| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:TAF4B-CHST9 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: TAF4B-CHST9 | FusionPDB ID: 88792 | FusionGDB2.0 ID: 88792 | Hgene | Tgene | Gene symbol | TAF4B | CHST9 | Gene ID | 493913 | 83539 |
| Gene name | PAPPA antisense RNA 1 | carbohydrate sulfotransferase 9 | |
| Synonyms | DIPAS|NCRNA00156|PAPPA-AS|PAPPAAS|PAPPAS|TAF2C2|TAF4B|TAFII105 | GALNAC4ST-2|GalNAc4ST2 | |
| Cytomap | 9q33.1 | 18q11.2 | |
| Type of gene | ncRNA | protein-coding | |
| Description | DIPLA1-antisense expressedPAPPA antisense RNA 1 (non-protein coding)PAPPA antisense RNA 1 (tail to tail) | carbohydrate sulfotransferase 9GalNAc-4-sulfotransferase 2N-acetylgalactosamine 4-O-sulfotransferase 2carbohydrate (N-acetylgalactosamine 4-0) sulfotransferase 9galNAc-4-O-sulfotransferase 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q7L1S5 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000269142, ENST00000400466, ENST00000578121, | ENST00000284224, ENST00000580774, ENST00000581714, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 4 X 4 X 2=32 | 12 X 11 X 6=792 |
| # samples | 4 | 14 | |
| ** MAII score | log2(4/32*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(14/792*10)=-2.50007360313464 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: TAF4B [Title/Abstract] AND CHST9 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | TAF4B(23807240)-CHST9(24628467), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | TAF4B-CHST9 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. TAF4B-CHST9 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CHST9 | GO:0006790 | sulfur compound metabolic process | 11445554 |
| Fusion gene breakpoints across TAF4B (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CHST9 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
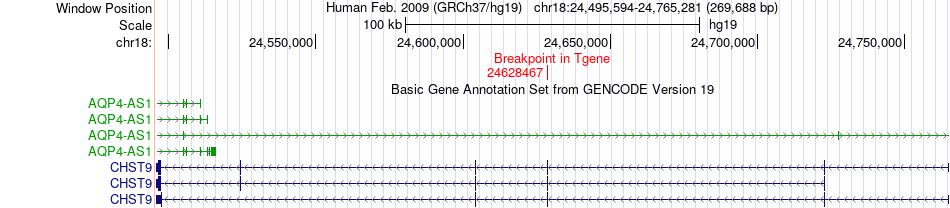 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-A2-A0YM-01A | TAF4B | chr18 | 23807240 | - | CHST9 | chr18 | 24628467 | - |
| ChimerDB4 | BRCA | TCGA-A2-A0YM | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000269142 | TAF4B | chr18 | 23807240 | + | ENST00000284224 | CHST9 | chr18 | 24628467 | - | 3180 | 1341 | 923 | 2551 | 542 |
| ENST00000269142 | TAF4B | chr18 | 23807240 | + | ENST00000581714 | CHST9 | chr18 | 24628467 | - | 3034 | 1341 | 923 | 2551 | 542 |
| ENST00000269142 | TAF4B | chr18 | 23807240 | + | ENST00000580774 | CHST9 | chr18 | 24628467 | - | 2994 | 1341 | 1407 | 2513 | 368 |
| ENST00000400466 | TAF4B | chr18 | 23807240 | + | ENST00000284224 | CHST9 | chr18 | 24628467 | - | 2671 | 832 | 414 | 2042 | 542 |
| ENST00000400466 | TAF4B | chr18 | 23807240 | + | ENST00000581714 | CHST9 | chr18 | 24628467 | - | 2525 | 832 | 414 | 2042 | 542 |
| ENST00000400466 | TAF4B | chr18 | 23807240 | + | ENST00000580774 | CHST9 | chr18 | 24628467 | - | 2485 | 832 | 898 | 2004 | 368 |
| ENST00000578121 | TAF4B | chr18 | 23807240 | + | ENST00000284224 | CHST9 | chr18 | 24628467 | - | 2630 | 791 | 373 | 2001 | 542 |
| ENST00000578121 | TAF4B | chr18 | 23807240 | + | ENST00000581714 | CHST9 | chr18 | 24628467 | - | 2484 | 791 | 373 | 2001 | 542 |
| ENST00000578121 | TAF4B | chr18 | 23807240 | + | ENST00000580774 | CHST9 | chr18 | 24628467 | - | 2444 | 791 | 857 | 1963 | 368 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000269142 | ENST00000284224 | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - | 0.002326649 | 0.99767333 |
| ENST00000269142 | ENST00000581714 | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - | 0.002452077 | 0.9975479 |
| ENST00000269142 | ENST00000580774 | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - | 0.001507128 | 0.99849284 |
| ENST00000400466 | ENST00000284224 | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - | 0.002620511 | 0.99737954 |
| ENST00000400466 | ENST00000581714 | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - | 0.002783736 | 0.9972162 |
| ENST00000400466 | ENST00000580774 | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - | 0.001640548 | 0.9983594 |
| ENST00000578121 | ENST00000284224 | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - | 0.002578416 | 0.9974216 |
| ENST00000578121 | ENST00000581714 | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - | 0.002724886 | 0.9972752 |
| ENST00000578121 | ENST00000580774 | TAF4B | chr18 | 23807240 | + | CHST9 | chr18 | 24628467 | - | 0.001618307 | 0.99838173 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >88792_88792_1_TAF4B-CHST9_TAF4B_chr18_23807240_ENST00000269142_CHST9_chr18_24628467_ENST00000284224_length(amino acids)=542AA_BP=139 MPRAKPPLTSAPGTAAPKLPLSPWGMPAGLTEPAGAAPPAAVSASGTVTMAPAGALPVRVESTPVALGAVTKAPVSVCVEPTASQPLRSP VGTLVTKVAPVSAPPKVSSGPRLPAPQIVAVKAPNTTTIQFPANLQLPPGRVEKRREQKVTSGWGPVKYLRPVPRIMSTEKIQEHITNQN PKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKDNKWKKT EETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHLKKLDSF DLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVGMDIHWE KVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLMFNYTTP -------------------------------------------------------------- >88792_88792_2_TAF4B-CHST9_TAF4B_chr18_23807240_ENST00000269142_CHST9_chr18_24628467_ENST00000580774_length(amino acids)=368AA_BP= MYPESNPKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKD NKWKKTEETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHL KKLDSFDLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVG MDIHWEKVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLM -------------------------------------------------------------- >88792_88792_3_TAF4B-CHST9_TAF4B_chr18_23807240_ENST00000269142_CHST9_chr18_24628467_ENST00000581714_length(amino acids)=542AA_BP=139 MPRAKPPLTSAPGTAAPKLPLSPWGMPAGLTEPAGAAPPAAVSASGTVTMAPAGALPVRVESTPVALGAVTKAPVSVCVEPTASQPLRSP VGTLVTKVAPVSAPPKVSSGPRLPAPQIVAVKAPNTTTIQFPANLQLPPGRVEKRREQKVTSGWGPVKYLRPVPRIMSTEKIQEHITNQN PKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKDNKWKKT EETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHLKKLDSF DLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVGMDIHWE KVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLMFNYTTP -------------------------------------------------------------- >88792_88792_4_TAF4B-CHST9_TAF4B_chr18_23807240_ENST00000400466_CHST9_chr18_24628467_ENST00000284224_length(amino acids)=542AA_BP=139 MPRAKPPLTSAPGTAAPKLPLSPWGMPAGLTEPAGAAPPAAVSASGTVTMAPAGALPVRVESTPVALGAVTKAPVSVCVEPTASQPLRSP VGTLVTKVAPVSAPPKVSSGPRLPAPQIVAVKAPNTTTIQFPANLQLPPGRVEKRREQKVTSGWGPVKYLRPVPRIMSTEKIQEHITNQN PKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKDNKWKKT EETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHLKKLDSF DLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVGMDIHWE KVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLMFNYTTP -------------------------------------------------------------- >88792_88792_5_TAF4B-CHST9_TAF4B_chr18_23807240_ENST00000400466_CHST9_chr18_24628467_ENST00000580774_length(amino acids)=368AA_BP= MYPESNPKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKD NKWKKTEETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHL KKLDSFDLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVG MDIHWEKVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLM -------------------------------------------------------------- >88792_88792_6_TAF4B-CHST9_TAF4B_chr18_23807240_ENST00000400466_CHST9_chr18_24628467_ENST00000581714_length(amino acids)=542AA_BP=139 MPRAKPPLTSAPGTAAPKLPLSPWGMPAGLTEPAGAAPPAAVSASGTVTMAPAGALPVRVESTPVALGAVTKAPVSVCVEPTASQPLRSP VGTLVTKVAPVSAPPKVSSGPRLPAPQIVAVKAPNTTTIQFPANLQLPPGRVEKRREQKVTSGWGPVKYLRPVPRIMSTEKIQEHITNQN PKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKDNKWKKT EETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHLKKLDSF DLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVGMDIHWE KVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLMFNYTTP -------------------------------------------------------------- >88792_88792_7_TAF4B-CHST9_TAF4B_chr18_23807240_ENST00000578121_CHST9_chr18_24628467_ENST00000284224_length(amino acids)=542AA_BP=139 MPRAKPPLTSAPGTAAPKLPLSPWGMPAGLTEPAGAAPPAAVSASGTVTMAPAGALPVRVESTPVALGAVTKAPVSVCVEPTASQPLRSP VGTLVTKVAPVSAPPKVSSGPRLPAPQIVAVKAPNTTTIQFPANLQLPPGRVEKRREQKVTSGWGPVKYLRPVPRIMSTEKIQEHITNQN PKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKDNKWKKT EETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHLKKLDSF DLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVGMDIHWE KVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLMFNYTTP -------------------------------------------------------------- >88792_88792_8_TAF4B-CHST9_TAF4B_chr18_23807240_ENST00000578121_CHST9_chr18_24628467_ENST00000580774_length(amino acids)=368AA_BP= MYPESNPKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKD NKWKKTEETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHL KKLDSFDLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVG MDIHWEKVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLM -------------------------------------------------------------- >88792_88792_9_TAF4B-CHST9_TAF4B_chr18_23807240_ENST00000578121_CHST9_chr18_24628467_ENST00000581714_length(amino acids)=542AA_BP=139 MPRAKPPLTSAPGTAAPKLPLSPWGMPAGLTEPAGAAPPAAVSASGTVTMAPAGALPVRVESTPVALGAVTKAPVSVCVEPTASQPLRSP VGTLVTKVAPVSAPPKVSSGPRLPAPQIVAVKAPNTTTIQFPANLQLPPGRVEKRREQKVTSGWGPVKYLRPVPRIMSTEKIQEHITNQN PKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKDNKWKKT EETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHLKKLDSF DLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVGMDIHWE KVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLMFNYTTP -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr18:23807240/chr18:24628467) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CHST9 |
| FUNCTION: Might normally function as a transcriptional repressor. EWS-fusion-proteins (EFPS) may play a role in the tumorigenic process. They may disturb gene expression by mimicking, or interfering with the normal function of CTD-POLII within the transcription initiation complex. They may also contribute to an aberrant activation of the fusion protein target genes. | FUNCTION: Catalyzes the transfer of sulfate to position 4 of non-reducing N-acetylgalactosamine (GalNAc) residues in both N-glycans and O-glycans. Participates in biosynthesis of glycoprotein hormones lutropin and thyrotropin, by mediating sulfation of their carbohydrate structures. Has a higher activity toward carbonic anhydrase VI than toward lutropin. Only active against terminal GalNAcbeta1,GalNAcbeta. Isoform 2, but not isoform 1, is active toward chondroitin. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000284224 | 1 | 6 | 220_226 | 40.333333333333336 | 444.0 | Nucleotide binding | PAPS | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000284224 | 1 | 6 | 280_288 | 40.333333333333336 | 444.0 | Nucleotide binding | PAPS | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000580774 | 1 | 5 | 220_226 | 40.333333333333336 | 75.0 | Nucleotide binding | PAPS | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000580774 | 1 | 5 | 280_288 | 40.333333333333336 | 75.0 | Nucleotide binding | PAPS | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000581714 | 0 | 5 | 220_226 | 40.333333333333336 | 444.0 | Nucleotide binding | PAPS | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000581714 | 0 | 5 | 280_288 | 40.333333333333336 | 444.0 | Nucleotide binding | PAPS |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TAF4B | chr18:23807240 | chr18:24628467 | ENST00000269142 | + | 1 | 15 | 722_787 | 114.33333333333333 | 863.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | TAF4B | chr18:23807240 | chr18:24628467 | ENST00000400466 | + | 1 | 10 | 722_787 | 114.33333333333333 | 619.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | TAF4B | chr18:23807240 | chr18:24628467 | ENST00000269142 | + | 1 | 15 | 256_353 | 114.33333333333333 | 863.0 | Domain | TAFH |
| Hgene | TAF4B | chr18:23807240 | chr18:24628467 | ENST00000269142 | + | 1 | 15 | 653_702 | 114.33333333333333 | 863.0 | Domain | Note=Histone-fold |
| Hgene | TAF4B | chr18:23807240 | chr18:24628467 | ENST00000400466 | + | 1 | 10 | 256_353 | 114.33333333333333 | 619.0 | Domain | TAFH |
| Hgene | TAF4B | chr18:23807240 | chr18:24628467 | ENST00000400466 | + | 1 | 10 | 653_702 | 114.33333333333333 | 619.0 | Domain | Note=Histone-fold |
| Hgene | TAF4B | chr18:23807240 | chr18:24628467 | ENST00000269142 | + | 1 | 15 | 516_556 | 114.33333333333333 | 863.0 | Motif | Note=Nuclear export signal |
| Hgene | TAF4B | chr18:23807240 | chr18:24628467 | ENST00000400466 | + | 1 | 10 | 516_556 | 114.33333333333333 | 619.0 | Motif | Note=Nuclear export signal |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000284224 | 1 | 6 | 1_12 | 40.333333333333336 | 444.0 | Topological domain | Cytoplasmic | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000284224 | 1 | 6 | 34_443 | 40.333333333333336 | 444.0 | Topological domain | Lumenal | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000580774 | 1 | 5 | 1_12 | 40.333333333333336 | 75.0 | Topological domain | Cytoplasmic | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000580774 | 1 | 5 | 34_443 | 40.333333333333336 | 75.0 | Topological domain | Lumenal | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000581714 | 0 | 5 | 1_12 | 40.333333333333336 | 444.0 | Topological domain | Cytoplasmic | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000581714 | 0 | 5 | 34_443 | 40.333333333333336 | 444.0 | Topological domain | Lumenal | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000284224 | 1 | 6 | 13_33 | 40.333333333333336 | 444.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000580774 | 1 | 5 | 13_33 | 40.333333333333336 | 75.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein | |
| Tgene | CHST9 | chr18:23807240 | chr18:24628467 | ENST00000581714 | 0 | 5 | 13_33 | 40.333333333333336 | 444.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file >>>1159_TAF4B_23807240_CHST9_24628467_1159_TAF4B_23807240_CHST9_24628467_ranked_0.pdb | TAF4B | 23807240 | 23807240 | ENST00000580774 | CHST9 | chr18 | 24628467 | - | MPRAKPPLTSAPGTAAPKLPLSPWGMPAGLTEPAGAAPPAAVSASGTVTMAPAGALPVRVESTPVALGAVTKAPVSVCVEPTASQPLRSP VGTLVTKVAPVSAPPKVSSGPRLPAPQIVAVKAPNTTTIQFPANLQLPPGRVEKRREQKVTSGWGPVKYLRPVPRIMSTEKIQEHITNQN PKFHMPEDVREKKENLLLNSERSTRLLTKTSHSQGGDQALSKSTGSPTEKLIEKRQGAKTVFNKFSNMNWPVDIHPLNKSLVKDNKWKKT EETQEKRRSFLQEFCKKYGGVSHHQSHLFHTVSRIYVEDKHKILYCEVPKAGCSNWKRILMVLNGLASSAYNISHNAVHYGKHLKKLDSF DLKGIYTRLNTYTKAVFVRDPMERLVSAFRDKFEHPNSYYHPVFGKAIIKKYRPNACEEALINGSGVKFKEFIHYLLDSHRPVGMDIHWE KVSKLCYPCLINYDFVGKFETLEEDANYFLQMIGAPKELKFPNFKDRHSSDERTNAQVVRQYLKDLTRTERQLIYDFYYLDYLMFNYTTP | 542 |
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
TAF4B_pLDDT.png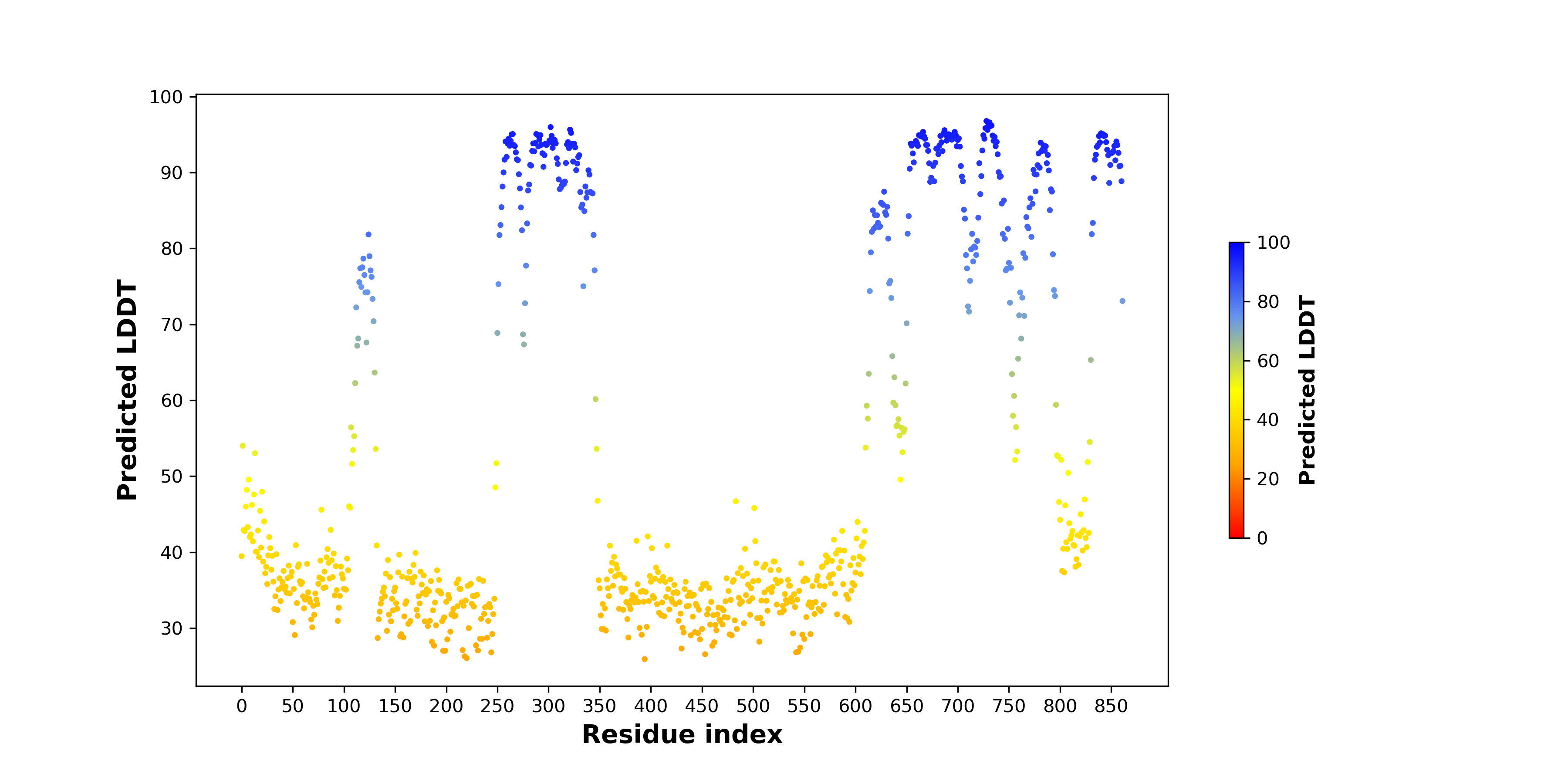  |
CHST9_pLDDT.png  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
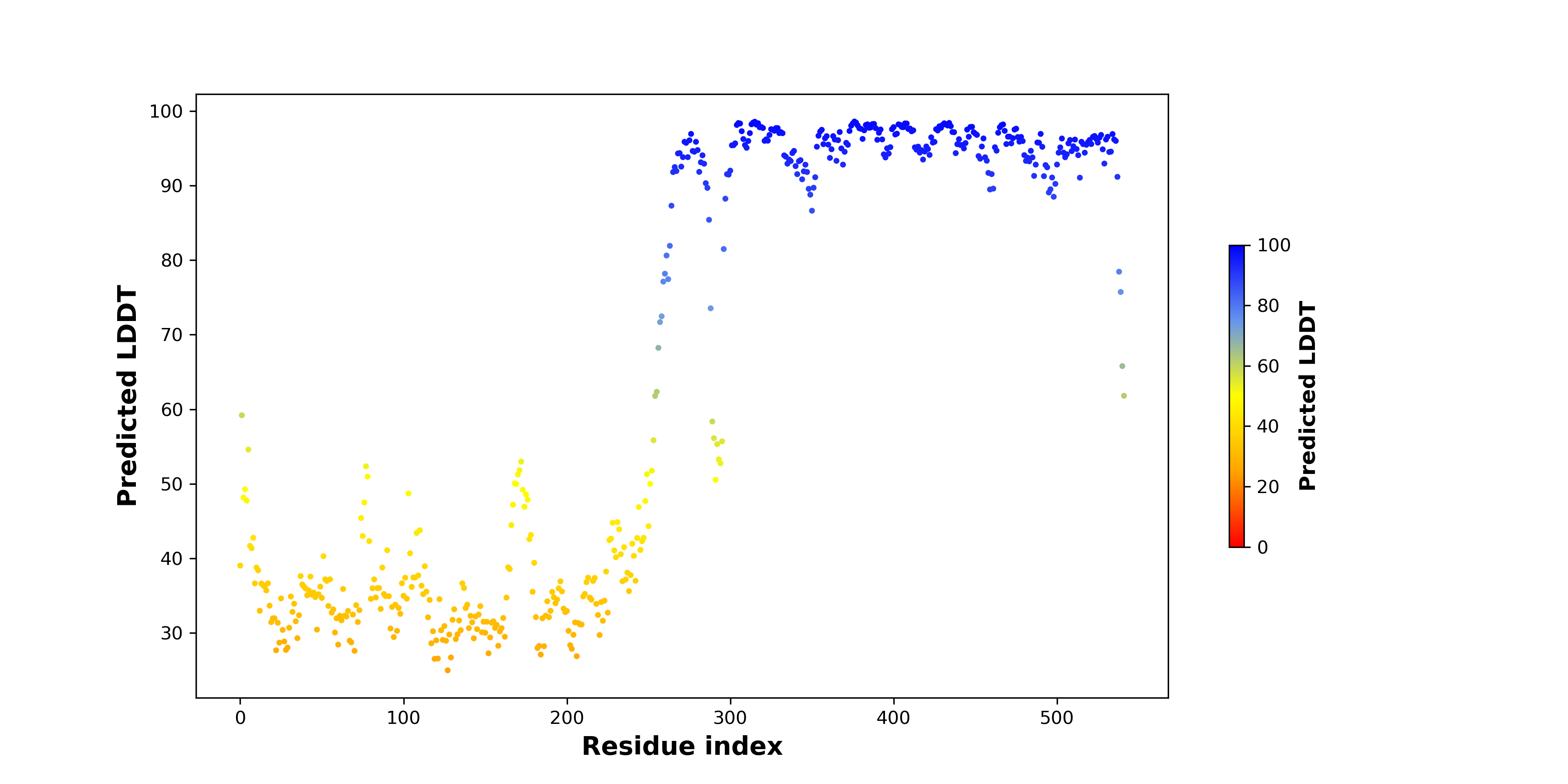 |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| TAF4B | |
| CHST9 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to TAF4B-CHST9 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to TAF4B-CHST9 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies