| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:NF2-EFCAB6 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: NF2-EFCAB6 | FusionPDB ID: 58721 | FusionGDB2.0 ID: 58721 | Hgene | Tgene | Gene symbol | NF2 | EFCAB6 | Gene ID | 4771 | 64800 |
| Gene name | neurofibromin 2 | EF-hand calcium binding domain 6 | |
| Synonyms | ACN|BANF|SCH | DJBP|HSCBCIP1|dJ185D5.1 | |
| Cytomap | 22q12.2 | 22q13.2-q13.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | merlinmoesin-ezrin-radixin likemoesin-ezrin-radixin-like proteinmoesin-ezrin-radizin-like proteinneurofibromin 2 (bilateral acoustic neuroma)schwannomerlinschwannomin | EF-hand calcium-binding domain-containing protein 6CAP-binding protein complex-interacting protein 1DJ-1-binding proteinepididymis secretory sperm binding protein | |
| Modification date | 20200322 | 20200313 | |
| UniProtAcc | P35240 | Q5THR3 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000334961, ENST00000338641, ENST00000353887, ENST00000361166, ENST00000361452, ENST00000361676, ENST00000397789, ENST00000403435, ENST00000403999, ENST00000347330, ENST00000413209, | ENST00000356087, ENST00000358439, ENST00000461800, ENST00000262726, ENST00000396231, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 15 X 11 X 7=1155 | 29 X 21 X 6=3654 |
| # samples | 18 | 31 | |
| ** MAII score | log2(18/1155*10)=-2.68182403997375 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(31/3654*10)=-3.55913651335325 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: NF2 [Title/Abstract] AND EFCAB6 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | NF2(30051665)-EFCAB6(44083461), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | NF2-EFCAB6 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NF2-EFCAB6 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NF2-EFCAB6 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. NF2-EFCAB6 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NF2 | GO:0008285 | negative regulation of cell proliferation | 12444102|20178741 |
| Hgene | NF2 | GO:0022408 | negative regulation of cell-cell adhesion | 17210637 |
| Hgene | NF2 | GO:0042532 | negative regulation of tyrosine phosphorylation of STAT protein | 12444102 |
| Hgene | NF2 | GO:0046426 | negative regulation of JAK-STAT cascade | 12444102 |
| Fusion gene breakpoints across NF2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
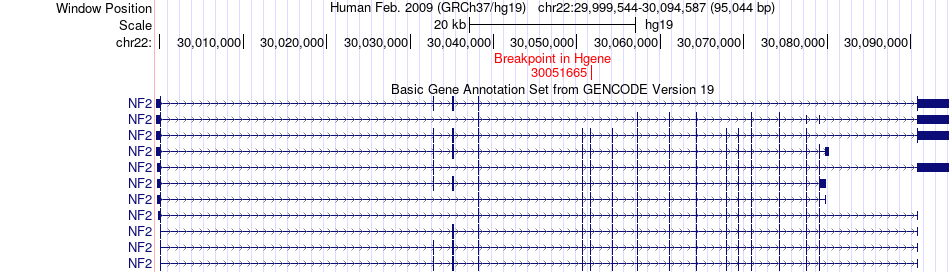 |
| Fusion gene breakpoints across EFCAB6 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SKCM | TCGA-FS-A4F4-06A | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000338641 | NF2 | chr22 | 30051665 | + | ENST00000396231 | EFCAB6 | chr22 | 44083461 | - | 4624 | 1040 | 360 | 4514 | 1384 |
| ENST00000338641 | NF2 | chr22 | 30051665 | + | ENST00000262726 | EFCAB6 | chr22 | 44083461 | - | 4624 | 1040 | 360 | 4514 | 1384 |
| ENST00000403435 | NF2 | chr22 | 30051665 | + | ENST00000396231 | EFCAB6 | chr22 | 44083461 | - | 4594 | 1010 | 330 | 4484 | 1384 |
| ENST00000403435 | NF2 | chr22 | 30051665 | + | ENST00000262726 | EFCAB6 | chr22 | 44083461 | - | 4594 | 1010 | 330 | 4484 | 1384 |
| ENST00000361452 | NF2 | chr22 | 30051665 | + | ENST00000396231 | EFCAB6 | chr22 | 44083461 | - | 4442 | 858 | 301 | 4332 | 1343 |
| ENST00000361452 | NF2 | chr22 | 30051665 | + | ENST00000262726 | EFCAB6 | chr22 | 44083461 | - | 4442 | 858 | 301 | 4332 | 1343 |
| ENST00000403999 | NF2 | chr22 | 30051665 | + | ENST00000396231 | EFCAB6 | chr22 | 44083461 | - | 4549 | 965 | 285 | 4439 | 1384 |
| ENST00000403999 | NF2 | chr22 | 30051665 | + | ENST00000262726 | EFCAB6 | chr22 | 44083461 | - | 4549 | 965 | 285 | 4439 | 1384 |
| ENST00000334961 | NF2 | chr22 | 30051665 | + | ENST00000396231 | EFCAB6 | chr22 | 44083461 | - | 4206 | 622 | 191 | 4096 | 1301 |
| ENST00000334961 | NF2 | chr22 | 30051665 | + | ENST00000262726 | EFCAB6 | chr22 | 44083461 | - | 4206 | 622 | 191 | 4096 | 1301 |
| ENST00000353887 | NF2 | chr22 | 30051665 | + | ENST00000396231 | EFCAB6 | chr22 | 44083461 | - | 4186 | 602 | 171 | 4076 | 1301 |
| ENST00000353887 | NF2 | chr22 | 30051665 | + | ENST00000262726 | EFCAB6 | chr22 | 44083461 | - | 4186 | 602 | 171 | 4076 | 1301 |
| ENST00000361166 | NF2 | chr22 | 30051665 | + | ENST00000396231 | EFCAB6 | chr22 | 44083461 | - | 4183 | 599 | 0 | 4073 | 1357 |
| ENST00000361166 | NF2 | chr22 | 30051665 | + | ENST00000262726 | EFCAB6 | chr22 | 44083461 | - | 4183 | 599 | 0 | 4073 | 1357 |
| ENST00000397789 | NF2 | chr22 | 30051665 | + | ENST00000396231 | EFCAB6 | chr22 | 44083461 | - | 4183 | 599 | 0 | 4073 | 1357 |
| ENST00000397789 | NF2 | chr22 | 30051665 | + | ENST00000262726 | EFCAB6 | chr22 | 44083461 | - | 4183 | 599 | 0 | 4073 | 1357 |
| ENST00000361676 | NF2 | chr22 | 30051665 | + | ENST00000396231 | EFCAB6 | chr22 | 44083461 | - | 4057 | 473 | 0 | 3947 | 1315 |
| ENST00000361676 | NF2 | chr22 | 30051665 | + | ENST00000262726 | EFCAB6 | chr22 | 44083461 | - | 4057 | 473 | 0 | 3947 | 1315 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000338641 | ENST00000396231 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001825922 | 0.9981741 |
| ENST00000338641 | ENST00000262726 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001825922 | 0.9981741 |
| ENST00000403435 | ENST00000396231 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001847987 | 0.99815196 |
| ENST00000403435 | ENST00000262726 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001847987 | 0.99815196 |
| ENST00000361452 | ENST00000396231 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001987133 | 0.9980129 |
| ENST00000361452 | ENST00000262726 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001987133 | 0.9980129 |
| ENST00000403999 | ENST00000396231 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001812882 | 0.9981871 |
| ENST00000403999 | ENST00000262726 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001812882 | 0.9981871 |
| ENST00000334961 | ENST00000396231 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001882141 | 0.9981179 |
| ENST00000334961 | ENST00000262726 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001882141 | 0.9981179 |
| ENST00000353887 | ENST00000396231 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001905291 | 0.99809474 |
| ENST00000353887 | ENST00000262726 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001905291 | 0.99809474 |
| ENST00000361166 | ENST00000396231 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001301367 | 0.9986986 |
| ENST00000361166 | ENST00000262726 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001301367 | 0.9986986 |
| ENST00000397789 | ENST00000396231 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001301367 | 0.9986986 |
| ENST00000397789 | ENST00000262726 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001301367 | 0.9986986 |
| ENST00000361676 | ENST00000396231 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001377607 | 0.9986224 |
| ENST00000361676 | ENST00000262726 | NF2 | chr22 | 30051665 | + | EFCAB6 | chr22 | 44083461 | - | 0.001377607 | 0.9986224 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >58721_58721_1_NF2-EFCAB6_NF2_chr22_30051665_ENST00000334961_EFCAB6_chr22_44083461_ENST00000262726_length(amino acids)=1301AA_BP=143 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEVKKQILDEKIYCPPEASVLLASYAV QAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRN SINSRNESHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEE NCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRI LYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEP NGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLK ESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADS ELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAV HRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLN SWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKD FCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDT MKTNTISREEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQ ELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIK YDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFR -------------------------------------------------------------- >58721_58721_2_NF2-EFCAB6_NF2_chr22_30051665_ENST00000334961_EFCAB6_chr22_44083461_ENST00000396231_length(amino acids)=1301AA_BP=143 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEVKKQILDEKIYCPPEASVLLASYAV QAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRN SINSRNESHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEE NCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRI LYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEP NGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLK ESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADS ELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAV HRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLN SWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKD FCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDT MKTNTISREEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQ ELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIK YDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFR -------------------------------------------------------------- >58721_58721_3_NF2-EFCAB6_NF2_chr22_30051665_ENST00000338641_EFCAB6_chr22_44083461_ENST00000262726_length(amino acids)=1384AA_BP=226 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFG LQYTIKDTVAWLKMDKKVLDHDVSKEEPVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDY DPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNE SHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKT SPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLA CIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVH DFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPY SAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQA HQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAED YFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRH DNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTD NQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTIS REEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSK SQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNG KFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYS -------------------------------------------------------------- >58721_58721_4_NF2-EFCAB6_NF2_chr22_30051665_ENST00000338641_EFCAB6_chr22_44083461_ENST00000396231_length(amino acids)=1384AA_BP=226 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFG LQYTIKDTVAWLKMDKKVLDHDVSKEEPVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDY DPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNE SHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKT SPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLA CIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVH DFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPY SAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQA HQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAED YFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRH DNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTD NQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTIS REEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSK SQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNG KFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYS -------------------------------------------------------------- >58721_58721_5_NF2-EFCAB6_NF2_chr22_30051665_ENST00000353887_EFCAB6_chr22_44083461_ENST00000262726_length(amino acids)=1301AA_BP=143 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEVKKQILDEKIYCPPEASVLLASYAV QAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRN SINSRNESHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEE NCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRI LYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEP NGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLK ESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADS ELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAV HRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLN SWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKD FCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDT MKTNTISREEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQ ELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIK YDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFR -------------------------------------------------------------- >58721_58721_6_NF2-EFCAB6_NF2_chr22_30051665_ENST00000353887_EFCAB6_chr22_44083461_ENST00000396231_length(amino acids)=1301AA_BP=143 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEVKKQILDEKIYCPPEASVLLASYAV QAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRN SINSRNESHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEE NCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRI LYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEP NGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLK ESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADS ELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAV HRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLN SWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKD FCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDT MKTNTISREEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQ ELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIK YDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFR -------------------------------------------------------------- >58721_58721_7_NF2-EFCAB6_NF2_chr22_30051665_ENST00000361166_EFCAB6_chr22_44083461_ENST00000262726_length(amino acids)=1357AA_BP=199 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFGLQYTIKDTVAWLKMDKKVLDHDVSKEE PVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMT PEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNESHKENIITKLFRHTEDHSASLKKALLI INTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITR NLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQK DEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGF EKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLL LNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGN GILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEK AVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKE ESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNF SCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTISREEFRAICNRRVQILTDEQFDRLWNEM PVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIE SRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMK IQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYSINLSEEEFFHILEYYDKTLSSKISYND -------------------------------------------------------------- >58721_58721_8_NF2-EFCAB6_NF2_chr22_30051665_ENST00000361166_EFCAB6_chr22_44083461_ENST00000396231_length(amino acids)=1357AA_BP=199 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFGLQYTIKDTVAWLKMDKKVLDHDVSKEE PVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMT PEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNESHKENIITKLFRHTEDHSASLKKALLI INTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITR NLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQK DEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGF EKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLL LNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGN GILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEK AVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKE ESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNF SCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTISREEFRAICNRRVQILTDEQFDRLWNEM PVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIE SRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMK IQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYSINLSEEEFFHILEYYDKTLSSKISYND -------------------------------------------------------------- >58721_58721_9_NF2-EFCAB6_NF2_chr22_30051665_ENST00000361452_EFCAB6_chr22_44083461_ENST00000262726_length(amino acids)=1343AA_BP=185 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFG LQYTIKDTVAWLKMDKKVKKQILDEKIYCPPEASVLLASYAVQAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAE HRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNESHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEF RYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDL GDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKL TEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGF EDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGL LGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYG FDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQD ISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQE AVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEK MPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTISREEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFL SRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQL LKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAET -------------------------------------------------------------- >58721_58721_10_NF2-EFCAB6_NF2_chr22_30051665_ENST00000361452_EFCAB6_chr22_44083461_ENST00000396231_length(amino acids)=1343AA_BP=185 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFG LQYTIKDTVAWLKMDKKVKKQILDEKIYCPPEASVLLASYAVQAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAE HRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNESHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEF RYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDL GDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKL TEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGF EDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGL LGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYG FDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQD ISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQE AVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEK MPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTISREEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFL SRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQL LKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAET -------------------------------------------------------------- >58721_58721_11_NF2-EFCAB6_NF2_chr22_30051665_ENST00000361676_EFCAB6_chr22_44083461_ENST00000262726_length(amino acids)=1315AA_BP=157 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEVLDHDVSKEEPVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIY CPPEASVLLASYAVQAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQ GLQVSSKGPLTKRNSINSRNESHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDT GVVNTSMFIDLIEENCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFI KLCSKIQDIGSGRILYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQD PAFKKRFLDFSKEPNGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFI TAEECLKLFPRRLKESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEA PQRLIRPKQKVADSELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQ EFLQKLGINYSPAVHRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEEC GCSLTEGELTHLLNSWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDT GFVKATEFGQVLKDFCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTS HYHAITQEFENFDTMKTNTISREEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPD VSEGTRSALSLPTQELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFN LDISKEECQQLIIKYDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSY -------------------------------------------------------------- >58721_58721_12_NF2-EFCAB6_NF2_chr22_30051665_ENST00000361676_EFCAB6_chr22_44083461_ENST00000396231_length(amino acids)=1315AA_BP=157 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEVLDHDVSKEEPVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIY CPPEASVLLASYAVQAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQ GLQVSSKGPLTKRNSINSRNESHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDT GVVNTSMFIDLIEENCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFI KLCSKIQDIGSGRILYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQD PAFKKRFLDFSKEPNGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFI TAEECLKLFPRRLKESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEA PQRLIRPKQKVADSELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQ EFLQKLGINYSPAVHRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEEC GCSLTEGELTHLLNSWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDT GFVKATEFGQVLKDFCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTS HYHAITQEFENFDTMKTNTISREEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPD VSEGTRSALSLPTQELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFN LDISKEECQQLIIKYDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSY -------------------------------------------------------------- >58721_58721_13_NF2-EFCAB6_NF2_chr22_30051665_ENST00000397789_EFCAB6_chr22_44083461_ENST00000262726_length(amino acids)=1357AA_BP=199 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFGLQYTIKDTVAWLKMDKKVLDHDVSKEE PVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMT PEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNESHKENIITKLFRHTEDHSASLKKALLI INTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITR NLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQK DEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGF EKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLL LNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGN GILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEK AVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKE ESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNF SCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTISREEFRAICNRRVQILTDEQFDRLWNEM PVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIE SRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMK IQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYSINLSEEEFFHILEYYDKTLSSKISYND -------------------------------------------------------------- >58721_58721_14_NF2-EFCAB6_NF2_chr22_30051665_ENST00000397789_EFCAB6_chr22_44083461_ENST00000396231_length(amino acids)=1357AA_BP=199 MAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFGLQYTIKDTVAWLKMDKKVLDHDVSKEE PVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDYDPSVHKRGFLAQEELLPKRVINLYQMT PEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNESHKENIITKLFRHTEDHSASLKKALLI INTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKTSPCTDAKTPFLLAWDSVEEIVHDTITR NLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLACIGIDGPPTVSPVLVPKDQLLSEHLQK DEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVHDFKKVLEDTGMPMDDDQYALLTTKIGF EKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPYSAFFKTDADRDGIINMHDLHRLLLHLL LNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQAHQYLVTKAKNRWSDLSKNFLETDNEGN GILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAEDYFNFMGHFTKPQQLQEEMKELQQSTEK AVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRHDNAINYLDFLRAVENSKSTGAQPKEKE ESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTDNQYHYFLRKLRIHLTPYINWKYFLQNF SCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTISREEFRAICNRRVQILTDEQFDRLWNEM PVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSKSQSHPCTPASTTVIPGTPPLQNCDPIE SRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNGKFAYCDFIQSCVLLLKAKESSLMHRMK IQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYSINLSEEEFFHILEYYDKTLSSKISYND -------------------------------------------------------------- >58721_58721_15_NF2-EFCAB6_NF2_chr22_30051665_ENST00000403435_EFCAB6_chr22_44083461_ENST00000262726_length(amino acids)=1384AA_BP=226 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFG LQYTIKDTVAWLKMDKKVLDHDVSKEEPVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDY DPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNE SHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKT SPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLA CIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVH DFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPY SAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQA HQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAED YFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRH DNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTD NQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTIS REEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSK SQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNG KFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYS -------------------------------------------------------------- >58721_58721_16_NF2-EFCAB6_NF2_chr22_30051665_ENST00000403435_EFCAB6_chr22_44083461_ENST00000396231_length(amino acids)=1384AA_BP=226 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFG LQYTIKDTVAWLKMDKKVLDHDVSKEEPVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDY DPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNE SHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKT SPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLA CIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVH DFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPY SAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQA HQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAED YFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRH DNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTD NQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTIS REEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSK SQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNG KFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYS -------------------------------------------------------------- >58721_58721_17_NF2-EFCAB6_NF2_chr22_30051665_ENST00000403999_EFCAB6_chr22_44083461_ENST00000262726_length(amino acids)=1384AA_BP=226 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFG LQYTIKDTVAWLKMDKKVLDHDVSKEEPVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDY DPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNE SHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKT SPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLA CIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVH DFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPY SAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQA HQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAED YFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRH DNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTD NQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTIS REEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSK SQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNG KFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYS -------------------------------------------------------------- >58721_58721_18_NF2-EFCAB6_NF2_chr22_30051665_ENST00000403999_EFCAB6_chr22_44083461_ENST00000396231_length(amino acids)=1384AA_BP=226 MCSNSRGAKGLRVQAVGREGPGPEPRAMAGAIASRMSFSSLKRKQPKTFTVRIVTMDAEMEFNCEMKWKGKDLFDLVCRTLGLRETWFFG LQYTIKDTVAWLKMDKKVLDHDVSKEEPVTFHFLAKFYPENAEEELVQEITQHLFFLQVKKQILDEKIYCPPEASVLLASYAVQAKYGDY DPSVHKRGFLAQEELLPKRVINLYQMTPEMWEERITAWYAEHRGRARFGLKATTKINWKQFLTSFHEPQGLQVSSKGPLTKRNSINSRNE SHKENIITKLFRHTEDHSASLKKALLIINTKPDGPITREEFRYILNCMAVKLSDSEFKELMQMLDPGDTGVVNTSMFIDLIEENCRMRKT SPCTDAKTPFLLAWDSVEEIVHDTITRNLQAFYNMLRSYDLGDTGRIGRNNFKKIMHVFCPFLTNAHFIKLCSKIQDIGSGRILYKKLLA CIGIDGPPTVSPVLVPKDQLLSEHLQKDEQQQPDLSERTKLTEDKTTLTKKMTTEEVIEKFKKCIQQQDPAFKKRFLDFSKEPNGKINVH DFKKVLEDTGMPMDDDQYALLTTKIGFEKEGMSYLDFAAGFEDPPMRGPETTPPQPPTPSKSYVNSHFITAEECLKLFPRRLKESFRDPY SAFFKTDADRDGIINMHDLHRLLLHLLLNLKDDEFERFLGLLGLRLSVTLNFREFQNLCEKRPWRTDEAPQRLIRPKQKVADSELACEQA HQYLVTKAKNRWSDLSKNFLETDNEGNGILRRRDIKNALYGFDIPLTPREFEKLWARYDTEGKGHITYQEFLQKLGINYSPAVHRPCAED YFNFMGHFTKPQQLQEEMKELQQSTEKAVAARDKLMDRHQDISKAFTKTDQSKTNYISICKMQEVLEECGCSLTEGELTHLLNSWGVSRH DNAINYLDFLRAVENSKSTGAQPKEKEESMPINFATLNPQEAVRKIQEVVESSQLALSTAFSALDKEDTGFVKATEFGQVLKDFCYKLTD NQYHYFLRKLRIHLTPYINWKYFLQNFSCFLEETADEWAEKMPKGPPPTSPKATADRDILARLHKAVTSHYHAITQEFENFDTMKTNTIS REEFRAICNRRVQILTDEQFDRLWNEMPVNAKGRLKYPDFLSRFSSETAATPMATGDSAVAQRGSSVPDVSEGTRSALSLPTQELRPGSK SQSHPCTPASTTVIPGTPPLQNCDPIESRLRKRIQGCWRQLLKECKEKDVARQGDINASDFLALVEKFNLDISKEECQQLIIKYDLKSNG KFAYCDFIQSCVLLLKAKESSLMHRMKIQNAHKMKEAGAETPSFYSALLRIQPKIVHCWRPMRRTFKSYDEAGTGLLSVADFRTVLRQYS -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:30051665/chr22:44083461) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NF2 | EFCAB6 |
| FUNCTION: Probable regulator of the Hippo/SWH (Sav/Wts/Hpo) signaling pathway, a signaling pathway that plays a pivotal role in tumor suppression by restricting proliferation and promoting apoptosis. Along with WWC1 can synergistically induce the phosphorylation of LATS1 and LATS2 and can probably function in the regulation of the Hippo/SWH (Sav/Wts/Hpo) signaling pathway. May act as a membrane stabilizing protein. May inhibit PI3 kinase by binding to AGAP2 and impairing its stimulating activity. Suppresses cell proliferation and tumorigenesis by inhibiting the CUL4A-RBX1-DDB1-VprBP/DCAF1 E3 ubiquitin-protein ligase complex. {ECO:0000269|PubMed:20159598, ECO:0000269|PubMed:20178741, ECO:0000269|PubMed:21167305}. | FUNCTION: Negatively regulates the androgen receptor by recruiting histone deacetylase complex, and protein DJ-1 antagonizes this inhibition by abrogation of this complex. {ECO:0000269|PubMed:12612053}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 754_765 | 343.6666666666667 | 1502.0 | Calcium binding | Ontology_term=ECO:0000255 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 754_765 | 191.66666666666666 | 1350.0 | Calcium binding | Ontology_term=ECO:0000255 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 1069_1104 | 343.6666666666667 | 1502.0 | Domain | EF-hand 12 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 1176_1211 | 343.6666666666667 | 1502.0 | Domain | EF-hand 13 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 1212_1247 | 343.6666666666667 | 1502.0 | Domain | EF-hand 14 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 1359_1394 | 343.6666666666667 | 1502.0 | Domain | EF-hand 15 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 1434_1469 | 343.6666666666667 | 1502.0 | Domain | EF-hand 16 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 1470_1501 | 343.6666666666667 | 1502.0 | Domain | EF-hand 17 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 403_438 | 343.6666666666667 | 1502.0 | Domain | EF-hand 4 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 439_474 | 343.6666666666667 | 1502.0 | Domain | EF-hand 5 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 504_539 | 343.6666666666667 | 1502.0 | Domain | EF-hand 6 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 634_669 | 343.6666666666667 | 1502.0 | Domain | EF-hand 7 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 741_776 | 343.6666666666667 | 1502.0 | Domain | EF-hand 8 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 847_882 | 343.6666666666667 | 1502.0 | Domain | EF-hand 9 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 883_918 | 343.6666666666667 | 1502.0 | Domain | EF-hand 10 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 964_999 | 343.6666666666667 | 1502.0 | Domain | EF-hand 11 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 1069_1104 | 191.66666666666666 | 1350.0 | Domain | EF-hand 12 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 1176_1211 | 191.66666666666666 | 1350.0 | Domain | EF-hand 13 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 1212_1247 | 191.66666666666666 | 1350.0 | Domain | EF-hand 14 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 1359_1394 | 191.66666666666666 | 1350.0 | Domain | EF-hand 15 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 1434_1469 | 191.66666666666666 | 1350.0 | Domain | EF-hand 16 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 1470_1501 | 191.66666666666666 | 1350.0 | Domain | EF-hand 17 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 297_332 | 191.66666666666666 | 1350.0 | Domain | EF-hand 3 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 403_438 | 191.66666666666666 | 1350.0 | Domain | EF-hand 4 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 439_474 | 191.66666666666666 | 1350.0 | Domain | EF-hand 5 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 504_539 | 191.66666666666666 | 1350.0 | Domain | EF-hand 6 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 634_669 | 191.66666666666666 | 1350.0 | Domain | EF-hand 7 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 741_776 | 191.66666666666666 | 1350.0 | Domain | EF-hand 8 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 847_882 | 191.66666666666666 | 1350.0 | Domain | EF-hand 9 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 883_918 | 191.66666666666666 | 1350.0 | Domain | EF-hand 10 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 964_999 | 191.66666666666666 | 1350.0 | Domain | EF-hand 11 |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000334961 | + | 4 | 15 | 327_465 | 116.66666666666667 | 451.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000338641 | + | 6 | 16 | 327_465 | 199.66666666666666 | 596.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000347330 | + | 1 | 10 | 327_465 | 0 | 1312.6666666666667 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000353887 | + | 4 | 15 | 327_465 | 116.66666666666667 | 406.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000361166 | + | 6 | 17 | 327_465 | 199.66666666666666 | 571.3333333333334 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000361452 | + | 5 | 16 | 327_465 | 158.66666666666666 | 1665.6666666666667 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000361676 | + | 5 | 16 | 327_465 | 157.66666666666666 | 531.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000397789 | + | 6 | 17 | 327_465 | 199.66666666666666 | 573.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000403435 | + | 6 | 17 | 327_465 | 199.66666666666666 | 541.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000403999 | + | 6 | 16 | 327_465 | 199.66666666666666 | 591.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000413209 | + | 1 | 5 | 327_465 | 0 | 166.0 | Compositional bias | Note=Glu-rich |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000334961 | + | 4 | 15 | 22_311 | 116.66666666666667 | 451.0 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000338641 | + | 6 | 16 | 22_311 | 199.66666666666666 | 596.0 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000347330 | + | 1 | 10 | 22_311 | 0 | 1312.6666666666667 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000353887 | + | 4 | 15 | 22_311 | 116.66666666666667 | 406.0 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000361166 | + | 6 | 17 | 22_311 | 199.66666666666666 | 571.3333333333334 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000361452 | + | 5 | 16 | 22_311 | 158.66666666666666 | 1665.6666666666667 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000361676 | + | 5 | 16 | 22_311 | 157.66666666666666 | 531.0 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000397789 | + | 6 | 17 | 22_311 | 199.66666666666666 | 573.0 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000403435 | + | 6 | 17 | 22_311 | 199.66666666666666 | 541.0 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000403999 | + | 6 | 16 | 22_311 | 199.66666666666666 | 591.0 | Domain | FERM |
| Hgene | NF2 | chr22:30051665 | chr22:44083461 | ENST00000413209 | + | 1 | 5 | 22_311 | 0 | 166.0 | Domain | FERM |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 172_207 | 343.6666666666667 | 1502.0 | Domain | EF-hand 2 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 297_332 | 343.6666666666667 | 1502.0 | Domain | EF-hand 3 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000262726 | 9 | 32 | 70_105 | 343.6666666666667 | 1502.0 | Domain | EF-hand 1 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 172_207 | 191.66666666666666 | 1350.0 | Domain | EF-hand 2 | |
| Tgene | EFCAB6 | chr22:30051665 | chr22:44083461 | ENST00000396231 | 7 | 30 | 70_105 | 191.66666666666666 | 1350.0 | Domain | EF-hand 1 |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| NF2 | |
| EFCAB6 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to NF2-EFCAB6 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to NF2-EFCAB6 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies