
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GNAS-CPB1 (FusionGDB2 ID:HG2778TG1360) |
Fusion Gene Summary for GNAS-CPB1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GNAS-CPB1 | Fusion gene ID: hg2778tg1360 | Hgene | Tgene | Gene symbol | GNAS | CPB1 | Gene ID | 2778 | 1360 |
| Gene name | GNAS complex locus | carboxypeptidase B1 | |
| Synonyms | AHO|C20orf45|GNAS1|GPSA|GSA|GSP|NESP|PITA3|POH|SCG6|SgVI | CPB|PASP|PCPB | |
| Cytomap | ('GNAS')('CPB1') 20q13.32 | 3q24 | |
| Type of gene | protein-coding | protein-coding | |
| Description | protein ALEXprotein GNASprotein SCG6 (secretogranin VI)G protein subunit alpha Sadenylate cyclase-stimulating G alpha proteinalternative gene product encoded by XL-exonextra large alphas proteinguanine nucleotide binding protein (G protein), alpha | carboxypeptidase Bcarboxypeptidase B1 (tissue)pancreas-specific proteinpancreatic carboxypeptidase Bprocarboxypeptidase Bprotaminasetissue carboxypeptidase B | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000313949, ENST00000371075, ENST00000371098, ENST00000464624, ENST00000354359, ENST00000371081, ENST00000371085, ENST00000371100, ENST00000265620, ENST00000306090, ENST00000306120, ENST00000371095, ENST00000371099, ENST00000371102, | ||
| Fusion gene scores | * DoF score | 44 X 25 X 16=17600 | 22 X 26 X 3=1716 |
| # samples | 51 | 19 | |
| ** MAII score | log2(51/17600*10)=-5.10893437155316 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(19/1716*10)=-3.1749782291686 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GNAS [Title/Abstract] AND CPB1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GNAS(57474040)-CPB1(148545789), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | GNAS-CPB1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. GNAS-CPB1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. GNAS-CPB1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. GNAS-CPB1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CPB1 | GO:0006508 | proteolysis | 1370825 |
| Fusion gene breakpoints across GNAS (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
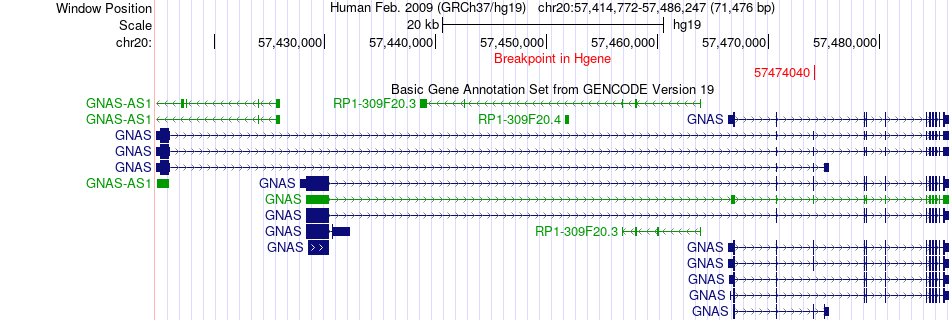 |
| Fusion gene breakpoints across CPB1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-A8-A091-01A | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
Top |
Fusion Gene ORF analysis for GNAS-CPB1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000313949 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-3CDS | ENST00000313949 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-3CDS | ENST00000371075 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-3CDS | ENST00000371075 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-3CDS | ENST00000371098 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-3CDS | ENST00000371098 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-3CDS | ENST00000464624 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-3CDS | ENST00000464624 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-intron | ENST00000313949 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-intron | ENST00000371075 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-intron | ENST00000371098 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 3UTR-intron | ENST00000464624 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 5CDS-intron | ENST00000354359 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 5CDS-intron | ENST00000371081 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 5CDS-intron | ENST00000371085 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| 5CDS-intron | ENST00000371100 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| In-frame | ENST00000354359 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| In-frame | ENST00000354359 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| In-frame | ENST00000371081 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| In-frame | ENST00000371081 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| In-frame | ENST00000371085 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| In-frame | ENST00000371085 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| In-frame | ENST00000371100 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| In-frame | ENST00000371100 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000265620 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000265620 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000306090 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000306090 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000306120 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000306120 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000371095 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000371095 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000371099 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000371099 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000371102 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-3CDS | ENST00000371102 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-intron | ENST00000265620 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-intron | ENST00000306090 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-intron | ENST00000306120 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-intron | ENST00000371095 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-intron | ENST00000371099 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| intron-intron | ENST00000371102 | ENST00000498639 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000371100 | GNAS | chr20 | 57474040 | + | ENST00000491148 | CPB1 | chr3 | 148545789 | + | 4106 | 2738 | 531 | 3920 | 1129 |
| ENST00000371100 | GNAS | chr20 | 57474040 | + | ENST00000282957 | CPB1 | chr3 | 148545789 | + | 4102 | 2738 | 531 | 3920 | 1129 |
| ENST00000371085 | GNAS | chr20 | 57474040 | + | ENST00000491148 | CPB1 | chr3 | 148545789 | + | 2049 | 681 | 424 | 1863 | 479 |
| ENST00000371085 | GNAS | chr20 | 57474040 | + | ENST00000282957 | CPB1 | chr3 | 148545789 | + | 2045 | 681 | 424 | 1863 | 479 |
| ENST00000354359 | GNAS | chr20 | 57474040 | + | ENST00000491148 | CPB1 | chr3 | 148545789 | + | 2049 | 681 | 424 | 1863 | 479 |
| ENST00000354359 | GNAS | chr20 | 57474040 | + | ENST00000282957 | CPB1 | chr3 | 148545789 | + | 2045 | 681 | 424 | 1863 | 479 |
| ENST00000371081 | GNAS | chr20 | 57474040 | + | ENST00000491148 | CPB1 | chr3 | 148545789 | + | 1636 | 268 | 11 | 1450 | 479 |
| ENST00000371081 | GNAS | chr20 | 57474040 | + | ENST00000282957 | CPB1 | chr3 | 148545789 | + | 1632 | 268 | 11 | 1450 | 479 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000371100 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + | 0.003612174 | 0.99638784 |
| ENST00000371100 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + | 0.003650705 | 0.9963492 |
| ENST00000371085 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + | 0.004547838 | 0.9954522 |
| ENST00000371085 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + | 0.004608859 | 0.99539113 |
| ENST00000354359 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + | 0.004547838 | 0.9954522 |
| ENST00000354359 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + | 0.004608859 | 0.99539113 |
| ENST00000371081 | ENST00000491148 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + | 0.002369054 | 0.99763095 |
| ENST00000371081 | ENST00000282957 | GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545789 | + | 0.002421083 | 0.9975789 |
Top |
Fusion Genomic Features for GNAS-CPB1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545788 | + | 0.001921903 | 0.9980781 |
| GNAS | chr20 | 57474040 | + | CPB1 | chr3 | 148545788 | + | 0.001921903 | 0.9980781 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
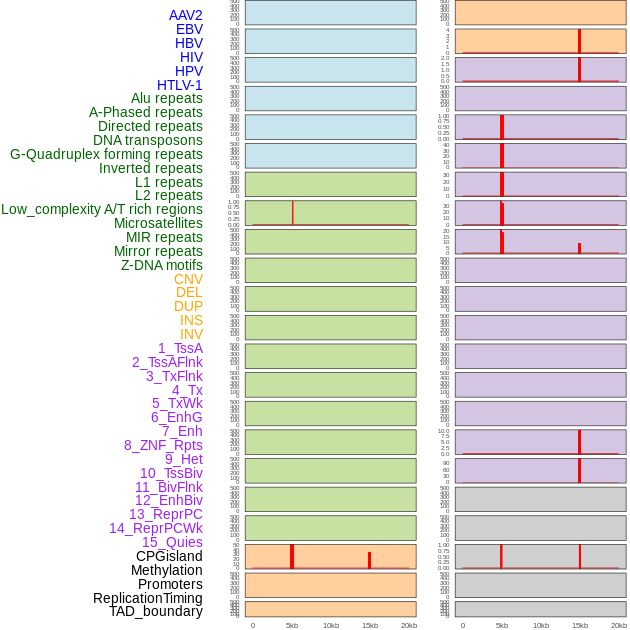 |
Top |
Fusion Protein Features for GNAS-CPB1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:57474040/chr3:148545789) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 641_667 | 728 | 1038.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000313949 | + | 3 | 13 | 78_142 | 299 | 26.333333333333332 | Compositional bias | Glu-rich |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371075 | + | 3 | 13 | 78_142 | 299 | 36.333333333333336 | Compositional bias | Glu-rich |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371098 | + | 3 | 4 | 78_142 | 299 | 20.333333333333332 | Compositional bias | Glu-rich |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 358_522 | 728 | 1038.0 | Compositional bias | Ala-rich |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 47_55 | 85 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 47_55 | 85 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 690_698 | 728 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 42_55 | 85 | 396.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 42_55 | 85 | 395.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 685_698 | 728 | 1038.0 | Region | G1 motif |
| Tgene | CPB1 | chr20:57474040 | chr3:148545789 | ENST00000282957 | 0 | 11 | 176_179 | 23 | 418.0 | Region | Substrate binding | |
| Tgene | CPB1 | chr20:57474040 | chr3:148545789 | ENST00000282957 | 0 | 11 | 251_252 | 23 | 418.0 | Region | Substrate binding | |
| Tgene | CPB1 | chr20:57474040 | chr3:148545789 | ENST00000282957 | 0 | 11 | 305_306 | 23 | 418.0 | Region | Substrate binding | |
| Tgene | CPB1 | chr20:57474040 | chr3:148545789 | ENST00000491148 | 1 | 12 | 176_179 | 23 | 418.0 | Region | Substrate binding | |
| Tgene | CPB1 | chr20:57474040 | chr3:148545789 | ENST00000491148 | 1 | 12 | 251_252 | 23 | 418.0 | Region | Substrate binding | |
| Tgene | CPB1 | chr20:57474040 | chr3:148545789 | ENST00000491148 | 1 | 12 | 305_306 | 23 | 418.0 | Region | Substrate binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 730_756 | 728 | 1038.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 641_667 | 0 | 1024.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 730_756 | 0 | 1024.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306120 | + | 1 | 1 | 238_476 | 0 | 626.0 | Compositional bias | Pro-rich |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 358_522 | 0 | 1024.0 | Compositional bias | Ala-rich |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 39_394 | 0 | 380.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 39_394 | 0 | 381.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 39_394 | 85 | 396.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 39_394 | 85 | 395.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 39_394 | 0 | 381.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 682_1037 | 728 | 1038.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 682_1037 | 0 | 1024.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 197_204 | 0 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 223_227 | 0 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 292_295 | 0 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 47_55 | 0 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 197_204 | 0 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 223_227 | 0 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 292_295 | 0 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 47_55 | 0 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 197_204 | 85 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 223_227 | 85 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 292_295 | 85 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 197_204 | 85 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 223_227 | 85 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 292_295 | 85 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 197_204 | 0 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 223_227 | 0 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 292_295 | 0 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 47_55 | 0 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 840_847 | 728 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 866_870 | 728 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 935_938 | 728 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 690_698 | 0 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 840_847 | 0 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 866_870 | 0 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 935_938 | 0 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 196_204 | 0 | 380.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 219_228 | 0 | 380.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 288_295 | 0 | 380.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 364_369 | 0 | 380.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000265620 | + | 1 | 12 | 42_55 | 0 | 380.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 196_204 | 0 | 381.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 219_228 | 0 | 381.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 288_295 | 0 | 381.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 364_369 | 0 | 381.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000306090 | + | 1 | 13 | 42_55 | 0 | 381.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 196_204 | 85 | 396.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 219_228 | 85 | 396.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 288_295 | 85 | 396.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000354359 | + | 3 | 13 | 364_369 | 85 | 396.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 196_204 | 85 | 395.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 219_228 | 85 | 395.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 288_295 | 85 | 395.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371085 | + | 3 | 13 | 364_369 | 85 | 395.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 196_204 | 0 | 381.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 219_228 | 0 | 381.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 288_295 | 0 | 381.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 364_369 | 0 | 381.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371095 | + | 1 | 12 | 42_55 | 0 | 381.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 1007_1012 | 728 | 1038.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 839_847 | 728 | 1038.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 862_871 | 728 | 1038.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371100 | + | 3 | 13 | 931_938 | 728 | 1038.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 1007_1012 | 0 | 1024.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 685_698 | 0 | 1024.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 839_847 | 0 | 1024.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 862_871 | 0 | 1024.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57474040 | chr3:148545789 | ENST00000371102 | + | 1 | 12 | 931_938 | 0 | 1024.0 | Region | G4 motif |
Top |
Fusion Gene Sequence for GNAS-CPB1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33614_33614_1_GNAS-CPB1_GNAS_chr20_57474040_ENST00000354359_CPB1_chr3_148545789_ENST00000282957_length(transcript)=2045nt_BP=681nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCGAGAAGGTGTTCCGTGTTAACGTTGAAGATGAAAATCA CATTAACATAATCCGCGAGTTGGCCAGCACGACCCAGATTGACTTCTGGAAGCCAGATTCTGTCACACAAATCAAACCTCACAGTACAGT TGACTTCCGTGTTAAAGCAGAAGATACTGTCACTGTGGAGAATGTTCTAAAGCAGAATGAACTACAATACAAGGTACTGATAAGCAACCT GAGAAATGTGGTGGAGGCTCAGTTTGATAGCCGGGTTCGTGCAACAGGACACAGTTATGAGAAGTACAACAAGTGGGAAACGATAGAGGC TTGGACTCAACAAGTCGCCACTGAGAATCCAGCCCTCATCTCTCGCAGTGTTATCGGAACCACATTTGAGGGACGCGCTATTTACCTCCT GAAGGTTGGCAAAGCTGGACAAAATAAGCCTGCCATTTTCATGGACTGTGGTTTCCATGCCAGAGAGTGGATTTCTCCTGCATTCTGCCA GTGGTTTGTAAGAGAGGCTGTTCGTACCTATGGACGTGAGATCCAAGTGACAGAGCTTCTCGACAAGTTAGACTTTTATGTCCTGCCTGT GCTCAATATTGATGGCTACATCTACACCTGGACCAAGAGCCGATTTTGGAGAAAGACTCGCTCCACCCATACTGGATCTAGCTGCATTGG CACAGACCCCAACAGAAATTTTGATGCTGGTTGGTGTGAAATTGGAGCCTCTCGAAACCCCTGTGATGAAACTTACTGTGGACCTGCCGC AGAGTCTGAAAAGGAGACCAAGGCCCTGGCTGATTTCATCCGCAACAAACTCTCTTCCATCAAGGCATATCTGACAATCCACTCGTACTC CCAAATGATGATCTACCCTTACTCATATGCTTACAAACTCGGTGAGAACAATGCTGAGTTGAATGCCCTGGCTAAAGCTACTGTGAAAGA ACTTGCCTCACTGCACGGCACCAAGTACACATATGGCCCGGGAGCTACAACAATCTATCCTGCTGCTGGGGGCTCTGACGACTGGGCTTA TGACCAAGGAATCAGATATTCCTTCACCTTTGAACTTCGAGATACAGGCAGATATGGCTTTCTCCTTCCAGAATCCCAGATCCGGGCTAC CTGCGAGGAGACCTTCCTGGCAATCAAGTATGTTGCCAGCTACGTCCTGGAACACCTGTACTAGTTGAGAAAGCTGATGGCCTTGTTTCA AAATTCTCATTTTTCATTTCTTTTCTTTCTTGAATTCTTATTTTGGTTTGCCTGGATGTTTTGCAGATCCCAATCTTTCTTTTAAGCTTC >33614_33614_1_GNAS-CPB1_GNAS_chr20_57474040_ENST00000354359_CPB1_chr3_148545789_ENST00000282957_length(amino acids)=479AA_BP=86 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEGGEEDPQAARSNSDGEKVF RVNVEDENHINIIRELASTTQIDFWKPDSVTQIKPHSTVDFRVKAEDTVTVENVLKQNELQYKVLISNLRNVVEAQFDSRVRATGHSYEK YNKWETIEAWTQQVATENPALISRSVIGTTFEGRAIYLLKVGKAGQNKPAIFMDCGFHAREWISPAFCQWFVREAVRTYGREIQVTELLD KLDFYVLPVLNIDGYIYTWTKSRFWRKTRSTHTGSSCIGTDPNRNFDAGWCEIGASRNPCDETYCGPAAESEKETKALADFIRNKLSSIK AYLTIHSYSQMMIYPYSYAYKLGENNAELNALAKATVKELASLHGTKYTYGPGATTIYPAAGGSDDWAYDQGIRYSFTFELRDTGRYGFL -------------------------------------------------------------- >33614_33614_2_GNAS-CPB1_GNAS_chr20_57474040_ENST00000354359_CPB1_chr3_148545789_ENST00000491148_length(transcript)=2049nt_BP=681nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCGAGAAGGTGTTCCGTGTTAACGTTGAAGATGAAAATCA CATTAACATAATCCGCGAGTTGGCCAGCACGACCCAGATTGACTTCTGGAAGCCAGATTCTGTCACACAAATCAAACCTCACAGTACAGT TGACTTCCGTGTTAAAGCAGAAGATACTGTCACTGTGGAGAATGTTCTAAAGCAGAATGAACTACAATACAAGGTACTGATAAGCAACCT GAGAAATGTGGTGGAGGCTCAGTTTGATAGCCGGGTTCGTGCAACAGGACACAGTTATGAGAAGTACAACAAGTGGGAAACGATAGAGGC TTGGACTCAACAAGTCGCCACTGAGAATCCAGCCCTCATCTCTCGCAGTGTTATCGGAACCACATTTGAGGGACGCGCTATTTACCTCCT GAAGGTTGGCAAAGCTGGACAAAATAAGCCTGCCATTTTCATGGACTGTGGTTTCCATGCCAGAGAGTGGATTTCTCCTGCATTCTGCCA GTGGTTTGTAAGAGAGGCTGTTCGTACCTATGGACGTGAGATCCAAGTGACAGAGCTTCTCGACAAGTTAGACTTTTATGTCCTGCCTGT GCTCAATATTGATGGCTACATCTACACCTGGACCAAGAGCCGATTTTGGAGAAAGACTCGCTCCACCCATACTGGATCTAGCTGCATTGG CACAGACCCCAACAGAAATTTTGATGCTGGTTGGTGTGAAATTGGAGCCTCTCGAAACCCCTGTGATGAAACTTACTGTGGACCTGCCGC AGAGTCTGAAAAGGAGACCAAGGCCCTGGCTGATTTCATCCGCAACAAACTCTCTTCCATCAAGGCATATCTGACAATCCACTCGTACTC CCAAATGATGATCTACCCTTACTCATATGCTTACAAACTCGGTGAGAACAATGCTGAGTTGAATGCCCTGGCTAAAGCTACTGTGAAAGA ACTTGCCTCACTGCACGGCACCAAGTACACATATGGCCCGGGAGCTACAACAATCTATCCTGCTGCTGGGGGCTCTGACGACTGGGCTTA TGACCAAGGAATCAGATATTCCTTCACCTTTGAACTTCGAGATACAGGCAGATATGGCTTTCTCCTTCCAGAATCCCAGATCCGGGCTAC CTGCGAGGAGACCTTCCTGGCAATCAAGTATGTTGCCAGCTACGTCCTGGAACACCTGTACTAGTTGAGAAAGCTGATGGCCTTGTTTCA AAATTCTCATTTTTCATTTCTTTTCTTTCTTGAATTCTTATTTTGGTTTGCCTGGATGTTTTGCAGATCCCAATCTTTCTTTTAAGCTTC >33614_33614_2_GNAS-CPB1_GNAS_chr20_57474040_ENST00000354359_CPB1_chr3_148545789_ENST00000491148_length(amino acids)=479AA_BP=86 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEGGEEDPQAARSNSDGEKVF RVNVEDENHINIIRELASTTQIDFWKPDSVTQIKPHSTVDFRVKAEDTVTVENVLKQNELQYKVLISNLRNVVEAQFDSRVRATGHSYEK YNKWETIEAWTQQVATENPALISRSVIGTTFEGRAIYLLKVGKAGQNKPAIFMDCGFHAREWISPAFCQWFVREAVRTYGREIQVTELLD KLDFYVLPVLNIDGYIYTWTKSRFWRKTRSTHTGSSCIGTDPNRNFDAGWCEIGASRNPCDETYCGPAAESEKETKALADFIRNKLSSIK AYLTIHSYSQMMIYPYSYAYKLGENNAELNALAKATVKELASLHGTKYTYGPGATTIYPAAGGSDDWAYDQGIRYSFTFELRDTGRYGFL -------------------------------------------------------------- >33614_33614_3_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371081_CPB1_chr3_148545789_ENST00000282957_length(transcript)=1632nt_BP=268nt CCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCG AGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTG TGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCG AGAAGGTGTTCCGTGTTAACGTTGAAGATGAAAATCACATTAACATAATCCGCGAGTTGGCCAGCACGACCCAGATTGACTTCTGGAAGC CAGATTCTGTCACACAAATCAAACCTCACAGTACAGTTGACTTCCGTGTTAAAGCAGAAGATACTGTCACTGTGGAGAATGTTCTAAAGC AGAATGAACTACAATACAAGGTACTGATAAGCAACCTGAGAAATGTGGTGGAGGCTCAGTTTGATAGCCGGGTTCGTGCAACAGGACACA GTTATGAGAAGTACAACAAGTGGGAAACGATAGAGGCTTGGACTCAACAAGTCGCCACTGAGAATCCAGCCCTCATCTCTCGCAGTGTTA TCGGAACCACATTTGAGGGACGCGCTATTTACCTCCTGAAGGTTGGCAAAGCTGGACAAAATAAGCCTGCCATTTTCATGGACTGTGGTT TCCATGCCAGAGAGTGGATTTCTCCTGCATTCTGCCAGTGGTTTGTAAGAGAGGCTGTTCGTACCTATGGACGTGAGATCCAAGTGACAG AGCTTCTCGACAAGTTAGACTTTTATGTCCTGCCTGTGCTCAATATTGATGGCTACATCTACACCTGGACCAAGAGCCGATTTTGGAGAA AGACTCGCTCCACCCATACTGGATCTAGCTGCATTGGCACAGACCCCAACAGAAATTTTGATGCTGGTTGGTGTGAAATTGGAGCCTCTC GAAACCCCTGTGATGAAACTTACTGTGGACCTGCCGCAGAGTCTGAAAAGGAGACCAAGGCCCTGGCTGATTTCATCCGCAACAAACTCT CTTCCATCAAGGCATATCTGACAATCCACTCGTACTCCCAAATGATGATCTACCCTTACTCATATGCTTACAAACTCGGTGAGAACAATG CTGAGTTGAATGCCCTGGCTAAAGCTACTGTGAAAGAACTTGCCTCACTGCACGGCACCAAGTACACATATGGCCCGGGAGCTACAACAA TCTATCCTGCTGCTGGGGGCTCTGACGACTGGGCTTATGACCAAGGAATCAGATATTCCTTCACCTTTGAACTTCGAGATACAGGCAGAT ATGGCTTTCTCCTTCCAGAATCCCAGATCCGGGCTACCTGCGAGGAGACCTTCCTGGCAATCAAGTATGTTGCCAGCTACGTCCTGGAAC ACCTGTACTAGTTGAGAAAGCTGATGGCCTTGTTTCAAAATTCTCATTTTTCATTTCTTTTCTTTCTTGAATTCTTATTTTGGTTTGCCT GGATGTTTTGCAGATCCCAATCTTTCTTTTAAGCTTCTGGGTCTATTAAACTAGGTAGATCTTTTCGTATTGATCATAATAAAAGTGAAT >33614_33614_3_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371081_CPB1_chr3_148545789_ENST00000282957_length(amino acids)=479AA_BP=86 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEGGEEDPQAARSNSDGEKVF RVNVEDENHINIIRELASTTQIDFWKPDSVTQIKPHSTVDFRVKAEDTVTVENVLKQNELQYKVLISNLRNVVEAQFDSRVRATGHSYEK YNKWETIEAWTQQVATENPALISRSVIGTTFEGRAIYLLKVGKAGQNKPAIFMDCGFHAREWISPAFCQWFVREAVRTYGREIQVTELLD KLDFYVLPVLNIDGYIYTWTKSRFWRKTRSTHTGSSCIGTDPNRNFDAGWCEIGASRNPCDETYCGPAAESEKETKALADFIRNKLSSIK AYLTIHSYSQMMIYPYSYAYKLGENNAELNALAKATVKELASLHGTKYTYGPGATTIYPAAGGSDDWAYDQGIRYSFTFELRDTGRYGFL -------------------------------------------------------------- >33614_33614_4_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371081_CPB1_chr3_148545789_ENST00000491148_length(transcript)=1636nt_BP=268nt CCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCG AGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTG TGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCG AGAAGGTGTTCCGTGTTAACGTTGAAGATGAAAATCACATTAACATAATCCGCGAGTTGGCCAGCACGACCCAGATTGACTTCTGGAAGC CAGATTCTGTCACACAAATCAAACCTCACAGTACAGTTGACTTCCGTGTTAAAGCAGAAGATACTGTCACTGTGGAGAATGTTCTAAAGC AGAATGAACTACAATACAAGGTACTGATAAGCAACCTGAGAAATGTGGTGGAGGCTCAGTTTGATAGCCGGGTTCGTGCAACAGGACACA GTTATGAGAAGTACAACAAGTGGGAAACGATAGAGGCTTGGACTCAACAAGTCGCCACTGAGAATCCAGCCCTCATCTCTCGCAGTGTTA TCGGAACCACATTTGAGGGACGCGCTATTTACCTCCTGAAGGTTGGCAAAGCTGGACAAAATAAGCCTGCCATTTTCATGGACTGTGGTT TCCATGCCAGAGAGTGGATTTCTCCTGCATTCTGCCAGTGGTTTGTAAGAGAGGCTGTTCGTACCTATGGACGTGAGATCCAAGTGACAG AGCTTCTCGACAAGTTAGACTTTTATGTCCTGCCTGTGCTCAATATTGATGGCTACATCTACACCTGGACCAAGAGCCGATTTTGGAGAA AGACTCGCTCCACCCATACTGGATCTAGCTGCATTGGCACAGACCCCAACAGAAATTTTGATGCTGGTTGGTGTGAAATTGGAGCCTCTC GAAACCCCTGTGATGAAACTTACTGTGGACCTGCCGCAGAGTCTGAAAAGGAGACCAAGGCCCTGGCTGATTTCATCCGCAACAAACTCT CTTCCATCAAGGCATATCTGACAATCCACTCGTACTCCCAAATGATGATCTACCCTTACTCATATGCTTACAAACTCGGTGAGAACAATG CTGAGTTGAATGCCCTGGCTAAAGCTACTGTGAAAGAACTTGCCTCACTGCACGGCACCAAGTACACATATGGCCCGGGAGCTACAACAA TCTATCCTGCTGCTGGGGGCTCTGACGACTGGGCTTATGACCAAGGAATCAGATATTCCTTCACCTTTGAACTTCGAGATACAGGCAGAT ATGGCTTTCTCCTTCCAGAATCCCAGATCCGGGCTACCTGCGAGGAGACCTTCCTGGCAATCAAGTATGTTGCCAGCTACGTCCTGGAAC ACCTGTACTAGTTGAGAAAGCTGATGGCCTTGTTTCAAAATTCTCATTTTTCATTTCTTTTCTTTCTTGAATTCTTATTTTGGTTTGCCT GGATGTTTTGCAGATCCCAATCTTTCTTTTAAGCTTCTGGGTCTATTAAACTAGGTAGATCTTTTCGTATTGATCATAATAAAAGTGAAT >33614_33614_4_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371081_CPB1_chr3_148545789_ENST00000491148_length(amino acids)=479AA_BP=86 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEGGEEDPQAARSNSDGEKVF RVNVEDENHINIIRELASTTQIDFWKPDSVTQIKPHSTVDFRVKAEDTVTVENVLKQNELQYKVLISNLRNVVEAQFDSRVRATGHSYEK YNKWETIEAWTQQVATENPALISRSVIGTTFEGRAIYLLKVGKAGQNKPAIFMDCGFHAREWISPAFCQWFVREAVRTYGREIQVTELLD KLDFYVLPVLNIDGYIYTWTKSRFWRKTRSTHTGSSCIGTDPNRNFDAGWCEIGASRNPCDETYCGPAAESEKETKALADFIRNKLSSIK AYLTIHSYSQMMIYPYSYAYKLGENNAELNALAKATVKELASLHGTKYTYGPGATTIYPAAGGSDDWAYDQGIRYSFTFELRDTGRYGFL -------------------------------------------------------------- >33614_33614_5_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371085_CPB1_chr3_148545789_ENST00000282957_length(transcript)=2045nt_BP=681nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCGAGAAGGTGTTCCGTGTTAACGTTGAAGATGAAAATCA CATTAACATAATCCGCGAGTTGGCCAGCACGACCCAGATTGACTTCTGGAAGCCAGATTCTGTCACACAAATCAAACCTCACAGTACAGT TGACTTCCGTGTTAAAGCAGAAGATACTGTCACTGTGGAGAATGTTCTAAAGCAGAATGAACTACAATACAAGGTACTGATAAGCAACCT GAGAAATGTGGTGGAGGCTCAGTTTGATAGCCGGGTTCGTGCAACAGGACACAGTTATGAGAAGTACAACAAGTGGGAAACGATAGAGGC TTGGACTCAACAAGTCGCCACTGAGAATCCAGCCCTCATCTCTCGCAGTGTTATCGGAACCACATTTGAGGGACGCGCTATTTACCTCCT GAAGGTTGGCAAAGCTGGACAAAATAAGCCTGCCATTTTCATGGACTGTGGTTTCCATGCCAGAGAGTGGATTTCTCCTGCATTCTGCCA GTGGTTTGTAAGAGAGGCTGTTCGTACCTATGGACGTGAGATCCAAGTGACAGAGCTTCTCGACAAGTTAGACTTTTATGTCCTGCCTGT GCTCAATATTGATGGCTACATCTACACCTGGACCAAGAGCCGATTTTGGAGAAAGACTCGCTCCACCCATACTGGATCTAGCTGCATTGG CACAGACCCCAACAGAAATTTTGATGCTGGTTGGTGTGAAATTGGAGCCTCTCGAAACCCCTGTGATGAAACTTACTGTGGACCTGCCGC AGAGTCTGAAAAGGAGACCAAGGCCCTGGCTGATTTCATCCGCAACAAACTCTCTTCCATCAAGGCATATCTGACAATCCACTCGTACTC CCAAATGATGATCTACCCTTACTCATATGCTTACAAACTCGGTGAGAACAATGCTGAGTTGAATGCCCTGGCTAAAGCTACTGTGAAAGA ACTTGCCTCACTGCACGGCACCAAGTACACATATGGCCCGGGAGCTACAACAATCTATCCTGCTGCTGGGGGCTCTGACGACTGGGCTTA TGACCAAGGAATCAGATATTCCTTCACCTTTGAACTTCGAGATACAGGCAGATATGGCTTTCTCCTTCCAGAATCCCAGATCCGGGCTAC CTGCGAGGAGACCTTCCTGGCAATCAAGTATGTTGCCAGCTACGTCCTGGAACACCTGTACTAGTTGAGAAAGCTGATGGCCTTGTTTCA AAATTCTCATTTTTCATTTCTTTTCTTTCTTGAATTCTTATTTTGGTTTGCCTGGATGTTTTGCAGATCCCAATCTTTCTTTTAAGCTTC >33614_33614_5_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371085_CPB1_chr3_148545789_ENST00000282957_length(amino acids)=479AA_BP=86 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEGGEEDPQAARSNSDGEKVF RVNVEDENHINIIRELASTTQIDFWKPDSVTQIKPHSTVDFRVKAEDTVTVENVLKQNELQYKVLISNLRNVVEAQFDSRVRATGHSYEK YNKWETIEAWTQQVATENPALISRSVIGTTFEGRAIYLLKVGKAGQNKPAIFMDCGFHAREWISPAFCQWFVREAVRTYGREIQVTELLD KLDFYVLPVLNIDGYIYTWTKSRFWRKTRSTHTGSSCIGTDPNRNFDAGWCEIGASRNPCDETYCGPAAESEKETKALADFIRNKLSSIK AYLTIHSYSQMMIYPYSYAYKLGENNAELNALAKATVKELASLHGTKYTYGPGATTIYPAAGGSDDWAYDQGIRYSFTFELRDTGRYGFL -------------------------------------------------------------- >33614_33614_6_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371085_CPB1_chr3_148545789_ENST00000491148_length(transcript)=2049nt_BP=681nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCGAGAAGGTGTTCCGTGTTAACGTTGAAGATGAAAATCA CATTAACATAATCCGCGAGTTGGCCAGCACGACCCAGATTGACTTCTGGAAGCCAGATTCTGTCACACAAATCAAACCTCACAGTACAGT TGACTTCCGTGTTAAAGCAGAAGATACTGTCACTGTGGAGAATGTTCTAAAGCAGAATGAACTACAATACAAGGTACTGATAAGCAACCT GAGAAATGTGGTGGAGGCTCAGTTTGATAGCCGGGTTCGTGCAACAGGACACAGTTATGAGAAGTACAACAAGTGGGAAACGATAGAGGC TTGGACTCAACAAGTCGCCACTGAGAATCCAGCCCTCATCTCTCGCAGTGTTATCGGAACCACATTTGAGGGACGCGCTATTTACCTCCT GAAGGTTGGCAAAGCTGGACAAAATAAGCCTGCCATTTTCATGGACTGTGGTTTCCATGCCAGAGAGTGGATTTCTCCTGCATTCTGCCA GTGGTTTGTAAGAGAGGCTGTTCGTACCTATGGACGTGAGATCCAAGTGACAGAGCTTCTCGACAAGTTAGACTTTTATGTCCTGCCTGT GCTCAATATTGATGGCTACATCTACACCTGGACCAAGAGCCGATTTTGGAGAAAGACTCGCTCCACCCATACTGGATCTAGCTGCATTGG CACAGACCCCAACAGAAATTTTGATGCTGGTTGGTGTGAAATTGGAGCCTCTCGAAACCCCTGTGATGAAACTTACTGTGGACCTGCCGC AGAGTCTGAAAAGGAGACCAAGGCCCTGGCTGATTTCATCCGCAACAAACTCTCTTCCATCAAGGCATATCTGACAATCCACTCGTACTC CCAAATGATGATCTACCCTTACTCATATGCTTACAAACTCGGTGAGAACAATGCTGAGTTGAATGCCCTGGCTAAAGCTACTGTGAAAGA ACTTGCCTCACTGCACGGCACCAAGTACACATATGGCCCGGGAGCTACAACAATCTATCCTGCTGCTGGGGGCTCTGACGACTGGGCTTA TGACCAAGGAATCAGATATTCCTTCACCTTTGAACTTCGAGATACAGGCAGATATGGCTTTCTCCTTCCAGAATCCCAGATCCGGGCTAC CTGCGAGGAGACCTTCCTGGCAATCAAGTATGTTGCCAGCTACGTCCTGGAACACCTGTACTAGTTGAGAAAGCTGATGGCCTTGTTTCA AAATTCTCATTTTTCATTTCTTTTCTTTCTTGAATTCTTATTTTGGTTTGCCTGGATGTTTTGCAGATCCCAATCTTTCTTTTAAGCTTC >33614_33614_6_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371085_CPB1_chr3_148545789_ENST00000491148_length(amino acids)=479AA_BP=86 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEGGEEDPQAARSNSDGEKVF RVNVEDENHINIIRELASTTQIDFWKPDSVTQIKPHSTVDFRVKAEDTVTVENVLKQNELQYKVLISNLRNVVEAQFDSRVRATGHSYEK YNKWETIEAWTQQVATENPALISRSVIGTTFEGRAIYLLKVGKAGQNKPAIFMDCGFHAREWISPAFCQWFVREAVRTYGREIQVTELLD KLDFYVLPVLNIDGYIYTWTKSRFWRKTRSTHTGSSCIGTDPNRNFDAGWCEIGASRNPCDETYCGPAAESEKETKALADFIRNKLSSIK AYLTIHSYSQMMIYPYSYAYKLGENNAELNALAKATVKELASLHGTKYTYGPGATTIYPAAGGSDDWAYDQGIRYSFTFELRDTGRYGFL -------------------------------------------------------------- >33614_33614_7_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371100_CPB1_chr3_148545789_ENST00000282957_length(transcript)=4102nt_BP=2738nt AAAGACTCCAAATCAGTCAGGGAGAGGAGTGGAAGGAGCCAAAACGTCCCTGCGAGGCCTGCGCTCACCAGCCCCCTTACCCAAAGTCCC GGGCCCCTGGCGCCAGGAGCAGGCTCCTGGAGCCGGAGCCAGCTCGGCACTGGAACCGGCGTCCTCTGGTGGCAGAGAGAGAGCGCTACT GGCGATTTTCGGACCGAATCGGCACGCTCGTCAGATCCAAGCAGGCGGGACTGGCCTGGAGCAAAAAGAAAGAGAGAGGAGGGCGTAAGG ATAGACCAAGGAAGAGGGGCTGGGGGGCAGCCTGGGGGCATGAAAAGTGGCCAGGAAGGAGCCAAGACTCCACCAGCAACAATTGAGTTG CTTCAGCCTCAGTCTAGGGTTCCTTCCAGGCCTTGAACCCCCCAACCTCACAAGGGTTGGAAAGTGAGGCCGGTGAACTTTCCAGCTGGT ACTTTGATTTTAAAATAATAATAATAATTTTTTCACCCTAGTTCGGTTGGGTGCTCCATCTTACGGAGCCCCAAACTTATTTTGAGAGGC CGCCACCGTGTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCC GAGCAACCACCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAAC GAGCCCATCCCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGG GAAGCTGGAGCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCT ACACTGGAGCAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGT GCCAGACCAGGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAA CTTCTCTTACAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGG CCTGCAAAGGCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGAC AGCCCACCCCCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTC ACTCCCGCCGCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACG GGCAGCAGCCCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGAC AGCCCCCCAATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAG GAAGCAGCAGAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCC TCAGCGGATACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCA CCAGCCGATCCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCC CCTGACGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCC CCTGCGGCTGCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGG GCAGCCCAAGTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAG GCTGCCGATCCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGAT GAAGGGGTGGCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGA AATCGCCGCCGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCC CAGCCCAAAGCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGG GCCCAGAAGCGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTG CTGCTTCTAGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGGGCGGC GAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCGAGAAGGTGTTCCGTGTTAACGTTGAAGATGAAAATCACATTAACATAATC CGCGAGTTGGCCAGCACGACCCAGATTGACTTCTGGAAGCCAGATTCTGTCACACAAATCAAACCTCACAGTACAGTTGACTTCCGTGTT AAAGCAGAAGATACTGTCACTGTGGAGAATGTTCTAAAGCAGAATGAACTACAATACAAGGTACTGATAAGCAACCTGAGAAATGTGGTG GAGGCTCAGTTTGATAGCCGGGTTCGTGCAACAGGACACAGTTATGAGAAGTACAACAAGTGGGAAACGATAGAGGCTTGGACTCAACAA GTCGCCACTGAGAATCCAGCCCTCATCTCTCGCAGTGTTATCGGAACCACATTTGAGGGACGCGCTATTTACCTCCTGAAGGTTGGCAAA GCTGGACAAAATAAGCCTGCCATTTTCATGGACTGTGGTTTCCATGCCAGAGAGTGGATTTCTCCTGCATTCTGCCAGTGGTTTGTAAGA GAGGCTGTTCGTACCTATGGACGTGAGATCCAAGTGACAGAGCTTCTCGACAAGTTAGACTTTTATGTCCTGCCTGTGCTCAATATTGAT GGCTACATCTACACCTGGACCAAGAGCCGATTTTGGAGAAAGACTCGCTCCACCCATACTGGATCTAGCTGCATTGGCACAGACCCCAAC AGAAATTTTGATGCTGGTTGGTGTGAAATTGGAGCCTCTCGAAACCCCTGTGATGAAACTTACTGTGGACCTGCCGCAGAGTCTGAAAAG GAGACCAAGGCCCTGGCTGATTTCATCCGCAACAAACTCTCTTCCATCAAGGCATATCTGACAATCCACTCGTACTCCCAAATGATGATC TACCCTTACTCATATGCTTACAAACTCGGTGAGAACAATGCTGAGTTGAATGCCCTGGCTAAAGCTACTGTGAAAGAACTTGCCTCACTG CACGGCACCAAGTACACATATGGCCCGGGAGCTACAACAATCTATCCTGCTGCTGGGGGCTCTGACGACTGGGCTTATGACCAAGGAATC AGATATTCCTTCACCTTTGAACTTCGAGATACAGGCAGATATGGCTTTCTCCTTCCAGAATCCCAGATCCGGGCTACCTGCGAGGAGACC TTCCTGGCAATCAAGTATGTTGCCAGCTACGTCCTGGAACACCTGTACTAGTTGAGAAAGCTGATGGCCTTGTTTCAAAATTCTCATTTT TCATTTCTTTTCTTTCTTGAATTCTTATTTTGGTTTGCCTGGATGTTTTGCAGATCCCAATCTTTCTTTTAAGCTTCTGGGTCTATTAAA >33614_33614_7_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371100_CPB1_chr3_148545789_ENST00000282957_length(amino acids)=1129AA_BP=736 MRGRHRVMGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNP AFREAGAHGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRG CSQLLLQVPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSA VRLTPAANAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPP VEEEAAEMEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDS GAAPDAPADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSP EIQAADPPTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRS ESPQPKASRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNG EGGEEDPQAARSNSDGEKVFRVNVEDENHINIIRELASTTQIDFWKPDSVTQIKPHSTVDFRVKAEDTVTVENVLKQNELQYKVLISNLR NVVEAQFDSRVRATGHSYEKYNKWETIEAWTQQVATENPALISRSVIGTTFEGRAIYLLKVGKAGQNKPAIFMDCGFHAREWISPAFCQW FVREAVRTYGREIQVTELLDKLDFYVLPVLNIDGYIYTWTKSRFWRKTRSTHTGSSCIGTDPNRNFDAGWCEIGASRNPCDETYCGPAAE SEKETKALADFIRNKLSSIKAYLTIHSYSQMMIYPYSYAYKLGENNAELNALAKATVKELASLHGTKYTYGPGATTIYPAAGGSDDWAYD -------------------------------------------------------------- >33614_33614_8_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371100_CPB1_chr3_148545789_ENST00000491148_length(transcript)=4106nt_BP=2738nt AAAGACTCCAAATCAGTCAGGGAGAGGAGTGGAAGGAGCCAAAACGTCCCTGCGAGGCCTGCGCTCACCAGCCCCCTTACCCAAAGTCCC GGGCCCCTGGCGCCAGGAGCAGGCTCCTGGAGCCGGAGCCAGCTCGGCACTGGAACCGGCGTCCTCTGGTGGCAGAGAGAGAGCGCTACT GGCGATTTTCGGACCGAATCGGCACGCTCGTCAGATCCAAGCAGGCGGGACTGGCCTGGAGCAAAAAGAAAGAGAGAGGAGGGCGTAAGG ATAGACCAAGGAAGAGGGGCTGGGGGGCAGCCTGGGGGCATGAAAAGTGGCCAGGAAGGAGCCAAGACTCCACCAGCAACAATTGAGTTG CTTCAGCCTCAGTCTAGGGTTCCTTCCAGGCCTTGAACCCCCCAACCTCACAAGGGTTGGAAAGTGAGGCCGGTGAACTTTCCAGCTGGT ACTTTGATTTTAAAATAATAATAATAATTTTTTCACCCTAGTTCGGTTGGGTGCTCCATCTTACGGAGCCCCAAACTTATTTTGAGAGGC CGCCACCGTGTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCC GAGCAACCACCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAAC GAGCCCATCCCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGG GAAGCTGGAGCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCT ACACTGGAGCAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGT GCCAGACCAGGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAA CTTCTCTTACAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGG CCTGCAAAGGCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGAC AGCCCACCCCCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTC ACTCCCGCCGCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACG GGCAGCAGCCCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGAC AGCCCCCCAATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAG GAAGCAGCAGAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCC TCAGCGGATACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCA CCAGCCGATCCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCC CCTGACGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCC CCTGCGGCTGCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGG GCAGCCCAAGTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAG GCTGCCGATCCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGAT GAAGGGGTGGCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGA AATCGCCGCCGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCC CAGCCCAAAGCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGG GCCCAGAAGCGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTG CTGCTTCTAGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGGGCGGC GAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCGAGAAGGTGTTCCGTGTTAACGTTGAAGATGAAAATCACATTAACATAATC CGCGAGTTGGCCAGCACGACCCAGATTGACTTCTGGAAGCCAGATTCTGTCACACAAATCAAACCTCACAGTACAGTTGACTTCCGTGTT AAAGCAGAAGATACTGTCACTGTGGAGAATGTTCTAAAGCAGAATGAACTACAATACAAGGTACTGATAAGCAACCTGAGAAATGTGGTG GAGGCTCAGTTTGATAGCCGGGTTCGTGCAACAGGACACAGTTATGAGAAGTACAACAAGTGGGAAACGATAGAGGCTTGGACTCAACAA GTCGCCACTGAGAATCCAGCCCTCATCTCTCGCAGTGTTATCGGAACCACATTTGAGGGACGCGCTATTTACCTCCTGAAGGTTGGCAAA GCTGGACAAAATAAGCCTGCCATTTTCATGGACTGTGGTTTCCATGCCAGAGAGTGGATTTCTCCTGCATTCTGCCAGTGGTTTGTAAGA GAGGCTGTTCGTACCTATGGACGTGAGATCCAAGTGACAGAGCTTCTCGACAAGTTAGACTTTTATGTCCTGCCTGTGCTCAATATTGAT GGCTACATCTACACCTGGACCAAGAGCCGATTTTGGAGAAAGACTCGCTCCACCCATACTGGATCTAGCTGCATTGGCACAGACCCCAAC AGAAATTTTGATGCTGGTTGGTGTGAAATTGGAGCCTCTCGAAACCCCTGTGATGAAACTTACTGTGGACCTGCCGCAGAGTCTGAAAAG GAGACCAAGGCCCTGGCTGATTTCATCCGCAACAAACTCTCTTCCATCAAGGCATATCTGACAATCCACTCGTACTCCCAAATGATGATC TACCCTTACTCATATGCTTACAAACTCGGTGAGAACAATGCTGAGTTGAATGCCCTGGCTAAAGCTACTGTGAAAGAACTTGCCTCACTG CACGGCACCAAGTACACATATGGCCCGGGAGCTACAACAATCTATCCTGCTGCTGGGGGCTCTGACGACTGGGCTTATGACCAAGGAATC AGATATTCCTTCACCTTTGAACTTCGAGATACAGGCAGATATGGCTTTCTCCTTCCAGAATCCCAGATCCGGGCTACCTGCGAGGAGACC TTCCTGGCAATCAAGTATGTTGCCAGCTACGTCCTGGAACACCTGTACTAGTTGAGAAAGCTGATGGCCTTGTTTCAAAATTCTCATTTT TCATTTCTTTTCTTTCTTGAATTCTTATTTTGGTTTGCCTGGATGTTTTGCAGATCCCAATCTTTCTTTTAAGCTTCTGGGTCTATTAAA >33614_33614_8_GNAS-CPB1_GNAS_chr20_57474040_ENST00000371100_CPB1_chr3_148545789_ENST00000491148_length(amino acids)=1129AA_BP=736 MRGRHRVMGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNP AFREAGAHGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRG CSQLLLQVPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSA VRLTPAANAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPP VEEEAAEMEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDS GAAPDAPADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSP EIQAADPPTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRS ESPQPKASRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNG EGGEEDPQAARSNSDGEKVFRVNVEDENHINIIRELASTTQIDFWKPDSVTQIKPHSTVDFRVKAEDTVTVENVLKQNELQYKVLISNLR NVVEAQFDSRVRATGHSYEKYNKWETIEAWTQQVATENPALISRSVIGTTFEGRAIYLLKVGKAGQNKPAIFMDCGFHAREWISPAFCQW FVREAVRTYGREIQVTELLDKLDFYVLPVLNIDGYIYTWTKSRFWRKTRSTHTGSSCIGTDPNRNFDAGWCEIGASRNPCDETYCGPAAE SEKETKALADFIRNKLSSIKAYLTIHSYSQMMIYPYSYAYKLGENNAELNALAKATVKELASLHGTKYTYGPGATTIYPAAGGSDDWAYD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GNAS-CPB1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GNAS-CPB1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GNAS-CPB1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | GNAS | C3494506 | Pseudohypoparathyroidism, Type Ia | 17 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C0242292 | McCune-Albright Syndrome | 7 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C0016065 | Polyostotic fibrous dysplasia | 5 | CTD_human;ORPHANET |
| Hgene | GNAS | C1864100 | PSEUDOHYPOPARATHYROIDISM, TYPE IB | 5 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Hgene | GNAS | C2931404 | Albright's hereditary osteodystrophy | 4 | CTD_human;GENOMICS_ENGLAND |
| Hgene | GNAS | C0033806 | Pseudohypoparathyroidism | 3 | CTD_human |
| Hgene | GNAS | C0334041 | Osteoma cutis | 3 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C0014130 | Endocrine System Diseases | 2 | CTD_human |
| Hgene | GNAS | C0016064 | Fibrous Dysplasia, Monostotic | 2 | ORPHANET |
| Hgene | GNAS | C0034013 | Precocious Puberty | 2 | CTD_human |
| Hgene | GNAS | C0221263 | Cafe-au-Lait Spots | 2 | CTD_human |
| Hgene | GNAS | C0271527 | Cryptogenic sexual precocity | 2 | CTD_human |
| Hgene | GNAS | C0342543 | Central Precocious Puberty | 2 | CTD_human |
| Hgene | GNAS | C1504412 | Testotoxicosis | 2 | CTD_human |
| Hgene | GNAS | C1857451 | Acth-Independent Macronodular Adrenal Hyperplasia | 2 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C2932716 | Pseudohypoparathyroidism Type 1C | 2 | GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C0001206 | Acromegaly | 1 | CTD_human |
| Hgene | GNAS | C0001624 | Adrenal Gland Neoplasms | 1 | CTD_human |
| Hgene | GNAS | C0003129 | Anoxemia | 1 | CTD_human |
| Hgene | GNAS | C0003130 | Anoxia | 1 | CTD_human |
| Hgene | GNAS | C0008370 | Cholestasis | 1 | GENOMICS_ENGLAND |
| Hgene | GNAS | C0009438 | Common Bile Duct Calculi | 1 | CTD_human |
| Hgene | GNAS | C0011573 | Endogenous depression | 1 | PSYGENET |
| Hgene | GNAS | C0019087 | Hemorrhagic Disorders | 1 | CTD_human |
| Hgene | GNAS | C0020538 | Hypertensive disease | 1 | CTD_human |
| Hgene | GNAS | C0020796 | Profound Mental Retardation | 1 | CTD_human |
| Hgene | GNAS | C0021655 | Insulin Resistance | 1 | CTD_human |
| Hgene | GNAS | C0023897 | Liver Diseases, Parasitic | 1 | CTD_human |
| Hgene | GNAS | C0025363 | Mental Retardation, Psychosocial | 1 | CTD_human |
| Hgene | GNAS | C0027819 | Neuroblastoma | 1 | CTD_human |
| Hgene | GNAS | C0028754 | Obesity | 1 | CTD_human |
| Hgene | GNAS | C0029396 | Heterotopic Ossification | 1 | CTD_human |
| Hgene | GNAS | C0032460 | Polycystic Ovary Syndrome | 1 | CTD_human |
| Hgene | GNAS | C0033835 | Pseudopseudohypoparathyroidism | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Hgene | GNAS | C0035204 | Respiration Disorders | 1 | CTD_human |
| Hgene | GNAS | C0036341 | Schizophrenia | 1 | PSYGENET |
| Hgene | GNAS | C0038587 | Substance Withdrawal Syndrome | 1 | CTD_human |
| Hgene | GNAS | C0039231 | Tachycardia | 1 | CTD_human |
| Hgene | GNAS | C0080203 | Tachyarrhythmia | 1 | CTD_human |
| Hgene | GNAS | C0086189 | Drug Withdrawal Symptoms | 1 | CTD_human |
| Hgene | GNAS | C0087169 | Withdrawal Symptoms | 1 | CTD_human |
| Hgene | GNAS | C0206698 | Cholangiocarcinoma | 1 | CTD_human |
| Hgene | GNAS | C0221357 | Brachydactyly | 1 | CTD_human |
| Hgene | GNAS | C0242184 | Hypoxia | 1 | CTD_human |
| Hgene | GNAS | C0242216 | Biliary calculi | 1 | CTD_human |
| Hgene | GNAS | C0345905 | Intrahepatic Cholangiocarcinoma | 1 | CTD_human |
| Hgene | GNAS | C0346302 | Growth Hormone-Secreting Pituitary Adenoma | 1 | CTD_human |
| Hgene | GNAS | C0700292 | Hypoxemia | 1 | CTD_human |
| Hgene | GNAS | C0750887 | Adrenal Cancer | 1 | CTD_human |
| Hgene | GNAS | C0917816 | Mental deficiency | 1 | CTD_human |
| Hgene | GNAS | C0920563 | Insulin Sensitivity | 1 | CTD_human |
| Hgene | GNAS | C1136382 | Sclerocystic Ovaries | 1 | CTD_human |
| Hgene | GNAS | C2932715 | Pseudohypoparathyroidism Type 1B | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Hgene | GNAS | C3489630 | Somatotrophinoma, Familial | 1 | CTD_human |
| Hgene | GNAS | C3697137 | Fibrous dysplasia of bone with intramuscular myxoma | 1 | ORPHANET |
| Hgene | GNAS | C3714756 | Intellectual Disability | 1 | CTD_human |
| Hgene | GNAS | C3805278 | Extrahepatic Cholangiocarcinoma | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies