| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:NUP214-CACNA1B |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: NUP214-CACNA1B | FusionPDB ID: 61038 | FusionGDB2.0 ID: 61038 | Hgene | Tgene | Gene symbol | NUP214 | CACNA1B | Gene ID | 8021 | 774 |
| Gene name | nucleoporin 214 | calcium voltage-gated channel subunit alpha1 B | |
| Synonyms | CAIN|CAN|IIAE9 | BIII|CACNL1A5|CACNN|Cav2.2|DYT23|NEDNEH | |
| Cytomap | 9q34.13 | 9q34.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nuclear pore complex protein Nup214CAN protein, putative oncogenenucleoporin 214kDa | voltage-dependent N-type calcium channel subunit alpha-1BCav2.2 voltage-gated Ca2+ channelbrain calcium channel IIIcalcium channel alpha12.2 subunitcalcium channel, L type, alpha-1 polypeptidecalcium channel, voltage-dependent, L type, alpha 1B subun | |
| Modification date | 20200322 | 20200313 | |
| UniProtAcc | P35658 | Q00975 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000359428, ENST00000411637, ENST00000451030, ENST00000465486, ENST00000483497, | ENST00000371365, ENST00000277550, ENST00000371367, ENST00000545473, ENST00000277549, ENST00000277551, ENST00000371355, ENST00000371357, ENST00000371363, ENST00000371372, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 11 X 15 X 5=825 | 7 X 8 X 4=224 |
| # samples | 14 | 7 | |
| ** MAII score | log2(14/825*10)=-2.55896729218821 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/224*10)=-1.67807190511264 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: NUP214 [Title/Abstract] AND CACNA1B [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | NUP214(134039531)-CACNA1B(141006850), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | NUP214-CACNA1B seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NUP214-CACNA1B seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NUP214-CACNA1B seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. NUP214-CACNA1B seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CACNA1B | GO:0050804 | modulation of chemical synaptic transmission | 23376566 |
| Tgene | CACNA1B | GO:1904645 | response to amyloid-beta | 23376566 |
| Fusion gene breakpoints across NUP214 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
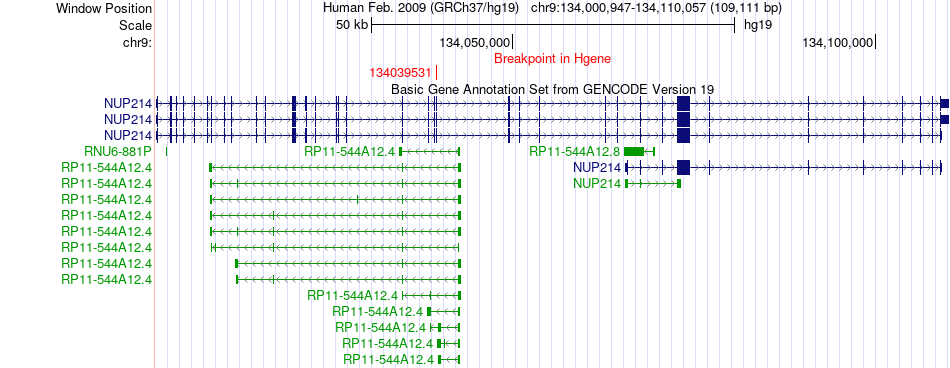 |
| Fusion gene breakpoints across CACNA1B (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-1849-01A | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000359428 | NUP214 | chr9 | 134039531 | + | ENST00000277551 | CACNA1B | chr9 | 141006850 | + | 4622 | 3037 | 21 | 4322 | 1433 |
| ENST00000359428 | NUP214 | chr9 | 134039531 | + | ENST00000371372 | CACNA1B | chr9 | 141006850 | + | 7254 | 3037 | 21 | 4628 | 1535 |
| ENST00000359428 | NUP214 | chr9 | 134039531 | + | ENST00000277549 | CACNA1B | chr9 | 141006850 | + | 7254 | 3037 | 21 | 4628 | 1535 |
| ENST00000359428 | NUP214 | chr9 | 134039531 | + | ENST00000371363 | CACNA1B | chr9 | 141006850 | + | 7254 | 3037 | 21 | 4628 | 1535 |
| ENST00000359428 | NUP214 | chr9 | 134039531 | + | ENST00000371355 | CACNA1B | chr9 | 141006850 | + | 7254 | 3037 | 21 | 4628 | 1535 |
| ENST00000359428 | NUP214 | chr9 | 134039531 | + | ENST00000371357 | CACNA1B | chr9 | 141006850 | + | 7254 | 3037 | 21 | 4628 | 1535 |
| ENST00000411637 | NUP214 | chr9 | 134039531 | + | ENST00000277551 | CACNA1B | chr9 | 141006850 | + | 4567 | 2982 | 8 | 4267 | 1419 |
| ENST00000411637 | NUP214 | chr9 | 134039531 | + | ENST00000371372 | CACNA1B | chr9 | 141006850 | + | 7199 | 2982 | 8 | 4573 | 1521 |
| ENST00000411637 | NUP214 | chr9 | 134039531 | + | ENST00000277549 | CACNA1B | chr9 | 141006850 | + | 7199 | 2982 | 8 | 4573 | 1521 |
| ENST00000411637 | NUP214 | chr9 | 134039531 | + | ENST00000371363 | CACNA1B | chr9 | 141006850 | + | 7199 | 2982 | 8 | 4573 | 1521 |
| ENST00000411637 | NUP214 | chr9 | 134039531 | + | ENST00000371355 | CACNA1B | chr9 | 141006850 | + | 7199 | 2982 | 8 | 4573 | 1521 |
| ENST00000411637 | NUP214 | chr9 | 134039531 | + | ENST00000371357 | CACNA1B | chr9 | 141006850 | + | 7199 | 2982 | 8 | 4573 | 1521 |
| ENST00000451030 | NUP214 | chr9 | 134039531 | + | ENST00000277551 | CACNA1B | chr9 | 141006850 | + | 4592 | 3007 | 0 | 4292 | 1430 |
| ENST00000451030 | NUP214 | chr9 | 134039531 | + | ENST00000371372 | CACNA1B | chr9 | 141006850 | + | 7224 | 3007 | 0 | 4598 | 1532 |
| ENST00000451030 | NUP214 | chr9 | 134039531 | + | ENST00000277549 | CACNA1B | chr9 | 141006850 | + | 7224 | 3007 | 0 | 4598 | 1532 |
| ENST00000451030 | NUP214 | chr9 | 134039531 | + | ENST00000371363 | CACNA1B | chr9 | 141006850 | + | 7224 | 3007 | 0 | 4598 | 1532 |
| ENST00000451030 | NUP214 | chr9 | 134039531 | + | ENST00000371355 | CACNA1B | chr9 | 141006850 | + | 7224 | 3007 | 0 | 4598 | 1532 |
| ENST00000451030 | NUP214 | chr9 | 134039531 | + | ENST00000371357 | CACNA1B | chr9 | 141006850 | + | 7224 | 3007 | 0 | 4598 | 1532 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000359428 | ENST00000277551 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001842046 | 0.9981579 |
| ENST00000359428 | ENST00000371372 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001090032 | 0.99890995 |
| ENST00000359428 | ENST00000277549 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001090032 | 0.99890995 |
| ENST00000359428 | ENST00000371363 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001090032 | 0.99890995 |
| ENST00000359428 | ENST00000371355 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001090032 | 0.99890995 |
| ENST00000359428 | ENST00000371357 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001090032 | 0.99890995 |
| ENST00000411637 | ENST00000277551 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001339139 | 0.9986608 |
| ENST00000411637 | ENST00000371372 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001912394 | 0.9980876 |
| ENST00000411637 | ENST00000277549 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001912394 | 0.9980876 |
| ENST00000411637 | ENST00000371363 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001912394 | 0.9980876 |
| ENST00000411637 | ENST00000371355 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001912394 | 0.9980876 |
| ENST00000411637 | ENST00000371357 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001912394 | 0.9980876 |
| ENST00000451030 | ENST00000277551 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001876267 | 0.9981237 |
| ENST00000451030 | ENST00000371372 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001251962 | 0.99874806 |
| ENST00000451030 | ENST00000277549 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001251962 | 0.99874806 |
| ENST00000451030 | ENST00000371363 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001251962 | 0.99874806 |
| ENST00000451030 | ENST00000371355 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001251962 | 0.99874806 |
| ENST00000451030 | ENST00000371357 | NUP214 | chr9 | 134039531 | + | CACNA1B | chr9 | 141006850 | + | 0.001251962 | 0.99874806 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >61038_61038_1_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000359428_CACNA1B_chr9_141006850_ENST00000277549_length(amino acids)=1535AA_BP=1005 MRGQLRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYG LVFAGGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPF AYHKLLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVI PCPPFYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAA SAASTEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPG VKSLIKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEP PSYSSGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSE KFTAAATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSGRSAQGSSSPVPSMVQKSPRITPPAAKPGSP QAKSLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLK TTLLEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFN TLANNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRN FLAKRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQM GPVSLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVD VQMQSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQ RSLEKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTA GQEPGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPL SQPLAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPD -------------------------------------------------------------- >61038_61038_2_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000359428_CACNA1B_chr9_141006850_ENST00000277551_length(amino acids)=1433AA_BP=1005 MRGQLRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYG LVFAGGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPF AYHKLLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVI PCPPFYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAA SAASTEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPG VKSLIKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEP PSYSSGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSE KFTAAATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSGRSAQGSSSPVPSMVQKSPRITPPAAKPGSP QAKSLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLK TTLLEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFN TLANNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRN FLAKRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQM GPVSLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVD VQMQSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQ RSLEKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTA -------------------------------------------------------------- >61038_61038_3_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000359428_CACNA1B_chr9_141006850_ENST00000371355_length(amino acids)=1535AA_BP=1005 MRGQLRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYG LVFAGGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPF AYHKLLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVI PCPPFYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAA SAASTEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPG VKSLIKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEP PSYSSGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSE KFTAAATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSGRSAQGSSSPVPSMVQKSPRITPPAAKPGSP QAKSLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLK TTLLEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFN TLANNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRN FLAKRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQM GPVSLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVD VQMQSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQ RSLEKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTA GQEPGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPL SQPLAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPD -------------------------------------------------------------- >61038_61038_4_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000359428_CACNA1B_chr9_141006850_ENST00000371357_length(amino acids)=1535AA_BP=1005 MRGQLRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYG LVFAGGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPF AYHKLLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVI PCPPFYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAA SAASTEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPG VKSLIKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEP PSYSSGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSE KFTAAATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSGRSAQGSSSPVPSMVQKSPRITPPAAKPGSP QAKSLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLK TTLLEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFN TLANNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRN FLAKRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQM GPVSLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVD VQMQSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQ RSLEKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTA GQEPGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPL SQPLAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPD -------------------------------------------------------------- >61038_61038_5_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000359428_CACNA1B_chr9_141006850_ENST00000371363_length(amino acids)=1535AA_BP=1005 MRGQLRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYG LVFAGGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPF AYHKLLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVI PCPPFYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAA SAASTEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPG VKSLIKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEP PSYSSGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSE KFTAAATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSGRSAQGSSSPVPSMVQKSPRITPPAAKPGSP QAKSLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLK TTLLEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFN TLANNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRN FLAKRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQM GPVSLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVD VQMQSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQ RSLEKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTA GQEPGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPL SQPLAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPD -------------------------------------------------------------- >61038_61038_6_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000359428_CACNA1B_chr9_141006850_ENST00000371372_length(amino acids)=1535AA_BP=1005 MRGQLRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYG LVFAGGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPF AYHKLLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVI PCPPFYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAA SAASTEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPG VKSLIKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEP PSYSSGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSE KFTAAATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSGRSAQGSSSPVPSMVQKSPRITPPAAKPGSP QAKSLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLK TTLLEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFN TLANNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRN FLAKRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQM GPVSLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVD VQMQSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQ RSLEKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTA GQEPGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPL SQPLAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPD -------------------------------------------------------------- >61038_61038_7_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000411637_CACNA1B_chr9_141006850_ENST00000277549_length(amino acids)=1521AA_BP=991 MRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSENSSQ SAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAKSLQPAVAEKQG HQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTLLEGFAGVEEAR EQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLANNREIINQQRK RLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLAKRKTPPVRSTA PAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPVSLFHPLKATLE QTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQMQSITRRGPDGE PQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSLEKGPSLSADMD GAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQEPGPHPQGSGSV NGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQPLAPGSRIGSDP -------------------------------------------------------------- >61038_61038_8_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000411637_CACNA1B_chr9_141006850_ENST00000277551_length(amino acids)=1419AA_BP=991 MRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSENSSQ SAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAKSLQPAVAEKQG HQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTLLEGFAGVEEAR EQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLANNREIINQQRK RLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLAKRKTPPVRSTA PAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPVSLFHPLKATLE QTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQMQSITRRGPDGE PQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSLEKGPSLSADMD GAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQEPGPHPQAGSAV -------------------------------------------------------------- >61038_61038_9_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000411637_CACNA1B_chr9_141006850_ENST00000371355_length(amino acids)=1521AA_BP=991 MRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSENSSQ SAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAKSLQPAVAEKQG HQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTLLEGFAGVEEAR EQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLANNREIINQQRK RLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLAKRKTPPVRSTA PAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPVSLFHPLKATLE QTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQMQSITRRGPDGE PQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSLEKGPSLSADMD GAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQEPGPHPQGSGSV NGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQPLAPGSRIGSDP -------------------------------------------------------------- >61038_61038_10_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000411637_CACNA1B_chr9_141006850_ENST00000371357_length(amino acids)=1521AA_BP=991 MRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSENSSQ SAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAKSLQPAVAEKQG HQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTLLEGFAGVEEAR EQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLANNREIINQQRK RLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLAKRKTPPVRSTA PAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPVSLFHPLKATLE QTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQMQSITRRGPDGE PQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSLEKGPSLSADMD GAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQEPGPHPQGSGSV NGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQPLAPGSRIGSDP -------------------------------------------------------------- >61038_61038_11_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000411637_CACNA1B_chr9_141006850_ENST00000371363_length(amino acids)=1521AA_BP=991 MRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSENSSQ SAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAKSLQPAVAEKQG HQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTLLEGFAGVEEAR EQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLANNREIINQQRK RLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLAKRKTPPVRSTA PAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPVSLFHPLKATLE QTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQMQSITRRGPDGE PQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSLEKGPSLSADMD GAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQEPGPHPQGSGSV NGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQPLAPGSRIGSDP -------------------------------------------------------------- >61038_61038_12_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000411637_CACNA1B_chr9_141006850_ENST00000371372_length(amino acids)=1521AA_BP=991 MRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSENSSQ SAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAKSLQPAVAEKQG HQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTLLEGFAGVEEAR EQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLANNREIINQQRK RLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLAKRKTPPVRSTA PAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPVSLFHPLKATLE QTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQMQSITRRGPDGE PQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSLEKGPSLSADMD GAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQEPGPHPQGSGSV NGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQPLAPGSRIGSDP -------------------------------------------------------------- >61038_61038_13_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000451030_CACNA1B_chr9_141006850_ENST00000277549_length(amino acids)=1532AA_BP=1002 LRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSEKFTA AATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAK SLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTL LEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLA NNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLA KRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPV SLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQM QSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSL EKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQE PGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQP LAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPDQDH -------------------------------------------------------------- >61038_61038_14_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000451030_CACNA1B_chr9_141006850_ENST00000277551_length(amino acids)=1430AA_BP=1002 LRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSEKFTA AATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAK SLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTL LEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLA NNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLA KRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPV SLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQM QSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSL EKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQE -------------------------------------------------------------- >61038_61038_15_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000451030_CACNA1B_chr9_141006850_ENST00000371355_length(amino acids)=1532AA_BP=1002 LRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSEKFTA AATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAK SLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTL LEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLA NNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLA KRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPV SLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQM QSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSL EKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQE PGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQP LAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPDQDH -------------------------------------------------------------- >61038_61038_16_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000451030_CACNA1B_chr9_141006850_ENST00000371357_length(amino acids)=1532AA_BP=1002 LRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSEKFTA AATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAK SLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTL LEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLA NNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLA KRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPV SLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQM QSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSL EKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQE PGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQP LAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPDQDH -------------------------------------------------------------- >61038_61038_17_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000451030_CACNA1B_chr9_141006850_ENST00000371363_length(amino acids)=1532AA_BP=1002 LRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSEKFTA AATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAK SLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTL LEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLA NNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLA KRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPV SLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQM QSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSL EKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQE PGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQP LAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPDQDH -------------------------------------------------------------- >61038_61038_18_NUP214-CACNA1B_NUP214_chr9_134039531_ENST00000451030_CACNA1B_chr9_141006850_ENST00000371372_length(amino acids)=1532AA_BP=1002 LRAAGAEGRKFAVERPGFRGQGRGRQRWLLRHTEGGAMGDEMDAMIPEREMKDFQFRALKKVRIFDSPEELPKERSSLLAVSNKYGLVFA GGASGLQIFPTKNLLIQNKPGDDPNKIVDKVQGLLVPMKFPIHHLALSCDNLTLSACMMSSEYGSIIAFFDVRTFSNEAKQQKRPFAYHK LLKDAGGMVIDMKWNPTVPSMVAVCLADGSIAVLQVTETVKVCATLPSTVAVTSVCWSPKGKQLAVGKQNGTVVQYLPTLQEKKVIPCPP FYESDHPVRVLDVLWIGTYVFAIVYAAADGTLETSPDVVMALLPKKEEKHPEIFVNFMEPCYGSCTERQHHYYLSYIEEWDLVLAASAAS TEVSILARQSDQINWESWLLEDSSRAELPVTDKSDDSLPMGVVVDYTNQVEITISDEKTLPPAPVLMLLSTDGVLCPFYMINQNPGVKSL IKTPERLSLEGERQPKSPGSTPTTPTSSQAPQKLDASAAAAPASLPPSSPAAPIATFSLLPAGGAPTVFSFGSSSLKSSATVTGEPPSYS SGSDSSKAAPGPGPSTFSFVPPSKASLAPTPAASPVAPSAASFSFGSSGFKPTLESTPVPSVSAPNIAMKPSFPPSTSAVKVNLSEKFTA AATSTPVSSSQSAPPMSPFSSASKPAASGPLSHPTPLSAPPSSVPLKSSVLPSPSAGRSAQGSSSPVPSMVQKSPRITPPAAKPGSPQAK SLQPAVAEKQGHQWKDSDPVMAGIGEEIAHFQKELEELKARTSKACFQVGTSEEMKMLRTESDDLHTFLLEIKETTESLHGDISSLKTTL LEGFAGVEEAREQNERNRDSGYLHLLYKRPLDPKSEAQLQEIRRLHQYVKFAVQDVNDVLDLEWDQHLEQKKKQRHLLVPERETLFNTLA NNREIINQQRKRLNHLVDSLQQLRLYKQTSLWSLSSAVPSQSSIHSFDSDLESLCNALLKTTIESHTKSLPKVPAKLSPMKQAQLRNFLA KRKTPPVRSTAPAGTKQHQCDAELRKEISVVWANLPQKTLDLLVPPHKPDEMTVGKVYAALMIFDFYKQNKTTRDQMQQAPGGLSQMGPV SLFHPLKATLEQTQPAVLRGARVFLRQKSSTSLSNGGAIQNQESGIKESVSWGTQRTQDAPHEARPPLERGHSTEIPVGRSGALAVDVQM QSITRRGPDGEPQPGLESQGRAASMPRLAAETQPVTDASPMKRSISTLAQRPRGTHLCSTTPDRPPPSQASSHHHHHRCHRRRDRKQRSL EKGPSLSADMDGAPSSAVGPGLPPGEGPTGCRRERERRQERGRSQERRQPSSSSSEKQRFYSCDRFGGREPPKPKPSLSSHPTSPTAGQE PGPHPQGSGSVNGSPLLSTSGASTPGRGGRRQLPQTPLTPRPSITYKTANSSPIHFAGAQTSLPAFSPGRLSRGLSEHNALLQRDPLSQP LAPGSRIGSDPYLGQRLDSEASVHALPEDTLTFEEAVATNSGRSSRTSYVSSLTSQSHPLRRVPNGYHCTLGLSSGGRARHSYHHPDQDH -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:134039531/chr9:141006850) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NUP214 | CACNA1B |
| FUNCTION: Part of the nuclear pore complex (PubMed:9049309). Has a critical role in nucleocytoplasmic transport (PubMed:31178128). May serve as a docking site in the receptor-mediated import of substrates across the nuclear pore complex (PubMed:31178128, PubMed:8108440). {ECO:0000269|PubMed:31178128, ECO:0000269|PubMed:9049309, ECO:0000303|PubMed:8108440}.; FUNCTION: (Microbial infection) Required for capsid disassembly of the human adenovirus 5 (HadV-5) leading to release of the viral genome to the nucleus (in vitro). {ECO:0000269|PubMed:25410864}. | FUNCTION: Voltage-sensitive calcium channels (VSCC) mediate the entry of calcium ions into excitable cells and are also involved in a variety of calcium-dependent processes, including muscle contraction, hormone or neurotransmitter release, gene expression, cell motility, cell division and cell death. The isoform alpha-1B gives rise to N-type calcium currents. N-type calcium channels belong to the 'high-voltage activated' (HVA) group and are specifically blocked by omega-conotoxin-GVIA (AC P01522) (AC P01522) (By similarity). They are however insensitive to dihydropyridines (DHP). Calcium channels containing alpha-1B subunit may play a role in directed migration of immature neurons. {ECO:0000250|UniProtKB:Q02294}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 41_404 | 964.3333333333334 | 2091.0 | Region | Note=Seven-bladed beta propeller |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 450_586 | 964.3333333333334 | 2091.0 | Region | (Microbial infection) Binds human adenovirus 5 (HAdV-5) protein L3 (hexon) |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 740_768 | 964.3333333333334 | 2091.0 | Region | Note=Leucine-zipper 1 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 861_882 | 964.3333333333334 | 2091.0 | Region | Note=Leucine-zipper 2 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 41_404 | 954.3333333333334 | 2081.0 | Region | Note=Seven-bladed beta propeller |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 450_586 | 954.3333333333334 | 2081.0 | Region | (Microbial infection) Binds human adenovirus 5 (HAdV-5) protein L3 (hexon) |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 740_768 | 954.3333333333334 | 2081.0 | Region | Note=Leucine-zipper 1 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 861_882 | 954.3333333333334 | 2081.0 | Region | Note=Leucine-zipper 2 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 41_404 | 965.3333333333334 | 2092.0 | Region | Note=Seven-bladed beta propeller |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 450_586 | 965.3333333333334 | 2092.0 | Region | (Microbial infection) Binds human adenovirus 5 (HAdV-5) protein L3 (hexon) |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 740_768 | 965.3333333333334 | 2092.0 | Region | Note=Leucine-zipper 1 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 861_882 | 965.3333333333334 | 2092.0 | Region | Note=Leucine-zipper 2 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 151_193 | 964.3333333333334 | 2091.0 | Repeat | Note=Blade 3 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 194_239 | 964.3333333333334 | 2091.0 | Repeat | Note=Blade 4 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 240_303 | 964.3333333333334 | 2091.0 | Repeat | Note=Blade 5 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 304_359 | 964.3333333333334 | 2091.0 | Repeat | Note=Blade 6 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 360_404 | 964.3333333333334 | 2091.0 | Repeat | Note=Blade 7 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 41_93 | 964.3333333333334 | 2091.0 | Repeat | Note=Blade 1 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 484_485 | 964.3333333333334 | 2091.0 | Repeat | 1 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 548_549 | 964.3333333333334 | 2091.0 | Repeat | 2 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 94_150 | 964.3333333333334 | 2091.0 | Repeat | Note=Blade 2 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 151_193 | 954.3333333333334 | 2081.0 | Repeat | Note=Blade 3 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 194_239 | 954.3333333333334 | 2081.0 | Repeat | Note=Blade 4 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 240_303 | 954.3333333333334 | 2081.0 | Repeat | Note=Blade 5 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 304_359 | 954.3333333333334 | 2081.0 | Repeat | Note=Blade 6 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 360_404 | 954.3333333333334 | 2081.0 | Repeat | Note=Blade 7 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 41_93 | 954.3333333333334 | 2081.0 | Repeat | Note=Blade 1 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 484_485 | 954.3333333333334 | 2081.0 | Repeat | 1 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 548_549 | 954.3333333333334 | 2081.0 | Repeat | 2 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 94_150 | 954.3333333333334 | 2081.0 | Repeat | Note=Blade 2 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 151_193 | 965.3333333333334 | 2092.0 | Repeat | Note=Blade 3 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 194_239 | 965.3333333333334 | 2092.0 | Repeat | Note=Blade 4 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 240_303 | 965.3333333333334 | 2092.0 | Repeat | Note=Blade 5 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 304_359 | 965.3333333333334 | 2092.0 | Repeat | Note=Blade 6 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 360_404 | 965.3333333333334 | 2092.0 | Repeat | Note=Blade 7 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 41_93 | 965.3333333333334 | 2092.0 | Repeat | Note=Blade 1 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 484_485 | 965.3333333333334 | 2092.0 | Repeat | 1 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 548_549 | 965.3333333333334 | 2092.0 | Repeat | 2 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 94_150 | 965.3333333333334 | 2092.0 | Repeat | Note=Blade 2 |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 2050_2054 | 1809.3333333333333 | 2340.0 | Compositional bias | Note=Poly-His | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 2118_2122 | 1809.3333333333333 | 2340.0 | Compositional bias | Note=Poly-Ser |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 680_1209 | 964.3333333333334 | 2091.0 | Coiled coil | Ontology_term=ECO:0000269 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 680_1209 | 954.3333333333334 | 2081.0 | Coiled coil | Ontology_term=ECO:0000269 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 680_1209 | 965.3333333333334 | 2092.0 | Coiled coil | Ontology_term=ECO:0000269 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1213_2090 | 964.3333333333334 | 2091.0 | Compositional bias | Note=Pro/Ser/Thr-rich |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1213_2090 | 954.3333333333334 | 2081.0 | Compositional bias | Note=Pro/Ser/Thr-rich |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1213_2090 | 965.3333333333334 | 2092.0 | Compositional bias | Note=Pro/Ser/Thr-rich |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1409_2084 | 964.3333333333334 | 2091.0 | Region | Note=18 X 4 AA approximate repeats |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1427_2085 | 964.3333333333334 | 2091.0 | Region | Note=11 X 3 AA approximate repeats |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 236_1418 | 964.3333333333334 | 2091.0 | Region | 44 X 2 AA repeats of F-G |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 481_2076 | 964.3333333333334 | 2091.0 | Region | Note=11 X 5 AA approximate repeats |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1409_2084 | 954.3333333333334 | 2081.0 | Region | Note=18 X 4 AA approximate repeats |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1427_2085 | 954.3333333333334 | 2081.0 | Region | Note=11 X 3 AA approximate repeats |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 236_1418 | 954.3333333333334 | 2081.0 | Region | 44 X 2 AA repeats of F-G |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 481_2076 | 954.3333333333334 | 2081.0 | Region | Note=11 X 5 AA approximate repeats |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1409_2084 | 965.3333333333334 | 2092.0 | Region | Note=18 X 4 AA approximate repeats |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1427_2085 | 965.3333333333334 | 2092.0 | Region | Note=11 X 3 AA approximate repeats |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 236_1418 | 965.3333333333334 | 2092.0 | Region | 44 X 2 AA repeats of F-G |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 481_2076 | 965.3333333333334 | 2092.0 | Region | Note=11 X 5 AA approximate repeats |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1225_1226 | 964.3333333333334 | 2091.0 | Repeat | 3 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1411_1412 | 964.3333333333334 | 2091.0 | Repeat | 4 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1427_1428 | 964.3333333333334 | 2091.0 | Repeat | 5 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1441_1442 | 964.3333333333334 | 2091.0 | Repeat | 6 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1473_1474 | 964.3333333333334 | 2091.0 | Repeat | 7 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1635_1636 | 964.3333333333334 | 2091.0 | Repeat | 8 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1674_1675 | 964.3333333333334 | 2091.0 | Repeat | 9 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1686_1687 | 964.3333333333334 | 2091.0 | Repeat | 10 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1713_1714 | 964.3333333333334 | 2091.0 | Repeat | 11 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1721_1722 | 964.3333333333334 | 2091.0 | Repeat | 12 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1726_1727 | 964.3333333333334 | 2091.0 | Repeat | 13 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1732_1733 | 964.3333333333334 | 2091.0 | Repeat | 14 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1756_1757 | 964.3333333333334 | 2091.0 | Repeat | 15 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1772_1773 | 964.3333333333334 | 2091.0 | Repeat | 16 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1786_1787 | 964.3333333333334 | 2091.0 | Repeat | 17 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1798_1799 | 964.3333333333334 | 2091.0 | Repeat | 18 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1806_1807 | 964.3333333333334 | 2091.0 | Repeat | 19 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1812_1813 | 964.3333333333334 | 2091.0 | Repeat | 20 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1819_1820 | 964.3333333333334 | 2091.0 | Repeat | 21 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1842_1843 | 964.3333333333334 | 2091.0 | Repeat | 22 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1851_1852 | 964.3333333333334 | 2091.0 | Repeat | 23 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1862_1863 | 964.3333333333334 | 2091.0 | Repeat | 24 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1874_1875 | 964.3333333333334 | 2091.0 | Repeat | 25 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1910_1911 | 964.3333333333334 | 2091.0 | Repeat | 26 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1922_1923 | 964.3333333333334 | 2091.0 | Repeat | 27 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1930_1931 | 964.3333333333334 | 2091.0 | Repeat | 28 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1938_1939 | 964.3333333333334 | 2091.0 | Repeat | 29 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1959_1960 | 964.3333333333334 | 2091.0 | Repeat | 30 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1970_1971 | 964.3333333333334 | 2091.0 | Repeat | 31 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1976_1977 | 964.3333333333334 | 2091.0 | Repeat | 32 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1982_1983 | 964.3333333333334 | 2091.0 | Repeat | 33 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1988_1989 | 964.3333333333334 | 2091.0 | Repeat | 34 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 1994_1995 | 964.3333333333334 | 2091.0 | Repeat | 35 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 2012_2013 | 964.3333333333334 | 2091.0 | Repeat | 36 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 2024_2025 | 964.3333333333334 | 2091.0 | Repeat | 37 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 2026_2027 | 964.3333333333334 | 2091.0 | Repeat | 38 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 2035_2036 | 964.3333333333334 | 2091.0 | Repeat | 39 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 2046_2047 | 964.3333333333334 | 2091.0 | Repeat | 40 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 2056_2057 | 964.3333333333334 | 2091.0 | Repeat | 41 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 2066_2067 | 964.3333333333334 | 2091.0 | Repeat | 42 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 2075_2076 | 964.3333333333334 | 2091.0 | Repeat | 43 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000359428 | + | 21 | 36 | 2085_2086 | 964.3333333333334 | 2091.0 | Repeat | 44 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1225_1226 | 954.3333333333334 | 2081.0 | Repeat | 3 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1411_1412 | 954.3333333333334 | 2081.0 | Repeat | 4 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1427_1428 | 954.3333333333334 | 2081.0 | Repeat | 5 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1441_1442 | 954.3333333333334 | 2081.0 | Repeat | 6 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1473_1474 | 954.3333333333334 | 2081.0 | Repeat | 7 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1635_1636 | 954.3333333333334 | 2081.0 | Repeat | 8 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1674_1675 | 954.3333333333334 | 2081.0 | Repeat | 9 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1686_1687 | 954.3333333333334 | 2081.0 | Repeat | 10 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1713_1714 | 954.3333333333334 | 2081.0 | Repeat | 11 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1721_1722 | 954.3333333333334 | 2081.0 | Repeat | 12 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1726_1727 | 954.3333333333334 | 2081.0 | Repeat | 13 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1732_1733 | 954.3333333333334 | 2081.0 | Repeat | 14 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1756_1757 | 954.3333333333334 | 2081.0 | Repeat | 15 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1772_1773 | 954.3333333333334 | 2081.0 | Repeat | 16 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1786_1787 | 954.3333333333334 | 2081.0 | Repeat | 17 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1798_1799 | 954.3333333333334 | 2081.0 | Repeat | 18 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1806_1807 | 954.3333333333334 | 2081.0 | Repeat | 19 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1812_1813 | 954.3333333333334 | 2081.0 | Repeat | 20 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1819_1820 | 954.3333333333334 | 2081.0 | Repeat | 21 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1842_1843 | 954.3333333333334 | 2081.0 | Repeat | 22 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1851_1852 | 954.3333333333334 | 2081.0 | Repeat | 23 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1862_1863 | 954.3333333333334 | 2081.0 | Repeat | 24 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1874_1875 | 954.3333333333334 | 2081.0 | Repeat | 25 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1910_1911 | 954.3333333333334 | 2081.0 | Repeat | 26 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1922_1923 | 954.3333333333334 | 2081.0 | Repeat | 27 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1930_1931 | 954.3333333333334 | 2081.0 | Repeat | 28 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1938_1939 | 954.3333333333334 | 2081.0 | Repeat | 29 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1959_1960 | 954.3333333333334 | 2081.0 | Repeat | 30 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1970_1971 | 954.3333333333334 | 2081.0 | Repeat | 31 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1976_1977 | 954.3333333333334 | 2081.0 | Repeat | 32 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1982_1983 | 954.3333333333334 | 2081.0 | Repeat | 33 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1988_1989 | 954.3333333333334 | 2081.0 | Repeat | 34 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 1994_1995 | 954.3333333333334 | 2081.0 | Repeat | 35 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 2012_2013 | 954.3333333333334 | 2081.0 | Repeat | 36 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 2024_2025 | 954.3333333333334 | 2081.0 | Repeat | 37 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 2026_2027 | 954.3333333333334 | 2081.0 | Repeat | 38 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 2035_2036 | 954.3333333333334 | 2081.0 | Repeat | 39 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 2046_2047 | 954.3333333333334 | 2081.0 | Repeat | 40 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 2056_2057 | 954.3333333333334 | 2081.0 | Repeat | 41 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 2066_2067 | 954.3333333333334 | 2081.0 | Repeat | 42 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 2075_2076 | 954.3333333333334 | 2081.0 | Repeat | 43 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000411637 | + | 21 | 36 | 2085_2086 | 954.3333333333334 | 2081.0 | Repeat | 44 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1225_1226 | 965.3333333333334 | 2092.0 | Repeat | 3 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1411_1412 | 965.3333333333334 | 2092.0 | Repeat | 4 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1427_1428 | 965.3333333333334 | 2092.0 | Repeat | 5 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1441_1442 | 965.3333333333334 | 2092.0 | Repeat | 6 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1473_1474 | 965.3333333333334 | 2092.0 | Repeat | 7 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1635_1636 | 965.3333333333334 | 2092.0 | Repeat | 8 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1674_1675 | 965.3333333333334 | 2092.0 | Repeat | 9 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1686_1687 | 965.3333333333334 | 2092.0 | Repeat | 10 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1713_1714 | 965.3333333333334 | 2092.0 | Repeat | 11 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1721_1722 | 965.3333333333334 | 2092.0 | Repeat | 12 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1726_1727 | 965.3333333333334 | 2092.0 | Repeat | 13 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1732_1733 | 965.3333333333334 | 2092.0 | Repeat | 14 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1756_1757 | 965.3333333333334 | 2092.0 | Repeat | 15 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1772_1773 | 965.3333333333334 | 2092.0 | Repeat | 16 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1786_1787 | 965.3333333333334 | 2092.0 | Repeat | 17 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1798_1799 | 965.3333333333334 | 2092.0 | Repeat | 18 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1806_1807 | 965.3333333333334 | 2092.0 | Repeat | 19 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1812_1813 | 965.3333333333334 | 2092.0 | Repeat | 20 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1819_1820 | 965.3333333333334 | 2092.0 | Repeat | 21 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1842_1843 | 965.3333333333334 | 2092.0 | Repeat | 22 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1851_1852 | 965.3333333333334 | 2092.0 | Repeat | 23 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1862_1863 | 965.3333333333334 | 2092.0 | Repeat | 24 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1874_1875 | 965.3333333333334 | 2092.0 | Repeat | 25 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1910_1911 | 965.3333333333334 | 2092.0 | Repeat | 26 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1922_1923 | 965.3333333333334 | 2092.0 | Repeat | 27 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1930_1931 | 965.3333333333334 | 2092.0 | Repeat | 28 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1938_1939 | 965.3333333333334 | 2092.0 | Repeat | 29 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1959_1960 | 965.3333333333334 | 2092.0 | Repeat | 30 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1970_1971 | 965.3333333333334 | 2092.0 | Repeat | 31 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1976_1977 | 965.3333333333334 | 2092.0 | Repeat | 32 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1982_1983 | 965.3333333333334 | 2092.0 | Repeat | 33 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1988_1989 | 965.3333333333334 | 2092.0 | Repeat | 34 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 1994_1995 | 965.3333333333334 | 2092.0 | Repeat | 35 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 2012_2013 | 965.3333333333334 | 2092.0 | Repeat | 36 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 2024_2025 | 965.3333333333334 | 2092.0 | Repeat | 37 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 2026_2027 | 965.3333333333334 | 2092.0 | Repeat | 38 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 2035_2036 | 965.3333333333334 | 2092.0 | Repeat | 39 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 2046_2047 | 965.3333333333334 | 2092.0 | Repeat | 40 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 2056_2057 | 965.3333333333334 | 2092.0 | Repeat | 41 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 2066_2067 | 965.3333333333334 | 2092.0 | Repeat | 42 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 2075_2076 | 965.3333333333334 | 2092.0 | Repeat | 43 |
| Hgene | NUP214 | chr9:134039531 | chr9:141006850 | ENST00000451030 | + | 21 | 36 | 2085_2086 | 965.3333333333334 | 2092.0 | Repeat | 44 |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1737_1748 | 1809.3333333333333 | 2340.0 | Calcium binding | Ontology_term=ECO:0000255 | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1724_1759 | 1809.3333333333333 | 2340.0 | Domain | EF-hand | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 451_458 | 1809.3333333333333 | 2340.0 | Nucleotide binding | ATP | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 379_396 | 1809.3333333333333 | 2340.0 | Region | Binding to the beta subunit | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1137_1419 | 1809.3333333333333 | 2340.0 | Repeat | Note=III | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1456_1711 | 1809.3333333333333 | 2340.0 | Repeat | Note=IV | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 468_712 | 1809.3333333333333 | 2340.0 | Repeat | Note=II | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 82_359 | 1809.3333333333333 | 2340.0 | Repeat | Note=I | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 115_132 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1170_1185 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1206_1217 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1237_1246 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1266_1284 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1305_1391 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1417_1471 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1491_1505 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1526_1533 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 153_163 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1553_1563 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1583_1601 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1622_1683 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1709_2339 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 184_187 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1_95 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 207_225 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 246_331 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 357_482 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 502_516 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 537_544 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 563_573 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 593_611 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 632_684 | 1809.3333333333333 | 2340.0 | Topological domain | Extracellular | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 710_1151 | 1809.3333333333333 | 2340.0 | Topological domain | Cytoplasmic | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1152_1169 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS1 of repeat III | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1186_1205 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS2 of repeat III | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1218_1236 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS3 of repeat III | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1247_1265 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS4 of repeat III | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1285_1304 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS5 of repeat III | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 133_152 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS2 of repeat I | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1392_1416 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS6 of repeat III | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1472_1490 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS1 of repeat IV | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1506_1525 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS2 of repeat IV | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1534_1552 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS3 of repeat IV | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1564_1582 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS4 of repeat IV | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1602_1621 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS5 of repeat IV | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 164_183 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS3 of repeat I | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 1684_1708 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS6 of repeat IV | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 188_206 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS4 of repeat I | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 226_245 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS5 of repeat I | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 332_356 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS6 of repeat I | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 483_501 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS1 of repeat II | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 517_536 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS2 of repeat II | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 545_562 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS3 of repeat II | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 574_592 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS4 of repeat II | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 612_631 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS5 of repeat II | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 685_709 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS6 of repeat II | |
| Tgene | CACNA1B | chr9:134039531 | chr9:141006850 | ENST00000371372 | 38 | 47 | 96_114 | 1809.3333333333333 | 2340.0 | Transmembrane | Helical%3B Name%3DS1 of repeat I |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| NUP214 | ZFP36, XPO1, NUP107, NXF2, NXF1, XPO5, CRM1, KAP104, IPO5, G3BP1, G3BP2, RAE1, APC, HDAC4, HDAC5, HDAC9, NUP88, SMAD1, Plk1, Nup88, Nup188, Nup214, CLEC4G, SMAD2, SMAD3, SMAD4, SIRT7, RANBP2, CUL3, CUL2, rev, NUPL2, NUP214, MEX67, ACOT13, PNPT1, HSPA1L, VPS4B, S100A6, EEF1A1, STRIP1, RPL19, NDUFA7, ITGA4, SOX2, LMNA, FBXO6, CUL7, OBSL1, NUP62, CLEC11A, DDX19A, KCMF1, CFL1, CSRP1, DYNC1LI1, TRIM28, TXNDC9, NTRK1, IFI16, NUP85, NUP35, KPNB1, UBE2I, NUPL1, NUP153, SEH1L, Ranbp2, Ube2i, Rcc1, Nup107, Kifc1, Nup155, Nup98, C11orf30, CDH1, RAN, FXR2, EMILIN1, SERPINB2, BRCA1, ORF10, CTNNB1, CUL4B, RNF31, ESR2, EZH2, SUZ12, MYC, CDK9, VCP, KIAA1429, NR2C2, HIST1H4A, PTPDC1, RHBDD1, RHBDF2, nsp9, BIRC3, LMBR1L, PLEKHA4, CYLD, ORF6, IMMP1L, IMMP2L, CTIF, DDX19B, GLE1, FARP1, Myo9b, ITSN1, PLEKHG6, ACACA, SUMO2, NFX1, NUPR1, DYRK1A, NUP155, SYNE3, NAA40, NXT2, SLFN11, CCNF, TAX1BP1, SIRT6, DVL2, ETV6, |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| NUP214 |  |
| CACNA1B |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to NUP214-CACNA1B |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to NUP214-CACNA1B |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | NUP214 | C0025958 | Microcephaly | 1 | GENOMICS_ENGLAND |
| Hgene | NUP214 | C0543888 | Epileptic encephalopathy | 1 | GENOMICS_ENGLAND |
| Hgene | NUP214 | C1836830 | Developmental regression | 1 | GENOMICS_ENGLAND |
| Hgene | NUP214 | C1961099 | Precursor T-Cell Lymphoblastic Leukemia-Lymphoma | 1 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies