPEGNPAKINLKRPPTAGSQFKASVATLMKNLQTKNPNYIRCIKPNDKKAAHIFNEALVCHQIRYLGLLENVRV RRAGYAFRQAYEPCLERYKMLCKQTWPHWKGPARSGVEVLFNELEIPVEEYSFGRSKIFIRNPRTLFKLEDLRKQRLEDLATLIQKIYRG WKCRTHFLLMKKSQIVIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDPMDSVALNTAYAYATVLTFC TLILAILHHLYFYHVQCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFLWAGPLQAIAVTALLWMEIG ISCLAGMAVLIILLPLQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKKEISKILRSSCLRGMNLASF FSASKIIVFVTFTTYVLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEISQRNRQLPSDGKKMVHVQD FTAFWDKASETPTLQGLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVFSGTLRSNILFGKKYEKERY EKVIKACALKKDLQLLEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFELCICQILHEKITILVTHQL QYLKAASQILILKDGKMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSSRPSLKDGALESQDVAYVLQ DWWLSYWANKQSMLNVTVNGGGNVTEKLDLNWYLGIYSGLTVATVLFGIARSLLVFYVLVNSSQTLHNKMFESILKAPVLFFDRNPIGRI LNRFSKDIGHLDDLLPLTFLDFIQTLLQVVGVVSVAVAVIPWIAIPLVPLGIIFIFLRRYFLETSRDVKRLESTTRSPVFSHLSSSLQGL WTIRAYKAEERCQELFDAHQDLHSEAWFLFLTTSRWFAVRLDAICAMFVIIVAFGSLILAKTLDAGQVGLALSYALTLMGMFQWCVRQSA EVENMMISVERVIEYTDLEKEAPWEYQKRPPPAWPHEGVIIFDNVNFMYSPGGPLVLKHLTALIKSQEKVGIVGRTGAGKSSLISALFRL SEPEGKIWIDKILTTEIGLHDLRKKMSIIPQEPVLFTGTMRKNLDPFNEHTDEELWNALQEVQLKETIEDLPGKMDTELAESGSNFSVGQ RQLVCLARAILRKNQILIIDEATANVDPRTDELIQKKIREKFAHCTVLTIAHRLNTIIDSDKIMVLDSGRLKEYDEPYVLLQNKESLFYK -------------------------------------------------------------- >56619_56619_3_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000339514_ABCC4_chr13_95887088_ENST00000376887_length(amino acids)=2066AA_BP=843 MSTPQLGAHGSLNRGAWRQYQSARRAVGRQPRDSLGRTAAAGAPQPRAGPASRSATGERGRRGGGVAPGEVAPGELETMAKMEVKTSLLD NMIGVGDMVLLEPLNEETFINNLKKRFDHSEIYTYIGSVVISVNPYRSLPIYSPEKVEEYRNRNFYELSPHIFALSDEAYRSLRDQDKDQ CILITGESGAGKTEASKLVMSYVAAVCGKGAEVNQVKEQLLQSNPVLEAFGNAKTVRNDNSSRFGKYMDIEFDFKGDPLGGVISNYLLEK SRVVKQPRGERNFHVFYQLLSGASEELLNKLKLERDFSRYNYLSLDSAKVNGVDDAANFRTVRNAMQIVGFMDHEAESVLAVVAAVLKLG NIEFKPESRVNGLDESKIKDKNELKEICELTGIDQSVLERAFSFRTVEAKQEKVSTTLNVAQAYYARDALAKNLYSRLFSWLVNRINESI KAQTKVRKKVMGVLDIYGFEIFEDNSFEQFIINYCNEKLQQIFIELTLKEEQEEYIREDIEWTHIDYFNNAIICDLIENNTNGILAMLDE ECLRPGTVTDETFLEKLNQVCATHQHFESRMSKCSRFLNDTSLPHSCFRIQHYAGKVLYQVEGFVDKNNDLLYRDLSQAMWKASHALIKS LFPEGNPAKINLKRPPTAGSQFKASVATLMKNLQTKNPNYIRCIKPNDKKAAHIFNEALVCHQIRYLGLLENVRVRRAGYAFRQAYEPCL ERYKMLCKQTWPHWKGPARSGVEVLFNELEIPVEEYSFGRSKIFIRNPRTLFKLEDLRKQRLEDLATLIQKIYRGWKCRTHFLLMKKSQI VIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDPMDSVALNTAYAYATVLTFCTLILAILHHLYFYHV QCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFLWAGPLQAIAVTALLWMEIGISCLAGMAVLIILLP LQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKKEISKILRSSCLRGMNLASFFSASKIIVFVTFTTY VLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEISQRNRQLPSDGKKMVHVQDFTAFWDKASETPTLQ GLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVFSGTLRSNILFGKKYEKERYEKVIKACALKKDLQL LEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFELCICQILHEKITILVTHQLQYLKAASQILILKDG KMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSSRPSLKDGALESQDTENVPVTLSEENRSEGKVGFQ AYKNYFRAGAHWIVFIFLILLNTAAQVAYVLQDWWLSYWANKQSMLNVTVNGGGNVTEKLDLNWYLGIYSGLTVATVLFGIARSLLVFYV LVNSSQTLHNKMFESILKAPVLFFDRNPIGRILNRFSKDIGHLDDLLPLTFLDFIQTLLQVVGVVSVAVAVIPWIAIPLVPLGIIFIFLR RYFLETSRDVKRLESTTRSPVFSHLSSSLQGLWTIRAYKAEERCQELFDAHQDLHSEAWFLFLTTSRWFAVRLDAICAMFVIIVAFGSLI LAKTLDAGQVGLALSYALTLMGMFQWCVRQSAEVENMMISVERVIEYTDLEKEAPWEYQKRPPPAWPHEGVIIFDNVNFMYSPGGPLVLK HLTALIKSQEKVGIVGRTGAGKSSLISALFRLSEPEGKIWIDKILTTEIGLHDLRKKMSIIPQEPVLFTGTMRKNLDPFNEHTDEELWNA LQEVQLKETIEDLPGKMDTELAESGSNFSVGQRQLVCLARAILRKNQILIIDEATANVDPRTDELIQKKIREKFAHCTVLTIAHRLNTII -------------------------------------------------------------- >56619_56619_4_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000339514_ABCC4_chr13_95887088_ENST00000412704_length(amino acids)=2019AA_BP=843 MSTPQLGAHGSLNRGAWRQYQSARRAVGRQPRDSLGRTAAAGAPQPRAGPASRSATGERGRRGGGVAPGEVAPGELETMAKMEVKTSLLD NMIGVGDMVLLEPLNEETFINNLKKRFDHSEIYTYIGSVVISVNPYRSLPIYSPEKVEEYRNRNFYELSPHIFALSDEAYRSLRDQDKDQ CILITGESGAGKTEASKLVMSYVAAVCGKGAEVNQVKEQLLQSNPVLEAFGNAKTVRNDNSSRFGKYMDIEFDFKGDPLGGVISNYLLEK SRVVKQPRGERNFHVFYQLLSGASEELLNKLKLERDFSRYNYLSLDSAKVNGVDDAANFRTVRNAMQIVGFMDHEAESVLAVVAAVLKLG NIEFKPESRVNGLDESKIKDKNELKEICELTGIDQSVLERAFSFRTVEAKQEKVSTTLNVAQAYYARDALAKNLYSRLFSWLVNRINESI KAQTKVRKKVMGVLDIYGFEIFEDNSFEQFIINYCNEKLQQIFIELTLKEEQEEYIREDIEWTHIDYFNNAIICDLIENNTNGILAMLDE ECLRPGTVTDETFLEKLNQVCATHQHFESRMSKCSRFLNDTSLPHSCFRIQHYAGKVLYQVEGFVDKNNDLLYRDLSQAMWKASHALIKS LFPEGNPAKINLKRPPTAGSQFKASVATLMKNLQTKNPNYIRCIKPNDKKAAHIFNEALVCHQIRYLGLLENVRVRRAGYAFRQAYEPCL ERYKMLCKQTWPHWKGPARSGVEVLFNELEIPVEEYSFGRSKIFIRNPRTLFKLEDLRKQRLEDLATLIQKIYRGWKCRTHFLLMKKSQI VIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDPMDSVALNTAYAYATVLTFCTLILAILHHLYFYHV QCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFLWAGPLQAIAVTALLWMEIGISCLAGMAVLIILLP LQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKKEISKILRSSCLRGMNLASFFSASKIIVFVTFTTY VLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEISQRNRQLPSDGKKMVHVQDFTAFWDKASETPTLQ GLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVFSGTLRSNILFGKKYEKERYEKVIKACALKKDLQL LEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFELCICQILHEKITILVTHQLQYLKAASQILILKDG KMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSSRPSLKDGALESQDVAYVLQDWWLSYWANKQSMLN VTVNGGGNVTEKLDLNWYLGIYSGLTVATVLFGIARSLLVFYVLVNSSQTLHNKMFESILKAPVLFFDRNPIGRILNRFSKDIGHLDDLL PLTFLDFIQTLLQVVGVVSVAVAVIPWIAIPLVPLGIIFIFLRRYFLETSRDVKRLESTTRSPVFSHLSSSLQGLWTIRAYKAEERCQEL FDAHQDLHSEAWFLFLTTSRWFAVRLDAICAMFVIIVAFGSLILAKTLDAGQVGLALSYALTLMGMFQWCVRQSAEVENMMISVERVIEY TDLEKEAPWEYQKRPPPAWPHEGVIIFDNVNFMYSPGGPLVLKHLTALIKSQEKVGIVGRTGAGKSSLISALFRLSEPEGKIWIDKILTT EIGLHDLRKKMSIIPQEPVLFTGTMRKNLDPFNEHTDEELWNALQEVQLKETIEDLPGKMDTELAESGSNFSVGQRQLVCLARAILRKNQ ILIIDEATANVDPRTDELIQKKIREKFAHCTVLTIAHRLNTIIDSDKIMVLDSGRLKEYDEPYVLLQNKESLFYKMVQQLGKAEAAALTE -------------------------------------------------------------- >56619_56619_5_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000392316_ABCC4_chr13_95887088_ENST00000376887_length(amino acids)=1991AA_BP=768 LETMAKMEVKTSLLDNMIGVGDMVLLEPLNEETFINNLKKRFDHSEIYTYIGSVVISVNPYRSLPIYSPEKVEEYRNRNFYELSPHIFAL SDEAYRSLRDQDKDQCILITGESGAGKTEASKLVMSYVAAVCGKGAEVNQVKEQLLQSNPVLEAFGNAKTVRNDNSSRFGKYMDIEFDFK GDPLGGVISNYLLEKSRVVKQPRGERNFHVFYQLLSGASEELLNKLKLERDFSRYNYLSLDSAKVNGVDDAANFRTVRNAMQIVGFMDHE AESVLAVVAAVLKLGNIEFKPESRVNGLDESKIKDKNELKEICELTGIDQSVLERAFSFRTVEAKQEKVSTTLNVAQAYYARDALAKNLY SRLFSWLVNRINESIKAQTKVRKKVMGVLDIYGFEIFEDNSFEQFIINYCNEKLQQIFIELTLKEEQEEYIREDIEWTHIDYFNNAIICD LIENNTNGILAMLDEECLRPGTVTDETFLEKLNQVCATHQHFESRMSKCSRFLNDTSLPHSCFRIQHYAGKVLYQVEGFVDKNNDLLYRD LSQAMWKASHALIKSLFPEGNPAKINLKRPPTAGSQFKASVATLMKNLQTKNPNYIRCIKPNDKKAAHIFNEALVCHQIRYLGLLENVRV RRAGYAFRQAYEPCLERYKMLCKQTWPHWKGPARSGVEVLFNELEIPVEEYSFGRSKIFIRNPRTLFKLEDLRKQRLEDLATLIQKIYRG WKCRTHFLLMKKSQIVIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDPMDSVALNTAYAYATVLTFC TLILAILHHLYFYHVQCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFLWAGPLQAIAVTALLWMEIG ISCLAGMAVLIILLPLQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKKEISKILRSSCLRGMNLASF FSASKIIVFVTFTTYVLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEISQRNRQLPSDGKKMVHVQD FTAFWDKASETPTLQGLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVFSGTLRSNILFGKKYEKERY EKVIKACALKKDLQLLEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFELCICQILHEKITILVTHQL QYLKAASQILILKDGKMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSSRPSLKDGALESQDTENVPV TLSEENRSEGKVGFQAYKNYFRAGAHWIVFIFLILLNTAAQVAYVLQDWWLSYWANKQSMLNVTVNGGGNVTEKLDLNWYLGIYSGLTVA TVLFGIARSLLVFYVLVNSSQTLHNKMFESILKAPVLFFDRNPIGRILNRFSKDIGHLDDLLPLTFLDFIQTLLQVVGVVSVAVAVIPWI AIPLVPLGIIFIFLRRYFLETSRDVKRLESTTRSPVFSHLSSSLQGLWTIRAYKAEERCQELFDAHQDLHSEAWFLFLTTSRWFAVRLDA ICAMFVIIVAFGSLILAKTLDAGQVGLALSYALTLMGMFQWCVRQSAEVENMMISVERVIEYTDLEKEAPWEYQKRPPPAWPHEGVIIFD NVNFMYSPGGPLVLKHLTALIKSQEKVGIVGRTGAGKSSLISALFRLSEPEGKIWIDKILTTEIGLHDLRKKMSIIPQEPVLFTGTMRKN LDPFNEHTDEELWNALQEVQLKETIEDLPGKMDTELAESGSNFSVGQRQLVCLARAILRKNQILIIDEATANVDPRTDELIQKKIREKFA HCTVLTIAHRLNTIIDSDKIMVLDSGRLKEYDEPYVLLQNKESLFYKMVQQLGKAEAAALTETAKQVYFKRNYPHIGHTDHMVTNTSNGQ -------------------------------------------------------------- >56619_56619_6_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000392316_ABCC4_chr13_95887088_ENST00000412704_length(amino acids)=1944AA_BP=768 LETMAKMEVKTSLLDNMIGVGDMVLLEPLNEETFINNLKKRFDHSEIYTYIGSVVISVNPYRSLPIYSPEKVEEYRNRNFYELSPHIFAL SDEAYRSLRDQDKDQCILITGESGAGKTEASKLVMSYVAAVCGKGAEVNQVKEQLLQSNPVLEAFGNAKTVRNDNSSRFGKYMDIEFDFK GDPLGGVISNYLLEKSRVVKQPRGERNFHVFYQLLSGASEELLNKLKLERDFSRYNYLSLDSAKVNGVDDAANFRTVRNAMQIVGFMDHE AESVLAVVAAVLKLGNIEFKPESRVNGLDESKIKDKNELKEICELTGIDQSVLERAFSFRTVEAKQEKVSTTLNVAQAYYARDALAKNLY SRLFSWLVNRINESIKAQTKVRKKVMGVLDIYGFEIFEDNSFEQFIINYCNEKLQQIFIELTLKEEQEEYIREDIEWTHIDYFNNAIICD LIENNTNGILAMLDEECLRPGTVTDETFLEKLNQVCATHQHFESRMSKCSRFLNDTSLPHSCFRIQHYAGKVLYQVEGFVDKNNDLLYRD LSQAMWKASHALIKSLFPEGNPAKINLKRPPTAGSQFKASVATLMKNLQTKNPNYIRCIKPNDKKAAHIFNEALVCHQIRYLGLLENVRV RRAGYAFRQAYEPCLERYKMLCKQTWPHWKGPARSGVEVLFNELEIPVEEYSFGRSKIFIRNPRTLFKLEDLRKQRLEDLATLIQKIYRG WKCRTHFLLMKKSQIVIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDPMDSVALNTAYAYATVLTFC TLILAILHHLYFYHVQCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFLWAGPLQAIAVTALLWMEIG ISCLAGMAVLIILLPLQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKKEISKILRSSCLRGMNLASF FSASKIIVFVTFTTYVLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEISQRNRQLPSDGKKMVHVQD FTAFWDKASETPTLQGLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVFSGTLRSNILFGKKYEKERY EKVIKACALKKDLQLLEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFELCICQILHEKITILVTHQL QYLKAASQILILKDGKMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSSRPSLKDGALESQDVAYVLQ DWWLSYWANKQSMLNVTVNGGGNVTEKLDLNWYLGIYSGLTVATVLFGIARSLLVFYVLVNSSQTLHNKMFESILKAPVLFFDRNPIGRI LNRFSKDIGHLDDLLPLTFLDFIQTLLQVVGVVSVAVAVIPWIAIPLVPLGIIFIFLRRYFLETSRDVKRLESTTRSPVFSHLSSSLQGL WTIRAYKAEERCQELFDAHQDLHSEAWFLFLTTSRWFAVRLDAICAMFVIIVAFGSLILAKTLDAGQVGLALSYALTLMGMFQWCVRQSA EVENMMISVERVIEYTDLEKEAPWEYQKRPPPAWPHEGVIIFDNVNFMYSPGGPLVLKHLTALIKSQEKVGIVGRTGAGKSSLISALFRL SEPEGKIWIDKILTTEIGLHDLRKKMSIIPQEPVLFTGTMRKNLDPFNEHTDEELWNALQEVQLKETIEDLPGKMDTELAESGSNFSVGQ RQLVCLARAILRKNQILIIDEATANVDPRTDELIQKKIREKFAHCTVLTIAHRLNTIIDSDKIMVLDSGRLKEYDEPYVLLQNKESLFYK -------------------------------------------------------------- >56619_56619_7_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000392318_ABCC4_chr13_95887088_ENST00000376887_length(amino acids)=2066AA_BP=843 MSTPQLGAHGSLNRGAWRQYQSARRAVGRQPRDSLGRTAAAGAPQPRAGPASRSATGERGRRGGGVAPGEVAPGELETMAKMEVKTSLLD NMIGVGDMVLLEPLNEETFINNLKKRFDHSEIYTYIGSVVISVNPYRSLPIYSPEKVEEYRNRNFYELSPHIFALSDEAYRSLRDQDKDQ CILITGESGAGKTEASKLVMSYVAAVCGKGAEVNQVKEQLLQSNPVLEAFGNAKTVRNDNSSRFGKYMDIEFDFKGDPLGGVISNYLLEK SRVVKQPRGERNFHVFYQLLSGASEELLNKLKLERDFSRYNYLSLDSAKVNGVDDAANFRTVRNAMQIVGFMDHEAESVLAVVAAVLKLG NIEFKPESRVNGLDESKIKDKNELKEICELTGIDQSVLERAFSFRTVEAKQEKVSTTLNVAQAYYARDALAKNLYSRLFSWLVNRINESI KAQTKVRKKVMGVLDIYGFEIFEDNSFEQFIINYCNEKLQQIFIELTLKEEQEEYIREDIEWTHIDYFNNAIICDLIENNTNGILAMLDE ECLRPGTVTDETFLEKLNQVCATHQHFESRMSKCSRFLNDTSLPHSCFRIQHYAGKVLYQVEGFVDKNNDLLYRDLSQAMWKASHALIKS LFPEGNPAKINLKRPPTAGSQFKASVATLMKNLQTKNPNYIRCIKPNDKKAAHIFNEALVCHQIRYLGLLENVRVRRAGYAFRQAYEPCL ERYKMLCKQTWPHWKGPARSGVEVLFNELEIPVEEYSFGRSKIFIRNPRTLFKLEDLRKQRLEDLATLIQKIYRGWKCRTHFLLMKKSQI VIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDPMDSVALNTAYAYATVLTFCTLILAILHHLYFYHV QCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFLWAGPLQAIAVTALLWMEIGISCLAGMAVLIILLP LQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKKEISKILRSSCLRGMNLASFFSASKIIVFVTFTTY VLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEISQRNRQLPSDGKKMVHVQDFTAFWDKASETPTLQ GLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVFSGTLRSNILFGKKYEKERYEKVIKACALKKDLQL LEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFELCICQILHEKITILVTHQLQYLKAASQILILKDG KMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSSRPSLKDGALESQDTENVPVTLSEENRSEGKVGFQ AYKNYFRAGAHWIVFIFLILLNTAAQVAYVLQDWWLSYWANKQSMLNVTVNGGGNVTEKLDLNWYLGIYSGLTVATVLFGIARSLLVFYV LVNSSQTLHNKMFESILKAPVLFFDRNPIGRILNRFSKDIGHLDDLLPLTFLDFIQTLLQVVGVVSVAVAVIPWIAIPLVPLGIIFIFLR RYFLETSRDVKRLESTTRSPVFSHLSSSLQGLWTIRAYKAEERCQELFDAHQDLHSEAWFLFLTTSRWFAVRLDAICAMFVIIVAFGSLI LAKTLDAGQVGLALSYALTLMGMFQWCVRQSAEVENMMISVERVIEYTDLEKEAPWEYQKRPPPAWPHEGVIIFDNVNFMYSPGGPLVLK HLTALIKSQEKVGIVGRTGAGKSSLISALFRLSEPEGKIWIDKILTTEIGLHDLRKKMSIIPQEPVLFTGTMRKNLDPFNEHTDEELWNA LQEVQLKETIEDLPGKMDTELAESGSNFSVGQRQLVCLARAILRKNQILIIDEATANVDPRTDELIQKKIREKFAHCTVLTIAHRLNTII -------------------------------------------------------------- >56619_56619_8_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000392318_ABCC4_chr13_95887088_ENST00000412704_length(amino acids)=2019AA_BP=843 MSTPQLGAHGSLNRGAWRQYQSARRAVGRQPRDSLGRTAAAGAPQPRAGPASRSATGERGRRGGGVAPGEVAPGELETMAKMEVKTSLLD NMIGVGDMVLLEPLNEETFINNLKKRFDHSEIYTYIGSVVISVNPYRSLPIYSPEKVEEYRNRNFYELSPHIFALSDEAYRSLRDQDKDQ CILITGESGAGKTEASKLVMSYVAAVCGKGAEVNQVKEQLLQSNPVLEAFGNAKTVRNDNSSRFGKYMDIEFDFKGDPLGGVISNYLLEK SRVVKQPRGERNFHVFYQLLSGASEELLNKLKLERDFSRYNYLSLDSAKVNGVDDAANFRTVRNAMQIVGFMDHEAESVLAVVAAVLKLG NIEFKPESRVNGLDESKIKDKNELKEICELTGIDQSVLERAFSFRTVEAKQEKVSTTLNVAQAYYARDALAKNLYSRLFSWLVNRINESI KAQTKVRKKVMGVLDIYGFEIFEDNSFEQFIINYCNEKLQQIFIELTLKEEQEEYIREDIEWTHIDYFNNAIICDLIENNTNGILAMLDE ECLRPGTVTDETFLEKLNQVCATHQHFESRMSKCSRFLNDTSLPHSCFRIQHYAGKVLYQVEGFVDKNNDLLYRDLSQAMWKASHALIKS LFPEGNPAKINLKRPPTAGSQFKASVATLMKNLQTKNPNYIRCIKPNDKKAAHIFNEALVCHQIRYLGLLENVRVRRAGYAFRQAYEPCL ERYKMLCKQTWPHWKGPARSGVEVLFNELEIPVEEYSFGRSKIFIRNPRTLFKLEDLRKQRLEDLATLIQKIYRGWKCRTHFLLMKKSQI VIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDPMDSVALNTAYAYATVLTFCTLILAILHHLYFYHV QCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFLWAGPLQAIAVTALLWMEIGISCLAGMAVLIILLP LQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKKEISKILRSSCLRGMNLASFFSASKIIVFVTFTTY VLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEISQRNRQLPSDGKKMVHVQDFTAFWDKASETPTLQ GLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVFSGTLRSNILFGKKYEKERYEKVIKACALKKDLQL LEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFELCICQILHEKITILVTHQLQYLKAASQILILKDG KMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSSRPSLKDGALESQDVAYVLQDWWLSYWANKQSMLN VTVNGGGNVTEKLDLNWYLGIYSGLTVATVLFGIARSLLVFYVLVNSSQTLHNKMFESILKAPVLFFDRNPIGRILNRFSKDIGHLDDLL PLTFLDFIQTLLQVVGVVSVAVAVIPWIAIPLVPLGIIFIFLRRYFLETSRDVKRLESTTRSPVFSHLSSSLQGLWTIRAYKAEERCQEL FDAHQDLHSEAWFLFLTTSRWFAVRLDAICAMFVIIVAFGSLILAKTLDAGQVGLALSYALTLMGMFQWCVRQSAEVENMMISVERVIEY TDLEKEAPWEYQKRPPPAWPHEGVIIFDNVNFMYSPGGPLVLKHLTALIKSQEKVGIVGRTGAGKSSLISALFRLSEPEGKIWIDKILTT EIGLHDLRKKMSIIPQEPVLFTGTMRKNLDPFNEHTDEELWNALQEVQLKETIEDLPGKMDTELAESGSNFSVGQRQLVCLARAILRKNQ ILIIDEATANVDPRTDELIQKKIREKFAHCTVLTIAHRLNTIIDSDKIMVLDSGRLKEYDEPYVLLQNKESLFYKMVQQLGKAEAAALTE -------------------------------------------------------------- >56619_56619_9_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000439065_ABCC4_chr13_95887088_ENST00000376887_length(amino acids)=1290AA_BP=67 MRKQRLEDLATLIQKIYRGWKCRTHFLLMKKSQIVIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDP MDSVALNTAYAYATVLTFCTLILAILHHLYFYHVQCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFL WAGPLQAIAVTALLWMEIGISCLAGMAVLIILLPLQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKK EISKILRSSCLRGMNLASFFSASKIIVFVTFTTYVLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEI SQRNRQLPSDGKKMVHVQDFTAFWDKASETPTLQGLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVF SGTLRSNILFGKKYEKERYEKVIKACALKKDLQLLEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFE LCICQILHEKITILVTHQLQYLKAASQILILKDGKMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSS RPSLKDGALESQDTENVPVTLSEENRSEGKVGFQAYKNYFRAGAHWIVFIFLILLNTAAQVAYVLQDWWLSYWANKQSMLNVTVNGGGNV TEKLDLNWYLGIYSGLTVATVLFGIARSLLVFYVLVNSSQTLHNKMFESILKAPVLFFDRNPIGRILNRFSKDIGHLDDLLPLTFLDFIQ TLLQVVGVVSVAVAVIPWIAIPLVPLGIIFIFLRRYFLETSRDVKRLESTTRSPVFSHLSSSLQGLWTIRAYKAEERCQELFDAHQDLHS EAWFLFLTTSRWFAVRLDAICAMFVIIVAFGSLILAKTLDAGQVGLALSYALTLMGMFQWCVRQSAEVENMMISVERVIEYTDLEKEAPW EYQKRPPPAWPHEGVIIFDNVNFMYSPGGPLVLKHLTALIKSQEKVGIVGRTGAGKSSLISALFRLSEPEGKIWIDKILTTEIGLHDLRK KMSIIPQEPVLFTGTMRKNLDPFNEHTDEELWNALQEVQLKETIEDLPGKMDTELAESGSNFSVGQRQLVCLARAILRKNQILIIDEATA NVDPRTDELIQKKIREKFAHCTVLTIAHRLNTIIDSDKIMVLDSGRLKEYDEPYVLLQNKESLFYKMVQQLGKAEAAALTETAKQVYFKR -------------------------------------------------------------- >56619_56619_10_MYO1B-ABCC4_MYO1B_chr2_192261223_ENST00000439065_ABCC4_chr13_95887088_ENST00000412704_length(amino acids)=1243AA_BP=67 MRKQRLEDLATLIQKIYRGWKCRTHFLLMKKSQIVIAAWYRRYAQQKRYQQTKSSALVIQSYIRGWKESAKVIQPIFLGKIINYFENYDP MDSVALNTAYAYATVLTFCTLILAILHHLYFYHVQCAGMRLRVAMCHMIYRKALRLSNMAMGKTTTGQIVNLLSNDVNKFDQVTVFLHFL WAGPLQAIAVTALLWMEIGISCLAGMAVLIILLPLQSCFGKLFSSLRSKTATFTDARIRTMNEVITGIRIIKMYAWEKSFSNLITNLRKK EISKILRSSCLRGMNLASFFSASKIIVFVTFTTYVLLGSVITASRVFVAVTLYGAVRLTVTLFFPSAIERVSEAIVSIRRIQTFLLLDEI SQRNRQLPSDGKKMVHVQDFTAFWDKASETPTLQGLSFTVRPGELLAVVGPVGAGKSSLLSAVLGELAPSHGLVSVHGRIAYVSQQPWVF SGTLRSNILFGKKYEKERYEKVIKACALKKDLQLLEDGDLTVIGDRGTTLSGGQKARVNLARAVYQDADIYLLDDPLSAVDAEVSRHLFE LCICQILHEKITILVTHQLQYLKAASQILILKDGKMVQKGTYTEFLKSGIDFGSLLKKDNEESEQPPVPGTPTLRNRTFSESSVWSQQSS RPSLKDGALESQDVAYVLQDWWLSYWANKQSMLNVTVNGGGNVTEKLDLNWYLGIYSGLTVATVLFGIARSLLVFYVLVNSSQTLHNKMF ESILKAPVLFFDRNPIGRILNRFSKDIGHLDDLLPLTFLDFIQTLLQVVGVVSVAVAVIPWIAIPLVPLGIIFIFLRRYFLETSRDVKRL ESTTRSPVFSHLSSSLQGLWTIRAYKAEERCQELFDAHQDLHSEAWFLFLTTSRWFAVRLDAICAMFVIIVAFGSLILAKTLDAGQVGLA LSYALTLMGMFQWCVRQSAEVENMMISVERVIEYTDLEKEAPWEYQKRPPPAWPHEGVIIFDNVNFMYSPGGPLVLKHLTALIKSQEKVG IVGRTGAGKSSLISALFRLSEPEGKIWIDKILTTEIGLHDLRKKMSIIPQEPVLFTGTMRKNLDPFNEHTDEELWNALQEVQLKETIEDL PGKMDTELAESGSNFSVGQRQLVCLARAILRKNQILIIDEATANVDPRTDELIQKKIREKFAHCTVLTIAHRLNTIIDSDKIMVLDSGRL -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:192261223/chr13:95887088) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| MYO1B | ABCC4 |
| FUNCTION: Motor protein that may participate in process critical to neuronal development and function such as cell migration, neurite outgrowth and vesicular transport. {ECO:0000250}. | FUNCTION: ATP-dependent transporter of the ATP-binding cassette (ABC) family that actively extrudes physiological compounds and xenobiotics from cells. Transports a range of endogenous molecules that have a key role in cellular communication and signaling, including cyclic nucleotides such as cyclic AMP (cAMP) and cyclic GMP (cGMP), bile acids, steroid conjugates, urate, and prostaglandins (PubMed:11856762, PubMed:12883481, PubMed:12523936, PubMed:12835412, PubMed:15364914, PubMed:15454390, PubMed:16282361, PubMed:17959747, PubMed:18300232, PubMed:26721430). Mediates the ATP-dependent efflux of glutathione conjugates such as leukotriene C4 (LTC4) and leukotriene B4 (LTB4) too. The presence of GSH is necessary for the ATP-dependent transport of LTB4, whereas GSH is not required for the transport of LTC4 (PubMed:17959747). Mediates the cotransport of bile acids with reduced glutathione (GSH) (PubMed:12883481, PubMed:12523936, PubMed:16282361). Transports a wide range of drugs and their metabolites, including anticancer, antiviral and antibiotics molecules (PubMed:11856762, PubMed:12105214, PubMed:15454390, PubMed:18300232, PubMed:17344354). Confers resistance to anticancer agents such as methotrexate (PubMed:11106685). {ECO:0000269|PubMed:11106685, ECO:0000269|PubMed:11856762, ECO:0000269|PubMed:12105214, ECO:0000269|PubMed:12523936, ECO:0000269|PubMed:12835412, ECO:0000269|PubMed:12883481, ECO:0000269|PubMed:15364914, ECO:0000269|PubMed:15454390, ECO:0000269|PubMed:16282361, ECO:0000269|PubMed:17344354, ECO:0000269|PubMed:17959747, ECO:0000269|PubMed:18300232, ECO:0000269|PubMed:26721430}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 15_701 | 765.0 | 1137.0 | Domain | Myosin motor |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 704_733 | 765.0 | 1137.0 | Domain | IQ 1 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 728_748 | 765.0 | 1137.0 | Domain | IQ 2 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 15_701 | 765.0 | 1079.0 | Domain | Myosin motor |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 704_733 | 765.0 | 1079.0 | Domain | IQ 1 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 728_748 | 765.0 | 1079.0 | Domain | IQ 2 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 15_701 | 765.0 | 1137.0 | Domain | Myosin motor |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 704_733 | 765.0 | 1137.0 | Domain | IQ 1 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 728_748 | 765.0 | 1137.0 | Domain | IQ 2 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 108_115 | 765.0 | 1137.0 | Nucleotide binding | ATP |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 108_115 | 765.0 | 1079.0 | Nucleotide binding | ATP |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 108_115 | 765.0 | 1137.0 | Nucleotide binding | ATP |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 578_600 | 765.0 | 1137.0 | Region | Actin-binding |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 578_600 | 765.0 | 1079.0 | Region | Actin-binding |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 578_600 | 765.0 | 1137.0 | Region | Actin-binding |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 1041_1274 | 102.0 | 1326.0 | Domain | ABC transporter 2 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 410_633 | 102.0 | 1326.0 | Domain | ABC transporter 1 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 714_1005 | 102.0 | 1326.0 | Domain | ABC transmembrane type-1 2 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 1041_1274 | 102.0 | 1279.0 | Domain | ABC transporter 2 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 410_633 | 102.0 | 1279.0 | Domain | ABC transporter 1 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 714_1005 | 102.0 | 1279.0 | Domain | ABC transmembrane type-1 2 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 1041_1274 | 102.0 | 860.0 | Domain | ABC transporter 2 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 410_633 | 102.0 | 860.0 | Domain | ABC transporter 1 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 714_1005 | 102.0 | 860.0 | Domain | ABC transmembrane type-1 2 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 1322_1325 | 102.0 | 1326.0 | Motif | Note=PDZ-binding | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 1322_1325 | 102.0 | 1279.0 | Motif | Note=PDZ-binding | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 1322_1325 | 102.0 | 860.0 | Motif | Note=PDZ-binding | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 1075_1082 | 102.0 | 1326.0 | Nucleotide binding | ATP 2 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 445_452 | 102.0 | 1326.0 | Nucleotide binding | ATP 1 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 1075_1082 | 102.0 | 1279.0 | Nucleotide binding | ATP 2 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 445_452 | 102.0 | 1279.0 | Nucleotide binding | ATP 1 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 1075_1082 | 102.0 | 860.0 | Nucleotide binding | ATP 2 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 445_452 | 102.0 | 860.0 | Nucleotide binding | ATP 1 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 1038_1058 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 136_156 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 207_227 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 228_248 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 328_348 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 351_371 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 440_460 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 710_730 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 771_791 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 836_856 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 858_878 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 954_974 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 977_997 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 1038_1058 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 136_156 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 207_227 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 228_248 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 328_348 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 351_371 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 440_460 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 710_730 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 771_791 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 836_856 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 858_878 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 954_974 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 977_997 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 1038_1058 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 136_156 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 207_227 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 228_248 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 328_348 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 351_371 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 440_460 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 710_730 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 771_791 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 836_856 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 858_878 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 954_974 | 102.0 | 860.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 977_997 | 102.0 | 860.0 | Transmembrane | Helical |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 750_779 | 765.0 | 1137.0 | Domain | IQ 3 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 779_808 | 765.0 | 1137.0 | Domain | IQ 4 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 808_837 | 765.0 | 1137.0 | Domain | IQ 5 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 837_866 | 765.0 | 1137.0 | Domain | IQ 6 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000304164 | - | 21 | 31 | 952_1136 | 765.0 | 1137.0 | Domain | TH1 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 750_779 | 765.0 | 1079.0 | Domain | IQ 3 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 779_808 | 765.0 | 1079.0 | Domain | IQ 4 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 808_837 | 765.0 | 1079.0 | Domain | IQ 5 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 837_866 | 765.0 | 1079.0 | Domain | IQ 6 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000339514 | - | 21 | 29 | 952_1136 | 765.0 | 1079.0 | Domain | TH1 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 750_779 | 765.0 | 1137.0 | Domain | IQ 3 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 779_808 | 765.0 | 1137.0 | Domain | IQ 4 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 808_837 | 765.0 | 1137.0 | Domain | IQ 5 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 837_866 | 765.0 | 1137.0 | Domain | IQ 6 |
| Hgene | MYO1B | chr2:192261223 | chr13:95887088 | ENST00000392318 | - | 21 | 31 | 952_1136 | 765.0 | 1137.0 | Domain | TH1 |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 92_377 | 102.0 | 1326.0 | Domain | ABC transmembrane type-1 1 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 92_377 | 102.0 | 1279.0 | Domain | ABC transmembrane type-1 1 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 92_377 | 102.0 | 860.0 | Domain | ABC transmembrane type-1 1 | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000376887 | 2 | 31 | 93_113 | 102.0 | 1326.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000412704 | 2 | 30 | 93_113 | 102.0 | 1279.0 | Transmembrane | Helical | |
| Tgene | ABCC4 | chr2:192261223 | chr13:95887088 | ENST00000431522 | 2 | 21 | 93_113 | 102.0 | 860.0 | Transmembrane | Helical |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| MYO1B | |
| ABCC4 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to MYO1B-ABCC4 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to MYO1B-ABCC4 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies