| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:NOS1AP-ASH1L |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: NOS1AP-ASH1L | FusionPDB ID: 59665 | FusionGDB2.0 ID: 59665 | Hgene | Tgene | Gene symbol | NOS1AP | ASH1L | Gene ID | 9722 | 55870 |
| Gene name | nitric oxide synthase 1 adaptor protein | ASH1 like histone lysine methyltransferase | |
| Synonyms | 6330408P19Rik|CAPON | ASH1|ASH1L1|KMT2H|MRD52 | |
| Cytomap | 1q23.3 | 1q22 | |
| Type of gene | protein-coding | protein-coding | |
| Description | carboxyl-terminal PDZ ligand of neuronal nitric oxide synthase proteinC-terminal PDZ domain ligand of neuronal nitric oxide synthase (CAPON)C-terminal PDZ ligand of neuronal nitric oxide synthase proteinligand of neuronal nitric oxide synthase with car | histone-lysine N-methyltransferase ASH1LASH1-like proteinabsent small and homeotic disks protein 1 homologash1 (absent, small, or homeotic)-likelysine N-methyltransferase 2Hprobable histone-lysine N-methyltransferase ASH1L | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O75052 | Q9NR48 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000361897, ENST00000530878, ENST00000454693, ENST00000493151, | ENST00000548830, ENST00000368346, ENST00000392403, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 15 X 9 X 8=1080 | 17 X 13 X 7=1547 |
| # samples | 18 | 18 | |
| ** MAII score | log2(18/1080*10)=-2.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(18/1547*10)=-3.10340438511936 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: NOS1AP [Title/Abstract] AND ASH1L [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | NOS1AP(162257226)-ASH1L(155452240), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | NOS1AP-ASH1L seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NOS1AP-ASH1L seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NOS1AP-ASH1L seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. NOS1AP-ASH1L seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NOS1AP | GO:0098974 | postsynaptic actin cytoskeleton organization | 26869880 |
| Tgene | ASH1L | GO:0097676 | histone H3-K36 dimethylation | 26002201 |
| Fusion gene breakpoints across NOS1AP (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
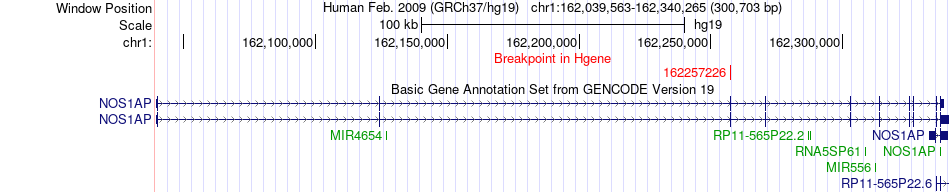 |
| Fusion gene breakpoints across ASH1L (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-L9-A444-01A | NOS1AP | chr1 | 162257226 | + | ASH1L | chr1 | 155452240 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000530878 | NOS1AP | chr1 | 162257226 | + | ENST00000368346 | ASH1L | chr1 | 155452240 | - | 11556 | 674 | 221 | 9163 | 2980 |
| ENST00000530878 | NOS1AP | chr1 | 162257226 | + | ENST00000392403 | ASH1L | chr1 | 155452240 | - | 10754 | 674 | 221 | 9148 | 2975 |
| ENST00000361897 | NOS1AP | chr1 | 162257226 | + | ENST00000368346 | ASH1L | chr1 | 155452240 | - | 11554 | 672 | 219 | 9161 | 2980 |
| ENST00000361897 | NOS1AP | chr1 | 162257226 | + | ENST00000392403 | ASH1L | chr1 | 155452240 | - | 10752 | 672 | 219 | 9146 | 2975 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000530878 | ENST00000368346 | NOS1AP | chr1 | 162257226 | + | ASH1L | chr1 | 155452240 | - | 0.000246575 | 0.9997534 |
| ENST00000530878 | ENST00000392403 | NOS1AP | chr1 | 162257226 | + | ASH1L | chr1 | 155452240 | - | 0.000239658 | 0.9997603 |
| ENST00000361897 | ENST00000368346 | NOS1AP | chr1 | 162257226 | + | ASH1L | chr1 | 155452240 | - | 0.00024601 | 0.999754 |
| ENST00000361897 | ENST00000392403 | NOS1AP | chr1 | 162257226 | + | ASH1L | chr1 | 155452240 | - | 0.000239259 | 0.9997607 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >59665_59665_1_NOS1AP-ASH1L_NOS1AP_chr1_162257226_ENST00000361897_ASH1L_chr1_155452240_ENST00000368346_length(amino acids)=2980AA_BP=151 MPLGPRHRSGSGRRAARAPPAQRSQAPPRVAAPSSSLPSPGSRQPLPAAAASEGAGPPRVTMPSKTKYNLVDDGHDLRIPLHNEDAFQHG ICFEAKYVGSLDVPRPNSRVEIVAAMRRIRYEFKAKNIKKKKVSIMVSVDGVKVILKKKKKDPSKLYKKADDVAAIECQSEEVIRLHSQG ENNPLSKKLSPVHSEMADYINATPSTLLGSRDPDLKDRALLNGGTSVTEKLAQLIATCPPSKSSKTKPKKLGTGTTAGLVSKDLIRKAGV GSVAGIIHKDLIKKPTISTAVGLVTKDPGKKPVFNAAVGLVNKDSVKKLGTGTTAVFINKNLGKKPGTITTVGLLSKDSGKKLGIGIVPG LVHKESGKKLGLGTVVGLVNKDLGKKLGSTVGLVAKDCAKKIVASSAMGLVNKDIGKKLMSCPLAGLISKDAINLKAEALLPTQEPLKAS CSTNINNQESQELSESLKDSATSKTFEKNVVRQNKESILEKFSVRKEIINLEKEMFNEGTCIQQDSFSSSEKGSYETSKHEKQPPVYCTS PDFKMGGASDVSTAKSPFSAVGESNLPSPSPTVSVNPLTRSPPETSSQLAPNPLLLSSTTELIEEISESVGKNQFTSESTHLNVGHRSVG HSISIECKGIDKEVNDSKTTHIDIPRISSSLGKKPSLTSESSIHTITPSVVNFTSLFSNKPFLKLGAVSASDKHCQVAESLSTSLQSKPL KKRKGRKPRWTKVVARSTCRSPKGLELERSELFKNVSCSSLSNSNSEPAKFMKNIGPPSFVDHDFLKRRLPKLSKSTAPSLALLADSEKP SHKSFATHKLSSSMCVSSDLLSDIYKPKRGRPKSKEMPQLEGPPKRTLKIPASKVFSLQSKEEQEPPILQPEIEIPSFKQGLSVSPFPKK RGRPKRQMRSPVKMKPPVLSVAPFVATESPSKLESESDNHRSSSDFFESEDQLQDPDDLDDSHRPSVCSMSDLEMEPDKKITKRNNGQLM KTIIRKINKMKTLKRKKLLNQILSSSVESSNKGKVQSKLHNTVSSLAATFGSKLGQQINVSKKGTIYIGKRRGRKPKTVLNGILSGSPTS LAVLEQTAQQAAGSALGQILPPLLPSSASSSEILPSPICSQSSGTSGGQSPVSSDAGFVEPSSVPYLHLHSRQGSMIQTLAMKKASKGRR RLSPPTLLPNSPSHLSELTSLKEATPSPISESHSDETIPSDSGIGTDNNSTSDRAEKFCGQKKRRHSFEHVSLIPPETSTVLSSLKEKHK HKCKRRNHDYLSYDKMKRQKRKRKKKYPQLRNRQDPDFIAELEELISRLSEIRITHRSHHFIPRDLLPTIFRINFNSFYTHPSFPLDPLH YIRKPDLKKKRGRPPKMREAMAEMPFMHSLSFPLSSTGFYPSYGMPYSPSPLTAAPIGLGYYGRYPPTLYPPPPSPSFTTPLPPPSYMHA GHLLLNPAKYHKKKHKLLRQEAFLTTSRTPLLSMSTYPSVPPEMAYGWMVEHKHRHRHKHREHRSSEQPQVSMDTGSSRSVLESLKRYRF GKDAVGERYKHKEKHRCHMSCPHLSPSKSLINREEQWVHREPSESSPLALGLQTPLQIDCSESSPSLSLGGFTPNSEPASSDEHTNLFTS AIGSCRVSNPNSSGRKKLTDSPGLFSAQDTSLNRLHRKESLPSNERAVQTLAGSQPTSDKPSQRPSESTNCSPTRKRSSSESTSSTVNGV PSRSPRLVASGDDSVDSLLQRMVQNEDQEPMEKSIDAVIATASAPPSSSPGRSHSKDRTLGKPDSLLVPAVTSDSCNNSISLLSEKLTSS CSPHHIKRSVVEAMQRQARKMCNYDKILATKKNLDHVNKILKAKKLQRQARTGNNFVKRRPGRPRKCPLQAVVSMQAFQAAQFVNPELNR DEEGAALHLSPDTVTDVIEAVVQSVNLNPEHKKGLKRKGWLLEEQTRKKQKPLPEEEEQENNKSFNEAPVEIPSPSETPAKPSEPESTLQ PVLSLIPREKKPPRPPKKKYQKAGLYSDVYKTTDPKSRLIQLKKEKLEYTPGEHEYGLFPAPIHVVFFVSGKYLRQKRIDFQLPYDILWQ WKHNQLYKKPDVPLYKKIRSNVYVDVKPLSGYEATTCNCKKPDDDTRKGCVDDCLNRMIFAECSPNTCPCGEQCCNQRIQRHEWVQCLER FRAEEKGWGIRTKEPLKAGQFIIEYLGEVVSEQEFRNRMIEQYHNHSDHYCLNLDSGMVIDSYRMGNEARFINHSCDPNCEMQKWSVNGV YRIGLYALKDMPAGTELTYDYNFHSFNVEKQQLCKCGFEKCRGIIGGKSQRVNGLTSSKNSQPMATHKKSGRSKEKRKSKHKLKKRRGHL SEEPSENINTPTRLTPQLQMKPMSNRERNFVLKHHVFLVRNWEKIRQKQEEVKHTSDNIHSASLYTRWNGICRDDGNIKSDVFMTQFSAL QTARSVRTRRLAAAEENIEVARAARLAQIFKEICDGIISYKDSSRQALAAPLLNLPPKKKNADYYEKISDPLDLITIEKQILTGYYKTVE AFDADMLKVFRNAEKYYGRKSPVGRDVCRLRKAYYNARHEASAQIDEIVGETASEADSSETSVSEKENGHEKDDDVIRCICGLYKDEGLM IQCDKCMVWQHCDCMGVNSDVEHYLCEQCDPRPVDREVPMIPRPHYAQPGCVYFICLLRDDLLLRQGDCVYLMRDSRRTPDGHPVRQSYR LLSHINRDKLDIFRIEKLWKNEKEERFAFGHHYFRPHETHHSPSRRFYHNELFRVPLYEIIPLEAVVGTCCVLDLYTYCKGRPKGVKEQD VYICDYRLDKSAHLFYKIHRNRYPVCTKPYAFDHFPKKLTPKKDFSPHYVPDNYKRNGGRSSWKSERSKPPLKDLGQEDDALPLIEEVLA SQEQAANEIPSLEEPEREGATANVSEGEKKTEESSQEPQSTCTPEERRHNQRERLNQILLNLLEKIPGKNAIDVTYLLEEGSGRKLRRRT -------------------------------------------------------------- >59665_59665_2_NOS1AP-ASH1L_NOS1AP_chr1_162257226_ENST00000361897_ASH1L_chr1_155452240_ENST00000392403_length(amino acids)=2975AA_BP=151 MPLGPRHRSGSGRRAARAPPAQRSQAPPRVAAPSSSLPSPGSRQPLPAAAASEGAGPPRVTMPSKTKYNLVDDGHDLRIPLHNEDAFQHG ICFEAKYVGSLDVPRPNSRVEIVAAMRRIRYEFKAKNIKKKKVSIMVSVDGVKVILKKKKKDPSKLYKKADDVAAIECQSEEVIRLHSQG ENNPLSKKLSPVHSEMADYINATPSTLLGSRDPDLKDRALLNGGTSVTEKLAQLIATCPPSKSSKTKPKKLGTGTTAGLVSKDLIRKAGV GSVAGIIHKDLIKKPTISTAVGLVTKDPGKKPVFNAAVGLVNKDSVKKLGTGTTAVFINKNLGKKPGTITTVGLLSKDSGKKLGIGIVPG LVHKESGKKLGLGTVVGLVNKDLGKKLGSTVGLVAKDCAKKIVASSAMGLVNKDIGKKLMSCPLAGLISKDAINLKAEALLPTQEPLKAS CSTNINNQESQELSESLKDSATSKTFEKNVVRQNKESILEKFSVRKEIINLEKEMFNEGTCIQQDSFSSSEKGSYETSKHEKQPPVYCTS PDFKMGGASDVSTAKSPFSAVGESNLPSPSPTVSVNPLTRSPPETSSQLAPNPLLLSSTTELIEEISESVGKNQFTSESTHLNVGHRSVG HSISIECKGIDKEVNDSKTTHIDIPRISSSLGKKPSLTSESSIHTITPSVVNFTSLFSNKPFLKLGAVSASDKHCQVAESLSTSLQSKPL KKRKGRKPRWTKVVARSTCRSPKGLELERSELFKNVSCSSLSNSNSEPAKFMKNIGPPSFVDHDFLKRRLPKLSKSTAPSLALLADSEKP SHKSFATHKLSSSMCVSSDLLSDIYKPKRGRPKSKEMPQLEGPPKRTLKIPASKVFSLQSKEEQEPPILQPEIEIPSFKQGLSVSPFPKK RGRPKRQMRSPVKMKPPVLSVAPFVATESPSKLESESDNHRSSSDFFESEDQLQDPDDLDDSHRPSVCSMSDLEMEPDKKITKRNNGQLM KTIIRKINKMKTLKRKKLLNQILSSSVESSNKGKVQSKLHNTVSSLAATFGSKLGQQINVSKKGTIYIGKRRGRKPKTVLNGILSGSPTS LAVLEQTAQQAAGSALGQILPPLLPSSASSSEILPSPICSQSSGTSGGQSPVSSDAGFVEPSSVPYLHLHSRQGSMIQTLAMKKASKGRR RLSPPTLLPNSPSHLSELTSLKEATPSPISESHSDETIPSDSGIGTDNNSTSDRAEKFCGQKKRRHSFEHVSLIPPETSTVLSSLKEKHK HKCKRRNHDYLSYDKMKRQKRKRKKKYPQLRNRQDPDFIAELEELISRLSEIRITHRSHHFIPRDLLPTIFRINFNSFYTHPSFPLDPLH YIRKPDLKKKRGRPPKMREAMAEMPFMHSLSFPLSSTGFYPSYGMPYSPSPLTAAPIGLGYYGRYPPTLYPPPPSPSFTTPLPPPSYMHA GHLLLNPAKYHKKKHKLLRQEAFLTTSRTPLLSMSTYPSVPPEMAYGWMVEHKHRHRHKHREHRSSEQPQVSMDTGSSRSVLESLKRYRF GKDAVGERYKHKEKHRCHMSCPHLSPSKSLINREEQWVHREPSESSPLALGLQTPLQIDCSESSPSLSLGGFTPNSEPASSDEHTNLFTS AIGSCRVSNPNSSGRKKLTDSPGLFSAQDTSLNRLHRKESLPSNERAVQTLAGSQPTSDKPSQRPSESTNCSPTRKRSSSESTSSTVNGV PSRSPRLVASGDDSVDSLLQRMVQNEDQEPMEKSIDAVIATASAPPSSSPGRSHSKDRTLGKPDSLLVPAVTSDSCNNSISLLSEKLTSS CSPHHIKRSVVEAMQRQARKMCNYDKILATKKNLDHVNKILKAKKLQRQARTGNNFVKRRPGRPRKCPLQAVVSMQAFQAAQFVNPELNR DEEGAALHLSPDTVTDVIEAVVQSVNLNPEHKKGLKRKGWLLEEQTRKKQKPLPEEEEQENNKSFNEAPVEIPSPSETPAKPSEPESTLQ PVLSLIPREKKPPRPPKKKYQKAGLYSDVYKTTDPKSRLIQLKKEKLEYTPGEHEYGLFPAPIHVGKYLRQKRIDFQLPYDILWQWKHNQ LYKKPDVPLYKKIRSNVYVDVKPLSGYEATTCNCKKPDDDTRKGCVDDCLNRMIFAECSPNTCPCGEQCCNQRIQRHEWVQCLERFRAEE KGWGIRTKEPLKAGQFIIEYLGEVVSEQEFRNRMIEQYHNHSDHYCLNLDSGMVIDSYRMGNEARFINHSCDPNCEMQKWSVNGVYRIGL YALKDMPAGTELTYDYNFHSFNVEKQQLCKCGFEKCRGIIGGKSQRVNGLTSSKNSQPMATHKKSGRSKEKRKSKHKLKKRRGHLSEEPS ENINTPTRLTPQLQMKPMSNRERNFVLKHHVFLVRNWEKIRQKQEEVKHTSDNIHSASLYTRWNGICRDDGNIKSDVFMTQFSALQTARS VRTRRLAAAEENIEVARAARLAQIFKEICDGIISYKDSSRQALAAPLLNLPPKKKNADYYEKISDPLDLITIEKQILTGYYKTVEAFDAD MLKVFRNAEKYYGRKSPVGRDVCRLRKAYYNARHEASAQIDEIVGETASEADSSETSVSEKENGHEKDDDVIRCICGLYKDEGLMIQCDK CMVWQHCDCMGVNSDVEHYLCEQCDPRPVDREVPMIPRPHYAQPGCVYFICLLRDDLLLRQGDCVYLMRDSRRTPDGHPVRQSYRLLSHI NRDKLDIFRIEKLWKNEKEERFAFGHHYFRPHETHHSPSRRFYHNELFRVPLYEIIPLEAVVGTCCVLDLYTYCKGRPKGVKEQDVYICD YRLDKSAHLFYKIHRNRYPVCTKPYAFDHFPKKLTPKKDFSPHYVPDNYKRNGGRSSWKSERSKPPLKDLGQEDDALPLIEEVLASQEQA ANEIPSLEEPEREGATANVSEGEKKTEESSQEPQSTCTPEERRHNQRERLNQILLNLLEKIPGKNAIDVTYLLEEGSGRKLRRRTLFIPE -------------------------------------------------------------- >59665_59665_3_NOS1AP-ASH1L_NOS1AP_chr1_162257226_ENST00000530878_ASH1L_chr1_155452240_ENST00000368346_length(amino acids)=2980AA_BP=151 MPLGPRHRSGSGRRAARAPPAQRSQAPPRVAAPSSSLPSPGSRQPLPAAAASEGAGPPRVTMPSKTKYNLVDDGHDLRIPLHNEDAFQHG ICFEAKYVGSLDVPRPNSRVEIVAAMRRIRYEFKAKNIKKKKVSIMVSVDGVKVILKKKKKDPSKLYKKADDVAAIECQSEEVIRLHSQG ENNPLSKKLSPVHSEMADYINATPSTLLGSRDPDLKDRALLNGGTSVTEKLAQLIATCPPSKSSKTKPKKLGTGTTAGLVSKDLIRKAGV GSVAGIIHKDLIKKPTISTAVGLVTKDPGKKPVFNAAVGLVNKDSVKKLGTGTTAVFINKNLGKKPGTITTVGLLSKDSGKKLGIGIVPG LVHKESGKKLGLGTVVGLVNKDLGKKLGSTVGLVAKDCAKKIVASSAMGLVNKDIGKKLMSCPLAGLISKDAINLKAEALLPTQEPLKAS CSTNINNQESQELSESLKDSATSKTFEKNVVRQNKESILEKFSVRKEIINLEKEMFNEGTCIQQDSFSSSEKGSYETSKHEKQPPVYCTS PDFKMGGASDVSTAKSPFSAVGESNLPSPSPTVSVNPLTRSPPETSSQLAPNPLLLSSTTELIEEISESVGKNQFTSESTHLNVGHRSVG HSISIECKGIDKEVNDSKTTHIDIPRISSSLGKKPSLTSESSIHTITPSVVNFTSLFSNKPFLKLGAVSASDKHCQVAESLSTSLQSKPL KKRKGRKPRWTKVVARSTCRSPKGLELERSELFKNVSCSSLSNSNSEPAKFMKNIGPPSFVDHDFLKRRLPKLSKSTAPSLALLADSEKP SHKSFATHKLSSSMCVSSDLLSDIYKPKRGRPKSKEMPQLEGPPKRTLKIPASKVFSLQSKEEQEPPILQPEIEIPSFKQGLSVSPFPKK RGRPKRQMRSPVKMKPPVLSVAPFVATESPSKLESESDNHRSSSDFFESEDQLQDPDDLDDSHRPSVCSMSDLEMEPDKKITKRNNGQLM KTIIRKINKMKTLKRKKLLNQILSSSVESSNKGKVQSKLHNTVSSLAATFGSKLGQQINVSKKGTIYIGKRRGRKPKTVLNGILSGSPTS LAVLEQTAQQAAGSALGQILPPLLPSSASSSEILPSPICSQSSGTSGGQSPVSSDAGFVEPSSVPYLHLHSRQGSMIQTLAMKKASKGRR RLSPPTLLPNSPSHLSELTSLKEATPSPISESHSDETIPSDSGIGTDNNSTSDRAEKFCGQKKRRHSFEHVSLIPPETSTVLSSLKEKHK HKCKRRNHDYLSYDKMKRQKRKRKKKYPQLRNRQDPDFIAELEELISRLSEIRITHRSHHFIPRDLLPTIFRINFNSFYTHPSFPLDPLH YIRKPDLKKKRGRPPKMREAMAEMPFMHSLSFPLSSTGFYPSYGMPYSPSPLTAAPIGLGYYGRYPPTLYPPPPSPSFTTPLPPPSYMHA GHLLLNPAKYHKKKHKLLRQEAFLTTSRTPLLSMSTYPSVPPEMAYGWMVEHKHRHRHKHREHRSSEQPQVSMDTGSSRSVLESLKRYRF GKDAVGERYKHKEKHRCHMSCPHLSPSKSLINREEQWVHREPSESSPLALGLQTPLQIDCSESSPSLSLGGFTPNSEPASSDEHTNLFTS AIGSCRVSNPNSSGRKKLTDSPGLFSAQDTSLNRLHRKESLPSNERAVQTLAGSQPTSDKPSQRPSESTNCSPTRKRSSSESTSSTVNGV PSRSPRLVASGDDSVDSLLQRMVQNEDQEPMEKSIDAVIATASAPPSSSPGRSHSKDRTLGKPDSLLVPAVTSDSCNNSISLLSEKLTSS CSPHHIKRSVVEAMQRQARKMCNYDKILATKKNLDHVNKILKAKKLQRQARTGNNFVKRRPGRPRKCPLQAVVSMQAFQAAQFVNPELNR DEEGAALHLSPDTVTDVIEAVVQSVNLNPEHKKGLKRKGWLLEEQTRKKQKPLPEEEEQENNKSFNEAPVEIPSPSETPAKPSEPESTLQ PVLSLIPREKKPPRPPKKKYQKAGLYSDVYKTTDPKSRLIQLKKEKLEYTPGEHEYGLFPAPIHVVFFVSGKYLRQKRIDFQLPYDILWQ WKHNQLYKKPDVPLYKKIRSNVYVDVKPLSGYEATTCNCKKPDDDTRKGCVDDCLNRMIFAECSPNTCPCGEQCCNQRIQRHEWVQCLER FRAEEKGWGIRTKEPLKAGQFIIEYLGEVVSEQEFRNRMIEQYHNHSDHYCLNLDSGMVIDSYRMGNEARFINHSCDPNCEMQKWSVNGV YRIGLYALKDMPAGTELTYDYNFHSFNVEKQQLCKCGFEKCRGIIGGKSQRVNGLTSSKNSQPMATHKKSGRSKEKRKSKHKLKKRRGHL SEEPSENINTPTRLTPQLQMKPMSNRERNFVLKHHVFLVRNWEKIRQKQEEVKHTSDNIHSASLYTRWNGICRDDGNIKSDVFMTQFSAL QTARSVRTRRLAAAEENIEVARAARLAQIFKEICDGIISYKDSSRQALAAPLLNLPPKKKNADYYEKISDPLDLITIEKQILTGYYKTVE AFDADMLKVFRNAEKYYGRKSPVGRDVCRLRKAYYNARHEASAQIDEIVGETASEADSSETSVSEKENGHEKDDDVIRCICGLYKDEGLM IQCDKCMVWQHCDCMGVNSDVEHYLCEQCDPRPVDREVPMIPRPHYAQPGCVYFICLLRDDLLLRQGDCVYLMRDSRRTPDGHPVRQSYR LLSHINRDKLDIFRIEKLWKNEKEERFAFGHHYFRPHETHHSPSRRFYHNELFRVPLYEIIPLEAVVGTCCVLDLYTYCKGRPKGVKEQD VYICDYRLDKSAHLFYKIHRNRYPVCTKPYAFDHFPKKLTPKKDFSPHYVPDNYKRNGGRSSWKSERSKPPLKDLGQEDDALPLIEEVLA SQEQAANEIPSLEEPEREGATANVSEGEKKTEESSQEPQSTCTPEERRHNQRERLNQILLNLLEKIPGKNAIDVTYLLEEGSGRKLRRRT -------------------------------------------------------------- >59665_59665_4_NOS1AP-ASH1L_NOS1AP_chr1_162257226_ENST00000530878_ASH1L_chr1_155452240_ENST00000392403_length(amino acids)=2975AA_BP=151 MPLGPRHRSGSGRRAARAPPAQRSQAPPRVAAPSSSLPSPGSRQPLPAAAASEGAGPPRVTMPSKTKYNLVDDGHDLRIPLHNEDAFQHG ICFEAKYVGSLDVPRPNSRVEIVAAMRRIRYEFKAKNIKKKKVSIMVSVDGVKVILKKKKKDPSKLYKKADDVAAIECQSEEVIRLHSQG ENNPLSKKLSPVHSEMADYINATPSTLLGSRDPDLKDRALLNGGTSVTEKLAQLIATCPPSKSSKTKPKKLGTGTTAGLVSKDLIRKAGV GSVAGIIHKDLIKKPTISTAVGLVTKDPGKKPVFNAAVGLVNKDSVKKLGTGTTAVFINKNLGKKPGTITTVGLLSKDSGKKLGIGIVPG LVHKESGKKLGLGTVVGLVNKDLGKKLGSTVGLVAKDCAKKIVASSAMGLVNKDIGKKLMSCPLAGLISKDAINLKAEALLPTQEPLKAS CSTNINNQESQELSESLKDSATSKTFEKNVVRQNKESILEKFSVRKEIINLEKEMFNEGTCIQQDSFSSSEKGSYETSKHEKQPPVYCTS PDFKMGGASDVSTAKSPFSAVGESNLPSPSPTVSVNPLTRSPPETSSQLAPNPLLLSSTTELIEEISESVGKNQFTSESTHLNVGHRSVG HSISIECKGIDKEVNDSKTTHIDIPRISSSLGKKPSLTSESSIHTITPSVVNFTSLFSNKPFLKLGAVSASDKHCQVAESLSTSLQSKPL KKRKGRKPRWTKVVARSTCRSPKGLELERSELFKNVSCSSLSNSNSEPAKFMKNIGPPSFVDHDFLKRRLPKLSKSTAPSLALLADSEKP SHKSFATHKLSSSMCVSSDLLSDIYKPKRGRPKSKEMPQLEGPPKRTLKIPASKVFSLQSKEEQEPPILQPEIEIPSFKQGLSVSPFPKK RGRPKRQMRSPVKMKPPVLSVAPFVATESPSKLESESDNHRSSSDFFESEDQLQDPDDLDDSHRPSVCSMSDLEMEPDKKITKRNNGQLM KTIIRKINKMKTLKRKKLLNQILSSSVESSNKGKVQSKLHNTVSSLAATFGSKLGQQINVSKKGTIYIGKRRGRKPKTVLNGILSGSPTS LAVLEQTAQQAAGSALGQILPPLLPSSASSSEILPSPICSQSSGTSGGQSPVSSDAGFVEPSSVPYLHLHSRQGSMIQTLAMKKASKGRR RLSPPTLLPNSPSHLSELTSLKEATPSPISESHSDETIPSDSGIGTDNNSTSDRAEKFCGQKKRRHSFEHVSLIPPETSTVLSSLKEKHK HKCKRRNHDYLSYDKMKRQKRKRKKKYPQLRNRQDPDFIAELEELISRLSEIRITHRSHHFIPRDLLPTIFRINFNSFYTHPSFPLDPLH YIRKPDLKKKRGRPPKMREAMAEMPFMHSLSFPLSSTGFYPSYGMPYSPSPLTAAPIGLGYYGRYPPTLYPPPPSPSFTTPLPPPSYMHA GHLLLNPAKYHKKKHKLLRQEAFLTTSRTPLLSMSTYPSVPPEMAYGWMVEHKHRHRHKHREHRSSEQPQVSMDTGSSRSVLESLKRYRF GKDAVGERYKHKEKHRCHMSCPHLSPSKSLINREEQWVHREPSESSPLALGLQTPLQIDCSESSPSLSLGGFTPNSEPASSDEHTNLFTS AIGSCRVSNPNSSGRKKLTDSPGLFSAQDTSLNRLHRKESLPSNERAVQTLAGSQPTSDKPSQRPSESTNCSPTRKRSSSESTSSTVNGV PSRSPRLVASGDDSVDSLLQRMVQNEDQEPMEKSIDAVIATASAPPSSSPGRSHSKDRTLGKPDSLLVPAVTSDSCNNSISLLSEKLTSS CSPHHIKRSVVEAMQRQARKMCNYDKILATKKNLDHVNKILKAKKLQRQARTGNNFVKRRPGRPRKCPLQAVVSMQAFQAAQFVNPELNR DEEGAALHLSPDTVTDVIEAVVQSVNLNPEHKKGLKRKGWLLEEQTRKKQKPLPEEEEQENNKSFNEAPVEIPSPSETPAKPSEPESTLQ PVLSLIPREKKPPRPPKKKYQKAGLYSDVYKTTDPKSRLIQLKKEKLEYTPGEHEYGLFPAPIHVGKYLRQKRIDFQLPYDILWQWKHNQ LYKKPDVPLYKKIRSNVYVDVKPLSGYEATTCNCKKPDDDTRKGCVDDCLNRMIFAECSPNTCPCGEQCCNQRIQRHEWVQCLERFRAEE KGWGIRTKEPLKAGQFIIEYLGEVVSEQEFRNRMIEQYHNHSDHYCLNLDSGMVIDSYRMGNEARFINHSCDPNCEMQKWSVNGVYRIGL YALKDMPAGTELTYDYNFHSFNVEKQQLCKCGFEKCRGIIGGKSQRVNGLTSSKNSQPMATHKKSGRSKEKRKSKHKLKKRRGHLSEEPS ENINTPTRLTPQLQMKPMSNRERNFVLKHHVFLVRNWEKIRQKQEEVKHTSDNIHSASLYTRWNGICRDDGNIKSDVFMTQFSALQTARS VRTRRLAAAEENIEVARAARLAQIFKEICDGIISYKDSSRQALAAPLLNLPPKKKNADYYEKISDPLDLITIEKQILTGYYKTVEAFDAD MLKVFRNAEKYYGRKSPVGRDVCRLRKAYYNARHEASAQIDEIVGETASEADSSETSVSEKENGHEKDDDVIRCICGLYKDEGLMIQCDK CMVWQHCDCMGVNSDVEHYLCEQCDPRPVDREVPMIPRPHYAQPGCVYFICLLRDDLLLRQGDCVYLMRDSRRTPDGHPVRQSYRLLSHI NRDKLDIFRIEKLWKNEKEERFAFGHHYFRPHETHHSPSRRFYHNELFRVPLYEIIPLEAVVGTCCVLDLYTYCKGRPKGVKEQDVYICD YRLDKSAHLFYKIHRNRYPVCTKPYAFDHFPKKLTPKKDFSPHYVPDNYKRNGGRSSWKSERSKPPLKDLGQEDDALPLIEEVLASQEQA ANEIPSLEEPEREGATANVSEGEKKTEESSQEPQSTCTPEERRHNQRERLNQILLNLLEKIPGKNAIDVTYLLEEGSGRKLRRRTLFIPE -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:162257226/chr1:155452240) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NOS1AP | ASH1L |
| FUNCTION: Adapter protein involved in neuronal nitric-oxide (NO) synthesis regulation via its association with nNOS/NOS1. The complex formed with NOS1 and synapsins is necessary for specific NO and synapsin functions at a presynaptic level. Mediates an indirect interaction between NOS1 and RASD1 leading to enhance the ability of NOS1 to activate RASD1. Competes with DLG4 for interaction with NOS1, possibly affecting NOS1 activity by regulating the interaction between NOS1 and DLG4 (By similarity). {ECO:0000250}. | FUNCTION: Histone methyltransferase specifically trimethylating 'Lys-36' of histone H3 forming H3K36me3 (PubMed:21239497). Also monomethylates 'Lys-9' of histone H3 (H3K9me1) in vitro (By similarity). The physiological significance of the H3K9me1 activity is unclear (By similarity). {ECO:0000250|UniProtKB:Q99MY8, ECO:0000269|PubMed:21239497}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 1380_1424 | 140.0 | 2970.0 | Compositional bias | Note=Pro-rich | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 1580_1791 | 140.0 | 2970.0 | Compositional bias | Note=Ser-rich | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 1380_1424 | 140.0 | 2965.0 | Compositional bias | Note=Pro-rich | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 1580_1791 | 140.0 | 2965.0 | Compositional bias | Note=Ser-rich | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 1347_1359 | 140.0 | 2970.0 | DNA binding | Note=A.T hook 2 | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 1847_1859 | 140.0 | 2970.0 | DNA binding | Note=A.T hook 3 | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 887_899 | 140.0 | 2970.0 | DNA binding | Note=A.T hook 1 | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 1347_1359 | 140.0 | 2965.0 | DNA binding | Note=A.T hook 2 | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 1847_1859 | 140.0 | 2965.0 | DNA binding | Note=A.T hook 3 | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 887_899 | 140.0 | 2965.0 | DNA binding | Note=A.T hook 1 | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 2091_2142 | 140.0 | 2970.0 | Domain | AWS | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 2145_2261 | 140.0 | 2970.0 | Domain | SET | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 2269_2285 | 140.0 | 2970.0 | Domain | Post-SET | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 2463_2533 | 140.0 | 2970.0 | Domain | Bromo | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 2661_2798 | 140.0 | 2970.0 | Domain | BAH | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 2091_2142 | 140.0 | 2965.0 | Domain | AWS | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 2145_2261 | 140.0 | 2965.0 | Domain | SET | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 2269_2285 | 140.0 | 2965.0 | Domain | Post-SET | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 2463_2533 | 140.0 | 2965.0 | Domain | Bromo | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 2661_2798 | 140.0 | 2965.0 | Domain | BAH | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 2069_2288 | 140.0 | 2970.0 | Region | Note=Catalytic domain | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 2069_2288 | 140.0 | 2965.0 | Region | Note=Catalytic domain | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000368346 | 1 | 28 | 2585_2631 | 140.0 | 2970.0 | Zinc finger | Note=PHD-type | |
| Tgene | ASH1L | chr1:162257226 | chr1:155452240 | ENST00000392403 | 1 | 28 | 2585_2631 | 140.0 | 2965.0 | Zinc finger | Note=PHD-type |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000361897 | + | 3 | 10 | 322_363 | 90.0 | 507.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000493151 | + | 1 | 2 | 322_363 | 0 | 212.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000530878 | + | 3 | 10 | 322_363 | 90.0 | 502.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000361897 | + | 3 | 10 | 301_308 | 90.0 | 507.0 | Compositional bias | Note=Poly-Gln |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000493151 | + | 1 | 2 | 301_308 | 0 | 212.0 | Compositional bias | Note=Poly-Gln |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000530878 | + | 3 | 10 | 301_308 | 90.0 | 502.0 | Compositional bias | Note=Poly-Gln |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000361897 | + | 3 | 10 | 26_196 | 90.0 | 507.0 | Domain | PID |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000493151 | + | 1 | 2 | 26_196 | 0 | 212.0 | Domain | PID |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000530878 | + | 3 | 10 | 26_196 | 90.0 | 502.0 | Domain | PID |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000361897 | + | 3 | 10 | 504_506 | 90.0 | 507.0 | Motif | PDZ-binding |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000493151 | + | 1 | 2 | 504_506 | 0 | 212.0 | Motif | PDZ-binding |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000530878 | + | 3 | 10 | 504_506 | 90.0 | 502.0 | Motif | PDZ-binding |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| NOS1AP | |
| ASH1L |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000361897 | + | 3 | 10 | 494_506 | 90.0 | 507.0 | NOS1 |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000493151 | + | 1 | 2 | 494_506 | 0 | 212.0 | NOS1 |
| Hgene | NOS1AP | chr1:162257226 | chr1:155452240 | ENST00000530878 | + | 3 | 10 | 494_506 | 90.0 | 502.0 | NOS1 |
Top |
Related Drugs to NOS1AP-ASH1L |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to NOS1AP-ASH1L |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies