
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CHGA-CROCC (FusionGDB2 ID:HG1113TG9696) |
Fusion Gene Summary for CHGA-CROCC |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CHGA-CROCC | Fusion gene ID: hg1113tg9696 | Hgene | Tgene | Gene symbol | CHGA | CROCC | Gene ID | 1113 | 9696 |
| Gene name | chromogranin A | ciliary rootlet coiled-coil, rootletin | |
| Synonyms | CGA | ROLT|TAX1BP2 | |
| Cytomap | ('CHGA')('CROCC') 14q32.12 | 1p36.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | chromogranin-ASP-Ibetagranin (N-terminal fragment of chromogranin A)catestatinchromofunginparathyroid secretory protein 1pituitary secretory protein I | rootletinTax1-binding protein 2ciliary rootlet coiled-coil proteinrootletin, ciliary rootlet protein | |
| Modification date | 20200315 | 20200313 | |
| UniProtAcc | P10645 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000216492, ENST00000334654, ENST00000553866, | ||
| Fusion gene scores | * DoF score | 11 X 15 X 3=495 | 7 X 7 X 4=196 |
| # samples | 15 | 7 | |
| ** MAII score | log2(15/495*10)=-1.72246602447109 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/196*10)=-1.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CHGA [Title/Abstract] AND CROCC [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CHGA(93398818)-CROCC(17256675), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | CHGA-CROCC seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CHGA-CROCC seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CHGA-CROCC seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CHGA-CROCC seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CHGA | GO:0002551 | mast cell chemotaxis | 21214543 |
| Hgene | CHGA | GO:0032762 | mast cell cytokine production | 21214543 |
| Hgene | CHGA | GO:0033604 | negative regulation of catecholamine secretion | 15326220 |
| Hgene | CHGA | GO:0043303 | mast cell degranulation | 21214543 |
| Hgene | CHGA | GO:0045576 | mast cell activation | 21214543 |
| Hgene | CHGA | GO:0050829 | defense response to Gram-negative bacterium | 15723172 |
| Hgene | CHGA | GO:0050830 | defense response to Gram-positive bacterium | 15723172 |
| Tgene | CROCC | GO:0007098 | centrosome cycle | 16203858 |
| Fusion gene breakpoints across CHGA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CROCC (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PCPG | TCGA-QR-A70C-01A | CHGA | chr14 | 93398818 | + | CROCC | chr1 | 17256675 | + |
Top |
Fusion Gene ORF analysis for CHGA-CROCC |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000216492 | ENST00000467938 | CHGA | chr14 | 93398818 | + | CROCC | chr1 | 17256675 | + |
| 5CDS-3UTR | ENST00000334654 | ENST00000467938 | CHGA | chr14 | 93398818 | + | CROCC | chr1 | 17256675 | + |
| In-frame | ENST00000216492 | ENST00000375541 | CHGA | chr14 | 93398818 | + | CROCC | chr1 | 17256675 | + |
| In-frame | ENST00000334654 | ENST00000375541 | CHGA | chr14 | 93398818 | + | CROCC | chr1 | 17256675 | + |
| intron-3CDS | ENST00000553866 | ENST00000375541 | CHGA | chr14 | 93398818 | + | CROCC | chr1 | 17256675 | + |
| intron-3UTR | ENST00000553866 | ENST00000467938 | CHGA | chr14 | 93398818 | + | CROCC | chr1 | 17256675 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000216492 | CHGA | chr14 | 93398818 | + | ENST00000375541 | CROCC | chr1 | 17256675 | + | 7459 | 1466 | 1058 | 6925 | 1955 |
| ENST00000334654 | CHGA | chr14 | 93398818 | + | ENST00000375541 | CROCC | chr1 | 17256675 | + | 6910 | 917 | 551 | 6376 | 1941 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000216492 | ENST00000375541 | CHGA | chr14 | 93398818 | + | CROCC | chr1 | 17256675 | + | 0.028792268 | 0.9712078 |
| ENST00000334654 | ENST00000375541 | CHGA | chr14 | 93398818 | + | CROCC | chr1 | 17256675 | + | 0.026627539 | 0.9733725 |
Top |
Fusion Genomic Features for CHGA-CROCC |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
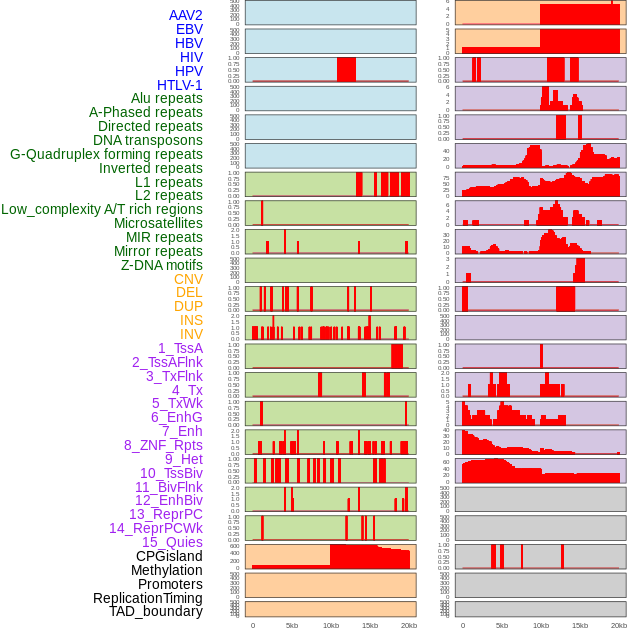 |
Top |
Fusion Protein Features for CHGA-CROCC |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr14:93398818/chr1:17256675) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CHGA | . |
| FUNCTION: [Pancreastatin]: Strongly inhibits glucose induced insulin release from the pancreas.; FUNCTION: [Catestatin]: Inhibits catecholamine release from chromaffin cells and noradrenergic neurons by acting as a non-competitive nicotinic cholinergic antagonist (PubMed:15326220). Displays antibacterial activity against Gram-positive bacteria S.aureus and M.luteus, and Gram-negative bacteria E.coli and P.aeruginosa (PubMed:15723172 and PubMed:24723458). Can induce mast cell migration, degranulation and production of cytokines and chemokines (PubMed:21214543). Acts as a potent scavenger of free radicals in vitro (PubMed:24723458). May play a role in the regulation of cardiac function and blood pressure (PubMed:18541522). {ECO:0000269|PubMed:15326220, ECO:0000269|PubMed:15723172, ECO:0000269|PubMed:21214543, ECO:0000269|PubMed:24723458, ECO:0000303|PubMed:18541522}.; FUNCTION: [Serpinin]: Regulates granule biogenesis in endocrine cells by up-regulating the transcription of protease nexin 1 (SERPINE2) via a cAMP-PKA-SP1 pathway. This leads to inhibition of granule protein degradation in the Golgi complex which in turn promotes granule formation. {ECO:0000250|UniProtKB:P26339}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CROCC | chr14:93398818 | chr1:17256675 | ENST00000375541 | 0 | 37 | 1091_1438 | 0 | 2018.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CROCC | chr14:93398818 | chr1:17256675 | ENST00000375541 | 0 | 37 | 1505_1704 | 0 | 2018.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CROCC | chr14:93398818 | chr1:17256675 | ENST00000375541 | 0 | 37 | 318_444 | 0 | 2018.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CROCC | chr14:93398818 | chr1:17256675 | ENST00000375541 | 0 | 37 | 546_1058 | 0 | 2018.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CROCC | chr14:93398818 | chr1:17256675 | ENST00000375541 | 0 | 37 | 70_262 | 0 | 2018.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CROCC | chr14:93398818 | chr1:17256675 | ENST00000375541 | 0 | 37 | 1921_1999 | 0 | 2018.0 | Compositional bias | Gln-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CHGA | chr14:93398818 | chr1:17256675 | ENST00000216492 | + | 1 | 8 | 181_191 | 0 | 458.0 | Region | Note=O-glycosylated at one site only in cerebrospinal fluid |
| Hgene | CHGA | chr14:93398818 | chr1:17256675 | ENST00000216492 | + | 1 | 8 | 41_59 | 0 | 458.0 | Region | Note=O-glycosylated at one site only in cerebrospinal fluid |
Top |
Fusion Gene Sequence for CHGA-CROCC |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >16436_16436_1_CHGA-CROCC_CHGA_chr14_93398818_ENST00000216492_CROCC_chr1_17256675_ENST00000375541_length(transcript)=7459nt_BP=1466nt AAGGGGGCGGCACCGCTGACGTCATTTCCGGGGTCGGGGTATATAAGCGGGGCGCGAGGGCGCTGCTGCTGCCACCGCTCCTGCCACTGC AGTGCTCGAGCCCCGTGCAGGGGAGCTTGCGGGAGGATCGACCGACAGACGGACGCACGCCGAGGCACTGCGCCCCCAGCCCCGCGCCGG TGCCACCGCAGCCCGACCCCGGCCGCCAGTCCAGCCGCCCCTCGCCCGGTGCCTAGGTGCCCGGCCCCACACCGCCAGCTGCTCGGCGCC CGGGTCCGCCATGCGCTCCGCCGCTGTCCTGGCTCTTCTGCTCTGCGCCGGGCAAGTCACTGCGCTCCCTGTGAACAGCCCTATGAATAA AGGGGATACCGAGGTGATGAAATGCATCGTTGAGGTCATCTCCGACACACTTTCCAAGCCCAGCCCCATGCCTGTCAGCCAGGAATGTTT TGAGACACTCCGAGGAGATGAACGGATCCTTTCCATTCTGAGACATCAGAATTTACTGAAGGAGCTCCAAGACCTCGCTCTCCAAGGCGC CAAGGAGAGGGCACATCAGCAGAAGAAACACAGCGGTTTTGAAGATGAACTCTCAGAGGTTCTTGAGAACCAGAGCAGCCAGGCCGAGCT GAAAGAGGCGGTGGAAGAGCCATCATCCAAGGATGTTATGGAGAAAAGAGAGGATTCCAAGGAGGCAGAGAAAAGTGGTGAAGCCACAGA CGGAGCCAGGCCCCAGGCCCTCCCGGAGCCCATGCAGGAGTCCAAGGCTGAGGGGAACAATCAGGCCCCTGGGGAGGAAGAGGAGGAGGA GGAGGAGGCCACCAACACCCACCCTCCAGCCAGCCTCCCCAGCCAGAAATACCCAGGCCCACAGGCCGAGGGGGACAGTGAGGGCCTCTC TCAGGGTCTGGTGGACAGAGAGAAGGGCCTGAGTGCAGAGCCAGGGTGGCAGGCAAAGAGAGAAGAGGAGGAGGAGGAGGAGGAGGAGGC TGAGGCTGGAGAGGAGGCTGTCCCCGAGGAAGAAGGCCCCACTGTAGTGCTGAACCCCCACCCGAGCCTTGGCTACAAGGAGATCCGGAA AGGCGAGAGAGGAGGAGGAGATGGCAGTGGTCCCGCAAGGCCTCTTCCGGGGTGGGAAGAGCGGAGAGCTGGAGCAGGAGGAGGAGCGGC TCTCCAAGGAGTGGGAGGACTCCAAACGCTGGAGCAAGATGGACCAGCTGGCCAAGGAGCTGACGGCTGAGAAGCGGCTGGAGGGGCAGG AGGAGGAGGAGGACAACCGGGACAGTTCCATGAAGCTCTCCTTCCGGGCCCGGGCCTACGGCTTCAGGGGCCCTGGGCCGCAGCTGCGAC GAGGCTGGAGGCCATCCTCCCGGGAGGACAGCCTTGAGGCGGGCCTGCCCCTCCAGGTCCGAGGCTACCCCGAGGAGAAGAAAGAGGAGG AGGGCAGCGCAAACCGCAGACCAGAGGGAGAGCTGGAGCAGCAGCGGCTGAGGGACACAGAGCACAGCCAAGACCTGGAAAGCGCCCTCA TCCGGCTGGAGGAGGAGCAGCAGAGGAGTGCCAGCCTGGCCCAGGTGAATGCCATGCTCCGAGAACAGCTGGACCAGGCAGGCTCGGCCA ACCAGGCTCTGAGTGAGGACATACGAAAGGTGACCAATGACTGGACACGCTGCCGCAAGGAGCTGGAGCACCGGGAGGCGGCGTGGAGGC GCGAGGAGGAGTCCTTCAACGCCTACTTCAGCAACGAGCACAGTCGCCTGCTCCTCCTCTGGAGGCAGGTGGTGGGGTTCCGGCGGCTGG TCAGCGAGGTGAAGATGTTCACTGAGAGGGACCTGCTGCAGCTGGGAGGGGAGCTGGCCCGGACATCACGAGCTGTCCAGGAGGCGGGCC TGGGACTGAGCACGGGCCTACGGCTGGCAGAGAGCCGGGCCGAGGCAGCCCTGGAGAAACAGGCCCTGCTGCAGGCCCAGCTGGAGGAGC AGCTGCGGGACAAGGTGCTCCGCGAGAAGGACCTGGCGCAGCAGCAGATGCAAAGCGACCTGGACAAGGCTGACCTCAGTGCCAGAGTGA CAGAGCTGGGCCTGGCAGTGAAGCGTCTTGAGAAGCAGAATCTGGAGAAGGATCAGGTCAACAAGGACCTCACTGAGAAGCTTGAGGCCC TGGAATCCCTGCGGCTACAGGAGCAGGCGGCCCTGGAGACAGAGGATGGAGAGGGGCTACAGCAGACCCTAAGGGACCTGGCACAGGCCG TCTTGTCAGACTCTGAGAGCGGCGTCCAGCTGAGCGGCTCTGAGCGCACCGCGGATGCTTCCAACGGCAGCCTGCGGGGGCTCTCGGGCC AGCGGACCCCGTCCCCACCGCGGCGCTCCTCGCCCGGCCGAGGCCGTTCACCCCGCCGAGGCCCCTCCCCGGCCTGCTCAGACTCCTCCA CGCTCGCCCTGATCCACTCCGCCCTGCACAAGCGCCAGCTGCAGGTCCAGGACATGCGTGGGCGCTATGAGGCAAGCCAGGACCTACTGG GCACCCTGCGGAAGCAGCTTAGCGACAGCGAGAGCGAGCGGCGGGCCCTAGAGGAACAGCTGCAGCGCCTGCGGGACAAGACCGACGGCG CCATGCAGGCCCACGAGGACGCCCAGCGCGAGGTGCAGCGGCTGCGGAGCGCCAACGAGCTCCTGAGCAGGGAGAAGAGCAACCTGGCCC ACAGCCTGCAGGTGGCCCAGCAGCAGGCCGAGGAGCTGCGGCAGGAGCGGGAGAAGCTGCAGGCTGCCCAGGAGGAGCTGCGGCGCCAGC GGGACCGGCTGGAGGAAGAGCAGGAGGACGCAGTGCAGGATGGCGCGCGGGTGCGCCGGGAGCTTGAGCGCAGCCATAGACAACTAGAGC AGCTGGAAGGGAAGCGCTCAGTCCTGGCCAAGGAGCTGGTGGAGGTGAGGGAGGCGCTGAGCCGCGCCACACTGCAACGGGACATGCTGC AGGCCGAGAAGGCCGAGGTGGCCGAGGCGCTGACCAAGGCTGAGGCTGGCCGCGTGGAGCTCGAGCTCTCCATGACCAAGCTGAGGGCAG AGGAGGCCTCCCTGCAGGACTCCCTGTCCAAGCTGAGCGCCCTCAACGAGAGCCTTGCTCAGGACAAGTTGGATCTGAACCGCCTTGTCG CCCAGCTGGAGGAAGAAAAGTCCGCCCTGCAGGGCCGGCAACGGCAGGCAGAGCAGGAGGCCACAGTGGCGCGGGAAGAGCAGGAACGGC TAGAGGAGCTGCGGTTGGAGCAGGAGGTGGCGCGGCAGGGCCTGGAGGGCTCCCTACGAGTGGCGGAGCAGGCCCAGGAGGCATTGGAGC AGCAGCTCCCCACGCTGCGCCATGAGCGCAGCCAGCTGCAGGAGCAGCTAGCGCAGCTCTCCCGGCAGCTGAGCGGGCGGGAGCAGGAGC TGGAGCAGGCCCGGCGGGAGGCCCAGCGGCAAGTGGAGGCGCTGGAGCGAGCGGCCCGTGAGAAGGAGGCGCTAGCCAAGGAGCACGCTG GCCTGGCTGTGCAGCTGGTGGCTGCGGAGCGTGAAGGCAGGACCCTGTCAGAGGAGGCCACACGCCTGCGCTTGGAGAAGGAAGCCCTGG AGGGCAGCCTGTTTGAGGTGCAACGGCAGCTGGCCCAGCTTGAGGCCCGCCGGGAGCAGCTGGAAGCCGAGGGGCAGGCCCTGCTGCTGG CCAAGGAGACCCTGACTGGGGAGTTGGCGGGCCTGCGGCAGCAAATAATAGCTACACAGGAGAAAGCCAGTCTAGACAAGGAGCTGATGG CCCAGAAGCTGGTGCAGGCTGAGCGGGAGGCCCAGGCCTCTCTGCGGGAGCAGCGGGCAGCTCACGAGGAGGACTTACAGCGACTCCAGC GTGAAAAGGAGGCAGCATGGCGGGAGCTGGAGGCCGAGCGGGCCCAGCTGCAGAGTCAGCTGCAGCGTGAGCAGGAGGAGCTGCTGGCCC GGCTGGAGGCTGAGAAGGAAGAGCTGAGTGAGGAGATTGCTGCCCTGCAGCAGGAGCGCGACGAGGGCCTCCTCCTAGCAGAGAGTGAGA AGCAGCAGGCCTTGTCTCTGAAGGAGTCTGAGAAGACGGCGCTGTCAGAGAAGTTGATGGGTACACGGCACAGCCTGGCCACCATCTCCC TGGAGATGGAGCGGCAGAAACGAGATGCCCAGAGCCGGCAGGAGCAGGACCGGAGCACCGTGAACGCTCTGACGTCTGAGCTGCGGGACC TACGGGCCCAGCGGGAGGAGGCTGCTGCGGCCCACGCCCAGGAGGTGAGGAGGCTGCAAGAGCAGGCCCGAGACCTGGGCAAGCAGCGGG ACTCCTGTCTTCGCGAGGCAGAAGAGCTTCGGACCCAGCTGCGTCTGCTGGAGGATGCCCGTGACGGGCTGCGGCGGGAGCTGCTGGAGG CCCAGCGCAAGCTGCGTGAGAGCCAGGAGGGCCGGGAGGTGCAGCGCCAGGAGGCAGGCGAGCTGCGACGCAGCCTGGGCGAGGGTGCCA AGGAGCGCGAGGCCCTGCGGCGTTCCAATGAGGAGCTTCGGTCTGCTGTGAAGAAGGCAGAGAGCGAGCGCATCAGCCTGAAGCTTGCCA ATGAGGACAAGGAGCAGAAGCTGGCACTCCTAGAGGAGGCACGGACAGCTGTGGGCAAGGAGGCCGGGGAGCTGCGAACTGGGCTGCAGG AGGTGGAGCGCTCACGGCTGGAGGCTCGGCGGGAGCTGCAGGAGCTCCGGCGTCAGATGAAGATGCTGGACAGTGAGAACACCAGACTGG GCCGGGAGCTGGCGGAGCTGCAGGGCCGCCTGGCGCTGGGCGAGCGGGCAGAGAAGGAGAGCAGGCGGGAGACCCTGGGCCTCCGGCAGA GGCTGCTGAAGGGCGAGGCCAGCCTGGAGGTGATGCGGCAGGAGCTCCAGGTAGCCCAGCGGAAGCTGCAGGAACAAGAAGGCGAGTTCC GGACCCGCGAGCGACGCCTGCTGGGCTCCCTGGAGGAGGCGCGTGGCACTGAAAAGCAGCAGCTGGACCACGCCCGCGGCCTGGAGCTGA AGCTGGAGGCGGCGCGGGCCGAGGCTGCAGAGCTGGGCCTGCGGCTGAGCGCAGCCGAGGGCCGGGCACAAGGCCTGGAGGCCGAGCTGG CCCGCGTGGAGGTGCAGCGGCGCGCGGCGGAGGCCCAGCTGGGTGGCCTGCGCTCGGCTCTGCGCCGGGGCCTCGGCCTCGGTCGCGCGC CCAGCCCAGCCCCGCGGCCAGTGCCCGGTTCCCCTGCCCGGGACGCACCCGCAGAAGGAAGCGGGGAAGGGCTCAACAGCCCCAGCACCT TAGAATGCAGCCCTGGGTCCCAGCCACCATCTCCAGGACCTGCCACCTCCCCAGCCTCTCCAGACCTGGACCCGGAGGCAGTGCGCGGGG CCCTCCGGGAATTCCTGCAAGAGCTGCGGAGTGCCCAGAGAGAACGGGACGAACTTCGGACCCAGACCAGTGCCCTGAATCGCCAGCTGG CCGAGATGGAGGCTGAGAGGGACAGCGCAACCTCGAGGGCCAGGCAGCTGCAGAAGGCGGTGGCTGAGAGTGAGGAAGCCCGGCGCAGTG TGGATGGGCGGCTGAGCGGGGTCCAGGCGGAGCTGGCGCTGCAGGAGGAGAGTGTGCGGCGCAGTGAGCGGGAGCGCCGGGCCACGCTGG ACCAGGTGGCCACACTGGAGAGGAGCCTGCAGGCCACCGAGAGCGAGCTCCGGGCCAGCCAGGAGAAGATCAGCAAGATGAAGGCCAATG AGACAAAGCTGGAGGGCGACAAGCGGCGCCTGAAGGAGGTTCTGGACGCCTCCGAGAGCCGCACTGTCAAGCTGGAGCTGCAGCGGCGCT CGCTTGAGGGGGAGCTGCAGCGCAGCCGCCTGGGCCTCAGTGACCGCGAGGCCCAAGCCCAGGCCCTCCAGGATCGGGTGGATTCCCTGC AGAGACAGGTGGCCGACAGCGAGGTGAAGGCAGGGACCCTGCAGCTGACCGTGGAGCGGCTGAATGGGGCCCTGGCTAAGGTGGAGGAAA GCGAGGGGGCCCTGCGGGACAAGGTGCGGGGCCTGACAGAGGCCCTGGCCCAGAGCAGTGCCAGCCTCAACAGCACCCGGGACAAGAACC TGCATCTGCAGAAGGCTCTGACCGCCTGTGAACATGACCGCCAAGTACTCCAGGAACGGCTGGATGCCGCCCGGCAGGCATTATCTGAGG CACGGAAGCAGAGCAGCTCCCTGGGCGAGCAGGTGCAGACGTTGCGAGGCGAGGTGGCTGACCTGGAACTGCAGCGGGTGGAGGCCGAGG GCCAGCTACAACAGCTACGGGAGGTGCTGCGGCAGCGGCAGGAGGGTGAGGCTGCAGCCCTGAACACCGTCCAGAAGCTGCAAGACGAGC GGCGGCTGCTGCAGGAGCGCCTGGGAAGCCTGCAGCGCGCCCTGGCTCAGCTGGAAGCTGAGAAGCGGGAGGTGGAGCGCTCAGCCCTGC GGCTGGAGAAGGACCGTGTAGCCCTCAGGAGGACGCTGGACAAGGTGGAGCGGGAGAAGCTTCGTAGCCATGAGGACACAGTGCGGCTGA GCGCAGAGAAGGGCCGCCTGGACCGCACCCTCACGGGGGCTGAGCTGGAGCTGGCAGAGGCGCAGAGGCAGATCCAGCAGCTGGAGGCGC AGGTGGTGGTGCTGGAGCAGAGCCACAGCCCGGCCCAGCTGGAGGTGGATGCGCAGCAGCAGCAGCTGGAGCTGCAGCAGGAGGTGGAGC GGCTGCGCAGCGCCCAGGCGCAGACTGAGCGCACCCTGGAGGCTCGGGAGCGGGCCCACCGCCAGAGGGTGCGTGGGCTGGAGGAGCAGG TGTCCACACTGAAGGGCCAGCTGCAGCAGGAGCTTCGAAGGAGCTCAGCACCCTTCTCCCCACCCTCCGGCCCCCCAGAGAAATGAGCTC CTGCTGGCATCTGGAGAACACCCCTGTGCCTGGGACAGGGGAGGACCCTTCTTTTGGACAGCCCCCCCACCCAGAGCCCGGTCCCTTGGG GGCCTCAAGCTGGGGTGGGATGAGGAGGCGCTCTGCTGGCAGTGCTGAGGACGGGTACTCCAGCTCCAGGCCTGGAGAGGCTTCCCAGCA ACACCTGCAGTCCAGCCCCCCTCTTCTAGGATGAGCCACTGTAGATCATTAAAGTTCCTCCTTGAGAGGCTGAGCCGTAGCCAGGATTGG GGAGAGCCCTTGTCTCTGGTCAGCCCTGGAGCATGGGATCGTGGGAAAGAGGAGGGGGACCAGGCCCAGGGCAGGGGTCAGAGGCCCAGG CCCTGACTTCGGCTTCCCAGAGATCTCTCCGCCTTAGTTAAGAGCATGTGTCGGGAAATTCCTCAGAGTGCTCAGAGTCCCTGTATTTTT ATACCTTTTTACAATGTTAACTGTTCAGAACTGTTTTTTGTAACAAAACCTTGTTTTTAAAAAAGTTTGTACAGCTGTG >16436_16436_1_CHGA-CROCC_CHGA_chr14_93398818_ENST00000216492_CROCC_chr1_17256675_ENST00000375541_length(amino acids)=1955AA_BP=136 MATRRSGKAREEEEMAVVPQGLFRGGKSGELEQEEERLSKEWEDSKRWSKMDQLAKELTAEKRLEGQEEEEDNRDSSMKLSFRARAYGFR GPGPQLRRGWRPSSREDSLEAGLPLQVRGYPEEKKEEEGSANRRPEGELEQQRLRDTEHSQDLESALIRLEEEQQRSASLAQVNAMLREQ LDQAGSANQALSEDIRKVTNDWTRCRKELEHREAAWRREEESFNAYFSNEHSRLLLLWRQVVGFRRLVSEVKMFTERDLLQLGGELARTS RAVQEAGLGLSTGLRLAESRAEAALEKQALLQAQLEEQLRDKVLREKDLAQQQMQSDLDKADLSARVTELGLAVKRLEKQNLEKDQVNKD LTEKLEALESLRLQEQAALETEDGEGLQQTLRDLAQAVLSDSESGVQLSGSERTADASNGSLRGLSGQRTPSPPRRSSPGRGRSPRRGPS PACSDSSTLALIHSALHKRQLQVQDMRGRYEASQDLLGTLRKQLSDSESERRALEEQLQRLRDKTDGAMQAHEDAQREVQRLRSANELLS REKSNLAHSLQVAQQQAEELRQEREKLQAAQEELRRQRDRLEEEQEDAVQDGARVRRELERSHRQLEQLEGKRSVLAKELVEVREALSRA TLQRDMLQAEKAEVAEALTKAEAGRVELELSMTKLRAEEASLQDSLSKLSALNESLAQDKLDLNRLVAQLEEEKSALQGRQRQAEQEATV AREEQERLEELRLEQEVARQGLEGSLRVAEQAQEALEQQLPTLRHERSQLQEQLAQLSRQLSGREQELEQARREAQRQVEALERAAREKE ALAKEHAGLAVQLVAAEREGRTLSEEATRLRLEKEALEGSLFEVQRQLAQLEARREQLEAEGQALLLAKETLTGELAGLRQQIIATQEKA SLDKELMAQKLVQAEREAQASLREQRAAHEEDLQRLQREKEAAWRELEAERAQLQSQLQREQEELLARLEAEKEELSEEIAALQQERDEG LLLAESEKQQALSLKESEKTALSEKLMGTRHSLATISLEMERQKRDAQSRQEQDRSTVNALTSELRDLRAQREEAAAAHAQEVRRLQEQA RDLGKQRDSCLREAEELRTQLRLLEDARDGLRRELLEAQRKLRESQEGREVQRQEAGELRRSLGEGAKEREALRRSNEELRSAVKKAESE RISLKLANEDKEQKLALLEEARTAVGKEAGELRTGLQEVERSRLEARRELQELRRQMKMLDSENTRLGRELAELQGRLALGERAEKESRR ETLGLRQRLLKGEASLEVMRQELQVAQRKLQEQEGEFRTRERRLLGSLEEARGTEKQQLDHARGLELKLEAARAEAAELGLRLSAAEGRA QGLEAELARVEVQRRAAEAQLGGLRSALRRGLGLGRAPSPAPRPVPGSPARDAPAEGSGEGLNSPSTLECSPGSQPPSPGPATSPASPDL DPEAVRGALREFLQELRSAQRERDELRTQTSALNRQLAEMEAERDSATSRARQLQKAVAESEEARRSVDGRLSGVQAELALQEESVRRSE RERRATLDQVATLERSLQATESELRASQEKISKMKANETKLEGDKRRLKEVLDASESRTVKLELQRRSLEGELQRSRLGLSDREAQAQAL QDRVDSLQRQVADSEVKAGTLQLTVERLNGALAKVEESEGALRDKVRGLTEALAQSSASLNSTRDKNLHLQKALTACEHDRQVLQERLDA ARQALSEARKQSSSLGEQVQTLRGEVADLELQRVEAEGQLQQLREVLRQRQEGEAAALNTVQKLQDERRLLQERLGSLQRALAQLEAEKR EVERSALRLEKDRVALRRTLDKVEREKLRSHEDTVRLSAEKGRLDRTLTGAELELAEAQRQIQQLEAQVVVLEQSHSPAQLEVDAQQQQL ELQQEVERLRSAQAQTERTLEARERAHRQRVRGLEEQVSTLKGQLQQELRRSSAPFSPPSGPPEK -------------------------------------------------------------- >16436_16436_2_CHGA-CROCC_CHGA_chr14_93398818_ENST00000334654_CROCC_chr1_17256675_ENST00000375541_length(transcript)=6910nt_BP=917nt CGAGCCCCGTGCAGGGGAGCTTGCGGGAGGATCGACCGACAGACGGACGCACGCCGAGGCACTGCGCCCCCAGCCCCGCGCCGGTGCCAC CGCAGCCCGACCCCGGCCGCCAGTCCAGCCGCCCCTCGCCCGGTGCCTAGGTGCCCGGCCCCACACCGCCAGCTGCTCGGCGCCCGGGTC CGCCATGCGCTCCGCCGCTGTCCTGGCTCTTCTGCTCTGCGCCGGGCAAGTCACTGCGCTCCCTGTGAACAGCCCTATGAATAAAGGGGA TACCGAGGTGATGAAATGCATCGTTGAGGTCATCTCCGACACACTTTCCAAGCCCAGCCCCATGCCTGTCAGCCAGGAATGTTTTGAGAC ACTCCGAGGAGATGAACGGATCCTTTCCATTCTGAGACATCAGAATTTACTGAAGGAGCTCCAAGACCTCGCTCTCCAAGGCGCCAAGGA GAGGGCACATCAGCAGAAGAAACACAGCGGTTTTGAAGATGAACTCTCAGAGGTTCTTGAGAACCAGAGCAGCCAGGCCGAGCTGAAAGG AGGAGGAGGAGATGGCAGTGGTCCCGCAAGGCCTCTTCCGGGGTGGGAAGAGCGGAGAGCTGGAGCAGGAGGAGGAGCGGCTCTCCAAGG AGTGGGAGGACTCCAAACGCTGGAGCAAGATGGACCAGCTGGCCAAGGAGCTGACGGCTGAGAAGCGGCTGGAGGGGCAGGAGGAGGAGG AGGACAACCGGGACAGTTCCATGAAGCTCTCCTTCCGGGCCCGGGCCTACGGCTTCAGGGGCCCTGGGCCGCAGCTGCGACGAGGCTGGA GGCCATCCTCCCGGGAGGACAGCCTTGAGGCGGGCCTGCCCCTCCAGGTCCGAGGCTACCCCGAGGAGAAGAAAGAGGAGGAGGGCAGCG CAAACCGCAGACCAGAGGGAGAGCTGGAGCAGCAGCGGCTGAGGGACACAGAGCACAGCCAAGACCTGGAAAGCGCCCTCATCCGGCTGG AGGAGGAGCAGCAGAGGAGTGCCAGCCTGGCCCAGGTGAATGCCATGCTCCGAGAACAGCTGGACCAGGCAGGCTCGGCCAACCAGGCTC TGAGTGAGGACATACGAAAGGTGACCAATGACTGGACACGCTGCCGCAAGGAGCTGGAGCACCGGGAGGCGGCGTGGAGGCGCGAGGAGG AGTCCTTCAACGCCTACTTCAGCAACGAGCACAGTCGCCTGCTCCTCCTCTGGAGGCAGGTGGTGGGGTTCCGGCGGCTGGTCAGCGAGG TGAAGATGTTCACTGAGAGGGACCTGCTGCAGCTGGGAGGGGAGCTGGCCCGGACATCACGAGCTGTCCAGGAGGCGGGCCTGGGACTGA GCACGGGCCTACGGCTGGCAGAGAGCCGGGCCGAGGCAGCCCTGGAGAAACAGGCCCTGCTGCAGGCCCAGCTGGAGGAGCAGCTGCGGG ACAAGGTGCTCCGCGAGAAGGACCTGGCGCAGCAGCAGATGCAAAGCGACCTGGACAAGGCTGACCTCAGTGCCAGAGTGACAGAGCTGG GCCTGGCAGTGAAGCGTCTTGAGAAGCAGAATCTGGAGAAGGATCAGGTCAACAAGGACCTCACTGAGAAGCTTGAGGCCCTGGAATCCC TGCGGCTACAGGAGCAGGCGGCCCTGGAGACAGAGGATGGAGAGGGGCTACAGCAGACCCTAAGGGACCTGGCACAGGCCGTCTTGTCAG ACTCTGAGAGCGGCGTCCAGCTGAGCGGCTCTGAGCGCACCGCGGATGCTTCCAACGGCAGCCTGCGGGGGCTCTCGGGCCAGCGGACCC CGTCCCCACCGCGGCGCTCCTCGCCCGGCCGAGGCCGTTCACCCCGCCGAGGCCCCTCCCCGGCCTGCTCAGACTCCTCCACGCTCGCCC TGATCCACTCCGCCCTGCACAAGCGCCAGCTGCAGGTCCAGGACATGCGTGGGCGCTATGAGGCAAGCCAGGACCTACTGGGCACCCTGC GGAAGCAGCTTAGCGACAGCGAGAGCGAGCGGCGGGCCCTAGAGGAACAGCTGCAGCGCCTGCGGGACAAGACCGACGGCGCCATGCAGG CCCACGAGGACGCCCAGCGCGAGGTGCAGCGGCTGCGGAGCGCCAACGAGCTCCTGAGCAGGGAGAAGAGCAACCTGGCCCACAGCCTGC AGGTGGCCCAGCAGCAGGCCGAGGAGCTGCGGCAGGAGCGGGAGAAGCTGCAGGCTGCCCAGGAGGAGCTGCGGCGCCAGCGGGACCGGC TGGAGGAAGAGCAGGAGGACGCAGTGCAGGATGGCGCGCGGGTGCGCCGGGAGCTTGAGCGCAGCCATAGACAACTAGAGCAGCTGGAAG GGAAGCGCTCAGTCCTGGCCAAGGAGCTGGTGGAGGTGAGGGAGGCGCTGAGCCGCGCCACACTGCAACGGGACATGCTGCAGGCCGAGA AGGCCGAGGTGGCCGAGGCGCTGACCAAGGCTGAGGCTGGCCGCGTGGAGCTCGAGCTCTCCATGACCAAGCTGAGGGCAGAGGAGGCCT CCCTGCAGGACTCCCTGTCCAAGCTGAGCGCCCTCAACGAGAGCCTTGCTCAGGACAAGTTGGATCTGAACCGCCTTGTCGCCCAGCTGG AGGAAGAAAAGTCCGCCCTGCAGGGCCGGCAACGGCAGGCAGAGCAGGAGGCCACAGTGGCGCGGGAAGAGCAGGAACGGCTAGAGGAGC TGCGGTTGGAGCAGGAGGTGGCGCGGCAGGGCCTGGAGGGCTCCCTACGAGTGGCGGAGCAGGCCCAGGAGGCATTGGAGCAGCAGCTCC CCACGCTGCGCCATGAGCGCAGCCAGCTGCAGGAGCAGCTAGCGCAGCTCTCCCGGCAGCTGAGCGGGCGGGAGCAGGAGCTGGAGCAGG CCCGGCGGGAGGCCCAGCGGCAAGTGGAGGCGCTGGAGCGAGCGGCCCGTGAGAAGGAGGCGCTAGCCAAGGAGCACGCTGGCCTGGCTG TGCAGCTGGTGGCTGCGGAGCGTGAAGGCAGGACCCTGTCAGAGGAGGCCACACGCCTGCGCTTGGAGAAGGAAGCCCTGGAGGGCAGCC TGTTTGAGGTGCAACGGCAGCTGGCCCAGCTTGAGGCCCGCCGGGAGCAGCTGGAAGCCGAGGGGCAGGCCCTGCTGCTGGCCAAGGAGA CCCTGACTGGGGAGTTGGCGGGCCTGCGGCAGCAAATAATAGCTACACAGGAGAAAGCCAGTCTAGACAAGGAGCTGATGGCCCAGAAGC TGGTGCAGGCTGAGCGGGAGGCCCAGGCCTCTCTGCGGGAGCAGCGGGCAGCTCACGAGGAGGACTTACAGCGACTCCAGCGTGAAAAGG AGGCAGCATGGCGGGAGCTGGAGGCCGAGCGGGCCCAGCTGCAGAGTCAGCTGCAGCGTGAGCAGGAGGAGCTGCTGGCCCGGCTGGAGG CTGAGAAGGAAGAGCTGAGTGAGGAGATTGCTGCCCTGCAGCAGGAGCGCGACGAGGGCCTCCTCCTAGCAGAGAGTGAGAAGCAGCAGG CCTTGTCTCTGAAGGAGTCTGAGAAGACGGCGCTGTCAGAGAAGTTGATGGGTACACGGCACAGCCTGGCCACCATCTCCCTGGAGATGG AGCGGCAGAAACGAGATGCCCAGAGCCGGCAGGAGCAGGACCGGAGCACCGTGAACGCTCTGACGTCTGAGCTGCGGGACCTACGGGCCC AGCGGGAGGAGGCTGCTGCGGCCCACGCCCAGGAGGTGAGGAGGCTGCAAGAGCAGGCCCGAGACCTGGGCAAGCAGCGGGACTCCTGTC TTCGCGAGGCAGAAGAGCTTCGGACCCAGCTGCGTCTGCTGGAGGATGCCCGTGACGGGCTGCGGCGGGAGCTGCTGGAGGCCCAGCGCA AGCTGCGTGAGAGCCAGGAGGGCCGGGAGGTGCAGCGCCAGGAGGCAGGCGAGCTGCGACGCAGCCTGGGCGAGGGTGCCAAGGAGCGCG AGGCCCTGCGGCGTTCCAATGAGGAGCTTCGGTCTGCTGTGAAGAAGGCAGAGAGCGAGCGCATCAGCCTGAAGCTTGCCAATGAGGACA AGGAGCAGAAGCTGGCACTCCTAGAGGAGGCACGGACAGCTGTGGGCAAGGAGGCCGGGGAGCTGCGAACTGGGCTGCAGGAGGTGGAGC GCTCACGGCTGGAGGCTCGGCGGGAGCTGCAGGAGCTCCGGCGTCAGATGAAGATGCTGGACAGTGAGAACACCAGACTGGGCCGGGAGC TGGCGGAGCTGCAGGGCCGCCTGGCGCTGGGCGAGCGGGCAGAGAAGGAGAGCAGGCGGGAGACCCTGGGCCTCCGGCAGAGGCTGCTGA AGGGCGAGGCCAGCCTGGAGGTGATGCGGCAGGAGCTCCAGGTAGCCCAGCGGAAGCTGCAGGAACAAGAAGGCGAGTTCCGGACCCGCG AGCGACGCCTGCTGGGCTCCCTGGAGGAGGCGCGTGGCACTGAAAAGCAGCAGCTGGACCACGCCCGCGGCCTGGAGCTGAAGCTGGAGG CGGCGCGGGCCGAGGCTGCAGAGCTGGGCCTGCGGCTGAGCGCAGCCGAGGGCCGGGCACAAGGCCTGGAGGCCGAGCTGGCCCGCGTGG AGGTGCAGCGGCGCGCGGCGGAGGCCCAGCTGGGTGGCCTGCGCTCGGCTCTGCGCCGGGGCCTCGGCCTCGGTCGCGCGCCCAGCCCAG CCCCGCGGCCAGTGCCCGGTTCCCCTGCCCGGGACGCACCCGCAGAAGGAAGCGGGGAAGGGCTCAACAGCCCCAGCACCTTAGAATGCA GCCCTGGGTCCCAGCCACCATCTCCAGGACCTGCCACCTCCCCAGCCTCTCCAGACCTGGACCCGGAGGCAGTGCGCGGGGCCCTCCGGG AATTCCTGCAAGAGCTGCGGAGTGCCCAGAGAGAACGGGACGAACTTCGGACCCAGACCAGTGCCCTGAATCGCCAGCTGGCCGAGATGG AGGCTGAGAGGGACAGCGCAACCTCGAGGGCCAGGCAGCTGCAGAAGGCGGTGGCTGAGAGTGAGGAAGCCCGGCGCAGTGTGGATGGGC GGCTGAGCGGGGTCCAGGCGGAGCTGGCGCTGCAGGAGGAGAGTGTGCGGCGCAGTGAGCGGGAGCGCCGGGCCACGCTGGACCAGGTGG CCACACTGGAGAGGAGCCTGCAGGCCACCGAGAGCGAGCTCCGGGCCAGCCAGGAGAAGATCAGCAAGATGAAGGCCAATGAGACAAAGC TGGAGGGCGACAAGCGGCGCCTGAAGGAGGTTCTGGACGCCTCCGAGAGCCGCACTGTCAAGCTGGAGCTGCAGCGGCGCTCGCTTGAGG GGGAGCTGCAGCGCAGCCGCCTGGGCCTCAGTGACCGCGAGGCCCAAGCCCAGGCCCTCCAGGATCGGGTGGATTCCCTGCAGAGACAGG TGGCCGACAGCGAGGTGAAGGCAGGGACCCTGCAGCTGACCGTGGAGCGGCTGAATGGGGCCCTGGCTAAGGTGGAGGAAAGCGAGGGGG CCCTGCGGGACAAGGTGCGGGGCCTGACAGAGGCCCTGGCCCAGAGCAGTGCCAGCCTCAACAGCACCCGGGACAAGAACCTGCATCTGC AGAAGGCTCTGACCGCCTGTGAACATGACCGCCAAGTACTCCAGGAACGGCTGGATGCCGCCCGGCAGGCATTATCTGAGGCACGGAAGC AGAGCAGCTCCCTGGGCGAGCAGGTGCAGACGTTGCGAGGCGAGGTGGCTGACCTGGAACTGCAGCGGGTGGAGGCCGAGGGCCAGCTAC AACAGCTACGGGAGGTGCTGCGGCAGCGGCAGGAGGGTGAGGCTGCAGCCCTGAACACCGTCCAGAAGCTGCAAGACGAGCGGCGGCTGC TGCAGGAGCGCCTGGGAAGCCTGCAGCGCGCCCTGGCTCAGCTGGAAGCTGAGAAGCGGGAGGTGGAGCGCTCAGCCCTGCGGCTGGAGA AGGACCGTGTAGCCCTCAGGAGGACGCTGGACAAGGTGGAGCGGGAGAAGCTTCGTAGCCATGAGGACACAGTGCGGCTGAGCGCAGAGA AGGGCCGCCTGGACCGCACCCTCACGGGGGCTGAGCTGGAGCTGGCAGAGGCGCAGAGGCAGATCCAGCAGCTGGAGGCGCAGGTGGTGG TGCTGGAGCAGAGCCACAGCCCGGCCCAGCTGGAGGTGGATGCGCAGCAGCAGCAGCTGGAGCTGCAGCAGGAGGTGGAGCGGCTGCGCA GCGCCCAGGCGCAGACTGAGCGCACCCTGGAGGCTCGGGAGCGGGCCCACCGCCAGAGGGTGCGTGGGCTGGAGGAGCAGGTGTCCACAC TGAAGGGCCAGCTGCAGCAGGAGCTTCGAAGGAGCTCAGCACCCTTCTCCCCACCCTCCGGCCCCCCAGAGAAATGAGCTCCTGCTGGCA TCTGGAGAACACCCCTGTGCCTGGGACAGGGGAGGACCCTTCTTTTGGACAGCCCCCCCACCCAGAGCCCGGTCCCTTGGGGGCCTCAAG CTGGGGTGGGATGAGGAGGCGCTCTGCTGGCAGTGCTGAGGACGGGTACTCCAGCTCCAGGCCTGGAGAGGCTTCCCAGCAACACCTGCA GTCCAGCCCCCCTCTTCTAGGATGAGCCACTGTAGATCATTAAAGTTCCTCCTTGAGAGGCTGAGCCGTAGCCAGGATTGGGGAGAGCCC TTGTCTCTGGTCAGCCCTGGAGCATGGGATCGTGGGAAAGAGGAGGGGGACCAGGCCCAGGGCAGGGGTCAGAGGCCCAGGCCCTGACTT CGGCTTCCCAGAGATCTCTCCGCCTTAGTTAAGAGCATGTGTCGGGAAATTCCTCAGAGTGCTCAGAGTCCCTGTATTTTTATACCTTTT TACAATGTTAACTGTTCAGAACTGTTTTTTGTAACAAAACCTTGTTTTTAAAAAAGTTTGTACAGCTGTG >16436_16436_2_CHGA-CROCC_CHGA_chr14_93398818_ENST00000334654_CROCC_chr1_17256675_ENST00000375541_length(amino acids)=1941AA_BP=122 MAVVPQGLFRGGKSGELEQEEERLSKEWEDSKRWSKMDQLAKELTAEKRLEGQEEEEDNRDSSMKLSFRARAYGFRGPGPQLRRGWRPSS REDSLEAGLPLQVRGYPEEKKEEEGSANRRPEGELEQQRLRDTEHSQDLESALIRLEEEQQRSASLAQVNAMLREQLDQAGSANQALSED IRKVTNDWTRCRKELEHREAAWRREEESFNAYFSNEHSRLLLLWRQVVGFRRLVSEVKMFTERDLLQLGGELARTSRAVQEAGLGLSTGL RLAESRAEAALEKQALLQAQLEEQLRDKVLREKDLAQQQMQSDLDKADLSARVTELGLAVKRLEKQNLEKDQVNKDLTEKLEALESLRLQ EQAALETEDGEGLQQTLRDLAQAVLSDSESGVQLSGSERTADASNGSLRGLSGQRTPSPPRRSSPGRGRSPRRGPSPACSDSSTLALIHS ALHKRQLQVQDMRGRYEASQDLLGTLRKQLSDSESERRALEEQLQRLRDKTDGAMQAHEDAQREVQRLRSANELLSREKSNLAHSLQVAQ QQAEELRQEREKLQAAQEELRRQRDRLEEEQEDAVQDGARVRRELERSHRQLEQLEGKRSVLAKELVEVREALSRATLQRDMLQAEKAEV AEALTKAEAGRVELELSMTKLRAEEASLQDSLSKLSALNESLAQDKLDLNRLVAQLEEEKSALQGRQRQAEQEATVAREEQERLEELRLE QEVARQGLEGSLRVAEQAQEALEQQLPTLRHERSQLQEQLAQLSRQLSGREQELEQARREAQRQVEALERAAREKEALAKEHAGLAVQLV AAEREGRTLSEEATRLRLEKEALEGSLFEVQRQLAQLEARREQLEAEGQALLLAKETLTGELAGLRQQIIATQEKASLDKELMAQKLVQA EREAQASLREQRAAHEEDLQRLQREKEAAWRELEAERAQLQSQLQREQEELLARLEAEKEELSEEIAALQQERDEGLLLAESEKQQALSL KESEKTALSEKLMGTRHSLATISLEMERQKRDAQSRQEQDRSTVNALTSELRDLRAQREEAAAAHAQEVRRLQEQARDLGKQRDSCLREA EELRTQLRLLEDARDGLRRELLEAQRKLRESQEGREVQRQEAGELRRSLGEGAKEREALRRSNEELRSAVKKAESERISLKLANEDKEQK LALLEEARTAVGKEAGELRTGLQEVERSRLEARRELQELRRQMKMLDSENTRLGRELAELQGRLALGERAEKESRRETLGLRQRLLKGEA SLEVMRQELQVAQRKLQEQEGEFRTRERRLLGSLEEARGTEKQQLDHARGLELKLEAARAEAAELGLRLSAAEGRAQGLEAELARVEVQR RAAEAQLGGLRSALRRGLGLGRAPSPAPRPVPGSPARDAPAEGSGEGLNSPSTLECSPGSQPPSPGPATSPASPDLDPEAVRGALREFLQ ELRSAQRERDELRTQTSALNRQLAEMEAERDSATSRARQLQKAVAESEEARRSVDGRLSGVQAELALQEESVRRSERERRATLDQVATLE RSLQATESELRASQEKISKMKANETKLEGDKRRLKEVLDASESRTVKLELQRRSLEGELQRSRLGLSDREAQAQALQDRVDSLQRQVADS EVKAGTLQLTVERLNGALAKVEESEGALRDKVRGLTEALAQSSASLNSTRDKNLHLQKALTACEHDRQVLQERLDAARQALSEARKQSSS LGEQVQTLRGEVADLELQRVEAEGQLQQLREVLRQRQEGEAAALNTVQKLQDERRLLQERLGSLQRALAQLEAEKREVERSALRLEKDRV ALRRTLDKVEREKLRSHEDTVRLSAEKGRLDRTLTGAELELAEAQRQIQQLEAQVVVLEQSHSPAQLEVDAQQQQLELQQEVERLRSAQA QTERTLEARERAHRQRVRGLEEQVSTLKGQLQQELRRSSAPFSPPSGPPEK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CHGA-CROCC |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CHGA-CROCC |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CHGA-CROCC |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | CHGA | C0007131 | Non-Small Cell Lung Carcinoma | 1 | CTD_human |
| Hgene | CHGA | C0031511 | Pheochromocytoma | 1 | CTD_human |
| Hgene | CHGA | C0036341 | Schizophrenia | 1 | PSYGENET |
| Hgene | CHGA | C1257877 | Pheochromocytoma, Extra-Adrenal | 1 | CTD_human |
| Tgene | C0035334 | Retinitis Pigmentosa | 1 | GENOMICS_ENGLAND |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies