
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ADCYAP1R1-GHRHR (FusionGDB2 ID:HG117TG2692) |
Fusion Gene Summary for ADCYAP1R1-GHRHR |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ADCYAP1R1-GHRHR | Fusion gene ID: hg117tg2692 | Hgene | Tgene | Gene symbol | ADCYAP1R1 | GHRHR | Gene ID | 117 | 2692 |
| Gene name | ADCYAP receptor type I | growth hormone releasing hormone receptor | |
| Synonyms | PAC1|PAC1R|PACAPR|PACAPRI | GHRFR|GRFR|IGHD1B|IGHD4 | |
| Cytomap | ('ADCYAP1R1')('GHRHR') 7p14.3 | 7p14.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | pituitary adenylate cyclase-activating polypeptide type I receptorPACAP receptor 1PACAP type I receptorPACAP-R1adenylate cyclase activating polypeptide 1 (pituitary) receptor type Ipituitary adenylate cyclase activating polypeptide 1 receptor type I | growth hormone-releasing hormone receptorGHRH receptorGRF receptor | |
| Modification date | 20200313 | 20200315 | |
| UniProtAcc | P41586 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000304166, ENST00000396211, ENST00000409363, ENST00000409489, | ||
| Fusion gene scores | * DoF score | 6 X 7 X 3=126 | 2 X 2 X 2=8 |
| # samples | 7 | 2 | |
| ** MAII score | log2(7/126*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(2/8*10)=1.32192809488736 | |
| Context | PubMed: ADCYAP1R1 [Title/Abstract] AND GHRHR [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ADCYAP1R1(31139824)-GHRHR(31014586), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ADCYAP1R1-GHRHR seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ADCYAP1R1-GHRHR seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ADCYAP1R1-GHRHR seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ADCYAP1R1-GHRHR seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ADCYAP1R1-GHRHR seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. ADCYAP1R1-GHRHR seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | GHRHR | GO:0007189 | adenylate cyclase-activating G protein-coupled receptor signaling pathway | 1333056|7680413 |
| Tgene | GHRHR | GO:0008284 | positive regulation of cell proliferation | 12867592 |
| Tgene | GHRHR | GO:0043627 | response to estrogen | 9482665 |
| Tgene | GHRHR | GO:0051384 | response to glucocorticoid | 9482665 |
| Fusion gene breakpoints across ADCYAP1R1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GHRHR (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PCPG | TCGA-P8-A5KC-01A | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| ChimerDB4 | PCPG | TCGA-P8-A5KC-01A | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
Top |
Fusion Gene ORF analysis for ADCYAP1R1-GHRHR |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000304166 | ENST00000461424 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| 5CDS-3UTR | ENST00000396211 | ENST00000461424 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| 5CDS-3UTR | ENST00000396211 | ENST00000461424 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| 5CDS-3UTR | ENST00000409363 | ENST00000461424 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| 5CDS-3UTR | ENST00000409489 | ENST00000461424 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| 5CDS-3UTR | ENST00000409489 | ENST00000461424 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| Frame-shift | ENST00000304166 | ENST00000409316 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| Frame-shift | ENST00000396211 | ENST00000409316 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| Frame-shift | ENST00000396211 | ENST00000409316 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| Frame-shift | ENST00000409363 | ENST00000409316 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| Frame-shift | ENST00000409489 | ENST00000409316 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| Frame-shift | ENST00000409489 | ENST00000409316 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000304166 | ENST00000326139 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000304166 | ENST00000409904 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000396211 | ENST00000326139 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000396211 | ENST00000326139 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000396211 | ENST00000409904 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000396211 | ENST00000409904 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000409363 | ENST00000326139 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000409363 | ENST00000409904 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000409489 | ENST00000326139 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000409489 | ENST00000326139 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000409489 | ENST00000409904 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + |
| In-frame | ENST00000409489 | ENST00000409904 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| intron-3CDS | ENST00000304166 | ENST00000326139 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| intron-3CDS | ENST00000304166 | ENST00000409316 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| intron-3CDS | ENST00000304166 | ENST00000409904 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| intron-3CDS | ENST00000409363 | ENST00000326139 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| intron-3CDS | ENST00000409363 | ENST00000409316 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| intron-3CDS | ENST00000409363 | ENST00000409904 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| intron-3UTR | ENST00000304166 | ENST00000461424 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| intron-3UTR | ENST00000409363 | ENST00000461424 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000396211 | ADCYAP1R1 | chr7 | 31139824 | + | ENST00000326139 | GHRHR | chr7 | 31014586 | + | 1945 | 1201 | 23 | 1660 | 545 |
| ENST00000396211 | ADCYAP1R1 | chr7 | 31139824 | + | ENST00000409904 | GHRHR | chr7 | 31014586 | + | 1936 | 1201 | 23 | 1660 | 545 |
| ENST00000409489 | ADCYAP1R1 | chr7 | 31139824 | + | ENST00000326139 | GHRHR | chr7 | 31014586 | + | 1984 | 1240 | 26 | 1699 | 557 |
| ENST00000409489 | ADCYAP1R1 | chr7 | 31139824 | + | ENST00000409904 | GHRHR | chr7 | 31014586 | + | 1975 | 1240 | 26 | 1699 | 557 |
| ENST00000304166 | ADCYAP1R1 | chr7 | 31132349 | + | ENST00000326139 | GHRHR | chr7 | 31014586 | + | 2079 | 1335 | 241 | 1794 | 517 |
| ENST00000304166 | ADCYAP1R1 | chr7 | 31132349 | + | ENST00000409904 | GHRHR | chr7 | 31014586 | + | 2070 | 1335 | 241 | 1794 | 517 |
| ENST00000409363 | ADCYAP1R1 | chr7 | 31132349 | + | ENST00000326139 | GHRHR | chr7 | 31014586 | + | 1950 | 1206 | 175 | 1665 | 496 |
| ENST00000409363 | ADCYAP1R1 | chr7 | 31132349 | + | ENST00000409904 | GHRHR | chr7 | 31014586 | + | 1941 | 1206 | 175 | 1665 | 496 |
| ENST00000396211 | ADCYAP1R1 | chr7 | 31132349 | + | ENST00000326139 | GHRHR | chr7 | 31014586 | + | 1861 | 1117 | 23 | 1576 | 517 |
| ENST00000396211 | ADCYAP1R1 | chr7 | 31132349 | + | ENST00000409904 | GHRHR | chr7 | 31014586 | + | 1852 | 1117 | 23 | 1576 | 517 |
| ENST00000409489 | ADCYAP1R1 | chr7 | 31132349 | + | ENST00000326139 | GHRHR | chr7 | 31014586 | + | 1816 | 1072 | 26 | 1531 | 501 |
| ENST00000409489 | ADCYAP1R1 | chr7 | 31132349 | + | ENST00000409904 | GHRHR | chr7 | 31014586 | + | 1807 | 1072 | 26 | 1531 | 501 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000396211 | ENST00000326139 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + | 0.002758142 | 0.99724185 |
| ENST00000396211 | ENST00000409904 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + | 0.002917704 | 0.9970823 |
| ENST00000409489 | ENST00000326139 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + | 0.003827177 | 0.99617285 |
| ENST00000409489 | ENST00000409904 | ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014586 | + | 0.004048243 | 0.9959518 |
| ENST00000304166 | ENST00000326139 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + | 0.002107472 | 0.99789256 |
| ENST00000304166 | ENST00000409904 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + | 0.002189323 | 0.99781066 |
| ENST00000409363 | ENST00000326139 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + | 0.003276439 | 0.9967236 |
| ENST00000409363 | ENST00000409904 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + | 0.003462361 | 0.9965377 |
| ENST00000396211 | ENST00000326139 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + | 0.001777508 | 0.99822253 |
| ENST00000396211 | ENST00000409904 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + | 0.001876208 | 0.9981238 |
| ENST00000409489 | ENST00000326139 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + | 0.001880257 | 0.9981198 |
| ENST00000409489 | ENST00000409904 | ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014586 | + | 0.001986023 | 0.998014 |
Top |
Fusion Genomic Features for ADCYAP1R1-GHRHR |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014585 | + | 0.006019883 | 0.99398017 |
| ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014585 | + | 0.003835702 | 0.9961643 |
| ADCYAP1R1 | chr7 | 31139824 | + | GHRHR | chr7 | 31014585 | + | 0.006019883 | 0.99398017 |
| ADCYAP1R1 | chr7 | 31132349 | + | GHRHR | chr7 | 31014585 | + | 0.003835702 | 0.9961643 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
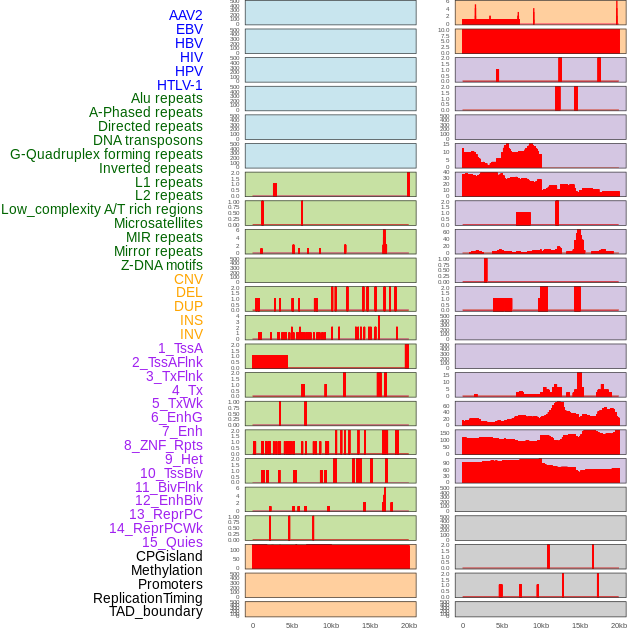 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
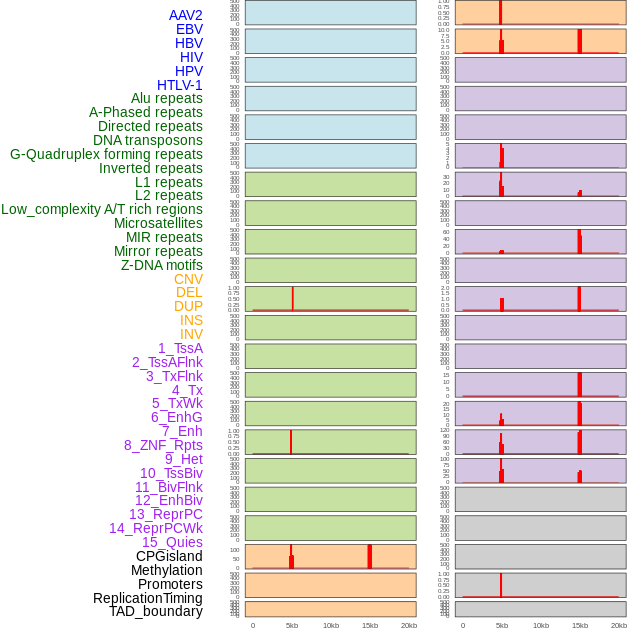 |
Top |
Fusion Protein Features for ADCYAP1R1-GHRHR |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:31139824/chr7:31014586) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ADCYAP1R1 | . |
| FUNCTION: This is a receptor for PACAP-27 and PACAP-38. The activity of this receptor is mediated by G proteins which activate adenylyl cyclase. May regulate the release of adrenocorticotropin, luteinizing hormone, growth hormone, prolactin, epinephrine, and catecholamine. May play a role in spermatogenesis and sperm motility. Causes smooth muscle relaxation and secretion in the gastrointestinal tract. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 125_139 | 348 | 469.0 | Region | Note=Important for ligand binding and specificity |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 125_139 | 348 | 497.0 | Region | Note=Important for ligand binding and specificity |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 125_139 | 327 | 448.0 | Region | Note=Important for ligand binding and specificity |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 125_139 | 376 | 497.0 | Region | Note=Important for ligand binding and specificity |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 179_186 | 348 | 469.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 206_227 | 348 | 469.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 21_155 | 348 | 469.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 254_268 | 348 | 469.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 292_309 | 348 | 469.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 333_350 | 348 | 469.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 179_186 | 348 | 497.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 206_227 | 348 | 497.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 21_155 | 348 | 497.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 254_268 | 348 | 497.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 292_309 | 348 | 497.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 333_350 | 348 | 497.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 179_186 | 327 | 448.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 206_227 | 327 | 448.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 21_155 | 327 | 448.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 254_268 | 327 | 448.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 292_309 | 327 | 448.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 179_186 | 376 | 497.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 206_227 | 376 | 497.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 21_155 | 376 | 497.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 254_268 | 376 | 497.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 292_309 | 376 | 497.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 333_350 | 376 | 497.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 156_178 | 348 | 469.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 187_205 | 348 | 469.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 228_253 | 348 | 469.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 269_291 | 348 | 469.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 310_332 | 348 | 469.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 156_178 | 348 | 497.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 187_205 | 348 | 497.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 228_253 | 348 | 497.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 269_291 | 348 | 497.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 310_332 | 348 | 497.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 156_178 | 327 | 448.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 187_205 | 327 | 448.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 228_253 | 327 | 448.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 269_291 | 327 | 448.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 156_178 | 376 | 497.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 187_205 | 376 | 497.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 228_253 | 376 | 497.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 269_291 | 376 | 497.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 310_332 | 376 | 497.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 351_371 | 376 | 497.0 | Transmembrane | Helical%3B Name%3D6 |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 305_329 | 270 | 424.0 | Topological domain | Cytoplasmic | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 349_361 | 270 | 424.0 | Topological domain | Extracellular | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 382_423 | 270 | 424.0 | Topological domain | Cytoplasmic | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 305_329 | 270 | 424.0 | Topological domain | Cytoplasmic | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 349_361 | 270 | 424.0 | Topological domain | Extracellular | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 382_423 | 270 | 424.0 | Topological domain | Cytoplasmic | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 281_304 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 330_348 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 362_381 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D7 | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 281_304 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 330_348 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 362_381 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D7 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 125_139 | 0 | 469.0 | Region | Note=Important for ligand binding and specificity |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 125_139 | 0 | 448.0 | Region | Note=Important for ligand binding and specificity |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 372_385 | 348 | 469.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 406_468 | 348 | 469.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 372_385 | 348 | 497.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 406_468 | 348 | 497.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 333_350 | 327 | 448.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 372_385 | 327 | 448.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 406_468 | 327 | 448.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 179_186 | 0 | 469.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 206_227 | 0 | 469.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 21_155 | 0 | 469.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 254_268 | 0 | 469.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 292_309 | 0 | 469.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 333_350 | 0 | 469.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 372_385 | 0 | 469.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 406_468 | 0 | 469.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 372_385 | 376 | 497.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 406_468 | 376 | 497.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 179_186 | 0 | 448.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 206_227 | 0 | 448.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 21_155 | 0 | 448.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 254_268 | 0 | 448.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 292_309 | 0 | 448.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 333_350 | 0 | 448.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 372_385 | 0 | 448.0 | Topological domain | Extracellular |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 406_468 | 0 | 448.0 | Topological domain | Cytoplasmic |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 351_371 | 348 | 469.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000304166 | + | 13 | 16 | 386_405 | 348 | 469.0 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 351_371 | 348 | 497.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000396211 | + | 12 | 16 | 386_405 | 348 | 497.0 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 310_332 | 327 | 448.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 351_371 | 327 | 448.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | ADCYAP1R1 | chr7:31132349 | chr7:31014586 | ENST00000409363 | + | 11 | 14 | 386_405 | 327 | 448.0 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 156_178 | 0 | 469.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 187_205 | 0 | 469.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 228_253 | 0 | 469.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 269_291 | 0 | 469.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 310_332 | 0 | 469.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 351_371 | 0 | 469.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000304166 | + | 1 | 16 | 386_405 | 0 | 469.0 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000396211 | + | 13 | 16 | 386_405 | 376 | 497.0 | Transmembrane | Helical%3B Name%3D7 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 156_178 | 0 | 448.0 | Transmembrane | Helical%3B Name%3D1 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 187_205 | 0 | 448.0 | Transmembrane | Helical%3B Name%3D2 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 228_253 | 0 | 448.0 | Transmembrane | Helical%3B Name%3D3 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 269_291 | 0 | 448.0 | Transmembrane | Helical%3B Name%3D4 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 310_332 | 0 | 448.0 | Transmembrane | Helical%3B Name%3D5 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 351_371 | 0 | 448.0 | Transmembrane | Helical%3B Name%3D6 |
| Hgene | ADCYAP1R1 | chr7:31139824 | chr7:31014586 | ENST00000409363 | + | 1 | 14 | 386_405 | 0 | 448.0 | Transmembrane | Helical%3B Name%3D7 |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 153_162 | 270 | 424.0 | Topological domain | Cytoplasmic | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 182_204 | 270 | 424.0 | Topological domain | Extracellular | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 228_240 | 270 | 424.0 | Topological domain | Cytoplasmic | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 23_132 | 270 | 424.0 | Topological domain | Extracellular | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 263_280 | 270 | 424.0 | Topological domain | Extracellular | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 153_162 | 270 | 424.0 | Topological domain | Cytoplasmic | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 182_204 | 270 | 424.0 | Topological domain | Extracellular | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 228_240 | 270 | 424.0 | Topological domain | Cytoplasmic | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 23_132 | 270 | 424.0 | Topological domain | Extracellular | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 263_280 | 270 | 424.0 | Topological domain | Extracellular | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 133_152 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 163_181 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 205_227 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | GHRHR | chr7:31132349 | chr7:31014586 | ENST00000326139 | 7 | 13 | 241_262 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 133_152 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 163_181 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 205_227 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | GHRHR | chr7:31139824 | chr7:31014586 | ENST00000326139 | 7 | 13 | 241_262 | 270 | 424.0 | Transmembrane | Helical%3B Name%3D4 |
Top |
Fusion Gene Sequence for ADCYAP1R1-GHRHR |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >2281_2281_1_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000304166_GHRHR_chr7_31014586_ENST00000326139_length(transcript)=2079nt_BP=1335nt GCGAGCGTGGTCCCCGCGTGCGCACACGCACACGCCGCCGCGCAGGGACACACGGACCCCGGCCGCCAGCCGGCCACACAGGCGCGGAGA CCCGGCTCGGCGCGCGCTCCTCGGCGCACACGCTCCCCATCCCCGCGCCGCGCGGGCCGCGGACTTGCAGGCTGCGCGTCCTTTGCGGAG TCTGCCCCGGCCCCACGGACAGGCCCCGCAGTGAGCAGCCCAGAGACACATTGGGGCTGACCTGCCGCTGCTGTCAGTGGGAGGCCAGTG GTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACGTTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGCATTCTGA CTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGAAGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTCCAGGCTG TCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCGCCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCCGAATCTT CAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAGAGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGGGAGTGGT GAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCTTCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTGAGACTGG GGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCTACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCATGGTCAT CCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACTTCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCTCCGTCTT CATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCAACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTTTCTTCCA CTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCGAGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTGAAAGGAG ATACTTCTACTGGTACACCATCATTGGCTGGGGGACCCCAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTGATGACAC AGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGTGGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTGTGCTTTT TATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGTCTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTGTGCTGGGACCTGGA CGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCATTGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCAT CCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCATACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCC ACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGCCAGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTC CTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCCTCAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCC TGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGACCACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGC CTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCAGCTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACC CCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCTCCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTG ACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCTCTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCT GTAAATGAA >2281_2281_1_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000304166_GHRHR_chr7_31014586_ENST00000326139_length(amino acids)=517AA_BP=127 MPLLSVGGQWCWPRSVMAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVL VSCPELFRIFNPDQVWETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTS LVTLTTAMVILCRFRKLHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTL LVETFFPERRYFYWYTIIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNE SSIYLCWDLDDTSPYWWIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGI RLPLELGLGSFQGFIVAILYCFLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKVLTSMC -------------------------------------------------------------- >2281_2281_2_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000304166_GHRHR_chr7_31014586_ENST00000409904_length(transcript)=2070nt_BP=1335nt GCGAGCGTGGTCCCCGCGTGCGCACACGCACACGCCGCCGCGCAGGGACACACGGACCCCGGCCGCCAGCCGGCCACACAGGCGCGGAGA CCCGGCTCGGCGCGCGCTCCTCGGCGCACACGCTCCCCATCCCCGCGCCGCGCGGGCCGCGGACTTGCAGGCTGCGCGTCCTTTGCGGAG TCTGCCCCGGCCCCACGGACAGGCCCCGCAGTGAGCAGCCCAGAGACACATTGGGGCTGACCTGCCGCTGCTGTCAGTGGGAGGCCAGTG GTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACGTTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGCATTCTGA CTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGAAGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTCCAGGCTG TCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCGCCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCCGAATCTT CAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAGAGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGGGAGTGGT GAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCTTCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTGAGACTGG GGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCTACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCATGGTCAT CCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACTTCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCTCCGTCTT CATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCAACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTTTCTTCCA CTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCGAGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTGAAAGGAG ATACTTCTACTGGTACACCATCATTGGCTGGGGGACCCCAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTGATGACAC AGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGTGGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTGTGCTTTT TATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGTCTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTGTGCTGGGACCTGGA CGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCATTGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCAT CCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCATACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCC ACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGCCAGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTC CTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCCTCAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCC TGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGACCACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGC CTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCAGCTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACC CCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCTCCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTG ACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCTCTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCT >2281_2281_2_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000304166_GHRHR_chr7_31014586_ENST00000409904_length(amino acids)=517AA_BP=127 MPLLSVGGQWCWPRSVMAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVL VSCPELFRIFNPDQVWETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTS LVTLTTAMVILCRFRKLHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTL LVETFFPERRYFYWYTIIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNE SSIYLCWDLDDTSPYWWIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGI RLPLELGLGSFQGFIVAILYCFLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKVLTSMC -------------------------------------------------------------- >2281_2281_3_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000396211_GHRHR_chr7_31014586_ENST00000326139_length(transcript)=1861nt_BP=1117nt CCCAGAGACACATTGGGGCTGACCTGCCGCTGCTGTCAGTGGGAGGCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACG TTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGCATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGA AGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTCCAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCG CCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCCGAATCTTCAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAG AGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGGGAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCT TCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTGAGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCT ACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCATGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACT TCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCTCCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCA ACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTTTCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCG AGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTGAAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCC CAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTGATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGT GGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTGTGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGT CTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTGTGCTGGGACCTGGACGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCA TTGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCATCCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCC ATACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCCACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGC CAGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTCCTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCC TCAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCCTGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGA CCACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGCCTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCA GCTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACCCCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCC TCCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTGACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCC TCTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCTGTAAATGAA >2281_2281_3_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000396211_GHRHR_chr7_31014586_ENST00000326139_length(amino acids)=517AA_BP=127 MPLLSVGGQWCWPRSVMAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVL VSCPELFRIFNPDQVWETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTS LVTLTTAMVILCRFRKLHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTL LVETFFPERRYFYWYTIIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNE SSIYLCWDLDDTSPYWWIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGI RLPLELGLGSFQGFIVAILYCFLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKVLTSMC -------------------------------------------------------------- >2281_2281_4_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000396211_GHRHR_chr7_31014586_ENST00000409904_length(transcript)=1852nt_BP=1117nt CCCAGAGACACATTGGGGCTGACCTGCCGCTGCTGTCAGTGGGAGGCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACG TTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGCATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGA AGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTCCAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCG CCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCCGAATCTTCAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAG AGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGGGAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCT TCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTGAGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCT ACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCATGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACT TCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCTCCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCA ACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTTTCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCG AGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTGAAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCC CAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTGATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGT GGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTGTGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGT CTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTGTGCTGGGACCTGGACGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCA TTGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCATCCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCC ATACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCCACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGC CAGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTCCTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCC TCAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCCTGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGA CCACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGCCTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCA GCTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACCCCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCC TCCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTGACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCC TCTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCT >2281_2281_4_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000396211_GHRHR_chr7_31014586_ENST00000409904_length(amino acids)=517AA_BP=127 MPLLSVGGQWCWPRSVMAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVL VSCPELFRIFNPDQVWETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTS LVTLTTAMVILCRFRKLHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTL LVETFFPERRYFYWYTIIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNE SSIYLCWDLDDTSPYWWIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGI RLPLELGLGSFQGFIVAILYCFLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKVLTSMC -------------------------------------------------------------- >2281_2281_5_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000409363_GHRHR_chr7_31014586_ENST00000326139_length(transcript)=1950nt_BP=1206nt CAGCCGGCCACACAGGCGCGGAGACCCGGCTCGGCGCGCGCTCCTCGGCGCACACGCTCCCCATCCCCGCGCCGCGCGGGCCGCGGACTT GCAGGCTGCGCGTCCTTTGCGGAGTCTGCCCCGGCCCCACGGACAGGCCCCGCAGTGAGCAGCCCAGAGACACATTGGGGCTGACCTGCC GCTGCTGTCAGTGGGAGGCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACGTTTCCCTGGCTGCTCTCCTCCTGCTGCC TATGGCCCCTGCCATGCATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGAAGATCCAGAGGGCCAATGAGCTGATGGG CTTCAATGATTCCTCTCCAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCGCCCATGTGGGTGAGATGGTCCTGGTCAG CTGCCCTGAGCTCTTCCGAATCTTCAACCCAGACCAAGACATGGGAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCTT CCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTGAGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCTA CACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCATGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACTT CATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCTCCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCAA CCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTTTCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCGA GGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTGAAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCCC AACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTGATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGTG GGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTGTGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGTC TCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTGTGCTGGGACCTGGACGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCAT TGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCATCCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCA TACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCCACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGCC AGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTCCTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCCT CAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCCTGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGAC CACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGCCTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCAG CTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACCCCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCT CCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTGACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCT CTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCTGTAAATGAA >2281_2281_5_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000409363_GHRHR_chr7_31014586_ENST00000326139_length(amino acids)=496AA_BP=106 MPLLSVGGQWCWPRSVMAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVL VSCPELFRIFNPDQDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTSLVTLTTAMVILCRFRKLHCTR NFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTLLVETFFPERRYFYWYTIIGWG TPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNESSIYLCWDLDDTSPYWWIIKG PIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGIRLPLELGLGSFQGFIVAILYC FLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKVLTSMC -------------------------------------------------------------- >2281_2281_6_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000409363_GHRHR_chr7_31014586_ENST00000409904_length(transcript)=1941nt_BP=1206nt CAGCCGGCCACACAGGCGCGGAGACCCGGCTCGGCGCGCGCTCCTCGGCGCACACGCTCCCCATCCCCGCGCCGCGCGGGCCGCGGACTT GCAGGCTGCGCGTCCTTTGCGGAGTCTGCCCCGGCCCCACGGACAGGCCCCGCAGTGAGCAGCCCAGAGACACATTGGGGCTGACCTGCC GCTGCTGTCAGTGGGAGGCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACGTTTCCCTGGCTGCTCTCCTCCTGCTGCC TATGGCCCCTGCCATGCATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGAAGATCCAGAGGGCCAATGAGCTGATGGG CTTCAATGATTCCTCTCCAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCGCCCATGTGGGTGAGATGGTCCTGGTCAG CTGCCCTGAGCTCTTCCGAATCTTCAACCCAGACCAAGACATGGGAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCTT CCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTGAGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCTA CACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCATGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACTT CATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCTCCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCAA CCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTTTCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCGA GGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTGAAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCCC AACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTGATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGTG GGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTGTGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGTC TCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTGTGCTGGGACCTGGACGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCAT TGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCATCCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCA TACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCCACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGCC AGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTCCTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCCT CAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCCTGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGAC CACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGCCTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCAG CTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACCCCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCT CCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTGACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCT CTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCT >2281_2281_6_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000409363_GHRHR_chr7_31014586_ENST00000409904_length(amino acids)=496AA_BP=106 MPLLSVGGQWCWPRSVMAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVL VSCPELFRIFNPDQDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTSLVTLTTAMVILCRFRKLHCTR NFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTLLVETFFPERRYFYWYTIIGWG TPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNESSIYLCWDLDDTSPYWWIIKG PIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGIRLPLELGLGSFQGFIVAILYC FLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKVLTSMC -------------------------------------------------------------- >2281_2281_7_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000409489_GHRHR_chr7_31014586_ENST00000326139_length(transcript)=1816nt_BP=1072nt GCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACGTTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGC ATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGAAGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTC CAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCGCCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCC GAATCTTCAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAGAGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGG GAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCTTCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTG AGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCTACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCA TGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACTTCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCT CCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCAACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTT TCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCGAGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTG AAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCCCAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTG ATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGTGGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTG TGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGTCTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTGTGCTGGG ACCTGGACGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCATTGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTA TCCGCATCCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCATACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCC TGATCCCACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGCCAGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGAC TGGGTTCCTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCCTCAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCC ATGACCCTGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGACCACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCT AGGCTGCCTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCAGCTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACAT CCCCACCCCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCTCCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCT ACCTCTGACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCTCTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAA TAAACCTGTAAATGAA >2281_2281_7_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000409489_GHRHR_chr7_31014586_ENST00000326139_length(amino acids)=501AA_BP=111 MAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVLVSCPELFRIFNPDQVW ETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTSLVTLTTAMVILCRFRK LHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTLLVETFFPERRYFYWYT IIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNESSIYLCWDLDDTSPYW WIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGIRLPLELGLGSFQGFIV AILYCFLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKVLTSMC -------------------------------------------------------------- >2281_2281_8_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000409489_GHRHR_chr7_31014586_ENST00000409904_length(transcript)=1807nt_BP=1072nt GCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACGTTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGC ATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGAAGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTC CAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCGCCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCC GAATCTTCAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAGAGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGG GAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCTTCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTG AGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCTACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCA TGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACTTCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCT CCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCAACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTT TCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCGAGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTG AAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCCCAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTG ATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGTGGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTG TGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGTCTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTGTGCTGGG ACCTGGACGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCATTGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTA TCCGCATCCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCATACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCC TGATCCCACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGCCAGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGAC TGGGTTCCTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCCTCAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCC ATGACCCTGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGACCACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCT AGGCTGCCTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCAGCTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACAT CCCCACCCCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCTCCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCT ACCTCTGACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCTCTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAA TAAACCT >2281_2281_8_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31132349_ENST00000409489_GHRHR_chr7_31014586_ENST00000409904_length(amino acids)=501AA_BP=111 MAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVLVSCPELFRIFNPDQVW ETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTSLVTLTTAMVILCRFRK LHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTLLVETFFPERRYFYWYT IIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNESSIYLCWDLDDTSPYW WIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGIRLPLELGLGSFQGFIV AILYCFLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKVLTSMC -------------------------------------------------------------- >2281_2281_9_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31139824_ENST00000396211_GHRHR_chr7_31014586_ENST00000326139_length(transcript)=1945nt_BP=1201nt CCCAGAGACACATTGGGGCTGACCTGCCGCTGCTGTCAGTGGGAGGCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACG TTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGCATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGA AGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTCCAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCG CCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCCGAATCTTCAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAG AGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGGGAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCT TCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTGAGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCT ACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCATGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACT TCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCTCCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCA ACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTTTCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCG AGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTGAAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCC CAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTGATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGT GGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTGTGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGT CTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTCAGCTGCGTGCAGAAATGCTACTGCAAGCCACAGCGGGCTCAGCAGCACTCTT GCAAGATGTCAGAACTGTCCACCATTACTCTGTGCTGGGACCTGGACGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCATTGTCC TCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCATCCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCATACCC AGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCCACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGCCAGACA ATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTCCTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCCTCAACC AAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCCTGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGACCACGC CTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGCCTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCAGCTACC ACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACCCCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCTCCCTG TCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTGACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCTCTTAC TGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCTGTAAATGAA >2281_2281_9_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31139824_ENST00000396211_GHRHR_chr7_31014586_ENST00000326139_length(amino acids)=545AA_BP=127 MPLLSVGGQWCWPRSVMAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVL VSCPELFRIFNPDQVWETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTS LVTLTTAMVILCRFRKLHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTL LVETFFPERRYFYWYTIIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNE SSIYFSCVQKCYCKPQRAQQHSCKMSELSTITLCWDLDDTSPYWWIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLS KSTLFLIPLFGIHYIIFNFLPDNAGLGIRLPLELGLGSFQGFIVAILYCFLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKV LTSMC -------------------------------------------------------------- >2281_2281_10_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31139824_ENST00000396211_GHRHR_chr7_31014586_ENST00000409904_length(transcript)=1936nt_BP=1201nt CCCAGAGACACATTGGGGCTGACCTGCCGCTGCTGTCAGTGGGAGGCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACG TTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGCATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGA AGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTCCAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCG CCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCCGAATCTTCAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAG AGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGGGAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCT TCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTGAGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCT ACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCATGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACT TCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCTCCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCA ACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTTTCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCG AGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTGAAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCC CAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTGATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGT GGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTGTGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGT CTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTCAGCTGCGTGCAGAAATGCTACTGCAAGCCACAGCGGGCTCAGCAGCACTCTT GCAAGATGTCAGAACTGTCCACCATTACTCTGTGCTGGGACCTGGACGACACCTCCCCCTACTGGTGGATCATCAAAGGGCCCATTGTCC TCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCATCCTGGTGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCATACCC AGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCCACTCTTTGGAATTCACTACATCATCTTCAACTTCCTGCCAGACA ATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTCCTTCCAGGGCTTCATTGTTGCCATCCTCTACTGCTTCCTCAACC AAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCCTGAGCTTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGACCACGC CTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGCCTCATCACGCCACTGGAGTCCACACTTGAATTTGGGCAGCTACC ACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACCCCAGCTGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCTCCCTG TCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTGACTTCTGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCTCTTAC TGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCT >2281_2281_10_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31139824_ENST00000396211_GHRHR_chr7_31014586_ENST00000409904_length(amino acids)=545AA_BP=127 MPLLSVGGQWCWPRSVMAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVL VSCPELFRIFNPDQVWETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTS LVTLTTAMVILCRFRKLHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTL LVETFFPERRYFYWYTIIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNE SSIYFSCVQKCYCKPQRAQQHSCKMSELSTITLCWDLDDTSPYWWIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQGSLHTQSQYWRLS KSTLFLIPLFGIHYIIFNFLPDNAGLGIRLPLELGLGSFQGFIVAILYCFLNQEVRTEISRKWHGHDPELLPAWRTRAKWTTPSRSAAKV LTSMC -------------------------------------------------------------- >2281_2281_11_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31139824_ENST00000409489_GHRHR_chr7_31014586_ENST00000326139_length(transcript)=1984nt_BP=1240nt GCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACGTTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGC ATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGAAGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTC CAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCGCCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCC GAATCTTCAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAGAGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGG GAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCTTCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTG AGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCTACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCA TGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACTTCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCT CCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCAACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTT TCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCGAGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTG AAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCCCAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTG ATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGTGGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTG TGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGTCTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTAACAAATT TAAGCCCGCGAGTCCCCAAGAAAGCCCGAGAGGACCCCCTGCCTGTGCCCTCAGACCAGCATTCACTCCCTTTCCTCAGCTGCGTGCAGA AATGCTACTGCAAGCCACAGCGGGCTCAGCAGCACTCTTGCAAGATGTCAGAACTGTCCACCATTACTCTGTGCTGGGACCTGGACGACA CCTCCCCCTACTGGTGGATCATCAAAGGGCCCATTGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCATCCTGG TGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCATACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCCACTCT TTGGAATTCACTACATCATCTTCAACTTCCTGCCAGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTCCTTCC AGGGCTTCATTGTTGCCATCCTCTACTGCTTCCTCAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCCTGAGC TTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGACCACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGCCTCAT CACGCCACTGGAGTCCACACTTGAATTTGGGCAGCTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACCCCAGC TGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCTCCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTGACTTC TGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCTCTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCTGTAAA TGAA >2281_2281_11_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31139824_ENST00000409489_GHRHR_chr7_31014586_ENST00000326139_length(amino acids)=557AA_BP=111 MAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVLVSCPELFRIFNPDQVW ETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTSLVTLTTAMVILCRFRK LHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTLLVETFFPERRYFYWYT IIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNESSIYLTNLSPRVPKKA REDPLPVPSDQHSLPFLSCVQKCYCKPQRAQQHSCKMSELSTITLCWDLDDTSPYWWIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQG SLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGIRLPLELGLGSFQGFIVAILYCFLNQEVRTEISRKWHGHDPELLPAWRTRA KWTTPSRSAAKVLTSMC -------------------------------------------------------------- >2281_2281_12_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31139824_ENST00000409489_GHRHR_chr7_31014586_ENST00000409904_length(transcript)=1975nt_BP=1240nt GCCAGTGGTGCTGGCCAAGAAGTGTCATGGCTGGTGTCGTGCACGTTTCCCTGGCTGCTCTCCTCCTGCTGCCTATGGCCCCTGCCATGC ATTCTGACTGCATCTTCAAGAAGGAGCAAGCCATGTGCCTGGAGAAGATCCAGAGGGCCAATGAGCTGATGGGCTTCAATGATTCCTCTC CAGGCTGTCCTGGGATGTGGGACAACATCACGTGTTGGAAGCCCGCCCATGTGGGTGAGATGGTCCTGGTCAGCTGCCCTGAGCTCTTCC GAATCTTCAACCCAGACCAAGTCTGGGAGACCGAAACCATTGGAGAGTCTGATTTTGGTGACAGTAACTCCTTAGATCTCTCAGACATGG GAGTGGTGAGCCGGAACTGCACGGAGGATGGCTGGTCGGAACCCTTCCCTCATTACTTTGATGCCTGTGGGTTTGATGAATATGAATCTG AGACTGGGGACCAGGATTATTACTACCTGTCAGTGAAGGCCCTCTACACGGTTGGCTACAGCACATCCCTCGTCACCCTCACCACTGCCA TGGTCATCCTTTGTCGCTTCCGGAAGCTGCACTGCACACGCAACTTCATCCACATGAACCTGTTTGTGTCGTTCATGCTGAGGGCGATCT CCGTCTTCATCAAAGACTGGATTCTGTATGCGGAGCAGGACAGCAACCACTGCTTCATCTCCACTGTGGAATGTAAGGCCGTCATGGTTT TCTTCCACTACTGTGTTGTGTCCAACTACTTCTGGCTGTTCATCGAGGGCCTGTACCTCTTCACTCTGCTGGTGGAGACCTTCTTCCCTG AAAGGAGATACTTCTACTGGTACACCATCATTGGCTGGGGGACCCCAACTGTGTGTGTGACAGTGTGGGCTACGCTGAGACTCTACTTTG ATGACACAGGCTGCTGGGATATGAATGACAGCACAGCTCTGTGGTGGGTGATCAAAGGCCCTGTGGTTGGCTCTATCATGGTTAACTTTG TGCTTTTTATTGGCATTATCGTCATCCTTGTGCAGAAACTTCAGTCTCCAGACATGGGAGGCAATGAGTCCAGCATCTACTTAACAAATT TAAGCCCGCGAGTCCCCAAGAAAGCCCGAGAGGACCCCCTGCCTGTGCCCTCAGACCAGCATTCACTCCCTTTCCTCAGCTGCGTGCAGA AATGCTACTGCAAGCCACAGCGGGCTCAGCAGCACTCTTGCAAGATGTCAGAACTGTCCACCATTACTCTGTGCTGGGACCTGGACGACA CCTCCCCCTACTGGTGGATCATCAAAGGGCCCATTGTCCTCTCGGTCGGGGTGAACTTTGGGCTTTTTCTCAATATTATCCGCATCCTGG TGAGGAAACTGGAGCCAGCTCAGGGCAGCCTCCATACCCAGTCTCAGTATTGGCGTCTCTCCAAGTCGACACTTTTCCTGATCCCACTCT TTGGAATTCACTACATCATCTTCAACTTCCTGCCAGACAATGCTGGCCTGGGCATCCGCCTCCCCCTGGAGCTGGGACTGGGTTCCTTCC AGGGCTTCATTGTTGCCATCCTCTACTGCTTCCTCAACCAAGAGGTGAGGACTGAGATCTCACGGAAGTGGCATGGCCATGACCCTGAGC TTCTGCCAGCCTGGAGGACCCGTGCTAAGTGGACCACGCCTTCCCGCTCGGCGGCAAAGGTGCTGACATCTATGTGCTAGGCTGCCTCAT CACGCCACTGGAGTCCACACTTGAATTTGGGCAGCTACCACGGGTCTGCCATGCTCTGGAGGAGCAAGGGGGCCACATCCCCACCCCAGC TGTTACCCAGCCCGGGGCAGGTGCAGCCCTTCCTCCCTGTCTCTGCATCTGACTCTCTTTTGAGGTCCCTGTATGTCTACCTCTGACTTC TGTGGTCCCTCTGTGTCTGCTCTCATCCATTCCTCTTACTGGGGCCTGGGGCTCTAGCCCAAGGCTCAGAGGAGCCAATAAACCT >2281_2281_12_ADCYAP1R1-GHRHR_ADCYAP1R1_chr7_31139824_ENST00000409489_GHRHR_chr7_31014586_ENST00000409904_length(amino acids)=557AA_BP=111 MAGVVHVSLAALLLLPMAPAMHSDCIFKKEQAMCLEKIQRANELMGFNDSSPGCPGMWDNITCWKPAHVGEMVLVSCPELFRIFNPDQVW ETETIGESDFGDSNSLDLSDMGVVSRNCTEDGWSEPFPHYFDACGFDEYESETGDQDYYYLSVKALYTVGYSTSLVTLTTAMVILCRFRK LHCTRNFIHMNLFVSFMLRAISVFIKDWILYAEQDSNHCFISTVECKAVMVFFHYCVVSNYFWLFIEGLYLFTLLVETFFPERRYFYWYT IIGWGTPTVCVTVWATLRLYFDDTGCWDMNDSTALWWVIKGPVVGSIMVNFVLFIGIIVILVQKLQSPDMGGNESSIYLTNLSPRVPKKA REDPLPVPSDQHSLPFLSCVQKCYCKPQRAQQHSCKMSELSTITLCWDLDDTSPYWWIIKGPIVLSVGVNFGLFLNIIRILVRKLEPAQG SLHTQSQYWRLSKSTLFLIPLFGIHYIIFNFLPDNAGLGIRLPLELGLGSFQGFIVAILYCFLNQEVRTEISRKWHGHDPELLPAWRTRA KWTTPSRSAAKVLTSMC -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ADCYAP1R1-GHRHR |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ADCYAP1R1-GHRHR |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ADCYAP1R1-GHRHR |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ADCYAP1R1 | C0004096 | Asthma | 1 | CTD_human |
| Hgene | ADCYAP1R1 | C0036341 | Schizophrenia | 1 | PSYGENET |
| Tgene | C4722273 | ISOLATED GROWTH HORMONE DEFICIENCY, TYPE IV | 5 | GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C2748571 | Isolated Growth Hormone Deficiency, Type IB | 2 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies