
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TMEM189-MMP23B (FusionGDB2 ID:HG387521TG8510) |
Fusion Gene Summary for TMEM189-MMP23B |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TMEM189-MMP23B | Fusion gene ID: hg387521tg8510 | Hgene | Tgene | Gene symbol | TMEM189 | MMP23B | Gene ID | 387521 | 8510 |
| Gene name | transmembrane protein 189 | matrix metallopeptidase 23B | |
| Synonyms | CarF|KUA | MIFR|MIFR-1|MMP22|MMP23A | |
| Cytomap | ('TMEM189')('MMP23B') 20q13.13 | 1p36.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | transmembrane protein 189 | matrix metalloproteinase-23MMP-21MMP-22MMP-23femalysinmatrix metalloproteinase 22matrix metalloproteinase 23Bmatrix metalloproteinase in the female reproductive tractmatrix metalloproteinase-21 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000371650, ENST00000371652, ENST00000371656, ENST00000557021, | ||
| Fusion gene scores | * DoF score | 7 X 9 X 6=378 | 1 X 1 X 1=1 |
| # samples | 8 | 1 | |
| ** MAII score | log2(8/378*10)=-2.24031432933371 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: TMEM189 [Title/Abstract] AND MMP23B [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | TMEM189(48744511)-MMP23B(1568566), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | TMEM189-MMP23B seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. TMEM189-MMP23B seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. TMEM189-MMP23B seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. TMEM189-MMP23B seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | TMEM189 | GO:0008611 | ether lipid biosynthetic process | 31604315 |
| Tgene | MMP23B | GO:0006508 | proteolysis | 9988691 |
| Fusion gene breakpoints across TMEM189 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
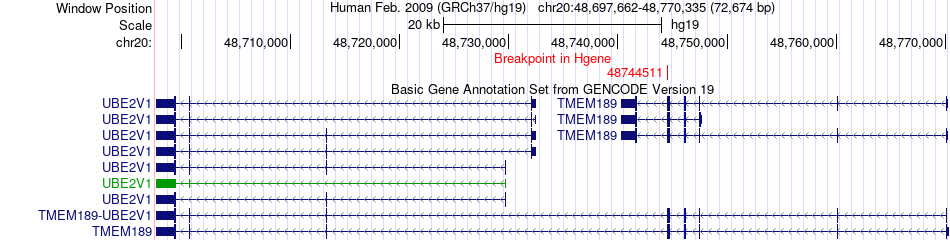 |
| Fusion gene breakpoints across MMP23B (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | TCGA-L5-A4OQ-11A | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + |
Top |
Fusion Gene ORF analysis for TMEM189-MMP23B |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000371650 | ENST00000378675 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + |
| Frame-shift | ENST00000371652 | ENST00000378675 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + |
| Frame-shift | ENST00000371656 | ENST00000378675 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + |
| Frame-shift | ENST00000557021 | ENST00000378675 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + |
| In-frame | ENST00000371650 | ENST00000356026 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + |
| In-frame | ENST00000371652 | ENST00000356026 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + |
| In-frame | ENST00000371656 | ENST00000356026 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + |
| In-frame | ENST00000557021 | ENST00000356026 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000557021 | TMEM189 | chr20 | 48744511 | - | ENST00000356026 | MMP23B | chr1 | 1568566 | + | 1627 | 852 | 110 | 1597 | 495 |
| ENST00000371650 | TMEM189 | chr20 | 48744511 | - | ENST00000356026 | MMP23B | chr1 | 1568566 | + | 1554 | 779 | 46 | 1524 | 492 |
| ENST00000371652 | TMEM189 | chr20 | 48744511 | - | ENST00000356026 | MMP23B | chr1 | 1568566 | + | 1563 | 788 | 46 | 1533 | 495 |
| ENST00000371656 | TMEM189 | chr20 | 48744511 | - | ENST00000356026 | MMP23B | chr1 | 1568566 | + | 1338 | 563 | 97 | 1308 | 403 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000557021 | ENST00000356026 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + | 0.14455307 | 0.855447 |
| ENST00000371650 | ENST00000356026 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + | 0.17211868 | 0.8278813 |
| ENST00000371652 | ENST00000356026 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + | 0.14698109 | 0.85301894 |
| ENST00000371656 | ENST00000356026 | TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + | 0.14911649 | 0.85088354 |
Top |
Fusion Genomic Features for TMEM189-MMP23B |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + | 0.9166014 | 0.08339861 |
| TMEM189 | chr20 | 48744511 | - | MMP23B | chr1 | 1568566 | + | 0.9166014 | 0.08339861 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for TMEM189-MMP23B |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:48744511/chr1:1568566) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TMEM189 | chr20:48744511 | chr1:1568566 | ENST00000371652 | - | 5 | 6 | 186_190 | 230 | 271.0 | Motif | Histidine box-1 |
| Hgene | TMEM189 | chr20:48744511 | chr1:1568566 | ENST00000371652 | - | 5 | 6 | 213_217 | 230 | 271.0 | Motif | Histidine box-2 |
| Hgene | TMEM189 | chr20:48744511 | chr1:1568566 | ENST00000371652 | - | 5 | 6 | 161_181 | 230 | 271.0 | Transmembrane | Helical |
| Hgene | TMEM189 | chr20:48744511 | chr1:1568566 | ENST00000371652 | - | 5 | 6 | 47_67 | 230 | 271.0 | Transmembrane | Helical |
| Hgene | TMEM189 | chr20:48744511 | chr1:1568566 | ENST00000371652 | - | 5 | 6 | 74_94 | 230 | 271.0 | Transmembrane | Helical |
| Tgene | MMP23B | chr20:48744511 | chr1:1568566 | ENST00000356026 | 2 | 8 | 295_380 | 142 | 391.0 | Domain | Note=Ig-like C2-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | MMP23B | chr20:48744511 | chr1:1568566 | ENST00000356026 | 2 | 8 | 1_19 | 142 | 391.0 | Topological domain | Cytoplasmic | |
| Tgene | MMP23B | chr20:48744511 | chr1:1568566 | ENST00000356026 | 2 | 8 | 41_390 | 142 | 391.0 | Topological domain | Lumenal | |
| Tgene | MMP23B | chr20:48744511 | chr1:1568566 | ENST00000356026 | 2 | 8 | 20_40 | 142 | 391.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
Top |
Fusion Gene Sequence for TMEM189-MMP23B |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >91847_91847_1_TMEM189-MMP23B_TMEM189_chr20_48744511_ENST00000371650_MMP23B_chr1_1568566_ENST00000356026_length(transcript)=1554nt_BP=779nt GCTGGGCGGTCATTGGGCGGCGTGATCTCGCCGCGGTTCCGCGGCCCTGCCGCCGCCGCCGCCAGCAGAGCGCACCGGGCCGATCGGGCG AGTGGCCATGGCGGGCGCCGAGAACTGGCCGGGCCAGCAGCTGGAGCTGGACGAGGACGAGGCGTCTTGTTGCCGCTGGGGCGCGCAGCA CGCCGGGGCCCGCGAGCTGGCTGCGCTCTACTCGCCAGGCAAGCGCCTCCAGGAGTGGTGCTCTGTGATCCTGTGCTTCAGCCTCATCGC CCACAACCTGGTCCATCTCCTGCTGCTGGCCCGCTGGGAGGACACACCCCTCGTCATACTCGGTGTTGTTGCAGGGGCTCTCATTGCTGA CTTCTTGTCTGGCCTGGTACACTGGGGTGCTGACACATGGGGCTCTGTGGAGCTGCCCATTGCTTTCATCCGACCCTTCCGGGAGCACCA CATTGACCCGACAGCTATCACACGGCACGACTTCATCGAGACCAACGGGGACAACTGCCTGGTGACACTGCTGCCGCTGCTAAACATGGC CTACAAGTTCCGCACCCACAGCCCTGAAGCCCTGGAGCAGCTATACCCCTGGGAGTGCTTCGTCTTCTGCCTGATCATCTTCGGCACCTT CACCAACCAGATCCACAAGTGGTCGCACACGTACTTTGGGCTGCCACGCTGGGTCACCCTCCTGCAGGACTGGCATGTCATCCTGCCACG TAAACACCATCGCATCCACCACGTCTCACCCCACGAGACCTACTTCTGCATCACCACAGGCTTCTACCCGATCAACCACACGGACTGCCT GGTCTCCGCGCTGCACCACTGCTTCGACGGCCCCACGGGGGAGCTGGCCCACGCCTTCTTCCCCCCGCACGGCGGCATCCACTTCGACGA CAGCGAGTACTGGGTCCTGGGCCCCACGCGCTACAGCTGGAAGAAAGGCGTGTGGCTCACGGACCTGGTGCACGTGGCGGCCCACGAGAT CGGCCACGCGCTGGGCCTGATGCACTCACAACACGGCCGGGCGCTCATGCACCTGAACGCCACGCTGCGCGGCTGGAAGGCGTTGTCCCA GGACGAGCTGTGGGGGCTGCACCGGCTCTACGGATGCCTCGACAGGCTGTTCGTGTGCGCGTCCTGGGCGCGGAGGGGCTTCTGCGACGC TCGCCGGCGGCTCATGAAGAGGCTCTGCCCCAGCAGCTGCGACTTCTGCTACGAATTCCCCTTCCCCACGGTGGCCACCACCCCACCGCC CCCCAGGACCAAAACCAGGCTGGTGCCCGAGGGCAGGAACGTGACCTTCCGCTGCGGCCAGAAGATCCTCCACAAGAAAGGGAAAGTGTA CTGGTACAAGGACCAGGAGCCCCTGGAGTTCTCCTACCCCGGCTACCTGGCCCTGGGCGAGGCGCACCTGAGCATCATCGCCAACGCCGT CAATGAGGGCACCTACACCTGCGTGGTGCGCCGCCAGCAGCGCGTGCTGACCACCTACTCCTGGCGAGTCCGTGTGCGGGGCTGAGCCCG >91847_91847_1_TMEM189-MMP23B_TMEM189_chr20_48744511_ENST00000371650_MMP23B_chr1_1568566_ENST00000356026_length(amino acids)=492AA_BP=244 MPPPPPAERTGPIGRVAMAGAENWPGQQLELDEDEASCCRWGAQHAGARELAALYSPGKRLQEWCSVILCFSLIAHNLVHLLLLARWEDT PLVILGVVAGALIADFLSGLVHWGADTWGSVELPIAFIRPFREHHIDPTAITRHDFIETNGDNCLVTLLPLLNMAYKFRTHSPEALEQLY PWECFVFCLIIFGTFTNQIHKWSHTYFGLPRWVTLLQDWHVILPRKHHRIHHVSPHETYFCITTGFYPINHTDCLVSALHHCFDGPTGEL AHAFFPPHGGIHFDDSEYWVLGPTRYSWKKGVWLTDLVHVAAHEIGHALGLMHSQHGRALMHLNATLRGWKALSQDELWGLHRLYGCLDR LFVCASWARRGFCDARRRLMKRLCPSSCDFCYEFPFPTVATTPPPPRTKTRLVPEGRNVTFRCGQKILHKKGKVYWYKDQEPLEFSYPGY -------------------------------------------------------------- >91847_91847_2_TMEM189-MMP23B_TMEM189_chr20_48744511_ENST00000371652_MMP23B_chr1_1568566_ENST00000356026_length(transcript)=1563nt_BP=788nt GCTGGGCGGTCATTGGGCGGCGTGATCTCGCCGCGGTTCCGCGGCCCTGCCGCCGCCGCCGCCAGCAGAGCGCACCGGGCCGATCGGGCG AGTGGCCATGGCGGGCGCCGAGAACTGGCCGGGCCAGCAGCTGGAGCTGGACGAGGACGAGGCGTCTTGTTGCCGCTGGGGCGCGCAGCA CGCCGGGGCCCGCGAGCTGGCTGCGCTCTACTCGCCAGGCAAGCGCCTCCAGGAGTGGTGCTCTGTGATCCTGTGCTTCAGCCTCATCGC CCACAACCTGGTCCATCTCCTGCTGCTGGCCCGCTGGGAGGACACACCCCTCGTCATACTCGGTGTTGTTGCAGGGGCTCTCATTGCTGA CTTCTTGTCTGGCCTGGTACACTGGGGTGCTGACACATGGGGCTCTGTGGAGCTGCCCATTGTGGGGAAGGCTTTCATCCGACCCTTCCG GGAGCACCACATTGACCCGACAGCTATCACACGGCACGACTTCATCGAGACCAACGGGGACAACTGCCTGGTGACACTGCTGCCGCTGCT AAACATGGCCTACAAGTTCCGCACCCACAGCCCTGAAGCCCTGGAGCAGCTATACCCCTGGGAGTGCTTCGTCTTCTGCCTGATCATCTT CGGCACCTTCACCAACCAGATCCACAAGTGGTCGCACACGTACTTTGGGCTGCCACGCTGGGTCACCCTCCTGCAGGACTGGCATGTCAT CCTGCCACGTAAACACCATCGCATCCACCACGTCTCACCCCACGAGACCTACTTCTGCATCACCACAGGCTTCTACCCGATCAACCACAC GGACTGCCTGGTCTCCGCGCTGCACCACTGCTTCGACGGCCCCACGGGGGAGCTGGCCCACGCCTTCTTCCCCCCGCACGGCGGCATCCA CTTCGACGACAGCGAGTACTGGGTCCTGGGCCCCACGCGCTACAGCTGGAAGAAAGGCGTGTGGCTCACGGACCTGGTGCACGTGGCGGC CCACGAGATCGGCCACGCGCTGGGCCTGATGCACTCACAACACGGCCGGGCGCTCATGCACCTGAACGCCACGCTGCGCGGCTGGAAGGC GTTGTCCCAGGACGAGCTGTGGGGGCTGCACCGGCTCTACGGATGCCTCGACAGGCTGTTCGTGTGCGCGTCCTGGGCGCGGAGGGGCTT CTGCGACGCTCGCCGGCGGCTCATGAAGAGGCTCTGCCCCAGCAGCTGCGACTTCTGCTACGAATTCCCCTTCCCCACGGTGGCCACCAC CCCACCGCCCCCCAGGACCAAAACCAGGCTGGTGCCCGAGGGCAGGAACGTGACCTTCCGCTGCGGCCAGAAGATCCTCCACAAGAAAGG GAAAGTGTACTGGTACAAGGACCAGGAGCCCCTGGAGTTCTCCTACCCCGGCTACCTGGCCCTGGGCGAGGCGCACCTGAGCATCATCGC CAACGCCGTCAATGAGGGCACCTACACCTGCGTGGTGCGCCGCCAGCAGCGCGTGCTGACCACCTACTCCTGGCGAGTCCGTGTGCGGGG >91847_91847_2_TMEM189-MMP23B_TMEM189_chr20_48744511_ENST00000371652_MMP23B_chr1_1568566_ENST00000356026_length(amino acids)=495AA_BP=247 MPPPPPAERTGPIGRVAMAGAENWPGQQLELDEDEASCCRWGAQHAGARELAALYSPGKRLQEWCSVILCFSLIAHNLVHLLLLARWEDT PLVILGVVAGALIADFLSGLVHWGADTWGSVELPIVGKAFIRPFREHHIDPTAITRHDFIETNGDNCLVTLLPLLNMAYKFRTHSPEALE QLYPWECFVFCLIIFGTFTNQIHKWSHTYFGLPRWVTLLQDWHVILPRKHHRIHHVSPHETYFCITTGFYPINHTDCLVSALHHCFDGPT GELAHAFFPPHGGIHFDDSEYWVLGPTRYSWKKGVWLTDLVHVAAHEIGHALGLMHSQHGRALMHLNATLRGWKALSQDELWGLHRLYGC LDRLFVCASWARRGFCDARRRLMKRLCPSSCDFCYEFPFPTVATTPPPPRTKTRLVPEGRNVTFRCGQKILHKKGKVYWYKDQEPLEFSY -------------------------------------------------------------- >91847_91847_3_TMEM189-MMP23B_TMEM189_chr20_48744511_ENST00000371656_MMP23B_chr1_1568566_ENST00000356026_length(transcript)=1338nt_BP=563nt CAAGTAACAGGCAGGAGGAGTGTTAAGCCTGAGGCTCCATCTTCAGGGAAGAAAACATCCCAACTAGAGAAGAAGGGACACCTTCCCCTC CTAACAAATGAATGAGCGGGCAATTGCAGGGGCTCTCATTGCTGACTTCTTGTCTGGCCTGGTACACTGGGGTGCTGACACATGGGGCTC TGTGGAGCTGCCCATTGTGGGGAAGGCTTTCATCCGACCCTTCCGGGAGCACCACATTGACCCGACAGCTATCACACGGCACGACTTCAT CGAGACCAACGGGGACAACTGCCTGGTGACACTGCTGCCGCTGCTAAACATGGCCTACAAGTTCCGCACCCACAGCCCTGAAGCCCTGGA GCAGCTATACCCCTGGGAGTGCTTCGTCTTCTGCCTGATCATCTTCGGCACCTTCACCAACCAGATCCACAAGTGGTCGCACACGTACTT TGGGCTGCCACGCTGGGTCACCCTCCTGCAGGACTGGCATGTCATCCTGCCACGTAAACACCATCGCATCCACCACGTCTCACCCCACGA GACCTACTTCTGCATCACCACAGGCTTCTACCCGATCAACCACACGGACTGCCTGGTCTCCGCGCTGCACCACTGCTTCGACGGCCCCAC GGGGGAGCTGGCCCACGCCTTCTTCCCCCCGCACGGCGGCATCCACTTCGACGACAGCGAGTACTGGGTCCTGGGCCCCACGCGCTACAG CTGGAAGAAAGGCGTGTGGCTCACGGACCTGGTGCACGTGGCGGCCCACGAGATCGGCCACGCGCTGGGCCTGATGCACTCACAACACGG CCGGGCGCTCATGCACCTGAACGCCACGCTGCGCGGCTGGAAGGCGTTGTCCCAGGACGAGCTGTGGGGGCTGCACCGGCTCTACGGATG CCTCGACAGGCTGTTCGTGTGCGCGTCCTGGGCGCGGAGGGGCTTCTGCGACGCTCGCCGGCGGCTCATGAAGAGGCTCTGCCCCAGCAG CTGCGACTTCTGCTACGAATTCCCCTTCCCCACGGTGGCCACCACCCCACCGCCCCCCAGGACCAAAACCAGGCTGGTGCCCGAGGGCAG GAACGTGACCTTCCGCTGCGGCCAGAAGATCCTCCACAAGAAAGGGAAAGTGTACTGGTACAAGGACCAGGAGCCCCTGGAGTTCTCCTA CCCCGGCTACCTGGCCCTGGGCGAGGCGCACCTGAGCATCATCGCCAACGCCGTCAATGAGGGCACCTACACCTGCGTGGTGCGCCGCCA >91847_91847_3_TMEM189-MMP23B_TMEM189_chr20_48744511_ENST00000371656_MMP23B_chr1_1568566_ENST00000356026_length(amino acids)=403AA_BP=155 MNERAIAGALIADFLSGLVHWGADTWGSVELPIVGKAFIRPFREHHIDPTAITRHDFIETNGDNCLVTLLPLLNMAYKFRTHSPEALEQL YPWECFVFCLIIFGTFTNQIHKWSHTYFGLPRWVTLLQDWHVILPRKHHRIHHVSPHETYFCITTGFYPINHTDCLVSALHHCFDGPTGE LAHAFFPPHGGIHFDDSEYWVLGPTRYSWKKGVWLTDLVHVAAHEIGHALGLMHSQHGRALMHLNATLRGWKALSQDELWGLHRLYGCLD RLFVCASWARRGFCDARRRLMKRLCPSSCDFCYEFPFPTVATTPPPPRTKTRLVPEGRNVTFRCGQKILHKKGKVYWYKDQEPLEFSYPG -------------------------------------------------------------- >91847_91847_4_TMEM189-MMP23B_TMEM189_chr20_48744511_ENST00000557021_MMP23B_chr1_1568566_ENST00000356026_length(transcript)=1627nt_BP=852nt AGCCCCGATTGGCTGTGACGCGCGGCCGGGCGAGGACCCCGCCCGCGCCGCCGCCGCGCCCGGCGCTGGGCGGTCATTGGGCGGCGTGAT CTCGCCGCGGTTCCGCGGCCCTGCCGCCGCCGCCGCCAGCAGAGCGCACCGGGCCGATCGGGCGAGTGGCCATGGCGGGCGCCGAGAACT GGCCGGGCCAGCAGCTGGAGCTGGACGAGGACGAGGCGTCTTGTTGCCGCTGGGGCGCGCAGCACGCCGGGGCCCGCGAGCTGGCTGCGC TCTACTCGCCAGGCAAGCGCCTCCAGGAGTGGTGCTCTGTGATCCTGTGCTTCAGCCTCATCGCCCACAACCTGGTCCATCTCCTGCTGC TGGCCCGCTGGGAGGACACACCCCTCGTCATACTCGGTGTTGTTGCAGGGGCTCTCATTGCTGACTTCTTGTCTGGCCTGGTACACTGGG GTGCTGACACATGGGGCTCTGTGGAGCTGCCCATTGTGGGGAAGGCTTTCATCCGACCCTTCCGGGAGCACCACATTGACCCGACAGCTA TCACACGGCACGACTTCATCGAGACCAACGGGGACAACTGCCTGGTGACACTGCTGCCGCTGCTAAACATGGCCTACAAGTTCCGCACCC ACAGCCCTGAAGCCCTGGAGCAGCTATACCCCTGGGAGTGCTTCGTCTTCTGCCTGATCATCTTCGGCACCTTCACCAACCAGATCCACA AGTGGTCGCACACGTACTTTGGGCTGCCACGCTGGGTCACCCTCCTGCAGGACTGGCATGTCATCCTGCCACGTAAACACCATCGCATCC ACCACGTCTCACCCCACGAGACCTACTTCTGCATCACCACAGGCTTCTACCCGATCAACCACACGGACTGCCTGGTCTCCGCGCTGCACC ACTGCTTCGACGGCCCCACGGGGGAGCTGGCCCACGCCTTCTTCCCCCCGCACGGCGGCATCCACTTCGACGACAGCGAGTACTGGGTCC TGGGCCCCACGCGCTACAGCTGGAAGAAAGGCGTGTGGCTCACGGACCTGGTGCACGTGGCGGCCCACGAGATCGGCCACGCGCTGGGCC TGATGCACTCACAACACGGCCGGGCGCTCATGCACCTGAACGCCACGCTGCGCGGCTGGAAGGCGTTGTCCCAGGACGAGCTGTGGGGGC TGCACCGGCTCTACGGATGCCTCGACAGGCTGTTCGTGTGCGCGTCCTGGGCGCGGAGGGGCTTCTGCGACGCTCGCCGGCGGCTCATGA AGAGGCTCTGCCCCAGCAGCTGCGACTTCTGCTACGAATTCCCCTTCCCCACGGTGGCCACCACCCCACCGCCCCCCAGGACCAAAACCA GGCTGGTGCCCGAGGGCAGGAACGTGACCTTCCGCTGCGGCCAGAAGATCCTCCACAAGAAAGGGAAAGTGTACTGGTACAAGGACCAGG AGCCCCTGGAGTTCTCCTACCCCGGCTACCTGGCCCTGGGCGAGGCGCACCTGAGCATCATCGCCAACGCCGTCAATGAGGGCACCTACA CCTGCGTGGTGCGCCGCCAGCAGCGCGTGCTGACCACCTACTCCTGGCGAGTCCGTGTGCGGGGCTGAGCCCGGCTGATAAAGCACTTTC >91847_91847_4_TMEM189-MMP23B_TMEM189_chr20_48744511_ENST00000557021_MMP23B_chr1_1568566_ENST00000356026_length(amino acids)=495AA_BP=247 MPPPPPAERTGPIGRVAMAGAENWPGQQLELDEDEASCCRWGAQHAGARELAALYSPGKRLQEWCSVILCFSLIAHNLVHLLLLARWEDT PLVILGVVAGALIADFLSGLVHWGADTWGSVELPIVGKAFIRPFREHHIDPTAITRHDFIETNGDNCLVTLLPLLNMAYKFRTHSPEALE QLYPWECFVFCLIIFGTFTNQIHKWSHTYFGLPRWVTLLQDWHVILPRKHHRIHHVSPHETYFCITTGFYPINHTDCLVSALHHCFDGPT GELAHAFFPPHGGIHFDDSEYWVLGPTRYSWKKGVWLTDLVHVAAHEIGHALGLMHSQHGRALMHLNATLRGWKALSQDELWGLHRLYGC LDRLFVCASWARRGFCDARRRLMKRLCPSSCDFCYEFPFPTVATTPPPPRTKTRLVPEGRNVTFRCGQKILHKKGKVYWYKDQEPLEFSY -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TMEM189-MMP23B |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TMEM189-MMP23B |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TMEM189-MMP23B |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies