
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:PLCD4-VIL1 (FusionGDB2 ID:HG84812TG7429) |
Fusion Gene Summary for PLCD4-VIL1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: PLCD4-VIL1 | Fusion gene ID: hg84812tg7429 | Hgene | Tgene | Gene symbol | PLCD4 | VIL1 | Gene ID | 84812 | 7429 |
| Gene name | phospholipase C delta 4 | villin 1 | |
| Synonyms | - | D2S1471|VIL | |
| Cytomap | ('PLCD4')('VIL1') 2q35 | 2q35 | |
| Type of gene | protein-coding | protein-coding | |
| Description | 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase delta-4PLC delta4phosphoinositide phospholipase C-delta-4 | villin-1 | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000417849, ENST00000432688, ENST00000450993, | ||
| Fusion gene scores | * DoF score | 3 X 3 X 2=18 | 3 X 4 X 3=36 |
| # samples | 4 | 4 | |
| ** MAII score | log2(4/18*10)=1.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(4/36*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: PLCD4 [Title/Abstract] AND VIL1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | PLCD4(219487601)-VIL1(219313946), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | PLCD4-VIL1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. PLCD4-VIL1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. PLCD4-VIL1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. PLCD4-VIL1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | VIL1 | GO:0007173 | epidermal growth factor receptor signaling pathway | 17229814 |
| Tgene | VIL1 | GO:0008360 | regulation of cell shape | 16921170 |
| Tgene | VIL1 | GO:0009617 | response to bacterium | 17182858 |
| Tgene | VIL1 | GO:0010634 | positive regulation of epithelial cell migration | 17229814 |
| Tgene | VIL1 | GO:0030041 | actin filament polymerization | 11500485 |
| Tgene | VIL1 | GO:0030042 | actin filament depolymerization | 11500485 |
| Tgene | VIL1 | GO:0030335 | positive regulation of cell migration | 16921170 |
| Tgene | VIL1 | GO:0032233 | positive regulation of actin filament bundle assembly | 19808673 |
| Tgene | VIL1 | GO:0051014 | actin filament severing | 16921170|17182858|19808673 |
| Tgene | VIL1 | GO:0051125 | regulation of actin nucleation | 16921170|17182858|19808673 |
| Tgene | VIL1 | GO:0051693 | actin filament capping | 16921170|17182858|19808673 |
| Tgene | VIL1 | GO:0060327 | cytoplasmic actin-based contraction involved in cell motility | 15342783 |
| Tgene | VIL1 | GO:0071364 | cellular response to epidermal growth factor stimulus | 17229814 |
| Fusion gene breakpoints across PLCD4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across VIL1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-E2-A1LE-01A | PLCD4 | chr2 | 219487601 | - | VIL1 | chr2 | 219313946 | + |
| ChimerDB4 | BRCA | TCGA-E2-A1LE-01A | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| ChimerDB4 | BRCA | TCGA-E2-A1LE | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
Top |
Fusion Gene ORF analysis for PLCD4-VIL1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000417849 | ENST00000440053 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| 5CDS-intron | ENST00000417849 | ENST00000440053 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
| 5CDS-intron | ENST00000432688 | ENST00000440053 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| 5CDS-intron | ENST00000432688 | ENST00000440053 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
| 5CDS-intron | ENST00000450993 | ENST00000440053 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| 5CDS-intron | ENST00000450993 | ENST00000440053 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
| In-frame | ENST00000417849 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| In-frame | ENST00000417849 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
| In-frame | ENST00000417849 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| In-frame | ENST00000417849 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
| In-frame | ENST00000432688 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| In-frame | ENST00000432688 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
| In-frame | ENST00000432688 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| In-frame | ENST00000432688 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
| In-frame | ENST00000450993 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| In-frame | ENST00000450993 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
| In-frame | ENST00000450993 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + |
| In-frame | ENST00000450993 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000450993 | PLCD4 | chr2 | 219487601 | + | ENST00000248444 | VIL1 | chr2 | 219313946 | + | 5184 | 1111 | 297 | 1127 | 276 |
| ENST00000450993 | PLCD4 | chr2 | 219487601 | + | ENST00000392114 | VIL1 | chr2 | 219313946 | + | 1413 | 1111 | 297 | 1127 | 276 |
| ENST00000417849 | PLCD4 | chr2 | 219487601 | + | ENST00000248444 | VIL1 | chr2 | 219313946 | + | 5030 | 957 | 143 | 973 | 276 |
| ENST00000417849 | PLCD4 | chr2 | 219487601 | + | ENST00000392114 | VIL1 | chr2 | 219313946 | + | 1259 | 957 | 143 | 973 | 276 |
| ENST00000432688 | PLCD4 | chr2 | 219487601 | + | ENST00000248444 | VIL1 | chr2 | 219313946 | + | 5087 | 1014 | 224 | 1030 | 268 |
| ENST00000432688 | PLCD4 | chr2 | 219487601 | + | ENST00000392114 | VIL1 | chr2 | 219313946 | + | 1316 | 1014 | 224 | 1030 | 268 |
| ENST00000450993 | PLCD4 | chr2 | 219487601 | + | ENST00000248444 | VIL1 | chr2 | 219313945 | + | 5184 | 1111 | 297 | 1127 | 276 |
| ENST00000450993 | PLCD4 | chr2 | 219487601 | + | ENST00000392114 | VIL1 | chr2 | 219313945 | + | 1413 | 1111 | 297 | 1127 | 276 |
| ENST00000417849 | PLCD4 | chr2 | 219487601 | + | ENST00000248444 | VIL1 | chr2 | 219313945 | + | 5030 | 957 | 143 | 973 | 276 |
| ENST00000417849 | PLCD4 | chr2 | 219487601 | + | ENST00000392114 | VIL1 | chr2 | 219313945 | + | 1259 | 957 | 143 | 973 | 276 |
| ENST00000432688 | PLCD4 | chr2 | 219487601 | + | ENST00000248444 | VIL1 | chr2 | 219313945 | + | 5087 | 1014 | 224 | 1030 | 268 |
| ENST00000432688 | PLCD4 | chr2 | 219487601 | + | ENST00000392114 | VIL1 | chr2 | 219313945 | + | 1316 | 1014 | 224 | 1030 | 268 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000450993 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + | 0.001162334 | 0.99883765 |
| ENST00000450993 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + | 0.007621899 | 0.9923781 |
| ENST00000417849 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + | 0.001097618 | 0.9989023 |
| ENST00000417849 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + | 0.004325056 | 0.9956749 |
| ENST00000432688 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + | 0.001211687 | 0.9987883 |
| ENST00000432688 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313946 | + | 0.00500604 | 0.994994 |
| ENST00000450993 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 0.001162334 | 0.99883765 |
| ENST00000450993 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 0.007621899 | 0.9923781 |
| ENST00000417849 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 0.001097618 | 0.9989023 |
| ENST00000417849 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 0.004325056 | 0.9956749 |
| ENST00000432688 | ENST00000248444 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 0.001211687 | 0.9987883 |
| ENST00000432688 | ENST00000392114 | PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 0.00500604 | 0.994994 |
Top |
Fusion Genomic Features for PLCD4-VIL1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 8.14E-10 | 1 |
| PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 8.14E-10 | 1 |
| PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 8.14E-10 | 1 |
| PLCD4 | chr2 | 219487601 | + | VIL1 | chr2 | 219313945 | + | 8.14E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
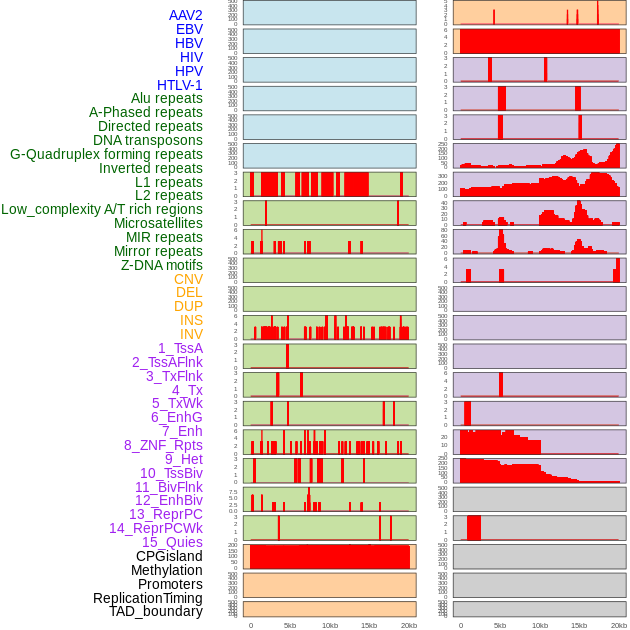 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
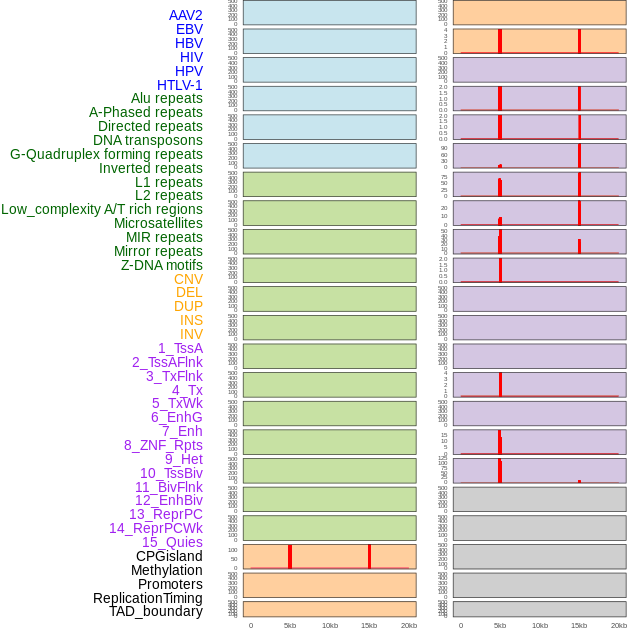 |
Top |
Fusion Protein Features for PLCD4-VIL1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:219487601/chr2:219313946) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 147_158 | 257 | 800.0 | Calcium binding | 1 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 183_194 | 257 | 800.0 | Calcium binding | 2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 147_158 | 257 | 763.0 | Calcium binding | 1 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 183_194 | 257 | 763.0 | Calcium binding | 2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 147_158 | 257 | 800.0 | Calcium binding | 1 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 183_194 | 257 | 800.0 | Calcium binding | 2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 147_158 | 257 | 763.0 | Calcium binding | 1 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 183_194 | 257 | 763.0 | Calcium binding | 2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 134_169 | 257 | 800.0 | Domain | EF-hand 1 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 16_124 | 257 | 800.0 | Domain | PH |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 170_205 | 257 | 800.0 | Domain | EF-hand 2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 203_237 | 257 | 800.0 | Domain | EF-hand 3 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 134_169 | 257 | 763.0 | Domain | EF-hand 1 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 16_124 | 257 | 763.0 | Domain | PH |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 170_205 | 257 | 763.0 | Domain | EF-hand 2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 203_237 | 257 | 763.0 | Domain | EF-hand 3 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 134_169 | 257 | 800.0 | Domain | EF-hand 1 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 16_124 | 257 | 800.0 | Domain | PH |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 170_205 | 257 | 800.0 | Domain | EF-hand 2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 203_237 | 257 | 800.0 | Domain | EF-hand 3 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 134_169 | 257 | 763.0 | Domain | EF-hand 1 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 16_124 | 257 | 763.0 | Domain | PH |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 170_205 | 257 | 763.0 | Domain | EF-hand 2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 203_237 | 257 | 763.0 | Domain | EF-hand 3 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 213_243 | 257 | 800.0 | Motif | GBA |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 213_243 | 257 | 763.0 | Motif | GBA |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 213_243 | 257 | 800.0 | Motif | GBA |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 213_243 | 257 | 763.0 | Motif | GBA |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 26_53 | 257 | 800.0 | Region | Substrate binding |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 26_53 | 257 | 763.0 | Region | Substrate binding |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 26_53 | 257 | 800.0 | Region | Substrate binding |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 26_53 | 257 | 763.0 | Region | Substrate binding |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 816_824 | 790 | 828.0 | Region | Note=LPA/PIP2-binding site 3 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 816_824 | 790 | 828.0 | Region | Note=LPA/PIP2-binding site 3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 440_473 | 257 | 800.0 | Compositional bias | Note=Glu-rich |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 479_486 | 257 | 800.0 | Compositional bias | Note=Poly-Lys |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 440_473 | 257 | 763.0 | Compositional bias | Note=Glu-rich |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 479_486 | 257 | 763.0 | Compositional bias | Note=Poly-Lys |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 440_473 | 257 | 800.0 | Compositional bias | Note=Glu-rich |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 479_486 | 257 | 800.0 | Compositional bias | Note=Poly-Lys |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 440_473 | 257 | 763.0 | Compositional bias | Note=Glu-rich |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 479_486 | 257 | 763.0 | Compositional bias | Note=Poly-Lys |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 290_435 | 257 | 800.0 | Domain | PI-PLC X-box |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 493_609 | 257 | 800.0 | Domain | PI-PLC Y-box |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 609_736 | 257 | 800.0 | Domain | C2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 290_435 | 257 | 763.0 | Domain | PI-PLC X-box |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 493_609 | 257 | 763.0 | Domain | PI-PLC Y-box |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 609_736 | 257 | 763.0 | Domain | C2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 290_435 | 257 | 800.0 | Domain | PI-PLC X-box |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 493_609 | 257 | 800.0 | Domain | PI-PLC Y-box |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 609_736 | 257 | 800.0 | Domain | C2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 290_435 | 257 | 763.0 | Domain | PI-PLC X-box |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 493_609 | 257 | 763.0 | Domain | PI-PLC Y-box |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 609_736 | 257 | 763.0 | Domain | C2 |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000417849 | + | 6 | 17 | 731_734 | 257 | 800.0 | Motif | Note=PDZ-binding |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313945 | ENST00000450993 | + | 6 | 16 | 731_734 | 257 | 763.0 | Motif | Note=PDZ-binding |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000417849 | + | 6 | 17 | 731_734 | 257 | 800.0 | Motif | Note=PDZ-binding |
| Hgene | PLCD4 | chr2:219487601 | chr2:219313946 | ENST00000450993 | + | 6 | 16 | 731_734 | 257 | 763.0 | Motif | Note=PDZ-binding |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 761_827 | 790 | 828.0 | Domain | HP | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 761_827 | 790 | 828.0 | Domain | HP | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 112_119 | 790 | 828.0 | Region | Note=LPA/PIP2-binding site 1 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 138_146 | 790 | 828.0 | Region | Note=LPA/PIP2-binding site 2 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 2_126 | 790 | 828.0 | Region | Note=Necessary for homodimerization | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 2_734 | 790 | 828.0 | Region | Note=Core | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 735_827 | 790 | 828.0 | Region | Note=Headpiece | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 112_119 | 790 | 828.0 | Region | Note=LPA/PIP2-binding site 1 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 138_146 | 790 | 828.0 | Region | Note=LPA/PIP2-binding site 2 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 2_126 | 790 | 828.0 | Region | Note=Necessary for homodimerization | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 2_734 | 790 | 828.0 | Region | Note=Core | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 735_827 | 790 | 828.0 | Region | Note=Headpiece | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 148_188 | 790 | 828.0 | Repeat | Note=Gelsolin-like 2 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 265_309 | 790 | 828.0 | Repeat | Note=Gelsolin-like 3 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 27_76 | 790 | 828.0 | Repeat | Note=Gelsolin-like 1 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 407_457 | 790 | 828.0 | Repeat | Note=Gelsolin-like 4 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 528_568 | 790 | 828.0 | Repeat | Note=Gelsolin-like 5 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313945 | ENST00000248444 | 18 | 20 | 631_672 | 790 | 828.0 | Repeat | Note=Gelsolin-like 6 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 148_188 | 790 | 828.0 | Repeat | Note=Gelsolin-like 2 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 265_309 | 790 | 828.0 | Repeat | Note=Gelsolin-like 3 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 27_76 | 790 | 828.0 | Repeat | Note=Gelsolin-like 1 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 407_457 | 790 | 828.0 | Repeat | Note=Gelsolin-like 4 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 528_568 | 790 | 828.0 | Repeat | Note=Gelsolin-like 5 | |
| Tgene | VIL1 | chr2:219487601 | chr2:219313946 | ENST00000248444 | 18 | 20 | 631_672 | 790 | 828.0 | Repeat | Note=Gelsolin-like 6 |
Top |
Fusion Gene Sequence for PLCD4-VIL1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >66008_66008_1_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000417849_VIL1_chr2_219313945_ENST00000248444_length(transcript)=5030nt_BP=957nt GTAGAAGAGGGGAGGAAACAAGCCAGTGCAAGGGGAGCAAAAGAGAAAAGGAGCCAGGCTGGGCTTCCTGATCCCACAGCATCGCAGAGC TCGGGAGGCACAGCTCACAGACACAGGAAACACAGGACTGCTATTCTGCTCTCCTGCCCACGGTGATCTGGTGCCAGCTGGTGGAACAGT GGGTGATGGCGTCCCTGCTGCAAGACCAGCTGACCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGT CCAAAAGCTGGAAGAAGCTAAGATACTTCAGACTTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGC CCAGCTTCTCAATCTCTGATGTGGAGACAATACGTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGC AGGGCTTCACCATTGTCTTCCATGGCCGCCGCTCCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGC TCCAGCTGTTGGTGGATCTTGTCACCAGCATGGACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAA ATCAGGATGGTAAGATGAGTTTCCAAGAAGTTCAGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTT TTCAGGCAGCAGACACGTCCCAGTCTGGAACCCTGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGC AGGAACTGTTTGAAAGTTTTTCAGCTGATGGGCAGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAG ACTGCACCTCTGAGCTTGCTCTGGAACTCATTGACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCC TTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAG CTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCA GATGTGCCTATGAGCACAAACTTCTGTGGCAAATGCCAGTTTTGTTTAATAATGTACCTATTCCTTCAGAAAGATGATACCCCAAAAGGA GCCTATGGTCCTCATTTCAACTTCTAAGGTCGCTAGATTGTTTCTATCCTGAGGTATTGCATCAATTTTAATACTCCTATAGTTTTCTCT TCTTAGAAGAGCACAAACACTCCATGGAACATTAGAGTTCTGAGGCACTACCCTAGCTTGTCCTCTATCATGACTCATTTTTATCTATGG CAGGTAGGCTGAAGCACTTTGCAGGTTTACATCTTCCCCAGAGTAACAGCTTTTCCTTTTCACATATACTTTCCTTACTGCCTTACTCAG TGGGTAAGTTAAAGGGCTGAAGGAGAGTTGAATGGTCCACAAGACTACCCTCTTAAGAGGTTTCACAAATTCCAAACAGTACCAGTGAGA GCAGCACTTCCACTGGGGCTAGGCTTGAGACCTAAAGGCAAGTATGAAATGCATATGCTACTTCACTCCCTCTCCCAACCCTTAATAATG AGGCAAAGCAAGAGCCTAGTGAAGGCCAATGCTAGGTTTACAAACTTACCCAGAAGCCTCTGCAAAGCTTCACAGGCTCCTCAGATGAAA ATAACAGGAATCAATGGGGACTACGGCCAGACACTGGTTTGCCATTCTGTTCCTTTTAAGAAGTAACAGTGCTGCAAGGAAGTCCATGTC AGAAAGCCAACAGAAGGTGATTTCCACAACTTTGAACAGGTTGTTACAAGTATCAGCAAGAATGTGTCCTTTTCAGAAATAACAGTCAAA TCAAAGAAGGTTAATAAAGGCTTTAATTTCATACACACAAAAAAACTCTATGCATAATTTAAAAAGGAAACAAAAACAAAGAAAAACCGT AAAGGATACAGAGGAACAGTTCTGCTAAAACACAGATAAAAGTGCCGCTCCATACAAAACATAAAGAATCAGAATCAAAAGTCACTCTGA ACATAAAGAAAAAAAATCATCTCACAAATAATGTGGCCACAGCTGCCAGAAAACCTGGTAGTGGCTCAATTAGGCAAAGTGTAGGAATCT CATTTTTGTTTTTCTCTCCTTAAGTTTAAAGAAACAACAATGACAATAGGCCAGAGAAGTTAGGGAGGGAAAGAAAAGCTCAAAGGGAGG GAAACCTGGGGACAAGAGGTGTGCACACCCACATGTGGTCTCACTCTTCACACAGGCCCACTATTTTTGAAGTAGACCAGTTTAGTTGAC TGTTCTTCTTTGTTCTGGCATCTGACTGGACCAACCTGGAACCTGGTCCAGACCCTCACCCACTCTATTCTTATGCCAATGGACATACCT ATACTTTGAACCTCTGTACTTTTAAGAAAAGTCCAATGTTACAAAATCAAATGCTTATATTCAGACTGGCACACTTTTTAAATAAAAACT CCATACACCTCAGACATATAGCACACATGGAGACAACTTACTAATTGTGTGTAAGTATGATACAATGAATGAGACTGCCTGAAGTCTAGT AATCAAAGCATGCCATAAGGTGAATGATTGTGGTTAAACACAGCAAAATAATTGTCACAAAACTTTCAAGGCCTAACAAATTAGAATTTT CCAATAAAAAATATATATTTTTTCAGATGTTAATAAGACATATCAGTAGAGACAAAATTAGGATTTTGAAGTAATGCAATAAAAAGATGT TGGAGGGCAGAAGTCTATTTAGTTTTTGTATACACTTGCAAGAGTGCATTACTCAGTATAAAGCAAAATGGGGAGGAAAAAGACATCCAT CCATTTTATTGGAACACTTTTATGTGACTTGAATCTGGTGTTAGGTTGTTGATTTTTCTAAAAATCTCCTATATATACAAAATCCATATG TACTTGGAGATCCAGCTGTTGCCCCCTGTTTAAAACAAAAGACCACCTCGGGGGGTCAATTAAATTAAAAAGGCCCTCCAACCACCCTAA ATGGGATAACTAAGAGTATCTACTGCAGTCATTTCAGAGGACAGAGAAGGAAAATATTTTAATTTGCTTTAATATAACCTCTTTTCAGTA GATCACAAATGAGTTTACAAACTACTTTTTTTTCTCTTTAATTTAGGTGTTTGCAGATAATTTTCATTATATCCGTAGCTGTATGTGTGT ATAGTTACATAATGGTAACTACACACGATACAGAAGAATCAGTAAATTCATGGATTATTTTGCTGAGGTTTTAAATTTTAAAGCCTCTGT TTCAGAATTTTATACTTGATCAAGGAGAAAAATAAATGTGTAGTCTAACATTTGCTTTCTGGAGTTAATTAACTGATCTGTAAGAACCAC TGCATATGTCTTAAAATGTAAACATATTTACATTTGTTGTATTTGTTATTGAGCCTTTAAGGTTAGGCCCAGAATGAACAGACCATAGCA AGTAAACAAATAATTTTTAGAATCAAAGTATTAATAGAAGACCAGTTCATGGATTTGCTTATTCTATCCTGCTGAGACAAAACTCATGAG TGTGCACACACATGTGAATATATCCCTACGAAACAGTCTATCTTCTCATAGGCTTAAATTATAGTCATGGCTATTAAAGAAATTAACAGC ATCCAGCCACATGCAACTTTCCAACCTTCAGTACTATTAGGTGATTAAAATCAACAAATATGAAGTTTAGTTCATTTTTCCCTTAAAATT CCAACAAAGATCAAAAGGTTGTATCTAGAACTAATTGCCATCAAGTTCCAATTCAATGTCATTTAAAGTAATGTAACCACACATTTGGTA TTTTCAATAGGAAGGTTAATTAGGTATTGTGCAAACTGCCTGCAACGGAAGCACTCAGTCCTTATCTAACTTGTCCCTTCCTGGCCCCAA CATGCTAACTGCCCCATCCCCAATTCTGGGCAAACTGATCACAATGTGCAAAAAATAATATATTATCTATTTATAATTTTAAAATATATA CAGCCAGCTCAAAAACAACAACAAACCCCATCAACATAGTCCAGCTGAAATCTCCACTGGTAGTCAAAGAAGTAGATTAAAGGAGTAAAG GAAGGAGAAGGCTGATAGGGCCACAAGAATGGACAGACATCAAGTAAAATTTGAGTCCCAAACATGCAAGTACATGAGCAGTGAGATAAC TTATATATTCCAATAACCTATTTTCAACAACTCCTGCCCAAGACATGAAGATCAAATCAGGTTTCTGAGGTAAGTGTACTTCTAAACCAT ACACACATGAAAGCTATGAAAGCAATTCAAATGAGGCTGCTTCATGAGGCAATCTAGACTTATGGCATTATTTCTACTTTTCTCCATGTT TTAATTGCAGCCTGCACTTTAAATCTTTCCCAATAATTTTTAACAGTGCCTCTCAAATGCAAAGACACGTAAAAGAATTAATAACTAGCC AAAGAATTTTATCACCGCTTCACTCATTTATAAGAAAACCAATTATTTCCAAGCAAAATCAAACCAAACCAAAGAGGCTCCTGGTAGAAA TGAAACAAAACTTTAAAGCTAGTTTTAAAACAAATATTTTCCTCTGCTCTAAACTACTCTGGCGTTTTCTACCACTCTACCATTTTGGAA CATTCATTACAATAAGGTATATAGGTAGATGGTAGGAGGCAAAGCATTTATCAGTAGTTGAGCAAAACTGCTGAGGCCATTTATAATTCA AAGAATGAAAACTTAGAATAGTTTACTACATTAGAATACATCCAAGTTCCAAGAGTAGGACTGGAGCTCTCTTAAGGCAATCTTTCAGAA >66008_66008_1_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000417849_VIL1_chr2_219313945_ENST00000248444_length(amino acids)=276AA_BP= MPTVIWCQLVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSE LLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLM NVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSD -------------------------------------------------------------- >66008_66008_2_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000417849_VIL1_chr2_219313945_ENST00000392114_length(transcript)=1259nt_BP=957nt GTAGAAGAGGGGAGGAAACAAGCCAGTGCAAGGGGAGCAAAAGAGAAAAGGAGCCAGGCTGGGCTTCCTGATCCCACAGCATCGCAGAGC TCGGGAGGCACAGCTCACAGACACAGGAAACACAGGACTGCTATTCTGCTCTCCTGCCCACGGTGATCTGGTGCCAGCTGGTGGAACAGT GGGTGATGGCGTCCCTGCTGCAAGACCAGCTGACCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGT CCAAAAGCTGGAAGAAGCTAAGATACTTCAGACTTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGC CCAGCTTCTCAATCTCTGATGTGGAGACAATACGTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGC AGGGCTTCACCATTGTCTTCCATGGCCGCCGCTCCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGC TCCAGCTGTTGGTGGATCTTGTCACCAGCATGGACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAA ATCAGGATGGTAAGATGAGTTTCCAAGAAGTTCAGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTT TTCAGGCAGCAGACACGTCCCAGTCTGGAACCCTGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGC AGGAACTGTTTGAAAGTTTTTCAGCTGATGGGCAGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAG ACTGCACCTCTGAGCTTGCTCTGGAACTCATTGACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCC TTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAG CTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCA >66008_66008_2_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000417849_VIL1_chr2_219313945_ENST00000392114_length(amino acids)=276AA_BP= MPTVIWCQLVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSE LLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLM NVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSD -------------------------------------------------------------- >66008_66008_3_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000417849_VIL1_chr2_219313946_ENST00000248444_length(transcript)=5030nt_BP=957nt GTAGAAGAGGGGAGGAAACAAGCCAGTGCAAGGGGAGCAAAAGAGAAAAGGAGCCAGGCTGGGCTTCCTGATCCCACAGCATCGCAGAGC TCGGGAGGCACAGCTCACAGACACAGGAAACACAGGACTGCTATTCTGCTCTCCTGCCCACGGTGATCTGGTGCCAGCTGGTGGAACAGT GGGTGATGGCGTCCCTGCTGCAAGACCAGCTGACCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGT CCAAAAGCTGGAAGAAGCTAAGATACTTCAGACTTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGC CCAGCTTCTCAATCTCTGATGTGGAGACAATACGTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGC AGGGCTTCACCATTGTCTTCCATGGCCGCCGCTCCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGC TCCAGCTGTTGGTGGATCTTGTCACCAGCATGGACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAA ATCAGGATGGTAAGATGAGTTTCCAAGAAGTTCAGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTT TTCAGGCAGCAGACACGTCCCAGTCTGGAACCCTGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGC AGGAACTGTTTGAAAGTTTTTCAGCTGATGGGCAGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAG ACTGCACCTCTGAGCTTGCTCTGGAACTCATTGACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCC TTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAG CTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCA GATGTGCCTATGAGCACAAACTTCTGTGGCAAATGCCAGTTTTGTTTAATAATGTACCTATTCCTTCAGAAAGATGATACCCCAAAAGGA GCCTATGGTCCTCATTTCAACTTCTAAGGTCGCTAGATTGTTTCTATCCTGAGGTATTGCATCAATTTTAATACTCCTATAGTTTTCTCT TCTTAGAAGAGCACAAACACTCCATGGAACATTAGAGTTCTGAGGCACTACCCTAGCTTGTCCTCTATCATGACTCATTTTTATCTATGG CAGGTAGGCTGAAGCACTTTGCAGGTTTACATCTTCCCCAGAGTAACAGCTTTTCCTTTTCACATATACTTTCCTTACTGCCTTACTCAG TGGGTAAGTTAAAGGGCTGAAGGAGAGTTGAATGGTCCACAAGACTACCCTCTTAAGAGGTTTCACAAATTCCAAACAGTACCAGTGAGA GCAGCACTTCCACTGGGGCTAGGCTTGAGACCTAAAGGCAAGTATGAAATGCATATGCTACTTCACTCCCTCTCCCAACCCTTAATAATG AGGCAAAGCAAGAGCCTAGTGAAGGCCAATGCTAGGTTTACAAACTTACCCAGAAGCCTCTGCAAAGCTTCACAGGCTCCTCAGATGAAA ATAACAGGAATCAATGGGGACTACGGCCAGACACTGGTTTGCCATTCTGTTCCTTTTAAGAAGTAACAGTGCTGCAAGGAAGTCCATGTC AGAAAGCCAACAGAAGGTGATTTCCACAACTTTGAACAGGTTGTTACAAGTATCAGCAAGAATGTGTCCTTTTCAGAAATAACAGTCAAA TCAAAGAAGGTTAATAAAGGCTTTAATTTCATACACACAAAAAAACTCTATGCATAATTTAAAAAGGAAACAAAAACAAAGAAAAACCGT AAAGGATACAGAGGAACAGTTCTGCTAAAACACAGATAAAAGTGCCGCTCCATACAAAACATAAAGAATCAGAATCAAAAGTCACTCTGA ACATAAAGAAAAAAAATCATCTCACAAATAATGTGGCCACAGCTGCCAGAAAACCTGGTAGTGGCTCAATTAGGCAAAGTGTAGGAATCT CATTTTTGTTTTTCTCTCCTTAAGTTTAAAGAAACAACAATGACAATAGGCCAGAGAAGTTAGGGAGGGAAAGAAAAGCTCAAAGGGAGG GAAACCTGGGGACAAGAGGTGTGCACACCCACATGTGGTCTCACTCTTCACACAGGCCCACTATTTTTGAAGTAGACCAGTTTAGTTGAC TGTTCTTCTTTGTTCTGGCATCTGACTGGACCAACCTGGAACCTGGTCCAGACCCTCACCCACTCTATTCTTATGCCAATGGACATACCT ATACTTTGAACCTCTGTACTTTTAAGAAAAGTCCAATGTTACAAAATCAAATGCTTATATTCAGACTGGCACACTTTTTAAATAAAAACT CCATACACCTCAGACATATAGCACACATGGAGACAACTTACTAATTGTGTGTAAGTATGATACAATGAATGAGACTGCCTGAAGTCTAGT AATCAAAGCATGCCATAAGGTGAATGATTGTGGTTAAACACAGCAAAATAATTGTCACAAAACTTTCAAGGCCTAACAAATTAGAATTTT CCAATAAAAAATATATATTTTTTCAGATGTTAATAAGACATATCAGTAGAGACAAAATTAGGATTTTGAAGTAATGCAATAAAAAGATGT TGGAGGGCAGAAGTCTATTTAGTTTTTGTATACACTTGCAAGAGTGCATTACTCAGTATAAAGCAAAATGGGGAGGAAAAAGACATCCAT CCATTTTATTGGAACACTTTTATGTGACTTGAATCTGGTGTTAGGTTGTTGATTTTTCTAAAAATCTCCTATATATACAAAATCCATATG TACTTGGAGATCCAGCTGTTGCCCCCTGTTTAAAACAAAAGACCACCTCGGGGGGTCAATTAAATTAAAAAGGCCCTCCAACCACCCTAA ATGGGATAACTAAGAGTATCTACTGCAGTCATTTCAGAGGACAGAGAAGGAAAATATTTTAATTTGCTTTAATATAACCTCTTTTCAGTA GATCACAAATGAGTTTACAAACTACTTTTTTTTCTCTTTAATTTAGGTGTTTGCAGATAATTTTCATTATATCCGTAGCTGTATGTGTGT ATAGTTACATAATGGTAACTACACACGATACAGAAGAATCAGTAAATTCATGGATTATTTTGCTGAGGTTTTAAATTTTAAAGCCTCTGT TTCAGAATTTTATACTTGATCAAGGAGAAAAATAAATGTGTAGTCTAACATTTGCTTTCTGGAGTTAATTAACTGATCTGTAAGAACCAC TGCATATGTCTTAAAATGTAAACATATTTACATTTGTTGTATTTGTTATTGAGCCTTTAAGGTTAGGCCCAGAATGAACAGACCATAGCA AGTAAACAAATAATTTTTAGAATCAAAGTATTAATAGAAGACCAGTTCATGGATTTGCTTATTCTATCCTGCTGAGACAAAACTCATGAG TGTGCACACACATGTGAATATATCCCTACGAAACAGTCTATCTTCTCATAGGCTTAAATTATAGTCATGGCTATTAAAGAAATTAACAGC ATCCAGCCACATGCAACTTTCCAACCTTCAGTACTATTAGGTGATTAAAATCAACAAATATGAAGTTTAGTTCATTTTTCCCTTAAAATT CCAACAAAGATCAAAAGGTTGTATCTAGAACTAATTGCCATCAAGTTCCAATTCAATGTCATTTAAAGTAATGTAACCACACATTTGGTA TTTTCAATAGGAAGGTTAATTAGGTATTGTGCAAACTGCCTGCAACGGAAGCACTCAGTCCTTATCTAACTTGTCCCTTCCTGGCCCCAA CATGCTAACTGCCCCATCCCCAATTCTGGGCAAACTGATCACAATGTGCAAAAAATAATATATTATCTATTTATAATTTTAAAATATATA CAGCCAGCTCAAAAACAACAACAAACCCCATCAACATAGTCCAGCTGAAATCTCCACTGGTAGTCAAAGAAGTAGATTAAAGGAGTAAAG GAAGGAGAAGGCTGATAGGGCCACAAGAATGGACAGACATCAAGTAAAATTTGAGTCCCAAACATGCAAGTACATGAGCAGTGAGATAAC TTATATATTCCAATAACCTATTTTCAACAACTCCTGCCCAAGACATGAAGATCAAATCAGGTTTCTGAGGTAAGTGTACTTCTAAACCAT ACACACATGAAAGCTATGAAAGCAATTCAAATGAGGCTGCTTCATGAGGCAATCTAGACTTATGGCATTATTTCTACTTTTCTCCATGTT TTAATTGCAGCCTGCACTTTAAATCTTTCCCAATAATTTTTAACAGTGCCTCTCAAATGCAAAGACACGTAAAAGAATTAATAACTAGCC AAAGAATTTTATCACCGCTTCACTCATTTATAAGAAAACCAATTATTTCCAAGCAAAATCAAACCAAACCAAAGAGGCTCCTGGTAGAAA TGAAACAAAACTTTAAAGCTAGTTTTAAAACAAATATTTTCCTCTGCTCTAAACTACTCTGGCGTTTTCTACCACTCTACCATTTTGGAA CATTCATTACAATAAGGTATATAGGTAGATGGTAGGAGGCAAAGCATTTATCAGTAGTTGAGCAAAACTGCTGAGGCCATTTATAATTCA AAGAATGAAAACTTAGAATAGTTTACTACATTAGAATACATCCAAGTTCCAAGAGTAGGACTGGAGCTCTCTTAAGGCAATCTTTCAGAA >66008_66008_3_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000417849_VIL1_chr2_219313946_ENST00000248444_length(amino acids)=276AA_BP= MPTVIWCQLVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSE LLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLM NVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSD -------------------------------------------------------------- >66008_66008_4_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000417849_VIL1_chr2_219313946_ENST00000392114_length(transcript)=1259nt_BP=957nt GTAGAAGAGGGGAGGAAACAAGCCAGTGCAAGGGGAGCAAAAGAGAAAAGGAGCCAGGCTGGGCTTCCTGATCCCACAGCATCGCAGAGC TCGGGAGGCACAGCTCACAGACACAGGAAACACAGGACTGCTATTCTGCTCTCCTGCCCACGGTGATCTGGTGCCAGCTGGTGGAACAGT GGGTGATGGCGTCCCTGCTGCAAGACCAGCTGACCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGT CCAAAAGCTGGAAGAAGCTAAGATACTTCAGACTTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGC CCAGCTTCTCAATCTCTGATGTGGAGACAATACGTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGC AGGGCTTCACCATTGTCTTCCATGGCCGCCGCTCCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGC TCCAGCTGTTGGTGGATCTTGTCACCAGCATGGACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAA ATCAGGATGGTAAGATGAGTTTCCAAGAAGTTCAGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTT TTCAGGCAGCAGACACGTCCCAGTCTGGAACCCTGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGC AGGAACTGTTTGAAAGTTTTTCAGCTGATGGGCAGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAG ACTGCACCTCTGAGCTTGCTCTGGAACTCATTGACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCC TTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAG CTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCA >66008_66008_4_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000417849_VIL1_chr2_219313946_ENST00000392114_length(amino acids)=276AA_BP= MPTVIWCQLVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSE LLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLM NVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSD -------------------------------------------------------------- >66008_66008_5_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000432688_VIL1_chr2_219313945_ENST00000248444_length(transcript)=5087nt_BP=1014nt AGAGAAAAGTGAGGCTGAGCAGAGGGACACGCATGCTACTGAGTTCTGAACCCAAGTGTCCTCCCTTCTGGACCACAGTCTCAAAATTCT CAAAGGAGATGAGACTCAGAGCCATTGCGAATTAGTGGAGTCAAAAGAGGGAACCAACTGGAAGAGGTGATGGGGAGAAGGGATGAGGAG AAGGAAGAGAAGAGGAGAGACTGACCTAGGTGATCTGGTGCCAGCTGGTGGAACAGTGGGTGATGGCGTCCCTGCTGCAAGACCAGCTGA CCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGTCCAAAAGCTGGAAGAAGCTAAGATACTTCAGAC TTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGCCCAGCTTCTCAATCTCTGATGTGGAGACAATAC GTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGCAGGGCTTCACCATTGTCTTCCATGGCCGCCGCT CCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGCTCCAGCTGTTGGTGGATCTTGTCACCAGCATGG ACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAAATCAGGATGGTAAGATGAGTTTCCAAGAAGTTC AGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTTTTCAGGCAGCAGACACGTCCCAGTCTGGAACCC TGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGCAGGAACTGTTTGAAAGTTTTTCAGCTGATGGGC AGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAGACTGCACCTCTGAGCTTGCTCTGGAACTCATTG ACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTG CCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTG TAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAA TGCCAGTTTTGTTTAATAATGTACCTATTCCTTCAGAAAGATGATACCCCAAAAGGAGCCTATGGTCCTCATTTCAACTTCTAAGGTCGC TAGATTGTTTCTATCCTGAGGTATTGCATCAATTTTAATACTCCTATAGTTTTCTCTTCTTAGAAGAGCACAAACACTCCATGGAACATT AGAGTTCTGAGGCACTACCCTAGCTTGTCCTCTATCATGACTCATTTTTATCTATGGCAGGTAGGCTGAAGCACTTTGCAGGTTTACATC TTCCCCAGAGTAACAGCTTTTCCTTTTCACATATACTTTCCTTACTGCCTTACTCAGTGGGTAAGTTAAAGGGCTGAAGGAGAGTTGAAT GGTCCACAAGACTACCCTCTTAAGAGGTTTCACAAATTCCAAACAGTACCAGTGAGAGCAGCACTTCCACTGGGGCTAGGCTTGAGACCT AAAGGCAAGTATGAAATGCATATGCTACTTCACTCCCTCTCCCAACCCTTAATAATGAGGCAAAGCAAGAGCCTAGTGAAGGCCAATGCT AGGTTTACAAACTTACCCAGAAGCCTCTGCAAAGCTTCACAGGCTCCTCAGATGAAAATAACAGGAATCAATGGGGACTACGGCCAGACA CTGGTTTGCCATTCTGTTCCTTTTAAGAAGTAACAGTGCTGCAAGGAAGTCCATGTCAGAAAGCCAACAGAAGGTGATTTCCACAACTTT GAACAGGTTGTTACAAGTATCAGCAAGAATGTGTCCTTTTCAGAAATAACAGTCAAATCAAAGAAGGTTAATAAAGGCTTTAATTTCATA CACACAAAAAAACTCTATGCATAATTTAAAAAGGAAACAAAAACAAAGAAAAACCGTAAAGGATACAGAGGAACAGTTCTGCTAAAACAC AGATAAAAGTGCCGCTCCATACAAAACATAAAGAATCAGAATCAAAAGTCACTCTGAACATAAAGAAAAAAAATCATCTCACAAATAATG TGGCCACAGCTGCCAGAAAACCTGGTAGTGGCTCAATTAGGCAAAGTGTAGGAATCTCATTTTTGTTTTTCTCTCCTTAAGTTTAAAGAA ACAACAATGACAATAGGCCAGAGAAGTTAGGGAGGGAAAGAAAAGCTCAAAGGGAGGGAAACCTGGGGACAAGAGGTGTGCACACCCACA TGTGGTCTCACTCTTCACACAGGCCCACTATTTTTGAAGTAGACCAGTTTAGTTGACTGTTCTTCTTTGTTCTGGCATCTGACTGGACCA ACCTGGAACCTGGTCCAGACCCTCACCCACTCTATTCTTATGCCAATGGACATACCTATACTTTGAACCTCTGTACTTTTAAGAAAAGTC CAATGTTACAAAATCAAATGCTTATATTCAGACTGGCACACTTTTTAAATAAAAACTCCATACACCTCAGACATATAGCACACATGGAGA CAACTTACTAATTGTGTGTAAGTATGATACAATGAATGAGACTGCCTGAAGTCTAGTAATCAAAGCATGCCATAAGGTGAATGATTGTGG TTAAACACAGCAAAATAATTGTCACAAAACTTTCAAGGCCTAACAAATTAGAATTTTCCAATAAAAAATATATATTTTTTCAGATGTTAA TAAGACATATCAGTAGAGACAAAATTAGGATTTTGAAGTAATGCAATAAAAAGATGTTGGAGGGCAGAAGTCTATTTAGTTTTTGTATAC ACTTGCAAGAGTGCATTACTCAGTATAAAGCAAAATGGGGAGGAAAAAGACATCCATCCATTTTATTGGAACACTTTTATGTGACTTGAA TCTGGTGTTAGGTTGTTGATTTTTCTAAAAATCTCCTATATATACAAAATCCATATGTACTTGGAGATCCAGCTGTTGCCCCCTGTTTAA AACAAAAGACCACCTCGGGGGGTCAATTAAATTAAAAAGGCCCTCCAACCACCCTAAATGGGATAACTAAGAGTATCTACTGCAGTCATT TCAGAGGACAGAGAAGGAAAATATTTTAATTTGCTTTAATATAACCTCTTTTCAGTAGATCACAAATGAGTTTACAAACTACTTTTTTTT CTCTTTAATTTAGGTGTTTGCAGATAATTTTCATTATATCCGTAGCTGTATGTGTGTATAGTTACATAATGGTAACTACACACGATACAG AAGAATCAGTAAATTCATGGATTATTTTGCTGAGGTTTTAAATTTTAAAGCCTCTGTTTCAGAATTTTATACTTGATCAAGGAGAAAAAT AAATGTGTAGTCTAACATTTGCTTTCTGGAGTTAATTAACTGATCTGTAAGAACCACTGCATATGTCTTAAAATGTAAACATATTTACAT TTGTTGTATTTGTTATTGAGCCTTTAAGGTTAGGCCCAGAATGAACAGACCATAGCAAGTAAACAAATAATTTTTAGAATCAAAGTATTA ATAGAAGACCAGTTCATGGATTTGCTTATTCTATCCTGCTGAGACAAAACTCATGAGTGTGCACACACATGTGAATATATCCCTACGAAA CAGTCTATCTTCTCATAGGCTTAAATTATAGTCATGGCTATTAAAGAAATTAACAGCATCCAGCCACATGCAACTTTCCAACCTTCAGTA CTATTAGGTGATTAAAATCAACAAATATGAAGTTTAGTTCATTTTTCCCTTAAAATTCCAACAAAGATCAAAAGGTTGTATCTAGAACTA ATTGCCATCAAGTTCCAATTCAATGTCATTTAAAGTAATGTAACCACACATTTGGTATTTTCAATAGGAAGGTTAATTAGGTATTGTGCA AACTGCCTGCAACGGAAGCACTCAGTCCTTATCTAACTTGTCCCTTCCTGGCCCCAACATGCTAACTGCCCCATCCCCAATTCTGGGCAA ACTGATCACAATGTGCAAAAAATAATATATTATCTATTTATAATTTTAAAATATATACAGCCAGCTCAAAAACAACAACAAACCCCATCA ACATAGTCCAGCTGAAATCTCCACTGGTAGTCAAAGAAGTAGATTAAAGGAGTAAAGGAAGGAGAAGGCTGATAGGGCCACAAGAATGGA CAGACATCAAGTAAAATTTGAGTCCCAAACATGCAAGTACATGAGCAGTGAGATAACTTATATATTCCAATAACCTATTTTCAACAACTC CTGCCCAAGACATGAAGATCAAATCAGGTTTCTGAGGTAAGTGTACTTCTAAACCATACACACATGAAAGCTATGAAAGCAATTCAAATG AGGCTGCTTCATGAGGCAATCTAGACTTATGGCATTATTTCTACTTTTCTCCATGTTTTAATTGCAGCCTGCACTTTAAATCTTTCCCAA TAATTTTTAACAGTGCCTCTCAAATGCAAAGACACGTAAAAGAATTAATAACTAGCCAAAGAATTTTATCACCGCTTCACTCATTTATAA GAAAACCAATTATTTCCAAGCAAAATCAAACCAAACCAAAGAGGCTCCTGGTAGAAATGAAACAAAACTTTAAAGCTAGTTTTAAAACAA ATATTTTCCTCTGCTCTAAACTACTCTGGCGTTTTCTACCACTCTACCATTTTGGAACATTCATTACAATAAGGTATATAGGTAGATGGT AGGAGGCAAAGCATTTATCAGTAGTTGAGCAAAACTGCTGAGGCCATTTATAATTCAAAGAATGAAAACTTAGAATAGTTTACTACATTA GAATACATCCAAGTTCCAAGAGTAGGACTGGAGCTCTCTTAAGGCAATCTTTCAGAAAAGATGTTGCATCTTCTGTGATGATGGTTTGTG >66008_66008_5_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000432688_VIL1_chr2_219313945_ENST00000248444_length(amino acids)=268AA_BP= MVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSELLRSLAEE LPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLMNVEMDQEY -------------------------------------------------------------- >66008_66008_6_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000432688_VIL1_chr2_219313945_ENST00000392114_length(transcript)=1316nt_BP=1014nt AGAGAAAAGTGAGGCTGAGCAGAGGGACACGCATGCTACTGAGTTCTGAACCCAAGTGTCCTCCCTTCTGGACCACAGTCTCAAAATTCT CAAAGGAGATGAGACTCAGAGCCATTGCGAATTAGTGGAGTCAAAAGAGGGAACCAACTGGAAGAGGTGATGGGGAGAAGGGATGAGGAG AAGGAAGAGAAGAGGAGAGACTGACCTAGGTGATCTGGTGCCAGCTGGTGGAACAGTGGGTGATGGCGTCCCTGCTGCAAGACCAGCTGA CCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGTCCAAAAGCTGGAAGAAGCTAAGATACTTCAGAC TTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGCCCAGCTTCTCAATCTCTGATGTGGAGACAATAC GTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGCAGGGCTTCACCATTGTCTTCCATGGCCGCCGCT CCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGCTCCAGCTGTTGGTGGATCTTGTCACCAGCATGG ACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAAATCAGGATGGTAAGATGAGTTTCCAAGAAGTTC AGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTTTTCAGGCAGCAGACACGTCCCAGTCTGGAACCC TGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGCAGGAACTGTTTGAAAGTTTTTCAGCTGATGGGC AGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAGACTGCACCTCTGAGCTTGCTCTGGAACTCATTG ACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTG CCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTG TAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAA >66008_66008_6_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000432688_VIL1_chr2_219313945_ENST00000392114_length(amino acids)=268AA_BP= MVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSELLRSLAEE LPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLMNVEMDQEY -------------------------------------------------------------- >66008_66008_7_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000432688_VIL1_chr2_219313946_ENST00000248444_length(transcript)=5087nt_BP=1014nt AGAGAAAAGTGAGGCTGAGCAGAGGGACACGCATGCTACTGAGTTCTGAACCCAAGTGTCCTCCCTTCTGGACCACAGTCTCAAAATTCT CAAAGGAGATGAGACTCAGAGCCATTGCGAATTAGTGGAGTCAAAAGAGGGAACCAACTGGAAGAGGTGATGGGGAGAAGGGATGAGGAG AAGGAAGAGAAGAGGAGAGACTGACCTAGGTGATCTGGTGCCAGCTGGTGGAACAGTGGGTGATGGCGTCCCTGCTGCAAGACCAGCTGA CCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGTCCAAAAGCTGGAAGAAGCTAAGATACTTCAGAC TTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGCCCAGCTTCTCAATCTCTGATGTGGAGACAATAC GTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGCAGGGCTTCACCATTGTCTTCCATGGCCGCCGCT CCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGCTCCAGCTGTTGGTGGATCTTGTCACCAGCATGG ACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAAATCAGGATGGTAAGATGAGTTTCCAAGAAGTTC AGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTTTTCAGGCAGCAGACACGTCCCAGTCTGGAACCC TGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGCAGGAACTGTTTGAAAGTTTTTCAGCTGATGGGC AGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAGACTGCACCTCTGAGCTTGCTCTGGAACTCATTG ACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTG CCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTG TAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAA TGCCAGTTTTGTTTAATAATGTACCTATTCCTTCAGAAAGATGATACCCCAAAAGGAGCCTATGGTCCTCATTTCAACTTCTAAGGTCGC TAGATTGTTTCTATCCTGAGGTATTGCATCAATTTTAATACTCCTATAGTTTTCTCTTCTTAGAAGAGCACAAACACTCCATGGAACATT AGAGTTCTGAGGCACTACCCTAGCTTGTCCTCTATCATGACTCATTTTTATCTATGGCAGGTAGGCTGAAGCACTTTGCAGGTTTACATC TTCCCCAGAGTAACAGCTTTTCCTTTTCACATATACTTTCCTTACTGCCTTACTCAGTGGGTAAGTTAAAGGGCTGAAGGAGAGTTGAAT GGTCCACAAGACTACCCTCTTAAGAGGTTTCACAAATTCCAAACAGTACCAGTGAGAGCAGCACTTCCACTGGGGCTAGGCTTGAGACCT AAAGGCAAGTATGAAATGCATATGCTACTTCACTCCCTCTCCCAACCCTTAATAATGAGGCAAAGCAAGAGCCTAGTGAAGGCCAATGCT AGGTTTACAAACTTACCCAGAAGCCTCTGCAAAGCTTCACAGGCTCCTCAGATGAAAATAACAGGAATCAATGGGGACTACGGCCAGACA CTGGTTTGCCATTCTGTTCCTTTTAAGAAGTAACAGTGCTGCAAGGAAGTCCATGTCAGAAAGCCAACAGAAGGTGATTTCCACAACTTT GAACAGGTTGTTACAAGTATCAGCAAGAATGTGTCCTTTTCAGAAATAACAGTCAAATCAAAGAAGGTTAATAAAGGCTTTAATTTCATA CACACAAAAAAACTCTATGCATAATTTAAAAAGGAAACAAAAACAAAGAAAAACCGTAAAGGATACAGAGGAACAGTTCTGCTAAAACAC AGATAAAAGTGCCGCTCCATACAAAACATAAAGAATCAGAATCAAAAGTCACTCTGAACATAAAGAAAAAAAATCATCTCACAAATAATG TGGCCACAGCTGCCAGAAAACCTGGTAGTGGCTCAATTAGGCAAAGTGTAGGAATCTCATTTTTGTTTTTCTCTCCTTAAGTTTAAAGAA ACAACAATGACAATAGGCCAGAGAAGTTAGGGAGGGAAAGAAAAGCTCAAAGGGAGGGAAACCTGGGGACAAGAGGTGTGCACACCCACA TGTGGTCTCACTCTTCACACAGGCCCACTATTTTTGAAGTAGACCAGTTTAGTTGACTGTTCTTCTTTGTTCTGGCATCTGACTGGACCA ACCTGGAACCTGGTCCAGACCCTCACCCACTCTATTCTTATGCCAATGGACATACCTATACTTTGAACCTCTGTACTTTTAAGAAAAGTC CAATGTTACAAAATCAAATGCTTATATTCAGACTGGCACACTTTTTAAATAAAAACTCCATACACCTCAGACATATAGCACACATGGAGA CAACTTACTAATTGTGTGTAAGTATGATACAATGAATGAGACTGCCTGAAGTCTAGTAATCAAAGCATGCCATAAGGTGAATGATTGTGG TTAAACACAGCAAAATAATTGTCACAAAACTTTCAAGGCCTAACAAATTAGAATTTTCCAATAAAAAATATATATTTTTTCAGATGTTAA TAAGACATATCAGTAGAGACAAAATTAGGATTTTGAAGTAATGCAATAAAAAGATGTTGGAGGGCAGAAGTCTATTTAGTTTTTGTATAC ACTTGCAAGAGTGCATTACTCAGTATAAAGCAAAATGGGGAGGAAAAAGACATCCATCCATTTTATTGGAACACTTTTATGTGACTTGAA TCTGGTGTTAGGTTGTTGATTTTTCTAAAAATCTCCTATATATACAAAATCCATATGTACTTGGAGATCCAGCTGTTGCCCCCTGTTTAA AACAAAAGACCACCTCGGGGGGTCAATTAAATTAAAAAGGCCCTCCAACCACCCTAAATGGGATAACTAAGAGTATCTACTGCAGTCATT TCAGAGGACAGAGAAGGAAAATATTTTAATTTGCTTTAATATAACCTCTTTTCAGTAGATCACAAATGAGTTTACAAACTACTTTTTTTT CTCTTTAATTTAGGTGTTTGCAGATAATTTTCATTATATCCGTAGCTGTATGTGTGTATAGTTACATAATGGTAACTACACACGATACAG AAGAATCAGTAAATTCATGGATTATTTTGCTGAGGTTTTAAATTTTAAAGCCTCTGTTTCAGAATTTTATACTTGATCAAGGAGAAAAAT AAATGTGTAGTCTAACATTTGCTTTCTGGAGTTAATTAACTGATCTGTAAGAACCACTGCATATGTCTTAAAATGTAAACATATTTACAT TTGTTGTATTTGTTATTGAGCCTTTAAGGTTAGGCCCAGAATGAACAGACCATAGCAAGTAAACAAATAATTTTTAGAATCAAAGTATTA ATAGAAGACCAGTTCATGGATTTGCTTATTCTATCCTGCTGAGACAAAACTCATGAGTGTGCACACACATGTGAATATATCCCTACGAAA CAGTCTATCTTCTCATAGGCTTAAATTATAGTCATGGCTATTAAAGAAATTAACAGCATCCAGCCACATGCAACTTTCCAACCTTCAGTA CTATTAGGTGATTAAAATCAACAAATATGAAGTTTAGTTCATTTTTCCCTTAAAATTCCAACAAAGATCAAAAGGTTGTATCTAGAACTA ATTGCCATCAAGTTCCAATTCAATGTCATTTAAAGTAATGTAACCACACATTTGGTATTTTCAATAGGAAGGTTAATTAGGTATTGTGCA AACTGCCTGCAACGGAAGCACTCAGTCCTTATCTAACTTGTCCCTTCCTGGCCCCAACATGCTAACTGCCCCATCCCCAATTCTGGGCAA ACTGATCACAATGTGCAAAAAATAATATATTATCTATTTATAATTTTAAAATATATACAGCCAGCTCAAAAACAACAACAAACCCCATCA ACATAGTCCAGCTGAAATCTCCACTGGTAGTCAAAGAAGTAGATTAAAGGAGTAAAGGAAGGAGAAGGCTGATAGGGCCACAAGAATGGA CAGACATCAAGTAAAATTTGAGTCCCAAACATGCAAGTACATGAGCAGTGAGATAACTTATATATTCCAATAACCTATTTTCAACAACTC CTGCCCAAGACATGAAGATCAAATCAGGTTTCTGAGGTAAGTGTACTTCTAAACCATACACACATGAAAGCTATGAAAGCAATTCAAATG AGGCTGCTTCATGAGGCAATCTAGACTTATGGCATTATTTCTACTTTTCTCCATGTTTTAATTGCAGCCTGCACTTTAAATCTTTCCCAA TAATTTTTAACAGTGCCTCTCAAATGCAAAGACACGTAAAAGAATTAATAACTAGCCAAAGAATTTTATCACCGCTTCACTCATTTATAA GAAAACCAATTATTTCCAAGCAAAATCAAACCAAACCAAAGAGGCTCCTGGTAGAAATGAAACAAAACTTTAAAGCTAGTTTTAAAACAA ATATTTTCCTCTGCTCTAAACTACTCTGGCGTTTTCTACCACTCTACCATTTTGGAACATTCATTACAATAAGGTATATAGGTAGATGGT AGGAGGCAAAGCATTTATCAGTAGTTGAGCAAAACTGCTGAGGCCATTTATAATTCAAAGAATGAAAACTTAGAATAGTTTACTACATTA GAATACATCCAAGTTCCAAGAGTAGGACTGGAGCTCTCTTAAGGCAATCTTTCAGAAAAGATGTTGCATCTTCTGTGATGATGGTTTGTG >66008_66008_7_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000432688_VIL1_chr2_219313946_ENST00000248444_length(amino acids)=268AA_BP= MVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSELLRSLAEE LPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLMNVEMDQEY -------------------------------------------------------------- >66008_66008_8_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000432688_VIL1_chr2_219313946_ENST00000392114_length(transcript)=1316nt_BP=1014nt AGAGAAAAGTGAGGCTGAGCAGAGGGACACGCATGCTACTGAGTTCTGAACCCAAGTGTCCTCCCTTCTGGACCACAGTCTCAAAATTCT CAAAGGAGATGAGACTCAGAGCCATTGCGAATTAGTGGAGTCAAAAGAGGGAACCAACTGGAAGAGGTGATGGGGAGAAGGGATGAGGAG AAGGAAGAGAAGAGGAGAGACTGACCTAGGTGATCTGGTGCCAGCTGGTGGAACAGTGGGTGATGGCGTCCCTGCTGCAAGACCAGCTGA CCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGTCCAAAAGCTGGAAGAAGCTAAGATACTTCAGAC TTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGCCCAGCTTCTCAATCTCTGATGTGGAGACAATAC GTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGCAGGGCTTCACCATTGTCTTCCATGGCCGCCGCT CCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGCTCCAGCTGTTGGTGGATCTTGTCACCAGCATGG ACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAAATCAGGATGGTAAGATGAGTTTCCAAGAAGTTC AGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTTTTCAGGCAGCAGACACGTCCCAGTCTGGAACCC TGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGCAGGAACTGTTTGAAAGTTTTTCAGCTGATGGGC AGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAGACTGCACCTCTGAGCTTGCTCTGGAACTCATTG ACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTG CCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTG TAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAA >66008_66008_8_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000432688_VIL1_chr2_219313946_ENST00000392114_length(amino acids)=268AA_BP= MVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSELLRSLAEE LPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLMNVEMDQEY -------------------------------------------------------------- >66008_66008_9_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000450993_VIL1_chr2_219313945_ENST00000248444_length(transcript)=5184nt_BP=1111nt CTTCTCTCCCCACCCCACCCCCACTACTCCCTCACATTGACCAGTGTCCTGGGCCTTTAAGAGTTGGATGGGCTGGACTGGAGAGAGCTC ACACCTCTCCCCTTCTTACTGCTTCCCTCCGGCTATAACTTGCCAGTCACAGCAGCCAGCTGCTGTAGAAGAGGGGAGGAAACAAGCCAG TGCAAGGGGAGCAAAAGAGAAAAGGAGCCAGGCTGGGCTTCCTGATCCCACAGCATCGCAGAGCTCGGGAGGCACAGCTCACAGACACAG GAAACACAGGACTGCTATTCTGCTCTCCTGCCCACGGTGATCTGGTGCCAGCTGGTGGAACAGTGGGTGATGGCGTCCCTGCTGCAAGAC CAGCTGACCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGTCCAAAAGCTGGAAGAAGCTAAGATAC TTCAGACTTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGCCCAGCTTCTCAATCTCTGATGTGGAG ACAATACGTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGCAGGGCTTCACCATTGTCTTCCATGGC CGCCGCTCCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGCTCCAGCTGTTGGTGGATCTTGTCACC AGCATGGACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAAATCAGGATGGTAAGATGAGTTTCCAA GAAGTTCAGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTTTTCAGGCAGCAGACACGTCCCAGTCT GGAACCCTGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGCAGGAACTGTTTGAAAGTTTTTCAGCT GATGGGCAGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAGACTGCACCTCTGAGCTTGCTCTGGAA CTCATTGACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTC TGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACC CTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTG TGGCAAATGCCAGTTTTGTTTAATAATGTACCTATTCCTTCAGAAAGATGATACCCCAAAAGGAGCCTATGGTCCTCATTTCAACTTCTA AGGTCGCTAGATTGTTTCTATCCTGAGGTATTGCATCAATTTTAATACTCCTATAGTTTTCTCTTCTTAGAAGAGCACAAACACTCCATG GAACATTAGAGTTCTGAGGCACTACCCTAGCTTGTCCTCTATCATGACTCATTTTTATCTATGGCAGGTAGGCTGAAGCACTTTGCAGGT TTACATCTTCCCCAGAGTAACAGCTTTTCCTTTTCACATATACTTTCCTTACTGCCTTACTCAGTGGGTAAGTTAAAGGGCTGAAGGAGA GTTGAATGGTCCACAAGACTACCCTCTTAAGAGGTTTCACAAATTCCAAACAGTACCAGTGAGAGCAGCACTTCCACTGGGGCTAGGCTT GAGACCTAAAGGCAAGTATGAAATGCATATGCTACTTCACTCCCTCTCCCAACCCTTAATAATGAGGCAAAGCAAGAGCCTAGTGAAGGC CAATGCTAGGTTTACAAACTTACCCAGAAGCCTCTGCAAAGCTTCACAGGCTCCTCAGATGAAAATAACAGGAATCAATGGGGACTACGG CCAGACACTGGTTTGCCATTCTGTTCCTTTTAAGAAGTAACAGTGCTGCAAGGAAGTCCATGTCAGAAAGCCAACAGAAGGTGATTTCCA CAACTTTGAACAGGTTGTTACAAGTATCAGCAAGAATGTGTCCTTTTCAGAAATAACAGTCAAATCAAAGAAGGTTAATAAAGGCTTTAA TTTCATACACACAAAAAAACTCTATGCATAATTTAAAAAGGAAACAAAAACAAAGAAAAACCGTAAAGGATACAGAGGAACAGTTCTGCT AAAACACAGATAAAAGTGCCGCTCCATACAAAACATAAAGAATCAGAATCAAAAGTCACTCTGAACATAAAGAAAAAAAATCATCTCACA AATAATGTGGCCACAGCTGCCAGAAAACCTGGTAGTGGCTCAATTAGGCAAAGTGTAGGAATCTCATTTTTGTTTTTCTCTCCTTAAGTT TAAAGAAACAACAATGACAATAGGCCAGAGAAGTTAGGGAGGGAAAGAAAAGCTCAAAGGGAGGGAAACCTGGGGACAAGAGGTGTGCAC ACCCACATGTGGTCTCACTCTTCACACAGGCCCACTATTTTTGAAGTAGACCAGTTTAGTTGACTGTTCTTCTTTGTTCTGGCATCTGAC TGGACCAACCTGGAACCTGGTCCAGACCCTCACCCACTCTATTCTTATGCCAATGGACATACCTATACTTTGAACCTCTGTACTTTTAAG AAAAGTCCAATGTTACAAAATCAAATGCTTATATTCAGACTGGCACACTTTTTAAATAAAAACTCCATACACCTCAGACATATAGCACAC ATGGAGACAACTTACTAATTGTGTGTAAGTATGATACAATGAATGAGACTGCCTGAAGTCTAGTAATCAAAGCATGCCATAAGGTGAATG ATTGTGGTTAAACACAGCAAAATAATTGTCACAAAACTTTCAAGGCCTAACAAATTAGAATTTTCCAATAAAAAATATATATTTTTTCAG ATGTTAATAAGACATATCAGTAGAGACAAAATTAGGATTTTGAAGTAATGCAATAAAAAGATGTTGGAGGGCAGAAGTCTATTTAGTTTT TGTATACACTTGCAAGAGTGCATTACTCAGTATAAAGCAAAATGGGGAGGAAAAAGACATCCATCCATTTTATTGGAACACTTTTATGTG ACTTGAATCTGGTGTTAGGTTGTTGATTTTTCTAAAAATCTCCTATATATACAAAATCCATATGTACTTGGAGATCCAGCTGTTGCCCCC TGTTTAAAACAAAAGACCACCTCGGGGGGTCAATTAAATTAAAAAGGCCCTCCAACCACCCTAAATGGGATAACTAAGAGTATCTACTGC AGTCATTTCAGAGGACAGAGAAGGAAAATATTTTAATTTGCTTTAATATAACCTCTTTTCAGTAGATCACAAATGAGTTTACAAACTACT TTTTTTTCTCTTTAATTTAGGTGTTTGCAGATAATTTTCATTATATCCGTAGCTGTATGTGTGTATAGTTACATAATGGTAACTACACAC GATACAGAAGAATCAGTAAATTCATGGATTATTTTGCTGAGGTTTTAAATTTTAAAGCCTCTGTTTCAGAATTTTATACTTGATCAAGGA GAAAAATAAATGTGTAGTCTAACATTTGCTTTCTGGAGTTAATTAACTGATCTGTAAGAACCACTGCATATGTCTTAAAATGTAAACATA TTTACATTTGTTGTATTTGTTATTGAGCCTTTAAGGTTAGGCCCAGAATGAACAGACCATAGCAAGTAAACAAATAATTTTTAGAATCAA AGTATTAATAGAAGACCAGTTCATGGATTTGCTTATTCTATCCTGCTGAGACAAAACTCATGAGTGTGCACACACATGTGAATATATCCC TACGAAACAGTCTATCTTCTCATAGGCTTAAATTATAGTCATGGCTATTAAAGAAATTAACAGCATCCAGCCACATGCAACTTTCCAACC TTCAGTACTATTAGGTGATTAAAATCAACAAATATGAAGTTTAGTTCATTTTTCCCTTAAAATTCCAACAAAGATCAAAAGGTTGTATCT AGAACTAATTGCCATCAAGTTCCAATTCAATGTCATTTAAAGTAATGTAACCACACATTTGGTATTTTCAATAGGAAGGTTAATTAGGTA TTGTGCAAACTGCCTGCAACGGAAGCACTCAGTCCTTATCTAACTTGTCCCTTCCTGGCCCCAACATGCTAACTGCCCCATCCCCAATTC TGGGCAAACTGATCACAATGTGCAAAAAATAATATATTATCTATTTATAATTTTAAAATATATACAGCCAGCTCAAAAACAACAACAAAC CCCATCAACATAGTCCAGCTGAAATCTCCACTGGTAGTCAAAGAAGTAGATTAAAGGAGTAAAGGAAGGAGAAGGCTGATAGGGCCACAA GAATGGACAGACATCAAGTAAAATTTGAGTCCCAAACATGCAAGTACATGAGCAGTGAGATAACTTATATATTCCAATAACCTATTTTCA ACAACTCCTGCCCAAGACATGAAGATCAAATCAGGTTTCTGAGGTAAGTGTACTTCTAAACCATACACACATGAAAGCTATGAAAGCAAT TCAAATGAGGCTGCTTCATGAGGCAATCTAGACTTATGGCATTATTTCTACTTTTCTCCATGTTTTAATTGCAGCCTGCACTTTAAATCT TTCCCAATAATTTTTAACAGTGCCTCTCAAATGCAAAGACACGTAAAAGAATTAATAACTAGCCAAAGAATTTTATCACCGCTTCACTCA TTTATAAGAAAACCAATTATTTCCAAGCAAAATCAAACCAAACCAAAGAGGCTCCTGGTAGAAATGAAACAAAACTTTAAAGCTAGTTTT AAAACAAATATTTTCCTCTGCTCTAAACTACTCTGGCGTTTTCTACCACTCTACCATTTTGGAACATTCATTACAATAAGGTATATAGGT AGATGGTAGGAGGCAAAGCATTTATCAGTAGTTGAGCAAAACTGCTGAGGCCATTTATAATTCAAAGAATGAAAACTTAGAATAGTTTAC TACATTAGAATACATCCAAGTTCCAAGAGTAGGACTGGAGCTCTCTTAAGGCAATCTTTCAGAAAAGATGTTGCATCTTCTGTGATGATG >66008_66008_9_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000450993_VIL1_chr2_219313945_ENST00000248444_length(amino acids)=276AA_BP= MPTVIWCQLVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSE LLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLM NVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSD -------------------------------------------------------------- >66008_66008_10_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000450993_VIL1_chr2_219313945_ENST00000392114_length(transcript)=1413nt_BP=1111nt CTTCTCTCCCCACCCCACCCCCACTACTCCCTCACATTGACCAGTGTCCTGGGCCTTTAAGAGTTGGATGGGCTGGACTGGAGAGAGCTC ACACCTCTCCCCTTCTTACTGCTTCCCTCCGGCTATAACTTGCCAGTCACAGCAGCCAGCTGCTGTAGAAGAGGGGAGGAAACAAGCCAG TGCAAGGGGAGCAAAAGAGAAAAGGAGCCAGGCTGGGCTTCCTGATCCCACAGCATCGCAGAGCTCGGGAGGCACAGCTCACAGACACAG GAAACACAGGACTGCTATTCTGCTCTCCTGCCCACGGTGATCTGGTGCCAGCTGGTGGAACAGTGGGTGATGGCGTCCCTGCTGCAAGAC CAGCTGACCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGTCCAAAAGCTGGAAGAAGCTAAGATAC TTCAGACTTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGCCCAGCTTCTCAATCTCTGATGTGGAG ACAATACGTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGCAGGGCTTCACCATTGTCTTCCATGGC CGCCGCTCCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGCTCCAGCTGTTGGTGGATCTTGTCACC AGCATGGACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAAATCAGGATGGTAAGATGAGTTTCCAA GAAGTTCAGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTTTTCAGGCAGCAGACACGTCCCAGTCT GGAACCCTGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGCAGGAACTGTTTGAAAGTTTTTCAGCT GATGGGCAGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAGACTGCACCTCTGAGCTTGCTCTGGAA CTCATTGACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTC TGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACC CTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTG >66008_66008_10_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000450993_VIL1_chr2_219313945_ENST00000392114_length(amino acids)=276AA_BP= MPTVIWCQLVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSE LLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLM NVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSD -------------------------------------------------------------- >66008_66008_11_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000450993_VIL1_chr2_219313946_ENST00000248444_length(transcript)=5184nt_BP=1111nt CTTCTCTCCCCACCCCACCCCCACTACTCCCTCACATTGACCAGTGTCCTGGGCCTTTAAGAGTTGGATGGGCTGGACTGGAGAGAGCTC ACACCTCTCCCCTTCTTACTGCTTCCCTCCGGCTATAACTTGCCAGTCACAGCAGCCAGCTGCTGTAGAAGAGGGGAGGAAACAAGCCAG TGCAAGGGGAGCAAAAGAGAAAAGGAGCCAGGCTGGGCTTCCTGATCCCACAGCATCGCAGAGCTCGGGAGGCACAGCTCACAGACACAG GAAACACAGGACTGCTATTCTGCTCTCCTGCCCACGGTGATCTGGTGCCAGCTGGTGGAACAGTGGGTGATGGCGTCCCTGCTGCAAGAC CAGCTGACCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGTCCAAAAGCTGGAAGAAGCTAAGATAC TTCAGACTTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGCCCAGCTTCTCAATCTCTGATGTGGAG ACAATACGTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGCAGGGCTTCACCATTGTCTTCCATGGC CGCCGCTCCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGCTCCAGCTGTTGGTGGATCTTGTCACC AGCATGGACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAAATCAGGATGGTAAGATGAGTTTCCAA GAAGTTCAGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTTTTCAGGCAGCAGACACGTCCCAGTCT GGAACCCTGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGCAGGAACTGTTTGAAAGTTTTTCAGCT GATGGGCAGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAGACTGCACCTCTGAGCTTGCTCTGGAA CTCATTGACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTC TGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACC CTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTG TGGCAAATGCCAGTTTTGTTTAATAATGTACCTATTCCTTCAGAAAGATGATACCCCAAAAGGAGCCTATGGTCCTCATTTCAACTTCTA AGGTCGCTAGATTGTTTCTATCCTGAGGTATTGCATCAATTTTAATACTCCTATAGTTTTCTCTTCTTAGAAGAGCACAAACACTCCATG GAACATTAGAGTTCTGAGGCACTACCCTAGCTTGTCCTCTATCATGACTCATTTTTATCTATGGCAGGTAGGCTGAAGCACTTTGCAGGT TTACATCTTCCCCAGAGTAACAGCTTTTCCTTTTCACATATACTTTCCTTACTGCCTTACTCAGTGGGTAAGTTAAAGGGCTGAAGGAGA GTTGAATGGTCCACAAGACTACCCTCTTAAGAGGTTTCACAAATTCCAAACAGTACCAGTGAGAGCAGCACTTCCACTGGGGCTAGGCTT GAGACCTAAAGGCAAGTATGAAATGCATATGCTACTTCACTCCCTCTCCCAACCCTTAATAATGAGGCAAAGCAAGAGCCTAGTGAAGGC CAATGCTAGGTTTACAAACTTACCCAGAAGCCTCTGCAAAGCTTCACAGGCTCCTCAGATGAAAATAACAGGAATCAATGGGGACTACGG CCAGACACTGGTTTGCCATTCTGTTCCTTTTAAGAAGTAACAGTGCTGCAAGGAAGTCCATGTCAGAAAGCCAACAGAAGGTGATTTCCA CAACTTTGAACAGGTTGTTACAAGTATCAGCAAGAATGTGTCCTTTTCAGAAATAACAGTCAAATCAAAGAAGGTTAATAAAGGCTTTAA TTTCATACACACAAAAAAACTCTATGCATAATTTAAAAAGGAAACAAAAACAAAGAAAAACCGTAAAGGATACAGAGGAACAGTTCTGCT AAAACACAGATAAAAGTGCCGCTCCATACAAAACATAAAGAATCAGAATCAAAAGTCACTCTGAACATAAAGAAAAAAAATCATCTCACA AATAATGTGGCCACAGCTGCCAGAAAACCTGGTAGTGGCTCAATTAGGCAAAGTGTAGGAATCTCATTTTTGTTTTTCTCTCCTTAAGTT TAAAGAAACAACAATGACAATAGGCCAGAGAAGTTAGGGAGGGAAAGAAAAGCTCAAAGGGAGGGAAACCTGGGGACAAGAGGTGTGCAC ACCCACATGTGGTCTCACTCTTCACACAGGCCCACTATTTTTGAAGTAGACCAGTTTAGTTGACTGTTCTTCTTTGTTCTGGCATCTGAC TGGACCAACCTGGAACCTGGTCCAGACCCTCACCCACTCTATTCTTATGCCAATGGACATACCTATACTTTGAACCTCTGTACTTTTAAG AAAAGTCCAATGTTACAAAATCAAATGCTTATATTCAGACTGGCACACTTTTTAAATAAAAACTCCATACACCTCAGACATATAGCACAC ATGGAGACAACTTACTAATTGTGTGTAAGTATGATACAATGAATGAGACTGCCTGAAGTCTAGTAATCAAAGCATGCCATAAGGTGAATG ATTGTGGTTAAACACAGCAAAATAATTGTCACAAAACTTTCAAGGCCTAACAAATTAGAATTTTCCAATAAAAAATATATATTTTTTCAG ATGTTAATAAGACATATCAGTAGAGACAAAATTAGGATTTTGAAGTAATGCAATAAAAAGATGTTGGAGGGCAGAAGTCTATTTAGTTTT TGTATACACTTGCAAGAGTGCATTACTCAGTATAAAGCAAAATGGGGAGGAAAAAGACATCCATCCATTTTATTGGAACACTTTTATGTG ACTTGAATCTGGTGTTAGGTTGTTGATTTTTCTAAAAATCTCCTATATATACAAAATCCATATGTACTTGGAGATCCAGCTGTTGCCCCC TGTTTAAAACAAAAGACCACCTCGGGGGGTCAATTAAATTAAAAAGGCCCTCCAACCACCCTAAATGGGATAACTAAGAGTATCTACTGC AGTCATTTCAGAGGACAGAGAAGGAAAATATTTTAATTTGCTTTAATATAACCTCTTTTCAGTAGATCACAAATGAGTTTACAAACTACT TTTTTTTCTCTTTAATTTAGGTGTTTGCAGATAATTTTCATTATATCCGTAGCTGTATGTGTGTATAGTTACATAATGGTAACTACACAC GATACAGAAGAATCAGTAAATTCATGGATTATTTTGCTGAGGTTTTAAATTTTAAAGCCTCTGTTTCAGAATTTTATACTTGATCAAGGA GAAAAATAAATGTGTAGTCTAACATTTGCTTTCTGGAGTTAATTAACTGATCTGTAAGAACCACTGCATATGTCTTAAAATGTAAACATA TTTACATTTGTTGTATTTGTTATTGAGCCTTTAAGGTTAGGCCCAGAATGAACAGACCATAGCAAGTAAACAAATAATTTTTAGAATCAA AGTATTAATAGAAGACCAGTTCATGGATTTGCTTATTCTATCCTGCTGAGACAAAACTCATGAGTGTGCACACACATGTGAATATATCCC TACGAAACAGTCTATCTTCTCATAGGCTTAAATTATAGTCATGGCTATTAAAGAAATTAACAGCATCCAGCCACATGCAACTTTCCAACC TTCAGTACTATTAGGTGATTAAAATCAACAAATATGAAGTTTAGTTCATTTTTCCCTTAAAATTCCAACAAAGATCAAAAGGTTGTATCT AGAACTAATTGCCATCAAGTTCCAATTCAATGTCATTTAAAGTAATGTAACCACACATTTGGTATTTTCAATAGGAAGGTTAATTAGGTA TTGTGCAAACTGCCTGCAACGGAAGCACTCAGTCCTTATCTAACTTGTCCCTTCCTGGCCCCAACATGCTAACTGCCCCATCCCCAATTC TGGGCAAACTGATCACAATGTGCAAAAAATAATATATTATCTATTTATAATTTTAAAATATATACAGCCAGCTCAAAAACAACAACAAAC CCCATCAACATAGTCCAGCTGAAATCTCCACTGGTAGTCAAAGAAGTAGATTAAAGGAGTAAAGGAAGGAGAAGGCTGATAGGGCCACAA GAATGGACAGACATCAAGTAAAATTTGAGTCCCAAACATGCAAGTACATGAGCAGTGAGATAACTTATATATTCCAATAACCTATTTTCA ACAACTCCTGCCCAAGACATGAAGATCAAATCAGGTTTCTGAGGTAAGTGTACTTCTAAACCATACACACATGAAAGCTATGAAAGCAAT TCAAATGAGGCTGCTTCATGAGGCAATCTAGACTTATGGCATTATTTCTACTTTTCTCCATGTTTTAATTGCAGCCTGCACTTTAAATCT TTCCCAATAATTTTTAACAGTGCCTCTCAAATGCAAAGACACGTAAAAGAATTAATAACTAGCCAAAGAATTTTATCACCGCTTCACTCA TTTATAAGAAAACCAATTATTTCCAAGCAAAATCAAACCAAACCAAAGAGGCTCCTGGTAGAAATGAAACAAAACTTTAAAGCTAGTTTT AAAACAAATATTTTCCTCTGCTCTAAACTACTCTGGCGTTTTCTACCACTCTACCATTTTGGAACATTCATTACAATAAGGTATATAGGT AGATGGTAGGAGGCAAAGCATTTATCAGTAGTTGAGCAAAACTGCTGAGGCCATTTATAATTCAAAGAATGAAAACTTAGAATAGTTTAC TACATTAGAATACATCCAAGTTCCAAGAGTAGGACTGGAGCTCTCTTAAGGCAATCTTTCAGAAAAGATGTTGCATCTTCTGTGATGATG >66008_66008_11_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000450993_VIL1_chr2_219313946_ENST00000248444_length(amino acids)=276AA_BP= MPTVIWCQLVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSE LLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLM NVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSD -------------------------------------------------------------- >66008_66008_12_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000450993_VIL1_chr2_219313946_ENST00000392114_length(transcript)=1413nt_BP=1111nt CTTCTCTCCCCACCCCACCCCCACTACTCCCTCACATTGACCAGTGTCCTGGGCCTTTAAGAGTTGGATGGGCTGGACTGGAGAGAGCTC ACACCTCTCCCCTTCTTACTGCTTCCCTCCGGCTATAACTTGCCAGTCACAGCAGCCAGCTGCTGTAGAAGAGGGGAGGAAACAAGCCAG TGCAAGGGGAGCAAAAGAGAAAAGGAGCCAGGCTGGGCTTCCTGATCCCACAGCATCGCAGAGCTCGGGAGGCACAGCTCACAGACACAG GAAACACAGGACTGCTATTCTGCTCTCCTGCCCACGGTGATCTGGTGCCAGCTGGTGGAACAGTGGGTGATGGCGTCCCTGCTGCAAGAC CAGCTGACCACTGATCAGGACTTGCTGCTGATGCAGGAAGGCATGCCGATGCGCAAGGTGAGGTCCAAAAGCTGGAAGAAGCTAAGATAC TTCAGACTTCAGAATGACGGCATGACAGTCTGGCATGCACGGCAGGCCAGGGGCAGTGCCAAGCCCAGCTTCTCAATCTCTGATGTGGAG ACAATACGTAATGGCCATGATTCCGAGTTGCTGCGTAGCCTGGCAGAGGAGCTCCCCCTGGAGCAGGGCTTCACCATTGTCTTCCATGGC CGCCGCTCCAACCTGGACCTGATGGCCAACAGTGTTGAGGAGGCCCAGATATGGATGCGAGGGCTCCAGCTGTTGGTGGATCTTGTCACC AGCATGGACCATCAGGAGCGCCTGGACCAATGGCTGAGCGATTGGTTTCAACGTGGAGACAAAAATCAGGATGGTAAGATGAGTTTCCAA GAAGTTCAGCGGTTATTGCACCTAATGAATGTGGAAATGGACCAAGAATATGCCTTCAGTCTTTTTCAGGCAGCAGACACGTCCCAGTCT GGAACCCTGGAAGGAGAAGAATTCGTACAGTTCTATAAGGCATTGACTAAACGTGCTGAGGTGCAGGAACTGTTTGAAAGTTTTTCAGCT GATGGGCAGAAGCTGACTCTGCTGGAATTTTTGGATTTCCTCCAAGAGGAGCAGAAGGAGAGAGACTGCACCTCTGAGCTTGCTCTGGAA CTCATTGACCGCTATGAACCTTCAGACAGTGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTC TGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACC CTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTG >66008_66008_12_PLCD4-VIL1_PLCD4_chr2_219487601_ENST00000450993_VIL1_chr2_219313946_ENST00000392114_length(amino acids)=276AA_BP= MPTVIWCQLVEQWVMASLLQDQLTTDQDLLLMQEGMPMRKVRSKSWKKLRYFRLQNDGMTVWHARQARGSAKPSFSISDVETIRNGHDSE LLRSLAEELPLEQGFTIVFHGRRSNLDLMANSVEEAQIWMRGLQLLVDLVTSMDHQERLDQWLSDWFQRGDKNQDGKMSFQEVQRLLHLM NVEMDQEYAFSLFQAADTSQSGTLEGEEFVQFYKALTKRAEVQELFESFSADGQKLTLLEFLDFLQEEQKERDCTSELALELIDRYEPSD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for PLCD4-VIL1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for PLCD4-VIL1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for PLCD4-VIL1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0008370 | Cholestasis | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies