
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GNA13-ASPSCR1 (FusionGDB2 ID:HG10672TG79058) |
Fusion Gene Summary for GNA13-ASPSCR1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GNA13-ASPSCR1 | Fusion gene ID: hg10672tg79058 | Hgene | Tgene | Gene symbol | GNA13 | ASPSCR1 | Gene ID | 10672 | 79058 |
| Gene name | G protein subunit alpha 13 | ASPSCR1 tether for SLC2A4, UBX domain containing | |
| Synonyms | G13 | ASPCR1|ASPL|ASPS|RCC17|TUG|UBXD9|UBXN9 | |
| Cytomap | ('GNA13')('ASPSCR1') 17q24.1 | 17q25.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | guanine nucleotide-binding protein subunit alpha-13g alpha-13guanine nucleotide binding protein (G protein), alpha 13 | tether containing UBX domain for GLUT4ASPSCR1, UBX domain containing tether for SLC2A4UBX domain protein 9UBX domain-containing protein 9alveolar soft part sarcoma chromosomal region candidate gene 1 proteinalveolar soft part sarcoma chromosome regio | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q14344 | Q9BZE9 | |
| Ensembl transtripts involved in fusion gene | ENST00000439174, ENST00000541118, | ||
| Fusion gene scores | * DoF score | 11 X 4 X 9=396 | 16 X 16 X 12=3072 |
| # samples | 16 | 19 | |
| ** MAII score | log2(16/396*10)=-1.30742852519225 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(19/3072*10)=-4.01510689239021 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GNA13 [Title/Abstract] AND ASPSCR1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GNA13(63049620)-ASPSCR1(79966913), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | GNA13-ASPSCR1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. GNA13-ASPSCR1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. GNA13-ASPSCR1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. GNA13-ASPSCR1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. GNA13-ASPSCR1 seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. GNA13-ASPSCR1 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across GNA13 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ASPSCR1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
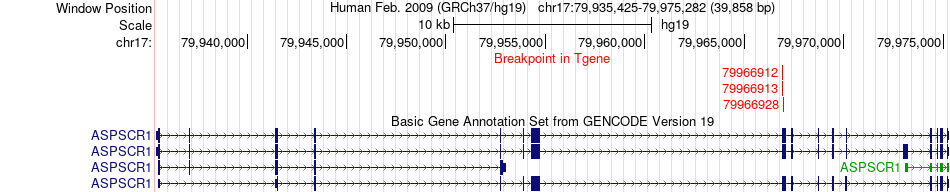 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | COAD | TCGA-D5-6929-01A | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| ChimerDB4 | COAD | TCGA-D5-6929-01A | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| ChimerDB4 | COAD | TCGA-D5-6929 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
Top |
Fusion Gene ORF analysis for GNA13-ASPSCR1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000439174 | ENST00000581647 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| 5CDS-intron | ENST00000439174 | ENST00000581647 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| 5CDS-intron | ENST00000439174 | ENST00000581647 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| 5CDS-intron | ENST00000439174 | ENST00000582404 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| 5CDS-intron | ENST00000439174 | ENST00000582404 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| 5CDS-intron | ENST00000439174 | ENST00000582404 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| 5CDS-intron | ENST00000541118 | ENST00000581647 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| 5CDS-intron | ENST00000541118 | ENST00000581647 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| 5CDS-intron | ENST00000541118 | ENST00000581647 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| 5CDS-intron | ENST00000541118 | ENST00000582404 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| 5CDS-intron | ENST00000541118 | ENST00000582404 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| 5CDS-intron | ENST00000541118 | ENST00000582404 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| Frame-shift | ENST00000541118 | ENST00000306729 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| Frame-shift | ENST00000541118 | ENST00000306729 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| Frame-shift | ENST00000541118 | ENST00000306729 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| Frame-shift | ENST00000541118 | ENST00000306739 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| Frame-shift | ENST00000541118 | ENST00000306739 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| Frame-shift | ENST00000541118 | ENST00000306739 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| Frame-shift | ENST00000541118 | ENST00000580534 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| Frame-shift | ENST00000541118 | ENST00000580534 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| Frame-shift | ENST00000541118 | ENST00000580534 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| In-frame | ENST00000439174 | ENST00000306729 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| In-frame | ENST00000439174 | ENST00000306729 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| In-frame | ENST00000439174 | ENST00000306729 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| In-frame | ENST00000439174 | ENST00000306739 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| In-frame | ENST00000439174 | ENST00000306739 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| In-frame | ENST00000439174 | ENST00000306739 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| In-frame | ENST00000439174 | ENST00000580534 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + |
| In-frame | ENST00000439174 | ENST00000580534 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + |
| In-frame | ENST00000439174 | ENST00000580534 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000439174 | GNA13 | chr17 | 63049620 | - | ENST00000306729 | ASPSCR1 | chr17 | 79966913 | + | 1849 | 756 | 66 | 1766 | 566 |
| ENST00000439174 | GNA13 | chr17 | 63049620 | - | ENST00000306739 | ASPSCR1 | chr17 | 79966913 | + | 1569 | 756 | 66 | 1484 | 472 |
| ENST00000439174 | GNA13 | chr17 | 63049620 | - | ENST00000580534 | ASPSCR1 | chr17 | 79966913 | + | 1642 | 756 | 66 | 1559 | 497 |
| ENST00000439174 | GNA13 | chr17 | 63049619 | - | ENST00000306729 | ASPSCR1 | chr17 | 79966912 | + | 1849 | 756 | 66 | 1766 | 566 |
| ENST00000439174 | GNA13 | chr17 | 63049619 | - | ENST00000306739 | ASPSCR1 | chr17 | 79966912 | + | 1569 | 756 | 66 | 1484 | 472 |
| ENST00000439174 | GNA13 | chr17 | 63049619 | - | ENST00000580534 | ASPSCR1 | chr17 | 79966912 | + | 1642 | 756 | 66 | 1559 | 497 |
| ENST00000439174 | GNA13 | chr17 | 63049620 | - | ENST00000306729 | ASPSCR1 | chr17 | 79966928 | + | 1833 | 756 | 791 | 1750 | 319 |
| ENST00000439174 | GNA13 | chr17 | 63049620 | - | ENST00000306739 | ASPSCR1 | chr17 | 79966928 | + | 1553 | 756 | 66 | 848 | 260 |
| ENST00000439174 | GNA13 | chr17 | 63049620 | - | ENST00000580534 | ASPSCR1 | chr17 | 79966928 | + | 1626 | 756 | 66 | 848 | 260 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000439174 | ENST00000306729 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + | 0.019307008 | 0.98069304 |
| ENST00000439174 | ENST00000306739 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + | 0.007812968 | 0.992187 |
| ENST00000439174 | ENST00000580534 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966913 | + | 0.008107416 | 0.9918926 |
| ENST00000439174 | ENST00000306729 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + | 0.019307008 | 0.98069304 |
| ENST00000439174 | ENST00000306739 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + | 0.007812968 | 0.992187 |
| ENST00000439174 | ENST00000580534 | GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + | 0.008107416 | 0.9918926 |
| ENST00000439174 | ENST00000306729 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + | 0.2261575 | 0.7738426 |
| ENST00000439174 | ENST00000306739 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + | 0.29800618 | 0.7019938 |
| ENST00000439174 | ENST00000580534 | GNA13 | chr17 | 63049620 | - | ASPSCR1 | chr17 | 79966928 | + | 0.30881664 | 0.6911834 |
Top |
Fusion Genomic Features for GNA13-ASPSCR1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + | 3.09E-07 | 0.99999964 |
| GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + | 3.09E-07 | 0.99999964 |
| GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + | 3.09E-07 | 0.99999964 |
| GNA13 | chr17 | 63049619 | - | ASPSCR1 | chr17 | 79966912 | + | 3.09E-07 | 0.99999964 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
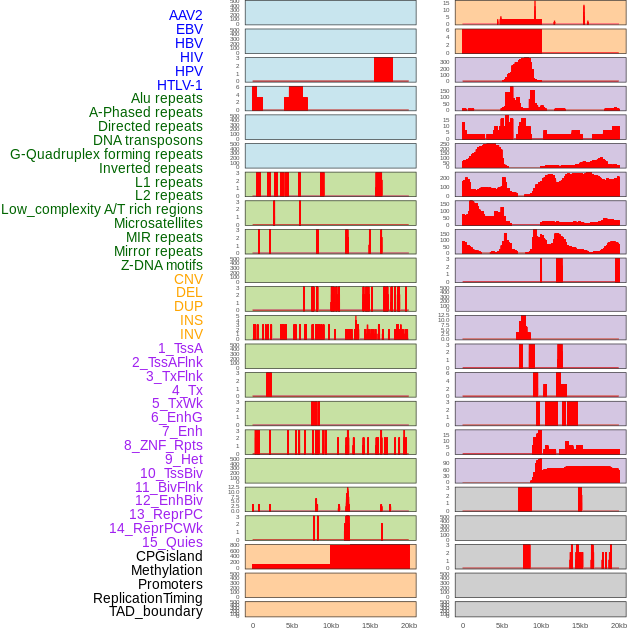 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
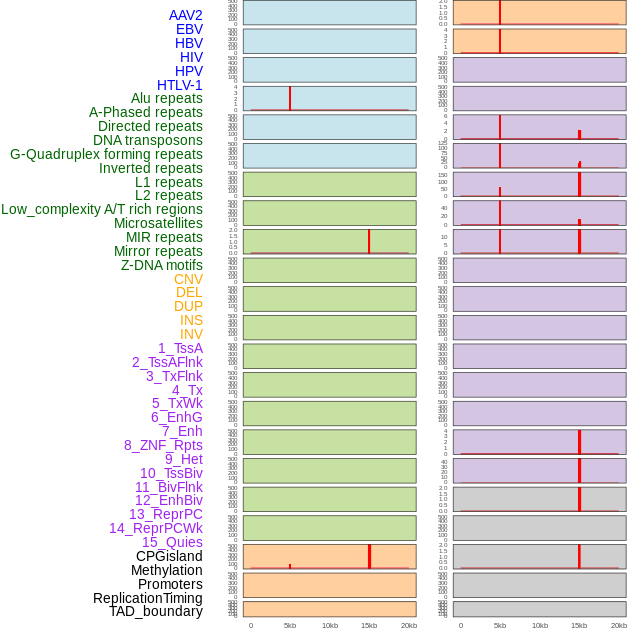 |
Top |
Fusion Protein Features for GNA13-ASPSCR1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:63049620/chr17:79966913) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GNA13 | ASPSCR1 |
| FUNCTION: Guanine nucleotide-binding proteins (G proteins) are involved as modulators or transducers in various transmembrane signaling systems (PubMed:15240885, PubMed:16787920, PubMed:16705036, PubMed:27084452). Activates effector molecule RhoA by binding and activating RhoGEFs (ARHGEF1/p115RhoGEF, ARHGEF11/PDZ-RhoGEF and ARHGEF12/LARG) (PubMed:15240885, PubMed:12515866). GNA13-dependent Rho signaling subsequently regulates transcription factor AP-1 (activating protein-1) (By similarity). Promotes tumor cell invasion and metastasis by activating RhoA/ROCK signaling pathway (PubMed:16787920, PubMed:16705036, PubMed:27084452). Inhibits CDH1-mediated cell adhesion in process independent from Rho activation (PubMed:11976333). {ECO:0000250|UniProtKB:P27601, ECO:0000269|PubMed:11976333, ECO:0000269|PubMed:12515866, ECO:0000269|PubMed:15240885, ECO:0000269|PubMed:16705036, ECO:0000269|PubMed:16787920, ECO:0000269|PubMed:27084452}. | FUNCTION: Tethering protein that sequesters GLUT4-containing vesicles in the cytoplasm in the absence of insulin. Modulates the amount of GLUT4 that is available at the cell surface (By similarity). Enhances VCP methylation catalyzed by VCPKMT. {ECO:0000250, ECO:0000269|PubMed:23349634}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNA13 | chr17:63049619 | chr17:79966912 | ENST00000439174 | - | 2 | 4 | 58_63 | 170 | 378.0 | Nucleotide binding | GTP |
| Hgene | GNA13 | chr17:63049620 | chr17:79966913 | ENST00000439174 | - | 2 | 4 | 58_63 | 170 | 378.0 | Nucleotide binding | GTP |
| Hgene | GNA13 | chr17:63049620 | chr17:79966928 | ENST00000439174 | - | 2 | 4 | 58_63 | 170 | 378.0 | Nucleotide binding | GTP |
| Hgene | GNA13 | chr17:63049619 | chr17:79966912 | ENST00000439174 | - | 2 | 4 | 50_63 | 170 | 378.0 | Region | G1 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966913 | ENST00000439174 | - | 2 | 4 | 50_63 | 170 | 378.0 | Region | G1 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966928 | ENST00000439174 | - | 2 | 4 | 50_63 | 170 | 378.0 | Region | G1 motif |
| Tgene | ASPSCR1 | chr17:63049619 | chr17:79966912 | ENST00000306729 | 6 | 17 | 386_462 | 311 | 648.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr17:63049619 | chr17:79966912 | ENST00000306739 | 6 | 16 | 386_462 | 311 | 554.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr17:63049619 | chr17:79966912 | ENST00000580534 | 5 | 15 | 386_462 | 234 | 502.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966913 | ENST00000306729 | 6 | 17 | 386_462 | 311 | 648.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966913 | ENST00000306739 | 6 | 16 | 386_462 | 311 | 554.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966913 | ENST00000580534 | 5 | 15 | 386_462 | 234 | 502.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966928 | ENST00000306729 | 0 | 17 | 386_462 | 0 | 648.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966928 | ENST00000306739 | 0 | 16 | 386_462 | 0 | 554.0 | Domain | UBX | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966928 | ENST00000580534 | 0 | 15 | 386_462 | 0 | 502.0 | Domain | UBX |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNA13 | chr17:63049619 | chr17:79966912 | ENST00000439174 | - | 2 | 4 | 47_377 | 170 | 378.0 | Domain | G-alpha |
| Hgene | GNA13 | chr17:63049620 | chr17:79966913 | ENST00000439174 | - | 2 | 4 | 47_377 | 170 | 378.0 | Domain | G-alpha |
| Hgene | GNA13 | chr17:63049620 | chr17:79966928 | ENST00000439174 | - | 2 | 4 | 47_377 | 170 | 378.0 | Domain | G-alpha |
| Hgene | GNA13 | chr17:63049619 | chr17:79966912 | ENST00000439174 | - | 2 | 4 | 197_200 | 170 | 378.0 | Nucleotide binding | GTP |
| Hgene | GNA13 | chr17:63049619 | chr17:79966912 | ENST00000439174 | - | 2 | 4 | 291_294 | 170 | 378.0 | Nucleotide binding | GTP |
| Hgene | GNA13 | chr17:63049620 | chr17:79966913 | ENST00000439174 | - | 2 | 4 | 197_200 | 170 | 378.0 | Nucleotide binding | GTP |
| Hgene | GNA13 | chr17:63049620 | chr17:79966913 | ENST00000439174 | - | 2 | 4 | 291_294 | 170 | 378.0 | Nucleotide binding | GTP |
| Hgene | GNA13 | chr17:63049620 | chr17:79966928 | ENST00000439174 | - | 2 | 4 | 197_200 | 170 | 378.0 | Nucleotide binding | GTP |
| Hgene | GNA13 | chr17:63049620 | chr17:79966928 | ENST00000439174 | - | 2 | 4 | 291_294 | 170 | 378.0 | Nucleotide binding | GTP |
| Hgene | GNA13 | chr17:63049619 | chr17:79966912 | ENST00000439174 | - | 2 | 4 | 195_203 | 170 | 378.0 | Region | G2 motif |
| Hgene | GNA13 | chr17:63049619 | chr17:79966912 | ENST00000439174 | - | 2 | 4 | 218_227 | 170 | 378.0 | Region | G3 motif |
| Hgene | GNA13 | chr17:63049619 | chr17:79966912 | ENST00000439174 | - | 2 | 4 | 287_294 | 170 | 378.0 | Region | G4 motif |
| Hgene | GNA13 | chr17:63049619 | chr17:79966912 | ENST00000439174 | - | 2 | 4 | 347_352 | 170 | 378.0 | Region | G5 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966913 | ENST00000439174 | - | 2 | 4 | 195_203 | 170 | 378.0 | Region | G2 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966913 | ENST00000439174 | - | 2 | 4 | 218_227 | 170 | 378.0 | Region | G3 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966913 | ENST00000439174 | - | 2 | 4 | 287_294 | 170 | 378.0 | Region | G4 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966913 | ENST00000439174 | - | 2 | 4 | 347_352 | 170 | 378.0 | Region | G5 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966928 | ENST00000439174 | - | 2 | 4 | 195_203 | 170 | 378.0 | Region | G2 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966928 | ENST00000439174 | - | 2 | 4 | 218_227 | 170 | 378.0 | Region | G3 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966928 | ENST00000439174 | - | 2 | 4 | 287_294 | 170 | 378.0 | Region | G4 motif |
| Hgene | GNA13 | chr17:63049620 | chr17:79966928 | ENST00000439174 | - | 2 | 4 | 347_352 | 170 | 378.0 | Region | G5 motif |
Top |
Fusion Gene Sequence for GNA13-ASPSCR1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33535_33535_1_GNA13-ASPSCR1_GNA13_chr17_63049619_ENST00000439174_ASPSCR1_chr17_79966912_ENST00000306729_length(transcript)=1849nt_BP=756nt GCTCCGGGGCCACCGCCCCTCCGGGGCCGGGCCCGCCCTCCTTCCCTCCCTCCCTCCCCCGCTGTCCTGGCCCGCCCTGCCCGGCCCGCC CTGCGAGTCAGTTCGCTGGTTCCCTCCCTCCCTGGGCGCGCTCGGGCCGCCGCCGCGCTCCCCGCCCTCGAGCCTCGGTGCCGGAGCCGC CCGCCGCCGGAGGAGGAGGTGGAGGGAGCCGGAGGGGCCCGCCGAGGCGGCGGCGGCGGCGGCAAGATGGCGGACTTCCTGCCGTCGCGG TCCGTGCTGTCCGTGTGCTTCCCCGGCTGCCTGCTGACGAGTGGCGAGGCCGAGCAGCAACGCAAGTCCAAGGAGATCGACAAATGCCTG TCTCGGGAAAAGACCTATGTGAAGCGGCTGGTGAAGATCCTGCTGCTGGGCGCGGGCGAGAGCGGCAAGTCCACCTTCCTGAAGCAGATG CGGATCATCCACGGGCAGGACTTCGACCAGCGCGCGCGCGAGGAGTTCCGCCCCACCATCTACAGCAACGTGATCAAAGGTATGAGGGTG CTGGTTGATGCTCGAGAGAAGCTTCATATTCCCTGGGGAGACAACTCAAACCAACAACATGGAGATAAGATGATGTCGTTTGATACCCGG GCCCCCATGGCAGCCCAAGGAATGGTGGAAACAAGGGTTTTCTTACAATATCTTCCTGCTATAAGAGCATTATGGGCAGACAGCGGCATA CAGAATGCCTATGACCGGCGTCGAGAATTTCAACTGCCCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTG GAGGAGCGGCTGCAGGCCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTC AAGAGTGAGCGGAAGCGCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCA AAGGTGGCTCTGAGGGTCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTC GTGAGGAGCCACCTGGGGAACCCCGAGCTGTCATTTTACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTC TTTCAGCCCCAGCTTGGTGACCGGGTGGCTCCATTCACCCTGGGTCCCTCGCTGAAACGGTGCCTGGGACCAGAGCAGAGAACACGCTTG CCAGTGGTAGGAGATGGAGGCGACGTGGACTCTGGGAGGCTTCTTTTTTGGGGTCCATCCAGAGGCCGAGCCTCTCCAAGCACTGGTCAG CCTCCATGCCACCCAGTCTGCCGACCCTCCTCTCCACCATCCCCTCGTCCGAGCAGTGGCGATCCCTCCCGAGTCAAGGCTGGGCACAAG CACGTGGGGACAGGCCGGGCGAACCTCTTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGC CTGCTGGAGCATGCCATCTCCCCATCTGCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCA GCCCCTGACCCTGCACCTAAGTCTGAGCCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTG AAGAGGAGCCTGGGCAAGGTGCCCAAGTGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGC CACAGGACCACCTCCTCTGCCAGCAGGAATAAAGACTTGTGCATCCCTC >33535_33535_1_GNA13-ASPSCR1_GNA13_chr17_63049619_ENST00000439174_ASPSCR1_chr17_79966912_ENST00000306729_length(amino acids)=566AA_BP=230 MARPARPALRVSSLVPSLPGRARAAAALPALEPRCRSRPPPEEEVEGAGGARRGGGGGGKMADFLPSRSVLSVCFPGCLLTSGEAEQQRK SKEIDKCLSREKTYVKRLVKILLLGAGESGKSTFLKQMRIIHGQDFDQRAREEFRPTIYSNVIKGMRVLVDAREKLHIPWGDNSNQQHGD KMMSFDTRAPMAAQGMVETRVFLQYLPAIRALWADSGIQNAYDRRREFQLPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDD VRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFYLFITPPKTV LDDHTQTLFQPQLGDRVAPFTLGPSLKRCLGPEQRTRLPVVGDGGDVDSGRLLFWGPSRGRASPSTGQPPCHPVCRPSSPPSPRPSSGDP SRVKAGHKHVGTGRANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPAPDPAPKSEPAAEEGALVPPEP IPGTAQPVKRSLGKVPKWLKLPASKR -------------------------------------------------------------- >33535_33535_2_GNA13-ASPSCR1_GNA13_chr17_63049619_ENST00000439174_ASPSCR1_chr17_79966912_ENST00000306739_length(transcript)=1569nt_BP=756nt GCTCCGGGGCCACCGCCCCTCCGGGGCCGGGCCCGCCCTCCTTCCCTCCCTCCCTCCCCCGCTGTCCTGGCCCGCCCTGCCCGGCCCGCC CTGCGAGTCAGTTCGCTGGTTCCCTCCCTCCCTGGGCGCGCTCGGGCCGCCGCCGCGCTCCCCGCCCTCGAGCCTCGGTGCCGGAGCCGC CCGCCGCCGGAGGAGGAGGTGGAGGGAGCCGGAGGGGCCCGCCGAGGCGGCGGCGGCGGCGGCAAGATGGCGGACTTCCTGCCGTCGCGG TCCGTGCTGTCCGTGTGCTTCCCCGGCTGCCTGCTGACGAGTGGCGAGGCCGAGCAGCAACGCAAGTCCAAGGAGATCGACAAATGCCTG TCTCGGGAAAAGACCTATGTGAAGCGGCTGGTGAAGATCCTGCTGCTGGGCGCGGGCGAGAGCGGCAAGTCCACCTTCCTGAAGCAGATG CGGATCATCCACGGGCAGGACTTCGACCAGCGCGCGCGCGAGGAGTTCCGCCCCACCATCTACAGCAACGTGATCAAAGGTATGAGGGTG CTGGTTGATGCTCGAGAGAAGCTTCATATTCCCTGGGGAGACAACTCAAACCAACAACATGGAGATAAGATGATGTCGTTTGATACCCGG GCCCCCATGGCAGCCCAAGGAATGGTGGAAACAAGGGTTTTCTTACAATATCTTCCTGCTATAAGAGCATTATGGGCAGACAGCGGCATA CAGAATGCCTATGACCGGCGTCGAGAATTTCAACTGCCCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTG GAGGAGCGGCTGCAGGCCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTC AAGAGTGAGCGGAAGCGCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCA AAGGTGGCTCTGAGGGTCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTC GTGAGGAGCCACCTGGGGAACCCCGAGCTGTCATTTTACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTC TTTCAGGCGAACCTCTTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCAT GCCATCTCCCCATCTGCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCT GCACCTAAGTCTGAGCCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTG GGCAAGGTGCCCAAGTGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACC TCCTCTGCCAGCAGGAATAAAGACTTGTGCATCCCTCAA >33535_33535_2_GNA13-ASPSCR1_GNA13_chr17_63049619_ENST00000439174_ASPSCR1_chr17_79966912_ENST00000306739_length(amino acids)=472AA_BP=230 MARPARPALRVSSLVPSLPGRARAAAALPALEPRCRSRPPPEEEVEGAGGARRGGGGGGKMADFLPSRSVLSVCFPGCLLTSGEAEQQRK SKEIDKCLSREKTYVKRLVKILLLGAGESGKSTFLKQMRIIHGQDFDQRAREEFRPTIYSNVIKGMRVLVDAREKLHIPWGDNSNQQHGD KMMSFDTRAPMAAQGMVETRVFLQYLPAIRALWADSGIQNAYDRRREFQLPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDD VRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFYLFITPPKTV LDDHTQTLFQANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPAPDPAPKSEPAAEEGALVPPEPIPGT AQPVKRSLGKVPKWLKLPASKR -------------------------------------------------------------- >33535_33535_3_GNA13-ASPSCR1_GNA13_chr17_63049619_ENST00000439174_ASPSCR1_chr17_79966912_ENST00000580534_length(transcript)=1642nt_BP=756nt GCTCCGGGGCCACCGCCCCTCCGGGGCCGGGCCCGCCCTCCTTCCCTCCCTCCCTCCCCCGCTGTCCTGGCCCGCCCTGCCCGGCCCGCC CTGCGAGTCAGTTCGCTGGTTCCCTCCCTCCCTGGGCGCGCTCGGGCCGCCGCCGCGCTCCCCGCCCTCGAGCCTCGGTGCCGGAGCCGC CCGCCGCCGGAGGAGGAGGTGGAGGGAGCCGGAGGGGCCCGCCGAGGCGGCGGCGGCGGCGGCAAGATGGCGGACTTCCTGCCGTCGCGG TCCGTGCTGTCCGTGTGCTTCCCCGGCTGCCTGCTGACGAGTGGCGAGGCCGAGCAGCAACGCAAGTCCAAGGAGATCGACAAATGCCTG TCTCGGGAAAAGACCTATGTGAAGCGGCTGGTGAAGATCCTGCTGCTGGGCGCGGGCGAGAGCGGCAAGTCCACCTTCCTGAAGCAGATG CGGATCATCCACGGGCAGGACTTCGACCAGCGCGCGCGCGAGGAGTTCCGCCCCACCATCTACAGCAACGTGATCAAAGGTATGAGGGTG CTGGTTGATGCTCGAGAGAAGCTTCATATTCCCTGGGGAGACAACTCAAACCAACAACATGGAGATAAGATGATGTCGTTTGATACCCGG GCCCCCATGGCAGCCCAAGGAATGGTGGAAACAAGGGTTTTCTTACAATATCTTCCTGCTATAAGAGCATTATGGGCAGACAGCGGCATA CAGAATGCCTATGACCGGCGTCGAGAATTTCAACTGCCCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTG GAGGAGCGGCTGCAGGCCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTC AAGAGTGAGCGGAAGCGCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCA AAGGTGGCTCTGAGGGTCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTC GTGAGGAGCCACCTGGGGAACCCCGAGCTGTCATTTTACCTGTGCCTGTCTTCCTTCGGGCGCATGGATGGGCGAGGTCCACGGTGCTTC CTAACACGTAGGTGCCTTCTCTCCTCAGTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAGGCGAACCTC TTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCATCTCCCCATCT GCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCACCTAAGTCTGAG CCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCAAGGTGCCCAAG TGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACCTCCTCTGCCAGCAGG AATAAAGACTTGTGCATCCCTC >33535_33535_3_GNA13-ASPSCR1_GNA13_chr17_63049619_ENST00000439174_ASPSCR1_chr17_79966912_ENST00000580534_length(amino acids)=497AA_BP=230 MARPARPALRVSSLVPSLPGRARAAAALPALEPRCRSRPPPEEEVEGAGGARRGGGGGGKMADFLPSRSVLSVCFPGCLLTSGEAEQQRK SKEIDKCLSREKTYVKRLVKILLLGAGESGKSTFLKQMRIIHGQDFDQRAREEFRPTIYSNVIKGMRVLVDAREKLHIPWGDNSNQQHGD KMMSFDTRAPMAAQGMVETRVFLQYLPAIRALWADSGIQNAYDRRREFQLPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDD VRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFYLCLSSFGRM DGRGPRCFLTRRCLLSSVITPPKTVLDDHTQTLFQANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPA PDPAPKSEPAAEEGALVPPEPIPGTAQPVKRSLGKVPKWLKLPASKR -------------------------------------------------------------- >33535_33535_4_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966913_ENST00000306729_length(transcript)=1849nt_BP=756nt GCTCCGGGGCCACCGCCCCTCCGGGGCCGGGCCCGCCCTCCTTCCCTCCCTCCCTCCCCCGCTGTCCTGGCCCGCCCTGCCCGGCCCGCC CTGCGAGTCAGTTCGCTGGTTCCCTCCCTCCCTGGGCGCGCTCGGGCCGCCGCCGCGCTCCCCGCCCTCGAGCCTCGGTGCCGGAGCCGC CCGCCGCCGGAGGAGGAGGTGGAGGGAGCCGGAGGGGCCCGCCGAGGCGGCGGCGGCGGCGGCAAGATGGCGGACTTCCTGCCGTCGCGG TCCGTGCTGTCCGTGTGCTTCCCCGGCTGCCTGCTGACGAGTGGCGAGGCCGAGCAGCAACGCAAGTCCAAGGAGATCGACAAATGCCTG TCTCGGGAAAAGACCTATGTGAAGCGGCTGGTGAAGATCCTGCTGCTGGGCGCGGGCGAGAGCGGCAAGTCCACCTTCCTGAAGCAGATG CGGATCATCCACGGGCAGGACTTCGACCAGCGCGCGCGCGAGGAGTTCCGCCCCACCATCTACAGCAACGTGATCAAAGGTATGAGGGTG CTGGTTGATGCTCGAGAGAAGCTTCATATTCCCTGGGGAGACAACTCAAACCAACAACATGGAGATAAGATGATGTCGTTTGATACCCGG GCCCCCATGGCAGCCCAAGGAATGGTGGAAACAAGGGTTTTCTTACAATATCTTCCTGCTATAAGAGCATTATGGGCAGACAGCGGCATA CAGAATGCCTATGACCGGCGTCGAGAATTTCAACTGCCCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTG GAGGAGCGGCTGCAGGCCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTC AAGAGTGAGCGGAAGCGCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCA AAGGTGGCTCTGAGGGTCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTC GTGAGGAGCCACCTGGGGAACCCCGAGCTGTCATTTTACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTC TTTCAGCCCCAGCTTGGTGACCGGGTGGCTCCATTCACCCTGGGTCCCTCGCTGAAACGGTGCCTGGGACCAGAGCAGAGAACACGCTTG CCAGTGGTAGGAGATGGAGGCGACGTGGACTCTGGGAGGCTTCTTTTTTGGGGTCCATCCAGAGGCCGAGCCTCTCCAAGCACTGGTCAG CCTCCATGCCACCCAGTCTGCCGACCCTCCTCTCCACCATCCCCTCGTCCGAGCAGTGGCGATCCCTCCCGAGTCAAGGCTGGGCACAAG CACGTGGGGACAGGCCGGGCGAACCTCTTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGC CTGCTGGAGCATGCCATCTCCCCATCTGCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCA GCCCCTGACCCTGCACCTAAGTCTGAGCCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTG AAGAGGAGCCTGGGCAAGGTGCCCAAGTGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGC CACAGGACCACCTCCTCTGCCAGCAGGAATAAAGACTTGTGCATCCCTC >33535_33535_4_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966913_ENST00000306729_length(amino acids)=566AA_BP=230 MARPARPALRVSSLVPSLPGRARAAAALPALEPRCRSRPPPEEEVEGAGGARRGGGGGGKMADFLPSRSVLSVCFPGCLLTSGEAEQQRK SKEIDKCLSREKTYVKRLVKILLLGAGESGKSTFLKQMRIIHGQDFDQRAREEFRPTIYSNVIKGMRVLVDAREKLHIPWGDNSNQQHGD KMMSFDTRAPMAAQGMVETRVFLQYLPAIRALWADSGIQNAYDRRREFQLPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDD VRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFYLFITPPKTV LDDHTQTLFQPQLGDRVAPFTLGPSLKRCLGPEQRTRLPVVGDGGDVDSGRLLFWGPSRGRASPSTGQPPCHPVCRPSSPPSPRPSSGDP SRVKAGHKHVGTGRANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPAPDPAPKSEPAAEEGALVPPEP IPGTAQPVKRSLGKVPKWLKLPASKR -------------------------------------------------------------- >33535_33535_5_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966913_ENST00000306739_length(transcript)=1569nt_BP=756nt GCTCCGGGGCCACCGCCCCTCCGGGGCCGGGCCCGCCCTCCTTCCCTCCCTCCCTCCCCCGCTGTCCTGGCCCGCCCTGCCCGGCCCGCC CTGCGAGTCAGTTCGCTGGTTCCCTCCCTCCCTGGGCGCGCTCGGGCCGCCGCCGCGCTCCCCGCCCTCGAGCCTCGGTGCCGGAGCCGC CCGCCGCCGGAGGAGGAGGTGGAGGGAGCCGGAGGGGCCCGCCGAGGCGGCGGCGGCGGCGGCAAGATGGCGGACTTCCTGCCGTCGCGG TCCGTGCTGTCCGTGTGCTTCCCCGGCTGCCTGCTGACGAGTGGCGAGGCCGAGCAGCAACGCAAGTCCAAGGAGATCGACAAATGCCTG TCTCGGGAAAAGACCTATGTGAAGCGGCTGGTGAAGATCCTGCTGCTGGGCGCGGGCGAGAGCGGCAAGTCCACCTTCCTGAAGCAGATG CGGATCATCCACGGGCAGGACTTCGACCAGCGCGCGCGCGAGGAGTTCCGCCCCACCATCTACAGCAACGTGATCAAAGGTATGAGGGTG CTGGTTGATGCTCGAGAGAAGCTTCATATTCCCTGGGGAGACAACTCAAACCAACAACATGGAGATAAGATGATGTCGTTTGATACCCGG GCCCCCATGGCAGCCCAAGGAATGGTGGAAACAAGGGTTTTCTTACAATATCTTCCTGCTATAAGAGCATTATGGGCAGACAGCGGCATA CAGAATGCCTATGACCGGCGTCGAGAATTTCAACTGCCCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTG GAGGAGCGGCTGCAGGCCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTC AAGAGTGAGCGGAAGCGCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCA AAGGTGGCTCTGAGGGTCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTC GTGAGGAGCCACCTGGGGAACCCCGAGCTGTCATTTTACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTC TTTCAGGCGAACCTCTTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCAT GCCATCTCCCCATCTGCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCT GCACCTAAGTCTGAGCCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTG GGCAAGGTGCCCAAGTGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACC TCCTCTGCCAGCAGGAATAAAGACTTGTGCATCCCTCAA >33535_33535_5_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966913_ENST00000306739_length(amino acids)=472AA_BP=230 MARPARPALRVSSLVPSLPGRARAAAALPALEPRCRSRPPPEEEVEGAGGARRGGGGGGKMADFLPSRSVLSVCFPGCLLTSGEAEQQRK SKEIDKCLSREKTYVKRLVKILLLGAGESGKSTFLKQMRIIHGQDFDQRAREEFRPTIYSNVIKGMRVLVDAREKLHIPWGDNSNQQHGD KMMSFDTRAPMAAQGMVETRVFLQYLPAIRALWADSGIQNAYDRRREFQLPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDD VRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFYLFITPPKTV LDDHTQTLFQANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPAPDPAPKSEPAAEEGALVPPEPIPGT AQPVKRSLGKVPKWLKLPASKR -------------------------------------------------------------- >33535_33535_6_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966913_ENST00000580534_length(transcript)=1642nt_BP=756nt GCTCCGGGGCCACCGCCCCTCCGGGGCCGGGCCCGCCCTCCTTCCCTCCCTCCCTCCCCCGCTGTCCTGGCCCGCCCTGCCCGGCCCGCC CTGCGAGTCAGTTCGCTGGTTCCCTCCCTCCCTGGGCGCGCTCGGGCCGCCGCCGCGCTCCCCGCCCTCGAGCCTCGGTGCCGGAGCCGC CCGCCGCCGGAGGAGGAGGTGGAGGGAGCCGGAGGGGCCCGCCGAGGCGGCGGCGGCGGCGGCAAGATGGCGGACTTCCTGCCGTCGCGG TCCGTGCTGTCCGTGTGCTTCCCCGGCTGCCTGCTGACGAGTGGCGAGGCCGAGCAGCAACGCAAGTCCAAGGAGATCGACAAATGCCTG TCTCGGGAAAAGACCTATGTGAAGCGGCTGGTGAAGATCCTGCTGCTGGGCGCGGGCGAGAGCGGCAAGTCCACCTTCCTGAAGCAGATG CGGATCATCCACGGGCAGGACTTCGACCAGCGCGCGCGCGAGGAGTTCCGCCCCACCATCTACAGCAACGTGATCAAAGGTATGAGGGTG CTGGTTGATGCTCGAGAGAAGCTTCATATTCCCTGGGGAGACAACTCAAACCAACAACATGGAGATAAGATGATGTCGTTTGATACCCGG GCCCCCATGGCAGCCCAAGGAATGGTGGAAACAAGGGTTTTCTTACAATATCTTCCTGCTATAAGAGCATTATGGGCAGACAGCGGCATA CAGAATGCCTATGACCGGCGTCGAGAATTTCAACTGCCCGTGGACCGGGAGCCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTG GAGGAGCGGCTGCAGGCCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTC AAGAGTGAGCGGAAGCGCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCA AAGGTGGCTCTGAGGGTCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTC GTGAGGAGCCACCTGGGGAACCCCGAGCTGTCATTTTACCTGTGCCTGTCTTCCTTCGGGCGCATGGATGGGCGAGGTCCACGGTGCTTC CTAACACGTAGGTGCCTTCTCTCCTCAGTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAGGCGAACCTC TTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCATCTCCCCATCT GCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCACCTAAGTCTGAG CCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCAAGGTGCCCAAG TGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACCTCCTCTGCCAGCAGG AATAAAGACTTGTGCATCCCTC >33535_33535_6_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966913_ENST00000580534_length(amino acids)=497AA_BP=230 MARPARPALRVSSLVPSLPGRARAAAALPALEPRCRSRPPPEEEVEGAGGARRGGGGGGKMADFLPSRSVLSVCFPGCLLTSGEAEQQRK SKEIDKCLSREKTYVKRLVKILLLGAGESGKSTFLKQMRIIHGQDFDQRAREEFRPTIYSNVIKGMRVLVDAREKLHIPWGDNSNQQHGD KMMSFDTRAPMAAQGMVETRVFLQYLPAIRALWADSGIQNAYDRRREFQLPVDREPVDREPVVCHPDLEERLQAWPAELPDEFFELTVDD VRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRDFVRSHLGNPELSFYLCLSSFGRM DGRGPRCFLTRRCLLSSVITPPKTVLDDHTQTLFQANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPLPA PDPAPKSEPAAEEGALVPPEPIPGTAQPVKRSLGKVPKWLKLPASKR -------------------------------------------------------------- >33535_33535_7_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966928_ENST00000306729_length(transcript)=1833nt_BP=756nt GCTCCGGGGCCACCGCCCCTCCGGGGCCGGGCCCGCCCTCCTTCCCTCCCTCCCTCCCCCGCTGTCCTGGCCCGCCCTGCCCGGCCCGCC CTGCGAGTCAGTTCGCTGGTTCCCTCCCTCCCTGGGCGCGCTCGGGCCGCCGCCGCGCTCCCCGCCCTCGAGCCTCGGTGCCGGAGCCGC CCGCCGCCGGAGGAGGAGGTGGAGGGAGCCGGAGGGGCCCGCCGAGGCGGCGGCGGCGGCGGCAAGATGGCGGACTTCCTGCCGTCGCGG TCCGTGCTGTCCGTGTGCTTCCCCGGCTGCCTGCTGACGAGTGGCGAGGCCGAGCAGCAACGCAAGTCCAAGGAGATCGACAAATGCCTG TCTCGGGAAAAGACCTATGTGAAGCGGCTGGTGAAGATCCTGCTGCTGGGCGCGGGCGAGAGCGGCAAGTCCACCTTCCTGAAGCAGATG CGGATCATCCACGGGCAGGACTTCGACCAGCGCGCGCGCGAGGAGTTCCGCCCCACCATCTACAGCAACGTGATCAAAGGTATGAGGGTG CTGGTTGATGCTCGAGAGAAGCTTCATATTCCCTGGGGAGACAACTCAAACCAACAACATGGAGATAAGATGATGTCGTTTGATACCCGG GCCCCCATGGCAGCCCAAGGAATGGTGGAAACAAGGGTTTTCTTACAATATCTTCCTGCTATAAGAGCATTATGGGCAGACAGCGGCATA CAGAATGCCTATGACCGGCGTCGAGAATTTCAACTGCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTGGAGGAGCGGCTGCAGG CCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTCAAGAGTGAGCGGAAGC GCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCAAAGGTGGCTCTGAGGG TCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTCGTGAGGAGCCACCTGG GGAACCCCGAGCTGTCATTTTACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAGCCCCAGCTTG GTGACCGGGTGGCTCCATTCACCCTGGGTCCCTCGCTGAAACGGTGCCTGGGACCAGAGCAGAGAACACGCTTGCCAGTGGTAGGAGATG GAGGCGACGTGGACTCTGGGAGGCTTCTTTTTTGGGGTCCATCCAGAGGCCGAGCCTCTCCAAGCACTGGTCAGCCTCCATGCCACCCAG TCTGCCGACCCTCCTCTCCACCATCCCCTCGTCCGAGCAGTGGCGATCCCTCCCGAGTCAAGGCTGGGCACAAGCACGTGGGGACAGGCC GGGCGAACCTCTTCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCA TCTCCCCATCTGCGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCAC CTAAGTCTGAGCCAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCA AGGTGCCCAAGTGGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACCTCCT CTGCCAGCAGGAATAAAGACTTGTGCATCCCTC >33535_33535_7_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966928_ENST00000306729_length(amino acids)=319AA_BP= MEERLQAWPAELPDEFFELTVDDVRRRLAQLKSERKRLEEAPLVTKAFREAQIKEKLERYPKVALRVLFPDRYVLQGFFRPSETVGDLRD FVRSHLGNPELSFYLFITPPKTVLDDHTQTLFQPQLGDRVAPFTLGPSLKRCLGPEQRTRLPVVGDGGDVDSGRLLFWGPSRGRASPSTG QPPCHPVCRPSSPPSPRPSSGDPSRVKAGHKHVGTGRANLFPAALVHLGAEEPAGVYLEPGLLEHAISPSAADVLVARYMSRAAGSPSPL PAPDPAPKSEPAAEEGALVPPEPIPGTAQPVKRSLGKVPKWLKLPASKR -------------------------------------------------------------- >33535_33535_8_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966928_ENST00000306739_length(transcript)=1553nt_BP=756nt GCTCCGGGGCCACCGCCCCTCCGGGGCCGGGCCCGCCCTCCTTCCCTCCCTCCCTCCCCCGCTGTCCTGGCCCGCCCTGCCCGGCCCGCC CTGCGAGTCAGTTCGCTGGTTCCCTCCCTCCCTGGGCGCGCTCGGGCCGCCGCCGCGCTCCCCGCCCTCGAGCCTCGGTGCCGGAGCCGC CCGCCGCCGGAGGAGGAGGTGGAGGGAGCCGGAGGGGCCCGCCGAGGCGGCGGCGGCGGCGGCAAGATGGCGGACTTCCTGCCGTCGCGG TCCGTGCTGTCCGTGTGCTTCCCCGGCTGCCTGCTGACGAGTGGCGAGGCCGAGCAGCAACGCAAGTCCAAGGAGATCGACAAATGCCTG TCTCGGGAAAAGACCTATGTGAAGCGGCTGGTGAAGATCCTGCTGCTGGGCGCGGGCGAGAGCGGCAAGTCCACCTTCCTGAAGCAGATG CGGATCATCCACGGGCAGGACTTCGACCAGCGCGCGCGCGAGGAGTTCCGCCCCACCATCTACAGCAACGTGATCAAAGGTATGAGGGTG CTGGTTGATGCTCGAGAGAAGCTTCATATTCCCTGGGGAGACAACTCAAACCAACAACATGGAGATAAGATGATGTCGTTTGATACCCGG GCCCCCATGGCAGCCCAAGGAATGGTGGAAACAAGGGTTTTCTTACAATATCTTCCTGCTATAAGAGCATTATGGGCAGACAGCGGCATA CAGAATGCCTATGACCGGCGTCGAGAATTTCAACTGCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTGGAGGAGCGGCTGCAGG CCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTCAAGAGTGAGCGGAAGC GCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCAAAGGTGGCTCTGAGGG TCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTCGTGAGGAGCCACCTGG GGAACCCCGAGCTGTCATTTTACCTGTTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAGGCGAACCTCT TCCCGGCCGCTCTGGTGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCATCTCCCCATCTG CGGCCGATGTGCTGGTGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCACCTAAGTCTGAGC CAGCTGCTGAGGAGGGGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCAAGGTGCCCAAGT GGCTGAAGCTGCCGGCCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACCTCCTCTGCCAGCAGGA ATAAAGACTTGTGCATCCCTCAA >33535_33535_8_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966928_ENST00000306739_length(amino acids)=260AA_BP=230 MARPARPALRVSSLVPSLPGRARAAAALPALEPRCRSRPPPEEEVEGAGGARRGGGGGGKMADFLPSRSVLSVCFPGCLLTSGEAEQQRK SKEIDKCLSREKTYVKRLVKILLLGAGESGKSTFLKQMRIIHGQDFDQRAREEFRPTIYSNVIKGMRVLVDAREKLHIPWGDNSNQQHGD KMMSFDTRAPMAAQGMVETRVFLQYLPAIRALWADSGIQNAYDRRREFQLPWTGSRWCATPTWRSGCRPGQRSCLMSSLS -------------------------------------------------------------- >33535_33535_9_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966928_ENST00000580534_length(transcript)=1626nt_BP=756nt GCTCCGGGGCCACCGCCCCTCCGGGGCCGGGCCCGCCCTCCTTCCCTCCCTCCCTCCCCCGCTGTCCTGGCCCGCCCTGCCCGGCCCGCC CTGCGAGTCAGTTCGCTGGTTCCCTCCCTCCCTGGGCGCGCTCGGGCCGCCGCCGCGCTCCCCGCCCTCGAGCCTCGGTGCCGGAGCCGC CCGCCGCCGGAGGAGGAGGTGGAGGGAGCCGGAGGGGCCCGCCGAGGCGGCGGCGGCGGCGGCAAGATGGCGGACTTCCTGCCGTCGCGG TCCGTGCTGTCCGTGTGCTTCCCCGGCTGCCTGCTGACGAGTGGCGAGGCCGAGCAGCAACGCAAGTCCAAGGAGATCGACAAATGCCTG TCTCGGGAAAAGACCTATGTGAAGCGGCTGGTGAAGATCCTGCTGCTGGGCGCGGGCGAGAGCGGCAAGTCCACCTTCCTGAAGCAGATG CGGATCATCCACGGGCAGGACTTCGACCAGCGCGCGCGCGAGGAGTTCCGCCCCACCATCTACAGCAACGTGATCAAAGGTATGAGGGTG CTGGTTGATGCTCGAGAGAAGCTTCATATTCCCTGGGGAGACAACTCAAACCAACAACATGGAGATAAGATGATGTCGTTTGATACCCGG GCCCCCATGGCAGCCCAAGGAATGGTGGAAACAAGGGTTTTCTTACAATATCTTCCTGCTATAAGAGCATTATGGGCAGACAGCGGCATA CAGAATGCCTATGACCGGCGTCGAGAATTTCAACTGCCGTGGACCGGGAGCCGGTGGTGTGCCACCCCGACCTGGAGGAGCGGCTGCAGG CCTGGCCAGCGGAGCTGCCTGATGAGTTCTTTGAGCTGACGGTGGACGACGTGAGAAGACGCTTGGCCCAGCTCAAGAGTGAGCGGAAGC GCCTGGAAGAAGCCCCCTTGGTGACCAAGGCCTTCAGGGAGGCGCAGATAAAGGAGAAGCTGGAGCGCTACCCAAAGGTGGCTCTGAGGG TCCTGTTCCCCGACCGCTACGTCCTACAGGGCTTCTTCCGCCCCAGCGAGACAGTGGGGGACTTGCGAGACTTCGTGAGGAGCCACCTGG GGAACCCCGAGCTGTCATTTTACCTGTGCCTGTCTTCCTTCGGGCGCATGGATGGGCGAGGTCCACGGTGCTTCCTAACACGTAGGTGCC TTCTCTCCTCAGTCATCACCCCTCCAAAAACAGTCCTGGACGACCACACGCAGACCCTCTTTCAGGCGAACCTCTTCCCGGCCGCTCTGG TGCACTTGGGAGCCGAGGAGCCGGCAGGTGTCTACCTGGAGCCTGGCCTGCTGGAGCATGCCATCTCCCCATCTGCGGCCGATGTGCTGG TGGCCAGGTACATGTCCAGGGCCGCCGGGTCCCCTTCCCCATTGCCAGCCCCTGACCCTGCACCTAAGTCTGAGCCAGCTGCTGAGGAGG GGGCGCTGGTCCCCCCTGAGCCCATCCCAGGGACGGCCCAGCCCGTGAAGAGGAGCCTGGGCAAGGTGCCCAAGTGGCTGAAGCTGCCGG CCAGCAAGAGGTGAGAGCTGCCAGCCTGAGGTGCCCACTCCGCCAGCCACAGGACCACCTCCTCTGCCAGCAGGAATAAAGACTTGTGCA TCCCTC >33535_33535_9_GNA13-ASPSCR1_GNA13_chr17_63049620_ENST00000439174_ASPSCR1_chr17_79966928_ENST00000580534_length(amino acids)=260AA_BP=230 MARPARPALRVSSLVPSLPGRARAAAALPALEPRCRSRPPPEEEVEGAGGARRGGGGGGKMADFLPSRSVLSVCFPGCLLTSGEAEQQRK SKEIDKCLSREKTYVKRLVKILLLGAGESGKSTFLKQMRIIHGQDFDQRAREEFRPTIYSNVIKGMRVLVDAREKLHIPWGDNSNQQHGD KMMSFDTRAPMAAQGMVETRVFLQYLPAIRALWADSGIQNAYDRRREFQLPWTGSRWCATPTWRSGCRPGQRSCLMSSLS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GNA13-ASPSCR1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | ASPSCR1 | chr17:63049619 | chr17:79966912 | ENST00000306729 | 6 | 17 | 317_380 | 311.0 | 648.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr17:63049619 | chr17:79966912 | ENST00000306739 | 6 | 16 | 317_380 | 311.0 | 554.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr17:63049619 | chr17:79966912 | ENST00000580534 | 5 | 15 | 317_380 | 234.0 | 502.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966913 | ENST00000306729 | 6 | 17 | 317_380 | 311.0 | 648.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966913 | ENST00000306739 | 6 | 16 | 317_380 | 311.0 | 554.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966913 | ENST00000580534 | 5 | 15 | 317_380 | 234.0 | 502.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966928 | ENST00000306729 | 0 | 17 | 317_380 | 0 | 648.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966928 | ENST00000306739 | 0 | 16 | 317_380 | 0 | 554.0 | GLUT4 | |
| Tgene | ASPSCR1 | chr17:63049620 | chr17:79966928 | ENST00000580534 | 0 | 15 | 317_380 | 0 | 502.0 | GLUT4 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GNA13-ASPSCR1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GNA13-ASPSCR1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | GNA13 | C0006413 | Burkitt Lymphoma | 1 | CTD_human |
| Hgene | GNA13 | C0343640 | African Burkitt's lymphoma | 1 | CTD_human |
| Hgene | GNA13 | C4721444 | Burkitt Leukemia | 1 | CTD_human |
| Tgene | C4518356 | MiT family translocation renal cell carcinoma | 3 | ORPHANET | |
| Tgene | C0206657 | Alveolar Soft Part Sarcoma | 1 | CTD_human;ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies