
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:IL1R1-IL1R2 (FusionGDB2 ID:HG3554TG7850) |
Fusion Gene Summary for IL1R1-IL1R2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: IL1R1-IL1R2 | Fusion gene ID: hg3554tg7850 | Hgene | Tgene | Gene symbol | IL1R1 | IL1R2 | Gene ID | 3554 | 7850 |
| Gene name | interleukin 1 receptor type 1 | interleukin 1 receptor type 2 | |
| Synonyms | CD121A|D2S1473|IL-1R-alpha|IL1R|IL1RA|P80 | CD121b|CDw121b|IL-1R-2|IL-1RT-2|IL-1RT2|IL1R2c|IL1RB | |
| Cytomap | ('IL1R1')('IL1R2') 2q11.2-q12.1 | 2q11.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | interleukin-1 receptor type 1CD121 antigen-like family member AIL-1R-1IL-1RT-1IL-1RT1interleukin 1 receptor alpha, type Iinterleukin-1 receptor alphainterleukin-1 receptor type I | interleukin-1 receptor type 2CD121 antigen-like family member BIL-1 type II receptorIL-1R-betaantigen CDw121binterleukin 1 receptor type II variant 3interleukin-1 receptor betainterleukin-1 receptor type IItype II interleukin-1 receptor, beta | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000233946, ENST00000409288, ENST00000409329, ENST00000409929, ENST00000410023, ENST00000424272, ENST00000409589, | ||
| Fusion gene scores | * DoF score | 4 X 6 X 6=144 | 5 X 6 X 6=180 |
| # samples | 7 | 7 | |
| ** MAII score | log2(7/144*10)=-1.04064198449735 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/180*10)=-1.36257007938471 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: IL1R1 [Title/Abstract] AND IL1R2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | IL1R1(102796334)-IL1R2(102638649), # samples:1 IL1R1(102782741)-IL1R2(102626024), # samples:1 IL1R1(102770477)-IL1R2(102632333), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | IL1R1-IL1R2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. IL1R1-IL1R2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. IL1R1-IL1R2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. IL1R1-IL1R2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | IL1R1 | GO:0032729 | positive regulation of interferon-gamma production | 10653850 |
| Hgene | IL1R1 | GO:0070498 | interleukin-1-mediated signaling pathway | 10383454 |
| Hgene | IL1R1 | GO:0070555 | response to interleukin-1 | 10383454 |
| Hgene | IL1R1 | GO:2000556 | positive regulation of T-helper 1 cell cytokine production | 10653850 |
| Fusion gene breakpoints across IL1R1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across IL1R2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-BH-A203-01A | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| ChimerDB4 | LIHC | TCGA-PD-A5DF-01A | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| ChimerDB4 | LUAD | TCGA-93-A4JO-01A | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
Top |
Fusion Gene ORF analysis for IL1R1-IL1R2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000233946 | ENST00000485335 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| 5CDS-intron | ENST00000233946 | ENST00000485335 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| 5CDS-intron | ENST00000409288 | ENST00000485335 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| 5CDS-intron | ENST00000409329 | ENST00000485335 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| 5CDS-intron | ENST00000409929 | ENST00000485335 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| 5CDS-intron | ENST00000410023 | ENST00000485335 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| 5CDS-intron | ENST00000410023 | ENST00000485335 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| 5CDS-intron | ENST00000424272 | ENST00000485335 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| 5UTR-3CDS | ENST00000233946 | ENST00000332549 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000233946 | ENST00000393414 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000233946 | ENST00000441002 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409288 | ENST00000332549 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409288 | ENST00000393414 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409288 | ENST00000441002 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409329 | ENST00000332549 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409329 | ENST00000393414 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409329 | ENST00000441002 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409589 | ENST00000332549 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409589 | ENST00000393414 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409589 | ENST00000441002 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409929 | ENST00000332549 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409929 | ENST00000393414 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000409929 | ENST00000441002 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000410023 | ENST00000332549 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000410023 | ENST00000393414 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000410023 | ENST00000441002 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000424272 | ENST00000332549 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000424272 | ENST00000393414 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-3CDS | ENST00000424272 | ENST00000441002 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-intron | ENST00000233946 | ENST00000485335 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-intron | ENST00000409288 | ENST00000485335 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-intron | ENST00000409329 | ENST00000485335 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-intron | ENST00000409589 | ENST00000485335 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-intron | ENST00000409929 | ENST00000485335 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-intron | ENST00000410023 | ENST00000485335 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| 5UTR-intron | ENST00000424272 | ENST00000485335 | IL1R1 | chr2 | 102770477 | - | IL1R2 | chr2 | 102632333 | + |
| In-frame | ENST00000233946 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000233946 | ENST00000332549 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| In-frame | ENST00000233946 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000233946 | ENST00000393414 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| In-frame | ENST00000233946 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000233946 | ENST00000441002 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| In-frame | ENST00000409288 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000409288 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000409288 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000409329 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000409329 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000409329 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000409929 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000409929 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000409929 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000410023 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000410023 | ENST00000332549 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| In-frame | ENST00000410023 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000410023 | ENST00000393414 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| In-frame | ENST00000410023 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000410023 | ENST00000441002 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| In-frame | ENST00000424272 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000424272 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| In-frame | ENST00000424272 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| intron-3CDS | ENST00000409288 | ENST00000332549 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409288 | ENST00000393414 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409288 | ENST00000441002 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409329 | ENST00000332549 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409329 | ENST00000393414 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409329 | ENST00000441002 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409589 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| intron-3CDS | ENST00000409589 | ENST00000332549 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409589 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| intron-3CDS | ENST00000409589 | ENST00000393414 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409589 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| intron-3CDS | ENST00000409589 | ENST00000441002 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409929 | ENST00000332549 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409929 | ENST00000393414 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000409929 | ENST00000441002 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000424272 | ENST00000332549 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000424272 | ENST00000393414 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-3CDS | ENST00000424272 | ENST00000441002 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-intron | ENST00000409288 | ENST00000485335 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-intron | ENST00000409329 | ENST00000485335 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-intron | ENST00000409589 | ENST00000485335 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + |
| intron-intron | ENST00000409589 | ENST00000485335 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-intron | ENST00000409929 | ENST00000485335 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| intron-intron | ENST00000424272 | ENST00000485335 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000410023 | IL1R1 | chr2 | 102796334 | - | ENST00000332549 | IL1R2 | chr2 | 102638649 | + | 5804 | 5143 | 276 | 2027 | 583 |
| ENST00000410023 | IL1R1 | chr2 | 102796334 | - | ENST00000393414 | IL1R2 | chr2 | 102638649 | + | 5677 | 5143 | 276 | 2027 | 583 |
| ENST00000410023 | IL1R1 | chr2 | 102796334 | - | ENST00000441002 | IL1R2 | chr2 | 102638649 | + | 5500 | 5143 | 276 | 2027 | 583 |
| ENST00000233946 | IL1R1 | chr2 | 102796334 | - | ENST00000332549 | IL1R2 | chr2 | 102638649 | + | 5568 | 4907 | 40 | 1791 | 583 |
| ENST00000233946 | IL1R1 | chr2 | 102796334 | - | ENST00000393414 | IL1R2 | chr2 | 102638649 | + | 5441 | 4907 | 40 | 1791 | 583 |
| ENST00000233946 | IL1R1 | chr2 | 102796334 | - | ENST00000441002 | IL1R2 | chr2 | 102638649 | + | 5264 | 4907 | 40 | 1791 | 583 |
| ENST00000424272 | IL1R1 | chr2 | 102782741 | - | ENST00000332549 | IL1R2 | chr2 | 102626024 | + | 2178 | 896 | 199 | 2025 | 608 |
| ENST00000424272 | IL1R1 | chr2 | 102782741 | - | ENST00000393414 | IL1R2 | chr2 | 102626024 | + | 2051 | 896 | 199 | 2025 | 608 |
| ENST00000424272 | IL1R1 | chr2 | 102782741 | - | ENST00000441002 | IL1R2 | chr2 | 102626024 | + | 1874 | 896 | 199 | 1719 | 506 |
| ENST00000409929 | IL1R1 | chr2 | 102782741 | - | ENST00000332549 | IL1R2 | chr2 | 102626024 | + | 2178 | 896 | 199 | 2025 | 608 |
| ENST00000409929 | IL1R1 | chr2 | 102782741 | - | ENST00000393414 | IL1R2 | chr2 | 102626024 | + | 2051 | 896 | 199 | 2025 | 608 |
| ENST00000409929 | IL1R1 | chr2 | 102782741 | - | ENST00000441002 | IL1R2 | chr2 | 102626024 | + | 1874 | 896 | 199 | 1719 | 506 |
| ENST00000409329 | IL1R1 | chr2 | 102782741 | - | ENST00000332549 | IL1R2 | chr2 | 102626024 | + | 2324 | 1042 | 345 | 2171 | 608 |
| ENST00000409329 | IL1R1 | chr2 | 102782741 | - | ENST00000393414 | IL1R2 | chr2 | 102626024 | + | 2197 | 1042 | 345 | 2171 | 608 |
| ENST00000409329 | IL1R1 | chr2 | 102782741 | - | ENST00000441002 | IL1R2 | chr2 | 102626024 | + | 2020 | 1042 | 345 | 1865 | 506 |
| ENST00000409288 | IL1R1 | chr2 | 102782741 | - | ENST00000332549 | IL1R2 | chr2 | 102626024 | + | 2255 | 973 | 276 | 2102 | 608 |
| ENST00000409288 | IL1R1 | chr2 | 102782741 | - | ENST00000393414 | IL1R2 | chr2 | 102626024 | + | 2128 | 973 | 276 | 2102 | 608 |
| ENST00000409288 | IL1R1 | chr2 | 102782741 | - | ENST00000441002 | IL1R2 | chr2 | 102626024 | + | 1951 | 973 | 276 | 1796 | 506 |
| ENST00000410023 | IL1R1 | chr2 | 102782741 | - | ENST00000332549 | IL1R2 | chr2 | 102626024 | + | 2255 | 973 | 276 | 2102 | 608 |
| ENST00000410023 | IL1R1 | chr2 | 102782741 | - | ENST00000393414 | IL1R2 | chr2 | 102626024 | + | 2128 | 973 | 276 | 2102 | 608 |
| ENST00000410023 | IL1R1 | chr2 | 102782741 | - | ENST00000441002 | IL1R2 | chr2 | 102626024 | + | 1951 | 973 | 276 | 1796 | 506 |
| ENST00000233946 | IL1R1 | chr2 | 102782741 | - | ENST00000332549 | IL1R2 | chr2 | 102626024 | + | 2019 | 737 | 40 | 1866 | 608 |
| ENST00000233946 | IL1R1 | chr2 | 102782741 | - | ENST00000393414 | IL1R2 | chr2 | 102626024 | + | 1892 | 737 | 40 | 1866 | 608 |
| ENST00000233946 | IL1R1 | chr2 | 102782741 | - | ENST00000441002 | IL1R2 | chr2 | 102626024 | + | 1715 | 737 | 40 | 1560 | 506 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000410023 | ENST00000332549 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + | 0.000235167 | 0.99976486 |
| ENST00000410023 | ENST00000393414 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + | 0.000249751 | 0.9997502 |
| ENST00000410023 | ENST00000441002 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + | 0.000231457 | 0.99976856 |
| ENST00000233946 | ENST00000332549 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + | 0.000214835 | 0.9997851 |
| ENST00000233946 | ENST00000393414 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + | 0.00022933 | 0.9997707 |
| ENST00000233946 | ENST00000441002 | IL1R1 | chr2 | 102796334 | - | IL1R2 | chr2 | 102638649 | + | 0.000208029 | 0.99979204 |
| ENST00000424272 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000363699 | 0.9996363 |
| ENST00000424272 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000490477 | 0.9995096 |
| ENST00000424272 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000425662 | 0.99957436 |
| ENST00000409929 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000363699 | 0.9996363 |
| ENST00000409929 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000490477 | 0.9995096 |
| ENST00000409929 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000425662 | 0.99957436 |
| ENST00000409329 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000458719 | 0.9995413 |
| ENST00000409329 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.00064136 | 0.9993586 |
| ENST00000409329 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000566265 | 0.9994337 |
| ENST00000409288 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000632793 | 0.9993672 |
| ENST00000409288 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000843285 | 0.9991567 |
| ENST00000409288 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000867507 | 0.9991326 |
| ENST00000410023 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000632793 | 0.9993672 |
| ENST00000410023 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000843285 | 0.9991567 |
| ENST00000410023 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000867507 | 0.9991326 |
| ENST00000233946 | ENST00000332549 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000344489 | 0.9996555 |
| ENST00000233946 | ENST00000393414 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000489887 | 0.99951017 |
| ENST00000233946 | ENST00000441002 | IL1R1 | chr2 | 102782741 | - | IL1R2 | chr2 | 102626024 | + | 0.000425968 | 0.999574 |
Top |
Fusion Genomic Features for IL1R1-IL1R2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
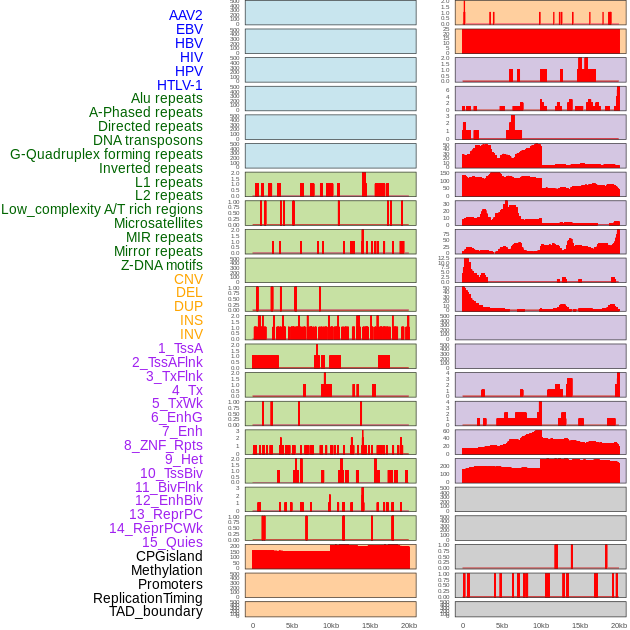 |
Top |
Fusion Protein Features for IL1R1-IL1R2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:102796334/chr2:102638649) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000233946 | - | 5 | 11 | 118_210 | 218 | 570.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000233946 | - | 5 | 11 | 23_110 | 218 | 570.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000410023 | - | 6 | 12 | 118_210 | 218 | 570.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000410023 | - | 6 | 12 | 23_110 | 218 | 570.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000233946 | - | 11 | 11 | 118_210 | 1608 | 570.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000233946 | - | 11 | 11 | 226_328 | 1608 | 570.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000233946 | - | 11 | 11 | 23_110 | 1608 | 570.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000233946 | - | 11 | 11 | 383_538 | 1608 | 570.0 | Domain | TIR |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000410023 | - | 12 | 12 | 118_210 | 1608 | 570.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000410023 | - | 12 | 12 | 226_328 | 1608 | 570.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000410023 | - | 12 | 12 | 23_110 | 1608 | 570.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000410023 | - | 12 | 12 | 383_538 | 1608 | 570.0 | Domain | TIR |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000233946 | - | 11 | 11 | 18_336 | 1608 | 570.0 | Topological domain | Extracellular |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000233946 | - | 11 | 11 | 357_569 | 1608 | 570.0 | Topological domain | Cytoplasmic |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000410023 | - | 12 | 12 | 18_336 | 1608 | 570.0 | Topological domain | Extracellular |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000410023 | - | 12 | 12 | 357_569 | 1608 | 570.0 | Topological domain | Cytoplasmic |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000233946 | - | 11 | 11 | 337_356 | 1608 | 570.0 | Transmembrane | Helical |
| Hgene | IL1R1 | chr2:102796334 | chr2:102638649 | ENST00000410023 | - | 12 | 12 | 337_356 | 1608 | 570.0 | Transmembrane | Helical |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000332549 | 1 | 9 | 134_223 | 22 | 399.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000332549 | 1 | 9 | 237_349 | 22 | 399.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000393414 | 1 | 9 | 134_223 | 22 | 399.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000393414 | 1 | 9 | 237_349 | 22 | 399.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000441002 | 0 | 6 | 134_223 | 22 | 297.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000441002 | 0 | 6 | 237_349 | 22 | 297.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000332549 | 4 | 9 | 237_349 | 229 | 399.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000393414 | 4 | 9 | 237_349 | 229 | 399.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000441002 | 3 | 6 | 237_349 | 229 | 297.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000332549 | 1 | 9 | 329_343 | 22 | 399.0 | Region | Contains proteolytic cleavage site | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000393414 | 1 | 9 | 329_343 | 22 | 399.0 | Region | Contains proteolytic cleavage site | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000441002 | 0 | 6 | 329_343 | 22 | 297.0 | Region | Contains proteolytic cleavage site | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000332549 | 4 | 9 | 329_343 | 229 | 399.0 | Region | Contains proteolytic cleavage site | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000393414 | 4 | 9 | 329_343 | 229 | 399.0 | Region | Contains proteolytic cleavage site | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000441002 | 3 | 6 | 329_343 | 229 | 297.0 | Region | Contains proteolytic cleavage site | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000332549 | 1 | 9 | 370_398 | 22 | 399.0 | Topological domain | Cytoplasmic | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000393414 | 1 | 9 | 370_398 | 22 | 399.0 | Topological domain | Cytoplasmic | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000441002 | 0 | 6 | 370_398 | 22 | 297.0 | Topological domain | Cytoplasmic | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000332549 | 4 | 9 | 370_398 | 229 | 399.0 | Topological domain | Cytoplasmic | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000393414 | 4 | 9 | 370_398 | 229 | 399.0 | Topological domain | Cytoplasmic | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000441002 | 3 | 6 | 370_398 | 229 | 297.0 | Topological domain | Cytoplasmic | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000332549 | 1 | 9 | 344_369 | 22 | 399.0 | Transmembrane | Helical | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000393414 | 1 | 9 | 344_369 | 22 | 399.0 | Transmembrane | Helical | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000441002 | 0 | 6 | 344_369 | 22 | 297.0 | Transmembrane | Helical | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000332549 | 4 | 9 | 344_369 | 229 | 399.0 | Transmembrane | Helical | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000393414 | 4 | 9 | 344_369 | 229 | 399.0 | Transmembrane | Helical | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000441002 | 3 | 6 | 344_369 | 229 | 297.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000233946 | - | 5 | 11 | 226_328 | 218 | 570.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000233946 | - | 5 | 11 | 383_538 | 218 | 570.0 | Domain | TIR |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000410023 | - | 6 | 12 | 226_328 | 218 | 570.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000410023 | - | 6 | 12 | 383_538 | 218 | 570.0 | Domain | TIR |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000233946 | - | 5 | 11 | 18_336 | 218 | 570.0 | Topological domain | Extracellular |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000233946 | - | 5 | 11 | 357_569 | 218 | 570.0 | Topological domain | Cytoplasmic |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000410023 | - | 6 | 12 | 18_336 | 218 | 570.0 | Topological domain | Extracellular |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000410023 | - | 6 | 12 | 357_569 | 218 | 570.0 | Topological domain | Cytoplasmic |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000233946 | - | 5 | 11 | 337_356 | 218 | 570.0 | Transmembrane | Helical |
| Hgene | IL1R1 | chr2:102782741 | chr2:102626024 | ENST00000410023 | - | 6 | 12 | 337_356 | 218 | 570.0 | Transmembrane | Helical |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000332549 | 1 | 9 | 18_124 | 22 | 399.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000393414 | 1 | 9 | 18_124 | 22 | 399.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000441002 | 0 | 6 | 18_124 | 22 | 297.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000332549 | 4 | 9 | 134_223 | 229 | 399.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000332549 | 4 | 9 | 18_124 | 229 | 399.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000393414 | 4 | 9 | 134_223 | 229 | 399.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000393414 | 4 | 9 | 18_124 | 229 | 399.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000441002 | 3 | 6 | 134_223 | 229 | 297.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000441002 | 3 | 6 | 18_124 | 229 | 297.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000332549 | 1 | 9 | 14_343 | 22 | 399.0 | Topological domain | Extracellular | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000393414 | 1 | 9 | 14_343 | 22 | 399.0 | Topological domain | Extracellular | |
| Tgene | IL1R2 | chr2:102782741 | chr2:102626024 | ENST00000441002 | 0 | 6 | 14_343 | 22 | 297.0 | Topological domain | Extracellular | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000332549 | 4 | 9 | 14_343 | 229 | 399.0 | Topological domain | Extracellular | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000393414 | 4 | 9 | 14_343 | 229 | 399.0 | Topological domain | Extracellular | |
| Tgene | IL1R2 | chr2:102796334 | chr2:102638649 | ENST00000441002 | 3 | 6 | 14_343 | 229 | 297.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for IL1R1-IL1R2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >39461_39461_1_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000233946_IL1R2_chr2_102626024_ENST00000332549_length(transcript)=2019nt_BP=737nt TAGACGCACCCTCTGAAGATGGTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGT GTTACTCAGACTTATTTGTTTCATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGT GTCATCTGCAAATGAAATTGATGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAA GACACCTGTATCTACAGAACAAGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACA TTACTATTGCGTGGTAAGAAATTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAA TGCACAAGCCATATTTAAGCAGAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAA TGAGTTACCTAAATTACAGTGGTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGT GATGAATGTGGCTGAAAAGCATAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAAT AGAATTTATTACTCTAGGGGCTGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGC CCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGAC GGTCCCAGGAGAAGAAGAGACACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGT CTGCACTACTAGAAATGCTTCTTACTGTGACAAAATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTC ATACCCGCAAATTTTAACCTTGTCAACCTCTGGGGTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGAT TCAATGGTACAAGGATTCTCTTCTTTTGGATAAAGACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGT GGCCCTGGAAGATGCTGGCTATTACCGCTGTGTCCTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACG CATCAAGAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCC GTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGG AGGCCGCGTGACCGAGGGGCCACGCCAGGAATATTCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAG AGAGGATTTGCACATGGATTTTAAATGTGTTGTCCATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCAC GTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAAC TGGAAAAGCAGATGGTCTGACTGTGCTATGGCCTCATCATCAAGACTTTCAATCCTATCCCAAGTGAAATAAATGGAATGAAATAATTCA AACACAAACTCCGTACGTCTTCTCTTATGGAAGTGGCTGTGTCTTTTTGAGGGACTCTGTTCTTTGCCTCAGTTGTCTACCAAAGGTGCC >39461_39461_1_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000233946_IL1R2_chr2_102626024_ENST00000332549_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_2_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000233946_IL1R2_chr2_102626024_ENST00000393414_length(transcript)=1892nt_BP=737nt TAGACGCACCCTCTGAAGATGGTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGT GTTACTCAGACTTATTTGTTTCATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGT GTCATCTGCAAATGAAATTGATGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAA GACACCTGTATCTACAGAACAAGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACA TTACTATTGCGTGGTAAGAAATTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAA TGCACAAGCCATATTTAAGCAGAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAA TGAGTTACCTAAATTACAGTGGTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGT GATGAATGTGGCTGAAAAGCATAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAAT AGAATTTATTACTCTAGGGGCTGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGC CCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGAC GGTCCCAGGAGAAGAAGAGACACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGT CTGCACTACTAGAAATGCTTCTTACTGTGACAAAATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTC ATACCCGCAAATTTTAACCTTGTCAACCTCTGGGGTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGAT TCAATGGTACAAGGATTCTCTTCTTTTGGATAAAGACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGT GGCCCTGGAAGATGCTGGCTATTACCGCTGTGTCCTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACG CATCAAGAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCC GTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGG AGGCCGCGTGACCGAGGGGCCACGCCAGGAATATTCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAG AGAGGATTTGCACATGGATTTTAAATGTGTTGTCCATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCAC GTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAAC TGGAAAAGCAGATGGTCTGACTGTGCTATGGCCTCATCATCAAGACTTTCAATCCTATCCCAAGTGAAATAAATGGAATGAAATAATTCA >39461_39461_2_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000233946_IL1R2_chr2_102626024_ENST00000393414_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_3_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000233946_IL1R2_chr2_102626024_ENST00000441002_length(transcript)=1715nt_BP=737nt TAGACGCACCCTCTGAAGATGGTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGT GTTACTCAGACTTATTTGTTTCATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGT GTCATCTGCAAATGAAATTGATGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAA GACACCTGTATCTACAGAACAAGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACA TTACTATTGCGTGGTAAGAAATTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAA TGCACAAGCCATATTTAAGCAGAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAA TGAGTTACCTAAATTACAGTGGTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGT GATGAATGTGGCTGAAAAGCATAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAAT AGAATTTATTACTCTAGGGGCTGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGC CCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGAC GGTCCCAGGAGAAGAAGAGACACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGT CTGCACTACTAGAAATGCTTCTTACTGTGACAAAATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTC ATACCCGCAAATTTTAACCTTGTCAACCTCTGGGGTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGAT TCAATGGTACAAGGATTCTCTTCTTTTGGATAAAGACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGT GGCCCTGGAAGATGCTGGCTATTACCGCTGTGTCCTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACG CATCAAGAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCC GTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGG AGGCCGCGTGACCGAGGGGCCACGCCAGTAAGTGGGCCAGGGTCTTCTGTTGAGAACTCTGTGGGTTTCGCTCTTCCTTTTGGAGACAGT TATCACTATGACCCACATACCACATTAAAAGTTACTTTTTTTGATTCCAAACTGTTGGATGTTTAGAATTTAAAAAATTGTATTTTGCTA >39461_39461_3_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000233946_IL1R2_chr2_102626024_ENST00000441002_length(amino acids)=506AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII -------------------------------------------------------------- >39461_39461_4_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409288_IL1R2_chr2_102626024_ENST00000332549_length(transcript)=2255nt_BP=973nt GCCGGAGCCGACTCGGAGCGCGCGGCGCCGGCCGGGAGGAGCCGGAGAGCGGCCGGGCCGGGCGGTGGGGGCGCCGGCCTGCCCCGCGCG CCCCAGGGAGCGGCAGGAATGTGACAATCGCGCGCCCGCGCACCGAAGCACTCCTCGCTCGGCTCCTAGGGCTCTCGCCCCTCTGAGCTG AGCCGGGTTCCGCCCGGGGCTGGGATCCCATCACCCTCCACGGCCGTCCGTCCAGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCT GAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTG ATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGT CCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATT CATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGC CTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTT GCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGC AAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTAT ACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGCTGCCAGAAGCTGC CGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGG GCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGACACGGATGTGGGCC CAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTCTTACTGTGACAAA ATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTTGTCAACCTCTGGG GTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCTTCTTTTGGATAAA GACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTATTACCGCTGTGTC CTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGAGACCATTCCTGTG ATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTA ACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATAT TCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTC CATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCA CTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCT CATCATCAAGACTTTCAATCCTATCCCAAGTGAAATAAATGGAATGAAATAATTCAAACACAAACTCCGTACGTCTTCTCTTATGGAAGT GGCTGTGTCTTTTTGAGGGACTCTGTTCTTTGCCTCAGTTGTCTACCAAAGGTGCCACATTTATAGTGGCTTTGTAGTAAAGGACTAAAG >39461_39461_4_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409288_IL1R2_chr2_102626024_ENST00000332549_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_5_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409288_IL1R2_chr2_102626024_ENST00000393414_length(transcript)=2128nt_BP=973nt GCCGGAGCCGACTCGGAGCGCGCGGCGCCGGCCGGGAGGAGCCGGAGAGCGGCCGGGCCGGGCGGTGGGGGCGCCGGCCTGCCCCGCGCG CCCCAGGGAGCGGCAGGAATGTGACAATCGCGCGCCCGCGCACCGAAGCACTCCTCGCTCGGCTCCTAGGGCTCTCGCCCCTCTGAGCTG AGCCGGGTTCCGCCCGGGGCTGGGATCCCATCACCCTCCACGGCCGTCCGTCCAGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCT GAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTG ATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGT CCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATT CATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGC CTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTT GCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGC AAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTAT ACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGCTGCCAGAAGCTGC CGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGG GCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGACACGGATGTGGGCC CAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTCTTACTGTGACAAA ATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTTGTCAACCTCTGGG GTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCTTCTTTTGGATAAA GACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTATTACCGCTGTGTC CTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGAGACCATTCCTGTG ATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTA ACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATAT TCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTC CATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCA CTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCT >39461_39461_5_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409288_IL1R2_chr2_102626024_ENST00000393414_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_6_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409288_IL1R2_chr2_102626024_ENST00000441002_length(transcript)=1951nt_BP=973nt GCCGGAGCCGACTCGGAGCGCGCGGCGCCGGCCGGGAGGAGCCGGAGAGCGGCCGGGCCGGGCGGTGGGGGCGCCGGCCTGCCCCGCGCG CCCCAGGGAGCGGCAGGAATGTGACAATCGCGCGCCCGCGCACCGAAGCACTCCTCGCTCGGCTCCTAGGGCTCTCGCCCCTCTGAGCTG AGCCGGGTTCCGCCCGGGGCTGGGATCCCATCACCCTCCACGGCCGTCCGTCCAGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCT GAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTG ATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGT CCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATT CATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGC CTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTT GCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGC AAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTAT ACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGCTGCCAGAAGCTGC CGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGG GCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGACACGGATGTGGGCC CAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTCTTACTGTGACAAA ATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTTGTCAACCTCTGGG GTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCTTCTTTTGGATAAA GACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTATTACCGCTGTGTC CTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGAGACCATTCCTGTG ATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTA ACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGTAAGTG GGCCAGGGTCTTCTGTTGAGAACTCTGTGGGTTTCGCTCTTCCTTTTGGAGACAGTTATCACTATGACCCACATACCACATTAAAAGTTA >39461_39461_6_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409288_IL1R2_chr2_102626024_ENST00000441002_length(amino acids)=506AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII -------------------------------------------------------------- >39461_39461_7_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409329_IL1R2_chr2_102626024_ENST00000332549_length(transcript)=2324nt_BP=1042nt GAGGGATTAAAGCCCTAAGAGGCTGTGACACAGCCATCTCCAAAACCCCACTTTCTCCTTCCTTTGAGCCTCCGTACCAGCTGGGGCGTC CGGCAAGATGTGAGTTGTCACTCTGCTGCGGCACAGACCTGAATTAACAACTCTAGCTAGGGCTGACTTCAAAAAGCACTTTCGTTTTTT AATAACCAACATCAGCTCAGCAGGCTTCATTTGGGAAAAGAAACCTTGTCGGATTACCCCGACATTCTCCACCTCCTGGGAGGCCAGCCA TTCCCAAATGCCCCAAGGATGAAGAACGGAGACGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTA AAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTGATTTCTTCTCTGGAGGCTGAT AAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGTCCTCTTAACCCAAATGAACAC AAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATTCATCAACACAAAGAGAAACTT TGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGCCTCAGAATTAAAATAAGTGCA AAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTTGCAGGAGACGGAGGACTTGTG TGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGCAAACCTCTACTTCTTGACAAT ATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTATACTTGTCATGCATCCTACACA TACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGCTGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTAC AAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATC AACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGACACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTT CTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTCTTACTGTGACAAAATGTCCATTGAGCTCAGAGTT TTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTTGTCAACCTCTGGGGTATTAGTATGCCCTGACCTG AGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCTTCTTTTGGATAAAGACAATGAGAAATTTCTAAGT GTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTATTACCGCTGTGTCCTGACATTTGCCCATGAAGGC CAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAAGACC ATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTGGACG GCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATATTCAGAAAATAATGAGAACTAC ATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTCCATAATACCCTGAGTTTTCAG ACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGG GGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCTCATCATCAAGACTTTCAATCC TATCCCAAGTGAAATAAATGGAATGAAATAATTCAAACACAAACTCCGTACGTCTTCTCTTATGGAAGTGGCTGTGTCTTTTTGAGGGAC >39461_39461_7_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409329_IL1R2_chr2_102626024_ENST00000332549_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_8_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409329_IL1R2_chr2_102626024_ENST00000393414_length(transcript)=2197nt_BP=1042nt GAGGGATTAAAGCCCTAAGAGGCTGTGACACAGCCATCTCCAAAACCCCACTTTCTCCTTCCTTTGAGCCTCCGTACCAGCTGGGGCGTC CGGCAAGATGTGAGTTGTCACTCTGCTGCGGCACAGACCTGAATTAACAACTCTAGCTAGGGCTGACTTCAAAAAGCACTTTCGTTTTTT AATAACCAACATCAGCTCAGCAGGCTTCATTTGGGAAAAGAAACCTTGTCGGATTACCCCGACATTCTCCACCTCCTGGGAGGCCAGCCA TTCCCAAATGCCCCAAGGATGAAGAACGGAGACGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTA AAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTGATTTCTTCTCTGGAGGCTGAT AAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGTCCTCTTAACCCAAATGAACAC AAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATTCATCAACACAAAGAGAAACTT TGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGCCTCAGAATTAAAATAAGTGCA AAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTTGCAGGAGACGGAGGACTTGTG TGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGCAAACCTCTACTTCTTGACAAT ATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTATACTTGTCATGCATCCTACACA TACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGCTGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTAC AAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATC AACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGACACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTT CTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTCTTACTGTGACAAAATGTCCATTGAGCTCAGAGTT TTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTTGTCAACCTCTGGGGTATTAGTATGCCCTGACCTG AGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCTTCTTTTGGATAAAGACAATGAGAAATTTCTAAGT GTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTATTACCGCTGTGTCCTGACATTTGCCCATGAAGGC CAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAAGACC ATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTGGACG GCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATATTCAGAAAATAATGAGAACTAC ATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTCCATAATACCCTGAGTTTTCAG ACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGG GGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCTCATCATCAAGACTTTCAATCC >39461_39461_8_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409329_IL1R2_chr2_102626024_ENST00000393414_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_9_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409329_IL1R2_chr2_102626024_ENST00000441002_length(transcript)=2020nt_BP=1042nt GAGGGATTAAAGCCCTAAGAGGCTGTGACACAGCCATCTCCAAAACCCCACTTTCTCCTTCCTTTGAGCCTCCGTACCAGCTGGGGCGTC CGGCAAGATGTGAGTTGTCACTCTGCTGCGGCACAGACCTGAATTAACAACTCTAGCTAGGGCTGACTTCAAAAAGCACTTTCGTTTTTT AATAACCAACATCAGCTCAGCAGGCTTCATTTGGGAAAAGAAACCTTGTCGGATTACCCCGACATTCTCCACCTCCTGGGAGGCCAGCCA TTCCCAAATGCCCCAAGGATGAAGAACGGAGACGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTA AAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTGATTTCTTCTCTGGAGGCTGAT AAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGTCCTCTTAACCCAAATGAACAC AAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATTCATCAACACAAAGAGAAACTT TGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGCCTCAGAATTAAAATAAGTGCA AAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTTGCAGGAGACGGAGGACTTGTG TGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGCAAACCTCTACTTCTTGACAAT ATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTATACTTGTCATGCATCCTACACA TACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGCTGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTAC AAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATC AACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGACACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTT CTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTCTTACTGTGACAAAATGTCCATTGAGCTCAGAGTT TTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTTGTCAACCTCTGGGGTATTAGTATGCCCTGACCTG AGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCTTCTTTTGGATAAAGACAATGAGAAATTTCTAAGT GTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTATTACCGCTGTGTCCTGACATTTGCCCATGAAGGC CAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAAGACC ATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTGGACG GCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGTAAGTGGGCCAGGGTCTTCTGTTGAGA ACTCTGTGGGTTTCGCTCTTCCTTTTGGAGACAGTTATCACTATGACCCACATACCACATTAAAAGTTACTTTTTTTGATTCCAAACTGT >39461_39461_9_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409329_IL1R2_chr2_102626024_ENST00000441002_length(amino acids)=506AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII -------------------------------------------------------------- >39461_39461_10_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409929_IL1R2_chr2_102626024_ENST00000332549_length(transcript)=2178nt_BP=896nt ATTGGCAGCTCTTCACTTGTATCTTTTCATATCAAAAATGGGAGGTGACACCCAGTTTAAGGAAAATTCCAAGGCATTTGTCTCGACTAA TGTGAAAGATGATTACAGTGGCCAGAGGACTGCCAAGGCTCCTTCTCAAGCTGCTTGAGTCAATGAGGGTAGACGCACCCTCTGAAGATG GTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTT CATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGA TGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACA AGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAA TTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCA GAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTG GTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCA TAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGC TGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCC CTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGAC ACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTC TTACTGTGACAAAATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTT GTCAACCTCTGGGGTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCT TCTTTTGGATAAAGACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTA TTACCGCTGTGTCCTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGA GACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAAC CGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCC ACGCCAGGAATATTCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTT TAAATGTGTTGTCCATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCT GGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGAC TGTGCTATGGCCTCATCATCAAGACTTTCAATCCTATCCCAAGTGAAATAAATGGAATGAAATAATTCAAACACAAACTCCGTACGTCTT CTCTTATGGAAGTGGCTGTGTCTTTTTGAGGGACTCTGTTCTTTGCCTCAGTTGTCTACCAAAGGTGCCACATTTATAGTGGCTTTGTAG >39461_39461_10_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409929_IL1R2_chr2_102626024_ENST00000332549_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_11_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409929_IL1R2_chr2_102626024_ENST00000393414_length(transcript)=2051nt_BP=896nt ATTGGCAGCTCTTCACTTGTATCTTTTCATATCAAAAATGGGAGGTGACACCCAGTTTAAGGAAAATTCCAAGGCATTTGTCTCGACTAA TGTGAAAGATGATTACAGTGGCCAGAGGACTGCCAAGGCTCCTTCTCAAGCTGCTTGAGTCAATGAGGGTAGACGCACCCTCTGAAGATG GTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTT CATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGA TGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACA AGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAA TTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCA GAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTG GTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCA TAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGC TGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCC CTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGAC ACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTC TTACTGTGACAAAATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTT GTCAACCTCTGGGGTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCT TCTTTTGGATAAAGACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTA TTACCGCTGTGTCCTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGA GACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAAC CGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCC ACGCCAGGAATATTCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTT TAAATGTGTTGTCCATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCT GGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGAC >39461_39461_11_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409929_IL1R2_chr2_102626024_ENST00000393414_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_12_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409929_IL1R2_chr2_102626024_ENST00000441002_length(transcript)=1874nt_BP=896nt ATTGGCAGCTCTTCACTTGTATCTTTTCATATCAAAAATGGGAGGTGACACCCAGTTTAAGGAAAATTCCAAGGCATTTGTCTCGACTAA TGTGAAAGATGATTACAGTGGCCAGAGGACTGCCAAGGCTCCTTCTCAAGCTGCTTGAGTCAATGAGGGTAGACGCACCCTCTGAAGATG GTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTT CATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGA TGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACA AGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAA TTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCA GAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTG GTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCA TAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGC TGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCC CTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGAC ACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTC TTACTGTGACAAAATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTT GTCAACCTCTGGGGTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCT TCTTTTGGATAAAGACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTA TTACCGCTGTGTCCTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGA GACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAAC CGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCC ACGCCAGTAAGTGGGCCAGGGTCTTCTGTTGAGAACTCTGTGGGTTTCGCTCTTCCTTTTGGAGACAGTTATCACTATGACCCACATACC >39461_39461_12_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000409929_IL1R2_chr2_102626024_ENST00000441002_length(amino acids)=506AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII -------------------------------------------------------------- >39461_39461_13_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000410023_IL1R2_chr2_102626024_ENST00000332549_length(transcript)=2255nt_BP=973nt GCCGGAGCCGACTCGGAGCGCGCGGCGCCGGCCGGGAGGAGCCGGAGAGCGGCCGGGCCGGGCGGTGGGGGCGCCGGCCTGCCCCGCGCG CCCCAGGGAGCGGCAGGAATGTGACAATCGCGCGCCCGCGCACCGAAGCACTCCTCGCTCGGCTCCTAGGGCTCTCGCCCCTCTGAGCTG AGCCGGGTTCCGCCCGGGGCTGGGATCCCATCACCCTCCACGGCCGTCCGTCCAGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCT GAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTG ATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGT CCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATT CATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGC CTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTT GCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGC AAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTAT ACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGCTGCCAGAAGCTGC CGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGG GCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGACACGGATGTGGGCC CAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTCTTACTGTGACAAA ATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTTGTCAACCTCTGGG GTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCTTCTTTTGGATAAA GACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTATTACCGCTGTGTC CTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGAGACCATTCCTGTG ATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTA ACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATAT TCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTC CATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCA CTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCT CATCATCAAGACTTTCAATCCTATCCCAAGTGAAATAAATGGAATGAAATAATTCAAACACAAACTCCGTACGTCTTCTCTTATGGAAGT GGCTGTGTCTTTTTGAGGGACTCTGTTCTTTGCCTCAGTTGTCTACCAAAGGTGCCACATTTATAGTGGCTTTGTAGTAAAGGACTAAAG >39461_39461_13_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000410023_IL1R2_chr2_102626024_ENST00000332549_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_14_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000410023_IL1R2_chr2_102626024_ENST00000393414_length(transcript)=2128nt_BP=973nt GCCGGAGCCGACTCGGAGCGCGCGGCGCCGGCCGGGAGGAGCCGGAGAGCGGCCGGGCCGGGCGGTGGGGGCGCCGGCCTGCCCCGCGCG CCCCAGGGAGCGGCAGGAATGTGACAATCGCGCGCCCGCGCACCGAAGCACTCCTCGCTCGGCTCCTAGGGCTCTCGCCCCTCTGAGCTG AGCCGGGTTCCGCCCGGGGCTGGGATCCCATCACCCTCCACGGCCGTCCGTCCAGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCT GAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTG ATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGT CCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATT CATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGC CTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTT GCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGC AAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTAT ACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGCTGCCAGAAGCTGC CGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGG GCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGACACGGATGTGGGCC CAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTCTTACTGTGACAAA ATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTTGTCAACCTCTGGG GTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCTTCTTTTGGATAAA GACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTATTACCGCTGTGTC CTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGAGACCATTCCTGTG ATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTA ACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATAT TCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTC CATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCA CTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCT >39461_39461_14_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000410023_IL1R2_chr2_102626024_ENST00000393414_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_15_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000410023_IL1R2_chr2_102626024_ENST00000441002_length(transcript)=1951nt_BP=973nt GCCGGAGCCGACTCGGAGCGCGCGGCGCCGGCCGGGAGGAGCCGGAGAGCGGCCGGGCCGGGCGGTGGGGGCGCCGGCCTGCCCCGCGCG CCCCAGGGAGCGGCAGGAATGTGACAATCGCGCGCCCGCGCACCGAAGCACTCCTCGCTCGGCTCCTAGGGCTCTCGCCCCTCTGAGCTG AGCCGGGTTCCGCCCGGGGCTGGGATCCCATCACCCTCCACGGCCGTCCGTCCAGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCT GAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTG ATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGT CCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATT CATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGC CTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTT GCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGC AAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTAT ACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGCTGCCAGAAGCTGC CGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCCCTACTGGTTGTGG GCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGACACGGATGTGGGCC CAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTCTTACTGTGACAAA ATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTTGTCAACCTCTGGG GTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCTTCTTTTGGATAAA GACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTATTACCGCTGTGTC CTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGAGACCATTCCTGTG ATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTA ACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGTAAGTG GGCCAGGGTCTTCTGTTGAGAACTCTGTGGGTTTCGCTCTTCCTTTTGGAGACAGTTATCACTATGACCCACATACCACATTAAAAGTTA >39461_39461_15_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000410023_IL1R2_chr2_102626024_ENST00000441002_length(amino acids)=506AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII -------------------------------------------------------------- >39461_39461_16_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000424272_IL1R2_chr2_102626024_ENST00000332549_length(transcript)=2178nt_BP=896nt ATTGGCAGCTCTTCACTTGTATCTTTTCATATCAAAAATGGGAGGTGACACCCAGTTTAAGGAAAATTCCAAGGCATTTGTCTCGACTAA TGTGAAAGATGATTACAGTGGCCAGAGGACTGCCAAGGCTCCTTCTCAAGCTGCTTGAGTCAATGAGGGTAGACGCACCCTCTGAAGATG GTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTT CATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGA TGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACA AGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAA TTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCA GAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTG GTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCA TAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGC TGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCC CTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGAC ACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTC TTACTGTGACAAAATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTT GTCAACCTCTGGGGTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCT TCTTTTGGATAAAGACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTA TTACCGCTGTGTCCTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGA GACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAAC CGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCC ACGCCAGGAATATTCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTT TAAATGTGTTGTCCATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCT GGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGAC TGTGCTATGGCCTCATCATCAAGACTTTCAATCCTATCCCAAGTGAAATAAATGGAATGAAATAATTCAAACACAAACTCCGTACGTCTT CTCTTATGGAAGTGGCTGTGTCTTTTTGAGGGACTCTGTTCTTTGCCTCAGTTGTCTACCAAAGGTGCCACATTTATAGTGGCTTTGTAG >39461_39461_16_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000424272_IL1R2_chr2_102626024_ENST00000332549_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_17_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000424272_IL1R2_chr2_102626024_ENST00000393414_length(transcript)=2051nt_BP=896nt ATTGGCAGCTCTTCACTTGTATCTTTTCATATCAAAAATGGGAGGTGACACCCAGTTTAAGGAAAATTCCAAGGCATTTGTCTCGACTAA TGTGAAAGATGATTACAGTGGCCAGAGGACTGCCAAGGCTCCTTCTCAAGCTGCTTGAGTCAATGAGGGTAGACGCACCCTCTGAAGATG GTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTT CATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGA TGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACA AGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAA TTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCA GAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTG GTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCA TAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGC TGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCC CTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGAC ACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTC TTACTGTGACAAAATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTT GTCAACCTCTGGGGTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCT TCTTTTGGATAAAGACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTA TTACCGCTGTGTCCTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGA GACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAAC CGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCC ACGCCAGGAATATTCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTT TAAATGTGTTGTCCATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCT GGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGAC >39461_39461_17_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000424272_IL1R2_chr2_102626024_ENST00000393414_length(amino acids)=608AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII SPLKTISASLGSRLTIPCKVFLGTGTPLTTMLWWTANDTHIESAYPGGRVTEGPRQEYSENNENYIEVPLIFDPVTREDLHMDFKCVVHN -------------------------------------------------------------- >39461_39461_18_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000424272_IL1R2_chr2_102626024_ENST00000441002_length(transcript)=1874nt_BP=896nt ATTGGCAGCTCTTCACTTGTATCTTTTCATATCAAAAATGGGAGGTGACACCCAGTTTAAGGAAAATTCCAAGGCATTTGTCTCGACTAA TGTGAAAGATGATTACAGTGGCCAGAGGACTGCCAAGGCTCCTTCTCAAGCTGCTTGAGTCAATGAGGGTAGACGCACCCTCTGAAGATG GTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTT CATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGA TGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACA AGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAA TTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCA GAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTG GTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCA TAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGGGGC TGCCAGAAGCTGCCGGTTTCGTGGGAGGCATTACAAGCGGGAGTTCAGGCTGGAAGGGGAGCCTGTAGCCCTGAGGTGCCCCCAGGTGCC CTACTGGTTGTGGGCCTCTGTCAGCCCCCGCATCAACCTGACATGGCATAAAAATGACTCTGCTAGGACGGTCCCAGGAGAAGAAGAGAC ACGGATGTGGGCCCAGGACGGTGCTCTGTGGCTTCTGCCAGCCTTGCAGGAGGACTCTGGCACCTACGTCTGCACTACTAGAAATGCTTC TTACTGTGACAAAATGTCCATTGAGCTCAGAGTTTTTGAGAATACAGATGCTTTCCTGCCGTTCATCTCATACCCGCAAATTTTAACCTT GTCAACCTCTGGGGTATTAGTATGCCCTGACCTGAGTGAATTCACCCGTGACAAAACTGACGTGAAGATTCAATGGTACAAGGATTCTCT TCTTTTGGATAAAGACAATGAGAAATTTCTAAGTGTGAGGGGGACCACTCACTTACTCGTACACGATGTGGCCCTGGAAGATGCTGGCTA TTACCGCTGTGTCCTGACATTTGCCCATGAAGGCCAGCAATACAACATCACTAGGAGTATTGAGCTACGCATCAAGAAAAAAAAAGAAGA GACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAAC CGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCC ACGCCAGTAAGTGGGCCAGGGTCTTCTGTTGAGAACTCTGTGGGTTTCGCTCTTCCTTTTGGAGACAGTTATCACTATGACCCACATACC >39461_39461_18_IL1R1-IL1R2_IL1R1_chr2_102782741_ENST00000424272_IL1R2_chr2_102626024_ENST00000441002_length(amino acids)=506AA_BP=232 MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLGAARSCRFRGRHYKREFRLEGEPVALRCPQVPYWLWAS VSPRINLTWHKNDSARTVPGEEETRMWAQDGALWLLPALQEDSGTYVCTTRNASYCDKMSIELRVFENTDAFLPFISYPQILTLSTSGVL VCPDLSEFTRDKTDVKIQWYKDSLLLDKDNEKFLSVRGTTHLLVHDVALEDAGYYRCVLTFAHEGQQYNITRSIELRIKKKKEETIPVII -------------------------------------------------------------- >39461_39461_19_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000233946_IL1R2_chr2_102638649_ENST00000332549_length(transcript)=5568nt_BP=4907nt TAGACGCACCCTCTGAAGATGGTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGT GTTACTCAGACTTATTTGTTTCATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGT GTCATCTGCAAATGAAATTGATGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAA GACACCTGTATCTACAGAACAAGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACA TTACTATTGCGTGGTAAGAAATTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAA TGCACAAGCCATATTTAAGCAGAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAA TGAGTTACCTAAATTACAGTGGTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGT GATGAATGTGGCTGAAAAGCATAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAAT AGAATTTATTACTCTAGAGGAAAACAAACCCACAAGGCCTGTGATTGTGAGCCCAGCTAATGAGACAATGGAAGTAGACTTGGGATCCCA GATACAATTGATCTGTAATGTCACCGGCCAGTTGAGTGACATTGCTTACTGGAAGTGGAATGGGTCAGTAATTGATGAAGATGACCCAGT GCTAGGGGAAGACTATTACAGTGTGGAAAATCCTGCAAACAAAAGAAGGAGTACCCTCATCACAGTGCTTAATATATCGGAAATTGAAAG TAGATTTTATAAACATCCATTTACCTGTTTTGCCAAGAATACACATGGTATAGATGCAGCATATATCCAGTTAATATATCCAGTCACTAA TTTCCAGAAGCACATGATTGGTATATGTGTCACGTTGACAGTCATAATTGTGTGTTCTGTTTTCATCTATAAAATCTTCAAGATTGACAT TGTGCTTTGGTACAGGGATTCCTGCTATGATTTTCTCCCAATAAAAGCTTCAGATGGAAAGACCTATGACGCATATATACTGTATCCAAA GACTGTTGGGGAAGGGTCTACCTCTGACTGTGATATTTTTGTGTTTAAAGTCTTGCCTGAGGTCTTGGAAAAACAGTGTGGATATAAGCT GTTCATTTATGGAAGGGATGACTACGTTGGGGAAGACATTGTTGAGGTCATTAATGAAAACGTAAAGAAAAGCAGAAGACTGATTATCAT TTTAGTCAGAGAAACATCAGGCTTCAGCTGGCTGGGTGGTTCATCTGAAGAGCAAATAGCCATGTATAATGCTCTTGTTCAGGATGGAAT TAAAGTTGTCCTGCTTGAGCTGGAGAAAATCCAAGACTATGAGAAAATGCCAGAATCGATTAAATTCATTAAGCAGAAACATGGGGCTAT CCGCTGGTCAGGGGACTTTACACAGGGACCACAGTCTGCAAAGACAAGGTTCTGGAAGAATGTCAGGTACCACATGCCAGTCCAGCGACG GTCACCTTCATCTAAACACCAGTTACTGTCACCAGCCACTAAGGAGAAACTGCAAAGAGAGGCTCACGTGCCTCTCGGGTAGCATGGAGA AGTTGCCAAGAGTTCTTTAGGTGCCTCCTGTCTTATGGCGTTGCAGGCCAGGTTATGCCTCATGCTGACTTGCAGAGTTCATGGAATGTA ACTATATCATCCTTTATCCCTGAGGTCACCTGGAATCAGATTATTAAGGGAATAAGCCATGACGTCAATAGCAGCCCAGGGCACTTCAGA GTAGAGGGCTTGGGAAGATCTTTTAAAAAGGCAGTAGGCCCGGTGTGGTGGCTCACGCCTATAATCCCAGCACTTTGGGAGGCTGAAGTG GGTGGATCACCAGAGGTCAGGAGTTCGAGACCAGCCCAGCCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATGAGCTAGGCA TGGTGGCACACGCCTGTAATCCCAGCTACACCTGAGGCTGAGGCAGGAGAATTGCTTGAACCGGGGAGACGGAGGTTGCAGTGAGCCGAG TTTGGGCCACTGCACTCTAGCCTGGCAACAGAGCAAGACTCCGTCTCAAAAAAAGGGCAATAAATGCCCTCTCTGAATGTTTGAACTGCC AAGAAAAGGCATGGAGACAGCGAACTAGAAGAAAGGGCAAGAAGGAAATAGCCACCGTCTACAGATGGCTTAGTTAAGTCATCCACAGCC CAAGGGCGGGGCTATGCCTTGTCTGGGGACCCTGTAGAGTCACTGACCCTGGAGCGGCTCTCCTGAGAGGTGCTGCAGGCAAAGTGAGAC TGACACCTCACTGAGGAAGGGAGACATATTCTTGGAGAACTTTCCATCTGCTTGTATTTTCCATACACATCCCCAGCCAGAAGTTAGTGT CCGAAGACCGAATTTTATTTTACAGAGCTTGAAAACTCACTTCAATGAACAAAGGGATTCTCCAGGATTCCAAAGTTTTGAAGTCATCTT AGCTTTCCACAGGAGGGAGAGAACTTAAAAAAGCAACAGTAGCAGGGAATTGATCCACTTCTTAATGCTTTCCTCCCTGGCATGACCATC CTGTCCTTTGTTATTATCCTGCATTTTACGTCTTTGGAGGAACAGCTCCCTAGTGGCTTCCTCCGTCTGCAATGTCCCTTGCACAGCCCA CACATGAACCATCCTTCCCATGATGCCGCTCTTCTGTCATCCCGCTCCTGCTGAAACACCTCCCAGGGGCTCCACCTGTTCAGGAGCTGA AGCCCATGCTTTCCCACCAGCATGTCACTCCCAGACCACCTCCCTGCCCTGTCCTCCAGCTTCCCCTCGCTGTCCTGCTGTGTGAATTCC CAGGTTGGCCTGGTGGCCATGTCGCCTGCCCCCAGCACTCCTCTGTCTCTGCTCTTGCCTGCACCCTTCCTCCTCCTTTGCCTAGGAGGC CTTCTCGCATTTTCTCTAGCTGATCAGAATTTTACCAAAATTCAGAACATCCTCCAATTCCACAGTCTCTGGGAGACTTTCCCTAAGAGG CGACTTCCTCTCCAGCCTTCTCTCTCTGGTCAGGCCCACTGCAGAGATGGTGGTGAGCACATCTGGGAGGCTGGTCTCCCTCCAGCTGGA ATTGCTGCTCTCTGAGGGAGAGGCTGTGGTGGCTGTCTCTGTCCCTCACTGCCTTCCAGGAGCAATTTGCACATGTAACATAGATTTATG TAATGCTTTATGTTTAAAAACATTCCCCAATTATCTTATTTAATTTTTGCAATTATTCTAATTTTATATATAGAGAAAGTGACCTATTTT TTAAAAAAATCACACTCTAAGTTCTATTGAACCTAGGACTTGAGCCTCCATTTCTGGCTTCTAGTCTGGTGTTCTGAGTACTTGATTTCA GGTCAATAACGGTCCCCCCTCACTCCACACTGGCACGTTTGTGAGAAGAAATGACATTTTGCTAGGAAGTGACCGAGTCTAGGAATGCTT TTATTCAAGACACCAAATTCCAAACTTCTAAATGTTGGAATTTTCAAAAATTGTGTTTAGATTTTATGAAAAACTCTTCTACTTTCATCT ATTCTTTCCCTAGAGGCAAACATTTCTTAAAATGTTTCATTTTCATTAAAAATGAAAGCCAAATTTATATGCCACCGATTGCAGGACACA AGCACAGTTTTAAGAGTTGTATGAACATGGAGAGGACTTTTGGTTTTTATATTTCTCGTATTTAATATGGGTGAACACCAACTTTTATTT GGAATAATAATTTTCCTCCTAAACAAAAACACATTGAGTTTAAGTCTCTGACTCTTGCCTTTCCACCTGCTTTCTCCTGGGCCCGCTTTG CCTGCTTGAAGGAACAGTGCTGTTCTGGAGCTGCTGTTCCAACAGACAGGGCCTAGCTTTCATTTGACACACAGACTACAGCCAGAAGCC CATGGAGCAGGGATGTCACGTCTTGAAAAGCCTATTAGATGTTTTACAAATTTAATTTTGCAGATTATTTTAGTCTGTCATCCAGAAAAT GTGTCAGCATGCATAGTGCTAAGAAAGCAAGCCAATTTGGAAACTTAGGTTAGTGACAAAATTGGCCAGAGAGTGGGGGTGATGATGACC AAGAATTACAAGTAGAATGGCAGCTGGAATTTAAGGAGGGACAAGAATCAATGGATAAGCGTGGGTGGAGGAAGATCCAAACAGAAAAGT GCAAAGTTATTCCCCATCTTCCAAGGGTTGAATTCTGGAGGAAGAAGACACATTCCTAGTTCCCCGTGAACTTCCTTTGACTTATTGTCC CCACTAAAACAAAACAAAAAACTTTTAATGCCTTCCACATTAATTAGATTTTCTTGCAGTTTTTTTATGGCATTTTTTTAAAGATGCCCT AAGTGTTGAAGAAGAGTTTGCAAATGCAACAAAATATTTAATTACCGGTTGTTAAAACTGGTTTAGCACAATTTATATTTTCCCTCTCTT GCCTTTCTTATTTGCAATAAAAGGTATTGAGCCATTTTTTAAATGACATTTTTGATAAATTATGTTTGTACTAGTTGATGAAGGAGTTTT TTTTAACCTGTTTATATAATTTTGCAGCAGAAGCCAAATTTTTTGTATATTAAAGCACCAAATTCATGTACAGCATGCATCACGGATCAA TAGACTGTACTTATTTTCCAATAAAATTTTCAAACTTTGTACTGTTAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAA GACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTG GACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATATTCAGAAAATAATGAGAA CTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTCCATAATACCCTGAGTTT TCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCACTGGCCTTCTTGGTTTT GGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCTCATCATCAAGACTTTCA ATCCTATCCCAAGTGAAATAAATGGAATGAAATAATTCAAACACAAACTCCGTACGTCTTCTCTTATGGAAGTGGCTGTGTCTTTTTGAG >39461_39461_19_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000233946_IL1R2_chr2_102638649_ENST00000332549_length(amino acids)=583AA_BP= MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSD IAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKHMIGICVTLT VIIVCSVFIYKIFKIDIVLWYRDSCYDFLPIKASDGKTYDAYILYPKTVGEGSTSDCDIFVFKVLPEVLEKQCGYKLFIYGRDDYVGEDI VEVINENVKKSRRLIIILVRETSGFSWLGGSSEEQIAMYNALVQDGIKVVLLELEKIQDYEKMPESIKFIKQKHGAIRWSGDFTQGPQSA -------------------------------------------------------------- >39461_39461_20_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000233946_IL1R2_chr2_102638649_ENST00000393414_length(transcript)=5441nt_BP=4907nt TAGACGCACCCTCTGAAGATGGTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGT GTTACTCAGACTTATTTGTTTCATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGT GTCATCTGCAAATGAAATTGATGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAA GACACCTGTATCTACAGAACAAGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACA TTACTATTGCGTGGTAAGAAATTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAA TGCACAAGCCATATTTAAGCAGAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAA TGAGTTACCTAAATTACAGTGGTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGT GATGAATGTGGCTGAAAAGCATAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAAT AGAATTTATTACTCTAGAGGAAAACAAACCCACAAGGCCTGTGATTGTGAGCCCAGCTAATGAGACAATGGAAGTAGACTTGGGATCCCA GATACAATTGATCTGTAATGTCACCGGCCAGTTGAGTGACATTGCTTACTGGAAGTGGAATGGGTCAGTAATTGATGAAGATGACCCAGT GCTAGGGGAAGACTATTACAGTGTGGAAAATCCTGCAAACAAAAGAAGGAGTACCCTCATCACAGTGCTTAATATATCGGAAATTGAAAG TAGATTTTATAAACATCCATTTACCTGTTTTGCCAAGAATACACATGGTATAGATGCAGCATATATCCAGTTAATATATCCAGTCACTAA TTTCCAGAAGCACATGATTGGTATATGTGTCACGTTGACAGTCATAATTGTGTGTTCTGTTTTCATCTATAAAATCTTCAAGATTGACAT TGTGCTTTGGTACAGGGATTCCTGCTATGATTTTCTCCCAATAAAAGCTTCAGATGGAAAGACCTATGACGCATATATACTGTATCCAAA GACTGTTGGGGAAGGGTCTACCTCTGACTGTGATATTTTTGTGTTTAAAGTCTTGCCTGAGGTCTTGGAAAAACAGTGTGGATATAAGCT GTTCATTTATGGAAGGGATGACTACGTTGGGGAAGACATTGTTGAGGTCATTAATGAAAACGTAAAGAAAAGCAGAAGACTGATTATCAT TTTAGTCAGAGAAACATCAGGCTTCAGCTGGCTGGGTGGTTCATCTGAAGAGCAAATAGCCATGTATAATGCTCTTGTTCAGGATGGAAT TAAAGTTGTCCTGCTTGAGCTGGAGAAAATCCAAGACTATGAGAAAATGCCAGAATCGATTAAATTCATTAAGCAGAAACATGGGGCTAT CCGCTGGTCAGGGGACTTTACACAGGGACCACAGTCTGCAAAGACAAGGTTCTGGAAGAATGTCAGGTACCACATGCCAGTCCAGCGACG GTCACCTTCATCTAAACACCAGTTACTGTCACCAGCCACTAAGGAGAAACTGCAAAGAGAGGCTCACGTGCCTCTCGGGTAGCATGGAGA AGTTGCCAAGAGTTCTTTAGGTGCCTCCTGTCTTATGGCGTTGCAGGCCAGGTTATGCCTCATGCTGACTTGCAGAGTTCATGGAATGTA ACTATATCATCCTTTATCCCTGAGGTCACCTGGAATCAGATTATTAAGGGAATAAGCCATGACGTCAATAGCAGCCCAGGGCACTTCAGA GTAGAGGGCTTGGGAAGATCTTTTAAAAAGGCAGTAGGCCCGGTGTGGTGGCTCACGCCTATAATCCCAGCACTTTGGGAGGCTGAAGTG GGTGGATCACCAGAGGTCAGGAGTTCGAGACCAGCCCAGCCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATGAGCTAGGCA TGGTGGCACACGCCTGTAATCCCAGCTACACCTGAGGCTGAGGCAGGAGAATTGCTTGAACCGGGGAGACGGAGGTTGCAGTGAGCCGAG TTTGGGCCACTGCACTCTAGCCTGGCAACAGAGCAAGACTCCGTCTCAAAAAAAGGGCAATAAATGCCCTCTCTGAATGTTTGAACTGCC AAGAAAAGGCATGGAGACAGCGAACTAGAAGAAAGGGCAAGAAGGAAATAGCCACCGTCTACAGATGGCTTAGTTAAGTCATCCACAGCC CAAGGGCGGGGCTATGCCTTGTCTGGGGACCCTGTAGAGTCACTGACCCTGGAGCGGCTCTCCTGAGAGGTGCTGCAGGCAAAGTGAGAC TGACACCTCACTGAGGAAGGGAGACATATTCTTGGAGAACTTTCCATCTGCTTGTATTTTCCATACACATCCCCAGCCAGAAGTTAGTGT CCGAAGACCGAATTTTATTTTACAGAGCTTGAAAACTCACTTCAATGAACAAAGGGATTCTCCAGGATTCCAAAGTTTTGAAGTCATCTT AGCTTTCCACAGGAGGGAGAGAACTTAAAAAAGCAACAGTAGCAGGGAATTGATCCACTTCTTAATGCTTTCCTCCCTGGCATGACCATC CTGTCCTTTGTTATTATCCTGCATTTTACGTCTTTGGAGGAACAGCTCCCTAGTGGCTTCCTCCGTCTGCAATGTCCCTTGCACAGCCCA CACATGAACCATCCTTCCCATGATGCCGCTCTTCTGTCATCCCGCTCCTGCTGAAACACCTCCCAGGGGCTCCACCTGTTCAGGAGCTGA AGCCCATGCTTTCCCACCAGCATGTCACTCCCAGACCACCTCCCTGCCCTGTCCTCCAGCTTCCCCTCGCTGTCCTGCTGTGTGAATTCC CAGGTTGGCCTGGTGGCCATGTCGCCTGCCCCCAGCACTCCTCTGTCTCTGCTCTTGCCTGCACCCTTCCTCCTCCTTTGCCTAGGAGGC CTTCTCGCATTTTCTCTAGCTGATCAGAATTTTACCAAAATTCAGAACATCCTCCAATTCCACAGTCTCTGGGAGACTTTCCCTAAGAGG CGACTTCCTCTCCAGCCTTCTCTCTCTGGTCAGGCCCACTGCAGAGATGGTGGTGAGCACATCTGGGAGGCTGGTCTCCCTCCAGCTGGA ATTGCTGCTCTCTGAGGGAGAGGCTGTGGTGGCTGTCTCTGTCCCTCACTGCCTTCCAGGAGCAATTTGCACATGTAACATAGATTTATG TAATGCTTTATGTTTAAAAACATTCCCCAATTATCTTATTTAATTTTTGCAATTATTCTAATTTTATATATAGAGAAAGTGACCTATTTT TTAAAAAAATCACACTCTAAGTTCTATTGAACCTAGGACTTGAGCCTCCATTTCTGGCTTCTAGTCTGGTGTTCTGAGTACTTGATTTCA GGTCAATAACGGTCCCCCCTCACTCCACACTGGCACGTTTGTGAGAAGAAATGACATTTTGCTAGGAAGTGACCGAGTCTAGGAATGCTT TTATTCAAGACACCAAATTCCAAACTTCTAAATGTTGGAATTTTCAAAAATTGTGTTTAGATTTTATGAAAAACTCTTCTACTTTCATCT ATTCTTTCCCTAGAGGCAAACATTTCTTAAAATGTTTCATTTTCATTAAAAATGAAAGCCAAATTTATATGCCACCGATTGCAGGACACA AGCACAGTTTTAAGAGTTGTATGAACATGGAGAGGACTTTTGGTTTTTATATTTCTCGTATTTAATATGGGTGAACACCAACTTTTATTT GGAATAATAATTTTCCTCCTAAACAAAAACACATTGAGTTTAAGTCTCTGACTCTTGCCTTTCCACCTGCTTTCTCCTGGGCCCGCTTTG CCTGCTTGAAGGAACAGTGCTGTTCTGGAGCTGCTGTTCCAACAGACAGGGCCTAGCTTTCATTTGACACACAGACTACAGCCAGAAGCC CATGGAGCAGGGATGTCACGTCTTGAAAAGCCTATTAGATGTTTTACAAATTTAATTTTGCAGATTATTTTAGTCTGTCATCCAGAAAAT GTGTCAGCATGCATAGTGCTAAGAAAGCAAGCCAATTTGGAAACTTAGGTTAGTGACAAAATTGGCCAGAGAGTGGGGGTGATGATGACC AAGAATTACAAGTAGAATGGCAGCTGGAATTTAAGGAGGGACAAGAATCAATGGATAAGCGTGGGTGGAGGAAGATCCAAACAGAAAAGT GCAAAGTTATTCCCCATCTTCCAAGGGTTGAATTCTGGAGGAAGAAGACACATTCCTAGTTCCCCGTGAACTTCCTTTGACTTATTGTCC CCACTAAAACAAAACAAAAAACTTTTAATGCCTTCCACATTAATTAGATTTTCTTGCAGTTTTTTTATGGCATTTTTTTAAAGATGCCCT AAGTGTTGAAGAAGAGTTTGCAAATGCAACAAAATATTTAATTACCGGTTGTTAAAACTGGTTTAGCACAATTTATATTTTCCCTCTCTT GCCTTTCTTATTTGCAATAAAAGGTATTGAGCCATTTTTTAAATGACATTTTTGATAAATTATGTTTGTACTAGTTGATGAAGGAGTTTT TTTTAACCTGTTTATATAATTTTGCAGCAGAAGCCAAATTTTTTGTATATTAAAGCACCAAATTCATGTACAGCATGCATCACGGATCAA TAGACTGTACTTATTTTCCAATAAAATTTTCAAACTTTGTACTGTTAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAA GACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTG GACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATATTCAGAAAATAATGAGAA CTACATTGAAGTGCCATTGATTTTTGATCCTGTCACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTCCATAATACCCTGAGTTT TCAGACACTACGCACCACAGTCAAGGAAGCCTCCTCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCACTGGCCTTCTTGGTTTT GGGGGGAATATGGATGCACAGACGGTGCAAACACAGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCTCATCATCAAGACTTTCA >39461_39461_20_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000233946_IL1R2_chr2_102638649_ENST00000393414_length(amino acids)=583AA_BP= MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSD IAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKHMIGICVTLT VIIVCSVFIYKIFKIDIVLWYRDSCYDFLPIKASDGKTYDAYILYPKTVGEGSTSDCDIFVFKVLPEVLEKQCGYKLFIYGRDDYVGEDI VEVINENVKKSRRLIIILVRETSGFSWLGGSSEEQIAMYNALVQDGIKVVLLELEKIQDYEKMPESIKFIKQKHGAIRWSGDFTQGPQSA -------------------------------------------------------------- >39461_39461_21_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000233946_IL1R2_chr2_102638649_ENST00000441002_length(transcript)=5264nt_BP=4907nt TAGACGCACCCTCTGAAGATGGTGACTCCCTCCTGAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGT GTTACTCAGACTTATTTGTTTCATAGCTCTACTGATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGT GTCATCTGCAAATGAAATTGATGTTCGTCCCTGTCCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAA GACACCTGTATCTACAGAACAAGCCTCCAGGATTCATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACA TTACTATTGCGTGGTAAGAAATTCATCTTACTGCCTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAA TGCACAAGCCATATTTAAGCAGAAACTACCCGTTGCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAA TGAGTTACCTAAATTACAGTGGTATAAGGATTGCAAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGT GATGAATGTGGCTGAAAAGCATAGAGGGAACTATACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAAT AGAATTTATTACTCTAGAGGAAAACAAACCCACAAGGCCTGTGATTGTGAGCCCAGCTAATGAGACAATGGAAGTAGACTTGGGATCCCA GATACAATTGATCTGTAATGTCACCGGCCAGTTGAGTGACATTGCTTACTGGAAGTGGAATGGGTCAGTAATTGATGAAGATGACCCAGT GCTAGGGGAAGACTATTACAGTGTGGAAAATCCTGCAAACAAAAGAAGGAGTACCCTCATCACAGTGCTTAATATATCGGAAATTGAAAG TAGATTTTATAAACATCCATTTACCTGTTTTGCCAAGAATACACATGGTATAGATGCAGCATATATCCAGTTAATATATCCAGTCACTAA TTTCCAGAAGCACATGATTGGTATATGTGTCACGTTGACAGTCATAATTGTGTGTTCTGTTTTCATCTATAAAATCTTCAAGATTGACAT TGTGCTTTGGTACAGGGATTCCTGCTATGATTTTCTCCCAATAAAAGCTTCAGATGGAAAGACCTATGACGCATATATACTGTATCCAAA GACTGTTGGGGAAGGGTCTACCTCTGACTGTGATATTTTTGTGTTTAAAGTCTTGCCTGAGGTCTTGGAAAAACAGTGTGGATATAAGCT GTTCATTTATGGAAGGGATGACTACGTTGGGGAAGACATTGTTGAGGTCATTAATGAAAACGTAAAGAAAAGCAGAAGACTGATTATCAT TTTAGTCAGAGAAACATCAGGCTTCAGCTGGCTGGGTGGTTCATCTGAAGAGCAAATAGCCATGTATAATGCTCTTGTTCAGGATGGAAT TAAAGTTGTCCTGCTTGAGCTGGAGAAAATCCAAGACTATGAGAAAATGCCAGAATCGATTAAATTCATTAAGCAGAAACATGGGGCTAT CCGCTGGTCAGGGGACTTTACACAGGGACCACAGTCTGCAAAGACAAGGTTCTGGAAGAATGTCAGGTACCACATGCCAGTCCAGCGACG GTCACCTTCATCTAAACACCAGTTACTGTCACCAGCCACTAAGGAGAAACTGCAAAGAGAGGCTCACGTGCCTCTCGGGTAGCATGGAGA AGTTGCCAAGAGTTCTTTAGGTGCCTCCTGTCTTATGGCGTTGCAGGCCAGGTTATGCCTCATGCTGACTTGCAGAGTTCATGGAATGTA ACTATATCATCCTTTATCCCTGAGGTCACCTGGAATCAGATTATTAAGGGAATAAGCCATGACGTCAATAGCAGCCCAGGGCACTTCAGA GTAGAGGGCTTGGGAAGATCTTTTAAAAAGGCAGTAGGCCCGGTGTGGTGGCTCACGCCTATAATCCCAGCACTTTGGGAGGCTGAAGTG GGTGGATCACCAGAGGTCAGGAGTTCGAGACCAGCCCAGCCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATGAGCTAGGCA TGGTGGCACACGCCTGTAATCCCAGCTACACCTGAGGCTGAGGCAGGAGAATTGCTTGAACCGGGGAGACGGAGGTTGCAGTGAGCCGAG TTTGGGCCACTGCACTCTAGCCTGGCAACAGAGCAAGACTCCGTCTCAAAAAAAGGGCAATAAATGCCCTCTCTGAATGTTTGAACTGCC AAGAAAAGGCATGGAGACAGCGAACTAGAAGAAAGGGCAAGAAGGAAATAGCCACCGTCTACAGATGGCTTAGTTAAGTCATCCACAGCC CAAGGGCGGGGCTATGCCTTGTCTGGGGACCCTGTAGAGTCACTGACCCTGGAGCGGCTCTCCTGAGAGGTGCTGCAGGCAAAGTGAGAC TGACACCTCACTGAGGAAGGGAGACATATTCTTGGAGAACTTTCCATCTGCTTGTATTTTCCATACACATCCCCAGCCAGAAGTTAGTGT CCGAAGACCGAATTTTATTTTACAGAGCTTGAAAACTCACTTCAATGAACAAAGGGATTCTCCAGGATTCCAAAGTTTTGAAGTCATCTT AGCTTTCCACAGGAGGGAGAGAACTTAAAAAAGCAACAGTAGCAGGGAATTGATCCACTTCTTAATGCTTTCCTCCCTGGCATGACCATC CTGTCCTTTGTTATTATCCTGCATTTTACGTCTTTGGAGGAACAGCTCCCTAGTGGCTTCCTCCGTCTGCAATGTCCCTTGCACAGCCCA CACATGAACCATCCTTCCCATGATGCCGCTCTTCTGTCATCCCGCTCCTGCTGAAACACCTCCCAGGGGCTCCACCTGTTCAGGAGCTGA AGCCCATGCTTTCCCACCAGCATGTCACTCCCAGACCACCTCCCTGCCCTGTCCTCCAGCTTCCCCTCGCTGTCCTGCTGTGTGAATTCC CAGGTTGGCCTGGTGGCCATGTCGCCTGCCCCCAGCACTCCTCTGTCTCTGCTCTTGCCTGCACCCTTCCTCCTCCTTTGCCTAGGAGGC CTTCTCGCATTTTCTCTAGCTGATCAGAATTTTACCAAAATTCAGAACATCCTCCAATTCCACAGTCTCTGGGAGACTTTCCCTAAGAGG CGACTTCCTCTCCAGCCTTCTCTCTCTGGTCAGGCCCACTGCAGAGATGGTGGTGAGCACATCTGGGAGGCTGGTCTCCCTCCAGCTGGA ATTGCTGCTCTCTGAGGGAGAGGCTGTGGTGGCTGTCTCTGTCCCTCACTGCCTTCCAGGAGCAATTTGCACATGTAACATAGATTTATG TAATGCTTTATGTTTAAAAACATTCCCCAATTATCTTATTTAATTTTTGCAATTATTCTAATTTTATATATAGAGAAAGTGACCTATTTT TTAAAAAAATCACACTCTAAGTTCTATTGAACCTAGGACTTGAGCCTCCATTTCTGGCTTCTAGTCTGGTGTTCTGAGTACTTGATTTCA GGTCAATAACGGTCCCCCCTCACTCCACACTGGCACGTTTGTGAGAAGAAATGACATTTTGCTAGGAAGTGACCGAGTCTAGGAATGCTT TTATTCAAGACACCAAATTCCAAACTTCTAAATGTTGGAATTTTCAAAAATTGTGTTTAGATTTTATGAAAAACTCTTCTACTTTCATCT ATTCTTTCCCTAGAGGCAAACATTTCTTAAAATGTTTCATTTTCATTAAAAATGAAAGCCAAATTTATATGCCACCGATTGCAGGACACA AGCACAGTTTTAAGAGTTGTATGAACATGGAGAGGACTTTTGGTTTTTATATTTCTCGTATTTAATATGGGTGAACACCAACTTTTATTT GGAATAATAATTTTCCTCCTAAACAAAAACACATTGAGTTTAAGTCTCTGACTCTTGCCTTTCCACCTGCTTTCTCCTGGGCCCGCTTTG CCTGCTTGAAGGAACAGTGCTGTTCTGGAGCTGCTGTTCCAACAGACAGGGCCTAGCTTTCATTTGACACACAGACTACAGCCAGAAGCC CATGGAGCAGGGATGTCACGTCTTGAAAAGCCTATTAGATGTTTTACAAATTTAATTTTGCAGATTATTTTAGTCTGTCATCCAGAAAAT GTGTCAGCATGCATAGTGCTAAGAAAGCAAGCCAATTTGGAAACTTAGGTTAGTGACAAAATTGGCCAGAGAGTGGGGGTGATGATGACC AAGAATTACAAGTAGAATGGCAGCTGGAATTTAAGGAGGGACAAGAATCAATGGATAAGCGTGGGTGGAGGAAGATCCAAACAGAAAAGT GCAAAGTTATTCCCCATCTTCCAAGGGTTGAATTCTGGAGGAAGAAGACACATTCCTAGTTCCCCGTGAACTTCCTTTGACTTATTGTCC CCACTAAAACAAAACAAAAAACTTTTAATGCCTTCCACATTAATTAGATTTTCTTGCAGTTTTTTTATGGCATTTTTTTAAAGATGCCCT AAGTGTTGAAGAAGAGTTTGCAAATGCAACAAAATATTTAATTACCGGTTGTTAAAACTGGTTTAGCACAATTTATATTTTCCCTCTCTT GCCTTTCTTATTTGCAATAAAAGGTATTGAGCCATTTTTTAAATGACATTTTTGATAAATTATGTTTGTACTAGTTGATGAAGGAGTTTT TTTTAACCTGTTTATATAATTTTGCAGCAGAAGCCAAATTTTTTGTATATTAAAGCACCAAATTCATGTACAGCATGCATCACGGATCAA TAGACTGTACTTATTTTCCAATAAAATTTTCAAACTTTGTACTGTTAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAA GACCATATCAGCTTCTCTGGGGTCAAGACTGACAATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTG GACGGCCAATGACACCCACATAGAGAGCGCCTACCCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGTAAGTGGGCCAGGGTCTTCTGTT GAGAACTCTGTGGGTTTCGCTCTTCCTTTTGGAGACAGTTATCACTATGACCCACATACCACATTAAAAGTTACTTTTTTTGATTCCAAA >39461_39461_21_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000233946_IL1R2_chr2_102638649_ENST00000441002_length(amino acids)=583AA_BP= MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSD IAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKHMIGICVTLT VIIVCSVFIYKIFKIDIVLWYRDSCYDFLPIKASDGKTYDAYILYPKTVGEGSTSDCDIFVFKVLPEVLEKQCGYKLFIYGRDDYVGEDI VEVINENVKKSRRLIIILVRETSGFSWLGGSSEEQIAMYNALVQDGIKVVLLELEKIQDYEKMPESIKFIKQKHGAIRWSGDFTQGPQSA -------------------------------------------------------------- >39461_39461_22_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000410023_IL1R2_chr2_102638649_ENST00000332549_length(transcript)=5804nt_BP=5143nt GCCGGAGCCGACTCGGAGCGCGCGGCGCCGGCCGGGAGGAGCCGGAGAGCGGCCGGGCCGGGCGGTGGGGGCGCCGGCCTGCCCCGCGCG CCCCAGGGAGCGGCAGGAATGTGACAATCGCGCGCCCGCGCACCGAAGCACTCCTCGCTCGGCTCCTAGGGCTCTCGCCCCTCTGAGCTG AGCCGGGTTCCGCCCGGGGCTGGGATCCCATCACCCTCCACGGCCGTCCGTCCAGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCT GAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTG ATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGT CCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATT CATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGC CTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTT GCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGC AAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTAT ACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGAGGAAAACAAACCCACA AGGCCTGTGATTGTGAGCCCAGCTAATGAGACAATGGAAGTAGACTTGGGATCCCAGATACAATTGATCTGTAATGTCACCGGCCAGTTG AGTGACATTGCTTACTGGAAGTGGAATGGGTCAGTAATTGATGAAGATGACCCAGTGCTAGGGGAAGACTATTACAGTGTGGAAAATCCT GCAAACAAAAGAAGGAGTACCCTCATCACAGTGCTTAATATATCGGAAATTGAAAGTAGATTTTATAAACATCCATTTACCTGTTTTGCC AAGAATACACATGGTATAGATGCAGCATATATCCAGTTAATATATCCAGTCACTAATTTCCAGAAGCACATGATTGGTATATGTGTCACG TTGACAGTCATAATTGTGTGTTCTGTTTTCATCTATAAAATCTTCAAGATTGACATTGTGCTTTGGTACAGGGATTCCTGCTATGATTTT CTCCCAATAAAAGCTTCAGATGGAAAGACCTATGACGCATATATACTGTATCCAAAGACTGTTGGGGAAGGGTCTACCTCTGACTGTGAT ATTTTTGTGTTTAAAGTCTTGCCTGAGGTCTTGGAAAAACAGTGTGGATATAAGCTGTTCATTTATGGAAGGGATGACTACGTTGGGGAA GACATTGTTGAGGTCATTAATGAAAACGTAAAGAAAAGCAGAAGACTGATTATCATTTTAGTCAGAGAAACATCAGGCTTCAGCTGGCTG GGTGGTTCATCTGAAGAGCAAATAGCCATGTATAATGCTCTTGTTCAGGATGGAATTAAAGTTGTCCTGCTTGAGCTGGAGAAAATCCAA GACTATGAGAAAATGCCAGAATCGATTAAATTCATTAAGCAGAAACATGGGGCTATCCGCTGGTCAGGGGACTTTACACAGGGACCACAG TCTGCAAAGACAAGGTTCTGGAAGAATGTCAGGTACCACATGCCAGTCCAGCGACGGTCACCTTCATCTAAACACCAGTTACTGTCACCA GCCACTAAGGAGAAACTGCAAAGAGAGGCTCACGTGCCTCTCGGGTAGCATGGAGAAGTTGCCAAGAGTTCTTTAGGTGCCTCCTGTCTT ATGGCGTTGCAGGCCAGGTTATGCCTCATGCTGACTTGCAGAGTTCATGGAATGTAACTATATCATCCTTTATCCCTGAGGTCACCTGGA ATCAGATTATTAAGGGAATAAGCCATGACGTCAATAGCAGCCCAGGGCACTTCAGAGTAGAGGGCTTGGGAAGATCTTTTAAAAAGGCAG TAGGCCCGGTGTGGTGGCTCACGCCTATAATCCCAGCACTTTGGGAGGCTGAAGTGGGTGGATCACCAGAGGTCAGGAGTTCGAGACCAG CCCAGCCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATGAGCTAGGCATGGTGGCACACGCCTGTAATCCCAGCTACACCTG AGGCTGAGGCAGGAGAATTGCTTGAACCGGGGAGACGGAGGTTGCAGTGAGCCGAGTTTGGGCCACTGCACTCTAGCCTGGCAACAGAGC AAGACTCCGTCTCAAAAAAAGGGCAATAAATGCCCTCTCTGAATGTTTGAACTGCCAAGAAAAGGCATGGAGACAGCGAACTAGAAGAAA GGGCAAGAAGGAAATAGCCACCGTCTACAGATGGCTTAGTTAAGTCATCCACAGCCCAAGGGCGGGGCTATGCCTTGTCTGGGGACCCTG TAGAGTCACTGACCCTGGAGCGGCTCTCCTGAGAGGTGCTGCAGGCAAAGTGAGACTGACACCTCACTGAGGAAGGGAGACATATTCTTG GAGAACTTTCCATCTGCTTGTATTTTCCATACACATCCCCAGCCAGAAGTTAGTGTCCGAAGACCGAATTTTATTTTACAGAGCTTGAAA ACTCACTTCAATGAACAAAGGGATTCTCCAGGATTCCAAAGTTTTGAAGTCATCTTAGCTTTCCACAGGAGGGAGAGAACTTAAAAAAGC AACAGTAGCAGGGAATTGATCCACTTCTTAATGCTTTCCTCCCTGGCATGACCATCCTGTCCTTTGTTATTATCCTGCATTTTACGTCTT TGGAGGAACAGCTCCCTAGTGGCTTCCTCCGTCTGCAATGTCCCTTGCACAGCCCACACATGAACCATCCTTCCCATGATGCCGCTCTTC TGTCATCCCGCTCCTGCTGAAACACCTCCCAGGGGCTCCACCTGTTCAGGAGCTGAAGCCCATGCTTTCCCACCAGCATGTCACTCCCAG ACCACCTCCCTGCCCTGTCCTCCAGCTTCCCCTCGCTGTCCTGCTGTGTGAATTCCCAGGTTGGCCTGGTGGCCATGTCGCCTGCCCCCA GCACTCCTCTGTCTCTGCTCTTGCCTGCACCCTTCCTCCTCCTTTGCCTAGGAGGCCTTCTCGCATTTTCTCTAGCTGATCAGAATTTTA CCAAAATTCAGAACATCCTCCAATTCCACAGTCTCTGGGAGACTTTCCCTAAGAGGCGACTTCCTCTCCAGCCTTCTCTCTCTGGTCAGG CCCACTGCAGAGATGGTGGTGAGCACATCTGGGAGGCTGGTCTCCCTCCAGCTGGAATTGCTGCTCTCTGAGGGAGAGGCTGTGGTGGCT GTCTCTGTCCCTCACTGCCTTCCAGGAGCAATTTGCACATGTAACATAGATTTATGTAATGCTTTATGTTTAAAAACATTCCCCAATTAT CTTATTTAATTTTTGCAATTATTCTAATTTTATATATAGAGAAAGTGACCTATTTTTTAAAAAAATCACACTCTAAGTTCTATTGAACCT AGGACTTGAGCCTCCATTTCTGGCTTCTAGTCTGGTGTTCTGAGTACTTGATTTCAGGTCAATAACGGTCCCCCCTCACTCCACACTGGC ACGTTTGTGAGAAGAAATGACATTTTGCTAGGAAGTGACCGAGTCTAGGAATGCTTTTATTCAAGACACCAAATTCCAAACTTCTAAATG TTGGAATTTTCAAAAATTGTGTTTAGATTTTATGAAAAACTCTTCTACTTTCATCTATTCTTTCCCTAGAGGCAAACATTTCTTAAAATG TTTCATTTTCATTAAAAATGAAAGCCAAATTTATATGCCACCGATTGCAGGACACAAGCACAGTTTTAAGAGTTGTATGAACATGGAGAG GACTTTTGGTTTTTATATTTCTCGTATTTAATATGGGTGAACACCAACTTTTATTTGGAATAATAATTTTCCTCCTAAACAAAAACACAT TGAGTTTAAGTCTCTGACTCTTGCCTTTCCACCTGCTTTCTCCTGGGCCCGCTTTGCCTGCTTGAAGGAACAGTGCTGTTCTGGAGCTGC TGTTCCAACAGACAGGGCCTAGCTTTCATTTGACACACAGACTACAGCCAGAAGCCCATGGAGCAGGGATGTCACGTCTTGAAAAGCCTA TTAGATGTTTTACAAATTTAATTTTGCAGATTATTTTAGTCTGTCATCCAGAAAATGTGTCAGCATGCATAGTGCTAAGAAAGCAAGCCA ATTTGGAAACTTAGGTTAGTGACAAAATTGGCCAGAGAGTGGGGGTGATGATGACCAAGAATTACAAGTAGAATGGCAGCTGGAATTTAA GGAGGGACAAGAATCAATGGATAAGCGTGGGTGGAGGAAGATCCAAACAGAAAAGTGCAAAGTTATTCCCCATCTTCCAAGGGTTGAATT CTGGAGGAAGAAGACACATTCCTAGTTCCCCGTGAACTTCCTTTGACTTATTGTCCCCACTAAAACAAAACAAAAAACTTTTAATGCCTT CCACATTAATTAGATTTTCTTGCAGTTTTTTTATGGCATTTTTTTAAAGATGCCCTAAGTGTTGAAGAAGAGTTTGCAAATGCAACAAAA TATTTAATTACCGGTTGTTAAAACTGGTTTAGCACAATTTATATTTTCCCTCTCTTGCCTTTCTTATTTGCAATAAAAGGTATTGAGCCA TTTTTTAAATGACATTTTTGATAAATTATGTTTGTACTAGTTGATGAAGGAGTTTTTTTTAACCTGTTTATATAATTTTGCAGCAGAAGC CAAATTTTTTGTATATTAAAGCACCAAATTCATGTACAGCATGCATCACGGATCAATAGACTGTACTTATTTTCCAATAAAATTTTCAAA CTTTGTACTGTTAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACA ATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTAC CCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATATTCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTC ACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTCCATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCC TCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACAC AGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCTCATCATCAAGACTTTCAATCCTATCCCAAGTGAAATAAATGGAATGAAATA ATTCAAACACAAACTCCGTACGTCTTCTCTTATGGAAGTGGCTGTGTCTTTTTGAGGGACTCTGTTCTTTGCCTCAGTTGTCTACCAAAG >39461_39461_22_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000410023_IL1R2_chr2_102638649_ENST00000332549_length(amino acids)=583AA_BP= MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSD IAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKHMIGICVTLT VIIVCSVFIYKIFKIDIVLWYRDSCYDFLPIKASDGKTYDAYILYPKTVGEGSTSDCDIFVFKVLPEVLEKQCGYKLFIYGRDDYVGEDI VEVINENVKKSRRLIIILVRETSGFSWLGGSSEEQIAMYNALVQDGIKVVLLELEKIQDYEKMPESIKFIKQKHGAIRWSGDFTQGPQSA -------------------------------------------------------------- >39461_39461_23_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000410023_IL1R2_chr2_102638649_ENST00000393414_length(transcript)=5677nt_BP=5143nt GCCGGAGCCGACTCGGAGCGCGCGGCGCCGGCCGGGAGGAGCCGGAGAGCGGCCGGGCCGGGCGGTGGGGGCGCCGGCCTGCCCCGCGCG CCCCAGGGAGCGGCAGGAATGTGACAATCGCGCGCCCGCGCACCGAAGCACTCCTCGCTCGGCTCCTAGGGCTCTCGCCCCTCTGAGCTG AGCCGGGTTCCGCCCGGGGCTGGGATCCCATCACCCTCCACGGCCGTCCGTCCAGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCT GAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTG ATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGT CCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATT CATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGC CTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTT GCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGC AAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTAT ACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGAGGAAAACAAACCCACA AGGCCTGTGATTGTGAGCCCAGCTAATGAGACAATGGAAGTAGACTTGGGATCCCAGATACAATTGATCTGTAATGTCACCGGCCAGTTG AGTGACATTGCTTACTGGAAGTGGAATGGGTCAGTAATTGATGAAGATGACCCAGTGCTAGGGGAAGACTATTACAGTGTGGAAAATCCT GCAAACAAAAGAAGGAGTACCCTCATCACAGTGCTTAATATATCGGAAATTGAAAGTAGATTTTATAAACATCCATTTACCTGTTTTGCC AAGAATACACATGGTATAGATGCAGCATATATCCAGTTAATATATCCAGTCACTAATTTCCAGAAGCACATGATTGGTATATGTGTCACG TTGACAGTCATAATTGTGTGTTCTGTTTTCATCTATAAAATCTTCAAGATTGACATTGTGCTTTGGTACAGGGATTCCTGCTATGATTTT CTCCCAATAAAAGCTTCAGATGGAAAGACCTATGACGCATATATACTGTATCCAAAGACTGTTGGGGAAGGGTCTACCTCTGACTGTGAT ATTTTTGTGTTTAAAGTCTTGCCTGAGGTCTTGGAAAAACAGTGTGGATATAAGCTGTTCATTTATGGAAGGGATGACTACGTTGGGGAA GACATTGTTGAGGTCATTAATGAAAACGTAAAGAAAAGCAGAAGACTGATTATCATTTTAGTCAGAGAAACATCAGGCTTCAGCTGGCTG GGTGGTTCATCTGAAGAGCAAATAGCCATGTATAATGCTCTTGTTCAGGATGGAATTAAAGTTGTCCTGCTTGAGCTGGAGAAAATCCAA GACTATGAGAAAATGCCAGAATCGATTAAATTCATTAAGCAGAAACATGGGGCTATCCGCTGGTCAGGGGACTTTACACAGGGACCACAG TCTGCAAAGACAAGGTTCTGGAAGAATGTCAGGTACCACATGCCAGTCCAGCGACGGTCACCTTCATCTAAACACCAGTTACTGTCACCA GCCACTAAGGAGAAACTGCAAAGAGAGGCTCACGTGCCTCTCGGGTAGCATGGAGAAGTTGCCAAGAGTTCTTTAGGTGCCTCCTGTCTT ATGGCGTTGCAGGCCAGGTTATGCCTCATGCTGACTTGCAGAGTTCATGGAATGTAACTATATCATCCTTTATCCCTGAGGTCACCTGGA ATCAGATTATTAAGGGAATAAGCCATGACGTCAATAGCAGCCCAGGGCACTTCAGAGTAGAGGGCTTGGGAAGATCTTTTAAAAAGGCAG TAGGCCCGGTGTGGTGGCTCACGCCTATAATCCCAGCACTTTGGGAGGCTGAAGTGGGTGGATCACCAGAGGTCAGGAGTTCGAGACCAG CCCAGCCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATGAGCTAGGCATGGTGGCACACGCCTGTAATCCCAGCTACACCTG AGGCTGAGGCAGGAGAATTGCTTGAACCGGGGAGACGGAGGTTGCAGTGAGCCGAGTTTGGGCCACTGCACTCTAGCCTGGCAACAGAGC AAGACTCCGTCTCAAAAAAAGGGCAATAAATGCCCTCTCTGAATGTTTGAACTGCCAAGAAAAGGCATGGAGACAGCGAACTAGAAGAAA GGGCAAGAAGGAAATAGCCACCGTCTACAGATGGCTTAGTTAAGTCATCCACAGCCCAAGGGCGGGGCTATGCCTTGTCTGGGGACCCTG TAGAGTCACTGACCCTGGAGCGGCTCTCCTGAGAGGTGCTGCAGGCAAAGTGAGACTGACACCTCACTGAGGAAGGGAGACATATTCTTG GAGAACTTTCCATCTGCTTGTATTTTCCATACACATCCCCAGCCAGAAGTTAGTGTCCGAAGACCGAATTTTATTTTACAGAGCTTGAAA ACTCACTTCAATGAACAAAGGGATTCTCCAGGATTCCAAAGTTTTGAAGTCATCTTAGCTTTCCACAGGAGGGAGAGAACTTAAAAAAGC AACAGTAGCAGGGAATTGATCCACTTCTTAATGCTTTCCTCCCTGGCATGACCATCCTGTCCTTTGTTATTATCCTGCATTTTACGTCTT TGGAGGAACAGCTCCCTAGTGGCTTCCTCCGTCTGCAATGTCCCTTGCACAGCCCACACATGAACCATCCTTCCCATGATGCCGCTCTTC TGTCATCCCGCTCCTGCTGAAACACCTCCCAGGGGCTCCACCTGTTCAGGAGCTGAAGCCCATGCTTTCCCACCAGCATGTCACTCCCAG ACCACCTCCCTGCCCTGTCCTCCAGCTTCCCCTCGCTGTCCTGCTGTGTGAATTCCCAGGTTGGCCTGGTGGCCATGTCGCCTGCCCCCA GCACTCCTCTGTCTCTGCTCTTGCCTGCACCCTTCCTCCTCCTTTGCCTAGGAGGCCTTCTCGCATTTTCTCTAGCTGATCAGAATTTTA CCAAAATTCAGAACATCCTCCAATTCCACAGTCTCTGGGAGACTTTCCCTAAGAGGCGACTTCCTCTCCAGCCTTCTCTCTCTGGTCAGG CCCACTGCAGAGATGGTGGTGAGCACATCTGGGAGGCTGGTCTCCCTCCAGCTGGAATTGCTGCTCTCTGAGGGAGAGGCTGTGGTGGCT GTCTCTGTCCCTCACTGCCTTCCAGGAGCAATTTGCACATGTAACATAGATTTATGTAATGCTTTATGTTTAAAAACATTCCCCAATTAT CTTATTTAATTTTTGCAATTATTCTAATTTTATATATAGAGAAAGTGACCTATTTTTTAAAAAAATCACACTCTAAGTTCTATTGAACCT AGGACTTGAGCCTCCATTTCTGGCTTCTAGTCTGGTGTTCTGAGTACTTGATTTCAGGTCAATAACGGTCCCCCCTCACTCCACACTGGC ACGTTTGTGAGAAGAAATGACATTTTGCTAGGAAGTGACCGAGTCTAGGAATGCTTTTATTCAAGACACCAAATTCCAAACTTCTAAATG TTGGAATTTTCAAAAATTGTGTTTAGATTTTATGAAAAACTCTTCTACTTTCATCTATTCTTTCCCTAGAGGCAAACATTTCTTAAAATG TTTCATTTTCATTAAAAATGAAAGCCAAATTTATATGCCACCGATTGCAGGACACAAGCACAGTTTTAAGAGTTGTATGAACATGGAGAG GACTTTTGGTTTTTATATTTCTCGTATTTAATATGGGTGAACACCAACTTTTATTTGGAATAATAATTTTCCTCCTAAACAAAAACACAT TGAGTTTAAGTCTCTGACTCTTGCCTTTCCACCTGCTTTCTCCTGGGCCCGCTTTGCCTGCTTGAAGGAACAGTGCTGTTCTGGAGCTGC TGTTCCAACAGACAGGGCCTAGCTTTCATTTGACACACAGACTACAGCCAGAAGCCCATGGAGCAGGGATGTCACGTCTTGAAAAGCCTA TTAGATGTTTTACAAATTTAATTTTGCAGATTATTTTAGTCTGTCATCCAGAAAATGTGTCAGCATGCATAGTGCTAAGAAAGCAAGCCA ATTTGGAAACTTAGGTTAGTGACAAAATTGGCCAGAGAGTGGGGGTGATGATGACCAAGAATTACAAGTAGAATGGCAGCTGGAATTTAA GGAGGGACAAGAATCAATGGATAAGCGTGGGTGGAGGAAGATCCAAACAGAAAAGTGCAAAGTTATTCCCCATCTTCCAAGGGTTGAATT CTGGAGGAAGAAGACACATTCCTAGTTCCCCGTGAACTTCCTTTGACTTATTGTCCCCACTAAAACAAAACAAAAAACTTTTAATGCCTT CCACATTAATTAGATTTTCTTGCAGTTTTTTTATGGCATTTTTTTAAAGATGCCCTAAGTGTTGAAGAAGAGTTTGCAAATGCAACAAAA TATTTAATTACCGGTTGTTAAAACTGGTTTAGCACAATTTATATTTTCCCTCTCTTGCCTTTCTTATTTGCAATAAAAGGTATTGAGCCA TTTTTTAAATGACATTTTTGATAAATTATGTTTGTACTAGTTGATGAAGGAGTTTTTTTTAACCTGTTTATATAATTTTGCAGCAGAAGC CAAATTTTTTGTATATTAAAGCACCAAATTCATGTACAGCATGCATCACGGATCAATAGACTGTACTTATTTTCCAATAAAATTTTCAAA CTTTGTACTGTTAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACA ATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTAC CCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGGAATATTCAGAAAATAATGAGAACTACATTGAAGTGCCATTGATTTTTGATCCTGTC ACAAGAGAGGATTTGCACATGGATTTTAAATGTGTTGTCCATAATACCCTGAGTTTTCAGACACTACGCACCACAGTCAAGGAAGCCTCC TCCACGTTCTCCTGGGGCATTGTGCTGGCCCCACTTTCACTGGCCTTCTTGGTTTTGGGGGGAATATGGATGCACAGACGGTGCAAACAC AGAACTGGAAAAGCAGATGGTCTGACTGTGCTATGGCCTCATCATCAAGACTTTCAATCCTATCCCAAGTGAAATAAATGGAATGAAATA >39461_39461_23_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000410023_IL1R2_chr2_102638649_ENST00000393414_length(amino acids)=583AA_BP= MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSD IAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKHMIGICVTLT VIIVCSVFIYKIFKIDIVLWYRDSCYDFLPIKASDGKTYDAYILYPKTVGEGSTSDCDIFVFKVLPEVLEKQCGYKLFIYGRDDYVGEDI VEVINENVKKSRRLIIILVRETSGFSWLGGSSEEQIAMYNALVQDGIKVVLLELEKIQDYEKMPESIKFIKQKHGAIRWSGDFTQGPQSA -------------------------------------------------------------- >39461_39461_24_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000410023_IL1R2_chr2_102638649_ENST00000441002_length(transcript)=5500nt_BP=5143nt GCCGGAGCCGACTCGGAGCGCGCGGCGCCGGCCGGGAGGAGCCGGAGAGCGGCCGGGCCGGGCGGTGGGGGCGCCGGCCTGCCCCGCGCG CCCCAGGGAGCGGCAGGAATGTGACAATCGCGCGCCCGCGCACCGAAGCACTCCTCGCTCGGCTCCTAGGGCTCTCGCCCCTCTGAGCTG AGCCGGGTTCCGCCCGGGGCTGGGATCCCATCACCCTCCACGGCCGTCCGTCCAGGTAGACGCACCCTCTGAAGATGGTGACTCCCTCCT GAGAAGCTGGACCCCTTGGTAAAAGACAAGGCCTTCTCCAAGAAGAATATGAAAGTGTTACTCAGACTTATTTGTTTCATAGCTCTACTG ATTTCTTCTCTGGAGGCTGATAAATGCAAGGAACGTGAAGAAAAAATAATTTTAGTGTCATCTGCAAATGAAATTGATGTTCGTCCCTGT CCTCTTAACCCAAATGAACACAAAGGCACTATAACTTGGTATAAAGATGACAGCAAGACACCTGTATCTACAGAACAAGCCTCCAGGATT CATCAACACAAAGAGAAACTTTGGTTTGTTCCTGCTAAGGTGGAGGATTCAGGACATTACTATTGCGTGGTAAGAAATTCATCTTACTGC CTCAGAATTAAAATAAGTGCAAAATTTGTGGAGAATGAGCCTAACTTATGTTATAATGCACAAGCCATATTTAAGCAGAAACTACCCGTT GCAGGAGACGGAGGACTTGTGTGCCCTTATATGGAGTTTTTTAAAAATGAAAATAATGAGTTACCTAAATTACAGTGGTATAAGGATTGC AAACCTCTACTTCTTGACAATATACACTTTAGTGGAGTCAAAGATAGGCTCATCGTGATGAATGTGGCTGAAAAGCATAGAGGGAACTAT ACTTGTCATGCATCCTACACATACTTGGGCAAGCAATATCCTATTACCCGGGTAATAGAATTTATTACTCTAGAGGAAAACAAACCCACA AGGCCTGTGATTGTGAGCCCAGCTAATGAGACAATGGAAGTAGACTTGGGATCCCAGATACAATTGATCTGTAATGTCACCGGCCAGTTG AGTGACATTGCTTACTGGAAGTGGAATGGGTCAGTAATTGATGAAGATGACCCAGTGCTAGGGGAAGACTATTACAGTGTGGAAAATCCT GCAAACAAAAGAAGGAGTACCCTCATCACAGTGCTTAATATATCGGAAATTGAAAGTAGATTTTATAAACATCCATTTACCTGTTTTGCC AAGAATACACATGGTATAGATGCAGCATATATCCAGTTAATATATCCAGTCACTAATTTCCAGAAGCACATGATTGGTATATGTGTCACG TTGACAGTCATAATTGTGTGTTCTGTTTTCATCTATAAAATCTTCAAGATTGACATTGTGCTTTGGTACAGGGATTCCTGCTATGATTTT CTCCCAATAAAAGCTTCAGATGGAAAGACCTATGACGCATATATACTGTATCCAAAGACTGTTGGGGAAGGGTCTACCTCTGACTGTGAT ATTTTTGTGTTTAAAGTCTTGCCTGAGGTCTTGGAAAAACAGTGTGGATATAAGCTGTTCATTTATGGAAGGGATGACTACGTTGGGGAA GACATTGTTGAGGTCATTAATGAAAACGTAAAGAAAAGCAGAAGACTGATTATCATTTTAGTCAGAGAAACATCAGGCTTCAGCTGGCTG GGTGGTTCATCTGAAGAGCAAATAGCCATGTATAATGCTCTTGTTCAGGATGGAATTAAAGTTGTCCTGCTTGAGCTGGAGAAAATCCAA GACTATGAGAAAATGCCAGAATCGATTAAATTCATTAAGCAGAAACATGGGGCTATCCGCTGGTCAGGGGACTTTACACAGGGACCACAG TCTGCAAAGACAAGGTTCTGGAAGAATGTCAGGTACCACATGCCAGTCCAGCGACGGTCACCTTCATCTAAACACCAGTTACTGTCACCA GCCACTAAGGAGAAACTGCAAAGAGAGGCTCACGTGCCTCTCGGGTAGCATGGAGAAGTTGCCAAGAGTTCTTTAGGTGCCTCCTGTCTT ATGGCGTTGCAGGCCAGGTTATGCCTCATGCTGACTTGCAGAGTTCATGGAATGTAACTATATCATCCTTTATCCCTGAGGTCACCTGGA ATCAGATTATTAAGGGAATAAGCCATGACGTCAATAGCAGCCCAGGGCACTTCAGAGTAGAGGGCTTGGGAAGATCTTTTAAAAAGGCAG TAGGCCCGGTGTGGTGGCTCACGCCTATAATCCCAGCACTTTGGGAGGCTGAAGTGGGTGGATCACCAGAGGTCAGGAGTTCGAGACCAG CCCAGCCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATGAGCTAGGCATGGTGGCACACGCCTGTAATCCCAGCTACACCTG AGGCTGAGGCAGGAGAATTGCTTGAACCGGGGAGACGGAGGTTGCAGTGAGCCGAGTTTGGGCCACTGCACTCTAGCCTGGCAACAGAGC AAGACTCCGTCTCAAAAAAAGGGCAATAAATGCCCTCTCTGAATGTTTGAACTGCCAAGAAAAGGCATGGAGACAGCGAACTAGAAGAAA GGGCAAGAAGGAAATAGCCACCGTCTACAGATGGCTTAGTTAAGTCATCCACAGCCCAAGGGCGGGGCTATGCCTTGTCTGGGGACCCTG TAGAGTCACTGACCCTGGAGCGGCTCTCCTGAGAGGTGCTGCAGGCAAAGTGAGACTGACACCTCACTGAGGAAGGGAGACATATTCTTG GAGAACTTTCCATCTGCTTGTATTTTCCATACACATCCCCAGCCAGAAGTTAGTGTCCGAAGACCGAATTTTATTTTACAGAGCTTGAAA ACTCACTTCAATGAACAAAGGGATTCTCCAGGATTCCAAAGTTTTGAAGTCATCTTAGCTTTCCACAGGAGGGAGAGAACTTAAAAAAGC AACAGTAGCAGGGAATTGATCCACTTCTTAATGCTTTCCTCCCTGGCATGACCATCCTGTCCTTTGTTATTATCCTGCATTTTACGTCTT TGGAGGAACAGCTCCCTAGTGGCTTCCTCCGTCTGCAATGTCCCTTGCACAGCCCACACATGAACCATCCTTCCCATGATGCCGCTCTTC TGTCATCCCGCTCCTGCTGAAACACCTCCCAGGGGCTCCACCTGTTCAGGAGCTGAAGCCCATGCTTTCCCACCAGCATGTCACTCCCAG ACCACCTCCCTGCCCTGTCCTCCAGCTTCCCCTCGCTGTCCTGCTGTGTGAATTCCCAGGTTGGCCTGGTGGCCATGTCGCCTGCCCCCA GCACTCCTCTGTCTCTGCTCTTGCCTGCACCCTTCCTCCTCCTTTGCCTAGGAGGCCTTCTCGCATTTTCTCTAGCTGATCAGAATTTTA CCAAAATTCAGAACATCCTCCAATTCCACAGTCTCTGGGAGACTTTCCCTAAGAGGCGACTTCCTCTCCAGCCTTCTCTCTCTGGTCAGG CCCACTGCAGAGATGGTGGTGAGCACATCTGGGAGGCTGGTCTCCCTCCAGCTGGAATTGCTGCTCTCTGAGGGAGAGGCTGTGGTGGCT GTCTCTGTCCCTCACTGCCTTCCAGGAGCAATTTGCACATGTAACATAGATTTATGTAATGCTTTATGTTTAAAAACATTCCCCAATTAT CTTATTTAATTTTTGCAATTATTCTAATTTTATATATAGAGAAAGTGACCTATTTTTTAAAAAAATCACACTCTAAGTTCTATTGAACCT AGGACTTGAGCCTCCATTTCTGGCTTCTAGTCTGGTGTTCTGAGTACTTGATTTCAGGTCAATAACGGTCCCCCCTCACTCCACACTGGC ACGTTTGTGAGAAGAAATGACATTTTGCTAGGAAGTGACCGAGTCTAGGAATGCTTTTATTCAAGACACCAAATTCCAAACTTCTAAATG TTGGAATTTTCAAAAATTGTGTTTAGATTTTATGAAAAACTCTTCTACTTTCATCTATTCTTTCCCTAGAGGCAAACATTTCTTAAAATG TTTCATTTTCATTAAAAATGAAAGCCAAATTTATATGCCACCGATTGCAGGACACAAGCACAGTTTTAAGAGTTGTATGAACATGGAGAG GACTTTTGGTTTTTATATTTCTCGTATTTAATATGGGTGAACACCAACTTTTATTTGGAATAATAATTTTCCTCCTAAACAAAAACACAT TGAGTTTAAGTCTCTGACTCTTGCCTTTCCACCTGCTTTCTCCTGGGCCCGCTTTGCCTGCTTGAAGGAACAGTGCTGTTCTGGAGCTGC TGTTCCAACAGACAGGGCCTAGCTTTCATTTGACACACAGACTACAGCCAGAAGCCCATGGAGCAGGGATGTCACGTCTTGAAAAGCCTA TTAGATGTTTTACAAATTTAATTTTGCAGATTATTTTAGTCTGTCATCCAGAAAATGTGTCAGCATGCATAGTGCTAAGAAAGCAAGCCA ATTTGGAAACTTAGGTTAGTGACAAAATTGGCCAGAGAGTGGGGGTGATGATGACCAAGAATTACAAGTAGAATGGCAGCTGGAATTTAA GGAGGGACAAGAATCAATGGATAAGCGTGGGTGGAGGAAGATCCAAACAGAAAAGTGCAAAGTTATTCCCCATCTTCCAAGGGTTGAATT CTGGAGGAAGAAGACACATTCCTAGTTCCCCGTGAACTTCCTTTGACTTATTGTCCCCACTAAAACAAAACAAAAAACTTTTAATGCCTT CCACATTAATTAGATTTTCTTGCAGTTTTTTTATGGCATTTTTTTAAAGATGCCCTAAGTGTTGAAGAAGAGTTTGCAAATGCAACAAAA TATTTAATTACCGGTTGTTAAAACTGGTTTAGCACAATTTATATTTTCCCTCTCTTGCCTTTCTTATTTGCAATAAAAGGTATTGAGCCA TTTTTTAAATGACATTTTTGATAAATTATGTTTGTACTAGTTGATGAAGGAGTTTTTTTTAACCTGTTTATATAATTTTGCAGCAGAAGC CAAATTTTTTGTATATTAAAGCACCAAATTCATGTACAGCATGCATCACGGATCAATAGACTGTACTTATTTTCCAATAAAATTTTCAAA CTTTGTACTGTTAAAAAAAAAGAAGAGACCATTCCTGTGATCATTTCCCCCCTCAAGACCATATCAGCTTCTCTGGGGTCAAGACTGACA ATCCCGTGTAAGGTGTTTCTGGGAACCGGCACACCCTTAACCACCATGCTGTGGTGGACGGCCAATGACACCCACATAGAGAGCGCCTAC CCGGGAGGCCGCGTGACCGAGGGGCCACGCCAGTAAGTGGGCCAGGGTCTTCTGTTGAGAACTCTGTGGGTTTCGCTCTTCCTTTTGGAG ACAGTTATCACTATGACCCACATACCACATTAAAAGTTACTTTTTTTGATTCCAAACTGTTGGATGTTTAGAATTTAAAAAATTGTATTT >39461_39461_24_IL1R1-IL1R2_IL1R1_chr2_102796334_ENST00000410023_IL1R2_chr2_102638649_ENST00000441002_length(amino acids)=583AA_BP= MDPLVKDKAFSKKNMKVLLRLICFIALLISSLEADKCKEREEKIILVSSANEIDVRPCPLNPNEHKGTITWYKDDSKTPVSTEQASRIHQ HKEKLWFVPAKVEDSGHYYCVVRNSSYCLRIKISAKFVENEPNLCYNAQAIFKQKLPVAGDGGLVCPYMEFFKNENNELPKLQWYKDCKP LLLDNIHFSGVKDRLIVMNVAEKHRGNYTCHASYTYLGKQYPITRVIEFITLEENKPTRPVIVSPANETMEVDLGSQIQLICNVTGQLSD IAYWKWNGSVIDEDDPVLGEDYYSVENPANKRRSTLITVLNISEIESRFYKHPFTCFAKNTHGIDAAYIQLIYPVTNFQKHMIGICVTLT VIIVCSVFIYKIFKIDIVLWYRDSCYDFLPIKASDGKTYDAYILYPKTVGEGSTSDCDIFVFKVLPEVLEKQCGYKLFIYGRDDYVGEDI VEVINENVKKSRRLIIILVRETSGFSWLGGSSEEQIAMYNALVQDGIKVVLLELEKIQDYEKMPESIKFIKQKHGAIRWSGDFTQGPQSA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for IL1R1-IL1R2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for IL1R1-IL1R2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for IL1R1-IL1R2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | IL1R1 | C0014175 | Endometriosis | 2 | CTD_human |
| Hgene | IL1R1 | C0269102 | Endometrioma | 2 | CTD_human |
| Hgene | IL1R1 | C0020517 | Hypersensitivity | 1 | CTD_human |
| Hgene | IL1R1 | C0032285 | Pneumonia | 1 | CTD_human |
| Hgene | IL1R1 | C0032300 | Lobar Pneumonia | 1 | CTD_human |
| Hgene | IL1R1 | C0037274 | Dermatologic disorders | 1 | CTD_human |
| Hgene | IL1R1 | C0887898 | Experimental Lung Inflammation | 1 | CTD_human |
| Hgene | IL1R1 | C1527304 | Allergic Reaction | 1 | CTD_human |
| Hgene | IL1R1 | C3714636 | Pneumonitis | 1 | CTD_human |
| Tgene | C0009324 | Ulcerative Colitis | 1 | CTD_human | |
| Tgene | C0019193 | Hepatitis, Toxic | 1 | CTD_human | |
| Tgene | C0020517 | Hypersensitivity | 1 | CTD_human | |
| Tgene | C0023895 | Liver diseases | 1 | CTD_human | |
| Tgene | C0024121 | Lung Neoplasms | 1 | CTD_human | |
| Tgene | C0032285 | Pneumonia | 1 | CTD_human | |
| Tgene | C0032300 | Lobar Pneumonia | 1 | CTD_human | |
| Tgene | C0038013 | Ankylosing spondylitis | 1 | CTD_human | |
| Tgene | C0086565 | Liver Dysfunction | 1 | CTD_human | |
| Tgene | C0242379 | Malignant neoplasm of lung | 1 | CTD_human | |
| Tgene | C0860207 | Drug-Induced Liver Disease | 1 | CTD_human | |
| Tgene | C0887898 | Experimental Lung Inflammation | 1 | CTD_human | |
| Tgene | C1262760 | Hepatitis, Drug-Induced | 1 | CTD_human | |
| Tgene | C1527304 | Allergic Reaction | 1 | CTD_human | |
| Tgene | C3658290 | Drug-Induced Acute Liver Injury | 1 | CTD_human | |
| Tgene | C3714636 | Pneumonitis | 1 | CTD_human | |
| Tgene | C4277682 | Chemical and Drug Induced Liver Injury | 1 | CTD_human | |
| Tgene | C4279912 | Chemically-Induced Liver Toxicity | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies