
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CHP1-RAD51 (FusionGDB2 ID:HG11261TG5888) |
Fusion Gene Summary for CHP1-RAD51 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CHP1-RAD51 | Fusion gene ID: hg11261tg5888 | Hgene | Tgene | Gene symbol | CHP1 | RAD51 | Gene ID | 11261 | 5888 |
| Gene name | calcineurin like EF-hand protein 1 | RAD51 recombinase | |
| Synonyms | CHP|SLC9A1BP|SPAX9|Sid470p|p22|p24 | BRCC5|FANCR|HRAD51|HsRad51|HsT16930|MRMV2|RAD51A|RECA | |
| Cytomap | ('CHP1')('RAD51') 15q15.1 | 15q15.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | calcineurin B homologous protein 1EF-hand calcium-binding domain-containing protein p22SLC9A1 binding proteincalcineurin B homologcalcineurin B-like proteincalcineurin homologous proteincalcium binding protein P22calcium-binding protein CHPcalcium | DNA repair protein RAD51 homolog 1BRCA1/BRCA2-containing complex, subunit 5RAD51 homolog ARecA, E. coli, homolog ofRecA-like proteinrecombination protein A | |
| Modification date | 20200313 | 20200322 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000558351, ENST00000334660, ENST00000560397, | ||
| Fusion gene scores | * DoF score | 11 X 13 X 7=1001 | 7 X 7 X 5=245 |
| # samples | 15 | 7 | |
| ** MAII score | log2(15/1001*10)=-2.73840756834011 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/245*10)=-1.8073549220576 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CHP1 [Title/Abstract] AND RAD51 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CHP1(41562816)-RAD51(41011003), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | CHP1-RAD51 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CHP1-RAD51 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CHP1-RAD51 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CHP1-RAD51 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CHP1 | GO:0010923 | negative regulation of phosphatase activity | 10593895 |
| Hgene | CHP1 | GO:0032088 | negative regulation of NF-kappaB transcription factor activity | 10593895 |
| Hgene | CHP1 | GO:0032417 | positive regulation of sodium:proton antiporter activity | 8901634|11350981 |
| Hgene | CHP1 | GO:0042308 | negative regulation of protein import into nucleus | 10593895 |
| Hgene | CHP1 | GO:0051453 | regulation of intracellular pH | 8901634|15035633 |
| Hgene | CHP1 | GO:0070885 | negative regulation of calcineurin-NFAT signaling cascade | 10593895 |
| Tgene | RAD51 | GO:0000724 | double-strand break repair via homologous recombination | 16428451 |
| Tgene | RAD51 | GO:0006268 | DNA unwinding involved in DNA replication | 7988572 |
| Tgene | RAD51 | GO:0006974 | cellular response to DNA damage stimulus | 23509288|25585578 |
| Tgene | RAD51 | GO:0010569 | regulation of double-strand break repair via homologous recombination | 23754376 |
| Tgene | RAD51 | GO:0031297 | replication fork processing | 25585578 |
| Tgene | RAD51 | GO:0051106 | positive regulation of DNA ligation | 8929543 |
| Tgene | RAD51 | GO:0071479 | cellular response to ionizing radiation | 23509288|23754376 |
| Tgene | RAD51 | GO:0072757 | cellular response to camptothecin | 23509288 |
| Fusion gene breakpoints across CHP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RAD51 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-55-8085-01A | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
Top |
Fusion Gene ORF analysis for CHP1-RAD51 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000558351 | ENST00000267868 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 3UTR-3CDS | ENST00000558351 | ENST00000423169 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 3UTR-intron | ENST00000558351 | ENST00000382643 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 3UTR-intron | ENST00000558351 | ENST00000530766 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 3UTR-intron | ENST00000558351 | ENST00000532743 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 3UTR-intron | ENST00000558351 | ENST00000557850 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 5CDS-intron | ENST00000334660 | ENST00000382643 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 5CDS-intron | ENST00000334660 | ENST00000530766 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 5CDS-intron | ENST00000334660 | ENST00000532743 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 5CDS-intron | ENST00000334660 | ENST00000557850 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 5CDS-intron | ENST00000560397 | ENST00000382643 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 5CDS-intron | ENST00000560397 | ENST00000530766 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 5CDS-intron | ENST00000560397 | ENST00000532743 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| 5CDS-intron | ENST00000560397 | ENST00000557850 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| In-frame | ENST00000334660 | ENST00000267868 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| In-frame | ENST00000334660 | ENST00000423169 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| In-frame | ENST00000560397 | ENST00000267868 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| In-frame | ENST00000560397 | ENST00000423169 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000334660 | CHP1 | chr15 | 41562816 | + | ENST00000423169 | RAD51 | chr15 | 41011003 | + | 1528 | 651 | 63 | 1058 | 331 |
| ENST00000334660 | CHP1 | chr15 | 41562816 | + | ENST00000267868 | RAD51 | chr15 | 41011003 | + | 2214 | 651 | 63 | 1235 | 390 |
| ENST00000560397 | CHP1 | chr15 | 41562816 | + | ENST00000423169 | RAD51 | chr15 | 41011003 | + | 1378 | 501 | 0 | 908 | 302 |
| ENST00000560397 | CHP1 | chr15 | 41562816 | + | ENST00000267868 | RAD51 | chr15 | 41011003 | + | 2064 | 501 | 0 | 1085 | 361 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000334660 | ENST00000423169 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + | 0.00143779 | 0.9985623 |
| ENST00000334660 | ENST00000267868 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + | 0.000817646 | 0.9991823 |
| ENST00000560397 | ENST00000423169 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + | 0.001148936 | 0.99885106 |
| ENST00000560397 | ENST00000267868 | CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011003 | + | 0.00069662 | 0.99930334 |
Top |
Fusion Genomic Features for CHP1-RAD51 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011002 | + | 5.77E-10 | 1 |
| CHP1 | chr15 | 41562816 | + | RAD51 | chr15 | 41011002 | + | 5.77E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
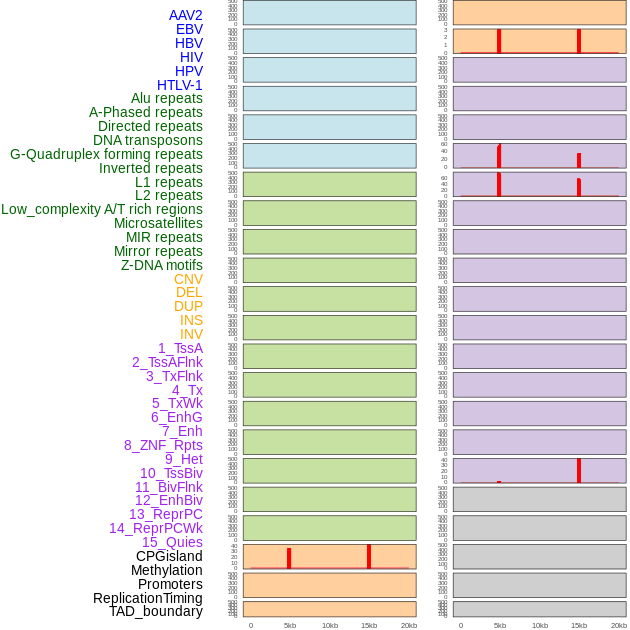 |
Top |
Fusion Protein Features for CHP1-RAD51 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr15:41562816/chr15:41011003) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CHP1 | chr15:41562816 | chr15:41011003 | ENST00000334660 | + | 5 | 7 | 123_134 | 137 | 196.0 | Calcium binding | Note=1 |
| Hgene | CHP1 | chr15:41562816 | chr15:41011003 | ENST00000334660 | + | 5 | 7 | 26_61 | 137 | 196.0 | Domain | EF-hand 1 |
| Hgene | CHP1 | chr15:41562816 | chr15:41011003 | ENST00000334660 | + | 5 | 7 | 66_101 | 137 | 196.0 | Domain | EF-hand 2 |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000557850 | 0 | 8 | 48_77 | 0 | 243.0 | Domain | Note=HhH | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000557850 | 0 | 8 | 127_134 | 0 | 243.0 | Nucleotide binding | ATP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CHP1 | chr15:41562816 | chr15:41011003 | ENST00000334660 | + | 5 | 7 | 164_175 | 137 | 196.0 | Calcium binding | Note=2 |
| Hgene | CHP1 | chr15:41562816 | chr15:41011003 | ENST00000334660 | + | 5 | 7 | 110_145 | 137 | 196.0 | Domain | EF-hand 3 |
| Hgene | CHP1 | chr15:41562816 | chr15:41011003 | ENST00000334660 | + | 5 | 7 | 151_186 | 137 | 196.0 | Domain | EF-hand 4 |
| Hgene | CHP1 | chr15:41562816 | chr15:41011003 | ENST00000334660 | + | 5 | 7 | 138_147 | 137 | 196.0 | Motif | Nuclear export signal 1 |
| Hgene | CHP1 | chr15:41562816 | chr15:41011003 | ENST00000334660 | + | 5 | 7 | 176_185 | 137 | 196.0 | Motif | Nuclear export signal 2 |
| Hgene | CHP1 | chr15:41562816 | chr15:41011003 | ENST00000334660 | + | 5 | 7 | 143_185 | 137 | 196.0 | Region | Note=Necessary for nuclear export signal |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000267868 | 4 | 10 | 48_77 | 145 | 340.0 | Domain | Note=HhH | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000382643 | 4 | 10 | 48_77 | 146 | 341.0 | Domain | Note=HhH | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000423169 | 4 | 9 | 48_77 | 145 | 281.0 | Domain | Note=HhH | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000532743 | 4 | 10 | 48_77 | 146 | 341.0 | Domain | Note=HhH | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000267868 | 4 | 10 | 127_134 | 145 | 340.0 | Nucleotide binding | ATP | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000382643 | 4 | 10 | 127_134 | 146 | 341.0 | Nucleotide binding | ATP | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000423169 | 4 | 9 | 127_134 | 145 | 281.0 | Nucleotide binding | ATP | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000532743 | 4 | 10 | 127_134 | 146 | 341.0 | Nucleotide binding | ATP |
Top |
Fusion Gene Sequence for CHP1-RAD51 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >16610_16610_1_CHP1-RAD51_CHP1_chr15_41562816_ENST00000334660_RAD51_chr15_41011003_ENST00000267868_length(transcript)=2214nt_BP=651nt CATTCGGGGCTGGAACTCGAACGCTGACGTTGGCTCCTGAGCCGGGCGCTGCCTCGCGCCTGATTGGCGGGTCCTCGGGGCCGCCCTCCC CAGCGCACCACCCCTGGGTTCCCTCCCGGGTCCGCAGTGGAAACACTGCCCTCTCCCTTCTTGACCCCTAGCCCTTCCTTCCCTCCCTCC TTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCGATGGGTTCTCGGGCCTCCACGTTACTGCGG GACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTTTTCCCACAGTCAAATCACTCGCCTCTACAGCCGGTTCACCAGCCTGGACAAA GGAGAGAATGGGACTCTCAGCCGGGAAGATTTCCAGAGGATTCCAGAACTTGCCATCAACCCACTGGGGGACCGGATCATCAATGCCTTC TTTCCAGAGGGAGAGGACCAGGTAAACTTCCGTGGATTCATGCGAACTTTGGCTCATTTCCGCCCCATTGAGGATAATGAAAAGAGCAAA GATGTGAATGGACCCGAACCACTCAACAGCCGAAGCAACAAACTGCACTTTGCTTTTCGACTATATGATTTGGATAAAGATGAAAAGATC TCCCGTGATGAGCTGTTACAGCTTCCCATTGACCGGGGTGGAGGTGAAGGAAAGGCCATGTACATTGACACTGAGGGTACCTTTAGGCCA GAACGGCTGCTGGCAGTGGCTGAGAGGTATGGTCTCTCTGGCAGTGATGTCCTGGATAATGTAGCATATGCTCGAGCGTTCAACACAGAC CACCAGACCCAGCTCCTTTATCAAGCATCAGCCATGATGGTAGAATCTAGGTATGCACTGCTTATTGTAGACAGTGCCACCGCCCTTTAC AGAACAGACTACTCGGGTCGAGGTGAGCTTTCAGCCAGGCAGATGCACTTGGCCAGGTTTCTGCGGATGCTTCTGCGACTCGCTGATGAG TTTGGTGTAGCAGTGGTAATCACTAATCAGGTGGTAGCTCAAGTGGATGGAGCAGCGATGTTTGCTGCTGATCCCAAAAAACCTATTGGA GGAAATATCATCGCCCATGCATCAACAACCAGATTGTATCTGAGGAAAGGAAGAGGGGAAACCAGAATCTGCAAAATCTACGACTCTCCC TGTCTTCCTGAAGCTGAAGCTATGTTCGCCATTAATGCAGATGGAGTGGGAGATGCCAAAGACTGAATCATTGGGTTTTTCCTCTGTTAA AAACCTTAAGTGCTGCAGCCTAATGAGAGTGCACTGCTCCCTGGGGTTCTCTACAGGCCTCTTCCTGTTGTGACTGCCAGGATAAAGCTT CCGGGAAAACAGCTATTATATCAGCTTTTCTGATGGTATAAACAGGAGACAGGTCAGTAGTCACAAACTGATCTAAAATGTTTATTCCTT CTGTAGTGTATTAATCTCTGTGTGTTTTCTTTGGTTTTGGAGGAGGGGTATGAAGTATCTTTGACATGGTGCCTTAGGAATGACTTGGGT TTAACAAGCTGTCTACTGGACAATCTTATGTTTCCAAGAGAACTAAAGCTGGAGAGACCTGACCCTTCTCTCACTTCTAAATTAATGGTA AAATAAAATGCCTCAGCTATGTAGCAAAGGGAATGGGTCTGCACAGATTCTTTTTTTCTGTCAGTAAAACTCTCAAGCAGGTTTTTAAGT TGTCTGTCTGAATGATCTTGTGTAAGGTTTTGGTTATGGAGTCTTGTGCCAAACCTACTAGGCCATTAGCCCTTCACCATCTACCTGCTT GGTCTTTCATTGCTAAGACTAACTCAAGATAATCCTAGAGTCTTAAAGCATTTCAGGCCAGTGTGGTGTCTTGCGCCTGTACTCCCAGCA CTTTGGGAGGCCGAGGCAGGTGGATCGCTTGAGCCCAGGAGTTTTAAGTCCAGCTTGGCCAAGGTGGTGAAATCCCATCTCTACAAAAAA TGCAGAACTTAATCTGGACACACTGTTACACGTGCCTGTAGTCCCAGCTACTCGATAGCCTGAGGTGGGAGAATCACTTAAGCCTGGAAG GTGGAAGTTGCAGTGAGTCGAGATTGCACTGCTGCATTCCAGCCAGGGTGACAGAGTGAGACCATGTTTCAAACAAGAAACATTTCAGAG GGTAAGTAAACAGATTTGATTGTGAGGCTTCTAATAAAGTAGTTATTAGTAGTG >16610_16610_1_CHP1-RAD51_CHP1_chr15_41562816_ENST00000334660_RAD51_chr15_41011003_ENST00000267868_length(amino acids)=390AA_BP=26 MAGPRGRPPQRTTPGFPPGSAVETLPSPFLTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGFSHSQITRL YSRFTSLDKGENGTLSREDFQRIPELAINPLGDRIINAFFPEGEDQVNFRGFMRTLAHFRPIEDNEKSKDVNGPEPLNSRSNKLHFAFRL YDLDKDEKISRDELLQLPIDRGGGEGKAMYIDTEGTFRPERLLAVAERYGLSGSDVLDNVAYARAFNTDHQTQLLYQASAMMVESRYALL IVDSATALYRTDYSGRGELSARQMHLARFLRMLLRLADEFGVAVVITNQVVAQVDGAAMFAADPKKPIGGNIIAHASTTRLYLRKGRGET RICKIYDSPCLPEAEAMFAINADGVGDAKD -------------------------------------------------------------- >16610_16610_2_CHP1-RAD51_CHP1_chr15_41562816_ENST00000334660_RAD51_chr15_41011003_ENST00000423169_length(transcript)=1528nt_BP=651nt CATTCGGGGCTGGAACTCGAACGCTGACGTTGGCTCCTGAGCCGGGCGCTGCCTCGCGCCTGATTGGCGGGTCCTCGGGGCCGCCCTCCC CAGCGCACCACCCCTGGGTTCCCTCCCGGGTCCGCAGTGGAAACACTGCCCTCTCCCTTCTTGACCCCTAGCCCTTCCTTCCCTCCCTCC TTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCGATGGGTTCTCGGGCCTCCACGTTACTGCGG GACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTTTTCCCACAGTCAAATCACTCGCCTCTACAGCCGGTTCACCAGCCTGGACAAA GGAGAGAATGGGACTCTCAGCCGGGAAGATTTCCAGAGGATTCCAGAACTTGCCATCAACCCACTGGGGGACCGGATCATCAATGCCTTC TTTCCAGAGGGAGAGGACCAGGTAAACTTCCGTGGATTCATGCGAACTTTGGCTCATTTCCGCCCCATTGAGGATAATGAAAAGAGCAAA GATGTGAATGGACCCGAACCACTCAACAGCCGAAGCAACAAACTGCACTTTGCTTTTCGACTATATGATTTGGATAAAGATGAAAAGATC TCCCGTGATGAGCTGTTACAGCTTCCCATTGACCGGGGTGGAGGTGAAGGAAAGGCCATGTACATTGACACTGAGGGTACCTTTAGGCCA GAACGGCTGCTGGCAGTGGCTGAGAGGTATGGTCTCTCTGGCAGTGATGTCCTGGATAATGTAGCATATGCTCGAGCGTTCAACACAGAC CACCAGACCCAGCTCCTTTATCAAGCATCAGCCATGATGGTAGAATCTAGGTATGCACTGCTTATTGTAGACAGTGCCACCGCCCTTTAC AGAACAGACTACTCGGGTCGAGGTGAGCTTTCAGCCAGGCAGATGCACTTGGCCAGGTTTCTGCGGATGCTTCTGCGACTCGCTGATGAG ATTGTATCTGAGGAAAGGAAGAGGGGAAACCAGAATCTGCAAAATCTACGACTCTCCCTGTCTTCCTGAAGCTGAAGCTATGTTCGCCAT TAATGCAGATGGAGTGGGAGATGCCAAAGACTGAATCATTGGGTTTTTCCTCTGTTAAAAACCTTAAGTGCTGCAGCCTAATGAGAGTGC ACTGCTCCCTGGGGTTCTCTACAGGCCTCTTCCTGTTGTGACTGCCAGGATAAAGCTTCCGGGAAAACAGCTATTATATCAGCTTTTCTG ATGGTATAAACAGGAGACAGGTCAGTAGTCACAAACTGATCTAAAATGTTTATTCCTTCTGTAGTGTATTAATCTCTGTGTGTTTTCTTT GGTTTTGGAGGAGGGGTATGAAGTATCTTTGACATGGTGCCTTAGGAATGACTTGGGTTTAACAAGCTGTCTACTGGACAATCTTATGTT TCCAAGAGAACTAAAGCTGGAGAGACCTGACCCTTCTCTCACTTCTAAATTAATGGTAAAATAAAATGCCTCAGCTATGTAGCAAAGG >16610_16610_2_CHP1-RAD51_CHP1_chr15_41562816_ENST00000334660_RAD51_chr15_41011003_ENST00000423169_length(amino acids)=331AA_BP=26 MAGPRGRPPQRTTPGFPPGSAVETLPSPFLTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGFSHSQITRL YSRFTSLDKGENGTLSREDFQRIPELAINPLGDRIINAFFPEGEDQVNFRGFMRTLAHFRPIEDNEKSKDVNGPEPLNSRSNKLHFAFRL YDLDKDEKISRDELLQLPIDRGGGEGKAMYIDTEGTFRPERLLAVAERYGLSGSDVLDNVAYARAFNTDHQTQLLYQASAMMVESRYALL IVDSATALYRTDYSGRGELSARQMHLARFLRMLLRLADEIVSEERKRGNQNLQNLRLSLSS -------------------------------------------------------------- >16610_16610_3_CHP1-RAD51_CHP1_chr15_41562816_ENST00000560397_RAD51_chr15_41011003_ENST00000267868_length(transcript)=2064nt_BP=501nt TTGACCCCTAGCCCTTCCTTCCCTCCCTCCTTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCG ATGGGTTCTCGGGCCTCCACGTTACTGCGGGACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTTTTCCCACAGTCAAATCACTCGC CTCTACAGCCGGTTCACCAGCCTGGACAAAGGAGAGAATGGGACTCTCAGCCGGGAAGATTTCCAGAGGATTCCAGAACTTGCCATCAAC CCACTGGGGGACCGGATCATCAATGCCTTCTTTCCAGAGGGAGAGGACCAGGTAAACTTCCGTGGATTCATGCGAACTTTGGCTCATTTC CGCCCCATTGAGGATAATGAAAAGAGCAAAGATGTGAATGGACCCGAACCACTCAACAGCCGAAGCAACAAACTGCACTTTGCTTTTCGA CTATATGATTTGGATAAAGATGAAAAGATCTCCCGTGATGAGCTGTTACAGCTTCCCATTGACCGGGGTGGAGGTGAAGGAAAGGCCATG TACATTGACACTGAGGGTACCTTTAGGCCAGAACGGCTGCTGGCAGTGGCTGAGAGGTATGGTCTCTCTGGCAGTGATGTCCTGGATAAT GTAGCATATGCTCGAGCGTTCAACACAGACCACCAGACCCAGCTCCTTTATCAAGCATCAGCCATGATGGTAGAATCTAGGTATGCACTG CTTATTGTAGACAGTGCCACCGCCCTTTACAGAACAGACTACTCGGGTCGAGGTGAGCTTTCAGCCAGGCAGATGCACTTGGCCAGGTTT CTGCGGATGCTTCTGCGACTCGCTGATGAGTTTGGTGTAGCAGTGGTAATCACTAATCAGGTGGTAGCTCAAGTGGATGGAGCAGCGATG TTTGCTGCTGATCCCAAAAAACCTATTGGAGGAAATATCATCGCCCATGCATCAACAACCAGATTGTATCTGAGGAAAGGAAGAGGGGAA ACCAGAATCTGCAAAATCTACGACTCTCCCTGTCTTCCTGAAGCTGAAGCTATGTTCGCCATTAATGCAGATGGAGTGGGAGATGCCAAA GACTGAATCATTGGGTTTTTCCTCTGTTAAAAACCTTAAGTGCTGCAGCCTAATGAGAGTGCACTGCTCCCTGGGGTTCTCTACAGGCCT CTTCCTGTTGTGACTGCCAGGATAAAGCTTCCGGGAAAACAGCTATTATATCAGCTTTTCTGATGGTATAAACAGGAGACAGGTCAGTAG TCACAAACTGATCTAAAATGTTTATTCCTTCTGTAGTGTATTAATCTCTGTGTGTTTTCTTTGGTTTTGGAGGAGGGGTATGAAGTATCT TTGACATGGTGCCTTAGGAATGACTTGGGTTTAACAAGCTGTCTACTGGACAATCTTATGTTTCCAAGAGAACTAAAGCTGGAGAGACCT GACCCTTCTCTCACTTCTAAATTAATGGTAAAATAAAATGCCTCAGCTATGTAGCAAAGGGAATGGGTCTGCACAGATTCTTTTTTTCTG TCAGTAAAACTCTCAAGCAGGTTTTTAAGTTGTCTGTCTGAATGATCTTGTGTAAGGTTTTGGTTATGGAGTCTTGTGCCAAACCTACTA GGCCATTAGCCCTTCACCATCTACCTGCTTGGTCTTTCATTGCTAAGACTAACTCAAGATAATCCTAGAGTCTTAAAGCATTTCAGGCCA GTGTGGTGTCTTGCGCCTGTACTCCCAGCACTTTGGGAGGCCGAGGCAGGTGGATCGCTTGAGCCCAGGAGTTTTAAGTCCAGCTTGGCC AAGGTGGTGAAATCCCATCTCTACAAAAAATGCAGAACTTAATCTGGACACACTGTTACACGTGCCTGTAGTCCCAGCTACTCGATAGCC TGAGGTGGGAGAATCACTTAAGCCTGGAAGGTGGAAGTTGCAGTGAGTCGAGATTGCACTGCTGCATTCCAGCCAGGGTGACAGAGTGAG ACCATGTTTCAAACAAGAAACATTTCAGAGGGTAAGTAAACAGATTTGATTGTGAGGCTTCTAATAAAGTAGTTATTAGTAGTG >16610_16610_3_CHP1-RAD51_CHP1_chr15_41562816_ENST00000560397_RAD51_chr15_41011003_ENST00000267868_length(amino acids)=361AA_BP=165 LTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGFSHSQITRLYSRFTSLDKGENGTLSREDFQRIPELAIN PLGDRIINAFFPEGEDQVNFRGFMRTLAHFRPIEDNEKSKDVNGPEPLNSRSNKLHFAFRLYDLDKDEKISRDELLQLPIDRGGGEGKAM YIDTEGTFRPERLLAVAERYGLSGSDVLDNVAYARAFNTDHQTQLLYQASAMMVESRYALLIVDSATALYRTDYSGRGELSARQMHLARF LRMLLRLADEFGVAVVITNQVVAQVDGAAMFAADPKKPIGGNIIAHASTTRLYLRKGRGETRICKIYDSPCLPEAEAMFAINADGVGDAK D -------------------------------------------------------------- >16610_16610_4_CHP1-RAD51_CHP1_chr15_41562816_ENST00000560397_RAD51_chr15_41011003_ENST00000423169_length(transcript)=1378nt_BP=501nt TTGACCCCTAGCCCTTCCTTCCCTCCCTCCTTCCCTCCTGTCGCCGTCTCTTCTGGCGCCGCTGCTCCCGGAGGAGCTCCCGGCACGGCG ATGGGTTCTCGGGCCTCCACGTTACTGCGGGACGAAGAGCTCGAGGAGATCAAGAAGGAGACCGGCTTTTCCCACAGTCAAATCACTCGC CTCTACAGCCGGTTCACCAGCCTGGACAAAGGAGAGAATGGGACTCTCAGCCGGGAAGATTTCCAGAGGATTCCAGAACTTGCCATCAAC CCACTGGGGGACCGGATCATCAATGCCTTCTTTCCAGAGGGAGAGGACCAGGTAAACTTCCGTGGATTCATGCGAACTTTGGCTCATTTC CGCCCCATTGAGGATAATGAAAAGAGCAAAGATGTGAATGGACCCGAACCACTCAACAGCCGAAGCAACAAACTGCACTTTGCTTTTCGA CTATATGATTTGGATAAAGATGAAAAGATCTCCCGTGATGAGCTGTTACAGCTTCCCATTGACCGGGGTGGAGGTGAAGGAAAGGCCATG TACATTGACACTGAGGGTACCTTTAGGCCAGAACGGCTGCTGGCAGTGGCTGAGAGGTATGGTCTCTCTGGCAGTGATGTCCTGGATAAT GTAGCATATGCTCGAGCGTTCAACACAGACCACCAGACCCAGCTCCTTTATCAAGCATCAGCCATGATGGTAGAATCTAGGTATGCACTG CTTATTGTAGACAGTGCCACCGCCCTTTACAGAACAGACTACTCGGGTCGAGGTGAGCTTTCAGCCAGGCAGATGCACTTGGCCAGGTTT CTGCGGATGCTTCTGCGACTCGCTGATGAGATTGTATCTGAGGAAAGGAAGAGGGGAAACCAGAATCTGCAAAATCTACGACTCTCCCTG TCTTCCTGAAGCTGAAGCTATGTTCGCCATTAATGCAGATGGAGTGGGAGATGCCAAAGACTGAATCATTGGGTTTTTCCTCTGTTAAAA ACCTTAAGTGCTGCAGCCTAATGAGAGTGCACTGCTCCCTGGGGTTCTCTACAGGCCTCTTCCTGTTGTGACTGCCAGGATAAAGCTTCC GGGAAAACAGCTATTATATCAGCTTTTCTGATGGTATAAACAGGAGACAGGTCAGTAGTCACAAACTGATCTAAAATGTTTATTCCTTCT GTAGTGTATTAATCTCTGTGTGTTTTCTTTGGTTTTGGAGGAGGGGTATGAAGTATCTTTGACATGGTGCCTTAGGAATGACTTGGGTTT AACAAGCTGTCTACTGGACAATCTTATGTTTCCAAGAGAACTAAAGCTGGAGAGACCTGACCCTTCTCTCACTTCTAAATTAATGGTAAA ATAAAATGCCTCAGCTATGTAGCAAAGG >16610_16610_4_CHP1-RAD51_CHP1_chr15_41562816_ENST00000560397_RAD51_chr15_41011003_ENST00000423169_length(amino acids)=302AA_BP=165 LTPSPSFPPSFPPVAVSSGAAAPGGAPGTAMGSRASTLLRDEELEEIKKETGFSHSQITRLYSRFTSLDKGENGTLSREDFQRIPELAIN PLGDRIINAFFPEGEDQVNFRGFMRTLAHFRPIEDNEKSKDVNGPEPLNSRSNKLHFAFRLYDLDKDEKISRDELLQLPIDRGGGEGKAM YIDTEGTFRPERLLAVAERYGLSGSDVLDNVAYARAFNTDHQTQLLYQASAMMVESRYALLIVDSATALYRTDYSGRGELSARQMHLARF LRMLLRLADEIVSEERKRGNQNLQNLRLSLSS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CHP1-RAD51 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000267868 | 4 | 10 | 184_257 | 145.0 | 340.0 | PALB2 | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000382643 | 4 | 10 | 184_257 | 146.0 | 341.0 | PALB2 | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000423169 | 4 | 9 | 184_257 | 145.0 | 281.0 | PALB2 | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000532743 | 4 | 10 | 184_257 | 146.0 | 341.0 | PALB2 | |
| Tgene | RAD51 | chr15:41562816 | chr15:41011003 | ENST00000557850 | 0 | 8 | 184_257 | 0 | 243.0 | PALB2 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CHP1-RAD51 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CHP1-RAD51 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0006142 | Malignant neoplasm of breast | 2 | CTD_human;UNIPROT | |
| Tgene | C0015625 | Fanconi Anemia | 2 | GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C0677776 | Hereditary Breast and Ovarian Cancer Syndrome | 2 | ORPHANET | |
| Tgene | C4284093 | FANCONI ANEMIA, COMPLEMENTATION GROUP R | 2 | CTD_human;UNIPROT | |
| Tgene | C0018671 | Head and Neck Neoplasms | 1 | CTD_human | |
| Tgene | C0018675 | Head Neoplasms | 1 | CTD_human | |
| Tgene | C0023465 | Acute monocytic leukemia | 1 | GENOMICS_ENGLAND | |
| Tgene | C0023467 | Leukemia, Myelocytic, Acute | 1 | GENOMICS_ENGLAND | |
| Tgene | C0027533 | Neck Neoplasms | 1 | CTD_human | |
| Tgene | C0265219 | Miller Dieker syndrome | 1 | GENOMICS_ENGLAND | |
| Tgene | C0278996 | Malignant Head and Neck Neoplasm | 1 | CTD_human | |
| Tgene | C0746787 | Cancer of Neck | 1 | CTD_human | |
| Tgene | C0751177 | Cancer of Head | 1 | CTD_human | |
| Tgene | C0887900 | Upper Aerodigestive Tract Neoplasms | 1 | CTD_human | |
| Tgene | C1449861 | Micronuclei, Chromosome-Defective | 1 | CTD_human | |
| Tgene | C1449862 | Micronuclei, Genotoxicant-Induced | 1 | CTD_human | |
| Tgene | C3281089 | MIRROR MOVEMENTS 2 | 1 | CTD_human;GENOMICS_ENGLAND | |
| Tgene | C3463824 | MYELODYSPLASTIC SYNDROME | 1 | GENOMICS_ENGLAND |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies