
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AGAP1-SPATA6 (FusionGDB2 ID:HG116987TG54558) |
Fusion Gene Summary for AGAP1-SPATA6 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AGAP1-SPATA6 | Fusion gene ID: hg116987tg54558 | Hgene | Tgene | Gene symbol | AGAP1 | SPATA6 | Gene ID | 116987 | 54558 |
| Gene name | ArfGAP with GTPase domain, ankyrin repeat and PH domain 1 | spermatogenesis associated 6 | |
| Synonyms | AGAP-1|CENTG2|GGAP1|cnt-g2 | HASH|SRF-1|SRF1 | |
| Cytomap | ('AGAP1')('SPATA6') 2q37.2 | 1p33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | arf-GAP with GTPase, ANK repeat and PH domain-containing protein 1Arf GAP with GTP-binding protein-like, ANK repeat and PH domains 1GTP-binding and GTPase-activating protein 1centaurin, gamma 2 | spermatogenesis-associated protein 6spermatogenesis-related factor-1testicular tissue protein Li 178 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000304032, ENST00000336665, ENST00000409538, ENST00000428334, ENST00000409457, | ||
| Fusion gene scores | * DoF score | 49 X 18 X 17=14994 | 6 X 5 X 6=180 |
| # samples | 48 | 7 | |
| ** MAII score | log2(48/14994*10)=-4.96520709119934 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/180*10)=-1.36257007938471 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: AGAP1 [Title/Abstract] AND SPATA6 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AGAP1(236817550)-SPATA6(48764565), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | AGAP1-SPATA6 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AGAP1-SPATA6 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AGAP1-SPATA6 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. AGAP1-SPATA6 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. AGAP1-SPATA6 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across AGAP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SPATA6 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | CESC | TCGA-EK-A2PM-01A | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
Top |
Fusion Gene ORF analysis for AGAP1-SPATA6 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000304032 | ENST00000463938 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| 5CDS-intron | ENST00000336665 | ENST00000463938 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| 5CDS-intron | ENST00000409538 | ENST00000463938 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| 5CDS-intron | ENST00000428334 | ENST00000463938 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| Frame-shift | ENST00000304032 | ENST00000371843 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| Frame-shift | ENST00000304032 | ENST00000371847 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| Frame-shift | ENST00000336665 | ENST00000371843 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| Frame-shift | ENST00000336665 | ENST00000371847 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| Frame-shift | ENST00000409538 | ENST00000371843 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| Frame-shift | ENST00000409538 | ENST00000371847 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| Frame-shift | ENST00000428334 | ENST00000371843 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| Frame-shift | ENST00000428334 | ENST00000371847 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| In-frame | ENST00000304032 | ENST00000396199 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| In-frame | ENST00000336665 | ENST00000396199 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| In-frame | ENST00000409538 | ENST00000396199 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| In-frame | ENST00000428334 | ENST00000396199 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| intron-3CDS | ENST00000409457 | ENST00000371843 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| intron-3CDS | ENST00000409457 | ENST00000371847 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| intron-3CDS | ENST00000409457 | ENST00000396199 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| intron-intron | ENST00000409457 | ENST00000463938 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000336665 | AGAP1 | chr2 | 236817550 | - | ENST00000396199 | SPATA6 | chr1 | 48764565 | - | 2150 | 1904 | 421 | 2109 | 562 |
| ENST00000304032 | AGAP1 | chr2 | 236817550 | - | ENST00000396199 | SPATA6 | chr1 | 48764565 | - | 2150 | 1904 | 421 | 2109 | 562 |
| ENST00000409538 | AGAP1 | chr2 | 236817550 | - | ENST00000396199 | SPATA6 | chr1 | 48764565 | - | 2861 | 2615 | 418 | 2820 | 800 |
| ENST00000428334 | AGAP1 | chr2 | 236817550 | - | ENST00000396199 | SPATA6 | chr1 | 48764565 | - | 1108 | 862 | 21 | 1067 | 348 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000336665 | ENST00000396199 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - | 0.003591266 | 0.99640876 |
| ENST00000304032 | ENST00000396199 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - | 0.003591266 | 0.99640876 |
| ENST00000409538 | ENST00000396199 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - | 0.005623155 | 0.99437684 |
| ENST00000428334 | ENST00000396199 | AGAP1 | chr2 | 236817550 | - | SPATA6 | chr1 | 48764565 | - | 0.005580823 | 0.99441916 |
Top |
Fusion Genomic Features for AGAP1-SPATA6 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
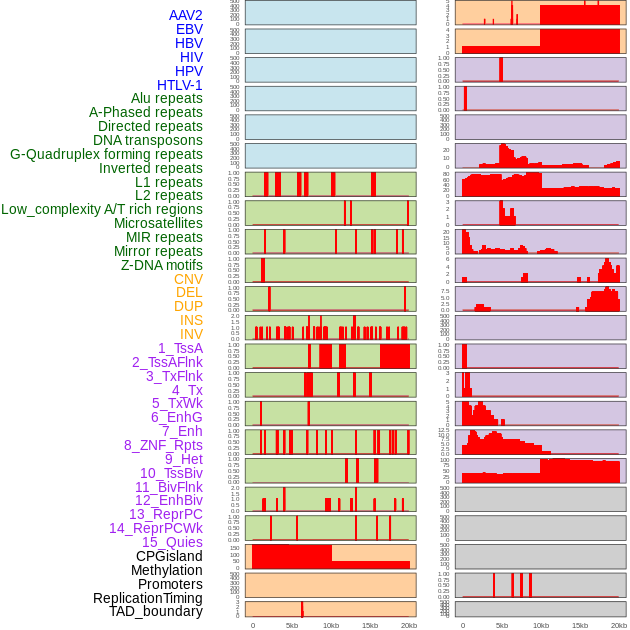 |
Top |
Fusion Protein Features for AGAP1-SPATA6 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:236817550/chr1:48764565) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000304032 | - | 11 | 18 | 122_126 | 441 | 858.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000304032 | - | 11 | 18 | 178_181 | 441 | 858.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000304032 | - | 11 | 18 | 78_85 | 441 | 858.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000336665 | - | 11 | 17 | 122_126 | 441 | 805.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000336665 | - | 11 | 17 | 178_181 | 441 | 805.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000336665 | - | 11 | 17 | 78_85 | 441 | 805.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000304032 | - | 11 | 18 | 66_276 | 441 | 858.0 | Region | Note=Small GTPase-like |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000336665 | - | 11 | 17 | 66_276 | 441 | 805.0 | Region | Note=Small GTPase-like |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000304032 | - | 11 | 18 | 346_588 | 441 | 858.0 | Domain | PH |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000304032 | - | 11 | 18 | 609_729 | 441 | 858.0 | Domain | Arf-GAP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000336665 | - | 11 | 17 | 346_588 | 441 | 805.0 | Domain | PH |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000336665 | - | 11 | 17 | 609_729 | 441 | 805.0 | Domain | Arf-GAP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000409457 | - | 1 | 10 | 346_588 | 0 | 406.0 | Domain | PH |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000409457 | - | 1 | 10 | 609_729 | 0 | 406.0 | Domain | Arf-GAP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000409457 | - | 1 | 10 | 122_126 | 0 | 406.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000409457 | - | 1 | 10 | 178_181 | 0 | 406.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000409457 | - | 1 | 10 | 78_85 | 0 | 406.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000409457 | - | 1 | 10 | 66_276 | 0 | 406.0 | Region | Note=Small GTPase-like |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000304032 | - | 11 | 18 | 768_797 | 441 | 858.0 | Repeat | Note=ANK 1 |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000304032 | - | 11 | 18 | 801_830 | 441 | 858.0 | Repeat | Note=ANK 2 |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000336665 | - | 11 | 17 | 768_797 | 441 | 805.0 | Repeat | Note=ANK 1 |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000336665 | - | 11 | 17 | 801_830 | 441 | 805.0 | Repeat | Note=ANK 2 |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000409457 | - | 1 | 10 | 768_797 | 0 | 406.0 | Repeat | Note=ANK 1 |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000409457 | - | 1 | 10 | 801_830 | 0 | 406.0 | Repeat | Note=ANK 2 |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000304032 | - | 11 | 18 | 624_647 | 441 | 858.0 | Zinc finger | C4-type |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000336665 | - | 11 | 17 | 624_647 | 441 | 805.0 | Zinc finger | C4-type |
| Hgene | AGAP1 | chr2:236817550 | chr1:48764565 | ENST00000409457 | - | 1 | 10 | 624_647 | 0 | 406.0 | Zinc finger | C4-type |
Top |
Fusion Gene Sequence for AGAP1-SPATA6 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >2787_2787_1_AGAP1-SPATA6_AGAP1_chr2_236817550_ENST00000304032_SPATA6_chr1_48764565_ENST00000396199_length(transcript)=2150nt_BP=1904nt CGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCCCGGCGCGCCGGGCGGCGC AGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGCCCTCGGCCCCGGCGCTCG GAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGCTCAGGAAGTCACCCGAGC AAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGCTGACCCGGGACGCCGGGG CCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCCGCGCCTTTCTTCTCGCGC CTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCCCCGGGGCGCGGGGCGGCG GCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGCTGCCATCCGGGCCGAGAT CCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGTGCTGCAGAACCAGATCCG GGAGCACGTCATCGCCATCGAAGATGCCTTCGTGAACAGCCAGGAATGGACGCTGAGTCGATCTGTCCCGGAGCTCAAAGTGGGAATTGT GGGTAACTTGGCCAGCGGCAAGTCTGCCCTGGTGCACCGGTACCTGACGGGCACATATGTCCAGGAGGAGTCTCCGGAAGGTGGCAGGTT CAAGAAAGAGATTGTCGTTGATGGACAGAGCTATCTGCTGCTGATCAGAGATGAAGGGGGCCCCCCGGAGGCGCAGTTTGCCATGTGGGT GGACGCTGTTATATTTGTCTTCAGCTTGGAGGATGAAATAAGTTTCCAGACCGTTTACCACTACTACAGTCGAATGGCCAACTATCGGAA CACGAGCGAGATTCCTCTGGTTCTGGTGGGAACCCAGGATGCCATAAGTTCTGCTAACCCGAGGGTCATCGATGACGCCAGGGCGAGGAA GCTCTCCAACGACCTGAAACGGTGCACGTACTACGAGACGTGTGCTACATACGGGCTGAATGTGGAGAGGGTCTTCCAGGACGTTGCCCA GAAGATTGTTGCCACAAGGAAGAAGCAGCAGCTGTCCATAGGACCCTGCAAGTCGCTACCTAATTCTCCCAGCCATTCCTCCGTCTGTTC CGCGCAGGTGTCTGCCGTGCACATCAGCCAGACAAGTAATGGAGGTGGGAGTTTAAGCGACTATTCCTCCTCCGTTCCATCGACTCCCAG CACCAGCCAGAAGGAACTTCGGATCGATGTTCCTCCCACTGCCAACACGCCCACGCCCGTTCGCAAGCAGTCTAAGCGCCGGTCCAACCT GTTCACCTCTCGGAAAGGGAGCGACCCAGACAAAGAGAAGAAAGGCCTGGAGAGTCGTGCGGACAGCATTGGGAGCGGCCGAGCCATCCC AATTAAACAGGGCATGCTGTTGAAGCGAAGTGGCAAATCGTTGAATAAAGAGTGGAAAAAGAAATATGTCACCCTGTGTGACAATGGCGT GCTGACCTATCATCCCAGTTTACATGATTACATGCAGAATGTTCATGGTAAGGAGATTGACCTTCTGAGAACCACTGTGAAAGTCCCAGG GAAGAGGCCACCCCGAGCCACGTCAGCCTGCGCACCCATCTCCAGCCCTAAAACCAATGGCCTATCCAAGGACATGAGCAGTTTACACAT CTCACCCAATTCAGCTCATGTCAGCAGCCACGTGGCACTTTCCATTTGGATGACGGTGAATACTGGTCCAACAGGGCAGCCTCTTATAAG GGAAAATCCCACCGACCCATCTTTGAGAACAGCATGGACAAGATGTACAGGAACTTATACAAAAAGGCCTGTAGTTCTGCTTCACATACA CAGGAAAGCTTCTGAGACCATCCATGATAAACCTCATTAGTGTCCGTGTCAATTTCTCAATGAAAATGTTTGATGTGATC >2787_2787_1_AGAP1-SPATA6_AGAP1_chr2_236817550_ENST00000304032_SPATA6_chr1_48764565_ENST00000396199_length(amino acids)=562AA_BP=489 MLRPRLSSRASSARRRRARLPGGCGAPGSAARGPRGAGRRRRGARGSGRGACTMNYQQQLANSAAIRAEIQRFESVHPNIYSIYELLERV EEPVLQNQIREHVIAIEDAFVNSQEWTLSRSVPELKVGIVGNLASGKSALVHRYLTGTYVQEESPEGGRFKKEIVVDGQSYLLLIRDEGG PPEAQFAMWVDAVIFVFSLEDEISFQTVYHYYSRMANYRNTSEIPLVLVGTQDAISSANPRVIDDARARKLSNDLKRCTYYETCATYGLN VERVFQDVAQKIVATRKKQQLSIGPCKSLPNSPSHSSVCSAQVSAVHISQTSNGGGSLSDYSSSVPSTPSTSQKELRIDVPPTANTPTPV RKQSKRRSNLFTSRKGSDPDKEKKGLESRADSIGSGRAIPIKQGMLLKRSGKSLNKEWKKKYVTLCDNGVLTYHPSLHDYMQNVHGKEID LLRTTVKVPGKRPPRATSACAPISSPKTNGLSKDMSSLHISPNSAHVSSHVALSIWMTVNTGPTGQPLIRENPTDPSLRTAWTRCTGTYT KRPVVLLHIHRKASETIHDKPH -------------------------------------------------------------- >2787_2787_2_AGAP1-SPATA6_AGAP1_chr2_236817550_ENST00000336665_SPATA6_chr1_48764565_ENST00000396199_length(transcript)=2150nt_BP=1904nt CGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCCCGGCGCGCCGGGCGGCGC AGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGCCCTCGGCCCCGGCGCTCG GAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGCTCAGGAAGTCACCCGAGC AAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGCTGACCCGGGACGCCGGGG CCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCCGCGCCTTTCTTCTCGCGC CTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCCCCGGGGCGCGGGGCGGCG GCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGCTGCCATCCGGGCCGAGAT CCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGTGCTGCAGAACCAGATCCG GGAGCACGTCATCGCCATCGAAGATGCCTTCGTGAACAGCCAGGAATGGACGCTGAGTCGATCTGTCCCGGAGCTCAAAGTGGGAATTGT GGGTAACTTGGCCAGCGGCAAGTCTGCCCTGGTGCACCGGTACCTGACGGGCACATATGTCCAGGAGGAGTCTCCGGAAGGTGGCAGGTT CAAGAAAGAGATTGTCGTTGATGGACAGAGCTATCTGCTGCTGATCAGAGATGAAGGGGGCCCCCCGGAGGCGCAGTTTGCCATGTGGGT GGACGCTGTTATATTTGTCTTCAGCTTGGAGGATGAAATAAGTTTCCAGACCGTTTACCACTACTACAGTCGAATGGCCAACTATCGGAA CACGAGCGAGATTCCTCTGGTTCTGGTGGGAACCCAGGATGCCATAAGTTCTGCTAACCCGAGGGTCATCGATGACGCCAGGGCGAGGAA GCTCTCCAACGACCTGAAACGGTGCACGTACTACGAGACGTGTGCTACATACGGGCTGAATGTGGAGAGGGTCTTCCAGGACGTTGCCCA GAAGATTGTTGCCACAAGGAAGAAGCAGCAGCTGTCCATAGGACCCTGCAAGTCGCTACCTAATTCTCCCAGCCATTCCTCCGTCTGTTC CGCGCAGGTGTCTGCCGTGCACATCAGCCAGACAAGTAATGGAGGTGGGAGTTTAAGCGACTATTCCTCCTCCGTTCCATCGACTCCCAG CACCAGCCAGAAGGAACTTCGGATCGATGTTCCTCCCACTGCCAACACGCCCACGCCCGTTCGCAAGCAGTCTAAGCGCCGGTCCAACCT GTTCACCTCTCGGAAAGGGAGCGACCCAGACAAAGAGAAGAAAGGCCTGGAGAGTCGTGCGGACAGCATTGGGAGCGGCCGAGCCATCCC AATTAAACAGGGCATGCTGTTGAAGCGAAGTGGCAAATCGTTGAATAAAGAGTGGAAAAAGAAATATGTCACCCTGTGTGACAATGGCGT GCTGACCTATCATCCCAGTTTACATGATTACATGCAGAATGTTCATGGTAAGGAGATTGACCTTCTGAGAACCACTGTGAAAGTCCCAGG GAAGAGGCCACCCCGAGCCACGTCAGCCTGCGCACCCATCTCCAGCCCTAAAACCAATGGCCTATCCAAGGACATGAGCAGTTTACACAT CTCACCCAATTCAGCTCATGTCAGCAGCCACGTGGCACTTTCCATTTGGATGACGGTGAATACTGGTCCAACAGGGCAGCCTCTTATAAG GGAAAATCCCACCGACCCATCTTTGAGAACAGCATGGACAAGATGTACAGGAACTTATACAAAAAGGCCTGTAGTTCTGCTTCACATACA CAGGAAAGCTTCTGAGACCATCCATGATAAACCTCATTAGTGTCCGTGTCAATTTCTCAATGAAAATGTTTGATGTGATC >2787_2787_2_AGAP1-SPATA6_AGAP1_chr2_236817550_ENST00000336665_SPATA6_chr1_48764565_ENST00000396199_length(amino acids)=562AA_BP=489 MLRPRLSSRASSARRRRARLPGGCGAPGSAARGPRGAGRRRRGARGSGRGACTMNYQQQLANSAAIRAEIQRFESVHPNIYSIYELLERV EEPVLQNQIREHVIAIEDAFVNSQEWTLSRSVPELKVGIVGNLASGKSALVHRYLTGTYVQEESPEGGRFKKEIVVDGQSYLLLIRDEGG PPEAQFAMWVDAVIFVFSLEDEISFQTVYHYYSRMANYRNTSEIPLVLVGTQDAISSANPRVIDDARARKLSNDLKRCTYYETCATYGLN VERVFQDVAQKIVATRKKQQLSIGPCKSLPNSPSHSSVCSAQVSAVHISQTSNGGGSLSDYSSSVPSTPSTSQKELRIDVPPTANTPTPV RKQSKRRSNLFTSRKGSDPDKEKKGLESRADSIGSGRAIPIKQGMLLKRSGKSLNKEWKKKYVTLCDNGVLTYHPSLHDYMQNVHGKEID LLRTTVKVPGKRPPRATSACAPISSPKTNGLSKDMSSLHISPNSAHVSSHVALSIWMTVNTGPTGQPLIRENPTDPSLRTAWTRCTGTYT KRPVVLLHIHRKASETIHDKPH -------------------------------------------------------------- >2787_2787_3_AGAP1-SPATA6_AGAP1_chr2_236817550_ENST00000409538_SPATA6_chr1_48764565_ENST00000396199_length(transcript)=2861nt_BP=2615nt GCGCGTTTCCATTTTAAACCGCCGCCCGCCGCCCGCCACCCGCCACCCTTCGGCCGCAGCCGGTGCAGCTGTCCGCGCGTCCCGGAGCCC AGGGAGTGGCGGAGGCTGCGGAACCGCCGAGCTGTGCAGCCGGAGCGGGAGGATGCGCACGGGCCCCGCGTCGTAGACAATGAAGCCGCG GGCGCCGCCGCCTGCCCTGGGCCCTGCGCACCGCGGCCGCACCTGCCGGCGAGAGCGCTCTAGCGCCTGACCGGCCGCCTCGCTTGGCCC CGCCGGCCCATGGCTCGGCGCCCCGGGCCCGGACCCCGGCACTCGGGCGGCGCGGCGCACGGGCCGGCGGGTGCCAGGGGCGCCGTCCCC GCAGCCTGAGTGCGGCCCTCGCGGTCAGCGGGGGGCGTGGGCCACACTCCCGGCCCGCCTGCCCTCCCCGCTTGGCCCGGCGCCCTCCCG GCCCGCGGGCTCGCTGGATGCGGCGGGGCCCCAGCGCGCGGGCGACATGTACTTGTTGGACGGCAGTGGCGAGCCCGCGTCGCCACCCGC GGACGCGATGCCGCGCGGGACGCCCCCCAGAAAGACTGTCTACCGCATCTCCGTGACCATGGTCAGGAAGGAGCAGCTGGCCGCGCCGGG CTCCGGCGGCCCGGACCCACGCCCGGTTCGGCGGCCCCGGCCCGCGCGCTCCCCGGACGCGCCCGGGAGGCTTGAGGAGGAGGCCGAGGA GGCGGAGGGCGCCGAGGAACCGGAGGGTCCCCGGCCGCGCGCTTGGGATTTCCGCACCTTCCGCACCCGCAGCACCGGGCAGCTGGAACT GGGGCGGCTCCGGCCGTGCGCACGCGGCCTGGAACCCGCGGACCTGGCCGGCAGCGCCCCGGCCGAGGAGGAGGGACGCGGCTCGCCCGC GTCCGGCAGCCCCGACGTGGAGGGGGCCCGGGCCGCGCCCCTGCGGCGGAGCCTGAGCTTCAGGCACTGGAGCGGGCCTGAGGCGCCGCA AGGCCGGACACTGGGCGGCGGAAGGCGCCACAGCAGCTCCGGGAGCCTGGCCTGGGCGCCGTGCGACGAGGCCGCGGCCGGGACCACCCT GGAGCCCGCGACCGCCACGCAGCCCGCCTCGGAGAAGCGCAACACCCTGGACGTGGGCGAGGTGCTCAGCAAGAACGACGCGCTCTCGGA CCTGGAGCGTTGGGAACGCAGTAAGAGCAAGAACCGCACGCTGGACAACAGCGACCTGCAGCGGCTGGAGCGCGCGCGGGCGGCGGCCGG GGCCGGCGCGGCCTCGGAGCACCGGCTGCTGCGCTTCTTCAGCGGCATCTTCGCGCGCAGGGACGGGGGCCCGGGCGGCGGGCCCTCGCC ACGGAGCGGAGCCTCGCGGCCACGCGGCTACTTCAGCCTGCGGCGGGCCCCGGCCGAAGCGCACTCGTCCAGCGCCGAGAGCATCGACGG CTCCCCGCGCAGAGATGCCTTCGTGAACAGCCAGGAATGGACGCTGAGTCGATCTGTCCCGGAGCTCAAAGTGGGAATTGTGGGTAACTT GGCCAGCGGCAAGTCTGCCCTGGTGCACCGGTACCTGACGGGCACATATGTCCAGGAGGAGTCTCCGGAAGGTGGCAGGTTCAAGAAAGA GATTGTCGTTGATGGACAGAGCTATCTGCTGCTGATCAGAGATGAAGGGGGCCCCCCGGAGGCGCAGTTTGCCATGTGGGTGGACGCTGT TATATTTGTCTTCAGCTTGGAGGATGAAATAAGTTTCCAGACCGTTTACCACTACTACAGTCGAATGGCCAACTATCGGAACACGAGCGA GATTCCTCTGGTTCTGGTGGGAACCCAGGATGCCATAAGTTCTGCTAACCCGAGGGTCATCGATGACGCCAGGGCGAGGAAGCTCTCCAA CGACCTGAAACGGTGCACGTACTACGAGACGTGTGCTACATACGGGCTGAATGTGGAGAGGGTCTTCCAGGACGTTGCCCAGAAGATTGT TGCCACAAGGAAGAAGCAGCAGCTGTCCATAGGACCCTGCAAGTCGCTACCTAATTCTCCCAGCCATTCCTCCGTCTGTTCCGCGCAGGT GTCTGCCGTGCACATCAGCCAGACAAGTAATGGAGGTGGGAGTTTAAGCGACTATTCCTCCTCCGTTCCATCGACTCCCAGCACCAGCCA GAAGGAACTTCGGATCGATGTTCCTCCCACTGCCAACACGCCCACGCCCGTTCGCAAGCAGTCTAAGCGCCGGTCCAACCTGTTCACCTC TCGGAAAGGGAGCGACCCAGACAAAGAGAAGAAAGGCCTGGAGAGTCGTGCGGACAGCATTGGGAGCGGCCGAGCCATCCCAATTAAACA GGGCATGCTGTTGAAGCGAAGTGGCAAATCGTTGAATAAAGAGTGGAAAAAGAAATATGTCACCCTGTGTGACAATGGCGTGCTGACCTA TCATCCCAGTTTACATGATTACATGCAGAATGTTCATGGTAAGGAGATTGACCTTCTGAGAACCACTGTGAAAGTCCCAGGGAAGAGGCC ACCCCGAGCCACGTCAGCCTGCGCACCCATCTCCAGCCCTAAAACCAATGGCCTATCCAAGGACATGAGCAGTTTACACATCTCACCCAA TTCAGCTCATGTCAGCAGCCACGTGGCACTTTCCATTTGGATGACGGTGAATACTGGTCCAACAGGGCAGCCTCTTATAAGGGAAAATCC CACCGACCCATCTTTGAGAACAGCATGGACAAGATGTACAGGAACTTATACAAAAAGGCCTGTAGTTCTGCTTCACATACACAGGAAAGC TTCTGAGACCATCCATGATAAACCTCATTAGTGTCCGTGTCAATTTCTCAATGAAAATGTTTGATGTGATC >2787_2787_3_AGAP1-SPATA6_AGAP1_chr2_236817550_ENST00000409538_SPATA6_chr1_48764565_ENST00000396199_length(amino acids)=800AA_BP=727 MPSPLGPAPSRPAGSLDAAGPQRAGDMYLLDGSGEPASPPADAMPRGTPPRKTVYRISVTMVRKEQLAAPGSGGPDPRPVRRPRPARSPD APGRLEEEAEEAEGAEEPEGPRPRAWDFRTFRTRSTGQLELGRLRPCARGLEPADLAGSAPAEEEGRGSPASGSPDVEGARAAPLRRSLS FRHWSGPEAPQGRTLGGGRRHSSSGSLAWAPCDEAAAGTTLEPATATQPASEKRNTLDVGEVLSKNDALSDLERWERSKSKNRTLDNSDL QRLERARAAAGAGAASEHRLLRFFSGIFARRDGGPGGGPSPRSGASRPRGYFSLRRAPAEAHSSSAESIDGSPRRDAFVNSQEWTLSRSV PELKVGIVGNLASGKSALVHRYLTGTYVQEESPEGGRFKKEIVVDGQSYLLLIRDEGGPPEAQFAMWVDAVIFVFSLEDEISFQTVYHYY SRMANYRNTSEIPLVLVGTQDAISSANPRVIDDARARKLSNDLKRCTYYETCATYGLNVERVFQDVAQKIVATRKKQQLSIGPCKSLPNS PSHSSVCSAQVSAVHISQTSNGGGSLSDYSSSVPSTPSTSQKELRIDVPPTANTPTPVRKQSKRRSNLFTSRKGSDPDKEKKGLESRADS IGSGRAIPIKQGMLLKRSGKSLNKEWKKKYVTLCDNGVLTYHPSLHDYMQNVHGKEIDLLRTTVKVPGKRPPRATSACAPISSPKTNGLS KDMSSLHISPNSAHVSSHVALSIWMTVNTGPTGQPLIRENPTDPSLRTAWTRCTGTYTKRPVVLLHIHRKASETIHDKPH -------------------------------------------------------------- >2787_2787_4_AGAP1-SPATA6_AGAP1_chr2_236817550_ENST00000428334_SPATA6_chr1_48764565_ENST00000396199_length(transcript)=1108nt_BP=862nt GTTTACCACTACTACAGTCGAATGGCCAACTATCGGAACACGAGCGAGATTCCTCTGGTTCTGGTGGGAACCCAGGATGCCATAAGTTCT GCTAACCCGAGGGTCATCGATGACGCCAGGGCGAGGAAGCTCTCCAACGACCTGAAACGGTGCACGTACTACGAGACGTGTGCTACATAC GGGCTGAATGTGGAGAGGGTCTTCCAGGACGTTGCCCAGAAGATTGTTGCCACAAGGAAGAAGCAGCAGCTGTCCATAGGACCCTGCAAG TCGCTACCTAATTCTCCCAGCCATTCCTCCGTCTGTTCCGCGCAGGTGTCTGCCGTGCACATCAGCCAGACAAGTAATGGAGGTGGGAGT TTAAGCGACTATTCCTCCTCCGTTCCATCGACTCCCAGCACCAGCCAGAAGGAACTTCGGATCGATGTTCCTCCCACTGCCAACACGCCC ACGCCCGTTCGCAAGCAGTCTAAGCGCCGGTCCAACCTGTTCACCTCTCGGAAAGGGAGCGACCCAGACAAAGAGAAGAAAGGCCTGGAG AGTCGTGCGGACAGCATTGGGAGCGGCCGAGCCATCCCAATTAAACAGGGCATGCTGTTGAAGCGAAGTGGCAAATCGTTGAATAAAGAG TGGAAAAAGAAATATGTCACCCTGTGTGACAATGGCGTGCTGACCTATCATCCCAGTTTACATGATTACATGCAGAATGTTCATGGTAAG GAGATTGACCTTCTGAGAACCACTGTGAAAGTCCCAGGGAAGAGGCCACCCCGAGCCACGTCAGCCTGCGCACCCATCTCCAGCCCTAAA ACCAATGGCCTATCCAAGGACATGAGCAGTTTACACATCTCACCCAATTCAGCTCATGTCAGCAGCCACGTGGCACTTTCCATTTGGATG ACGGTGAATACTGGTCCAACAGGGCAGCCTCTTATAAGGGAAAATCCCACCGACCCATCTTTGAGAACAGCATGGACAAGATGTACAGGA ACTTATACAAAAAGGCCTGTAGTTCTGCTTCACATACACAGGAAAGCTTCTGAGACCATCCATGATAAACCTCATTAGTGTCCGTGTCAA TTTCTCAATGAAAATGTTTGATGTGATC >2787_2787_4_AGAP1-SPATA6_AGAP1_chr2_236817550_ENST00000428334_SPATA6_chr1_48764565_ENST00000396199_length(amino acids)=348AA_BP=275 MANYRNTSEIPLVLVGTQDAISSANPRVIDDARARKLSNDLKRCTYYETCATYGLNVERVFQDVAQKIVATRKKQQLSIGPCKSLPNSPS HSSVCSAQVSAVHISQTSNGGGSLSDYSSSVPSTPSTSQKELRIDVPPTANTPTPVRKQSKRRSNLFTSRKGSDPDKEKKGLESRADSIG SGRAIPIKQGMLLKRSGKSLNKEWKKKYVTLCDNGVLTYHPSLHDYMQNVHGKEIDLLRTTVKVPGKRPPRATSACAPISSPKTNGLSKD MSSLHISPNSAHVSSHVALSIWMTVNTGPTGQPLIRENPTDPSLRTAWTRCTGTYTKRPVVLLHIHRKASETIHDKPH -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AGAP1-SPATA6 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AGAP1-SPATA6 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AGAP1-SPATA6 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | AGAP1 | C0004352 | Autistic Disorder | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies