
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AGFG1-TAF1A (FusionGDB2 ID:HG3267TG9015) |
Fusion Gene Summary for AGFG1-TAF1A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AGFG1-TAF1A | Fusion gene ID: hg3267tg9015 | Hgene | Tgene | Gene symbol | AGFG1 | TAF1A | Gene ID | 3267 | 9015 |
| Gene name | ArfGAP with FG repeats 1 | TATA-box binding protein associated factor, RNA polymerase I subunit A | |
| Synonyms | HRB|RAB|RIP | MGC:17061|RAFI48|SL1|TAFI48 | |
| Cytomap | ('AGFG1')('TAF1A') 2q36.3 | 1q41 | |
| Type of gene | protein-coding | protein-coding | |
| Description | arf-GAP domain and FG repeat-containing protein 1HIV-1 Rev-binding proteinRab, Rev/Rex activation domain-binding proteinarf-GAP domain and FG repeats-containing protein 1hRIP, Rev interacting proteinnucleoporin-like protein RIPrev-interacting protei | TATA box-binding protein-associated factor RNA polymerase I subunit ARNA polymerase I-specific TBP-associated factor 48 kDaSL1, 48kD subunitTATA box binding protein (TBP)-associated factor, RNA polymerase I, A, 48kDTATA box binding protein (TBP)-assoc | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000486932, ENST00000310078, ENST00000373671, ENST00000409171, ENST00000409315, ENST00000409979, | ||
| Fusion gene scores | * DoF score | 13 X 9 X 8=936 | 1 X 1 X 1=1 |
| # samples | 15 | 1 | |
| ** MAII score | log2(15/936*10)=-2.64154602908752 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: AGFG1 [Title/Abstract] AND TAF1A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AGFG1(228388641)-TAF1A(222737467), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | AGFG1-TAF1A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AGFG1-TAF1A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across AGFG1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TAF1A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-2290 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
Top |
Fusion Gene ORF analysis for AGFG1-TAF1A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000486932 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 3UTR-3CDS | ENST00000486932 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 3UTR-3CDS | ENST00000486932 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 3UTR-3CDS | ENST00000486932 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 3UTR-intron | ENST00000486932 | ENST00000465263 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 3UTR-intron | ENST00000486932 | ENST00000543857 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000310078 | ENST00000465263 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000310078 | ENST00000543857 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000373671 | ENST00000465263 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000373671 | ENST00000543857 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000409171 | ENST00000465263 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000409171 | ENST00000543857 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000409315 | ENST00000465263 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000409315 | ENST00000543857 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000409979 | ENST00000465263 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| 5CDS-intron | ENST00000409979 | ENST00000543857 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000310078 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000310078 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000310078 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000310078 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000373671 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000373671 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000373671 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000373671 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409171 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409171 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409171 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409171 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409315 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409315 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409315 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409315 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409979 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409979 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409979 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| In-frame | ENST00000409979 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000409979 | AGFG1 | chr2 | 228388641 | + | ENST00000366890 | TAF1A | chr1 | 222737467 | - | 1673 | 810 | 45 | 1268 | 407 |
| ENST00000409979 | AGFG1 | chr2 | 228388641 | + | ENST00000350027 | TAF1A | chr1 | 222737467 | - | 1673 | 810 | 45 | 1268 | 407 |
| ENST00000409979 | AGFG1 | chr2 | 228388641 | + | ENST00000352967 | TAF1A | chr1 | 222737467 | - | 1621 | 810 | 45 | 1268 | 407 |
| ENST00000409979 | AGFG1 | chr2 | 228388641 | + | ENST00000391882 | TAF1A | chr1 | 222737467 | - | 1605 | 810 | 45 | 1268 | 407 |
| ENST00000310078 | AGFG1 | chr2 | 228388641 | + | ENST00000366890 | TAF1A | chr1 | 222737467 | - | 1663 | 800 | 35 | 1258 | 407 |
| ENST00000310078 | AGFG1 | chr2 | 228388641 | + | ENST00000350027 | TAF1A | chr1 | 222737467 | - | 1663 | 800 | 35 | 1258 | 407 |
| ENST00000310078 | AGFG1 | chr2 | 228388641 | + | ENST00000352967 | TAF1A | chr1 | 222737467 | - | 1611 | 800 | 35 | 1258 | 407 |
| ENST00000310078 | AGFG1 | chr2 | 228388641 | + | ENST00000391882 | TAF1A | chr1 | 222737467 | - | 1595 | 800 | 35 | 1258 | 407 |
| ENST00000409315 | AGFG1 | chr2 | 228388641 | + | ENST00000366890 | TAF1A | chr1 | 222737467 | - | 1456 | 593 | 23 | 1051 | 342 |
| ENST00000409315 | AGFG1 | chr2 | 228388641 | + | ENST00000350027 | TAF1A | chr1 | 222737467 | - | 1456 | 593 | 23 | 1051 | 342 |
| ENST00000409315 | AGFG1 | chr2 | 228388641 | + | ENST00000352967 | TAF1A | chr1 | 222737467 | - | 1404 | 593 | 23 | 1051 | 342 |
| ENST00000409315 | AGFG1 | chr2 | 228388641 | + | ENST00000391882 | TAF1A | chr1 | 222737467 | - | 1388 | 593 | 23 | 1051 | 342 |
| ENST00000373671 | AGFG1 | chr2 | 228388641 | + | ENST00000366890 | TAF1A | chr1 | 222737467 | - | 1453 | 590 | 20 | 1048 | 342 |
| ENST00000373671 | AGFG1 | chr2 | 228388641 | + | ENST00000350027 | TAF1A | chr1 | 222737467 | - | 1453 | 590 | 20 | 1048 | 342 |
| ENST00000373671 | AGFG1 | chr2 | 228388641 | + | ENST00000352967 | TAF1A | chr1 | 222737467 | - | 1401 | 590 | 20 | 1048 | 342 |
| ENST00000373671 | AGFG1 | chr2 | 228388641 | + | ENST00000391882 | TAF1A | chr1 | 222737467 | - | 1385 | 590 | 20 | 1048 | 342 |
| ENST00000409171 | AGFG1 | chr2 | 228388641 | + | ENST00000366890 | TAF1A | chr1 | 222737467 | - | 1453 | 590 | 20 | 1048 | 342 |
| ENST00000409171 | AGFG1 | chr2 | 228388641 | + | ENST00000350027 | TAF1A | chr1 | 222737467 | - | 1453 | 590 | 20 | 1048 | 342 |
| ENST00000409171 | AGFG1 | chr2 | 228388641 | + | ENST00000352967 | TAF1A | chr1 | 222737467 | - | 1401 | 590 | 20 | 1048 | 342 |
| ENST00000409171 | AGFG1 | chr2 | 228388641 | + | ENST00000391882 | TAF1A | chr1 | 222737467 | - | 1385 | 590 | 20 | 1048 | 342 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000409979 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.014799377 | 0.98520064 |
| ENST00000409979 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.014799377 | 0.98520064 |
| ENST00000409979 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.002745414 | 0.99725455 |
| ENST00000409979 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.002858038 | 0.9971419 |
| ENST00000310078 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.014717949 | 0.9852821 |
| ENST00000310078 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.014717949 | 0.9852821 |
| ENST00000310078 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.002716706 | 0.99728334 |
| ENST00000310078 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.002841406 | 0.99715865 |
| ENST00000409315 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.018220425 | 0.9817795 |
| ENST00000409315 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.018220425 | 0.9817795 |
| ENST00000409315 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.00307759 | 0.99692243 |
| ENST00000409315 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.003204734 | 0.99679524 |
| ENST00000373671 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.017200535 | 0.9827995 |
| ENST00000373671 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.017200535 | 0.9827995 |
| ENST00000373671 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.002859322 | 0.99714065 |
| ENST00000373671 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.003009515 | 0.99699044 |
| ENST00000409171 | ENST00000366890 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.017200535 | 0.9827995 |
| ENST00000409171 | ENST00000350027 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.017200535 | 0.9827995 |
| ENST00000409171 | ENST00000352967 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.002859322 | 0.99714065 |
| ENST00000409171 | ENST00000391882 | AGFG1 | chr2 | 228388641 | + | TAF1A | chr1 | 222737467 | - | 0.003009515 | 0.99699044 |
Top |
Fusion Genomic Features for AGFG1-TAF1A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
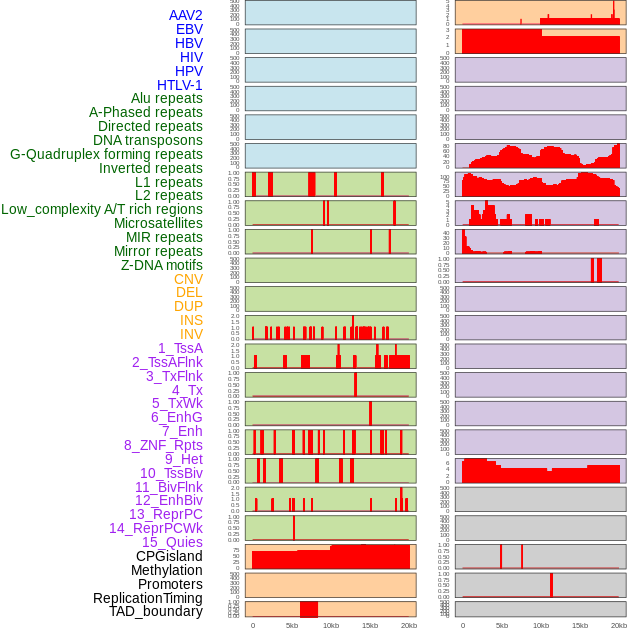 |
Top |
Fusion Protein Features for AGFG1-TAF1A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:228388641/chr1:222737467) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AGFG1 | chr2:228388641 | chr1:222737467 | ENST00000310078 | + | 4 | 13 | 11_135 | 180 | 563.0 | Domain | Arf-GAP |
| Hgene | AGFG1 | chr2:228388641 | chr1:222737467 | ENST00000373671 | + | 4 | 12 | 11_135 | 180 | 523.0 | Domain | Arf-GAP |
| Hgene | AGFG1 | chr2:228388641 | chr1:222737467 | ENST00000409171 | + | 4 | 13 | 11_135 | 180 | 561.0 | Domain | Arf-GAP |
| Hgene | AGFG1 | chr2:228388641 | chr1:222737467 | ENST00000310078 | + | 4 | 13 | 29_52 | 180 | 563.0 | Zinc finger | C4-type |
| Hgene | AGFG1 | chr2:228388641 | chr1:222737467 | ENST00000373671 | + | 4 | 12 | 29_52 | 180 | 523.0 | Zinc finger | C4-type |
| Hgene | AGFG1 | chr2:228388641 | chr1:222737467 | ENST00000409171 | + | 4 | 13 | 29_52 | 180 | 561.0 | Zinc finger | C4-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for AGFG1-TAF1A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >2874_2874_1_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000310078_TAF1A_chr1_222737467_ENST00000350027_length(transcript)=1663nt_BP=800nt AGGAGAAGTCGGGAAGGTGGCGGCGGCGGCGGCGGTTGTCCCGGCTGTGCCGGTTGGTGTGGCCCGTCAGCCCGCGTACCACAGCGCCCG GGCCGCGTCGAGCCCAGTACAGCCAAGCCGCTGCGGCCGGGTCCGGCGCGGGCGGCGCGCGCAGACGGAGGGCGGCGGCCGCGGCCAGGG CGGCCCGTGGGACCGCGGGCCCCCGGCGCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCA GCGCGAAGCGGAAGCAGGAGGAGAAGCACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACC AGCGCGGCCCCACCTACGTTAACATGACGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACA GGGTGAAATCTATCTCCATGACAACATTCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGC TAGGATTATTTGATGATAGATCTTCAGCAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGA AAAGATGGTATGTCCCGCCAGAACAAGCCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCA CACCTGAGGTCAAACCACTGAAATCTCTTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATC AGATTGTACCATCTCATAAATTGATGTTGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGG TATTATTTGGAGTCTTAGATTTTGCCGGATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGG GAAACCACCTTGCGTGGGTTCAAGAAGAGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTG ATTGGAAGGAAGATACAGCTTTGGCCTGTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTT TAAAGCAAGATCACCAAATCTTAGGGAAGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGAT ACTGAATTTTAGTTATTTCACAGTTGTAGCTACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAGGAATTTTGAA AAGAGAGAAGGATTTAGAAAAAAGACTCTTTCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGCCGAGGTGGGT GGATCATGAGGTCAGGAGTTCAAGACCAGCCTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCTGGGCGCAGTG GCGGGCATTTGTAATCCCAGATACTCGGGAGGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCGAGATTGC >2874_2874_1_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000310078_TAF1A_chr1_222737467_ENST00000350027_length(amino acids)=407AA_BP=254 MSRLCRLVWPVSPRTTAPGPRRAQYSQAAAAGSGAGGARRRRAAAAARAARGTAGPRRSAARLPALPASSLGAAAMAASAKRKQEEKHLK MLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIP DFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQILYQIVPSHKLMLEF HTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEK -------------------------------------------------------------- >2874_2874_2_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000310078_TAF1A_chr1_222737467_ENST00000352967_length(transcript)=1611nt_BP=800nt AGGAGAAGTCGGGAAGGTGGCGGCGGCGGCGGCGGTTGTCCCGGCTGTGCCGGTTGGTGTGGCCCGTCAGCCCGCGTACCACAGCGCCCG GGCCGCGTCGAGCCCAGTACAGCCAAGCCGCTGCGGCCGGGTCCGGCGCGGGCGGCGCGCGCAGACGGAGGGCGGCGGCCGCGGCCAGGG CGGCCCGTGGGACCGCGGGCCCCCGGCGCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCA GCGCGAAGCGGAAGCAGGAGGAGAAGCACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACC AGCGCGGCCCCACCTACGTTAACATGACGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACA GGGTGAAATCTATCTCCATGACAACATTCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGC TAGGATTATTTGATGATAGATCTTCAGCAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGA AAAGATGGTATGTCCCGCCAGAACAAGCCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCA CACCTGAGGTCAAACCACTGAAATCTCTTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATC AGATTGTACCATCTCATAAATTGATGTTGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGG TATTATTTGGAGTCTTAGATTTTGCCGGATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGG GAAACCACCTTGCGTGGGTTCAAGAAGAGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTG ATTGGAAGGAAGATACAGCTTTGGCCTGTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTT TAAAGCAAGATCACCAAATCTTAGGGAAGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGAT ACTGAATTTTAGTTATTTCACAGTTGTAGCTACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGTATTAAGAAGC TTATATTACTACAAAAAACTTATTTTTATATATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCCTTTGCTCTTT GTAACTATGTCTGTTTTCTTTTTTGTAATGTTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTACAGAATATAG >2874_2874_2_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000310078_TAF1A_chr1_222737467_ENST00000352967_length(amino acids)=407AA_BP=254 MSRLCRLVWPVSPRTTAPGPRRAQYSQAAAAGSGAGGARRRRAAAAARAARGTAGPRRSAARLPALPASSLGAAAMAASAKRKQEEKHLK MLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIP DFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQILYQIVPSHKLMLEF HTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEK -------------------------------------------------------------- >2874_2874_3_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000310078_TAF1A_chr1_222737467_ENST00000366890_length(transcript)=1663nt_BP=800nt AGGAGAAGTCGGGAAGGTGGCGGCGGCGGCGGCGGTTGTCCCGGCTGTGCCGGTTGGTGTGGCCCGTCAGCCCGCGTACCACAGCGCCCG GGCCGCGTCGAGCCCAGTACAGCCAAGCCGCTGCGGCCGGGTCCGGCGCGGGCGGCGCGCGCAGACGGAGGGCGGCGGCCGCGGCCAGGG CGGCCCGTGGGACCGCGGGCCCCCGGCGCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCA GCGCGAAGCGGAAGCAGGAGGAGAAGCACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACC AGCGCGGCCCCACCTACGTTAACATGACGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACA GGGTGAAATCTATCTCCATGACAACATTCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGC TAGGATTATTTGATGATAGATCTTCAGCAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGA AAAGATGGTATGTCCCGCCAGAACAAGCCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCA CACCTGAGGTCAAACCACTGAAATCTCTTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATC AGATTGTACCATCTCATAAATTGATGTTGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGG TATTATTTGGAGTCTTAGATTTTGCCGGATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGG GAAACCACCTTGCGTGGGTTCAAGAAGAGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTG ATTGGAAGGAAGATACAGCTTTGGCCTGTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTT TAAAGCAAGATCACCAAATCTTAGGGAAGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGAT ACTGAATTTTAGTTATTTCACAGTTGTAGCTACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAGGAATTTTGAA AAGAGAGAAGGATTTAGAAAAAAGACTCTTTCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGCCGAGGTGGGT GGATCATGAGGTCAGGAGTTCAAGACCAGCCTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCTGGGCGCAGTG GCGGGCATTTGTAATCCCAGATACTCGGGAGGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCGAGATTGC >2874_2874_3_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000310078_TAF1A_chr1_222737467_ENST00000366890_length(amino acids)=407AA_BP=254 MSRLCRLVWPVSPRTTAPGPRRAQYSQAAAAGSGAGGARRRRAAAAARAARGTAGPRRSAARLPALPASSLGAAAMAASAKRKQEEKHLK MLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIP DFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQILYQIVPSHKLMLEF HTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEK -------------------------------------------------------------- >2874_2874_4_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000310078_TAF1A_chr1_222737467_ENST00000391882_length(transcript)=1595nt_BP=800nt AGGAGAAGTCGGGAAGGTGGCGGCGGCGGCGGCGGTTGTCCCGGCTGTGCCGGTTGGTGTGGCCCGTCAGCCCGCGTACCACAGCGCCCG GGCCGCGTCGAGCCCAGTACAGCCAAGCCGCTGCGGCCGGGTCCGGCGCGGGCGGCGCGCGCAGACGGAGGGCGGCGGCCGCGGCCAGGG CGGCCCGTGGGACCGCGGGCCCCCGGCGCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCA GCGCGAAGCGGAAGCAGGAGGAGAAGCACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACC AGCGCGGCCCCACCTACGTTAACATGACGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACA GGGTGAAATCTATCTCCATGACAACATTCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGC TAGGATTATTTGATGATAGATCTTCAGCAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGA AAAGATGGTATGTCCCGCCAGAACAAGCCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCA CACCTGAGGTCAAACCACTGAAATCTCTTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATC AGATTGTACCATCTCATAAATTGATGTTGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGG TATTATTTGGAGTCTTAGATTTTGCCGGATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGG GAAACCACCTTGCGTGGGTTCAAGAAGAGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTG ATTGGAAGGAAGATACAGCTTTGGCCTGTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTT TAAAGCAAGATCACCAAATCTTAGGGAAGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGAT ACTGAATTTTAGTTATTTCACAGTTGTAGCTACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGTATTAAGAAGC TTATATTACTACAAAAAACTTATTTTTATATATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCCTTTGCTCTTT GTAACTATGTCTGTTTTCTTTTTTGTAATGTTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTACAGAATATAG >2874_2874_4_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000310078_TAF1A_chr1_222737467_ENST00000391882_length(amino acids)=407AA_BP=254 MSRLCRLVWPVSPRTTAPGPRRAQYSQAAAAGSGAGGARRRRAAAAARAARGTAGPRRSAARLPALPASSLGAAAMAASAKRKQEEKHLK MLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIP DFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQILYQIVPSHKLMLEF HTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEK -------------------------------------------------------------- >2874_2874_5_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000373671_TAF1A_chr1_222737467_ENST00000350027_length(transcript)=1453nt_BP=590nt GCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACC TGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGG TCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACATTCA CACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAA TTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCA AAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTT TAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGG AATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGAT GCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGT GGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTG AGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGA AAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGC TACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAGGAATTTTGAAAAGAGAGAAGGATTTAGAAAAAAGACTCTT TCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGCCGAGGTGGGTGGATCATGAGGTCAGGAGTTCAAGACCAGC CTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCTGGGCGCAGTGGCGGGCATTTGTAATCCCAGATACTCGGGA GGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCGAGATTGCACCACCGTACTCCTGCCTGGGCGACAGAAC >2874_2874_5_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000373671_TAF1A_chr1_222737467_ENST00000350027_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_6_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000373671_TAF1A_chr1_222737467_ENST00000352967_length(transcript)=1401nt_BP=590nt GCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACC TGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGG TCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACATTCA CACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAA TTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCA AAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTT TAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGG AATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGAT GCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGT GGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTG AGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGA AAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGC TACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGTATTAAGAAGCTTATATTACTACAAAAAACTTATTTTTATA TATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCCTTTGCTCTTTGTAACTATGTCTGTTTTCTTTTTTGTAATG TTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTACAGAATATAGCTCTACAGCAGTTATTGTTTGCAAATACTT >2874_2874_6_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000373671_TAF1A_chr1_222737467_ENST00000352967_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_7_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000373671_TAF1A_chr1_222737467_ENST00000366890_length(transcript)=1453nt_BP=590nt GCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACC TGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGG TCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACATTCA CACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAA TTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCA AAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTT TAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGG AATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGAT GCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGT GGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTG AGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGA AAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGC TACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAGGAATTTTGAAAAGAGAGAAGGATTTAGAAAAAAGACTCTT TCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGCCGAGGTGGGTGGATCATGAGGTCAGGAGTTCAAGACCAGC CTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCTGGGCGCAGTGGCGGGCATTTGTAATCCCAGATACTCGGGA GGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCGAGATTGCACCACCGTACTCCTGCCTGGGCGACAGAAC >2874_2874_7_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000373671_TAF1A_chr1_222737467_ENST00000366890_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_8_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000373671_TAF1A_chr1_222737467_ENST00000391882_length(transcript)=1385nt_BP=590nt GCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACC TGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGG TCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACATTCA CACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAA TTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCA AAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTT TAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGG AATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGAT GCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGT GGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTG AGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGA AAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGC TACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGTATTAAGAAGCTTATATTACTACAAAAAACTTATTTTTATA TATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCCTTTGCTCTTTGTAACTATGTCTGTTTTCTTTTTTGTAATG TTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTACAGAATATAGCTCTACAGCAGTTATTGTTTGCAAATACTT >2874_2874_8_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000373671_TAF1A_chr1_222737467_ENST00000391882_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_9_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409171_TAF1A_chr1_222737467_ENST00000350027_length(transcript)=1453nt_BP=590nt GCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACC TGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGG TCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACATTCA CACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAA TTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCA AAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTT TAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGG AATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGAT GCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGT GGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTG AGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGA AAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGC TACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAGGAATTTTGAAAAGAGAGAAGGATTTAGAAAAAAGACTCTT TCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGCCGAGGTGGGTGGATCATGAGGTCAGGAGTTCAAGACCAGC CTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCTGGGCGCAGTGGCGGGCATTTGTAATCCCAGATACTCGGGA GGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCGAGATTGCACCACCGTACTCCTGCCTGGGCGACAGAAC >2874_2874_9_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409171_TAF1A_chr1_222737467_ENST00000350027_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_10_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409171_TAF1A_chr1_222737467_ENST00000352967_length(transcript)=1401nt_BP=590nt GCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACC TGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGG TCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACATTCA CACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAA TTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCA AAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTT TAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGG AATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGAT GCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGT GGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTG AGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGA AAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGC TACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGTATTAAGAAGCTTATATTACTACAAAAAACTTATTTTTATA TATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCCTTTGCTCTTTGTAACTATGTCTGTTTTCTTTTTTGTAATG TTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTACAGAATATAGCTCTACAGCAGTTATTGTTTGCAAATACTT >2874_2874_10_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409171_TAF1A_chr1_222737467_ENST00000352967_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_11_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409171_TAF1A_chr1_222737467_ENST00000366890_length(transcript)=1453nt_BP=590nt GCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACC TGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGG TCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACATTCA CACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAA TTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCA AAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTT TAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGG AATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGAT GCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGT GGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTG AGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGA AAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGC TACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAGGAATTTTGAAAAGAGAGAAGGATTTAGAAAAAAGACTCTT TCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGCCGAGGTGGGTGGATCATGAGGTCAGGAGTTCAAGACCAGC CTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCTGGGCGCAGTGGCGGGCATTTGTAATCCCAGATACTCGGGA GGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCGAGATTGCACCACCGTACTCCTGCCTGGGCGACAGAAC >2874_2874_11_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409171_TAF1A_chr1_222737467_ENST00000366890_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_12_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409171_TAF1A_chr1_222737467_ENST00000391882_length(transcript)=1385nt_BP=590nt GCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACC TGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGG TCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACATTCA CACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAA TTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCA AAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTT TAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGG AATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGAT GCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGT GGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTG AGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGA AAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGC TACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGTATTAAGAAGCTTATATTACTACAAAAAACTTATTTTTATA TATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCCTTTGCTCTTTGTAACTATGTCTGTTTTCTTTTTTGTAATG TTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTACAGAATATAGCTCTACAGCAGTTATTGTTTGCAAATACTT >2874_2874_12_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409171_TAF1A_chr1_222737467_ENST00000391882_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_13_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409315_TAF1A_chr1_222737467_ENST00000350027_length(transcript)=1456nt_BP=593nt GCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGC ACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGA CGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACAT TCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAG CAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAG CCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTC TTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGT TGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCG GATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAG AGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCT GTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGA AGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGT AGCTACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAGGAATTTTGAAAAGAGAGAAGGATTTAGAAAAAAGACT CTTTCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGCCGAGGTGGGTGGATCATGAGGTCAGGAGTTCAAGACC AGCCTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCTGGGCGCAGTGGCGGGCATTTGTAATCCCAGATACTCG GGAGGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCGAGATTGCACCACCGTACTCCTGCCTGGGCGACAG >2874_2874_13_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409315_TAF1A_chr1_222737467_ENST00000350027_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_14_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409315_TAF1A_chr1_222737467_ENST00000352967_length(transcript)=1404nt_BP=593nt GCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGC ACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGA CGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACAT TCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAG CAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAG CCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTC TTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGT TGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCG GATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAG AGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCT GTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGA AGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGT AGCTACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGTATTAAGAAGCTTATATTACTACAAAAAACTTATTTTT ATATATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCCTTTGCTCTTTGTAACTATGTCTGTTTTCTTTTTTGTA ATGTTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTACAGAATATAGCTCTACAGCAGTTATTGTTTGCAAATA >2874_2874_14_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409315_TAF1A_chr1_222737467_ENST00000352967_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_15_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409315_TAF1A_chr1_222737467_ENST00000366890_length(transcript)=1456nt_BP=593nt GCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGC ACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGA CGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACAT TCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAG CAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAG CCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTC TTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGT TGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCG GATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAG AGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCT GTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGA AGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGT AGCTACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAGGAATTTTGAAAAGAGAGAAGGATTTAGAAAAAAGACT CTTTCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGCCGAGGTGGGTGGATCATGAGGTCAGGAGTTCAAGACC AGCCTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCTGGGCGCAGTGGCGGGCATTTGTAATCCCAGATACTCG GGAGGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAGCCGAGATTGCACCACCGTACTCCTGCCTGGGCGACAG >2874_2874_15_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409315_TAF1A_chr1_222737467_ENST00000366890_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_16_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409315_TAF1A_chr1_222737467_ENST00000391882_length(transcript)=1388nt_BP=593nt GCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCCATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGC ACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTCGACTGCGACCAGCGCGGCCCCACCTACGTTAACATGA CGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAATCCACCACACAGGGTGAAATCTATCTCCATGACAACAT TCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAACAGATTTGGCTAGGATTATTTGATGATAGATCTTCAG CAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAGTATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAG CCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGCACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTC TTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAGATTTTGTATCAGATTGTACCATCTCATAAATTGATGT TGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTGGGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCG GATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAATATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAG AGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGGGCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCT GTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTCCGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGA AGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCAAGACTCTGATACTGAATTTTAGTTATTTCACAGTTGT AGCTACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGTATTAAGAAGCTTATATTACTACAAAAAACTTATTTTT ATATATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCCTTTGCTCTTTGTAACTATGTCTGTTTTCTTTTTTGTA ATGTTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTACAGAATATAGCTCTACAGCAGTTATTGTTTGCAAATA >2874_2874_16_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409315_TAF1A_chr1_222737467_ENST00000391882_length(amino acids)=342AA_BP=189 MPASSLGAAAMAASAKRKQEEKHLKMLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEF LQKHGNEVCKQIWLGLFDDRSSAIPDFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPT LHLNKGTPSQILYQIVPSHKLMLEFHTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNW -------------------------------------------------------------- >2874_2874_17_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409979_TAF1A_chr1_222737467_ENST00000350027_length(transcript)=1673nt_BP=810nt TTTTCCCCTCAGGAGAAGTCGGGAAGGTGGCGGCGGCGGCGGCGGTTGTCCCGGCTGTGCCGGTTGGTGTGGCCCGTCAGCCCGCGTACC ACAGCGCCCGGGCCGCGTCGAGCCCAGTACAGCCAAGCCGCTGCGGCCGGGTCCGGCGCGGGCGGCGCGCGCAGACGGAGGGCGGCGGCC GCGGCCAGGGCGGCCCGTGGGACCGCGGGCCCCCGGCGCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCC ATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTC GACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAAT CCACCACACAGGGTGAAATCTATCTCCATGACAACATTCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAA CAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAG TATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGC ACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAG ATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTG GGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAAT ATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGG GCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTC CGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCA AGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGCTACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAG GAATTTTGAAAAGAGAGAAGGATTTAGAAAAAAGACTCTTTCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGC CGAGGTGGGTGGATCATGAGGTCAGGAGTTCAAGACCAGCCTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCT GGGCGCAGTGGCGGGCATTTGTAATCCCAGATACTCGGGAGGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAG >2874_2874_17_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409979_TAF1A_chr1_222737467_ENST00000350027_length(amino acids)=407AA_BP=254 MSRLCRLVWPVSPRTTAPGPRRAQYSQAAAAGSGAGGARRRRAAAAARAARGTAGPRRSAARLPALPASSLGAAAMAASAKRKQEEKHLK MLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIP DFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQILYQIVPSHKLMLEF HTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEK -------------------------------------------------------------- >2874_2874_18_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409979_TAF1A_chr1_222737467_ENST00000352967_length(transcript)=1621nt_BP=810nt TTTTCCCCTCAGGAGAAGTCGGGAAGGTGGCGGCGGCGGCGGCGGTTGTCCCGGCTGTGCCGGTTGGTGTGGCCCGTCAGCCCGCGTACC ACAGCGCCCGGGCCGCGTCGAGCCCAGTACAGCCAAGCCGCTGCGGCCGGGTCCGGCGCGGGCGGCGCGCGCAGACGGAGGGCGGCGGCC GCGGCCAGGGCGGCCCGTGGGACCGCGGGCCCCCGGCGCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCC ATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTC GACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAAT CCACCACACAGGGTGAAATCTATCTCCATGACAACATTCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAA CAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAG TATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGC ACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAG ATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTG GGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAAT ATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGG GCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTC CGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCA AGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGCTACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGT ATTAAGAAGCTTATATTACTACAAAAAACTTATTTTTATATATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCC TTTGCTCTTTGTAACTATGTCTGTTTTCTTTTTTGTAATGTTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTA CAGAATATAGCTCTACAGCAGTTATTGTTTGCAAATACTTTGCCTCTTGCTATTGTGTAATAAACTGTAACTTGTAGTGCTGTGAAATGT >2874_2874_18_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409979_TAF1A_chr1_222737467_ENST00000352967_length(amino acids)=407AA_BP=254 MSRLCRLVWPVSPRTTAPGPRRAQYSQAAAAGSGAGGARRRRAAAAARAARGTAGPRRSAARLPALPASSLGAAAMAASAKRKQEEKHLK MLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIP DFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQILYQIVPSHKLMLEF HTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEK -------------------------------------------------------------- >2874_2874_19_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409979_TAF1A_chr1_222737467_ENST00000366890_length(transcript)=1673nt_BP=810nt TTTTCCCCTCAGGAGAAGTCGGGAAGGTGGCGGCGGCGGCGGCGGTTGTCCCGGCTGTGCCGGTTGGTGTGGCCCGTCAGCCCGCGTACC ACAGCGCCCGGGCCGCGTCGAGCCCAGTACAGCCAAGCCGCTGCGGCCGGGTCCGGCGCGGGCGGCGCGCGCAGACGGAGGGCGGCGGCC GCGGCCAGGGCGGCCCGTGGGACCGCGGGCCCCCGGCGCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCC ATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTC GACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAAT CCACCACACAGGGTGAAATCTATCTCCATGACAACATTCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAA CAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAG TATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGC ACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAG ATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTG GGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAAT ATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGG GCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTC CGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCA AGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGCTACACAGTATACCACCATGAAGAAATATATTGGTGATGAGTTCTATTGAG GAATTTTGAAAAGAGAGAAGGATTTAGAAAAAAGACTCTTTCTCGGCCGGGCGCAGTGGCTCACACTTCTAATCCCAGCACTTGGGAGGC CGAGGTGGGTGGATCATGAGGTCAGGAGTTCAAGACCAGCCTGGCCAACACAGTGAAACCCTGTCTCTACTAAAAATACAAAAAGTAGCT GGGCGCAGTGGCGGGCATTTGTAATCCCAGATACTCGGGAGGCTGAAGCAGGAGAATTGCTTGAACCCGGGAGGTGGAGGTTGCAGTGAG >2874_2874_19_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409979_TAF1A_chr1_222737467_ENST00000366890_length(amino acids)=407AA_BP=254 MSRLCRLVWPVSPRTTAPGPRRAQYSQAAAAGSGAGGARRRRAAAAARAARGTAGPRRSAARLPALPASSLGAAAMAASAKRKQEEKHLK MLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIP DFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQILYQIVPSHKLMLEF HTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEK -------------------------------------------------------------- >2874_2874_20_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409979_TAF1A_chr1_222737467_ENST00000391882_length(transcript)=1605nt_BP=810nt TTTTCCCCTCAGGAGAAGTCGGGAAGGTGGCGGCGGCGGCGGCGGTTGTCCCGGCTGTGCCGGTTGGTGTGGCCCGTCAGCCCGCGTACC ACAGCGCCCGGGCCGCGTCGAGCCCAGTACAGCCAAGCCGCTGCGGCCGGGTCCGGCGCGGGCGGCGCGCGCAGACGGAGGGCGGCGGCC GCGGCCAGGGCGGCCCGTGGGACCGCGGGCCCCCGGCGCAGCGCTGCCCGGCTCCCGGCCCTGCCGGCCTCCTCCCTTGGCGCCGCGGCC ATGGCGGCCAGCGCGAAGCGGAAGCAGGAGGAGAAGCACCTGAAGATGCTGCGGGACATGACCGGCCTCCCGCACAACCGAAAGTGCTTC GACTGCGACCAGCGCGGCCCCACCTACGTTAACATGACGGTCGGCTCCTTCGTGTGTACCTCCTGCTCCGGCAGCCTGCGAGGATTAAAT CCACCACACAGGGTGAAATCTATCTCCATGACAACATTCACACAACAGGAAATTGAATTCTTACAAAAACATGGAAATGAAGTCTGTAAA CAGATTTGGCTAGGATTATTTGATGATAGATCTTCAGCAATTCCAGACTTCAGGGATCCACAAAAAGTGAAAGAGTTTCTACAAGAAAAG TATGAAAAGAAAAGATGGTATGTCCCGCCAGAACAAGCCAAAGTCGTGGCATCAGTTCATGCATCTATTTCAGGGTCCTCTGCCAGTAGC ACAAGCAGCACACCTGAGGTCAAACCACTGAAATCTCTTTTAGGGGATTCTGCACCAACACTGCACTTAAATAAGGGCACACCTAGTCAG ATTTTGTATCAGATTGTACCATCTCATAAATTGATGTTGGAATTCCATACATTACTTAGAAAATCAGAAAAAGAAGAACACCGTAAACTG GGGTTGGAGGTATTATTTGGAGTCTTAGATTTTGCCGGATGCACTAAGAATATAACTGCTTGGAAATACTTGGCAAAATATCTGAAAAAT ATCTTAATGGGAAACCACCTTGCGTGGGTTCAAGAAGAGTGGAACTCCAGGAAAAACTGGTGGCCAGGCTTTCATTTCAGCTACTTTTGG GCAAAAAGTGATTGGAAGGAAGATACAGCTTTGGCCTGTGAGAAAGCTTTTGTGGCTGGTTTACTGTTAGGAAAAGGTTGTAGATATTTC CGGTATATTTTAAAGCAAGATCACCAAATCTTAGGGAAGAAAATTAAGCGGATGAAGAGATCTGTGAAAAAATACAGTATTGTAAATCCA AGACTCTGATACTGAATTTTAGTTATTTCACAGTTGTAGCTACACAGTAAGTAGCTTGGTAGATAGTTATTGAATGTATTTATGTAGTGT ATTAAGAAGCTTATATTACTACAAAAAACTTATTTTTATATATTTTTATATTTTTGTATTATTTATAGCTAGAGAAACAATATTACTGCC TTTGCTCTTTGTAACTATGTCTGTTTTCTTTTTTGTAATGTTAAATGTTACATTTGTTAAGGAATAATTCTTCAAATGACAAACTAATTA >2874_2874_20_AGFG1-TAF1A_AGFG1_chr2_228388641_ENST00000409979_TAF1A_chr1_222737467_ENST00000391882_length(amino acids)=407AA_BP=254 MSRLCRLVWPVSPRTTAPGPRRAQYSQAAAAGSGAGGARRRRAAAAARAARGTAGPRRSAARLPALPASSLGAAAMAASAKRKQEEKHLK MLRDMTGLPHNRKCFDCDQRGPTYVNMTVGSFVCTSCSGSLRGLNPPHRVKSISMTTFTQQEIEFLQKHGNEVCKQIWLGLFDDRSSAIP DFRDPQKVKEFLQEKYEKKRWYVPPEQAKVVASVHASISGSSASSTSSTPEVKPLKSLLGDSAPTLHLNKGTPSQILYQIVPSHKLMLEF HTLLRKSEKEEHRKLGLEVLFGVLDFAGCTKNITAWKYLAKYLKNILMGNHLAWVQEEWNSRKNWWPGFHFSYFWAKSDWKEDTALACEK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AGFG1-TAF1A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AGFG1-TAF1A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AGFG1-TAF1A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | AGFG1 | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human |
| Tgene | C0340427 | Familial dilated cardiomyopathy | 1 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies