
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CPS1-NDUFS1 (FusionGDB2 ID:HG1373TG4719) |
Fusion Gene Summary for CPS1-NDUFS1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CPS1-NDUFS1 | Fusion gene ID: hg1373tg4719 | Hgene | Tgene | Gene symbol | CPS1 | NDUFS1 | Gene ID | 1373 | 4719 |
| Gene name | carbamoyl-phosphate synthase 1 | NADH:ubiquinone oxidoreductase core subunit S1 | |
| Synonyms | CPSASE1|PHN | CI-75Kd|CI-75k|MC1DN5|PRO1304 | |
| Cytomap | ('CPS1')('NDUFS1') 2q34 | 2q33.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | carbamoyl-phosphate synthase [ammonia], mitochondrialcarbamoyl-phosphate synthase (ammonia)carbamoyl-phosphate synthase 1, mitochondrialcarbamoylphosphate synthetase I | NADH-ubiquinone oxidoreductase 75 kDa subunit, mitochondrialNADH dehydrogenase (ubiquinone) Fe-S protein 1, 75kDa (NADH-coenzyme Q reductase)complex I 75kDa subunitcomplex I, mitochondrial respiratory chain, 75-kD subunitmitochondrial NADH-ubiquinone | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P31327 | P28331 | |
| Ensembl transtripts involved in fusion gene | ENST00000233072, ENST00000430249, ENST00000451903, ENST00000497121, | ||
| Fusion gene scores | * DoF score | 10 X 11 X 4=440 | 7 X 7 X 6=294 |
| # samples | 11 | 7 | |
| ** MAII score | log2(11/440*10)=-2 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/294*10)=-2.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CPS1 [Title/Abstract] AND NDUFS1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CPS1(211477017)-NDUFS1(206989000), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | CPS1-NDUFS1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CPS1-NDUFS1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CPS1-NDUFS1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CPS1-NDUFS1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CPS1-NDUFS1 seems lost the major protein functional domain in Hgene partner, which is a cell metabolism gene due to the frame-shifted ORF. CPS1-NDUFS1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CPS1 | GO:0032496 | response to lipopolysaccharide | 15897806 |
| Hgene | CPS1 | GO:0050667 | homocysteine metabolic process | 20031578 |
| Tgene | NDUFS1 | GO:0008637 | apoptotic mitochondrial changes | 15186778 |
| Fusion gene breakpoints across CPS1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NDUFS1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
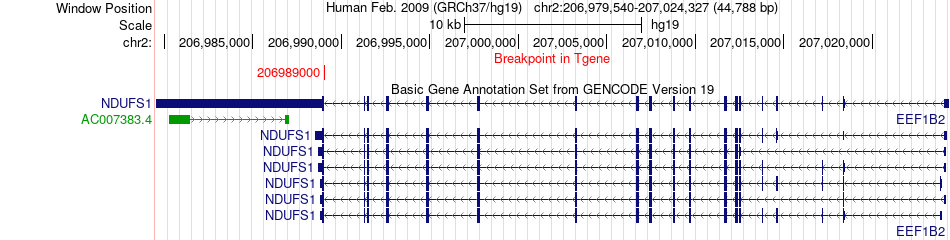 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-D7-A4Z0-01A | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
Top |
Fusion Gene ORF analysis for CPS1-NDUFS1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000233072 | ENST00000233190 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| Frame-shift | ENST00000430249 | ENST00000233190 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| Frame-shift | ENST00000451903 | ENST00000233190 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000233072 | ENST00000423725 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000233072 | ENST00000432169 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000233072 | ENST00000440274 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000233072 | ENST00000449699 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000233072 | ENST00000455934 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000233072 | ENST00000457011 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000430249 | ENST00000423725 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000430249 | ENST00000432169 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000430249 | ENST00000440274 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000430249 | ENST00000449699 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000430249 | ENST00000455934 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000430249 | ENST00000457011 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000451903 | ENST00000423725 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000451903 | ENST00000432169 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000451903 | ENST00000440274 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000451903 | ENST00000449699 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000451903 | ENST00000455934 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| In-frame | ENST00000451903 | ENST00000457011 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| intron-3CDS | ENST00000497121 | ENST00000233190 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| intron-3CDS | ENST00000497121 | ENST00000423725 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| intron-3CDS | ENST00000497121 | ENST00000432169 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| intron-3CDS | ENST00000497121 | ENST00000440274 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| intron-3CDS | ENST00000497121 | ENST00000449699 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| intron-3CDS | ENST00000497121 | ENST00000455934 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| intron-3CDS | ENST00000497121 | ENST00000457011 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000430249 | CPS1 | chr2 | 211477017 | + | ENST00000423725 | NDUFS1 | chr2 | 206989000 | - | 3099 | 2641 | 55 | 2712 | 885 |
| ENST00000430249 | CPS1 | chr2 | 211477017 | + | ENST00000457011 | NDUFS1 | chr2 | 206989000 | - | 2973 | 2641 | 55 | 2712 | 885 |
| ENST00000430249 | CPS1 | chr2 | 211477017 | + | ENST00000440274 | NDUFS1 | chr2 | 206989000 | - | 2962 | 2641 | 55 | 2712 | 885 |
| ENST00000430249 | CPS1 | chr2 | 211477017 | + | ENST00000455934 | NDUFS1 | chr2 | 206989000 | - | 2819 | 2641 | 55 | 2712 | 885 |
| ENST00000430249 | CPS1 | chr2 | 211477017 | + | ENST00000449699 | NDUFS1 | chr2 | 206989000 | - | 2817 | 2641 | 55 | 2712 | 885 |
| ENST00000430249 | CPS1 | chr2 | 211477017 | + | ENST00000432169 | NDUFS1 | chr2 | 206989000 | - | 2817 | 2641 | 55 | 2712 | 885 |
| ENST00000233072 | CPS1 | chr2 | 211477017 | + | ENST00000423725 | NDUFS1 | chr2 | 206989000 | - | 3222 | 2764 | 196 | 2835 | 879 |
| ENST00000233072 | CPS1 | chr2 | 211477017 | + | ENST00000457011 | NDUFS1 | chr2 | 206989000 | - | 3096 | 2764 | 196 | 2835 | 879 |
| ENST00000233072 | CPS1 | chr2 | 211477017 | + | ENST00000440274 | NDUFS1 | chr2 | 206989000 | - | 3085 | 2764 | 196 | 2835 | 879 |
| ENST00000233072 | CPS1 | chr2 | 211477017 | + | ENST00000455934 | NDUFS1 | chr2 | 206989000 | - | 2942 | 2764 | 196 | 2835 | 879 |
| ENST00000233072 | CPS1 | chr2 | 211477017 | + | ENST00000449699 | NDUFS1 | chr2 | 206989000 | - | 2940 | 2764 | 196 | 2835 | 879 |
| ENST00000233072 | CPS1 | chr2 | 211477017 | + | ENST00000432169 | NDUFS1 | chr2 | 206989000 | - | 2940 | 2764 | 196 | 2835 | 879 |
| ENST00000451903 | CPS1 | chr2 | 211477017 | + | ENST00000423725 | NDUFS1 | chr2 | 206989000 | - | 2171 | 1713 | 312 | 1784 | 490 |
| ENST00000451903 | CPS1 | chr2 | 211477017 | + | ENST00000457011 | NDUFS1 | chr2 | 206989000 | - | 2045 | 1713 | 312 | 1784 | 490 |
| ENST00000451903 | CPS1 | chr2 | 211477017 | + | ENST00000440274 | NDUFS1 | chr2 | 206989000 | - | 2034 | 1713 | 312 | 1784 | 490 |
| ENST00000451903 | CPS1 | chr2 | 211477017 | + | ENST00000455934 | NDUFS1 | chr2 | 206989000 | - | 1891 | 1713 | 312 | 1784 | 490 |
| ENST00000451903 | CPS1 | chr2 | 211477017 | + | ENST00000449699 | NDUFS1 | chr2 | 206989000 | - | 1889 | 1713 | 312 | 1784 | 490 |
| ENST00000451903 | CPS1 | chr2 | 211477017 | + | ENST00000432169 | NDUFS1 | chr2 | 206989000 | - | 1889 | 1713 | 312 | 1784 | 490 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000430249 | ENST00000423725 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.000764917 | 0.99923515 |
| ENST00000430249 | ENST00000457011 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.001042585 | 0.9989574 |
| ENST00000430249 | ENST00000440274 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.001034688 | 0.99896526 |
| ENST00000430249 | ENST00000455934 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.001293757 | 0.9987062 |
| ENST00000430249 | ENST00000449699 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.001323058 | 0.99867696 |
| ENST00000430249 | ENST00000432169 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.001323058 | 0.99867696 |
| ENST00000233072 | ENST00000423725 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.00049848 | 0.99950147 |
| ENST00000233072 | ENST00000457011 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.000653958 | 0.9993461 |
| ENST00000233072 | ENST00000440274 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.000647495 | 0.9993525 |
| ENST00000233072 | ENST00000455934 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.000832822 | 0.9991672 |
| ENST00000233072 | ENST00000449699 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.0008463 | 0.99915373 |
| ENST00000233072 | ENST00000432169 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.0008463 | 0.99915373 |
| ENST00000451903 | ENST00000423725 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.000879831 | 0.9991202 |
| ENST00000451903 | ENST00000457011 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.001248359 | 0.99875164 |
| ENST00000451903 | ENST00000440274 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.001255758 | 0.99874425 |
| ENST00000451903 | ENST00000455934 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.001793467 | 0.9982065 |
| ENST00000451903 | ENST00000449699 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.00182217 | 0.9981779 |
| ENST00000451903 | ENST00000432169 | CPS1 | chr2 | 211477017 | + | NDUFS1 | chr2 | 206989000 | - | 0.00182217 | 0.9981779 |
Top |
Fusion Genomic Features for CPS1-NDUFS1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
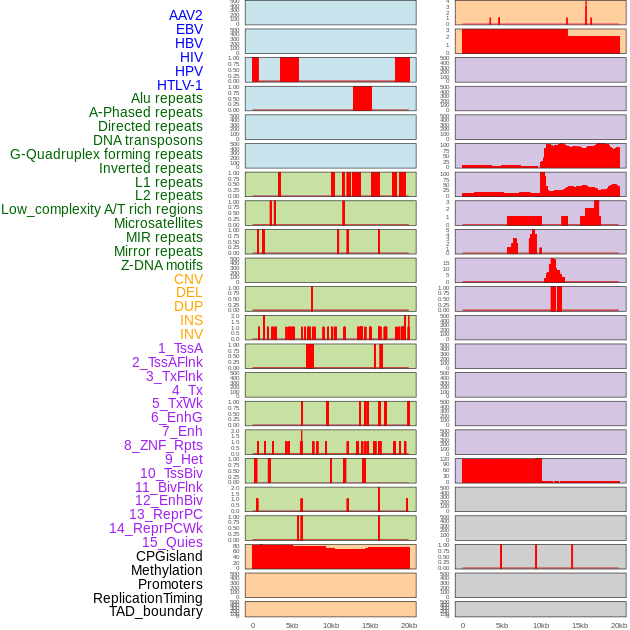 |
Top |
Fusion Protein Features for CPS1-NDUFS1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:211477017/chr2:206989000) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CPS1 | NDUFS1 |
| FUNCTION: Involved in the urea cycle of ureotelic animals where the enzyme plays an important role in removing excess ammonia from the cell. | FUNCTION: Core subunit of the mitochondrial membrane respiratory chain NADH dehydrogenase (Complex I) which catalyzes electron transfer from NADH through the respiratory chain, using ubiquinone as an electron acceptor (PubMed:30879903, PubMed:31557978). Essential for catalysing the entry and efficient transfer of electrons within complex I (PubMed:31557978). Plays a key role in the assembly and stability of complex I and participates in the association of complex I with ubiquinol-cytochrome reductase complex (Complex III) to form supercomplexes (PubMed:30879903, PubMed:31557978). {ECO:0000269|PubMed:30879903, ECO:0000269|PubMed:31557978}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000233072 | + | 20 | 38 | 219_404 | 856 | 1501.0 | Domain | Note=Glutamine amidotransferase type-1 |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000233072 | + | 20 | 38 | 551_743 | 856 | 1501.0 | Domain | Note=ATP-grasp 1 |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000430249 | + | 21 | 39 | 219_404 | 862 | 1507.0 | Domain | Note=Glutamine amidotransferase type-1 |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000430249 | + | 21 | 39 | 551_743 | 862 | 1507.0 | Domain | Note=ATP-grasp 1 |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000451903 | + | 10 | 28 | 219_404 | 405 | 1050.0 | Domain | Note=Glutamine amidotransferase type-1 |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000233072 | + | 20 | 38 | 39_218 | 856 | 1501.0 | Region | Note=Anthranilate phosphoribosyltransferase homolog |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000430249 | + | 21 | 39 | 39_218 | 862 | 1507.0 | Region | Note=Anthranilate phosphoribosyltransferase homolog |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000451903 | + | 10 | 28 | 39_218 | 405 | 1050.0 | Region | Note=Anthranilate phosphoribosyltransferase homolog |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000233072 | + | 20 | 38 | 1093_1284 | 856 | 1501.0 | Domain | Note=ATP-grasp 2 |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000233072 | + | 20 | 38 | 1355_1500 | 856 | 1501.0 | Domain | MGS-like |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000430249 | + | 21 | 39 | 1093_1284 | 862 | 1507.0 | Domain | Note=ATP-grasp 2 |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000430249 | + | 21 | 39 | 1355_1500 | 862 | 1507.0 | Domain | MGS-like |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000451903 | + | 10 | 28 | 1093_1284 | 405 | 1050.0 | Domain | Note=ATP-grasp 2 |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000451903 | + | 10 | 28 | 1355_1500 | 405 | 1050.0 | Domain | MGS-like |
| Hgene | CPS1 | chr2:211477017 | chr2:206989000 | ENST00000451903 | + | 10 | 28 | 551_743 | 405 | 1050.0 | Domain | Note=ATP-grasp 1 |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000233190 | 17 | 19 | 108_147 | 697 | 728.0 | Domain | 4Fe-4S His(Cys)3-ligated-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000233190 | 17 | 19 | 245_301 | 697 | 728.0 | Domain | 4Fe-4S Mo/W bis-MGD-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000233190 | 17 | 19 | 30_108 | 697 | 728.0 | Domain | 2Fe-2S ferredoxin-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000423725 | 16 | 18 | 108_147 | 640 | 671.0 | Domain | 4Fe-4S His(Cys)3-ligated-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000423725 | 16 | 18 | 245_301 | 640 | 671.0 | Domain | 4Fe-4S Mo/W bis-MGD-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000423725 | 16 | 18 | 30_108 | 640 | 671.0 | Domain | 2Fe-2S ferredoxin-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000432169 | 14 | 16 | 108_147 | 586 | 617.0 | Domain | 4Fe-4S His(Cys)3-ligated-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000432169 | 14 | 16 | 245_301 | 586 | 617.0 | Domain | 4Fe-4S Mo/W bis-MGD-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000432169 | 14 | 16 | 30_108 | 586 | 617.0 | Domain | 2Fe-2S ferredoxin-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000440274 | 16 | 18 | 108_147 | 661 | 692.0 | Domain | 4Fe-4S His(Cys)3-ligated-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000440274 | 16 | 18 | 245_301 | 661 | 692.0 | Domain | 4Fe-4S Mo/W bis-MGD-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000440274 | 16 | 18 | 30_108 | 661 | 692.0 | Domain | 2Fe-2S ferredoxin-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000449699 | 17 | 19 | 108_147 | 697 | 728.0 | Domain | 4Fe-4S His(Cys)3-ligated-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000449699 | 17 | 19 | 245_301 | 697 | 728.0 | Domain | 4Fe-4S Mo/W bis-MGD-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000449699 | 17 | 19 | 30_108 | 697 | 728.0 | Domain | 2Fe-2S ferredoxin-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000455934 | 17 | 19 | 108_147 | 711 | 742.0 | Domain | 4Fe-4S His(Cys)3-ligated-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000455934 | 17 | 19 | 245_301 | 711 | 742.0 | Domain | 4Fe-4S Mo/W bis-MGD-type | |
| Tgene | NDUFS1 | chr2:211477017 | chr2:206989000 | ENST00000455934 | 17 | 19 | 30_108 | 711 | 742.0 | Domain | 2Fe-2S ferredoxin-type |
Top |
Fusion Gene Sequence for CPS1-NDUFS1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >19093_19093_1_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000423725_length(transcript)=3222nt_BP=2764nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGATGTCAAAGTGTACGGCAAAGGAAACCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCT AGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCCCTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACC GGGGAACCCAGCTCTTGCAGAACCACTAATTCAGAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTAC AGGAAACTTAATAACAGGATTGGCTGCTGGTGCCAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATAT CACAAACAAACAGGCTTTCATTACTGCTCAGAATCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAA TGTCAACGATCAAACAAATGAGGGGATTATGCATGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAAT AGACACTGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACT AGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGG ATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGG CTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAAT TCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGG AACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTT TGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTT AGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTC AGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGC CATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAAT CAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGT GAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAAT CCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCG CTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTT TGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATC TAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACA ATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTT GCCGCAGATAATTAATGGACAACTGTAGTGCAGTGATCCTTTACAGGTTTATTTCTTTGTAAAAAAAAATAATAATAATTTGAATCATGT AATATTTAAGGTTATACTATGCCTATTTGAAAATGATATTAGTTATCAACTTTGCAGTTTGAAAAACATGTATTGTGTGTAAAGGTTAAA TAACAAAACTATGCAGATGCTCTTAAAAGCATTGATAACCTTTGTGACGAACATAAAGAGATCCTTAAATTATGAGTTGTTGGCTTATCT >19093_19093_1_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000423725_length(amino acids)=879AA_BP=856 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGGPGNPAL AEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFVNVNDQT NEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVK AMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVES IMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWK EIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLS RSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQ -------------------------------------------------------------- >19093_19093_2_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000432169_length(transcript)=2940nt_BP=2764nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGATGTCAAAGTGTACGGCAAAGGAAACCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCT AGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCCCTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACC GGGGAACCCAGCTCTTGCAGAACCACTAATTCAGAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTAC AGGAAACTTAATAACAGGATTGGCTGCTGGTGCCAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATAT CACAAACAAACAGGCTTTCATTACTGCTCAGAATCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAA TGTCAACGATCAAACAAATGAGGGGATTATGCATGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAAT AGACACTGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACT AGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGG ATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGG CTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAAT TCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGG AACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTT TGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTT AGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTC AGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGC CATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAAT CAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGT GAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAAT CCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCG CTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTT TGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATC TAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACA ATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTT >19093_19093_2_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000432169_length(amino acids)=879AA_BP=856 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGGPGNPAL AEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFVNVNDQT NEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVK AMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVES IMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWK EIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLS RSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQ -------------------------------------------------------------- >19093_19093_3_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000440274_length(transcript)=3085nt_BP=2764nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGATGTCAAAGTGTACGGCAAAGGAAACCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCT AGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCCCTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACC GGGGAACCCAGCTCTTGCAGAACCACTAATTCAGAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTAC AGGAAACTTAATAACAGGATTGGCTGCTGGTGCCAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATAT CACAAACAAACAGGCTTTCATTACTGCTCAGAATCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAA TGTCAACGATCAAACAAATGAGGGGATTATGCATGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAAT AGACACTGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACT AGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGG ATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGG CTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAAT TCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGG AACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTT TGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTT AGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTC AGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGC CATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAAT CAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGT GAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAAT CCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCG CTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTT TGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATC TAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACA ATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTT GCCGCAGATAATTAATGGACAACTGTAGTGCAGTGATCCTTTACAGGTTTATTTCTTTGTAAAAAAAAATAATAATAATTTGAATCATGT AATATTTAAGGTTATACTATGCCTATTTGAAAATGATATTAGTTATCAACTTTGCAGTTTGAAAAACATGTATTGTGTGTAAAGGTTAAA >19093_19093_3_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000440274_length(amino acids)=879AA_BP=856 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGGPGNPAL AEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFVNVNDQT NEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVK AMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVES IMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWK EIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLS RSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQ -------------------------------------------------------------- >19093_19093_4_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000449699_length(transcript)=2940nt_BP=2764nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGATGTCAAAGTGTACGGCAAAGGAAACCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCT AGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCCCTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACC GGGGAACCCAGCTCTTGCAGAACCACTAATTCAGAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTAC AGGAAACTTAATAACAGGATTGGCTGCTGGTGCCAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATAT CACAAACAAACAGGCTTTCATTACTGCTCAGAATCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAA TGTCAACGATCAAACAAATGAGGGGATTATGCATGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAAT AGACACTGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACT AGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGG ATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGG CTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAAT TCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGG AACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTT TGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTT AGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTC AGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGC CATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAAT CAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGT GAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAAT CCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCG CTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTT TGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATC TAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACA ATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTT >19093_19093_4_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000449699_length(amino acids)=879AA_BP=856 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGGPGNPAL AEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFVNVNDQT NEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVK AMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVES IMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWK EIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLS RSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQ -------------------------------------------------------------- >19093_19093_5_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000455934_length(transcript)=2942nt_BP=2764nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGATGTCAAAGTGTACGGCAAAGGAAACCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCT AGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCCCTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACC GGGGAACCCAGCTCTTGCAGAACCACTAATTCAGAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTAC AGGAAACTTAATAACAGGATTGGCTGCTGGTGCCAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATAT CACAAACAAACAGGCTTTCATTACTGCTCAGAATCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAA TGTCAACGATCAAACAAATGAGGGGATTATGCATGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAAT AGACACTGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACT AGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGG ATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGG CTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAAT TCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGG AACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTT TGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTT AGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTC AGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGC CATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAAT CAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGT GAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAAT CCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCG CTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTT TGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATC TAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACA ATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTT >19093_19093_5_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000455934_length(amino acids)=879AA_BP=856 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGGPGNPAL AEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFVNVNDQT NEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVK AMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVES IMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWK EIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLS RSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQ -------------------------------------------------------------- >19093_19093_6_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000457011_length(transcript)=3096nt_BP=2764nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGATGTCAAAGTGTACGGCAAAGGAAACCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCT AGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCCCTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACC GGGGAACCCAGCTCTTGCAGAACCACTAATTCAGAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTAC AGGAAACTTAATAACAGGATTGGCTGCTGGTGCCAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATAT CACAAACAAACAGGCTTTCATTACTGCTCAGAATCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAA TGTCAACGATCAAACAAATGAGGGGATTATGCATGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAAT AGACACTGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACT AGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGG ATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGG CTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAAT TCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGG AACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTT TGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTT AGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTC AGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGC CATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAAT CAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGT GAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAAT CCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCG CTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTT TGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATC TAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACA ATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTT GCCGCAGATAATTAATGGACAACTGTAGTGCAGTGATCCTTTACAGGTTTATTTCTTTGTAAAAAAAAATAATAATAATTTGAATCATGT AATATTTAAGGTTATACTATGCCTATTTGAAAATGATATTAGTTATCAACTTTGCAGTTTGAAAAACATGTATTGTGTGTAAAGGTTAAA >19093_19093_6_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000233072_NDUFS1_chr2_206989000_ENST00000457011_length(amino acids)=879AA_BP=856 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGGPGNPAL AEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFVNVNDQT NEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVK AMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVES IMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWK EIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLS RSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQ -------------------------------------------------------------- >19093_19093_7_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000423725_length(transcript)=3099nt_BP=2641nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGATGTCAAAGTGTACGGCAAAGGAAA CCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCTAGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCC CTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACCGGGGAACCCAGCTCTTGCAGAACCACTAATTCA GAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTACAGGAAACTTAATAACAGGATTGGCTGCTGGTGC CAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATATCACAAACAAACAGGCTTTCATTACTGCTCAGAA TCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAATGTCAACGATCAAACAAATGAGGGGATTATGCA TGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAATAGACACTGAGTACCTGTTTGATTCCTTTTTCTC ACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCT TATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAA TGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCC CATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTG TGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGA CAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGC AGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTT GATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGT GGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGT GGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGA ATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGC CTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGG GAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAG CCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTG CCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACC AAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGT GCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAG TGATCCTTTACAGGTTTATTTCTTTGTAAAAAAAAATAATAATAATTTGAATCATGTAATATTTAAGGTTATACTATGCCTATTTGAAAA TGATATTAGTTATCAACTTTGCAGTTTGAAAAACATGTATTGTGTGTAAAGGTTAAATAACAAAACTATGCAGATGCTCTTAAAAGCATT GATAACCTTTGTGACGAACATAAAGAGATCCTTAAATTATGAGTTGTTGGCTTATCTTCATAAATAATTTGTCTGTAAAATGGATGAAAT >19093_19093_7_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000423725_length(amino acids)=885AA_BP=862 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGG PGNPALAEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFV NVNDQTNEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYS GSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVL GTSVESIMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEK SVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIE VNARLSRSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRT -------------------------------------------------------------- >19093_19093_8_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000432169_length(transcript)=2817nt_BP=2641nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGATGTCAAAGTGTACGGCAAAGGAAA CCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCTAGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCC CTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACCGGGGAACCCAGCTCTTGCAGAACCACTAATTCA GAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTACAGGAAACTTAATAACAGGATTGGCTGCTGGTGC CAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATATCACAAACAAACAGGCTTTCATTACTGCTCAGAA TCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAATGTCAACGATCAAACAAATGAGGGGATTATGCA TGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAATAGACACTGAGTACCTGTTTGATTCCTTTTTCTC ACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCT TATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAA TGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCC CATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTG TGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGA CAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGC AGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTT GATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGT GGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGT GGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGA ATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGC CTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGG GAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAG CCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTG CCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACC AAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGT GCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAG >19093_19093_8_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000432169_length(amino acids)=885AA_BP=862 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGG PGNPALAEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFV NVNDQTNEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYS GSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVL GTSVESIMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEK SVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIE VNARLSRSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRT -------------------------------------------------------------- >19093_19093_9_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000440274_length(transcript)=2962nt_BP=2641nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGATGTCAAAGTGTACGGCAAAGGAAA CCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCTAGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCC CTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACCGGGGAACCCAGCTCTTGCAGAACCACTAATTCA GAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTACAGGAAACTTAATAACAGGATTGGCTGCTGGTGC CAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATATCACAAACAAACAGGCTTTCATTACTGCTCAGAA TCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAATGTCAACGATCAAACAAATGAGGGGATTATGCA TGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAATAGACACTGAGTACCTGTTTGATTCCTTTTTCTC ACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCT TATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAA TGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCC CATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTG TGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGA CAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGC AGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTT GATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGT GGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGT GGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGA ATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGC CTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGG GAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAG CCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTG CCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACC AAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGT GCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAG TGATCCTTTACAGGTTTATTTCTTTGTAAAAAAAAATAATAATAATTTGAATCATGTAATATTTAAGGTTATACTATGCCTATTTGAAAA >19093_19093_9_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000440274_length(amino acids)=885AA_BP=862 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGG PGNPALAEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFV NVNDQTNEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYS GSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVL GTSVESIMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEK SVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIE VNARLSRSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRT -------------------------------------------------------------- >19093_19093_10_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000449699_length(transcript)=2817nt_BP=2641nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGATGTCAAAGTGTACGGCAAAGGAAA CCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCTAGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCC CTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACCGGGGAACCCAGCTCTTGCAGAACCACTAATTCA GAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTACAGGAAACTTAATAACAGGATTGGCTGCTGGTGC CAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATATCACAAACAAACAGGCTTTCATTACTGCTCAGAA TCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAATGTCAACGATCAAACAAATGAGGGGATTATGCA TGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAATAGACACTGAGTACCTGTTTGATTCCTTTTTCTC ACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCT TATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAA TGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCC CATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTG TGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGA CAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGC AGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTT GATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGT GGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGT GGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGA ATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGC CTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGG GAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAG CCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTG CCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACC AAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGT GCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAG >19093_19093_10_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000449699_length(amino acids)=885AA_BP=862 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGG PGNPALAEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFV NVNDQTNEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYS GSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVL GTSVESIMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEK SVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIE VNARLSRSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRT -------------------------------------------------------------- >19093_19093_11_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000455934_length(transcript)=2819nt_BP=2641nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGATGTCAAAGTGTACGGCAAAGGAAA CCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCTAGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCC CTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACCGGGGAACCCAGCTCTTGCAGAACCACTAATTCA GAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTACAGGAAACTTAATAACAGGATTGGCTGCTGGTGC CAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATATCACAAACAAACAGGCTTTCATTACTGCTCAGAA TCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAATGTCAACGATCAAACAAATGAGGGGATTATGCA TGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAATAGACACTGAGTACCTGTTTGATTCCTTTTTCTC ACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCT TATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAA TGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCC CATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTG TGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGA CAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGC AGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTT GATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGT GGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGT GGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGA ATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGC CTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGG GAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAG CCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTG CCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACC AAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGT GCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAG >19093_19093_11_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000455934_length(amino acids)=885AA_BP=862 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGG PGNPALAEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFV NVNDQTNEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYS GSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVL GTSVESIMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEK SVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIE VNARLSRSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRT -------------------------------------------------------------- >19093_19093_12_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000457011_length(transcript)=2973nt_BP=2641nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGATGTCAAAGTGTACGGCAAAGGAAA CCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCTAGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCC CTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACCGGGGAACCCAGCTCTTGCAGAACCACTAATTCA GAATGTCAGAAAGATTTTGGAGAGTGATCGCAAGGAGCCATTGTTTGGAATCAGTACAGGAAACTTAATAACAGGATTGGCTGCTGGTGC CAAAACCTACAAGATGTCCATGGCCAACAGAGGGCAGAATCAGCCTGTTTTGAATATCACAAACAAACAGGCTTTCATTACTGCTCAGAA TCATGGCTATGCCTTGGACAACACCCTCCCTGCTGGCTGGAAACCACTTTTTGTGAATGTCAACGATCAAACAAATGAGGGGATTATGCA TGAGAGCAAACCCTTCTTCGCTGTGCAGTTCCACCCAGAGGTCACCCCGGGGCCAATAGACACTGAGTACCTGTTTGATTCCTTTTTCTC ACTGATAAAGAAAGGAAAAGCTACCACCATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCT TATTCTAGGATCAGGAGGTCTGTCCATTGGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAA TGTCAAAACTGTTCTGATGAACCCAAACATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCC CATCACCCCTCAGTTTGTCACAGAGGTCATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTG TGGAGTGGAACTATTCAAGAGAGGTGTGCTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGA CAGGCAGCTGTTTTCAGATAAACTAAATGAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGC AGCAGACACCATTGGCTACCCAGTGATGATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTT GATGGACCTCAGCACAAAGGCCTTTGCTATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGT GGTTCGAGATGCTGATGACAATTGTGTCACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGT GGCTCCTGCCCAGACACTCTCCAATGCCGAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGA ATGCAACATTCAGTTTGCCCTTCATCCTACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGC CTCAAAAGCCACTGGCTACCCATTGGCATTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGG GAAGACATCAGCCTGTTTTGAACCTAGCCTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAG CCGAATTGGTAGCTCTATGAAAAGTGTAGGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTG CCACCCATCTATAGAAGGTTTCACTCCCCGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACC AAGCAGCACGCGTATCTATGCCATTGCCAAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGT GCCCAGGCAGTAGAGGAACCATCCATATGCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAG TGATCCTTTACAGGTTTATTTCTTTGTAAAAAAAAATAATAATAATTTGAATCATGTAATATTTAAGGTTATACTATGCCTATTTGAAAA TGATATTAGTTATCAACTTTGCAGTTTGAAAAACATGTATTGTGTGTAAAGGTTAAATAACAAAACTATGCAGATGCTCTTAAAAGCATT >19093_19093_12_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000430249_NDUFS1_chr2_206989000_ENST00000457011_length(amino acids)=885AA_BP=862 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGG PGNPALAEPLIQNVRKILESDRKEPLFGISTGNLITGLAAGAKTYKMSMANRGQNQPVLNITNKQAFITAQNHGYALDNTLPAGWKPLFV NVNDQTNEGIMHESKPFFAVQFHPEVTPGPIDTEYLFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYS GSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQADTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVL GTSVESIMATEDRQLFSDKLNEINEKIAPSFAVESIEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEK SVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVHTGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIE VNARLSRSSALASKATGYPLAFIAAKIALGIPLPEIKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRT -------------------------------------------------------------- >19093_19093_13_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000423725_length(transcript)=2171nt_BP=1713nt GAGAATAAACAGCAGCAGGAGAAGGAGGGGAAGGGTGTTGGAGGGGAGAGAGGGCATGCATGCACATACATAGATGATTCAGACGGCTTC AGAAAAGAACCACAAGGAATGCTTAGAGGAGTTTTGTATTTAATCTAAATATTTTTACTTTTTTGTGTGTGAGCTCTTAGTTCATTGTTC AAACCCATCTTTCCAAATAAATTCTTCTGGTGATATCCAGAAAAATCTGAAGTCTATTGTGACTTCCCCACACCCAGGGGCCTCCAGTAG CAAATCTTCATTGTCAGAACTCTCAGAAAAGACTTCGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACC ATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATT GGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAAC ATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTC ATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTG CTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAAT GAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATG ATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCT ATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTC ACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCC GAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCT ACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCA TTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGC CTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTA GGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCC CGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCC AAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATAT GCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAGTGATCCTTTACAGGTTTATTTCTTTGTA AAAAAAAATAATAATAATTTGAATCATGTAATATTTAAGGTTATACTATGCCTATTTGAAAATGATATTAGTTATCAACTTTGCAGTTTG AAAAACATGTATTGTGTGTAAAGGTTAAATAACAAAACTATGCAGATGCTCTTAAAAGCATTGATAACCTTTGTGACGAACATAAAGAGA TCCTTAAATTATGAGTTGTTGGCTTATCTTCATAAATAATTTGTCTGTAAAATGGATGAAATGAAAAGAGGTTCAATTAAAACCTACTTT >19093_19093_13_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000423725_length(amino acids)=490AA_BP=467 MFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQA DTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVESIMATEDRQLFSDKLNEINEKIAPSFAVES IEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVH TGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLSRSSALASKATGYPLAFIAAKIALGIPLPE IKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQKALRMCHPSIEGFTPRLPMNKEWPSNLDL -------------------------------------------------------------- >19093_19093_14_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000432169_length(transcript)=1889nt_BP=1713nt GAGAATAAACAGCAGCAGGAGAAGGAGGGGAAGGGTGTTGGAGGGGAGAGAGGGCATGCATGCACATACATAGATGATTCAGACGGCTTC AGAAAAGAACCACAAGGAATGCTTAGAGGAGTTTTGTATTTAATCTAAATATTTTTACTTTTTTGTGTGTGAGCTCTTAGTTCATTGTTC AAACCCATCTTTCCAAATAAATTCTTCTGGTGATATCCAGAAAAATCTGAAGTCTATTGTGACTTCCCCACACCCAGGGGCCTCCAGTAG CAAATCTTCATTGTCAGAACTCTCAGAAAAGACTTCGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACC ATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATT GGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAAC ATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTC ATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTG CTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAAT GAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATG ATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCT ATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTC ACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCC GAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCT ACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCA TTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGC CTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTA GGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCC CGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCC AAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATAT >19093_19093_14_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000432169_length(amino acids)=490AA_BP=467 MFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQA DTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVESIMATEDRQLFSDKLNEINEKIAPSFAVES IEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVH TGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLSRSSALASKATGYPLAFIAAKIALGIPLPE IKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQKALRMCHPSIEGFTPRLPMNKEWPSNLDL -------------------------------------------------------------- >19093_19093_15_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000440274_length(transcript)=2034nt_BP=1713nt GAGAATAAACAGCAGCAGGAGAAGGAGGGGAAGGGTGTTGGAGGGGAGAGAGGGCATGCATGCACATACATAGATGATTCAGACGGCTTC AGAAAAGAACCACAAGGAATGCTTAGAGGAGTTTTGTATTTAATCTAAATATTTTTACTTTTTTGTGTGTGAGCTCTTAGTTCATTGTTC AAACCCATCTTTCCAAATAAATTCTTCTGGTGATATCCAGAAAAATCTGAAGTCTATTGTGACTTCCCCACACCCAGGGGCCTCCAGTAG CAAATCTTCATTGTCAGAACTCTCAGAAAAGACTTCGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACC ATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATT GGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAAC ATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTC ATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTG CTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAAT GAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATG ATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCT ATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTC ACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCC GAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCT ACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCA TTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGC CTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTA GGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCC CGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCC AAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATAT GCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAGTGATCCTTTACAGGTTTATTTCTTTGTA AAAAAAAATAATAATAATTTGAATCATGTAATATTTAAGGTTATACTATGCCTATTTGAAAATGATATTAGTTATCAACTTTGCAGTTTG >19093_19093_15_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000440274_length(amino acids)=490AA_BP=467 MFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQA DTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVESIMATEDRQLFSDKLNEINEKIAPSFAVES IEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVH TGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLSRSSALASKATGYPLAFIAAKIALGIPLPE IKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQKALRMCHPSIEGFTPRLPMNKEWPSNLDL -------------------------------------------------------------- >19093_19093_16_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000449699_length(transcript)=1889nt_BP=1713nt GAGAATAAACAGCAGCAGGAGAAGGAGGGGAAGGGTGTTGGAGGGGAGAGAGGGCATGCATGCACATACATAGATGATTCAGACGGCTTC AGAAAAGAACCACAAGGAATGCTTAGAGGAGTTTTGTATTTAATCTAAATATTTTTACTTTTTTGTGTGTGAGCTCTTAGTTCATTGTTC AAACCCATCTTTCCAAATAAATTCTTCTGGTGATATCCAGAAAAATCTGAAGTCTATTGTGACTTCCCCACACCCAGGGGCCTCCAGTAG CAAATCTTCATTGTCAGAACTCTCAGAAAAGACTTCGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACC ATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATT GGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAAC ATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTC ATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTG CTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAAT GAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATG ATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCT ATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTC ACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCC GAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCT ACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCA TTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGC CTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTA GGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCC CGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCC AAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATAT >19093_19093_16_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000449699_length(amino acids)=490AA_BP=467 MFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQA DTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVESIMATEDRQLFSDKLNEINEKIAPSFAVES IEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVH TGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLSRSSALASKATGYPLAFIAAKIALGIPLPE IKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQKALRMCHPSIEGFTPRLPMNKEWPSNLDL -------------------------------------------------------------- >19093_19093_17_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000455934_length(transcript)=1891nt_BP=1713nt GAGAATAAACAGCAGCAGGAGAAGGAGGGGAAGGGTGTTGGAGGGGAGAGAGGGCATGCATGCACATACATAGATGATTCAGACGGCTTC AGAAAAGAACCACAAGGAATGCTTAGAGGAGTTTTGTATTTAATCTAAATATTTTTACTTTTTTGTGTGTGAGCTCTTAGTTCATTGTTC AAACCCATCTTTCCAAATAAATTCTTCTGGTGATATCCAGAAAAATCTGAAGTCTATTGTGACTTCCCCACACCCAGGGGCCTCCAGTAG CAAATCTTCATTGTCAGAACTCTCAGAAAAGACTTCGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACC ATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATT GGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAAC ATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTC ATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTG CTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAAT GAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATG ATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCT ATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTC ACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCC GAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCT ACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCA TTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGC CTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTA GGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCC CGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCC AAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATAT GCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAGTGATCCTTTACAGGTTTATTTCTTTGTA >19093_19093_17_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000455934_length(amino acids)=490AA_BP=467 MFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQA DTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVESIMATEDRQLFSDKLNEINEKIAPSFAVES IEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVH TGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLSRSSALASKATGYPLAFIAAKIALGIPLPE IKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQKALRMCHPSIEGFTPRLPMNKEWPSNLDL -------------------------------------------------------------- >19093_19093_18_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000457011_length(transcript)=2045nt_BP=1713nt GAGAATAAACAGCAGCAGGAGAAGGAGGGGAAGGGTGTTGGAGGGGAGAGAGGGCATGCATGCACATACATAGATGATTCAGACGGCTTC AGAAAAGAACCACAAGGAATGCTTAGAGGAGTTTTGTATTTAATCTAAATATTTTTACTTTTTTGTGTGTGAGCTCTTAGTTCATTGTTC AAACCCATCTTTCCAAATAAATTCTTCTGGTGATATCCAGAAAAATCTGAAGTCTATTGTGACTTCCCCACACCCAGGGGCCTCCAGTAG CAAATCTTCATTGTCAGAACTCTCAGAAAAGACTTCGAGTACCTGTTTGATTCCTTTTTCTCACTGATAAAGAAAGGAAAAGCTACCACC ATTACATCAGTCTTACCGAAGCCAGCACTAGTTGCATCTCGGGTTGAGGTTTCCAAAGTCCTTATTCTAGGATCAGGAGGTCTGTCCATT GGTCAGGCTGGAGAATTTGATTACTCAGGATCTCAAGCTGTAAAAGCCATGAAGGAAGAAAATGTCAAAACTGTTCTGATGAACCCAAAC ATTGCATCAGTCCAGACCAATGAGGTGGGCTTAAAGCAAGCGGATACTGTCTACTTTCTTCCCATCACCCCTCAGTTTGTCACAGAGGTC ATCAAGGCAGAACAGCCAGATGGGTTAATTCTGGGCATGGGTGGCCAGACAGCTCTGAACTGTGGAGTGGAACTATTCAAGAGAGGTGTG CTCAAGGAATATGGTGTGAAAGTCCTGGGAACTTCAGTTGAGTCCATTATGGCTACGGAAGACAGGCAGCTGTTTTCAGATAAACTAAAT GAGATCAATGAAAAGATTGCTCCAAGTTTTGCAGTGGAATCGATTGAGGATGCACTGAAGGCAGCAGACACCATTGGCTACCCAGTGATG ATCCGTTCCGCCTATGCACTGGGTGGGTTAGGCTCAGGCATCTGTCCCAACAGAGAGACTTTGATGGACCTCAGCACAAAGGCCTTTGCT ATGACCAACCAAATTCTGGTGGAGAAGTCAGTGACAGGTTGGAAAGAAATAGAATATGAAGTGGTTCGAGATGCTGATGACAATTGTGTC ACTGTCTGTAACATGGAAAATGTTGATGCCATGGGTGTTCACACAGGTGACTCAGTTGTTGTGGCTCCTGCCCAGACACTCTCCAATGCC GAGTTTCAGATGTTGAGACGTACTTCAATCAATGTTGTTCGCCACTTGGGCATTGTGGGTGAATGCAACATTCAGTTTGCCCTTCATCCT ACCTCAATGGAATACTGCATCATTGAAGTGAATGCCAGACTGTCCCGAAGCTCTGCTCTGGCCTCAAAAGCCACTGGCTACCCATTGGCA TTCATTGCTGCAAAGATTGCCCTAGGAATCCCACTTCCAGAAATTAAGAACGTCGTATCCGGGAAGACATCAGCCTGTTTTGAACCTAGC CTGGATTACATGGTCACCAAGATTCCCCGCTGGGATCTTGACCGTTTTCATGGAACATCTAGCCGAATTGGTAGCTCTATGAAAAGTGTA GGAGAGGTCATGGCTATTGGTCGTACCTTTGAGGAGAGTTTCCAGAAAGCTTTACGGATGTGCCACCCATCTATAGAAGGTTTCACTCCC CGTCTCCCAATGAACAAAGAATGGCCATCTAATTTAGATCTTAGAAAAGAGTTGTCTGAACCAAGCAGCACGCGTATCTATGCCATTGCC AAGATTCAATTAGCAGAGCCTCACAGACAATGGCCAAATGTGTCAAAGCTGTCACAGAGGGTGCCCAGGCAGTAGAGGAACCATCCATAT GCTGAAGCTTCTACTAGGATCCCAGTTTTGCCGCAGATAATTAATGGACAACTGTAGTGCAGTGATCCTTTACAGGTTTATTTCTTTGTA AAAAAAAATAATAATAATTTGAATCATGTAATATTTAAGGTTATACTATGCCTATTTGAAAATGATATTAGTTATCAACTTTGCAGTTTG >19093_19093_18_CPS1-NDUFS1_CPS1_chr2_211477017_ENST00000451903_NDUFS1_chr2_206989000_ENST00000457011_length(amino acids)=490AA_BP=467 MFDSFFSLIKKGKATTITSVLPKPALVASRVEVSKVLILGSGGLSIGQAGEFDYSGSQAVKAMKEENVKTVLMNPNIASVQTNEVGLKQA DTVYFLPITPQFVTEVIKAEQPDGLILGMGGQTALNCGVELFKRGVLKEYGVKVLGTSVESIMATEDRQLFSDKLNEINEKIAPSFAVES IEDALKAADTIGYPVMIRSAYALGGLGSGICPNRETLMDLSTKAFAMTNQILVEKSVTGWKEIEYEVVRDADDNCVTVCNMENVDAMGVH TGDSVVVAPAQTLSNAEFQMLRRTSINVVRHLGIVGECNIQFALHPTSMEYCIIEVNARLSRSSALASKATGYPLAFIAAKIALGIPLPE IKNVVSGKTSACFEPSLDYMVTKIPRWDLDRFHGTSSRIGSSMKSVGEVMAIGRTFEESFQKALRMCHPSIEGFTPRLPMNKEWPSNLDL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CPS1-NDUFS1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CPS1-NDUFS1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
| Hgene | CPS1 | P31327 | DB06775 | Carglumic acid | Allosteric modulator | Small molecule | Approved |
| Tgene | NDUFS1 | P28331 | DB00157 | NADH | Small molecule | Approved|Nutraceutical |
Top |
Related Diseases for CPS1-NDUFS1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | CPS1 | C4082171 | Hyperammonemia Due to Carbamoyl Phosphate Synthetase 1 Deficiency | 19 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Hgene | CPS1 | C0751753 | Carbamoyl-Phosphate Synthase I Deficiency Disease | 13 | CLINGEN;CTD_human;ORPHANET |
| Hgene | CPS1 | C0220994 | Hyperammonemia | 2 | CTD_human |
| Hgene | CPS1 | C4085580 | Carbamoyl Phosphate Synthase 1 Deficiency | 2 | CTD_human |
| Hgene | CPS1 | C0009421 | Comatose | 1 | CTD_human |
| Hgene | CPS1 | C0019193 | Hepatitis, Toxic | 1 | CTD_human |
| Hgene | CPS1 | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human |
| Hgene | CPS1 | C0031190 | Persistent Fetal Circulation Syndrome | 1 | CTD_human |
| Hgene | CPS1 | C0032927 | Precancerous Conditions | 1 | CTD_human |
| Hgene | CPS1 | C0282313 | Condition, Preneoplastic | 1 | CTD_human |
| Hgene | CPS1 | C0376618 | Endotoxemia | 1 | CTD_human |
| Hgene | CPS1 | C0860207 | Drug-Induced Liver Disease | 1 | CTD_human |
| Hgene | CPS1 | C0860634 | Psychogenic coma | 1 | CTD_human |
| Hgene | CPS1 | C1262760 | Hepatitis, Drug-Induced | 1 | CTD_human |
| Hgene | CPS1 | C3658290 | Drug-Induced Acute Liver Injury | 1 | CTD_human |
| Hgene | CPS1 | C4277682 | Chemical and Drug Induced Liver Injury | 1 | CTD_human |
| Hgene | CPS1 | C4279912 | Chemically-Induced Liver Toxicity | 1 | CTD_human |
| Tgene | C0023264 | Leigh Disease | 12 | CLINGEN;GENOMICS_ENGLAND | |
| Tgene | C1838951 | LEIGH SYNDROME DUE TO MITOCHONDRIAL COMPLEX I DEFICIENCY | 12 | CLINGEN | |
| Tgene | C1850597 | Leigh Syndrome Due To Mitochondrial Complex II Deficiency | 12 | CLINGEN | |
| Tgene | C1850598 | Leigh Syndrome due to Mitochondrial Complex III Deficiency | 12 | CLINGEN | |
| Tgene | C1850599 | Leigh Syndrome due to Mitochondrial Complex IV Deficiency | 12 | CLINGEN | |
| Tgene | C1850600 | Leigh Syndrome due to Mitochondrial Complex V Deficiency | 12 | CLINGEN | |
| Tgene | C2931891 | Necrotizing encephalopathy, infantile subacute, of Leigh | 12 | CLINGEN | |
| Tgene | C1838979 | MITOCHONDRIAL COMPLEX I DEFICIENCY | 5 | GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C1656427 | Early onset schizophrenia | 2 | PSYGENET | |
| Tgene | C0007194 | Hypertrophic Cardiomyopathy | 1 | CTD_human | |
| Tgene | C0024623 | Malignant neoplasm of stomach | 1 | CTD_human | |
| Tgene | C0036341 | Schizophrenia | 1 | PSYGENET | |
| Tgene | C0038356 | Stomach Neoplasms | 1 | CTD_human | |
| Tgene | C0235874 | Disease Exacerbation | 1 | CTD_human | |
| Tgene | C0751651 | Mitochondrial Diseases | 1 | GENOMICS_ENGLAND | |
| Tgene | C1708349 | Hereditary Diffuse Gastric Cancer | 1 | CTD_human | |
| Tgene | C4551472 | Hypertrophic obstructive cardiomyopathy | 1 | CTD_human | |
| Tgene | C4748754 | MITOCHONDRIAL COMPLEX I DEFICIENCY, NUCLEAR TYPE 5 | 1 | GENOMICS_ENGLAND;UNIPROT |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies