| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:ATP2B1-CEP290 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: ATP2B1-CEP290 | FusionPDB ID: 7848 | FusionGDB2.0 ID: 7848 | Hgene | Tgene | Gene symbol | ATP2B1 | CEP290 | Gene ID | 490 | 80184 |
| Gene name | ATPase plasma membrane Ca2+ transporting 1 | centrosomal protein 290 | |
| Synonyms | PMCA1|PMCA1kb | 3H11Ag|BBS14|CT87|JBTS5|LCA10|MKS4|NPHP6|POC3|SLSN6|rd16 | |
| Cytomap | 12q21.33 | 12q21.32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | plasma membrane calcium-transporting ATPase 1ATPase, Ca++ transporting, plasma membrane 1plasma membrane calcium pump | centrosomal protein of 290 kDaBardet-Biedl syndrome 14 proteinCTCL tumor antigen se2-2Meckel syndrome, type 4POC3 centriolar protein homologcancer/testis antigen 87centrosomal protein 290kDamonoclonal antibody 3H11 antigennephrocytsin-6prostate c | |
| Modification date | 20200322 | 20200328 | |
| UniProtAcc | P20020 | O15078 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000261173, ENST00000348959, ENST00000359142, ENST00000393164, ENST00000428670, | ENST00000309041, ENST00000397838, ENST00000547691, ENST00000552810, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 15 X 12 X 6=1080 | 9 X 9 X 6=486 |
| # samples | 13 | 9 | |
| ** MAII score | log2(13/1080*10)=-3.05444778402238 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/486*10)=-2.43295940727611 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: ATP2B1 [Title/Abstract] AND CEP290 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | ATP2B1(90010579)-CEP290(88478629), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ATP2B1-CEP290 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ATP2B1-CEP290 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ATP2B1-CEP290 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ATP2B1-CEP290 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ATP2B1 | GO:0051480 | regulation of cytosolic calcium ion concentration | 18029012 |
| Hgene | ATP2B1 | GO:1990034 | calcium ion export across plasma membrane | 18029012 |
| Tgene | CEP290 | GO:0045893 | positive regulation of transcription, DNA-templated | 16682973 |
| Tgene | CEP290 | GO:0060271 | cilium assembly | 26386044 |
| Fusion gene breakpoints across ATP2B1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
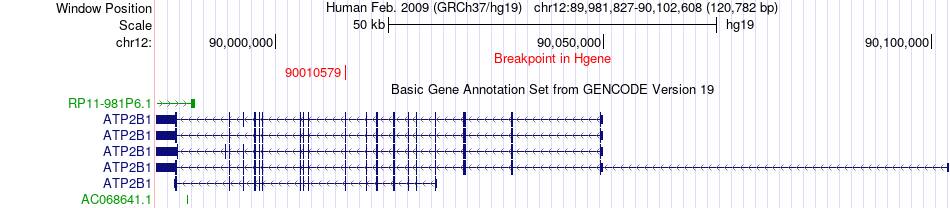 |
| Fusion gene breakpoints across CEP290 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | CESC | TCGA-C5-A7CH-01A | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000348959 | ATP2B1 | chr12 | 90010579 | - | ENST00000547691 | CEP290 | chr12 | 88478629 | - | 5419 | 2248 | 181 | 5250 | 1689 |
| ENST00000348959 | ATP2B1 | chr12 | 90010579 | - | ENST00000552810 | CEP290 | chr12 | 88478629 | - | 5415 | 2248 | 181 | 5250 | 1689 |
| ENST00000348959 | ATP2B1 | chr12 | 90010579 | - | ENST00000397838 | CEP290 | chr12 | 88478629 | - | 5251 | 2248 | 181 | 5250 | 1690 |
| ENST00000348959 | ATP2B1 | chr12 | 90010579 | - | ENST00000309041 | CEP290 | chr12 | 88478629 | - | 5251 | 2248 | 181 | 5250 | 1690 |
| ENST00000261173 | ATP2B1 | chr12 | 90010579 | - | ENST00000547691 | CEP290 | chr12 | 88478629 | - | 5419 | 2248 | 181 | 5250 | 1689 |
| ENST00000261173 | ATP2B1 | chr12 | 90010579 | - | ENST00000552810 | CEP290 | chr12 | 88478629 | - | 5415 | 2248 | 181 | 5250 | 1689 |
| ENST00000261173 | ATP2B1 | chr12 | 90010579 | - | ENST00000397838 | CEP290 | chr12 | 88478629 | - | 5251 | 2248 | 181 | 5250 | 1690 |
| ENST00000261173 | ATP2B1 | chr12 | 90010579 | - | ENST00000309041 | CEP290 | chr12 | 88478629 | - | 5251 | 2248 | 181 | 5250 | 1690 |
| ENST00000359142 | ATP2B1 | chr12 | 90010579 | - | ENST00000547691 | CEP290 | chr12 | 88478629 | - | 5463 | 2292 | 225 | 5294 | 1689 |
| ENST00000359142 | ATP2B1 | chr12 | 90010579 | - | ENST00000552810 | CEP290 | chr12 | 88478629 | - | 5459 | 2292 | 225 | 5294 | 1689 |
| ENST00000359142 | ATP2B1 | chr12 | 90010579 | - | ENST00000397838 | CEP290 | chr12 | 88478629 | - | 5295 | 2292 | 225 | 5294 | 1689 |
| ENST00000359142 | ATP2B1 | chr12 | 90010579 | - | ENST00000309041 | CEP290 | chr12 | 88478629 | - | 5295 | 2292 | 225 | 5294 | 1689 |
| ENST00000428670 | ATP2B1 | chr12 | 90010579 | - | ENST00000547691 | CEP290 | chr12 | 88478629 | - | 5695 | 2524 | 457 | 5526 | 1689 |
| ENST00000428670 | ATP2B1 | chr12 | 90010579 | - | ENST00000552810 | CEP290 | chr12 | 88478629 | - | 5691 | 2524 | 457 | 5526 | 1689 |
| ENST00000428670 | ATP2B1 | chr12 | 90010579 | - | ENST00000397838 | CEP290 | chr12 | 88478629 | - | 5527 | 2524 | 457 | 5526 | 1690 |
| ENST00000428670 | ATP2B1 | chr12 | 90010579 | - | ENST00000309041 | CEP290 | chr12 | 88478629 | - | 5527 | 2524 | 457 | 5526 | 1690 |
| ENST00000393164 | ATP2B1 | chr12 | 90010579 | - | ENST00000547691 | CEP290 | chr12 | 88478629 | - | 4560 | 1389 | 93 | 4391 | 1432 |
| ENST00000393164 | ATP2B1 | chr12 | 90010579 | - | ENST00000552810 | CEP290 | chr12 | 88478629 | - | 4556 | 1389 | 93 | 4391 | 1432 |
| ENST00000393164 | ATP2B1 | chr12 | 90010579 | - | ENST00000397838 | CEP290 | chr12 | 88478629 | - | 4392 | 1389 | 93 | 4391 | 1432 |
| ENST00000393164 | ATP2B1 | chr12 | 90010579 | - | ENST00000309041 | CEP290 | chr12 | 88478629 | - | 4392 | 1389 | 93 | 4391 | 1432 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000348959 | ENST00000547691 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000619476 | 0.99938047 |
| ENST00000348959 | ENST00000552810 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.00061791 | 0.999382 |
| ENST00000348959 | ENST00000397838 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000716947 | 0.999283 |
| ENST00000348959 | ENST00000309041 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000716947 | 0.999283 |
| ENST00000261173 | ENST00000547691 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000619476 | 0.99938047 |
| ENST00000261173 | ENST00000552810 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.00061791 | 0.999382 |
| ENST00000261173 | ENST00000397838 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000716947 | 0.999283 |
| ENST00000261173 | ENST00000309041 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000716947 | 0.999283 |
| ENST00000359142 | ENST00000547691 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000619998 | 0.99938 |
| ENST00000359142 | ENST00000552810 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000618601 | 0.9993814 |
| ENST00000359142 | ENST00000397838 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000717707 | 0.9992823 |
| ENST00000359142 | ENST00000309041 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000717707 | 0.9992823 |
| ENST00000428670 | ENST00000547691 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000737274 | 0.99926275 |
| ENST00000428670 | ENST00000552810 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000735551 | 0.9992644 |
| ENST00000428670 | ENST00000397838 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000860967 | 0.99913895 |
| ENST00000428670 | ENST00000309041 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000860967 | 0.99913895 |
| ENST00000393164 | ENST00000547691 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000815171 | 0.9991848 |
| ENST00000393164 | ENST00000552810 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.000813401 | 0.9991866 |
| ENST00000393164 | ENST00000397838 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.001005696 | 0.9989943 |
| ENST00000393164 | ENST00000309041 | ATP2B1 | chr12 | 90010579 | - | CEP290 | chr12 | 88478629 | - | 0.001005696 | 0.9989943 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >7848_7848_1_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000261173_CEP290_chr12_88478629_ENST00000309041_length(amino acids)=1690AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_2_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000261173_CEP290_chr12_88478629_ENST00000397838_length(amino acids)=1690AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_3_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000261173_CEP290_chr12_88478629_ENST00000547691_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_4_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000261173_CEP290_chr12_88478629_ENST00000552810_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_5_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000348959_CEP290_chr12_88478629_ENST00000309041_length(amino acids)=1690AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_6_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000348959_CEP290_chr12_88478629_ENST00000397838_length(amino acids)=1690AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_7_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000348959_CEP290_chr12_88478629_ENST00000547691_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_8_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000348959_CEP290_chr12_88478629_ENST00000552810_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_9_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000359142_CEP290_chr12_88478629_ENST00000309041_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_10_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000359142_CEP290_chr12_88478629_ENST00000397838_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_11_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000359142_CEP290_chr12_88478629_ENST00000547691_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_12_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000359142_CEP290_chr12_88478629_ENST00000552810_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_13_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000393164_CEP290_chr12_88478629_ENST00000309041_length(amino acids)=1432AA_BP=432 MFLVIGTHVMEGSGRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEK DKKKANLPKKEKSVLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPL AVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSK ILPPEKEGGLPRHVGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSA NGEAKVFRPRDRDDIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILS RDKVINELRLRLPATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHR LELQADSSLNKFKQTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHE DEVKKVKAEVEDLKYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISAT SQKEAHLNVQQIVDRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRL TSGLQGKPLTDNKQSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLK DLFAKADKEKLTLQRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFS KDTYSKPSISGIESDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTI PELEKTIGLMKKVVEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKET DAAEKLRIAKNNLEILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATERE QKVNKYNEDLEQQIKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDL -------------------------------------------------------------- >7848_7848_14_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000393164_CEP290_chr12_88478629_ENST00000397838_length(amino acids)=1432AA_BP=432 MFLVIGTHVMEGSGRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEK DKKKANLPKKEKSVLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPL AVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSK ILPPEKEGGLPRHVGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSA NGEAKVFRPRDRDDIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILS RDKVINELRLRLPATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHR LELQADSSLNKFKQTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHE DEVKKVKAEVEDLKYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISAT SQKEAHLNVQQIVDRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRL TSGLQGKPLTDNKQSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLK DLFAKADKEKLTLQRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFS KDTYSKPSISGIESDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTI PELEKTIGLMKKVVEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKET DAAEKLRIAKNNLEILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATERE QKVNKYNEDLEQQIKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDL -------------------------------------------------------------- >7848_7848_15_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000393164_CEP290_chr12_88478629_ENST00000547691_length(amino acids)=1432AA_BP=432 MFLVIGTHVMEGSGRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEK DKKKANLPKKEKSVLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPL AVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSK ILPPEKEGGLPRHVGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSA NGEAKVFRPRDRDDIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILS RDKVINELRLRLPATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHR LELQADSSLNKFKQTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHE DEVKKVKAEVEDLKYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISAT SQKEAHLNVQQIVDRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRL TSGLQGKPLTDNKQSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLK DLFAKADKEKLTLQRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFS KDTYSKPSISGIESDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTI PELEKTIGLMKKVVEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKET DAAEKLRIAKNNLEILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATERE QKVNKYNEDLEQQIKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDL -------------------------------------------------------------- >7848_7848_16_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000393164_CEP290_chr12_88478629_ENST00000552810_length(amino acids)=1432AA_BP=432 MFLVIGTHVMEGSGRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEK DKKKANLPKKEKSVLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPL AVTISLAYSVKKMMKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSK ILPPEKEGGLPRHVGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSA NGEAKVFRPRDRDDIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILS RDKVINELRLRLPATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHR LELQADSSLNKFKQTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHE DEVKKVKAEVEDLKYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISAT SQKEAHLNVQQIVDRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRL TSGLQGKPLTDNKQSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLK DLFAKADKEKLTLQRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFS KDTYSKPSISGIESDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTI PELEKTIGLMKKVVEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKET DAAEKLRIAKNNLEILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATERE QKVNKYNEDLEQQIKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDL -------------------------------------------------------------- >7848_7848_17_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000428670_CEP290_chr12_88478629_ENST00000309041_length(amino acids)=1690AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_18_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000428670_CEP290_chr12_88478629_ENST00000397838_length(amino acids)=1690AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_19_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000428670_CEP290_chr12_88478629_ENST00000547691_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- >7848_7848_20_ATP2B1-CEP290_ATP2B1_chr12_90010579_ENST00000428670_CEP290_chr12_88478629_ENST00000552810_length(amino acids)=1689AA_BP=689 MGDMANNSVAYSGVKNSLKEANHDGDFGITLAELRALMELRSTDALRKIQESYGDVYGICTKLKTSPNEGLSGNPADLERREAVFGKNFI PPKKPKTFLQLVWEALQDVTLIILEIAAIVSLGLSFYQPPEGDNALCGEVSVGEEEGEGETGWIEGAAILLSVVCVVLVTAFNDWSKEKQ FRGLQSRIEQEQKFTVIRGGQVIQIPVADITVGDIAQVKYGDLLPADGILIQGNDLKIDESSLTGESDHVKKSLDKDPLLLSGTHVMEGS GRMVVTAVGVNSQTGIIFTLLGAGGEEEEKKDEKKKEKKNKKQDGAIENRNKAKAQDGAAMEMQPLKSEEGGDGDEKDKKKANLPKKEKS VLQGKLTKLAVQIGKAGLLMSAITVIILVLYFVIDTFWVQKRPWLAECTPIYIQYFVKFFIIGVTVLVVAVPEGLPLAVTISLAYSVKKM MKDNNLVRHLDACETMGNATAICSDKTGTLTMNRMTVVQAYINEKHYKKVPEPEAIPPNILSYLVTGISVNCAYTSKILPPEKEGGLPRH VGNKTECALLGLLLDLKRDYQDVRNEIPEEALYKVYTFNSVRKSMSTVLKNSDGSYRIFSKGASEIILKKCFKILSANGEAKVFRPRDRD DIVKTVIEPMASEGLRTICLAFRDFPAGEPEPEWDNENDIVTGLTCIAVVGIEDPVRPEKLKEKESALRLAEQNILSRDKVINELRLRLP ATAEREKLIAELGRKEMEPKSHHTLKIAHQTIANMQARLNQKEEVLKKYQRLLEKAREEQREIVKKHEEDLHILHHRLELQADSSLNKFK QTAWDLMKQSPTPVPTNKHFIRLAEMEQTVAEQDDSLSSLLVKLKKVSQDLERQREITELKVKEFENIKLQLQENHEDEVKKVKAEVEDL KYLLDQSQKESQCLKSELQAQKEANSRAPTTTMRNLVERLKSQLALKEKQQKALSRALLELRAEMTAAAEERIISATSQKEAHLNVQQIV DRHTRELKTQVEDLNENLLKLKEALKTSKNRENSLTDNLNDLNNELQKKQKAYNKILREKEEIDQENDELKRQIKRLTSGLQGKPLTDNK QSLIEELQRKVKKLENQLEGKVEEVDLKPMKEKNAKEELIRWEEGKKWQAKIEGIRNKLKEKEGEVFTLTKQLNTLKDLFAKADKEKLTL QRKLKTTGMTVDQVLGIRALESEKELEELKKRNLDLENDILYMRAHQALPRDSVVEDLHLQNRYLQEKLHALEKQFSKDTYSKPSISGIE SDDHCQREQELQKENLKLSSENIELKFQLEQANKDLPRLKNQVRDLKEMCEFLKKEKAEVQRKLGHVRGSGRSGKTIPELEKTIGLMKKV VEKVQRENEQLKKASGILTSEKMANIEQENEKLKAELEKLKAHLGHQLSMHYESKTKGTEKIIAENERLRKELKKETDAAEKLRIAKNNL EILNEKMTVQLEETGKRLQFAESRGPQLEGADSKSWKSIVVTRMYETKLKELETDIAKKNQSITDLKQLVKEATEREQKVNKYNEDLEQQ IKILKHVPEGAETEQGLKRELQVLRLANHQLDKEKAELIHQIEANKDQSGAESTIPDADQLKEKIKDLETQLKMSDLEKQHLKEEIKKLK -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:90010579/chr12:88478629) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ATP2B1 | CEP290 |
| FUNCTION: Catalyzes the hydrolysis of ATP coupled with the transport of calcium from the cytoplasm to the extracellular space thereby maintaining intracellular calcium homeostasis. Plays a role in blood pressure regulation through regulation of intracellular calcium concentration and nitric oxide production leading to regulation of vascular smooth muscle cells vasoconstriction. Positively regulates bone mineralization through absorption of calcium from the intestine. Plays dual roles in osteoclast differentiation and survival by regulating RANKL-induced calcium oscillations in preosteoclasts and mediating calcium extrusion in mature osteoclasts (By similarity). Regulates insulin sensitivity through calcium/calmodulin signaling pathway by regulating AKT1 activation and NOS3 activation in endothelial cells (PubMed:29104511). {ECO:0000250|UniProtKB:G5E829, ECO:0000269|PubMed:29104511}. | FUNCTION: Involved in early and late steps in cilia formation. Its association with CCP110 is required for inhibition of primary cilia formation by CCP110 (PubMed:18694559). May play a role in early ciliogenesis in the disappearance of centriolar satellites and in the transition of primary ciliar vesicles (PCVs) to capped ciliary vesicles (CCVs). Required for the centrosomal recruitment of RAB8A and for the targeting of centriole satellite proteins to centrosomes such as of PCM1 (PubMed:24421332). Required for the correct localization of ciliary and phototransduction proteins in retinal photoreceptor cells; may play a role in ciliary transport processes (By similarity). Required for efficient recruitment of RAB8A to primary cilium (PubMed:17705300). In the ciliary transition zone is part of the tectonic-like complex which is required for tissue-specific ciliogenesis and may regulate ciliary membrane composition (By similarity). Involved in regulation of the BBSome complex integrity, specifically for presence of BBS2, BBS5 and BBS8/TTC8 in the complex, and in ciliary targeting of selected BBSome cargos. May play a role in controlling entry of the BBSome complex to cilia possibly implicating IQCB1/NPHP5 (PubMed:25552655). Activates ATF4-mediated transcription (PubMed:16682973). {ECO:0000250|UniProtKB:Q6A078, ECO:0000269|PubMed:16682973, ECO:0000269|PubMed:17705300, ECO:0000269|PubMed:18694559, ECO:0000269|PubMed:24421332, ECO:0000269|PubMed:25552655}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 296_299 | 689.0 | 1221.0 | Compositional bias | Note=Poly-Glu |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 296_299 | 689.0 | 1185.0 | Compositional bias | Note=Poly-Glu |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 296_299 | 689.0 | 1177.0 | Compositional bias | Note=Poly-Glu |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 296_299 | 689.0 | 1221.0 | Compositional bias | Note=Poly-Glu |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 127_154 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 176_366 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 2_105 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 387_418 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 127_154 | 689.0 | 1185.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 176_366 | 689.0 | 1185.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 2_105 | 689.0 | 1185.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 387_418 | 689.0 | 1185.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 127_154 | 689.0 | 1177.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 176_366 | 689.0 | 1177.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 2_105 | 689.0 | 1177.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 387_418 | 689.0 | 1177.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 127_154 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 176_366 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 2_105 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 387_418 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 106_126 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 155_175 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 367_386 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 419_439 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 106_126 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 155_175 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 367_386 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 419_439 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 106_126 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 155_175 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 367_386 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 419_439 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 106_126 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 155_175 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 367_386 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 419_439 | 689.0 | 1221.0 | Transmembrane | Helical |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000397838 | 25 | 46 | 1071_1498 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000397838 | 25 | 46 | 1533_1584 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000397838 | 25 | 46 | 1635_2452 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000397838 | 25 | 46 | 598_664 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000397838 | 25 | 46 | 697_931 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000397838 | 25 | 46 | 958_1027 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000547691 | 8 | 29 | 1071_1498 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000547691 | 8 | 29 | 1533_1584 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000547691 | 8 | 29 | 1635_2452 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000547691 | 8 | 29 | 598_664 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000547691 | 8 | 29 | 697_931 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000547691 | 8 | 29 | 958_1027 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 1533_1584 | 1479.0 | 2480.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 1635_2452 | 1479.0 | 2480.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000397838 | 25 | 46 | 1966_2479 | 539.0 | 1540.0 | Region | Self-association (with itself or N-terminus) | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000547691 | 8 | 29 | 1966_2479 | 539.0 | 1540.0 | Region | Self-association (with itself or N-terminus) | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 1966_2479 | 1479.0 | 2480.0 | Region | Self-association (with itself or N-terminus) |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 1100_1117 | 689.0 | 1221.0 | Region | Calmodulin-binding subdomain A |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 1118_1220 | 689.0 | 1221.0 | Region | Required for basolateral membrane targeting |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 1100_1117 | 689.0 | 1185.0 | Region | Calmodulin-binding subdomain A |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 1118_1220 | 689.0 | 1185.0 | Region | Required for basolateral membrane targeting |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 1100_1117 | 689.0 | 1177.0 | Region | Calmodulin-binding subdomain A |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 1118_1220 | 689.0 | 1177.0 | Region | Required for basolateral membrane targeting |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 1100_1117 | 689.0 | 1221.0 | Region | Calmodulin-binding subdomain A |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 1118_1220 | 689.0 | 1221.0 | Region | Required for basolateral membrane targeting |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 1028_1039 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 1061_1220 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 440_855 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 877_882 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 904_927 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 949_971 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 992_1005 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 1028_1039 | 689.0 | 1185.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 1061_1220 | 689.0 | 1185.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 440_855 | 689.0 | 1185.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 877_882 | 689.0 | 1185.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 904_927 | 689.0 | 1185.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 949_971 | 689.0 | 1185.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 992_1005 | 689.0 | 1185.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 1028_1039 | 689.0 | 1177.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 1061_1220 | 689.0 | 1177.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 440_855 | 689.0 | 1177.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 877_882 | 689.0 | 1177.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 904_927 | 689.0 | 1177.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 949_971 | 689.0 | 1177.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 992_1005 | 689.0 | 1177.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 1028_1039 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 1061_1220 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 440_855 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 877_882 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 904_927 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 949_971 | 689.0 | 1221.0 | Topological domain | Extracellular |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 992_1005 | 689.0 | 1221.0 | Topological domain | Cytoplasmic |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 1006_1027 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 1040_1060 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 856_876 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 883_903 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 928_948 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000261173 | - | 11 | 20 | 972_991 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 1006_1027 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 1040_1060 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 856_876 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 883_903 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 928_948 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000348959 | - | 11 | 19 | 972_991 | 689.0 | 1185.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 1006_1027 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 1040_1060 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 856_876 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 883_903 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 928_948 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000359142 | - | 11 | 21 | 972_991 | 689.0 | 1177.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 1006_1027 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 1040_1060 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 856_876 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 883_903 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 928_948 | 689.0 | 1221.0 | Transmembrane | Helical |
| Hgene | ATP2B1 | chr12:90010579 | chr12:88478629 | ENST00000428670 | - | 12 | 21 | 972_991 | 689.0 | 1221.0 | Transmembrane | Helical |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000397838 | 25 | 46 | 59_565 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000547691 | 8 | 29 | 59_565 | 539.0 | 1540.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 1071_1498 | 1479.0 | 2480.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 598_664 | 1479.0 | 2480.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 59_565 | 1479.0 | 2480.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 697_931 | 1479.0 | 2480.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 958_1027 | 1479.0 | 2480.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000397838 | 25 | 46 | 1_695 | 539.0 | 1540.0 | Region | Self-association (with itself or C-terminus) | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000547691 | 8 | 29 | 1_695 | 539.0 | 1540.0 | Region | Self-association (with itself or C-terminus) | |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 1_695 | 1479.0 | 2480.0 | Region | Self-association (with itself or C-terminus) |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| ATP2B1 | |
| CEP290 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | CEP290 | chr12:90010579 | chr12:88478629 | ENST00000552810 | 33 | 54 | 696_896 | 1479.0 | 2480.0 | IQCB1 |
Top |
Related Drugs to ATP2B1-CEP290 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to ATP2B1-CEP290 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies