
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ADD3-VIL1 (FusionGDB2 ID:HG120TG7429) |
Fusion Gene Summary for ADD3-VIL1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ADD3-VIL1 | Fusion gene ID: hg120tg7429 | Hgene | Tgene | Gene symbol | ADD3 | VIL1 | Gene ID | 120 | 7429 |
| Gene name | adducin 3 | villin 1 | |
| Synonyms | ADDL|CPSQ3 | D2S1471|VIL | |
| Cytomap | ('ADD3')('VIL1') 10q25.1-q25.2 | 2q35 | |
| Type of gene | protein-coding | protein-coding | |
| Description | gamma-adducinadducin 3 (gamma)adducin-like protein 70 | villin-1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9UEY8 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000497125, ENST00000277900, ENST00000356080, ENST00000360162, | ||
| Fusion gene scores | * DoF score | 13 X 10 X 5=650 | 3 X 4 X 3=36 |
| # samples | 14 | 4 | |
| ** MAII score | log2(14/650*10)=-2.21501289097085 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/36*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: ADD3 [Title/Abstract] AND VIL1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ADD3(111877180)-VIL1(219305444), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ADD3-VIL1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ADD3-VIL1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ADD3-VIL1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ADD3-VIL1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | VIL1 | GO:0007173 | epidermal growth factor receptor signaling pathway | 17229814 |
| Tgene | VIL1 | GO:0008360 | regulation of cell shape | 16921170 |
| Tgene | VIL1 | GO:0009617 | response to bacterium | 17182858 |
| Tgene | VIL1 | GO:0010634 | positive regulation of epithelial cell migration | 17229814 |
| Tgene | VIL1 | GO:0030041 | actin filament polymerization | 11500485 |
| Tgene | VIL1 | GO:0030042 | actin filament depolymerization | 11500485 |
| Tgene | VIL1 | GO:0030335 | positive regulation of cell migration | 16921170 |
| Tgene | VIL1 | GO:0032233 | positive regulation of actin filament bundle assembly | 19808673 |
| Tgene | VIL1 | GO:0051014 | actin filament severing | 16921170|17182858|19808673 |
| Tgene | VIL1 | GO:0051125 | regulation of actin nucleation | 16921170|17182858|19808673 |
| Tgene | VIL1 | GO:0051693 | actin filament capping | 16921170|17182858|19808673 |
| Tgene | VIL1 | GO:0060327 | cytoplasmic actin-based contraction involved in cell motility | 15342783 |
| Tgene | VIL1 | GO:0071364 | cellular response to epidermal growth factor stimulus | 17229814 |
| Fusion gene breakpoints across ADD3 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across VIL1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-HU-8604 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
Top |
Fusion Gene ORF analysis for ADD3-VIL1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000497125 | ENST00000248444 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| 3UTR-3CDS | ENST00000497125 | ENST00000392114 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| 3UTR-intron | ENST00000497125 | ENST00000440053 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| 5CDS-intron | ENST00000277900 | ENST00000440053 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| 5CDS-intron | ENST00000356080 | ENST00000440053 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| 5CDS-intron | ENST00000360162 | ENST00000440053 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| In-frame | ENST00000277900 | ENST00000248444 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| In-frame | ENST00000277900 | ENST00000392114 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| In-frame | ENST00000356080 | ENST00000248444 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| In-frame | ENST00000356080 | ENST00000392114 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| In-frame | ENST00000360162 | ENST00000248444 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| In-frame | ENST00000360162 | ENST00000392114 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000360162 | ADD3 | chr10 | 111877180 | + | ENST00000248444 | VIL1 | chr2 | 219305444 | + | 5158 | 944 | 377 | 1198 | 273 |
| ENST00000360162 | ADD3 | chr10 | 111877180 | + | ENST00000392114 | VIL1 | chr2 | 219305444 | + | 1387 | 944 | 377 | 1198 | 273 |
| ENST00000356080 | ADD3 | chr10 | 111877180 | + | ENST00000248444 | VIL1 | chr2 | 219305444 | + | 5148 | 934 | 367 | 1188 | 273 |
| ENST00000356080 | ADD3 | chr10 | 111877180 | + | ENST00000392114 | VIL1 | chr2 | 219305444 | + | 1377 | 934 | 367 | 1188 | 273 |
| ENST00000277900 | ADD3 | chr10 | 111877180 | + | ENST00000248444 | VIL1 | chr2 | 219305444 | + | 5146 | 932 | 365 | 1186 | 273 |
| ENST00000277900 | ADD3 | chr10 | 111877180 | + | ENST00000392114 | VIL1 | chr2 | 219305444 | + | 1375 | 932 | 365 | 1186 | 273 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000360162 | ENST00000248444 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + | 0.000671421 | 0.9993286 |
| ENST00000360162 | ENST00000392114 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + | 0.002248344 | 0.99775165 |
| ENST00000356080 | ENST00000248444 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + | 0.000735743 | 0.9992643 |
| ENST00000356080 | ENST00000392114 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + | 0.003640755 | 0.9963593 |
| ENST00000277900 | ENST00000248444 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + | 0.000737432 | 0.9992625 |
| ENST00000277900 | ENST00000392114 | ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + | 0.003864795 | 0.99613523 |
Top |
Fusion Genomic Features for ADD3-VIL1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + | 2.63E-09 | 1 |
| ADD3 | chr10 | 111877180 | + | VIL1 | chr2 | 219305444 | + | 2.63E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
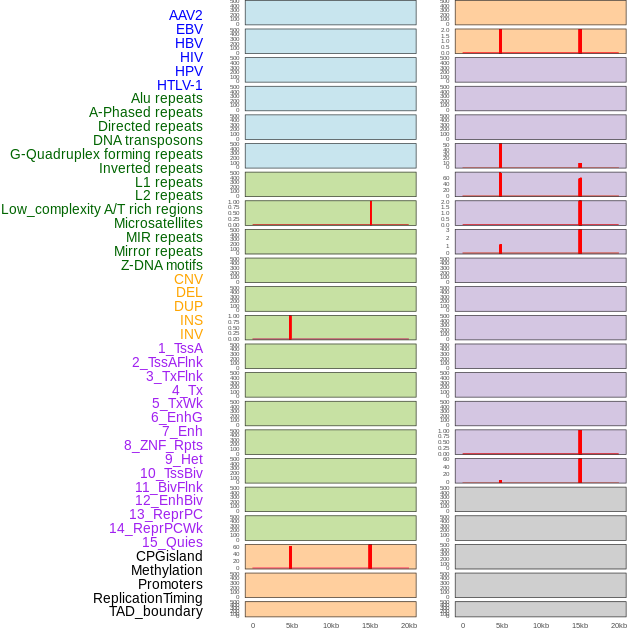 |
Top |
Fusion Protein Features for ADD3-VIL1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:111877180/chr2:219305444) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ADD3 | . |
| FUNCTION: Membrane-cytoskeleton-associated protein that promotes the assembly of the spectrin-actin network. Plays a role in actin filament capping (PubMed:23836506). Binds to calmodulin. {ECO:0000269|PubMed:23836506}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 761_827 | 743 | 828.0 | Domain | HP | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 816_824 | 743 | 828.0 | Region | Note=LPA/PIP2-binding site 3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 112_119 | 743 | 828.0 | Region | Note=LPA/PIP2-binding site 1 | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 138_146 | 743 | 828.0 | Region | Note=LPA/PIP2-binding site 2 | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 2_126 | 743 | 828.0 | Region | Note=Necessary for homodimerization | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 2_734 | 743 | 828.0 | Region | Note=Core | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 735_827 | 743 | 828.0 | Region | Note=Headpiece | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 148_188 | 743 | 828.0 | Repeat | Note=Gelsolin-like 2 | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 265_309 | 743 | 828.0 | Repeat | Note=Gelsolin-like 3 | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 27_76 | 743 | 828.0 | Repeat | Note=Gelsolin-like 1 | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 407_457 | 743 | 828.0 | Repeat | Note=Gelsolin-like 4 | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 528_568 | 743 | 828.0 | Repeat | Note=Gelsolin-like 5 | |
| Tgene | VIL1 | chr10:111877180 | chr2:219305444 | ENST00000248444 | 17 | 20 | 631_672 | 743 | 828.0 | Repeat | Note=Gelsolin-like 6 |
Top |
Fusion Gene Sequence for ADD3-VIL1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >2315_2315_1_ADD3-VIL1_ADD3_chr10_111877180_ENST00000277900_VIL1_chr2_219305444_ENST00000248444_length(transcript)=5146nt_BP=932nt GGCGCTCGGCTAGTCCCGCCAGAGCGCGAGCCGCCAGCCCGTAACGGTCGCCAGTGTGAGGGGCGGGAGGGAAAGAAGAGGGGTTTAAAT TAGATTTTTTAAAACACAGAGCAAGCGCCAGAGGCGTCGGCATCCCAGGTGTCGCCGCTTCCTGCTGCACAGGGCTCGGCGTACAGGTCC CTCCCTCCTCAAGCCCCCTCCCCTTCTCCCGCCCTACCCTCTGGGGCTCTGCGGCGCTTAAGAGGCGGCCGCAGCGGCGGATCCGGCGGC TGCTGCAGCCCGGGCGGCTGCCGAGAAGGAGGGAGGGGAAACACAAAGCCGGCTACGCGCTGCGAGATAACAAGAGTAATCCACAGACTT AAAACATGAGCTCAGATGCCAGCCAAGGCGTGATTACCACTCCTCCTCCTCCCAGCATGCCTCACAAAGAGAGATATTTTGACCGCATCA ATGAAAATGACCCAGAATACATTAGGGAGAGGAACATGTCTCCTGATCTACGACAAGACTTCAACATGATGGAGCAGAGGAAACGAGTTA CTCAGATCCTGCAAAGTCCTGCCTTTCGGGAAGACTTGGAATGCCTTATTCAAGAACAGATGAAGAAAGGCCACAACCCAACTGGATTAC TAGCATTACAGCAGATTGCAGATTACATCATGGCCAATTCTTTCTCGGGTTTTTCTTCACCTCCTCTCAGTCTTGGCATGGTCACACCTA TCAATGACCTTCCTGGTGCAGATACATCCTCATATGTGAAGGGAGAAAAACTTACTCGCTGTAAACTTGCCAGCCTGTACAGACTTGTAG ACTTGTTTGGATGGGCACACCTGGCAAATACCTATATCTCAGTAAGAATAAGTAAGGAGCAAGACCACATTATAATAATTCCCAGAGGCC TATCTTTTTCTGAAGCTACAGCCTCCAATTTGGAGGTCACAAGCCCCAAAGTGGACGTGTTCAATGCTAACAGCAACCTCAGTTCTGGGC CTCTGCCCATCTTCCCCCTGGAGCAGCTAGTGAACAAGCCTGTAGAGGAGCTCCCCGAGGGTGTGGACCCCAGCAGGAAGGAGGAACACC TGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAG AAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCC TACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAATGCCAGTTTTGTTTAATAATGTACCTATTCC TTCAGAAAGATGATACCCCAAAAGGAGCCTATGGTCCTCATTTCAACTTCTAAGGTCGCTAGATTGTTTCTATCCTGAGGTATTGCATCA ATTTTAATACTCCTATAGTTTTCTCTTCTTAGAAGAGCACAAACACTCCATGGAACATTAGAGTTCTGAGGCACTACCCTAGCTTGTCCT CTATCATGACTCATTTTTATCTATGGCAGGTAGGCTGAAGCACTTTGCAGGTTTACATCTTCCCCAGAGTAACAGCTTTTCCTTTTCACA TATACTTTCCTTACTGCCTTACTCAGTGGGTAAGTTAAAGGGCTGAAGGAGAGTTGAATGGTCCACAAGACTACCCTCTTAAGAGGTTTC ACAAATTCCAAACAGTACCAGTGAGAGCAGCACTTCCACTGGGGCTAGGCTTGAGACCTAAAGGCAAGTATGAAATGCATATGCTACTTC ACTCCCTCTCCCAACCCTTAATAATGAGGCAAAGCAAGAGCCTAGTGAAGGCCAATGCTAGGTTTACAAACTTACCCAGAAGCCTCTGCA AAGCTTCACAGGCTCCTCAGATGAAAATAACAGGAATCAATGGGGACTACGGCCAGACACTGGTTTGCCATTCTGTTCCTTTTAAGAAGT AACAGTGCTGCAAGGAAGTCCATGTCAGAAAGCCAACAGAAGGTGATTTCCACAACTTTGAACAGGTTGTTACAAGTATCAGCAAGAATG TGTCCTTTTCAGAAATAACAGTCAAATCAAAGAAGGTTAATAAAGGCTTTAATTTCATACACACAAAAAAACTCTATGCATAATTTAAAA AGGAAACAAAAACAAAGAAAAACCGTAAAGGATACAGAGGAACAGTTCTGCTAAAACACAGATAAAAGTGCCGCTCCATACAAAACATAA AGAATCAGAATCAAAAGTCACTCTGAACATAAAGAAAAAAAATCATCTCACAAATAATGTGGCCACAGCTGCCAGAAAACCTGGTAGTGG CTCAATTAGGCAAAGTGTAGGAATCTCATTTTTGTTTTTCTCTCCTTAAGTTTAAAGAAACAACAATGACAATAGGCCAGAGAAGTTAGG GAGGGAAAGAAAAGCTCAAAGGGAGGGAAACCTGGGGACAAGAGGTGTGCACACCCACATGTGGTCTCACTCTTCACACAGGCCCACTAT TTTTGAAGTAGACCAGTTTAGTTGACTGTTCTTCTTTGTTCTGGCATCTGACTGGACCAACCTGGAACCTGGTCCAGACCCTCACCCACT CTATTCTTATGCCAATGGACATACCTATACTTTGAACCTCTGTACTTTTAAGAAAAGTCCAATGTTACAAAATCAAATGCTTATATTCAG ACTGGCACACTTTTTAAATAAAAACTCCATACACCTCAGACATATAGCACACATGGAGACAACTTACTAATTGTGTGTAAGTATGATACA ATGAATGAGACTGCCTGAAGTCTAGTAATCAAAGCATGCCATAAGGTGAATGATTGTGGTTAAACACAGCAAAATAATTGTCACAAAACT TTCAAGGCCTAACAAATTAGAATTTTCCAATAAAAAATATATATTTTTTCAGATGTTAATAAGACATATCAGTAGAGACAAAATTAGGAT TTTGAAGTAATGCAATAAAAAGATGTTGGAGGGCAGAAGTCTATTTAGTTTTTGTATACACTTGCAAGAGTGCATTACTCAGTATAAAGC AAAATGGGGAGGAAAAAGACATCCATCCATTTTATTGGAACACTTTTATGTGACTTGAATCTGGTGTTAGGTTGTTGATTTTTCTAAAAA TCTCCTATATATACAAAATCCATATGTACTTGGAGATCCAGCTGTTGCCCCCTGTTTAAAACAAAAGACCACCTCGGGGGGTCAATTAAA TTAAAAAGGCCCTCCAACCACCCTAAATGGGATAACTAAGAGTATCTACTGCAGTCATTTCAGAGGACAGAGAAGGAAAATATTTTAATT TGCTTTAATATAACCTCTTTTCAGTAGATCACAAATGAGTTTACAAACTACTTTTTTTTCTCTTTAATTTAGGTGTTTGCAGATAATTTT CATTATATCCGTAGCTGTATGTGTGTATAGTTACATAATGGTAACTACACACGATACAGAAGAATCAGTAAATTCATGGATTATTTTGCT GAGGTTTTAAATTTTAAAGCCTCTGTTTCAGAATTTTATACTTGATCAAGGAGAAAAATAAATGTGTAGTCTAACATTTGCTTTCTGGAG TTAATTAACTGATCTGTAAGAACCACTGCATATGTCTTAAAATGTAAACATATTTACATTTGTTGTATTTGTTATTGAGCCTTTAAGGTT AGGCCCAGAATGAACAGACCATAGCAAGTAAACAAATAATTTTTAGAATCAAAGTATTAATAGAAGACCAGTTCATGGATTTGCTTATTC TATCCTGCTGAGACAAAACTCATGAGTGTGCACACACATGTGAATATATCCCTACGAAACAGTCTATCTTCTCATAGGCTTAAATTATAG TCATGGCTATTAAAGAAATTAACAGCATCCAGCCACATGCAACTTTCCAACCTTCAGTACTATTAGGTGATTAAAATCAACAAATATGAA GTTTAGTTCATTTTTCCCTTAAAATTCCAACAAAGATCAAAAGGTTGTATCTAGAACTAATTGCCATCAAGTTCCAATTCAATGTCATTT AAAGTAATGTAACCACACATTTGGTATTTTCAATAGGAAGGTTAATTAGGTATTGTGCAAACTGCCTGCAACGGAAGCACTCAGTCCTTA TCTAACTTGTCCCTTCCTGGCCCCAACATGCTAACTGCCCCATCCCCAATTCTGGGCAAACTGATCACAATGTGCAAAAAATAATATATT ATCTATTTATAATTTTAAAATATATACAGCCAGCTCAAAAACAACAACAAACCCCATCAACATAGTCCAGCTGAAATCTCCACTGGTAGT CAAAGAAGTAGATTAAAGGAGTAAAGGAAGGAGAAGGCTGATAGGGCCACAAGAATGGACAGACATCAAGTAAAATTTGAGTCCCAAACA TGCAAGTACATGAGCAGTGAGATAACTTATATATTCCAATAACCTATTTTCAACAACTCCTGCCCAAGACATGAAGATCAAATCAGGTTT CTGAGGTAAGTGTACTTCTAAACCATACACACATGAAAGCTATGAAAGCAATTCAAATGAGGCTGCTTCATGAGGCAATCTAGACTTATG GCATTATTTCTACTTTTCTCCATGTTTTAATTGCAGCCTGCACTTTAAATCTTTCCCAATAATTTTTAACAGTGCCTCTCAAATGCAAAG ACACGTAAAAGAATTAATAACTAGCCAAAGAATTTTATCACCGCTTCACTCATTTATAAGAAAACCAATTATTTCCAAGCAAAATCAAAC CAAACCAAAGAGGCTCCTGGTAGAAATGAAACAAAACTTTAAAGCTAGTTTTAAAACAAATATTTTCCTCTGCTCTAAACTACTCTGGCG TTTTCTACCACTCTACCATTTTGGAACATTCATTACAATAAGGTATATAGGTAGATGGTAGGAGGCAAAGCATTTATCAGTAGTTGAGCA AAACTGCTGAGGCCATTTATAATTCAAAGAATGAAAACTTAGAATAGTTTACTACATTAGAATACATCCAAGTTCCAAGAGTAGGACTGG AGCTCTCTTAAGGCAATCTTTCAGAAAAGATGTTGCATCTTCTGTGATGATGGTTTGTGTTTTTTTTGTTTTTGTTTTCGTTTTTTTTAA TGAGATGGAGTCTCAC >2315_2315_1_ADD3-VIL1_ADD3_chr10_111877180_ENST00000277900_VIL1_chr2_219305444_ENST00000248444_length(amino acids)=273AA_BP=189 MSSDASQGVITTPPPPSMPHKERYFDRINENDPEYIRERNMSPDLRQDFNMMEQRKRVTQILQSPAFREDLECLIQEQMKKGHNPTGLLA LQQIADYIMANSFSGFSSPPLSLGMVTPINDLPGADTSSYVKGEKLTRCKLASLYRLVDLFGWAHLANTYISVRISKEQDHIIIIPRGLS FSEATASNLEVTSPKVDVFNANSNLSSGPLPIFPLEQLVNKPVEELPEGVDPSRKEEHLSIEDFTQAFGMTPAAFSALPRWKQQNLKKEK GLF -------------------------------------------------------------- >2315_2315_2_ADD3-VIL1_ADD3_chr10_111877180_ENST00000277900_VIL1_chr2_219305444_ENST00000392114_length(transcript)=1375nt_BP=932nt GGCGCTCGGCTAGTCCCGCCAGAGCGCGAGCCGCCAGCCCGTAACGGTCGCCAGTGTGAGGGGCGGGAGGGAAAGAAGAGGGGTTTAAAT TAGATTTTTTAAAACACAGAGCAAGCGCCAGAGGCGTCGGCATCCCAGGTGTCGCCGCTTCCTGCTGCACAGGGCTCGGCGTACAGGTCC CTCCCTCCTCAAGCCCCCTCCCCTTCTCCCGCCCTACCCTCTGGGGCTCTGCGGCGCTTAAGAGGCGGCCGCAGCGGCGGATCCGGCGGC TGCTGCAGCCCGGGCGGCTGCCGAGAAGGAGGGAGGGGAAACACAAAGCCGGCTACGCGCTGCGAGATAACAAGAGTAATCCACAGACTT AAAACATGAGCTCAGATGCCAGCCAAGGCGTGATTACCACTCCTCCTCCTCCCAGCATGCCTCACAAAGAGAGATATTTTGACCGCATCA ATGAAAATGACCCAGAATACATTAGGGAGAGGAACATGTCTCCTGATCTACGACAAGACTTCAACATGATGGAGCAGAGGAAACGAGTTA CTCAGATCCTGCAAAGTCCTGCCTTTCGGGAAGACTTGGAATGCCTTATTCAAGAACAGATGAAGAAAGGCCACAACCCAACTGGATTAC TAGCATTACAGCAGATTGCAGATTACATCATGGCCAATTCTTTCTCGGGTTTTTCTTCACCTCCTCTCAGTCTTGGCATGGTCACACCTA TCAATGACCTTCCTGGTGCAGATACATCCTCATATGTGAAGGGAGAAAAACTTACTCGCTGTAAACTTGCCAGCCTGTACAGACTTGTAG ACTTGTTTGGATGGGCACACCTGGCAAATACCTATATCTCAGTAAGAATAAGTAAGGAGCAAGACCACATTATAATAATTCCCAGAGGCC TATCTTTTTCTGAAGCTACAGCCTCCAATTTGGAGGTCACAAGCCCCAAAGTGGACGTGTTCAATGCTAACAGCAACCTCAGTTCTGGGC CTCTGCCCATCTTCCCCCTGGAGCAGCTAGTGAACAAGCCTGTAGAGGAGCTCCCCGAGGGTGTGGACCCCAGCAGGAAGGAGGAACACC TGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAAAG AAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCACCGATATTAGTCC TACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAATGCCAGTTTTGTTTAATAATGTACCTATTCC TTCAGAAAGATGATACCCCAAAAGG >2315_2315_2_ADD3-VIL1_ADD3_chr10_111877180_ENST00000277900_VIL1_chr2_219305444_ENST00000392114_length(amino acids)=273AA_BP=189 MSSDASQGVITTPPPPSMPHKERYFDRINENDPEYIRERNMSPDLRQDFNMMEQRKRVTQILQSPAFREDLECLIQEQMKKGHNPTGLLA LQQIADYIMANSFSGFSSPPLSLGMVTPINDLPGADTSSYVKGEKLTRCKLASLYRLVDLFGWAHLANTYISVRISKEQDHIIIIPRGLS FSEATASNLEVTSPKVDVFNANSNLSSGPLPIFPLEQLVNKPVEELPEGVDPSRKEEHLSIEDFTQAFGMTPAAFSALPRWKQQNLKKEK GLF -------------------------------------------------------------- >2315_2315_3_ADD3-VIL1_ADD3_chr10_111877180_ENST00000356080_VIL1_chr2_219305444_ENST00000248444_length(transcript)=5148nt_BP=934nt GGGGCGCTCGGCTAGTCCCGCCAGAGCGCGAGCCGCCAGCCCGTAACGGTCGCCAGTGTGAGGGGCGGGAGGGAAAGAAGAGGGGTTTAA ATTAGATTTTTTAAAACACAGAGCAAGCGCCAGAGGCGTCGGCATCCCAGGTGTCGCCGCTTCCTGCTGCACAGGGCTCGGCGTACAGGT CCCTCCCTCCTCAAGCCCCCTCCCCTTCTCCCGCCCTACCCTCTGGGGCTCTGCGGCGCTTAAGAGGCGGCCGCAGCGGCGGATCCGGCG GCTGCTGCAGCCCGGGCGGCTGCCGAGAAGGAGGGAGGGGAAACACAAAGCCGGCTACGCGCTGCGAGATAACAAGAGTAATCCACAGAC TTAAAACATGAGCTCAGATGCCAGCCAAGGCGTGATTACCACTCCTCCTCCTCCCAGCATGCCTCACAAAGAGAGATATTTTGACCGCAT CAATGAAAATGACCCAGAATACATTAGGGAGAGGAACATGTCTCCTGATCTACGACAAGACTTCAACATGATGGAGCAGAGGAAACGAGT TACTCAGATCCTGCAAAGTCCTGCCTTTCGGGAAGACTTGGAATGCCTTATTCAAGAACAGATGAAGAAAGGCCACAACCCAACTGGATT ACTAGCATTACAGCAGATTGCAGATTACATCATGGCCAATTCTTTCTCGGGTTTTTCTTCACCTCCTCTCAGTCTTGGCATGGTCACACC TATCAATGACCTTCCTGGTGCAGATACATCCTCATATGTGAAGGGAGAAAAACTTACTCGCTGTAAACTTGCCAGCCTGTACAGACTTGT AGACTTGTTTGGATGGGCACACCTGGCAAATACCTATATCTCAGTAAGAATAAGTAAGGAGCAAGACCACATTATAATAATTCCCAGAGG CCTATCTTTTTCTGAAGCTACAGCCTCCAATTTGGAGGTCACAAGCCCCAAAGTGGACGTGTTCAATGCTAACAGCAACCTCAGTTCTGG GCCTCTGCCCATCTTCCCCCTGGAGCAGCTAGTGAACAAGCCTGTAGAGGAGCTCCCCGAGGGTGTGGACCCCAGCAGGAAGGAGGAACA CCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAA AGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCACCGATATTAGT CCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAATGCCAGTTTTGTTTAATAATGTACCTATT CCTTCAGAAAGATGATACCCCAAAAGGAGCCTATGGTCCTCATTTCAACTTCTAAGGTCGCTAGATTGTTTCTATCCTGAGGTATTGCAT CAATTTTAATACTCCTATAGTTTTCTCTTCTTAGAAGAGCACAAACACTCCATGGAACATTAGAGTTCTGAGGCACTACCCTAGCTTGTC CTCTATCATGACTCATTTTTATCTATGGCAGGTAGGCTGAAGCACTTTGCAGGTTTACATCTTCCCCAGAGTAACAGCTTTTCCTTTTCA CATATACTTTCCTTACTGCCTTACTCAGTGGGTAAGTTAAAGGGCTGAAGGAGAGTTGAATGGTCCACAAGACTACCCTCTTAAGAGGTT TCACAAATTCCAAACAGTACCAGTGAGAGCAGCACTTCCACTGGGGCTAGGCTTGAGACCTAAAGGCAAGTATGAAATGCATATGCTACT TCACTCCCTCTCCCAACCCTTAATAATGAGGCAAAGCAAGAGCCTAGTGAAGGCCAATGCTAGGTTTACAAACTTACCCAGAAGCCTCTG CAAAGCTTCACAGGCTCCTCAGATGAAAATAACAGGAATCAATGGGGACTACGGCCAGACACTGGTTTGCCATTCTGTTCCTTTTAAGAA GTAACAGTGCTGCAAGGAAGTCCATGTCAGAAAGCCAACAGAAGGTGATTTCCACAACTTTGAACAGGTTGTTACAAGTATCAGCAAGAA TGTGTCCTTTTCAGAAATAACAGTCAAATCAAAGAAGGTTAATAAAGGCTTTAATTTCATACACACAAAAAAACTCTATGCATAATTTAA AAAGGAAACAAAAACAAAGAAAAACCGTAAAGGATACAGAGGAACAGTTCTGCTAAAACACAGATAAAAGTGCCGCTCCATACAAAACAT AAAGAATCAGAATCAAAAGTCACTCTGAACATAAAGAAAAAAAATCATCTCACAAATAATGTGGCCACAGCTGCCAGAAAACCTGGTAGT GGCTCAATTAGGCAAAGTGTAGGAATCTCATTTTTGTTTTTCTCTCCTTAAGTTTAAAGAAACAACAATGACAATAGGCCAGAGAAGTTA GGGAGGGAAAGAAAAGCTCAAAGGGAGGGAAACCTGGGGACAAGAGGTGTGCACACCCACATGTGGTCTCACTCTTCACACAGGCCCACT ATTTTTGAAGTAGACCAGTTTAGTTGACTGTTCTTCTTTGTTCTGGCATCTGACTGGACCAACCTGGAACCTGGTCCAGACCCTCACCCA CTCTATTCTTATGCCAATGGACATACCTATACTTTGAACCTCTGTACTTTTAAGAAAAGTCCAATGTTACAAAATCAAATGCTTATATTC AGACTGGCACACTTTTTAAATAAAAACTCCATACACCTCAGACATATAGCACACATGGAGACAACTTACTAATTGTGTGTAAGTATGATA CAATGAATGAGACTGCCTGAAGTCTAGTAATCAAAGCATGCCATAAGGTGAATGATTGTGGTTAAACACAGCAAAATAATTGTCACAAAA CTTTCAAGGCCTAACAAATTAGAATTTTCCAATAAAAAATATATATTTTTTCAGATGTTAATAAGACATATCAGTAGAGACAAAATTAGG ATTTTGAAGTAATGCAATAAAAAGATGTTGGAGGGCAGAAGTCTATTTAGTTTTTGTATACACTTGCAAGAGTGCATTACTCAGTATAAA GCAAAATGGGGAGGAAAAAGACATCCATCCATTTTATTGGAACACTTTTATGTGACTTGAATCTGGTGTTAGGTTGTTGATTTTTCTAAA AATCTCCTATATATACAAAATCCATATGTACTTGGAGATCCAGCTGTTGCCCCCTGTTTAAAACAAAAGACCACCTCGGGGGGTCAATTA AATTAAAAAGGCCCTCCAACCACCCTAAATGGGATAACTAAGAGTATCTACTGCAGTCATTTCAGAGGACAGAGAAGGAAAATATTTTAA TTTGCTTTAATATAACCTCTTTTCAGTAGATCACAAATGAGTTTACAAACTACTTTTTTTTCTCTTTAATTTAGGTGTTTGCAGATAATT TTCATTATATCCGTAGCTGTATGTGTGTATAGTTACATAATGGTAACTACACACGATACAGAAGAATCAGTAAATTCATGGATTATTTTG CTGAGGTTTTAAATTTTAAAGCCTCTGTTTCAGAATTTTATACTTGATCAAGGAGAAAAATAAATGTGTAGTCTAACATTTGCTTTCTGG AGTTAATTAACTGATCTGTAAGAACCACTGCATATGTCTTAAAATGTAAACATATTTACATTTGTTGTATTTGTTATTGAGCCTTTAAGG TTAGGCCCAGAATGAACAGACCATAGCAAGTAAACAAATAATTTTTAGAATCAAAGTATTAATAGAAGACCAGTTCATGGATTTGCTTAT TCTATCCTGCTGAGACAAAACTCATGAGTGTGCACACACATGTGAATATATCCCTACGAAACAGTCTATCTTCTCATAGGCTTAAATTAT AGTCATGGCTATTAAAGAAATTAACAGCATCCAGCCACATGCAACTTTCCAACCTTCAGTACTATTAGGTGATTAAAATCAACAAATATG AAGTTTAGTTCATTTTTCCCTTAAAATTCCAACAAAGATCAAAAGGTTGTATCTAGAACTAATTGCCATCAAGTTCCAATTCAATGTCAT TTAAAGTAATGTAACCACACATTTGGTATTTTCAATAGGAAGGTTAATTAGGTATTGTGCAAACTGCCTGCAACGGAAGCACTCAGTCCT TATCTAACTTGTCCCTTCCTGGCCCCAACATGCTAACTGCCCCATCCCCAATTCTGGGCAAACTGATCACAATGTGCAAAAAATAATATA TTATCTATTTATAATTTTAAAATATATACAGCCAGCTCAAAAACAACAACAAACCCCATCAACATAGTCCAGCTGAAATCTCCACTGGTA GTCAAAGAAGTAGATTAAAGGAGTAAAGGAAGGAGAAGGCTGATAGGGCCACAAGAATGGACAGACATCAAGTAAAATTTGAGTCCCAAA CATGCAAGTACATGAGCAGTGAGATAACTTATATATTCCAATAACCTATTTTCAACAACTCCTGCCCAAGACATGAAGATCAAATCAGGT TTCTGAGGTAAGTGTACTTCTAAACCATACACACATGAAAGCTATGAAAGCAATTCAAATGAGGCTGCTTCATGAGGCAATCTAGACTTA TGGCATTATTTCTACTTTTCTCCATGTTTTAATTGCAGCCTGCACTTTAAATCTTTCCCAATAATTTTTAACAGTGCCTCTCAAATGCAA AGACACGTAAAAGAATTAATAACTAGCCAAAGAATTTTATCACCGCTTCACTCATTTATAAGAAAACCAATTATTTCCAAGCAAAATCAA ACCAAACCAAAGAGGCTCCTGGTAGAAATGAAACAAAACTTTAAAGCTAGTTTTAAAACAAATATTTTCCTCTGCTCTAAACTACTCTGG CGTTTTCTACCACTCTACCATTTTGGAACATTCATTACAATAAGGTATATAGGTAGATGGTAGGAGGCAAAGCATTTATCAGTAGTTGAG CAAAACTGCTGAGGCCATTTATAATTCAAAGAATGAAAACTTAGAATAGTTTACTACATTAGAATACATCCAAGTTCCAAGAGTAGGACT GGAGCTCTCTTAAGGCAATCTTTCAGAAAAGATGTTGCATCTTCTGTGATGATGGTTTGTGTTTTTTTTGTTTTTGTTTTCGTTTTTTTT AATGAGATGGAGTCTCAC >2315_2315_3_ADD3-VIL1_ADD3_chr10_111877180_ENST00000356080_VIL1_chr2_219305444_ENST00000248444_length(amino acids)=273AA_BP=189 MSSDASQGVITTPPPPSMPHKERYFDRINENDPEYIRERNMSPDLRQDFNMMEQRKRVTQILQSPAFREDLECLIQEQMKKGHNPTGLLA LQQIADYIMANSFSGFSSPPLSLGMVTPINDLPGADTSSYVKGEKLTRCKLASLYRLVDLFGWAHLANTYISVRISKEQDHIIIIPRGLS FSEATASNLEVTSPKVDVFNANSNLSSGPLPIFPLEQLVNKPVEELPEGVDPSRKEEHLSIEDFTQAFGMTPAAFSALPRWKQQNLKKEK GLF -------------------------------------------------------------- >2315_2315_4_ADD3-VIL1_ADD3_chr10_111877180_ENST00000356080_VIL1_chr2_219305444_ENST00000392114_length(transcript)=1377nt_BP=934nt GGGGCGCTCGGCTAGTCCCGCCAGAGCGCGAGCCGCCAGCCCGTAACGGTCGCCAGTGTGAGGGGCGGGAGGGAAAGAAGAGGGGTTTAA ATTAGATTTTTTAAAACACAGAGCAAGCGCCAGAGGCGTCGGCATCCCAGGTGTCGCCGCTTCCTGCTGCACAGGGCTCGGCGTACAGGT CCCTCCCTCCTCAAGCCCCCTCCCCTTCTCCCGCCCTACCCTCTGGGGCTCTGCGGCGCTTAAGAGGCGGCCGCAGCGGCGGATCCGGCG GCTGCTGCAGCCCGGGCGGCTGCCGAGAAGGAGGGAGGGGAAACACAAAGCCGGCTACGCGCTGCGAGATAACAAGAGTAATCCACAGAC TTAAAACATGAGCTCAGATGCCAGCCAAGGCGTGATTACCACTCCTCCTCCTCCCAGCATGCCTCACAAAGAGAGATATTTTGACCGCAT CAATGAAAATGACCCAGAATACATTAGGGAGAGGAACATGTCTCCTGATCTACGACAAGACTTCAACATGATGGAGCAGAGGAAACGAGT TACTCAGATCCTGCAAAGTCCTGCCTTTCGGGAAGACTTGGAATGCCTTATTCAAGAACAGATGAAGAAAGGCCACAACCCAACTGGATT ACTAGCATTACAGCAGATTGCAGATTACATCATGGCCAATTCTTTCTCGGGTTTTTCTTCACCTCCTCTCAGTCTTGGCATGGTCACACC TATCAATGACCTTCCTGGTGCAGATACATCCTCATATGTGAAGGGAGAAAAACTTACTCGCTGTAAACTTGCCAGCCTGTACAGACTTGT AGACTTGTTTGGATGGGCACACCTGGCAAATACCTATATCTCAGTAAGAATAAGTAAGGAGCAAGACCACATTATAATAATTCCCAGAGG CCTATCTTTTTCTGAAGCTACAGCCTCCAATTTGGAGGTCACAAGCCCCAAAGTGGACGTGTTCAATGCTAACAGCAACCTCAGTTCTGG GCCTCTGCCCATCTTCCCCCTGGAGCAGCTAGTGAACAAGCCTGTAGAGGAGCTCCCCGAGGGTGTGGACCCCAGCAGGAAGGAGGAACA CCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAAACCTCAAGAA AGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCACCGATATTAGT CCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAATGCCAGTTTTGTTTAATAATGTACCTATT CCTTCAGAAAGATGATACCCCAAAAGG >2315_2315_4_ADD3-VIL1_ADD3_chr10_111877180_ENST00000356080_VIL1_chr2_219305444_ENST00000392114_length(amino acids)=273AA_BP=189 MSSDASQGVITTPPPPSMPHKERYFDRINENDPEYIRERNMSPDLRQDFNMMEQRKRVTQILQSPAFREDLECLIQEQMKKGHNPTGLLA LQQIADYIMANSFSGFSSPPLSLGMVTPINDLPGADTSSYVKGEKLTRCKLASLYRLVDLFGWAHLANTYISVRISKEQDHIIIIPRGLS FSEATASNLEVTSPKVDVFNANSNLSSGPLPIFPLEQLVNKPVEELPEGVDPSRKEEHLSIEDFTQAFGMTPAAFSALPRWKQQNLKKEK GLF -------------------------------------------------------------- >2315_2315_5_ADD3-VIL1_ADD3_chr10_111877180_ENST00000360162_VIL1_chr2_219305444_ENST00000248444_length(transcript)=5158nt_BP=944nt AGTCCACAAAACTCCCTGATTCCATCCTCTCTGCCTCTTATGAAGCAATACTAGAGAGGAAAAACAAAACCCATTCCTTTAAGAAAGATT CCGCCTCCTCTCATAAGCAAGCGCCTAATGGTAATTGTAGAGTTTACTAAGTCAAACACTTACTACTCAGCATTGAGAGAAGCTGCTGCT GCTAATGCTGCTGCTGCTGCTGCCGCCGCCGCCGCTGCTGCTGCTGCTGTTGGTCTGAGGCTGCAGTAGGTTTCTGTGCAGCATTGCAGA ATCCACACCTAGAGAACAGAAGACACAGACACGTACGTCTACTACCCTTGTTAGAAGGAAGCTTTGGATCTTCGGTGGATAACAAGAGTA ATCCACAGACTTAAAACATGAGCTCAGATGCCAGCCAAGGCGTGATTACCACTCCTCCTCCTCCCAGCATGCCTCACAAAGAGAGATATT TTGACCGCATCAATGAAAATGACCCAGAATACATTAGGGAGAGGAACATGTCTCCTGATCTACGACAAGACTTCAACATGATGGAGCAGA GGAAACGAGTTACTCAGATCCTGCAAAGTCCTGCCTTTCGGGAAGACTTGGAATGCCTTATTCAAGAACAGATGAAGAAAGGCCACAACC CAACTGGATTACTAGCATTACAGCAGATTGCAGATTACATCATGGCCAATTCTTTCTCGGGTTTTTCTTCACCTCCTCTCAGTCTTGGCA TGGTCACACCTATCAATGACCTTCCTGGTGCAGATACATCCTCATATGTGAAGGGAGAAAAACTTACTCGCTGTAAACTTGCCAGCCTGT ACAGACTTGTAGACTTGTTTGGATGGGCACACCTGGCAAATACCTATATCTCAGTAAGAATAAGTAAGGAGCAAGACCACATTATAATAA TTCCCAGAGGCCTATCTTTTTCTGAAGCTACAGCCTCCAATTTGGAGGTCACAAGCCCCAAAGTGGACGTGTTCAATGCTAACAGCAACC TCAGTTCTGGGCCTCTGCCCATCTTCCCCCTGGAGCAGCTAGTGAACAAGCCTGTAGAGGAGCTCCCCGAGGGTGTGGACCCCAGCAGGA AGGAGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAA ACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCAC CGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAATGCCAGTTTTGTTTAATAA TGTACCTATTCCTTCAGAAAGATGATACCCCAAAAGGAGCCTATGGTCCTCATTTCAACTTCTAAGGTCGCTAGATTGTTTCTATCCTGA GGTATTGCATCAATTTTAATACTCCTATAGTTTTCTCTTCTTAGAAGAGCACAAACACTCCATGGAACATTAGAGTTCTGAGGCACTACC CTAGCTTGTCCTCTATCATGACTCATTTTTATCTATGGCAGGTAGGCTGAAGCACTTTGCAGGTTTACATCTTCCCCAGAGTAACAGCTT TTCCTTTTCACATATACTTTCCTTACTGCCTTACTCAGTGGGTAAGTTAAAGGGCTGAAGGAGAGTTGAATGGTCCACAAGACTACCCTC TTAAGAGGTTTCACAAATTCCAAACAGTACCAGTGAGAGCAGCACTTCCACTGGGGCTAGGCTTGAGACCTAAAGGCAAGTATGAAATGC ATATGCTACTTCACTCCCTCTCCCAACCCTTAATAATGAGGCAAAGCAAGAGCCTAGTGAAGGCCAATGCTAGGTTTACAAACTTACCCA GAAGCCTCTGCAAAGCTTCACAGGCTCCTCAGATGAAAATAACAGGAATCAATGGGGACTACGGCCAGACACTGGTTTGCCATTCTGTTC CTTTTAAGAAGTAACAGTGCTGCAAGGAAGTCCATGTCAGAAAGCCAACAGAAGGTGATTTCCACAACTTTGAACAGGTTGTTACAAGTA TCAGCAAGAATGTGTCCTTTTCAGAAATAACAGTCAAATCAAAGAAGGTTAATAAAGGCTTTAATTTCATACACACAAAAAAACTCTATG CATAATTTAAAAAGGAAACAAAAACAAAGAAAAACCGTAAAGGATACAGAGGAACAGTTCTGCTAAAACACAGATAAAAGTGCCGCTCCA TACAAAACATAAAGAATCAGAATCAAAAGTCACTCTGAACATAAAGAAAAAAAATCATCTCACAAATAATGTGGCCACAGCTGCCAGAAA ACCTGGTAGTGGCTCAATTAGGCAAAGTGTAGGAATCTCATTTTTGTTTTTCTCTCCTTAAGTTTAAAGAAACAACAATGACAATAGGCC AGAGAAGTTAGGGAGGGAAAGAAAAGCTCAAAGGGAGGGAAACCTGGGGACAAGAGGTGTGCACACCCACATGTGGTCTCACTCTTCACA CAGGCCCACTATTTTTGAAGTAGACCAGTTTAGTTGACTGTTCTTCTTTGTTCTGGCATCTGACTGGACCAACCTGGAACCTGGTCCAGA CCCTCACCCACTCTATTCTTATGCCAATGGACATACCTATACTTTGAACCTCTGTACTTTTAAGAAAAGTCCAATGTTACAAAATCAAAT GCTTATATTCAGACTGGCACACTTTTTAAATAAAAACTCCATACACCTCAGACATATAGCACACATGGAGACAACTTACTAATTGTGTGT AAGTATGATACAATGAATGAGACTGCCTGAAGTCTAGTAATCAAAGCATGCCATAAGGTGAATGATTGTGGTTAAACACAGCAAAATAAT TGTCACAAAACTTTCAAGGCCTAACAAATTAGAATTTTCCAATAAAAAATATATATTTTTTCAGATGTTAATAAGACATATCAGTAGAGA CAAAATTAGGATTTTGAAGTAATGCAATAAAAAGATGTTGGAGGGCAGAAGTCTATTTAGTTTTTGTATACACTTGCAAGAGTGCATTAC TCAGTATAAAGCAAAATGGGGAGGAAAAAGACATCCATCCATTTTATTGGAACACTTTTATGTGACTTGAATCTGGTGTTAGGTTGTTGA TTTTTCTAAAAATCTCCTATATATACAAAATCCATATGTACTTGGAGATCCAGCTGTTGCCCCCTGTTTAAAACAAAAGACCACCTCGGG GGGTCAATTAAATTAAAAAGGCCCTCCAACCACCCTAAATGGGATAACTAAGAGTATCTACTGCAGTCATTTCAGAGGACAGAGAAGGAA AATATTTTAATTTGCTTTAATATAACCTCTTTTCAGTAGATCACAAATGAGTTTACAAACTACTTTTTTTTCTCTTTAATTTAGGTGTTT GCAGATAATTTTCATTATATCCGTAGCTGTATGTGTGTATAGTTACATAATGGTAACTACACACGATACAGAAGAATCAGTAAATTCATG GATTATTTTGCTGAGGTTTTAAATTTTAAAGCCTCTGTTTCAGAATTTTATACTTGATCAAGGAGAAAAATAAATGTGTAGTCTAACATT TGCTTTCTGGAGTTAATTAACTGATCTGTAAGAACCACTGCATATGTCTTAAAATGTAAACATATTTACATTTGTTGTATTTGTTATTGA GCCTTTAAGGTTAGGCCCAGAATGAACAGACCATAGCAAGTAAACAAATAATTTTTAGAATCAAAGTATTAATAGAAGACCAGTTCATGG ATTTGCTTATTCTATCCTGCTGAGACAAAACTCATGAGTGTGCACACACATGTGAATATATCCCTACGAAACAGTCTATCTTCTCATAGG CTTAAATTATAGTCATGGCTATTAAAGAAATTAACAGCATCCAGCCACATGCAACTTTCCAACCTTCAGTACTATTAGGTGATTAAAATC AACAAATATGAAGTTTAGTTCATTTTTCCCTTAAAATTCCAACAAAGATCAAAAGGTTGTATCTAGAACTAATTGCCATCAAGTTCCAAT TCAATGTCATTTAAAGTAATGTAACCACACATTTGGTATTTTCAATAGGAAGGTTAATTAGGTATTGTGCAAACTGCCTGCAACGGAAGC ACTCAGTCCTTATCTAACTTGTCCCTTCCTGGCCCCAACATGCTAACTGCCCCATCCCCAATTCTGGGCAAACTGATCACAATGTGCAAA AAATAATATATTATCTATTTATAATTTTAAAATATATACAGCCAGCTCAAAAACAACAACAAACCCCATCAACATAGTCCAGCTGAAATC TCCACTGGTAGTCAAAGAAGTAGATTAAAGGAGTAAAGGAAGGAGAAGGCTGATAGGGCCACAAGAATGGACAGACATCAAGTAAAATTT GAGTCCCAAACATGCAAGTACATGAGCAGTGAGATAACTTATATATTCCAATAACCTATTTTCAACAACTCCTGCCCAAGACATGAAGAT CAAATCAGGTTTCTGAGGTAAGTGTACTTCTAAACCATACACACATGAAAGCTATGAAAGCAATTCAAATGAGGCTGCTTCATGAGGCAA TCTAGACTTATGGCATTATTTCTACTTTTCTCCATGTTTTAATTGCAGCCTGCACTTTAAATCTTTCCCAATAATTTTTAACAGTGCCTC TCAAATGCAAAGACACGTAAAAGAATTAATAACTAGCCAAAGAATTTTATCACCGCTTCACTCATTTATAAGAAAACCAATTATTTCCAA GCAAAATCAAACCAAACCAAAGAGGCTCCTGGTAGAAATGAAACAAAACTTTAAAGCTAGTTTTAAAACAAATATTTTCCTCTGCTCTAA ACTACTCTGGCGTTTTCTACCACTCTACCATTTTGGAACATTCATTACAATAAGGTATATAGGTAGATGGTAGGAGGCAAAGCATTTATC AGTAGTTGAGCAAAACTGCTGAGGCCATTTATAATTCAAAGAATGAAAACTTAGAATAGTTTACTACATTAGAATACATCCAAGTTCCAA GAGTAGGACTGGAGCTCTCTTAAGGCAATCTTTCAGAAAAGATGTTGCATCTTCTGTGATGATGGTTTGTGTTTTTTTTGTTTTTGTTTT CGTTTTTTTTAATGAGATGGAGTCTCAC >2315_2315_5_ADD3-VIL1_ADD3_chr10_111877180_ENST00000360162_VIL1_chr2_219305444_ENST00000248444_length(amino acids)=273AA_BP=189 MSSDASQGVITTPPPPSMPHKERYFDRINENDPEYIRERNMSPDLRQDFNMMEQRKRVTQILQSPAFREDLECLIQEQMKKGHNPTGLLA LQQIADYIMANSFSGFSSPPLSLGMVTPINDLPGADTSSYVKGEKLTRCKLASLYRLVDLFGWAHLANTYISVRISKEQDHIIIIPRGLS FSEATASNLEVTSPKVDVFNANSNLSSGPLPIFPLEQLVNKPVEELPEGVDPSRKEEHLSIEDFTQAFGMTPAAFSALPRWKQQNLKKEK GLF -------------------------------------------------------------- >2315_2315_6_ADD3-VIL1_ADD3_chr10_111877180_ENST00000360162_VIL1_chr2_219305444_ENST00000392114_length(transcript)=1387nt_BP=944nt AGTCCACAAAACTCCCTGATTCCATCCTCTCTGCCTCTTATGAAGCAATACTAGAGAGGAAAAACAAAACCCATTCCTTTAAGAAAGATT CCGCCTCCTCTCATAAGCAAGCGCCTAATGGTAATTGTAGAGTTTACTAAGTCAAACACTTACTACTCAGCATTGAGAGAAGCTGCTGCT GCTAATGCTGCTGCTGCTGCTGCCGCCGCCGCCGCTGCTGCTGCTGCTGTTGGTCTGAGGCTGCAGTAGGTTTCTGTGCAGCATTGCAGA ATCCACACCTAGAGAACAGAAGACACAGACACGTACGTCTACTACCCTTGTTAGAAGGAAGCTTTGGATCTTCGGTGGATAACAAGAGTA ATCCACAGACTTAAAACATGAGCTCAGATGCCAGCCAAGGCGTGATTACCACTCCTCCTCCTCCCAGCATGCCTCACAAAGAGAGATATT TTGACCGCATCAATGAAAATGACCCAGAATACATTAGGGAGAGGAACATGTCTCCTGATCTACGACAAGACTTCAACATGATGGAGCAGA GGAAACGAGTTACTCAGATCCTGCAAAGTCCTGCCTTTCGGGAAGACTTGGAATGCCTTATTCAAGAACAGATGAAGAAAGGCCACAACC CAACTGGATTACTAGCATTACAGCAGATTGCAGATTACATCATGGCCAATTCTTTCTCGGGTTTTTCTTCACCTCCTCTCAGTCTTGGCA TGGTCACACCTATCAATGACCTTCCTGGTGCAGATACATCCTCATATGTGAAGGGAGAAAAACTTACTCGCTGTAAACTTGCCAGCCTGT ACAGACTTGTAGACTTGTTTGGATGGGCACACCTGGCAAATACCTATATCTCAGTAAGAATAAGTAAGGAGCAAGACCACATTATAATAA TTCCCAGAGGCCTATCTTTTTCTGAAGCTACAGCCTCCAATTTGGAGGTCACAAGCCCCAAAGTGGACGTGTTCAATGCTAACAGCAACC TCAGTTCTGGGCCTCTGCCCATCTTCCCCCTGGAGCAGCTAGTGAACAAGCCTGTAGAGGAGCTCCCCGAGGGTGTGGACCCCAGCAGGA AGGAGGAACACCTGTCCATTGAAGATTTCACTCAGGCCTTTGGGATGACTCCAGCTGCCTTCTCTGCTCTGCCTCGATGGAAGCAACAAA ACCTCAAGAAAGAAAAAGGACTATTTTGAGAAGAGTAGCTGTGGTTGTAAAGCAGTACCCTACCCTGATTGTAGGGTCTCATTTTCTCAC CGATATTAGTCCTACACCAATTGAAGTGAAATTTTGCAGATGTGCCTATGAGCACAAACTTCTGTGGCAAATGCCAGTTTTGTTTAATAA TGTACCTATTCCTTCAGAAAGATGATACCCCAAAAGG >2315_2315_6_ADD3-VIL1_ADD3_chr10_111877180_ENST00000360162_VIL1_chr2_219305444_ENST00000392114_length(amino acids)=273AA_BP=189 MSSDASQGVITTPPPPSMPHKERYFDRINENDPEYIRERNMSPDLRQDFNMMEQRKRVTQILQSPAFREDLECLIQEQMKKGHNPTGLLA LQQIADYIMANSFSGFSSPPLSLGMVTPINDLPGADTSSYVKGEKLTRCKLASLYRLVDLFGWAHLANTYISVRISKEQDHIIIIPRGLS FSEATASNLEVTSPKVDVFNANSNLSSGPLPIFPLEQLVNKPVEELPEGVDPSRKEEHLSIEDFTQAFGMTPAAFSALPRWKQQNLKKEK GLF -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ADD3-VIL1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | ADD3 | chr10:111877180 | chr2:219305444 | ENST00000277900 | + | 5 | 14 | 684_701 | 189.0 | 675.0 | calmodulin |
| Hgene | ADD3 | chr10:111877180 | chr2:219305444 | ENST00000356080 | + | 5 | 15 | 684_701 | 189.0 | 707.0 | calmodulin |
| Hgene | ADD3 | chr10:111877180 | chr2:219305444 | ENST00000360162 | + | 5 | 14 | 684_701 | 189.0 | 675.0 | calmodulin |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ADD3-VIL1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ADD3-VIL1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ADD3 | C0005586 | Bipolar Disorder | 1 | CTD_human |
| Hgene | ADD3 | C0005587 | Depression, Bipolar | 1 | CTD_human |
| Hgene | ADD3 | C0007786 | Brain Ischemia | 1 | CTD_human |
| Hgene | ADD3 | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human |
| Hgene | ADD3 | C0024713 | Manic Disorder | 1 | CTD_human |
| Hgene | ADD3 | C0149504 | Encephalopathy, Toxic | 1 | CTD_human |
| Hgene | ADD3 | C0154659 | Toxic Encephalitis | 1 | CTD_human |
| Hgene | ADD3 | C0235032 | Neurotoxicity Syndromes | 1 | CTD_human |
| Hgene | ADD3 | C0338831 | Manic | 1 | CTD_human |
| Hgene | ADD3 | C0917798 | Cerebral Ischemia | 1 | CTD_human |
| Hgene | ADD3 | C2751938 | Cerebral Palsy, Spastic Quadriplegic, 1 | 1 | ORPHANET |
| Hgene | ADD3 | C4310767 | CEREBRAL PALSY, SPASTIC QUADRIPLEGIC, 3 | 1 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Tgene | C0008370 | Cholestasis | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies