
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AP4B1-PARP14 (FusionGDB2 ID:HG10717TG54625) |
Fusion Gene Summary for AP4B1-PARP14 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AP4B1-PARP14 | Fusion gene ID: hg10717tg54625 | Hgene | Tgene | Gene symbol | AP4B1 | PARP14 | Gene ID | 10717 | 54625 |
| Gene name | adaptor related protein complex 4 subunit beta 1 | poly(ADP-ribose) polymerase family member 14 | |
| Synonyms | BETA-4|CPSQ5|SPG47 | ARTD8|BAL2|PARP-14|pART8 | |
| Cytomap | ('AP4B1')('PARP14') 1p13.2 | 3q21.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AP-4 complex subunit beta-1AP-4 adaptor complex subunit betaadaptor related protein complex 4 beta 1 subunitbeta 4 subunit of AP-4beta4-adaptinspastic paraplegia 47 | protein mono-ADP-ribosyltransferase PARP14ADP-ribosyltransferase diphtheria toxin-like 8B-aggressive lymphoma 2b aggressive lymphoma protein 2collaborator of STAT6poly [ADP-ribose] polymerase 14 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9Y6B7 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000256658, ENST00000369566, ENST00000369567, ENST00000369569, ENST00000462591, | ||
| Fusion gene scores | * DoF score | 3 X 3 X 3=27 | 12 X 9 X 6=648 |
| # samples | 3 | 15 | |
| ** MAII score | log2(3/27*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(15/648*10)=-2.11103131238874 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: AP4B1 [Title/Abstract] AND PARP14 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AP4B1(114447227)-PARP14(122446659), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | AP4B1-PARP14 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AP4B1-PARP14 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PARP14 | GO:0006471 | protein ADP-ribosylation | 27796300 |
| Fusion gene breakpoints across AP4B1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PARP14 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | TCGA-HU-A4GC-11A | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
Top |
Fusion Gene ORF analysis for AP4B1-PARP14 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000256658 | ENST00000475640 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| 5CDS-intron | ENST00000369566 | ENST00000475640 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| 5CDS-intron | ENST00000369567 | ENST00000475640 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| 5CDS-intron | ENST00000369569 | ENST00000475640 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| Frame-shift | ENST00000256658 | ENST00000474629 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| In-frame | ENST00000369566 | ENST00000474629 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| In-frame | ENST00000369567 | ENST00000474629 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| In-frame | ENST00000369569 | ENST00000474629 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| intron-3CDS | ENST00000462591 | ENST00000474629 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| intron-intron | ENST00000462591 | ENST00000475640 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000369567 | AP4B1 | chr1 | 114447227 | - | ENST00000474629 | PARP14 | chr3 | 122446659 | + | 2932 | 224 | 281 | 688 | 135 |
| ENST00000369569 | AP4B1 | chr1 | 114447227 | - | ENST00000474629 | PARP14 | chr3 | 122446659 | + | 3102 | 394 | 451 | 858 | 135 |
| ENST00000369566 | AP4B1 | chr1 | 114447227 | - | ENST00000474629 | PARP14 | chr3 | 122446659 | + | 2967 | 259 | 316 | 723 | 135 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000369567 | ENST00000474629 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + | 0.006563945 | 0.9934361 |
| ENST00000369569 | ENST00000474629 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + | 0.009533709 | 0.99046636 |
| ENST00000369566 | ENST00000474629 | AP4B1 | chr1 | 114447227 | - | PARP14 | chr3 | 122446659 | + | 0.012142015 | 0.98785794 |
Top |
Fusion Genomic Features for AP4B1-PARP14 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| AP4B1 | chr1 | 114447226 | - | PARP14 | chr3 | 122446658 | + | 3.21E-10 | 1 |
| AP4B1 | chr1 | 114447226 | - | PARP14 | chr3 | 122446658 | + | 3.21E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
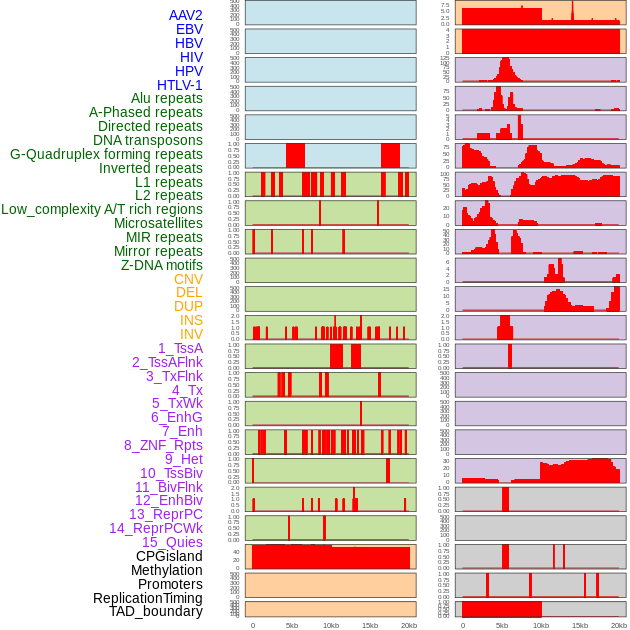 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
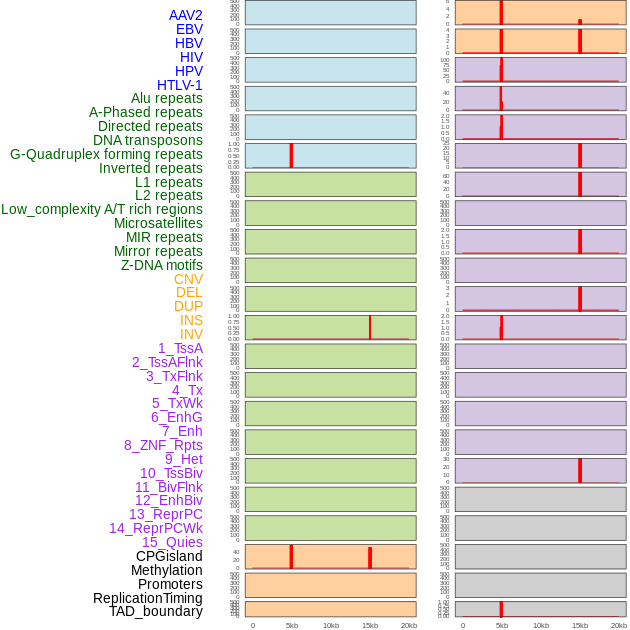 |
Top |
Fusion Protein Features for AP4B1-PARP14 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:114447227/chr3:122446659) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| AP4B1 | . |
| FUNCTION: Component of the adaptor protein complex 4 (AP-4). Adaptor protein complexes are vesicle coat components involved both in vesicle formation and cargo selection. They control the vesicular transport of proteins in different trafficking pathways (PubMed:10066790, PubMed:10436028). AP-4 forms a non clathrin-associated coat on vesicles departing the trans-Golgi network (TGN) and may be involved in the targeting of proteins from the trans-Golgi network (TGN) to the endosomal-lysosomal system. It is also involved in protein sorting to the basolateral membrane in epithelial cells and the proper asymmetric localization of somatodendritic proteins in neurons. AP-4 is involved in the recognition and binding of tyrosine-based sorting signals found in the cytoplasmic part of cargos, but may also recognize other types of sorting signal (Probable). {ECO:0000269|PubMed:10066790, ECO:0000269|PubMed:10436028, ECO:0000305|PubMed:10066790, ECO:0000305|PubMed:10436028}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AP4B1 | chr1:114447227 | chr3:122446659 | ENST00000256658 | - | 2 | 11 | 534_600 | 37 | 740.0 | Region | Hinge |
| Hgene | AP4B1 | chr1:114447227 | chr3:122446659 | ENST00000369569 | - | 1 | 10 | 534_600 | 37 | 740.0 | Region | Hinge |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1003_1190 | 1647 | 1802.0 | Domain | Macro 2 | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1216_1387 | 1647 | 1802.0 | Domain | Macro 3 | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1523_1601 | 1647 | 1802.0 | Domain | WWE | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1605_1801 | 1647 | 1802.0 | Domain | PARP catalytic | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 791_978 | 1647 | 1802.0 | Domain | Macro 1 | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1023_1024 | 1647 | 1802.0 | Region | Substrate 2 binding | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1046_1049 | 1647 | 1802.0 | Region | Substrate 2 binding | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1133_1137 | 1647 | 1802.0 | Region | Substrate 2 binding | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1175_1178 | 1647 | 1802.0 | Region | Substrate 2 binding | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1235_1236 | 1647 | 1802.0 | Region | Substrate 3 binding | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 1332_1336 | 1647 | 1802.0 | Region | Substrate 3 binding | |
| Tgene | PARP14 | chr1:114447227 | chr3:122446659 | ENST00000474629 | 14 | 17 | 922_926 | 1647 | 1802.0 | Region | Substrate 1 binding |
Top |
Fusion Gene Sequence for AP4B1-PARP14 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5306_5306_1_AP4B1-PARP14_AP4B1_chr1_114447227_ENST00000369566_PARP14_chr3_122446659_ENST00000474629_length(transcript)=2967nt_BP=259nt CTACGGAAGCCGAGCCTGAGGCGAGATCTCGCCTTTTGTATTTTCACTGACTCATATTTCCTTTACTCAGGCTCCCACATCAGGACGAGA AGGAGCCCTCGAGTTACCGTGGGAGCTGTGGGAGCTGCCCTGTGACTCTTAGGAAGATGCCGTACCTTGGCTCCGAGGACGTGGTGAAGG AGCTGAAGAAGGCTCTGTGCAATCCTCACATTCAAGCTGATAGGCTGCGCTACCGGAATGTCATCCAGCGAGTGATTAGATTGAGAGGAT CCAGAATCCAGATCTCTGGAATAGCTACCAGGCAAAGAAAAAAACTATGGATGCCAAGAATGGCCAGACAATGAATGAGAAGCAACTCTT CCATGGGACAGATGCCGGCTCCGTGCCACACGTCAATCGAAATGGCTTTAACCGCAGCTATGCCGGAAAGAATGCTGTGGCATATGGAAA GGGAACCTATTTTGCTGTCAATGCCAATTATTCTGCCAATGATACGTACTCCAGACCAGATGCAAATGGGAGAAAGCATGTGTATTATGT GCGAGTACTTACTGGAATCTATACACATGGAAATCATTCATTAATTGTGCCTCCTTCAAAGAACCCTCAAAATCCTACTGACCTGTATGA CACTGTCACAGATAATGTGCACCATCCAAGTTTATTTGTGGCATTTTATGACTACCAAGCATACCCAGAGTACCTTATTACGTTTAGAAA ATAACACTTTGGTATCCTTCCCACAAAATTATTCTCCATTTGTACATATCTAGTTGTAAAACAAGTTTTAGCTTTTTTTTTTAATTCCTC TTAACAGATTTTTCTAATATCCAAGGATCATTCTTTGTCGCTGAAGTCAGTCTTTCTTCAGCTTCCCTTTCATAATGGAAATGAACTTAT TATCTTGAGAGCAAATAACTTGGAAAATTTAAATGAGATAATGCAGTTGCAACTGTGTGTCCACAAGTATGGACATCAAATCTGTGGGAA AAGAACAGGTTTGTATTTTCAGGAAGGAGAGAATAACAGTCTTATAGACAGAGGGCACAGCTAAGCACAGCTGCCACTGCAGGAGACAGG CCCCATGTCAGGATGCCATAGTGCTGTGGGGAGCACAGTATTACCCAGTGGGTAGGGCTTCTGTCTTCCCTGGGAGCAGGGATGGTATCT TAGTCAATTTTTTTCCCTTGAGATGAGGTCTGTGCCTGATGTACAACGGATACTCCATAAATGTTTGACAAACCAACGAAGAATGAAAAA AAGCCTAGTCAGACTCCCATCCAAAGTAGGAACTATCTCTTTAACATTCTTGACTCACTATCACTTTACCTCAAATTGAACAGATTCCAT GACGGAACTTCATTCTTCACAAACTAGCCAGTGACATGTGGGACAGCTCTGGCCAGGGCTCTGGGACTGCAGTGTACTTGCGCTCTGCAC GGTCCAGGAGCTGTGATGTGGCTGTGGTCTAGGGGAATCCTGCCTGCCCCATGGAGTTGCGCAGCACAACCCTGGCTCCAATTGCCAGAA GGCTCTTTTTAATGCTGAACCAAAATGTGCCTTTTTTTTTTTTTTTTTGAGATGGAGTTTCACTCTTGTTGCCCAGGCTGGAGTGCAATG GCGCGATCTCAGCTCACTGCAGCCACTGCCTCCCAGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGATTACAGGCATGC GCTAACACACCCAGCTAATTTTGTATTTTTAGTAGAGACGAGGTTTCTCCATGTTCGACAGGCTGGTCTCGAACTCCCACCTCAGCCTCC CAAACTGCTGGGATTACAGGTGTGAGCCACCGTGACCAGCCAATGTGCCTTCTTATAGTGTCTACTCATTGGTCTTTGTTCTGCCCAGTG ATAACAATGGGATAACGCCTGCTACACATCTTCATTGTGAAACCCTTCCCCTGTGCTGAGATTAAATGAACTCTAAGATTATTAAATAGT ATATTTTCCTTGACAGCCTAGCGTTTGATGATTTTAAAGCCTTATGTATAAATAAACCAAAGGAAGTAAGCAGTCATATTGCTAATTTGC TAACTCCTATCTATTGAATGGTGAAGTTTTAAAAATTTCCCCAGGTAAGTTTAAGATTCAAACACCATCTATTGAGCACCTACATTGTGT GCCAGGTAGTAAAATAGGTGCTTTCATACACATTGTCTCAATTCCTGTGAGGTCAGAATTATCTCTGCATTTGAAACTTGAGGAAACATG CTCAGAGTGCAAGAAGCTTCCTTGCCTGAGATCACCTAGAAAGGAACCCTCAGAGCCGGCAACTGAATCTTGGTCCCTGTGATGTCAAGC CCATTGCTCTCCCACTGCAGAACATGGCCTCTAGATTAATGCCACCGATTCAGGAACACCTCCGACAGTCTTGAAATACCCCCATGTTGC CTTGTTTGTTTTTTCCTTCTGGCTTCTTCTATTACAGTCTCTTCATTGGAAGCTCTGTAGGCCAAGGCCAGAGCTGATACTGACACGGAG CCAATGCAGATAGCACATCAGATGCTAGGGGTCGCTGGGAGGATTAAGGGACTTAATCTGCTAGGAACACCTGTACTTGAAGTGGAGGAG GCTAGGGGGCCACAGTTGCTGCTTCATTAACATAGAGGTTTTGGATTTTTTTCTCTTGTGGTTTGTTTTTTAAGTGGATTGGCAGACTCC TTGTTGCTTAAGAGTGGCTTTCTAGGCAGGCCACTGGCATCTGAATTCATCATTGACAATAAATGTAAGAAATTGGAATAAAAAAGAGAG ACCTGCTGTTATTCGCTTTTGTTCTCCAGTGATTTGATTAACTCAGGGCAAGGCTGAATATCAGAGTGTATCGCACTGAAGAATAATAAT CCATTCAGTAATGTTATAGTTATCCTCAATCTAAATATGTCAACTGTCATTTTGCTACTTTTCAAATAAAATACTTGAAAACTGTCA >5306_5306_1_AP4B1-PARP14_AP4B1_chr1_114447227_ENST00000369566_PARP14_chr3_122446659_ENST00000474629_length(amino acids)=135AA_BP= MDAKNGQTMNEKQLFHGTDAGSVPHVNRNGFNRSYAGKNAVAYGKGTYFAVNANYSANDTYSRPDANGRKHVYYVRVLTGIYTHGNHSLI VPPSKNPQNPTDLYDTVTDNVHHPSLFVAFYDYQAYPEYLITFRK -------------------------------------------------------------- >5306_5306_2_AP4B1-PARP14_AP4B1_chr1_114447227_ENST00000369567_PARP14_chr3_122446659_ENST00000474629_length(transcript)=2932nt_BP=224nt TTGTATTTTCACTGACTCATATTTCCTTTACTCAGGCTCCCACATCAGGACGAGAAGGAGCCCTCGAGTTACCGTGGGAGCTGTGGGAGC TGCCCTGTGACTCTTAGGAAGATGCCGTACCTTGGCTCCGAGGACGTGGTGAAGGAGCTGAAGAAGGCTCTGTGCAATCCTCACATTCAA GCTGATAGGCTGCGCTACCGGAATGTCATCCAGCGAGTGATTAGATTGAGAGGATCCAGAATCCAGATCTCTGGAATAGCTACCAGGCAA AGAAAAAAACTATGGATGCCAAGAATGGCCAGACAATGAATGAGAAGCAACTCTTCCATGGGACAGATGCCGGCTCCGTGCCACACGTCA ATCGAAATGGCTTTAACCGCAGCTATGCCGGAAAGAATGCTGTGGCATATGGAAAGGGAACCTATTTTGCTGTCAATGCCAATTATTCTG CCAATGATACGTACTCCAGACCAGATGCAAATGGGAGAAAGCATGTGTATTATGTGCGAGTACTTACTGGAATCTATACACATGGAAATC ATTCATTAATTGTGCCTCCTTCAAAGAACCCTCAAAATCCTACTGACCTGTATGACACTGTCACAGATAATGTGCACCATCCAAGTTTAT TTGTGGCATTTTATGACTACCAAGCATACCCAGAGTACCTTATTACGTTTAGAAAATAACACTTTGGTATCCTTCCCACAAAATTATTCT CCATTTGTACATATCTAGTTGTAAAACAAGTTTTAGCTTTTTTTTTTAATTCCTCTTAACAGATTTTTCTAATATCCAAGGATCATTCTT TGTCGCTGAAGTCAGTCTTTCTTCAGCTTCCCTTTCATAATGGAAATGAACTTATTATCTTGAGAGCAAATAACTTGGAAAATTTAAATG AGATAATGCAGTTGCAACTGTGTGTCCACAAGTATGGACATCAAATCTGTGGGAAAAGAACAGGTTTGTATTTTCAGGAAGGAGAGAATA ACAGTCTTATAGACAGAGGGCACAGCTAAGCACAGCTGCCACTGCAGGAGACAGGCCCCATGTCAGGATGCCATAGTGCTGTGGGGAGCA CAGTATTACCCAGTGGGTAGGGCTTCTGTCTTCCCTGGGAGCAGGGATGGTATCTTAGTCAATTTTTTTCCCTTGAGATGAGGTCTGTGC CTGATGTACAACGGATACTCCATAAATGTTTGACAAACCAACGAAGAATGAAAAAAAGCCTAGTCAGACTCCCATCCAAAGTAGGAACTA TCTCTTTAACATTCTTGACTCACTATCACTTTACCTCAAATTGAACAGATTCCATGACGGAACTTCATTCTTCACAAACTAGCCAGTGAC ATGTGGGACAGCTCTGGCCAGGGCTCTGGGACTGCAGTGTACTTGCGCTCTGCACGGTCCAGGAGCTGTGATGTGGCTGTGGTCTAGGGG AATCCTGCCTGCCCCATGGAGTTGCGCAGCACAACCCTGGCTCCAATTGCCAGAAGGCTCTTTTTAATGCTGAACCAAAATGTGCCTTTT TTTTTTTTTTTTTGAGATGGAGTTTCACTCTTGTTGCCCAGGCTGGAGTGCAATGGCGCGATCTCAGCTCACTGCAGCCACTGCCTCCCA GGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGATTACAGGCATGCGCTAACACACCCAGCTAATTTTGTATTTTTAGTAG AGACGAGGTTTCTCCATGTTCGACAGGCTGGTCTCGAACTCCCACCTCAGCCTCCCAAACTGCTGGGATTACAGGTGTGAGCCACCGTGA CCAGCCAATGTGCCTTCTTATAGTGTCTACTCATTGGTCTTTGTTCTGCCCAGTGATAACAATGGGATAACGCCTGCTACACATCTTCAT TGTGAAACCCTTCCCCTGTGCTGAGATTAAATGAACTCTAAGATTATTAAATAGTATATTTTCCTTGACAGCCTAGCGTTTGATGATTTT AAAGCCTTATGTATAAATAAACCAAAGGAAGTAAGCAGTCATATTGCTAATTTGCTAACTCCTATCTATTGAATGGTGAAGTTTTAAAAA TTTCCCCAGGTAAGTTTAAGATTCAAACACCATCTATTGAGCACCTACATTGTGTGCCAGGTAGTAAAATAGGTGCTTTCATACACATTG TCTCAATTCCTGTGAGGTCAGAATTATCTCTGCATTTGAAACTTGAGGAAACATGCTCAGAGTGCAAGAAGCTTCCTTGCCTGAGATCAC CTAGAAAGGAACCCTCAGAGCCGGCAACTGAATCTTGGTCCCTGTGATGTCAAGCCCATTGCTCTCCCACTGCAGAACATGGCCTCTAGA TTAATGCCACCGATTCAGGAACACCTCCGACAGTCTTGAAATACCCCCATGTTGCCTTGTTTGTTTTTTCCTTCTGGCTTCTTCTATTAC AGTCTCTTCATTGGAAGCTCTGTAGGCCAAGGCCAGAGCTGATACTGACACGGAGCCAATGCAGATAGCACATCAGATGCTAGGGGTCGC TGGGAGGATTAAGGGACTTAATCTGCTAGGAACACCTGTACTTGAAGTGGAGGAGGCTAGGGGGCCACAGTTGCTGCTTCATTAACATAG AGGTTTTGGATTTTTTTCTCTTGTGGTTTGTTTTTTAAGTGGATTGGCAGACTCCTTGTTGCTTAAGAGTGGCTTTCTAGGCAGGCCACT GGCATCTGAATTCATCATTGACAATAAATGTAAGAAATTGGAATAAAAAAGAGAGACCTGCTGTTATTCGCTTTTGTTCTCCAGTGATTT GATTAACTCAGGGCAAGGCTGAATATCAGAGTGTATCGCACTGAAGAATAATAATCCATTCAGTAATGTTATAGTTATCCTCAATCTAAA TATGTCAACTGTCATTTTGCTACTTTTCAAATAAAATACTTGAAAACTGTCA >5306_5306_2_AP4B1-PARP14_AP4B1_chr1_114447227_ENST00000369567_PARP14_chr3_122446659_ENST00000474629_length(amino acids)=135AA_BP= MDAKNGQTMNEKQLFHGTDAGSVPHVNRNGFNRSYAGKNAVAYGKGTYFAVNANYSANDTYSRPDANGRKHVYYVRVLTGIYTHGNHSLI VPPSKNPQNPTDLYDTVTDNVHHPSLFVAFYDYQAYPEYLITFRK -------------------------------------------------------------- >5306_5306_3_AP4B1-PARP14_AP4B1_chr1_114447227_ENST00000369569_PARP14_chr3_122446659_ENST00000474629_length(transcript)=3102nt_BP=394nt GGACCTAGAAGTAGCGGGAGCGATCTGTGGGCGGGGCGAACGGCCTGCCGGCCGACGGTAGGGCCTGAAGAGCCTAGGGTGGGGCTCGCG GTGTCGCGGAGGGCGTGGAAGTGTGTCAGGGCCAGCGTGCCGGCCCTACGGAAGCCGAGCCTGAGGCGAGATCTCGCCTTTTGTATTTTC ACTGACTCATATTTCCTTTACTCAGGCTCCCACATCAGGACGAGAAGGAGCCCTCGAGTTACCGTGGGAGCTGTGGGAGCTGCCCTGTGA CTCTTAGGAAGATGCCGTACCTTGGCTCCGAGGACGTGGTGAAGGAGCTGAAGAAGGCTCTGTGCAATCCTCACATTCAAGCTGATAGGC TGCGCTACCGGAATGTCATCCAGCGAGTGATTAGATTGAGAGGATCCAGAATCCAGATCTCTGGAATAGCTACCAGGCAAAGAAAAAAAC TATGGATGCCAAGAATGGCCAGACAATGAATGAGAAGCAACTCTTCCATGGGACAGATGCCGGCTCCGTGCCACACGTCAATCGAAATGG CTTTAACCGCAGCTATGCCGGAAAGAATGCTGTGGCATATGGAAAGGGAACCTATTTTGCTGTCAATGCCAATTATTCTGCCAATGATAC GTACTCCAGACCAGATGCAAATGGGAGAAAGCATGTGTATTATGTGCGAGTACTTACTGGAATCTATACACATGGAAATCATTCATTAAT TGTGCCTCCTTCAAAGAACCCTCAAAATCCTACTGACCTGTATGACACTGTCACAGATAATGTGCACCATCCAAGTTTATTTGTGGCATT TTATGACTACCAAGCATACCCAGAGTACCTTATTACGTTTAGAAAATAACACTTTGGTATCCTTCCCACAAAATTATTCTCCATTTGTAC ATATCTAGTTGTAAAACAAGTTTTAGCTTTTTTTTTTAATTCCTCTTAACAGATTTTTCTAATATCCAAGGATCATTCTTTGTCGCTGAA GTCAGTCTTTCTTCAGCTTCCCTTTCATAATGGAAATGAACTTATTATCTTGAGAGCAAATAACTTGGAAAATTTAAATGAGATAATGCA GTTGCAACTGTGTGTCCACAAGTATGGACATCAAATCTGTGGGAAAAGAACAGGTTTGTATTTTCAGGAAGGAGAGAATAACAGTCTTAT AGACAGAGGGCACAGCTAAGCACAGCTGCCACTGCAGGAGACAGGCCCCATGTCAGGATGCCATAGTGCTGTGGGGAGCACAGTATTACC CAGTGGGTAGGGCTTCTGTCTTCCCTGGGAGCAGGGATGGTATCTTAGTCAATTTTTTTCCCTTGAGATGAGGTCTGTGCCTGATGTACA ACGGATACTCCATAAATGTTTGACAAACCAACGAAGAATGAAAAAAAGCCTAGTCAGACTCCCATCCAAAGTAGGAACTATCTCTTTAAC ATTCTTGACTCACTATCACTTTACCTCAAATTGAACAGATTCCATGACGGAACTTCATTCTTCACAAACTAGCCAGTGACATGTGGGACA GCTCTGGCCAGGGCTCTGGGACTGCAGTGTACTTGCGCTCTGCACGGTCCAGGAGCTGTGATGTGGCTGTGGTCTAGGGGAATCCTGCCT GCCCCATGGAGTTGCGCAGCACAACCCTGGCTCCAATTGCCAGAAGGCTCTTTTTAATGCTGAACCAAAATGTGCCTTTTTTTTTTTTTT TTTGAGATGGAGTTTCACTCTTGTTGCCCAGGCTGGAGTGCAATGGCGCGATCTCAGCTCACTGCAGCCACTGCCTCCCAGGTTCAAGTG ATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGATTACAGGCATGCGCTAACACACCCAGCTAATTTTGTATTTTTAGTAGAGACGAGGTT TCTCCATGTTCGACAGGCTGGTCTCGAACTCCCACCTCAGCCTCCCAAACTGCTGGGATTACAGGTGTGAGCCACCGTGACCAGCCAATG TGCCTTCTTATAGTGTCTACTCATTGGTCTTTGTTCTGCCCAGTGATAACAATGGGATAACGCCTGCTACACATCTTCATTGTGAAACCC TTCCCCTGTGCTGAGATTAAATGAACTCTAAGATTATTAAATAGTATATTTTCCTTGACAGCCTAGCGTTTGATGATTTTAAAGCCTTAT GTATAAATAAACCAAAGGAAGTAAGCAGTCATATTGCTAATTTGCTAACTCCTATCTATTGAATGGTGAAGTTTTAAAAATTTCCCCAGG TAAGTTTAAGATTCAAACACCATCTATTGAGCACCTACATTGTGTGCCAGGTAGTAAAATAGGTGCTTTCATACACATTGTCTCAATTCC TGTGAGGTCAGAATTATCTCTGCATTTGAAACTTGAGGAAACATGCTCAGAGTGCAAGAAGCTTCCTTGCCTGAGATCACCTAGAAAGGA ACCCTCAGAGCCGGCAACTGAATCTTGGTCCCTGTGATGTCAAGCCCATTGCTCTCCCACTGCAGAACATGGCCTCTAGATTAATGCCAC CGATTCAGGAACACCTCCGACAGTCTTGAAATACCCCCATGTTGCCTTGTTTGTTTTTTCCTTCTGGCTTCTTCTATTACAGTCTCTTCA TTGGAAGCTCTGTAGGCCAAGGCCAGAGCTGATACTGACACGGAGCCAATGCAGATAGCACATCAGATGCTAGGGGTCGCTGGGAGGATT AAGGGACTTAATCTGCTAGGAACACCTGTACTTGAAGTGGAGGAGGCTAGGGGGCCACAGTTGCTGCTTCATTAACATAGAGGTTTTGGA TTTTTTTCTCTTGTGGTTTGTTTTTTAAGTGGATTGGCAGACTCCTTGTTGCTTAAGAGTGGCTTTCTAGGCAGGCCACTGGCATCTGAA TTCATCATTGACAATAAATGTAAGAAATTGGAATAAAAAAGAGAGACCTGCTGTTATTCGCTTTTGTTCTCCAGTGATTTGATTAACTCA GGGCAAGGCTGAATATCAGAGTGTATCGCACTGAAGAATAATAATCCATTCAGTAATGTTATAGTTATCCTCAATCTAAATATGTCAACT GTCATTTTGCTACTTTTCAAATAAAATACTTGAAAACTGTCA >5306_5306_3_AP4B1-PARP14_AP4B1_chr1_114447227_ENST00000369569_PARP14_chr3_122446659_ENST00000474629_length(amino acids)=135AA_BP= MDAKNGQTMNEKQLFHGTDAGSVPHVNRNGFNRSYAGKNAVAYGKGTYFAVNANYSANDTYSRPDANGRKHVYYVRVLTGIYTHGNHSLI VPPSKNPQNPTDLYDTVTDNVHHPSLFVAFYDYQAYPEYLITFRK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AP4B1-PARP14 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AP4B1-PARP14 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AP4B1-PARP14 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | AP4B1 | C3279738 | SPASTIC PARAPLEGIA 47, AUTOSOMAL RECESSIVE | 2 | CTD_human;GENOMICS_ENGLAND |
| Hgene | AP4B1 | C4755264 | Severe intellectual disability and progressive spastic paraplegia | 2 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies