
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:FMR1-FIP1L1 (FusionGDB2 ID:HG2332TG81608) |
Fusion Gene Summary for FMR1-FIP1L1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: FMR1-FIP1L1 | Fusion gene ID: hg2332tg81608 | Hgene | Tgene | Gene symbol | FMR1 | FIP1L1 | Gene ID | 2332 | 81608 |
| Gene name | FMRP translational regulator 1 | factor interacting with PAPOLA and CPSF1 | |
| Synonyms | FMRP|FRAXA|POF|POF1 | FIP1|Rhe|hFip1 | |
| Cytomap | ('FMR1')('FIP1L1') Xq27.3 | 4q12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | synaptic functional regulator FMR1fragile X mental retardation 1fragile X mental retardation protein 1truncated FMRP | pre-mRNA 3'-end-processing factor FIP1FIP1 like 1FIP1-like 1 proteinFIP1L1 cleavage and polyadenylation specific factor subunitfactor interacting with PAPrearranged in hypereosinophilia | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q06787 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000218200, ENST00000334557, ENST00000370470, ENST00000370471, ENST00000370475, ENST00000370477, ENST00000439526, ENST00000440235, ENST00000492846, | ||
| Fusion gene scores | * DoF score | 7 X 3 X 6=126 | 17 X 15 X 11=2805 |
| # samples | 7 | 23 | |
| ** MAII score | log2(7/126*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(23/2805*10)=-3.60829500455178 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: FMR1 [Title/Abstract] AND FIP1L1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | FMR1(146993748)-FIP1L1(54265896), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | FMR1-FIP1L1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. FMR1-FIP1L1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. FMR1-FIP1L1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. FMR1-FIP1L1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | FMR1 | GO:0000381 | regulation of alternative mRNA splicing, via spliceosome | 18653529 |
| Hgene | FMR1 | GO:0002092 | positive regulation of receptor internalization | 25561520 |
| Hgene | FMR1 | GO:0006974 | cellular response to DNA damage stimulus | 24813610 |
| Hgene | FMR1 | GO:0033129 | positive regulation of histone phosphorylation | 24813610 |
| Hgene | FMR1 | GO:0045727 | positive regulation of translation | 19097999|19166269 |
| Hgene | FMR1 | GO:0051489 | regulation of filopodium assembly | 16631377 |
| Hgene | FMR1 | GO:0060998 | regulation of dendritic spine development | 16631377 |
| Hgene | FMR1 | GO:0098586 | cellular response to virus | 24514761 |
| Hgene | FMR1 | GO:0098908 | regulation of neuronal action potential | 25561520 |
| Hgene | FMR1 | GO:1902416 | positive regulation of mRNA binding | 25464849 |
| Hgene | FMR1 | GO:2000637 | positive regulation of gene silencing by miRNA | 17057366 |
| Hgene | FMR1 | GO:2001022 | positive regulation of response to DNA damage stimulus | 24813610 |
| Fusion gene breakpoints across FMR1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across FIP1L1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-CV-A45U | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
Top |
Fusion Gene ORF analysis for FMR1-FIP1L1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000218200 | ENST00000510668 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| 5CDS-intron | ENST00000334557 | ENST00000510668 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| 5CDS-intron | ENST00000370470 | ENST00000510668 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| 5CDS-intron | ENST00000370471 | ENST00000510668 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| 5CDS-intron | ENST00000370475 | ENST00000510668 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| 5CDS-intron | ENST00000370477 | ENST00000510668 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| 5CDS-intron | ENST00000439526 | ENST00000510668 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000218200 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000218200 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000218200 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000218200 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000218200 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000334557 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000334557 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000334557 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000334557 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000334557 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370470 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370470 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370470 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370470 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370470 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370471 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370471 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370471 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370471 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370471 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370475 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370475 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370475 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370475 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370475 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370477 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370477 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370477 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370477 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000370477 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000439526 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000439526 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000439526 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000439526 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| In-frame | ENST00000439526 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000440235 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000440235 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000440235 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000440235 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000440235 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000492846 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000492846 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000492846 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000492846 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-3CDS | ENST00000492846 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-intron | ENST00000440235 | ENST00000510668 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| intron-intron | ENST00000492846 | ENST00000510668 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000218200 | FMR1 | chrX | 146993748 | + | ENST00000507166 | FIP1L1 | chr4 | 54265896 | + | 2125 | 280 | 160 | 2124 | 655 |
| ENST00000218200 | FMR1 | chrX | 146993748 | + | ENST00000358575 | FIP1L1 | chr4 | 54265896 | + | 1606 | 280 | 160 | 1386 | 408 |
| ENST00000218200 | FMR1 | chrX | 146993748 | + | ENST00000337488 | FIP1L1 | chr4 | 54265896 | + | 1579 | 280 | 160 | 1359 | 399 |
| ENST00000218200 | FMR1 | chrX | 146993748 | + | ENST00000507922 | FIP1L1 | chr4 | 54265896 | + | 787 | 280 | 160 | 756 | 198 |
| ENST00000218200 | FMR1 | chrX | 146993748 | + | ENST00000306932 | FIP1L1 | chr4 | 54265896 | + | 1424 | 280 | 160 | 1251 | 363 |
| ENST00000370471 | FMR1 | chrX | 146993748 | + | ENST00000507166 | FIP1L1 | chr4 | 54265896 | + | 2125 | 280 | 160 | 2124 | 655 |
| ENST00000370471 | FMR1 | chrX | 146993748 | + | ENST00000358575 | FIP1L1 | chr4 | 54265896 | + | 1606 | 280 | 160 | 1386 | 408 |
| ENST00000370471 | FMR1 | chrX | 146993748 | + | ENST00000337488 | FIP1L1 | chr4 | 54265896 | + | 1579 | 280 | 160 | 1359 | 399 |
| ENST00000370471 | FMR1 | chrX | 146993748 | + | ENST00000507922 | FIP1L1 | chr4 | 54265896 | + | 787 | 280 | 160 | 756 | 198 |
| ENST00000370471 | FMR1 | chrX | 146993748 | + | ENST00000306932 | FIP1L1 | chr4 | 54265896 | + | 1424 | 280 | 160 | 1251 | 363 |
| ENST00000370477 | FMR1 | chrX | 146993748 | + | ENST00000507166 | FIP1L1 | chr4 | 54265896 | + | 2113 | 268 | 148 | 2112 | 655 |
| ENST00000370477 | FMR1 | chrX | 146993748 | + | ENST00000358575 | FIP1L1 | chr4 | 54265896 | + | 1594 | 268 | 148 | 1374 | 408 |
| ENST00000370477 | FMR1 | chrX | 146993748 | + | ENST00000337488 | FIP1L1 | chr4 | 54265896 | + | 1567 | 268 | 148 | 1347 | 399 |
| ENST00000370477 | FMR1 | chrX | 146993748 | + | ENST00000507922 | FIP1L1 | chr4 | 54265896 | + | 775 | 268 | 148 | 744 | 198 |
| ENST00000370477 | FMR1 | chrX | 146993748 | + | ENST00000306932 | FIP1L1 | chr4 | 54265896 | + | 1412 | 268 | 148 | 1239 | 363 |
| ENST00000334557 | FMR1 | chrX | 146993748 | + | ENST00000507166 | FIP1L1 | chr4 | 54265896 | + | 2024 | 179 | 59 | 2023 | 655 |
| ENST00000334557 | FMR1 | chrX | 146993748 | + | ENST00000358575 | FIP1L1 | chr4 | 54265896 | + | 1505 | 179 | 59 | 1285 | 408 |
| ENST00000334557 | FMR1 | chrX | 146993748 | + | ENST00000337488 | FIP1L1 | chr4 | 54265896 | + | 1478 | 179 | 59 | 1258 | 399 |
| ENST00000334557 | FMR1 | chrX | 146993748 | + | ENST00000507922 | FIP1L1 | chr4 | 54265896 | + | 686 | 179 | 59 | 655 | 198 |
| ENST00000334557 | FMR1 | chrX | 146993748 | + | ENST00000306932 | FIP1L1 | chr4 | 54265896 | + | 1323 | 179 | 59 | 1150 | 363 |
| ENST00000439526 | FMR1 | chrX | 146993748 | + | ENST00000507166 | FIP1L1 | chr4 | 54265896 | + | 2024 | 179 | 59 | 2023 | 655 |
| ENST00000439526 | FMR1 | chrX | 146993748 | + | ENST00000358575 | FIP1L1 | chr4 | 54265896 | + | 1505 | 179 | 59 | 1285 | 408 |
| ENST00000439526 | FMR1 | chrX | 146993748 | + | ENST00000337488 | FIP1L1 | chr4 | 54265896 | + | 1478 | 179 | 59 | 1258 | 399 |
| ENST00000439526 | FMR1 | chrX | 146993748 | + | ENST00000507922 | FIP1L1 | chr4 | 54265896 | + | 686 | 179 | 59 | 655 | 198 |
| ENST00000439526 | FMR1 | chrX | 146993748 | + | ENST00000306932 | FIP1L1 | chr4 | 54265896 | + | 1323 | 179 | 59 | 1150 | 363 |
| ENST00000370475 | FMR1 | chrX | 146993748 | + | ENST00000507166 | FIP1L1 | chr4 | 54265896 | + | 2024 | 179 | 59 | 2023 | 655 |
| ENST00000370475 | FMR1 | chrX | 146993748 | + | ENST00000358575 | FIP1L1 | chr4 | 54265896 | + | 1505 | 179 | 59 | 1285 | 408 |
| ENST00000370475 | FMR1 | chrX | 146993748 | + | ENST00000337488 | FIP1L1 | chr4 | 54265896 | + | 1478 | 179 | 59 | 1258 | 399 |
| ENST00000370475 | FMR1 | chrX | 146993748 | + | ENST00000507922 | FIP1L1 | chr4 | 54265896 | + | 686 | 179 | 59 | 655 | 198 |
| ENST00000370475 | FMR1 | chrX | 146993748 | + | ENST00000306932 | FIP1L1 | chr4 | 54265896 | + | 1323 | 179 | 59 | 1150 | 363 |
| ENST00000370470 | FMR1 | chrX | 146993748 | + | ENST00000507166 | FIP1L1 | chr4 | 54265896 | + | 1896 | 51 | 0 | 1895 | 631 |
| ENST00000370470 | FMR1 | chrX | 146993748 | + | ENST00000358575 | FIP1L1 | chr4 | 54265896 | + | 1377 | 51 | 0 | 1157 | 385 |
| ENST00000370470 | FMR1 | chrX | 146993748 | + | ENST00000337488 | FIP1L1 | chr4 | 54265896 | + | 1350 | 51 | 0 | 1130 | 376 |
| ENST00000370470 | FMR1 | chrX | 146993748 | + | ENST00000507922 | FIP1L1 | chr4 | 54265896 | + | 558 | 51 | 0 | 527 | 175 |
| ENST00000370470 | FMR1 | chrX | 146993748 | + | ENST00000306932 | FIP1L1 | chr4 | 54265896 | + | 1195 | 51 | 0 | 1022 | 340 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000218200 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.003420336 | 0.9965797 |
| ENST00000218200 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.016237194 | 0.98376274 |
| ENST00000218200 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.01062985 | 0.9893701 |
| ENST00000218200 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.010497479 | 0.98950255 |
| ENST00000218200 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.014470562 | 0.9855295 |
| ENST00000370471 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.003420336 | 0.9965797 |
| ENST00000370471 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.016237194 | 0.98376274 |
| ENST00000370471 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.01062985 | 0.9893701 |
| ENST00000370471 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.010497479 | 0.98950255 |
| ENST00000370471 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.014470562 | 0.9855295 |
| ENST00000370477 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.003613992 | 0.99638605 |
| ENST00000370477 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.017130291 | 0.9828697 |
| ENST00000370477 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.01131137 | 0.98868865 |
| ENST00000370477 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.009717943 | 0.99028206 |
| ENST00000370477 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.015412188 | 0.9845878 |
| ENST00000334557 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.003560521 | 0.9964394 |
| ENST00000334557 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.019101437 | 0.98089856 |
| ENST00000334557 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.012717979 | 0.9872821 |
| ENST00000334557 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.009641513 | 0.99035853 |
| ENST00000334557 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.017868744 | 0.98213124 |
| ENST00000439526 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.003560521 | 0.9964394 |
| ENST00000439526 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.019101437 | 0.98089856 |
| ENST00000439526 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.012717979 | 0.9872821 |
| ENST00000439526 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.009641513 | 0.99035853 |
| ENST00000439526 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.017868744 | 0.98213124 |
| ENST00000370475 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.003560521 | 0.9964394 |
| ENST00000370475 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.019101437 | 0.98089856 |
| ENST00000370475 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.012717979 | 0.9872821 |
| ENST00000370475 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.009641513 | 0.99035853 |
| ENST00000370475 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.017868744 | 0.98213124 |
| ENST00000370470 | ENST00000507166 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.002459956 | 0.9975401 |
| ENST00000370470 | ENST00000358575 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.019863257 | 0.98013675 |
| ENST00000370470 | ENST00000337488 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.011988658 | 0.9880114 |
| ENST00000370470 | ENST00000507922 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.02670579 | 0.97329426 |
| ENST00000370470 | ENST00000306932 | FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 0.015541088 | 0.9844589 |
Top |
Fusion Genomic Features for FMR1-FIP1L1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 1.49E-09 | 1 |
| FMR1 | chrX | 146993748 | + | FIP1L1 | chr4 | 54265896 | + | 1.49E-09 | 1 |
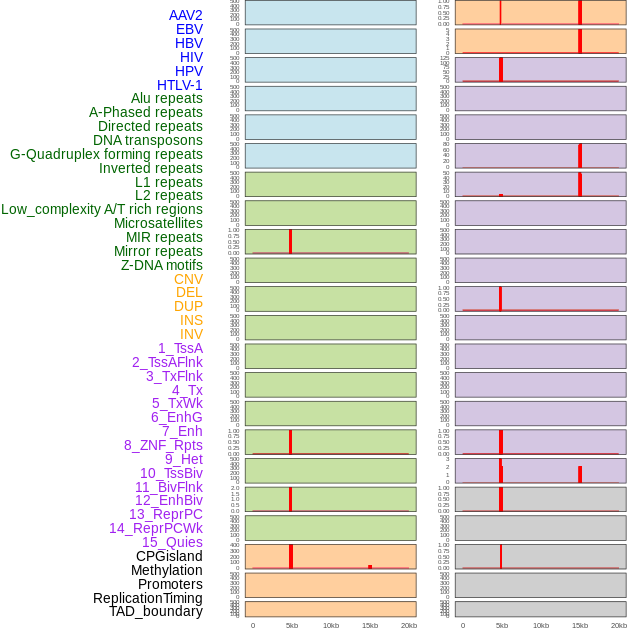
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for FMR1-FIP1L1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chrX:146993748/chr4:54265896) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| FMR1 | . |
| FUNCTION: Multifunctional polyribosome-associated RNA-binding protein that plays a central role in neuronal development and synaptic plasticity through the regulation of alternative mRNA splicing, mRNA stability, mRNA dendritic transport and postsynaptic local protein synthesis of a subset of mRNAs (PubMed:16631377, PubMed:18653529, PubMed:19166269, PubMed:23235829, PubMed:25464849). Plays a role in the alternative splicing of its own mRNA (PubMed:18653529). Plays a role in mRNA nuclear export (By similarity). Together with export factor NXF2, is involved in the regulation of the NXF1 mRNA stability in neurons (By similarity). Stabilizes the scaffolding postsynaptic density protein DLG4/PSD-95 and the myelin basic protein (MBP) mRNAs in hippocampal neurons and glial cells, respectively; this stabilization is further increased in response to metabotropic glutamate receptor (mGluR) stimulation (By similarity). Plays a role in selective delivery of a subset of dendritic mRNAs to synaptic sites in response to mGluR activation in a kinesin-dependent manner (By similarity). Plays a role as a repressor of mRNA translation during the transport of dendritic mRNAs to postsynaptic dendritic spines (PubMed:11532944, PubMed:11157796, PubMed:12594214, PubMed:23235829). Component of the CYFIP1-EIF4E-FMR1 complex which blocks cap-dependent mRNA translation initiation (By similarity). Represses mRNA translation by stalling ribosomal translocation during elongation (By similarity). Reports are contradictory with regards to its ability to mediate translation inhibition of MBP mRNA in oligodendrocytes (PubMed:23891804). Also involved in the recruitment of the RNA helicase MOV10 to a subset of mRNAs and hence regulates microRNA (miRNA)-mediated translational repression by AGO2 (PubMed:14703574, PubMed:17057366, PubMed:25464849). Facilitates the assembly of miRNAs on specific target mRNAs (PubMed:17057366). Plays also a role as an activator of mRNA translation of a subset of dendritic mRNAs at synapses (PubMed:19097999, PubMed:19166269). In response to mGluR stimulation, FMR1-target mRNAs are rapidly derepressed, allowing for local translation at synapses (By similarity). Binds to a large subset of dendritic mRNAs that encode a myriad of proteins involved in pre- and postsynaptic functions (PubMed:7692601, PubMed:11719189, PubMed:11157796, PubMed:12594214, PubMed:17417632, PubMed:23235829, PubMed:24448548). Binds to 5'-ACU[GU]-3' and/or 5'-[AU]GGA-3' RNA consensus sequences within mRNA targets, mainly at coding sequence (CDS) and 3'-untranslated region (UTR) and less frequently at 5'-UTR (PubMed:23235829). Binds to intramolecular G-quadruplex structures in the 5'- or 3'-UTRs of mRNA targets (PubMed:11719189, PubMed:18579868, PubMed:25464849, PubMed:25692235). Binds to G-quadruplex structures in the 3'-UTR of its own mRNA (PubMed:7692601, PubMed:11532944, PubMed:12594214, PubMed:15282548, PubMed:18653529). Binds also to RNA ligands harboring a kissing complex (kc) structure; this binding may mediate the association of FMR1 with polyribosomes (PubMed:15805463). Binds mRNAs containing U-rich target sequences (PubMed:12927206). Binds to a triple stem-loop RNA structure, called Sod1 stem loop interacting with FMRP (SoSLIP), in the 5'-UTR region of superoxide dismutase SOD1 mRNA (PubMed:19166269). Binds to the dendritic, small non-coding brain cytoplasmic RNA 1 (BC1); which may increase the association of the CYFIP1-EIF4E-FMR1 complex to FMR1 target mRNAs at synapses (By similarity). Associates with export factor NXF1 mRNA-containing ribonucleoprotein particles (mRNPs) in a NXF2-dependent manner (By similarity). Binds to a subset of miRNAs in the brain (PubMed:14703574, PubMed:17057366). May associate with nascent transcripts in a nuclear protein NXF1-dependent manner (PubMed:18936162). In vitro, binds to RNA homopolymer; preferentially on poly(G) and to a lesser extent on poly(U), but not on poly(A) or poly(C) (PubMed:7688265, PubMed:7781595, PubMed:12950170, PubMed:15381419, PubMed:8156595). Moreover, plays a role in the modulation of the sodium-activated potassium channel KCNT1 gating activity (PubMed:20512134). Negatively regulates the voltage-dependent calcium channel current density in soma and presynaptic terminals of dorsal root ganglion (DRG) neurons, and hence regulates synaptic vesicle exocytosis (By similarity). Modulates the voltage-dependent calcium channel CACNA1B expression at the plasma membrane by targeting the channels for proteosomal degradation (By similarity). Plays a role in regulation of MAP1B-dependent microtubule dynamics during neuronal development (By similarity). Recently, has been shown to play a translation-independent role in the modulation of presynaptic action potential (AP) duration and neurotransmitter release via large-conductance calcium-activated potassium (BK) channels in hippocampal and cortical excitatory neurons (PubMed:25561520). Finally, FMR1 may be involved in the control of DNA damage response (DDR) mechanisms through the regulation of ATR-dependent signaling pathways such as histone H2AX/H2A.x and BRCA1 phosphorylations (PubMed:24813610). {ECO:0000250|UniProtKB:P35922, ECO:0000250|UniProtKB:Q80WE1, ECO:0000269|PubMed:11157796, ECO:0000269|PubMed:11532944, ECO:0000269|PubMed:11719189, ECO:0000269|PubMed:12594214, ECO:0000269|PubMed:12927206, ECO:0000269|PubMed:12950170, ECO:0000269|PubMed:14703574, ECO:0000269|PubMed:15282548, ECO:0000269|PubMed:15381419, ECO:0000269|PubMed:15805463, ECO:0000269|PubMed:16631377, ECO:0000269|PubMed:17057366, ECO:0000269|PubMed:17417632, ECO:0000269|PubMed:18579868, ECO:0000269|PubMed:18653529, ECO:0000269|PubMed:18936162, ECO:0000269|PubMed:19097999, ECO:0000269|PubMed:19166269, ECO:0000269|PubMed:20512134, ECO:0000269|PubMed:23235829, ECO:0000269|PubMed:23891804, ECO:0000269|PubMed:24448548, ECO:0000269|PubMed:24813610, ECO:0000269|PubMed:25464849, ECO:0000269|PubMed:25561520, ECO:0000269|PubMed:25692235, ECO:0000269|PubMed:7688265, ECO:0000269|PubMed:7692601, ECO:0000269|PubMed:7781595, ECO:0000269|PubMed:8156595}.; FUNCTION: [Isoform 10]: binds to RNA homopolymer; preferentially on poly(G) and to a lesser extent on poly(U), but not on poly(A) or poly(C) (PubMed:24204304). May bind to RNA in Cajal bodies (PubMed:24204304). {ECO:0000269|PubMed:24204304}.; FUNCTION: [Isoform 6]: binds to RNA homopolymer; preferentially on poly(G) and to a lesser extent on poly(U), but not on poly(A) or poly(C) (PubMed:24204304). May bind to RNA in Cajal bodies (PubMed:24204304). {ECO:0000269|PubMed:24204304}.; FUNCTION: (Microbial infection) Acts as a positive regulator of influenza A virus (IAV) replication. Required for the assembly and nuclear export of the viral ribonucleoprotein (vRNP) components. {ECO:0000269|PubMed:24514761}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000306932 | 6 | 15 | 356_406 | 197 | 521.0 | Compositional bias | Note=Pro-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000306932 | 6 | 15 | 456_562 | 197 | 521.0 | Compositional bias | Note=Arg-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000306932 | 6 | 15 | 478_594 | 197 | 521.0 | Compositional bias | Note=Glu-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000337488 | 8 | 18 | 356_406 | 235 | 595.0 | Compositional bias | Note=Pro-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000337488 | 8 | 18 | 456_562 | 235 | 595.0 | Compositional bias | Note=Arg-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000337488 | 8 | 18 | 478_594 | 235 | 595.0 | Compositional bias | Note=Glu-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000358575 | 7 | 18 | 356_406 | 220 | 589.0 | Compositional bias | Note=Pro-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000358575 | 7 | 18 | 456_562 | 220 | 589.0 | Compositional bias | Note=Arg-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000358575 | 7 | 18 | 478_594 | 220 | 589.0 | Compositional bias | Note=Glu-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507166 | 8 | 24 | 356_406 | 235 | 850.0 | Compositional bias | Note=Pro-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507166 | 8 | 24 | 456_562 | 235 | 850.0 | Compositional bias | Note=Arg-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507166 | 8 | 24 | 478_594 | 235 | 850.0 | Compositional bias | Note=Glu-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507922 | 7 | 12 | 356_406 | 220 | 379.0 | Compositional bias | Note=Pro-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507922 | 7 | 12 | 456_562 | 220 | 379.0 | Compositional bias | Note=Arg-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507922 | 7 | 12 | 478_594 | 220 | 379.0 | Compositional bias | Note=Glu-rich | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000306932 | 6 | 15 | 457_490 | 197 | 521.0 | Region | Arg/Asp/Glu-rich domain | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000337488 | 8 | 18 | 457_490 | 235 | 595.0 | Region | Arg/Asp/Glu-rich domain | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000358575 | 7 | 18 | 457_490 | 220 | 589.0 | Region | Arg/Asp/Glu-rich domain | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507166 | 8 | 24 | 457_490 | 235 | 850.0 | Region | Arg/Asp/Glu-rich domain | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507922 | 7 | 12 | 457_490 | 220 | 379.0 | Region | Arg/Asp/Glu-rich domain |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370470 | + | 1 | 17 | 222_251 | 17 | 591.0 | Domain | KH 1 |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370470 | + | 1 | 17 | 285_314 | 17 | 591.0 | Domain | KH 2 |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370470 | + | 1 | 17 | 4_50 | 17 | 591.0 | Domain | Agenet-like 1 |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370470 | + | 1 | 17 | 63_115 | 17 | 591.0 | Domain | Agenet-like 2 |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370475 | + | 1 | 17 | 222_251 | 17 | 633.0 | Domain | KH 1 |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370475 | + | 1 | 17 | 285_314 | 17 | 633.0 | Domain | KH 2 |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370475 | + | 1 | 17 | 4_50 | 17 | 633.0 | Domain | Agenet-like 1 |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370475 | + | 1 | 17 | 63_115 | 17 | 633.0 | Domain | Agenet-like 2 |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370470 | + | 1 | 17 | 424_443 | 17 | 591.0 | Motif | Nuclear export signal |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370475 | + | 1 | 17 | 424_443 | 17 | 633.0 | Motif | Nuclear export signal |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370470 | + | 1 | 17 | 1_184 | 17 | 591.0 | Region | Required for nuclear localization |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370470 | + | 1 | 17 | 397_491 | 17 | 591.0 | Region | Required for nuclear export |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370470 | + | 1 | 17 | 534_548 | 17 | 591.0 | Region | Note=RNA-binding RGG-box |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370475 | + | 1 | 17 | 1_184 | 17 | 633.0 | Region | Required for nuclear localization |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370475 | + | 1 | 17 | 397_491 | 17 | 633.0 | Region | Required for nuclear export |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370475 | + | 1 | 17 | 534_548 | 17 | 633.0 | Region | Note=RNA-binding RGG-box |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000306932 | 6 | 15 | 1_356 | 197 | 521.0 | Region | Note=Necessary for stimulating PAPOLA activity | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000337488 | 8 | 18 | 1_356 | 235 | 595.0 | Region | Note=Necessary for stimulating PAPOLA activity | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000358575 | 7 | 18 | 1_356 | 220 | 589.0 | Region | Note=Necessary for stimulating PAPOLA activity | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507166 | 8 | 24 | 1_356 | 235 | 850.0 | Region | Note=Necessary for stimulating PAPOLA activity | |
| Tgene | FIP1L1 | chrX:146993748 | chr4:54265896 | ENST00000507922 | 7 | 12 | 1_356 | 220 | 379.0 | Region | Note=Necessary for stimulating PAPOLA activity |
Top |
Fusion Gene Sequence for FMR1-FIP1L1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >30780_30780_1_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000306932_length(transcript)=1424nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGG CAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCC GTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGAT TCCACCACCGGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAG TCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAG CAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGA AAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAG GGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGA AACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATC TAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTT TTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTT >30780_30780_1_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000306932_length(amino acids)=363AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRRLPGAIDVIGQTI TISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFLPPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESG HSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSD EERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESEEGDSHRRHKHKKSKRSKEGKEAGSEPAPEQESTEAT -------------------------------------------------------------- >30780_30780_2_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000337488_length(transcript)=1579nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGT TGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAAC TATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAA TTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAG CACTGCTCCACCTCTGATTCCACCACCGGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACA TTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCC TAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGA CCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGA AGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACG ACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAG ACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACC TGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAG AAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTTTTCATGTTAAGTTAAA >30780_30780_2_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000337488_length(amino acids)=399AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRER DRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESE -------------------------------------------------------------- >30780_30780_3_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000358575_length(transcript)=1606nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGT TGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAAC TATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAA TTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAG CACTGCTCCACCTCTGATTCCACCACCGGGTATTCCAATAACTGTACCACCTCCAGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATC TCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCA TCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAG AGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCC TACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGA AAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGA AAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCC TGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATC TTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAA >30780_30780_3_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000358575_length(amino acids)=408AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGIPITVPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYAR REKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRS -------------------------------------------------------------- >30780_30780_4_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000507166_length(transcript)=2125nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGT TGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAAC TATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGCTGCCTTATGACTCAAGATGGGAGTTTCCAAGAGATGG ACTAGTGCTTGGTCGGGTCTTGGGGTCTGGAGCGTTTGGGAAGGTGGTTGAAGGAACAGCCTATGGATTAAGCCGGTCCCAACCTGTCAT GAAAGTTGCAGTGAAGATGCTAAAACCCACGGCCAGATCCAGTGAAAAACAAGCTCTCATGTCTGAACTGAAGATAATGACTCACCTGGG GCCACATTTGAACATTGTAAACTTGCTGGGAGCCTGCACCAAGTCAGGCCCCATTTACATCATCACAGAGTATTGCTTCTATGGAGATTT GGTCAACTATTTGCATAAGAATAGGGATAGCTTCCTGAGCCACCACCCAGAGAAGCCAAAGAAAGAGCTGGATATCTTTGGATTGAACCC TGCTGATGAAAGCACACGGAGCTATGTTATTTTATCTTTTGAAAACAATGGTGACTACATGGACATGAAGCAGGCTGATACTACACAGTA TGTCCCCATGCTAGAAAGGAAAGAGGTTTCTAAATATTCCGACATCCAGAGATCACTCTATGATCGTCCAGCCTCATATAAGAAGAAATC TATGTTAGACTCAGAAGTCAAAAACCTCCTTTCAGATGATAACTCAGAAGGCCTTACTTTATTGGATTTGTTGAGCTTCACCTATCAAGT TGCCCGAGGAATGGAGTTTTTGGCTTCAAAAAATTGTGTCCACCGTGATCTGGCTGCTCGCAACGTCCTCCTGGCACAAGGAAAAATTGT GAAGATCTGTGACTTTGGCCTGGCCAGAGACATCATGCATGATTCGAACTATGTGTCGAAAGGCAGTACCTTTCTGCCCGTGAAGTGGAT GGCTCCTGAGAGCATCTTTGACAACCTCTACACCACACTGAGTGATGTCTGGTCTTATGGCATTCTGCTCTGGGAGATCTTTTCCCTTGG TGGCACCCCTTACCCCGGCATGATGGTGGATTCTACTTTCTACAATAAGATCAAGAGTGGGTACCGGATGGCCAAGCCTGACCACGCTAC CAGTGAAGTCTACGAGATCATGGTGAAATGCTGGAACAGTGAGCCGGAGAAGAGACCCTCCTTTTACCACCTGAGTGAGATTGTGGAGAA TCTGCTGCCTGGACAATATAAAAAGAGTTATGAAAAAATTCACCTGGACTTCCTGAAGAGTGACCATCCTGCTGTGGCACGCATGCGTGT GGACTCAGACAATGCATACATTGGTGTCACCTACAAAAACGAGGAAGACAAGCTGAAGGACTGGGAGGGTGGTCTGGATGAGCAGAGACT GAGCGCTGACAGTGGCTACATCATTCCTCTGCCTGACATTGACCCTGTCCCTGAGGAGGAGGACCTGGGCAAGAGGAACAGACACAGCTC GCAGACCTCTGAAGAGAGTGCCATTGAGACGGGTTCCAGCAGTTCCACCTTCATCAAGAGAGAGGACGAGACCATTGAAGACATCGACAT >30780_30780_4_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000507166_length(amino acids)=655AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQLPYDSRWEFPRDGLVLGRVLGSGAFGKVVEGTAYGL SRSQPVMKVAVKMLKPTARSSEKQALMSELKIMTHLGPHLNIVNLLGACTKSGPIYIITEYCFYGDLVNYLHKNRDSFLSHHPEKPKKEL DIFGLNPADESTRSYVILSFENNGDYMDMKQADTTQYVPMLERKEVSKYSDIQRSLYDRPASYKKKSMLDSEVKNLLSDDNSEGLTLLDL LSFTYQVARGMEFLASKNCVHRDLAARNVLLAQGKIVKICDFGLARDIMHDSNYVSKGSTFLPVKWMAPESIFDNLYTTLSDVWSYGILL WEIFSLGGTPYPGMMVDSTFYNKIKSGYRMAKPDHATSEVYEIMVKCWNSEPEKRPSFYHLSEIVENLLPGQYKKSYEKIHLDFLKSDHP AVARMRVDSDNAYIGVTYKNEEDKLKDWEGGLDEQRLSADSGYIIPLPDIDPVPEEEDLGKRNRHSSQTSEESAIETGSSSSTFIKREDE -------------------------------------------------------------- >30780_30780_5_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000507922_length(transcript)=787nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGT TGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAAC TATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAA TTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAG >30780_30780_5_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000218200_FIP1L1_chr4_54265896_ENST00000507922_length(amino acids)=198AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL -------------------------------------------------------------- >30780_30780_6_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000306932_length(transcript)=1323nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGGCAGGCGACGGG CAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCCGTTTTTCCCTC CAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGATTCCACCACCGG GTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCAC GTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGG ACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCA CCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAG AAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATA AGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCA AAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTG TGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGT >30780_30780_6_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000306932_length(amino acids)=363AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRRLPGAIDVIGQTI TISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFLPPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESG HSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSD EERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESEEGDSHRRHKHKKSKRSKEGKEAGSEPAPEQESTEAT -------------------------------------------------------------- >30780_30780_7_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000337488_length(transcript)=1478nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAAC CACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCAC CTCTGATTCCACCACCGGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTT ATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGG ACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGG ACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACA GATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGA AAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACA AAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGG CATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTT AAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTTTTCATGTTAAGTTAAAAATCTTTGTCT >30780_30780_7_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000337488_length(amino acids)=399AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRER DRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESE -------------------------------------------------------------- >30780_30780_8_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000358575_length(transcript)=1505nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAAC CACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCAC CTCTGATTCCACCACCGGGTATTCCAATAACTGTACCACCTCCAGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAA CAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTT CTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACA GAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTG TTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAAC GACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAG GAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGA GCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTT CTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTT >30780_30780_8_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000358575_length(amino acids)=408AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGIPITVPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYAR REKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRS -------------------------------------------------------------- >30780_30780_9_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000507166_length(transcript)=2024nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGCTGCCTTATGACTCAAGATGGGAGTTTCCAAGAGATGGACTAGTGCTTG GTCGGGTCTTGGGGTCTGGAGCGTTTGGGAAGGTGGTTGAAGGAACAGCCTATGGATTAAGCCGGTCCCAACCTGTCATGAAAGTTGCAG TGAAGATGCTAAAACCCACGGCCAGATCCAGTGAAAAACAAGCTCTCATGTCTGAACTGAAGATAATGACTCACCTGGGGCCACATTTGA ACATTGTAAACTTGCTGGGAGCCTGCACCAAGTCAGGCCCCATTTACATCATCACAGAGTATTGCTTCTATGGAGATTTGGTCAACTATT TGCATAAGAATAGGGATAGCTTCCTGAGCCACCACCCAGAGAAGCCAAAGAAAGAGCTGGATATCTTTGGATTGAACCCTGCTGATGAAA GCACACGGAGCTATGTTATTTTATCTTTTGAAAACAATGGTGACTACATGGACATGAAGCAGGCTGATACTACACAGTATGTCCCCATGC TAGAAAGGAAAGAGGTTTCTAAATATTCCGACATCCAGAGATCACTCTATGATCGTCCAGCCTCATATAAGAAGAAATCTATGTTAGACT CAGAAGTCAAAAACCTCCTTTCAGATGATAACTCAGAAGGCCTTACTTTATTGGATTTGTTGAGCTTCACCTATCAAGTTGCCCGAGGAA TGGAGTTTTTGGCTTCAAAAAATTGTGTCCACCGTGATCTGGCTGCTCGCAACGTCCTCCTGGCACAAGGAAAAATTGTGAAGATCTGTG ACTTTGGCCTGGCCAGAGACATCATGCATGATTCGAACTATGTGTCGAAAGGCAGTACCTTTCTGCCCGTGAAGTGGATGGCTCCTGAGA GCATCTTTGACAACCTCTACACCACACTGAGTGATGTCTGGTCTTATGGCATTCTGCTCTGGGAGATCTTTTCCCTTGGTGGCACCCCTT ACCCCGGCATGATGGTGGATTCTACTTTCTACAATAAGATCAAGAGTGGGTACCGGATGGCCAAGCCTGACCACGCTACCAGTGAAGTCT ACGAGATCATGGTGAAATGCTGGAACAGTGAGCCGGAGAAGAGACCCTCCTTTTACCACCTGAGTGAGATTGTGGAGAATCTGCTGCCTG GACAATATAAAAAGAGTTATGAAAAAATTCACCTGGACTTCCTGAAGAGTGACCATCCTGCTGTGGCACGCATGCGTGTGGACTCAGACA ATGCATACATTGGTGTCACCTACAAAAACGAGGAAGACAAGCTGAAGGACTGGGAGGGTGGTCTGGATGAGCAGAGACTGAGCGCTGACA GTGGCTACATCATTCCTCTGCCTGACATTGACCCTGTCCCTGAGGAGGAGGACCTGGGCAAGAGGAACAGACACAGCTCGCAGACCTCTG AAGAGAGTGCCATTGAGACGGGTTCCAGCAGTTCCACCTTCATCAAGAGAGAGGACGAGACCATTGAAGACATCGACATGATGGATGACA >30780_30780_9_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000507166_length(amino acids)=655AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQLPYDSRWEFPRDGLVLGRVLGSGAFGKVVEGTAYGL SRSQPVMKVAVKMLKPTARSSEKQALMSELKIMTHLGPHLNIVNLLGACTKSGPIYIITEYCFYGDLVNYLHKNRDSFLSHHPEKPKKEL DIFGLNPADESTRSYVILSFENNGDYMDMKQADTTQYVPMLERKEVSKYSDIQRSLYDRPASYKKKSMLDSEVKNLLSDDNSEGLTLLDL LSFTYQVARGMEFLASKNCVHRDLAARNVLLAQGKIVKICDFGLARDIMHDSNYVSKGSTFLPVKWMAPESIFDNLYTTLSDVWSYGILL WEIFSLGGTPYPGMMVDSTFYNKIKSGYRMAKPDHATSEVYEIMVKCWNSEPEKRPSFYHLSEIVENLLPGQYKKSYEKIHLDFLKSDHP AVARMRVDSDNAYIGVTYKNEEDKLKDWEGGLDEQRLSADSGYIIPLPDIDPVPEEEDLGKRNRHSSQTSEESAIETGSSSSTFIKREDE -------------------------------------------------------------- >30780_30780_10_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000507922_length(transcript)=686nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAAC CACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCAC >30780_30780_10_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000334557_FIP1L1_chr4_54265896_ENST00000507922_length(amino acids)=198AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL -------------------------------------------------------------- >30780_30780_11_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000306932_length(transcript)=1195nt_BP=51nt ATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACT GCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGACTGGGCTTCCACCGAGCAGGAGATTACCTGGGGCAATT GATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGA TCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTT CTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGATTCCACCACCGGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTT ATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTT CCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAG AGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACA CCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAA GAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGT GAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAA CAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGT TATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAG >30780_30780_11_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000306932_length(amino acids)=340AA_BP=14 MEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSER SATEVDNNFSKPPPFFPPGAPPTHLPPPPFLPPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHL PGSAPSWPSLVDTSKQWDYYARREKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREK -------------------------------------------------------------- >30780_30780_12_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000337488_length(transcript)=1350nt_BP=51nt ATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACT GCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAG TCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGG AGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATA CAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCAC CTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGATTCCACCACCGGGTTTTCCTCCTCCACCAGGC GCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAAT GTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAG AAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAG CGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCAC AGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGT AGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGC AGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGT AGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTT TTTTCCAAAATAAAAGAGTGAATTTTTCATGTTAAGTTAAAAATCTTTGTCTTGTACTATTTCAAAAATAAAAAGACAGCAATGACTTTA >30780_30780_12_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000337488_length(amino acids)=376AA_BP=14 MEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTASRKANSSVGKWQDRYGRAESPDLR RLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFLPPPPTVSTAPPLIPPPGFPPPPG APPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRERDRDRERDRDRDRERERTRERERE RDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESEEGDSHRRHKHKKSKRSKEGKEAG -------------------------------------------------------------- >30780_30780_13_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000358575_length(transcript)=1377nt_BP=51nt ATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACT GCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAG TCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGG AGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATA CAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCAC CTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGATTCCACCACCGGGTATTCCAATAACTGTACCA CCTCCAGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGT TCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAG CAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGA GAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAGGGAA TATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACC AGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATCTAAA AGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGG CCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTC TGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTTTTCATGTTAAGTTAAAAATCTTTGTCTTGTACTATTTC >30780_30780_13_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000358575_length(amino acids)=385AA_BP=14 MEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTASRKANSSVGKWQDRYGRAESPDLR RLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFLPPPPTVSTAPPLIPPPGIPITVP PPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRERDRDRERDRDRDRER ERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESEEGDSHRRHKHKKSK -------------------------------------------------------------- >30780_30780_14_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000507166_length(transcript)=1896nt_BP=51nt ATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACT GCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAG TCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGG AGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATA CAGCTGCCTTATGACTCAAGATGGGAGTTTCCAAGAGATGGACTAGTGCTTGGTCGGGTCTTGGGGTCTGGAGCGTTTGGGAAGGTGGTT GAAGGAACAGCCTATGGATTAAGCCGGTCCCAACCTGTCATGAAAGTTGCAGTGAAGATGCTAAAACCCACGGCCAGATCCAGTGAAAAA CAAGCTCTCATGTCTGAACTGAAGATAATGACTCACCTGGGGCCACATTTGAACATTGTAAACTTGCTGGGAGCCTGCACCAAGTCAGGC CCCATTTACATCATCACAGAGTATTGCTTCTATGGAGATTTGGTCAACTATTTGCATAAGAATAGGGATAGCTTCCTGAGCCACCACCCA GAGAAGCCAAAGAAAGAGCTGGATATCTTTGGATTGAACCCTGCTGATGAAAGCACACGGAGCTATGTTATTTTATCTTTTGAAAACAAT GGTGACTACATGGACATGAAGCAGGCTGATACTACACAGTATGTCCCCATGCTAGAAAGGAAAGAGGTTTCTAAATATTCCGACATCCAG AGATCACTCTATGATCGTCCAGCCTCATATAAGAAGAAATCTATGTTAGACTCAGAAGTCAAAAACCTCCTTTCAGATGATAACTCAGAA GGCCTTACTTTATTGGATTTGTTGAGCTTCACCTATCAAGTTGCCCGAGGAATGGAGTTTTTGGCTTCAAAAAATTGTGTCCACCGTGAT CTGGCTGCTCGCAACGTCCTCCTGGCACAAGGAAAAATTGTGAAGATCTGTGACTTTGGCCTGGCCAGAGACATCATGCATGATTCGAAC TATGTGTCGAAAGGCAGTACCTTTCTGCCCGTGAAGTGGATGGCTCCTGAGAGCATCTTTGACAACCTCTACACCACACTGAGTGATGTC TGGTCTTATGGCATTCTGCTCTGGGAGATCTTTTCCCTTGGTGGCACCCCTTACCCCGGCATGATGGTGGATTCTACTTTCTACAATAAG ATCAAGAGTGGGTACCGGATGGCCAAGCCTGACCACGCTACCAGTGAAGTCTACGAGATCATGGTGAAATGCTGGAACAGTGAGCCGGAG AAGAGACCCTCCTTTTACCACCTGAGTGAGATTGTGGAGAATCTGCTGCCTGGACAATATAAAAAGAGTTATGAAAAAATTCACCTGGAC TTCCTGAAGAGTGACCATCCTGCTGTGGCACGCATGCGTGTGGACTCAGACAATGCATACATTGGTGTCACCTACAAAAACGAGGAAGAC AAGCTGAAGGACTGGGAGGGTGGTCTGGATGAGCAGAGACTGAGCGCTGACAGTGGCTACATCATTCCTCTGCCTGACATTGACCCTGTC CCTGAGGAGGAGGACCTGGGCAAGAGGAACAGACACAGCTCGCAGACCTCTGAAGAGAGTGCCATTGAGACGGGTTCCAGCAGTTCCACC TTCATCAAGAGAGAGGACGAGACCATTGAAGACATCGACATGATGGATGACATCGGCATAGACTCTTCAGACCTGGTGGAAGACAGCTTC >30780_30780_14_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000507166_length(amino acids)=631AA_BP=14 MEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTASRKANSSVGKWQDRYGRAESPDLR RLPGAIDVIGQTITISRVEGRRRANENSNIQLPYDSRWEFPRDGLVLGRVLGSGAFGKVVEGTAYGLSRSQPVMKVAVKMLKPTARSSEK QALMSELKIMTHLGPHLNIVNLLGACTKSGPIYIITEYCFYGDLVNYLHKNRDSFLSHHPEKPKKELDIFGLNPADESTRSYVILSFENN GDYMDMKQADTTQYVPMLERKEVSKYSDIQRSLYDRPASYKKKSMLDSEVKNLLSDDNSEGLTLLDLLSFTYQVARGMEFLASKNCVHRD LAARNVLLAQGKIVKICDFGLARDIMHDSNYVSKGSTFLPVKWMAPESIFDNLYTTLSDVWSYGILLWEIFSLGGTPYPGMMVDSTFYNK IKSGYRMAKPDHATSEVYEIMVKCWNSEPEKRPSFYHLSEIVENLLPGQYKKSYEKIHLDFLKSDHPAVARMRVDSDNAYIGVTYKNEED KLKDWEGGLDEQRLSADSGYIIPLPDIDPVPEEEDLGKRNRHSSQTSEESAIETGSSSSTFIKREDETIEDIDMMDDIGIDSSDLVEDSF -------------------------------------------------------------- >30780_30780_15_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000507922_length(transcript)=558nt_BP=51nt ATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACT GCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAG TCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGG AGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATA CAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCAC CTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGATTCCACCACCGGGTAAATAGTAAATAAGACAT >30780_30780_15_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370470_FIP1L1_chr4_54265896_ENST00000507922_length(amino acids)=175AA_BP=14 MEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTASRKANSSVGKWQDRYGRAESPDLR -------------------------------------------------------------- >30780_30780_16_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000306932_length(transcript)=1424nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGG CAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCC GTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGAT TCCACCACCGGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAG TCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAG CAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGA AAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAG GGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGA AACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATC TAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTT TTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTT >30780_30780_16_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000306932_length(amino acids)=363AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRRLPGAIDVIGQTI TISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFLPPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESG HSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSD EERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESEEGDSHRRHKHKKSKRSKEGKEAGSEPAPEQESTEAT -------------------------------------------------------------- >30780_30780_17_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000337488_length(transcript)=1579nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGT TGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAAC TATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAA TTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAG CACTGCTCCACCTCTGATTCCACCACCGGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACA TTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCC TAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGA CCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGA AGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACG ACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAG ACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACC TGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAG AAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTTTTCATGTTAAGTTAAA >30780_30780_17_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000337488_length(amino acids)=399AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRER DRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESE -------------------------------------------------------------- >30780_30780_18_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000358575_length(transcript)=1606nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGT TGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAAC TATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAA TTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAG CACTGCTCCACCTCTGATTCCACCACCGGGTATTCCAATAACTGTACCACCTCCAGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATC TCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCA TCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAG AGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCC TACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGA AAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGA AAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCC TGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATC TTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAA >30780_30780_18_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000358575_length(amino acids)=408AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGIPITVPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYAR REKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRS -------------------------------------------------------------- >30780_30780_19_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000507166_length(transcript)=2125nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGT TGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAAC TATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGCTGCCTTATGACTCAAGATGGGAGTTTCCAAGAGATGG ACTAGTGCTTGGTCGGGTCTTGGGGTCTGGAGCGTTTGGGAAGGTGGTTGAAGGAACAGCCTATGGATTAAGCCGGTCCCAACCTGTCAT GAAAGTTGCAGTGAAGATGCTAAAACCCACGGCCAGATCCAGTGAAAAACAAGCTCTCATGTCTGAACTGAAGATAATGACTCACCTGGG GCCACATTTGAACATTGTAAACTTGCTGGGAGCCTGCACCAAGTCAGGCCCCATTTACATCATCACAGAGTATTGCTTCTATGGAGATTT GGTCAACTATTTGCATAAGAATAGGGATAGCTTCCTGAGCCACCACCCAGAGAAGCCAAAGAAAGAGCTGGATATCTTTGGATTGAACCC TGCTGATGAAAGCACACGGAGCTATGTTATTTTATCTTTTGAAAACAATGGTGACTACATGGACATGAAGCAGGCTGATACTACACAGTA TGTCCCCATGCTAGAAAGGAAAGAGGTTTCTAAATATTCCGACATCCAGAGATCACTCTATGATCGTCCAGCCTCATATAAGAAGAAATC TATGTTAGACTCAGAAGTCAAAAACCTCCTTTCAGATGATAACTCAGAAGGCCTTACTTTATTGGATTTGTTGAGCTTCACCTATCAAGT TGCCCGAGGAATGGAGTTTTTGGCTTCAAAAAATTGTGTCCACCGTGATCTGGCTGCTCGCAACGTCCTCCTGGCACAAGGAAAAATTGT GAAGATCTGTGACTTTGGCCTGGCCAGAGACATCATGCATGATTCGAACTATGTGTCGAAAGGCAGTACCTTTCTGCCCGTGAAGTGGAT GGCTCCTGAGAGCATCTTTGACAACCTCTACACCACACTGAGTGATGTCTGGTCTTATGGCATTCTGCTCTGGGAGATCTTTTCCCTTGG TGGCACCCCTTACCCCGGCATGATGGTGGATTCTACTTTCTACAATAAGATCAAGAGTGGGTACCGGATGGCCAAGCCTGACCACGCTAC CAGTGAAGTCTACGAGATCATGGTGAAATGCTGGAACAGTGAGCCGGAGAAGAGACCCTCCTTTTACCACCTGAGTGAGATTGTGGAGAA TCTGCTGCCTGGACAATATAAAAAGAGTTATGAAAAAATTCACCTGGACTTCCTGAAGAGTGACCATCCTGCTGTGGCACGCATGCGTGT GGACTCAGACAATGCATACATTGGTGTCACCTACAAAAACGAGGAAGACAAGCTGAAGGACTGGGAGGGTGGTCTGGATGAGCAGAGACT GAGCGCTGACAGTGGCTACATCATTCCTCTGCCTGACATTGACCCTGTCCCTGAGGAGGAGGACCTGGGCAAGAGGAACAGACACAGCTC GCAGACCTCTGAAGAGAGTGCCATTGAGACGGGTTCCAGCAGTTCCACCTTCATCAAGAGAGAGGACGAGACCATTGAAGACATCGACAT >30780_30780_19_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000507166_length(amino acids)=655AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQLPYDSRWEFPRDGLVLGRVLGSGAFGKVVEGTAYGL SRSQPVMKVAVKMLKPTARSSEKQALMSELKIMTHLGPHLNIVNLLGACTKSGPIYIITEYCFYGDLVNYLHKNRDSFLSHHPEKPKKEL DIFGLNPADESTRSYVILSFENNGDYMDMKQADTTQYVPMLERKEVSKYSDIQRSLYDRPASYKKKSMLDSEVKNLLSDDNSEGLTLLDL LSFTYQVARGMEFLASKNCVHRDLAARNVLLAQGKIVKICDFGLARDIMHDSNYVSKGSTFLPVKWMAPESIFDNLYTTLSDVWSYGILL WEIFSLGGTPYPGMMVDSTFYNKIKSGYRMAKPDHATSEVYEIMVKCWNSEPEKRPSFYHLSEIVENLLPGQYKKSYEKIHLDFLKSDHP AVARMRVDSDNAYIGVTYKNEEDKLKDWEGGLDEQRLSADSGYIIPLPDIDPVPEEEDLGKRNRHSSQTSEESAIETGSSSSTFIKREDE -------------------------------------------------------------- >30780_30780_20_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000507922_length(transcript)=787nt_BP=280nt ACTTCCGGTGGAGGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCG TGCGGCAGCGCGGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCA GCCCACCTCTCGGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGC TTTCTACAAGGTACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTC TTTGTTCAAGACTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGT TGGGAAGTGGCAGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAAC TATCAGCCGAGTAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAA TTTTAGCAAACCACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAG >30780_30780_20_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370471_FIP1L1_chr4_54265896_ENST00000507922_length(amino acids)=198AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL -------------------------------------------------------------- >30780_30780_21_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000306932_length(transcript)=1323nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGGCAGGCGACGGG CAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCCGTTTTTCCCTC CAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGATTCCACCACCGG GTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCAC GTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGG ACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCA CCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAG AAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATA AGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCA AAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTG TGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGT >30780_30780_21_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000306932_length(amino acids)=363AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRRLPGAIDVIGQTI TISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFLPPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESG HSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSD EERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESEEGDSHRRHKHKKSKRSKEGKEAGSEPAPEQESTEAT -------------------------------------------------------------- >30780_30780_22_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000337488_length(transcript)=1478nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAAC CACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCAC CTCTGATTCCACCACCGGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTT ATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGG ACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGG ACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACA GATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGA AAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACA AAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGG CATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTT AAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTTTTCATGTTAAGTTAAAAATCTTTGTCT >30780_30780_22_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000337488_length(amino acids)=399AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRER DRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESE -------------------------------------------------------------- >30780_30780_23_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000358575_length(transcript)=1505nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAAC CACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCAC CTCTGATTCCACCACCGGGTATTCCAATAACTGTACCACCTCCAGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAA CAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTT CTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACA GAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTG TTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAAC GACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAG GAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGA GCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTT CTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTT >30780_30780_23_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000358575_length(amino acids)=408AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGIPITVPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYAR REKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRS -------------------------------------------------------------- >30780_30780_24_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000507166_length(transcript)=2024nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGCTGCCTTATGACTCAAGATGGGAGTTTCCAAGAGATGGACTAGTGCTTG GTCGGGTCTTGGGGTCTGGAGCGTTTGGGAAGGTGGTTGAAGGAACAGCCTATGGATTAAGCCGGTCCCAACCTGTCATGAAAGTTGCAG TGAAGATGCTAAAACCCACGGCCAGATCCAGTGAAAAACAAGCTCTCATGTCTGAACTGAAGATAATGACTCACCTGGGGCCACATTTGA ACATTGTAAACTTGCTGGGAGCCTGCACCAAGTCAGGCCCCATTTACATCATCACAGAGTATTGCTTCTATGGAGATTTGGTCAACTATT TGCATAAGAATAGGGATAGCTTCCTGAGCCACCACCCAGAGAAGCCAAAGAAAGAGCTGGATATCTTTGGATTGAACCCTGCTGATGAAA GCACACGGAGCTATGTTATTTTATCTTTTGAAAACAATGGTGACTACATGGACATGAAGCAGGCTGATACTACACAGTATGTCCCCATGC TAGAAAGGAAAGAGGTTTCTAAATATTCCGACATCCAGAGATCACTCTATGATCGTCCAGCCTCATATAAGAAGAAATCTATGTTAGACT CAGAAGTCAAAAACCTCCTTTCAGATGATAACTCAGAAGGCCTTACTTTATTGGATTTGTTGAGCTTCACCTATCAAGTTGCCCGAGGAA TGGAGTTTTTGGCTTCAAAAAATTGTGTCCACCGTGATCTGGCTGCTCGCAACGTCCTCCTGGCACAAGGAAAAATTGTGAAGATCTGTG ACTTTGGCCTGGCCAGAGACATCATGCATGATTCGAACTATGTGTCGAAAGGCAGTACCTTTCTGCCCGTGAAGTGGATGGCTCCTGAGA GCATCTTTGACAACCTCTACACCACACTGAGTGATGTCTGGTCTTATGGCATTCTGCTCTGGGAGATCTTTTCCCTTGGTGGCACCCCTT ACCCCGGCATGATGGTGGATTCTACTTTCTACAATAAGATCAAGAGTGGGTACCGGATGGCCAAGCCTGACCACGCTACCAGTGAAGTCT ACGAGATCATGGTGAAATGCTGGAACAGTGAGCCGGAGAAGAGACCCTCCTTTTACCACCTGAGTGAGATTGTGGAGAATCTGCTGCCTG GACAATATAAAAAGAGTTATGAAAAAATTCACCTGGACTTCCTGAAGAGTGACCATCCTGCTGTGGCACGCATGCGTGTGGACTCAGACA ATGCATACATTGGTGTCACCTACAAAAACGAGGAAGACAAGCTGAAGGACTGGGAGGGTGGTCTGGATGAGCAGAGACTGAGCGCTGACA GTGGCTACATCATTCCTCTGCCTGACATTGACCCTGTCCCTGAGGAGGAGGACCTGGGCAAGAGGAACAGACACAGCTCGCAGACCTCTG AAGAGAGTGCCATTGAGACGGGTTCCAGCAGTTCCACCTTCATCAAGAGAGAGGACGAGACCATTGAAGACATCGACATGATGGATGACA >30780_30780_24_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000507166_length(amino acids)=655AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQLPYDSRWEFPRDGLVLGRVLGSGAFGKVVEGTAYGL SRSQPVMKVAVKMLKPTARSSEKQALMSELKIMTHLGPHLNIVNLLGACTKSGPIYIITEYCFYGDLVNYLHKNRDSFLSHHPEKPKKEL DIFGLNPADESTRSYVILSFENNGDYMDMKQADTTQYVPMLERKEVSKYSDIQRSLYDRPASYKKKSMLDSEVKNLLSDDNSEGLTLLDL LSFTYQVARGMEFLASKNCVHRDLAARNVLLAQGKIVKICDFGLARDIMHDSNYVSKGSTFLPVKWMAPESIFDNLYTTLSDVWSYGILL WEIFSLGGTPYPGMMVDSTFYNKIKSGYRMAKPDHATSEVYEIMVKCWNSEPEKRPSFYHLSEIVENLLPGQYKKSYEKIHLDFLKSDHP AVARMRVDSDNAYIGVTYKNEEDKLKDWEGGLDEQRLSADSGYIIPLPDIDPVPEEEDLGKRNRHSSQTSEESAIETGSSSSTFIKREDE -------------------------------------------------------------- >30780_30780_25_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000507922_length(transcript)=686nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAAC CACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCAC >30780_30780_25_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370475_FIP1L1_chr4_54265896_ENST00000507922_length(amino acids)=198AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL -------------------------------------------------------------- >30780_30780_26_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000306932_length(transcript)=1412nt_BP=268nt GGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCGTGCGGCAGCGCG GCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTCG GGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGT ACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGAC TGGGCTTCCACCGAGCAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGGCAGGCGACGGGC AAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCCGTTTTTCCCTCC AGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGATTCCACCACCGGG TTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCACG TGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGGA CTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCAC CAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAGA AAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATAA GTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCAA AGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTGT GTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGTT >30780_30780_26_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000306932_length(amino acids)=363AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRRLPGAIDVIGQTI TISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFLPPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESG HSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSD EERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESEEGDSHRRHKHKKSKRSKEGKEAGSEPAPEQESTEAT -------------------------------------------------------------- >30780_30780_27_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000337488_length(transcript)=1567nt_BP=268nt GGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCGTGCGGCAGCGCG GCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTCG GGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGT ACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGAC TGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGCA GGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGT AGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACC ACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACC TCTGATTCCACCACCGGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTA TGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGA CACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGA CAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAG ATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAA AGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAA AAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGC ATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTA AATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTTTTCATGTTAAGTTAAAAATCTTTGTCTT >30780_30780_27_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000337488_length(amino acids)=399AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRER DRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESE -------------------------------------------------------------- >30780_30780_28_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000358575_length(transcript)=1594nt_BP=268nt GGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCGTGCGGCAGCGCG GCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTCG GGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGT ACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGAC TGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGCA GGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGT AGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACC ACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACC TCTGATTCCACCACCGGGTATTCCAATAACTGTACCACCTCCAGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAAC AATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTC TGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAG AGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGT TTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACG ACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGG AGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAG CACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTC TGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTTT >30780_30780_28_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000358575_length(amino acids)=408AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGIPITVPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYAR REKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRS -------------------------------------------------------------- >30780_30780_29_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000507166_length(transcript)=2113nt_BP=268nt GGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCGTGCGGCAGCGCG GCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTCG GGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGT ACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGAC TGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGCA GGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGT AGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGCTGCCTTATGACTCAAGATGGGAGTTTCCAAGAGATGGACTAGTGCTTGG TCGGGTCTTGGGGTCTGGAGCGTTTGGGAAGGTGGTTGAAGGAACAGCCTATGGATTAAGCCGGTCCCAACCTGTCATGAAAGTTGCAGT GAAGATGCTAAAACCCACGGCCAGATCCAGTGAAAAACAAGCTCTCATGTCTGAACTGAAGATAATGACTCACCTGGGGCCACATTTGAA CATTGTAAACTTGCTGGGAGCCTGCACCAAGTCAGGCCCCATTTACATCATCACAGAGTATTGCTTCTATGGAGATTTGGTCAACTATTT GCATAAGAATAGGGATAGCTTCCTGAGCCACCACCCAGAGAAGCCAAAGAAAGAGCTGGATATCTTTGGATTGAACCCTGCTGATGAAAG CACACGGAGCTATGTTATTTTATCTTTTGAAAACAATGGTGACTACATGGACATGAAGCAGGCTGATACTACACAGTATGTCCCCATGCT AGAAAGGAAAGAGGTTTCTAAATATTCCGACATCCAGAGATCACTCTATGATCGTCCAGCCTCATATAAGAAGAAATCTATGTTAGACTC AGAAGTCAAAAACCTCCTTTCAGATGATAACTCAGAAGGCCTTACTTTATTGGATTTGTTGAGCTTCACCTATCAAGTTGCCCGAGGAAT GGAGTTTTTGGCTTCAAAAAATTGTGTCCACCGTGATCTGGCTGCTCGCAACGTCCTCCTGGCACAAGGAAAAATTGTGAAGATCTGTGA CTTTGGCCTGGCCAGAGACATCATGCATGATTCGAACTATGTGTCGAAAGGCAGTACCTTTCTGCCCGTGAAGTGGATGGCTCCTGAGAG CATCTTTGACAACCTCTACACCACACTGAGTGATGTCTGGTCTTATGGCATTCTGCTCTGGGAGATCTTTTCCCTTGGTGGCACCCCTTA CCCCGGCATGATGGTGGATTCTACTTTCTACAATAAGATCAAGAGTGGGTACCGGATGGCCAAGCCTGACCACGCTACCAGTGAAGTCTA CGAGATCATGGTGAAATGCTGGAACAGTGAGCCGGAGAAGAGACCCTCCTTTTACCACCTGAGTGAGATTGTGGAGAATCTGCTGCCTGG ACAATATAAAAAGAGTTATGAAAAAATTCACCTGGACTTCCTGAAGAGTGACCATCCTGCTGTGGCACGCATGCGTGTGGACTCAGACAA TGCATACATTGGTGTCACCTACAAAAACGAGGAAGACAAGCTGAAGGACTGGGAGGGTGGTCTGGATGAGCAGAGACTGAGCGCTGACAG TGGCTACATCATTCCTCTGCCTGACATTGACCCTGTCCCTGAGGAGGAGGACCTGGGCAAGAGGAACAGACACAGCTCGCAGACCTCTGA AGAGAGTGCCATTGAGACGGGTTCCAGCAGTTCCACCTTCATCAAGAGAGAGGACGAGACCATTGAAGACATCGACATGATGGATGACAT >30780_30780_29_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000507166_length(amino acids)=655AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQLPYDSRWEFPRDGLVLGRVLGSGAFGKVVEGTAYGL SRSQPVMKVAVKMLKPTARSSEKQALMSELKIMTHLGPHLNIVNLLGACTKSGPIYIITEYCFYGDLVNYLHKNRDSFLSHHPEKPKKEL DIFGLNPADESTRSYVILSFENNGDYMDMKQADTTQYVPMLERKEVSKYSDIQRSLYDRPASYKKKSMLDSEVKNLLSDDNSEGLTLLDL LSFTYQVARGMEFLASKNCVHRDLAARNVLLAQGKIVKICDFGLARDIMHDSNYVSKGSTFLPVKWMAPESIFDNLYTTLSDVWSYGILL WEIFSLGGTPYPGMMVDSTFYNKIKSGYRMAKPDHATSEVYEIMVKCWNSEPEKRPSFYHLSEIVENLLPGQYKKSYEKIHLDFLKSDHP AVARMRVDSDNAYIGVTYKNEEDKLKDWEGGLDEQRLSADSGYIIPLPDIDPVPEEEDLGKRNRHSSQTSEESAIETGSSSSTFIKREDE -------------------------------------------------------------- >30780_30780_30_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000507922_length(transcript)=775nt_BP=268nt GGGCCGCCTCTGAGCGGGCGGCGGGCCGACGGCGAGCGCGGGCGGCGGCGGTGACGGAGGCGCCGCTGCCAGGGGGCGTGCGGCAGCGCG GCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTCG GGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGGT ACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGAC TGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGCA GGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGT AGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACC ACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACC >30780_30780_30_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000370477_FIP1L1_chr4_54265896_ENST00000507922_length(amino acids)=198AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL -------------------------------------------------------------- >30780_30780_31_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000306932_length(transcript)=1323nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAGTAGAAGGCAGGCGACGGG CAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAACCACCTCCGTTTTTCCCTC CAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCACCTCTGATTCCACCACCGG GTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCAC GTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGG ACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCA CCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAG AAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATA AGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCA AAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTG TGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGT >30780_30780_31_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000306932_length(amino acids)=363AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRRLPGAIDVIGQTI TISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFLPPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESG HSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSD EERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESEEGDSHRRHKHKKSKRSKEGKEAGSEPAPEQESTEAT -------------------------------------------------------------- >30780_30780_32_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000337488_length(transcript)=1478nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAAC CACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCAC CTCTGATTCCACCACCGGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAACAATAGAAAGTGGACATTCCTCTGGTT ATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTTCTGCTCCTTCGTGGCCTAGTCTTGTGG ACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACAGAGACAGAGAGCGAGACCGTGATCGGG ACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTGTTTTCAACAGCGATGAAGAACGATACA GATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAACGACATAGAGAAAGACGACACAGGGAGA AAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAGGAGATAGTCACAGGAGACACAAACACA AAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGAGCACCGAAGCTACACCTGCAGAATAGG CATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTTCTGGATAATGTTTAAGAAATTTACCTT AAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTTTTCATGTTAAGTTAAAAATCTTTGTCT >30780_30780_32_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000337488_length(amino acids)=399AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYARREKDRDRER DRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRSNSRRRHESE -------------------------------------------------------------- >30780_30780_33_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000358575_length(transcript)=1505nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAAC CACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCAC CTCTGATTCCACCACCGGGTATTCCAATAACTGTACCACCTCCAGGTTTTCCTCCTCCACCAGGCGCTCCACCTCCATCTCTTATACCAA CAATAGAAAGTGGACATTCCTCTGGTTATGATAGTCGTTCTGCACGTGCATTTCCATATGGCAATGTTGCCTTTCCCCATCTTCCTGGTT CTGCTCCTTCGTGGCCTAGTCTTGTGGACACCAGCAAGCAGTGGGACTATTATGCCAGAAGAGAGAAAGACCGAGATAGAGAGAGAGACA GAGACAGAGAGCGAGACCGTGATCGGGACAGAGAAAGAGAACGCACCAGAGAGAGAGAGAGGGAGCGTGATCACAGTCCTACACCAAGTG TTTTCAACAGCGATGAAGAACGATACAGATACAGGGAATATGCAGAAAGAGGTTATGAGCGTCACAGAGCAAGTCGAGAAAAAGAAGAAC GACATAGAGAAAGACGACACAGGGAGAAAGAGGAAACCAGACATAAGTCTTCTCGAAGTAATAGTAGACGTCGCCATGAAAGTGAAGAAG GAGATAGTCACAGGAGACACAAACACAAAAAATCTAAAAGAAGCAAAGAAGGAAAAGAAGCGGGCAGTGAGCCTGCCCCTGAACAGGAGA GCACCGAAGCTACACCTGCAGAATAGGCATGGTTTTGGCCTTTTGTGTATATTAGTACCAGAAGTAGATACTATAAATCTTGTTATTTTT CTGGATAATGTTTAAGAAATTTACCTTAAATCTTGTTCTGTTTGTTAGTATGAAAAGTTAACTTTTTTTCCAAAATAAAAGAGTGAATTT >30780_30780_33_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000358575_length(amino acids)=408AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL PPPPTVSTAPPLIPPPGIPITVPPPGFPPPPGAPPPSLIPTIESGHSSGYDSRSARAFPYGNVAFPHLPGSAPSWPSLVDTSKQWDYYAR REKDRDRERDRDRERDRDRDRERERTRERERERDHSPTPSVFNSDEERYRYREYAERGYERHRASREKEERHRERRHREKEETRHKSSRS -------------------------------------------------------------- >30780_30780_34_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000507166_length(transcript)=2024nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGCTGCCTTATGACTCAAGATGGGAGTTTCCAAGAGATGGACTAGTGCTTG GTCGGGTCTTGGGGTCTGGAGCGTTTGGGAAGGTGGTTGAAGGAACAGCCTATGGATTAAGCCGGTCCCAACCTGTCATGAAAGTTGCAG TGAAGATGCTAAAACCCACGGCCAGATCCAGTGAAAAACAAGCTCTCATGTCTGAACTGAAGATAATGACTCACCTGGGGCCACATTTGA ACATTGTAAACTTGCTGGGAGCCTGCACCAAGTCAGGCCCCATTTACATCATCACAGAGTATTGCTTCTATGGAGATTTGGTCAACTATT TGCATAAGAATAGGGATAGCTTCCTGAGCCACCACCCAGAGAAGCCAAAGAAAGAGCTGGATATCTTTGGATTGAACCCTGCTGATGAAA GCACACGGAGCTATGTTATTTTATCTTTTGAAAACAATGGTGACTACATGGACATGAAGCAGGCTGATACTACACAGTATGTCCCCATGC TAGAAAGGAAAGAGGTTTCTAAATATTCCGACATCCAGAGATCACTCTATGATCGTCCAGCCTCATATAAGAAGAAATCTATGTTAGACT CAGAAGTCAAAAACCTCCTTTCAGATGATAACTCAGAAGGCCTTACTTTATTGGATTTGTTGAGCTTCACCTATCAAGTTGCCCGAGGAA TGGAGTTTTTGGCTTCAAAAAATTGTGTCCACCGTGATCTGGCTGCTCGCAACGTCCTCCTGGCACAAGGAAAAATTGTGAAGATCTGTG ACTTTGGCCTGGCCAGAGACATCATGCATGATTCGAACTATGTGTCGAAAGGCAGTACCTTTCTGCCCGTGAAGTGGATGGCTCCTGAGA GCATCTTTGACAACCTCTACACCACACTGAGTGATGTCTGGTCTTATGGCATTCTGCTCTGGGAGATCTTTTCCCTTGGTGGCACCCCTT ACCCCGGCATGATGGTGGATTCTACTTTCTACAATAAGATCAAGAGTGGGTACCGGATGGCCAAGCCTGACCACGCTACCAGTGAAGTCT ACGAGATCATGGTGAAATGCTGGAACAGTGAGCCGGAGAAGAGACCCTCCTTTTACCACCTGAGTGAGATTGTGGAGAATCTGCTGCCTG GACAATATAAAAAGAGTTATGAAAAAATTCACCTGGACTTCCTGAAGAGTGACCATCCTGCTGTGGCACGCATGCGTGTGGACTCAGACA ATGCATACATTGGTGTCACCTACAAAAACGAGGAAGACAAGCTGAAGGACTGGGAGGGTGGTCTGGATGAGCAGAGACTGAGCGCTGACA GTGGCTACATCATTCCTCTGCCTGACATTGACCCTGTCCCTGAGGAGGAGGACCTGGGCAAGAGGAACAGACACAGCTCGCAGACCTCTG AAGAGAGTGCCATTGAGACGGGTTCCAGCAGTTCCACCTTCATCAAGAGAGAGGACGAGACCATTGAAGACATCGACATGATGGATGACA >30780_30780_34_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000507166_length(amino acids)=655AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQLPYDSRWEFPRDGLVLGRVLGSGAFGKVVEGTAYGL SRSQPVMKVAVKMLKPTARSSEKQALMSELKIMTHLGPHLNIVNLLGACTKSGPIYIITEYCFYGDLVNYLHKNRDSFLSHHPEKPKKEL DIFGLNPADESTRSYVILSFENNGDYMDMKQADTTQYVPMLERKEVSKYSDIQRSLYDRPASYKKKSMLDSEVKNLLSDDNSEGLTLLDL LSFTYQVARGMEFLASKNCVHRDLAARNVLLAQGKIVKICDFGLARDIMHDSNYVSKGSTFLPVKWMAPESIFDNLYTTLSDVWSYGILL WEIFSLGGTPYPGMMVDSTFYNKIKSGYRMAKPDHATSEVYEIMVKCWNSEPEKRPSFYHLSEIVENLLPGQYKKSYEKIHLDFLKSDHP AVARMRVDSDNAYIGVTYKNEEDKLKDWEGGLDEQRLSADSGYIIPLPDIDPVPEEEDLGKRNRHSSQTSEESAIETGSSSSTFIKREDE -------------------------------------------------------------- >30780_30780_35_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000507922_length(transcript)=686nt_BP=179nt GGCGGCGGCGGCGGCGGCGGCGGCGGCGGAGGCGGCGGCGGCGGCGGCGGCGGCGGCGGCTGGGCCTCGAGCGCCCGCAGCCCACCTCTC GGGGGCGGGCTCCCGGCGCTAGCAGGGCTGAAGAGAAGATGGAGGAGCTGGTGGTGGAAGTGCGGGGCTCCAATGGCGCTTTCTACAAGG TACAGCAGGGAAGAACTGGAAACTCAGAGAAAGAAACTGCCCTTCCATCTACAAAAGCTGAGTTTACTTCTCCTCCTTCTTTGTTCAAGA CTGGGCTTCCACCGAGCAGAAACAGCACTTCTTCTCAGTCTCAGACAAGTACTGCCTCCAGAAAAGCCAATTCAAGCGTTGGGAAGTGGC AGGATCGATATGGGAGGGCCGAATCACCTGATCTAAGGAGATTACCTGGGGCAATTGATGTTATCGGTCAGACTATAACTATCAGCCGAG TAGAAGGCAGGCGACGGGCAAATGAGAACAGCAACATACAGGTCCTTTCTGAAAGATCTGCTACTGAAGTAGACAACAATTTTAGCAAAC CACCTCCGTTTTTCCCTCCAGGAGCTCCTCCCACTCACCTTCCACCTCCTCCATTTCTTCCACCTCCTCCGACTGTCAGCACTGCTCCAC >30780_30780_35_FMR1-FIP1L1_FMR1_chrX_146993748_ENST00000439526_FIP1L1_chr4_54265896_ENST00000507922_length(amino acids)=198AA_BP=37 MGLERPQPTSRGRAPGASRAEEKMEELVVEVRGSNGAFYKVQQGRTGNSEKETALPSTKAEFTSPPSLFKTGLPPSRNSTSSQSQTSTAS RKANSSVGKWQDRYGRAESPDLRRLPGAIDVIGQTITISRVEGRRRANENSNIQVLSERSATEVDNNFSKPPPFFPPGAPPTHLPPPPFL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for FMR1-FIP1L1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370470 | + | 1 | 17 | 419_632 | 17.0 | 591.0 | RANBP9 |
| Hgene | FMR1 | chrX:146993748 | chr4:54265896 | ENST00000370475 | + | 1 | 17 | 419_632 | 17.0 | 633.0 | RANBP9 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for FMR1-FIP1L1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for FMR1-FIP1L1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | FMR1 | C0016667 | Fragile X Syndrome | 37 | CLINGEN;CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Hgene | FMR1 | C0751156 | FRAXA Syndrome | 8 | CTD_human |
| Hgene | FMR1 | C0751157 | FRAXE Syndrome | 8 | CTD_human |
| Hgene | FMR1 | C0004352 | Autistic Disorder | 5 | CTD_human |
| Hgene | FMR1 | C0020796 | Profound Mental Retardation | 2 | CTD_human |
| Hgene | FMR1 | C0025363 | Mental Retardation, Psychosocial | 2 | CTD_human |
| Hgene | FMR1 | C0036341 | Schizophrenia | 2 | PSYGENET |
| Hgene | FMR1 | C0041696 | Unipolar Depression | 2 | PSYGENET |
| Hgene | FMR1 | C0376634 | Craniofacial Abnormalities | 2 | CTD_human |
| Hgene | FMR1 | C0917816 | Mental deficiency | 2 | CTD_human |
| Hgene | FMR1 | C1269683 | Major Depressive Disorder | 2 | PSYGENET |
| Hgene | FMR1 | C1839780 | FRAGILE X TREMOR/ATAXIA SYNDROME | 2 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Hgene | FMR1 | C3714756 | Intellectual Disability | 2 | CTD_human |
| Hgene | FMR1 | C0000768 | Congenital Abnormality | 1 | CTD_human |
| Hgene | FMR1 | C0003469 | Anxiety Disorders | 1 | CTD_human |
| Hgene | FMR1 | C0009241 | Cognition Disorders | 1 | CTD_human |
| Hgene | FMR1 | C0018051 | Gonadal Dysgenesis | 1 | CTD_human |
| Hgene | FMR1 | C0085215 | Ovarian Failure, Premature | 1 | CTD_human |
| Hgene | FMR1 | C0086132 | Depressive Symptoms | 1 | PSYGENET |
| Hgene | FMR1 | C0086367 | Gonadotropin-Resistant Ovary Syndrome | 1 | CTD_human |
| Hgene | FMR1 | C0282631 | Facies | 1 | CTD_human |
| Hgene | FMR1 | C0338908 | Mixed anxiety and depressive disorder | 1 | PSYGENET |
| Hgene | FMR1 | C0376280 | Anxiety States, Neurotic | 1 | CTD_human |
| Hgene | FMR1 | C0949331 | Gonadal Agenesis | 1 | CTD_human |
| Hgene | FMR1 | C1279420 | Anxiety neurosis (finding) | 1 | CTD_human |
| Hgene | FMR1 | C2678248 | Mood instability | 1 | PSYGENET |
| Hgene | FMR1 | C3275521 | CHROMOSOME Xq27.3-q28 DUPLICATION SYNDROME | 1 | ORPHANET |
| Hgene | FMR1 | C3494522 | Hypergonadotropic Ovarian Failure, X-Linked | 1 | CTD_human |
| Hgene | FMR1 | C4552079 | Premature Ovarian Failure 1 | 1 | CTD_human;GENOMICS_ENGLAND |
| Tgene | C0346421 | Chronic eosinophilic leukemia | 4 | ORPHANET | |
| Tgene | C0206141 | Idiopathic Hypereosinophilic Syndrome | 2 | CTD_human | |
| Tgene | C0206142 | Eosinophilic leukemia | 2 | CTD_human | |
| Tgene | C0206143 | Loeffler's Endocarditis | 2 | CTD_human | |
| Tgene | C1540912 | Hypereosinophilic syndrome | 2 | CTD_human | |
| Tgene | C0018801 | Heart failure | 1 | CTD_human | |
| Tgene | C0018802 | Congestive heart failure | 1 | CTD_human | |
| Tgene | C0023212 | Left-Sided Heart Failure | 1 | CTD_human | |
| Tgene | C0023487 | Acute Promyelocytic Leukemia | 1 | ORPHANET | |
| Tgene | C0235527 | Heart Failure, Right-Sided | 1 | CTD_human | |
| Tgene | C1959583 | Myocardial Failure | 1 | CTD_human | |
| Tgene | C1961112 | Heart Decompensation | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies