
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CDH8-RFX1 (FusionGDB2 ID:HG1006TG5989) |
Fusion Gene Summary for CDH8-RFX1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CDH8-RFX1 | Fusion gene ID: hg1006tg5989 | Hgene | Tgene | Gene symbol | CDH8 | RFX1 | Gene ID | 1006 | 5989 |
| Gene name | cadherin 8 | regulatory factor X1 | |
| Synonyms | Nbla04261 | EFC|RFX | |
| Cytomap | ('CDH8')('RFX1') 16q21 | 19p13.12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cadherin-8cadherin 8, type 2 | MHC class II regulatory factor RFX1MHC class II regulatory factor RFXenhancer factor Cregulatory factor X, 1 (influences HLA class II expression)trans-acting regulatory factor 1transcription factor RFX1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P55286 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000299345, ENST00000577390, ENST00000577730, ENST00000584337, ENST00000580044, | ||
| Fusion gene scores | * DoF score | 4 X 4 X 2=32 | 5 X 4 X 4=80 |
| # samples | 4 | 4 | |
| ** MAII score | log2(4/32*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(4/80*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CDH8 [Title/Abstract] AND RFX1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CDH8(61935083)-RFX1(14083939), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | CDH8-RFX1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CDH8-RFX1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CDH8-RFX1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CDH8-RFX1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CDH8-RFX1 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. CDH8-RFX1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. CDH8-RFX1 seems lost the major protein functional domain in Tgene partner, which is a transcription factor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across CDH8 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RFX1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | CESC | TCGA-DS-A5RQ-01A | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
Top |
Fusion Gene ORF analysis for CDH8-RFX1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000299345 | ENST00000586913 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| 5CDS-intron | ENST00000577390 | ENST00000586913 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| 5CDS-intron | ENST00000577730 | ENST00000586913 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| 5CDS-intron | ENST00000584337 | ENST00000586913 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| Frame-shift | ENST00000577730 | ENST00000254325 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| In-frame | ENST00000299345 | ENST00000254325 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| In-frame | ENST00000577390 | ENST00000254325 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| In-frame | ENST00000584337 | ENST00000254325 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| intron-3CDS | ENST00000580044 | ENST00000254325 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| intron-intron | ENST00000580044 | ENST00000586913 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000299345 | CDH8 | chr16 | 61935083 | - | ENST00000254325 | RFX1 | chr19 | 14083939 | - | 4670 | 1502 | 1536 | 3512 | 658 |
| ENST00000577390 | CDH8 | chr16 | 61935083 | - | ENST00000254325 | RFX1 | chr19 | 14083939 | - | 4670 | 1502 | 1536 | 3512 | 658 |
| ENST00000584337 | CDH8 | chr16 | 61935083 | - | ENST00000254325 | RFX1 | chr19 | 14083939 | - | 4237 | 1069 | 1103 | 3079 | 658 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000299345 | ENST00000254325 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - | 0.006956976 | 0.99304307 |
| ENST00000577390 | ENST00000254325 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - | 0.006956976 | 0.99304307 |
| ENST00000584337 | ENST00000254325 | CDH8 | chr16 | 61935083 | - | RFX1 | chr19 | 14083939 | - | 0.007183759 | 0.9928162 |
Top |
Fusion Genomic Features for CDH8-RFX1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
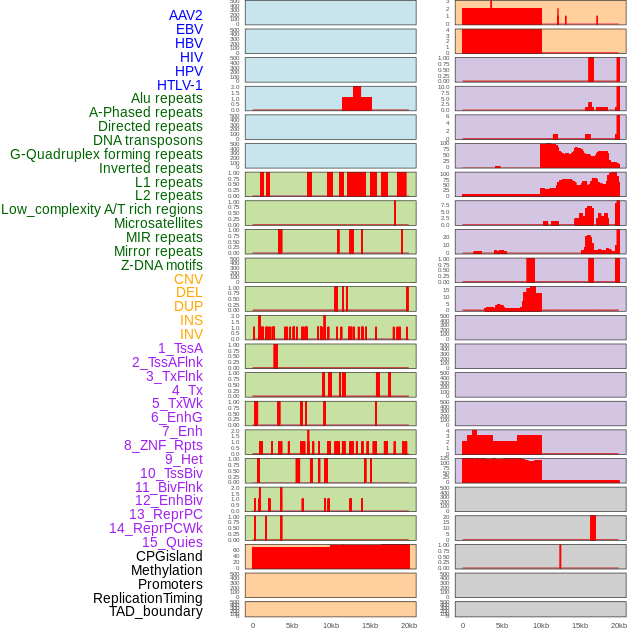 |
Top |
Fusion Protein Features for CDH8-RFX1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr16:61935083/chr19:14083939) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CDH8 | . |
| FUNCTION: Cadherins are calcium-dependent cell adhesion proteins. They preferentially interact with themselves in a homophilic manner in connecting cells; cadherins may thus contribute to the sorting of heterogeneous cell types. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CDH8 | chr16:61935083 | chr19:14083939 | ENST00000577390 | - | 3 | 12 | 62_167 | 182 | 800.0 | Domain | Cadherin 1 |
| Tgene | RFX1 | chr16:61935083 | chr19:14083939 | ENST00000254325 | 7 | 21 | 381_411 | 309 | 980.0 | Compositional bias | Note=Gly-rich | |
| Tgene | RFX1 | chr16:61935083 | chr19:14083939 | ENST00000254325 | 7 | 21 | 920_936 | 309 | 980.0 | Compositional bias | Note=Asp/Glu-rich (acidic) | |
| Tgene | RFX1 | chr16:61935083 | chr19:14083939 | ENST00000254325 | 7 | 21 | 438_513 | 309 | 980.0 | DNA binding | RFX-type winged-helix | |
| Tgene | RFX1 | chr16:61935083 | chr19:14083939 | ENST00000254325 | 7 | 21 | 744_979 | 309 | 980.0 | Region | Note=Necessary for dimerization |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CDH8 | chr16:61935083 | chr19:14083939 | ENST00000577390 | - | 3 | 12 | 168_276 | 182 | 800.0 | Domain | Cadherin 2 |
| Hgene | CDH8 | chr16:61935083 | chr19:14083939 | ENST00000577390 | - | 3 | 12 | 277_391 | 182 | 800.0 | Domain | Cadherin 3 |
| Hgene | CDH8 | chr16:61935083 | chr19:14083939 | ENST00000577390 | - | 3 | 12 | 392_494 | 182 | 800.0 | Domain | Cadherin 4 |
| Hgene | CDH8 | chr16:61935083 | chr19:14083939 | ENST00000577390 | - | 3 | 12 | 495_616 | 182 | 800.0 | Domain | Cadherin 5 |
| Hgene | CDH8 | chr16:61935083 | chr19:14083939 | ENST00000577390 | - | 3 | 12 | 62_621 | 182 | 800.0 | Topological domain | Extracellular |
| Hgene | CDH8 | chr16:61935083 | chr19:14083939 | ENST00000577390 | - | 3 | 12 | 643_799 | 182 | 800.0 | Topological domain | Cytoplasmic |
| Hgene | CDH8 | chr16:61935083 | chr19:14083939 | ENST00000577390 | - | 3 | 12 | 622_642 | 182 | 800.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for CDH8-RFX1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >15097_15097_1_CDH8-RFX1_CDH8_chr16_61935083_ENST00000299345_RFX1_chr19_14083939_ENST00000254325_length(transcript)=4670nt_BP=1502nt AACATAACGCCAGCCCCAGAGCTCAGGTGAGACCTCTAGAGAGAAAGCTCGCAGGTACCTCATCCGCATGCTGTTATTATCTGCCAGCCC ACTTATCCAGGAGCTCGGTCCTCAGCGGGCTGCGCGCACCGCGCGGAAGGGCGCATCTTCACCTCGTGGCTCTGGCGGCAGAGACGCGCG GGGCTTGCTCGGGAGCGAGGAGCGAAAAGTTGTGCGCCCACTTGGGTAGGGGGAAAGAGAGCGATCGAGCCAGCGCGGGAGAGCGAAGGG GGAAGGCGGGGAGGGGGCGGGGAGGGGGGACTGCTTACATGAATTTCCAAGTGGTAGACCTGCCTCTGCGCTCTGCCCAATGAGATCCGT CAGGGGAGGCACCCGGCTCACTTTTCCACATCACTTCACAGTTACATTTGGCAGGCAGGCGGGCTCGCACGCCGGAGCGCTCAGCCCAGA ATTAGTGGATTTATTTGGAATCTCCCTGCCTCCTCCAAGCTCCGCCGCCGCCGCCGGCTTGTGCATAGACGGTAGCGTCAAGACACCAGC TGCACTTTGGGTTGCGGACACCCAGAGCCCAGCGCGCCCGCCCTGCGTCTCCGCACCAAGCCCTGTAGCTCCGAGAGGCATGAACGGAAT CCGGAGGCGCCTGCCTAGCGAGCGAGGACCGGTCGGCGCTTGCCGCCCTCGGGAGCTAACCCCGAGCACCTCCAGCCATTTGTGAACCTG GAGGCTTGACATTCGCCAGCGCAGGGCCCCACAAGAGAAATTTCAATGAAAAGAAAAGCCAATGGATTGTGGTCTTAGAAAAGCTGCTTA GATGATGTCTGTTTCCCGTGCTATAGACACGTGGCAGAGCTGTAAGTAAATGCTCGGCACTGCATGATGAATTGGATGGCTGCAGACCGG AGACAAAAAAAATAATTGTCTCATTTTCGTGGTGATTTGCTTAACTGGTGGGACCATGCCAGAACGGCTAGCGGAAATGCTCTTGGATCT CTGGACTCCATTAATAATATTATGGATTACTCTTCCCCCTTGCATTTACATGGCTCCGATGAATCAGTCTCAAGTTTTAATGAGTGGATC CCCTTTGGAACTAAACAGTCTGGGTGAAGAACAGCGAATTTTGAACCGCTCCAAAAGAGGCTGGGTTTGGAATCAAATGTTTGTCCTGGA AGAGTTTTCTGGACCTGAACCGATTCTTGTTGGCCGGCTACACACAGACCTGGATCCTGGGAGCAAAAAAATCAAGTATATCCTATCAGG TGATGGAGCTGGGACCATATTTCAAATAAATGATGTAACTGGAGATATCCATGCTATAAAAAGACTTGACCGGGAGGAAAAGGCTGAGTA TACCCTAACAGCTCAAGCAGTGGACTGGGAGACAAGCAAACCTCTGGAGCCTCCTTCTGAATTTATTATTAAAGTTCAAGACATCAATGA CAATGCACCAGAGTTTCTTAATGGACCCTATCATGCTACTGTGCCAGAAATGTCCATTTTGGCCGTTCCAGCACCTACTCCTATCCCGAG ACGCCGCTGTACACGCAGACGGCAAGCACCAGCTACTACGAGGCCGCAGGCACGGCCACCCAGGTCAGCACCCCCGCCACCTCCCAGGCG GTGGCCAGCAGTGGCTCCATGCCCATGTACGTGTCCGGCAGCCAGGTCGTCGCCAGCTCCACCAGCACTGGGGCTGGGGCCAGCAACAGC AGCGGAGGTGGTGGCAGTGGTGGTGGCGGCGGCGGCGGGGGAGGCGGTGGCGGGGGTGGCAGTGGCAGCACCGGAGGCGGCGGCAGCGGA GCAGGCACCTACGTGATCCAAGGCGGCTACATGCTGGGCAGTGCCAGCCAGTCTTACTCTCACACCACCCGTGCCTCGCCAGCCACGGTC CAGTGGCTCCTGGACAACTATGAGACGGCTGAGGGCGTGAGTCTGCCACGGAGCACCCTCTACTGCCACTACTTACTGCACTGCCAGGAG CAGAAGCTGGAGCCCGTCAACGCCGCCTCCTTCGGCAAGCTCATCCGCTCCGTCTTCATGGGCCTGCGAACCCGCCGTCTGGGCACCAGG GGCAACTCCAAGTACCACTACTATGGCCTGCGCATCAAGGCCAGCTCACCCCTGCTGCGGCTGATGGAGGACCAGCAGCACATGGCCATG CGGGGCCAGCCCTTCTCGCAGAAGCAGAGGCTCAAGCCCATCCAGAAGATGGAAGGCATGACCAACGGCGTGGCGGTGGGGCAGCAGCCG AGCACGGGGCTGTCGGACATCAGCGCCCAGGTGCAGCAGTACCAGCAATTTTTGGATGCCTCTCGGAGCCTCCCTGACTTCACAGAGCTC GACCTCCAGGGCAAGGTGCTGCCTGAGGGCGTCGGGCCCGGGGACATCAAAGCCTTCCAGGTCCTGTACCGGGAACACTGTGAGGCCATT GTCGACGTCATGGTGAACCTGCAGTTCACCCTGGTGGAGACGCTGTGGAAGACCTTCTGGAGGTACAACCTCAGCCAGCCCAGTGAGGCG CCACCGCTGGCTGTACATGACGAGGCCGAGAAGCGACTGCCCAAAGCCATCCTGGTGCTCCTCTCCAAGTTCGAGCCCGTGCTCCAATGG ACCAAGCACTGTGACAACGTGCTGTACCAGGGCCTGGTGGAAATCCTCATTCCCGACGTGCTGCGGCCCATCCCCAGTGCCTTGACCCAA GCGATCCGGAACTTTGCCAAGAGCCTGGAGAGCTGGCTCACCCACGCCATGGTCAACATCCCCGAGGAGATGCTGCGGGTGAAGGTGGCC GCGGCTGGCGCCTTCGCGCAGACACTGCGGCGCTACACGTCGCTCAACCACCTGGCGCAGGCGGCGCGCGCTGTGCTGCAGAACACCGCA CAGATCAACCAGATGCTGAGCGACCTCAACCGCGTGGACTTCGCCAACGTGCAGGAGCAGGCCTCGTGGGTGTGCCGCTGCGAGGACCGC GTGGTGCAGCGGCTGGAGCAGGACTTCAAGGTGACGCTGCAGCAGCAGAACTCGCTGGAGCAGTGGGCGGCCTGGCTGGACGGCGTGGTG AGCCAGGTGCTCAAGCCCTACCAGGGCAGCGCCGGCTTCCCCAAGGCCGCCAAGCTCTTCCTCCTCAAGTGGTCCTTCTACAGCTCCATG GTGATCCGGGACCTGACCCTGCGCAGCGCCGCCAGCTTCGGTTCCTTCCACCTCATCCGGCTGCTCTACGACGAGTACATGTACTACCTG ATCGAGCACCGCGTAGCCCAGGCCAAGGGCGAGACCCCCATCGCCGTCATGGGCGAGTTCGCCAATCTGGCCACCTCCCTGAACCCCCTG GACCCCGACAAAGACGAGGAGGAAGAAGAGGAGGAGGAGAGCGAGGACGAGCTGCCGCAGGACATCTCACTGGCGGCTGGCGGCGAGTCA CCCGCGCTGGGCCCGGAGACCCTGGAGCCGCCGGCCAAGCTGGCGCGGACTGACGCGCGCGGCCTCTTCGTGCAGGCGCTGCCCTCCAGC TAAGCCCTTGGCCTCCCCGCCCCACCCGCCCCCGCCACCCCTCCACGCCAGGGTCCCTCAAAGCTTCTGTGGCTTCGTGGTCACTGCTCC AGCCTCAGCCAGGGCAGGGAGGGGGACTCCGAGACAGGGAAGACCGGGGCCCTCCTCCCTTATGGGGCCGGCACAATCAGTGGGCTGGGC GGAGCCGCAGCTGCAAACTCTGACACAAAAGACGTGCCTTAAGGAACCCGCCGCGTGCCCAGGTGCCCCGCGGGGCATCCAGCTCGGCCC CTTGGCCGCCCCCCTCCCAGGCCCCAGCGTCTTCTCCCCAGCCCCGTCCTCCCACCACCCCAGGGGGCAGGCAGGCAGGCCCCCTCCCGT GCGAAACTGTTAACTTATTCAGCTCGCTGGCTTTGCACAGCCTGTCCTGGGCCCAGCCCTGAGCCCCGGGCCGGCGCAGGTGGGCGTCAC CTGGGGACTCCCCACTGTCAGCAGCAGCCCCGGGACACCCTACCCCCAGCAACCCCACTGCTTCCCCTTCTTGGTATTAAGTGCAATTAA AGCCGTGGGTGTCGCATCTTCTCCAGCGCTGGGCCCTCCCTTGCCCCCAAGCTCAAGAAGGGGGCACTGCCCGGCCCGGCTGTGAGGAGG GCGGCAGGGGGCACGGCCTCCAGCTTCCAAAGAGCAGCGAGCCGCGGAGCCGGGGAGTGCCCACAGACCCCAGCCCCCGCGCCCCCGCCC TCCGCCGCTGGTTTGTAATGGAACCTTTTCTGTGCCCCTATCTTCCCGGAGACCACGCTTCTCCTCCGTGCCGTGCGACCCCCACCCCAT GACTATTGTGCGATTCGTGAGCGCCGCCCGAGCGGAGTTGGTAACTTGTTGGGTTTTTTTCCAACCATCATGGCCTTATCTGTTCCAGTT TTCTCAGTGTTTTCAGCCTGTGAGATAGATGTTTATGGCAAGAAAAAGGAAAAAAAAATGGAAATCTGACCTATTGTATAAAAATCACTA TTTTGTGTGCTCCGCGTGCTATAGCTTTTGGGGCGGCCCTGCCCAGTCCCCGTGCCCACGGGGCTCCCTCTCCCGGTGGTGAAAGTGTCC ACACGTGTGGTAGTCTAGTGTGCCGAGCTGTTTTCTACCTTTTTGTAGTCTTTCTTAAAACAATAAATTCCGCTGTGATA >15097_15097_1_CDH8-RFX1_CDH8_chr16_61935083_ENST00000299345_RFX1_chr19_14083939_ENST00000254325_length(amino acids)=658AA_BP=43 MYTQTASTSYYEAAGTATQVSTPATSQAVASSGSMPMYVSGSQVVASSTSTGAGASNSSGGGGSGGGGGGGGGGGGGGSGSTGGGGSGAG TYVIQGGYMLGSASQSYSHTTRASPATVQWLLDNYETAEGVSLPRSTLYCHYLLHCQEQKLEPVNAASFGKLIRSVFMGLRTRRLGTRGN SKYHYYGLRIKASSPLLRLMEDQQHMAMRGQPFSQKQRLKPIQKMEGMTNGVAVGQQPSTGLSDISAQVQQYQQFLDASRSLPDFTELDL QGKVLPEGVGPGDIKAFQVLYREHCEAIVDVMVNLQFTLVETLWKTFWRYNLSQPSEAPPLAVHDEAEKRLPKAILVLLSKFEPVLQWTK HCDNVLYQGLVEILIPDVLRPIPSALTQAIRNFAKSLESWLTHAMVNIPEEMLRVKVAAAGAFAQTLRRYTSLNHLAQAARAVLQNTAQI NQMLSDLNRVDFANVQEQASWVCRCEDRVVQRLEQDFKVTLQQQNSLEQWAAWLDGVVSQVLKPYQGSAGFPKAAKLFLLKWSFYSSMVI RDLTLRSAASFGSFHLIRLLYDEYMYYLIEHRVAQAKGETPIAVMGEFANLATSLNPLDPDKDEEEEEEEESEDELPQDISLAAGGESPA LGPETLEPPAKLARTDARGLFVQALPSS -------------------------------------------------------------- >15097_15097_2_CDH8-RFX1_CDH8_chr16_61935083_ENST00000577390_RFX1_chr19_14083939_ENST00000254325_length(transcript)=4670nt_BP=1502nt AACATAACGCCAGCCCCAGAGCTCAGGTGAGACCTCTAGAGAGAAAGCTCGCAGGTACCTCATCCGCATGCTGTTATTATCTGCCAGCCC ACTTATCCAGGAGCTCGGTCCTCAGCGGGCTGCGCGCACCGCGCGGAAGGGCGCATCTTCACCTCGTGGCTCTGGCGGCAGAGACGCGCG GGGCTTGCTCGGGAGCGAGGAGCGAAAAGTTGTGCGCCCACTTGGGTAGGGGGAAAGAGAGCGATCGAGCCAGCGCGGGAGAGCGAAGGG GGAAGGCGGGGAGGGGGCGGGGAGGGGGGACTGCTTACATGAATTTCCAAGTGGTAGACCTGCCTCTGCGCTCTGCCCAATGAGATCCGT CAGGGGAGGCACCCGGCTCACTTTTCCACATCACTTCACAGTTACATTTGGCAGGCAGGCGGGCTCGCACGCCGGAGCGCTCAGCCCAGA ATTAGTGGATTTATTTGGAATCTCCCTGCCTCCTCCAAGCTCCGCCGCCGCCGCCGGCTTGTGCATAGACGGTAGCGTCAAGACACCAGC TGCACTTTGGGTTGCGGACACCCAGAGCCCAGCGCGCCCGCCCTGCGTCTCCGCACCAAGCCCTGTAGCTCCGAGAGGCATGAACGGAAT CCGGAGGCGCCTGCCTAGCGAGCGAGGACCGGTCGGCGCTTGCCGCCCTCGGGAGCTAACCCCGAGCACCTCCAGCCATTTGTGAACCTG GAGGCTTGACATTCGCCAGCGCAGGGCCCCACAAGAGAAATTTCAATGAAAAGAAAAGCCAATGGATTGTGGTCTTAGAAAAGCTGCTTA GATGATGTCTGTTTCCCGTGCTATAGACACGTGGCAGAGCTGTAAGTAAATGCTCGGCACTGCATGATGAATTGGATGGCTGCAGACCGG AGACAAAAAAAATAATTGTCTCATTTTCGTGGTGATTTGCTTAACTGGTGGGACCATGCCAGAACGGCTAGCGGAAATGCTCTTGGATCT CTGGACTCCATTAATAATATTATGGATTACTCTTCCCCCTTGCATTTACATGGCTCCGATGAATCAGTCTCAAGTTTTAATGAGTGGATC CCCTTTGGAACTAAACAGTCTGGGTGAAGAACAGCGAATTTTGAACCGCTCCAAAAGAGGCTGGGTTTGGAATCAAATGTTTGTCCTGGA AGAGTTTTCTGGACCTGAACCGATTCTTGTTGGCCGGCTACACACAGACCTGGATCCTGGGAGCAAAAAAATCAAGTATATCCTATCAGG TGATGGAGCTGGGACCATATTTCAAATAAATGATGTAACTGGAGATATCCATGCTATAAAAAGACTTGACCGGGAGGAAAAGGCTGAGTA TACCCTAACAGCTCAAGCAGTGGACTGGGAGACAAGCAAACCTCTGGAGCCTCCTTCTGAATTTATTATTAAAGTTCAAGACATCAATGA CAATGCACCAGAGTTTCTTAATGGACCCTATCATGCTACTGTGCCAGAAATGTCCATTTTGGCCGTTCCAGCACCTACTCCTATCCCGAG ACGCCGCTGTACACGCAGACGGCAAGCACCAGCTACTACGAGGCCGCAGGCACGGCCACCCAGGTCAGCACCCCCGCCACCTCCCAGGCG GTGGCCAGCAGTGGCTCCATGCCCATGTACGTGTCCGGCAGCCAGGTCGTCGCCAGCTCCACCAGCACTGGGGCTGGGGCCAGCAACAGC AGCGGAGGTGGTGGCAGTGGTGGTGGCGGCGGCGGCGGGGGAGGCGGTGGCGGGGGTGGCAGTGGCAGCACCGGAGGCGGCGGCAGCGGA GCAGGCACCTACGTGATCCAAGGCGGCTACATGCTGGGCAGTGCCAGCCAGTCTTACTCTCACACCACCCGTGCCTCGCCAGCCACGGTC CAGTGGCTCCTGGACAACTATGAGACGGCTGAGGGCGTGAGTCTGCCACGGAGCACCCTCTACTGCCACTACTTACTGCACTGCCAGGAG CAGAAGCTGGAGCCCGTCAACGCCGCCTCCTTCGGCAAGCTCATCCGCTCCGTCTTCATGGGCCTGCGAACCCGCCGTCTGGGCACCAGG GGCAACTCCAAGTACCACTACTATGGCCTGCGCATCAAGGCCAGCTCACCCCTGCTGCGGCTGATGGAGGACCAGCAGCACATGGCCATG CGGGGCCAGCCCTTCTCGCAGAAGCAGAGGCTCAAGCCCATCCAGAAGATGGAAGGCATGACCAACGGCGTGGCGGTGGGGCAGCAGCCG AGCACGGGGCTGTCGGACATCAGCGCCCAGGTGCAGCAGTACCAGCAATTTTTGGATGCCTCTCGGAGCCTCCCTGACTTCACAGAGCTC GACCTCCAGGGCAAGGTGCTGCCTGAGGGCGTCGGGCCCGGGGACATCAAAGCCTTCCAGGTCCTGTACCGGGAACACTGTGAGGCCATT GTCGACGTCATGGTGAACCTGCAGTTCACCCTGGTGGAGACGCTGTGGAAGACCTTCTGGAGGTACAACCTCAGCCAGCCCAGTGAGGCG CCACCGCTGGCTGTACATGACGAGGCCGAGAAGCGACTGCCCAAAGCCATCCTGGTGCTCCTCTCCAAGTTCGAGCCCGTGCTCCAATGG ACCAAGCACTGTGACAACGTGCTGTACCAGGGCCTGGTGGAAATCCTCATTCCCGACGTGCTGCGGCCCATCCCCAGTGCCTTGACCCAA GCGATCCGGAACTTTGCCAAGAGCCTGGAGAGCTGGCTCACCCACGCCATGGTCAACATCCCCGAGGAGATGCTGCGGGTGAAGGTGGCC GCGGCTGGCGCCTTCGCGCAGACACTGCGGCGCTACACGTCGCTCAACCACCTGGCGCAGGCGGCGCGCGCTGTGCTGCAGAACACCGCA CAGATCAACCAGATGCTGAGCGACCTCAACCGCGTGGACTTCGCCAACGTGCAGGAGCAGGCCTCGTGGGTGTGCCGCTGCGAGGACCGC GTGGTGCAGCGGCTGGAGCAGGACTTCAAGGTGACGCTGCAGCAGCAGAACTCGCTGGAGCAGTGGGCGGCCTGGCTGGACGGCGTGGTG AGCCAGGTGCTCAAGCCCTACCAGGGCAGCGCCGGCTTCCCCAAGGCCGCCAAGCTCTTCCTCCTCAAGTGGTCCTTCTACAGCTCCATG GTGATCCGGGACCTGACCCTGCGCAGCGCCGCCAGCTTCGGTTCCTTCCACCTCATCCGGCTGCTCTACGACGAGTACATGTACTACCTG ATCGAGCACCGCGTAGCCCAGGCCAAGGGCGAGACCCCCATCGCCGTCATGGGCGAGTTCGCCAATCTGGCCACCTCCCTGAACCCCCTG GACCCCGACAAAGACGAGGAGGAAGAAGAGGAGGAGGAGAGCGAGGACGAGCTGCCGCAGGACATCTCACTGGCGGCTGGCGGCGAGTCA CCCGCGCTGGGCCCGGAGACCCTGGAGCCGCCGGCCAAGCTGGCGCGGACTGACGCGCGCGGCCTCTTCGTGCAGGCGCTGCCCTCCAGC TAAGCCCTTGGCCTCCCCGCCCCACCCGCCCCCGCCACCCCTCCACGCCAGGGTCCCTCAAAGCTTCTGTGGCTTCGTGGTCACTGCTCC AGCCTCAGCCAGGGCAGGGAGGGGGACTCCGAGACAGGGAAGACCGGGGCCCTCCTCCCTTATGGGGCCGGCACAATCAGTGGGCTGGGC GGAGCCGCAGCTGCAAACTCTGACACAAAAGACGTGCCTTAAGGAACCCGCCGCGTGCCCAGGTGCCCCGCGGGGCATCCAGCTCGGCCC CTTGGCCGCCCCCCTCCCAGGCCCCAGCGTCTTCTCCCCAGCCCCGTCCTCCCACCACCCCAGGGGGCAGGCAGGCAGGCCCCCTCCCGT GCGAAACTGTTAACTTATTCAGCTCGCTGGCTTTGCACAGCCTGTCCTGGGCCCAGCCCTGAGCCCCGGGCCGGCGCAGGTGGGCGTCAC CTGGGGACTCCCCACTGTCAGCAGCAGCCCCGGGACACCCTACCCCCAGCAACCCCACTGCTTCCCCTTCTTGGTATTAAGTGCAATTAA AGCCGTGGGTGTCGCATCTTCTCCAGCGCTGGGCCCTCCCTTGCCCCCAAGCTCAAGAAGGGGGCACTGCCCGGCCCGGCTGTGAGGAGG GCGGCAGGGGGCACGGCCTCCAGCTTCCAAAGAGCAGCGAGCCGCGGAGCCGGGGAGTGCCCACAGACCCCAGCCCCCGCGCCCCCGCCC TCCGCCGCTGGTTTGTAATGGAACCTTTTCTGTGCCCCTATCTTCCCGGAGACCACGCTTCTCCTCCGTGCCGTGCGACCCCCACCCCAT GACTATTGTGCGATTCGTGAGCGCCGCCCGAGCGGAGTTGGTAACTTGTTGGGTTTTTTTCCAACCATCATGGCCTTATCTGTTCCAGTT TTCTCAGTGTTTTCAGCCTGTGAGATAGATGTTTATGGCAAGAAAAAGGAAAAAAAAATGGAAATCTGACCTATTGTATAAAAATCACTA TTTTGTGTGCTCCGCGTGCTATAGCTTTTGGGGCGGCCCTGCCCAGTCCCCGTGCCCACGGGGCTCCCTCTCCCGGTGGTGAAAGTGTCC ACACGTGTGGTAGTCTAGTGTGCCGAGCTGTTTTCTACCTTTTTGTAGTCTTTCTTAAAACAATAAATTCCGCTGTGATA >15097_15097_2_CDH8-RFX1_CDH8_chr16_61935083_ENST00000577390_RFX1_chr19_14083939_ENST00000254325_length(amino acids)=658AA_BP=43 MYTQTASTSYYEAAGTATQVSTPATSQAVASSGSMPMYVSGSQVVASSTSTGAGASNSSGGGGSGGGGGGGGGGGGGGSGSTGGGGSGAG TYVIQGGYMLGSASQSYSHTTRASPATVQWLLDNYETAEGVSLPRSTLYCHYLLHCQEQKLEPVNAASFGKLIRSVFMGLRTRRLGTRGN SKYHYYGLRIKASSPLLRLMEDQQHMAMRGQPFSQKQRLKPIQKMEGMTNGVAVGQQPSTGLSDISAQVQQYQQFLDASRSLPDFTELDL QGKVLPEGVGPGDIKAFQVLYREHCEAIVDVMVNLQFTLVETLWKTFWRYNLSQPSEAPPLAVHDEAEKRLPKAILVLLSKFEPVLQWTK HCDNVLYQGLVEILIPDVLRPIPSALTQAIRNFAKSLESWLTHAMVNIPEEMLRVKVAAAGAFAQTLRRYTSLNHLAQAARAVLQNTAQI NQMLSDLNRVDFANVQEQASWVCRCEDRVVQRLEQDFKVTLQQQNSLEQWAAWLDGVVSQVLKPYQGSAGFPKAAKLFLLKWSFYSSMVI RDLTLRSAASFGSFHLIRLLYDEYMYYLIEHRVAQAKGETPIAVMGEFANLATSLNPLDPDKDEEEEEEEESEDELPQDISLAAGGESPA LGPETLEPPAKLARTDARGLFVQALPSS -------------------------------------------------------------- >15097_15097_3_CDH8-RFX1_CDH8_chr16_61935083_ENST00000584337_RFX1_chr19_14083939_ENST00000254325_length(transcript)=4237nt_BP=1069nt GGAGCGCTCAGCCCAGAATTAGTGGATTTATTTGGAATCTCCCTGCCTCCTCCAAGCTCCGCCGCCGCCGCCGGCTTGTGCATAGACGGT AGCGTCAAGACACCAGCTGCACTTTGGGTTGCGGACACCCAGAGCCCAGCGCGCCCGCCCTGCGTCTCCGCACCAAGCCCTGTAGCTCCG AGAGGCATGAACGGAATCCGGAGGCGCCTGCCTAGCGAGCGAGGACCGGTCGGCGCTTGCCGCCCTCGGGAGCTAACCCCGAGCACCTCC AGCCATTTGTGAACCTGGAGGCTTGACATTCGCCAGCGCAGGGCCCCACAAGAGAAATTTCAATGAAAAGAAAAGCCAATGGATTGTGGT CTTAGAAAAGCTGCTTAGATGATGTCTGTTTCCCGTGCTATAGACACGTGGCAGAGCTGTAAGTAAATGCTCGGCACTGCATGATGAATT GGATGGCTGCAGACCGGAGACAAAAAAAATAATTGTCTCATTTTCGTGGTGATTTGCTTAACTGGTGGGACCATGCCAGAACGGCTAGCG GAAATGCTCTTGGATCTCTGGACTCCATTAATAATATTATGGATTACTCTTCCCCCTTGCATTTACATGGCTCCGATGAATCAGTCTCAA GTTTTAATGAGTGGATCCCCTTTGGAACTAAACAGTCTGGGTGAAGAACAGCGAATTTTGAACCGCTCCAAAAGAGGCTGGGTTTGGAAT CAAATGTTTGTCCTGGAAGAGTTTTCTGGACCTGAACCGATTCTTGTTGGCCGGCTACACACAGACCTGGATCCTGGGAGCAAAAAAATC AAGTATATCCTATCAGGTGATGGAGCTGGGACCATATTTCAAATAAATGATGTAACTGGAGATATCCATGCTATAAAAAGACTTGACCGG GAGGAAAAGGCTGAGTATACCCTAACAGCTCAAGCAGTGGACTGGGAGACAAGCAAACCTCTGGAGCCTCCTTCTGAATTTATTATTAAA GTTCAAGACATCAATGACAATGCACCAGAGTTTCTTAATGGACCCTATCATGCTACTGTGCCAGAAATGTCCATTTTGGCCGTTCCAGCA CCTACTCCTATCCCGAGACGCCGCTGTACACGCAGACGGCAAGCACCAGCTACTACGAGGCCGCAGGCACGGCCACCCAGGTCAGCACCC CCGCCACCTCCCAGGCGGTGGCCAGCAGTGGCTCCATGCCCATGTACGTGTCCGGCAGCCAGGTCGTCGCCAGCTCCACCAGCACTGGGG CTGGGGCCAGCAACAGCAGCGGAGGTGGTGGCAGTGGTGGTGGCGGCGGCGGCGGGGGAGGCGGTGGCGGGGGTGGCAGTGGCAGCACCG GAGGCGGCGGCAGCGGAGCAGGCACCTACGTGATCCAAGGCGGCTACATGCTGGGCAGTGCCAGCCAGTCTTACTCTCACACCACCCGTG CCTCGCCAGCCACGGTCCAGTGGCTCCTGGACAACTATGAGACGGCTGAGGGCGTGAGTCTGCCACGGAGCACCCTCTACTGCCACTACT TACTGCACTGCCAGGAGCAGAAGCTGGAGCCCGTCAACGCCGCCTCCTTCGGCAAGCTCATCCGCTCCGTCTTCATGGGCCTGCGAACCC GCCGTCTGGGCACCAGGGGCAACTCCAAGTACCACTACTATGGCCTGCGCATCAAGGCCAGCTCACCCCTGCTGCGGCTGATGGAGGACC AGCAGCACATGGCCATGCGGGGCCAGCCCTTCTCGCAGAAGCAGAGGCTCAAGCCCATCCAGAAGATGGAAGGCATGACCAACGGCGTGG CGGTGGGGCAGCAGCCGAGCACGGGGCTGTCGGACATCAGCGCCCAGGTGCAGCAGTACCAGCAATTTTTGGATGCCTCTCGGAGCCTCC CTGACTTCACAGAGCTCGACCTCCAGGGCAAGGTGCTGCCTGAGGGCGTCGGGCCCGGGGACATCAAAGCCTTCCAGGTCCTGTACCGGG AACACTGTGAGGCCATTGTCGACGTCATGGTGAACCTGCAGTTCACCCTGGTGGAGACGCTGTGGAAGACCTTCTGGAGGTACAACCTCA GCCAGCCCAGTGAGGCGCCACCGCTGGCTGTACATGACGAGGCCGAGAAGCGACTGCCCAAAGCCATCCTGGTGCTCCTCTCCAAGTTCG AGCCCGTGCTCCAATGGACCAAGCACTGTGACAACGTGCTGTACCAGGGCCTGGTGGAAATCCTCATTCCCGACGTGCTGCGGCCCATCC CCAGTGCCTTGACCCAAGCGATCCGGAACTTTGCCAAGAGCCTGGAGAGCTGGCTCACCCACGCCATGGTCAACATCCCCGAGGAGATGC TGCGGGTGAAGGTGGCCGCGGCTGGCGCCTTCGCGCAGACACTGCGGCGCTACACGTCGCTCAACCACCTGGCGCAGGCGGCGCGCGCTG TGCTGCAGAACACCGCACAGATCAACCAGATGCTGAGCGACCTCAACCGCGTGGACTTCGCCAACGTGCAGGAGCAGGCCTCGTGGGTGT GCCGCTGCGAGGACCGCGTGGTGCAGCGGCTGGAGCAGGACTTCAAGGTGACGCTGCAGCAGCAGAACTCGCTGGAGCAGTGGGCGGCCT GGCTGGACGGCGTGGTGAGCCAGGTGCTCAAGCCCTACCAGGGCAGCGCCGGCTTCCCCAAGGCCGCCAAGCTCTTCCTCCTCAAGTGGT CCTTCTACAGCTCCATGGTGATCCGGGACCTGACCCTGCGCAGCGCCGCCAGCTTCGGTTCCTTCCACCTCATCCGGCTGCTCTACGACG AGTACATGTACTACCTGATCGAGCACCGCGTAGCCCAGGCCAAGGGCGAGACCCCCATCGCCGTCATGGGCGAGTTCGCCAATCTGGCCA CCTCCCTGAACCCCCTGGACCCCGACAAAGACGAGGAGGAAGAAGAGGAGGAGGAGAGCGAGGACGAGCTGCCGCAGGACATCTCACTGG CGGCTGGCGGCGAGTCACCCGCGCTGGGCCCGGAGACCCTGGAGCCGCCGGCCAAGCTGGCGCGGACTGACGCGCGCGGCCTCTTCGTGC AGGCGCTGCCCTCCAGCTAAGCCCTTGGCCTCCCCGCCCCACCCGCCCCCGCCACCCCTCCACGCCAGGGTCCCTCAAAGCTTCTGTGGC TTCGTGGTCACTGCTCCAGCCTCAGCCAGGGCAGGGAGGGGGACTCCGAGACAGGGAAGACCGGGGCCCTCCTCCCTTATGGGGCCGGCA CAATCAGTGGGCTGGGCGGAGCCGCAGCTGCAAACTCTGACACAAAAGACGTGCCTTAAGGAACCCGCCGCGTGCCCAGGTGCCCCGCGG GGCATCCAGCTCGGCCCCTTGGCCGCCCCCCTCCCAGGCCCCAGCGTCTTCTCCCCAGCCCCGTCCTCCCACCACCCCAGGGGGCAGGCA GGCAGGCCCCCTCCCGTGCGAAACTGTTAACTTATTCAGCTCGCTGGCTTTGCACAGCCTGTCCTGGGCCCAGCCCTGAGCCCCGGGCCG GCGCAGGTGGGCGTCACCTGGGGACTCCCCACTGTCAGCAGCAGCCCCGGGACACCCTACCCCCAGCAACCCCACTGCTTCCCCTTCTTG GTATTAAGTGCAATTAAAGCCGTGGGTGTCGCATCTTCTCCAGCGCTGGGCCCTCCCTTGCCCCCAAGCTCAAGAAGGGGGCACTGCCCG GCCCGGCTGTGAGGAGGGCGGCAGGGGGCACGGCCTCCAGCTTCCAAAGAGCAGCGAGCCGCGGAGCCGGGGAGTGCCCACAGACCCCAG CCCCCGCGCCCCCGCCCTCCGCCGCTGGTTTGTAATGGAACCTTTTCTGTGCCCCTATCTTCCCGGAGACCACGCTTCTCCTCCGTGCCG TGCGACCCCCACCCCATGACTATTGTGCGATTCGTGAGCGCCGCCCGAGCGGAGTTGGTAACTTGTTGGGTTTTTTTCCAACCATCATGG CCTTATCTGTTCCAGTTTTCTCAGTGTTTTCAGCCTGTGAGATAGATGTTTATGGCAAGAAAAAGGAAAAAAAAATGGAAATCTGACCTA TTGTATAAAAATCACTATTTTGTGTGCTCCGCGTGCTATAGCTTTTGGGGCGGCCCTGCCCAGTCCCCGTGCCCACGGGGCTCCCTCTCC CGGTGGTGAAAGTGTCCACACGTGTGGTAGTCTAGTGTGCCGAGCTGTTTTCTACCTTTTTGTAGTCTTTCTTAAAACAATAAATTCCGC TGTGATA >15097_15097_3_CDH8-RFX1_CDH8_chr16_61935083_ENST00000584337_RFX1_chr19_14083939_ENST00000254325_length(amino acids)=658AA_BP=43 MYTQTASTSYYEAAGTATQVSTPATSQAVASSGSMPMYVSGSQVVASSTSTGAGASNSSGGGGSGGGGGGGGGGGGGGSGSTGGGGSGAG TYVIQGGYMLGSASQSYSHTTRASPATVQWLLDNYETAEGVSLPRSTLYCHYLLHCQEQKLEPVNAASFGKLIRSVFMGLRTRRLGTRGN SKYHYYGLRIKASSPLLRLMEDQQHMAMRGQPFSQKQRLKPIQKMEGMTNGVAVGQQPSTGLSDISAQVQQYQQFLDASRSLPDFTELDL QGKVLPEGVGPGDIKAFQVLYREHCEAIVDVMVNLQFTLVETLWKTFWRYNLSQPSEAPPLAVHDEAEKRLPKAILVLLSKFEPVLQWTK HCDNVLYQGLVEILIPDVLRPIPSALTQAIRNFAKSLESWLTHAMVNIPEEMLRVKVAAAGAFAQTLRRYTSLNHLAQAARAVLQNTAQI NQMLSDLNRVDFANVQEQASWVCRCEDRVVQRLEQDFKVTLQQQNSLEQWAAWLDGVVSQVLKPYQGSAGFPKAAKLFLLKWSFYSSMVI RDLTLRSAASFGSFHLIRLLYDEYMYYLIEHRVAQAKGETPIAVMGEFANLATSLNPLDPDKDEEEEEEEESEDELPQDISLAAGGESPA LGPETLEPPAKLARTDARGLFVQALPSS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CDH8-RFX1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CDH8-RFX1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CDH8-RFX1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | CDH8 | C0001973 | Alcoholic Intoxication, Chronic | 1 | PSYGENET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies