
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GNAS-PSAP (FusionGDB2 ID:HG2778TG5660) |
Fusion Gene Summary for GNAS-PSAP |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GNAS-PSAP | Fusion gene ID: hg2778tg5660 | Hgene | Tgene | Gene symbol | GNAS | PSAP | Gene ID | 2778 | 5660 |
| Gene name | GNAS complex locus | prosaposin | |
| Synonyms | AHO|C20orf45|GNAS1|GPSA|GSA|GSP|NESP|PITA3|POH|SCG6|SgVI | GLBA|SAP1|SAP2 | |
| Cytomap | ('GNAS')('PSAP') 20q13.32 | 10q22.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | protein ALEXprotein GNASprotein SCG6 (secretogranin VI)G protein subunit alpha Sadenylate cyclase-stimulating G alpha proteinalternative gene product encoded by XL-exonextra large alphas proteinguanine nucleotide binding protein (G protein), alpha | prosaposinproactivator polypeptidesaposin-Asaposin-Bsaposin-Csaposin-Dsphingolipid activator protein-1sphingolipid activator protein-2 | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000313949, ENST00000371075, ENST00000464624, ENST00000265620, ENST00000306090, ENST00000354359, ENST00000371085, ENST00000371095, ENST00000371100, ENST00000371102, ENST00000306120, ENST00000371081, ENST00000371098, ENST00000371099, | ||
| Fusion gene scores | * DoF score | 44 X 25 X 16=17600 | 25 X 26 X 8=5200 |
| # samples | 51 | 30 | |
| ** MAII score | log2(51/17600*10)=-5.10893437155316 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(30/5200*10)=-4.11547721741994 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GNAS [Title/Abstract] AND PSAP [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GNAS(57486241)-PSAP(73579657), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | GNAS-PSAP seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. GNAS-PSAP seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. GNAS-PSAP seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. GNAS-PSAP seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. GNAS-PSAP seems lost the major protein functional domain in Hgene partner, which is a cell metabolism gene due to the frame-shifted ORF. GNAS-PSAP seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. GNAS-PSAP seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PSAP | GO:0007041 | lysosomal transport | 26370502 |
| Tgene | PSAP | GO:1905572 | ganglioside GM1 transport to membrane | 1454804 |
| Fusion gene breakpoints across GNAS (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
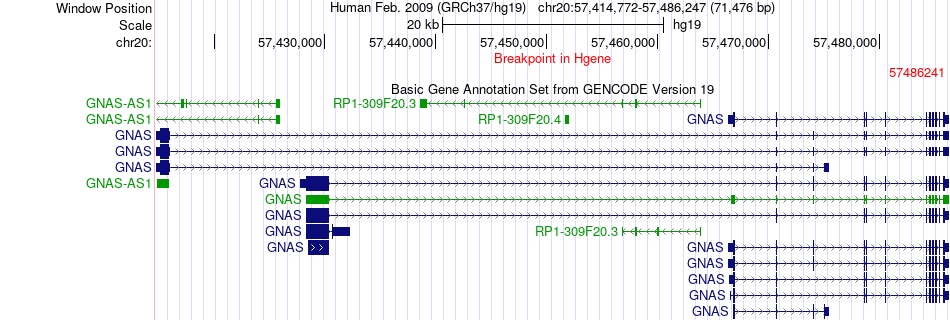 |
| Fusion gene breakpoints across PSAP (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ACC | TCGA-OR-A5JG-01A | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
Top |
Fusion Gene ORF analysis for GNAS-PSAP |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000313949 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| Frame-shift | ENST00000313949 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| Frame-shift | ENST00000371075 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| Frame-shift | ENST00000371075 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| Frame-shift | ENST00000464624 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| Frame-shift | ENST00000464624 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000265620 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000265620 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000306090 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000306090 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000354359 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000354359 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000371085 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000371085 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000371095 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000371095 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000371100 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000371100 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000371102 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| In-frame | ENST00000371102 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| intron-3CDS | ENST00000306120 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| intron-3CDS | ENST00000306120 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| intron-3CDS | ENST00000371081 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| intron-3CDS | ENST00000371081 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| intron-3CDS | ENST00000371098 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| intron-3CDS | ENST00000371098 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| intron-3CDS | ENST00000371099 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| intron-3CDS | ENST00000371099 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000371100 | GNAS | chr20 | 57486241 | - | ENST00000394936 | PSAP | chr10 | 73579657 | - | 5742 | 4029 | 531 | 3665 | 1044 |
| ENST00000371100 | GNAS | chr20 | 57486241 | - | ENST00000394934 | PSAP | chr10 | 73579657 | - | 5739 | 4029 | 531 | 3665 | 1044 |
| ENST00000371102 | GNAS | chr20 | 57486241 | - | ENST00000394936 | PSAP | chr10 | 73579657 | - | 5151 | 3438 | 3 | 3074 | 1023 |
| ENST00000371102 | GNAS | chr20 | 57486241 | - | ENST00000394934 | PSAP | chr10 | 73579657 | - | 5148 | 3438 | 3 | 3074 | 1023 |
| ENST00000371095 | GNAS | chr20 | 57486241 | - | ENST00000394936 | PSAP | chr10 | 73579657 | - | 3644 | 1931 | 1582 | 2 | 527 |
| ENST00000371095 | GNAS | chr20 | 57486241 | - | ENST00000394934 | PSAP | chr10 | 73579657 | - | 3641 | 1931 | 1582 | 2 | 527 |
| ENST00000371085 | GNAS | chr20 | 57486241 | - | ENST00000394936 | PSAP | chr10 | 73579657 | - | 3685 | 1972 | 1623 | 1 | 541 |
| ENST00000371085 | GNAS | chr20 | 57486241 | - | ENST00000394934 | PSAP | chr10 | 73579657 | - | 3682 | 1972 | 1623 | 1 | 541 |
| ENST00000354359 | GNAS | chr20 | 57486241 | - | ENST00000394936 | PSAP | chr10 | 73579657 | - | 3688 | 1975 | 1626 | 1 | 542 |
| ENST00000354359 | GNAS | chr20 | 57486241 | - | ENST00000394934 | PSAP | chr10 | 73579657 | - | 3685 | 1975 | 1626 | 1 | 542 |
| ENST00000265620 | GNAS | chr20 | 57486241 | - | ENST00000394936 | PSAP | chr10 | 73579657 | - | 3579 | 1866 | 1517 | 0 | 506 |
| ENST00000265620 | GNAS | chr20 | 57486241 | - | ENST00000394934 | PSAP | chr10 | 73579657 | - | 3576 | 1866 | 1517 | 0 | 506 |
| ENST00000306090 | GNAS | chr20 | 57486241 | - | ENST00000394936 | PSAP | chr10 | 73579657 | - | 3355 | 1642 | 1299 | 1 | 433 |
| ENST00000306090 | GNAS | chr20 | 57486241 | - | ENST00000394934 | PSAP | chr10 | 73579657 | - | 3352 | 1642 | 1299 | 1 | 433 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000371100 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.003772812 | 0.99622726 |
| ENST00000371100 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.003766262 | 0.99623376 |
| ENST00000371102 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.002199012 | 0.997801 |
| ENST00000371102 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.002194398 | 0.99780566 |
| ENST00000371095 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.003135648 | 0.9968644 |
| ENST00000371095 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.003172447 | 0.99682754 |
| ENST00000371085 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.003109415 | 0.9968906 |
| ENST00000371085 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.003134872 | 0.9968651 |
| ENST00000354359 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.002380929 | 0.9976191 |
| ENST00000354359 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.002399487 | 0.9976005 |
| ENST00000265620 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.002029379 | 0.99797064 |
| ENST00000265620 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.002050094 | 0.9979499 |
| ENST00000306090 | ENST00000394936 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.002901675 | 0.9970983 |
| ENST00000306090 | ENST00000394934 | GNAS | chr20 | 57486241 | - | PSAP | chr10 | 73579657 | - | 0.002918944 | 0.997081 |
Top |
Fusion Genomic Features for GNAS-PSAP |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
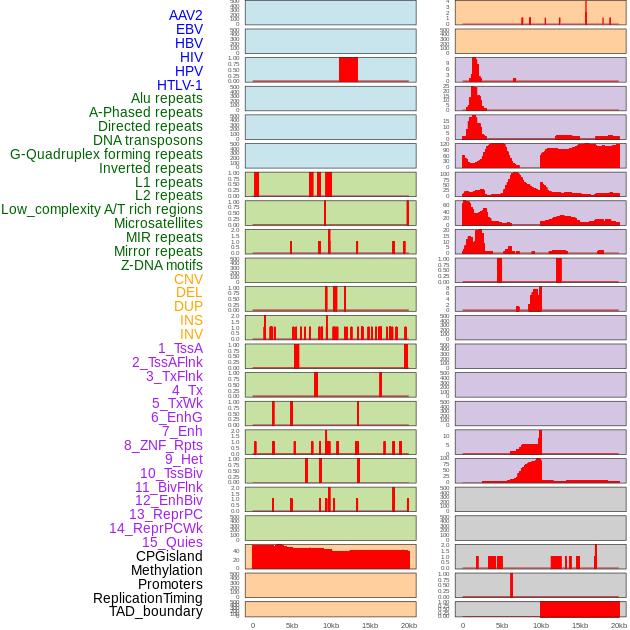 |
Top |
Fusion Protein Features for GNAS-PSAP |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:57486241/chr10:73579657) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 641_667 | 1159 | 1038.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 730_756 | 1159 | 1038.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 641_667 | 1145 | 1024.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 730_756 | 1145 | 1024.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000313949 | - | 13 | 13 | 78_142 | 729 | 26.333333333333332 | Compositional bias | Glu-rich |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371075 | - | 13 | 13 | 78_142 | 730 | 36.333333333333336 | Compositional bias | Glu-rich |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 358_522 | 1159 | 1038.0 | Compositional bias | Ala-rich |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 358_522 | 1145 | 1024.0 | Compositional bias | Ala-rich |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 39_394 | 501 | 380.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 39_394 | 500 | 381.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 39_394 | 517 | 396.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 39_394 | 516 | 395.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 39_394 | 502 | 381.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 682_1037 | 1159 | 1038.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 682_1037 | 1145 | 1024.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 197_204 | 501 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 223_227 | 501 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 292_295 | 501 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 47_55 | 501 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 197_204 | 500 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 223_227 | 500 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 292_295 | 500 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 47_55 | 500 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 197_204 | 517 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 223_227 | 517 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 292_295 | 517 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 47_55 | 517 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 197_204 | 516 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 223_227 | 516 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 292_295 | 516 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 47_55 | 516 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 197_204 | 502 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 223_227 | 502 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 292_295 | 502 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 47_55 | 502 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 690_698 | 1159 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 840_847 | 1159 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 866_870 | 1159 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 935_938 | 1159 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 690_698 | 1145 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 840_847 | 1145 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 866_870 | 1145 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 935_938 | 1145 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 196_204 | 501 | 380.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 219_228 | 501 | 380.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 288_295 | 501 | 380.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 364_369 | 501 | 380.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000265620 | - | 12 | 12 | 42_55 | 501 | 380.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 196_204 | 500 | 381.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 219_228 | 500 | 381.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 288_295 | 500 | 381.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 364_369 | 500 | 381.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306090 | - | 13 | 13 | 42_55 | 500 | 381.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 196_204 | 517 | 396.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 219_228 | 517 | 396.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 288_295 | 517 | 396.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 364_369 | 517 | 396.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000354359 | - | 13 | 13 | 42_55 | 517 | 396.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 196_204 | 516 | 395.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 219_228 | 516 | 395.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 288_295 | 516 | 395.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 364_369 | 516 | 395.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371085 | - | 13 | 13 | 42_55 | 516 | 395.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 196_204 | 502 | 381.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 219_228 | 502 | 381.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 288_295 | 502 | 381.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 364_369 | 502 | 381.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371095 | - | 12 | 12 | 42_55 | 502 | 381.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 1007_1012 | 1159 | 1038.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 685_698 | 1159 | 1038.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 839_847 | 1159 | 1038.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 862_871 | 1159 | 1038.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371100 | - | 13 | 13 | 931_938 | 1159 | 1038.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 1007_1012 | 1145 | 1024.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 685_698 | 1145 | 1024.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 839_847 | 1145 | 1024.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 862_871 | 1145 | 1024.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371102 | - | 12 | 12 | 931_938 | 1145 | 1024.0 | Region | G4 motif |
| Tgene | PSAP | chr20:57486241 | chr10:73579657 | ENST00000394936 | 8 | 14 | 405_486 | 335 | 525.0 | Domain | Saposin B-type 4 | |
| Tgene | PSAP | chr20:57486241 | chr10:73579657 | ENST00000394936 | 8 | 14 | 488_524 | 335 | 525.0 | Domain | Saposin A-type 2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000306120 | - | 1 | 1 | 238_476 | 0 | 626.0 | Compositional bias | Pro-rich |
| Hgene | GNAS | chr20:57486241 | chr10:73579657 | ENST00000371098 | - | 1 | 4 | 78_142 | 0 | 20.333333333333332 | Compositional bias | Glu-rich |
| Tgene | PSAP | chr20:57486241 | chr10:73579657 | ENST00000394936 | 8 | 14 | 18_58 | 335 | 525.0 | Domain | Saposin A-type 1 | |
| Tgene | PSAP | chr20:57486241 | chr10:73579657 | ENST00000394936 | 8 | 14 | 194_275 | 335 | 525.0 | Domain | Saposin B-type 2 | |
| Tgene | PSAP | chr20:57486241 | chr10:73579657 | ENST00000394936 | 8 | 14 | 311_392 | 335 | 525.0 | Domain | Saposin B-type 3 | |
| Tgene | PSAP | chr20:57486241 | chr10:73579657 | ENST00000394936 | 8 | 14 | 59_142 | 335 | 525.0 | Domain | Saposin B-type 1 |
Top |
Fusion Gene Sequence for GNAS-PSAP |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33640_33640_1_GNAS-PSAP_GNAS_chr20_57486241_ENST00000265620_PSAP_chr10_73579657_ENST00000394934_length(transcript)=3576nt_BP=1866nt GGGCGGCGGCGGGGGCCCGGCCGAGGCAATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCT CGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTT CCCGCCCGTCCGCGCGCCCCGCGGCCCGCGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCG CCCGGCGCTGCCCCGGCCCTCCCGGCCCGCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCC GCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAG CTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAG ATGAGGATCCTGCATGTTAATGGGTTTAATGGAGATGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATTGAA ACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGTGTG ATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTACGAA CGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGCGAT CAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGACGTG GGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTACAAC ATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGCACC ATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCAGAA TTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGATGAG TTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGCCGT GTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTAAAG CCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTCCCT TCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAAAAG GAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAACAAA TGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGAAATACTCGACGCTTTTGAC AAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTGCTG GAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAGCCA AAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATCCTG GCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTGATC GAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACTGAG AAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTGTGG AACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGATCTG TTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCTAGC CCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCATGG CGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTTCTG AGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGGCCT CTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATTCCC ACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTGTGA TTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAACCTG CTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATGTCC CTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCGAGC TCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAGCTG TCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTATTA >33640_33640_1_GNAS-PSAP_GNAS_chr20_57486241_ENST00000265620_PSAP_chr10_73579657_ENST00000394934_length(amino acids)=506AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLISIKPINMQDPHLLHNGAFTRFSSTQQQQAVRGPVDLLVLLQLLLD LFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARARLLGKERAGRTAGRGPRGARTGGKGRV -------------------------------------------------------------- >33640_33640_2_GNAS-PSAP_GNAS_chr20_57486241_ENST00000265620_PSAP_chr10_73579657_ENST00000394936_length(transcript)=3579nt_BP=1866nt GGGCGGCGGCGGGGGCCCGGCCGAGGCAATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCT CGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTT CCCGCCCGTCCGCGCGCCCCGCGGCCCGCGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCG CCCGGCGCTGCCCCGGCCCTCCCGGCCCGCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCC GCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAG CTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAG ATGAGGATCCTGCATGTTAATGGGTTTAATGGAGATGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATTGAA ACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGTGTG ATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTACGAA CGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGCGAT CAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGACGTG GGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTACAAC ATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGCACC ATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCAGAA TTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGATGAG TTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGCCGT GTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTAAAG CCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTCCCT TCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAAAAG GAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAACAAA TGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGAAATACTCGACGCTTTTGAC AAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTGCTG GAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAGCCA AAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATCCTG GCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTGATC GAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACTGAG AAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTGTGG AACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGATCTG TTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCTAGC CCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCATGG CGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTTCTG AGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGGCCT CTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATTCCC ACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTGTGA TTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAACCTG CTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATGTCC CTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCGAGC TCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAGCTG TCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTATTA >33640_33640_2_GNAS-PSAP_GNAS_chr20_57486241_ENST00000265620_PSAP_chr10_73579657_ENST00000394936_length(amino acids)=506AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLISIKPINMQDPHLLHNGAFTRFSSTQQQQAVRGPVDLLVLLQLLLD LFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARARLLGKERAGRTAGRGPRGARTGGKGRV -------------------------------------------------------------- >33640_33640_3_GNAS-PSAP_GNAS_chr20_57486241_ENST00000306090_PSAP_chr10_73579657_ENST00000394934_length(transcript)=3352nt_BP=1642nt CAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCG GGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCG CAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCT GCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGACAGTGA GAAGGCAACCAAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGT GGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTA TGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTA CTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAAT CTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTG CTTCAACGATGTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCA GGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCT CGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGA GCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCA CTACTGCTACCCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCA CCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTA CAAGCAGTTAATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCA GCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAA AAATAAATAAAACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATC AAAATAAAAATTAAATGTGAGCAAAGAAATACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCA GGAGGTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTG CTCTGGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTA TTTGGATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCA GAAGCAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAA AATTGGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGAC AGCAGCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATT GGTTTTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTT CTGTGTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTA GATGGATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGT TTCTTGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAG GTGGCCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAA GATTAGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTG GGACATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTT CTGTGGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGT GGACAGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCT CATAGATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGG TCTGCTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTT GCCAGGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTATTAAATGGACTTCGTGATTTTTGTTTTGCACTAAAGTTTCTGTGATT >33640_33640_3_GNAS-PSAP_GNAS_chr20_57486241_ENST00000306090_PSAP_chr10_73579657_ENST00000394934_length(amino acids)=433AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLTVSIKPINMQDPHLLHNGAFTRFSSTQQQQAVRGPVDLLVLLQLLL -------------------------------------------------------------- >33640_33640_4_GNAS-PSAP_GNAS_chr20_57486241_ENST00000306090_PSAP_chr10_73579657_ENST00000394936_length(transcript)=3355nt_BP=1642nt CAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCG GGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCG CAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCT GCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGACAGTGA GAAGGCAACCAAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGT GGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTA TGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTA CTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAAT CTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTG CTTCAACGATGTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCA GGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCT CGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGA GCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCA CTACTGCTACCCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCA CCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTA CAAGCAGTTAATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCA GCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAA AAATAAATAAAACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATC AAAATAAAAATTAAATGTGAGCAAAGAAATACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCA GGAGGTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTG CTCTGGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTA TTTGGATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCA GAAGCAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAA AATTGGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGAC AGCAGCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATT GGTTTTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTT CTGTGTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTA GATGGATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGT TTCTTGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAG GTGGCCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAA GATTAGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTG GGACATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTT CTGTGGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGT GGACAGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCT CATAGATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGG TCTGCTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTT GCCAGGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTATTAAATGGACTTCGTGATTTTTGTTTTGCACTAAAGTTTCTGTGATT >33640_33640_4_GNAS-PSAP_GNAS_chr20_57486241_ENST00000306090_PSAP_chr10_73579657_ENST00000394936_length(amino acids)=433AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLTVSIKPINMQDPHLLHNGAFTRFSSTQQQQAVRGPVDLLVLLQLLL -------------------------------------------------------------- >33640_33640_5_GNAS-PSAP_GNAS_chr20_57486241_ENST00000354359_PSAP_chr10_73579657_ENST00000394934_length(transcript)=3685nt_BP=1975nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCAGTGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAA CCTGAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGT GGACTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGG AGTGCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGC TGACTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAA CTTCCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGT GGCCAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAA CAACAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGAT TGAGGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAA GTACTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGA CACTGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAA CCCCCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATT AACAAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTA AGGCGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAA ATGAAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGA AATACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTC CATCCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGAC CGTTCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAG CACCAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGA GTACGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAA GCCCTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCA TTGCAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGG GAATGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGT CTGCAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTT TTAGCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCT TGGTTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCC TCCCCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTT TTTAAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCT GTCCCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCA TCTGCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGC TCGTGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAA ATAAATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGG GTGTGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCA >33640_33640_5_GNAS-PSAP_GNAS_chr20_57486241_ENST00000354359_PSAP_chr10_73579657_ENST00000394934_length(amino acids)=542AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLTAIAVAPCSLRVLFAALSIKPINMQDPHLLHNGAFTRFSSTQQQQA VRGPVDLLVLLQLLLDLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARARLLGKERAGRT AGRGPRGARTGGKGRVSVGPRGARSSPPLEPRPRGLMAAAGPRRTRAGAAGAAAAAAAAAALIASAGPPPPPRAKSAAAGGGRRGEEEAA -------------------------------------------------------------- >33640_33640_6_GNAS-PSAP_GNAS_chr20_57486241_ENST00000354359_PSAP_chr10_73579657_ENST00000394936_length(transcript)=3688nt_BP=1975nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGCAGTGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAA CCTGAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGT GGACTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGG AGTGCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGC TGACTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAA CTTCCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGT GGCCAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAA CAACAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGAT TGAGGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAA GTACTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGA CACTGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAA CCCCCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATT AACAAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTA AGGCGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAA ATGAAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGA AATACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTC CATCCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGAC CGTTCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAG CACCAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGA GTACGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAA GCCCTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCA TTGCAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGG GAATGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGT CTGCAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTT TTAGCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCT TGGTTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCC TCCCCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTT TTTAAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCT GTCCCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCA TCTGCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGC TCGTGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAA ATAAATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGG GTGTGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCA >33640_33640_6_GNAS-PSAP_GNAS_chr20_57486241_ENST00000354359_PSAP_chr10_73579657_ENST00000394936_length(amino acids)=542AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLTAIAVAPCSLRVLFAALSIKPINMQDPHLLHNGAFTRFSSTQQQQA VRGPVDLLVLLQLLLDLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARARLLGKERAGRT AGRGPRGARTGGKGRVSVGPRGARSSPPLEPRPRGLMAAAGPRRTRAGAAGAAAAAAAAAALIASAGPPPPPRAKSAAAGGGRRGEEEAA -------------------------------------------------------------- >33640_33640_7_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371085_PSAP_chr10_73579657_ENST00000394934_length(transcript)=3682nt_BP=1972nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGTGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAACCT GAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGA CTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGT GCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGA CTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTT CCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGTGGC CAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAA CAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGA GGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTA CTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGACAC TGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCC CCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATTAAC AAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGG CGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAAATG AAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGAAAT ACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTCCAT CCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGACCGT TCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAGCAC CAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGAGTA CGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAAGCC CTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCATTG CAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGGGAA TGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGTCTG CAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTTTTA GCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCTTGG TTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCCTCC CCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTTTTT AAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCTGTC CCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCATCT GCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGCTCG TGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAAATA AATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGGGTG TGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCAGGA >33640_33640_7_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371085_PSAP_chr10_73579657_ENST00000394934_length(amino acids)=541AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLTIAVAPCSLRVLFAALSIKPINMQDPHLLHNGAFTRFSSTQQQQAV RGPVDLLVLLQLLLDLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARARLLGKERAGRTA GRGPRGARTGGKGRVSVGPRGARSSPPLEPRPRGLMAAAGPRRTRAGAAGAAAAAAAAAALIASAGPPPPPRAKSAAAGGGRRGEEEAAA -------------------------------------------------------------- >33640_33640_8_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371085_PSAP_chr10_73579657_ENST00000394936_length(transcript)=3685nt_BP=1972nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGGGCGGCGAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGTGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAACCT GAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGA CTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGT GCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGA CTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTT CCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGTGGC CAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAA CAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGA GGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTA CTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGACAC TGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCC CCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATTAAC AAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGG CGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAAATG AAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGAAAT ACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTCCAT CCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGACCGT TCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAGCAC CAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGAGTA CGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAAGCC CTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCATTG CAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGGGAA TGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGTCTG CAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTTTTA GCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCTTGG TTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCCTCC CCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTTTTT AAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCTGTC CCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCATCT GCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGCTCG TGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAAATA AATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGGGTG TGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCAGGA >33640_33640_8_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371085_PSAP_chr10_73579657_ENST00000394936_length(amino acids)=541AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLTIAVAPCSLRVLFAALSIKPINMQDPHLLHNGAFTRFSSTQQQQAV RGPVDLLVLLQLLLDLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARARLLGKERAGRTA GRGPRGARTGGKGRVSVGPRGARSSPPLEPRPRGLMAAAGPRRTRAGAAGAAAAAAAAAALIASAGPPPPPRAKSAAAGGGRRGEEEAAA -------------------------------------------------------------- >33640_33640_9_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371095_PSAP_chr10_73579657_ENST00000394934_length(transcript)=3641nt_BP=1931nt CTCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCA ATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTC GGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCG CGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCC GCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGA CCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGG CCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTA ATGGAGACAGTGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACC TGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCC CTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTG ACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCC TGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCA AGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGA CCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACA AGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGG ATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTG GAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCA TTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTG AAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCC CCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTC TCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGC ATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGAAATACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGT CCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGT GCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGT GCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCT TCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATC CTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACT GGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCT TGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGC TCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGT GCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTC TGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTG GTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACA AAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGA AGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGG TGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGC CTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGC CTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAG AGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACG CTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTATTAAATGGACTTCGTGATTTTTGTTTTG >33640_33640_9_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371095_PSAP_chr10_73579657_ENST00000394934_length(amino acids)=527AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLTVSIKPINMQDPHLLHNGAFTRFSSTQQQQAVRGPVDLLVLLQLLL DLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARARLLGKERAGRTAGRGPRGARTGGKGR -------------------------------------------------------------- >33640_33640_10_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371095_PSAP_chr10_73579657_ENST00000394936_length(transcript)=3644nt_BP=1931nt CTCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCA ATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTC GGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCG CGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCC GCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGA CCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGG CCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTA ATGGAGACAGTGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACC TGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCC CTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTG ACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCC TGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCA AGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGA CCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACA AGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGG ATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTG GAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCA TTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTG AAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCC CCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTC TCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGC ATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGAAATACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGT CCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGT GCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGT GCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCT TCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATC CTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACT GGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCT TGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGC TCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGT GCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTC TGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTG GTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACA AAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGA AGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGG TGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGC CTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGC CTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAG AGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACG CTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTATTAAATGGACTTCGTGATTTTTGTTTTG >33640_33640_10_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371095_PSAP_chr10_73579657_ENST00000394936_length(amino acids)=527AA_BP= MGVPFLEQLVLTKVHALNDVTAVVEHTADVLSVHSAGEMRVAVVTPISTGSADPQKLISNEVLGPGHAWVLSGLGSSILRSSVASKFWKV VLNLRFPSKDFLSEQILLVEEQDHRDGAQPSVVPDALEEVQSLLQAVGLVVLPDDHVVAAAGHHEDDGSHIVEALDPLAAFIALATHVKH VEVDFVHLELGLKDSRSQDTAAKQVLIARHIVSLLDHVDLVQEVLGTVNQLVLVGAFVAGTHSFILPQSLGMLIEFGREVKVRHVHHTQD VVHSELVLGVGQLHGGHQVAHGGHNGFNRLFQVVFDVLHFGCLLTVSIKPINMQDPHLLHNGAFTRFSSTQQQQAVRGPVDLLVLLQLLL DLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARARLLGKERAGRTAGRGPRGARTGGKGR -------------------------------------------------------------- >33640_33640_11_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371100_PSAP_chr10_73579657_ENST00000394934_length(transcript)=5739nt_BP=4029nt AAAGACTCCAAATCAGTCAGGGAGAGGAGTGGAAGGAGCCAAAACGTCCCTGCGAGGCCTGCGCTCACCAGCCCCCTTACCCAAAGTCCC GGGCCCCTGGCGCCAGGAGCAGGCTCCTGGAGCCGGAGCCAGCTCGGCACTGGAACCGGCGTCCTCTGGTGGCAGAGAGAGAGCGCTACT GGCGATTTTCGGACCGAATCGGCACGCTCGTCAGATCCAAGCAGGCGGGACTGGCCTGGAGCAAAAAGAAAGAGAGAGGAGGGCGTAAGG ATAGACCAAGGAAGAGGGGCTGGGGGGCAGCCTGGGGGCATGAAAAGTGGCCAGGAAGGAGCCAAGACTCCACCAGCAACAATTGAGTTG CTTCAGCCTCAGTCTAGGGTTCCTTCCAGGCCTTGAACCCCCCAACCTCACAAGGGTTGGAAAGTGAGGCCGGTGAACTTTCCAGCTGGT ACTTTGATTTTAAAATAATAATAATAATTTTTTCACCCTAGTTCGGTTGGGTGCTCCATCTTACGGAGCCCCAAACTTATTTTGAGAGGC CGCCACCGTGTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCC GAGCAACCACCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAAC GAGCCCATCCCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGG GAAGCTGGAGCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCT ACACTGGAGCAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGT GCCAGACCAGGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAA CTTCTCTTACAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGG CCTGCAAAGGCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGAC AGCCCACCCCCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTC ACTCCCGCCGCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACG GGCAGCAGCCCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGAC AGCCCCCCAATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAG GAAGCAGCAGAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCC TCAGCGGATACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCA CCAGCCGATCCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCC CCTGACGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCC CCTGCGGCTGCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGG GCAGCCCAAGTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAG GCTGCCGATCCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGAT GAAGGGGTGGCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGA AATCGCCGCCGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCC CAGCCCAAAGCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGG GCCCAGAAGCGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTG CTGCTTCTAGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGGGCGGC GAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGTGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATT GAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGT GTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTAC GAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGC GATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGAC GTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTAC AACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGC ACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCA GAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGAT GAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGC CGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTA AAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTC CCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAA AAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAAC AAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGAAATACTCGACGCTTTT GACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTG CTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAG CCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATC CTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTG ATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACT GAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTG TGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGAT CTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCT AGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCA TGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTT CTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGG CCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATT CCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTG TGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAAC CTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATG TCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCG AGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAG CTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTA >33640_33640_11_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371100_PSAP_chr10_73579657_ENST00000394934_length(amino acids)=1044AA_BP= MRGRHRVMGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNP AFREAGAHGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRG CSQLLLQVPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSA VRLTPAANAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPP VEEEAAEMEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDS GAAPDAPADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSP EIQAADPPTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRS ESPQPKASRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNG EGGEEDPQAARSNSDGEKATKVQDIKNNLKEAIETIVAAMSNLVPPVELANPENQFRVDYILSVMNVPDFDFPPEFYEHAKALWEDEGVR ACYERSNEYQLIDCAQYFLDKIDVIKQADYVPSDQDLLRCRVLTSGIFETKFQVDKVNFHMFDVGGQRDERRKWIQCFNDVTAIIFVVAS SSYNMVIREDNQTNRLQEALNLFKSIWNNRWLRTISVILFLNKQDLLAEKVLAGKSKIEDYFPEFARYTTPEDATPEPGEDPRVTRAKYF -------------------------------------------------------------- >33640_33640_12_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371100_PSAP_chr10_73579657_ENST00000394936_length(transcript)=5742nt_BP=4029nt AAAGACTCCAAATCAGTCAGGGAGAGGAGTGGAAGGAGCCAAAACGTCCCTGCGAGGCCTGCGCTCACCAGCCCCCTTACCCAAAGTCCC GGGCCCCTGGCGCCAGGAGCAGGCTCCTGGAGCCGGAGCCAGCTCGGCACTGGAACCGGCGTCCTCTGGTGGCAGAGAGAGAGCGCTACT GGCGATTTTCGGACCGAATCGGCACGCTCGTCAGATCCAAGCAGGCGGGACTGGCCTGGAGCAAAAAGAAAGAGAGAGGAGGGCGTAAGG ATAGACCAAGGAAGAGGGGCTGGGGGGCAGCCTGGGGGCATGAAAAGTGGCCAGGAAGGAGCCAAGACTCCACCAGCAACAATTGAGTTG CTTCAGCCTCAGTCTAGGGTTCCTTCCAGGCCTTGAACCCCCCAACCTCACAAGGGTTGGAAAGTGAGGCCGGTGAACTTTCCAGCTGGT ACTTTGATTTTAAAATAATAATAATAATTTTTTCACCCTAGTTCGGTTGGGTGCTCCATCTTACGGAGCCCCAAACTTATTTTGAGAGGC CGCCACCGTGTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCC GAGCAACCACCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAAC GAGCCCATCCCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGG GAAGCTGGAGCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCT ACACTGGAGCAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGT GCCAGACCAGGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAA CTTCTCTTACAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGG CCTGCAAAGGCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGAC AGCCCACCCCCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTC ACTCCCGCCGCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACG GGCAGCAGCCCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGAC AGCCCCCCAATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAG GAAGCAGCAGAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCC TCAGCGGATACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCA CCAGCCGATCCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCC CCTGACGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCC CCTGCGGCTGCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGG GCAGCCCAAGTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAG GCTGCCGATCCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGAT GAAGGGGTGGCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGA AATCGCCGCCGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCC CAGCCCAAAGCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGG GCCCAGAAGCGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTG CTGCTTCTAGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGGGCGGC GAAGAGGACCCGCAGGCTGCAAGGAGCAACAGCGATGGTGAGAAGGCAACCAAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATT GAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGT GTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTAC GAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGACAAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGC GATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGAC GTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGATGTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTAC AACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGC ACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCA GAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGAT GAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTACCCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGC CGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTA AAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTAATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTC CCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAGATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAA AAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAAAACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAAC AAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAATTAAATGTGAGCAAAGAAAAAGAAATACTCGACGCTTTT GACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAGGTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTG CTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCTGGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAG CCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTGGATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATC CTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAGCAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTG ATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATTGGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACT GAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCAGCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTG TGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTTTTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGAT CTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGTGTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCT AGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATGGATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCA TGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCTTGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTT CTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGGCCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGG CCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATTAGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATT CCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGACATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTG TGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGTGGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAAC CTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGACAGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATG TCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATAGATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCG AGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTGCTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAG CTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCAGGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTA >33640_33640_12_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371100_PSAP_chr10_73579657_ENST00000394936_length(amino acids)=1044AA_BP= MRGRHRVMGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNP AFREAGAHGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRG CSQLLLQVPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSA VRLTPAANAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPP VEEEAAEMEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDS GAAPDAPADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSP EIQAADPPTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRS ESPQPKASRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNG EGGEEDPQAARSNSDGEKATKVQDIKNNLKEAIETIVAAMSNLVPPVELANPENQFRVDYILSVMNVPDFDFPPEFYEHAKALWEDEGVR ACYERSNEYQLIDCAQYFLDKIDVIKQADYVPSDQDLLRCRVLTSGIFETKFQVDKVNFHMFDVGGQRDERRKWIQCFNDVTAIIFVVAS SSYNMVIREDNQTNRLQEALNLFKSIWNNRWLRTISVILFLNKQDLLAEKVLAGKSKIEDYFPEFARYTTPEDATPEPGEDPRVTRAKYF -------------------------------------------------------------- >33640_33640_13_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371102_PSAP_chr10_73579657_ENST00000394934_length(transcript)=5148nt_BP=3438nt GTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCCGAGCAACCA CCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAACGAGCCCATC CCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGGGAAGCTGGA GCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCTACACTGGAG CAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGTGCCAGACCA GGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAACTTCTCTTA CAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGGCCTGCAAAG GCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGACAGCCCACCC CCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTCACTCCCGCC GCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACGGGCAGCAGC CCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGACAGCCCCCCA ATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAGGAAGCAGCA GAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCCTCAGCGGAT ACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCACCAGCCGAT CCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCC CCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCCCCTGCGGCT GCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGGGCAGCCCAA GTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAGGCTGCCGAT CCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGATGAAGGGGTG GCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGAAATCGCCGC CGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCCCAGCCCAAA GCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGGGCCCAGAAG CGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTGCTGCTTCTA GGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGACAGTGAGAAGGCAACC AAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCC AACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCC AAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGAC AAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACC AAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGAT GTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTG AACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAA GTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAG GACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTAC CCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAG TACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTA ATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAG ATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAA AACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAA TTAAATGTGAGCAAAGAAAAAGAAATACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAG GTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCT GGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTG GATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAG CAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATT GGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCA GCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTT TTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGT GTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATG GATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCT TGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGG CCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATT AGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGAC ATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGT GGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGAC AGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATA GATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTG CTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCA GGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTATTAAATGGACTTCGTGATTTTTGTTTTGCACTAAAGTTTCTGTGATTTAAC >33640_33640_13_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371102_PSAP_chr10_73579657_ENST00000394934_length(amino acids)=1023AA_BP= MGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNPAFREAGA HGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRGCSQLLLQ VPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSAVRLTPAA NAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPPVEEEAAE MEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDSGAAPDAP ADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSPEIQAADP PTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRSESPQPKA SRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNGDSEKATK VQDIKNNLKEAIETIVAAMSNLVPPVELANPENQFRVDYILSVMNVPDFDFPPEFYEHAKALWEDEGVRACYERSNEYQLIDCAQYFLDK IDVIKQADYVPSDQDLLRCRVLTSGIFETKFQVDKVNFHMFDVGGQRDERRKWIQCFNDVTAIIFVVASSSYNMVIREDNQTNRLQEALN LFKSIWNNRWLRTISVILFLNKQDLLAEKVLAGKSKIEDYFPEFARYTTPEDATPEPGEDPRVTRAKYFIRDEFLRISTASGDGRHYCYP -------------------------------------------------------------- >33640_33640_14_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371102_PSAP_chr10_73579657_ENST00000394936_length(transcript)=5151nt_BP=3438nt GTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCCGAGCAACCA CCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAACGAGCCCATC CCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGGGAAGCTGGA GCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCTACACTGGAG CAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGTGCCAGACCA GGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAACTTCTCTTA CAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGGCCTGCAAAG GCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGACAGCCCACCC CCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTCACTCCCGCC GCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACGGGCAGCAGC CCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGACAGCCCCCCA ATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAGGAAGCAGCA GAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCCTCAGCGGAT ACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCACCAGCCGAT CCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCC CCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCCCCTGCGGCT GCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGGGCAGCCCAA GTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAGGCTGCCGAT CCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGATGAAGGGGTG GCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGAAATCGCCGC CGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCCCAGCCCAAA GCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGGGCCCAGAAG CGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTGCTGCTTCTA GGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGACAGTGAGAAGGCAACC AAAGTGCAGGACATCAAAAACAACCTGAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTGGAGCTGGCC AACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGTGTGATGAACGTGCCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCC AAGGCTCTGTGGGAGGATGAAGGAGTGCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTACTTCCTGGAC AAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGCGATCAGGACCTGCTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACC AAGTTCCAGGTGGACAAAGTCAACTTCCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGCTTCAACGAT GTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTACAACATGGTCATCCGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTG AACCTCTTCAAGAGCATCTGGAACAACAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTCGCTGAGAAA GTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCAGAATTTGCTCGCTACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAG GACCCACGCGTGACCCGGGCCAAGTACTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCACTACTGCTAC CCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGCCGTGTGTTCAACGACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAG TACGAGCTGCTCTAAGAAGGGAACCCCCAAATTTAATTAAAGCCTTAAGCACAATTAATTAAAAGTGAAACGTAATTGTACAAGCAGTTA ATCACCCACCATAGGGCATGATTAACAAAGCAACCTTTCCCTTCCCCCGAGTGATTTTGCGAAACCCCCTTTTCCCTTCAGCTTGCTTAG ATGTTCCAAATTTAGAAAGCTTAAGGCGGCCTACAGAAAAAGGAAAAAAGGCCACAAAAGTTCCCTCTCACTTTCAGTAAAAATAAATAA AACAGCAGCAGCAAACAAATAAAATGAAATAAAAGAAACAAATGAAATAAATATTGTGTTGTGCAGCATTAAAAAAAATCAAAATAAAAA TTAAATGTGAGCAAAGAAAAAGAAATACTCGACGCTTTTGACAAAATGTGCTCGAAGCTGCCGAAGTCCCTGTCGGAAGAGTGCCAGGAG GTGGTGGACACGTACGGCAGCTCCATCCTGTCCATCCTGCTGGAGGAGGTCAGCCCTGAGCTGGTGTGCAGCATGCTGCACCTCTGCTCT GGCACGCGGCTGCCTGCACTGACCGTTCACGTGACTCAGCCAAAGGACGGTGGCTTCTGCGAAGTGTGCAAGAAGCTGGTGGGTTATTTG GATCGCAACCTGGAGAAAAACAGCACCAAGCAGGAGATCCTGGCTGCTCTTGAGAAAGGCTGCAGCTTCCTGCCAGACCCTTACCAGAAG CAGTGTGATCAGTTTGTGGCAGAGTACGAGCCCGTGCTGATCGAGATCCTGGTGGAGGTGATGGATCCTTCCTTCGTGTGCTTGAAAATT GGAGCCTGCCCCTCGGCCCATAAGCCCTTGTTGGGAACTGAGAAGTGTATATGGGGCCCAAGCTACTGGTGCCAGAACACAGAGACAGCA GCCCAGTGCAATGCTGTCGAGCATTGCAAACGCCATGTGTGGAACTAGGAGGAGGAATATTCCATCTTGGCAGAAACCACAGCATTGGTT TTTTTCTACTTGTGTGTCTGGGGGAATGAACGCACAGATCTGTTTGACTTTGTTATAAAAATAGGGCTCCCCCACCTCCCCCATTTCTGT GTCCTTTATTGTAGCATTGCTGTCTGCAAGGGAGCCCCTAGCCCCTGGCAGACATAGCTGCTTCAGTGCCCCTTTTCTCTCTGCTAGATG GATGTTGATGCACTGGAGGTCTTTTAGCCTGCCCTTGCATGGCGCCTGCTGGAGGAGGAGAGAGCTCTGCTGGCATGAGCCACAGTTTCT TGACTGGAGGCCATCAACCCTCTTGGTTGAGGCCTTGTTCTGAGCCCTGACATGTGCTTGGGCACTGGTGGGCCTGGGCTTCTGAGGTGG CCTCCTGCCCTGATCAGGGACCCTCCCCGCTTTCCTGGGCCTCTCAGTTGAACAAAGCAGCAAAACAAAGGCAGTTTTATATGAAAGATT AGAAGCCTGGAATAATCAGGCTTTTTAAATGATGTAATTCCCACTGTAATAGCATAGGGATTTTGGAAGCAGCTGCTGGTGGCTTGGGAC ATCAGTGGGGCCAAGGGTTCTCTGTCCCTGGTTCAACTGTGATTTGGCTTTCCCGTGTCTTTCCTGGTGATGCCTTGTTTGGGGTTCTGT GGGTTTGGGTGGGAAGAGGGCCATCTGCCTGAATGTAACCTGCTAGCTCTCCGAAGGCCCTGCGGGCCTGGCTTGTGTGAGCGTGTGGAC AGTGGTGGCCGCGCTGTGCCTGCTCGTGTTGCCTACATGTCCCTGGCTGTTGAGGCGCTGCTTCAGCCTGCACCCCTCCCTTGTCTCATA GATGCTCCTTTTGACCTTTTCAAATAAATATGGATGGCGAGCTCCTAGGCCTCTGGCTTCCTGGTAGAGGGCGGCATGCCGAAGGGTCTG CTGGGTGTGGATTGGATGCTGGGGTGTGGGGGTTGGAAGCTGTCTGTGGCCCACTTGGGCACCCACGCTTCTGTCCACTTCTGGTTGCCA GGAGACAGCAAGCAAAGCCAGCAGGACATGAAGTTGCTATTAAATGGACTTCGTGATTTTTGTTTTGCACTAAAGTTTCTGTGATTTAAC >33640_33640_14_GNAS-PSAP_GNAS_chr20_57486241_ENST00000371102_PSAP_chr10_73579657_ENST00000394936_length(amino acids)=1023AA_BP= MGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNPAFREAGA HGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRGCSQLLLQ VPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSAVRLTPAA NAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPPVEEEAAE MEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDSGAAPDAP ADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSPEIQAADP PTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRSESPQPKA SRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNGDSEKATK VQDIKNNLKEAIETIVAAMSNLVPPVELANPENQFRVDYILSVMNVPDFDFPPEFYEHAKALWEDEGVRACYERSNEYQLIDCAQYFLDK IDVIKQADYVPSDQDLLRCRVLTSGIFETKFQVDKVNFHMFDVGGQRDERRKWIQCFNDVTAIIFVVASSSYNMVIREDNQTNRLQEALN LFKSIWNNRWLRTISVILFLNKQDLLAEKVLAGKSKIEDYFPEFARYTTPEDATPEPGEDPRVTRAKYFIRDEFLRISTASGDGRHYCYP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GNAS-PSAP |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GNAS-PSAP |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GNAS-PSAP |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | GNAS | C3494506 | Pseudohypoparathyroidism, Type Ia | 17 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C0242292 | McCune-Albright Syndrome | 7 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C0016065 | Polyostotic fibrous dysplasia | 5 | CTD_human;ORPHANET |
| Hgene | GNAS | C1864100 | PSEUDOHYPOPARATHYROIDISM, TYPE IB | 5 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Hgene | GNAS | C2931404 | Albright's hereditary osteodystrophy | 4 | CTD_human;GENOMICS_ENGLAND |
| Hgene | GNAS | C0033806 | Pseudohypoparathyroidism | 3 | CTD_human |
| Hgene | GNAS | C0334041 | Osteoma cutis | 3 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C0014130 | Endocrine System Diseases | 2 | CTD_human |
| Hgene | GNAS | C0016064 | Fibrous Dysplasia, Monostotic | 2 | ORPHANET |
| Hgene | GNAS | C0034013 | Precocious Puberty | 2 | CTD_human |
| Hgene | GNAS | C0221263 | Cafe-au-Lait Spots | 2 | CTD_human |
| Hgene | GNAS | C0271527 | Cryptogenic sexual precocity | 2 | CTD_human |
| Hgene | GNAS | C0342543 | Central Precocious Puberty | 2 | CTD_human |
| Hgene | GNAS | C1504412 | Testotoxicosis | 2 | CTD_human |
| Hgene | GNAS | C1857451 | Acth-Independent Macronodular Adrenal Hyperplasia | 2 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C2932716 | Pseudohypoparathyroidism Type 1C | 2 | GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | GNAS | C0001206 | Acromegaly | 1 | CTD_human |
| Hgene | GNAS | C0001624 | Adrenal Gland Neoplasms | 1 | CTD_human |
| Hgene | GNAS | C0003129 | Anoxemia | 1 | CTD_human |
| Hgene | GNAS | C0003130 | Anoxia | 1 | CTD_human |
| Hgene | GNAS | C0008370 | Cholestasis | 1 | GENOMICS_ENGLAND |
| Hgene | GNAS | C0009438 | Common Bile Duct Calculi | 1 | CTD_human |
| Hgene | GNAS | C0011573 | Endogenous depression | 1 | PSYGENET |
| Hgene | GNAS | C0019087 | Hemorrhagic Disorders | 1 | CTD_human |
| Hgene | GNAS | C0020538 | Hypertensive disease | 1 | CTD_human |
| Hgene | GNAS | C0020796 | Profound Mental Retardation | 1 | CTD_human |
| Hgene | GNAS | C0021655 | Insulin Resistance | 1 | CTD_human |
| Hgene | GNAS | C0023897 | Liver Diseases, Parasitic | 1 | CTD_human |
| Hgene | GNAS | C0025363 | Mental Retardation, Psychosocial | 1 | CTD_human |
| Hgene | GNAS | C0027819 | Neuroblastoma | 1 | CTD_human |
| Hgene | GNAS | C0028754 | Obesity | 1 | CTD_human |
| Hgene | GNAS | C0029396 | Heterotopic Ossification | 1 | CTD_human |
| Hgene | GNAS | C0032460 | Polycystic Ovary Syndrome | 1 | CTD_human |
| Hgene | GNAS | C0033835 | Pseudopseudohypoparathyroidism | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Hgene | GNAS | C0035204 | Respiration Disorders | 1 | CTD_human |
| Hgene | GNAS | C0036341 | Schizophrenia | 1 | PSYGENET |
| Hgene | GNAS | C0038587 | Substance Withdrawal Syndrome | 1 | CTD_human |
| Hgene | GNAS | C0039231 | Tachycardia | 1 | CTD_human |
| Hgene | GNAS | C0080203 | Tachyarrhythmia | 1 | CTD_human |
| Hgene | GNAS | C0086189 | Drug Withdrawal Symptoms | 1 | CTD_human |
| Hgene | GNAS | C0087169 | Withdrawal Symptoms | 1 | CTD_human |
| Hgene | GNAS | C0206698 | Cholangiocarcinoma | 1 | CTD_human |
| Hgene | GNAS | C0221357 | Brachydactyly | 1 | CTD_human |
| Hgene | GNAS | C0242184 | Hypoxia | 1 | CTD_human |
| Hgene | GNAS | C0242216 | Biliary calculi | 1 | CTD_human |
| Hgene | GNAS | C0345905 | Intrahepatic Cholangiocarcinoma | 1 | CTD_human |
| Hgene | GNAS | C0346302 | Growth Hormone-Secreting Pituitary Adenoma | 1 | CTD_human |
| Hgene | GNAS | C0700292 | Hypoxemia | 1 | CTD_human |
| Hgene | GNAS | C0750887 | Adrenal Cancer | 1 | CTD_human |
| Hgene | GNAS | C0917816 | Mental deficiency | 1 | CTD_human |
| Hgene | GNAS | C0920563 | Insulin Sensitivity | 1 | CTD_human |
| Hgene | GNAS | C1136382 | Sclerocystic Ovaries | 1 | CTD_human |
| Hgene | GNAS | C2932715 | Pseudohypoparathyroidism Type 1B | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Hgene | GNAS | C3489630 | Somatotrophinoma, Familial | 1 | CTD_human |
| Hgene | GNAS | C3697137 | Fibrous dysplasia of bone with intramuscular myxoma | 1 | ORPHANET |
| Hgene | GNAS | C3714756 | Intellectual Disability | 1 | CTD_human |
| Hgene | GNAS | C3805278 | Extrahepatic Cholangiocarcinoma | 1 | CTD_human |
| Tgene | C0268262 | Metachromatic Leukodystrophy due to Saposin B Deficiency | 8 | CTD_human;GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C2673635 | Combined Saposin Deficiency | 6 | CTD_human;GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C2673266 | KRABBE DISEASE, ATYPICAL, DUE TO SAPOSIN A DEFICIENCY | 5 | CTD_human;GENOMICS_ENGLAND | |
| Tgene | C1864651 | GAUCHER DISEASE, ATYPICAL, DUE TO SAPOSIN C DEFICIENCY | 4 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT | |
| Tgene | C0751273 | Infantile Globoid Cell Leukodystrophy | 1 | ORPHANET | |
| Tgene | C0751276 | Metachromatic leukodystrophy, juvenile type | 1 | ORPHANET | |
| Tgene | C0751278 | Metachromatic Leukodystrophy, Infant | 1 | ORPHANET | |
| Tgene | C0751279 | Metachromatic Leukodystrophy, Adult-Type (disorder) | 1 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies