| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:ATP6V0A1-STAT3 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: ATP6V0A1-STAT3 | FusionPDB ID: 8093 | FusionGDB2.0 ID: 8093 | Hgene | Tgene | Gene symbol | ATP6V0A1 | STAT3 | Gene ID | 535 | 6774 |
| Gene name | ATPase H+ transporting V0 subunit a1 | signal transducer and activator of transcription 3 | |
| Synonyms | ATP6N1|ATP6N1A|Stv1|VPP1|Vph1|a1 | ADMIO|ADMIO1|APRF|HIES | |
| Cytomap | 17q21.2 | 17q21.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | V-type proton ATPase 116 kDa subunit a isoform 1V-type proton ATPase 116 kDa subunit aATPase, H+ transporting, lysosomal V0 subunit a1ATPase, H+ transporting, lysosomal non-catalytic accessory protein 1 (110/116kD)H(+)-transporting two-sector ATPase, | signal transducer and activator of transcription 3DNA-binding protein APRFacute-phase response factor | |
| Modification date | 20200324 | 20200329 | |
| UniProtAcc | Q93050 | . | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000264649, ENST00000343619, ENST00000393829, ENST00000537728, ENST00000544137, ENST00000546249, ENST00000585525, ENST00000587797, | ENST00000389272, ENST00000404395, ENST00000588969, ENST00000590776, ENST00000264657, ENST00000585517, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 20 X 17 X 9=3060 | 17 X 21 X 8=2856 |
| # samples | 22 | 21 | |
| ** MAII score | log2(22/3060*10)=-3.79795622405535 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(21/2856*10)=-3.76553474636298 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: ATP6V0A1 [Title/Abstract] AND STAT3 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | ATP6V0A1(40666478)-STAT3(40498731), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ATP6V0A1-STAT3 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ATP6V0A1-STAT3 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | STAT3 | GO:0006355 | regulation of transcription, DNA-templated | 15664994|17344214 |
| Tgene | STAT3 | GO:0006606 | protein import into nucleus | 18234692 |
| Tgene | STAT3 | GO:0010507 | negative regulation of autophagy | 26962683 |
| Tgene | STAT3 | GO:0010628 | positive regulation of gene expression | 23820254 |
| Tgene | STAT3 | GO:0030522 | intracellular receptor signaling pathway | 17324931 |
| Tgene | STAT3 | GO:0032355 | response to estradiol | 12552091 |
| Tgene | STAT3 | GO:0032870 | cellular response to hormone stimulus | 12552091 |
| Tgene | STAT3 | GO:0033210 | leptin-mediated signaling pathway | 17344214 |
| Tgene | STAT3 | GO:0035278 | miRNA mediated inhibition of translation | 23820254 |
| Tgene | STAT3 | GO:0044320 | cellular response to leptin stimulus | 17344214 |
| Tgene | STAT3 | GO:0044321 | response to leptin | 17344214 |
| Tgene | STAT3 | GO:0045893 | positive regulation of transcription, DNA-templated | 19390056 |
| Tgene | STAT3 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 17324931|27050391|31462771 |
| Tgene | STAT3 | GO:0051726 | regulation of cell cycle | 17344214 |
| Tgene | STAT3 | GO:0060396 | growth hormone receptor signaling pathway | 10925297 |
| Tgene | STAT3 | GO:0060397 | JAK-STAT cascade involved in growth hormone signaling pathway | 12552091 |
| Tgene | STAT3 | GO:0070102 | interleukin-6-mediated signaling pathway | 12359225|12552091|17324931|24429361 |
| Tgene | STAT3 | GO:1902895 | positive regulation of pri-miRNA transcription by RNA polymerase II | 19390056|23820254 |
| Tgene | STAT3 | GO:2000637 | positive regulation of gene silencing by miRNA | 23820254 |
| Fusion gene breakpoints across ATP6V0A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
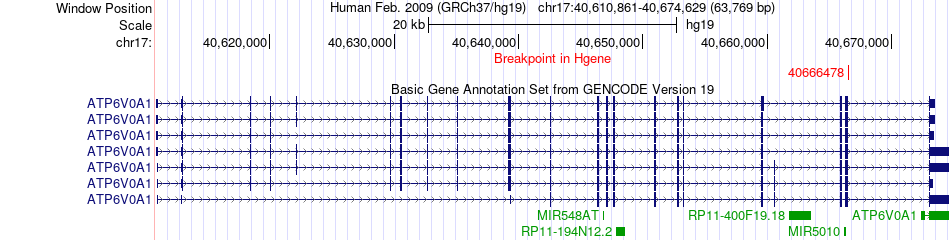 |
| Fusion gene breakpoints across STAT3 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-L5-A8NH-01A | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - |
| ChimerDB4 | ESCA | TCGA-L5-A8NH | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000393829 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000264657 | STAT3 | chr17 | 40498731 | - | 7175 | 2569 | 74 | 4753 | 1559 |
| ENST00000393829 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000585517 | STAT3 | chr17 | 40498731 | - | 5595 | 2569 | 74 | 4609 | 1511 |
| ENST00000546249 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000264657 | STAT3 | chr17 | 40498731 | - | 7193 | 2587 | 74 | 4771 | 1565 |
| ENST00000546249 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000585517 | STAT3 | chr17 | 40498731 | - | 5613 | 2587 | 74 | 4627 | 1517 |
| ENST00000537728 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000264657 | STAT3 | chr17 | 40498731 | - | 7012 | 2406 | 40 | 4590 | 1516 |
| ENST00000537728 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000585517 | STAT3 | chr17 | 40498731 | - | 5432 | 2406 | 40 | 4446 | 1468 |
| ENST00000264649 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000264657 | STAT3 | chr17 | 40498731 | - | 7160 | 2554 | 38 | 4738 | 1566 |
| ENST00000264649 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000585517 | STAT3 | chr17 | 40498731 | - | 5580 | 2554 | 38 | 4594 | 1518 |
| ENST00000585525 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000264657 | STAT3 | chr17 | 40498731 | - | 7020 | 2414 | 30 | 4598 | 1522 |
| ENST00000585525 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000585517 | STAT3 | chr17 | 40498731 | - | 5440 | 2414 | 30 | 4454 | 1474 |
| ENST00000343619 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000264657 | STAT3 | chr17 | 40498731 | - | 7149 | 2543 | 30 | 4727 | 1565 |
| ENST00000343619 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000585517 | STAT3 | chr17 | 40498731 | - | 5569 | 2543 | 30 | 4583 | 1517 |
| ENST00000544137 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000264657 | STAT3 | chr17 | 40498731 | - | 6101 | 1495 | 14 | 3679 | 1221 |
| ENST00000544137 | ATP6V0A1 | chr17 | 40666478 | + | ENST00000585517 | STAT3 | chr17 | 40498731 | - | 4521 | 1495 | 14 | 3535 | 1173 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000393829 | ENST00000264657 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000612246 | 0.99938774 |
| ENST00000393829 | ENST00000585517 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.001603685 | 0.99839634 |
| ENST00000546249 | ENST00000264657 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000375266 | 0.9996247 |
| ENST00000546249 | ENST00000585517 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000705942 | 0.99929404 |
| ENST00000537728 | ENST00000264657 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000538729 | 0.99946123 |
| ENST00000537728 | ENST00000585517 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.001433655 | 0.9985663 |
| ENST00000264649 | ENST00000264657 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000622212 | 0.9993777 |
| ENST00000264649 | ENST00000585517 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.001641209 | 0.9983588 |
| ENST00000585525 | ENST00000264657 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000333527 | 0.99966645 |
| ENST00000585525 | ENST00000585517 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000608305 | 0.9993917 |
| ENST00000343619 | ENST00000264657 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.00036105 | 0.9996389 |
| ENST00000343619 | ENST00000585517 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000658927 | 0.9993411 |
| ENST00000544137 | ENST00000264657 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000368224 | 0.99963176 |
| ENST00000544137 | ENST00000585517 | ATP6V0A1 | chr17 | 40666478 | + | STAT3 | chr17 | 40498731 | - | 0.000828147 | 0.99917185 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >8093_8093_1_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000264649_STAT3_chr17_40498731_ENST00000264657_length(amino acids)=1566AA_BP=839 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEAELHHQQM ADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNR VKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAE VWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGH GILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQL NPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFY KWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGP TEEDAEIIQHDQLSTHSEDADEFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFF FTAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARI VARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQS VTRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKL EELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGD VAALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVI SNICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENM AGKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQ LNNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCRPESQEHPEADPGSAAPYLKTKFICVTPTTCSNTIDLPMSPRTLDSL -------------------------------------------------------------- >8093_8093_2_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000264649_STAT3_chr17_40498731_ENST00000585517_length(amino acids)=1518AA_BP=839 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEAELHHQQM ADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNR VKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAE VWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGH GILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQL NPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFY KWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGP TEEDAEIIQHDQLSTHSEDADEFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFF FTAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARI VARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQS VTRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKL EELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGD VAALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVI SNICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENM AGKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQ -------------------------------------------------------------- >8093_8093_3_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000343619_STAT3_chr17_40498731_ENST00000264657_length(amino acids)=1565AA_BP=838 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEMADPDLLE ESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEG FRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTD LDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLF AVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGV FGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDA HTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEI IQHDQLSTHSEDADEPSEDEVFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFF TAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIV ARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSV TRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLE ELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDV AALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVIS NICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMA GKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQL NNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCRPESQEHPEADPGSAAPYLKTKFICVTPTTCSNTIDLPMSPRTLDSLM -------------------------------------------------------------- >8093_8093_4_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000343619_STAT3_chr17_40498731_ENST00000585517_length(amino acids)=1517AA_BP=838 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEMADPDLLE ESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEG FRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTD LDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLF AVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGV FGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDA HTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEI IQHDQLSTHSEDADEPSEDEVFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFF TAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIV ARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSV TRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLE ELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDV AALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVIS NICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMA GKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQL -------------------------------------------------------------- >8093_8093_5_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000393829_STAT3_chr17_40498731_ENST00000264657_length(amino acids)=1559AA_BP=832 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEMADPDLLE ESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEG FRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTD LDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLF AVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGV FGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDA HTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEI IQHDQLSTHSEDADEFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFFTAFATL TVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIVARCLWE ESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSVTRQKMQ QLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLEELQQKV SYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDVAALRGS RKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVISNICQMP NAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMAGKGFSF WVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQLNNMSFA EIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCRPESQEHPEADPGSAAPYLKTKFICVTPTTCSNTIDLPMSPRTLDSLMQFGNNG -------------------------------------------------------------- >8093_8093_6_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000393829_STAT3_chr17_40498731_ENST00000585517_length(amino acids)=1511AA_BP=832 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEMADPDLLE ESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEG FRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTD LDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLF AVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGV FGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDA HTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEI IQHDQLSTHSEDADEFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFFTAFATL TVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIVARCLWE ESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSVTRQKMQ QLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLEELQQKV SYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDVAALRGS RKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVISNICQMP NAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMAGKGFSF WVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQLNNMSFA -------------------------------------------------------------- >8093_8093_7_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000537728_STAT3_chr17_40498731_ENST00000264657_length(amino acids)=1516AA_BP=789 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEMADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCR GNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRV LQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTY GFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGL IYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGV SLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVV ALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEIIQHDQLSTHSEDADEFDFGDTMVHQAIHTIEYCLGCISNTASY LRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFFTAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEI DQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIVARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKR VQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSVTRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWK RRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLEELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPD RPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDVAALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRA NCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVISNICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSS TTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMAGKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPG TFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQLNNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCRPESQEH -------------------------------------------------------------- >8093_8093_8_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000537728_STAT3_chr17_40498731_ENST00000585517_length(amino acids)=1468AA_BP=789 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEMADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCR GNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRV LQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTY GFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGL IYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGV SLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVV ALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEIIQHDQLSTHSEDADEFDFGDTMVHQAIHTIEYCLGCISNTASY LRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFFTAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEI DQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIVARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKR VQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSVTRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWK RRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLEELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPD RPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDVAALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRA NCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVISNICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSS TTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMAGKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPG TFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQLNNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCRPESQEH -------------------------------------------------------------- >8093_8093_9_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000544137_STAT3_chr17_40498731_ENST00000264657_length(amino acids)=1221AA_BP=494 MAAVVSVAVAVAEFGGWREIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLF AVMFGDFGHGILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEET LRGNPVLQLNPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLF GYLVILIFYKWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNF GGIRVGNGPTEEDAEIIQHDQLSTHSEDADEPSEDEVFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIG LSVKSLAGGLVLFFFFTAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQF LQSRYLEKPMEIARIVARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTL KSQGDMQDLNGNNQSVTRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITS LAESQLQTRQQIKKLEELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELN YQLKIKVCIDKDSGDVAALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQG LKIDLETHSLPVVVISNICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNY SGCQITWAKFCKENMAGKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDIS GKTQIQSVEPYTKQQLNNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCRPESQEHPEADPGSAAPYLKTKFICVTPTTCS -------------------------------------------------------------- >8093_8093_10_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000544137_STAT3_chr17_40498731_ENST00000585517_length(amino acids)=1173AA_BP=494 MAAVVSVAVAVAEFGGWREIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLF AVMFGDFGHGILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEET LRGNPVLQLNPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLF GYLVILIFYKWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNF GGIRVGNGPTEEDAEIIQHDQLSTHSEDADEPSEDEVFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIG LSVKSLAGGLVLFFFFTAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQF LQSRYLEKPMEIARIVARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTL KSQGDMQDLNGNNQSVTRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITS LAESQLQTRQQIKKLEELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELN YQLKIKVCIDKDSGDVAALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQG LKIDLETHSLPVVVISNICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNY SGCQITWAKFCKENMAGKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDIS GKTQIQSVEPYTKQQLNNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCRPESQEHPEADPGSAAPYLKTKFICVTPFIDA -------------------------------------------------------------- >8093_8093_11_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000546249_STAT3_chr17_40498731_ENST00000264657_length(amino acids)=1565AA_BP=838 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEMADPDLLE ESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEG FRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTD LDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLF AVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGV FGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDA HTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEI IQHDQLSTHSEDADEPSTSGQFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFF TAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIV ARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSV TRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLE ELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDV AALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVIS NICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMA GKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQL NNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCRPESQEHPEADPGSAAPYLKTKFICVTPTTCSNTIDLPMSPRTLDSLM -------------------------------------------------------------- >8093_8093_12_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000546249_STAT3_chr17_40498731_ENST00000585517_length(amino acids)=1517AA_BP=838 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEMADPDLLE ESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEG FRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTD LDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLF AVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGV FGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDA HTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEI IQHDQLSTHSEDADEPSTSGQFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFF TAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIV ARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSV TRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLE ELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDV AALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVIS NICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMA GKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQL -------------------------------------------------------------- >8093_8093_13_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000585525_STAT3_chr17_40498731_ENST00000264657_length(amino acids)=1522AA_BP=795 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEMADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCR GNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRV LQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTY GFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGL IYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGV SLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVV ALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEIIQHDQLSTHSEDADEPSEDEVFDFGDTMVHQAIHTIEYCLGCI SNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFFTAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFH NLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIVARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHL QDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSVTRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDE ELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLEELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPC MPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDVAALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRC GNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVISNICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVL SWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMAGKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAIL STKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQLNNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCR -------------------------------------------------------------- >8093_8093_14_ATP6V0A1-STAT3_ATP6V0A1_chr17_40666478_ENST00000585525_STAT3_chr17_40498731_ENST00000585517_length(amino acids)=1474AA_BP=795 MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEMADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCR GNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNRVKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRV LQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAEVWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTY GFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGHGILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGL IYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQLNPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGV SLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFYKWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVV ALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGPTEEDAEIIQHDQLSTHSEDADEPSEDEVFDFGDTMVHQAIHTIEYCLGCI SNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFFFTAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFH NLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARIVARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHL QDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQSVTRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDE ELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKLEELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPC MPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGDVAALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRC GNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVISNICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVL SWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENMAGKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAIL STKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQLNNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCR -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:40666478/chr17:40498731) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ATP6V0A1 | . |
| FUNCTION: Required for assembly and activity of the vacuolar ATPase. Potential role in differential targeting and regulation of the enzyme for a specific organelle (By similarity). {ECO:0000250}. | FUNCTION: Might normally function as a transcriptional repressor. EWS-fusion-proteins (EFPS) may play a role in the tumorigenic process. They may disturb gene expression by mimicking, or interfering with the normal function of CTD-POLII within the transcription initiation complex. They may also contribute to an aberrant activation of the fusion protein target genes. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 1_388 | 807.6666666666666 | 839.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 408_409 | 807.6666666666666 | 839.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 427_441 | 807.6666666666666 | 839.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 472_534 | 807.6666666666666 | 839.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 555_572 | 807.6666666666666 | 839.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 594_638 | 807.6666666666666 | 839.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 659_724 | 807.6666666666666 | 839.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 750_770 | 807.6666666666666 | 839.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 1_388 | 806.6666666666666 | 838.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 408_409 | 806.6666666666666 | 838.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 427_441 | 806.6666666666666 | 838.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 472_534 | 806.6666666666666 | 838.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 555_572 | 806.6666666666666 | 838.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 594_638 | 806.6666666666666 | 838.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 659_724 | 806.6666666666666 | 838.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 750_770 | 806.6666666666666 | 838.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 1_388 | 800.6666666666666 | 832.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 408_409 | 800.6666666666666 | 832.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 427_441 | 800.6666666666666 | 832.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 472_534 | 800.6666666666666 | 832.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 555_572 | 800.6666666666666 | 832.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 594_638 | 800.6666666666666 | 832.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 659_724 | 800.6666666666666 | 832.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 750_770 | 800.6666666666666 | 832.0 | Topological domain | Vacuolar |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 389_407 | 807.6666666666666 | 839.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 410_426 | 807.6666666666666 | 839.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 442_471 | 807.6666666666666 | 839.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 535_554 | 807.6666666666666 | 839.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 573_593 | 807.6666666666666 | 839.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 639_658 | 807.6666666666666 | 839.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 725_749 | 807.6666666666666 | 839.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 771_809 | 807.6666666666666 | 839.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 389_407 | 806.6666666666666 | 838.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 410_426 | 806.6666666666666 | 838.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 442_471 | 806.6666666666666 | 838.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 535_554 | 806.6666666666666 | 838.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 573_593 | 806.6666666666666 | 838.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 639_658 | 806.6666666666666 | 838.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 725_749 | 806.6666666666666 | 838.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 771_809 | 806.6666666666666 | 838.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 389_407 | 800.6666666666666 | 832.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 410_426 | 800.6666666666666 | 832.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 442_471 | 800.6666666666666 | 832.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 535_554 | 800.6666666666666 | 832.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 573_593 | 800.6666666666666 | 832.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 639_658 | 800.6666666666666 | 832.0 | Transmembrane | Helical |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 725_749 | 800.6666666666666 | 832.0 | Transmembrane | Helical |
| Tgene | STAT3 | chr17:40666478 | chr17:40498731 | ENST00000264657 | 1 | 24 | 580_670 | 42.666666666666664 | 771.0 | Domain | SH2 | |
| Tgene | STAT3 | chr17:40666478 | chr17:40498731 | ENST00000404395 | 1 | 24 | 580_670 | 42.666666666666664 | 770.0 | Domain | SH2 | |
| Tgene | STAT3 | chr17:40666478 | chr17:40498731 | ENST00000588969 | 1 | 24 | 580_670 | 42.666666666666664 | 771.0 | Domain | SH2 | |
| Tgene | STAT3 | chr17:40666478 | chr17:40498731 | ENST00000264657 | 1 | 24 | 150_162 | 42.666666666666664 | 771.0 | Motif | Note=Essential for nuclear import | |
| Tgene | STAT3 | chr17:40666478 | chr17:40498731 | ENST00000404395 | 1 | 24 | 150_162 | 42.666666666666664 | 770.0 | Motif | Note=Essential for nuclear import | |
| Tgene | STAT3 | chr17:40666478 | chr17:40498731 | ENST00000588969 | 1 | 24 | 150_162 | 42.666666666666664 | 771.0 | Motif | Note=Essential for nuclear import |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000264649 | + | 20 | 21 | 810_837 | 807.6666666666666 | 839.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000343619 | + | 21 | 22 | 810_837 | 806.6666666666666 | 838.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 810_837 | 800.6666666666666 | 832.0 | Topological domain | Cytoplasmic |
| Hgene | ATP6V0A1 | chr17:40666478 | chr17:40498731 | ENST00000393829 | + | 20 | 21 | 771_809 | 800.6666666666666 | 832.0 | Transmembrane | Helical |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file >>>2088_ATP6V0A1_40666478_STAT3_40498731_ranked_0.pdb | ATP6V0A1 | 40666478 | 40666478 | ENST00000585517 | STAT3 | chr17 | 40498731 | - | MAAVVSVAVAVAEFGGWREIQVLTRLVPSATMGELFRSEEMTLAQLFLQSEAAYCCVSELGELGKVQFRDLNPDVNVFQRKFVNEVRRCE EMDRKLRFVEKEIRKANIPIMDTGENPEVPFPRDMIDLEANFEKIENELKEINTNQEALKRNFLELTELKFILRKTQQFFDEAELHHQQM ADPDLLEESSSLLEPSEMGRGTPLRLGFVAGVINRERIPTFERMLWRVCRGNVFLRQAEIENPLEDPVTGDYVHKSVFIIFFQGDQLKNR VKKICEGFRASLYPCPETPQERKEMASGVNTRIDDLQMVLNQTEDHRQRVLQAAAKNIRVWFIKVRKMKAIYHTLNLCNIDVTQKCLIAE VWCPVTDLDSIQFALRRGTEHSGSTVPSILNRMQTNQTPPTYNKTNKFTYGFQNIVDAYGIGTYREINPAPYTIITFPFLFAVMFGDFGH GILMTLFAVWMVLRESRILSQKNENEMFSTVFSGRYIILLMGVFSMYTGLIYNDCFSKSLNIFGSSWSVRPMFTYNWTEETLRGNPVLQL NPALPGVFGGPYPFGIDPIWNIATNKLTFLNSFKMKMSVILGIIHMLFGVSLSLFNHIYFKKPLNIYFGFIPEIIFMTSLFGYLVILIFY KWTAYDAHTSENAPSLLIHFINMFLFSYPESGYSMLYSGQKGIQCFLVVVALLCVPWMLLFKPLVLRRQYLRRKHLGTLNFGGIRVGNGP TEEDAEIIQHDQLSTHSEDADEFDFGDTMVHQAIHTIEYCLGCISNTASYLRLWALSLAHAQLSEVLWTMVIHIGLSVKSLAGGLVLFFF FTAFATLTVAILLIMEGLSAFLHALRLHWAYAASKESHATLVFHNLLGEIDQQYSRFLQESNVLYQHNLRRIKQFLQSRYLEKPMEIARI VARCLWEESRLLQTAATAAQQGGQANHPTAAVVTEKQQMLEQHLQDVRKRVQDLEQKMKVVENLQDDFDFNYKTLKSQGDMQDLNGNNQS VTRQKMQQLEQMLTALDQMRRSIVSELAGLLSAMEYVQKTLTDEELADWKRRQQIACIGGPPNICLDRLENWITSLAESQLQTRQQIKKL EELQQKVSYKGDPIVQHRPMLEERIVELFRNLMKSAFVVERQPCMPMHPDRPLVIKTGVQFTTKVRLLVKFPELNYQLKIKVCIDKDSGD VAALRGSRKFNILGTNTKVMNMEESNNGSLSAEFKHLTLREQRCGNGGRANCDASLIVTEELHLITFETEVYHQGLKIDLETHSLPVVVI SNICQMPNAWASILWYNMLTNNPKNVNFFTKPPIGTWDQVAEVLSWQFSSTTKRGLSIEQLTTLAEKLLGPGVNYSGCQITWAKFCKENM AGKGFSFWVWLDNIIDLVKKYILALWNEGYIMGFISKERERAILSTKPPGTFLLRFSESSKEGGVTFTWVEKDISGKTQIQSVEPYTKQQ LNNMSFAEIIMGYKIMDATNILVSPLVYLYPDIPKEEAFGKYCRPESQEHPEADPGSAAPYLKTKFICVTPTTCSNTIDLPMSPRTLDSL | 1566 |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
ATP6V0A1_pLDDT.png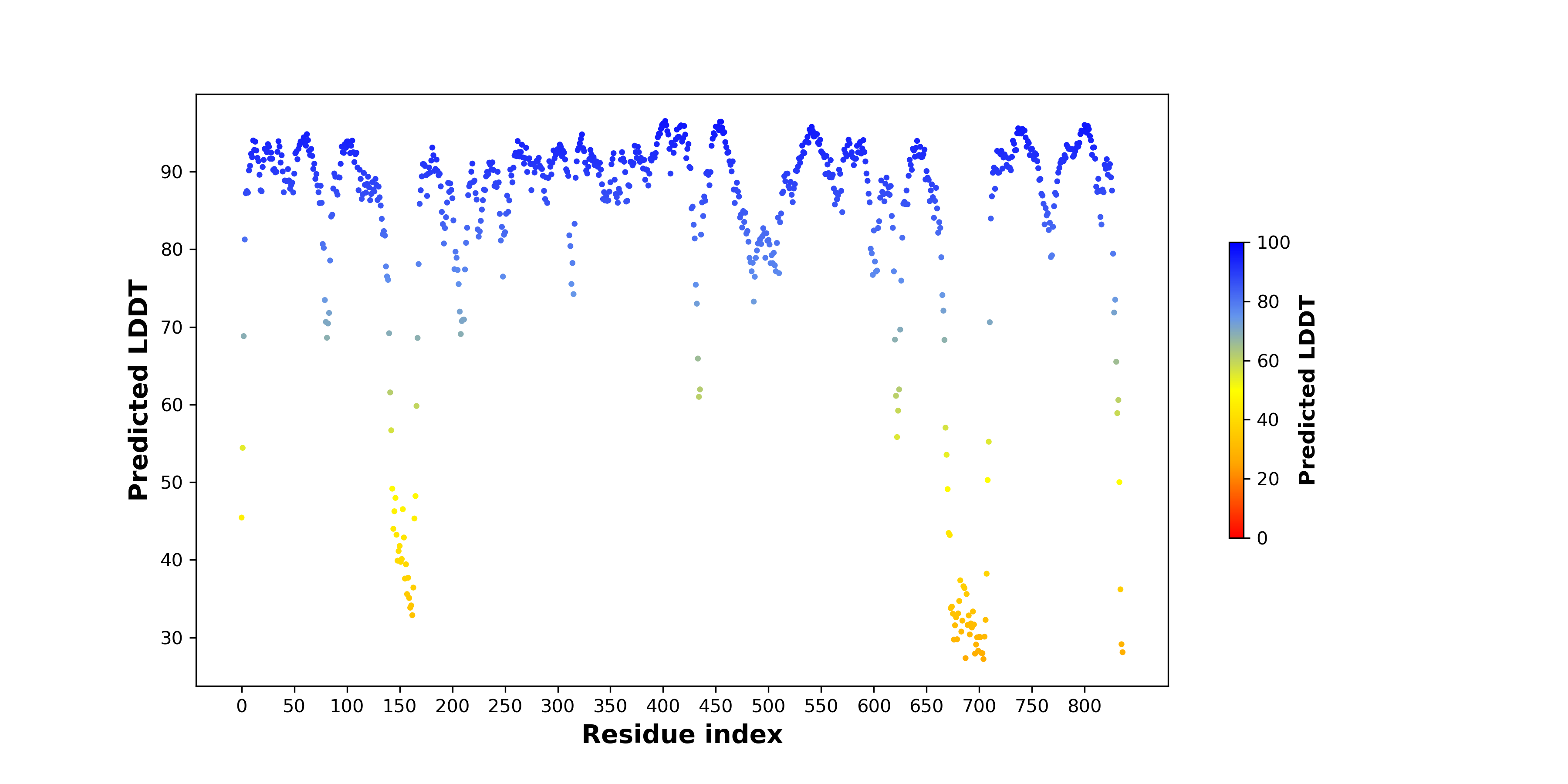  |
STAT3_pLDDT.png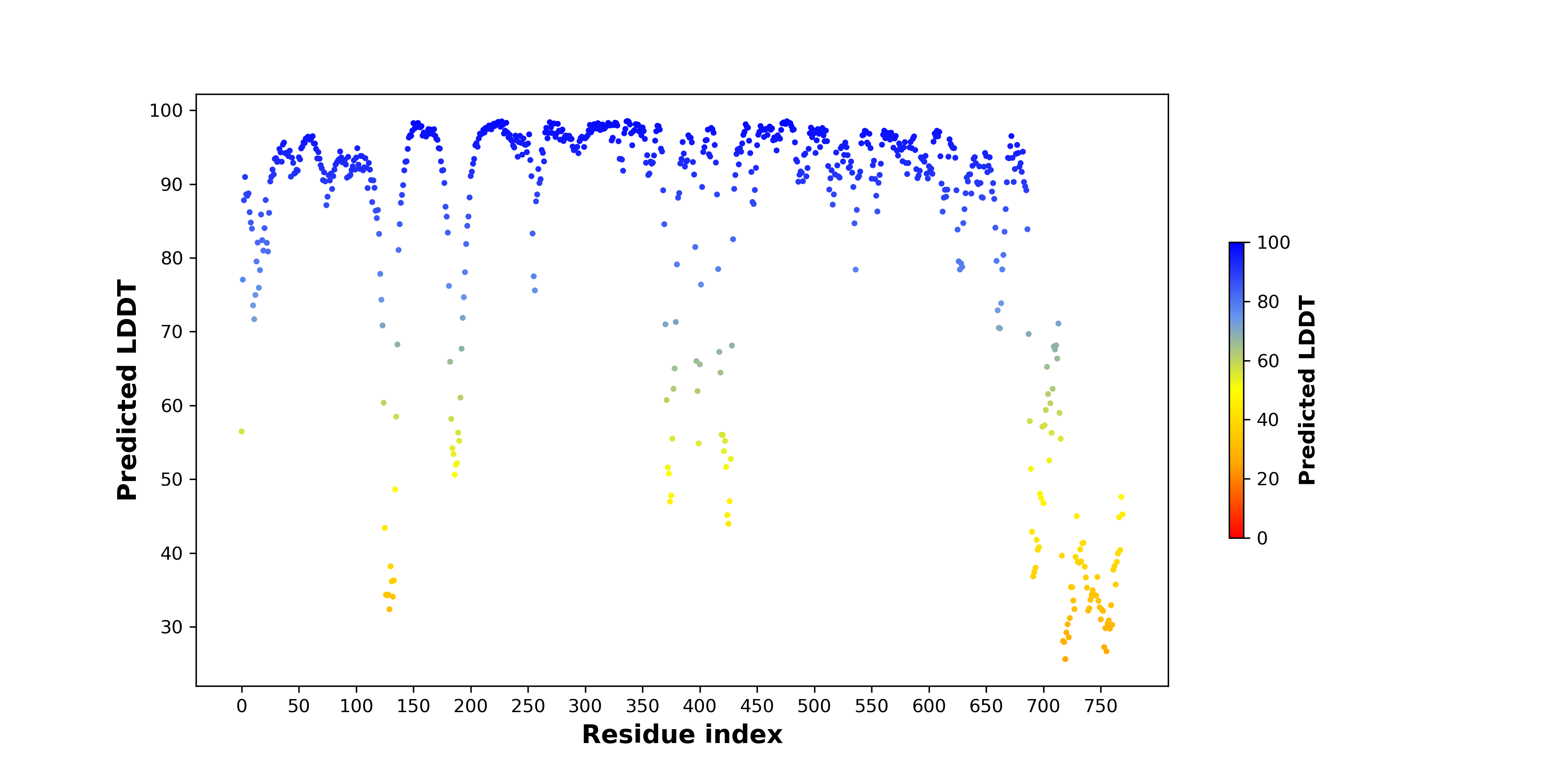  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
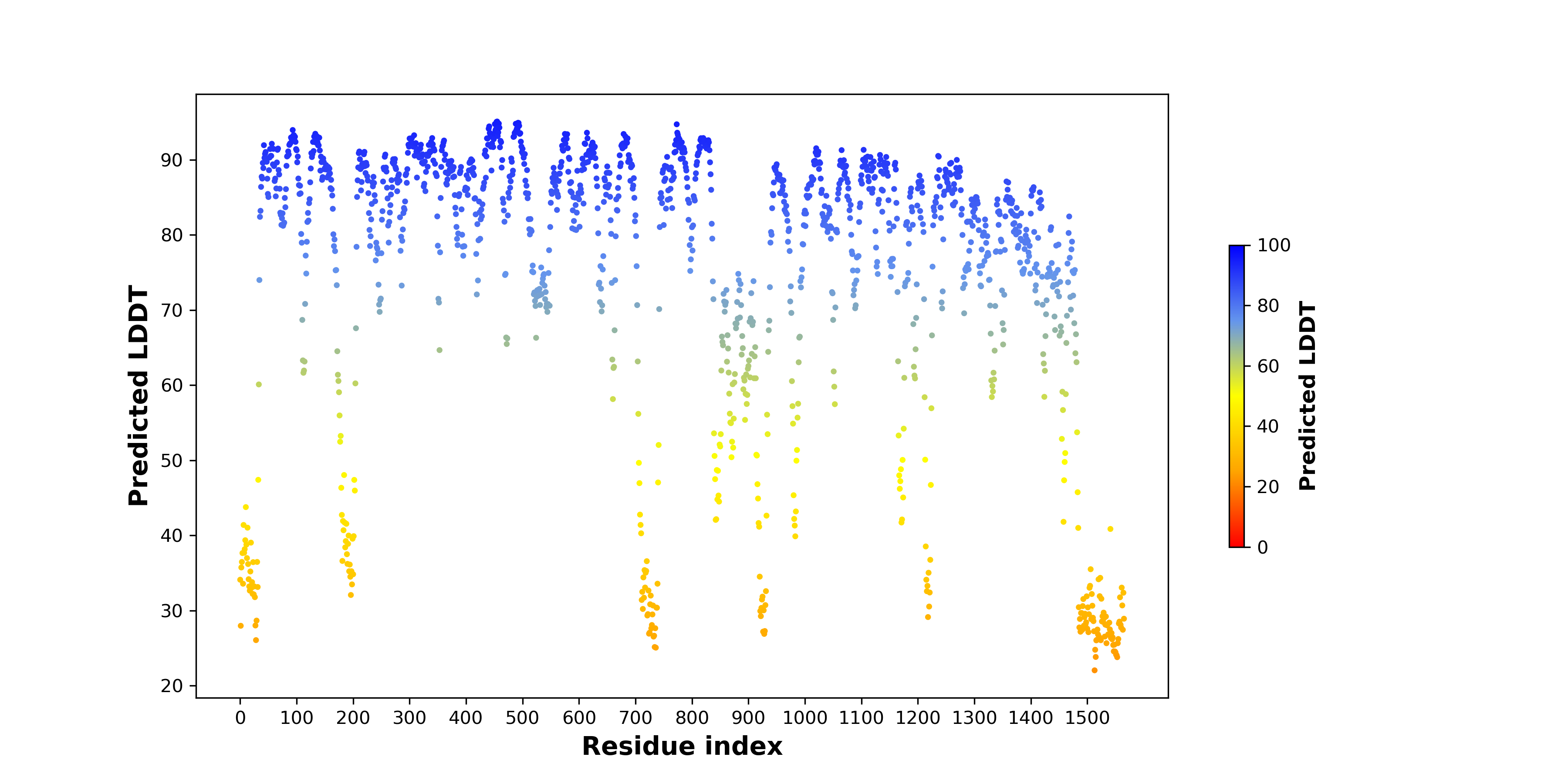 |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| ATP6V0A1 | |
| STAT3 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to ATP6V0A1-STAT3 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to ATP6V0A1-STAT3 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies