
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:UQCC1-TRPC4AP (FusionGDB2 ID:HG55245TG26133) |
Fusion Gene Summary for UQCC1-TRPC4AP |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: UQCC1-TRPC4AP | Fusion gene ID: hg55245tg26133 | Hgene | Tgene | Gene symbol | UQCC1 | TRPC4AP | Gene ID | 55245 | 26133 |
| Gene name | ubiquinol-cytochrome c reductase complex assembly factor 1 | transient receptor potential cation channel subfamily C member 4 associated protein | |
| Synonyms | BFZB|C20orf44|CBP3|UQCC | C20orf188|PPP1R158|TRRP4AP|TRUSS | |
| Cytomap | ('UQCC1')('TRPC4AP') 20q11.22 | 20q11.22 | |
| Type of gene | protein-coding | protein-coding | |
| Description | ubiquinol-cytochrome-c reductase complex assembly factor 1bFGF-repressed Zic-binding proteinbasic FGF-repressed Zic-binding proteincytochrome B protein synthesis 3 homologubiquinol-cytochrome c reductase complex chaperone CBP3 homolog | short transient receptor potential channel 4-associated proteinTNF-receptor ubiquitous scaffolding/signaling proteinTRP4-associated proteinprotein phosphatase 1, regulatory subunit 158trpc4-associated proteintumor necrosis factor receptor-associated | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000349714, ENST00000359226, ENST00000374380, ENST00000374384, ENST00000374385, ENST00000397554, ENST00000407996, ENST00000542501, ENST00000374377, ENST00000491125, ENST00000540457, ENST00000397556, | ENST00000542501, ENST00000397554, ENST00000491125, ENST00000349714, ENST00000359226, ENST00000374377, ENST00000374380, ENST00000374384, ENST00000374385, ENST00000397556, ENST00000407996, ENST00000540457, | |
| Fusion gene scores | * DoF score | 20 X 11 X 12=2640 | 8 X 7 X 5=280 |
| # samples | 20 | 8 | |
| ** MAII score | log2(20/2640*10)=-3.72246602447109 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/280*10)=-1.8073549220576 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: UQCC1 [Title/Abstract] AND TRPC4AP [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | UQCC1(33999743)-TRPC4AP(33645374), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | UQCC1-TRPC4AP seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. UQCC1-TRPC4AP seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. TRPC4AP-UQCC1 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. TRPC4AP-UQCC1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | UQCC1 | GO:0034551 | mitochondrial respiratory chain complex III assembly | 24385928 |
| Hgene | UQCC1 | GO:0070131 | positive regulation of mitochondrial translation | 24385928 |
| Tgene | TRPC4AP | GO:0006511 | ubiquitin-dependent protein catabolic process | 20551172 |
| Tgene | TRPC4AP | GO:0016567 | protein ubiquitination | 20551172 |
| Fusion gene breakpoints across UQCC1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TRPC4AP (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-BR-8078-01A | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
Top |
Fusion Gene ORF analysis for UQCC1-TRPC4AP |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000349714 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000349714 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000359226 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000359226 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000374380 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000374380 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000374384 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000374384 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000374385 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000374385 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000397554 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000397554 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000407996 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000407996 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000542501 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5CDS-intron | ENST00000542501 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-3CDS | ENST00000374377 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-3CDS | ENST00000374377 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-3CDS | ENST00000491125 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-3CDS | ENST00000491125 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-3CDS | ENST00000540457 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-3CDS | ENST00000540457 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-intron | ENST00000374377 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-intron | ENST00000374377 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-intron | ENST00000491125 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-intron | ENST00000491125 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-intron | ENST00000540457 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| 5UTR-intron | ENST00000540457 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000349714 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000349714 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000359226 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000359226 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000374380 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000374380 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000374384 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000374384 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000374385 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000374385 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000397554 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000397554 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000407996 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000407996 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000542501 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| In-frame | ENST00000542501 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| intron-3CDS | ENST00000397556 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| intron-3CDS | ENST00000397556 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| intron-intron | ENST00000397556 | ENST00000432634 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| intron-intron | ENST00000397556 | ENST00000539834 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000349714 | UQCC1 | chr20 | 33999743 | - | ENST00000451813 | TRPC4AP | chr20 | 33645374 | - | 2722 | 24 | 0 | 1979 | 659 |
| ENST00000349714 | UQCC1 | chr20 | 33999743 | - | ENST00000252015 | TRPC4AP | chr20 | 33645374 | - | 2746 | 24 | 0 | 2003 | 667 |
| ENST00000359226 | UQCC1 | chr20 | 33999743 | - | ENST00000451813 | TRPC4AP | chr20 | 33645374 | - | 2729 | 31 | 7 | 1986 | 659 |
| ENST00000359226 | UQCC1 | chr20 | 33999743 | - | ENST00000252015 | TRPC4AP | chr20 | 33645374 | - | 2753 | 31 | 7 | 2010 | 667 |
| ENST00000374384 | UQCC1 | chr20 | 33999743 | - | ENST00000451813 | TRPC4AP | chr20 | 33645374 | - | 2732 | 34 | 1 | 1989 | 662 |
| ENST00000374384 | UQCC1 | chr20 | 33999743 | - | ENST00000252015 | TRPC4AP | chr20 | 33645374 | - | 2756 | 34 | 1 | 2013 | 670 |
| ENST00000374380 | UQCC1 | chr20 | 33999743 | - | ENST00000451813 | TRPC4AP | chr20 | 33645374 | - | 2790 | 92 | 59 | 2047 | 662 |
| ENST00000374380 | UQCC1 | chr20 | 33999743 | - | ENST00000252015 | TRPC4AP | chr20 | 33645374 | - | 2814 | 92 | 59 | 2071 | 670 |
| ENST00000374385 | UQCC1 | chr20 | 33999743 | - | ENST00000451813 | TRPC4AP | chr20 | 33645374 | - | 2900 | 202 | 169 | 2157 | 662 |
| ENST00000374385 | UQCC1 | chr20 | 33999743 | - | ENST00000252015 | TRPC4AP | chr20 | 33645374 | - | 2924 | 202 | 169 | 2181 | 670 |
| ENST00000407996 | UQCC1 | chr20 | 33999743 | - | ENST00000451813 | TRPC4AP | chr20 | 33645374 | - | 2732 | 34 | 1 | 1989 | 662 |
| ENST00000407996 | UQCC1 | chr20 | 33999743 | - | ENST00000252015 | TRPC4AP | chr20 | 33645374 | - | 2756 | 34 | 1 | 2013 | 670 |
| ENST00000542501 | UQCC1 | chr20 | 33999743 | - | ENST00000451813 | TRPC4AP | chr20 | 33645374 | - | 2732 | 34 | 1 | 1989 | 662 |
| ENST00000542501 | UQCC1 | chr20 | 33999743 | - | ENST00000252015 | TRPC4AP | chr20 | 33645374 | - | 2756 | 34 | 1 | 2013 | 670 |
| ENST00000397554 | UQCC1 | chr20 | 33999743 | - | ENST00000451813 | TRPC4AP | chr20 | 33645374 | - | 2733 | 35 | 2 | 1990 | 662 |
| ENST00000397554 | UQCC1 | chr20 | 33999743 | - | ENST00000252015 | TRPC4AP | chr20 | 33645374 | - | 2757 | 35 | 2 | 2014 | 670 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000349714 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.003632475 | 0.9963676 |
| ENST00000349714 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.004374143 | 0.99562585 |
| ENST00000359226 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.003690095 | 0.99630994 |
| ENST00000359226 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.004433855 | 0.99556607 |
| ENST00000374384 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.003658844 | 0.99634117 |
| ENST00000374384 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.004403003 | 0.99559706 |
| ENST00000374380 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.003410649 | 0.9965893 |
| ENST00000374380 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.004109005 | 0.995891 |
| ENST00000374385 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.003640595 | 0.9963594 |
| ENST00000374385 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.004403864 | 0.9955961 |
| ENST00000407996 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.003658844 | 0.99634117 |
| ENST00000407996 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.004403003 | 0.99559706 |
| ENST00000542501 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.003658844 | 0.99634117 |
| ENST00000542501 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.004403003 | 0.99559706 |
| ENST00000397554 | ENST00000451813 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.003661457 | 0.9963386 |
| ENST00000397554 | ENST00000252015 | UQCC1 | chr20 | 33999743 | - | TRPC4AP | chr20 | 33645374 | - | 0.004404332 | 0.99559563 |
Top |
Fusion Genomic Features for UQCC1-TRPC4AP |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
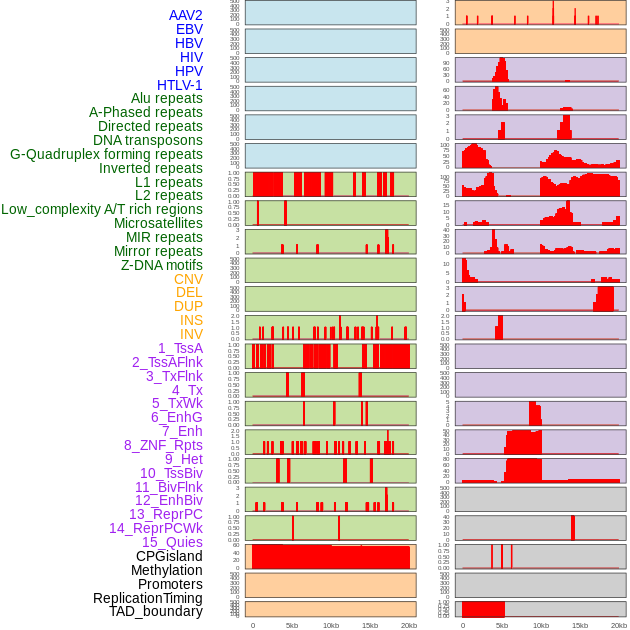 |
Top |
Fusion Protein Features for UQCC1-TRPC4AP |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:33999743/chr20:33645374) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for UQCC1-TRPC4AP |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >96966_96966_1_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000349714_TRPC4AP_chr20_33645374_ENST00000252015_length(transcript)=2746nt_BP=24nt ATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAAAATAAGTGAT GAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAAGAATGACTTT GTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGTTAAAAAGGAA ATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCGGATTCTGGCT GTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTTGAGTTTGGGG CCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCGAAAGGTGTCA GAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGCCCTGATGCGA GTGGCCAATGAGGAGTCAGAGCACAATCAAGCCTCCATTGTGTTCCCTCCTCCAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCA GCCAGAACCCAGCTGCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATG GGGCGTCAGCGAAACCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGG AAGCATTCAGCATCTGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGG CTTCTTCAGAGCTTCAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAG GCCAACATCCCTGAGGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAG GTCATGAAGAAGGAGCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCA GACCAGATGTTCCTGCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAG AGTTACTTTGACCTCCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTC CAGGTATTCCTGAAGCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAAC CAGGTGGATATGAAAGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTC CGCCTCATCAACATCATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGA CGGAAAGAGCGGCTGCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCAC AACCTGCTGCGCTTCTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATAC TGGAAGGAGACAGTGTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATA GACAGGGACTTCACTGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCC CTGCCCTGTTCCCGTTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTG GTCCCCCTGGGTCTGAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCC TGGGGCCCAGGGCCACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAG AGTGGGGAGGAAGATATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCT GAGCCCTGGGCAGGGGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTC TGTTTGCTCATTGGCCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTG TGCCTGCCCTGCCTCTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAAT >96966_96966_1_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000349714_TRPC4AP_chr20_33645374_ENST00000252015_length(amino acids)=667AA_BP=8 MALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGVKKE MIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATRKVS ESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQASIVFPPPGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLM GRQRNQVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLK ANIPEVEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQ SYFDLLGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLF RLINIIHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSY -------------------------------------------------------------- >96966_96966_2_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000349714_TRPC4AP_chr20_33645374_ENST00000451813_length(transcript)=2722nt_BP=24nt ATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAAAATAAGTGAT GAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAAGAATGACTTT GTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGTTAAAAAGGAA ATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCGGATTCTGGCT GTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTTGAGTTTGGGG CCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCGAAAGGTGTCA GAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGCCCTGATGCGA GTGGCCAATGAGGAGTCAGAGCACAATCAAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGCCAGAACCCAGCTGCCCCAGTCA ATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGGGCGTCAGCGAAACCAGGTTCAC AGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAAGCATTCAGCATCTGCCCTTGTC CTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCTTCTTCAGAGCTTCAGTGACCAC CACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGCCAACATCCCTGAGGTGGAAGCT GTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGTCATGAAGAAGGAGCCAGCAGAG TCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGACCAGATGTTCCTGCTGAAGCGA GGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAGTTACTTTGACCTCCTGGGGGAG CTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCAGGTATTCCTGAAGCAGATCAAC AGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCAGGTGGATATGAAAGTTGCCGAG GTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCGCCTCATCAACATCATCCACGTG CAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACGGAAAGAGCGGCTGCCCCTGTAC CTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAACCTGCTGCGCTTCTGGCAGCAG CACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTGGAAGGAGACAGTGTCCATCCTG TTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGACAGGGACTTCACTGAGGAGTGA CCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCTGCCCTGTTCCCGTTCCTCCCTG CTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGTCCCCCTGGGTCTGAGGGCCCTA GGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTGGGGCCCAGGGCCACCCAGAGGT AAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAGTGGGGAGGAAGATATGGGTGAC CCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGAGCCCTGGGCAGGGGTGGTGGGT ACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTGTTTGCTCATTGGCCGCTGTGTT CATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTGCCTGCCCTGCCTCTGCCTGAGG CAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAAACCAATTAAATGGAGACTATTA >96966_96966_2_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000349714_TRPC4AP_chr20_33645374_ENST00000451813_length(amino acids)=659AA_BP=8 MALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGVKKE MIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATRKVS ESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLMGRQRNQVH RMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLKANIPEVEA VLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQSYFDLLGE LMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLFRLINIIHV QTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSYWKETVSIL -------------------------------------------------------------- >96966_96966_3_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000359226_TRPC4AP_chr20_33645374_ENST00000252015_length(transcript)=2753nt_BP=31nt GAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAAAAT AAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAAGAA TGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGTTAA AAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCGGAT TCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTTGAG TTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCGAAA GGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGCCCT GATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGCCTCCATTGTGTTCCCTCCTCCAGGGGCTTCTGAGGAGAATGGCCTGCCTCA CACGTCAGCCAGAACCCAGCTGCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCT GCTGATGGGGCGTCAGCGAAACCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGAT TTGGAGGAAGCATTCAGCATCTGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTT TTTGAGGCTTCTTCAGAGCTTCAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTC TCTCAAGGCCAACATCCCTGAGGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCT GCTGCAGGTCATGAAGAAGGAGCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTC CTATGCAGACCAGATGTTCCTGCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGT GCTCCAGAGTTACTTTGACCTCCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGC AAAGTTCCAGGTATTCCTGAAGCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATT TGAAAACCAGGTGGATATGAAAGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTT CCTCTTCCGCCTCATCAACATCATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCT GGCCCGACGGAAAGAGCGGCTGCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAA CTTCCACAACCTGCTGCGCTTCTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTT CTCATACTGGAAGGAGACAGTGTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACAT GGACATAGACAGGGACTTCACTGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCC ACACGCCCTGCCCTGTTCCCGTTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAA GCCCTTGGTCCCCCTGGGTCTGAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTC AGAACCCTGGGGCCCAGGGCCACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCA GTCCCAGAGTGGGGAGGAAGATATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAA GGCTTCTGAGCCCTGGGCAGGGGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCT CTGGTTCTGTTTGCTCATTGGCCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGG GCAGCTGTGCCTGCCCTGCCTCTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAAC >96966_96966_3_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000359226_TRPC4AP_chr20_33645374_ENST00000252015_length(amino acids)=667AA_BP=8 MALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGVKKE MIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATRKVS ESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQASIVFPPPGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLM GRQRNQVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLK ANIPEVEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQ SYFDLLGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLF RLINIIHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSY -------------------------------------------------------------- >96966_96966_4_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000359226_TRPC4AP_chr20_33645374_ENST00000451813_length(transcript)=2729nt_BP=31nt GAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAAAAT AAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAAGAA TGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGTTAA AAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCGGAT TCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTTGAG TTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCGAAA GGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGCCCT GATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGCCAGAACCCAGCTGCC CCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGGGCGTCAGCGAAACCA GGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAAGCATTCAGCATCTGC CCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCTTCTTCAGAGCTTCAG TGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGCCAACATCCCTGAGGT GGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGTCATGAAGAAGGAGCC AGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGACCAGATGTTCCTGCT GAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAGTTACTTTGACCTCCT GGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCAGGTATTCCTGAAGCA GATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCAGGTGGATATGAAAGT TGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCGCCTCATCAACATCAT CCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACGGAAAGAGCGGCTGCC CCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAACCTGCTGCGCTTCTG GCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTGGAAGGAGACAGTGTC CATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGACAGGGACTTCACTGA GGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCTGCCCTGTTCCCGTTC CTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGTCCCCCTGGGTCTGAG GGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTGGGGCCCAGGGCCACC CAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAGTGGGGAGGAAGATAT GGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGAGCCCTGGGCAGGGGT GGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTGTTTGCTCATTGGCCG CTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTGCCTGCCCTGCCTCTG CCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAAACCAATTAAATGGAG >96966_96966_4_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000359226_TRPC4AP_chr20_33645374_ENST00000451813_length(amino acids)=659AA_BP=8 MALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGVKKE MIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATRKVS ESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLMGRQRNQVH RMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLKANIPEVEA VLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQSYFDLLGE LMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLFRLINIIHV QTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSYWKETVSIL -------------------------------------------------------------- >96966_96966_5_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374380_TRPC4AP_chr20_33645374_ENST00000252015_length(transcript)=2814nt_BP=92nt CAAAAGGAGGACGTAGAAAAGGGGACACCGGAAACTCACTCTTCACCCGGAAATGGTTATTGAGGAACATGGCGTTGCTGGTGCGAGTCC TTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAAAATAAGTGATGAAATGTCCAAGGACTGCTTGA GTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAAGAATGACTTTGTGATCTTCCTGTTTACATTGA TGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGTTAAAAAGGAAATGATCCGACTAGATGAAGTCC CCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCGGATTCTGGCTGTCACCATTTCAGAGATGGATA CAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTTGAGTTTGGGGCCTTCTGCAGCTGAAATCAATC AAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCGAAAGGTGTCAGAGTCAACGGGCACAGCCAGCT TCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGCCCTGATGCGAGTGGCCAATGAGGAGTCAGAGC ACAATCAAGCCTCCATTGTGTTCCCTCCTCCAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGCCAGAACCCAGCTGCCCCAGT CAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGGGCGTCAGCGAAACCAGGTTC ACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAAGCATTCAGCATCTGCCCTTG TCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCTTCTTCAGAGCTTCAGTGACC ACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGCCAACATCCCTGAGGTGGAAG CTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGTCATGAAGAAGGAGCCAGCAG AGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGACCAGATGTTCCTGCTGAAGC GAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAGTTACTTTGACCTCCTGGGGG AGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCAGGTATTCCTGAAGCAGATCA ACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCAGGTGGATATGAAAGTTGCCG AGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCGCCTCATCAACATCATCCACG TGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACGGAAAGAGCGGCTGCCCCTGT ACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAACCTGCTGCGCTTCTGGCAGC AGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTGGAAGGAGACAGTGTCCATCC TGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGACAGGGACTTCACTGAGGAGT GACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCTGCCCTGTTCCCGTTCCTCCC TGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGTCCCCCTGGGTCTGAGGGCCC TAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTGGGGCCCAGGGCCACCCAGAG GTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAGTGGGGAGGAAGATATGGGTG ACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGAGCCCTGGGCAGGGGTGGTGG GTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTGTTTGCTCATTGGCCGCTGTG TTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTGCCTGCCCTGCCTCTGCCTGA GGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAAACCAATTAAATGGAGACTAT >96966_96966_5_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374380_TRPC4AP_chr20_33645374_ENST00000252015_length(amino acids)=670AA_BP=1 MRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQASIVFPPPGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCV LLMGRQRNQVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAI SLKANIPEVEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRD VLQSYFDLLGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMS FLFRLINIIHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCIS -------------------------------------------------------------- >96966_96966_6_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374380_TRPC4AP_chr20_33645374_ENST00000451813_length(transcript)=2790nt_BP=92nt CAAAAGGAGGACGTAGAAAAGGGGACACCGGAAACTCACTCTTCACCCGGAAATGGTTATTGAGGAACATGGCGTTGCTGGTGCGAGTCC TTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAAAATAAGTGATGAAATGTCCAAGGACTGCTTGA GTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAAGAATGACTTTGTGATCTTCCTGTTTACATTGA TGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGTTAAAAAGGAAATGATCCGACTAGATGAAGTCC CCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCGGATTCTGGCTGTCACCATTTCAGAGATGGATA CAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTTGAGTTTGGGGCCTTCTGCAGCTGAAATCAATC AAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCGAAAGGTGTCAGAGTCAACGGGCACAGCCAGCT TCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGCCCTGATGCGAGTGGCCAATGAGGAGTCAGAGC ACAATCAAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGCCAGAACCCAGCTGCCCCAGTCAATGAAGATTATGCATGAGATCA TGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGGGCGTCAGCGAAACCAGGTTCACAGAATGATTGCAGAGTTCAAGC TGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAAGCATTCAGCATCTGCCCTTGTCCTCCATGGTCACAACCAGAACT GTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCTTCTTCAGAGCTTCAGTGACCACCACGAGAACAAGTACTTGTTAC TCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGCCAACATCCCTGAGGTGGAAGCTGTCCTCAACACCGACAGGAGTT TGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGTCATGAAGAAGGAGCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAG CTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGACCAGATGTTCCTGCTGAAGCGAGGCCTCTTGGAGCACATCCTTT ACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAGTTACTTTGACCTCCTGGGGGAGCTGATGAAGTTCAACGTTGATG CATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCAGGTATTCCTGAAGCAGATCAACAGCTCCCTGGTGGACTCCAACA TGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCAGGTGGATATGAAAGTTGCCGAGGTACTGTCTGAATGCCGCCTGC TCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCGCCTCATCAACATCATCCACGTGCAGACGCTGACCCAGGAGAACG TCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACGGAAAGAGCGGCTGCCCCTGTACCTGCGGCTGCTGCAGCGGATGG AGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAACCTGCTGCGCTTCTGGCAGCAGCACTACCTGCACAAGGACAAGG ACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTGGAAGGAGACAGTGTCCATCCTGTTGAACCCGGACCGGCAGTCAC CCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGACAGGGACTTCACTGAGGAGTGACCTTGGGCCAGGCCTCGGGAGG CTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCTGCCCTGTTCCCGTTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGT CTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGTCCCCCTGGGTCTGAGGGCCCTAGGTCATGGAGAGCCTCAGTCCC CATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTGGGGCCCAGGGCCACCCAGAGGTAAGAGGACATTTAGCATTAGCT CTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAGTGGGGAGGAAGATATGGGTGACCCCCACCCCCCATCTGTGAGCC AAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGAGCCCTGGGCAGGGGTGGTGGGTACCAGAGAATGCTGCCTTCCCC CAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTGTTTGCTCATTGGCCGCTGTGTTCATCCAAGGGGGTTCTCCCAGA AGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTGCCTGCCCTGCCTCTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTG GACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAAACCAATTAAATGGAGACTATTAAATAACTTTATTTTAAAAATGA >96966_96966_6_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374380_TRPC4AP_chr20_33645374_ENST00000451813_length(amino acids)=662AA_BP=1 MRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLMGRQRN QVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLKANIPE VEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQSYFDL LGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLFRLINI IHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSYWKETV -------------------------------------------------------------- >96966_96966_7_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374384_TRPC4AP_chr20_33645374_ENST00000252015_length(transcript)=2756nt_BP=34nt ATTGAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAA AATAAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAA GAATGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGT TAAAAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCG GATTCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTT GAGTTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCG AAAGGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGC CCTGATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGCCTCCATTGTGTTCCCTCCTCCAGGGGCTTCTGAGGAGAATGGCCTGCC TCACACGTCAGCCAGAACCCAGCTGCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGT GCTGCTGATGGGGCGTCAGCGAAACCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACT GATTTGGAGGAAGCATTCAGCATCTGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACA GTTTTTGAGGCTTCTTCAGAGCTTCAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCAT CTCTCTCAAGGCCAACATCCCTGAGGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCG TCTGCTGCAGGTCATGAAGAAGGAGCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCAC CTCCTATGCAGACCAGATGTTCCTGCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGA TGTGCTCCAGAGTTACTTTGACCTCCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGA TGCAAAGTTCCAGGTATTCCTGAAGCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCG ATTTGAAAACCAGGTGGATATGAAAGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTC CTTCCTCTTCCGCCTCATCAACATCATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGAT GCTGGCCCGACGGAAAGAGCGGCTGCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAA CAACTTCCACAACCTGCTGCGCTTCTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAG CTTCTCATACTGGAAGGAGACAGTGTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTA CATGGACATAGACAGGGACTTCACTGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGAT GCCACACGCCCTGCCCTGTTCCCGTTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTA GAAGCCCTTGGTCCCCCTGGGTCTGAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCC TTCAGAACCCTGGGGCCCAGGGCCACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAG TCAGTCCCAGAGTGGGGAGGAAGATATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGC AAAGGCTTCTGAGCCCTGGGCAGGGGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCT CCTCTGGTTCTGTTTGCTCATTGGCCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCAC GGGGCAGCTGTGCCTGCCCTGCCTCTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATT >96966_96966_7_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374384_TRPC4AP_chr20_33645374_ENST00000252015_length(amino acids)=670AA_BP=0 LRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQASIVFPPPGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCV LLMGRQRNQVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAI SLKANIPEVEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRD VLQSYFDLLGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMS FLFRLINIIHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCIS -------------------------------------------------------------- >96966_96966_8_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374384_TRPC4AP_chr20_33645374_ENST00000451813_length(transcript)=2732nt_BP=34nt ATTGAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAA AATAAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAA GAATGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGT TAAAAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCG GATTCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTT GAGTTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCG AAAGGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGC CCTGATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGCCAGAACCCAGCT GCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGGGCGTCAGCGAAA CCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAAGCATTCAGCATC TGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCTTCTTCAGAGCTT CAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGCCAACATCCCTGA GGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGTCATGAAGAAGGA GCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGACCAGATGTTCCT GCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAGTTACTTTGACCT CCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCAGGTATTCCTGAA GCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCAGGTGGATATGAA AGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCGCCTCATCAACAT CATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACGGAAAGAGCGGCT GCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAACCTGCTGCGCTT CTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTGGAAGGAGACAGT GTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGACAGGGACTTCAC TGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCTGCCCTGTTCCCG TTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGTCCCCCTGGGTCT GAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTGGGGCCCAGGGCC ACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAGTGGGGAGGAAGA TATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGAGCCCTGGGCAGG GGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTGTTTGCTCATTGG CCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTGCCTGCCCTGCCT CTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAAACCAATTAAATG >96966_96966_8_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374384_TRPC4AP_chr20_33645374_ENST00000451813_length(amino acids)=662AA_BP=0 LRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLMGRQRN QVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLKANIPE VEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQSYFDL LGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLFRLINI IHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSYWKETV -------------------------------------------------------------- >96966_96966_9_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374385_TRPC4AP_chr20_33645374_ENST00000252015_length(transcript)=2924nt_BP=202nt CAGGGAGAGCGTGCCCGGGCACGACAGCCTGGTGCACAGCCGAGAAAACAACAGCGCGTGCGCGTAGCGACCTCTTTGCGCCTGCGCCCC CCTTGCCAGTCTTTCGCCGGCAAAAGGAGGACGTAGAAAAGGGGACACCGGAAACTCACTCTTCACCCGGAAATGGTTATTGAGGAACAT GGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAAAATAAGTGATGA AATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAAGAATGACTTTGT GATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGTTAAAAAGGAAAT GATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCGGATTCTGGCTGT CACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTTGAGTTTGGGGCC TTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCGAAAGGTGTCAGA GTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGCCCTGATGCGAGT GGCCAATGAGGAGTCAGAGCACAATCAAGCCTCCATTGTGTTCCCTCCTCCAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGC CAGAACCCAGCTGCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGG GCGTCAGCGAAACCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAA GCATTCAGCATCTGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCT TCTTCAGAGCTTCAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGC CAACATCCCTGAGGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGT CATGAAGAAGGAGCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGA CCAGATGTTCCTGCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAG TTACTTTGACCTCCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCA GGTATTCCTGAAGCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCA GGTGGATATGAAAGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCG CCTCATCAACATCATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACG GAAAGAGCGGCTGCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAA CCTGCTGCGCTTCTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTG GAAGGAGACAGTGTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGA CAGGGACTTCACTGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCT GCCCTGTTCCCGTTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGT CCCCCTGGGTCTGAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTG GGGCCCAGGGCCACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAG TGGGGAGGAAGATATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGA GCCCTGGGCAGGGGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTG TTTGCTCATTGGCCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTG CCTGCCCTGCCTCTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAA >96966_96966_9_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374385_TRPC4AP_chr20_33645374_ENST00000252015_length(amino acids)=670AA_BP=1 MRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQASIVFPPPGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCV LLMGRQRNQVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAI SLKANIPEVEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRD VLQSYFDLLGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMS FLFRLINIIHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCIS -------------------------------------------------------------- >96966_96966_10_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374385_TRPC4AP_chr20_33645374_ENST00000451813_length(transcript)=2900nt_BP=202nt CAGGGAGAGCGTGCCCGGGCACGACAGCCTGGTGCACAGCCGAGAAAACAACAGCGCGTGCGCGTAGCGACCTCTTTGCGCCTGCGCCCC CCTTGCCAGTCTTTCGCCGGCAAAAGGAGGACGTAGAAAAGGGGACACCGGAAACTCACTCTTCACCCGGAAATGGTTATTGAGGAACAT GGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAAAATAAGTGATGA AATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAAGAATGACTTTGT GATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGTTAAAAAGGAAAT GATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCGGATTCTGGCTGT CACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTTGAGTTTGGGGCC TTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCGAAAGGTGTCAGA GTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGCCCTGATGCGAGT GGCCAATGAGGAGTCAGAGCACAATCAAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGCCAGAACCCAGCTGCCCCAGTCAAT GAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGGGCGTCAGCGAAACCAGGTTCACAG AATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAAGCATTCAGCATCTGCCCTTGTCCT CCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCTTCTTCAGAGCTTCAGTGACCACCA CGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGCCAACATCCCTGAGGTGGAAGCTGT CCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGTCATGAAGAAGGAGCCAGCAGAGTC GTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGACCAGATGTTCCTGCTGAAGCGAGG CCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAGTTACTTTGACCTCCTGGGGGAGCT GATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCAGGTATTCCTGAAGCAGATCAACAG CTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCAGGTGGATATGAAAGTTGCCGAGGT ACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCGCCTCATCAACATCATCCACGTGCA GACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACGGAAAGAGCGGCTGCCCCTGTACCT GCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAACCTGCTGCGCTTCTGGCAGCAGCA CTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTGGAAGGAGACAGTGTCCATCCTGTT GAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGACAGGGACTTCACTGAGGAGTGACC TTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCTGCCCTGTTCCCGTTCCTCCCTGCT GCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGTCCCCCTGGGTCTGAGGGCCCTAGG TCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTGGGGCCCAGGGCCACCCAGAGGTAA GAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAGTGGGGAGGAAGATATGGGTGACCC CCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGAGCCCTGGGCAGGGGTGGTGGGTAC CAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTGTTTGCTCATTGGCCGCTGTGTTCA TCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTGCCTGCCCTGCCTCTGCCTGAGGCA GCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAAACCAATTAAATGGAGACTATTAAA >96966_96966_10_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000374385_TRPC4AP_chr20_33645374_ENST00000451813_length(amino acids)=662AA_BP=1 MRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLMGRQRN QVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLKANIPE VEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQSYFDL LGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLFRLINI IHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSYWKETV -------------------------------------------------------------- >96966_96966_11_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000397554_TRPC4AP_chr20_33645374_ENST00000252015_length(transcript)=2757nt_BP=35nt TATTGAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGA AAATAAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAA AGAATGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTG TTAAAAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCC GGATTCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCT TGAGTTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTC GAAAGGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATG CCCTGATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGCCTCCATTGTGTTCCCTCCTCCAGGGGCTTCTGAGGAGAATGGCCTGC CTCACACGTCAGCCAGAACCCAGCTGCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCG TGCTGCTGATGGGGCGTCAGCGAAACCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAAC TGATTTGGAGGAAGCATTCAGCATCTGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATAC AGTTTTTGAGGCTTCTTCAGAGCTTCAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCA TCTCTCTCAAGGCCAACATCCCTGAGGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTC GTCTGCTGCAGGTCATGAAGAAGGAGCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCA CCTCCTATGCAGACCAGATGTTCCTGCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGG ATGTGCTCCAGAGTTACTTTGACCTCCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCG ATGCAAAGTTCCAGGTATTCCTGAAGCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACC GATTTGAAAACCAGGTGGATATGAAAGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGT CCTTCCTCTTCCGCCTCATCAACATCATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGA TGCTGGCCCGACGGAAAGAGCGGCTGCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCA ACAACTTCCACAACCTGCTGCGCTTCTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCA GCTTCTCATACTGGAAGGAGACAGTGTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCT ACATGGACATAGACAGGGACTTCACTGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGA TGCCACACGCCCTGCCCTGTTCCCGTTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCT AGAAGCCCTTGGTCCCCCTGGGTCTGAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTC CTTCAGAACCCTGGGGCCCAGGGCCACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCA GTCAGTCCCAGAGTGGGGAGGAAGATATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGG CAAAGGCTTCTGAGCCCTGGGCAGGGGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGC TCCTCTGGTTCTGTTTGCTCATTGGCCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCA CGGGGCAGCTGTGCCTGCCCTGCCTCTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTAT >96966_96966_11_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000397554_TRPC4AP_chr20_33645374_ENST00000252015_length(amino acids)=670AA_BP=0 LRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQASIVFPPPGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCV LLMGRQRNQVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAI SLKANIPEVEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRD VLQSYFDLLGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMS FLFRLINIIHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCIS -------------------------------------------------------------- >96966_96966_12_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000397554_TRPC4AP_chr20_33645374_ENST00000451813_length(transcript)=2733nt_BP=35nt TATTGAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGA AAATAAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAA AGAATGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTG TTAAAAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCC GGATTCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCT TGAGTTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTC GAAAGGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATG CCCTGATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGCCAGAACCCAGC TGCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGGGCGTCAGCGAA ACCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAAGCATTCAGCAT CTGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCTTCTTCAGAGCT TCAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGCCAACATCCCTG AGGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGTCATGAAGAAGG AGCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGACCAGATGTTCC TGCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAGTTACTTTGACC TCCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCAGGTATTCCTGA AGCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCAGGTGGATATGA AAGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCGCCTCATCAACA TCATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACGGAAAGAGCGGC TGCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAACCTGCTGCGCT TCTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTGGAAGGAGACAG TGTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGACAGGGACTTCA CTGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCTGCCCTGTTCCC GTTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGTCCCCCTGGGTC TGAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTGGGGCCCAGGGC CACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAGTGGGGAGGAAG ATATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGAGCCCTGGGCAG GGGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTGTTTGCTCATTG GCCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTGCCTGCCCTGCC TCTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAAACCAATTAAAT >96966_96966_12_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000397554_TRPC4AP_chr20_33645374_ENST00000451813_length(amino acids)=662AA_BP=0 LRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLMGRQRN QVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLKANIPE VEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQSYFDL LGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLFRLINI IHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSYWKETV -------------------------------------------------------------- >96966_96966_13_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000407996_TRPC4AP_chr20_33645374_ENST00000252015_length(transcript)=2756nt_BP=34nt ATTGAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAA AATAAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAA GAATGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGT TAAAAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCG GATTCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTT GAGTTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCG AAAGGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGC CCTGATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGCCTCCATTGTGTTCCCTCCTCCAGGGGCTTCTGAGGAGAATGGCCTGCC TCACACGTCAGCCAGAACCCAGCTGCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGT GCTGCTGATGGGGCGTCAGCGAAACCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACT GATTTGGAGGAAGCATTCAGCATCTGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACA GTTTTTGAGGCTTCTTCAGAGCTTCAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCAT CTCTCTCAAGGCCAACATCCCTGAGGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCG TCTGCTGCAGGTCATGAAGAAGGAGCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCAC CTCCTATGCAGACCAGATGTTCCTGCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGA TGTGCTCCAGAGTTACTTTGACCTCCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGA TGCAAAGTTCCAGGTATTCCTGAAGCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCG ATTTGAAAACCAGGTGGATATGAAAGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTC CTTCCTCTTCCGCCTCATCAACATCATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGAT GCTGGCCCGACGGAAAGAGCGGCTGCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAA CAACTTCCACAACCTGCTGCGCTTCTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAG CTTCTCATACTGGAAGGAGACAGTGTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTA CATGGACATAGACAGGGACTTCACTGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGAT GCCACACGCCCTGCCCTGTTCCCGTTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTA GAAGCCCTTGGTCCCCCTGGGTCTGAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCC TTCAGAACCCTGGGGCCCAGGGCCACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAG TCAGTCCCAGAGTGGGGAGGAAGATATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGC AAAGGCTTCTGAGCCCTGGGCAGGGGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCT CCTCTGGTTCTGTTTGCTCATTGGCCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCAC GGGGCAGCTGTGCCTGCCCTGCCTCTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATT >96966_96966_13_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000407996_TRPC4AP_chr20_33645374_ENST00000252015_length(amino acids)=670AA_BP=0 LRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQASIVFPPPGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCV LLMGRQRNQVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAI SLKANIPEVEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRD VLQSYFDLLGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMS FLFRLINIIHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCIS -------------------------------------------------------------- >96966_96966_14_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000407996_TRPC4AP_chr20_33645374_ENST00000451813_length(transcript)=2732nt_BP=34nt ATTGAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAA AATAAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAA GAATGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGT TAAAAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCG GATTCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTT GAGTTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCG AAAGGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGC CCTGATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGCCAGAACCCAGCT GCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGGGCGTCAGCGAAA CCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAAGCATTCAGCATC TGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCTTCTTCAGAGCTT CAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGCCAACATCCCTGA GGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGTCATGAAGAAGGA GCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGACCAGATGTTCCT GCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAGTTACTTTGACCT CCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCAGGTATTCCTGAA GCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCAGGTGGATATGAA AGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCGCCTCATCAACAT CATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACGGAAAGAGCGGCT GCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAACCTGCTGCGCTT CTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTGGAAGGAGACAGT GTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGACAGGGACTTCAC TGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCTGCCCTGTTCCCG TTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGTCCCCCTGGGTCT GAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTGGGGCCCAGGGCC ACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAGTGGGGAGGAAGA TATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGAGCCCTGGGCAGG GGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTGTTTGCTCATTGG CCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTGCCTGCCCTGCCT CTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAAACCAATTAAATG >96966_96966_14_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000407996_TRPC4AP_chr20_33645374_ENST00000451813_length(amino acids)=662AA_BP=0 LRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLMGRQRN QVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLKANIPE VEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQSYFDL LGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLFRLINI IHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSYWKETV -------------------------------------------------------------- >96966_96966_15_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000542501_TRPC4AP_chr20_33645374_ENST00000252015_length(transcript)=2756nt_BP=34nt ATTGAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAA AATAAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAA GAATGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGT TAAAAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCG GATTCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTT GAGTTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCG AAAGGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGC CCTGATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGCCTCCATTGTGTTCCCTCCTCCAGGGGCTTCTGAGGAGAATGGCCTGCC TCACACGTCAGCCAGAACCCAGCTGCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGT GCTGCTGATGGGGCGTCAGCGAAACCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACT GATTTGGAGGAAGCATTCAGCATCTGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACA GTTTTTGAGGCTTCTTCAGAGCTTCAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCAT CTCTCTCAAGGCCAACATCCCTGAGGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCG TCTGCTGCAGGTCATGAAGAAGGAGCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCAC CTCCTATGCAGACCAGATGTTCCTGCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGA TGTGCTCCAGAGTTACTTTGACCTCCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGA TGCAAAGTTCCAGGTATTCCTGAAGCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCG ATTTGAAAACCAGGTGGATATGAAAGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTC CTTCCTCTTCCGCCTCATCAACATCATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGAT GCTGGCCCGACGGAAAGAGCGGCTGCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAA CAACTTCCACAACCTGCTGCGCTTCTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAG CTTCTCATACTGGAAGGAGACAGTGTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTA CATGGACATAGACAGGGACTTCACTGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGAT GCCACACGCCCTGCCCTGTTCCCGTTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTA GAAGCCCTTGGTCCCCCTGGGTCTGAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCC TTCAGAACCCTGGGGCCCAGGGCCACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAG TCAGTCCCAGAGTGGGGAGGAAGATATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGC AAAGGCTTCTGAGCCCTGGGCAGGGGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCT CCTCTGGTTCTGTTTGCTCATTGGCCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCAC GGGGCAGCTGTGCCTGCCCTGCCTCTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATT >96966_96966_15_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000542501_TRPC4AP_chr20_33645374_ENST00000252015_length(amino acids)=670AA_BP=0 LRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQASIVFPPPGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCV LLMGRQRNQVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAI SLKANIPEVEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRD VLQSYFDLLGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMS FLFRLINIIHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCIS -------------------------------------------------------------- >96966_96966_16_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000542501_TRPC4AP_chr20_33645374_ENST00000451813_length(transcript)=2732nt_BP=34nt ATTGAGGAACATGGCGTTGCTGGTGCGAGTCCTTCTTCTTGTAGAAATTCTTATGAGGCCTACGATCTCTATCCGGGGACAGAAACTGAA AATAAGTGATGAAATGTCCAAGGACTGCTTGAGTATCCTGTATAATACCTGTGTCTGTACAGAGGGAGTTACAAAGCGTTTGGCAGAAAA GAATGACTTTGTGATCTTCCTGTTTACATTGATGACAAGTAAGAAGACATTCTTACAAACAGCAACCCTCATTGAAGATATTTTGGGTGT TAAAAAGGAAATGATCCGACTAGATGAAGTCCCCAATCTGAGTTCCTTAGTATCCAATTTCGATCAGCAGCAGCTCGCTAATTTCTGCCG GATTCTGGCTGTCACCATTTCAGAGATGGATACAGGGAATGATGACAAGCACACGCTTCTTGCCAAAAATGCTCAACAGAAGAAGAGCTT GAGTTTGGGGCCTTCTGCAGCTGAAATCAATCAAGCGGCCCTTCTCAGCATTCCTGGCTTTGTTGAGCGGCTTTGCAAACTGGCGACTCG AAAGGTGTCAGAGTCAACGGGCACAGCCAGCTTCCTTCAGGAGTTGGAAGAGTGGTACACATGGCTAGACAATGCTTTGGTGCTAGATGC CCTGATGCGAGTGGCCAATGAGGAGTCAGAGCACAATCAAGGGGCTTCTGAGGAGAATGGCCTGCCTCACACGTCAGCCAGAACCCAGCT GCCCCAGTCAATGAAGATTATGCATGAGATCATGTACAAACTGGAAGTGCTCTATGTCCTCTGCGTGCTGCTGATGGGGCGTCAGCGAAA CCAGGTTCACAGAATGATTGCAGAGTTCAAGCTGATCCCTGGACTTAATAATTTGTTTGACAAACTGATTTGGAGGAAGCATTCAGCATC TGCCCTTGTCCTCCATGGTCACAACCAGAACTGTGACTGTAGCCCGGACATCACCTTGAAGATACAGTTTTTGAGGCTTCTTCAGAGCTT CAGTGACCACCACGAGAACAAGTACTTGTTACTCAACAACCAGGAGCTGAATGAACTCAGTGCCATCTCTCTCAAGGCCAACATCCCTGA GGTGGAAGCTGTCCTCAACACCGACAGGAGTTTGGTGTGTGATGGGAAGAGGGGCTTATTAACTCGTCTGCTGCAGGTCATGAAGAAGGA GCCAGCAGAGTCGTCTTTCAGGTTTTGGCAAGCTCGGGCTGTGGAGAGTTTCCTCCGAGGGACCACCTCCTATGCAGACCAGATGTTCCT GCTGAAGCGAGGCCTCTTGGAGCACATCCTTTACTGCATTGTGGACAGCGAGTGTAAGTCAAGGGATGTGCTCCAGAGTTACTTTGACCT CCTGGGGGAGCTGATGAAGTTCAACGTTGATGCATTCAAGAGATTCAATAAATATATCAACACCGATGCAAAGTTCCAGGTATTCCTGAA GCAGATCAACAGCTCCCTGGTGGACTCCAACATGCTGGTGCGCTGTGTCACTCTGTCCCTGGACCGATTTGAAAACCAGGTGGATATGAA AGTTGCCGAGGTACTGTCTGAATGCCGCCTGCTCGCCTACATATCCCAGGTGCCCACGCAGATGTCCTTCCTCTTCCGCCTCATCAACAT CATCCACGTGCAGACGCTGACCCAGGAGAACGTCAGCTGCCTCAACACCAGCCTGGTGATCCTGATGCTGGCCCGACGGAAAGAGCGGCT GCCCCTGTACCTGCGGCTGCTGCAGCGGATGGAGCACAGCAAGAAGTACCCCGGCTTCCTGCTCAACAACTTCCACAACCTGCTGCGCTT CTGGCAGCAGCACTACCTGCACAAGGACAAGGACAGCACCTGCCTAGAGAACAGCTCCTGCATCAGCTTCTCATACTGGAAGGAGACAGT GTCCATCCTGTTGAACCCGGACCGGCAGTCACCCTCTGCTCTCGTTAGCTACATTGAGGAGCCCTACATGGACATAGACAGGGACTTCAC TGAGGAGTGACCTTGGGCCAGGCCTCGGGAGGCTGCTGGGCCAGTGTGGGTGAGCGTGGGTACGATGCCACACGCCCTGCCCTGTTCCCG TTCCTCCCTGCTGCTCTCTGCCTGCCCCAGGTCTTTGGGTACAGGCTTGGTGGGAGGGAAGTCCTAGAAGCCCTTGGTCCCCCTGGGTCT GAGGGCCCTAGGTCATGGAGAGCCTCAGTCCCCATAATGAGGACAGGGTACCATGCCCACCTTTCCTTCAGAACCCTGGGGCCCAGGGCC ACCCAGAGGTAAGAGGACATTTAGCATTAGCTCTGTGTGAGCTCCTGCCGGTTTCTTGGCTGTCAGTCAGTCCCAGAGTGGGGAGGAAGA TATGGGTGACCCCCACCCCCCATCTGTGAGCCAAGCCTCCCTTGTCCCTGGCCTTTGGACCCAGGCAAAGGCTTCTGAGCCCTGGGCAGG GGTGGTGGGTACCAGAGAATGCTGCCTTCCCCCAAGCCTGCCCCTCTGCCTCATTTTCCTGTAGCTCCTCTGGTTCTGTTTGCTCATTGG CCGCTGTGTTCATCCAAGGGGGTTCTCCCAGAAGTGAGGGGCCTTTCCCTCCATCCCTTGGGGCACGGGGCAGCTGTGCCTGCCCTGCCT CTGCCTGAGGCAGCCGCTCCTGCCTGAGCCTGGACATGGGGCCCTTCCTTGTGTTGCCAATTTATTAACAGCAAATAAACCAATTAAATG >96966_96966_16_UQCC1-TRPC4AP_UQCC1_chr20_33999743_ENST00000542501_TRPC4AP_chr20_33645374_ENST00000451813_length(amino acids)=662AA_BP=0 LRNMALLVRVLLLVEILMRPTISIRGQKLKISDEMSKDCLSILYNTCVCTEGVTKRLAEKNDFVIFLFTLMTSKKTFLQTATLIEDILGV KKEMIRLDEVPNLSSLVSNFDQQQLANFCRILAVTISEMDTGNDDKHTLLAKNAQQKKSLSLGPSAAEINQAALLSIPGFVERLCKLATR KVSESTGTASFLQELEEWYTWLDNALVLDALMRVANEESEHNQGASEENGLPHTSARTQLPQSMKIMHEIMYKLEVLYVLCVLLMGRQRN QVHRMIAEFKLIPGLNNLFDKLIWRKHSASALVLHGHNQNCDCSPDITLKIQFLRLLQSFSDHHENKYLLLNNQELNELSAISLKANIPE VEAVLNTDRSLVCDGKRGLLTRLLQVMKKEPAESSFRFWQARAVESFLRGTTSYADQMFLLKRGLLEHILYCIVDSECKSRDVLQSYFDL LGELMKFNVDAFKRFNKYINTDAKFQVFLKQINSSLVDSNMLVRCVTLSLDRFENQVDMKVAEVLSECRLLAYISQVPTQMSFLFRLINI IHVQTLTQENVSCLNTSLVILMLARRKERLPLYLRLLQRMEHSKKYPGFLLNNFHNLLRFWQQHYLHKDKDSTCLENSSCISFSYWKETV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for UQCC1-TRPC4AP |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | TRPC4AP | chr20:33999743 | chr20:33645374 | ENST00000252015 | 2 | 19 | 2_400 | 138.0 | 798.0 | TNFRSF1A |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for UQCC1-TRPC4AP |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for UQCC1-TRPC4AP |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies