| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:APPL2-CIT |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: APPL2-CIT | FusionPDB ID: 5685 | FusionGDB2.0 ID: 5685 | Hgene | Tgene | Gene symbol | APPL2 | CIT | Gene ID | 55198 | 79947 |
| Gene name | adaptor protein, phosphotyrosine interacting with PH domain and leucine zipper 2 | dehydrodolichyl diphosphate synthase subunit | |
| Synonyms | DIP13B | CIT|CPT|DEDSM|DS|HDS|RP59|hCIT | |
| Cytomap | 12q23.3 | 1p36.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | DCC-interacting protein 13-betaDIP13 betaadapter protein containing PH domain, PTB domain and leucine zipper motif 2adaptor protein, phosphotyrosine interaction, PH domain and leucine zipper containing 2 | dehydrodolichyl diphosphate synthase complex subunit DHDDScis-IPTasecis-isoprenyltransferasecis-prenyl transferasecis-prenyltransferase subunit hCITdedol-PP synthasedehydrodolichyl diphosphate syntase complex subunit DHDDSepididymis tissue protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q8NEU8 | Q96RK1 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000258530, ENST00000551662, ENST00000539978, ENST00000546731, ENST00000549573, | ENST00000537607, ENST00000261833, ENST00000392521, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 9 X 10 X 5=450 | 4 X 4 X 4=64 |
| # samples | 10 | 5 | |
| ** MAII score | log2(10/450*10)=-2.16992500144231 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/64*10)=-0.356143810225275 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: APPL2 [Title/Abstract] AND CIT [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | APPL2(105629737)-CIT(120198859), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | APPL2-CIT seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. APPL2-CIT seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. APPL2-CIT seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. APPL2-CIT seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | APPL2 | GO:0006606 | protein import into nucleus | 26583432 |
| Hgene | APPL2 | GO:0051289 | protein homotetramerization | 23055524 |
| Hgene | APPL2 | GO:2000045 | regulation of G1/S transition of mitotic cell cycle | 15016378 |
| Tgene | CIT | GO:0006489 | dolichyl diphosphate biosynthetic process | 28842490 |
| Fusion gene breakpoints across APPL2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CIT (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-34-5232-01A | APPL2 | chr12 | 105629737 | - | CIT | chr12 | 120198859 | - |
| ChimerDB4 | LUSC | TCGA-34-5232 | APPL2 | chr12 | 105629736 | - | CIT | chr12 | 120198859 | - |
| ChimerDB4 | LUSC | TCGA-34-5232 | APPL2 | chr12 | 105629737 | - | CIT | chr12 | 120198859 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000258530 | APPL2 | chr12 | 105629737 | - | ENST00000392521 | CIT | chr12 | 120198859 | - | 6628 | 280 | 79 | 4185 | 1368 |
| ENST00000258530 | APPL2 | chr12 | 105629737 | - | ENST00000261833 | CIT | chr12 | 120198859 | - | 6627 | 280 | 79 | 4185 | 1368 |
| ENST00000551662 | APPL2 | chr12 | 105629737 | - | ENST00000392521 | CIT | chr12 | 120198859 | - | 6473 | 125 | 23 | 4030 | 1335 |
| ENST00000551662 | APPL2 | chr12 | 105629737 | - | ENST00000261833 | CIT | chr12 | 120198859 | - | 6472 | 125 | 23 | 4030 | 1335 |
| ENST00000258530 | APPL2 | chr12 | 105629736 | - | ENST00000392521 | CIT | chr12 | 120198859 | - | 6628 | 280 | 79 | 4185 | 1368 |
| ENST00000258530 | APPL2 | chr12 | 105629736 | - | ENST00000261833 | CIT | chr12 | 120198859 | - | 6627 | 280 | 79 | 4185 | 1368 |
| ENST00000551662 | APPL2 | chr12 | 105629736 | - | ENST00000392521 | CIT | chr12 | 120198859 | - | 6473 | 125 | 23 | 4030 | 1335 |
| ENST00000551662 | APPL2 | chr12 | 105629736 | - | ENST00000261833 | CIT | chr12 | 120198859 | - | 6472 | 125 | 23 | 4030 | 1335 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000258530 | ENST00000392521 | APPL2 | chr12 | 105629737 | - | CIT | chr12 | 120198859 | - | 0.002610473 | 0.9973895 |
| ENST00000258530 | ENST00000261833 | APPL2 | chr12 | 105629737 | - | CIT | chr12 | 120198859 | - | 0.002618573 | 0.9973814 |
| ENST00000551662 | ENST00000392521 | APPL2 | chr12 | 105629737 | - | CIT | chr12 | 120198859 | - | 0.002159267 | 0.99784076 |
| ENST00000551662 | ENST00000261833 | APPL2 | chr12 | 105629737 | - | CIT | chr12 | 120198859 | - | 0.002166164 | 0.9978338 |
| ENST00000258530 | ENST00000392521 | APPL2 | chr12 | 105629736 | - | CIT | chr12 | 120198859 | - | 0.002610473 | 0.9973895 |
| ENST00000258530 | ENST00000261833 | APPL2 | chr12 | 105629736 | - | CIT | chr12 | 120198859 | - | 0.002618573 | 0.9973814 |
| ENST00000551662 | ENST00000392521 | APPL2 | chr12 | 105629736 | - | CIT | chr12 | 120198859 | - | 0.002159267 | 0.99784076 |
| ENST00000551662 | ENST00000261833 | APPL2 | chr12 | 105629736 | - | CIT | chr12 | 120198859 | - | 0.002166164 | 0.9978338 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >5685_5685_1_APPL2-CIT_APPL2_chr12_105629736_ENST00000258530_CIT_chr12_120198859_ENST00000261833_length(amino acids)=1368AA_BP=67 MARRGRARGRRGHGVAAASPEPRAGECSRPPRLLPSVLPTQPSAEPRRTMPAVDKLLLEEALQDSPQVLDNQIKKDLADKETLENMMQRH EEEAHEKGKILSEQKAMINAMDSKIRSLEQRIVELSEANKLAANSSLFTQRNMKAQEEMISELRQQKFYLETQAGKLEAQNRKLEEQLEK ISHQDHSDKNRLLELETRLREVSLEHEEQKLELKRQLTELQLSLQERESQLTALQAARAALESQLRQAKTELEETTAEAEEEIQALTAHR DEIQRKFDALRNSCTVITDLEEQLNQLTEDNAELNNQNFYLSKQLDEASGANDEIVQLRSEVDHLRREITEREMQLTSQKQTMEALKTTC TMLEEQVMDLEALNDELLEKERQWEAWRSVLGDEKSQFECRVRELQRMLDTEKQSRARADQRITESRQVVELAVKEHKAEILALQQALKE QKLKAESLSDKLNDLEKKHAMLEMNARSLQQKLETERELKQRLLEEQAKLQQQMDLQKNHIFRLTQGLQEALDRADLLKTERSDLEYQLE NIQVLYSHEKVKMEGTISQQTKLIDFLQAKMDQPAKKKKGLFSRRKEDPALPTQVPLQYNELKLALEKEKARCAELEEALQKTRIELRSA REEAAHRKATDHPHPSTPATARQQIAMSAIVRSPEHQPSAMSLLAPPSSRRKESSTPEEFSRRLKERMHHNIPHRFNVGLNMRATKCAVC LDTVHFGRQASKCLECQVMCHPKCSTCLPATCGLPAEYATHFTEAFCRDKMNSPGLQTKEPSSSLHLEGWMKVPRNNKRGQQGWDRKYIV LEGSKVLIYDNEAREAGQRPVEEFELCLPDGDVSIHGAVGASELANTAKADVPYILKMESHPHTTCWPGRTLYLLAPSFPDKQRWVTALE SVVAGGRVSREKAEADAKLLGNSLLKLEGDDRLDMNCTLPFSDQVVLVGTEEGLYALNVLKNSLTHVPGIGAVFQIYIIKDLEKLLMIAG EERALCLVDVKKVKQSLAQSHLPAQPDISPNIFEAVKGCHLFGAGKIENGLCICAAMPSKVVILRYNENLSKYCIRKEIETSEPCSCIHF TNYSILIGTNKFYEIDMKQYTLEEFLDKNDHSLAPAVFAASSNSFPVSIVQVNSAGQREEYLLCFHEFGVFVDSYGRRSRTDDLKWSRLP LAFAYREPYLFVTHFNSLEVIEIQARSSAGTPARAYLDIPNPRYLGPAISSGAIYLASSYQDKLRVICCKGNLVKESGTEHHRGPSTSRS SPNKRGPPTYNEHITKRVASSPAPPEGPSHPREPSTPHRYREGRTELRRDKSPGRPLEREKSPGRMLSTRRERSPGRLFEDSSRGRLPAG -------------------------------------------------------------- >5685_5685_2_APPL2-CIT_APPL2_chr12_105629736_ENST00000258530_CIT_chr12_120198859_ENST00000392521_length(amino acids)=1368AA_BP=67 MARRGRARGRRGHGVAAASPEPRAGECSRPPRLLPSVLPTQPSAEPRRTMPAVDKLLLEEALQDSPQVLDNQIKKDLADKETLENMMQRH EEEAHEKGKILSEQKAMINAMDSKIRSLEQRIVELSEANKLAANSSLFTQRNMKAQEEMISELRQQKFYLETQAGKLEAQNRKLEEQLEK ISHQDHSDKNRLLELETRLREVSLEHEEQKLELKRQLTELQLSLQERESQLTALQAARAALESQLRQAKTELEETTAEAEEEIQALTAHR DEIQRKFDALRNSCTVITDLEEQLNQLTEDNAELNNQNFYLSKQLDEASGANDEIVQLRSEVDHLRREITEREMQLTSQKQTMEALKTTC TMLEEQVMDLEALNDELLEKERQWEAWRSVLGDEKSQFECRVRELQRMLDTEKQSRARADQRITESRQVVELAVKEHKAEILALQQALKE QKLKAESLSDKLNDLEKKHAMLEMNARSLQQKLETERELKQRLLEEQAKLQQQMDLQKNHIFRLTQGLQEALDRADLLKTERSDLEYQLE NIQVLYSHEKVKMEGTISQQTKLIDFLQAKMDQPAKKKKGLFSRRKEDPALPTQVPLQYNELKLALEKEKARCAELEEALQKTRIELRSA REEAAHRKATDHPHPSTPATARQQIAMSAIVRSPEHQPSAMSLLAPPSSRRKESSTPEEFSRRLKERMHHNIPHRFNVGLNMRATKCAVC LDTVHFGRQASKCLECQVMCHPKCSTCLPATCGLPAEYATHFTEAFCRDKMNSPGLQTKEPSSSLHLEGWMKVPRNNKRGQQGWDRKYIV LEGSKVLIYDNEAREAGQRPVEEFELCLPDGDVSIHGAVGASELANTAKADVPYILKMESHPHTTCWPGRTLYLLAPSFPDKQRWVTALE SVVAGGRVSREKAEADAKLLGNSLLKLEGDDRLDMNCTLPFSDQVVLVGTEEGLYALNVLKNSLTHVPGIGAVFQIYIIKDLEKLLMIAG EERALCLVDVKKVKQSLAQSHLPAQPDISPNIFEAVKGCHLFGAGKIENGLCICAAMPSKVVILRYNENLSKYCIRKEIETSEPCSCIHF TNYSILIGTNKFYEIDMKQYTLEEFLDKNDHSLAPAVFAASSNSFPVSIVQVNSAGQREEYLLCFHEFGVFVDSYGRRSRTDDLKWSRLP LAFAYREPYLFVTHFNSLEVIEIQARSSAGTPARAYLDIPNPRYLGPAISSGAIYLASSYQDKLRVICCKGNLVKESGTEHHRGPSTSRS SPNKRGPPTYNEHITKRVASSPAPPEGPSHPREPSTPHRYREGRTELRRDKSPGRPLEREKSPGRMLSTRRERSPGRLFEDSSRGRLPAG -------------------------------------------------------------- >5685_5685_3_APPL2-CIT_APPL2_chr12_105629736_ENST00000551662_CIT_chr12_120198859_ENST00000261833_length(amino acids)=1335AA_BP=34 MPSVLPTQPSAEPRRTMPAVDKLLLEEALQDSPQVLDNQIKKDLADKETLENMMQRHEEEAHEKGKILSEQKAMINAMDSKIRSLEQRIV ELSEANKLAANSSLFTQRNMKAQEEMISELRQQKFYLETQAGKLEAQNRKLEEQLEKISHQDHSDKNRLLELETRLREVSLEHEEQKLEL KRQLTELQLSLQERESQLTALQAARAALESQLRQAKTELEETTAEAEEEIQALTAHRDEIQRKFDALRNSCTVITDLEEQLNQLTEDNAE LNNQNFYLSKQLDEASGANDEIVQLRSEVDHLRREITEREMQLTSQKQTMEALKTTCTMLEEQVMDLEALNDELLEKERQWEAWRSVLGD EKSQFECRVRELQRMLDTEKQSRARADQRITESRQVVELAVKEHKAEILALQQALKEQKLKAESLSDKLNDLEKKHAMLEMNARSLQQKL ETERELKQRLLEEQAKLQQQMDLQKNHIFRLTQGLQEALDRADLLKTERSDLEYQLENIQVLYSHEKVKMEGTISQQTKLIDFLQAKMDQ PAKKKKGLFSRRKEDPALPTQVPLQYNELKLALEKEKARCAELEEALQKTRIELRSAREEAAHRKATDHPHPSTPATARQQIAMSAIVRS PEHQPSAMSLLAPPSSRRKESSTPEEFSRRLKERMHHNIPHRFNVGLNMRATKCAVCLDTVHFGRQASKCLECQVMCHPKCSTCLPATCG LPAEYATHFTEAFCRDKMNSPGLQTKEPSSSLHLEGWMKVPRNNKRGQQGWDRKYIVLEGSKVLIYDNEAREAGQRPVEEFELCLPDGDV SIHGAVGASELANTAKADVPYILKMESHPHTTCWPGRTLYLLAPSFPDKQRWVTALESVVAGGRVSREKAEADAKLLGNSLLKLEGDDRL DMNCTLPFSDQVVLVGTEEGLYALNVLKNSLTHVPGIGAVFQIYIIKDLEKLLMIAGEERALCLVDVKKVKQSLAQSHLPAQPDISPNIF EAVKGCHLFGAGKIENGLCICAAMPSKVVILRYNENLSKYCIRKEIETSEPCSCIHFTNYSILIGTNKFYEIDMKQYTLEEFLDKNDHSL APAVFAASSNSFPVSIVQVNSAGQREEYLLCFHEFGVFVDSYGRRSRTDDLKWSRLPLAFAYREPYLFVTHFNSLEVIEIQARSSAGTPA RAYLDIPNPRYLGPAISSGAIYLASSYQDKLRVICCKGNLVKESGTEHHRGPSTSRSSPNKRGPPTYNEHITKRVASSPAPPEGPSHPRE -------------------------------------------------------------- >5685_5685_4_APPL2-CIT_APPL2_chr12_105629736_ENST00000551662_CIT_chr12_120198859_ENST00000392521_length(amino acids)=1335AA_BP=34 MPSVLPTQPSAEPRRTMPAVDKLLLEEALQDSPQVLDNQIKKDLADKETLENMMQRHEEEAHEKGKILSEQKAMINAMDSKIRSLEQRIV ELSEANKLAANSSLFTQRNMKAQEEMISELRQQKFYLETQAGKLEAQNRKLEEQLEKISHQDHSDKNRLLELETRLREVSLEHEEQKLEL KRQLTELQLSLQERESQLTALQAARAALESQLRQAKTELEETTAEAEEEIQALTAHRDEIQRKFDALRNSCTVITDLEEQLNQLTEDNAE LNNQNFYLSKQLDEASGANDEIVQLRSEVDHLRREITEREMQLTSQKQTMEALKTTCTMLEEQVMDLEALNDELLEKERQWEAWRSVLGD EKSQFECRVRELQRMLDTEKQSRARADQRITESRQVVELAVKEHKAEILALQQALKEQKLKAESLSDKLNDLEKKHAMLEMNARSLQQKL ETERELKQRLLEEQAKLQQQMDLQKNHIFRLTQGLQEALDRADLLKTERSDLEYQLENIQVLYSHEKVKMEGTISQQTKLIDFLQAKMDQ PAKKKKGLFSRRKEDPALPTQVPLQYNELKLALEKEKARCAELEEALQKTRIELRSAREEAAHRKATDHPHPSTPATARQQIAMSAIVRS PEHQPSAMSLLAPPSSRRKESSTPEEFSRRLKERMHHNIPHRFNVGLNMRATKCAVCLDTVHFGRQASKCLECQVMCHPKCSTCLPATCG LPAEYATHFTEAFCRDKMNSPGLQTKEPSSSLHLEGWMKVPRNNKRGQQGWDRKYIVLEGSKVLIYDNEAREAGQRPVEEFELCLPDGDV SIHGAVGASELANTAKADVPYILKMESHPHTTCWPGRTLYLLAPSFPDKQRWVTALESVVAGGRVSREKAEADAKLLGNSLLKLEGDDRL DMNCTLPFSDQVVLVGTEEGLYALNVLKNSLTHVPGIGAVFQIYIIKDLEKLLMIAGEERALCLVDVKKVKQSLAQSHLPAQPDISPNIF EAVKGCHLFGAGKIENGLCICAAMPSKVVILRYNENLSKYCIRKEIETSEPCSCIHFTNYSILIGTNKFYEIDMKQYTLEEFLDKNDHSL APAVFAASSNSFPVSIVQVNSAGQREEYLLCFHEFGVFVDSYGRRSRTDDLKWSRLPLAFAYREPYLFVTHFNSLEVIEIQARSSAGTPA RAYLDIPNPRYLGPAISSGAIYLASSYQDKLRVICCKGNLVKESGTEHHRGPSTSRSSPNKRGPPTYNEHITKRVASSPAPPEGPSHPRE -------------------------------------------------------------- >5685_5685_5_APPL2-CIT_APPL2_chr12_105629737_ENST00000258530_CIT_chr12_120198859_ENST00000261833_length(amino acids)=1368AA_BP=67 MARRGRARGRRGHGVAAASPEPRAGECSRPPRLLPSVLPTQPSAEPRRTMPAVDKLLLEEALQDSPQVLDNQIKKDLADKETLENMMQRH EEEAHEKGKILSEQKAMINAMDSKIRSLEQRIVELSEANKLAANSSLFTQRNMKAQEEMISELRQQKFYLETQAGKLEAQNRKLEEQLEK ISHQDHSDKNRLLELETRLREVSLEHEEQKLELKRQLTELQLSLQERESQLTALQAARAALESQLRQAKTELEETTAEAEEEIQALTAHR DEIQRKFDALRNSCTVITDLEEQLNQLTEDNAELNNQNFYLSKQLDEASGANDEIVQLRSEVDHLRREITEREMQLTSQKQTMEALKTTC TMLEEQVMDLEALNDELLEKERQWEAWRSVLGDEKSQFECRVRELQRMLDTEKQSRARADQRITESRQVVELAVKEHKAEILALQQALKE QKLKAESLSDKLNDLEKKHAMLEMNARSLQQKLETERELKQRLLEEQAKLQQQMDLQKNHIFRLTQGLQEALDRADLLKTERSDLEYQLE NIQVLYSHEKVKMEGTISQQTKLIDFLQAKMDQPAKKKKGLFSRRKEDPALPTQVPLQYNELKLALEKEKARCAELEEALQKTRIELRSA REEAAHRKATDHPHPSTPATARQQIAMSAIVRSPEHQPSAMSLLAPPSSRRKESSTPEEFSRRLKERMHHNIPHRFNVGLNMRATKCAVC LDTVHFGRQASKCLECQVMCHPKCSTCLPATCGLPAEYATHFTEAFCRDKMNSPGLQTKEPSSSLHLEGWMKVPRNNKRGQQGWDRKYIV LEGSKVLIYDNEAREAGQRPVEEFELCLPDGDVSIHGAVGASELANTAKADVPYILKMESHPHTTCWPGRTLYLLAPSFPDKQRWVTALE SVVAGGRVSREKAEADAKLLGNSLLKLEGDDRLDMNCTLPFSDQVVLVGTEEGLYALNVLKNSLTHVPGIGAVFQIYIIKDLEKLLMIAG EERALCLVDVKKVKQSLAQSHLPAQPDISPNIFEAVKGCHLFGAGKIENGLCICAAMPSKVVILRYNENLSKYCIRKEIETSEPCSCIHF TNYSILIGTNKFYEIDMKQYTLEEFLDKNDHSLAPAVFAASSNSFPVSIVQVNSAGQREEYLLCFHEFGVFVDSYGRRSRTDDLKWSRLP LAFAYREPYLFVTHFNSLEVIEIQARSSAGTPARAYLDIPNPRYLGPAISSGAIYLASSYQDKLRVICCKGNLVKESGTEHHRGPSTSRS SPNKRGPPTYNEHITKRVASSPAPPEGPSHPREPSTPHRYREGRTELRRDKSPGRPLEREKSPGRMLSTRRERSPGRLFEDSSRGRLPAG -------------------------------------------------------------- >5685_5685_6_APPL2-CIT_APPL2_chr12_105629737_ENST00000258530_CIT_chr12_120198859_ENST00000392521_length(amino acids)=1368AA_BP=67 MARRGRARGRRGHGVAAASPEPRAGECSRPPRLLPSVLPTQPSAEPRRTMPAVDKLLLEEALQDSPQVLDNQIKKDLADKETLENMMQRH EEEAHEKGKILSEQKAMINAMDSKIRSLEQRIVELSEANKLAANSSLFTQRNMKAQEEMISELRQQKFYLETQAGKLEAQNRKLEEQLEK ISHQDHSDKNRLLELETRLREVSLEHEEQKLELKRQLTELQLSLQERESQLTALQAARAALESQLRQAKTELEETTAEAEEEIQALTAHR DEIQRKFDALRNSCTVITDLEEQLNQLTEDNAELNNQNFYLSKQLDEASGANDEIVQLRSEVDHLRREITEREMQLTSQKQTMEALKTTC TMLEEQVMDLEALNDELLEKERQWEAWRSVLGDEKSQFECRVRELQRMLDTEKQSRARADQRITESRQVVELAVKEHKAEILALQQALKE QKLKAESLSDKLNDLEKKHAMLEMNARSLQQKLETERELKQRLLEEQAKLQQQMDLQKNHIFRLTQGLQEALDRADLLKTERSDLEYQLE NIQVLYSHEKVKMEGTISQQTKLIDFLQAKMDQPAKKKKGLFSRRKEDPALPTQVPLQYNELKLALEKEKARCAELEEALQKTRIELRSA REEAAHRKATDHPHPSTPATARQQIAMSAIVRSPEHQPSAMSLLAPPSSRRKESSTPEEFSRRLKERMHHNIPHRFNVGLNMRATKCAVC LDTVHFGRQASKCLECQVMCHPKCSTCLPATCGLPAEYATHFTEAFCRDKMNSPGLQTKEPSSSLHLEGWMKVPRNNKRGQQGWDRKYIV LEGSKVLIYDNEAREAGQRPVEEFELCLPDGDVSIHGAVGASELANTAKADVPYILKMESHPHTTCWPGRTLYLLAPSFPDKQRWVTALE SVVAGGRVSREKAEADAKLLGNSLLKLEGDDRLDMNCTLPFSDQVVLVGTEEGLYALNVLKNSLTHVPGIGAVFQIYIIKDLEKLLMIAG EERALCLVDVKKVKQSLAQSHLPAQPDISPNIFEAVKGCHLFGAGKIENGLCICAAMPSKVVILRYNENLSKYCIRKEIETSEPCSCIHF TNYSILIGTNKFYEIDMKQYTLEEFLDKNDHSLAPAVFAASSNSFPVSIVQVNSAGQREEYLLCFHEFGVFVDSYGRRSRTDDLKWSRLP LAFAYREPYLFVTHFNSLEVIEIQARSSAGTPARAYLDIPNPRYLGPAISSGAIYLASSYQDKLRVICCKGNLVKESGTEHHRGPSTSRS SPNKRGPPTYNEHITKRVASSPAPPEGPSHPREPSTPHRYREGRTELRRDKSPGRPLEREKSPGRMLSTRRERSPGRLFEDSSRGRLPAG -------------------------------------------------------------- >5685_5685_7_APPL2-CIT_APPL2_chr12_105629737_ENST00000551662_CIT_chr12_120198859_ENST00000261833_length(amino acids)=1335AA_BP=34 MPSVLPTQPSAEPRRTMPAVDKLLLEEALQDSPQVLDNQIKKDLADKETLENMMQRHEEEAHEKGKILSEQKAMINAMDSKIRSLEQRIV ELSEANKLAANSSLFTQRNMKAQEEMISELRQQKFYLETQAGKLEAQNRKLEEQLEKISHQDHSDKNRLLELETRLREVSLEHEEQKLEL KRQLTELQLSLQERESQLTALQAARAALESQLRQAKTELEETTAEAEEEIQALTAHRDEIQRKFDALRNSCTVITDLEEQLNQLTEDNAE LNNQNFYLSKQLDEASGANDEIVQLRSEVDHLRREITEREMQLTSQKQTMEALKTTCTMLEEQVMDLEALNDELLEKERQWEAWRSVLGD EKSQFECRVRELQRMLDTEKQSRARADQRITESRQVVELAVKEHKAEILALQQALKEQKLKAESLSDKLNDLEKKHAMLEMNARSLQQKL ETERELKQRLLEEQAKLQQQMDLQKNHIFRLTQGLQEALDRADLLKTERSDLEYQLENIQVLYSHEKVKMEGTISQQTKLIDFLQAKMDQ PAKKKKGLFSRRKEDPALPTQVPLQYNELKLALEKEKARCAELEEALQKTRIELRSAREEAAHRKATDHPHPSTPATARQQIAMSAIVRS PEHQPSAMSLLAPPSSRRKESSTPEEFSRRLKERMHHNIPHRFNVGLNMRATKCAVCLDTVHFGRQASKCLECQVMCHPKCSTCLPATCG LPAEYATHFTEAFCRDKMNSPGLQTKEPSSSLHLEGWMKVPRNNKRGQQGWDRKYIVLEGSKVLIYDNEAREAGQRPVEEFELCLPDGDV SIHGAVGASELANTAKADVPYILKMESHPHTTCWPGRTLYLLAPSFPDKQRWVTALESVVAGGRVSREKAEADAKLLGNSLLKLEGDDRL DMNCTLPFSDQVVLVGTEEGLYALNVLKNSLTHVPGIGAVFQIYIIKDLEKLLMIAGEERALCLVDVKKVKQSLAQSHLPAQPDISPNIF EAVKGCHLFGAGKIENGLCICAAMPSKVVILRYNENLSKYCIRKEIETSEPCSCIHFTNYSILIGTNKFYEIDMKQYTLEEFLDKNDHSL APAVFAASSNSFPVSIVQVNSAGQREEYLLCFHEFGVFVDSYGRRSRTDDLKWSRLPLAFAYREPYLFVTHFNSLEVIEIQARSSAGTPA RAYLDIPNPRYLGPAISSGAIYLASSYQDKLRVICCKGNLVKESGTEHHRGPSTSRSSPNKRGPPTYNEHITKRVASSPAPPEGPSHPRE -------------------------------------------------------------- >5685_5685_8_APPL2-CIT_APPL2_chr12_105629737_ENST00000551662_CIT_chr12_120198859_ENST00000392521_length(amino acids)=1335AA_BP=34 MPSVLPTQPSAEPRRTMPAVDKLLLEEALQDSPQVLDNQIKKDLADKETLENMMQRHEEEAHEKGKILSEQKAMINAMDSKIRSLEQRIV ELSEANKLAANSSLFTQRNMKAQEEMISELRQQKFYLETQAGKLEAQNRKLEEQLEKISHQDHSDKNRLLELETRLREVSLEHEEQKLEL KRQLTELQLSLQERESQLTALQAARAALESQLRQAKTELEETTAEAEEEIQALTAHRDEIQRKFDALRNSCTVITDLEEQLNQLTEDNAE LNNQNFYLSKQLDEASGANDEIVQLRSEVDHLRREITEREMQLTSQKQTMEALKTTCTMLEEQVMDLEALNDELLEKERQWEAWRSVLGD EKSQFECRVRELQRMLDTEKQSRARADQRITESRQVVELAVKEHKAEILALQQALKEQKLKAESLSDKLNDLEKKHAMLEMNARSLQQKL ETERELKQRLLEEQAKLQQQMDLQKNHIFRLTQGLQEALDRADLLKTERSDLEYQLENIQVLYSHEKVKMEGTISQQTKLIDFLQAKMDQ PAKKKKGLFSRRKEDPALPTQVPLQYNELKLALEKEKARCAELEEALQKTRIELRSAREEAAHRKATDHPHPSTPATARQQIAMSAIVRS PEHQPSAMSLLAPPSSRRKESSTPEEFSRRLKERMHHNIPHRFNVGLNMRATKCAVCLDTVHFGRQASKCLECQVMCHPKCSTCLPATCG LPAEYATHFTEAFCRDKMNSPGLQTKEPSSSLHLEGWMKVPRNNKRGQQGWDRKYIVLEGSKVLIYDNEAREAGQRPVEEFELCLPDGDV SIHGAVGASELANTAKADVPYILKMESHPHTTCWPGRTLYLLAPSFPDKQRWVTALESVVAGGRVSREKAEADAKLLGNSLLKLEGDDRL DMNCTLPFSDQVVLVGTEEGLYALNVLKNSLTHVPGIGAVFQIYIIKDLEKLLMIAGEERALCLVDVKKVKQSLAQSHLPAQPDISPNIF EAVKGCHLFGAGKIENGLCICAAMPSKVVILRYNENLSKYCIRKEIETSEPCSCIHFTNYSILIGTNKFYEIDMKQYTLEEFLDKNDHSL APAVFAASSNSFPVSIVQVNSAGQREEYLLCFHEFGVFVDSYGRRSRTDDLKWSRLPLAFAYREPYLFVTHFNSLEVIEIQARSSAGTPA RAYLDIPNPRYLGPAISSGAIYLASSYQDKLRVICCKGNLVKESGTEHHRGPSTSRSSPNKRGPPTYNEHITKRVASSPAPPEGPSHPRE -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:105629737/chr12:120198859) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| APPL2 | CIT |
| FUNCTION: Multifunctional adapter protein that binds to various membrane receptors, nuclear factors and signaling proteins to regulate many processes, such as cell proliferation, immune response, endosomal trafficking and cell metabolism (PubMed:26583432, PubMed:15016378, PubMed:24879834). Regulates signaling pathway leading to cell proliferation through interaction with RAB5A and subunits of the NuRD/MeCP1 complex (PubMed:15016378). Plays a role in immune response by modulating phagocytosis, inflammatory and innate immune responses. In macrophages, enhances Fc-gamma receptor-mediated phagocytosis through interaction with RAB31 leading to activation of PI3K/Akt signaling. In response to LPS, modulates inflammatory responses by playing a key role on the regulation of TLR4 signaling and in the nuclear translocation of RELA/NF-kappa-B p65 and the secretion of pro- and anti-inflammatory cytokines. Also functions as a negative regulator of innate immune response via inhibition of AKT1 signaling pathway by forming a complex with APPL1 and PIK3R1 (By similarity). Plays a role in endosomal trafficking of TGFBR1 from the endosomes to the nucleus (PubMed:26583432). Plays a role in cell metabolism by regulating adiponecting ans insulin signaling pathways and adaptative thermogenesis (PubMed:24879834) (By similarity). In muscle, negatively regulates adiponectin-simulated glucose uptake and fatty acid oxidation by inhibiting adiponectin signaling pathway through APPL1 sequestration thereby antagonizing APPL1 action (By similarity). In muscles, negativeliy regulates insulin-induced plasma membrane recruitment of GLUT4 and glucose uptake through interaction with TBC1D1 (PubMed:24879834). Plays a role in cold and diet-induced adaptive thermogenesis by activating ventromedial hypothalamus (VMH) neurons throught AMPK inhibition which enhances sympathetic outflow to subcutaneous white adipose tissue (sWAT), sWAT beiging and cold tolerance (By similarity). Also plays a role in other signaling pathways namely Wnt/beta-catenin, HGF and glucocorticoid receptor signaling (PubMed:19433865) (By similarity). Positive regulator of beta-catenin/TCF-dependent transcription through direct interaction with RUVBL2/reptin resulting in the relief of RUVBL2-mediated repression of beta-catenin/TCF target genes by modulating the interactions within the beta-catenin-reptin-HDAC complex (PubMed:19433865). May affect adult neurogenesis in hippocampus and olfactory system via regulating the sensitivity of glucocorticoid receptor. Required for fibroblast migration through HGF cell signaling (By similarity). {ECO:0000250|UniProtKB:Q8K3G9, ECO:0000269|PubMed:15016378, ECO:0000269|PubMed:19433865, ECO:0000269|PubMed:24879834, ECO:0000269|PubMed:26583432}. | FUNCTION: Acts as transcriptional coactivator for TFAP2/AP-2. Enhances estrogen-dependent transactivation mediated by estrogen receptors. May function as an inhibitor of transactivation by HIF1A by disrupting HIF1A interaction with CREBBP. May be involved in regulation of gene expression during development and differentiation of blood cells, endothelial cells and mammary epithelial cells. {ECO:0000269|PubMed:11744733, ECO:0000269|PubMed:15342390}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000261833 | 17 | 47 | 1443_1563 | 726.0 | 2028.0 | Domain | PH | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000261833 | 17 | 47 | 1591_1881 | 726.0 | 2028.0 | Domain | CNH | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000392521 | 18 | 48 | 1443_1563 | 768.0 | 2070.0 | Domain | PH | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000392521 | 18 | 48 | 1591_1881 | 768.0 | 2070.0 | Domain | CNH | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000261833 | 17 | 47 | 1443_1563 | 726.0 | 2028.0 | Domain | PH | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000261833 | 17 | 47 | 1591_1881 | 726.0 | 2028.0 | Domain | CNH | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000392521 | 18 | 48 | 1443_1563 | 768.0 | 2070.0 | Domain | PH | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000392521 | 18 | 48 | 1591_1881 | 768.0 | 2070.0 | Domain | CNH | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000261833 | 17 | 47 | 1953_1958 | 726.0 | 2028.0 | Motif | SH3-binding | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000392521 | 18 | 48 | 1953_1958 | 768.0 | 2070.0 | Motif | SH3-binding | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000261833 | 17 | 47 | 1953_1958 | 726.0 | 2028.0 | Motif | SH3-binding | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000392521 | 18 | 48 | 1953_1958 | 768.0 | 2070.0 | Motif | SH3-binding | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000261833 | 17 | 47 | 1362_1411 | 726.0 | 2028.0 | Zinc finger | Phorbol-ester/DAG-type | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000392521 | 18 | 48 | 1362_1411 | 768.0 | 2070.0 | Zinc finger | Phorbol-ester/DAG-type | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000261833 | 17 | 47 | 1362_1411 | 726.0 | 2028.0 | Zinc finger | Phorbol-ester/DAG-type | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000392521 | 18 | 48 | 1362_1411 | 768.0 | 2070.0 | Zinc finger | Phorbol-ester/DAG-type |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000258530 | - | 1 | 21 | 277_375 | 18.0 | 665.0 | Domain | PH |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000258530 | - | 1 | 21 | 3_268 | 18.0 | 665.0 | Domain | BAR |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000258530 | - | 1 | 21 | 488_637 | 18.0 | 665.0 | Domain | PID |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000539978 | - | 1 | 21 | 277_375 | 0 | 622.0 | Domain | PH |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000539978 | - | 1 | 21 | 3_268 | 0 | 622.0 | Domain | BAR |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000539978 | - | 1 | 21 | 488_637 | 0 | 622.0 | Domain | PID |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000551662 | - | 1 | 21 | 277_375 | 18.0 | 671.0 | Domain | PH |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000551662 | - | 1 | 21 | 3_268 | 18.0 | 671.0 | Domain | BAR |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000551662 | - | 1 | 21 | 488_637 | 18.0 | 671.0 | Domain | PID |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000258530 | - | 1 | 21 | 277_375 | 18.0 | 665.0 | Domain | PH |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000258530 | - | 1 | 21 | 3_268 | 18.0 | 665.0 | Domain | BAR |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000258530 | - | 1 | 21 | 488_637 | 18.0 | 665.0 | Domain | PID |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000539978 | - | 1 | 21 | 277_375 | 0 | 622.0 | Domain | PH |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000539978 | - | 1 | 21 | 3_268 | 0 | 622.0 | Domain | BAR |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000539978 | - | 1 | 21 | 488_637 | 0 | 622.0 | Domain | PID |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000551662 | - | 1 | 21 | 277_375 | 18.0 | 671.0 | Domain | PH |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000551662 | - | 1 | 21 | 3_268 | 18.0 | 671.0 | Domain | BAR |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000551662 | - | 1 | 21 | 488_637 | 18.0 | 671.0 | Domain | PID |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000258530 | - | 1 | 21 | 1_428 | 18.0 | 665.0 | Region | Required for RAB5A binding |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000539978 | - | 1 | 21 | 1_428 | 0 | 622.0 | Region | Required for RAB5A binding |
| Hgene | APPL2 | chr12:105629736 | chr12:120198859 | ENST00000551662 | - | 1 | 21 | 1_428 | 18.0 | 671.0 | Region | Required for RAB5A binding |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000258530 | - | 1 | 21 | 1_428 | 18.0 | 665.0 | Region | Required for RAB5A binding |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000539978 | - | 1 | 21 | 1_428 | 0 | 622.0 | Region | Required for RAB5A binding |
| Hgene | APPL2 | chr12:105629737 | chr12:120198859 | ENST00000551662 | - | 1 | 21 | 1_428 | 18.0 | 671.0 | Region | Required for RAB5A binding |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000261833 | 17 | 47 | 453_1297 | 726.0 | 2028.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000392521 | 18 | 48 | 453_1297 | 768.0 | 2070.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000261833 | 17 | 47 | 453_1297 | 726.0 | 2028.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000392521 | 18 | 48 | 453_1297 | 768.0 | 2070.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000261833 | 17 | 47 | 361_431 | 726.0 | 2028.0 | Domain | AGC-kinase C-terminal | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000261833 | 17 | 47 | 97_360 | 726.0 | 2028.0 | Domain | Protein kinase | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000392521 | 18 | 48 | 361_431 | 768.0 | 2070.0 | Domain | AGC-kinase C-terminal | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000392521 | 18 | 48 | 97_360 | 768.0 | 2070.0 | Domain | Protein kinase | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000261833 | 17 | 47 | 361_431 | 726.0 | 2028.0 | Domain | AGC-kinase C-terminal | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000261833 | 17 | 47 | 97_360 | 726.0 | 2028.0 | Domain | Protein kinase | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000392521 | 18 | 48 | 361_431 | 768.0 | 2070.0 | Domain | AGC-kinase C-terminal | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000392521 | 18 | 48 | 97_360 | 768.0 | 2070.0 | Domain | Protein kinase | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000261833 | 17 | 47 | 103_111 | 726.0 | 2028.0 | Nucleotide binding | ATP | |
| Tgene | CIT | chr12:105629736 | chr12:120198859 | ENST00000392521 | 18 | 48 | 103_111 | 768.0 | 2070.0 | Nucleotide binding | ATP | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000261833 | 17 | 47 | 103_111 | 726.0 | 2028.0 | Nucleotide binding | ATP | |
| Tgene | CIT | chr12:105629737 | chr12:120198859 | ENST00000392521 | 18 | 48 | 103_111 | 768.0 | 2070.0 | Nucleotide binding | ATP |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file >>>2024_APPL2_105629737_CIT_120198859_ranked_0.pdb | APPL2 | 105629736 | 105629737 | ENST00000261833 | CIT | chr12 | 120198859 | - | MARRGRARGRRGHGVAAASPEPRAGECSRPPRLLPSVLPTQPSAEPRRTMPAVDKLLLEEALQDSPQVLDNQIKKDLADKETLENMMQRH EEEAHEKGKILSEQKAMINAMDSKIRSLEQRIVELSEANKLAANSSLFTQRNMKAQEEMISELRQQKFYLETQAGKLEAQNRKLEEQLEK ISHQDHSDKNRLLELETRLREVSLEHEEQKLELKRQLTELQLSLQERESQLTALQAARAALESQLRQAKTELEETTAEAEEEIQALTAHR DEIQRKFDALRNSCTVITDLEEQLNQLTEDNAELNNQNFYLSKQLDEASGANDEIVQLRSEVDHLRREITEREMQLTSQKQTMEALKTTC TMLEEQVMDLEALNDELLEKERQWEAWRSVLGDEKSQFECRVRELQRMLDTEKQSRARADQRITESRQVVELAVKEHKAEILALQQALKE QKLKAESLSDKLNDLEKKHAMLEMNARSLQQKLETERELKQRLLEEQAKLQQQMDLQKNHIFRLTQGLQEALDRADLLKTERSDLEYQLE NIQVLYSHEKVKMEGTISQQTKLIDFLQAKMDQPAKKKKGLFSRRKEDPALPTQVPLQYNELKLALEKEKARCAELEEALQKTRIELRSA REEAAHRKATDHPHPSTPATARQQIAMSAIVRSPEHQPSAMSLLAPPSSRRKESSTPEEFSRRLKERMHHNIPHRFNVGLNMRATKCAVC LDTVHFGRQASKCLECQVMCHPKCSTCLPATCGLPAEYATHFTEAFCRDKMNSPGLQTKEPSSSLHLEGWMKVPRNNKRGQQGWDRKYIV LEGSKVLIYDNEAREAGQRPVEEFELCLPDGDVSIHGAVGASELANTAKADVPYILKMESHPHTTCWPGRTLYLLAPSFPDKQRWVTALE SVVAGGRVSREKAEADAKLLGNSLLKLEGDDRLDMNCTLPFSDQVVLVGTEEGLYALNVLKNSLTHVPGIGAVFQIYIIKDLEKLLMIAG EERALCLVDVKKVKQSLAQSHLPAQPDISPNIFEAVKGCHLFGAGKIENGLCICAAMPSKVVILRYNENLSKYCIRKEIETSEPCSCIHF TNYSILIGTNKFYEIDMKQYTLEEFLDKNDHSLAPAVFAASSNSFPVSIVQVNSAGQREEYLLCFHEFGVFVDSYGRRSRTDDLKWSRLP LAFAYREPYLFVTHFNSLEVIEIQARSSAGTPARAYLDIPNPRYLGPAISSGAIYLASSYQDKLRVICCKGNLVKESGTEHHRGPSTSRS SPNKRGPPTYNEHITKRVASSPAPPEGPSHPREPSTPHRYREGRTELRRDKSPGRPLEREKSPGRMLSTRRERSPGRLFEDSSRGRLPAG | 1368 |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
APPL2_pLDDT.png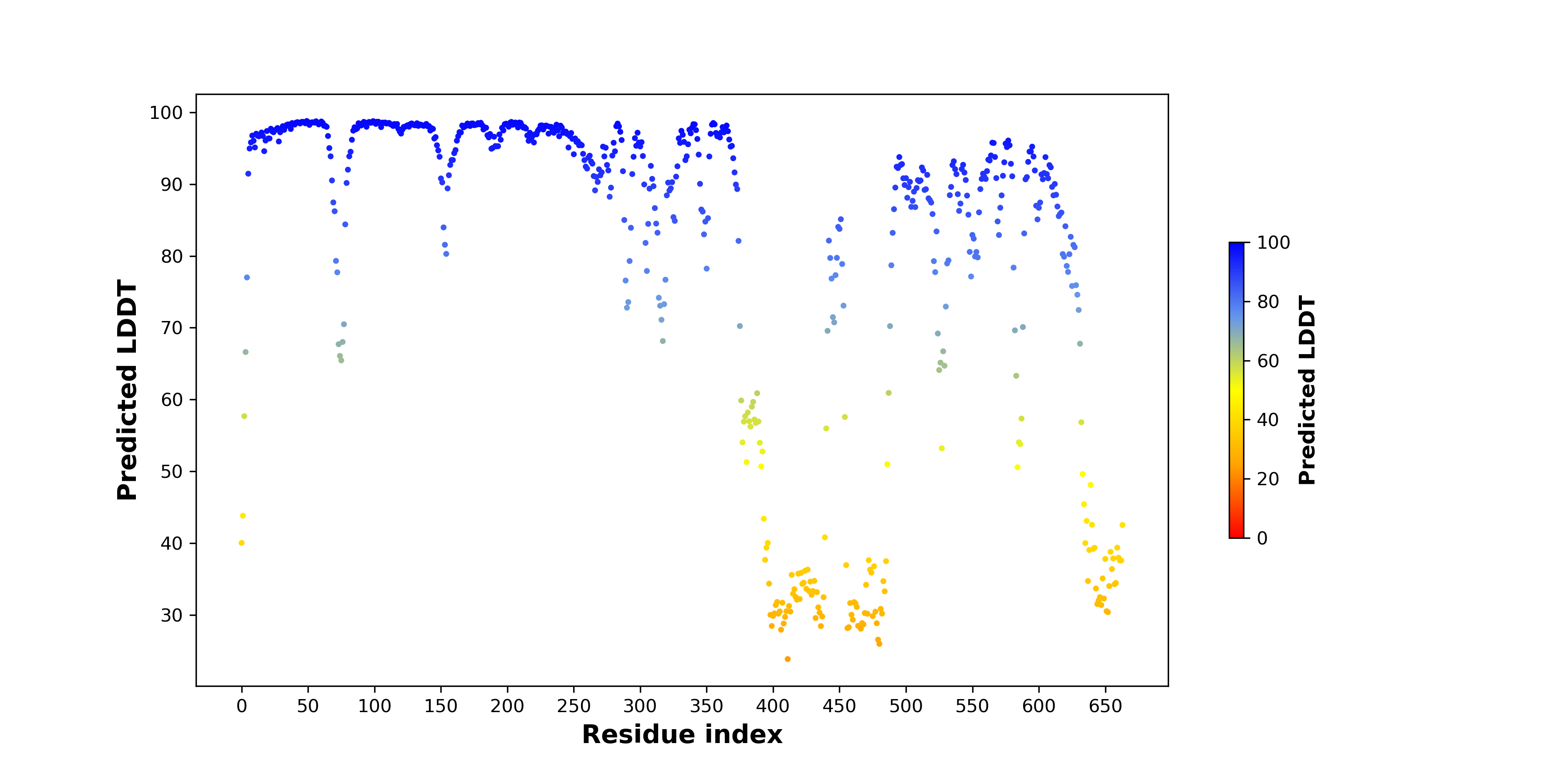  |
CIT_pLDDT.png  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
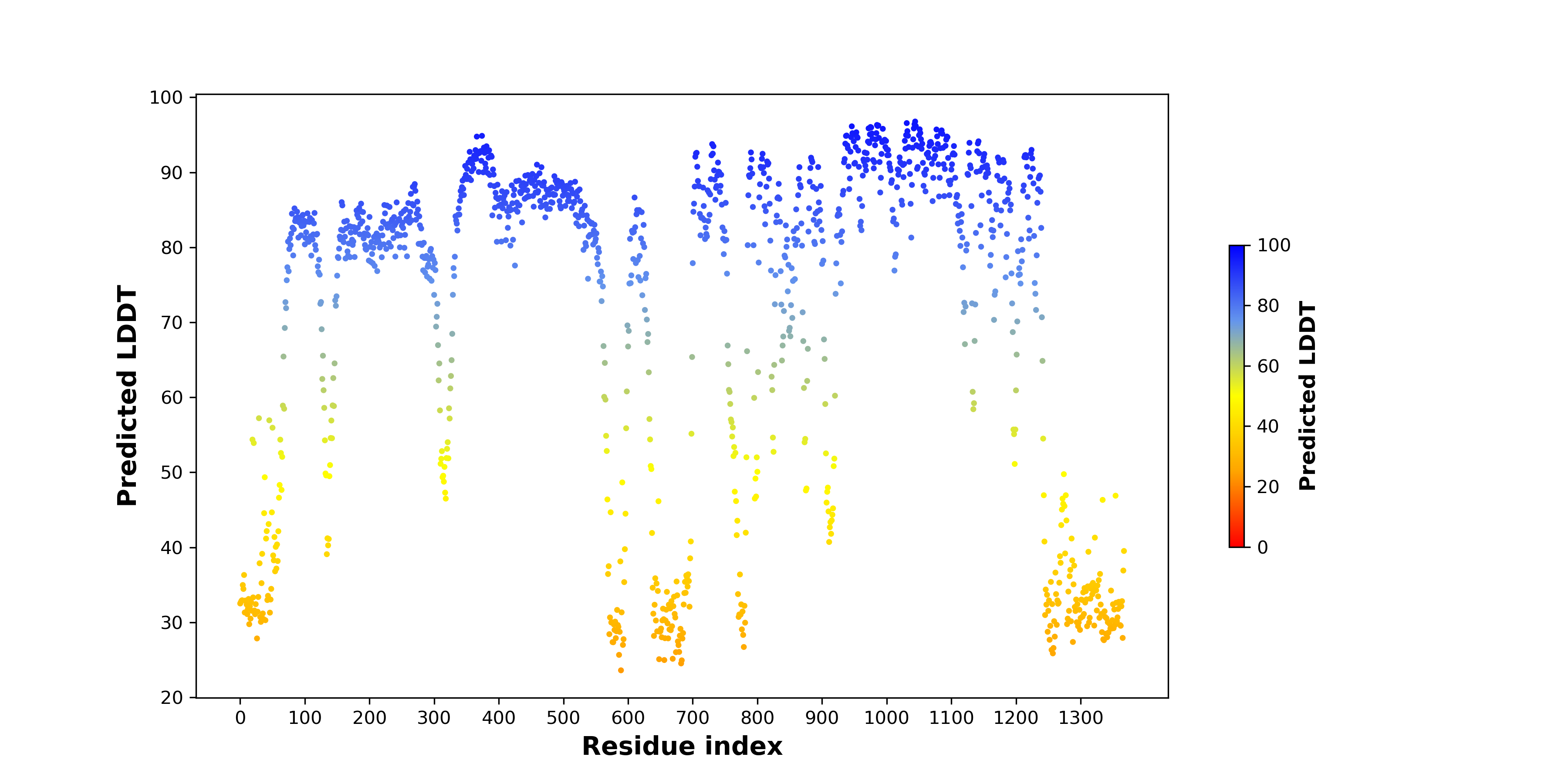 |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| APPL2 | |
| CIT |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to APPL2-CIT |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to APPL2-CIT |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies