
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CHKA-PC (FusionGDB2 ID:HG1119TG5091) |
Fusion Gene Summary for CHKA-PC |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CHKA-PC | Fusion gene ID: hg1119tg5091 | Hgene | Tgene | Gene symbol | CHKA | PC | Gene ID | 1119 | 5091 |
| Gene name | choline kinase alpha | pyruvate carboxylase | |
| Synonyms | CHK|CK|CKI|EK | PCB | |
| Cytomap | ('CHKA')('PC') 11q13.2 | 11q13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | choline kinase alphaCHETK-alphaethanolamine kinase | pyruvate carboxylase, mitochondrialpyruvic carboxylase | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000265689, ENST00000356135, ENST00000533728, | ||
| Fusion gene scores | * DoF score | 12 X 7 X 5=420 | 13 X 8 X 7=728 |
| # samples | 13 | 13 | |
| ** MAII score | log2(13/420*10)=-1.69187770463767 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(13/728*10)=-2.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CHKA [Title/Abstract] AND PC [Title/Abstract] AND fusion [Title/Abstract] | ||
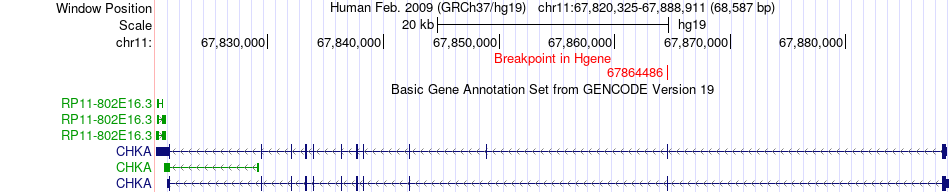
| Most frequent breakpoint | CHKA(67864486)-PC(66639630), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | CHKA-PC seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CHKA-PC seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CHKA | GO:0006646 | phosphatidylethanolamine biosynthetic process | 19915674 |
| Hgene | CHKA | GO:0006656 | phosphatidylcholine biosynthetic process | 19915674 |
| Fusion gene breakpoints across CHKA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PC (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-LL-A440-01A | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
Top |
Fusion Gene ORF analysis for CHKA-PC |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000265689 | ENST00000524491 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| 5CDS-5UTR | ENST00000356135 | ENST00000524491 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| 5CDS-intron | ENST00000265689 | ENST00000393955 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| 5CDS-intron | ENST00000265689 | ENST00000528224 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| 5CDS-intron | ENST00000265689 | ENST00000529047 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| 5CDS-intron | ENST00000356135 | ENST00000393955 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| 5CDS-intron | ENST00000356135 | ENST00000528224 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| 5CDS-intron | ENST00000356135 | ENST00000529047 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| In-frame | ENST00000265689 | ENST00000355677 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| In-frame | ENST00000265689 | ENST00000393958 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| In-frame | ENST00000265689 | ENST00000393960 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| In-frame | ENST00000356135 | ENST00000355677 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| In-frame | ENST00000356135 | ENST00000393958 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| In-frame | ENST00000356135 | ENST00000393960 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| intron-3CDS | ENST00000533728 | ENST00000355677 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| intron-3CDS | ENST00000533728 | ENST00000393958 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| intron-3CDS | ENST00000533728 | ENST00000393960 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| intron-5UTR | ENST00000533728 | ENST00000524491 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| intron-intron | ENST00000533728 | ENST00000393955 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| intron-intron | ENST00000533728 | ENST00000528224 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| intron-intron | ENST00000533728 | ENST00000529047 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000265689 | CHKA | chr11 | 67864486 | - | ENST00000393958 | PC | chr11 | 66639630 | - | 4400 | 489 | 18 | 4025 | 1335 |
| ENST00000265689 | CHKA | chr11 | 67864486 | - | ENST00000393960 | PC | chr11 | 66639630 | - | 4399 | 489 | 18 | 4025 | 1335 |
| ENST00000265689 | CHKA | chr11 | 67864486 | - | ENST00000355677 | PC | chr11 | 66639630 | - | 2109 | 489 | 18 | 2078 | 686 |
| ENST00000356135 | CHKA | chr11 | 67864486 | - | ENST00000393958 | PC | chr11 | 66639630 | - | 4640 | 729 | 210 | 4265 | 1351 |
| ENST00000356135 | CHKA | chr11 | 67864486 | - | ENST00000393960 | PC | chr11 | 66639630 | - | 4639 | 729 | 210 | 4265 | 1351 |
| ENST00000356135 | CHKA | chr11 | 67864486 | - | ENST00000355677 | PC | chr11 | 66639630 | - | 2349 | 729 | 210 | 2318 | 702 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000265689 | ENST00000393958 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - | 0.001679328 | 0.99832064 |
| ENST00000265689 | ENST00000393960 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - | 0.001674463 | 0.9983255 |
| ENST00000265689 | ENST00000355677 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - | 0.028914135 | 0.9710859 |
| ENST00000356135 | ENST00000393958 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - | 0.002286848 | 0.9977132 |
| ENST00000356135 | ENST00000393960 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - | 0.002278744 | 0.99772125 |
| ENST00000356135 | ENST00000355677 | CHKA | chr11 | 67864486 | - | PC | chr11 | 66639630 | - | 0.030612355 | 0.9693877 |
Top |
Fusion Genomic Features for CHKA-PC |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
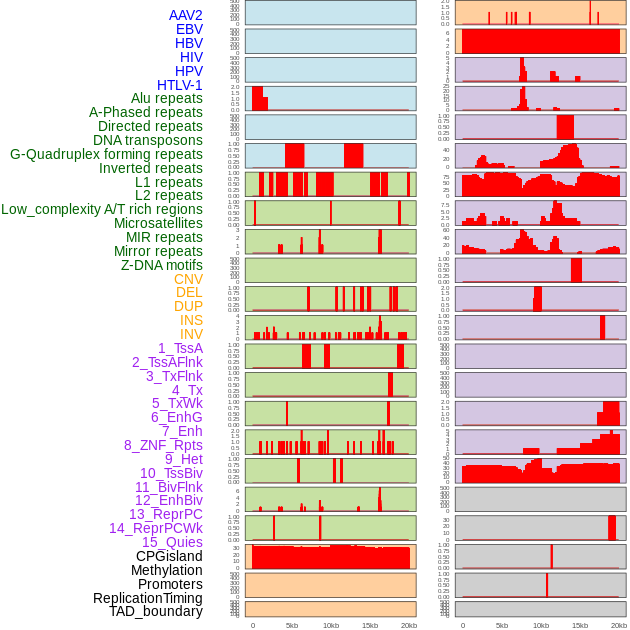
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
Top |
Fusion Protein Features for CHKA-PC |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:67864486/chr11:66639630) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CHKA | chr11:67864486 | chr11:66639630 | ENST00000265689 | - | 2 | 12 | 50_85 | 154 | 458.0 | Compositional bias | Note=Pro-rich |
| Hgene | CHKA | chr11:67864486 | chr11:66639630 | ENST00000356135 | - | 2 | 11 | 50_85 | 154 | 440.0 | Compositional bias | Note=Pro-rich |
| Hgene | CHKA | chr11:67864486 | chr11:66639630 | ENST00000265689 | - | 2 | 12 | 117_123 | 154 | 458.0 | Nucleotide binding | Note=ATP |
| Hgene | CHKA | chr11:67864486 | chr11:66639630 | ENST00000356135 | - | 2 | 11 | 117_123 | 154 | 440.0 | Nucleotide binding | Note=ATP |
| Hgene | CHKA | chr11:67864486 | chr11:66639630 | ENST00000265689 | - | 2 | 12 | 119_121 | 154 | 458.0 | Region | Note=Substrate binding |
| Hgene | CHKA | chr11:67864486 | chr11:66639630 | ENST00000356135 | - | 2 | 11 | 119_121 | 154 | 440.0 | Region | Note=Substrate binding |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393955 | 0 | 21 | 1109_1178 | 0 | 1179.0 | Domain | Biotinyl-binding | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393955 | 0 | 21 | 156_353 | 0 | 1179.0 | Domain | ATP-grasp | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393955 | 0 | 21 | 36_486 | 0 | 1179.0 | Domain | Note=Biotin carboxylation | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393955 | 0 | 21 | 563_832 | 0 | 1179.0 | Domain | Pyruvate carboxyltransferase | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393958 | 1 | 22 | 1109_1178 | 0 | 1179.0 | Domain | Biotinyl-binding | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393958 | 1 | 22 | 156_353 | 0 | 1179.0 | Domain | ATP-grasp | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393958 | 1 | 22 | 36_486 | 0 | 1179.0 | Domain | Note=Biotin carboxylation | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393958 | 1 | 22 | 563_832 | 0 | 1179.0 | Domain | Pyruvate carboxyltransferase | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393960 | 2 | 23 | 1109_1178 | 0 | 1179.0 | Domain | Biotinyl-binding | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393960 | 2 | 23 | 156_353 | 0 | 1179.0 | Domain | ATP-grasp | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393960 | 2 | 23 | 36_486 | 0 | 1179.0 | Domain | Note=Biotin carboxylation | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393960 | 2 | 23 | 563_832 | 0 | 1179.0 | Domain | Pyruvate carboxyltransferase | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393955 | 0 | 21 | 571_575 | 0 | 1179.0 | Region | Note=Substrate binding | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393958 | 1 | 22 | 571_575 | 0 | 1179.0 | Region | Note=Substrate binding | |
| Tgene | PC | chr11:67864486 | chr11:66639630 | ENST00000393960 | 2 | 23 | 571_575 | 0 | 1179.0 | Region | Note=Substrate binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CHKA | chr11:67864486 | chr11:66639630 | ENST00000265689 | - | 2 | 12 | 207_213 | 154 | 458.0 | Nucleotide binding | Note=ATP |
| Hgene | CHKA | chr11:67864486 | chr11:66639630 | ENST00000356135 | - | 2 | 11 | 207_213 | 154 | 440.0 | Nucleotide binding | Note=ATP |
Top |
Fusion Gene Sequence for CHKA-PC |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >16501_16501_1_CHKA-PC_CHKA_chr11_67864486_ENST00000265689_PC_chr11_66639630_ENST00000355677_length(transcript)=2109nt_BP=489nt CCGCGCCTCCTCGGCCGCCTGTCGGGCATGAAAACCAAATTCTGCACCGGGGGCGAGGCGGAGCCCTCGCCGCTCGGGCTGCTGCTGAGC TGCGGTAGCGGCAGCGCGGCCCCGGCGCCCGGCGTGGGGCAGCAGCGCGACGCCGCCAGCGACCTCGAGTCCAAGCAGCTGGGCGGCCAA CAGCCGCCGCTCGCGCTGCCCCCTCCGCCGCCGCTGCCGCTGCCGCTGCCGCTGCCCCAGCCCCCGCCGCCGCAGCCGCCCGCAGACGAG CAGCCGGAGCCCCGGACGCGGCGCAGGGCCTATCTGTGGTGCAAGGAGTTCCTGCCCGGCGCCTGGCGGGGCCTCCGCGAGGACGAGTTC CACATCAGTGTCATCAGAGGCGGCCTTAGCAACATGCTGTTCCAGTGCTCCCTACCTGACACCACAGCCACCCTTGGTGATGAGCCTCGG AAAGTGCTCCTGCGGCTGTATGGAGCGATTTTGCAGATGATGCTGAAGTTCCGAACAGTCCATGGGGGCCTGAGGCTCCTGGGAATCCGC CGAACCTCCACCGCCCCCGCTGCCTCCCCAAATGTCCGGCGCCTGGAGTATAAGCCCATCAAGAAAGTCATGGTGGCCAACAGAGGTGAG ATTGCCATCCGTGTGTTCCGGGCCTGCACGGAGCTGGGCATCCGCACCGTAGCCATCTACTCTGAGCAGGACACGGGCCAGATGCACCGG CAGAAAGCAGATGAAGCCTATCTCATCGGCCGCGGCCTGGCCCCCGTGCAGGCCTACCTGCACATCCCAGACATCATCAAGGTGGCCAAG GAGAACAACGTAGATGCAGTGCACCCTGGCTACGGGTTCCTCTCTGAGCGAGCGGACTTCGCCCAGGCCTGCCAGGATGCAGGGGTCCGG TTTATTGGGCCAAGCCCAGAAGTGGTCCGCAAGATGGGAGACAAGGTGGAGGCCCGGGCCATCGCCATTGCTGCGGGTGTTCCCGTTGTC CCTGGCACAGATGCCCCCATCACGTCCCTGCATGAGGCCCACGAGTTCTCCAACACCTACGGCTTCCCCATCATCTTCAAGGCGGCCTAT GGGGGTGGAGGGCGTGGCATGAGGGTGGTGCACAGCTACGAGGAGCTGGAGGAGAATTACACCCGGGCCTACTCAGAGGCTCTGGCCGCC TTTGGGAATGGGGCGCTGTTTGTGGAGAAGTTCATCGAGAAGCCACGGCACATCGAGGTGCAGATCTTGGGGGACCAGTATGGGAACATC CTGCACCTGTACGAGCGAGACTGCTCCATCCAGCGGCGGCACCAGAAGGTGGTCGAGATTGCCCCCGCCGCCCACCTGGACCCGCAGCTT CGGACTCGGCTCACCAGCGACTCTGTGAAACTCGCTAAACAGGTGGGCTACGAGAACGCAGGCACCGTGGAGTTCCTGGTGGACAGGCAC GGCAAGCACTACTTCATCGAGGTCAACTCCCGCCTGCAGGTGGAGCACACGGTCACAGAGGAGATCACCGACGTAGACCTGGTCCATGCT CAGATCCACGTGGCTGAGGGCAGGAGCCTACCCGACCTGGGCCTGCGGCAGGAGAACATCCGCATCAACGGGTGTGCCATCCAGTGCCGG GTCACCACCGAGGACCCCGCGCGCAGCTTCCAGCCGGACACCGGCCGCATTGAGGTGTTCCGGAGCGGAGAGGGCATGGGCATCCGCCTG GATAATGCTTCCGCCTTCCAAGGAGCCGTCATCTCGCCCCACTACGACTCCCTGCTGGTCAAAGTCATTGCCCACGGCAAAGACCACCCC ACGGCCGCCACCAAGATGAGCAGGGCCCTTGCGGAGTTCCGCGTCCGAGGTGTGAAGGTCAGAAGACACCAGGCACAGCCCTTGGCCGCA GCCCTGGGCCGCCCCTGTGGACAGGAAGCCAGGAGGCCCCAGGCTGCTGTGACTGCCCCCACCGGCCCTGGTAGCCCCACCCTTGTCCGT GTGCCACCAGCGGCCCGTGTCCTGTCCTCCCGTCTCGGGGGACCTAGCCAGACAACACCAGAGACTAGCACTGAGGTGTCCCCAACAATT TTATTATAAATAAAAACAAGACTCCCAGTGGGTGGCTGC >16501_16501_1_CHKA-PC_CHKA_chr11_67864486_ENST00000265689_PC_chr11_66639630_ENST00000355677_length(amino acids)=686AA_BP=27 MSGMKTKFCTGGEAEPSPLGLLLSCGSGSAAPAPGVGQQRDAASDLESKQLGGQQPPLALPPPPPLPLPLPLPQPPPPQPPADEQPEPRT RRRAYLWCKEFLPGAWRGLREDEFHISVIRGGLSNMLFQCSLPDTTATLGDEPRKVLLRLYGAILQMMLKFRTVHGGLRLLGIRRTSTAP AASPNVRRLEYKPIKKVMVANRGEIAIRVFRACTELGIRTVAIYSEQDTGQMHRQKADEAYLIGRGLAPVQAYLHIPDIIKVAKENNVDA VHPGYGFLSERADFAQACQDAGVRFIGPSPEVVRKMGDKVEARAIAIAAGVPVVPGTDAPITSLHEAHEFSNTYGFPIIFKAAYGGGGRG MRVVHSYEELEENYTRAYSEALAAFGNGALFVEKFIEKPRHIEVQILGDQYGNILHLYERDCSIQRRHQKVVEIAPAAHLDPQLRTRLTS DSVKLAKQVGYENAGTVEFLVDRHGKHYFIEVNSRLQVEHTVTEEITDVDLVHAQIHVAEGRSLPDLGLRQENIRINGCAIQCRVTTEDP ARSFQPDTGRIEVFRSGEGMGIRLDNASAFQGAVISPHYDSLLVKVIAHGKDHPTAATKMSRALAEFRVRGVKVRRHQAQPLAAALGRPC GQEARRPQAAVTAPTGPGSPTLVRVPPAARVLSSRLGGPSQTTPETSTEVSPTILL -------------------------------------------------------------- >16501_16501_2_CHKA-PC_CHKA_chr11_67864486_ENST00000265689_PC_chr11_66639630_ENST00000393958_length(transcript)=4400nt_BP=489nt CCGCGCCTCCTCGGCCGCCTGTCGGGCATGAAAACCAAATTCTGCACCGGGGGCGAGGCGGAGCCCTCGCCGCTCGGGCTGCTGCTGAGC TGCGGTAGCGGCAGCGCGGCCCCGGCGCCCGGCGTGGGGCAGCAGCGCGACGCCGCCAGCGACCTCGAGTCCAAGCAGCTGGGCGGCCAA CAGCCGCCGCTCGCGCTGCCCCCTCCGCCGCCGCTGCCGCTGCCGCTGCCGCTGCCCCAGCCCCCGCCGCCGCAGCCGCCCGCAGACGAG CAGCCGGAGCCCCGGACGCGGCGCAGGGCCTATCTGTGGTGCAAGGAGTTCCTGCCCGGCGCCTGGCGGGGCCTCCGCGAGGACGAGTTC CACATCAGTGTCATCAGAGGCGGCCTTAGCAACATGCTGTTCCAGTGCTCCCTACCTGACACCACAGCCACCCTTGGTGATGAGCCTCGG AAAGTGCTCCTGCGGCTGTATGGAGCGATTTTGCAGATGATGCTGAAGTTCCGAACAGTCCATGGGGGCCTGAGGCTCCTGGGAATCCGC CGAACCTCCACCGCCCCCGCTGCCTCCCCAAATGTCCGGCGCCTGGAGTATAAGCCCATCAAGAAAGTCATGGTGGCCAACAGAGGTGAG ATTGCCATCCGTGTGTTCCGGGCCTGCACGGAGCTGGGCATCCGCACCGTAGCCATCTACTCTGAGCAGGACACGGGCCAGATGCACCGG CAGAAAGCAGATGAAGCCTATCTCATCGGCCGCGGCCTGGCCCCCGTGCAGGCCTACCTGCACATCCCAGACATCATCAAGGTGGCCAAG GAGAACAACGTAGATGCAGTGCACCCTGGCTACGGGTTCCTCTCTGAGCGAGCGGACTTCGCCCAGGCCTGCCAGGATGCAGGGGTCCGG TTTATTGGGCCAAGCCCAGAAGTGGTCCGCAAGATGGGAGACAAGGTGGAGGCCCGGGCCATCGCCATTGCTGCGGGTGTTCCCGTTGTC CCTGGCACAGATGCCCCCATCACGTCCCTGCATGAGGCCCACGAGTTCTCCAACACCTACGGCTTCCCCATCATCTTCAAGGCGGCCTAT GGGGGTGGAGGGCGTGGCATGAGGGTGGTGCACAGCTACGAGGAGCTGGAGGAGAATTACACCCGGGCCTACTCAGAGGCTCTGGCCGCC TTTGGGAATGGGGCGCTGTTTGTGGAGAAGTTCATCGAGAAGCCACGGCACATCGAGGTGCAGATCTTGGGGGACCAGTATGGGAACATC CTGCACCTGTACGAGCGAGACTGCTCCATCCAGCGGCGGCACCAGAAGGTGGTCGAGATTGCCCCCGCCGCCCACCTGGACCCGCAGCTT CGGACTCGGCTCACCAGCGACTCTGTGAAACTCGCTAAACAGGTGGGCTACGAGAACGCAGGCACCGTGGAGTTCCTGGTGGACAGGCAC GGCAAGCACTACTTCATCGAGGTCAACTCCCGCCTGCAGGTGGAGCACACGGTCACAGAGGAGATCACCGACGTAGACCTGGTCCATGCT CAGATCCACGTGGCTGAGGGCAGGAGCCTACCCGACCTGGGCCTGCGGCAGGAGAACATCCGCATCAACGGGTGTGCCATCCAGTGCCGG GTCACCACCGAGGACCCCGCGCGCAGCTTCCAGCCGGACACCGGCCGCATTGAGGTGTTCCGGAGCGGAGAGGGCATGGGCATCCGCCTG GATAATGCTTCCGCCTTCCAAGGAGCCGTCATCTCGCCCCACTACGACTCCCTGCTGGTCAAAGTCATTGCCCACGGCAAAGACCACCCC ACGGCCGCCACCAAGATGAGCAGGGCCCTTGCGGAGTTCCGCGTCCGAGGTGTGAAGACCAACATCGCCTTCCTGCAGAATGTGCTCAAC AACCAGCAGTTCCTGGCAGGCACTGTGGACACCCAGTTCATCGACGAGAACCCAGAGCTGTTCCAGCTGCGGCCTGCACAGAACCGGGCC CAAAAGCTGTTGCACTACCTCGGCCATGTCATGGTAAACGGTCCAACCACCCCGATTCCCGTCAAGGCCAGCCCCAGCCCCACGGACCCC GTTGTCCCTGCAGTGCCCATAGGCCCGCCCCCGGCTGGTTTCAGAGACATCCTGCTGCGAGAGGGGCCTGAGGGCTTTGCTCGAGCTGTG CGGAACCACCCGGGGCTGCTGCTGATGGACACGACCTTCAGGGACGCCCACCAGTCACTGCTGGCCACTCGTGTGCGCACCCACGATCTC AAAAAGATCGCCCCCTATGTTGCCCACAACTTCAGCAAGCTCTTCAGCATGGAGAACTGGGGAGGAGCCACGTTTGACGTCGCCATGCGC TTCCTGTATGAGTGCCCCTGGCGGCGGCTGCAGGAGCTCCGGGAGCTCATCCCCAACATCCCTTTCCAGATGCTGCTGCGGGGGGCCAAT GCTGTGGGCTACACCAACTACCCAGACAACGTGGTCTTCAAGTTCTGTGAAGTGGCCAAAGAGAATGGCATGGATGTCTTCCGTGTGTTT GACTCCCTCAACTACTTGCCCAACATGCTGCTGGGCATGGAGGCGGCAGGAAGTGCCGGAGGCGTGGTGGAGGCTGCCATCTCATACACG GGCGACGTGGCCGACCCCAGCCGCACCAAGTACTCACTGCAGTACTACATGGGCTTGGCCGAAGAGCTGGTGCGAGCTGGCACCCACATC CTGTGCATCAAGGACATGGCCGGGCTGCTGAAGCCCACGGCCTGCACCATGCTGGTCAGCTCCCTCCGGGACCGCTTCCCCGACCTCCCA CTGCACATCCACACCCACGACACGTCAGGGGCAGGCGTGGCAGCCATGCTGGCCTGTGCCCAGGCTGGAGCTGATGTGGTGGATGTGGCA GCTGATTCCATGTCTGGGATGACTTCACAGCCCAGCATGGGGGCCCTGGTGGCCTGTACCAGAGGGACTCCCCTGGACACAGAGGTGCCC ATGGAGCGCGTGTTTGACTACAGTGAGTACTGGGAGGGGGCTCGGGGACTGTACGCGGCCTTCGACTGCACGGCCACCATGAAGTCTGGC AACTCGGACGTGTATGAAAATGAGATCCCAGGGGGCCAGTACACCAACCTGCACTTCCAGGCCCACAGCATGGGGCTTGGCTCCAAGTTC AAGGAGGTCAAGAAGGCCTATGTGGAGGCCAACCAGATGCTGGGCGATCTCATCAAGGTGACGCCCTCCTCCAAGATCGTGGGGGACCTG GCCCAGTTTATGGTGCAGAATGGATTGAGCCGGGCAGAGGCCGAAGCTCAGGCGGAAGAGCTGTCCTTTCCCCGCTCCGTGGTGGAGTTC CTGCAGGGCTACATCGGTGTCCCCCATGGGGGGTTCCCCGAACCCTTTCGCTCTAAGGTACTGAAGGACCTGCCAAGGGTGGAGGGGCGG CCTGGAGCCTCCCTCCCTCCCCTGGATCTGCAGGCACTGGAGAAGGAGCTGGTAGACCGGCATGGGGAGGAGGTGACGCCGGAAGATGTG CTCTCAGCAGCTATGTACCCCGATGTGTTTGCCCACTTCAAGGACTTCACTGCCACCTTTGGCCCCCTGGATAGCCTGAATACTCGCCTC TTCCTGCAGGGACCCAAGATCGCAGAGGAGTTTGAGGTGGAGCTGGAGCGGGGCAAGACGCTGCACATCAAAGCCCTGGCCGTGAGCGAC CTGAACCGGGCCGGCCAGAGGCAGGTCTTCTTTGAGCTCAATGGGCAGCTGCGGTCCATCTTGGTCAAGGACACCCAGGCCATGAAGGAG ATGCACTTCCACCCCAAGGCCCTAAAGGACGTGAAGGGCCAGATCGGGGCGCCCATGCCTGGGAAGGTGATAGACATCAAAGTGGTGGCA GGGGCCAAGGTGGCCAAGGGCCAGCCCCTGTGTGTGCTCAGTGCCATGAAGATGGAGACTGTGGTGACCTCACCCATGGAGGGTACTGTC CGCAAGGTTCATGTGACCAAGGACATGACACTGGAAGGTGACGACCTCATCCTGGAGATCGAGTGATCTTGCCCCAGACCGGCAGCCTGG CCATCCCCAAGCCTTCAACAGAAGCTGTGCTGCCACGGCAGGCCCAGGCCAGCCAGTGCCCGAGGCCAGGAAGGCCGGGCCGTGGAGGTC CTGTCCACAGCTGGACAGGAGAGACACCGCCTGCGGTGGTTCATTCCTTTCAGCCATCGTCCTTTCCTCCGGCGGACAGCTGCTTACATG TTCATCTCTTGCCAAATAAGGGTCCCCTCCTCACTGGAGACTACAAGTGGTGGGTCAGGTGGTCCTAGGACCCAGGGGAGGTTTAGGGGT CCTATCTCCTGGGGGAAGGGGAGATCTAAGATGTCCCAGGTCCTGGGAAGTTTACTCAATAAAGCTGGCTTTCCCCTGCC >16501_16501_2_CHKA-PC_CHKA_chr11_67864486_ENST00000265689_PC_chr11_66639630_ENST00000393958_length(amino acids)=1335AA_BP=27 MSGMKTKFCTGGEAEPSPLGLLLSCGSGSAAPAPGVGQQRDAASDLESKQLGGQQPPLALPPPPPLPLPLPLPQPPPPQPPADEQPEPRT RRRAYLWCKEFLPGAWRGLREDEFHISVIRGGLSNMLFQCSLPDTTATLGDEPRKVLLRLYGAILQMMLKFRTVHGGLRLLGIRRTSTAP AASPNVRRLEYKPIKKVMVANRGEIAIRVFRACTELGIRTVAIYSEQDTGQMHRQKADEAYLIGRGLAPVQAYLHIPDIIKVAKENNVDA VHPGYGFLSERADFAQACQDAGVRFIGPSPEVVRKMGDKVEARAIAIAAGVPVVPGTDAPITSLHEAHEFSNTYGFPIIFKAAYGGGGRG MRVVHSYEELEENYTRAYSEALAAFGNGALFVEKFIEKPRHIEVQILGDQYGNILHLYERDCSIQRRHQKVVEIAPAAHLDPQLRTRLTS DSVKLAKQVGYENAGTVEFLVDRHGKHYFIEVNSRLQVEHTVTEEITDVDLVHAQIHVAEGRSLPDLGLRQENIRINGCAIQCRVTTEDP ARSFQPDTGRIEVFRSGEGMGIRLDNASAFQGAVISPHYDSLLVKVIAHGKDHPTAATKMSRALAEFRVRGVKTNIAFLQNVLNNQQFLA GTVDTQFIDENPELFQLRPAQNRAQKLLHYLGHVMVNGPTTPIPVKASPSPTDPVVPAVPIGPPPAGFRDILLREGPEGFARAVRNHPGL LLMDTTFRDAHQSLLATRVRTHDLKKIAPYVAHNFSKLFSMENWGGATFDVAMRFLYECPWRRLQELRELIPNIPFQMLLRGANAVGYTN YPDNVVFKFCEVAKENGMDVFRVFDSLNYLPNMLLGMEAAGSAGGVVEAAISYTGDVADPSRTKYSLQYYMGLAEELVRAGTHILCIKDM AGLLKPTACTMLVSSLRDRFPDLPLHIHTHDTSGAGVAAMLACAQAGADVVDVAADSMSGMTSQPSMGALVACTRGTPLDTEVPMERVFD YSEYWEGARGLYAAFDCTATMKSGNSDVYENEIPGGQYTNLHFQAHSMGLGSKFKEVKKAYVEANQMLGDLIKVTPSSKIVGDLAQFMVQ NGLSRAEAEAQAEELSFPRSVVEFLQGYIGVPHGGFPEPFRSKVLKDLPRVEGRPGASLPPLDLQALEKELVDRHGEEVTPEDVLSAAMY PDVFAHFKDFTATFGPLDSLNTRLFLQGPKIAEEFEVELERGKTLHIKALAVSDLNRAGQRQVFFELNGQLRSILVKDTQAMKEMHFHPK ALKDVKGQIGAPMPGKVIDIKVVAGAKVAKGQPLCVLSAMKMETVVTSPMEGTVRKVHVTKDMTLEGDDLILEIE -------------------------------------------------------------- >16501_16501_3_CHKA-PC_CHKA_chr11_67864486_ENST00000265689_PC_chr11_66639630_ENST00000393960_length(transcript)=4399nt_BP=489nt CCGCGCCTCCTCGGCCGCCTGTCGGGCATGAAAACCAAATTCTGCACCGGGGGCGAGGCGGAGCCCTCGCCGCTCGGGCTGCTGCTGAGC TGCGGTAGCGGCAGCGCGGCCCCGGCGCCCGGCGTGGGGCAGCAGCGCGACGCCGCCAGCGACCTCGAGTCCAAGCAGCTGGGCGGCCAA CAGCCGCCGCTCGCGCTGCCCCCTCCGCCGCCGCTGCCGCTGCCGCTGCCGCTGCCCCAGCCCCCGCCGCCGCAGCCGCCCGCAGACGAG CAGCCGGAGCCCCGGACGCGGCGCAGGGCCTATCTGTGGTGCAAGGAGTTCCTGCCCGGCGCCTGGCGGGGCCTCCGCGAGGACGAGTTC CACATCAGTGTCATCAGAGGCGGCCTTAGCAACATGCTGTTCCAGTGCTCCCTACCTGACACCACAGCCACCCTTGGTGATGAGCCTCGG AAAGTGCTCCTGCGGCTGTATGGAGCGATTTTGCAGATGATGCTGAAGTTCCGAACAGTCCATGGGGGCCTGAGGCTCCTGGGAATCCGC CGAACCTCCACCGCCCCCGCTGCCTCCCCAAATGTCCGGCGCCTGGAGTATAAGCCCATCAAGAAAGTCATGGTGGCCAACAGAGGTGAG ATTGCCATCCGTGTGTTCCGGGCCTGCACGGAGCTGGGCATCCGCACCGTAGCCATCTACTCTGAGCAGGACACGGGCCAGATGCACCGG CAGAAAGCAGATGAAGCCTATCTCATCGGCCGCGGCCTGGCCCCCGTGCAGGCCTACCTGCACATCCCAGACATCATCAAGGTGGCCAAG GAGAACAACGTAGATGCAGTGCACCCTGGCTACGGGTTCCTCTCTGAGCGAGCGGACTTCGCCCAGGCCTGCCAGGATGCAGGGGTCCGG TTTATTGGGCCAAGCCCAGAAGTGGTCCGCAAGATGGGAGACAAGGTGGAGGCCCGGGCCATCGCCATTGCTGCGGGTGTTCCCGTTGTC CCTGGCACAGATGCCCCCATCACGTCCCTGCATGAGGCCCACGAGTTCTCCAACACCTACGGCTTCCCCATCATCTTCAAGGCGGCCTAT GGGGGTGGAGGGCGTGGCATGAGGGTGGTGCACAGCTACGAGGAGCTGGAGGAGAATTACACCCGGGCCTACTCAGAGGCTCTGGCCGCC TTTGGGAATGGGGCGCTGTTTGTGGAGAAGTTCATCGAGAAGCCACGGCACATCGAGGTGCAGATCTTGGGGGACCAGTATGGGAACATC CTGCACCTGTACGAGCGAGACTGCTCCATCCAGCGGCGGCACCAGAAGGTGGTCGAGATTGCCCCCGCCGCCCACCTGGACCCGCAGCTT CGGACTCGGCTCACCAGCGACTCTGTGAAACTCGCTAAACAGGTGGGCTACGAGAACGCAGGCACCGTGGAGTTCCTGGTGGACAGGCAC GGCAAGCACTACTTCATCGAGGTCAACTCCCGCCTGCAGGTGGAGCACACGGTCACAGAGGAGATCACCGACGTAGACCTGGTCCATGCT CAGATCCACGTGGCTGAGGGCAGGAGCCTACCCGACCTGGGCCTGCGGCAGGAGAACATCCGCATCAACGGGTGTGCCATCCAGTGCCGG GTCACCACCGAGGACCCCGCGCGCAGCTTCCAGCCGGACACCGGCCGCATTGAGGTGTTCCGGAGCGGAGAGGGCATGGGCATCCGCCTG GATAATGCTTCCGCCTTCCAAGGAGCCGTCATCTCGCCCCACTACGACTCCCTGCTGGTCAAAGTCATTGCCCACGGCAAAGACCACCCC ACGGCCGCCACCAAGATGAGCAGGGCCCTTGCGGAGTTCCGCGTCCGAGGTGTGAAGACCAACATCGCCTTCCTGCAGAATGTGCTCAAC AACCAGCAGTTCCTGGCAGGCACTGTGGACACCCAGTTCATCGACGAGAACCCAGAGCTGTTCCAGCTGCGGCCTGCACAGAACCGGGCC CAAAAGCTGTTGCACTACCTCGGCCATGTCATGGTAAACGGTCCAACCACCCCGATTCCCGTCAAGGCCAGCCCCAGCCCCACGGACCCC GTTGTCCCTGCAGTGCCCATAGGCCCGCCCCCGGCTGGTTTCAGAGACATCCTGCTGCGAGAGGGGCCTGAGGGCTTTGCTCGAGCTGTG CGGAACCACCCGGGGCTGCTGCTGATGGACACGACCTTCAGGGACGCCCACCAGTCACTGCTGGCCACTCGTGTGCGCACCCACGATCTC AAAAAGATCGCCCCCTATGTTGCCCACAACTTCAGCAAGCTCTTCAGCATGGAGAACTGGGGAGGAGCCACGTTTGACGTCGCCATGCGC TTCCTGTATGAGTGCCCCTGGCGGCGGCTGCAGGAGCTCCGGGAGCTCATCCCCAACATCCCTTTCCAGATGCTGCTGCGGGGGGCCAAT GCTGTGGGCTACACCAACTACCCAGACAACGTGGTCTTCAAGTTCTGTGAAGTGGCCAAAGAGAATGGCATGGATGTCTTCCGTGTGTTT GACTCCCTCAACTACTTGCCCAACATGCTGCTGGGCATGGAGGCGGCAGGAAGTGCCGGAGGCGTGGTGGAGGCTGCCATCTCATACACG GGCGACGTGGCCGACCCCAGCCGCACCAAGTACTCACTGCAGTACTACATGGGCTTGGCCGAAGAGCTGGTGCGAGCTGGCACCCACATC CTGTGCATCAAGGACATGGCCGGGCTGCTGAAGCCCACGGCCTGCACCATGCTGGTCAGCTCCCTCCGGGACCGCTTCCCCGACCTCCCA CTGCACATCCACACCCACGACACGTCAGGGGCAGGCGTGGCAGCCATGCTGGCCTGTGCCCAGGCTGGAGCTGATGTGGTGGATGTGGCA GCTGATTCCATGTCTGGGATGACTTCACAGCCCAGCATGGGGGCCCTGGTGGCCTGTACCAGAGGGACTCCCCTGGACACAGAGGTGCCC ATGGAGCGCGTGTTTGACTACAGTGAGTACTGGGAGGGGGCTCGGGGACTGTACGCGGCCTTCGACTGCACGGCCACCATGAAGTCTGGC AACTCGGACGTGTATGAAAATGAGATCCCAGGGGGCCAGTACACCAACCTGCACTTCCAGGCCCACAGCATGGGGCTTGGCTCCAAGTTC AAGGAGGTCAAGAAGGCCTATGTGGAGGCCAACCAGATGCTGGGCGATCTCATCAAGGTGACGCCCTCCTCCAAGATCGTGGGGGACCTG GCCCAGTTTATGGTGCAGAATGGATTGAGCCGGGCAGAGGCCGAAGCTCAGGCGGAAGAGCTGTCCTTTCCCCGCTCCGTGGTGGAGTTC CTGCAGGGCTACATCGGTGTCCCCCATGGGGGGTTCCCCGAACCCTTTCGCTCTAAGGTACTGAAGGACCTGCCAAGGGTGGAGGGGCGG CCTGGAGCCTCCCTCCCTCCCCTGGATCTGCAGGCACTGGAGAAGGAGCTGGTAGACCGGCATGGGGAGGAGGTGACGCCGGAAGATGTG CTCTCAGCAGCTATGTACCCCGATGTGTTTGCCCACTTCAAGGACTTCACTGCCACCTTTGGCCCCCTGGATAGCCTGAATACTCGCCTC TTCCTGCAGGGACCCAAGATCGCAGAGGAGTTTGAGGTGGAGCTGGAGCGGGGCAAGACGCTGCACATCAAAGCCCTGGCCGTGAGCGAC CTGAACCGGGCCGGCCAGAGGCAGGTCTTCTTTGAGCTCAATGGGCAGCTGCGGTCCATCTTGGTCAAGGACACCCAGGCCATGAAGGAG ATGCACTTCCACCCCAAGGCCCTAAAGGACGTGAAGGGCCAGATCGGGGCGCCCATGCCTGGGAAGGTGATAGACATCAAAGTGGTGGCA GGGGCCAAGGTGGCCAAGGGCCAGCCCCTGTGTGTGCTCAGTGCCATGAAGATGGAGACTGTGGTGACCTCACCCATGGAGGGTACTGTC CGCAAGGTTCATGTGACCAAGGACATGACACTGGAAGGTGACGACCTCATCCTGGAGATCGAGTGATCTTGCCCCAGACCGGCAGCCTGG CCATCCCCAAGCCTTCAACAGAAGCTGTGCTGCCACGGCAGGCCCAGGCCAGCCAGTGCCCGAGGCCAGGAAGGCCGGGCCGTGGAGGTC CTGTCCACAGCTGGACAGGAGAGACACCGCCTGCGGTGGTTCATTCCTTTCAGCCATCGTCCTTTCCTCCGGCGGACAGCTGCTTACATG TTCATCTCTTGCCAAATAAGGGTCCCCTCCTCACTGGAGACTACAAGTGGTGGGTCAGGTGGTCCTAGGACCCAGGGGAGGTTTAGGGGT CCTATCTCCTGGGGGAAGGGGAGATCTAAGATGTCCCAGGTCCTGGGAAGTTTACTCAATAAAGCTGGCTTTCCCCTGC >16501_16501_3_CHKA-PC_CHKA_chr11_67864486_ENST00000265689_PC_chr11_66639630_ENST00000393960_length(amino acids)=1335AA_BP=27 MSGMKTKFCTGGEAEPSPLGLLLSCGSGSAAPAPGVGQQRDAASDLESKQLGGQQPPLALPPPPPLPLPLPLPQPPPPQPPADEQPEPRT RRRAYLWCKEFLPGAWRGLREDEFHISVIRGGLSNMLFQCSLPDTTATLGDEPRKVLLRLYGAILQMMLKFRTVHGGLRLLGIRRTSTAP AASPNVRRLEYKPIKKVMVANRGEIAIRVFRACTELGIRTVAIYSEQDTGQMHRQKADEAYLIGRGLAPVQAYLHIPDIIKVAKENNVDA VHPGYGFLSERADFAQACQDAGVRFIGPSPEVVRKMGDKVEARAIAIAAGVPVVPGTDAPITSLHEAHEFSNTYGFPIIFKAAYGGGGRG MRVVHSYEELEENYTRAYSEALAAFGNGALFVEKFIEKPRHIEVQILGDQYGNILHLYERDCSIQRRHQKVVEIAPAAHLDPQLRTRLTS DSVKLAKQVGYENAGTVEFLVDRHGKHYFIEVNSRLQVEHTVTEEITDVDLVHAQIHVAEGRSLPDLGLRQENIRINGCAIQCRVTTEDP ARSFQPDTGRIEVFRSGEGMGIRLDNASAFQGAVISPHYDSLLVKVIAHGKDHPTAATKMSRALAEFRVRGVKTNIAFLQNVLNNQQFLA GTVDTQFIDENPELFQLRPAQNRAQKLLHYLGHVMVNGPTTPIPVKASPSPTDPVVPAVPIGPPPAGFRDILLREGPEGFARAVRNHPGL LLMDTTFRDAHQSLLATRVRTHDLKKIAPYVAHNFSKLFSMENWGGATFDVAMRFLYECPWRRLQELRELIPNIPFQMLLRGANAVGYTN YPDNVVFKFCEVAKENGMDVFRVFDSLNYLPNMLLGMEAAGSAGGVVEAAISYTGDVADPSRTKYSLQYYMGLAEELVRAGTHILCIKDM AGLLKPTACTMLVSSLRDRFPDLPLHIHTHDTSGAGVAAMLACAQAGADVVDVAADSMSGMTSQPSMGALVACTRGTPLDTEVPMERVFD YSEYWEGARGLYAAFDCTATMKSGNSDVYENEIPGGQYTNLHFQAHSMGLGSKFKEVKKAYVEANQMLGDLIKVTPSSKIVGDLAQFMVQ NGLSRAEAEAQAEELSFPRSVVEFLQGYIGVPHGGFPEPFRSKVLKDLPRVEGRPGASLPPLDLQALEKELVDRHGEEVTPEDVLSAAMY PDVFAHFKDFTATFGPLDSLNTRLFLQGPKIAEEFEVELERGKTLHIKALAVSDLNRAGQRQVFFELNGQLRSILVKDTQAMKEMHFHPK ALKDVKGQIGAPMPGKVIDIKVVAGAKVAKGQPLCVLSAMKMETVVTSPMEGTVRKVHVTKDMTLEGDDLILEIE -------------------------------------------------------------- >16501_16501_4_CHKA-PC_CHKA_chr11_67864486_ENST00000356135_PC_chr11_66639630_ENST00000355677_length(transcript)=2349nt_BP=729nt GTGGCGAGCGCGAGGGCGGGCTGTGACGCGGCCGGCGCTCCTCGTGCGGCGGCGGCAGAGGAGCGAGTGCAGCGGCCAGCAGCACATCCC CGCTCCACAGTCGCCGCAGTCGCCGCAGCCGCCGCCGCCGCCCCGCGCGCCCAACCGCCGCGGCCCCCTGCCCCGCCGGCCTGCCAGTGA GAGAGCGGCGAGGGGGCGCCCGGCCGGACTCTGAGCCTAGTCCTCTCGCGCTGCGGCCGCCCGCGCCTCCTCGGCCGCCTGTCGGGCATG AAAACCAAATTCTGCACCGGGGGCGAGGCGGAGCCCTCGCCGCTCGGGCTGCTGCTGAGCTGCGGTAGCGGCAGCGCGGCCCCGGCGCCC GGCGTGGGGCAGCAGCGCGACGCCGCCAGCGACCTCGAGTCCAAGCAGCTGGGCGGCCAACAGCCGCCGCTCGCGCTGCCCCCTCCGCCG CCGCTGCCGCTGCCGCTGCCGCTGCCCCAGCCCCCGCCGCCGCAGCCGCCCGCAGACGAGCAGCCGGAGCCCCGGACGCGGCGCAGGGCC TATCTGTGGTGCAAGGAGTTCCTGCCCGGCGCCTGGCGGGGCCTCCGCGAGGACGAGTTCCACATCAGTGTCATCAGAGGCGGCCTTAGC AACATGCTGTTCCAGTGCTCCCTACCTGACACCACAGCCACCCTTGGTGATGAGCCTCGGAAAGTGCTCCTGCGGCTGTATGGAGCGATT TTGCAGATGATGCTGAAGTTCCGAACAGTCCATGGGGGCCTGAGGCTCCTGGGAATCCGCCGAACCTCCACCGCCCCCGCTGCCTCCCCA AATGTCCGGCGCCTGGAGTATAAGCCCATCAAGAAAGTCATGGTGGCCAACAGAGGTGAGATTGCCATCCGTGTGTTCCGGGCCTGCACG GAGCTGGGCATCCGCACCGTAGCCATCTACTCTGAGCAGGACACGGGCCAGATGCACCGGCAGAAAGCAGATGAAGCCTATCTCATCGGC CGCGGCCTGGCCCCCGTGCAGGCCTACCTGCACATCCCAGACATCATCAAGGTGGCCAAGGAGAACAACGTAGATGCAGTGCACCCTGGC TACGGGTTCCTCTCTGAGCGAGCGGACTTCGCCCAGGCCTGCCAGGATGCAGGGGTCCGGTTTATTGGGCCAAGCCCAGAAGTGGTCCGC AAGATGGGAGACAAGGTGGAGGCCCGGGCCATCGCCATTGCTGCGGGTGTTCCCGTTGTCCCTGGCACAGATGCCCCCATCACGTCCCTG CATGAGGCCCACGAGTTCTCCAACACCTACGGCTTCCCCATCATCTTCAAGGCGGCCTATGGGGGTGGAGGGCGTGGCATGAGGGTGGTG CACAGCTACGAGGAGCTGGAGGAGAATTACACCCGGGCCTACTCAGAGGCTCTGGCCGCCTTTGGGAATGGGGCGCTGTTTGTGGAGAAG TTCATCGAGAAGCCACGGCACATCGAGGTGCAGATCTTGGGGGACCAGTATGGGAACATCCTGCACCTGTACGAGCGAGACTGCTCCATC CAGCGGCGGCACCAGAAGGTGGTCGAGATTGCCCCCGCCGCCCACCTGGACCCGCAGCTTCGGACTCGGCTCACCAGCGACTCTGTGAAA CTCGCTAAACAGGTGGGCTACGAGAACGCAGGCACCGTGGAGTTCCTGGTGGACAGGCACGGCAAGCACTACTTCATCGAGGTCAACTCC CGCCTGCAGGTGGAGCACACGGTCACAGAGGAGATCACCGACGTAGACCTGGTCCATGCTCAGATCCACGTGGCTGAGGGCAGGAGCCTA CCCGACCTGGGCCTGCGGCAGGAGAACATCCGCATCAACGGGTGTGCCATCCAGTGCCGGGTCACCACCGAGGACCCCGCGCGCAGCTTC CAGCCGGACACCGGCCGCATTGAGGTGTTCCGGAGCGGAGAGGGCATGGGCATCCGCCTGGATAATGCTTCCGCCTTCCAAGGAGCCGTC ATCTCGCCCCACTACGACTCCCTGCTGGTCAAAGTCATTGCCCACGGCAAAGACCACCCCACGGCCGCCACCAAGATGAGCAGGGCCCTT GCGGAGTTCCGCGTCCGAGGTGTGAAGGTCAGAAGACACCAGGCACAGCCCTTGGCCGCAGCCCTGGGCCGCCCCTGTGGACAGGAAGCC AGGAGGCCCCAGGCTGCTGTGACTGCCCCCACCGGCCCTGGTAGCCCCACCCTTGTCCGTGTGCCACCAGCGGCCCGTGTCCTGTCCTCC CGTCTCGGGGGACCTAGCCAGACAACACCAGAGACTAGCACTGAGGTGTCCCCAACAATTTTATTATAAATAAAAACAAGACTCCCAGTG GGTGGCTGC >16501_16501_4_CHKA-PC_CHKA_chr11_67864486_ENST00000356135_PC_chr11_66639630_ENST00000355677_length(amino acids)=702AA_BP=43 MSLVLSRCGRPRLLGRLSGMKTKFCTGGEAEPSPLGLLLSCGSGSAAPAPGVGQQRDAASDLESKQLGGQQPPLALPPPPPLPLPLPLPQ PPPPQPPADEQPEPRTRRRAYLWCKEFLPGAWRGLREDEFHISVIRGGLSNMLFQCSLPDTTATLGDEPRKVLLRLYGAILQMMLKFRTV HGGLRLLGIRRTSTAPAASPNVRRLEYKPIKKVMVANRGEIAIRVFRACTELGIRTVAIYSEQDTGQMHRQKADEAYLIGRGLAPVQAYL HIPDIIKVAKENNVDAVHPGYGFLSERADFAQACQDAGVRFIGPSPEVVRKMGDKVEARAIAIAAGVPVVPGTDAPITSLHEAHEFSNTY GFPIIFKAAYGGGGRGMRVVHSYEELEENYTRAYSEALAAFGNGALFVEKFIEKPRHIEVQILGDQYGNILHLYERDCSIQRRHQKVVEI APAAHLDPQLRTRLTSDSVKLAKQVGYENAGTVEFLVDRHGKHYFIEVNSRLQVEHTVTEEITDVDLVHAQIHVAEGRSLPDLGLRQENI RINGCAIQCRVTTEDPARSFQPDTGRIEVFRSGEGMGIRLDNASAFQGAVISPHYDSLLVKVIAHGKDHPTAATKMSRALAEFRVRGVKV RRHQAQPLAAALGRPCGQEARRPQAAVTAPTGPGSPTLVRVPPAARVLSSRLGGPSQTTPETSTEVSPTILL -------------------------------------------------------------- >16501_16501_5_CHKA-PC_CHKA_chr11_67864486_ENST00000356135_PC_chr11_66639630_ENST00000393958_length(transcript)=4640nt_BP=729nt GTGGCGAGCGCGAGGGCGGGCTGTGACGCGGCCGGCGCTCCTCGTGCGGCGGCGGCAGAGGAGCGAGTGCAGCGGCCAGCAGCACATCCC CGCTCCACAGTCGCCGCAGTCGCCGCAGCCGCCGCCGCCGCCCCGCGCGCCCAACCGCCGCGGCCCCCTGCCCCGCCGGCCTGCCAGTGA GAGAGCGGCGAGGGGGCGCCCGGCCGGACTCTGAGCCTAGTCCTCTCGCGCTGCGGCCGCCCGCGCCTCCTCGGCCGCCTGTCGGGCATG AAAACCAAATTCTGCACCGGGGGCGAGGCGGAGCCCTCGCCGCTCGGGCTGCTGCTGAGCTGCGGTAGCGGCAGCGCGGCCCCGGCGCCC GGCGTGGGGCAGCAGCGCGACGCCGCCAGCGACCTCGAGTCCAAGCAGCTGGGCGGCCAACAGCCGCCGCTCGCGCTGCCCCCTCCGCCG CCGCTGCCGCTGCCGCTGCCGCTGCCCCAGCCCCCGCCGCCGCAGCCGCCCGCAGACGAGCAGCCGGAGCCCCGGACGCGGCGCAGGGCC TATCTGTGGTGCAAGGAGTTCCTGCCCGGCGCCTGGCGGGGCCTCCGCGAGGACGAGTTCCACATCAGTGTCATCAGAGGCGGCCTTAGC AACATGCTGTTCCAGTGCTCCCTACCTGACACCACAGCCACCCTTGGTGATGAGCCTCGGAAAGTGCTCCTGCGGCTGTATGGAGCGATT TTGCAGATGATGCTGAAGTTCCGAACAGTCCATGGGGGCCTGAGGCTCCTGGGAATCCGCCGAACCTCCACCGCCCCCGCTGCCTCCCCA AATGTCCGGCGCCTGGAGTATAAGCCCATCAAGAAAGTCATGGTGGCCAACAGAGGTGAGATTGCCATCCGTGTGTTCCGGGCCTGCACG GAGCTGGGCATCCGCACCGTAGCCATCTACTCTGAGCAGGACACGGGCCAGATGCACCGGCAGAAAGCAGATGAAGCCTATCTCATCGGC CGCGGCCTGGCCCCCGTGCAGGCCTACCTGCACATCCCAGACATCATCAAGGTGGCCAAGGAGAACAACGTAGATGCAGTGCACCCTGGC TACGGGTTCCTCTCTGAGCGAGCGGACTTCGCCCAGGCCTGCCAGGATGCAGGGGTCCGGTTTATTGGGCCAAGCCCAGAAGTGGTCCGC AAGATGGGAGACAAGGTGGAGGCCCGGGCCATCGCCATTGCTGCGGGTGTTCCCGTTGTCCCTGGCACAGATGCCCCCATCACGTCCCTG CATGAGGCCCACGAGTTCTCCAACACCTACGGCTTCCCCATCATCTTCAAGGCGGCCTATGGGGGTGGAGGGCGTGGCATGAGGGTGGTG CACAGCTACGAGGAGCTGGAGGAGAATTACACCCGGGCCTACTCAGAGGCTCTGGCCGCCTTTGGGAATGGGGCGCTGTTTGTGGAGAAG TTCATCGAGAAGCCACGGCACATCGAGGTGCAGATCTTGGGGGACCAGTATGGGAACATCCTGCACCTGTACGAGCGAGACTGCTCCATC CAGCGGCGGCACCAGAAGGTGGTCGAGATTGCCCCCGCCGCCCACCTGGACCCGCAGCTTCGGACTCGGCTCACCAGCGACTCTGTGAAA CTCGCTAAACAGGTGGGCTACGAGAACGCAGGCACCGTGGAGTTCCTGGTGGACAGGCACGGCAAGCACTACTTCATCGAGGTCAACTCC CGCCTGCAGGTGGAGCACACGGTCACAGAGGAGATCACCGACGTAGACCTGGTCCATGCTCAGATCCACGTGGCTGAGGGCAGGAGCCTA CCCGACCTGGGCCTGCGGCAGGAGAACATCCGCATCAACGGGTGTGCCATCCAGTGCCGGGTCACCACCGAGGACCCCGCGCGCAGCTTC CAGCCGGACACCGGCCGCATTGAGGTGTTCCGGAGCGGAGAGGGCATGGGCATCCGCCTGGATAATGCTTCCGCCTTCCAAGGAGCCGTC ATCTCGCCCCACTACGACTCCCTGCTGGTCAAAGTCATTGCCCACGGCAAAGACCACCCCACGGCCGCCACCAAGATGAGCAGGGCCCTT GCGGAGTTCCGCGTCCGAGGTGTGAAGACCAACATCGCCTTCCTGCAGAATGTGCTCAACAACCAGCAGTTCCTGGCAGGCACTGTGGAC ACCCAGTTCATCGACGAGAACCCAGAGCTGTTCCAGCTGCGGCCTGCACAGAACCGGGCCCAAAAGCTGTTGCACTACCTCGGCCATGTC ATGGTAAACGGTCCAACCACCCCGATTCCCGTCAAGGCCAGCCCCAGCCCCACGGACCCCGTTGTCCCTGCAGTGCCCATAGGCCCGCCC CCGGCTGGTTTCAGAGACATCCTGCTGCGAGAGGGGCCTGAGGGCTTTGCTCGAGCTGTGCGGAACCACCCGGGGCTGCTGCTGATGGAC ACGACCTTCAGGGACGCCCACCAGTCACTGCTGGCCACTCGTGTGCGCACCCACGATCTCAAAAAGATCGCCCCCTATGTTGCCCACAAC TTCAGCAAGCTCTTCAGCATGGAGAACTGGGGAGGAGCCACGTTTGACGTCGCCATGCGCTTCCTGTATGAGTGCCCCTGGCGGCGGCTG CAGGAGCTCCGGGAGCTCATCCCCAACATCCCTTTCCAGATGCTGCTGCGGGGGGCCAATGCTGTGGGCTACACCAACTACCCAGACAAC GTGGTCTTCAAGTTCTGTGAAGTGGCCAAAGAGAATGGCATGGATGTCTTCCGTGTGTTTGACTCCCTCAACTACTTGCCCAACATGCTG CTGGGCATGGAGGCGGCAGGAAGTGCCGGAGGCGTGGTGGAGGCTGCCATCTCATACACGGGCGACGTGGCCGACCCCAGCCGCACCAAG TACTCACTGCAGTACTACATGGGCTTGGCCGAAGAGCTGGTGCGAGCTGGCACCCACATCCTGTGCATCAAGGACATGGCCGGGCTGCTG AAGCCCACGGCCTGCACCATGCTGGTCAGCTCCCTCCGGGACCGCTTCCCCGACCTCCCACTGCACATCCACACCCACGACACGTCAGGG GCAGGCGTGGCAGCCATGCTGGCCTGTGCCCAGGCTGGAGCTGATGTGGTGGATGTGGCAGCTGATTCCATGTCTGGGATGACTTCACAG CCCAGCATGGGGGCCCTGGTGGCCTGTACCAGAGGGACTCCCCTGGACACAGAGGTGCCCATGGAGCGCGTGTTTGACTACAGTGAGTAC TGGGAGGGGGCTCGGGGACTGTACGCGGCCTTCGACTGCACGGCCACCATGAAGTCTGGCAACTCGGACGTGTATGAAAATGAGATCCCA GGGGGCCAGTACACCAACCTGCACTTCCAGGCCCACAGCATGGGGCTTGGCTCCAAGTTCAAGGAGGTCAAGAAGGCCTATGTGGAGGCC AACCAGATGCTGGGCGATCTCATCAAGGTGACGCCCTCCTCCAAGATCGTGGGGGACCTGGCCCAGTTTATGGTGCAGAATGGATTGAGC CGGGCAGAGGCCGAAGCTCAGGCGGAAGAGCTGTCCTTTCCCCGCTCCGTGGTGGAGTTCCTGCAGGGCTACATCGGTGTCCCCCATGGG GGGTTCCCCGAACCCTTTCGCTCTAAGGTACTGAAGGACCTGCCAAGGGTGGAGGGGCGGCCTGGAGCCTCCCTCCCTCCCCTGGATCTG CAGGCACTGGAGAAGGAGCTGGTAGACCGGCATGGGGAGGAGGTGACGCCGGAAGATGTGCTCTCAGCAGCTATGTACCCCGATGTGTTT GCCCACTTCAAGGACTTCACTGCCACCTTTGGCCCCCTGGATAGCCTGAATACTCGCCTCTTCCTGCAGGGACCCAAGATCGCAGAGGAG TTTGAGGTGGAGCTGGAGCGGGGCAAGACGCTGCACATCAAAGCCCTGGCCGTGAGCGACCTGAACCGGGCCGGCCAGAGGCAGGTCTTC TTTGAGCTCAATGGGCAGCTGCGGTCCATCTTGGTCAAGGACACCCAGGCCATGAAGGAGATGCACTTCCACCCCAAGGCCCTAAAGGAC GTGAAGGGCCAGATCGGGGCGCCCATGCCTGGGAAGGTGATAGACATCAAAGTGGTGGCAGGGGCCAAGGTGGCCAAGGGCCAGCCCCTG TGTGTGCTCAGTGCCATGAAGATGGAGACTGTGGTGACCTCACCCATGGAGGGTACTGTCCGCAAGGTTCATGTGACCAAGGACATGACA CTGGAAGGTGACGACCTCATCCTGGAGATCGAGTGATCTTGCCCCAGACCGGCAGCCTGGCCATCCCCAAGCCTTCAACAGAAGCTGTGC TGCCACGGCAGGCCCAGGCCAGCCAGTGCCCGAGGCCAGGAAGGCCGGGCCGTGGAGGTCCTGTCCACAGCTGGACAGGAGAGACACCGC CTGCGGTGGTTCATTCCTTTCAGCCATCGTCCTTTCCTCCGGCGGACAGCTGCTTACATGTTCATCTCTTGCCAAATAAGGGTCCCCTCC TCACTGGAGACTACAAGTGGTGGGTCAGGTGGTCCTAGGACCCAGGGGAGGTTTAGGGGTCCTATCTCCTGGGGGAAGGGGAGATCTAAG ATGTCCCAGGTCCTGGGAAGTTTACTCAATAAAGCTGGCTTTCCCCTGCC >16501_16501_5_CHKA-PC_CHKA_chr11_67864486_ENST00000356135_PC_chr11_66639630_ENST00000393958_length(amino acids)=1351AA_BP=43 MSLVLSRCGRPRLLGRLSGMKTKFCTGGEAEPSPLGLLLSCGSGSAAPAPGVGQQRDAASDLESKQLGGQQPPLALPPPPPLPLPLPLPQ PPPPQPPADEQPEPRTRRRAYLWCKEFLPGAWRGLREDEFHISVIRGGLSNMLFQCSLPDTTATLGDEPRKVLLRLYGAILQMMLKFRTV HGGLRLLGIRRTSTAPAASPNVRRLEYKPIKKVMVANRGEIAIRVFRACTELGIRTVAIYSEQDTGQMHRQKADEAYLIGRGLAPVQAYL HIPDIIKVAKENNVDAVHPGYGFLSERADFAQACQDAGVRFIGPSPEVVRKMGDKVEARAIAIAAGVPVVPGTDAPITSLHEAHEFSNTY GFPIIFKAAYGGGGRGMRVVHSYEELEENYTRAYSEALAAFGNGALFVEKFIEKPRHIEVQILGDQYGNILHLYERDCSIQRRHQKVVEI APAAHLDPQLRTRLTSDSVKLAKQVGYENAGTVEFLVDRHGKHYFIEVNSRLQVEHTVTEEITDVDLVHAQIHVAEGRSLPDLGLRQENI RINGCAIQCRVTTEDPARSFQPDTGRIEVFRSGEGMGIRLDNASAFQGAVISPHYDSLLVKVIAHGKDHPTAATKMSRALAEFRVRGVKT NIAFLQNVLNNQQFLAGTVDTQFIDENPELFQLRPAQNRAQKLLHYLGHVMVNGPTTPIPVKASPSPTDPVVPAVPIGPPPAGFRDILLR EGPEGFARAVRNHPGLLLMDTTFRDAHQSLLATRVRTHDLKKIAPYVAHNFSKLFSMENWGGATFDVAMRFLYECPWRRLQELRELIPNI PFQMLLRGANAVGYTNYPDNVVFKFCEVAKENGMDVFRVFDSLNYLPNMLLGMEAAGSAGGVVEAAISYTGDVADPSRTKYSLQYYMGLA EELVRAGTHILCIKDMAGLLKPTACTMLVSSLRDRFPDLPLHIHTHDTSGAGVAAMLACAQAGADVVDVAADSMSGMTSQPSMGALVACT RGTPLDTEVPMERVFDYSEYWEGARGLYAAFDCTATMKSGNSDVYENEIPGGQYTNLHFQAHSMGLGSKFKEVKKAYVEANQMLGDLIKV TPSSKIVGDLAQFMVQNGLSRAEAEAQAEELSFPRSVVEFLQGYIGVPHGGFPEPFRSKVLKDLPRVEGRPGASLPPLDLQALEKELVDR HGEEVTPEDVLSAAMYPDVFAHFKDFTATFGPLDSLNTRLFLQGPKIAEEFEVELERGKTLHIKALAVSDLNRAGQRQVFFELNGQLRSI LVKDTQAMKEMHFHPKALKDVKGQIGAPMPGKVIDIKVVAGAKVAKGQPLCVLSAMKMETVVTSPMEGTVRKVHVTKDMTLEGDDLILEI E -------------------------------------------------------------- >16501_16501_6_CHKA-PC_CHKA_chr11_67864486_ENST00000356135_PC_chr11_66639630_ENST00000393960_length(transcript)=4639nt_BP=729nt GTGGCGAGCGCGAGGGCGGGCTGTGACGCGGCCGGCGCTCCTCGTGCGGCGGCGGCAGAGGAGCGAGTGCAGCGGCCAGCAGCACATCCC CGCTCCACAGTCGCCGCAGTCGCCGCAGCCGCCGCCGCCGCCCCGCGCGCCCAACCGCCGCGGCCCCCTGCCCCGCCGGCCTGCCAGTGA GAGAGCGGCGAGGGGGCGCCCGGCCGGACTCTGAGCCTAGTCCTCTCGCGCTGCGGCCGCCCGCGCCTCCTCGGCCGCCTGTCGGGCATG AAAACCAAATTCTGCACCGGGGGCGAGGCGGAGCCCTCGCCGCTCGGGCTGCTGCTGAGCTGCGGTAGCGGCAGCGCGGCCCCGGCGCCC GGCGTGGGGCAGCAGCGCGACGCCGCCAGCGACCTCGAGTCCAAGCAGCTGGGCGGCCAACAGCCGCCGCTCGCGCTGCCCCCTCCGCCG CCGCTGCCGCTGCCGCTGCCGCTGCCCCAGCCCCCGCCGCCGCAGCCGCCCGCAGACGAGCAGCCGGAGCCCCGGACGCGGCGCAGGGCC TATCTGTGGTGCAAGGAGTTCCTGCCCGGCGCCTGGCGGGGCCTCCGCGAGGACGAGTTCCACATCAGTGTCATCAGAGGCGGCCTTAGC AACATGCTGTTCCAGTGCTCCCTACCTGACACCACAGCCACCCTTGGTGATGAGCCTCGGAAAGTGCTCCTGCGGCTGTATGGAGCGATT TTGCAGATGATGCTGAAGTTCCGAACAGTCCATGGGGGCCTGAGGCTCCTGGGAATCCGCCGAACCTCCACCGCCCCCGCTGCCTCCCCA AATGTCCGGCGCCTGGAGTATAAGCCCATCAAGAAAGTCATGGTGGCCAACAGAGGTGAGATTGCCATCCGTGTGTTCCGGGCCTGCACG GAGCTGGGCATCCGCACCGTAGCCATCTACTCTGAGCAGGACACGGGCCAGATGCACCGGCAGAAAGCAGATGAAGCCTATCTCATCGGC CGCGGCCTGGCCCCCGTGCAGGCCTACCTGCACATCCCAGACATCATCAAGGTGGCCAAGGAGAACAACGTAGATGCAGTGCACCCTGGC TACGGGTTCCTCTCTGAGCGAGCGGACTTCGCCCAGGCCTGCCAGGATGCAGGGGTCCGGTTTATTGGGCCAAGCCCAGAAGTGGTCCGC AAGATGGGAGACAAGGTGGAGGCCCGGGCCATCGCCATTGCTGCGGGTGTTCCCGTTGTCCCTGGCACAGATGCCCCCATCACGTCCCTG CATGAGGCCCACGAGTTCTCCAACACCTACGGCTTCCCCATCATCTTCAAGGCGGCCTATGGGGGTGGAGGGCGTGGCATGAGGGTGGTG CACAGCTACGAGGAGCTGGAGGAGAATTACACCCGGGCCTACTCAGAGGCTCTGGCCGCCTTTGGGAATGGGGCGCTGTTTGTGGAGAAG TTCATCGAGAAGCCACGGCACATCGAGGTGCAGATCTTGGGGGACCAGTATGGGAACATCCTGCACCTGTACGAGCGAGACTGCTCCATC CAGCGGCGGCACCAGAAGGTGGTCGAGATTGCCCCCGCCGCCCACCTGGACCCGCAGCTTCGGACTCGGCTCACCAGCGACTCTGTGAAA CTCGCTAAACAGGTGGGCTACGAGAACGCAGGCACCGTGGAGTTCCTGGTGGACAGGCACGGCAAGCACTACTTCATCGAGGTCAACTCC CGCCTGCAGGTGGAGCACACGGTCACAGAGGAGATCACCGACGTAGACCTGGTCCATGCTCAGATCCACGTGGCTGAGGGCAGGAGCCTA CCCGACCTGGGCCTGCGGCAGGAGAACATCCGCATCAACGGGTGTGCCATCCAGTGCCGGGTCACCACCGAGGACCCCGCGCGCAGCTTC CAGCCGGACACCGGCCGCATTGAGGTGTTCCGGAGCGGAGAGGGCATGGGCATCCGCCTGGATAATGCTTCCGCCTTCCAAGGAGCCGTC ATCTCGCCCCACTACGACTCCCTGCTGGTCAAAGTCATTGCCCACGGCAAAGACCACCCCACGGCCGCCACCAAGATGAGCAGGGCCCTT GCGGAGTTCCGCGTCCGAGGTGTGAAGACCAACATCGCCTTCCTGCAGAATGTGCTCAACAACCAGCAGTTCCTGGCAGGCACTGTGGAC ACCCAGTTCATCGACGAGAACCCAGAGCTGTTCCAGCTGCGGCCTGCACAGAACCGGGCCCAAAAGCTGTTGCACTACCTCGGCCATGTC ATGGTAAACGGTCCAACCACCCCGATTCCCGTCAAGGCCAGCCCCAGCCCCACGGACCCCGTTGTCCCTGCAGTGCCCATAGGCCCGCCC CCGGCTGGTTTCAGAGACATCCTGCTGCGAGAGGGGCCTGAGGGCTTTGCTCGAGCTGTGCGGAACCACCCGGGGCTGCTGCTGATGGAC ACGACCTTCAGGGACGCCCACCAGTCACTGCTGGCCACTCGTGTGCGCACCCACGATCTCAAAAAGATCGCCCCCTATGTTGCCCACAAC TTCAGCAAGCTCTTCAGCATGGAGAACTGGGGAGGAGCCACGTTTGACGTCGCCATGCGCTTCCTGTATGAGTGCCCCTGGCGGCGGCTG CAGGAGCTCCGGGAGCTCATCCCCAACATCCCTTTCCAGATGCTGCTGCGGGGGGCCAATGCTGTGGGCTACACCAACTACCCAGACAAC GTGGTCTTCAAGTTCTGTGAAGTGGCCAAAGAGAATGGCATGGATGTCTTCCGTGTGTTTGACTCCCTCAACTACTTGCCCAACATGCTG CTGGGCATGGAGGCGGCAGGAAGTGCCGGAGGCGTGGTGGAGGCTGCCATCTCATACACGGGCGACGTGGCCGACCCCAGCCGCACCAAG TACTCACTGCAGTACTACATGGGCTTGGCCGAAGAGCTGGTGCGAGCTGGCACCCACATCCTGTGCATCAAGGACATGGCCGGGCTGCTG AAGCCCACGGCCTGCACCATGCTGGTCAGCTCCCTCCGGGACCGCTTCCCCGACCTCCCACTGCACATCCACACCCACGACACGTCAGGG GCAGGCGTGGCAGCCATGCTGGCCTGTGCCCAGGCTGGAGCTGATGTGGTGGATGTGGCAGCTGATTCCATGTCTGGGATGACTTCACAG CCCAGCATGGGGGCCCTGGTGGCCTGTACCAGAGGGACTCCCCTGGACACAGAGGTGCCCATGGAGCGCGTGTTTGACTACAGTGAGTAC TGGGAGGGGGCTCGGGGACTGTACGCGGCCTTCGACTGCACGGCCACCATGAAGTCTGGCAACTCGGACGTGTATGAAAATGAGATCCCA GGGGGCCAGTACACCAACCTGCACTTCCAGGCCCACAGCATGGGGCTTGGCTCCAAGTTCAAGGAGGTCAAGAAGGCCTATGTGGAGGCC AACCAGATGCTGGGCGATCTCATCAAGGTGACGCCCTCCTCCAAGATCGTGGGGGACCTGGCCCAGTTTATGGTGCAGAATGGATTGAGC CGGGCAGAGGCCGAAGCTCAGGCGGAAGAGCTGTCCTTTCCCCGCTCCGTGGTGGAGTTCCTGCAGGGCTACATCGGTGTCCCCCATGGG GGGTTCCCCGAACCCTTTCGCTCTAAGGTACTGAAGGACCTGCCAAGGGTGGAGGGGCGGCCTGGAGCCTCCCTCCCTCCCCTGGATCTG CAGGCACTGGAGAAGGAGCTGGTAGACCGGCATGGGGAGGAGGTGACGCCGGAAGATGTGCTCTCAGCAGCTATGTACCCCGATGTGTTT GCCCACTTCAAGGACTTCACTGCCACCTTTGGCCCCCTGGATAGCCTGAATACTCGCCTCTTCCTGCAGGGACCCAAGATCGCAGAGGAG TTTGAGGTGGAGCTGGAGCGGGGCAAGACGCTGCACATCAAAGCCCTGGCCGTGAGCGACCTGAACCGGGCCGGCCAGAGGCAGGTCTTC TTTGAGCTCAATGGGCAGCTGCGGTCCATCTTGGTCAAGGACACCCAGGCCATGAAGGAGATGCACTTCCACCCCAAGGCCCTAAAGGAC GTGAAGGGCCAGATCGGGGCGCCCATGCCTGGGAAGGTGATAGACATCAAAGTGGTGGCAGGGGCCAAGGTGGCCAAGGGCCAGCCCCTG TGTGTGCTCAGTGCCATGAAGATGGAGACTGTGGTGACCTCACCCATGGAGGGTACTGTCCGCAAGGTTCATGTGACCAAGGACATGACA CTGGAAGGTGACGACCTCATCCTGGAGATCGAGTGATCTTGCCCCAGACCGGCAGCCTGGCCATCCCCAAGCCTTCAACAGAAGCTGTGC TGCCACGGCAGGCCCAGGCCAGCCAGTGCCCGAGGCCAGGAAGGCCGGGCCGTGGAGGTCCTGTCCACAGCTGGACAGGAGAGACACCGC CTGCGGTGGTTCATTCCTTTCAGCCATCGTCCTTTCCTCCGGCGGACAGCTGCTTACATGTTCATCTCTTGCCAAATAAGGGTCCCCTCC TCACTGGAGACTACAAGTGGTGGGTCAGGTGGTCCTAGGACCCAGGGGAGGTTTAGGGGTCCTATCTCCTGGGGGAAGGGGAGATCTAAG ATGTCCCAGGTCCTGGGAAGTTTACTCAATAAAGCTGGCTTTCCCCTGC >16501_16501_6_CHKA-PC_CHKA_chr11_67864486_ENST00000356135_PC_chr11_66639630_ENST00000393960_length(amino acids)=1351AA_BP=43 MSLVLSRCGRPRLLGRLSGMKTKFCTGGEAEPSPLGLLLSCGSGSAAPAPGVGQQRDAASDLESKQLGGQQPPLALPPPPPLPLPLPLPQ PPPPQPPADEQPEPRTRRRAYLWCKEFLPGAWRGLREDEFHISVIRGGLSNMLFQCSLPDTTATLGDEPRKVLLRLYGAILQMMLKFRTV HGGLRLLGIRRTSTAPAASPNVRRLEYKPIKKVMVANRGEIAIRVFRACTELGIRTVAIYSEQDTGQMHRQKADEAYLIGRGLAPVQAYL HIPDIIKVAKENNVDAVHPGYGFLSERADFAQACQDAGVRFIGPSPEVVRKMGDKVEARAIAIAAGVPVVPGTDAPITSLHEAHEFSNTY GFPIIFKAAYGGGGRGMRVVHSYEELEENYTRAYSEALAAFGNGALFVEKFIEKPRHIEVQILGDQYGNILHLYERDCSIQRRHQKVVEI APAAHLDPQLRTRLTSDSVKLAKQVGYENAGTVEFLVDRHGKHYFIEVNSRLQVEHTVTEEITDVDLVHAQIHVAEGRSLPDLGLRQENI RINGCAIQCRVTTEDPARSFQPDTGRIEVFRSGEGMGIRLDNASAFQGAVISPHYDSLLVKVIAHGKDHPTAATKMSRALAEFRVRGVKT NIAFLQNVLNNQQFLAGTVDTQFIDENPELFQLRPAQNRAQKLLHYLGHVMVNGPTTPIPVKASPSPTDPVVPAVPIGPPPAGFRDILLR EGPEGFARAVRNHPGLLLMDTTFRDAHQSLLATRVRTHDLKKIAPYVAHNFSKLFSMENWGGATFDVAMRFLYECPWRRLQELRELIPNI PFQMLLRGANAVGYTNYPDNVVFKFCEVAKENGMDVFRVFDSLNYLPNMLLGMEAAGSAGGVVEAAISYTGDVADPSRTKYSLQYYMGLA EELVRAGTHILCIKDMAGLLKPTACTMLVSSLRDRFPDLPLHIHTHDTSGAGVAAMLACAQAGADVVDVAADSMSGMTSQPSMGALVACT RGTPLDTEVPMERVFDYSEYWEGARGLYAAFDCTATMKSGNSDVYENEIPGGQYTNLHFQAHSMGLGSKFKEVKKAYVEANQMLGDLIKV TPSSKIVGDLAQFMVQNGLSRAEAEAQAEELSFPRSVVEFLQGYIGVPHGGFPEPFRSKVLKDLPRVEGRPGASLPPLDLQALEKELVDR HGEEVTPEDVLSAAMYPDVFAHFKDFTATFGPLDSLNTRLFLQGPKIAEEFEVELERGKTLHIKALAVSDLNRAGQRQVFFELNGQLRSI LVKDTQAMKEMHFHPKALKDVKGQIGAPMPGKVIDIKVVAGAKVAKGQPLCVLSAMKMETVVTSPMEGTVRKVHVTKDMTLEGDDLILEI E -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CHKA-PC |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CHKA-PC |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CHKA-PC |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | CHKA | C0038219 | Status Dysraphicus | 1 | CTD_human |
| Hgene | CHKA | C0080178 | Spina Bifida | 1 | CTD_human |
| Hgene | CHKA | C0266508 | Rachischisis | 1 | CTD_human |
| Tgene | C0034341 | Pyruvate Carboxylase Deficiency Disease | 2 | CTD_human;GENOMICS_ENGLAND | |
| Tgene | C0005586 | Bipolar Disorder | 1 | CTD_human | |
| Tgene | C0005587 | Depression, Bipolar | 1 | CTD_human | |
| Tgene | C0006413 | Burkitt Lymphoma | 1 | CTD_human | |
| Tgene | C0019193 | Hepatitis, Toxic | 1 | CTD_human | |
| Tgene | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human | |
| Tgene | C0024713 | Manic Disorder | 1 | CTD_human | |
| Tgene | C0338831 | Manic | 1 | CTD_human | |
| Tgene | C0343640 | African Burkitt's lymphoma | 1 | CTD_human | |
| Tgene | C0860207 | Drug-Induced Liver Disease | 1 | CTD_human | |
| Tgene | C1262760 | Hepatitis, Drug-Induced | 1 | CTD_human | |
| Tgene | C3658290 | Drug-Induced Acute Liver Injury | 1 | CTD_human | |
| Tgene | C4277682 | Chemical and Drug Induced Liver Injury | 1 | CTD_human | |
| Tgene | C4279912 | Chemically-Induced Liver Toxicity | 1 | CTD_human | |
| Tgene | C4721444 | Burkitt Leukemia | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies