
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SULT1A1-NONO (FusionGDB2 ID:HG6817TG4841) |
Fusion Gene Summary for SULT1A1-NONO |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SULT1A1-NONO | Fusion gene ID: hg6817tg4841 | Hgene | Tgene | Gene symbol | SULT1A1 | NONO | Gene ID | 6817 | 4841 |
| Gene name | sulfotransferase family 1A member 1 | non-POU domain containing octamer binding | |
| Synonyms | HAST1/HAST2|P-PST|PST|ST1A1|ST1A3|STP|STP1|TSPST1 | MRXS34|NMT55|NRB54|P54|P54NRB|PPP1R114 | |
| Cytomap | ('SULT1A1')('NONO') 16p11.2 | Xq13.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | sulfotransferase 1A1P-PST 1aryl sulfotransferase 1phenol-sulfating phenol sulfotransferase 1sulfotransferase family, cytosolic, 1A, phenol-preferring, member 1thermostable phenol sulfotransferase1ts-PST | non-POU domain-containing octamer-binding protein54 kDa nuclear RNA- and DNA-binding protein55 kDa nuclear proteinDNA-binding p52/p100 complex, 52 kDa subunitnon-POU domain-containing octamer (ATGCAAAT) binding proteinp54(nrb)protein phosphatase 1, | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000314752, ENST00000395607, ENST00000395609, ENST00000569554, ENST00000350842, | ||
| Fusion gene scores | * DoF score | 2 X 2 X 2=8 | 8 X 8 X 3=192 |
| # samples | 2 | 8 | |
| ** MAII score | log2(2/8*10)=1.32192809488736 | log2(8/192*10)=-1.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SULT1A1 [Title/Abstract] AND NONO [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SULT1A1(28619612)-NONO(70519789), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | SULT1A1-NONO seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. SULT1A1-NONO seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. SULT1A1-NONO seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. SULT1A1-NONO seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. SULT1A1-NONO seems lost the major protein functional domain in Hgene partner, which is a cell metabolism gene due to the frame-shifted ORF. SULT1A1-NONO seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. SULT1A1-NONO seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SULT1A1 | GO:0006068 | ethanol catabolic process | 23207770 |
| Hgene | SULT1A1 | GO:0006805 | xenobiotic metabolic process | 12471039|20056724 |
| Hgene | SULT1A1 | GO:0008210 | estrogen metabolic process | 16221673 |
| Hgene | SULT1A1 | GO:0009812 | flavonoid metabolic process | 20056724 |
| Hgene | SULT1A1 | GO:0050427 | 3'-phosphoadenosine 5'-phosphosulfate metabolic process | 23207770 |
| Hgene | SULT1A1 | GO:0051923 | sulfation | 19548878|20056724|23207770 |
| Tgene | NONO | GO:0002218 | activation of innate immune response | 28712728 |
| Tgene | NONO | GO:1903377 | negative regulation of oxidative stress-induced neuron intrinsic apoptotic signaling pathway | 15790595 |
| Fusion gene breakpoints across SULT1A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NONO (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChiTaRS5.0 | N/A | BM920046 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
Top |
Fusion Gene ORF analysis for SULT1A1-NONO |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000314752 | ENST00000490044 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| 5CDS-3UTR | ENST00000395607 | ENST00000490044 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| 5CDS-3UTR | ENST00000395609 | ENST00000490044 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| 5CDS-3UTR | ENST00000569554 | ENST00000490044 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| Frame-shift | ENST00000314752 | ENST00000373856 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| Frame-shift | ENST00000314752 | ENST00000535149 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| Frame-shift | ENST00000395607 | ENST00000276079 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| Frame-shift | ENST00000395607 | ENST00000373841 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| Frame-shift | ENST00000395609 | ENST00000276079 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| Frame-shift | ENST00000395609 | ENST00000373841 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| Frame-shift | ENST00000569554 | ENST00000373856 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| Frame-shift | ENST00000569554 | ENST00000535149 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| In-frame | ENST00000314752 | ENST00000276079 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| In-frame | ENST00000314752 | ENST00000373841 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| In-frame | ENST00000395607 | ENST00000373856 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| In-frame | ENST00000395607 | ENST00000535149 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| In-frame | ENST00000395609 | ENST00000373856 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| In-frame | ENST00000395609 | ENST00000535149 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| In-frame | ENST00000569554 | ENST00000276079 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| In-frame | ENST00000569554 | ENST00000373841 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| intron-3CDS | ENST00000350842 | ENST00000276079 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| intron-3CDS | ENST00000350842 | ENST00000373841 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| intron-3CDS | ENST00000350842 | ENST00000373856 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| intron-3CDS | ENST00000350842 | ENST00000535149 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| intron-3UTR | ENST00000350842 | ENST00000490044 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000395607 | SULT1A1 | chr16 | 28619612 | - | ENST00000535149 | NONO | chrX | 70519789 | + | 1871 | 646 | 274 | 780 | 168 |
| ENST00000395607 | SULT1A1 | chr16 | 28619612 | - | ENST00000373856 | NONO | chrX | 70519789 | + | 974 | 646 | 274 | 780 | 168 |
| ENST00000395609 | SULT1A1 | chr16 | 28619612 | - | ENST00000535149 | NONO | chrX | 70519789 | + | 2356 | 1131 | 759 | 1265 | 168 |
| ENST00000395609 | SULT1A1 | chr16 | 28619612 | - | ENST00000373856 | NONO | chrX | 70519789 | + | 1459 | 1131 | 759 | 1265 | 168 |
| ENST00000569554 | SULT1A1 | chr16 | 28619612 | - | ENST00000276079 | NONO | chrX | 70519789 | + | 1664 | 437 | 65 | 571 | 168 |
| ENST00000569554 | SULT1A1 | chr16 | 28619612 | - | ENST00000373841 | NONO | chrX | 70519789 | + | 1664 | 437 | 65 | 571 | 168 |
| ENST00000314752 | SULT1A1 | chr16 | 28619612 | - | ENST00000276079 | NONO | chrX | 70519789 | + | 1680 | 453 | 81 | 587 | 168 |
| ENST00000314752 | SULT1A1 | chr16 | 28619612 | - | ENST00000373841 | NONO | chrX | 70519789 | + | 1680 | 453 | 81 | 587 | 168 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000395607 | ENST00000535149 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + | 0.008296344 | 0.9917036 |
| ENST00000395607 | ENST00000373856 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + | 0.0175743 | 0.9824257 |
| ENST00000395609 | ENST00000535149 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + | 0.015243316 | 0.98475665 |
| ENST00000395609 | ENST00000373856 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + | 0.014467693 | 0.98553234 |
| ENST00000569554 | ENST00000276079 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + | 0.004993368 | 0.99500656 |
| ENST00000569554 | ENST00000373841 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + | 0.004993368 | 0.99500656 |
| ENST00000314752 | ENST00000276079 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + | 0.005041665 | 0.99495834 |
| ENST00000314752 | ENST00000373841 | SULT1A1 | chr16 | 28619612 | - | NONO | chrX | 70519789 | + | 0.005041665 | 0.99495834 |
Top |
Fusion Genomic Features for SULT1A1-NONO |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| SULT1A1 | chr16 | 28619611 | - | NONO | chrX | 70519791 | + | 0.000313813 | 0.99968624 |
| SULT1A1 | chr16 | 28619611 | - | NONO | chrX | 70519791 | + | 0.000313813 | 0.99968624 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
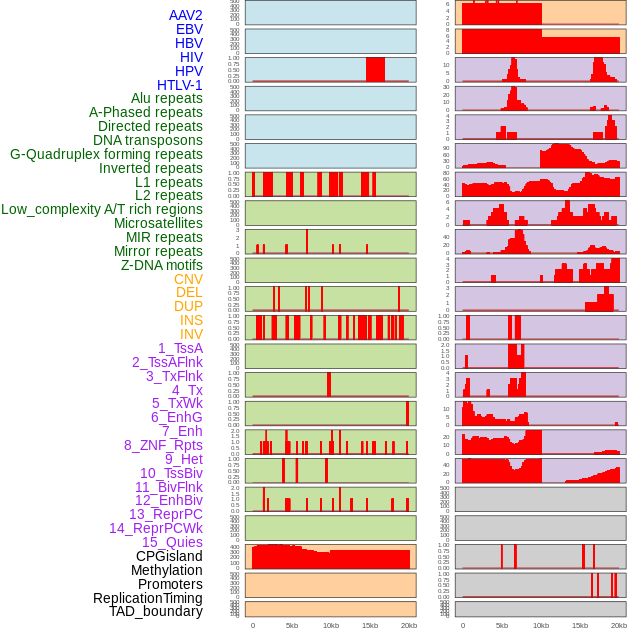 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
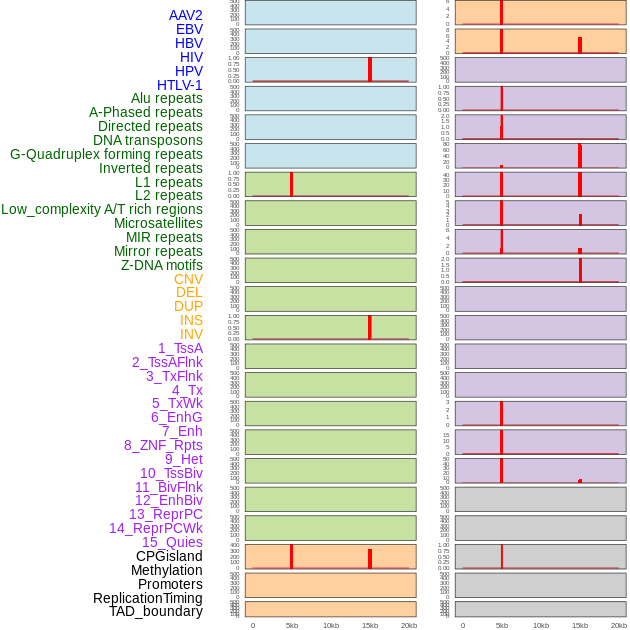 |
Top |
Fusion Protein Features for SULT1A1-NONO |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr16:28619612/chrX:70519789) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000314752 | - | 4 | 8 | 48_53 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000395607 | - | 4 | 8 | 48_53 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000395609 | - | 6 | 10 | 48_53 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000569554 | - | 3 | 7 | 48_53 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000314752 | - | 4 | 8 | 106_108 | 124 | 296.0 | Region | Substrate binding |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000395607 | - | 4 | 8 | 106_108 | 124 | 296.0 | Region | Substrate binding |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000395609 | - | 6 | 10 | 106_108 | 124 | 296.0 | Region | Substrate binding |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000569554 | - | 3 | 7 | 106_108 | 124 | 296.0 | Region | Substrate binding |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000535149 | 8 | 10 | 348_351 | 338 | 383.0 | Compositional bias | Note=Poly-Arg |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000314752 | - | 4 | 8 | 227_232 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000314752 | - | 4 | 8 | 255_259 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000350842 | - | 1 | 6 | 227_232 | 0 | 218.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000350842 | - | 1 | 6 | 255_259 | 0 | 218.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000350842 | - | 1 | 6 | 48_53 | 0 | 218.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000395607 | - | 4 | 8 | 227_232 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000395607 | - | 4 | 8 | 255_259 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000395609 | - | 6 | 10 | 227_232 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000395609 | - | 6 | 10 | 255_259 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000569554 | - | 3 | 7 | 227_232 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000569554 | - | 3 | 7 | 255_259 | 124 | 296.0 | Nucleotide binding | PAPS |
| Hgene | SULT1A1 | chr16:28619612 | chrX:70519789 | ENST00000350842 | - | 1 | 6 | 106_108 | 0 | 218.0 | Region | Substrate binding |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000276079 | 10 | 12 | 268_372 | 427 | 472.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373841 | 9 | 11 | 268_372 | 427 | 472.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373856 | 11 | 13 | 268_372 | 427 | 472.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000535149 | 8 | 10 | 268_372 | 338 | 383.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000276079 | 10 | 12 | 30_35 | 427 | 472.0 | Compositional bias | Note=Poly-Gln | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000276079 | 10 | 12 | 348_351 | 427 | 472.0 | Compositional bias | Note=Poly-Arg | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000276079 | 10 | 12 | 36_42 | 427 | 472.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373841 | 9 | 11 | 30_35 | 427 | 472.0 | Compositional bias | Note=Poly-Gln | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373841 | 9 | 11 | 348_351 | 427 | 472.0 | Compositional bias | Note=Poly-Arg | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373841 | 9 | 11 | 36_42 | 427 | 472.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373856 | 11 | 13 | 30_35 | 427 | 472.0 | Compositional bias | Note=Poly-Gln | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373856 | 11 | 13 | 348_351 | 427 | 472.0 | Compositional bias | Note=Poly-Arg | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373856 | 11 | 13 | 36_42 | 427 | 472.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000535149 | 8 | 10 | 30_35 | 338 | 383.0 | Compositional bias | Note=Poly-Gln | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000535149 | 8 | 10 | 36_42 | 338 | 383.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000276079 | 10 | 12 | 148_229 | 427 | 472.0 | Domain | RRM 2 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000276079 | 10 | 12 | 74_141 | 427 | 472.0 | Domain | RRM 1 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373841 | 9 | 11 | 148_229 | 427 | 472.0 | Domain | RRM 2 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373841 | 9 | 11 | 74_141 | 427 | 472.0 | Domain | RRM 1 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373856 | 11 | 13 | 148_229 | 427 | 472.0 | Domain | RRM 2 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373856 | 11 | 13 | 74_141 | 427 | 472.0 | Domain | RRM 1 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000535149 | 8 | 10 | 148_229 | 338 | 383.0 | Domain | RRM 2 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000535149 | 8 | 10 | 74_141 | 338 | 383.0 | Domain | RRM 1 | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000276079 | 10 | 12 | 54_373 | 427 | 472.0 | Region | Note=DBHS | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373841 | 9 | 11 | 54_373 | 427 | 472.0 | Region | Note=DBHS | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000373856 | 11 | 13 | 54_373 | 427 | 472.0 | Region | Note=DBHS | |
| Tgene | NONO | chr16:28619612 | chrX:70519789 | ENST00000535149 | 8 | 10 | 54_373 | 338 | 383.0 | Region | Note=DBHS |
Top |
Fusion Gene Sequence for SULT1A1-NONO |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >88052_88052_1_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000314752_NONO_chrX_70519789_ENST00000276079_length(transcript)=1680nt_BP=453nt CCTGCATTCCCCACACAACACCCACAATCAGCCACTGCGGGCGAGGAGGGCACGAGGCCAGGTTCCCAAGAGCTCAGGAACATGGAGCTG ATCCAGGACACCTCCCGCCCGCCACTGGAGTACGTGAAGGGGGTCCCGCTCATCAAGTACTTTGCAGAGGCACTGGGGCCCCTGCAGAGC TTCCAGGCCCGGCCTGATGACCTGCTCATCAGCACCTACCCCAAGTCCGGCACTACCTGGGTAAGCCAGATTCTGGACATGATCTACCAG GGTGGTGACCTGGAGAAGTGTCACCGAGCTCCCATCTTCATGCGGGTGCCCTTCCTTGAGTTCAAAGCCCCAGGGATTCCCTCAGGGATG GAGACTCTGAAAGACACACCGGCCCCACGACTCCTGAAGACACACCTGCCCCTGGCTCTGCTCCCCCAGACTCTGTTGGATCAGAAGGTC AAGACCCCACCAACAACTGAACGCTTTGGTCAGGCTGCTACAATGGAAGGAATTGGGGCAATTGGTGGAACTCCTCCTGCATTCAACCGT GCAGCTCCTGGAGCTGAATTTGCCCCAAACAAACGTCGCCGATACTAATAAGTTGCAGTGTCTAGTTTCTCAAAACCCTTAAAAGAAGGA CCCTTTTTGGACTAGCCAGAATTCTACCCTGGAAAAGTGTTAGGGATTCCTTCCAATAGTTAGATCTACCCTGCCTGTACTACTCTAGGG AGTATGCTGGAGGCAGAGGGCAAGGGAGGGGTGGTATTAAACAAGTCAATTCTGTGTGGTATATTGTTTAATCAGTTCTGTGTGGTGCAT TCCTGAAGTCTCTAATGTGACTGTTGAGGGCCTGGGGAAACCATGGCAAAGTGGATCCAGTTAGAGCCCATTAATCTTGATCATTCCGGT TTTTTTTTTTTTTGTCCATCTTGTTTCATTTGCTTGCCCCGCCCCCGAGACGGAGTCTTACTCTGTCGCCCAGGCTGGAGTGTAGTGGCA TGATCTCGGCTCACTGCAATCTCTGCCTCCCGGGTTCAAGCTTGTCCAGGTTGATCTTGAACTCCTGACCTCGTGATCTACCCACCTCGG CCTCCCAAAATGCTGGGATTACAGGGGTGAGCCACCGTGCCCAACCTCACTTGCTTCTTATCCTTACACTCCCCCAGCCCCAGAGAAACT GCCACATACACCACAAAAACCAAACATCCCCCAATGACCTTAGCCCCATTGCTCCATTCACTCCCAGGTGAGAATTCAGGCAAACGTCCA CAAAGGTCACAGGCAGCGTACATACGGTTCTGTTATACCCCATATATTACCCCTTCATGTCCTAAAGAAGACATTTTCTCTTAGAGATTT TCATTTTAGTGTATCTTTAAAAAAAAATCTTGTGTTAACTTGCCTCCATCTTTTTCTTGGGTGAGGACACCCAGGAATGACCCTTTTGTG TCTATGATGTTGCTGTTCACAGCTTTTCTTGATAGGCCTAGTACAATCTTGGGAACAGGGTTACTGTATACTGAAGGTCTGACAGTAGCT CTTAGACTCGCCTATCTTAGGTAGTCATGCTGTGCATTTTTTTTTTCATTGGTGTACTGTGTTTGATTTGTCTCATATATTTGGAGTTTT >88052_88052_1_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000314752_NONO_chrX_70519789_ENST00000276079_length(amino acids)=168AA_BP=123 MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLISTYPKSGTTWVSQILDMIYQGGDLEKCHRAPIFMRVPFLEFKAPGIP -------------------------------------------------------------- >88052_88052_2_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000314752_NONO_chrX_70519789_ENST00000373841_length(transcript)=1680nt_BP=453nt CCTGCATTCCCCACACAACACCCACAATCAGCCACTGCGGGCGAGGAGGGCACGAGGCCAGGTTCCCAAGAGCTCAGGAACATGGAGCTG ATCCAGGACACCTCCCGCCCGCCACTGGAGTACGTGAAGGGGGTCCCGCTCATCAAGTACTTTGCAGAGGCACTGGGGCCCCTGCAGAGC TTCCAGGCCCGGCCTGATGACCTGCTCATCAGCACCTACCCCAAGTCCGGCACTACCTGGGTAAGCCAGATTCTGGACATGATCTACCAG GGTGGTGACCTGGAGAAGTGTCACCGAGCTCCCATCTTCATGCGGGTGCCCTTCCTTGAGTTCAAAGCCCCAGGGATTCCCTCAGGGATG GAGACTCTGAAAGACACACCGGCCCCACGACTCCTGAAGACACACCTGCCCCTGGCTCTGCTCCCCCAGACTCTGTTGGATCAGAAGGTC AAGACCCCACCAACAACTGAACGCTTTGGTCAGGCTGCTACAATGGAAGGAATTGGGGCAATTGGTGGAACTCCTCCTGCATTCAACCGT GCAGCTCCTGGAGCTGAATTTGCCCCAAACAAACGTCGCCGATACTAATAAGTTGCAGTGTCTAGTTTCTCAAAACCCTTAAAAGAAGGA CCCTTTTTGGACTAGCCAGAATTCTACCCTGGAAAAGTGTTAGGGATTCCTTCCAATAGTTAGATCTACCCTGCCTGTACTACTCTAGGG AGTATGCTGGAGGCAGAGGGCAAGGGAGGGGTGGTATTAAACAAGTCAATTCTGTGTGGTATATTGTTTAATCAGTTCTGTGTGGTGCAT TCCTGAAGTCTCTAATGTGACTGTTGAGGGCCTGGGGAAACCATGGCAAAGTGGATCCAGTTAGAGCCCATTAATCTTGATCATTCCGGT TTTTTTTTTTTTTGTCCATCTTGTTTCATTTGCTTGCCCCGCCCCCGAGACGGAGTCTTACTCTGTCGCCCAGGCTGGAGTGTAGTGGCA TGATCTCGGCTCACTGCAATCTCTGCCTCCCGGGTTCAAGCTTGTCCAGGTTGATCTTGAACTCCTGACCTCGTGATCTACCCACCTCGG CCTCCCAAAATGCTGGGATTACAGGGGTGAGCCACCGTGCCCAACCTCACTTGCTTCTTATCCTTACACTCCCCCAGCCCCAGAGAAACT GCCACATACACCACAAAAACCAAACATCCCCCAATGACCTTAGCCCCATTGCTCCATTCACTCCCAGGTGAGAATTCAGGCAAACGTCCA CAAAGGTCACAGGCAGCGTACATACGGTTCTGTTATACCCCATATATTACCCCTTCATGTCCTAAAGAAGACATTTTCTCTTAGAGATTT TCATTTTAGTGTATCTTTAAAAAAAAATCTTGTGTTAACTTGCCTCCATCTTTTTCTTGGGTGAGGACACCCAGGAATGACCCTTTTGTG TCTATGATGTTGCTGTTCACAGCTTTTCTTGATAGGCCTAGTACAATCTTGGGAACAGGGTTACTGTATACTGAAGGTCTGACAGTAGCT CTTAGACTCGCCTATCTTAGGTAGTCATGCTGTGCATTTTTTTTTTCATTGGTGTACTGTGTTTGATTTGTCTCATATATTTGGAGTTTT >88052_88052_2_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000314752_NONO_chrX_70519789_ENST00000373841_length(amino acids)=168AA_BP=123 MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLISTYPKSGTTWVSQILDMIYQGGDLEKCHRAPIFMRVPFLEFKAPGIP -------------------------------------------------------------- >88052_88052_3_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000395607_NONO_chrX_70519789_ENST00000373856_length(transcript)=974nt_BP=646nt TTTCCACATGTGAGGGGCTGAGGGGCTCAAGGAGGGGAGCATCTCCACTGGGTGGAGGCTGGGGGTCCCAGCAGGAAGTGGTGAGACAAA GGGCGCTGGCTGGCAGGGAGACAGCACAGGAAGGTCCTAGAGCTTCCTCAGTGCAGCTGGACTCTCCTGGAGACCTTCACACACCCTGAC ATCTGGGCCTTGCCCGACGAGGGTGCTTTCACTGGTCTGCACCATGGCCCAGGCCCTGGGATTTTGAACAGCTCCGCAGGTGAATGAAAG GAACATGGAGCTGATCCAGGACACCTCCCGCCCGCCACTGGAGTACGTGAAGGGGGTCCCGCTCATCAAGTACTTTGCAGAGGCACTGGG GCCCCTGCAGAGCTTCCAGGCCCGGCCTGATGACCTGCTCATCAGCACCTACCCCAAGTCCGGCACTACCTGGGTAAGCCAGATTCTGGA CATGATCTACCAGGGTGGTGACCTGGAGAAGTGTCACCGAGCTCCCATCTTCATGCGGGTGCCCTTCCTTGAGTTCAAAGCCCCAGGGAT TCCCTCAGGGATGGAGACTCTGAAAGACACACCGGCCCCACGACTCCTGAAGACACACCTGCCCCTGGCTCTGCTCCCCCAGACTCTGTT GGATCAGAAGGTCAAGACCCCACCAACAACTGAACGCTTTGGTCAGGCTGCTACAATGGAAGGAATTGGGGCAATTGGTGGAACTCCTCC TGCATTCAACCGTGCAGCTCCTGGAGCTGAATTTGCCCCAAACAAACGTCGCCGATACTAATAAGTTGCAGTGTCTAGTTTCTCAAAACC CTTAAAAGAAGGACCCTTTTTGGACTAGCCAGAATTCTACCCTGGAAAAGTGTTAGGGATTCCTTCCAATAGTTAGATCTACCCTGCCTG >88052_88052_3_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000395607_NONO_chrX_70519789_ENST00000373856_length(amino acids)=168AA_BP=123 MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLISTYPKSGTTWVSQILDMIYQGGDLEKCHRAPIFMRVPFLEFKAPGIP -------------------------------------------------------------- >88052_88052_4_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000395607_NONO_chrX_70519789_ENST00000535149_length(transcript)=1871nt_BP=646nt TTTCCACATGTGAGGGGCTGAGGGGCTCAAGGAGGGGAGCATCTCCACTGGGTGGAGGCTGGGGGTCCCAGCAGGAAGTGGTGAGACAAA GGGCGCTGGCTGGCAGGGAGACAGCACAGGAAGGTCCTAGAGCTTCCTCAGTGCAGCTGGACTCTCCTGGAGACCTTCACACACCCTGAC ATCTGGGCCTTGCCCGACGAGGGTGCTTTCACTGGTCTGCACCATGGCCCAGGCCCTGGGATTTTGAACAGCTCCGCAGGTGAATGAAAG GAACATGGAGCTGATCCAGGACACCTCCCGCCCGCCACTGGAGTACGTGAAGGGGGTCCCGCTCATCAAGTACTTTGCAGAGGCACTGGG GCCCCTGCAGAGCTTCCAGGCCCGGCCTGATGACCTGCTCATCAGCACCTACCCCAAGTCCGGCACTACCTGGGTAAGCCAGATTCTGGA CATGATCTACCAGGGTGGTGACCTGGAGAAGTGTCACCGAGCTCCCATCTTCATGCGGGTGCCCTTCCTTGAGTTCAAAGCCCCAGGGAT TCCCTCAGGGATGGAGACTCTGAAAGACACACCGGCCCCACGACTCCTGAAGACACACCTGCCCCTGGCTCTGCTCCCCCAGACTCTGTT GGATCAGAAGGTCAAGACCCCACCAACAACTGAACGCTTTGGTCAGGCTGCTACAATGGAAGGAATTGGGGCAATTGGTGGAACTCCTCC TGCATTCAACCGTGCAGCTCCTGGAGCTGAATTTGCCCCAAACAAACGTCGCCGATACTAATAAGTTGCAGTGTCTAGTTTCTCAAAACC CTTAAAAGAAGGACCCTTTTTGGACTAGCCAGAATTCTACCCTGGAAAAGTGTTAGGGATTCCTTCCAATAGTTAGATCTACCCTGCCTG TACTACTCTAGGGAGTATGCTGGAGGCAGAGGGCAAGGGAGGGGTGGTATTAAACAAGTCAATTCTGTGTGGTATATTGTTTAATCAGTT CTGTGTGGTGCATTCCTGAAGTCTCTAATGTGACTGTTGAGGGCCTGGGGAAACCATGGCAAAGTGGATCCAGTTAGAGCCCATTAATCT TGATCATTCCGGTTTTTTTTTTTTTTGTCCATCTTGTTTCATTTGCTTGCCCCGCCCCCGAGACGGAGTCTTACTCTGTCGCCCAGGCTG GAGTGTAGTGGCATGATCTCGGCTCACTGCAATCTCTGCCTCCCGGGTTCAAGCTTGTCCAGGTTGATCTTGAACTCCTGACCTCGTGAT CTACCCACCTCGGCCTCCCAAAATGCTGGGATTACAGGGGTGAGCCACCGTGCCCAACCTCACTTGCTTCTTATCCTTACACTCCCCCAG CCCCAGAGAAACTGCCACATACACCACAAAAACCAAACATCCCCCAATGACCTTAGCCCCATTGCTCCATTCACTCCCAGGTGAGAATTC AGGCAAACGTCCACAAAGGTCACAGGCAGCGTACATACGGTTCTGTTATACCCCATATATTACCCCTTCATGTCCTAAAGAAGACATTTT CTCTTAGAGATTTTCATTTTAGTGTATCTTTAAAAAAAAATCTTGTGTTAACTTGCCTCCATCTTTTTCTTGGGTGAGGACACCCAGGAA TGACCCTTTTGTGTCTATGATGTTGCTGTTCACAGCTTTTCTTGATAGGCCTAGTACAATCTTGGGAACAGGGTTACTGTATACTGAAGG TCTGACAGTAGCTCTTAGACTCGCCTATCTTAGGTAGTCATGCTGTGCATTTTTTTTTTCATTGGTGTACTGTGTTTGATTTGTCTCATA >88052_88052_4_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000395607_NONO_chrX_70519789_ENST00000535149_length(amino acids)=168AA_BP=123 MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLISTYPKSGTTWVSQILDMIYQGGDLEKCHRAPIFMRVPFLEFKAPGIP -------------------------------------------------------------- >88052_88052_5_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000395609_NONO_chrX_70519789_ENST00000373856_length(transcript)=1459nt_BP=1131nt CGAGGCCCGGAGGCGGTGCAGGAAGCCTCCGACCACGCGGGCTCCTGATCGCGGGCGCCCACAGCGCGGACATGGCGGGCTGGTGGCCGG CGTTGTCGCGCACGGCCCGGCGCCACCCGTGGCCCACCAACGTGCTGCTCTACGTTGCTCGAGCAACGTAGCTCTACGCTCTACGAGCGT GCCGTAGCTCGCTCGTCTCCGCCGGGGACGTGCTGCAGCAACGGCTGCAGGGCCGCTAGGCCGACTGGCGCCAGACGCGGCGCGTGGCCA CGTTGGTGGTGACCTTCCACGCCAACTTCAACTACGTGTGGCTGGGCCTGCTGGAGCGCGCGCTCCCGGGCCGAGCGCCGCGCGCCATGC TGGCCAAGTTGCTGTGCGACCAGGTGGTCGGTGCGCCCATCGCGGTCTCGGCCTTCTACGCCGGTATGAGCATTCTCCAGGGAAAGGATG ACATATTTTTGGACCTGAAACAGAAATTCTGGAACACCTATATGCAAACTCAGTCGTGGCTTTGGAGATCACTTTAAGCTTGTCTCCAGC TGGCACACTAAGGAGGGTAATGGAGAAGCTCCCCCACCCCCAACCCCACCCCTTCCTTCCGGAAGCAAATCTAAGTCCAGCCCCGGCTCC AGATCCCTCCCACAGTGGACCTAGGAAACCCTCAGCTCAGAGAACAACCCTGCATTCCCCACACAACACCCACAATCAGCCACTGCGGGC GAGGAGGGCACGAGGCCAGGTTCCCAAGAGCTCAGGAACATGGAGCTGATCCAGGACACCTCCCGCCCGCCACTGGAGTACGTGAAGGGG GTCCCGCTCATCAAGTACTTTGCAGAGGCACTGGGGCCCCTGCAGAGCTTCCAGGCCCGGCCTGATGACCTGCTCATCAGCACCTACCCC AAGTCCGGCACTACCTGGGTAAGCCAGATTCTGGACATGATCTACCAGGGTGGTGACCTGGAGAAGTGTCACCGAGCTCCCATCTTCATG CGGGTGCCCTTCCTTGAGTTCAAAGCCCCAGGGATTCCCTCAGGGATGGAGACTCTGAAAGACACACCGGCCCCACGACTCCTGAAGACA CACCTGCCCCTGGCTCTGCTCCCCCAGACTCTGTTGGATCAGAAGGTCAAGACCCCACCAACAACTGAACGCTTTGGTCAGGCTGCTACA ATGGAAGGAATTGGGGCAATTGGTGGAACTCCTCCTGCATTCAACCGTGCAGCTCCTGGAGCTGAATTTGCCCCAAACAAACGTCGCCGA TACTAATAAGTTGCAGTGTCTAGTTTCTCAAAACCCTTAAAAGAAGGACCCTTTTTGGACTAGCCAGAATTCTACCCTGGAAAAGTGTTA GGGATTCCTTCCAATAGTTAGATCTACCCTGCCTGTACTACTCTAGGGAGTATGCTGGAGGCAGAGGGCAAGGGAGGGGTGGTATTAAAC >88052_88052_5_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000395609_NONO_chrX_70519789_ENST00000373856_length(amino acids)=168AA_BP=123 MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLISTYPKSGTTWVSQILDMIYQGGDLEKCHRAPIFMRVPFLEFKAPGIP -------------------------------------------------------------- >88052_88052_6_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000395609_NONO_chrX_70519789_ENST00000535149_length(transcript)=2356nt_BP=1131nt CGAGGCCCGGAGGCGGTGCAGGAAGCCTCCGACCACGCGGGCTCCTGATCGCGGGCGCCCACAGCGCGGACATGGCGGGCTGGTGGCCGG CGTTGTCGCGCACGGCCCGGCGCCACCCGTGGCCCACCAACGTGCTGCTCTACGTTGCTCGAGCAACGTAGCTCTACGCTCTACGAGCGT GCCGTAGCTCGCTCGTCTCCGCCGGGGACGTGCTGCAGCAACGGCTGCAGGGCCGCTAGGCCGACTGGCGCCAGACGCGGCGCGTGGCCA CGTTGGTGGTGACCTTCCACGCCAACTTCAACTACGTGTGGCTGGGCCTGCTGGAGCGCGCGCTCCCGGGCCGAGCGCCGCGCGCCATGC TGGCCAAGTTGCTGTGCGACCAGGTGGTCGGTGCGCCCATCGCGGTCTCGGCCTTCTACGCCGGTATGAGCATTCTCCAGGGAAAGGATG ACATATTTTTGGACCTGAAACAGAAATTCTGGAACACCTATATGCAAACTCAGTCGTGGCTTTGGAGATCACTTTAAGCTTGTCTCCAGC TGGCACACTAAGGAGGGTAATGGAGAAGCTCCCCCACCCCCAACCCCACCCCTTCCTTCCGGAAGCAAATCTAAGTCCAGCCCCGGCTCC AGATCCCTCCCACAGTGGACCTAGGAAACCCTCAGCTCAGAGAACAACCCTGCATTCCCCACACAACACCCACAATCAGCCACTGCGGGC GAGGAGGGCACGAGGCCAGGTTCCCAAGAGCTCAGGAACATGGAGCTGATCCAGGACACCTCCCGCCCGCCACTGGAGTACGTGAAGGGG GTCCCGCTCATCAAGTACTTTGCAGAGGCACTGGGGCCCCTGCAGAGCTTCCAGGCCCGGCCTGATGACCTGCTCATCAGCACCTACCCC AAGTCCGGCACTACCTGGGTAAGCCAGATTCTGGACATGATCTACCAGGGTGGTGACCTGGAGAAGTGTCACCGAGCTCCCATCTTCATG CGGGTGCCCTTCCTTGAGTTCAAAGCCCCAGGGATTCCCTCAGGGATGGAGACTCTGAAAGACACACCGGCCCCACGACTCCTGAAGACA CACCTGCCCCTGGCTCTGCTCCCCCAGACTCTGTTGGATCAGAAGGTCAAGACCCCACCAACAACTGAACGCTTTGGTCAGGCTGCTACA ATGGAAGGAATTGGGGCAATTGGTGGAACTCCTCCTGCATTCAACCGTGCAGCTCCTGGAGCTGAATTTGCCCCAAACAAACGTCGCCGA TACTAATAAGTTGCAGTGTCTAGTTTCTCAAAACCCTTAAAAGAAGGACCCTTTTTGGACTAGCCAGAATTCTACCCTGGAAAAGTGTTA GGGATTCCTTCCAATAGTTAGATCTACCCTGCCTGTACTACTCTAGGGAGTATGCTGGAGGCAGAGGGCAAGGGAGGGGTGGTATTAAAC AAGTCAATTCTGTGTGGTATATTGTTTAATCAGTTCTGTGTGGTGCATTCCTGAAGTCTCTAATGTGACTGTTGAGGGCCTGGGGAAACC ATGGCAAAGTGGATCCAGTTAGAGCCCATTAATCTTGATCATTCCGGTTTTTTTTTTTTTTGTCCATCTTGTTTCATTTGCTTGCCCCGC CCCCGAGACGGAGTCTTACTCTGTCGCCCAGGCTGGAGTGTAGTGGCATGATCTCGGCTCACTGCAATCTCTGCCTCCCGGGTTCAAGCT TGTCCAGGTTGATCTTGAACTCCTGACCTCGTGATCTACCCACCTCGGCCTCCCAAAATGCTGGGATTACAGGGGTGAGCCACCGTGCCC AACCTCACTTGCTTCTTATCCTTACACTCCCCCAGCCCCAGAGAAACTGCCACATACACCACAAAAACCAAACATCCCCCAATGACCTTA GCCCCATTGCTCCATTCACTCCCAGGTGAGAATTCAGGCAAACGTCCACAAAGGTCACAGGCAGCGTACATACGGTTCTGTTATACCCCA TATATTACCCCTTCATGTCCTAAAGAAGACATTTTCTCTTAGAGATTTTCATTTTAGTGTATCTTTAAAAAAAAATCTTGTGTTAACTTG CCTCCATCTTTTTCTTGGGTGAGGACACCCAGGAATGACCCTTTTGTGTCTATGATGTTGCTGTTCACAGCTTTTCTTGATAGGCCTAGT ACAATCTTGGGAACAGGGTTACTGTATACTGAAGGTCTGACAGTAGCTCTTAGACTCGCCTATCTTAGGTAGTCATGCTGTGCATTTTTT TTTTCATTGGTGTACTGTGTTTGATTTGTCTCATATATTTGGAGTTTTTCTGAAAAATGGAGCAGTAATGCAGCATCAACCTATTAAAAT >88052_88052_6_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000395609_NONO_chrX_70519789_ENST00000535149_length(amino acids)=168AA_BP=123 MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLISTYPKSGTTWVSQILDMIYQGGDLEKCHRAPIFMRVPFLEFKAPGIP -------------------------------------------------------------- >88052_88052_7_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000569554_NONO_chrX_70519789_ENST00000276079_length(transcript)=1664nt_BP=437nt CCACTTTCTTGCTGTTGTGATGGTGGTAAGGGAACGGGCCTGGCTCTGGCCCCTGACGCAGGAACATGGAGCTGATCCAGGACACCTCCC GCCCGCCACTGGAGTACGTGAAGGGGGTCCCGCTCATCAAGTACTTTGCAGAGGCACTGGGGCCCCTGCAGAGCTTCCAGGCCCGGCCTG ATGACCTGCTCATCAGCACCTACCCCAAGTCCGGCACTACCTGGGTAAGCCAGATTCTGGACATGATCTACCAGGGTGGTGACCTGGAGA AGTGTCACCGAGCTCCCATCTTCATGCGGGTGCCCTTCCTTGAGTTCAAAGCCCCAGGGATTCCCTCAGGGATGGAGACTCTGAAAGACA CACCGGCCCCACGACTCCTGAAGACACACCTGCCCCTGGCTCTGCTCCCCCAGACTCTGTTGGATCAGAAGGTCAAGACCCCACCAACAA CTGAACGCTTTGGTCAGGCTGCTACAATGGAAGGAATTGGGGCAATTGGTGGAACTCCTCCTGCATTCAACCGTGCAGCTCCTGGAGCTG AATTTGCCCCAAACAAACGTCGCCGATACTAATAAGTTGCAGTGTCTAGTTTCTCAAAACCCTTAAAAGAAGGACCCTTTTTGGACTAGC CAGAATTCTACCCTGGAAAAGTGTTAGGGATTCCTTCCAATAGTTAGATCTACCCTGCCTGTACTACTCTAGGGAGTATGCTGGAGGCAG AGGGCAAGGGAGGGGTGGTATTAAACAAGTCAATTCTGTGTGGTATATTGTTTAATCAGTTCTGTGTGGTGCATTCCTGAAGTCTCTAAT GTGACTGTTGAGGGCCTGGGGAAACCATGGCAAAGTGGATCCAGTTAGAGCCCATTAATCTTGATCATTCCGGTTTTTTTTTTTTTTGTC CATCTTGTTTCATTTGCTTGCCCCGCCCCCGAGACGGAGTCTTACTCTGTCGCCCAGGCTGGAGTGTAGTGGCATGATCTCGGCTCACTG CAATCTCTGCCTCCCGGGTTCAAGCTTGTCCAGGTTGATCTTGAACTCCTGACCTCGTGATCTACCCACCTCGGCCTCCCAAAATGCTGG GATTACAGGGGTGAGCCACCGTGCCCAACCTCACTTGCTTCTTATCCTTACACTCCCCCAGCCCCAGAGAAACTGCCACATACACCACAA AAACCAAACATCCCCCAATGACCTTAGCCCCATTGCTCCATTCACTCCCAGGTGAGAATTCAGGCAAACGTCCACAAAGGTCACAGGCAG CGTACATACGGTTCTGTTATACCCCATATATTACCCCTTCATGTCCTAAAGAAGACATTTTCTCTTAGAGATTTTCATTTTAGTGTATCT TTAAAAAAAAATCTTGTGTTAACTTGCCTCCATCTTTTTCTTGGGTGAGGACACCCAGGAATGACCCTTTTGTGTCTATGATGTTGCTGT TCACAGCTTTTCTTGATAGGCCTAGTACAATCTTGGGAACAGGGTTACTGTATACTGAAGGTCTGACAGTAGCTCTTAGACTCGCCTATC TTAGGTAGTCATGCTGTGCATTTTTTTTTTCATTGGTGTACTGTGTTTGATTTGTCTCATATATTTGGAGTTTTTCTGAAAAATGGAGCA >88052_88052_7_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000569554_NONO_chrX_70519789_ENST00000276079_length(amino acids)=168AA_BP=123 MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLISTYPKSGTTWVSQILDMIYQGGDLEKCHRAPIFMRVPFLEFKAPGIP -------------------------------------------------------------- >88052_88052_8_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000569554_NONO_chrX_70519789_ENST00000373841_length(transcript)=1664nt_BP=437nt CCACTTTCTTGCTGTTGTGATGGTGGTAAGGGAACGGGCCTGGCTCTGGCCCCTGACGCAGGAACATGGAGCTGATCCAGGACACCTCCC GCCCGCCACTGGAGTACGTGAAGGGGGTCCCGCTCATCAAGTACTTTGCAGAGGCACTGGGGCCCCTGCAGAGCTTCCAGGCCCGGCCTG ATGACCTGCTCATCAGCACCTACCCCAAGTCCGGCACTACCTGGGTAAGCCAGATTCTGGACATGATCTACCAGGGTGGTGACCTGGAGA AGTGTCACCGAGCTCCCATCTTCATGCGGGTGCCCTTCCTTGAGTTCAAAGCCCCAGGGATTCCCTCAGGGATGGAGACTCTGAAAGACA CACCGGCCCCACGACTCCTGAAGACACACCTGCCCCTGGCTCTGCTCCCCCAGACTCTGTTGGATCAGAAGGTCAAGACCCCACCAACAA CTGAACGCTTTGGTCAGGCTGCTACAATGGAAGGAATTGGGGCAATTGGTGGAACTCCTCCTGCATTCAACCGTGCAGCTCCTGGAGCTG AATTTGCCCCAAACAAACGTCGCCGATACTAATAAGTTGCAGTGTCTAGTTTCTCAAAACCCTTAAAAGAAGGACCCTTTTTGGACTAGC CAGAATTCTACCCTGGAAAAGTGTTAGGGATTCCTTCCAATAGTTAGATCTACCCTGCCTGTACTACTCTAGGGAGTATGCTGGAGGCAG AGGGCAAGGGAGGGGTGGTATTAAACAAGTCAATTCTGTGTGGTATATTGTTTAATCAGTTCTGTGTGGTGCATTCCTGAAGTCTCTAAT GTGACTGTTGAGGGCCTGGGGAAACCATGGCAAAGTGGATCCAGTTAGAGCCCATTAATCTTGATCATTCCGGTTTTTTTTTTTTTTGTC CATCTTGTTTCATTTGCTTGCCCCGCCCCCGAGACGGAGTCTTACTCTGTCGCCCAGGCTGGAGTGTAGTGGCATGATCTCGGCTCACTG CAATCTCTGCCTCCCGGGTTCAAGCTTGTCCAGGTTGATCTTGAACTCCTGACCTCGTGATCTACCCACCTCGGCCTCCCAAAATGCTGG GATTACAGGGGTGAGCCACCGTGCCCAACCTCACTTGCTTCTTATCCTTACACTCCCCCAGCCCCAGAGAAACTGCCACATACACCACAA AAACCAAACATCCCCCAATGACCTTAGCCCCATTGCTCCATTCACTCCCAGGTGAGAATTCAGGCAAACGTCCACAAAGGTCACAGGCAG CGTACATACGGTTCTGTTATACCCCATATATTACCCCTTCATGTCCTAAAGAAGACATTTTCTCTTAGAGATTTTCATTTTAGTGTATCT TTAAAAAAAAATCTTGTGTTAACTTGCCTCCATCTTTTTCTTGGGTGAGGACACCCAGGAATGACCCTTTTGTGTCTATGATGTTGCTGT TCACAGCTTTTCTTGATAGGCCTAGTACAATCTTGGGAACAGGGTTACTGTATACTGAAGGTCTGACAGTAGCTCTTAGACTCGCCTATC TTAGGTAGTCATGCTGTGCATTTTTTTTTTCATTGGTGTACTGTGTTTGATTTGTCTCATATATTTGGAGTTTTTCTGAAAAATGGAGCA >88052_88052_8_SULT1A1-NONO_SULT1A1_chr16_28619612_ENST00000569554_NONO_chrX_70519789_ENST00000373841_length(amino acids)=168AA_BP=123 MELIQDTSRPPLEYVKGVPLIKYFAEALGPLQSFQARPDDLLISTYPKSGTTWVSQILDMIYQGGDLEKCHRAPIFMRVPFLEFKAPGIP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SULT1A1-NONO |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SULT1A1-NONO |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SULT1A1-NONO |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | SULT1A1 | C0004403 | Autosome Abnormalities | 1 | CTD_human |
| Hgene | SULT1A1 | C0006142 | Malignant neoplasm of breast | 1 | CTD_human |
| Hgene | SULT1A1 | C0007102 | Malignant tumor of colon | 1 | CTD_human |
| Hgene | SULT1A1 | C0008625 | Chromosome Aberrations | 1 | CTD_human |
| Hgene | SULT1A1 | C0009375 | Colonic Neoplasms | 1 | CTD_human |
| Hgene | SULT1A1 | C0033578 | Prostatic Neoplasms | 1 | CTD_human |
| Hgene | SULT1A1 | C0042076 | Urologic Neoplasms | 1 | CTD_human |
| Hgene | SULT1A1 | C0086132 | Depressive Symptoms | 1 | PSYGENET |
| Hgene | SULT1A1 | C0151744 | Myocardial Ischemia | 1 | CTD_human |
| Hgene | SULT1A1 | C0376358 | Malignant neoplasm of prostate | 1 | CTD_human |
| Hgene | SULT1A1 | C0678222 | Breast Carcinoma | 1 | CTD_human |
| Hgene | SULT1A1 | C0751571 | Cancer of Urinary Tract | 1 | CTD_human |
| Hgene | SULT1A1 | C0919532 | Genomic Instability | 1 | CTD_human |
| Hgene | SULT1A1 | C1257931 | Mammary Neoplasms, Human | 1 | CTD_human |
| Hgene | SULT1A1 | C1458155 | Mammary Neoplasms | 1 | CTD_human |
| Hgene | SULT1A1 | C4704874 | Mammary Carcinoma, Human | 1 | CTD_human |
| Tgene | C4225417 | MENTAL RETARDATION, X-LINKED, SYNDROMIC 34 | 2 | CTD_human;GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C4518356 | MiT family translocation renal cell carcinoma | 2 | ORPHANET | |
| Tgene | C0027708 | Nephroblastoma | 1 | CTD_human | |
| Tgene | C0271650 | Impaired glucose tolerance | 1 | CTD_human | |
| Tgene | C2677504 | AUTISM, SUSCEPTIBILITY TO, 15 | 1 | GENOMICS_ENGLAND | |
| Tgene | C2930471 | Bilateral Wilms Tumor | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies