
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PCYOX1-CEL (FusionGDB2 ID:HG51449TG1056) |
Fusion Gene Summary for PCYOX1-CEL |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PCYOX1-CEL | Fusion gene ID: hg51449tg1056 | Hgene | Tgene | Gene symbol | PCYOX1 | CEL | Gene ID | 51449 | 1056 |
| Gene name | prenylcysteine oxidase 1 | carboxyl ester lipase | |
| Synonyms | PCL1 | BAL|BSDL|BSSL|CELL|CEase|FAP|FAPP|LIPA|MODY8 | |
| Cytomap | ('PCYOX1')('CEL') 2p13.3 | 9q34.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | prenylcysteine oxidase 1prenylcysteine lyase | bile salt-activated lipasebile salt-dependent lipase, oncofetal isoformbucelipasecarboxyl ester hydrolasecarboxyl ester lipase (bile salt-stimulated lipase)cholesterol esterasefetoacinar pancreatic proteinlysophospholipase, pancreaticsterol estera | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000264441, ENST00000433351, ENST00000505044, ENST00000545138, | ||
| Fusion gene scores | * DoF score | 4 X 3 X 2=24 | 5 X 6 X 4=120 |
| # samples | 4 | 6 | |
| ** MAII score | log2(4/24*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(6/120*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: PCYOX1 [Title/Abstract] AND CEL [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PCYOX1(70488361)-CEL(135937365), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | PCYOX1-CEL seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. PCYOX1-CEL seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | PCYOX1 | GO:0030327 | prenylated protein catabolic process | 10585463 |
| Tgene | CEL | GO:0006707 | cholesterol catabolic process | 12031288 |
| Tgene | CEL | GO:0030157 | pancreatic juice secretion | 1854805 |
| Fusion gene breakpoints across PCYOX1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CEL (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChiTaRS5.0 | N/A | M54994 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + |
Top |
Fusion Gene ORF analysis for PCYOX1-CEL |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000264441 | ENST00000351304 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + |
| In-frame | ENST00000264441 | ENST00000372080 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + |
| In-frame | ENST00000433351 | ENST00000351304 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + |
| In-frame | ENST00000433351 | ENST00000372080 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + |
| In-frame | ENST00000505044 | ENST00000351304 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + |
| In-frame | ENST00000505044 | ENST00000372080 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + |
| In-frame | ENST00000545138 | ENST00000351304 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + |
| In-frame | ENST00000545138 | ENST00000372080 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000505044 | PCYOX1 | chr2 | 70488361 | - | ENST00000351304 | CEL | chr9 | 135937365 | + | 2776 | 590 | 216 | 2678 | 820 |
| ENST00000505044 | PCYOX1 | chr2 | 70488361 | - | ENST00000372080 | CEL | chr9 | 135937365 | + | 2974 | 590 | 216 | 2876 | 886 |
| ENST00000433351 | PCYOX1 | chr2 | 70488361 | - | ENST00000351304 | CEL | chr9 | 135937365 | + | 2690 | 504 | 28 | 2592 | 854 |
| ENST00000433351 | PCYOX1 | chr2 | 70488361 | - | ENST00000372080 | CEL | chr9 | 135937365 | + | 2888 | 504 | 28 | 2790 | 920 |
| ENST00000264441 | PCYOX1 | chr2 | 70488361 | - | ENST00000351304 | CEL | chr9 | 135937365 | + | 2678 | 492 | 16 | 2580 | 854 |
| ENST00000264441 | PCYOX1 | chr2 | 70488361 | - | ENST00000372080 | CEL | chr9 | 135937365 | + | 2876 | 492 | 16 | 2778 | 920 |
| ENST00000545138 | PCYOX1 | chr2 | 70488361 | - | ENST00000351304 | CEL | chr9 | 135937365 | + | 2616 | 430 | 110 | 2518 | 802 |
| ENST00000545138 | PCYOX1 | chr2 | 70488361 | - | ENST00000372080 | CEL | chr9 | 135937365 | + | 2814 | 430 | 110 | 2716 | 868 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000505044 | ENST00000351304 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + | 0.003507279 | 0.9964927 |
| ENST00000505044 | ENST00000372080 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + | 0.002602306 | 0.99739766 |
| ENST00000433351 | ENST00000351304 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + | 0.00147668 | 0.9985233 |
| ENST00000433351 | ENST00000372080 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + | 0.000945164 | 0.99905485 |
| ENST00000264441 | ENST00000351304 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + | 0.00136517 | 0.99863476 |
| ENST00000264441 | ENST00000372080 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + | 0.000892443 | 0.99910754 |
| ENST00000545138 | ENST00000351304 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + | 0.003104525 | 0.99689543 |
| ENST00000545138 | ENST00000372080 | PCYOX1 | chr2 | 70488361 | - | CEL | chr9 | 135937365 | + | 0.002289538 | 0.99771047 |
Top |
Fusion Genomic Features for PCYOX1-CEL |
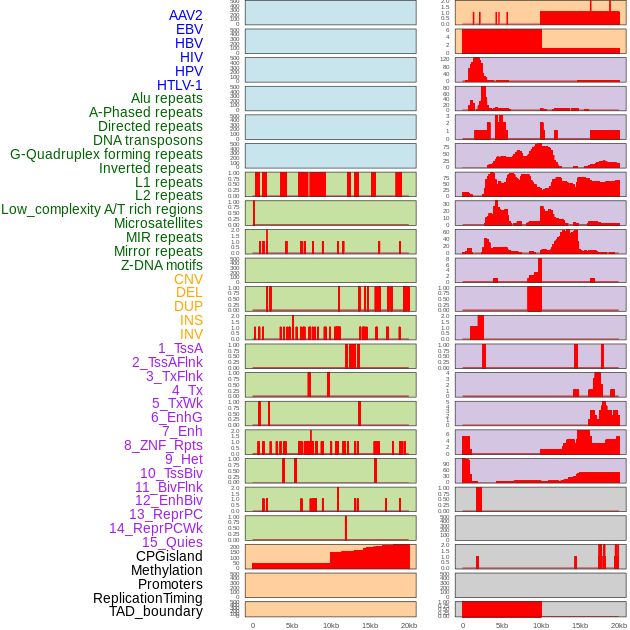
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
Top |
Fusion Protein Features for PCYOX1-CEL |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:70488361/chr9:135937365) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 21_121 | 22 | 688.0 | Region | Note=Heparin-binding | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 559_745 | 22 | 688.0 | Region | Note=17 X 11 AA tandem repeats%2C glycodomain%2C O-linked (mucin type) | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 559_569 | 22 | 688.0 | Repeat | Note=1 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 570_580 | 22 | 688.0 | Repeat | Note=2 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 581_591 | 22 | 688.0 | Repeat | Note=3 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 592_602 | 22 | 688.0 | Repeat | Note=4 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 603_613 | 22 | 688.0 | Repeat | Note=5 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 614_624 | 22 | 688.0 | Repeat | Note=6 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 625_635 | 22 | 688.0 | Repeat | Note=7 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 636_646 | 22 | 688.0 | Repeat | Note=8 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 647_657 | 22 | 688.0 | Repeat | Note=9 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 658_668 | 22 | 688.0 | Repeat | Note=10 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 669_679 | 22 | 688.0 | Repeat | Note=11 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 680_690 | 22 | 688.0 | Repeat | Note=12 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 691_701 | 22 | 688.0 | Repeat | Note=13 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 702_712 | 22 | 688.0 | Repeat | Note=14 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 713_723 | 22 | 688.0 | Repeat | Note=15 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 724_734 | 22 | 688.0 | Repeat | Note=16 | |
| Tgene | CEL | chr2:70488361 | chr9:135937365 | ENST00000351304 | -1 | 10 | 735_745 | 22 | 688.0 | Repeat | Note=17 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for PCYOX1-CEL |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >63548_63548_1_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000264441_CEL_chr9_135937365_ENST00000351304_length(transcript)=2678nt_BP=492nt AGAGCTTGTGGAGGCCATGGGGCGCGTCGTCGCGGAGCTCGTCTCCTCGCTGCTGGGGTTGTGGCTGTTGCTGTGCAGCTGCGGATGCCC CGAGGGCGCCGAGCTGCGTGCTCCGCCAGATAAAATCGCGATTATTGGAGCCGGAATTGGTGGCACTTCAGCAGCCTATTACCTGCGGCA GAAATTTGGGAAAGATGTGAAGATAGACCTGTTTGAAAGAGAAGAGGTCGGGGGCCGCCTGGCTACCATGATGGTGCAGGGGCAAGAATA CGAGGCAGGAGGTTCTGTCATCCATCCTTTAAATCTGCACATGAAACGTTTTGTCAAAGACCTGGCCTCTGGTGGCCTACTGGGGATATA TAATGGAGAGACTCTGGTATTTGAGGAGAGCAACTGGTTCATAATTAACGTGATTAAATTAGTTTGGCGCTATGGATTTCAATCCCTCCG TATGCACATGTGGGTAGAGGACGTGTTAGACAAGTTCATGAGGGCCACCCAGAGGCTGATGCTCACCATGGGGCGCCTGCAACTGGTTGT GTTGGGCCTCACCTGCTGCTGGGCAGTGGCGAGTGCCGCGAAGCTGGGCGCCGTGTACACAGAAGGTGGGTTCGTGGAAGGCGTCAATAA GAAGCTCGGCCTCCTGGGTGACTCTGTGGACATCTTCAAGGGCATCCCCTTCGCAGCTCCCACCAAGGCCCTGGAAAATCCTCAGCCACA TCCTGGCTGGCAAGGGACCCTGAAGGCCAAGAACTTCAAGAAGAGATGCCTGCAGGCCACCATCACCCAGGACAGCACCTACGGGGATGA AGACTGCCTGTACCTCAACATTTGGGTGCCCCAGGGCAGGAAGCAAGTCTCCCGGGACCTGCCCGTTATGATCTGGATCTATGGAGGCGC CTTCCTCATGGGGTCCGGCCATGGGGCCAACTTCCTCAACAACTACCTGTATGACGGCGAGGAGATCGCCACACGCGGAAACGTCATCGT GGTCACCTTCAACTACCGTGTCGGCCCCCTTGGGTTCCTCAGCACTGGGGACGCCAATCTGCCAGGTAACTATGGCCTTCGGGATCAGCA CATGGCCATTGCTTGGGTGAAGAGGAATATCGCGGCCTTCGGGGGGGACCCCAACAACATCACGCTCTTCGGGGAGTCTGCTGGAGGTGC CAGCGTCTCTCTGCAGACCCTCTCCCCCTACAACAAGGGCCTCATCCGGCGAGCCATCAGCCAGAGCGGCGTGGCCCTGAGTCCCTGGGT CATCCAGAAAAACCCACTCTTCTGGGCCAAAAAGGTGGCTGAGAAGGTGGGTTGCCCTGTGGGTGATGCCGCCAGGATGGCCCAGTGTCT GAAGGTTACTGATCCCCGAGCCCTGACGCTGGCCTATAAGGTGCCGCTGGCAGGCCTGGAGTACCCCATGCTGCACTATGTGGGCTTCGT CCCTGTCATTGATGGAGACTTCATCCCCGCTGACCCGATCAACCTGTACGCCAACGCCGCCGACATCGACTATATAGCAGGCACCAACAA CATGGACGGCCACATCTTCGCCAGCATCGACATGCCTGCCATCAACAAGGGCAACAAGAAAGTCACGGAGGAGGACTTCTACAAGCTGGT CAGTGAGTTCACAATCACCAAGGGGCTCAGAGGCGCCAAGACGACCTTTGATGTCTACACCGAGTCCTGGGCCCAGGACCCATCCCAGGA GAATAAGAAGAAGACTGTGGTGGACTTTGAGACCGATGTCCTCTTCCTGGTGCCCACCGAGATTGCCCTAGCCCAGCACAGAGCCAATGC CAAGGACCCCAACATGGGCGACTCGGCTGTGCCCACACACTGGGAACCCTACACTACGGAAAACAGCGGCTACCTGGAGATCACCAAGAA GATGGGCAGCAGCTCCATGAAGCGGAGCCTGAGAACCAACTTCCTGCGCTACTGGACCCTCACCTATCTGGCGCTGCCCACAGTGACCGA CCAGGAGGCCACCCCTGTGCCCCCCACAGGGGACTCCGAGGCCACTCCCGTGCCCCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCC CACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCC CGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGG GGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCGCCCACGGG TGACGCCGGGCCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGAC CCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCTGTGCCCCCCACGGGTGACTCTGAGGCTGC CCCTGTGCCCCCCACAGATGACTCCAAGGAAGCTCAGATGCCTGCAGTCATTAGGTTTTAGCGTCCCATGAGCCTTGGTATCAAGAGGCC >63548_63548_1_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000264441_CEL_chr9_135937365_ENST00000351304_length(amino acids)=854AA_BP=158 MGRVVAELVSSLLGLWLLLCSCGCPEGAELRAPPDKIAIIGAGIGGTSAAYYLRQKFGKDVKIDLFEREEVGGRLATMMVQGQEYEAGGS VIHPLNLHMKRFVKDLASGGLLGIYNGETLVFEESNWFIINVIKLVWRYGFQSLRMHMWVEDVLDKFMRATQRLMLTMGRLQLVVLGLTC CWAVASAAKLGAVYTEGGFVEGVNKKLGLLGDSVDIFKGIPFAAPTKALENPQPHPGWQGTLKAKNFKKRCLQATITQDSTYGDEDCLYL NIWVPQGRKQVSRDLPVMIWIYGGAFLMGSGHGANFLNNYLYDGEEIATRGNVIVVTFNYRVGPLGFLSTGDANLPGNYGLRDQHMAIAW VKRNIAAFGGDPNNITLFGESAGGASVSLQTLSPYNKGLIRRAISQSGVALSPWVIQKNPLFWAKKVAEKVGCPVGDAARMAQCLKVTDP RALTLAYKVPLAGLEYPMLHYVGFVPVIDGDFIPADPINLYANAADIDYIAGTNNMDGHIFASIDMPAINKGNKKVTEEDFYKLVSEFTI TKGLRGAKTTFDVYTESWAQDPSQENKKKTVVDFETDVLFLVPTEIALAQHRANAKDPNMGDSAVPTHWEPYTTENSGYLEITKKMGSSS MKRSLRTNFLRYWTLTYLALPTVTDQEATPVPPTGDSEATPVPPTGDSETAPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTG DSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDAGPPPVPPTGDSGAPPVPPTGDSGAPPVTPTGDS -------------------------------------------------------------- >63548_63548_2_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000264441_CEL_chr9_135937365_ENST00000372080_length(transcript)=2876nt_BP=492nt AGAGCTTGTGGAGGCCATGGGGCGCGTCGTCGCGGAGCTCGTCTCCTCGCTGCTGGGGTTGTGGCTGTTGCTGTGCAGCTGCGGATGCCC CGAGGGCGCCGAGCTGCGTGCTCCGCCAGATAAAATCGCGATTATTGGAGCCGGAATTGGTGGCACTTCAGCAGCCTATTACCTGCGGCA GAAATTTGGGAAAGATGTGAAGATAGACCTGTTTGAAAGAGAAGAGGTCGGGGGCCGCCTGGCTACCATGATGGTGCAGGGGCAAGAATA CGAGGCAGGAGGTTCTGTCATCCATCCTTTAAATCTGCACATGAAACGTTTTGTCAAAGACCTGGCCTCTGGTGGCCTACTGGGGATATA TAATGGAGAGACTCTGGTATTTGAGGAGAGCAACTGGTTCATAATTAACGTGATTAAATTAGTTTGGCGCTATGGATTTCAATCCCTCCG TATGCACATGTGGGTAGAGGACGTGTTAGACAAGTTCATGAGGGCCACCCAGAGGCTGATGCTCACCATGGGGCGCCTGCAACTGGTTGT GTTGGGCCTCACCTGCTGCTGGGCAGTGGCGAGTGCCGCGAAGCTGGGCGCCGTGTACACAGAAGGTGGGTTCGTGGAAGGCGTCAATAA GAAGCTCGGCCTCCTGGGTGACTCTGTGGACATCTTCAAGGGCATCCCCTTCGCAGCTCCCACCAAGGCCCTGGAAAATCCTCAGCCACA TCCTGGCTGGCAAGGGACCCTGAAGGCCAAGAACTTCAAGAAGAGATGCCTGCAGGCCACCATCACCCAGGACAGCACCTACGGGGATGA AGACTGCCTGTACCTCAACATTTGGGTGCCCCAGGGCAGGAAGCAAGTCTCCCGGGACCTGCCCGTTATGATCTGGATCTATGGAGGCGC CTTCCTCATGGGGTCCGGCCATGGGGCCAACTTCCTCAACAACTACCTGTATGACGGCGAGGAGATCGCCACACGCGGAAACGTCATCGT GGTCACCTTCAACTACCGTGTCGGCCCCCTTGGGTTCCTCAGCACTGGGGACGCCAATCTGCCAGGTAACTATGGCCTTCGGGATCAGCA CATGGCCATTGCTTGGGTGAAGAGGAATATCGCGGCCTTCGGGGGGGACCCCAACAACATCACGCTCTTCGGGGAGTCTGCTGGAGGTGC CAGCGTCTCTCTGCAGACCCTCTCCCCCTACAACAAGGGCCTCATCCGGCGAGCCATCAGCCAGAGCGGCGTGGCCCTGAGTCCCTGGGT CATCCAGAAAAACCCACTCTTCTGGGCCAAAAAGGTGGCTGAGAAGGTGGGTTGCCCTGTGGGTGATGCCGCCAGGATGGCCCAGTGTCT GAAGGTTACTGATCCCCGAGCCCTGACGCTGGCCTATAAGGTGCCGCTGGCAGGCCTGGAGTACCCCATGCTGCACTATGTGGGCTTCGT CCCTGTCATTGATGGAGACTTCATCCCCGCTGACCCGATCAACCTGTACGCCAACGCCGCCGACATCGACTATATAGCAGGCACCAACAA CATGGACGGCCACATCTTCGCCAGCATCGACATGCCTGCCATCAACAAGGGCAACAAGAAAGTCACGGAGGAGGACTTCTACAAGCTGGT CAGTGAGTTCACAATCACCAAGGGGCTCAGAGGCGCCAAGACGACCTTTGATGTCTACACCGAGTCCTGGGCCCAGGACCCATCCCAGGA GAATAAGAAGAAGACTGTGGTGGACTTTGAGACCGATGTCCTCTTCCTGGTGCCCACCGAGATTGCCCTAGCCCAGCACAGAGCCAATGC CAAGAGTGCCAAGACCTACGCCTACCTGTTTTCCCATCCCTCTCGGATGCCCGTCTACCCCAAATGGGTGGGGGCCGACCATGCAGATGA CATTCAGTACGTTTTCGGGAAGCCCTTCGCCACCCCCACGGGCTACCGGCCCCAAGACAGGACAGTCTCTAAGGCCATGATCGCCTACTG GACCAACTTTGCCAAAACAGGGGACCCCAACATGGGCGACTCGGCTGTGCCCACACACTGGGAACCCTACACTACGGAAAACAGCGGCTA CCTGGAGATCACCAAGAAGATGGGCAGCAGCTCCATGAAGCGGAGCCTGAGAACCAACTTCCTGCGCTACTGGACCCTCACCTATCTGGC GCTGCCCACAGTGACCGACCAGGAGGCCACCCCTGTGCCCCCCACAGGGGACTCCGAGGCCACTCCCGTGCCCCCCACGGGTGACTCCGA GACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGG TGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCC GCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCC CCCCGTGCCGCCCACGGGTGACGCCGGGCCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCGCCCACGGGTGACTC CGGGGCCCCCCCCGTGACCCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCTGTGCCCCCCAC GGGTGACTCTGAGGCTGCCCCTGTGCCCCCCACAGATGACTCCAAGGAAGCTCAGATGCCTGCAGTCATTAGGTTTTAGCGTCCCATGAG >63548_63548_2_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000264441_CEL_chr9_135937365_ENST00000372080_length(amino acids)=920AA_BP=158 MGRVVAELVSSLLGLWLLLCSCGCPEGAELRAPPDKIAIIGAGIGGTSAAYYLRQKFGKDVKIDLFEREEVGGRLATMMVQGQEYEAGGS VIHPLNLHMKRFVKDLASGGLLGIYNGETLVFEESNWFIINVIKLVWRYGFQSLRMHMWVEDVLDKFMRATQRLMLTMGRLQLVVLGLTC CWAVASAAKLGAVYTEGGFVEGVNKKLGLLGDSVDIFKGIPFAAPTKALENPQPHPGWQGTLKAKNFKKRCLQATITQDSTYGDEDCLYL NIWVPQGRKQVSRDLPVMIWIYGGAFLMGSGHGANFLNNYLYDGEEIATRGNVIVVTFNYRVGPLGFLSTGDANLPGNYGLRDQHMAIAW VKRNIAAFGGDPNNITLFGESAGGASVSLQTLSPYNKGLIRRAISQSGVALSPWVIQKNPLFWAKKVAEKVGCPVGDAARMAQCLKVTDP RALTLAYKVPLAGLEYPMLHYVGFVPVIDGDFIPADPINLYANAADIDYIAGTNNMDGHIFASIDMPAINKGNKKVTEEDFYKLVSEFTI TKGLRGAKTTFDVYTESWAQDPSQENKKKTVVDFETDVLFLVPTEIALAQHRANAKSAKTYAYLFSHPSRMPVYPKWVGADHADDIQYVF GKPFATPTGYRPQDRTVSKAMIAYWTNFAKTGDPNMGDSAVPTHWEPYTTENSGYLEITKKMGSSSMKRSLRTNFLRYWTLTYLALPTVT DQEATPVPPTGDSEATPVPPTGDSETAPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDS GAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDAGPPPVPPTGDSGAPPVPPTGDSGAPPVTPTGDSETAPVPPTGDSGAPPVPPTGDSEA -------------------------------------------------------------- >63548_63548_3_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000433351_CEL_chr9_135937365_ENST00000351304_length(transcript)=2690nt_BP=504nt GAGGCCAGCTGCAGAGCTTGTGGAGGCCATGGGGCGCGTCGTCGCGGAGCTCGTCTCCTCGCTGCTGGGGTTGTGGCTGTTGCTGTGCAG CTGCGGATGCCCCGAGGGCGCCGAGCTGCGTGCTCCGCCAGATAAAATCGCGATTATTGGAGCCGGAATTGGTGGCACTTCAGCAGCCTA TTACCTGCGGCAGAAATTTGGGAAAGATGTGAAGATAGACCTGTTTGAAAGAGAAGAGGTCGGGGGCCGCCTGGCTACCATGATGGTGCA GGGGCAAGAATACGAGGCAGGAGGTTCTGTCATCCATCCTTTAAATCTGCACATGAAACGTTTTGTCAAAGACCTGGCCTCTGGTGGCCT ACTGGGGATATATAATGGAGAGACTCTGGTATTTGAGGAGAGCAACTGGTTCATAATTAACGTGATTAAATTAGTTTGGCGCTATGGATT TCAATCCCTCCGTATGCACATGTGGGTAGAGGACGTGTTAGACAAGTTCATGAGGGCCACCCAGAGGCTGATGCTCACCATGGGGCGCCT GCAACTGGTTGTGTTGGGCCTCACCTGCTGCTGGGCAGTGGCGAGTGCCGCGAAGCTGGGCGCCGTGTACACAGAAGGTGGGTTCGTGGA AGGCGTCAATAAGAAGCTCGGCCTCCTGGGTGACTCTGTGGACATCTTCAAGGGCATCCCCTTCGCAGCTCCCACCAAGGCCCTGGAAAA TCCTCAGCCACATCCTGGCTGGCAAGGGACCCTGAAGGCCAAGAACTTCAAGAAGAGATGCCTGCAGGCCACCATCACCCAGGACAGCAC CTACGGGGATGAAGACTGCCTGTACCTCAACATTTGGGTGCCCCAGGGCAGGAAGCAAGTCTCCCGGGACCTGCCCGTTATGATCTGGAT CTATGGAGGCGCCTTCCTCATGGGGTCCGGCCATGGGGCCAACTTCCTCAACAACTACCTGTATGACGGCGAGGAGATCGCCACACGCGG AAACGTCATCGTGGTCACCTTCAACTACCGTGTCGGCCCCCTTGGGTTCCTCAGCACTGGGGACGCCAATCTGCCAGGTAACTATGGCCT TCGGGATCAGCACATGGCCATTGCTTGGGTGAAGAGGAATATCGCGGCCTTCGGGGGGGACCCCAACAACATCACGCTCTTCGGGGAGTC TGCTGGAGGTGCCAGCGTCTCTCTGCAGACCCTCTCCCCCTACAACAAGGGCCTCATCCGGCGAGCCATCAGCCAGAGCGGCGTGGCCCT GAGTCCCTGGGTCATCCAGAAAAACCCACTCTTCTGGGCCAAAAAGGTGGCTGAGAAGGTGGGTTGCCCTGTGGGTGATGCCGCCAGGAT GGCCCAGTGTCTGAAGGTTACTGATCCCCGAGCCCTGACGCTGGCCTATAAGGTGCCGCTGGCAGGCCTGGAGTACCCCATGCTGCACTA TGTGGGCTTCGTCCCTGTCATTGATGGAGACTTCATCCCCGCTGACCCGATCAACCTGTACGCCAACGCCGCCGACATCGACTATATAGC AGGCACCAACAACATGGACGGCCACATCTTCGCCAGCATCGACATGCCTGCCATCAACAAGGGCAACAAGAAAGTCACGGAGGAGGACTT CTACAAGCTGGTCAGTGAGTTCACAATCACCAAGGGGCTCAGAGGCGCCAAGACGACCTTTGATGTCTACACCGAGTCCTGGGCCCAGGA CCCATCCCAGGAGAATAAGAAGAAGACTGTGGTGGACTTTGAGACCGATGTCCTCTTCCTGGTGCCCACCGAGATTGCCCTAGCCCAGCA CAGAGCCAATGCCAAGGACCCCAACATGGGCGACTCGGCTGTGCCCACACACTGGGAACCCTACACTACGGAAAACAGCGGCTACCTGGA GATCACCAAGAAGATGGGCAGCAGCTCCATGAAGCGGAGCCTGAGAACCAACTTCCTGCGCTACTGGACCCTCACCTATCTGGCGCTGCC CACAGTGACCGACCAGGAGGCCACCCCTGTGCCCCCCACAGGGGACTCCGAGGCCACTCCCGTGCCCCCCACGGGTGACTCCGAGACCGC CCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTC CGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCAC GGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGT GCCGCCCACGGGTGACGCCGGGCCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGC CCCCCCCGTGACCCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCTGTGCCCCCCACGGGTGA CTCTGAGGCTGCCCCTGTGCCCCCCACAGATGACTCCAAGGAAGCTCAGATGCCTGCAGTCATTAGGTTTTAGCGTCCCATGAGCCTTGG >63548_63548_3_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000433351_CEL_chr9_135937365_ENST00000351304_length(amino acids)=854AA_BP=158 MGRVVAELVSSLLGLWLLLCSCGCPEGAELRAPPDKIAIIGAGIGGTSAAYYLRQKFGKDVKIDLFEREEVGGRLATMMVQGQEYEAGGS VIHPLNLHMKRFVKDLASGGLLGIYNGETLVFEESNWFIINVIKLVWRYGFQSLRMHMWVEDVLDKFMRATQRLMLTMGRLQLVVLGLTC CWAVASAAKLGAVYTEGGFVEGVNKKLGLLGDSVDIFKGIPFAAPTKALENPQPHPGWQGTLKAKNFKKRCLQATITQDSTYGDEDCLYL NIWVPQGRKQVSRDLPVMIWIYGGAFLMGSGHGANFLNNYLYDGEEIATRGNVIVVTFNYRVGPLGFLSTGDANLPGNYGLRDQHMAIAW VKRNIAAFGGDPNNITLFGESAGGASVSLQTLSPYNKGLIRRAISQSGVALSPWVIQKNPLFWAKKVAEKVGCPVGDAARMAQCLKVTDP RALTLAYKVPLAGLEYPMLHYVGFVPVIDGDFIPADPINLYANAADIDYIAGTNNMDGHIFASIDMPAINKGNKKVTEEDFYKLVSEFTI TKGLRGAKTTFDVYTESWAQDPSQENKKKTVVDFETDVLFLVPTEIALAQHRANAKDPNMGDSAVPTHWEPYTTENSGYLEITKKMGSSS MKRSLRTNFLRYWTLTYLALPTVTDQEATPVPPTGDSEATPVPPTGDSETAPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTG DSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDAGPPPVPPTGDSGAPPVPPTGDSGAPPVTPTGDS -------------------------------------------------------------- >63548_63548_4_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000433351_CEL_chr9_135937365_ENST00000372080_length(transcript)=2888nt_BP=504nt GAGGCCAGCTGCAGAGCTTGTGGAGGCCATGGGGCGCGTCGTCGCGGAGCTCGTCTCCTCGCTGCTGGGGTTGTGGCTGTTGCTGTGCAG CTGCGGATGCCCCGAGGGCGCCGAGCTGCGTGCTCCGCCAGATAAAATCGCGATTATTGGAGCCGGAATTGGTGGCACTTCAGCAGCCTA TTACCTGCGGCAGAAATTTGGGAAAGATGTGAAGATAGACCTGTTTGAAAGAGAAGAGGTCGGGGGCCGCCTGGCTACCATGATGGTGCA GGGGCAAGAATACGAGGCAGGAGGTTCTGTCATCCATCCTTTAAATCTGCACATGAAACGTTTTGTCAAAGACCTGGCCTCTGGTGGCCT ACTGGGGATATATAATGGAGAGACTCTGGTATTTGAGGAGAGCAACTGGTTCATAATTAACGTGATTAAATTAGTTTGGCGCTATGGATT TCAATCCCTCCGTATGCACATGTGGGTAGAGGACGTGTTAGACAAGTTCATGAGGGCCACCCAGAGGCTGATGCTCACCATGGGGCGCCT GCAACTGGTTGTGTTGGGCCTCACCTGCTGCTGGGCAGTGGCGAGTGCCGCGAAGCTGGGCGCCGTGTACACAGAAGGTGGGTTCGTGGA AGGCGTCAATAAGAAGCTCGGCCTCCTGGGTGACTCTGTGGACATCTTCAAGGGCATCCCCTTCGCAGCTCCCACCAAGGCCCTGGAAAA TCCTCAGCCACATCCTGGCTGGCAAGGGACCCTGAAGGCCAAGAACTTCAAGAAGAGATGCCTGCAGGCCACCATCACCCAGGACAGCAC CTACGGGGATGAAGACTGCCTGTACCTCAACATTTGGGTGCCCCAGGGCAGGAAGCAAGTCTCCCGGGACCTGCCCGTTATGATCTGGAT CTATGGAGGCGCCTTCCTCATGGGGTCCGGCCATGGGGCCAACTTCCTCAACAACTACCTGTATGACGGCGAGGAGATCGCCACACGCGG AAACGTCATCGTGGTCACCTTCAACTACCGTGTCGGCCCCCTTGGGTTCCTCAGCACTGGGGACGCCAATCTGCCAGGTAACTATGGCCT TCGGGATCAGCACATGGCCATTGCTTGGGTGAAGAGGAATATCGCGGCCTTCGGGGGGGACCCCAACAACATCACGCTCTTCGGGGAGTC TGCTGGAGGTGCCAGCGTCTCTCTGCAGACCCTCTCCCCCTACAACAAGGGCCTCATCCGGCGAGCCATCAGCCAGAGCGGCGTGGCCCT GAGTCCCTGGGTCATCCAGAAAAACCCACTCTTCTGGGCCAAAAAGGTGGCTGAGAAGGTGGGTTGCCCTGTGGGTGATGCCGCCAGGAT GGCCCAGTGTCTGAAGGTTACTGATCCCCGAGCCCTGACGCTGGCCTATAAGGTGCCGCTGGCAGGCCTGGAGTACCCCATGCTGCACTA TGTGGGCTTCGTCCCTGTCATTGATGGAGACTTCATCCCCGCTGACCCGATCAACCTGTACGCCAACGCCGCCGACATCGACTATATAGC AGGCACCAACAACATGGACGGCCACATCTTCGCCAGCATCGACATGCCTGCCATCAACAAGGGCAACAAGAAAGTCACGGAGGAGGACTT CTACAAGCTGGTCAGTGAGTTCACAATCACCAAGGGGCTCAGAGGCGCCAAGACGACCTTTGATGTCTACACCGAGTCCTGGGCCCAGGA CCCATCCCAGGAGAATAAGAAGAAGACTGTGGTGGACTTTGAGACCGATGTCCTCTTCCTGGTGCCCACCGAGATTGCCCTAGCCCAGCA CAGAGCCAATGCCAAGAGTGCCAAGACCTACGCCTACCTGTTTTCCCATCCCTCTCGGATGCCCGTCTACCCCAAATGGGTGGGGGCCGA CCATGCAGATGACATTCAGTACGTTTTCGGGAAGCCCTTCGCCACCCCCACGGGCTACCGGCCCCAAGACAGGACAGTCTCTAAGGCCAT GATCGCCTACTGGACCAACTTTGCCAAAACAGGGGACCCCAACATGGGCGACTCGGCTGTGCCCACACACTGGGAACCCTACACTACGGA AAACAGCGGCTACCTGGAGATCACCAAGAAGATGGGCAGCAGCTCCATGAAGCGGAGCCTGAGAACCAACTTCCTGCGCTACTGGACCCT CACCTATCTGGCGCTGCCCACAGTGACCGACCAGGAGGCCACCCCTGTGCCCCCCACAGGGGACTCCGAGGCCACTCCCGTGCCCCCCAC GGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGT GCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGC CCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGA CTCCGGCGCCCCCCCCGTGCCGCCCACGGGTGACGCCGGGCCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCGCC CACGGGTGACTCCGGGGCCCCCCCCGTGACCCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCC TGTGCCCCCCACGGGTGACTCTGAGGCTGCCCCTGTGCCCCCCACAGATGACTCCAAGGAAGCTCAGATGCCTGCAGTCATTAGGTTTTA GCGTCCCATGAGCCTTGGTATCAAGAGGCCACAAGAGTGGGACCCCAGGGGCTCCCCTCCCATCTTGAGCTCTTCCTGAATAAAGCCTCA >63548_63548_4_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000433351_CEL_chr9_135937365_ENST00000372080_length(amino acids)=920AA_BP=158 MGRVVAELVSSLLGLWLLLCSCGCPEGAELRAPPDKIAIIGAGIGGTSAAYYLRQKFGKDVKIDLFEREEVGGRLATMMVQGQEYEAGGS VIHPLNLHMKRFVKDLASGGLLGIYNGETLVFEESNWFIINVIKLVWRYGFQSLRMHMWVEDVLDKFMRATQRLMLTMGRLQLVVLGLTC CWAVASAAKLGAVYTEGGFVEGVNKKLGLLGDSVDIFKGIPFAAPTKALENPQPHPGWQGTLKAKNFKKRCLQATITQDSTYGDEDCLYL NIWVPQGRKQVSRDLPVMIWIYGGAFLMGSGHGANFLNNYLYDGEEIATRGNVIVVTFNYRVGPLGFLSTGDANLPGNYGLRDQHMAIAW VKRNIAAFGGDPNNITLFGESAGGASVSLQTLSPYNKGLIRRAISQSGVALSPWVIQKNPLFWAKKVAEKVGCPVGDAARMAQCLKVTDP RALTLAYKVPLAGLEYPMLHYVGFVPVIDGDFIPADPINLYANAADIDYIAGTNNMDGHIFASIDMPAINKGNKKVTEEDFYKLVSEFTI TKGLRGAKTTFDVYTESWAQDPSQENKKKTVVDFETDVLFLVPTEIALAQHRANAKSAKTYAYLFSHPSRMPVYPKWVGADHADDIQYVF GKPFATPTGYRPQDRTVSKAMIAYWTNFAKTGDPNMGDSAVPTHWEPYTTENSGYLEITKKMGSSSMKRSLRTNFLRYWTLTYLALPTVT DQEATPVPPTGDSEATPVPPTGDSETAPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDS GAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDAGPPPVPPTGDSGAPPVPPTGDSGAPPVTPTGDSETAPVPPTGDSGAPPVPPTGDSEA -------------------------------------------------------------- >63548_63548_5_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000505044_CEL_chr9_135937365_ENST00000351304_length(transcript)=2776nt_BP=590nt ATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGCGCCCGCCACTATGCCGAGCTAAATTTTTGTATTTTTAGTAGAGACGGGG TTTCACCGTGTTAGCCAGGATGGTCTCGATCTCCTGACCTCATGATCCACCCACCTCGGCCTCCCAAAGTGCTGGGATTACAGGCTTGAG CCACCGCGCCCGGCCAGCTTCTGCCTTCGATGTCTTCTGAAGGAGGCGATTATTGGAGCCGGAATTGGTGGCACTTCAGCAGCCTATTAC CTGCGGCAGAAATTTGGGAAAGATGTGAAGATAGACCTGTTTGAAAGAGAAGAGGTCGGGGGCCGCCTGGCTACCATGATGGTGCAGGGG CAAGAATACGAGGCAGGAGGTTCTGTCATCCATCCTTTAAATCTGCACATGAAACGTTTTGTCAAAGACCTGGCCTCTGGTGGCCTACTG GGGATATATAATGGAGAGACTCTGGTATTTGAGGAGAGCAACTGGTTCATAATTAACGTGATTAAATTAGTTTGGCGCTATGGATTTCAA TCCCTCCGTATGCACATGTGGGTAGAGGACGTGTTAGACAAGTTCATGAGGGCCACCCAGAGGCTGATGCTCACCATGGGGCGCCTGCAA CTGGTTGTGTTGGGCCTCACCTGCTGCTGGGCAGTGGCGAGTGCCGCGAAGCTGGGCGCCGTGTACACAGAAGGTGGGTTCGTGGAAGGC GTCAATAAGAAGCTCGGCCTCCTGGGTGACTCTGTGGACATCTTCAAGGGCATCCCCTTCGCAGCTCCCACCAAGGCCCTGGAAAATCCT CAGCCACATCCTGGCTGGCAAGGGACCCTGAAGGCCAAGAACTTCAAGAAGAGATGCCTGCAGGCCACCATCACCCAGGACAGCACCTAC GGGGATGAAGACTGCCTGTACCTCAACATTTGGGTGCCCCAGGGCAGGAAGCAAGTCTCCCGGGACCTGCCCGTTATGATCTGGATCTAT GGAGGCGCCTTCCTCATGGGGTCCGGCCATGGGGCCAACTTCCTCAACAACTACCTGTATGACGGCGAGGAGATCGCCACACGCGGAAAC GTCATCGTGGTCACCTTCAACTACCGTGTCGGCCCCCTTGGGTTCCTCAGCACTGGGGACGCCAATCTGCCAGGTAACTATGGCCTTCGG GATCAGCACATGGCCATTGCTTGGGTGAAGAGGAATATCGCGGCCTTCGGGGGGGACCCCAACAACATCACGCTCTTCGGGGAGTCTGCT GGAGGTGCCAGCGTCTCTCTGCAGACCCTCTCCCCCTACAACAAGGGCCTCATCCGGCGAGCCATCAGCCAGAGCGGCGTGGCCCTGAGT CCCTGGGTCATCCAGAAAAACCCACTCTTCTGGGCCAAAAAGGTGGCTGAGAAGGTGGGTTGCCCTGTGGGTGATGCCGCCAGGATGGCC CAGTGTCTGAAGGTTACTGATCCCCGAGCCCTGACGCTGGCCTATAAGGTGCCGCTGGCAGGCCTGGAGTACCCCATGCTGCACTATGTG GGCTTCGTCCCTGTCATTGATGGAGACTTCATCCCCGCTGACCCGATCAACCTGTACGCCAACGCCGCCGACATCGACTATATAGCAGGC ACCAACAACATGGACGGCCACATCTTCGCCAGCATCGACATGCCTGCCATCAACAAGGGCAACAAGAAAGTCACGGAGGAGGACTTCTAC AAGCTGGTCAGTGAGTTCACAATCACCAAGGGGCTCAGAGGCGCCAAGACGACCTTTGATGTCTACACCGAGTCCTGGGCCCAGGACCCA TCCCAGGAGAATAAGAAGAAGACTGTGGTGGACTTTGAGACCGATGTCCTCTTCCTGGTGCCCACCGAGATTGCCCTAGCCCAGCACAGA GCCAATGCCAAGGACCCCAACATGGGCGACTCGGCTGTGCCCACACACTGGGAACCCTACACTACGGAAAACAGCGGCTACCTGGAGATC ACCAAGAAGATGGGCAGCAGCTCCATGAAGCGGAGCCTGAGAACCAACTTCCTGCGCTACTGGACCCTCACCTATCTGGCGCTGCCCACA GTGACCGACCAGGAGGCCACCCCTGTGCCCCCCACAGGGGACTCCGAGGCCACTCCCGTGCCCCCCACGGGTGACTCCGAGACCGCCCCC GTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGG GCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGT GACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCG CCCACGGGTGACGCCGGGCCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCC CCCGTGACCCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCTGTGCCCCCCACGGGTGACTCT GAGGCTGCCCCTGTGCCCCCCACAGATGACTCCAAGGAAGCTCAGATGCCTGCAGTCATTAGGTTTTAGCGTCCCATGAGCCTTGGTATC >63548_63548_5_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000505044_CEL_chr9_135937365_ENST00000351304_length(amino acids)=820AA_BP=124 MKEAIIGAGIGGTSAAYYLRQKFGKDVKIDLFEREEVGGRLATMMVQGQEYEAGGSVIHPLNLHMKRFVKDLASGGLLGIYNGETLVFEE SNWFIINVIKLVWRYGFQSLRMHMWVEDVLDKFMRATQRLMLTMGRLQLVVLGLTCCWAVASAAKLGAVYTEGGFVEGVNKKLGLLGDSV DIFKGIPFAAPTKALENPQPHPGWQGTLKAKNFKKRCLQATITQDSTYGDEDCLYLNIWVPQGRKQVSRDLPVMIWIYGGAFLMGSGHGA NFLNNYLYDGEEIATRGNVIVVTFNYRVGPLGFLSTGDANLPGNYGLRDQHMAIAWVKRNIAAFGGDPNNITLFGESAGGASVSLQTLSP YNKGLIRRAISQSGVALSPWVIQKNPLFWAKKVAEKVGCPVGDAARMAQCLKVTDPRALTLAYKVPLAGLEYPMLHYVGFVPVIDGDFIP ADPINLYANAADIDYIAGTNNMDGHIFASIDMPAINKGNKKVTEEDFYKLVSEFTITKGLRGAKTTFDVYTESWAQDPSQENKKKTVVDF ETDVLFLVPTEIALAQHRANAKDPNMGDSAVPTHWEPYTTENSGYLEITKKMGSSSMKRSLRTNFLRYWTLTYLALPTVTDQEATPVPPT GDSEATPVPPTGDSETAPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGD SGAPPVPPTGDSGAPPVPPTGDAGPPPVPPTGDSGAPPVPPTGDSGAPPVTPTGDSETAPVPPTGDSGAPPVPPTGDSEAAPVPPTDDSK -------------------------------------------------------------- >63548_63548_6_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000505044_CEL_chr9_135937365_ENST00000372080_length(transcript)=2974nt_BP=590nt ATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGACTACAGGCGCCCGCCACTATGCCGAGCTAAATTTTTGTATTTTTAGTAGAGACGGGG TTTCACCGTGTTAGCCAGGATGGTCTCGATCTCCTGACCTCATGATCCACCCACCTCGGCCTCCCAAAGTGCTGGGATTACAGGCTTGAG CCACCGCGCCCGGCCAGCTTCTGCCTTCGATGTCTTCTGAAGGAGGCGATTATTGGAGCCGGAATTGGTGGCACTTCAGCAGCCTATTAC CTGCGGCAGAAATTTGGGAAAGATGTGAAGATAGACCTGTTTGAAAGAGAAGAGGTCGGGGGCCGCCTGGCTACCATGATGGTGCAGGGG CAAGAATACGAGGCAGGAGGTTCTGTCATCCATCCTTTAAATCTGCACATGAAACGTTTTGTCAAAGACCTGGCCTCTGGTGGCCTACTG GGGATATATAATGGAGAGACTCTGGTATTTGAGGAGAGCAACTGGTTCATAATTAACGTGATTAAATTAGTTTGGCGCTATGGATTTCAA TCCCTCCGTATGCACATGTGGGTAGAGGACGTGTTAGACAAGTTCATGAGGGCCACCCAGAGGCTGATGCTCACCATGGGGCGCCTGCAA CTGGTTGTGTTGGGCCTCACCTGCTGCTGGGCAGTGGCGAGTGCCGCGAAGCTGGGCGCCGTGTACACAGAAGGTGGGTTCGTGGAAGGC GTCAATAAGAAGCTCGGCCTCCTGGGTGACTCTGTGGACATCTTCAAGGGCATCCCCTTCGCAGCTCCCACCAAGGCCCTGGAAAATCCT CAGCCACATCCTGGCTGGCAAGGGACCCTGAAGGCCAAGAACTTCAAGAAGAGATGCCTGCAGGCCACCATCACCCAGGACAGCACCTAC GGGGATGAAGACTGCCTGTACCTCAACATTTGGGTGCCCCAGGGCAGGAAGCAAGTCTCCCGGGACCTGCCCGTTATGATCTGGATCTAT GGAGGCGCCTTCCTCATGGGGTCCGGCCATGGGGCCAACTTCCTCAACAACTACCTGTATGACGGCGAGGAGATCGCCACACGCGGAAAC GTCATCGTGGTCACCTTCAACTACCGTGTCGGCCCCCTTGGGTTCCTCAGCACTGGGGACGCCAATCTGCCAGGTAACTATGGCCTTCGG GATCAGCACATGGCCATTGCTTGGGTGAAGAGGAATATCGCGGCCTTCGGGGGGGACCCCAACAACATCACGCTCTTCGGGGAGTCTGCT GGAGGTGCCAGCGTCTCTCTGCAGACCCTCTCCCCCTACAACAAGGGCCTCATCCGGCGAGCCATCAGCCAGAGCGGCGTGGCCCTGAGT CCCTGGGTCATCCAGAAAAACCCACTCTTCTGGGCCAAAAAGGTGGCTGAGAAGGTGGGTTGCCCTGTGGGTGATGCCGCCAGGATGGCC CAGTGTCTGAAGGTTACTGATCCCCGAGCCCTGACGCTGGCCTATAAGGTGCCGCTGGCAGGCCTGGAGTACCCCATGCTGCACTATGTG GGCTTCGTCCCTGTCATTGATGGAGACTTCATCCCCGCTGACCCGATCAACCTGTACGCCAACGCCGCCGACATCGACTATATAGCAGGC ACCAACAACATGGACGGCCACATCTTCGCCAGCATCGACATGCCTGCCATCAACAAGGGCAACAAGAAAGTCACGGAGGAGGACTTCTAC AAGCTGGTCAGTGAGTTCACAATCACCAAGGGGCTCAGAGGCGCCAAGACGACCTTTGATGTCTACACCGAGTCCTGGGCCCAGGACCCA TCCCAGGAGAATAAGAAGAAGACTGTGGTGGACTTTGAGACCGATGTCCTCTTCCTGGTGCCCACCGAGATTGCCCTAGCCCAGCACAGA GCCAATGCCAAGAGTGCCAAGACCTACGCCTACCTGTTTTCCCATCCCTCTCGGATGCCCGTCTACCCCAAATGGGTGGGGGCCGACCAT GCAGATGACATTCAGTACGTTTTCGGGAAGCCCTTCGCCACCCCCACGGGCTACCGGCCCCAAGACAGGACAGTCTCTAAGGCCATGATC GCCTACTGGACCAACTTTGCCAAAACAGGGGACCCCAACATGGGCGACTCGGCTGTGCCCACACACTGGGAACCCTACACTACGGAAAAC AGCGGCTACCTGGAGATCACCAAGAAGATGGGCAGCAGCTCCATGAAGCGGAGCCTGAGAACCAACTTCCTGCGCTACTGGACCCTCACC TATCTGGCGCTGCCCACAGTGACCGACCAGGAGGCCACCCCTGTGCCCCCCACAGGGGACTCCGAGGCCACTCCCGTGCCCCCCACGGGT GACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCG CCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCC CCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCC GGCGCCCCCCCCGTGCCGCCCACGGGTGACGCCGGGCCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCGCCCACG GGTGACTCCGGGGCCCCCCCCGTGACCCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCTGTG CCCCCCACGGGTGACTCTGAGGCTGCCCCTGTGCCCCCCACAGATGACTCCAAGGAAGCTCAGATGCCTGCAGTCATTAGGTTTTAGCGT CCCATGAGCCTTGGTATCAAGAGGCCACAAGAGTGGGACCCCAGGGGCTCCCCTCCCATCTTGAGCTCTTCCTGAATAAAGCCTCATACC >63548_63548_6_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000505044_CEL_chr9_135937365_ENST00000372080_length(amino acids)=886AA_BP=124 MKEAIIGAGIGGTSAAYYLRQKFGKDVKIDLFEREEVGGRLATMMVQGQEYEAGGSVIHPLNLHMKRFVKDLASGGLLGIYNGETLVFEE SNWFIINVIKLVWRYGFQSLRMHMWVEDVLDKFMRATQRLMLTMGRLQLVVLGLTCCWAVASAAKLGAVYTEGGFVEGVNKKLGLLGDSV DIFKGIPFAAPTKALENPQPHPGWQGTLKAKNFKKRCLQATITQDSTYGDEDCLYLNIWVPQGRKQVSRDLPVMIWIYGGAFLMGSGHGA NFLNNYLYDGEEIATRGNVIVVTFNYRVGPLGFLSTGDANLPGNYGLRDQHMAIAWVKRNIAAFGGDPNNITLFGESAGGASVSLQTLSP YNKGLIRRAISQSGVALSPWVIQKNPLFWAKKVAEKVGCPVGDAARMAQCLKVTDPRALTLAYKVPLAGLEYPMLHYVGFVPVIDGDFIP ADPINLYANAADIDYIAGTNNMDGHIFASIDMPAINKGNKKVTEEDFYKLVSEFTITKGLRGAKTTFDVYTESWAQDPSQENKKKTVVDF ETDVLFLVPTEIALAQHRANAKSAKTYAYLFSHPSRMPVYPKWVGADHADDIQYVFGKPFATPTGYRPQDRTVSKAMIAYWTNFAKTGDP NMGDSAVPTHWEPYTTENSGYLEITKKMGSSSMKRSLRTNFLRYWTLTYLALPTVTDQEATPVPPTGDSEATPVPPTGDSETAPVPPTGD SGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDAG -------------------------------------------------------------- >63548_63548_7_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000545138_CEL_chr9_135937365_ENST00000351304_length(transcript)=2616nt_BP=430nt ATTCACACTTCAGGGCGGCTTTCAGCTCTGGTCGGAATAGGACTGTGCATTCCCAGGCGTGGAGAGCGATTATTGGAGCCGGAATTGGTG GCACTTCAGCAGCCTATTACCTGCGGCAGAAATTTGGGAAAGATGTGAAGATAGACCTGTTTGAAAGAGAAGAGGTCGGGGGCCGCCTGG CTACCATGATGGTGCAGGGGCAAGAATACGAGGCAGGAGGTTCTGTCATCCATCCTTTAAATCTGCACATGAAACGTTTTGTCAAAGACC TGGCCTCTGGTGGCCTACTGGGGATATATAATGGAGAGACTCTGGTATTTGAGGAGAGCAACTGGTTCATAATTAACGTGATTAAATTAG TTTGGCGCTATGGATTTCAATCCCTCCGTATGCACATGTGGGTAGAGGACGTGTTAGACAAGTTCATGAGGGCCACCCAGAGGCTGATGC TCACCATGGGGCGCCTGCAACTGGTTGTGTTGGGCCTCACCTGCTGCTGGGCAGTGGCGAGTGCCGCGAAGCTGGGCGCCGTGTACACAG AAGGTGGGTTCGTGGAAGGCGTCAATAAGAAGCTCGGCCTCCTGGGTGACTCTGTGGACATCTTCAAGGGCATCCCCTTCGCAGCTCCCA CCAAGGCCCTGGAAAATCCTCAGCCACATCCTGGCTGGCAAGGGACCCTGAAGGCCAAGAACTTCAAGAAGAGATGCCTGCAGGCCACCA TCACCCAGGACAGCACCTACGGGGATGAAGACTGCCTGTACCTCAACATTTGGGTGCCCCAGGGCAGGAAGCAAGTCTCCCGGGACCTGC CCGTTATGATCTGGATCTATGGAGGCGCCTTCCTCATGGGGTCCGGCCATGGGGCCAACTTCCTCAACAACTACCTGTATGACGGCGAGG AGATCGCCACACGCGGAAACGTCATCGTGGTCACCTTCAACTACCGTGTCGGCCCCCTTGGGTTCCTCAGCACTGGGGACGCCAATCTGC CAGGTAACTATGGCCTTCGGGATCAGCACATGGCCATTGCTTGGGTGAAGAGGAATATCGCGGCCTTCGGGGGGGACCCCAACAACATCA CGCTCTTCGGGGAGTCTGCTGGAGGTGCCAGCGTCTCTCTGCAGACCCTCTCCCCCTACAACAAGGGCCTCATCCGGCGAGCCATCAGCC AGAGCGGCGTGGCCCTGAGTCCCTGGGTCATCCAGAAAAACCCACTCTTCTGGGCCAAAAAGGTGGCTGAGAAGGTGGGTTGCCCTGTGG GTGATGCCGCCAGGATGGCCCAGTGTCTGAAGGTTACTGATCCCCGAGCCCTGACGCTGGCCTATAAGGTGCCGCTGGCAGGCCTGGAGT ACCCCATGCTGCACTATGTGGGCTTCGTCCCTGTCATTGATGGAGACTTCATCCCCGCTGACCCGATCAACCTGTACGCCAACGCCGCCG ACATCGACTATATAGCAGGCACCAACAACATGGACGGCCACATCTTCGCCAGCATCGACATGCCTGCCATCAACAAGGGCAACAAGAAAG TCACGGAGGAGGACTTCTACAAGCTGGTCAGTGAGTTCACAATCACCAAGGGGCTCAGAGGCGCCAAGACGACCTTTGATGTCTACACCG AGTCCTGGGCCCAGGACCCATCCCAGGAGAATAAGAAGAAGACTGTGGTGGACTTTGAGACCGATGTCCTCTTCCTGGTGCCCACCGAGA TTGCCCTAGCCCAGCACAGAGCCAATGCCAAGGACCCCAACATGGGCGACTCGGCTGTGCCCACACACTGGGAACCCTACACTACGGAAA ACAGCGGCTACCTGGAGATCACCAAGAAGATGGGCAGCAGCTCCATGAAGCGGAGCCTGAGAACCAACTTCCTGCGCTACTGGACCCTCA CCTATCTGGCGCTGCCCACAGTGACCGACCAGGAGGCCACCCCTGTGCCCCCCACAGGGGACTCCGAGGCCACTCCCGTGCCCCCCACGG GTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGC CGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCC CCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACT CCGGCGCCCCCCCCGTGCCGCCCACGGGTGACGCCGGGCCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCGCCCA CGGGTGACTCCGGGGCCCCCCCCGTGACCCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCTG TGCCCCCCACGGGTGACTCTGAGGCTGCCCCTGTGCCCCCCACAGATGACTCCAAGGAAGCTCAGATGCCTGCAGTCATTAGGTTTTAGC GTCCCATGAGCCTTGGTATCAAGAGGCCACAAGAGTGGGACCCCAGGGGCTCCCCTCCCATCTTGAGCTCTTCCTGAATAAAGCCTCATA >63548_63548_7_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000545138_CEL_chr9_135937365_ENST00000351304_length(amino acids)=802AA_BP=106 MRQKFGKDVKIDLFEREEVGGRLATMMVQGQEYEAGGSVIHPLNLHMKRFVKDLASGGLLGIYNGETLVFEESNWFIINVIKLVWRYGFQ SLRMHMWVEDVLDKFMRATQRLMLTMGRLQLVVLGLTCCWAVASAAKLGAVYTEGGFVEGVNKKLGLLGDSVDIFKGIPFAAPTKALENP QPHPGWQGTLKAKNFKKRCLQATITQDSTYGDEDCLYLNIWVPQGRKQVSRDLPVMIWIYGGAFLMGSGHGANFLNNYLYDGEEIATRGN VIVVTFNYRVGPLGFLSTGDANLPGNYGLRDQHMAIAWVKRNIAAFGGDPNNITLFGESAGGASVSLQTLSPYNKGLIRRAISQSGVALS PWVIQKNPLFWAKKVAEKVGCPVGDAARMAQCLKVTDPRALTLAYKVPLAGLEYPMLHYVGFVPVIDGDFIPADPINLYANAADIDYIAG TNNMDGHIFASIDMPAINKGNKKVTEEDFYKLVSEFTITKGLRGAKTTFDVYTESWAQDPSQENKKKTVVDFETDVLFLVPTEIALAQHR ANAKDPNMGDSAVPTHWEPYTTENSGYLEITKKMGSSSMKRSLRTNFLRYWTLTYLALPTVTDQEATPVPPTGDSEATPVPPTGDSETAP VPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVP -------------------------------------------------------------- >63548_63548_8_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000545138_CEL_chr9_135937365_ENST00000372080_length(transcript)=2814nt_BP=430nt ATTCACACTTCAGGGCGGCTTTCAGCTCTGGTCGGAATAGGACTGTGCATTCCCAGGCGTGGAGAGCGATTATTGGAGCCGGAATTGGTG GCACTTCAGCAGCCTATTACCTGCGGCAGAAATTTGGGAAAGATGTGAAGATAGACCTGTTTGAAAGAGAAGAGGTCGGGGGCCGCCTGG CTACCATGATGGTGCAGGGGCAAGAATACGAGGCAGGAGGTTCTGTCATCCATCCTTTAAATCTGCACATGAAACGTTTTGTCAAAGACC TGGCCTCTGGTGGCCTACTGGGGATATATAATGGAGAGACTCTGGTATTTGAGGAGAGCAACTGGTTCATAATTAACGTGATTAAATTAG TTTGGCGCTATGGATTTCAATCCCTCCGTATGCACATGTGGGTAGAGGACGTGTTAGACAAGTTCATGAGGGCCACCCAGAGGCTGATGC TCACCATGGGGCGCCTGCAACTGGTTGTGTTGGGCCTCACCTGCTGCTGGGCAGTGGCGAGTGCCGCGAAGCTGGGCGCCGTGTACACAG AAGGTGGGTTCGTGGAAGGCGTCAATAAGAAGCTCGGCCTCCTGGGTGACTCTGTGGACATCTTCAAGGGCATCCCCTTCGCAGCTCCCA CCAAGGCCCTGGAAAATCCTCAGCCACATCCTGGCTGGCAAGGGACCCTGAAGGCCAAGAACTTCAAGAAGAGATGCCTGCAGGCCACCA TCACCCAGGACAGCACCTACGGGGATGAAGACTGCCTGTACCTCAACATTTGGGTGCCCCAGGGCAGGAAGCAAGTCTCCCGGGACCTGC CCGTTATGATCTGGATCTATGGAGGCGCCTTCCTCATGGGGTCCGGCCATGGGGCCAACTTCCTCAACAACTACCTGTATGACGGCGAGG AGATCGCCACACGCGGAAACGTCATCGTGGTCACCTTCAACTACCGTGTCGGCCCCCTTGGGTTCCTCAGCACTGGGGACGCCAATCTGC CAGGTAACTATGGCCTTCGGGATCAGCACATGGCCATTGCTTGGGTGAAGAGGAATATCGCGGCCTTCGGGGGGGACCCCAACAACATCA CGCTCTTCGGGGAGTCTGCTGGAGGTGCCAGCGTCTCTCTGCAGACCCTCTCCCCCTACAACAAGGGCCTCATCCGGCGAGCCATCAGCC AGAGCGGCGTGGCCCTGAGTCCCTGGGTCATCCAGAAAAACCCACTCTTCTGGGCCAAAAAGGTGGCTGAGAAGGTGGGTTGCCCTGTGG GTGATGCCGCCAGGATGGCCCAGTGTCTGAAGGTTACTGATCCCCGAGCCCTGACGCTGGCCTATAAGGTGCCGCTGGCAGGCCTGGAGT ACCCCATGCTGCACTATGTGGGCTTCGTCCCTGTCATTGATGGAGACTTCATCCCCGCTGACCCGATCAACCTGTACGCCAACGCCGCCG ACATCGACTATATAGCAGGCACCAACAACATGGACGGCCACATCTTCGCCAGCATCGACATGCCTGCCATCAACAAGGGCAACAAGAAAG TCACGGAGGAGGACTTCTACAAGCTGGTCAGTGAGTTCACAATCACCAAGGGGCTCAGAGGCGCCAAGACGACCTTTGATGTCTACACCG AGTCCTGGGCCCAGGACCCATCCCAGGAGAATAAGAAGAAGACTGTGGTGGACTTTGAGACCGATGTCCTCTTCCTGGTGCCCACCGAGA TTGCCCTAGCCCAGCACAGAGCCAATGCCAAGAGTGCCAAGACCTACGCCTACCTGTTTTCCCATCCCTCTCGGATGCCCGTCTACCCCA AATGGGTGGGGGCCGACCATGCAGATGACATTCAGTACGTTTTCGGGAAGCCCTTCGCCACCCCCACGGGCTACCGGCCCCAAGACAGGA CAGTCTCTAAGGCCATGATCGCCTACTGGACCAACTTTGCCAAAACAGGGGACCCCAACATGGGCGACTCGGCTGTGCCCACACACTGGG AACCCTACACTACGGAAAACAGCGGCTACCTGGAGATCACCAAGAAGATGGGCAGCAGCTCCATGAAGCGGAGCCTGAGAACCAACTTCC TGCGCTACTGGACCCTCACCTATCTGGCGCTGCCCACAGTGACCGACCAGGAGGCCACCCCTGTGCCCCCCACAGGGGACTCCGAGGCCA CTCCCGTGCCCCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACT CCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCA CGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCG TGCCGCCCACGGGTGACTCCGGCGCCCCCCCCGTGCCGCCCACGGGTGACGCCGGGCCCCCCCCCGTGCCGCCCACGGGTGACTCCGGCG CCCCCCCCGTGCCGCCCACGGGTGACTCCGGGGCCCCCCCCGTGACCCCCACGGGTGACTCCGAGACCGCCCCCGTGCCGCCCACGGGTG ACTCCGGGGCCCCCCCTGTGCCCCCCACGGGTGACTCTGAGGCTGCCCCTGTGCCCCCCACAGATGACTCCAAGGAAGCTCAGATGCCTG CAGTCATTAGGTTTTAGCGTCCCATGAGCCTTGGTATCAAGAGGCCACAAGAGTGGGACCCCAGGGGCTCCCCTCCCATCTTGAGCTCTT >63548_63548_8_PCYOX1-CEL_PCYOX1_chr2_70488361_ENST00000545138_CEL_chr9_135937365_ENST00000372080_length(amino acids)=868AA_BP=106 MRQKFGKDVKIDLFEREEVGGRLATMMVQGQEYEAGGSVIHPLNLHMKRFVKDLASGGLLGIYNGETLVFEESNWFIINVIKLVWRYGFQ SLRMHMWVEDVLDKFMRATQRLMLTMGRLQLVVLGLTCCWAVASAAKLGAVYTEGGFVEGVNKKLGLLGDSVDIFKGIPFAAPTKALENP QPHPGWQGTLKAKNFKKRCLQATITQDSTYGDEDCLYLNIWVPQGRKQVSRDLPVMIWIYGGAFLMGSGHGANFLNNYLYDGEEIATRGN VIVVTFNYRVGPLGFLSTGDANLPGNYGLRDQHMAIAWVKRNIAAFGGDPNNITLFGESAGGASVSLQTLSPYNKGLIRRAISQSGVALS PWVIQKNPLFWAKKVAEKVGCPVGDAARMAQCLKVTDPRALTLAYKVPLAGLEYPMLHYVGFVPVIDGDFIPADPINLYANAADIDYIAG TNNMDGHIFASIDMPAINKGNKKVTEEDFYKLVSEFTITKGLRGAKTTFDVYTESWAQDPSQENKKKTVVDFETDVLFLVPTEIALAQHR ANAKSAKTYAYLFSHPSRMPVYPKWVGADHADDIQYVFGKPFATPTGYRPQDRTVSKAMIAYWTNFAKTGDPNMGDSAVPTHWEPYTTEN SGYLEITKKMGSSSMKRSLRTNFLRYWTLTYLALPTVTDQEATPVPPTGDSEATPVPPTGDSETAPVPPTGDSGAPPVPPTGDSGAPPVP PTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDSGAPPVPPTGDAGPPPVPPTGDSGAPPVPPT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PCYOX1-CEL |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PCYOX1-CEL |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PCYOX1-CEL |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | PCYOX1 | C0043094 | Weight Gain | 1 | CTD_human |
| Tgene | C1853297 | MATURITY-ONSET DIABETES OF THE YOUNG, TYPE 8, WITH EXOCRINE DYSFUNCTION | 2 | CTD_human;GENOMICS_ENGLAND | |
| Tgene | C0149521 | Pancreatitis, Chronic | 1 | CTD_human | |
| Tgene | C0342276 | Maturity onset diabetes mellitus in young | 1 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies