| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:AURKA-SOGA1 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: AURKA-SOGA1 | FusionPDB ID: 8490 | FusionGDB2.0 ID: 8490 | Hgene | Tgene | Gene symbol | AURKA | SOGA1 | Gene ID | 6790 | 140710 |
| Gene name | aurora kinase A | suppressor of glucose, autophagy associated 1 | |
| Synonyms | AIK|ARK1|AURA|BTAK|PPP1R47|STK15|STK6|STK7 | C20orf117|KIAA0889|SOGA | |
| Cytomap | 20q13.2 | 20q11.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | aurora kinase Aaurora 2aurora/IPL1-like kinaseaurora/IPL1-related kinase 1breast tumor-amplified kinaseprotein phosphatase 1, regulatory subunit 47serine/threonine protein kinase 15serine/threonine-protein kinase 6serine/threonine-protein kinase a | protein SOGA1SOGA family member 1suppressor of glucose by autophagysuppressor of glucose from autophagysuppressor of glucose, autophagy-associated protein 1 | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | Q9NWT8 | O94964 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000312783, ENST00000347343, ENST00000371356, ENST00000395907, ENST00000395909, ENST00000395911, ENST00000395913, ENST00000395914, ENST00000395915, | ENST00000357779, ENST00000456801, ENST00000237536, ENST00000279034, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 6 X 8 X 3=144 | 10 X 10 X 4=400 |
| # samples | 8 | 12 | |
| ** MAII score | log2(8/144*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/400*10)=-1.73696559416621 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: AURKA [Title/Abstract] AND SOGA1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | AURKA(54956489)-SOGA1(35445872), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | AURKA-SOGA1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AURKA-SOGA1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. AURKA-SOGA1 seems lost the major protein functional domain in Hgene partner, which is a epigenetic factor due to the frame-shifted ORF. AURKA-SOGA1 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. AURKA-SOGA1 seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. AURKA-SOGA1 seems lost the major protein functional domain in Hgene partner, which is a kinase due to the frame-shifted ORF. AURKA-SOGA1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | AURKA | GO:0006468 | protein phosphorylation | 21600873|21820309 |
| Hgene | AURKA | GO:0009611 | response to wounding | 19435814 |
| Hgene | AURKA | GO:0032091 | negative regulation of protein binding | 21820309 |
| Hgene | AURKA | GO:0097421 | liver regeneration | 19435814 |
| Fusion gene breakpoints across AURKA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
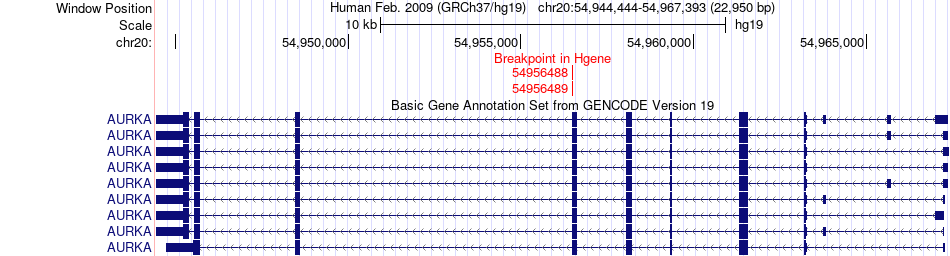 |
| Fusion gene breakpoints across SOGA1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-61-1728-01A | AURKA | chr20 | 54956489 | - | SOGA1 | chr20 | 35445872 | - |
| ChimerDB4 | OV | TCGA-61-1728 | AURKA | chr20 | 54956488 | - | SOGA1 | chr20 | 35445872 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000371356 | AURKA | chr20 | 54956489 | - | ENST00000237536 | SOGA1 | chr20 | 35445872 | - | 13795 | 837 | 18 | 4751 | 1577 |
| ENST00000371356 | AURKA | chr20 | 54956489 | - | ENST00000279034 | SOGA1 | chr20 | 35445872 | - | 3856 | 837 | 18 | 3530 | 1170 |
| ENST00000312783 | AURKA | chr20 | 54956489 | - | ENST00000237536 | SOGA1 | chr20 | 35445872 | - | 13906 | 948 | 243 | 4862 | 1539 |
| ENST00000312783 | AURKA | chr20 | 54956489 | - | ENST00000279034 | SOGA1 | chr20 | 35445872 | - | 3967 | 948 | 243 | 3641 | 1132 |
| ENST00000395913 | AURKA | chr20 | 54956489 | - | ENST00000237536 | SOGA1 | chr20 | 35445872 | - | 13852 | 894 | 159 | 4808 | 1549 |
| ENST00000395913 | AURKA | chr20 | 54956489 | - | ENST00000279034 | SOGA1 | chr20 | 35445872 | - | 3913 | 894 | 159 | 3587 | 1142 |
| ENST00000371356 | AURKA | chr20 | 54956488 | - | ENST00000237536 | SOGA1 | chr20 | 35445872 | - | 13795 | 837 | 18 | 4751 | 1577 |
| ENST00000371356 | AURKA | chr20 | 54956488 | - | ENST00000279034 | SOGA1 | chr20 | 35445872 | - | 3856 | 837 | 18 | 3530 | 1170 |
| ENST00000312783 | AURKA | chr20 | 54956488 | - | ENST00000237536 | SOGA1 | chr20 | 35445872 | - | 13906 | 948 | 243 | 4862 | 1539 |
| ENST00000312783 | AURKA | chr20 | 54956488 | - | ENST00000279034 | SOGA1 | chr20 | 35445872 | - | 3967 | 948 | 243 | 3641 | 1132 |
| ENST00000395913 | AURKA | chr20 | 54956488 | - | ENST00000237536 | SOGA1 | chr20 | 35445872 | - | 13852 | 894 | 159 | 4808 | 1549 |
| ENST00000395913 | AURKA | chr20 | 54956488 | - | ENST00000279034 | SOGA1 | chr20 | 35445872 | - | 3913 | 894 | 159 | 3587 | 1142 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000371356 | ENST00000237536 | AURKA | chr20 | 54956489 | - | SOGA1 | chr20 | 35445872 | - | 0.000988644 | 0.9990113 |
| ENST00000371356 | ENST00000279034 | AURKA | chr20 | 54956489 | - | SOGA1 | chr20 | 35445872 | - | 0.008388676 | 0.9916113 |
| ENST00000312783 | ENST00000237536 | AURKA | chr20 | 54956489 | - | SOGA1 | chr20 | 35445872 | - | 0.00114484 | 0.9988551 |
| ENST00000312783 | ENST00000279034 | AURKA | chr20 | 54956489 | - | SOGA1 | chr20 | 35445872 | - | 0.009892589 | 0.9901074 |
| ENST00000395913 | ENST00000237536 | AURKA | chr20 | 54956489 | - | SOGA1 | chr20 | 35445872 | - | 0.001056832 | 0.99894315 |
| ENST00000395913 | ENST00000279034 | AURKA | chr20 | 54956489 | - | SOGA1 | chr20 | 35445872 | - | 0.009010821 | 0.99098915 |
| ENST00000371356 | ENST00000237536 | AURKA | chr20 | 54956488 | - | SOGA1 | chr20 | 35445872 | - | 0.000988644 | 0.9990113 |
| ENST00000371356 | ENST00000279034 | AURKA | chr20 | 54956488 | - | SOGA1 | chr20 | 35445872 | - | 0.008388676 | 0.9916113 |
| ENST00000312783 | ENST00000237536 | AURKA | chr20 | 54956488 | - | SOGA1 | chr20 | 35445872 | - | 0.00114484 | 0.9988551 |
| ENST00000312783 | ENST00000279034 | AURKA | chr20 | 54956488 | - | SOGA1 | chr20 | 35445872 | - | 0.009892589 | 0.9901074 |
| ENST00000395913 | ENST00000237536 | AURKA | chr20 | 54956488 | - | SOGA1 | chr20 | 35445872 | - | 0.001056832 | 0.99894315 |
| ENST00000395913 | ENST00000279034 | AURKA | chr20 | 54956488 | - | SOGA1 | chr20 | 35445872 | - | 0.009010821 | 0.99098915 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >8490_8490_1_AURKA-SOGA1_AURKA_chr20_54956488_ENST00000312783_SOGA1_chr20_35445872_ENST00000237536_length(amino acids)=1539AA_BP=235 MDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSNSSQRIPLQAQKLVSSHKPVQNQKQKQLQATSVPHPVSR PLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKGKFGNVYLAREKQSKFILALKVLFKAQLEKAGVEHQLRR EVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQRTATHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAK EESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMK DHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEE LAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAAL VSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPL GSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLS QERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSE GDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAE LKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLS QLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSS EPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQMQRSYTAPDKTGIRVYYSPPVARRLGVPVVHDKEGKIIIEPGFLFTTAKPKESAE ADGLAESSYGRWLCNFSRQRLDGGSAGSPSAAGPGFPAALHDFEMSGNMSDDMKEITNCVRQAMRSGSLERKVKSTSSQTVGLASVGTQT IRTVSVGLQTDPPRSSLHGKAWSPRSSSLVSVRSKQISSSLDKVHSRIERPCCSPKYGSPKLQRRSVSKLDSSKDRSLWNLHQGKQNGSA WARSTTTRDSPVLRNINDGLSSLFSVVEHSGSTESVWKLGMSETRAKPEPPKYGIVQEFFRNVCGRAPSPTSSAGEEGTKKPEPLSPASY HQPEGVARILNKKAAKLGSSEEVRLTMLPQVGKDGVLRDGDGAVVLPNEDAVCDCSTQSLTSCFARSSRSAIRHSPSKCRLHPSESSWGG -------------------------------------------------------------- >8490_8490_2_AURKA-SOGA1_AURKA_chr20_54956488_ENST00000312783_SOGA1_chr20_35445872_ENST00000279034_length(amino acids)=1132AA_BP=235 MDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSNSSQRIPLQAQKLVSSHKPVQNQKQKQLQATSVPHPVSR PLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKGKFGNVYLAREKQSKFILALKVLFKAQLEKAGVEHQLRR EVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQRTATHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAK EESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMK DHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEE LAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAAL VSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPL GSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLS QERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSE GDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAE LKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLS QLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSS -------------------------------------------------------------- >8490_8490_3_AURKA-SOGA1_AURKA_chr20_54956488_ENST00000371356_SOGA1_chr20_35445872_ENST00000237536_length(amino acids)=1577AA_BP=3 MGRRLECNGVISAHCNLCFLGLSDSPASASRVAGITGIMDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSN SSQRIPLQAQKLVSSHKPVQNQKQKQLQATSVPHPVSRPLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKG KFGNVYLAREKQSKFILALKVLFKAQLEKAGVEHQLRREVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQR TATHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRET ELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELE DQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGD SAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAIL VRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRS FRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQE KNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADM KVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQ LQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKS VSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQMQRSYTAPDKTGIRVYY SPPVARRLGVPVVHDKEGKIIIEPGFLFTTAKPKESAEADGLAESSYGRWLCNFSRQRLDGGSAGSPSAAGPGFPAALHDFEMSGNMSDD MKEITNCVRQAMRSGSLERKVKSTSSQTVGLASVGTQTIRTVSVGLQTDPPRSSLHGKAWSPRSSSLVSVRSKQISSSLDKVHSRIERPC CSPKYGSPKLQRRSVSKLDSSKDRSLWNLHQGKQNGSAWARSTTTRDSPVLRNINDGLSSLFSVVEHSGSTESVWKLGMSETRAKPEPPK YGIVQEFFRNVCGRAPSPTSSAGEEGTKKPEPLSPASYHQPEGVARILNKKAAKLGSSEEVRLTMLPQVGKDGVLRDGDGAVVLPNEDAV -------------------------------------------------------------- >8490_8490_4_AURKA-SOGA1_AURKA_chr20_54956488_ENST00000371356_SOGA1_chr20_35445872_ENST00000279034_length(amino acids)=1170AA_BP=3 MGRRLECNGVISAHCNLCFLGLSDSPASASRVAGITGIMDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSN SSQRIPLQAQKLVSSHKPVQNQKQKQLQATSVPHPVSRPLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKG KFGNVYLAREKQSKFILALKVLFKAQLEKAGVEHQLRREVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQR TATHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRET ELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELE DQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGD SAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAIL VRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRS FRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQE KNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADM KVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQ LQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKS VSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGSQKLPFLLILAPPQPPPIL -------------------------------------------------------------- >8490_8490_5_AURKA-SOGA1_AURKA_chr20_54956488_ENST00000395913_SOGA1_chr20_35445872_ENST00000237536_length(amino acids)=1549AA_BP=245 MGRRWEPTGIMDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSNSSQRIPLQAQKLVSSHKPVQNQKQKQLQ ATSVPHPVSRPLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKGKFGNVYLAREKQSKFILALKVLFKAQLE KAGVEHQLRREVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQRTATHSLKKRGTRSLGKADKKTLVQEDSA DLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENR GLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSC SVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEV LPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQ QESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHD SLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKR WRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKA KATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQ QVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLP NNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQMQRSYTAPDKTGIRVYYSPPVARRLGVPVVHDKEGKIIIEPGFLF TTAKPKESAEADGLAESSYGRWLCNFSRQRLDGGSAGSPSAAGPGFPAALHDFEMSGNMSDDMKEITNCVRQAMRSGSLERKVKSTSSQT VGLASVGTQTIRTVSVGLQTDPPRSSLHGKAWSPRSSSLVSVRSKQISSSLDKVHSRIERPCCSPKYGSPKLQRRSVSKLDSSKDRSLWN LHQGKQNGSAWARSTTTRDSPVLRNINDGLSSLFSVVEHSGSTESVWKLGMSETRAKPEPPKYGIVQEFFRNVCGRAPSPTSSAGEEGTK KPEPLSPASYHQPEGVARILNKKAAKLGSSEEVRLTMLPQVGKDGVLRDGDGAVVLPNEDAVCDCSTQSLTSCFARSSRSAIRHSPSKCR -------------------------------------------------------------- >8490_8490_6_AURKA-SOGA1_AURKA_chr20_54956488_ENST00000395913_SOGA1_chr20_35445872_ENST00000279034_length(amino acids)=1142AA_BP=245 MGRRWEPTGIMDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSNSSQRIPLQAQKLVSSHKPVQNQKQKQLQ ATSVPHPVSRPLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKGKFGNVYLAREKQSKFILALKVLFKAQLE KAGVEHQLRREVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQRTATHSLKKRGTRSLGKADKKTLVQEDSA DLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENR GLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSC SVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEV LPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQ QESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHD SLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKR WRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKA KATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQ QVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLP -------------------------------------------------------------- >8490_8490_7_AURKA-SOGA1_AURKA_chr20_54956489_ENST00000312783_SOGA1_chr20_35445872_ENST00000237536_length(amino acids)=1539AA_BP=235 MDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSNSSQRIPLQAQKLVSSHKPVQNQKQKQLQATSVPHPVSR PLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKGKFGNVYLAREKQSKFILALKVLFKAQLEKAGVEHQLRR EVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQRTATHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAK EESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMK DHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEE LAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAAL VSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPL GSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLS QERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSE GDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAE LKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLS QLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSS EPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQMQRSYTAPDKTGIRVYYSPPVARRLGVPVVHDKEGKIIIEPGFLFTTAKPKESAE ADGLAESSYGRWLCNFSRQRLDGGSAGSPSAAGPGFPAALHDFEMSGNMSDDMKEITNCVRQAMRSGSLERKVKSTSSQTVGLASVGTQT IRTVSVGLQTDPPRSSLHGKAWSPRSSSLVSVRSKQISSSLDKVHSRIERPCCSPKYGSPKLQRRSVSKLDSSKDRSLWNLHQGKQNGSA WARSTTTRDSPVLRNINDGLSSLFSVVEHSGSTESVWKLGMSETRAKPEPPKYGIVQEFFRNVCGRAPSPTSSAGEEGTKKPEPLSPASY HQPEGVARILNKKAAKLGSSEEVRLTMLPQVGKDGVLRDGDGAVVLPNEDAVCDCSTQSLTSCFARSSRSAIRHSPSKCRLHPSESSWGG -------------------------------------------------------------- >8490_8490_8_AURKA-SOGA1_AURKA_chr20_54956489_ENST00000312783_SOGA1_chr20_35445872_ENST00000279034_length(amino acids)=1132AA_BP=235 MDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSNSSQRIPLQAQKLVSSHKPVQNQKQKQLQATSVPHPVSR PLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKGKFGNVYLAREKQSKFILALKVLFKAQLEKAGVEHQLRR EVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQRTATHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAK EESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMK DHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEE LAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAAL VSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPL GSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLS QERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSE GDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAE LKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLS QLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSS -------------------------------------------------------------- >8490_8490_9_AURKA-SOGA1_AURKA_chr20_54956489_ENST00000371356_SOGA1_chr20_35445872_ENST00000237536_length(amino acids)=1577AA_BP=3 MGRRLECNGVISAHCNLCFLGLSDSPASASRVAGITGIMDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSN SSQRIPLQAQKLVSSHKPVQNQKQKQLQATSVPHPVSRPLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKG KFGNVYLAREKQSKFILALKVLFKAQLEKAGVEHQLRREVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQR TATHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRET ELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELE DQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGD SAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAIL VRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRS FRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQE KNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADM KVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQ LQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKS VSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQMQRSYTAPDKTGIRVYY SPPVARRLGVPVVHDKEGKIIIEPGFLFTTAKPKESAEADGLAESSYGRWLCNFSRQRLDGGSAGSPSAAGPGFPAALHDFEMSGNMSDD MKEITNCVRQAMRSGSLERKVKSTSSQTVGLASVGTQTIRTVSVGLQTDPPRSSLHGKAWSPRSSSLVSVRSKQISSSLDKVHSRIERPC CSPKYGSPKLQRRSVSKLDSSKDRSLWNLHQGKQNGSAWARSTTTRDSPVLRNINDGLSSLFSVVEHSGSTESVWKLGMSETRAKPEPPK YGIVQEFFRNVCGRAPSPTSSAGEEGTKKPEPLSPASYHQPEGVARILNKKAAKLGSSEEVRLTMLPQVGKDGVLRDGDGAVVLPNEDAV -------------------------------------------------------------- >8490_8490_10_AURKA-SOGA1_AURKA_chr20_54956489_ENST00000371356_SOGA1_chr20_35445872_ENST00000279034_length(amino acids)=1170AA_BP=3 MGRRLECNGVISAHCNLCFLGLSDSPASASRVAGITGIMDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSN SSQRIPLQAQKLVSSHKPVQNQKQKQLQATSVPHPVSRPLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKG KFGNVYLAREKQSKFILALKVLFKAQLEKAGVEHQLRREVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQR TATHSLKKRGTRSLGKADKKTLVQEDSADLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRET ELKVHLKLVEEEANLLSRRIVELEVENRGLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELE DQNKLLLNELAKFRSEHELDVALSEDSCSVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGD SAQCVPAPLGETHESHAVRLCRAREAEVLPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAIL VRLSVLQQELNAFTRKADAVLGCSVKEQQESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRS FRPYRAEDNDSYASEIKELQLVLAEAHDSLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQE KNMLVQESQQFKHNFLLLFMKLRWFLKRWRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADM KVTLKELCWLLRDERRGLTELQQQFAKAKATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQ LQISERNWSQEKLQLVERLQGEKQQVEQQVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKS VSSMSEFESLLDCSPYLAGGDARGKKLPNNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGSQKLPFLLILAPPQPPPIL -------------------------------------------------------------- >8490_8490_11_AURKA-SOGA1_AURKA_chr20_54956489_ENST00000395913_SOGA1_chr20_35445872_ENST00000237536_length(amino acids)=1549AA_BP=245 MGRRWEPTGIMDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSNSSQRIPLQAQKLVSSHKPVQNQKQKQLQ ATSVPHPVSRPLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKGKFGNVYLAREKQSKFILALKVLFKAQLE KAGVEHQLRREVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQRTATHSLKKRGTRSLGKADKKTLVQEDSA DLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENR GLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSC SVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEV LPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQ QESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHD SLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKR WRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKA KATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQ QVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLP NNPAFGFVSSEPGDPEKDTKEKPGLSSRDCNHLGALACQDPPGRQMQRSYTAPDKTGIRVYYSPPVARRLGVPVVHDKEGKIIIEPGFLF TTAKPKESAEADGLAESSYGRWLCNFSRQRLDGGSAGSPSAAGPGFPAALHDFEMSGNMSDDMKEITNCVRQAMRSGSLERKVKSTSSQT VGLASVGTQTIRTVSVGLQTDPPRSSLHGKAWSPRSSSLVSVRSKQISSSLDKVHSRIERPCCSPKYGSPKLQRRSVSKLDSSKDRSLWN LHQGKQNGSAWARSTTTRDSPVLRNINDGLSSLFSVVEHSGSTESVWKLGMSETRAKPEPPKYGIVQEFFRNVCGRAPSPTSSAGEEGTK KPEPLSPASYHQPEGVARILNKKAAKLGSSEEVRLTMLPQVGKDGVLRDGDGAVVLPNEDAVCDCSTQSLTSCFARSSRSAIRHSPSKCR -------------------------------------------------------------- >8490_8490_12_AURKA-SOGA1_AURKA_chr20_54956489_ENST00000395913_SOGA1_chr20_35445872_ENST00000279034_length(amino acids)=1142AA_BP=245 MGRRWEPTGIMDRSKENCISGPVKATAPVGGPKRVLVTQQFPCQNPLPVNSGQAQRVLCPSNSSQRIPLQAQKLVSSHKPVQNQKQKQLQ ATSVPHPVSRPLNNTQKSKQPLPSAPENNPEEELASKQKNEESKKRQWALEDFEIGRPLGKGKFGNVYLAREKQSKFILALKVLFKAQLE KAGVEHQLRREVEIQSHLRHPNILRLYGYFHDATRVYLILEYAPLGTVYRELQKLSKFDEQRTATHSLKKRGTRSLGKADKKTLVQEDSA DLKCQLHFAKEESALMCKKLTKLAKENDSMKEELLKYRSLYGDLDSALSAEELADAPHSRETELKVHLKLVEEEANLLSRRIVELEVENR GLRAEMDDMKDHGGGCGGPEARLAFSALGGGECGESLAELRRHLQFVEEEAELLRRSSAELEDQNKLLLNELAKFRSEHELDVALSEDSC SVLSEPSQEELAAAKLQIGELSGKVKKLQYENRVLLSNLQRCDLASCQSTRPMLETDAEAGDSAQCVPAPLGETHESHAVRLCRAREAEV LPGLREQAALVSKAIDVLVADANGFTAGLRLCLDNECADFRLHEAPDNSEGPRDTKLIHAILVRLSVLQQELNAFTRKADAVLGCSVKEQ QESFSSLPPLGSQGLSKEILLAKDLGSDFQPPDFRDLPEWEPRIREAFRTGDLDSKPDPSRSFRPYRAEDNDSYASEIKELQLVLAEAHD SLRGLQEQLSQERQLRKEEADNFNQKMVQLKEDQQRALLRREFELQSLSLQRRLEQKFWSQEKNMLVQESQQFKHNFLLLFMKLRWFLKR WRQGKVLPSEGDDFLEVNSMKELYLLMEEEEINAQHSDNKACTGDSWTQNTPNEYIKTLADMKVTLKELCWLLRDERRGLTELQQQFAKA KATWETERAELKGHTSQMELKTGKGAGERAGPDWKAALQREREEQQHLLAESYSAVMELTRQLQISERNWSQEKLQLVERLQGEKQQVEQ QVKELQNRLSQLQKAADPWVLKHSELEKQDNSWKETRSEKIHDKEAVSEVELGGNGLKRTKSVSSMSEFESLLDCSPYLAGGDARGKKLP -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:54956489/chr20:35445872) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| AURKA | SOGA1 |
| FUNCTION: May act as a negative regulator of Aurora-A kinase, by down-regulation through proteasome-dependent degradation. | FUNCTION: Regulates autophagy by playing a role in the reduction of glucose production in an adiponectin- and insulin-dependent manner. {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000312783 | - | 7 | 10 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000347343 | - | 6 | 9 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000371356 | - | 7 | 10 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395909 | - | 8 | 11 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395911 | - | 7 | 10 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395913 | - | 6 | 9 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395914 | - | 7 | 10 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395915 | - | 6 | 9 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000312783 | - | 7 | 10 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000347343 | - | 6 | 9 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000371356 | - | 7 | 10 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395909 | - | 8 | 11 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395911 | - | 7 | 10 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395913 | - | 6 | 9 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395914 | - | 7 | 10 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395915 | - | 6 | 9 | 211_213 | 235.0 | 404.0 | Nucleotide binding | ATP |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000312783 | - | 7 | 10 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000347343 | - | 6 | 9 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000371356 | - | 7 | 10 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395909 | - | 8 | 11 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395911 | - | 7 | 10 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395913 | - | 6 | 9 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395914 | - | 7 | 10 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395915 | - | 6 | 9 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000312783 | - | 7 | 10 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000347343 | - | 6 | 9 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000371356 | - | 7 | 10 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395909 | - | 8 | 11 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395911 | - | 7 | 10 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395913 | - | 6 | 9 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395914 | - | 7 | 10 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395915 | - | 6 | 9 | 133_383 | 235.0 | 404.0 | Domain | Protein kinase |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000312783 | - | 7 | 10 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000347343 | - | 6 | 9 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000371356 | - | 7 | 10 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395909 | - | 8 | 11 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395911 | - | 7 | 10 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395913 | - | 6 | 9 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395914 | - | 7 | 10 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395915 | - | 6 | 9 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000312783 | - | 7 | 10 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000347343 | - | 6 | 9 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000371356 | - | 7 | 10 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395909 | - | 8 | 11 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395911 | - | 7 | 10 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395913 | - | 6 | 9 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395914 | - | 7 | 10 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395915 | - | 6 | 9 | 260_261 | 235.0 | 404.0 | Nucleotide binding | ATP |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000312783 | - | 7 | 10 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000347343 | - | 6 | 9 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000371356 | - | 7 | 10 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395909 | - | 8 | 11 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395911 | - | 7 | 10 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395913 | - | 6 | 9 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395914 | - | 7 | 10 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956488 | chr20:35445872 | ENST00000395915 | - | 6 | 9 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000312783 | - | 7 | 10 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000347343 | - | 6 | 9 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000371356 | - | 7 | 10 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395909 | - | 8 | 11 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395911 | - | 7 | 10 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395913 | - | 6 | 9 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395914 | - | 7 | 10 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
| Hgene | AURKA | chr20:54956489 | chr20:35445872 | ENST00000395915 | - | 6 | 9 | 280_293 | 235.0 | 404.0 | Region | Activation segment |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| AURKA | |
| SOGA1 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to AURKA-SOGA1 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to AURKA-SOGA1 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies