| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:NRXN2-NSD1 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: NRXN2-NSD1 | FusionPDB ID: 60375 | FusionGDB2.0 ID: 60375 | Hgene | Tgene | Gene symbol | NRXN2 | NSD1 | Gene ID | 9379 | 64324 |
| Gene name | neurexin 2 | nuclear receptor binding SET domain protein 1 | |
| Synonyms | - | ARA267|KMT3B|SOTOS|SOTOS1|STO | |
| Cytomap | 11q13.1 | 5q35.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | neurexin-2-betaneurexin II | histone-lysine N-methyltransferase, H3 lysine-36 and H4 lysine-20 specificH3-K36-HMTaseH4-K20-HMTaseNR-binding SET domain-containing proteinandrogen receptor coactivator 267 kDa proteinandrogen receptor-associated coregulator 267androgen receptor-as | |
| Modification date | 20200313 | 20200321 | |
| UniProtAcc | Q9P2S2 | . | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000265459, ENST00000301894, ENST00000377551, ENST00000377559, ENST00000409571, ENST00000496291, | ENST00000511258, ENST00000347982, ENST00000354179, ENST00000361032, ENST00000439151, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 4 X 4 X 3=48 | 12 X 14 X 7=1176 |
| # samples | 4 | 17 | |
| ** MAII score | log2(4/48*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(17/1176*10)=-2.79028140869866 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: NRXN2 [Title/Abstract] AND NSD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | NRXN2(64387766)-NSD1(176666757), # samples:1 NRXN2(64387766)-NSD1(176665238), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | NRXN2-NSD1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NRXN2-NSD1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NRXN2-NSD1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. NRXN2-NSD1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. NRXN2-NSD1 seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. NRXN2-NSD1 seems lost the major protein functional domain in Tgene partner, which is a epigenetic factor due to the frame-shifted ORF. NRXN2-NSD1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. NRXN2-NSD1 seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | NSD1 | GO:0045893 | positive regulation of transcription, DNA-templated | 11509567 |
| Fusion gene breakpoints across NRXN2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
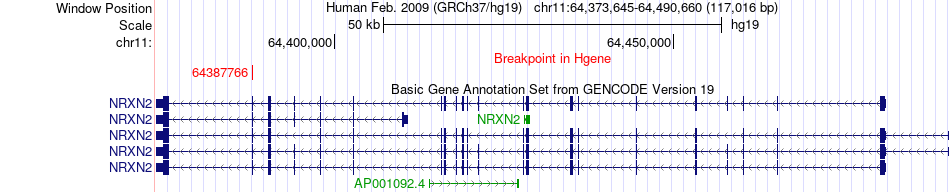 |
| Fusion gene breakpoints across NSD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
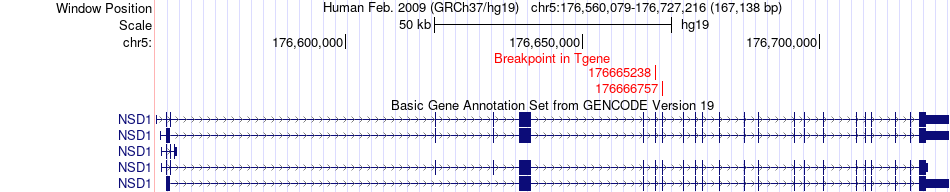 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCS | TCGA-N5-A4RT-01A | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176665238 | + |
| ChimerDB4 | UCS | TCGA-N5-A4RT-01A | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000377559 | NRXN2 | chr11 | 64387766 | - | ENST00000354179 | NSD1 | chr5 | 176666757 | + | 13154 | 4504 | 417 | 8402 | 2661 |
| ENST00000377559 | NRXN2 | chr11 | 64387766 | - | ENST00000439151 | NSD1 | chr5 | 176666757 | + | 13159 | 4504 | 417 | 8402 | 2661 |
| ENST00000377559 | NRXN2 | chr11 | 64387766 | - | ENST00000347982 | NSD1 | chr5 | 176666757 | + | 8706 | 4504 | 417 | 8402 | 2661 |
| ENST00000377559 | NRXN2 | chr11 | 64387766 | - | ENST00000361032 | NSD1 | chr5 | 176666757 | + | 13154 | 4504 | 417 | 8402 | 2661 |
| ENST00000265459 | NRXN2 | chr11 | 64387766 | - | ENST00000354179 | NSD1 | chr5 | 176666757 | + | 13364 | 4714 | 417 | 8612 | 2731 |
| ENST00000265459 | NRXN2 | chr11 | 64387766 | - | ENST00000439151 | NSD1 | chr5 | 176666757 | + | 13369 | 4714 | 417 | 8612 | 2731 |
| ENST00000265459 | NRXN2 | chr11 | 64387766 | - | ENST00000347982 | NSD1 | chr5 | 176666757 | + | 8916 | 4714 | 417 | 8612 | 2731 |
| ENST00000265459 | NRXN2 | chr11 | 64387766 | - | ENST00000361032 | NSD1 | chr5 | 176666757 | + | 13364 | 4714 | 417 | 8612 | 2731 |
| ENST00000301894 | NRXN2 | chr11 | 64387766 | - | ENST00000354179 | NSD1 | chr5 | 176666757 | + | 10276 | 1626 | 512 | 5524 | 1670 |
| ENST00000301894 | NRXN2 | chr11 | 64387766 | - | ENST00000439151 | NSD1 | chr5 | 176666757 | + | 10281 | 1626 | 512 | 5524 | 1670 |
| ENST00000301894 | NRXN2 | chr11 | 64387766 | - | ENST00000347982 | NSD1 | chr5 | 176666757 | + | 5828 | 1626 | 512 | 5524 | 1670 |
| ENST00000301894 | NRXN2 | chr11 | 64387766 | - | ENST00000361032 | NSD1 | chr5 | 176666757 | + | 10276 | 1626 | 512 | 5524 | 1670 |
| ENST00000377551 | NRXN2 | chr11 | 64387766 | - | ENST00000354179 | NSD1 | chr5 | 176666757 | + | 13114 | 4464 | 167 | 8362 | 2731 |
| ENST00000377551 | NRXN2 | chr11 | 64387766 | - | ENST00000439151 | NSD1 | chr5 | 176666757 | + | 13119 | 4464 | 167 | 8362 | 2731 |
| ENST00000377551 | NRXN2 | chr11 | 64387766 | - | ENST00000347982 | NSD1 | chr5 | 176666757 | + | 8666 | 4464 | 167 | 8362 | 2731 |
| ENST00000377551 | NRXN2 | chr11 | 64387766 | - | ENST00000361032 | NSD1 | chr5 | 176666757 | + | 13114 | 4464 | 167 | 8362 | 2731 |
| ENST00000409571 | NRXN2 | chr11 | 64387766 | - | ENST00000354179 | NSD1 | chr5 | 176666757 | + | 13125 | 4475 | 199 | 8373 | 2724 |
| ENST00000409571 | NRXN2 | chr11 | 64387766 | - | ENST00000439151 | NSD1 | chr5 | 176666757 | + | 13130 | 4475 | 199 | 8373 | 2724 |
| ENST00000409571 | NRXN2 | chr11 | 64387766 | - | ENST00000347982 | NSD1 | chr5 | 176666757 | + | 8677 | 4475 | 199 | 8373 | 2724 |
| ENST00000409571 | NRXN2 | chr11 | 64387766 | - | ENST00000361032 | NSD1 | chr5 | 176666757 | + | 13125 | 4475 | 199 | 8373 | 2724 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000377559 | ENST00000354179 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.001001899 | 0.9989981 |
| ENST00000377559 | ENST00000439151 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.001002206 | 0.99899775 |
| ENST00000377559 | ENST00000347982 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.002355493 | 0.9976445 |
| ENST00000377559 | ENST00000361032 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.001001899 | 0.9989981 |
| ENST00000265459 | ENST00000354179 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.001009894 | 0.9989901 |
| ENST00000265459 | ENST00000439151 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.001010194 | 0.99898976 |
| ENST00000265459 | ENST00000347982 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.002339815 | 0.99766016 |
| ENST00000265459 | ENST00000361032 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.001009894 | 0.9989901 |
| ENST00000301894 | ENST00000354179 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.000668528 | 0.9993315 |
| ENST00000301894 | ENST00000439151 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.000668442 | 0.9993316 |
| ENST00000301894 | ENST00000347982 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.001742362 | 0.9982577 |
| ENST00000301894 | ENST00000361032 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.000668528 | 0.9993315 |
| ENST00000377551 | ENST00000354179 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.00069926 | 0.9993007 |
| ENST00000377551 | ENST00000439151 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.000699421 | 0.9993006 |
| ENST00000377551 | ENST00000347982 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.001656509 | 0.99834347 |
| ENST00000377551 | ENST00000361032 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.00069926 | 0.9993007 |
| ENST00000409571 | ENST00000354179 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.000731804 | 0.99926823 |
| ENST00000409571 | ENST00000439151 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.00073205 | 0.999268 |
| ENST00000409571 | ENST00000347982 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.001728341 | 0.9982717 |
| ENST00000409571 | ENST00000361032 | NRXN2 | chr11 | 64387766 | - | NSD1 | chr5 | 176666757 | + | 0.000731804 | 0.99926823 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >60375_60375_1_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000265459_NSD1_chr5_176666757_ENST00000347982_length(amino acids)=2731AA_BP=1432 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVNKLHYLVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNT ADLPGSPVSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTE PNGLLLFSQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATG DSEILDLESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVC REGWNRFICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVN LDCLRVGCAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGL VFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYI HYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGC LASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPN DRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWP VNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEG HLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQ RKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEI PGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNE CRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCL AAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVG RYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELR QLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVE IFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVN GDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCG DAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEP GEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTK SQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLIT SSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPV LESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPG LVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSL -------------------------------------------------------------- >60375_60375_2_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000265459_NSD1_chr5_176666757_ENST00000354179_length(amino acids)=2731AA_BP=1432 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVNKLHYLVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNT ADLPGSPVSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTE PNGLLLFSQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATG DSEILDLESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVC REGWNRFICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVN LDCLRVGCAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGL VFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYI HYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGC LASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPN DRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWP VNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEG HLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQ RKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEI PGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNE CRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCL AAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVG RYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELR QLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVE IFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVN GDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCG DAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEP GEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTK SQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLIT SSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPV LESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPG LVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSL -------------------------------------------------------------- >60375_60375_3_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000265459_NSD1_chr5_176666757_ENST00000361032_length(amino acids)=2731AA_BP=1432 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVNKLHYLVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNT ADLPGSPVSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTE PNGLLLFSQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATG DSEILDLESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVC REGWNRFICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVN LDCLRVGCAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGL VFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYI HYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGC LASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPN DRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWP VNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEG HLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQ RKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEI PGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNE CRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCL AAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVG RYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELR QLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVE IFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVN GDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCG DAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEP GEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTK SQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLIT SSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPV LESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPG LVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSL -------------------------------------------------------------- >60375_60375_4_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000265459_NSD1_chr5_176666757_ENST00000439151_length(amino acids)=2731AA_BP=1432 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVNKLHYLVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNT ADLPGSPVSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTE PNGLLLFSQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATG DSEILDLESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVC REGWNRFICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVN LDCLRVGCAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGL VFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYI HYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGC LASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPN DRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWP VNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEG HLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQ RKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEI PGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNE CRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCL AAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVG RYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELR QLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVE IFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVN GDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCG DAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEP GEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTK SQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLIT SSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPV LESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPG LVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSL -------------------------------------------------------------- >60375_60375_5_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000301894_NSD1_chr5_176666757_ENST00000347982_length(amino acids)=1670AA_BP=7 MPPGGSGPGGCPRRPPALAGPLPPPPPPPPPPLLPLLPLLLLLLLGAAEGARVSSSLSTTHHVHHFHSKHGTVPIAINRMPFLTRGGHAG TTYIFGKGGALITYTWPPNDRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYH VVRFTRSGGNATLQVDSWPVNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYN GLKVLALAAESDPNVRTEGHLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSD DEDLEECEPSTGNYESKRQRKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRH AAAKMQCKKVKNDDSSKEIPGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAF HLECLGLTEMPRGKFICNECRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKG RLMRCVRCPVAYHANDFCLAAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCN DCKAGKKPHYREIVWVKVGRYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKK ALQEAAARFEELKAQKELRQLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCP AGGRCQNQCFSKRQYPEVEIFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYA RFMNHCCQPNCETQKWSVNGDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGK RRTQGEITKEREDECFSCGDAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKL DGRLSCTEHDPCGPNPLEPGEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERT DSRPQPLDKVRDLAGSGTKSQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLE KTSVPTGLRLPPPDRLLITSSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQK ERAASPHQVTPQADEKMPVLESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQAS GRASAGAEQTPGPLSQSPGLVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLA -------------------------------------------------------------- >60375_60375_6_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000301894_NSD1_chr5_176666757_ENST00000354179_length(amino acids)=1670AA_BP=7 MPPGGSGPGGCPRRPPALAGPLPPPPPPPPPPLLPLLPLLLLLLLGAAEGARVSSSLSTTHHVHHFHSKHGTVPIAINRMPFLTRGGHAG TTYIFGKGGALITYTWPPNDRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYH VVRFTRSGGNATLQVDSWPVNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYN GLKVLALAAESDPNVRTEGHLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSD DEDLEECEPSTGNYESKRQRKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRH AAAKMQCKKVKNDDSSKEIPGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAF HLECLGLTEMPRGKFICNECRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKG RLMRCVRCPVAYHANDFCLAAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCN DCKAGKKPHYREIVWVKVGRYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKK ALQEAAARFEELKAQKELRQLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCP AGGRCQNQCFSKRQYPEVEIFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYA RFMNHCCQPNCETQKWSVNGDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGK RRTQGEITKEREDECFSCGDAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKL DGRLSCTEHDPCGPNPLEPGEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERT DSRPQPLDKVRDLAGSGTKSQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLE KTSVPTGLRLPPPDRLLITSSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQK ERAASPHQVTPQADEKMPVLESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQAS GRASAGAEQTPGPLSQSPGLVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLA -------------------------------------------------------------- >60375_60375_7_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000301894_NSD1_chr5_176666757_ENST00000361032_length(amino acids)=1670AA_BP=7 MPPGGSGPGGCPRRPPALAGPLPPPPPPPPPPLLPLLPLLLLLLLGAAEGARVSSSLSTTHHVHHFHSKHGTVPIAINRMPFLTRGGHAG TTYIFGKGGALITYTWPPNDRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYH VVRFTRSGGNATLQVDSWPVNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYN GLKVLALAAESDPNVRTEGHLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSD DEDLEECEPSTGNYESKRQRKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRH AAAKMQCKKVKNDDSSKEIPGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAF HLECLGLTEMPRGKFICNECRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKG RLMRCVRCPVAYHANDFCLAAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCN DCKAGKKPHYREIVWVKVGRYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKK ALQEAAARFEELKAQKELRQLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCP AGGRCQNQCFSKRQYPEVEIFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYA RFMNHCCQPNCETQKWSVNGDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGK RRTQGEITKEREDECFSCGDAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKL DGRLSCTEHDPCGPNPLEPGEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERT DSRPQPLDKVRDLAGSGTKSQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLE KTSVPTGLRLPPPDRLLITSSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQK ERAASPHQVTPQADEKMPVLESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQAS GRASAGAEQTPGPLSQSPGLVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLA -------------------------------------------------------------- >60375_60375_8_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000301894_NSD1_chr5_176666757_ENST00000439151_length(amino acids)=1670AA_BP=7 MPPGGSGPGGCPRRPPALAGPLPPPPPPPPPPLLPLLPLLLLLLLGAAEGARVSSSLSTTHHVHHFHSKHGTVPIAINRMPFLTRGGHAG TTYIFGKGGALITYTWPPNDRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYH VVRFTRSGGNATLQVDSWPVNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYN GLKVLALAAESDPNVRTEGHLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSD DEDLEECEPSTGNYESKRQRKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRH AAAKMQCKKVKNDDSSKEIPGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAF HLECLGLTEMPRGKFICNECRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKG RLMRCVRCPVAYHANDFCLAAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCN DCKAGKKPHYREIVWVKVGRYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKK ALQEAAARFEELKAQKELRQLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCP AGGRCQNQCFSKRQYPEVEIFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYA RFMNHCCQPNCETQKWSVNGDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGK RRTQGEITKEREDECFSCGDAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKL DGRLSCTEHDPCGPNPLEPGEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERT DSRPQPLDKVRDLAGSGTKSQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLE KTSVPTGLRLPPPDRLLITSSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQK ERAASPHQVTPQADEKMPVLESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQAS GRASAGAEQTPGPLSQSPGLVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLA -------------------------------------------------------------- >60375_60375_9_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000377551_NSD1_chr5_176666757_ENST00000347982_length(amino acids)=2731AA_BP=1432 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVNKLHYLVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNT ADLPGSPVSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTE PNGLLLFSQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATG DSEILDLESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVC REGWNRFICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVN LDCLRVGCAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGL VFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYI HYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGC LASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPN DRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWP VNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEG HLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQ RKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEI PGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNE CRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCL AAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVG RYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELR QLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVE IFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVN GDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCG DAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEP GEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTK SQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLIT SSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPV LESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPG LVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSL -------------------------------------------------------------- >60375_60375_10_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000377551_NSD1_chr5_176666757_ENST00000354179_length(amino acids)=2731AA_BP=1432 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVNKLHYLVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNT ADLPGSPVSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTE PNGLLLFSQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATG DSEILDLESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVC REGWNRFICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVN LDCLRVGCAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGL VFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYI HYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGC LASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPN DRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWP VNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEG HLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQ RKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEI PGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNE CRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCL AAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVG RYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELR QLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVE IFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVN GDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCG DAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEP GEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTK SQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLIT SSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPV LESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPG LVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSL -------------------------------------------------------------- >60375_60375_11_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000377551_NSD1_chr5_176666757_ENST00000361032_length(amino acids)=2731AA_BP=1432 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVNKLHYLVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNT ADLPGSPVSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTE PNGLLLFSQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATG DSEILDLESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVC REGWNRFICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVN LDCLRVGCAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGL VFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYI HYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGC LASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPN DRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWP VNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEG HLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQ RKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEI PGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNE CRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCL AAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVG RYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELR QLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVE IFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVN GDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCG DAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEP GEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTK SQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLIT SSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPV LESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPG LVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSL -------------------------------------------------------------- >60375_60375_12_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000377551_NSD1_chr5_176666757_ENST00000439151_length(amino acids)=2731AA_BP=1432 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVNKLHYLVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNT ADLPGSPVSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTE PNGLLLFSQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATG DSEILDLESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVC REGWNRFICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVN LDCLRVGCAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGL VFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYI HYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGC LASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPN DRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWP VNERYPAGNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEG HLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQ RKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEI PGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNE CRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCL AAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVG RYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELR QLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVE IFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVN GDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCG DAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEP GEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTK SQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLIT SSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPV LESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPG LVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSL -------------------------------------------------------------- >60375_60375_13_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000377559_NSD1_chr5_176666757_ENST00000347982_length(amino acids)=2661AA_BP=1362 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGAVWLVINLGSGAFEALVEPVNGKFN DNAWHDVRVTRNLRQHAGIGHAMVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNTADLPGSPVSNNFMGCLKDVVYKNNDFKLELS RLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTEPNGLLLFSQGRRAGGGAGSHSSAQRADYFAM ELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATGDSEILDLESELYLGGLPEGGRVDLPLPPEVW TAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVCREGWNRFICDCIGTGFLGRVCEREATVLSYD GSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVNLGKGPETLFAGHKLNDNEWHTVRVVRRGKSL QLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGLVFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSR SSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYIHYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHT LKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGCLASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESC ANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPNDRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHI DQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWPVNERYPAGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYY NGLKVLALAAESDPNVRTEGHLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPS DDEDLEECEPSTGNYESKRQRKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQR HAAAKMQCKKVKNDDSSKEIPGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGA FHLECLGLTEMPRGKFICNECRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASK GRLMRCVRCPVAYHANDFCLAAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYC NDCKAGKKPHYREIVWVKVGRYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYK KALQEAAARFEELKAQKELRQLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVC PAGGRCQNQCFSKRQYPEVEIFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNY ARFMNHCCQPNCETQKWSVNGDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQG KRRTQGEITKEREDECFSCGDAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISK LDGRLSCTEHDPCGPNPLEPGEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLER TDSRPQPLDKVRDLAGSGTKSQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSL EKTSVPTGLRLPPPDRLLITSSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQ KERAASPHQVTPQADEKMPVLESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQA SGRASAGAEQTPGPLSQSPGLVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTL -------------------------------------------------------------- >60375_60375_14_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000377559_NSD1_chr5_176666757_ENST00000354179_length(amino acids)=2661AA_BP=1362 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGAVWLVINLGSGAFEALVEPVNGKFN DNAWHDVRVTRNLRQHAGIGHAMVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNTADLPGSPVSNNFMGCLKDVVYKNNDFKLELS RLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTEPNGLLLFSQGRRAGGGAGSHSSAQRADYFAM ELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATGDSEILDLESELYLGGLPEGGRVDLPLPPEVW TAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVCREGWNRFICDCIGTGFLGRVCEREATVLSYD GSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVNLGKGPETLFAGHKLNDNEWHTVRVVRRGKSL QLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGLVFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSR SSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYIHYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHT LKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGCLASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESC ANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPNDRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHI DQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWPVNERYPAGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYY NGLKVLALAAESDPNVRTEGHLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPS DDEDLEECEPSTGNYESKRQRKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQR HAAAKMQCKKVKNDDSSKEIPGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGA FHLECLGLTEMPRGKFICNECRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASK GRLMRCVRCPVAYHANDFCLAAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYC NDCKAGKKPHYREIVWVKVGRYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYK KALQEAAARFEELKAQKELRQLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVC PAGGRCQNQCFSKRQYPEVEIFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNY ARFMNHCCQPNCETQKWSVNGDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQG KRRTQGEITKEREDECFSCGDAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISK LDGRLSCTEHDPCGPNPLEPGEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLER TDSRPQPLDKVRDLAGSGTKSQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSL EKTSVPTGLRLPPPDRLLITSSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQ KERAASPHQVTPQADEKMPVLESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQA SGRASAGAEQTPGPLSQSPGLVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTL -------------------------------------------------------------- >60375_60375_15_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000377559_NSD1_chr5_176666757_ENST00000361032_length(amino acids)=2661AA_BP=1362 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGAVWLVINLGSGAFEALVEPVNGKFN DNAWHDVRVTRNLRQHAGIGHAMVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNTADLPGSPVSNNFMGCLKDVVYKNNDFKLELS RLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTEPNGLLLFSQGRRAGGGAGSHSSAQRADYFAM ELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATGDSEILDLESELYLGGLPEGGRVDLPLPPEVW TAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVCREGWNRFICDCIGTGFLGRVCEREATVLSYD GSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVNLGKGPETLFAGHKLNDNEWHTVRVVRRGKSL QLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGLVFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSR SSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYIHYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHT LKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGCLASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESC ANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPNDRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHI DQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWPVNERYPAGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYY NGLKVLALAAESDPNVRTEGHLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPS DDEDLEECEPSTGNYESKRQRKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQR HAAAKMQCKKVKNDDSSKEIPGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGA FHLECLGLTEMPRGKFICNECRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASK GRLMRCVRCPVAYHANDFCLAAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYC NDCKAGKKPHYREIVWVKVGRYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYK KALQEAAARFEELKAQKELRQLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVC PAGGRCQNQCFSKRQYPEVEIFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNY ARFMNHCCQPNCETQKWSVNGDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQG KRRTQGEITKEREDECFSCGDAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISK LDGRLSCTEHDPCGPNPLEPGEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLER TDSRPQPLDKVRDLAGSGTKSQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSL EKTSVPTGLRLPPPDRLLITSSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQ KERAASPHQVTPQADEKMPVLESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQA SGRASAGAEQTPGPLSQSPGLVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTL -------------------------------------------------------------- >60375_60375_16_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000377559_NSD1_chr5_176666757_ENST00000439151_length(amino acids)=2661AA_BP=1362 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGAVWLVINLGSGAFEALVEPVNGKFN DNAWHDVRVTRNLRQHAGIGHAMVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNTADLPGSPVSNNFMGCLKDVVYKNNDFKLELS RLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTEPNGLLLFSQGRRAGGGAGSHSSAQRADYFAM ELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATGDSEILDLESELYLGGLPEGGRVDLPLPPEVW TAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVCREGWNRFICDCIGTGFLGRVCEREATVLSYD GSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVNLGKGPETLFAGHKLNDNEWHTVRVVRRGKSL QLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGLVFNGQPYMDQCKDGDITYCELNARFGLRAIVADPVTFKSR SSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYIHYVFDLGNGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHT LKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGCLASVDLNGRLPDLIADALHRIGQVERGCDGPSTTCTEESC ANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPNDRPSTRMDRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHI DQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWPVNERYPAGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYY NGLKVLALAAESDPNVRTEGHLRLVGEGPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPS DDEDLEECEPSTGNYESKRQRKPTKKLLESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQR HAAAKMQCKKVKNDDSSKEIPGSEGELMPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGA FHLECLGLTEMPRGKFICNECRTGIHTCFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASK GRLMRCVRCPVAYHANDFCLAAGSKILASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYC NDCKAGKKPHYREIVWVKVGRYRWWPAEICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYK KALQEAAARFEELKAQKELRQLQEDRKNDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVC PAGGRCQNQCFSKRQYPEVEIFRTLQRGWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNY ARFMNHCCQPNCETQKWSVNGDTRVGLFALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQG KRRTQGEITKEREDECFSCGDAGQLVSCKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISK LDGRLSCTEHDPCGPNPLEPGEIREYVPPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLER TDSRPQPLDKVRDLAGSGTKSQSLVSSQRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSL EKTSVPTGLRLPPPDRLLITSSPKPQTSDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQ KERAASPHQVTPQADEKMPVLESSSWPASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQA SGRASAGAEQTPGPLSQSPGLVKQAKQMVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTL -------------------------------------------------------------- >60375_60375_17_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000409571_NSD1_chr5_176666757_ENST00000347982_length(amino acids)=2724AA_BP=1425 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNTADLPGSP VSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTEPNGLLLF SQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATGDSEILDL ESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVCREGWNRF ICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVNLDCLRVG CAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGLVFNGQPY MDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYIHYVFDLG NGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGCLASVDLN GRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPNDRPSTRM DRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWPVNERYPA GNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEGHLRLVGE GPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQRKPTKKL LESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEIPGSEGEL MPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNECRTGIHT CFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCLAAGSKIL ASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVGRYRWWPA EICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELRQLQEDRK NDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVEIFRTLQR GWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVNGDTRVGL FALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCGDAGQLVS CKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEPGEIREYV PPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTKSQSLVSS QRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLITSSPKPQT SDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPVLESSSWP ASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPGLVKQAKQ MVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSLGRGQDPK -------------------------------------------------------------- >60375_60375_18_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000409571_NSD1_chr5_176666757_ENST00000354179_length(amino acids)=2724AA_BP=1425 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNTADLPGSP VSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTEPNGLLLF SQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATGDSEILDL ESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVCREGWNRF ICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVNLDCLRVG CAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGLVFNGQPY MDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYIHYVFDLG NGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGCLASVDLN GRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPNDRPSTRM DRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWPVNERYPA GNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEGHLRLVGE GPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQRKPTKKL LESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEIPGSEGEL MPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNECRTGIHT CFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCLAAGSKIL ASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVGRYRWWPA EICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELRQLQEDRK NDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVEIFRTLQR GWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVNGDTRVGL FALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCGDAGQLVS CKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEPGEIREYV PPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTKSQSLVSS QRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLITSSPKPQT SDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPVLESSSWP ASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPGLVKQAKQ MVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSLGRGQDPK -------------------------------------------------------------- >60375_60375_19_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000409571_NSD1_chr5_176666757_ENST00000361032_length(amino acids)=2724AA_BP=1425 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNTADLPGSP VSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTEPNGLLLF SQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATGDSEILDL ESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVCREGWNRF ICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVNLDCLRVG CAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGLVFNGQPY MDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYIHYVFDLG NGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGCLASVDLN GRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPNDRPSTRM DRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWPVNERYPA GNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEGHLRLVGE GPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQRKPTKKL LESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEIPGSEGEL MPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNECRTGIHT CFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCLAAGSKIL ASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVGRYRWWPA EICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELRQLQEDRK NDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVEIFRTLQR GWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVNGDTRVGL FALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCGDAGQLVS CKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEPGEIREYV PPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTKSQSLVSS QRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLITSSPKPQT SDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPVLESSSWP ASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPGLVKQAKQ MVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSLGRGQDPK -------------------------------------------------------------- >60375_60375_20_NRXN2-NSD1_NRXN2_chr11_64387766_ENST00000409571_NSD1_chr5_176666757_ENST00000439151_length(amino acids)=2724AA_BP=1425 MSGGRGPGGAGAAVGMASGSRWRPTPPPLLLLLLLALAARADGLEFGGGPGQWARYARWAGAASSGELSFSLRTNATRALLLYLDDGGDC DFLELLLVDGRLRLRFTLSCAEPATLQLDTPVADDRWHMVLLTRDARRTALAVDGEARAAEVRSKRREMQVASDLFVGGIPPDVRLSALT LSTVKYEPPFRGLLANLKLGERPPALLGSQGLRGATADPLCAPARNPCANGGLCTVLAPGEVGCDCSHTGFGGKFCSEEEHPMEGPAHLT LNSEVGSLLFSEGGAGRGGAGDVHQPTKGKEEFVATFKGNEFFCYDLSHNPIQSSTDEITLAFRTLQRNGLMLHTGKSADYVNLSLKSGA VWLVINLGSGAFEALVEPVNGKFNDNAWHDVRVTRNLRQHAGIGHAMVTISVDGILTTTGYTQEDYTMLGSDDFFYIGGSPNTADLPGSP VSNNFMGCLKDVVYKNNDFKLELSRLAKEGDPKMKLQGDLSFRCEDVAALDPVTFESPEAFVALPRWSAKRTGSISLDFRTTEPNGLLLF SQGRRAGGGAGSHSSAQRADYFAMELLDGHLYLLLDMGSGGIKLRASSRKVNDGEWCHVDFQRDGRKGSISVNSRSTPFLATGDSEILDL ESELYLGGLPEGGRVDLPLPPEVWTAALRAGYVGCVRDLFIDGRSRDLRGLAEAQGAVGVAPFCSRETLKQCASAPCRNGGVCREGWNRF ICDCIGTGFLGRVCEREATVLSYDGSMYMKIMLPNAMHTEAEDVSLRFMSQRAYGLMMATTSRESADTLRLELDGGQMKLTVNLDCLRVG CAPSKGPETLFAGHKLNDNEWHTVRVVRRGKSLQLSVDNVTVEGQMAGAHMRLEFHNIETGIMTERRFISVVPSNFIGHLSGLVFNGQPY MDQCKDGDITYCELNARFGLRAIVADPVTFKSRSSYLALATLQAYASMHLFFQFKTTAPDGLLLFNSGNGNDFIVIELVKGYIHYVFDLG NGPSLMKGNSDKPVNDNQWHNVVVSRDPGNVHTLKIDSRTVTQHSNGARNLDLKGELYIGGLSKNMFSNLPKLVASRDGFQGCLASVDLN GRLPDLIADALHRIGQVERGCDGPSTTCTEESCANQGVCLQQWDGFTCDCTMTSYGGPVCNDPGTTYIFGKGGALITYTWPPNDRPSTRM DRLAVGFSTHQRSAVLVRVDSASGLGDYLQLHIDQGTVGVIFNVGTDDITIDEPNAIVSDGKYHVVRFTRSGGNATLQVDSWPVNERYPA GNFDNERLAIARQRIPYRLGRVVDEWLLDKGRQLTIFNSQAAIKIGGRDQGRPFQGQVSGLYYNGLKVLALAAESDPNVRTEGHLRLVGE GPSVLLSAETTATTLLADMATTIMETTTTMATTTTRRGRSPTLRDSTTQNTDDLLVASAECPSDDEDLEECEPSTGNYESKRQRKPTKKL LESNDLDPGFMPKKGDLGLSKKCYEAGHLENGITESCATSYSKDFGGGTTKIFDKPRKRKRQRHAAAKMQCKKVKNDDSSKEIPGSEGEL MPHRTATSPKETVEEGVEHDPGMPASKKMQGERGGGAALKENVCQNCEKLGELLLCEAQCCGAFHLECLGLTEMPRGKFICNECRTGIHT CFVCKQSGEDVKRCLLPLCGKFYHEECVQKYPPTVMQNKGFRCSLHICITCHAANPANVSASKGRLMRCVRCPVAYHANDFCLAAGSKIL ASNSIICPNHFTPRRGCRNHEHVNVSWCFVCSEGGSLLCCDSCPAAFHRECLNIDIPEGNWYCNDCKAGKKPHYREIVWVKVGRYRWWPA EICHPRAVPSNIDKMRHDVGEFPVLFFGSNDYLWTHQARVFPYMEGDVSSKDKMGKGVDGTYKKALQEAAARFEELKAQKELRQLQEDRK NDKKPPPYKHIKVNRPIGRVQIFTADLSEIPRCNCKATDENPCGIDSECINRMLLYECHPTVCPAGGRCQNQCFSKRQYPEVEIFRTLQR GWGLRTKTDIKKGEFVNEYVGELIDEEECRARIRYAQEHDITNFYMLTLDKDRIIDAGPKGNYARFMNHCCQPNCETQKWSVNGDTRVGL FALSDIKAGTELTFNYNLECLGNGKTVCKCGAPNCSGFLGVRPKNQPIATEEKSKKFKKKQQGKRRTQGEITKEREDECFSCGDAGQLVS CKKPGCPKVYHADCLNLTKRPAGKWECPWHQCDICGKEAASFCEMCPSSFCKQHREGMLFISKLDGRLSCTEHDPCGPNPLEPGEIREYV PPPVPLPPGPSTHLAEQSTGMAAQAPKMSDKPPADTNQMLSLSKKALAGTCQRPLLPERPLERTDSRPQPLDKVRDLAGSGTKSQSLVSS QRPLDRPPAVAGPRPQLSDKPSPVTSPSSSPSVRSQPLERPLGTADPRLDKSIGAASPRPQSLEKTSVPTGLRLPPPDRLLITSSPKPQT SDRPTDKPHASLSQRLPPPEKVLSAVVQTLVAKEKALRPVDQNTQSKNRAALVMDLIDLTPRQKERAASPHQVTPQADEKMPVLESSSWP ASKGLGHMPRAVEKGCVSDPLQTSGKAAAPSEDPWQAVKSLTQARLLSQPPAKAFLYEPTTQASGRASAGAEQTPGPLSQSPGLVKQAKQ MVGGQQLPALAAKSGQSFRSLGKAPASLPTEEKKLVTTEQSPWALGKASSRAGLWPIVAGQTLAQSCWSAGSTQTLAQTCWSLGRGQDPK -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:64387766/chr5:176666757) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NRXN2 | . |
| FUNCTION: Neuronal cell surface protein that may be involved in cell recognition and cell adhesion. May mediate intracellular signaling. | FUNCTION: Might normally function as a transcriptional repressor. EWS-fusion-proteins (EFPS) may play a role in the tumorigenic process. They may disturb gene expression by mimicking, or interfering with the normal function of CTD-POLII within the transcription initiation complex. They may also contribute to an aberrant activation of the fusion protein target genes. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 1368_1371 | 1417.3333333333333 | 1713.0 | Compositional bias | Note=Poly-Thr |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 1374_1377 | 1417.3333333333333 | 1713.0 | Compositional bias | Note=Poly-Thr |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000301894 | - | 6 | 7 | 322_325 | 371.3333333333333 | 667.0 | Compositional bias | Note=Poly-Thr |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000301894 | - | 6 | 7 | 328_331 | 371.3333333333333 | 667.0 | Compositional bias | Note=Poly-Thr |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 1368_1371 | 1417.3333333333333 | 1713.0 | Compositional bias | Note=Poly-Thr |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 1374_1377 | 1417.3333333333333 | 1713.0 | Compositional bias | Note=Poly-Thr |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 1096_1133 | 1417.3333333333333 | 1713.0 | Domain | EGF-like 3 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 1137_1345 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 6 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 202_242 | 1417.3333333333333 | 1713.0 | Domain | EGF-like 1 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 289_486 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 2 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 29_206 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 1 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 493_686 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 3 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 690_727 | 1417.3333333333333 | 1713.0 | Domain | EGF-like 2 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 732_904 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 4 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 918_1093 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 5 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000301894 | - | 6 | 7 | 91_299 | 371.3333333333333 | 667.0 | Domain | Laminin G-like |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 1096_1133 | 1417.3333333333333 | 1713.0 | Domain | EGF-like 3 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 1137_1345 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 6 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 202_242 | 1417.3333333333333 | 1713.0 | Domain | EGF-like 1 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 289_486 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 2 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 29_206 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 1 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 493_686 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 3 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 690_727 | 1417.3333333333333 | 1713.0 | Domain | EGF-like 2 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 732_904 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 4 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 918_1093 | 1417.3333333333333 | 1713.0 | Domain | Laminin G-like 5 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 1096_1133 | 1347.3333333333333 | 1643.0 | Domain | EGF-like 3 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 1137_1345 | 1347.3333333333333 | 1643.0 | Domain | Laminin G-like 6 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 202_242 | 1347.3333333333333 | 1643.0 | Domain | EGF-like 1 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 289_486 | 1347.3333333333333 | 1643.0 | Domain | Laminin G-like 2 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 29_206 | 1347.3333333333333 | 1643.0 | Domain | Laminin G-like 1 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 493_686 | 1347.3333333333333 | 1643.0 | Domain | Laminin G-like 3 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 690_727 | 1347.3333333333333 | 1643.0 | Domain | EGF-like 2 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 732_904 | 1347.3333333333333 | 1643.0 | Domain | Laminin G-like 4 |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 918_1093 | 1347.3333333333333 | 1643.0 | Domain | Laminin G-like 5 |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 2207_2421 | 1128.3333333333333 | 2428.0 | Compositional bias | Note=Pro-rich | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 2207_2421 | 1128.3333333333333 | 2428.0 | Compositional bias | Note=Pro-rich | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 2207_2421 | 1294.3333333333333 | 2594.0 | Compositional bias | Note=Pro-rich | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 2207_2421 | 1397.3333333333333 | 2697.0 | Compositional bias | Note=Pro-rich | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 1756_1818 | 1128.3333333333333 | 2428.0 | Domain | PWWP 2 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 1890_1940 | 1128.3333333333333 | 2428.0 | Domain | AWS | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 1942_2059 | 1128.3333333333333 | 2428.0 | Domain | SET | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 2066_2082 | 1128.3333333333333 | 2428.0 | Domain | Post-SET | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 1756_1818 | 1128.3333333333333 | 2428.0 | Domain | PWWP 2 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 1890_1940 | 1128.3333333333333 | 2428.0 | Domain | AWS | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 1942_2059 | 1128.3333333333333 | 2428.0 | Domain | SET | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 2066_2082 | 1128.3333333333333 | 2428.0 | Domain | Post-SET | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 1756_1818 | 1294.3333333333333 | 2594.0 | Domain | PWWP 2 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 1890_1940 | 1294.3333333333333 | 2594.0 | Domain | AWS | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 1942_2059 | 1294.3333333333333 | 2594.0 | Domain | SET | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 2066_2082 | 1294.3333333333333 | 2594.0 | Domain | Post-SET | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 1756_1818 | 1397.3333333333333 | 2697.0 | Domain | PWWP 2 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 1890_1940 | 1397.3333333333333 | 2697.0 | Domain | AWS | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 1942_2059 | 1397.3333333333333 | 2697.0 | Domain | SET | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 2066_2082 | 1397.3333333333333 | 2697.0 | Domain | Post-SET | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 1952_1954 | 1128.3333333333333 | 2428.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 1994_1997 | 1128.3333333333333 | 2428.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 2020_2021 | 1128.3333333333333 | 2428.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 2060_2066 | 1128.3333333333333 | 2428.0 | Region | Note=Inhibits enzyme activity in the absence of bound histone | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 1952_1954 | 1128.3333333333333 | 2428.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 1994_1997 | 1128.3333333333333 | 2428.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 2020_2021 | 1128.3333333333333 | 2428.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 2060_2066 | 1128.3333333333333 | 2428.0 | Region | Note=Inhibits enzyme activity in the absence of bound histone | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 1952_1954 | 1294.3333333333333 | 2594.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 1994_1997 | 1294.3333333333333 | 2594.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 2020_2021 | 1294.3333333333333 | 2594.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 2060_2066 | 1294.3333333333333 | 2594.0 | Region | Note=Inhibits enzyme activity in the absence of bound histone | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 1952_1954 | 1397.3333333333333 | 2697.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 1994_1997 | 1397.3333333333333 | 2697.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 2020_2021 | 1397.3333333333333 | 2697.0 | Region | Note=S-adenosyl-L-methionine binding | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 2060_2066 | 1397.3333333333333 | 2697.0 | Region | Note=Inhibits enzyme activity in the absence of bound histone | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 1543_1589 | 1128.3333333333333 | 2428.0 | Zinc finger | PHD-type 1 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 1590_1646 | 1128.3333333333333 | 2428.0 | Zinc finger | PHD-type 2 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 1707_1751 | 1128.3333333333333 | 2428.0 | Zinc finger | PHD-type 3 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 2118_2165 | 1128.3333333333333 | 2428.0 | Zinc finger | PHD-type 4%3B atypical | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 1543_1589 | 1128.3333333333333 | 2428.0 | Zinc finger | PHD-type 1 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 1590_1646 | 1128.3333333333333 | 2428.0 | Zinc finger | PHD-type 2 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 1707_1751 | 1128.3333333333333 | 2428.0 | Zinc finger | PHD-type 3 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 2118_2165 | 1128.3333333333333 | 2428.0 | Zinc finger | PHD-type 4%3B atypical | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 1543_1589 | 1294.3333333333333 | 2594.0 | Zinc finger | PHD-type 1 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 1590_1646 | 1294.3333333333333 | 2594.0 | Zinc finger | PHD-type 2 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 1707_1751 | 1294.3333333333333 | 2594.0 | Zinc finger | PHD-type 3 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 2118_2165 | 1294.3333333333333 | 2594.0 | Zinc finger | PHD-type 4%3B atypical | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 1543_1589 | 1397.3333333333333 | 2697.0 | Zinc finger | PHD-type 1 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 1590_1646 | 1397.3333333333333 | 2697.0 | Zinc finger | PHD-type 2 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 1707_1751 | 1397.3333333333333 | 2697.0 | Zinc finger | PHD-type 3 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 2118_2165 | 1397.3333333333333 | 2697.0 | Zinc finger | PHD-type 4%3B atypical |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 1444_1447 | 1417.3333333333333 | 1713.0 | Compositional bias | Note=Poly-Pro |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 1644_1647 | 1417.3333333333333 | 1713.0 | Compositional bias | Note=Poly-Ala |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000301894 | - | 6 | 7 | 398_401 | 371.3333333333333 | 667.0 | Compositional bias | Note=Poly-Pro |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000301894 | - | 6 | 7 | 598_601 | 371.3333333333333 | 667.0 | Compositional bias | Note=Poly-Ala |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 1444_1447 | 1417.3333333333333 | 1713.0 | Compositional bias | Note=Poly-Pro |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 1644_1647 | 1417.3333333333333 | 1713.0 | Compositional bias | Note=Poly-Ala |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 1368_1371 | 1347.3333333333333 | 1643.0 | Compositional bias | Note=Poly-Thr |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 1374_1377 | 1347.3333333333333 | 1643.0 | Compositional bias | Note=Poly-Thr |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 1444_1447 | 1347.3333333333333 | 1643.0 | Compositional bias | Note=Poly-Pro |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 1644_1647 | 1347.3333333333333 | 1643.0 | Compositional bias | Note=Poly-Ala |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 1658_1712 | 1417.3333333333333 | 1713.0 | Topological domain | Cytoplasmic |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 29_1636 | 1417.3333333333333 | 1713.0 | Topological domain | Extracellular |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000301894 | - | 6 | 7 | 51_590 | 371.3333333333333 | 667.0 | Topological domain | Extracellular |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000301894 | - | 6 | 7 | 612_666 | 371.3333333333333 | 667.0 | Topological domain | Cytoplasmic |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 1658_1712 | 1417.3333333333333 | 1713.0 | Topological domain | Cytoplasmic |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 29_1636 | 1417.3333333333333 | 1713.0 | Topological domain | Extracellular |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 1658_1712 | 1347.3333333333333 | 1643.0 | Topological domain | Cytoplasmic |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 29_1636 | 1347.3333333333333 | 1643.0 | Topological domain | Extracellular |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000265459 | - | 22 | 23 | 1637_1657 | 1417.3333333333333 | 1713.0 | Transmembrane | Helical |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000301894 | - | 6 | 7 | 591_611 | 371.3333333333333 | 667.0 | Transmembrane | Helical |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377551 | - | 21 | 22 | 1637_1657 | 1417.3333333333333 | 1713.0 | Transmembrane | Helical |
| Hgene | NRXN2 | chr11:64387766 | chr5:176666757 | ENST00000377559 | - | 19 | 20 | 1637_1657 | 1347.3333333333333 | 1643.0 | Transmembrane | Helical |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000347982 | 7 | 24 | 323_388 | 1128.3333333333333 | 2428.0 | Domain | PWWP 1 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000354179 | 7 | 24 | 323_388 | 1128.3333333333333 | 2428.0 | Domain | PWWP 1 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000361032 | 3 | 20 | 323_388 | 1294.3333333333333 | 2594.0 | Domain | PWWP 1 | |
| Tgene | NSD1 | chr11:64387766 | chr5:176666757 | ENST00000439151 | 6 | 23 | 323_388 | 1397.3333333333333 | 2697.0 | Domain | PWWP 1 |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| NRXN2 | |
| NSD1 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to NRXN2-NSD1 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to NRXN2-NSD1 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies