
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AGAP1-PINX1 (FusionGDB2 ID:HG116987TG54984) |
Fusion Gene Summary for AGAP1-PINX1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AGAP1-PINX1 | Fusion gene ID: hg116987tg54984 | Hgene | Tgene | Gene symbol | AGAP1 | PINX1 | Gene ID | 116987 | 54984 |
| Gene name | ArfGAP with GTPase domain, ankyrin repeat and PH domain 1 | PIN2 (TERF1) interacting telomerase inhibitor 1 | |
| Synonyms | AGAP-1|CENTG2|GGAP1|cnt-g2 | Gno1|LPTL|LPTS|Pxr1 | |
| Cytomap | ('AGAP1')('PINX1') 2q37.2 | 8p23.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | arf-GAP with GTPase, ANK repeat and PH domain-containing protein 1Arf GAP with GTP-binding protein-like, ANK repeat and PH domains 1GTP-binding and GTPase-activating protein 1centaurin, gamma 2 | PIN2/TERF1-interacting telomerase inhibitor 167-11-3 proteinPIN2-interacting protein 1TRF1-interacting protein 1hepatocellular carcinoma-related putative tumor suppressorliver-related putative tumor suppressorpin2-interacting protein X1protein 67-1 | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000304032, ENST00000336665, ENST00000409457, ENST00000409538, ENST00000428334, | ||
| Fusion gene scores | * DoF score | 49 X 18 X 17=14994 | 6 X 4 X 5=120 |
| # samples | 48 | 6 | |
| ** MAII score | log2(48/14994*10)=-4.96520709119934 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/120*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: AGAP1 [Title/Abstract] AND PINX1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AGAP1(236403493)-PINX1(10683754), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | AGAP1-PINX1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AGAP1-PINX1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AGAP1-PINX1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. AGAP1-PINX1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PINX1 | GO:0007004 | telomere maintenance via telomerase | 11701125 |
| Tgene | PINX1 | GO:0010972 | negative regulation of G2/M transition of mitotic cell cycle | 11701125 |
| Tgene | PINX1 | GO:0032211 | negative regulation of telomere maintenance via telomerase | 11701125 |
| Tgene | PINX1 | GO:0051974 | negative regulation of telomerase activity | 11701125 |
| Tgene | PINX1 | GO:1902570 | protein localization to nucleolus | 24415760 |
| Tgene | PINX1 | GO:1904744 | positive regulation of telomeric DNA binding | 19265708|24415760 |
| Tgene | PINX1 | GO:1904751 | positive regulation of protein localization to nucleolus | 19265708 |
| Fusion gene breakpoints across AGAP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PINX1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-1544-01A | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| ChimerDB4 | OV | TCGA-24-1544 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
Top |
Fusion Gene ORF analysis for AGAP1-PINX1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000304032 | ENST00000520018 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| 5CDS-intron | ENST00000336665 | ENST00000520018 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| 5CDS-intron | ENST00000409457 | ENST00000520018 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| In-frame | ENST00000304032 | ENST00000314787 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| In-frame | ENST00000304032 | ENST00000426190 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| In-frame | ENST00000304032 | ENST00000519088 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| In-frame | ENST00000336665 | ENST00000314787 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| In-frame | ENST00000336665 | ENST00000426190 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| In-frame | ENST00000336665 | ENST00000519088 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| In-frame | ENST00000409457 | ENST00000314787 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| In-frame | ENST00000409457 | ENST00000426190 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| In-frame | ENST00000409457 | ENST00000519088 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| intron-3CDS | ENST00000409538 | ENST00000314787 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| intron-3CDS | ENST00000409538 | ENST00000426190 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| intron-3CDS | ENST00000409538 | ENST00000519088 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| intron-3CDS | ENST00000428334 | ENST00000314787 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| intron-3CDS | ENST00000428334 | ENST00000426190 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| intron-3CDS | ENST00000428334 | ENST00000519088 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| intron-intron | ENST00000409538 | ENST00000520018 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| intron-intron | ENST00000428334 | ENST00000520018 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000336665 | AGAP1 | chr2 | 236403493 | + | ENST00000314787 | PINX1 | chr8 | 10683754 | - | 1867 | 743 | 421 | 1428 | 335 |
| ENST00000336665 | AGAP1 | chr2 | 236403493 | + | ENST00000426190 | PINX1 | chr8 | 10683754 | - | 1788 | 743 | 969 | 202 | 255 |
| ENST00000336665 | AGAP1 | chr2 | 236403493 | + | ENST00000519088 | PINX1 | chr8 | 10683754 | - | 1594 | 743 | 969 | 202 | 255 |
| ENST00000304032 | AGAP1 | chr2 | 236403493 | + | ENST00000314787 | PINX1 | chr8 | 10683754 | - | 1867 | 743 | 421 | 1428 | 335 |
| ENST00000304032 | AGAP1 | chr2 | 236403493 | + | ENST00000426190 | PINX1 | chr8 | 10683754 | - | 1788 | 743 | 969 | 202 | 255 |
| ENST00000304032 | AGAP1 | chr2 | 236403493 | + | ENST00000519088 | PINX1 | chr8 | 10683754 | - | 1594 | 743 | 969 | 202 | 255 |
| ENST00000409457 | AGAP1 | chr2 | 236403493 | + | ENST00000314787 | PINX1 | chr8 | 10683754 | - | 1885 | 761 | 439 | 1446 | 335 |
| ENST00000409457 | AGAP1 | chr2 | 236403493 | + | ENST00000426190 | PINX1 | chr8 | 10683754 | - | 1806 | 761 | 987 | 220 | 255 |
| ENST00000409457 | AGAP1 | chr2 | 236403493 | + | ENST00000519088 | PINX1 | chr8 | 10683754 | - | 1612 | 761 | 987 | 220 | 255 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000336665 | ENST00000314787 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - | 0.00400909 | 0.99599093 |
| ENST00000336665 | ENST00000426190 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - | 0.007289785 | 0.99271023 |
| ENST00000336665 | ENST00000519088 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - | 0.006479423 | 0.99352056 |
| ENST00000304032 | ENST00000314787 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - | 0.00400909 | 0.99599093 |
| ENST00000304032 | ENST00000426190 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - | 0.007289785 | 0.99271023 |
| ENST00000304032 | ENST00000519088 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - | 0.006479423 | 0.99352056 |
| ENST00000409457 | ENST00000314787 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - | 0.004374708 | 0.99562526 |
| ENST00000409457 | ENST00000426190 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - | 0.00872486 | 0.9912751 |
| ENST00000409457 | ENST00000519088 | AGAP1 | chr2 | 236403493 | + | PINX1 | chr8 | 10683754 | - | 0.00716112 | 0.9928389 |
Top |
Fusion Genomic Features for AGAP1-PINX1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
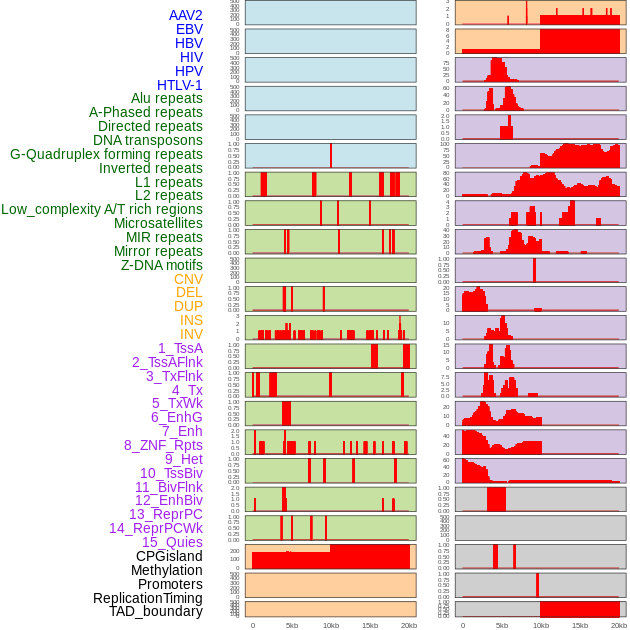 |
Top |
Fusion Protein Features for AGAP1-PINX1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:236403493/chr8:10683754) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PINX1 | chr2:236403493 | chr8:10683754 | ENST00000314787 | 3 | 7 | 287_297 | 100 | 329.0 | Motif | Note=TBM | |
| Tgene | PINX1 | chr2:236403493 | chr8:10683754 | ENST00000519088 | 3 | 6 | 287_297 | 100 | 175.0 | Motif | Note=TBM | |
| Tgene | PINX1 | chr2:236403493 | chr8:10683754 | ENST00000314787 | 3 | 7 | 254_328 | 100 | 329.0 | Region | Note=Telomerase inhibitory domain (TID) | |
| Tgene | PINX1 | chr2:236403493 | chr8:10683754 | ENST00000519088 | 3 | 6 | 254_328 | 100 | 175.0 | Region | Note=Telomerase inhibitory domain (TID) |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000304032 | + | 1 | 18 | 346_588 | 54 | 858.0 | Domain | PH |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000304032 | + | 1 | 18 | 609_729 | 54 | 858.0 | Domain | Arf-GAP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000336665 | + | 1 | 17 | 346_588 | 54 | 805.0 | Domain | PH |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000336665 | + | 1 | 17 | 609_729 | 54 | 805.0 | Domain | Arf-GAP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000409457 | + | 1 | 10 | 346_588 | 54 | 406.0 | Domain | PH |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000409457 | + | 1 | 10 | 609_729 | 54 | 406.0 | Domain | Arf-GAP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000304032 | + | 1 | 18 | 122_126 | 54 | 858.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000304032 | + | 1 | 18 | 178_181 | 54 | 858.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000304032 | + | 1 | 18 | 78_85 | 54 | 858.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000336665 | + | 1 | 17 | 122_126 | 54 | 805.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000336665 | + | 1 | 17 | 178_181 | 54 | 805.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000336665 | + | 1 | 17 | 78_85 | 54 | 805.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000409457 | + | 1 | 10 | 122_126 | 54 | 406.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000409457 | + | 1 | 10 | 178_181 | 54 | 406.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000409457 | + | 1 | 10 | 78_85 | 54 | 406.0 | Nucleotide binding | GTP |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000304032 | + | 1 | 18 | 66_276 | 54 | 858.0 | Region | Note=Small GTPase-like |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000336665 | + | 1 | 17 | 66_276 | 54 | 805.0 | Region | Note=Small GTPase-like |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000409457 | + | 1 | 10 | 66_276 | 54 | 406.0 | Region | Note=Small GTPase-like |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000304032 | + | 1 | 18 | 768_797 | 54 | 858.0 | Repeat | Note=ANK 1 |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000304032 | + | 1 | 18 | 801_830 | 54 | 858.0 | Repeat | Note=ANK 2 |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000336665 | + | 1 | 17 | 768_797 | 54 | 805.0 | Repeat | Note=ANK 1 |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000336665 | + | 1 | 17 | 801_830 | 54 | 805.0 | Repeat | Note=ANK 2 |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000409457 | + | 1 | 10 | 768_797 | 54 | 406.0 | Repeat | Note=ANK 1 |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000409457 | + | 1 | 10 | 801_830 | 54 | 406.0 | Repeat | Note=ANK 2 |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000304032 | + | 1 | 18 | 624_647 | 54 | 858.0 | Zinc finger | C4-type |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000336665 | + | 1 | 17 | 624_647 | 54 | 805.0 | Zinc finger | C4-type |
| Hgene | AGAP1 | chr2:236403493 | chr8:10683754 | ENST00000409457 | + | 1 | 10 | 624_647 | 54 | 406.0 | Zinc finger | C4-type |
| Tgene | PINX1 | chr2:236403493 | chr8:10683754 | ENST00000314787 | 3 | 7 | 26_72 | 100 | 329.0 | Domain | G-patch | |
| Tgene | PINX1 | chr2:236403493 | chr8:10683754 | ENST00000519088 | 3 | 6 | 26_72 | 100 | 175.0 | Domain | G-patch |
Top |
Fusion Gene Sequence for AGAP1-PINX1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >2778_2778_1_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000304032_PINX1_chr8_10683754_ENST00000314787_length(transcript)=1867nt_BP=743nt CGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCCCGGCGCGCCGGGCGGCGC AGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGCCCTCGGCCCCGGCGCTCG GAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGCTCAGGAAGTCACCCGAGC AAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGCTGACCCGGGACGCCGGGG CCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCCGCGCCTTTCTTCTCGCGC CTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCCCCGGGGCGCGGGGCGGCG GCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGCTGCCATCCGGGCCGAGAT CCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGTGCTGCAGAACCAGATCCG GGAGCACGTCATCGCCATCGAAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCG TGTTCACTATATGAAATTCACAAAAGGGAAGGATCTGTCATCTCGGAGCAAAACAGATCTTGACTGCATTTTTGGGAAAAGACAGAGTAA GAAGACTCCCGAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCCAGGAGTACTTTGC CAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAACGTAAAAGGGGGAA GAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAAAGCCCGAGAGGGC CGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGAGTTCCAAGGCCTC TGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGAAGAAAAAGCTGCA AAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAATGAATCCTTCCCAG CCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCACCCCAGAGCGCCT GGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGGAGGACCTTTTTAA TGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCAGCAAGAGAGTTTAATTATAATCATTACAAAT ACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTGTGTGTGTCACTATCTCCGTTTGCTCTCGGTT CCCTTCAATAACAATGAATGGTGCTTTCTTCTGAAAGACTCAGCCTAATTAAAGGATTAAGAGGCAA >2778_2778_1_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000304032_PINX1_chr8_10683754_ENST00000314787_length(amino acids)=335AA_BP=107 MLRPRLSSRASSARRRRARLPGGCGAPGSAARGPRGAGRRRRGARGSGRGACTMNYQQQLANSAAIRAEIQRFESVHPNIYSIYELLERV EEPVLQNQIREHVIAIEDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGKDLSSRSKTDLDCIFGKRQSKKTPEGDASPSTPEENETTTT SAFTIQEYFAKRMAALKNKPQVPVPGSDISETQVERKRGKKRNKEATGKDVESYLQPKAKRHTEGKPERAEAQERVAKKKSAPAEEQLRG PCWDQSSKASAQDAGDHVQPPEGRDFTLKPKKRRGKKKLQKPVEIAEDATLEETLVKKKKKKDSK -------------------------------------------------------------- >2778_2778_2_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000304032_PINX1_chr8_10683754_ENST00000426190_length(transcript)=1788nt_BP=743nt CGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCCCGGCGCGCCGGGCGGCGC AGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGCCCTCGGCCCCGGCGCTCG GAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGCTCAGGAAGTCACCCGAGC AAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGCTGACCCGGGACGCCGGGG CCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCCGCGCCTTTCTTCTCGCGC CTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCCCCGGGGCGCGGGGCGGCG GCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGCTGCCATCCGGGCCGAGAT CCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGTGCTGCAGAACCAGATCCG GGAGCACGTCATCGCCATCGAAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCG TGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCC AGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAAC GTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAA AGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGA GTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGA AGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAAT GAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCA CCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGG AGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCAGCAAGAGAGTTTAATTAT AATCATTACAAATACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTGTGTGTGTCACTATCTCCG TTTGCTCTCGGTTCCCTTCAATAACAATGAATGGTGCTTTCTTCTGAAAGACTCAGCCTAATTAAAGGATTAAGAGGC >2778_2778_2_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000304032_PINX1_chr8_10683754_ENST00000426190_length(amino acids)=255AA_BP=0 MSDPGTGTWGLFFSAAIRLAKYSWMVKALVVVVSFSSGVEGLASPFCEFHIVNTVFGDFGLFLKAKRFLFLLVRGIFDGDDVLPDLVLQH RLLHALQQLVDGVDVGVDRLEALDLGPDGSRVGQLLLVVHGAGAAPGAARPPPPPPRAPGPAGRRARGAAAPGEPGPPAAGGGGARRKAR AEQARGWPAGSVHGRDARPASERAPASRVSGPPGGSAPPWSAPRRVRPAPKEACSGDFLSRSRLPALGAAPRSSH -------------------------------------------------------------- >2778_2778_3_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000304032_PINX1_chr8_10683754_ENST00000519088_length(transcript)=1594nt_BP=743nt CGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCCCGGCGCGCCGGGCGGCGC AGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGCCCTCGGCCCCGGCGCTCG GAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGCTCAGGAAGTCACCCGAGC AAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGCTGACCCGGGACGCCGGGG CCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCCGCGCCTTTCTTCTCGCGC CTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCCCCGGGGCGCGGGGCGGCG GCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGCTGCCATCCGGGCCGAGAT CCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGTGCTGCAGAACCAGATCCG GGAGCACGTCATCGCCATCGAAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCG TGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCC AGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAAC GTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAA AGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGA GTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGA AGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAAT GAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCA CCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGG AGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGA >2778_2778_3_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000304032_PINX1_chr8_10683754_ENST00000519088_length(amino acids)=255AA_BP=0 MSDPGTGTWGLFFSAAIRLAKYSWMVKALVVVVSFSSGVEGLASPFCEFHIVNTVFGDFGLFLKAKRFLFLLVRGIFDGDDVLPDLVLQH RLLHALQQLVDGVDVGVDRLEALDLGPDGSRVGQLLLVVHGAGAAPGAARPPPPPPRAPGPAGRRARGAAAPGEPGPPAAGGGGARRKAR AEQARGWPAGSVHGRDARPASERAPASRVSGPPGGSAPPWSAPRRVRPAPKEACSGDFLSRSRLPALGAAPRSSH -------------------------------------------------------------- >2778_2778_4_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000336665_PINX1_chr8_10683754_ENST00000314787_length(transcript)=1867nt_BP=743nt CGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCCCGGCGCGCCGGGCGGCGC AGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGCCCTCGGCCCCGGCGCTCG GAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGCTCAGGAAGTCACCCGAGC AAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGCTGACCCGGGACGCCGGGG CCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCCGCGCCTTTCTTCTCGCGC CTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCCCCGGGGCGCGGGGCGGCG GCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGCTGCCATCCGGGCCGAGAT CCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGTGCTGCAGAACCAGATCCG GGAGCACGTCATCGCCATCGAAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCG TGTTCACTATATGAAATTCACAAAAGGGAAGGATCTGTCATCTCGGAGCAAAACAGATCTTGACTGCATTTTTGGGAAAAGACAGAGTAA GAAGACTCCCGAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCCAGGAGTACTTTGC CAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAACGTAAAAGGGGGAA GAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAAAGCCCGAGAGGGC CGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGAGTTCCAAGGCCTC TGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGAAGAAAAAGCTGCA AAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAATGAATCCTTCCCAG CCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCACCCCAGAGCGCCT GGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGGAGGACCTTTTTAA TGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCAGCAAGAGAGTTTAATTATAATCATTACAAAT ACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTGTGTGTGTCACTATCTCCGTTTGCTCTCGGTT CCCTTCAATAACAATGAATGGTGCTTTCTTCTGAAAGACTCAGCCTAATTAAAGGATTAAGAGGCAA >2778_2778_4_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000336665_PINX1_chr8_10683754_ENST00000314787_length(amino acids)=335AA_BP=107 MLRPRLSSRASSARRRRARLPGGCGAPGSAARGPRGAGRRRRGARGSGRGACTMNYQQQLANSAAIRAEIQRFESVHPNIYSIYELLERV EEPVLQNQIREHVIAIEDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGKDLSSRSKTDLDCIFGKRQSKKTPEGDASPSTPEENETTTT SAFTIQEYFAKRMAALKNKPQVPVPGSDISETQVERKRGKKRNKEATGKDVESYLQPKAKRHTEGKPERAEAQERVAKKKSAPAEEQLRG PCWDQSSKASAQDAGDHVQPPEGRDFTLKPKKRRGKKKLQKPVEIAEDATLEETLVKKKKKKDSK -------------------------------------------------------------- >2778_2778_5_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000336665_PINX1_chr8_10683754_ENST00000426190_length(transcript)=1788nt_BP=743nt CGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCCCGGCGCGCCGGGCGGCGC AGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGCCCTCGGCCCCGGCGCTCG GAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGCTCAGGAAGTCACCCGAGC AAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGCTGACCCGGGACGCCGGGG CCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCCGCGCCTTTCTTCTCGCGC CTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCCCCGGGGCGCGGGGCGGCG GCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGCTGCCATCCGGGCCGAGAT CCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGTGCTGCAGAACCAGATCCG GGAGCACGTCATCGCCATCGAAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCG TGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCC AGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAAC GTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAA AGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGA GTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGA AGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAAT GAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCA CCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGG AGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCAGCAAGAGAGTTTAATTAT AATCATTACAAATACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTGTGTGTGTCACTATCTCCG TTTGCTCTCGGTTCCCTTCAATAACAATGAATGGTGCTTTCTTCTGAAAGACTCAGCCTAATTAAAGGATTAAGAGGC >2778_2778_5_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000336665_PINX1_chr8_10683754_ENST00000426190_length(amino acids)=255AA_BP=0 MSDPGTGTWGLFFSAAIRLAKYSWMVKALVVVVSFSSGVEGLASPFCEFHIVNTVFGDFGLFLKAKRFLFLLVRGIFDGDDVLPDLVLQH RLLHALQQLVDGVDVGVDRLEALDLGPDGSRVGQLLLVVHGAGAAPGAARPPPPPPRAPGPAGRRARGAAAPGEPGPPAAGGGGARRKAR AEQARGWPAGSVHGRDARPASERAPASRVSGPPGGSAPPWSAPRRVRPAPKEACSGDFLSRSRLPALGAAPRSSH -------------------------------------------------------------- >2778_2778_6_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000336665_PINX1_chr8_10683754_ENST00000519088_length(transcript)=1594nt_BP=743nt CGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCCCGGCGCGCCGGGCGGCGC AGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGCCCTCGGCCCCGGCGCTCG GAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGCTCAGGAAGTCACCCGAGC AAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGCTGACCCGGGACGCCGGGG CCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCCGCGCCTTTCTTCTCGCGC CTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCCCCGGGGCGCGGGGCGGCG GCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGCTGCCATCCGGGCCGAGAT CCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGTGCTGCAGAACCAGATCCG GGAGCACGTCATCGCCATCGAAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTCCAAAATCTCCAAAAACCG TGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCACCATCC AGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGTGGAAC GTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGAGGGAA AGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGACCAGA GTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAGAGGGA AGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTCCAAAT GAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGAGTTCA CCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTCCCAGG AGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGA >2778_2778_6_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000336665_PINX1_chr8_10683754_ENST00000519088_length(amino acids)=255AA_BP=0 MSDPGTGTWGLFFSAAIRLAKYSWMVKALVVVVSFSSGVEGLASPFCEFHIVNTVFGDFGLFLKAKRFLFLLVRGIFDGDDVLPDLVLQH RLLHALQQLVDGVDVGVDRLEALDLGPDGSRVGQLLLVVHGAGAAPGAARPPPPPPRAPGPAGRRARGAAAPGEPGPPAAGGGGARRKAR AEQARGWPAGSVHGRDARPASERAPASRVSGPPGGSAPPWSAPRRVRPAPKEACSGDFLSRSRLPALGAAPRSSH -------------------------------------------------------------- >2778_2778_7_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000409457_PINX1_chr8_10683754_ENST00000314787_length(transcript)=1885nt_BP=761nt GGCGCTCGGAGCGGGCTCCGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCC CGGCGCGCCGGGCGGCGCAGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGC CCTCGGCCCCGGCGCTCGGAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGC TCAGGAAGTCACCCGAGCAAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGC TGACCCGGGACGCCGGGGCCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCC GCGCCTTTCTTCTCGCGCCTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCC CCGGGGCGCGGGGCGGCGGCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGC TGCCATCCGGGCCGAGATCCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGT GCTGCAGAACCAGATCCGGGAGCACGTCATCGCCATCGAAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTC CAAAATCTCCAAAAACCGTGTTCACTATATGAAATTCACAAAAGGGAAGGATCTGTCATCTCGGAGCAAAACAGATCTTGACTGCATTTT TGGGAAAAGACAGAGTAAGAAGACTCCCGAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAACCAGCGCCTTCAC CATCCAGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTTCTGAGACGCAGGT GGAACGTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCAAGAGGCACACGGA GGGAAAGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAGGCCCCTGCTGGGA CCAGAGTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGCCCAAAAAGAGGAG AGGGAAGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGAAGAAGAAAGATTC CAAATGAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTGAAGTCACAGCAGA GTTCACCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCCCCAAGTTACATTC CCAGGAGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCAGCAAGAGAGTTTA ATTATAATCATTACAAATACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTGTGTGTGTCACTAT CTCCGTTTGCTCTCGGTTCCCTTCAATAACAATGAATGGTGCTTTCTTCTGAAAGACTCAGCCTAATTAAAGGATTAAGAGGCAA >2778_2778_7_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000409457_PINX1_chr8_10683754_ENST00000314787_length(amino acids)=335AA_BP=107 MLRPRLSSRASSARRRRARLPGGCGAPGSAARGPRGAGRRRRGARGSGRGACTMNYQQQLANSAAIRAEIQRFESVHPNIYSIYELLERV EEPVLQNQIREHVIAIEDSSDKKEKKSFSLEEKSKISKNRVHYMKFTKGKDLSSRSKTDLDCIFGKRQSKKTPEGDASPSTPEENETTTT SAFTIQEYFAKRMAALKNKPQVPVPGSDISETQVERKRGKKRNKEATGKDVESYLQPKAKRHTEGKPERAEAQERVAKKKSAPAEEQLRG PCWDQSSKASAQDAGDHVQPPEGRDFTLKPKKRRGKKKLQKPVEIAEDATLEETLVKKKKKKDSK -------------------------------------------------------------- >2778_2778_8_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000409457_PINX1_chr8_10683754_ENST00000426190_length(transcript)=1806nt_BP=761nt GGCGCTCGGAGCGGGCTCCGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCC CGGCGCGCCGGGCGGCGCAGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGC CCTCGGCCCCGGCGCTCGGAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGC TCAGGAAGTCACCCGAGCAAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGC TGACCCGGGACGCCGGGGCCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCC GCGCCTTTCTTCTCGCGCCTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCC CCGGGGCGCGGGGCGGCGGCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGC TGCCATCCGGGCCGAGATCCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGT GCTGCAGAACCAGATCCGGGAGCACGTCATCGCCATCGAAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTC CAAAATCTCCAAAAACCGTGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAA CCAGCGCCTTCACCATCCAGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTT CTGAGACGCAGGTGGAACGTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCA AGAGGCACACGGAGGGAAAGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAG GCCCCTGCTGGGACCAGAGTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGC CCAAAAAGAGGAGAGGGAAGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGA AGAAGAAAGATTCCAAATGAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTG AAGTCACAGCAGAGTTCACCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCC CCAAGTTACATTCCCAGGAGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGAGCCCTTCA GCAAGAGAGTTTAATTATAATCATTACAAATACATGCATTCATGTAAGTGTGCACACGTGTGTGTGCATGTGCGCATCTGTGTGTGTGTG TGTGTGTCACTATCTCCGTTTGCTCTCGGTTCCCTTCAATAACAATGAATGGTGCTTTCTTCTGAAAGACTCAGCCTAATTAAAGGATTA AGAGGC >2778_2778_8_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000409457_PINX1_chr8_10683754_ENST00000426190_length(amino acids)=255AA_BP=0 MSDPGTGTWGLFFSAAIRLAKYSWMVKALVVVVSFSSGVEGLASPFCEFHIVNTVFGDFGLFLKAKRFLFLLVRGIFDGDDVLPDLVLQH RLLHALQQLVDGVDVGVDRLEALDLGPDGSRVGQLLLVVHGAGAAPGAARPPPPPPRAPGPAGRRARGAAAPGEPGPPAAGGGGARRKAR AEQARGWPAGSVHGRDARPASERAPASRVSGPPGGSAPPWSAPRRVRPAPKEACSGDFLSRSRLPALGAAPRSSH -------------------------------------------------------------- >2778_2778_9_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000409457_PINX1_chr8_10683754_ENST00000519088_length(transcript)=1612nt_BP=761nt GGCGCTCGGAGCGGGCTCCGCGGCTTGCAAGGCGCCTGCGACTCGGTCCCAGGTCGGCGGGCGGCGCACGGCGGGCTCGCGCGGGGGCCC CGGCGCGCCGGGCGGCGCAGTACGCAGCGCGCGGACCCACGCCACGGCCAGGAGCCCAGAGCAGCGCGGCCACACTGCCCAGGGGTCGGC CCTCGGCCCCGGCGCTCGGAGCGCGGCGGCTGCCTGGGCTTTAATGGCTGCTCCGCGGAGCAGCGCCTAGGGCTGGAAGGCGGCTGCGGC TCAGGAAGTCACCCGAGCAAGCCTCCTTCGGGGCCGGCCGCACCCGCCGCGGCGCGCTCCATGGGGGCGCGCTCCCCCCGGGCGGCCCGC TGACCCGGGACGCCGGGGCCCGCTCGCTCGCCGGCCGCGCGTCCCGGCCATGAACTGAGCCCGCGGGCCAGCCCCGCGCCTGCTCCGCCC GCGCCTTTCTTCTCGCGCCTCCTCCGCCCGCCGCCGGCGGGCCCGGCTCCCCGGGGGCTGCGGCGCCCCGGGCTCGGCGGCCCGCGGGCC CCGGGGCGCGGGGCGGCGGCGGCGGGGGGCGCGCGGCTCCGGGCGCGGCGCCTGCACCATGAACTACCAGCAGCAGCTGGCCAACTCGGC TGCCATCCGGGCCGAGATCCAGCGCTTCGAGTCGGTCCACCCCAACATCTACTCCATCTACGAGCTGCTGGAGCGCGTGGAGGAGCCGGT GCTGCAGAACCAGATCCGGGAGCACGTCATCGCCATCGAAGATTCCTCGGACAAGAAGGAAAAGAAATCTTTTAGCCTTGAGGAAAAGTC CAAAATCTCCAAAAACCGTGTTCACTATATGAAATTCACAAAAGGGCGATGCCAGTCCCTCCACTCCAGAGGAGAACGAAACCACGACAA CCAGCGCCTTCACCATCCAGGAGTACTTTGCCAAGCGGATGGCAGCACTGAAGAACAAGCCCCAGGTTCCAGTTCCAGGGTCTGACATTT CTGAGACGCAGGTGGAACGTAAAAGGGGGAAGAAAAGAAATAAAGAGGCCACAGGTAAAGATGTGGAAAGTTACCTCCAGCCTAAGGCCA AGAGGCACACGGAGGGAAAGCCCGAGAGGGCCGAGGCCCAGGAGCGAGTGGCCAAGAAGAAGAGCGCGCCAGCAGAAGAGCAGCTCAGAG GCCCCTGCTGGGACCAGAGTTCCAAGGCCTCTGCTCAGGATGCAGGGGACCATGTGCAGCCGCCTGAGGGCCGGGACTTCACCCTGAAGC CCAAAAAGAGGAGAGGGAAGAAAAAGCTGCAAAAACCAGTAGAGATAGCAGAGGACGCTACACTAGAAGAAACGCTAGTGAAAAAGAAGA AGAAGAAAGATTCCAAATGAATCCTTCCCAGCCGGGGCCTTCCGACCACTCAGCTGTCAGGGCACTGCGGGGGCAGACACCTCTGGCCTG AAGTCACAGCAGAGTTCACCCCAGAGCGCCTGGGCGCATCTTGTGGCATGCCCATGGGCTGCCGAGTCCTGCCCTCTCGCCACATTTCCC CCAAGTTACATTCCCAGGAGGACCTTTTTAATGTTCTCAATCGTGGCTCTCAGACACAAATAAATTTTTTTGTAAACTCTGA >2778_2778_9_AGAP1-PINX1_AGAP1_chr2_236403493_ENST00000409457_PINX1_chr8_10683754_ENST00000519088_length(amino acids)=255AA_BP=0 MSDPGTGTWGLFFSAAIRLAKYSWMVKALVVVVSFSSGVEGLASPFCEFHIVNTVFGDFGLFLKAKRFLFLLVRGIFDGDDVLPDLVLQH RLLHALQQLVDGVDVGVDRLEALDLGPDGSRVGQLLLVVHGAGAAPGAARPPPPPPRAPGPAGRRARGAAAPGEPGPPAAGGGGARRKAR AEQARGWPAGSVHGRDARPASERAPASRVSGPPGGSAPPWSAPRRVRPAPKEACSGDFLSRSRLPALGAAPRSSH -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AGAP1-PINX1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AGAP1-PINX1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AGAP1-PINX1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | AGAP1 | C0004352 | Autistic Disorder | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies