
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:MEIS1-SUPT3H (FusionGDB2 ID:HG4211TG8464) |
Fusion Gene Summary for MEIS1-SUPT3H |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: MEIS1-SUPT3H | Fusion gene ID: hg4211tg8464 | Hgene | Tgene | Gene symbol | MEIS1 | SUPT3H | Gene ID | 4211 | 8464 |
| Gene name | Meis homeobox 1 | SPT3 homolog, SAGA and STAGA complex component | |
| Synonyms | - | SPT3|SPT3L | |
| Cytomap | ('MEIS1')('SUPT3H') 2p14 | 6p21.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | homeobox protein Meis1Meis1, myeloid ecotropic viral integration site 1 homologWUGSC:H_NH0444B04.1leukemogenic homolog protein | transcription initiation protein SPT3 homologSPT3-like proteinsuppressor of Ty 3 homolog | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O00470 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000272369, ENST00000398506, ENST00000407092, ENST00000488550, ENST00000495021, ENST00000560281, ENST00000409517, ENST00000444274, | ||
| Fusion gene scores | * DoF score | 3 X 2 X 3=18 | 19 X 9 X 9=1539 |
| # samples | 3 | 22 | |
| ** MAII score | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(22/1539*10)=-2.80641780280355 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: MEIS1 [Title/Abstract] AND SUPT3H [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | MEIS1(66739426)-SUPT3H(44900500), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | MEIS1-SUPT3H seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. MEIS1-SUPT3H seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. MEIS1-SUPT3H seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. MEIS1-SUPT3H seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | SUPT3H | GO:0016578 | histone deubiquitination | 18206972 |
| Tgene | SUPT3H | GO:0043966 | histone H3 acetylation | 11564863 |
| Fusion gene breakpoints across MEIS1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
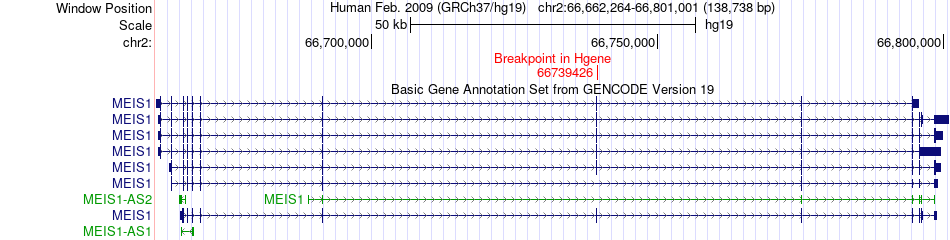 |
| Fusion gene breakpoints across SUPT3H (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
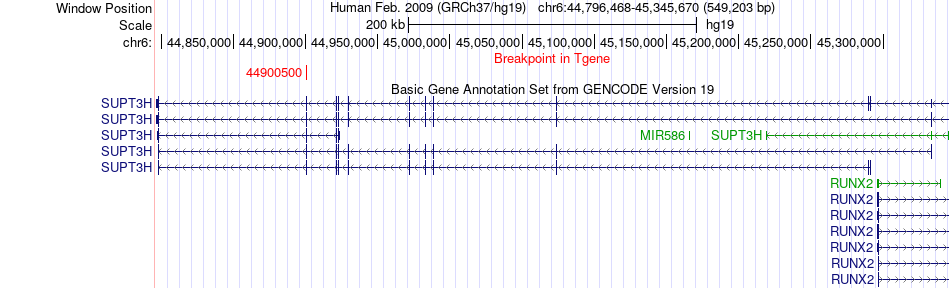 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-1546 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
Top |
Fusion Gene ORF analysis for MEIS1-SUPT3H |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000272369 | ENST00000459689 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| 5CDS-intron | ENST00000398506 | ENST00000459689 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| 5CDS-intron | ENST00000407092 | ENST00000459689 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| 5CDS-intron | ENST00000488550 | ENST00000459689 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| 5CDS-intron | ENST00000495021 | ENST00000459689 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| 5CDS-intron | ENST00000560281 | ENST00000459689 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000272369 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000272369 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000272369 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000272369 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000272369 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000398506 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000398506 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000398506 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000398506 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000398506 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000407092 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000407092 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000407092 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000407092 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000407092 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000488550 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000488550 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000488550 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000488550 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000488550 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000495021 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000495021 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000495021 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000495021 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000495021 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000560281 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000560281 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000560281 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000560281 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| In-frame | ENST00000560281 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000409517 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000409517 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000409517 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000409517 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000409517 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000444274 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000444274 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000444274 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000444274 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-3CDS | ENST00000444274 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-intron | ENST00000409517 | ENST00000459689 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| intron-intron | ENST00000444274 | ENST00000459689 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000560281 | MEIS1 | chr2 | 66739426 | + | ENST00000371460 | SUPT3H | chr6 | 44900500 | - | 2849 | 1612 | 724 | 1764 | 346 |
| ENST00000560281 | MEIS1 | chr2 | 66739426 | + | ENST00000371459 | SUPT3H | chr6 | 44900500 | - | 2736 | 1612 | 724 | 1764 | 346 |
| ENST00000560281 | MEIS1 | chr2 | 66739426 | + | ENST00000371461 | SUPT3H | chr6 | 44900500 | - | 1765 | 1612 | 724 | 1764 | 347 |
| ENST00000560281 | MEIS1 | chr2 | 66739426 | + | ENST00000306867 | SUPT3H | chr6 | 44900500 | - | 1765 | 1612 | 724 | 1764 | 347 |
| ENST00000560281 | MEIS1 | chr2 | 66739426 | + | ENST00000371458 | SUPT3H | chr6 | 44900500 | - | 1833 | 1612 | 724 | 1788 | 354 |
| ENST00000407092 | MEIS1 | chr2 | 66739426 | + | ENST00000371460 | SUPT3H | chr6 | 44900500 | - | 2582 | 1345 | 457 | 1497 | 346 |
| ENST00000407092 | MEIS1 | chr2 | 66739426 | + | ENST00000371459 | SUPT3H | chr6 | 44900500 | - | 2469 | 1345 | 457 | 1497 | 346 |
| ENST00000407092 | MEIS1 | chr2 | 66739426 | + | ENST00000371461 | SUPT3H | chr6 | 44900500 | - | 1498 | 1345 | 457 | 1497 | 347 |
| ENST00000407092 | MEIS1 | chr2 | 66739426 | + | ENST00000306867 | SUPT3H | chr6 | 44900500 | - | 1498 | 1345 | 457 | 1497 | 347 |
| ENST00000407092 | MEIS1 | chr2 | 66739426 | + | ENST00000371458 | SUPT3H | chr6 | 44900500 | - | 1566 | 1345 | 457 | 1521 | 354 |
| ENST00000272369 | MEIS1 | chr2 | 66739426 | + | ENST00000371460 | SUPT3H | chr6 | 44900500 | - | 2582 | 1345 | 457 | 1497 | 346 |
| ENST00000272369 | MEIS1 | chr2 | 66739426 | + | ENST00000371459 | SUPT3H | chr6 | 44900500 | - | 2469 | 1345 | 457 | 1497 | 346 |
| ENST00000272369 | MEIS1 | chr2 | 66739426 | + | ENST00000371461 | SUPT3H | chr6 | 44900500 | - | 1498 | 1345 | 457 | 1497 | 347 |
| ENST00000272369 | MEIS1 | chr2 | 66739426 | + | ENST00000306867 | SUPT3H | chr6 | 44900500 | - | 1498 | 1345 | 457 | 1497 | 347 |
| ENST00000272369 | MEIS1 | chr2 | 66739426 | + | ENST00000371458 | SUPT3H | chr6 | 44900500 | - | 1566 | 1345 | 457 | 1521 | 354 |
| ENST00000488550 | MEIS1 | chr2 | 66739426 | + | ENST00000371460 | SUPT3H | chr6 | 44900500 | - | 2424 | 1187 | 299 | 1339 | 346 |
| ENST00000488550 | MEIS1 | chr2 | 66739426 | + | ENST00000371459 | SUPT3H | chr6 | 44900500 | - | 2311 | 1187 | 299 | 1339 | 346 |
| ENST00000488550 | MEIS1 | chr2 | 66739426 | + | ENST00000371461 | SUPT3H | chr6 | 44900500 | - | 1340 | 1187 | 299 | 1339 | 347 |
| ENST00000488550 | MEIS1 | chr2 | 66739426 | + | ENST00000306867 | SUPT3H | chr6 | 44900500 | - | 1340 | 1187 | 299 | 1339 | 347 |
| ENST00000488550 | MEIS1 | chr2 | 66739426 | + | ENST00000371458 | SUPT3H | chr6 | 44900500 | - | 1408 | 1187 | 299 | 1363 | 354 |
| ENST00000398506 | MEIS1 | chr2 | 66739426 | + | ENST00000371460 | SUPT3H | chr6 | 44900500 | - | 2457 | 1220 | 311 | 1372 | 353 |
| ENST00000398506 | MEIS1 | chr2 | 66739426 | + | ENST00000371459 | SUPT3H | chr6 | 44900500 | - | 2344 | 1220 | 311 | 1372 | 353 |
| ENST00000398506 | MEIS1 | chr2 | 66739426 | + | ENST00000371461 | SUPT3H | chr6 | 44900500 | - | 1373 | 1220 | 311 | 1372 | 354 |
| ENST00000398506 | MEIS1 | chr2 | 66739426 | + | ENST00000306867 | SUPT3H | chr6 | 44900500 | - | 1373 | 1220 | 311 | 1372 | 354 |
| ENST00000398506 | MEIS1 | chr2 | 66739426 | + | ENST00000371458 | SUPT3H | chr6 | 44900500 | - | 1441 | 1220 | 311 | 1396 | 361 |
| ENST00000495021 | MEIS1 | chr2 | 66739426 | + | ENST00000371460 | SUPT3H | chr6 | 44900500 | - | 2237 | 1000 | 307 | 1152 | 281 |
| ENST00000495021 | MEIS1 | chr2 | 66739426 | + | ENST00000371459 | SUPT3H | chr6 | 44900500 | - | 2124 | 1000 | 307 | 1152 | 281 |
| ENST00000495021 | MEIS1 | chr2 | 66739426 | + | ENST00000371461 | SUPT3H | chr6 | 44900500 | - | 1153 | 1000 | 307 | 1152 | 282 |
| ENST00000495021 | MEIS1 | chr2 | 66739426 | + | ENST00000306867 | SUPT3H | chr6 | 44900500 | - | 1153 | 1000 | 307 | 1152 | 282 |
| ENST00000495021 | MEIS1 | chr2 | 66739426 | + | ENST00000371458 | SUPT3H | chr6 | 44900500 | - | 1221 | 1000 | 307 | 1176 | 289 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000560281 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.001686079 | 0.9983139 |
| ENST00000560281 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.002286342 | 0.9977137 |
| ENST00000560281 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.006212758 | 0.9937873 |
| ENST00000560281 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.006212758 | 0.9937873 |
| ENST00000560281 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.005830564 | 0.9941695 |
| ENST00000407092 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.001086236 | 0.99891376 |
| ENST00000407092 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.001546957 | 0.998453 |
| ENST00000407092 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.004705878 | 0.99529415 |
| ENST00000407092 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.004705878 | 0.99529415 |
| ENST00000407092 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.004074754 | 0.9959253 |
| ENST00000272369 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.001086236 | 0.99891376 |
| ENST00000272369 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.001546957 | 0.998453 |
| ENST00000272369 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.004705878 | 0.99529415 |
| ENST00000272369 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.004705878 | 0.99529415 |
| ENST00000272369 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.004074754 | 0.9959253 |
| ENST00000488550 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.001119097 | 0.9988809 |
| ENST00000488550 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.001598491 | 0.99840146 |
| ENST00000488550 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.005817703 | 0.9941823 |
| ENST00000488550 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.005817703 | 0.9941823 |
| ENST00000488550 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.004998949 | 0.995001 |
| ENST00000398506 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.002624213 | 0.99737585 |
| ENST00000398506 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.003396314 | 0.9966037 |
| ENST00000398506 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.011069707 | 0.9889303 |
| ENST00000398506 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.011069707 | 0.9889303 |
| ENST00000398506 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.010830211 | 0.9891698 |
| ENST00000495021 | ENST00000371460 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.001994684 | 0.99800533 |
| ENST00000495021 | ENST00000371459 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.002547302 | 0.9974527 |
| ENST00000495021 | ENST00000371461 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.008588384 | 0.99141157 |
| ENST00000495021 | ENST00000306867 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.008588384 | 0.99141157 |
| ENST00000495021 | ENST00000371458 | MEIS1 | chr2 | 66739426 | + | SUPT3H | chr6 | 44900500 | - | 0.009759298 | 0.9902407 |
Top |
Fusion Genomic Features for MEIS1-SUPT3H |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
Top |
Fusion Protein Features for MEIS1-SUPT3H |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:66739426/chr6:44900500) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| MEIS1 | . |
| FUNCTION: Acts as a transcriptional regulator of PAX6. Acts as a transcriptional activator of PF4 in complex with PBX1 or PBX2. Required for hematopoiesis, megakaryocyte lineage development and vascular patterning. May function as a cofactor for HOXA7 and HOXA9 in the induction of myeloid leukemias. {ECO:0000269|PubMed:12609849}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000272369 | + | 8 | 13 | 194_240 | 296 | 1109.3333333333333 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000272369 | + | 8 | 13 | 242_269 | 296 | 1109.3333333333333 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000272369 | + | 8 | 13 | 262_269 | 296 | 1109.3333333333333 | Compositional bias | Note=Poly-Asp |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000398506 | + | 7 | 11 | 194_240 | 294 | 464.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000398506 | + | 7 | 11 | 242_269 | 294 | 464.0 | Compositional bias | Note=Asp/Glu-rich (acidic) |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000398506 | + | 7 | 11 | 262_269 | 294 | 464.0 | Compositional bias | Note=Poly-Asp |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000272369 | + | 8 | 13 | 272_334 | 296 | 1109.3333333333333 | DNA binding | Homeobox%3B TALE-type |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000398506 | + | 7 | 11 | 272_334 | 294 | 464.0 | DNA binding | Homeobox%3B TALE-type |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000272369 | + | 8 | 13 | 335_390 | 296 | 1109.3333333333333 | Region | Required for transcriptional activation |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000398506 | + | 7 | 11 | 335_390 | 294 | 464.0 | Region | Required for transcriptional activation |
Top |
Fusion Gene Sequence for MEIS1-SUPT3H |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >52889_52889_1_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000306867_length(transcript)=1498nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC >52889_52889_1_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000306867_length(amino acids)=347AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_2_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000371458_length(transcript)=1566nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC ACTTTCCCCATTCACAATTTCTTTTTCTTTGACAGAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTG >52889_52889_2_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000371458_length(amino acids)=354AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_3_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000371459_length(transcript)=2469nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC ACTTTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGTGCCTGCAACAACAGG AAAGGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGAGTGGGCTGGTCTGTT GTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTCAGCTAATTAATGGCA GGATGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTACTGCCCTCAGCTCAC ATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTTTGGAACAAGGAAACA AAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTTTTAGTGACAGCTATC CATTTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCACTCCACTTATAGTAT GTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTCTTCCTCCATCTTCAT TTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGTATTCAGAATCAGTAG AAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTAATTTCTTGCTGTTAG CAGCCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAATATAGCAGATGTAAT >52889_52889_3_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000371459_length(amino acids)=346AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_4_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000371460_length(transcript)=2582nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC ACTTTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGTGCCTGCAACAACAGG AAAGGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGAGTGGGCTGGTCTGTT GTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTCAGCTAATTAATGGCA GGATGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTACTGCCCTCAGCTCAC ATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTTTGGAACAAGGAAACA AAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTTTTAGTGACAGCTATC CATTTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCACTCCACTTATAGTAT GTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTCTTCCTCCATCTTCAT TTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGTATTCAGAATCAGTAG AAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTAATTTCTTGCTGTTAG CAGCCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAATATAGCAGATGTAAT TGTACAGTTCCTGATTAAACTTCAGTTGCAAAAAAGAAAGTTATTTCTTTAATTCTGTGGGAGTTTTGTATAATTTTACTTTTATGGTTT >52889_52889_4_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000371460_length(amino acids)=346AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_5_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000371461_length(transcript)=1498nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC >52889_52889_5_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000272369_SUPT3H_chr6_44900500_ENST00000371461_length(amino acids)=347AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_6_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000306867_length(transcript)=1373nt_BP=1220nt GAGACATGCCCGTTTCACCTTCTACCCTCGGGAGAATGCTTCTCTTTCTCTCTTTCTTTCTTCTTTCCTTCTTGCCAAAGGAGCCTGAAT TTCTAAACTAGTTGATAGGGACACAAGTTAGGGCAAGATCATTCATCCCAGACGAGTCTCGCTGAGAATTCTGTATTTTTTACTTAAAGC TTTAATTTTAAAATAAGAAAAACTCAGCTTTATAGATGCAAGGCCACCGAATTCCGGGTGGAAGGACCCAGCTGTATTGACCTTATATAA GCTCGGTGCCTTGCCGTTCTCCCATTTGCCCGCCTGGCCTCCTGAACCTTCTTTCTCTCCTGTTTGTCATGCAGTACGACGATCTACCCC ATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGA ACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACG CTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTA CCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCG CAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAG AGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATA GAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACA CGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATG GCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTC CCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCA TCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACTTTCCCCATTCACAAATGCCTACCGCAGGAATG >52889_52889_6_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000306867_length(amino acids)=354AA_BP=303 MNLLSLLFVMQYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPL FPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRY ISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDD -------------------------------------------------------------- >52889_52889_7_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000371458_length(transcript)=1441nt_BP=1220nt GAGACATGCCCGTTTCACCTTCTACCCTCGGGAGAATGCTTCTCTTTCTCTCTTTCTTTCTTCTTTCCTTCTTGCCAAAGGAGCCTGAAT TTCTAAACTAGTTGATAGGGACACAAGTTAGGGCAAGATCATTCATCCCAGACGAGTCTCGCTGAGAATTCTGTATTTTTTACTTAAAGC TTTAATTTTAAAATAAGAAAAACTCAGCTTTATAGATGCAAGGCCACCGAATTCCGGGTGGAAGGACCCAGCTGTATTGACCTTATATAA GCTCGGTGCCTTGCCGTTCTCCCATTTGCCCGCCTGGCCTCCTGAACCTTCTTTCTCTCCTGTTTGTCATGCAGTACGACGATCTACCCC ATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGA ACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACG CTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTA CCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCG CAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAG AGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATA GAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACA CGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATG GCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTC CCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCA TCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACTTTCCCCATTCACAATTTCTTTTTCTTTGACAG AATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGTGCCTGCAACAACAGGAAAGGCAATGTTATAT >52889_52889_7_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000371458_length(amino acids)=361AA_BP=303 MNLLSLLFVMQYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPL FPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRY ISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDD DDPDKDKKRHKKRGIFPKVATNIMRAWLFQHLTSTAACGVEAHSDAIQPCHIREAIRRYSHRIGPLSPFTISFSLTECLPQEWDGFSSLL -------------------------------------------------------------- >52889_52889_8_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000371459_length(transcript)=2344nt_BP=1220nt GAGACATGCCCGTTTCACCTTCTACCCTCGGGAGAATGCTTCTCTTTCTCTCTTTCTTTCTTCTTTCCTTCTTGCCAAAGGAGCCTGAAT TTCTAAACTAGTTGATAGGGACACAAGTTAGGGCAAGATCATTCATCCCAGACGAGTCTCGCTGAGAATTCTGTATTTTTTACTTAAAGC TTTAATTTTAAAATAAGAAAAACTCAGCTTTATAGATGCAAGGCCACCGAATTCCGGGTGGAAGGACCCAGCTGTATTGACCTTATATAA GCTCGGTGCCTTGCCGTTCTCCCATTTGCCCGCCTGGCCTCCTGAACCTTCTTTCTCTCCTGTTTGTCATGCAGTACGACGATCTACCCC ATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGA ACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACG CTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTA CCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCG CAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAG AGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATA GAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACA CGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATG GCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTC CCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCA TCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACTTTCCCCATTCACAAATGCCTACCGCAGGAATG GGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGTGCCTGCAACAACAGGAAAGGCAATGTTATATTAAGGTGATTTCTTGTGAA CAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGAGTGGGCTGGTCTGTTGTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCA GCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTCAGCTAATTAATGGCAGGATGTTTAGGATAGTCTGTAGGTGGACAAGAATG CAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTACTGCCCTCAGCTCACATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGT TTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTTTGGAACAAGGAAACAAAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTA CACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTTTTAGTGACAGCTATCCATTTTATAAACTTACAGTAATCAAAGATCTAACA GACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCACTCCACTTATAGTATGTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGC CATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTCTTCCTCCATCTTCATTTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATC CACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGTATTCAGAATCAGTAGAAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTC AAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTAATTTCTTGCTGTTAGCAGCCGAGCTACCCTTCTGGCATCTATACTTTCTC CAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAATATAGCAGATGTAATTGTACAGTTCCTGATTAAACTTCAGTTGCAAAAAA >52889_52889_8_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000371459_length(amino acids)=353AA_BP=303 MNLLSLLFVMQYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPL FPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRY ISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDD -------------------------------------------------------------- >52889_52889_9_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000371460_length(transcript)=2457nt_BP=1220nt GAGACATGCCCGTTTCACCTTCTACCCTCGGGAGAATGCTTCTCTTTCTCTCTTTCTTTCTTCTTTCCTTCTTGCCAAAGGAGCCTGAAT TTCTAAACTAGTTGATAGGGACACAAGTTAGGGCAAGATCATTCATCCCAGACGAGTCTCGCTGAGAATTCTGTATTTTTTACTTAAAGC TTTAATTTTAAAATAAGAAAAACTCAGCTTTATAGATGCAAGGCCACCGAATTCCGGGTGGAAGGACCCAGCTGTATTGACCTTATATAA GCTCGGTGCCTTGCCGTTCTCCCATTTGCCCGCCTGGCCTCCTGAACCTTCTTTCTCTCCTGTTTGTCATGCAGTACGACGATCTACCCC ATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGA ACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACG CTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTA CCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCG CAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAG AGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATA GAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACA CGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATG GCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTC CCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCA TCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACTTTCCCCATTCACAAATGCCTACCGCAGGAATG GGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGTGCCTGCAACAACAGGAAAGGCAATGTTATATTAAGGTGATTTCTTGTGAA CAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGAGTGGGCTGGTCTGTTGTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCA GCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTCAGCTAATTAATGGCAGGATGTTTAGGATAGTCTGTAGGTGGACAAGAATG CAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTACTGCCCTCAGCTCACATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGT TTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTTTGGAACAAGGAAACAAAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTA CACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTTTTAGTGACAGCTATCCATTTTATAAACTTACAGTAATCAAAGATCTAACA GACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCACTCCACTTATAGTATGTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGC CATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTCTTCCTCCATCTTCATTTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATC CACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGTATTCAGAATCAGTAGAAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTC AAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTAATTTCTTGCTGTTAGCAGCCGAGCTACCCTTCTGGCATCTATACTTTCTC CAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAATATAGCAGATGTAATTGTACAGTTCCTGATTAAACTTCAGTTGCAAAAAA GAAAGTTATTTCTTTAATTCTGTGGGAGTTTTGTATAATTTTACTTTTATGGTTTTTACACATACTTGAAACACTCTTTCTAAAGAATTA >52889_52889_9_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000371460_length(amino acids)=353AA_BP=303 MNLLSLLFVMQYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPL FPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRY ISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDD -------------------------------------------------------------- >52889_52889_10_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000371461_length(transcript)=1373nt_BP=1220nt GAGACATGCCCGTTTCACCTTCTACCCTCGGGAGAATGCTTCTCTTTCTCTCTTTCTTTCTTCTTTCCTTCTTGCCAAAGGAGCCTGAAT TTCTAAACTAGTTGATAGGGACACAAGTTAGGGCAAGATCATTCATCCCAGACGAGTCTCGCTGAGAATTCTGTATTTTTTACTTAAAGC TTTAATTTTAAAATAAGAAAAACTCAGCTTTATAGATGCAAGGCCACCGAATTCCGGGTGGAAGGACCCAGCTGTATTGACCTTATATAA GCTCGGTGCCTTGCCGTTCTCCCATTTGCCCGCCTGGCCTCCTGAACCTTCTTTCTCTCCTGTTTGTCATGCAGTACGACGATCTACCCC ATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGA ACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACG CTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTA CCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCG CAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAG AGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATA GAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACA CGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATG GCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTC CCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCA TCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACTTTCCCCATTCACAAATGCCTACCGCAGGAATG >52889_52889_10_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000398506_SUPT3H_chr6_44900500_ENST00000371461_length(amino acids)=354AA_BP=303 MNLLSLLFVMQYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPL FPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRY ISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDD -------------------------------------------------------------- >52889_52889_11_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000306867_length(transcript)=1498nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC >52889_52889_11_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000306867_length(amino acids)=347AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_12_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000371458_length(transcript)=1566nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC ACTTTCCCCATTCACAATTTCTTTTTCTTTGACAGAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTG >52889_52889_12_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000371458_length(amino acids)=354AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_13_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000371459_length(transcript)=2469nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC ACTTTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGTGCCTGCAACAACAGG AAAGGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGAGTGGGCTGGTCTGTT GTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTCAGCTAATTAATGGCA GGATGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTACTGCCCTCAGCTCAC ATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTTTGGAACAAGGAAACA AAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTTTTAGTGACAGCTATC CATTTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCACTCCACTTATAGTAT GTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTCTTCCTCCATCTTCAT TTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGTATTCAGAATCAGTAG AAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTAATTTCTTGCTGTTAG CAGCCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAATATAGCAGATGTAAT >52889_52889_13_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000371459_length(amino acids)=346AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_14_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000371460_length(transcript)=2582nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC ACTTTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGTGCCTGCAACAACAGG AAAGGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGAGTGGGCTGGTCTGTT GTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTCAGCTAATTAATGGCA GGATGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTACTGCCCTCAGCTCAC ATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTTTGGAACAAGGAAACA AAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTTTTAGTGACAGCTATC CATTTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCACTCCACTTATAGTAT GTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTCTTCCTCCATCTTCAT TTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGTATTCAGAATCAGTAG AAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTAATTTCTTGCTGTTAG CAGCCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAATATAGCAGATGTAAT TGTACAGTTCCTGATTAAACTTCAGTTGCAAAAAAGAAAGTTATTTCTTTAATTCTGTGGGAGTTTTGTATAATTTTACTTTTATGGTTT >52889_52889_14_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000371460_length(amino acids)=346AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_15_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000371461_length(transcript)=1498nt_BP=1345nt ATTTGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGG CAGAAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGAT TTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCT TCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTT TTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGA GAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCA TGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGC CATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGC ACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAA TGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGC CATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAA AGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAAC TGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTC ACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAA GGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCAC TGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCC >52889_52889_15_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000407092_SUPT3H_chr6_44900500_ENST00000371461_length(amino acids)=347AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_16_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000306867_length(transcript)=1340nt_BP=1187nt CTTTTTTTTTTTTTAAACTGATTTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGC TCAGTGACTCGGGCGCTTTGCTTCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCG TCGTGCTTTTTTTTTTTTTTTTTTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAG TTGAAGTAGGAAGGGAGCCAGAGAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCT CCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACC CGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGAC ACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACG TCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAAC TGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCC ACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATA TAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCC CTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAG GTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGC TGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGAC >52889_52889_16_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000306867_length(amino acids)=347AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_17_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000371458_length(transcript)=1408nt_BP=1187nt CTTTTTTTTTTTTTAAACTGATTTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGC TCAGTGACTCGGGCGCTTTGCTTCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCG TCGTGCTTTTTTTTTTTTTTTTTTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAG TTGAAGTAGGAAGGGAGCCAGAGAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCT CCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACC CGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGAC ACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACG TCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAAC TGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCC ACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATA TAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCC CTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAG GTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGC TGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGAC GCTACAGCCACAGGATTGGCCCACTTTCCCCATTCACAATTTCTTTTTCTTTGACAGAATGCCTACCGCAGGAATGGGATGGCTTTTCTA >52889_52889_17_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000371458_length(amino acids)=354AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_18_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000371459_length(transcript)=2311nt_BP=1187nt CTTTTTTTTTTTTTAAACTGATTTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGC TCAGTGACTCGGGCGCTTTGCTTCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCG TCGTGCTTTTTTTTTTTTTTTTTTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAG TTGAAGTAGGAAGGGAGCCAGAGAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCT CCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACC CGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGAC ACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACG TCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAAC TGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCC ACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATA TAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCC CTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAG GTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGC TGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGAC GCTACAGCCACAGGATTGGCCCACTTTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACT GTGATGTGCCTGCAACAACAGGAAAGGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATC TGAGGGAGTGGGCTGGTCTGTTGTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGG GCTGTTCAGCTAATTAATGGCAGGATGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGT AGATTTACTGCCCTCAGCTCACATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAAT CCAGGTTTGGAACAAGGAAACAAAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGAC ATGTGTTTTAGTGACAGCTATCCATTTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTC CCCTTCACTCCACTTATAGTATGTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACA GAACCTCTTCCTCCATCTTCATTTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAA GCCAAGTATTCAGAATCAGTAGAAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGG CTGGGTAATTTCTTGCTGTTAGCAGCCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAA >52889_52889_18_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000371459_length(amino acids)=346AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_19_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000371460_length(transcript)=2424nt_BP=1187nt CTTTTTTTTTTTTTAAACTGATTTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGC TCAGTGACTCGGGCGCTTTGCTTCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCG TCGTGCTTTTTTTTTTTTTTTTTTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAG TTGAAGTAGGAAGGGAGCCAGAGAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCT CCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACC CGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGAC ACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACG TCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAAC TGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCC ACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATA TAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCC CTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAG GTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGC TGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGAC GCTACAGCCACAGGATTGGCCCACTTTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACT GTGATGTGCCTGCAACAACAGGAAAGGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATC TGAGGGAGTGGGCTGGTCTGTTGTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGG GCTGTTCAGCTAATTAATGGCAGGATGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGT AGATTTACTGCCCTCAGCTCACATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAAT CCAGGTTTGGAACAAGGAAACAAAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGAC ATGTGTTTTAGTGACAGCTATCCATTTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTC CCCTTCACTCCACTTATAGTATGTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACA GAACCTCTTCCTCCATCTTCATTTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAA GCCAAGTATTCAGAATCAGTAGAAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGG CTGGGTAATTTCTTGCTGTTAGCAGCCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAA ACCAAAATATAGCAGATGTAATTGTACAGTTCCTGATTAAACTTCAGTTGCAAAAAAGAAAGTTATTTCTTTAATTCTGTGGGAGTTTTG >52889_52889_19_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000371460_length(amino acids)=346AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_20_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000371461_length(transcript)=1340nt_BP=1187nt CTTTTTTTTTTTTTAAACTGATTTTTGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGC TCAGTGACTCGGGCGCTTTGCTTCAGGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCG TCGTGCTTTTTTTTTTTTTTTTTTTTTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAG TTGAAGTAGGAAGGGAGCCAGAGAGGCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCT CCACGATGTATGGGGACCCGCATGCAGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACC CGCACACAGCTCATACCAACGCCATGGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGAC ACCCCCTCTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACG TCTGCTCGTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAAC TGGATAACTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCC ACCGGTATATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATA TAACAAGATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCC CTTCCAGCGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAG GTGACGATGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGC TGTTCCAGCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGAC >52889_52889_20_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000488550_SUPT3H_chr6_44900500_ENST00000371461_length(amino acids)=347AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_21_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000306867_length(transcript)=1153nt_BP=1000nt GTTGACAGTCGGCCCCACGGCCATGGACGTCCTTTCCCCAAGTTAGCTGAGCGCCTGCCACCGAGATCCCCCGAGCCTGGGCTTCGCGCG GCCGCCTAGGAGGAACCCGCAGGAACCAGCCCTCCCCAACTCTCCGCCCGGCGCCTTTCTCCTCCACCGGATCCTGGATGTGCAGTGGAG GGGACGAGGGCTTGTCGGGTGGGAAACTTAATTCAAAATGGCTGCTGGAAACGCTTGGGTTTTATTCGTAGCAAATGTTGCCAATTTCTC CGGCCAGATACGCTAAACCGATCCTCAGATACCGTCCATGGCTCAGGGCCTCCGACTTCAGGGCTCCAGGAGGAAGGGGAGACACCCCCT CTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTC GTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAA CTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTA TATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAG ATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAG CGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGA TGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCA GCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAG >52889_52889_21_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000306867_length(amino acids)=282AA_BP=231 MAQGLRLQGSRRKGRHPLFPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFH LLELEKVHELCDNFCHRYISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSS EQGDGLDNSVASPSTGDDDDPDKDKKRHKKRGIFPKVATNIMRAWLFQHLTSTAACGVEAHSDAIQPCHIREAIRRYSHRIGPLSPFTNA -------------------------------------------------------------- >52889_52889_22_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000371458_length(transcript)=1221nt_BP=1000nt GTTGACAGTCGGCCCCACGGCCATGGACGTCCTTTCCCCAAGTTAGCTGAGCGCCTGCCACCGAGATCCCCCGAGCCTGGGCTTCGCGCG GCCGCCTAGGAGGAACCCGCAGGAACCAGCCCTCCCCAACTCTCCGCCCGGCGCCTTTCTCCTCCACCGGATCCTGGATGTGCAGTGGAG GGGACGAGGGCTTGTCGGGTGGGAAACTTAATTCAAAATGGCTGCTGGAAACGCTTGGGTTTTATTCGTAGCAAATGTTGCCAATTTCTC CGGCCAGATACGCTAAACCGATCCTCAGATACCGTCCATGGCTCAGGGCCTCCGACTTCAGGGCTCCAGGAGGAAGGGGAGACACCCCCT CTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTC GTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAA CTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTA TATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAG ATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAG CGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGA TGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCA GCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAG CCACAGGATTGGCCCACTTTCCCCATTCACAATTTCTTTTTCTTTGACAGAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCT >52889_52889_22_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000371458_length(amino acids)=289AA_BP=231 MAQGLRLQGSRRKGRHPLFPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFH LLELEKVHELCDNFCHRYISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSS EQGDGLDNSVASPSTGDDDDPDKDKKRHKKRGIFPKVATNIMRAWLFQHLTSTAACGVEAHSDAIQPCHIREAIRRYSHRIGPLSPFTIS -------------------------------------------------------------- >52889_52889_23_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000371459_length(transcript)=2124nt_BP=1000nt GTTGACAGTCGGCCCCACGGCCATGGACGTCCTTTCCCCAAGTTAGCTGAGCGCCTGCCACCGAGATCCCCCGAGCCTGGGCTTCGCGCG GCCGCCTAGGAGGAACCCGCAGGAACCAGCCCTCCCCAACTCTCCGCCCGGCGCCTTTCTCCTCCACCGGATCCTGGATGTGCAGTGGAG GGGACGAGGGCTTGTCGGGTGGGAAACTTAATTCAAAATGGCTGCTGGAAACGCTTGGGTTTTATTCGTAGCAAATGTTGCCAATTTCTC CGGCCAGATACGCTAAACCGATCCTCAGATACCGTCCATGGCTCAGGGCCTCCGACTTCAGGGCTCCAGGAGGAAGGGGAGACACCCCCT CTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTC GTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAA CTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTA TATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAG ATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAG CGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGA TGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCA GCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAG CCACAGGATTGGCCCACTTTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGT GCCTGCAACAACAGGAAAGGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGA GTGGGCTGGTCTGTTGTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTC AGCTAATTAATGGCAGGATGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTA CTGCCCTCAGCTCACATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTT TGGAACAAGGAAACAAAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTT TTAGTGACAGCTATCCATTTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCA CTCCACTTATAGTATGTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTC TTCCTCCATCTTCATTTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGT ATTCAGAATCAGTAGAAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTA ATTTCTTGCTGTTAGCAGCCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAA >52889_52889_23_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000371459_length(amino acids)=281AA_BP=231 MAQGLRLQGSRRKGRHPLFPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFH LLELEKVHELCDNFCHRYISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSS EQGDGLDNSVASPSTGDDDDPDKDKKRHKKRGIFPKVATNIMRAWLFQHLTSTAACGVEAHSDAIQPCHIREAIRRYSHRIGPLSPFTNA -------------------------------------------------------------- >52889_52889_24_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000371460_length(transcript)=2237nt_BP=1000nt GTTGACAGTCGGCCCCACGGCCATGGACGTCCTTTCCCCAAGTTAGCTGAGCGCCTGCCACCGAGATCCCCCGAGCCTGGGCTTCGCGCG GCCGCCTAGGAGGAACCCGCAGGAACCAGCCCTCCCCAACTCTCCGCCCGGCGCCTTTCTCCTCCACCGGATCCTGGATGTGCAGTGGAG GGGACGAGGGCTTGTCGGGTGGGAAACTTAATTCAAAATGGCTGCTGGAAACGCTTGGGTTTTATTCGTAGCAAATGTTGCCAATTTCTC CGGCCAGATACGCTAAACCGATCCTCAGATACCGTCCATGGCTCAGGGCCTCCGACTTCAGGGCTCCAGGAGGAAGGGGAGACACCCCCT CTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTC GTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAA CTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTA TATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAG ATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAG CGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGA TGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCA GCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAG CCACAGGATTGGCCCACTTTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGT GCCTGCAACAACAGGAAAGGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGA GTGGGCTGGTCTGTTGTGACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTC AGCTAATTAATGGCAGGATGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTA CTGCCCTCAGCTCACATACCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTT TGGAACAAGGAAACAAAATTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTT TTAGTGACAGCTATCCATTTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCA CTCCACTTATAGTATGTGTCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTC TTCCTCCATCTTCATTTCCCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGT ATTCAGAATCAGTAGAAGGGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTA ATTTCTTGCTGTTAGCAGCCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAA TATAGCAGATGTAATTGTACAGTTCCTGATTAAACTTCAGTTGCAAAAAAGAAAGTTATTTCTTTAATTCTGTGGGAGTTTTGTATAATT >52889_52889_24_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000371460_length(amino acids)=281AA_BP=231 MAQGLRLQGSRRKGRHPLFPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFH LLELEKVHELCDNFCHRYISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSS EQGDGLDNSVASPSTGDDDDPDKDKKRHKKRGIFPKVATNIMRAWLFQHLTSTAACGVEAHSDAIQPCHIREAIRRYSHRIGPLSPFTNA -------------------------------------------------------------- >52889_52889_25_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000371461_length(transcript)=1153nt_BP=1000nt GTTGACAGTCGGCCCCACGGCCATGGACGTCCTTTCCCCAAGTTAGCTGAGCGCCTGCCACCGAGATCCCCCGAGCCTGGGCTTCGCGCG GCCGCCTAGGAGGAACCCGCAGGAACCAGCCCTCCCCAACTCTCCGCCCGGCGCCTTTCTCCTCCACCGGATCCTGGATGTGCAGTGGAG GGGACGAGGGCTTGTCGGGTGGGAAACTTAATTCAAAATGGCTGCTGGAAACGCTTGGGTTTTATTCGTAGCAAATGTTGCCAATTTCTC CGGCCAGATACGCTAAACCGATCCTCAGATACCGTCCATGGCTCAGGGCCTCCGACTTCAGGGCTCCAGGAGGAAGGGGAGACACCCCCT CTTCCCTCTCTTAGCACTGATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTC GTCAGAGTCATTCAATGAAGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAA CTTGATGATTCAAGCCATACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTA TATTAGCTGTTTGAAAGGGAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAG ATCAGCAAATCTAACTGACCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAG CGGTGGCCACACGTCACACAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGA TGATGACCCTGATAAGGACAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCA GCATCTAACAAGCACTGCAGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAG >52889_52889_25_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000495021_SUPT3H_chr6_44900500_ENST00000371461_length(amino acids)=282AA_BP=231 MAQGLRLQGSRRKGRHPLFPLLALIFEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFH LLELEKVHELCDNFCHRYISCLKGKMPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSS EQGDGLDNSVASPSTGDDDDPDKDKKRHKKRGIFPKVATNIMRAWLFQHLTSTAACGVEAHSDAIQPCHIREAIRRYSHRIGPLSPFTNA -------------------------------------------------------------- >52889_52889_26_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000306867_length(transcript)=1765nt_BP=1612nt CGGAATCCACCTCTCCGCCTGTGCAACACACACTTTACACACGCACGGGGACTGCAAGCGGGCAGCATCGATCGTGGCTCCTTTAAGACA AACTCAGACAGACATTTTTTTTAACCCTCCTTCTCTAATCTCCTTCCAGTGCAGCACTTGCAAAGAGGGAGAGAGAGGGAGAGAAAGAAA GAGAGAGAGAGAAGAGAGAAACTGATTAGGAATTAGGACTGATTCAAGGGAAGCGAGCGCTAGGGCTTTGTGCATTTGAATATTAACATT TGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGGCAG AAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGATTTT TGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCTTCA GGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTTTTT TTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGAGAG GCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGC AGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCAT GGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACT GATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGA AGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCAT ACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGG GAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGA CCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACA CAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGA CAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGC AGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACT >52889_52889_26_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000306867_length(amino acids)=347AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_27_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000371458_length(transcript)=1833nt_BP=1612nt CGGAATCCACCTCTCCGCCTGTGCAACACACACTTTACACACGCACGGGGACTGCAAGCGGGCAGCATCGATCGTGGCTCCTTTAAGACA AACTCAGACAGACATTTTTTTTAACCCTCCTTCTCTAATCTCCTTCCAGTGCAGCACTTGCAAAGAGGGAGAGAGAGGGAGAGAAAGAAA GAGAGAGAGAGAAGAGAGAAACTGATTAGGAATTAGGACTGATTCAAGGGAAGCGAGCGCTAGGGCTTTGTGCATTTGAATATTAACATT TGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGGCAG AAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGATTTT TGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCTTCA GGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTTTTT TTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGAGAG GCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGC AGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCAT GGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACT GATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGA AGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCAT ACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGG GAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGA CCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACA CAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGA CAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGC AGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACT TTCCCCATTCACAATTTCTTTTTCTTTGACAGAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATG >52889_52889_27_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000371458_length(amino acids)=354AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_28_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000371459_length(transcript)=2736nt_BP=1612nt CGGAATCCACCTCTCCGCCTGTGCAACACACACTTTACACACGCACGGGGACTGCAAGCGGGCAGCATCGATCGTGGCTCCTTTAAGACA AACTCAGACAGACATTTTTTTTAACCCTCCTTCTCTAATCTCCTTCCAGTGCAGCACTTGCAAAGAGGGAGAGAGAGGGAGAGAAAGAAA GAGAGAGAGAGAAGAGAGAAACTGATTAGGAATTAGGACTGATTCAAGGGAAGCGAGCGCTAGGGCTTTGTGCATTTGAATATTAACATT TGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGGCAG AAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGATTTT TGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCTTCA GGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTTTTT TTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGAGAG GCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGC AGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCAT GGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACT GATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGA AGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCAT ACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGG GAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGA CCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACA CAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGA CAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGC AGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACT TTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGTGCCTGCAACAACAGGAAA GGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGAGTGGGCTGGTCTGTTGTG ACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTCAGCTAATTAATGGCAGGA TGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTACTGCCCTCAGCTCACATA CCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTTTGGAACAAGGAAACAAAA TTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTTTTAGTGACAGCTATCCAT TTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCACTCCACTTATAGTATGTG TCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTCTTCCTCCATCTTCATTTC CCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGTATTCAGAATCAGTAGAAG GGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTAATTTCTTGCTGTTAGCAG CCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAATATAGCAGATGTAATTGT >52889_52889_28_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000371459_length(amino acids)=346AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_29_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000371460_length(transcript)=2849nt_BP=1612nt CGGAATCCACCTCTCCGCCTGTGCAACACACACTTTACACACGCACGGGGACTGCAAGCGGGCAGCATCGATCGTGGCTCCTTTAAGACA AACTCAGACAGACATTTTTTTTAACCCTCCTTCTCTAATCTCCTTCCAGTGCAGCACTTGCAAAGAGGGAGAGAGAGGGAGAGAAAGAAA GAGAGAGAGAGAAGAGAGAAACTGATTAGGAATTAGGACTGATTCAAGGGAAGCGAGCGCTAGGGCTTTGTGCATTTGAATATTAACATT TGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGGCAG AAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGATTTT TGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCTTCA GGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTTTTT TTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGAGAG GCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGC AGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCAT GGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACT GATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGA AGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCAT ACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGG GAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGA CCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACA CAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGA CAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGC AGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACT TTCCCCATTCACAAATGCCTACCGCAGGAATGGGATGGCTTTTCTAGCCTGCTGATGTGACAACTGTGATGTGCCTGCAACAACAGGAAA GGCAATGTTATATTAAGGTGATTTCTTGTGAACAAAATAAAATACAAATTTACCTTTCTTTTATCTGAGGGAGTGGGCTGGTCTGTTGTG ACTTTCAACTTGCTGACTCCTCCTCTTTTCCAGCCCCTCAACCATCGGTCTTGTTTACTAGATGGGCTGTTCAGCTAATTAATGGCAGGA TGTTTAGGATAGTCTGTAGGTGGACAAGAATGCAGATCACACAGTTTTGAAATTTTAATTTGAGTAGATTTACTGCCCTCAGCTCACATA CCTTAAAAGCAGTGGTTGCCCCCGTCCAGCGTTTTGTCTGCATTTTATTTGATATATTTTATAATCCAGGTTTGGAACAAGGAAACAAAA TTAAAAGGACAGTGAGTTTTCGCCTTCCCTTACACCACCAACTTTACTTTCCAACATTTGTTGACATGTGTTTTAGTGACAGCTATCCAT TTTATAAACTTACAGTAATCAAAGATCTAACAGACCTGATAAATCACCTGTTCCCACCTCCTTTCCCCTTCACTCCACTTATAGTATGTG TCATTTTCAATGCCTGCTTCCCAACTTCCTGCCATCTGCCTTTCATGTGTGTTTTTCCTCACACAGAACCTCTTCCTCCATCTTCATTTC CCTCCTTTTCCTGTTCCTCCAATCCCCAGATCCACCACTCCTGCACATGCCATACACATTTAGAAGCCAAGTATTCAGAATCAGTAGAAG GGGAGCAGAGTGATTTCTTGCTTCCTCCCTTCAAAGCACTACCACACCTAGACTGGAAATGTGGGCTGGGTAATTTCTTGCTGTTAGCAG CCGAGCTACCCTTCTGGCATCTATACTTTCTCCAGTAAATGAGGAACCGTAACTCTTTGGAACAAACCAAAATATAGCAGATGTAATTGT ACAGTTCCTGATTAAACTTCAGTTGCAAAAAAGAAAGTTATTTCTTTAATTCTGTGGGAGTTTTGTATAATTTTACTTTTATGGTTTTTA >52889_52889_29_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000371460_length(amino acids)=346AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- >52889_52889_30_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000371461_length(transcript)=1765nt_BP=1612nt CGGAATCCACCTCTCCGCCTGTGCAACACACACTTTACACACGCACGGGGACTGCAAGCGGGCAGCATCGATCGTGGCTCCTTTAAGACA AACTCAGACAGACATTTTTTTTAACCCTCCTTCTCTAATCTCCTTCCAGTGCAGCACTTGCAAAGAGGGAGAGAGAGGGAGAGAAAGAAA GAGAGAGAGAGAAGAGAGAAACTGATTAGGAATTAGGACTGATTCAAGGGAAGCGAGCGCTAGGGCTTTGTGCATTTGAATATTAACATT TGAGGTGTTCTGACCAGAAGAAGACAGAGCGGATGATCATTCATTCACCACGTTGACAACCTCGCCTGTGATTGACAGCTGGAGTGGCAG AAAGCCATGAGATTTGGTAGTTGGGTCTGAGGGGCGCTCTTTTTTTTCCTTTTCTTTCTTTCTTTCTTTTTTTTTTTTTAAACTGATTTT TGGGGGAGAGAAGATCTGCTTTTTTTTGCCCCCGCTGCTGTCTTGGAAACGGAGCGCTTTTATGCTCAGTGACTCGGGCGCTTTGCTTCA GGTCCCGTAGACCGAAGATCTGGGACCAGTAGCTCACGTTGCTGGAGACGTTAAGGGATTTTTCGTCGTGCTTTTTTTTTTTTTTTTTTT TTTTTCCGGGGGAGTTTGAATATTTGTTTCTTTTCACACTGGCCTTAAAGAGGATATATTAGAAGTTGAAGTAGGAAGGGAGCCAGAGAG GCCGATGGCGCAAAGGTACGACGATCTACCCCATTACGGGGGCATGGATGGAGTAGGCATCCCCTCCACGATGTATGGGGACCCGCATGC AGCCAGGTCCATGCAGCCGGTCCACCACCTGAACCACGGGCCTCCTCTGCACTCGCATCAGTACCCGCACACAGCTCATACCAACGCCAT GGCCCCCAGCATGGGCTCCTCTGTCAATGACGCTTTAAAGAGAGATAAAGATGCCATTTATGGACACCCCCTCTTCCCTCTCTTAGCACT GATTTTTGAGAAATGTGAATTAGCTACTTGTACCCCCCGCGAGCCGGGGGTGGCGGGCGGGGACGTCTGCTCGTCAGAGTCATTCAATGA AGATATAGCCGTGTTCGCCAAACAGATTCGCGCAGAAAAACCTCTATTTTCTTCTAATCCAGAACTGGATAACTTGATGATTCAAGCCAT ACAAGTATTAAGGTTTCATCTATTGGAATTAGAGAAGGTACACGAATTATGTGACAATTTCTGCCACCGGTATATTAGCTGTTTGAAAGG GAAAATGCCTATCGATTTGGTGATAGACGATAGAGAAGGAGGATCAAAATCAGACAGTGAAGATATAACAAGATCAGCAAATCTAACTGA CCAGCCCTCTTGGAACAGAGATCATGATGACACGGCATCTACTCGTTCAGGAGGAACCCCAGGCCCTTCCAGCGGTGGCCACACGTCACA CAGTGGGGACAACAGCAGTGAGCAAGGTGATGGCTTGGACAACAGTGTAGCTTCCCCCAGCACAGGTGACGATGATGACCCTGATAAGGA CAAAAAGCGTCACAAAAAGCGTGGCATCTTTCCCAAAGTAGCCACAAATATCATGAGGGCGTGGCTGTTCCAGCATCTAACAAGCACTGC AGCCTGTGGTGTTGAGGCTCACAGCGATGCCATCCAGCCCTGCCACATCAGAGAGGCCATTCGACGCTACAGCCACAGGATTGGCCCACT >52889_52889_30_MEIS1-SUPT3H_MEIS1_chr2_66739426_ENST00000560281_SUPT3H_chr6_44900500_ENST00000371461_length(amino acids)=347AA_BP=296 MAQRYDDLPHYGGMDGVGIPSTMYGDPHAARSMQPVHHLNHGPPLHSHQYPHTAHTNAMAPSMGSSVNDALKRDKDAIYGHPLFPLLALI FEKCELATCTPREPGVAGGDVCSSESFNEDIAVFAKQIRAEKPLFSSNPELDNLMIQAIQVLRFHLLELEKVHELCDNFCHRYISCLKGK MPIDLVIDDREGGSKSDSEDITRSANLTDQPSWNRDHDDTASTRSGGTPGPSSGGHTSHSGDNSSEQGDGLDNSVASPSTGDDDDPDKDK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for MEIS1-SUPT3H |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000272369 | + | 8 | 13 | 299_329 | 296.0 | 1109.3333333333333 | DNA |
| Hgene | MEIS1 | chr2:66739426 | chr6:44900500 | ENST00000398506 | + | 7 | 11 | 299_329 | 294.0 | 464.0 | DNA |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for MEIS1-SUPT3H |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for MEIS1-SUPT3H |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | MEIS1 | C0035258 | Restless Legs Syndrome | 2 | CTD_human |
| Hgene | MEIS1 | C0006142 | Malignant neoplasm of breast | 1 | CTD_human |
| Hgene | MEIS1 | C0021603 | Sleep Initiation and Maintenance Disorders | 1 | CTD_human |
| Hgene | MEIS1 | C0033139 | Primary Insomnia | 1 | CTD_human |
| Hgene | MEIS1 | C0270541 | Rebound Insomnia | 1 | CTD_human |
| Hgene | MEIS1 | C0349255 | Nonorganic Insomnia | 1 | CTD_human |
| Hgene | MEIS1 | C0393759 | Transient Insomnia | 1 | CTD_human |
| Hgene | MEIS1 | C0541798 | Early Awakening | 1 | CTD_human |
| Hgene | MEIS1 | C0678222 | Breast Carcinoma | 1 | CTD_human |
| Hgene | MEIS1 | C0751249 | Chronic Insomnia | 1 | CTD_human |
| Hgene | MEIS1 | C0751250 | Psychophysiological Insomnia | 1 | CTD_human |
| Hgene | MEIS1 | C0751251 | Secondary Insomnia | 1 | CTD_human |
| Hgene | MEIS1 | C0751252 | Sleep Initiation Dysfunction | 1 | CTD_human |
| Hgene | MEIS1 | C0917801 | Sleeplessness | 1 | CTD_human |
| Hgene | MEIS1 | C1257931 | Mammary Neoplasms, Human | 1 | CTD_human |
| Hgene | MEIS1 | C1458155 | Mammary Neoplasms | 1 | CTD_human |
| Hgene | MEIS1 | C4704874 | Mammary Carcinoma, Human | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies