
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CTSA-ATP6V0A4 (FusionGDB2 ID:HG5476TG50617) |
Fusion Gene Summary for CTSA-ATP6V0A4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CTSA-ATP6V0A4 | Fusion gene ID: hg5476tg50617 | Hgene | Tgene | Gene symbol | CTSA | ATP6V0A4 | Gene ID | 5476 | 50617 |
| Gene name | cathepsin A | ATPase H+ transporting V0 subunit a4 | |
| Synonyms | GLB2|GSL|NGBE|PPCA|PPGB | A4|ATP6N1B|ATP6N2|RDRTA2|RTA1C|RTADR|STV1|VPH1|VPP2 | |
| Cytomap | ('CTSA')('ATP6V0A4') 20q13.12 | 7q34 | |
| Type of gene | protein-coding | protein-coding | |
| Description | lysosomal protective proteinbeta-galactosidase 2beta-galactosidase protective proteincarboxypeptidase Ccarboxypeptidase Y-like kininasecarboxypeptidase-Ldeamidaselysosomal carboxypeptidase Aprotective protein cathepsin Aurinary kininase | V-type proton ATPase 116 kDa subunit a isoform 4V-type proton ATPase 116 kDa subunit aATPase, H+ transporting, lysosomal (vacuolar proton pump) non-catalytic accessory protein 1BATPase, H+ transporting, lysosomal (vacuolar proton pump) non-catalytic ac | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000191018, ENST00000354880, ENST00000372459, ENST00000372484, | ||
| Fusion gene scores | * DoF score | 7 X 7 X 5=245 | 4 X 4 X 2=32 |
| # samples | 8 | 4 | |
| ** MAII score | log2(8/245*10)=-1.61470984411521 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/32*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: CTSA [Title/Abstract] AND ATP6V0A4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CTSA(44526658)-ATP6V0A4(138406708), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CTSA | GO:0006508 | proteolysis | 12505983 |
| Fusion gene breakpoints across CTSA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ATP6V0A4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
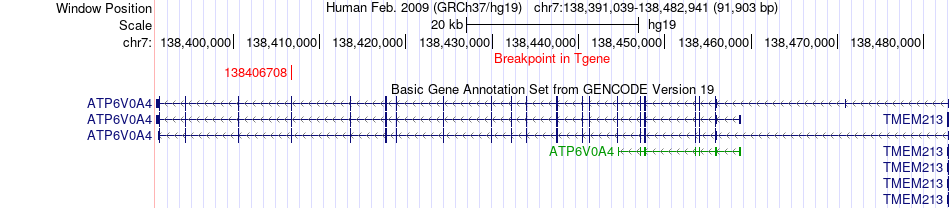 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChiTaRS5.0 | N/A | BF823719 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
Top |
Fusion Gene ORF analysis for CTSA-ATP6V0A4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000191018 | ENST00000483139 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| 5CDS-intron | ENST00000354880 | ENST00000483139 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| 5CDS-intron | ENST00000372459 | ENST00000483139 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| 5CDS-intron | ENST00000372484 | ENST00000483139 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000191018 | ENST00000310018 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000191018 | ENST00000353492 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000191018 | ENST00000393054 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000354880 | ENST00000310018 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000354880 | ENST00000353492 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000354880 | ENST00000393054 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000372459 | ENST00000310018 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000372459 | ENST00000353492 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000372459 | ENST00000393054 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000372484 | ENST00000310018 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000372484 | ENST00000353492 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| In-frame | ENST00000372484 | ENST00000393054 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000372484 | CTSA | chr20 | 44526658 | - | ENST00000393054 | ATP6V0A4 | chr7 | 138406708 | + | 2460 | 1680 | 282 | 1685 | 467 |
| ENST00000372484 | CTSA | chr20 | 44526658 | - | ENST00000310018 | ATP6V0A4 | chr7 | 138406708 | + | 2460 | 1680 | 282 | 1685 | 467 |
| ENST00000372484 | CTSA | chr20 | 44526658 | - | ENST00000353492 | ATP6V0A4 | chr7 | 138406708 | + | 2229 | 1680 | 282 | 1685 | 467 |
| ENST00000354880 | CTSA | chr20 | 44526658 | - | ENST00000393054 | ATP6V0A4 | chr7 | 138406708 | + | 2131 | 1351 | 4 | 1356 | 450 |
| ENST00000354880 | CTSA | chr20 | 44526658 | - | ENST00000310018 | ATP6V0A4 | chr7 | 138406708 | + | 2131 | 1351 | 4 | 1356 | 450 |
| ENST00000354880 | CTSA | chr20 | 44526658 | - | ENST00000353492 | ATP6V0A4 | chr7 | 138406708 | + | 1900 | 1351 | 4 | 1356 | 450 |
| ENST00000191018 | CTSA | chr20 | 44526658 | - | ENST00000393054 | ATP6V0A4 | chr7 | 138406708 | + | 2209 | 1429 | 85 | 1434 | 449 |
| ENST00000191018 | CTSA | chr20 | 44526658 | - | ENST00000310018 | ATP6V0A4 | chr7 | 138406708 | + | 2209 | 1429 | 85 | 1434 | 449 |
| ENST00000191018 | CTSA | chr20 | 44526658 | - | ENST00000353492 | ATP6V0A4 | chr7 | 138406708 | + | 1978 | 1429 | 85 | 1434 | 449 |
| ENST00000372459 | CTSA | chr20 | 44526658 | - | ENST00000393054 | ATP6V0A4 | chr7 | 138406708 | + | 2317 | 1537 | 193 | 1542 | 449 |
| ENST00000372459 | CTSA | chr20 | 44526658 | - | ENST00000310018 | ATP6V0A4 | chr7 | 138406708 | + | 2317 | 1537 | 193 | 1542 | 449 |
| ENST00000372459 | CTSA | chr20 | 44526658 | - | ENST00000353492 | ATP6V0A4 | chr7 | 138406708 | + | 2086 | 1537 | 193 | 1542 | 449 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000372484 | ENST00000393054 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.005933968 | 0.994066 |
| ENST00000372484 | ENST00000310018 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.005933968 | 0.994066 |
| ENST00000372484 | ENST00000353492 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.005899973 | 0.99410003 |
| ENST00000354880 | ENST00000393054 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.005898973 | 0.994101 |
| ENST00000354880 | ENST00000310018 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.005898973 | 0.994101 |
| ENST00000354880 | ENST00000353492 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.005569542 | 0.9944305 |
| ENST00000191018 | ENST00000393054 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.001382589 | 0.9986174 |
| ENST00000191018 | ENST00000310018 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.001382589 | 0.9986174 |
| ENST00000191018 | ENST00000353492 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.001717556 | 0.99828243 |
| ENST00000372459 | ENST00000393054 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.001682181 | 0.99831784 |
| ENST00000372459 | ENST00000310018 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.001682181 | 0.99831784 |
| ENST00000372459 | ENST00000353492 | CTSA | chr20 | 44526658 | - | ATP6V0A4 | chr7 | 138406708 | + | 0.002036182 | 0.9979638 |
Top |
Fusion Genomic Features for CTSA-ATP6V0A4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
Top |
Fusion Protein Features for CTSA-ATP6V0A4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:44526658/chr7:138406708) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 1_390 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 410_411 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 429_443 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 474_538 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 559_576 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 598_642 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 663_727 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 753_773 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 813_840 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 1_390 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 410_411 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 429_443 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 474_538 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 559_576 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 598_642 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 663_727 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 753_773 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 813_840 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 1_390 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 410_411 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 429_443 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 474_538 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 559_576 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 598_642 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 663_727 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 753_773 | 0 | 841.0 | Topological domain | Vacuolar | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 813_840 | 0 | 841.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 391_409 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 412_428 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 444_473 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 539_558 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 577_597 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 643_662 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 728_752 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000310018 | 0 | 22 | 774_812 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 391_409 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 412_428 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 444_473 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 539_558 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 577_597 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 643_662 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 728_752 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000353492 | 0 | 21 | 774_812 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 391_409 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 412_428 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 444_473 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 539_558 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 577_597 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 643_662 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 728_752 | 0 | 841.0 | Transmembrane | Helical | |
| Tgene | ATP6V0A4 | chr20:44526658 | chr7:138406708 | ENST00000393054 | 0 | 21 | 774_812 | 0 | 841.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for CTSA-ATP6V0A4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >20447_20447_1_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000191018_ATP6V0A4_chr7_138406708_ENST00000310018_length(transcript)=2209nt_BP=1429nt CGGGCGCCTCCTGGAGAGCAAGGACGCGGGGGAGCAGAGGTGAGCTGGCACCGGAGGCTGGAGGGGATCCCCGAGCCCGGGATCGATGAT CCGAGCCGCGCCGCCGCCGCTGTTCCTGCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGGCGAGGCAGCCCCCGACCA GGACGAGATCCAGCGCCTCCCCGGGCTGGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGGCTCCGGCTCCAAGCACCT CCACTACTGGTTTGTGGAGTCCCAGAAGGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCCCGGCTGCAGCTCACTAGA TGGGCTCCTCACAGAGCATGGCCCCTTCCTGGTCCAGCCAGATGGTGTCACCCTGGAGTACAACCCCTATTCTTGGAATCTGATTGCCAA TGTGTTATACCTGGAGTCCCCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGACACTGAGGTCGCCCAGAG CAATTTTGAGGCCCTTCAAGATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGGGGAGAGCTATGCTGGCAT CTACATCCCCACCCTGGCCGTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAATGGACTCTCCTCCTATGA GCAGAATGACAACTCCCTGGTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCTCCAGACCCACTGCTGCTC TCAAAACAAGTGTAACTTCTATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCATCGTGGGCAACTCTGGCCT CAACATCTACAATCTCTATGCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGTTGTGGTCCAGGATTTGGG CAACATCTTCACTCGCCTGCCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCGCATGGACCCCCCCTGCAC CAACACAACAGCTGCTTCCACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCTGCCACAATGGGACATGTG CAACTTTCTGGTAAACTTACAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAGCTCACAGAAATACCAGAT CCTATTATATAATGGAGATGTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAACCAGAAGCGGCCCTGGTT AGTGAAGTACGGGGACAGCGGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCACGATCAAGGGTTGAGTTCC AGAACAAGTTCTATGTCGGGGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAGCCGAGGAGTAGGCTGAGG GCTGCACCTCCCACGGTGGTCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAAGGCGCTCAATGGGAAGGT TGTTCTTGGCTCACCTGAAGCATGAAACTGTGTATTATTTGGACGTCAGCCTGTGGATTTGATACGACTTAACCACGTCAGAGGAAGGAC TTTGGCAAGTGATATTGTCTTCATGTGGGGTATTAATTCTCAAATAATAAAGTAATTGACAAATGAGGGGAGAATGCTAAACAGATGTCT TCTTGCAATATTTTAAATATTGTATTTGAGAAAATAAACATCTGAGTCATTCAACTGTCTGAAGTGCTCTGGACTATGGTGATGAACAGC GGCCTTCAGACGCGAGGCTGGGGAGGAATCGTCGGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGACAGTAGCCATCCTTCTGATC ATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTGCGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCACCAAGCCATCCACACCATCG AGTACTGCCTGGGCTGCATTTCAAACACAGCCTCCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGCACTTCTAGCCGTTCTGGCCA >20447_20447_1_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000191018_ATP6V0A4_chr7_138406708_ENST00000310018_length(amino acids)=449AA_BP= MIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKDPENSPVVLWLNGGPGCSS LDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESYA GIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGNS GLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQWD -------------------------------------------------------------- >20447_20447_2_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000191018_ATP6V0A4_chr7_138406708_ENST00000353492_length(transcript)=1978nt_BP=1429nt CGGGCGCCTCCTGGAGAGCAAGGACGCGGGGGAGCAGAGGTGAGCTGGCACCGGAGGCTGGAGGGGATCCCCGAGCCCGGGATCGATGAT CCGAGCCGCGCCGCCGCCGCTGTTCCTGCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGGCGAGGCAGCCCCCGACCA GGACGAGATCCAGCGCCTCCCCGGGCTGGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGGCTCCGGCTCCAAGCACCT CCACTACTGGTTTGTGGAGTCCCAGAAGGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCCCGGCTGCAGCTCACTAGA TGGGCTCCTCACAGAGCATGGCCCCTTCCTGGTCCAGCCAGATGGTGTCACCCTGGAGTACAACCCCTATTCTTGGAATCTGATTGCCAA TGTGTTATACCTGGAGTCCCCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGACACTGAGGTCGCCCAGAG CAATTTTGAGGCCCTTCAAGATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGGGGAGAGCTATGCTGGCAT CTACATCCCCACCCTGGCCGTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAATGGACTCTCCTCCTATGA GCAGAATGACAACTCCCTGGTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCTCCAGACCCACTGCTGCTC TCAAAACAAGTGTAACTTCTATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCATCGTGGGCAACTCTGGCCT CAACATCTACAATCTCTATGCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGTTGTGGTCCAGGATTTGGG CAACATCTTCACTCGCCTGCCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCGCATGGACCCCCCCTGCAC CAACACAACAGCTGCTTCCACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCTGCCACAATGGGACATGTG CAACTTTCTGGTAAACTTACAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAGCTCACAGAAATACCAGAT CCTATTATATAATGGAGATGTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAACCAGAAGCGGCCCTGGTT AGTGAAGTACGGGGACAGCGGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCACGATCAAGGGTTGAGTTCC AGAACAAGTTCTATGTCGGGGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAGCCGAGGAGTAGGCTGAGG GCTGCACCTCCCACGGTGGTCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAAGGCGCTCAATGGGAAGGT TAACTGTCTGAAGTGCTCTGGACTATGGTGATGAACAGCGGCCTTCAGACGCGAGGCTGGGGAGGAATCGTCGGGGTTTTTATTATTTTT GCCGTATTTGCTGTCCTGACAGTAGCCATCCTTCTGATCATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTGCGACTGCACTGTTCAACT TTGGAGACGTCTTTGTCCACCAAGCCATCCACACCATCGAGTACTGCCTGGGCTGCATTTCAAACACAGCCTCCTACCTGCGGCTCTGGG >20447_20447_2_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000191018_ATP6V0A4_chr7_138406708_ENST00000353492_length(amino acids)=449AA_BP= MIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKDPENSPVVLWLNGGPGCSS LDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESYA GIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGNS GLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQWD -------------------------------------------------------------- >20447_20447_3_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000191018_ATP6V0A4_chr7_138406708_ENST00000393054_length(transcript)=2209nt_BP=1429nt CGGGCGCCTCCTGGAGAGCAAGGACGCGGGGGAGCAGAGGTGAGCTGGCACCGGAGGCTGGAGGGGATCCCCGAGCCCGGGATCGATGAT CCGAGCCGCGCCGCCGCCGCTGTTCCTGCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGGCGAGGCAGCCCCCGACCA GGACGAGATCCAGCGCCTCCCCGGGCTGGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGGCTCCGGCTCCAAGCACCT CCACTACTGGTTTGTGGAGTCCCAGAAGGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCCCGGCTGCAGCTCACTAGA TGGGCTCCTCACAGAGCATGGCCCCTTCCTGGTCCAGCCAGATGGTGTCACCCTGGAGTACAACCCCTATTCTTGGAATCTGATTGCCAA TGTGTTATACCTGGAGTCCCCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGACACTGAGGTCGCCCAGAG CAATTTTGAGGCCCTTCAAGATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGGGGAGAGCTATGCTGGCAT CTACATCCCCACCCTGGCCGTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAATGGACTCTCCTCCTATGA GCAGAATGACAACTCCCTGGTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCTCCAGACCCACTGCTGCTC TCAAAACAAGTGTAACTTCTATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCATCGTGGGCAACTCTGGCCT CAACATCTACAATCTCTATGCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGTTGTGGTCCAGGATTTGGG CAACATCTTCACTCGCCTGCCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCGCATGGACCCCCCCTGCAC CAACACAACAGCTGCTTCCACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCTGCCACAATGGGACATGTG CAACTTTCTGGTAAACTTACAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAGCTCACAGAAATACCAGAT CCTATTATATAATGGAGATGTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAACCAGAAGCGGCCCTGGTT AGTGAAGTACGGGGACAGCGGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCACGATCAAGGGTTGAGTTCC AGAACAAGTTCTATGTCGGGGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAGCCGAGGAGTAGGCTGAGG GCTGCACCTCCCACGGTGGTCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAAGGCGCTCAATGGGAAGGT TGTTCTTGGCTCACCTGAAGCATGAAACTGTGTATTATTTGGACGTCAGCCTGTGGATTTGATACGACTTAACCACGTCAGAGGAAGGAC TTTGGCAAGTGATATTGTCTTCATGTGGGGTATTAATTCTCAAATAATAAAGTAATTGACAAATGAGGGGAGAATGCTAAACAGATGTCT TCTTGCAATATTTTAAATATTGTATTTGAGAAAATAAACATCTGAGTCATTCAACTGTCTGAAGTGCTCTGGACTATGGTGATGAACAGC GGCCTTCAGACGCGAGGCTGGGGAGGAATCGTCGGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGACAGTAGCCATCCTTCTGATC ATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTGCGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCACCAAGCCATCCACACCATCG AGTACTGCCTGGGCTGCATTTCAAACACAGCCTCCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGCACTTCTAGCCGTTCTGGCCA >20447_20447_3_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000191018_ATP6V0A4_chr7_138406708_ENST00000393054_length(amino acids)=449AA_BP= MIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKDPENSPVVLWLNGGPGCSS LDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESYA GIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGNS GLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQWD -------------------------------------------------------------- >20447_20447_4_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000354880_ATP6V0A4_chr7_138406708_ENST00000310018_length(transcript)=2131nt_BP=1351nt ACACATGACTTCCAGTCCCCGGGCGCCTCCTGGAGAGCAAGGACGCGGGGGAGCAGAGATGATCCGAGCCGCGCCGCCGCCGCTGTTCCT GCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGGCGAGGCAGCCCCCGACCAGGACGAGATCCAGCGCCTCCCCGGGCT GGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGGCTCCGGCTCCAAGCACCTCCACTACTGGTTTGTGGAGTCCCAGAA GGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCCCGGCTGCAGCTCACTAGATGGGCTCCTCACAGAGCATGGCCCCTT CCTGATTGCCAATGTGTTATACCTGGAGTCCCCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGACACTGA GGTCGCCCAGAGCAATTTTGAGGCCCTTCAAGATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGGGGAGAG CTATGCTGGCATCTACATCCCCACCCTGGCCGTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAATGGACT CTCCTCCTATGAGCAGAATGACAACTCCCTGGTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCTCCAGAC CCACTGCTGCTCTCAAAACAAGTGTAACTTCTATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCATCGTGGG CAACTCTGGCCTCAACATCTACAATCTCTATGCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGTTGTGGT CCAGGATTTGGGCAACATCTTCACTCGCCTGCCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCGCATGGA CCCCCCCTGCACCAACACAACAGCTGCTTCCACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCTGCCACA ATGGGACATGTGCAACTTTCTGGTAAACTTACAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAGCTCACA GAAATACCAGATCCTATTATATAATGGAGATGTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAACCAGAA GCGGCCCTGGTTAGTGAAGTACGGGGACAGCGGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCACGATCAA GGGTTGAGTTCCAGAACAAGTTCTATGTCGGGGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAGCCGAGG AGTAGGCTGAGGGCTGCACCTCCCACGGTGGTCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAAGGCGCT CAATGGGAAGGTTGTTCTTGGCTCACCTGAAGCATGAAACTGTGTATTATTTGGACGTCAGCCTGTGGATTTGATACGACTTAACCACGT CAGAGGAAGGACTTTGGCAAGTGATATTGTCTTCATGTGGGGTATTAATTCTCAAATAATAAAGTAATTGACAAATGAGGGGAGAATGCT AAACAGATGTCTTCTTGCAATATTTTAAATATTGTATTTGAGAAAATAAACATCTGAGTCATTCAACTGTCTGAAGTGCTCTGGACTATG GTGATGAACAGCGGCCTTCAGACGCGAGGCTGGGGAGGAATCGTCGGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGACAGTAGCC ATCCTTCTGATCATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTGCGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCACCAAGCCA TCCACACCATCGAGTACTGCCTGGGCTGCATTTCAAACACAGCCTCCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGCACTTCTAG >20447_20447_4_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000354880_ATP6V0A4_chr7_138406708_ENST00000310018_length(amino acids)=450AA_BP= MTSSPRAPPGEQGRGGAEMIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKD PENSPVVLWLNGGPGCSSLDGLLTEHGPFLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESY AGIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGN SGLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQW DMCNFLVNLQYRRLYRSMNSQYLKLLSSQKYQILLYNGDVDMACNFMGDEWFVDSLNQKRPWLVKYGDSGEQIAGFVKEFSHIAFLTIKG -------------------------------------------------------------- >20447_20447_5_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000354880_ATP6V0A4_chr7_138406708_ENST00000353492_length(transcript)=1900nt_BP=1351nt ACACATGACTTCCAGTCCCCGGGCGCCTCCTGGAGAGCAAGGACGCGGGGGAGCAGAGATGATCCGAGCCGCGCCGCCGCCGCTGTTCCT GCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGGCGAGGCAGCCCCCGACCAGGACGAGATCCAGCGCCTCCCCGGGCT GGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGGCTCCGGCTCCAAGCACCTCCACTACTGGTTTGTGGAGTCCCAGAA GGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCCCGGCTGCAGCTCACTAGATGGGCTCCTCACAGAGCATGGCCCCTT CCTGATTGCCAATGTGTTATACCTGGAGTCCCCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGACACTGA GGTCGCCCAGAGCAATTTTGAGGCCCTTCAAGATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGGGGAGAG CTATGCTGGCATCTACATCCCCACCCTGGCCGTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAATGGACT CTCCTCCTATGAGCAGAATGACAACTCCCTGGTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCTCCAGAC CCACTGCTGCTCTCAAAACAAGTGTAACTTCTATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCATCGTGGG CAACTCTGGCCTCAACATCTACAATCTCTATGCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGTTGTGGT CCAGGATTTGGGCAACATCTTCACTCGCCTGCCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCGCATGGA CCCCCCCTGCACCAACACAACAGCTGCTTCCACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCTGCCACA ATGGGACATGTGCAACTTTCTGGTAAACTTACAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAGCTCACA GAAATACCAGATCCTATTATATAATGGAGATGTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAACCAGAA GCGGCCCTGGTTAGTGAAGTACGGGGACAGCGGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCACGATCAA GGGTTGAGTTCCAGAACAAGTTCTATGTCGGGGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAGCCGAGG AGTAGGCTGAGGGCTGCACCTCCCACGGTGGTCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAAGGCGCT CAATGGGAAGGTTAACTGTCTGAAGTGCTCTGGACTATGGTGATGAACAGCGGCCTTCAGACGCGAGGCTGGGGAGGAATCGTCGGGGTT TTTATTATTTTTGCCGTATTTGCTGTCCTGACAGTAGCCATCCTTCTGATCATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTGCGACTG CACTGTTCAACTTTGGAGACGTCTTTGTCCACCAAGCCATCCACACCATCGAGTACTGCCTGGGCTGCATTTCAAACACAGCCTCCTACC TGCGGCTCTGGGCCCTCAGCCTGGCTCATGCACTTCTAGCCGTTCTGGCCAGAGGACTTCTGCAGATACCCACGGGGCTCTGGACGACCA >20447_20447_5_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000354880_ATP6V0A4_chr7_138406708_ENST00000353492_length(amino acids)=450AA_BP= MTSSPRAPPGEQGRGGAEMIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKD PENSPVVLWLNGGPGCSSLDGLLTEHGPFLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESY AGIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGN SGLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQW DMCNFLVNLQYRRLYRSMNSQYLKLLSSQKYQILLYNGDVDMACNFMGDEWFVDSLNQKRPWLVKYGDSGEQIAGFVKEFSHIAFLTIKG -------------------------------------------------------------- >20447_20447_6_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000354880_ATP6V0A4_chr7_138406708_ENST00000393054_length(transcript)=2131nt_BP=1351nt ACACATGACTTCCAGTCCCCGGGCGCCTCCTGGAGAGCAAGGACGCGGGGGAGCAGAGATGATCCGAGCCGCGCCGCCGCCGCTGTTCCT GCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGGCGAGGCAGCCCCCGACCAGGACGAGATCCAGCGCCTCCCCGGGCT GGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGGCTCCGGCTCCAAGCACCTCCACTACTGGTTTGTGGAGTCCCAGAA GGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCCCGGCTGCAGCTCACTAGATGGGCTCCTCACAGAGCATGGCCCCTT CCTGATTGCCAATGTGTTATACCTGGAGTCCCCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGACACTGA GGTCGCCCAGAGCAATTTTGAGGCCCTTCAAGATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGGGGAGAG CTATGCTGGCATCTACATCCCCACCCTGGCCGTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAATGGACT CTCCTCCTATGAGCAGAATGACAACTCCCTGGTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCTCCAGAC CCACTGCTGCTCTCAAAACAAGTGTAACTTCTATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCATCGTGGG CAACTCTGGCCTCAACATCTACAATCTCTATGCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGTTGTGGT CCAGGATTTGGGCAACATCTTCACTCGCCTGCCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCGCATGGA CCCCCCCTGCACCAACACAACAGCTGCTTCCACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCTGCCACA ATGGGACATGTGCAACTTTCTGGTAAACTTACAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAGCTCACA GAAATACCAGATCCTATTATATAATGGAGATGTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAACCAGAA GCGGCCCTGGTTAGTGAAGTACGGGGACAGCGGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCACGATCAA GGGTTGAGTTCCAGAACAAGTTCTATGTCGGGGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAGCCGAGG AGTAGGCTGAGGGCTGCACCTCCCACGGTGGTCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAAGGCGCT CAATGGGAAGGTTGTTCTTGGCTCACCTGAAGCATGAAACTGTGTATTATTTGGACGTCAGCCTGTGGATTTGATACGACTTAACCACGT CAGAGGAAGGACTTTGGCAAGTGATATTGTCTTCATGTGGGGTATTAATTCTCAAATAATAAAGTAATTGACAAATGAGGGGAGAATGCT AAACAGATGTCTTCTTGCAATATTTTAAATATTGTATTTGAGAAAATAAACATCTGAGTCATTCAACTGTCTGAAGTGCTCTGGACTATG GTGATGAACAGCGGCCTTCAGACGCGAGGCTGGGGAGGAATCGTCGGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGACAGTAGCC ATCCTTCTGATCATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTGCGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCACCAAGCCA TCCACACCATCGAGTACTGCCTGGGCTGCATTTCAAACACAGCCTCCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGCACTTCTAG >20447_20447_6_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000354880_ATP6V0A4_chr7_138406708_ENST00000393054_length(amino acids)=450AA_BP= MTSSPRAPPGEQGRGGAEMIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKD PENSPVVLWLNGGPGCSSLDGLLTEHGPFLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESY AGIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGN SGLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQW DMCNFLVNLQYRRLYRSMNSQYLKLLSSQKYQILLYNGDVDMACNFMGDEWFVDSLNQKRPWLVKYGDSGEQIAGFVKEFSHIAFLTIKG -------------------------------------------------------------- >20447_20447_7_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372459_ATP6V0A4_chr7_138406708_ENST00000310018_length(transcript)=2317nt_BP=1537nt AGAGGTGAGCTGGCACCGGAGGCTGGAGGGGATCCCCGAGCCCGGGATCGGTGCGCGGCAGAGGAGGCTCGCGGGTGGGAGCTGGCGCTG GGGCCGGGGCTTCCCTCGCGGAGGCGCCGCCAGCAACTCCCCGGGGGCTGCTGCACGGAAGCGCTGAGGAGCGAGTCAACAGCCCCTCTG CTGCCTCCCGTAGATGATCCGAGCCGCGCCGCCGCCGCTGTTCCTGCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGG CGAGGCAGCCCCCGACCAGGACGAGATCCAGCGCCTCCCCGGGCTGGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGG CTCCGGCTCCAAGCACCTCCACTACTGGTTTGTGGAGTCCCAGAAGGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCC CGGCTGCAGCTCACTAGATGGGCTCCTCACAGAGCATGGCCCCTTCCTGGTCCAGCCAGATGGTGTCACCCTGGAGTACAACCCCTATTC TTGGAATCTGATTGCCAATGTGTTATACCTGGAGTCCCCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGA CACTGAGGTCGCCCAGAGCAATTTTGAGGCCCTTCAAGATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGG GGAGAGCTATGCTGGCATCTACATCCCCACCCTGGCCGTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAA TGGACTCTCCTCCTATGAGCAGAATGACAACTCCCTGGTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCT CCAGACCCACTGCTGCTCTCAAAACAAGTGTAACTTCTATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCAT CGTGGGCAACTCTGGCCTCAACATCTACAATCTCTATGCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGT TGTGGTCCAGGATTTGGGCAACATCTTCACTCGCCTGCCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCG CATGGACCCCCCCTGCACCAACACAACAGCTGCTTCCACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCT GCCACAATGGGACATGTGCAACTTTCTGGTAAACTTACAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAG CTCACAGAAATACCAGATCCTATTATATAATGGAGATGTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAA CCAGAAGCGGCCCTGGTTAGTGAAGTACGGGGACAGCGGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCAC GATCAAGGGTTGAGTTCCAGAACAAGTTCTATGTCGGGGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAG CCGAGGAGTAGGCTGAGGGCTGCACCTCCCACGGTGGTCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAA GGCGCTCAATGGGAAGGTTGTTCTTGGCTCACCTGAAGCATGAAACTGTGTATTATTTGGACGTCAGCCTGTGGATTTGATACGACTTAA CCACGTCAGAGGAAGGACTTTGGCAAGTGATATTGTCTTCATGTGGGGTATTAATTCTCAAATAATAAAGTAATTGACAAATGAGGGGAG AATGCTAAACAGATGTCTTCTTGCAATATTTTAAATATTGTATTTGAGAAAATAAACATCTGAGTCATTCAACTGTCTGAAGTGCTCTGG ACTATGGTGATGAACAGCGGCCTTCAGACGCGAGGCTGGGGAGGAATCGTCGGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGACA GTAGCCATCCTTCTGATCATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTGCGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCACC AAGCCATCCACACCATCGAGTACTGCCTGGGCTGCATTTCAAACACAGCCTCCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGCAC >20447_20447_7_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372459_ATP6V0A4_chr7_138406708_ENST00000310018_length(amino acids)=449AA_BP= MIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKDPENSPVVLWLNGGPGCSS LDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESYA GIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGNS GLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQWD -------------------------------------------------------------- >20447_20447_8_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372459_ATP6V0A4_chr7_138406708_ENST00000353492_length(transcript)=2086nt_BP=1537nt AGAGGTGAGCTGGCACCGGAGGCTGGAGGGGATCCCCGAGCCCGGGATCGGTGCGCGGCAGAGGAGGCTCGCGGGTGGGAGCTGGCGCTG GGGCCGGGGCTTCCCTCGCGGAGGCGCCGCCAGCAACTCCCCGGGGGCTGCTGCACGGAAGCGCTGAGGAGCGAGTCAACAGCCCCTCTG CTGCCTCCCGTAGATGATCCGAGCCGCGCCGCCGCCGCTGTTCCTGCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGG CGAGGCAGCCCCCGACCAGGACGAGATCCAGCGCCTCCCCGGGCTGGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGG CTCCGGCTCCAAGCACCTCCACTACTGGTTTGTGGAGTCCCAGAAGGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCC CGGCTGCAGCTCACTAGATGGGCTCCTCACAGAGCATGGCCCCTTCCTGGTCCAGCCAGATGGTGTCACCCTGGAGTACAACCCCTATTC TTGGAATCTGATTGCCAATGTGTTATACCTGGAGTCCCCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGA CACTGAGGTCGCCCAGAGCAATTTTGAGGCCCTTCAAGATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGG GGAGAGCTATGCTGGCATCTACATCCCCACCCTGGCCGTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAA TGGACTCTCCTCCTATGAGCAGAATGACAACTCCCTGGTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCT CCAGACCCACTGCTGCTCTCAAAACAAGTGTAACTTCTATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCAT CGTGGGCAACTCTGGCCTCAACATCTACAATCTCTATGCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGT TGTGGTCCAGGATTTGGGCAACATCTTCACTCGCCTGCCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCG CATGGACCCCCCCTGCACCAACACAACAGCTGCTTCCACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCT GCCACAATGGGACATGTGCAACTTTCTGGTAAACTTACAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAG CTCACAGAAATACCAGATCCTATTATATAATGGAGATGTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAA CCAGAAGCGGCCCTGGTTAGTGAAGTACGGGGACAGCGGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCAC GATCAAGGGTTGAGTTCCAGAACAAGTTCTATGTCGGGGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAG CCGAGGAGTAGGCTGAGGGCTGCACCTCCCACGGTGGTCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAA GGCGCTCAATGGGAAGGTTAACTGTCTGAAGTGCTCTGGACTATGGTGATGAACAGCGGCCTTCAGACGCGAGGCTGGGGAGGAATCGTC GGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGACAGTAGCCATCCTTCTGATCATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTG CGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCACCAAGCCATCCACACCATCGAGTACTGCCTGGGCTGCATTTCAAACACAGCCT CCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGCACTTCTAGCCGTTCTGGCCAGAGGACTTCTGCAGATACCCACGGGGCTCTGGA >20447_20447_8_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372459_ATP6V0A4_chr7_138406708_ENST00000353492_length(amino acids)=449AA_BP= MIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKDPENSPVVLWLNGGPGCSS LDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESYA GIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGNS GLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQWD -------------------------------------------------------------- >20447_20447_9_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372459_ATP6V0A4_chr7_138406708_ENST00000393054_length(transcript)=2317nt_BP=1537nt AGAGGTGAGCTGGCACCGGAGGCTGGAGGGGATCCCCGAGCCCGGGATCGGTGCGCGGCAGAGGAGGCTCGCGGGTGGGAGCTGGCGCTG GGGCCGGGGCTTCCCTCGCGGAGGCGCCGCCAGCAACTCCCCGGGGGCTGCTGCACGGAAGCGCTGAGGAGCGAGTCAACAGCCCCTCTG CTGCCTCCCGTAGATGATCCGAGCCGCGCCGCCGCCGCTGTTCCTGCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGG CGAGGCAGCCCCCGACCAGGACGAGATCCAGCGCCTCCCCGGGCTGGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGG CTCCGGCTCCAAGCACCTCCACTACTGGTTTGTGGAGTCCCAGAAGGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCC CGGCTGCAGCTCACTAGATGGGCTCCTCACAGAGCATGGCCCCTTCCTGGTCCAGCCAGATGGTGTCACCCTGGAGTACAACCCCTATTC TTGGAATCTGATTGCCAATGTGTTATACCTGGAGTCCCCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGA CACTGAGGTCGCCCAGAGCAATTTTGAGGCCCTTCAAGATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGG GGAGAGCTATGCTGGCATCTACATCCCCACCCTGGCCGTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAA TGGACTCTCCTCCTATGAGCAGAATGACAACTCCCTGGTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCT CCAGACCCACTGCTGCTCTCAAAACAAGTGTAACTTCTATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCAT CGTGGGCAACTCTGGCCTCAACATCTACAATCTCTATGCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGT TGTGGTCCAGGATTTGGGCAACATCTTCACTCGCCTGCCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCG CATGGACCCCCCCTGCACCAACACAACAGCTGCTTCCACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCT GCCACAATGGGACATGTGCAACTTTCTGGTAAACTTACAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAG CTCACAGAAATACCAGATCCTATTATATAATGGAGATGTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAA CCAGAAGCGGCCCTGGTTAGTGAAGTACGGGGACAGCGGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCAC GATCAAGGGTTGAGTTCCAGAACAAGTTCTATGTCGGGGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAG CCGAGGAGTAGGCTGAGGGCTGCACCTCCCACGGTGGTCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAA GGCGCTCAATGGGAAGGTTGTTCTTGGCTCACCTGAAGCATGAAACTGTGTATTATTTGGACGTCAGCCTGTGGATTTGATACGACTTAA CCACGTCAGAGGAAGGACTTTGGCAAGTGATATTGTCTTCATGTGGGGTATTAATTCTCAAATAATAAAGTAATTGACAAATGAGGGGAG AATGCTAAACAGATGTCTTCTTGCAATATTTTAAATATTGTATTTGAGAAAATAAACATCTGAGTCATTCAACTGTCTGAAGTGCTCTGG ACTATGGTGATGAACAGCGGCCTTCAGACGCGAGGCTGGGGAGGAATCGTCGGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGACA GTAGCCATCCTTCTGATCATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTGCGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCACC AAGCCATCCACACCATCGAGTACTGCCTGGGCTGCATTTCAAACACAGCCTCCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGCAC >20447_20447_9_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372459_ATP6V0A4_chr7_138406708_ENST00000393054_length(amino acids)=449AA_BP= MIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKDPENSPVVLWLNGGPGCSS LDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFRLFPEYKNNKLFLTGESYA GIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNKDLECVTNLQEVARIVGNS GLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLNNPYVRKALNIPEQLPQWD -------------------------------------------------------------- >20447_20447_10_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372484_ATP6V0A4_chr7_138406708_ENST00000310018_length(transcript)=2460nt_BP=1680nt GCAATGATGGTGACCGCAAGGCGACCTTGTAAGGCATTTCCCCCCTGACTCCCTTCCCCGAGCCTCTGCCCGGGGGTCCTAGCGCCGCTT TCTCAGCCATCCCGCCTACAACTTAGCCGTCCACAACAGGATCATCTGATCGCGTGCGCCCGGGCTACGATCTGCGAGGCCCGCGGACCT TGACCCGGCATTGACCGCCACCGCCCCCCAGGTCCGTAGGGACCAAAGAAGGGGCGGGAGGAAGACTGTCACGTGGCGCCGGAGTTCACG TGACTCGTACACATGACTTCCAGTCCCCGGGCGCCTCCTGGAGAGCAAGGACGCGGGGGAGCAGAGATGATCCGAGCCGCGCCGCCGCCG CTGTTCCTGCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGGCGAGGCAGCCCCCGACCAGGACGAGATCCAGCGCCTC CCCGGGCTGGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGGCTCCGGCTCCAAGCACCTCCACTACTGGTTTGTGGAG TCCCAGAAGGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCCCGGCTGCAGCTCACTAGATGGGCTCCTCACAGAGCAT GGCCCCTTCCTGGTCCAGCCAGATGGTGTCACCCTGGAGTACAACCCCTATTCTTGGAATCTGATTGCCAATGTGTTATACCTGGAGTCC CCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGACACTGAGGTCGCCCAGAGCAATTTTGAGGCCCTTCAA GATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGGGGAGAGCTATGCTGGCATCTACATCCCCACCCTGGCC GTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAATGGACTCTCCTCCTATGAGCAGAATGACAACTCCCTG GTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCTCCAGACCCACTGCTGCTCTCAAAACAAGTGTAACTTC TATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCATCGTGGGCAACTCTGGCCTCAACATCTACAATCTCTAT GCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGTTGTGGTCCAGGATTTGGGCAACATCTTCACTCGCCTG CCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCGCATGGACCCCCCCTGCACCAACACAACAGCTGCTTCC ACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCTGCCACAATGGGACATGTGCAACTTTCTGGTAAACTTA CAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAGCTCACAGAAATACCAGATCCTATTATATAATGGAGAT GTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAACCAGAAGCGGCCCTGGTTAGTGAAGTACGGGGACAGC GGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCACGATCAAGGGTTGAGTTCCAGAACAAGTTCTATGTCGG GGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAGCCGAGGAGTAGGCTGAGGGCTGCACCTCCCACGGTGG TCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAAGGCGCTCAATGGGAAGGTTGTTCTTGGCTCACCTGAA GCATGAAACTGTGTATTATTTGGACGTCAGCCTGTGGATTTGATACGACTTAACCACGTCAGAGGAAGGACTTTGGCAAGTGATATTGTC TTCATGTGGGGTATTAATTCTCAAATAATAAAGTAATTGACAAATGAGGGGAGAATGCTAAACAGATGTCTTCTTGCAATATTTTAAATA TTGTATTTGAGAAAATAAACATCTGAGTCATTCAACTGTCTGAAGTGCTCTGGACTATGGTGATGAACAGCGGCCTTCAGACGCGAGGCT GGGGAGGAATCGTCGGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGACAGTAGCCATCCTTCTGATCATGGAGGGCCTCTCTGCTT TCCTGCACGCCCTGCGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCACCAAGCCATCCACACCATCGAGTACTGCCTGGGCTGCAT TTCAAACACAGCCTCCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGCACTTCTAGCCGTTCTGGCCAGAGGACTTCTGCAGATACC >20447_20447_10_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372484_ATP6V0A4_chr7_138406708_ENST00000310018_length(amino acids)=467AA_BP= MTSSPRAPPGEQGRGGAEMIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKD PENSPVVLWLNGGPGCSSLDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFR LFPEYKNNKLFLTGESYAGIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNK DLECVTNLQEVARIVGNSGLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLN NPYVRKALNIPEQLPQWDMCNFLVNLQYRRLYRSMNSQYLKLLSSQKYQILLYNGDVDMACNFMGDEWFVDSLNQKRPWLVKYGDSGEQI -------------------------------------------------------------- >20447_20447_11_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372484_ATP6V0A4_chr7_138406708_ENST00000353492_length(transcript)=2229nt_BP=1680nt GCAATGATGGTGACCGCAAGGCGACCTTGTAAGGCATTTCCCCCCTGACTCCCTTCCCCGAGCCTCTGCCCGGGGGTCCTAGCGCCGCTT TCTCAGCCATCCCGCCTACAACTTAGCCGTCCACAACAGGATCATCTGATCGCGTGCGCCCGGGCTACGATCTGCGAGGCCCGCGGACCT TGACCCGGCATTGACCGCCACCGCCCCCCAGGTCCGTAGGGACCAAAGAAGGGGCGGGAGGAAGACTGTCACGTGGCGCCGGAGTTCACG TGACTCGTACACATGACTTCCAGTCCCCGGGCGCCTCCTGGAGAGCAAGGACGCGGGGGAGCAGAGATGATCCGAGCCGCGCCGCCGCCG CTGTTCCTGCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGGCGAGGCAGCCCCCGACCAGGACGAGATCCAGCGCCTC CCCGGGCTGGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGGCTCCGGCTCCAAGCACCTCCACTACTGGTTTGTGGAG TCCCAGAAGGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCCCGGCTGCAGCTCACTAGATGGGCTCCTCACAGAGCAT GGCCCCTTCCTGGTCCAGCCAGATGGTGTCACCCTGGAGTACAACCCCTATTCTTGGAATCTGATTGCCAATGTGTTATACCTGGAGTCC CCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGACACTGAGGTCGCCCAGAGCAATTTTGAGGCCCTTCAA GATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGGGGAGAGCTATGCTGGCATCTACATCCCCACCCTGGCC GTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAATGGACTCTCCTCCTATGAGCAGAATGACAACTCCCTG GTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCTCCAGACCCACTGCTGCTCTCAAAACAAGTGTAACTTC TATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCATCGTGGGCAACTCTGGCCTCAACATCTACAATCTCTAT GCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGTTGTGGTCCAGGATTTGGGCAACATCTTCACTCGCCTG CCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCGCATGGACCCCCCCTGCACCAACACAACAGCTGCTTCC ACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCTGCCACAATGGGACATGTGCAACTTTCTGGTAAACTTA CAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAGCTCACAGAAATACCAGATCCTATTATATAATGGAGAT GTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAACCAGAAGCGGCCCTGGTTAGTGAAGTACGGGGACAGC GGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCACGATCAAGGGTTGAGTTCCAGAACAAGTTCTATGTCGG GGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAGCCGAGGAGTAGGCTGAGGGCTGCACCTCCCACGGTGG TCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAAGGCGCTCAATGGGAAGGTTAACTGTCTGAAGTGCTCT GGACTATGGTGATGAACAGCGGCCTTCAGACGCGAGGCTGGGGAGGAATCGTCGGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGA CAGTAGCCATCCTTCTGATCATGGAGGGCCTCTCTGCTTTCCTGCACGCCCTGCGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCA CCAAGCCATCCACACCATCGAGTACTGCCTGGGCTGCATTTCAAACACAGCCTCCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGC >20447_20447_11_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372484_ATP6V0A4_chr7_138406708_ENST00000353492_length(amino acids)=467AA_BP= MTSSPRAPPGEQGRGGAEMIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKD PENSPVVLWLNGGPGCSSLDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFR LFPEYKNNKLFLTGESYAGIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNK DLECVTNLQEVARIVGNSGLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLN NPYVRKALNIPEQLPQWDMCNFLVNLQYRRLYRSMNSQYLKLLSSQKYQILLYNGDVDMACNFMGDEWFVDSLNQKRPWLVKYGDSGEQI -------------------------------------------------------------- >20447_20447_12_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372484_ATP6V0A4_chr7_138406708_ENST00000393054_length(transcript)=2460nt_BP=1680nt GCAATGATGGTGACCGCAAGGCGACCTTGTAAGGCATTTCCCCCCTGACTCCCTTCCCCGAGCCTCTGCCCGGGGGTCCTAGCGCCGCTT TCTCAGCCATCCCGCCTACAACTTAGCCGTCCACAACAGGATCATCTGATCGCGTGCGCCCGGGCTACGATCTGCGAGGCCCGCGGACCT TGACCCGGCATTGACCGCCACCGCCCCCCAGGTCCGTAGGGACCAAAGAAGGGGCGGGAGGAAGACTGTCACGTGGCGCCGGAGTTCACG TGACTCGTACACATGACTTCCAGTCCCCGGGCGCCTCCTGGAGAGCAAGGACGCGGGGGAGCAGAGATGATCCGAGCCGCGCCGCCGCCG CTGTTCCTGCTGCTGCTGCTGCTGCTGCTGCTAGTGTCCTGGGCGTCCCGAGGCGAGGCAGCCCCCGACCAGGACGAGATCCAGCGCCTC CCCGGGCTGGCCAAGCAGCCGTCTTTCCGCCAGTACTCCGGCTACCTCAAAGGCTCCGGCTCCAAGCACCTCCACTACTGGTTTGTGGAG TCCCAGAAGGATCCCGAGAACAGCCCTGTGGTGCTTTGGCTCAATGGGGGTCCCGGCTGCAGCTCACTAGATGGGCTCCTCACAGAGCAT GGCCCCTTCCTGGTCCAGCCAGATGGTGTCACCCTGGAGTACAACCCCTATTCTTGGAATCTGATTGCCAATGTGTTATACCTGGAGTCC CCAGCTGGGGTGGGCTTCTCCTACTCCGATGACAAGTTTTATGCAACTAATGACACTGAGGTCGCCCAGAGCAATTTTGAGGCCCTTCAA GATTTCTTCCGCCTCTTTCCGGAGTACAAGAACAACAAACTTTTCCTGACCGGGGAGAGCTATGCTGGCATCTACATCCCCACCCTGGCC GTGCTGGTCATGCAGGATCCCAGCATGAACCTTCAGGGGCTGGCTGTGGGCAATGGACTCTCCTCCTATGAGCAGAATGACAACTCCCTG GTCTACTTTGCCTACTACCATGGCCTTCTGGGGAACAGGCTTTGGTCTTCTCTCCAGACCCACTGCTGCTCTCAAAACAAGTGTAACTTC TATGACAACAAAGACCTGGAATGCGTGACCAATCTTCAGGAAGTGGCCCGCATCGTGGGCAACTCTGGCCTCAACATCTACAATCTCTAT GCCCCGTGTGCTGGAGGGGTGCCCAGCCATTTTAGGTATGAGAAGGACACTGTTGTGGTCCAGGATTTGGGCAACATCTTCACTCGCCTG CCACTCAAGCGGATGTGGCATCAGGCACTGCTGCGCTCAGGGGATAAAGTGCGCATGGACCCCCCCTGCACCAACACAACAGCTGCTTCC ACCTACCTCAACAACCCGTACGTGCGGAAGGCCCTCAACATCCCGGAGCAGCTGCCACAATGGGACATGTGCAACTTTCTGGTAAACTTA CAGTACCGCCGTCTCTACCGAAGCATGAACTCCCAGTATCTGAAGCTGCTTAGCTCACAGAAATACCAGATCCTATTATATAATGGAGAT GTAGACATGGCCTGCAATTTCATGGGGGATGAGTGGTTTGTGGATTCCCTCAACCAGAAGCGGCCCTGGTTAGTGAAGTACGGGGACAGC GGGGAGCAGATTGCCGGCTTCGTGAAGGAGTTCTCCCACATCGCCTTTCTCACGATCAAGGGTTGAGTTCCAGAACAAGTTCTATGTCGG GGATGGTTACAAGTTTTCTCCATTCTCCTTTAAACACATCCTGGATGGCACAGCCGAGGAGTAGGCTGAGGGCTGCACCTCCCACGGTGG TCACCATGCCAATGAAGGAAGTTCAGTCTTGTCTTTGATATCAGCCCCTGCAAGGCGCTCAATGGGAAGGTTGTTCTTGGCTCACCTGAA GCATGAAACTGTGTATTATTTGGACGTCAGCCTGTGGATTTGATACGACTTAACCACGTCAGAGGAAGGACTTTGGCAAGTGATATTGTC TTCATGTGGGGTATTAATTCTCAAATAATAAAGTAATTGACAAATGAGGGGAGAATGCTAAACAGATGTCTTCTTGCAATATTTTAAATA TTGTATTTGAGAAAATAAACATCTGAGTCATTCAACTGTCTGAAGTGCTCTGGACTATGGTGATGAACAGCGGCCTTCAGACGCGAGGCT GGGGAGGAATCGTCGGGGTTTTTATTATTTTTGCCGTATTTGCTGTCCTGACAGTAGCCATCCTTCTGATCATGGAGGGCCTCTCTGCTT TCCTGCACGCCCTGCGACTGCACTGTTCAACTTTGGAGACGTCTTTGTCCACCAAGCCATCCACACCATCGAGTACTGCCTGGGCTGCAT TTCAAACACAGCCTCCTACCTGCGGCTCTGGGCCCTCAGCCTGGCTCATGCACTTCTAGCCGTTCTGGCCAGAGGACTTCTGCAGATACC >20447_20447_12_CTSA-ATP6V0A4_CTSA_chr20_44526658_ENST00000372484_ATP6V0A4_chr7_138406708_ENST00000393054_length(amino acids)=467AA_BP= MTSSPRAPPGEQGRGGAEMIRAAPPPLFLLLLLLLLLVSWASRGEAAPDQDEIQRLPGLAKQPSFRQYSGYLKGSGSKHLHYWFVESQKD PENSPVVLWLNGGPGCSSLDGLLTEHGPFLVQPDGVTLEYNPYSWNLIANVLYLESPAGVGFSYSDDKFYATNDTEVAQSNFEALQDFFR LFPEYKNNKLFLTGESYAGIYIPTLAVLVMQDPSMNLQGLAVGNGLSSYEQNDNSLVYFAYYHGLLGNRLWSSLQTHCCSQNKCNFYDNK DLECVTNLQEVARIVGNSGLNIYNLYAPCAGGVPSHFRYEKDTVVVQDLGNIFTRLPLKRMWHQALLRSGDKVRMDPPCTNTTAASTYLN NPYVRKALNIPEQLPQWDMCNFLVNLQYRRLYRSMNSQYLKLLSSQKYQILLYNGDVDMACNFMGDEWFVDSLNQKRPWLVKYGDSGEQI -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CTSA-ATP6V0A4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CTSA-ATP6V0A4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CTSA-ATP6V0A4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | CTSA | C0268233 | GALACTOSIALIDOSIS | 7 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Tgene | C1864498 | RENAL TUBULAR ACIDOSIS, DISTAL, AUTOSOMAL RECESSIVE | 3 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies