
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CLTA-RIN2 (FusionGDB2 ID:HG1211TG54453) |
Fusion Gene Summary for CLTA-RIN2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CLTA-RIN2 | Fusion gene ID: hg1211tg54453 | Hgene | Tgene | Gene symbol | CLTA | RIN2 | Gene ID | 1211 | 54453 |
| Gene name | clathrin light chain A | Ras and Rab interactor 2 | |
| Synonyms | LCA | MACS|RASSF4 | |
| Cytomap | ('CLTA')('RIN2') 9p13.3 | 20p11.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | clathrin light chain Aclathrin, light polypeptide (Lca) | ras and Rab interactor 2RAB5 interacting protein 2RAS association (RalGDS/AF-6) domain containing protein JC265RAS association domain family 4RAS inhibitor JC265RAS interaction/interference protein 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P09496 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000242285, ENST00000345519, ENST00000396603, ENST00000433436, ENST00000466396, ENST00000470744, ENST00000538225, ENST00000540080, | ||
| Fusion gene scores | * DoF score | 11 X 10 X 7=770 | 13 X 13 X 5=845 |
| # samples | 13 | 14 | |
| ** MAII score | log2(13/770*10)=-2.56634682255381 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(14/845*10)=-2.59352451422458 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CLTA [Title/Abstract] AND RIN2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CLTA(36205689)-RIN2(19981391), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | CLTA-RIN2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CLTA-RIN2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CLTA-RIN2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CLTA-RIN2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CLTA-RIN2 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across CLTA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
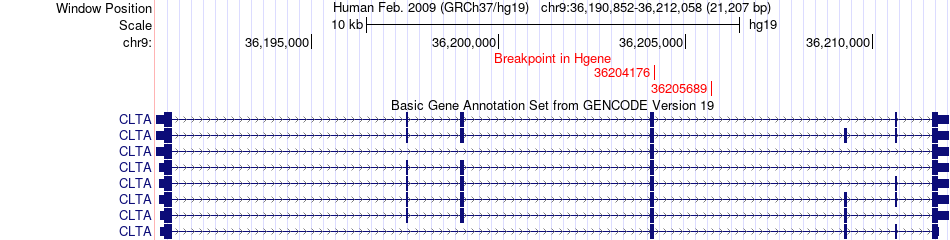 |
| Fusion gene breakpoints across RIN2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CD-8535-01A | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| ChimerDB4 | STAD | TCGA-CD-8535-01A | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
Top |
Fusion Gene ORF analysis for CLTA-RIN2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000242285 | ENST00000484638 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| 5CDS-3UTR | ENST00000345519 | ENST00000484638 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| 5CDS-3UTR | ENST00000396603 | ENST00000484638 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| 5CDS-3UTR | ENST00000433436 | ENST00000484638 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| 5CDS-3UTR | ENST00000466396 | ENST00000484638 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| 5CDS-3UTR | ENST00000470744 | ENST00000484638 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| 5CDS-3UTR | ENST00000538225 | ENST00000484638 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| 5CDS-3UTR | ENST00000540080 | ENST00000484638 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| Frame-shift | ENST00000242285 | ENST00000255006 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| Frame-shift | ENST00000345519 | ENST00000255006 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| Frame-shift | ENST00000396603 | ENST00000255006 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| Frame-shift | ENST00000433436 | ENST00000255006 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| Frame-shift | ENST00000466396 | ENST00000255006 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| Frame-shift | ENST00000470744 | ENST00000255006 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| Frame-shift | ENST00000538225 | ENST00000255006 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| Frame-shift | ENST00000540080 | ENST00000255006 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| In-frame | ENST00000242285 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| In-frame | ENST00000345519 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| In-frame | ENST00000396603 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| In-frame | ENST00000433436 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| In-frame | ENST00000466396 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| In-frame | ENST00000470744 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| In-frame | ENST00000538225 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| In-frame | ENST00000540080 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + |
| intron-3CDS | ENST00000242285 | ENST00000255006 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000242285 | ENST00000440354 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000345519 | ENST00000255006 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000345519 | ENST00000440354 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000396603 | ENST00000255006 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000396603 | ENST00000440354 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000433436 | ENST00000255006 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000433436 | ENST00000440354 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000466396 | ENST00000255006 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000466396 | ENST00000440354 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000470744 | ENST00000255006 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000470744 | ENST00000440354 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000538225 | ENST00000255006 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000538225 | ENST00000440354 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000540080 | ENST00000255006 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3CDS | ENST00000540080 | ENST00000440354 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3UTR | ENST00000242285 | ENST00000484638 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3UTR | ENST00000345519 | ENST00000484638 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3UTR | ENST00000396603 | ENST00000484638 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3UTR | ENST00000433436 | ENST00000484638 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3UTR | ENST00000466396 | ENST00000484638 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3UTR | ENST00000470744 | ENST00000484638 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3UTR | ENST00000538225 | ENST00000484638 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| intron-3UTR | ENST00000540080 | ENST00000484638 | CLTA | chr9 | 36205689 | + | RIN2 | chr20 | 19981391 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000540080 | CLTA | chr9 | 36204176 | + | ENST00000440354 | RIN2 | chr20 | 19981397 | + | 1125 | 530 | 192 | 872 | 226 |
| ENST00000433436 | CLTA | chr9 | 36204176 | + | ENST00000440354 | RIN2 | chr20 | 19981397 | + | 1281 | 686 | 192 | 1028 | 278 |
| ENST00000538225 | CLTA | chr9 | 36204176 | + | ENST00000440354 | RIN2 | chr20 | 19981397 | + | 1281 | 686 | 192 | 1028 | 278 |
| ENST00000345519 | CLTA | chr9 | 36204176 | + | ENST00000440354 | RIN2 | chr20 | 19981397 | + | 1214 | 619 | 125 | 961 | 278 |
| ENST00000470744 | CLTA | chr9 | 36204176 | + | ENST00000440354 | RIN2 | chr20 | 19981397 | + | 1205 | 610 | 116 | 952 | 278 |
| ENST00000242285 | CLTA | chr9 | 36204176 | + | ENST00000440354 | RIN2 | chr20 | 19981397 | + | 1200 | 605 | 111 | 947 | 278 |
| ENST00000466396 | CLTA | chr9 | 36204176 | + | ENST00000440354 | RIN2 | chr20 | 19981397 | + | 1018 | 423 | 85 | 765 | 226 |
| ENST00000396603 | CLTA | chr9 | 36204176 | + | ENST00000440354 | RIN2 | chr20 | 19981397 | + | 1174 | 579 | 85 | 921 | 278 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000540080 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + | 0.019825686 | 0.9801743 |
| ENST00000433436 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + | 0.006985731 | 0.9930143 |
| ENST00000538225 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + | 0.006985731 | 0.9930143 |
| ENST00000345519 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + | 0.00570667 | 0.99429333 |
| ENST00000470744 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + | 0.004402831 | 0.9955972 |
| ENST00000242285 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + | 0.004773378 | 0.9952266 |
| ENST00000466396 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + | 0.013358844 | 0.9866412 |
| ENST00000396603 | ENST00000440354 | CLTA | chr9 | 36204176 | + | RIN2 | chr20 | 19981397 | + | 0.004774302 | 0.99522567 |
Top |
Fusion Genomic Features for CLTA-RIN2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
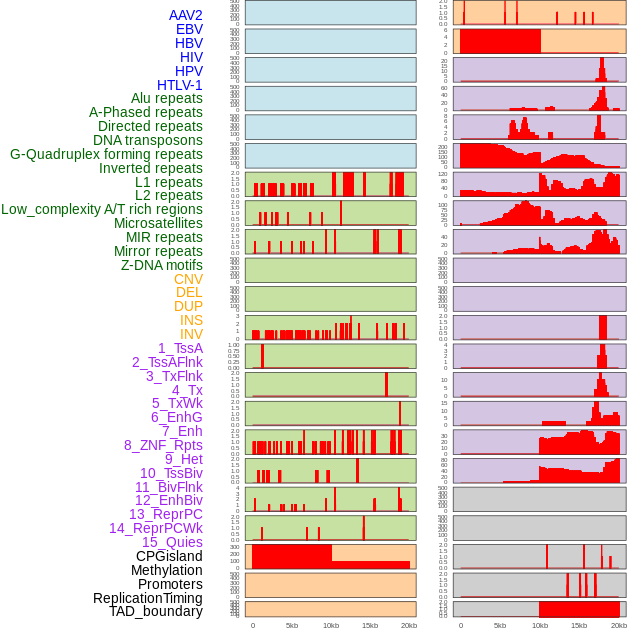 |
Top |
Fusion Protein Features for CLTA-RIN2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:36205689/chr20:19981391) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CLTA | . |
| FUNCTION: Clathrin is the major protein of the polyhedral coat of coated pits and vesicles. Acts as component of the TACC3/ch-TOG/clathrin complex proposed to contribute to stabilization of kinetochore fibers of the mitotic spindle by acting as inter-microtubule bridge (PubMed:15858577, PubMed:21297582). {ECO:0000305|PubMed:15858577, ECO:0000305|PubMed:21297582}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CLTA | chr9:36204176 | chr20:19981397 | ENST00000242285 | + | 4 | 7 | 100_162 | 161 | 249.0 | Region | Note=Involved in binding clathrin heavy chain |
| Hgene | CLTA | chr9:36204176 | chr20:19981397 | ENST00000345519 | + | 4 | 5 | 100_162 | 161 | 219.0 | Region | Note=Involved in binding clathrin heavy chain |
| Hgene | CLTA | chr9:36204176 | chr20:19981397 | ENST00000396603 | + | 4 | 6 | 100_162 | 161 | 237.0 | Region | Note=Involved in binding clathrin heavy chain |
| Hgene | CLTA | chr9:36204176 | chr20:19981397 | ENST00000433436 | + | 4 | 7 | 100_162 | 161 | 249.0 | Region | Note=Involved in binding clathrin heavy chain |
| Hgene | CLTA | chr9:36204176 | chr20:19981397 | ENST00000470744 | + | 4 | 6 | 100_162 | 161 | 231.0 | Region | Note=Involved in binding clathrin heavy chain |
| Hgene | CLTA | chr9:36204176 | chr20:19981397 | ENST00000538225 | + | 4 | 6 | 100_162 | 161 | 231.0 | Region | Note=Involved in binding clathrin heavy chain |
| Tgene | RIN2 | chr9:36204176 | chr20:19981397 | ENST00000255006 | 0 | 12 | 307_314 | 0 | 945.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | RIN2 | chr9:36204176 | chr20:19981397 | ENST00000255006 | 0 | 12 | 618_757 | 0 | 945.0 | Domain | VPS9 | |
| Tgene | RIN2 | chr9:36204176 | chr20:19981397 | ENST00000255006 | 0 | 12 | 787_878 | 0 | 945.0 | Domain | Ras-associating | |
| Tgene | RIN2 | chr9:36204176 | chr20:19981397 | ENST00000255006 | 0 | 12 | 97_190 | 0 | 945.0 | Domain | SH2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CLTA | chr9:36204176 | chr20:19981397 | ENST00000540080 | + | 2 | 3 | 100_162 | 109 | 167.0 | Region | Note=Involved in binding clathrin heavy chain |
Top |
Fusion Gene Sequence for CLTA-RIN2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >17372_17372_1_CLTA-RIN2_CLTA_chr9_36204176_ENST00000242285_RIN2_chr20_19981397_ENST00000440354_length(transcript)=1200nt_BP=605nt CCTCCTGGCGCTTGTCCTCCTCTCCCAGTCGGCACCACAGCGGTGGCTGCCGGGCGTGGTGTCGGTGGGTCGGTTGGTTTTTGTCTCACC GTTGGTGTCCGTGCCGTTCAGTTGCCCGCCATGGCTGAGCTGGATCCGTTCGGCGCCCCTGCCGGCGCCCCTGGCGGTCCCGCGCTGGGG AACGGAGTGGCCGGCGCCGGCGAAGAAGACCCGGCTGCGGCCTTCTTGGCGCAGCAAGAGAGCGAGATTGCGGGCATCGAGAACGACGAG GCCTTCGCCATCCTGGACGGCGGCGCCCCCGGGCCCCAGCCGCACGGCGAGCCGCCGGGGGGTCCGGATGCTGTTGATGGAGTAATGAAT GGTGAATACTACCAGGAAAGTAATGGTCCAACAGACAGTTATGCAGCTATTTCACAAGTGGATCGATTGCAGTCAGAGCCTGAAAGTATC CGTAAATGGAGAGAAGAACAAATGGAACGCTTGGAAGCCCTTGATGCCAATTCTCGGAAGCAAGAAGCAGAGTGGAAAGAAAAGGCAATA AAGGAGCTAGAAGAATGGTATGCAAGACAGGACGAGCAGCTACAGAAAACAAAAGCAAACAACAGCTCTTTCTCTTCGTTGACGAGACAT GGCAGCAGCTGGCAGAGGACACTTACCCTCAAAAAATCAAGGCGGAGCTGCACAGCCGACCACAGCCCCACATCTTCCACTTTGTCTACA AACGCATCAAGAACGATCCTTATGGCATCATTTTCCAGAACGGGGAAGAAGACCTCACCACCTCCTAGAAGACAGGCGGGACTTCCCAGT GGTGCATCCAAAGGGGAGCTGGAAGCCTTGCCTTCCCGCTTCTACATGCTTGAGCTTGAAAAGCAGTCACCTCCTCGGGGACCCCTCAGT GTAGTGACTAAGCCATCCACAGGCCAACTCGGCCAAGGGCAACTTTAGCCACGCAAGGTAGCTGAGGTTTGTGAAACAGTAGGATTCTCT TTTGGCAATGGAGAATTGCATCTGATGGTTCAAGTGTCCTGAGATTGTTTGCTACCTACCCCCAGTCAGGTTCTAGGTTGGCTTACAGGT ATGTATATGTGCAGAAGAAACACTTAAGATACAAGTTCTTTTGAATTCAACAGCAGATGCTTGCGATGCAGTGCGTCAGGTGATTCTCAC TCCTGTGGATGGCTTCATCCCTGCCTTCCT >17372_17372_1_CLTA-RIN2_CLTA_chr9_36204176_ENST00000242285_RIN2_chr20_19981397_ENST00000440354_length(amino acids)=278AA_BP=165 MPAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQES NGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNSSFSSLTRHGSSWQRT LTLKKSRRSCTADHSPTSSTLSTNASRTILMASFSRTGKKTSPPPRRQAGLPSGASKGELEALPSRFYMLELEKQSPPRGPLSVVTKPST GQLGQGQL -------------------------------------------------------------- >17372_17372_2_CLTA-RIN2_CLTA_chr9_36204176_ENST00000345519_RIN2_chr20_19981397_ENST00000440354_length(transcript)=1214nt_BP=619nt GCTTTACCCGTCTCCCTCCTGGCGCTTGTCCTCCTCTCCCAGTCGGCACCACAGCGGTGGCTGCCGGGCGTGGTGTCGGTGGGTCGGTTG GTTTTTGTCTCACCGTTGGTGTCCGTGCCGTTCAGTTGCCCGCCATGGCTGAGCTGGATCCGTTCGGCGCCCCTGCCGGCGCCCCTGGCG GTCCCGCGCTGGGGAACGGAGTGGCCGGCGCCGGCGAAGAAGACCCGGCTGCGGCCTTCTTGGCGCAGCAAGAGAGCGAGATTGCGGGCA TCGAGAACGACGAGGCCTTCGCCATCCTGGACGGCGGCGCCCCCGGGCCCCAGCCGCACGGCGAGCCGCCGGGGGGTCCGGATGCTGTTG ATGGAGTAATGAATGGTGAATACTACCAGGAAAGTAATGGTCCAACAGACAGTTATGCAGCTATTTCACAAGTGGATCGATTGCAGTCAG AGCCTGAAAGTATCCGTAAATGGAGAGAAGAACAAATGGAACGCTTGGAAGCCCTTGATGCCAATTCTCGGAAGCAAGAAGCAGAGTGGA AAGAAAAGGCAATAAAGGAGCTAGAAGAATGGTATGCAAGACAGGACGAGCAGCTACAGAAAACAAAAGCAAACAACAGCTCTTTCTCTT CGTTGACGAGACATGGCAGCAGCTGGCAGAGGACACTTACCCTCAAAAAATCAAGGCGGAGCTGCACAGCCGACCACAGCCCCACATCTT CCACTTTGTCTACAAACGCATCAAGAACGATCCTTATGGCATCATTTTCCAGAACGGGGAAGAAGACCTCACCACCTCCTAGAAGACAGG CGGGACTTCCCAGTGGTGCATCCAAAGGGGAGCTGGAAGCCTTGCCTTCCCGCTTCTACATGCTTGAGCTTGAAAAGCAGTCACCTCCTC GGGGACCCCTCAGTGTAGTGACTAAGCCATCCACAGGCCAACTCGGCCAAGGGCAACTTTAGCCACGCAAGGTAGCTGAGGTTTGTGAAA CAGTAGGATTCTCTTTTGGCAATGGAGAATTGCATCTGATGGTTCAAGTGTCCTGAGATTGTTTGCTACCTACCCCCAGTCAGGTTCTAG GTTGGCTTACAGGTATGTATATGTGCAGAAGAAACACTTAAGATACAAGTTCTTTTGAATTCAACAGCAGATGCTTGCGATGCAGTGCGT CAGGTGATTCTCACTCCTGTGGATGGCTTCATCCCTGCCTTCCT >17372_17372_2_CLTA-RIN2_CLTA_chr9_36204176_ENST00000345519_RIN2_chr20_19981397_ENST00000440354_length(amino acids)=278AA_BP=165 MPAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQES NGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNSSFSSLTRHGSSWQRT LTLKKSRRSCTADHSPTSSTLSTNASRTILMASFSRTGKKTSPPPRRQAGLPSGASKGELEALPSRFYMLELEKQSPPRGPLSVVTKPST GQLGQGQL -------------------------------------------------------------- >17372_17372_3_CLTA-RIN2_CLTA_chr9_36204176_ENST00000396603_RIN2_chr20_19981397_ENST00000440354_length(transcript)=1174nt_BP=579nt AGTCGGCACCACAGCGGTGGCTGCCGGGCGTGGTGTCGGTGGGTCGGTTGGTTTTTGTCTCACCGTTGGTGTCCGTGCCGTTCAGTTGCC CGCCATGGCTGAGCTGGATCCGTTCGGCGCCCCTGCCGGCGCCCCTGGCGGTCCCGCGCTGGGGAACGGAGTGGCCGGCGCCGGCGAAGA AGACCCGGCTGCGGCCTTCTTGGCGCAGCAAGAGAGCGAGATTGCGGGCATCGAGAACGACGAGGCCTTCGCCATCCTGGACGGCGGCGC CCCCGGGCCCCAGCCGCACGGCGAGCCGCCGGGGGGTCCGGATGCTGTTGATGGAGTAATGAATGGTGAATACTACCAGGAAAGTAATGG TCCAACAGACAGTTATGCAGCTATTTCACAAGTGGATCGATTGCAGTCAGAGCCTGAAAGTATCCGTAAATGGAGAGAAGAACAAATGGA ACGCTTGGAAGCCCTTGATGCCAATTCTCGGAAGCAAGAAGCAGAGTGGAAAGAAAAGGCAATAAAGGAGCTAGAAGAATGGTATGCAAG ACAGGACGAGCAGCTACAGAAAACAAAAGCAAACAACAGCTCTTTCTCTTCGTTGACGAGACATGGCAGCAGCTGGCAGAGGACACTTAC CCTCAAAAAATCAAGGCGGAGCTGCACAGCCGACCACAGCCCCACATCTTCCACTTTGTCTACAAACGCATCAAGAACGATCCTTATGGC ATCATTTTCCAGAACGGGGAAGAAGACCTCACCACCTCCTAGAAGACAGGCGGGACTTCCCAGTGGTGCATCCAAAGGGGAGCTGGAAGC CTTGCCTTCCCGCTTCTACATGCTTGAGCTTGAAAAGCAGTCACCTCCTCGGGGACCCCTCAGTGTAGTGACTAAGCCATCCACAGGCCA ACTCGGCCAAGGGCAACTTTAGCCACGCAAGGTAGCTGAGGTTTGTGAAACAGTAGGATTCTCTTTTGGCAATGGAGAATTGCATCTGAT GGTTCAAGTGTCCTGAGATTGTTTGCTACCTACCCCCAGTCAGGTTCTAGGTTGGCTTACAGGTATGTATATGTGCAGAAGAAACACTTA AGATACAAGTTCTTTTGAATTCAACAGCAGATGCTTGCGATGCAGTGCGTCAGGTGATTCTCACTCCTGTGGATGGCTTCATCCCTGCCT TCCT >17372_17372_3_CLTA-RIN2_CLTA_chr9_36204176_ENST00000396603_RIN2_chr20_19981397_ENST00000440354_length(amino acids)=278AA_BP=165 MPAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQES NGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNSSFSSLTRHGSSWQRT LTLKKSRRSCTADHSPTSSTLSTNASRTILMASFSRTGKKTSPPPRRQAGLPSGASKGELEALPSRFYMLELEKQSPPRGPLSVVTKPST GQLGQGQL -------------------------------------------------------------- >17372_17372_4_CLTA-RIN2_CLTA_chr9_36204176_ENST00000433436_RIN2_chr20_19981397_ENST00000440354_length(transcript)=1281nt_BP=686nt GATTGGTTGTTCCCTTTTCGGCTCTGCAACACCGCCTAGACCGACCGGATACACGGGTAGGGCTTCCGCTTTACCCGTCTCCCTCCTGGC GCTTGTCCTCCTCTCCCAGTCGGCACCACAGCGGTGGCTGCCGGGCGTGGTGTCGGTGGGTCGGTTGGTTTTTGTCTCACCGTTGGTGTC CGTGCCGTTCAGTTGCCCGCCATGGCTGAGCTGGATCCGTTCGGCGCCCCTGCCGGCGCCCCTGGCGGTCCCGCGCTGGGGAACGGAGTG GCCGGCGCCGGCGAAGAAGACCCGGCTGCGGCCTTCTTGGCGCAGCAAGAGAGCGAGATTGCGGGCATCGAGAACGACGAGGCCTTCGCC ATCCTGGACGGCGGCGCCCCCGGGCCCCAGCCGCACGGCGAGCCGCCGGGGGGTCCGGATGCTGTTGATGGAGTAATGAATGGTGAATAC TACCAGGAAAGTAATGGTCCAACAGACAGTTATGCAGCTATTTCACAAGTGGATCGATTGCAGTCAGAGCCTGAAAGTATCCGTAAATGG AGAGAAGAACAAATGGAACGCTTGGAAGCCCTTGATGCCAATTCTCGGAAGCAAGAAGCAGAGTGGAAAGAAAAGGCAATAAAGGAGCTA GAAGAATGGTATGCAAGACAGGACGAGCAGCTACAGAAAACAAAAGCAAACAACAGCTCTTTCTCTTCGTTGACGAGACATGGCAGCAGC TGGCAGAGGACACTTACCCTCAAAAAATCAAGGCGGAGCTGCACAGCCGACCACAGCCCCACATCTTCCACTTTGTCTACAAACGCATCA AGAACGATCCTTATGGCATCATTTTCCAGAACGGGGAAGAAGACCTCACCACCTCCTAGAAGACAGGCGGGACTTCCCAGTGGTGCATCC AAAGGGGAGCTGGAAGCCTTGCCTTCCCGCTTCTACATGCTTGAGCTTGAAAAGCAGTCACCTCCTCGGGGACCCCTCAGTGTAGTGACT AAGCCATCCACAGGCCAACTCGGCCAAGGGCAACTTTAGCCACGCAAGGTAGCTGAGGTTTGTGAAACAGTAGGATTCTCTTTTGGCAAT GGAGAATTGCATCTGATGGTTCAAGTGTCCTGAGATTGTTTGCTACCTACCCCCAGTCAGGTTCTAGGTTGGCTTACAGGTATGTATATG TGCAGAAGAAACACTTAAGATACAAGTTCTTTTGAATTCAACAGCAGATGCTTGCGATGCAGTGCGTCAGGTGATTCTCACTCCTGTGGA TGGCTTCATCCCTGCCTTCCT >17372_17372_4_CLTA-RIN2_CLTA_chr9_36204176_ENST00000433436_RIN2_chr20_19981397_ENST00000440354_length(amino acids)=278AA_BP=165 MPAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQES NGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNSSFSSLTRHGSSWQRT LTLKKSRRSCTADHSPTSSTLSTNASRTILMASFSRTGKKTSPPPRRQAGLPSGASKGELEALPSRFYMLELEKQSPPRGPLSVVTKPST GQLGQGQL -------------------------------------------------------------- >17372_17372_5_CLTA-RIN2_CLTA_chr9_36204176_ENST00000466396_RIN2_chr20_19981397_ENST00000440354_length(transcript)=1018nt_BP=423nt AGTCGGCACCACAGCGGTGGCTGCCGGGCGTGGTGTCGGTGGGTCGGTTGGTTTTTGTCTCACCGTTGGTGTCCGTGCCGTTCAGTTGCC CGCCATGGCTGAGCTGGATCCGTTCGGCGCCCCTGCCGGCGCCCCTGGCGGTCCCGCGCTGGGGAACGGAGTGGCCGGCGCCGGCGAAGA AGACCCGGCTGCGGCCTTCTTGGCGCAGCAAGAGAGCGAGATTGCGGGCATCGAGAACGACGAGGCCTTCGCCATCCTGGACGGCGGCGC CCCCGGGCCCCAGCCGCACGGCGAGCCGCCGGGGGGTCCGGATGCCAATTCTCGGAAGCAAGAAGCAGAGTGGAAAGAAAAGGCAATAAA GGAGCTAGAAGAATGGTATGCAAGACAGGACGAGCAGCTACAGAAAACAAAAGCAAACAACAGCTCTTTCTCTTCGTTGACGAGACATGG CAGCAGCTGGCAGAGGACACTTACCCTCAAAAAATCAAGGCGGAGCTGCACAGCCGACCACAGCCCCACATCTTCCACTTTGTCTACAAA CGCATCAAGAACGATCCTTATGGCATCATTTTCCAGAACGGGGAAGAAGACCTCACCACCTCCTAGAAGACAGGCGGGACTTCCCAGTGG TGCATCCAAAGGGGAGCTGGAAGCCTTGCCTTCCCGCTTCTACATGCTTGAGCTTGAAAAGCAGTCACCTCCTCGGGGACCCCTCAGTGT AGTGACTAAGCCATCCACAGGCCAACTCGGCCAAGGGCAACTTTAGCCACGCAAGGTAGCTGAGGTTTGTGAAACAGTAGGATTCTCTTT TGGCAATGGAGAATTGCATCTGATGGTTCAAGTGTCCTGAGATTGTTTGCTACCTACCCCCAGTCAGGTTCTAGGTTGGCTTACAGGTAT GTATATGTGCAGAAGAAACACTTAAGATACAAGTTCTTTTGAATTCAACAGCAGATGCTTGCGATGCAGTGCGTCAGGTGATTCTCACTC CTGTGGATGGCTTCATCCCTGCCTTCCT >17372_17372_5_CLTA-RIN2_CLTA_chr9_36204176_ENST00000466396_RIN2_chr20_19981397_ENST00000440354_length(amino acids)=226AA_BP=113 MPAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDANSRKQEAEWKEKA IKELEEWYARQDEQLQKTKANNSSFSSLTRHGSSWQRTLTLKKSRRSCTADHSPTSSTLSTNASRTILMASFSRTGKKTSPPPRRQAGLP SGASKGELEALPSRFYMLELEKQSPPRGPLSVVTKPSTGQLGQGQL -------------------------------------------------------------- >17372_17372_6_CLTA-RIN2_CLTA_chr9_36204176_ENST00000470744_RIN2_chr20_19981397_ENST00000440354_length(transcript)=1205nt_BP=610nt GTCTCCCTCCTGGCGCTTGTCCTCCTCTCCCAGTCGGCACCACAGCGGTGGCTGCCGGGCGTGGTGTCGGTGGGTCGGTTGGTTTTTGTC TCACCGTTGGTGTCCGTGCCGTTCAGTTGCCCGCCATGGCTGAGCTGGATCCGTTCGGCGCCCCTGCCGGCGCCCCTGGCGGTCCCGCGC TGGGGAACGGAGTGGCCGGCGCCGGCGAAGAAGACCCGGCTGCGGCCTTCTTGGCGCAGCAAGAGAGCGAGATTGCGGGCATCGAGAACG ACGAGGCCTTCGCCATCCTGGACGGCGGCGCCCCCGGGCCCCAGCCGCACGGCGAGCCGCCGGGGGGTCCGGATGCTGTTGATGGAGTAA TGAATGGTGAATACTACCAGGAAAGTAATGGTCCAACAGACAGTTATGCAGCTATTTCACAAGTGGATCGATTGCAGTCAGAGCCTGAAA GTATCCGTAAATGGAGAGAAGAACAAATGGAACGCTTGGAAGCCCTTGATGCCAATTCTCGGAAGCAAGAAGCAGAGTGGAAAGAAAAGG CAATAAAGGAGCTAGAAGAATGGTATGCAAGACAGGACGAGCAGCTACAGAAAACAAAAGCAAACAACAGCTCTTTCTCTTCGTTGACGA GACATGGCAGCAGCTGGCAGAGGACACTTACCCTCAAAAAATCAAGGCGGAGCTGCACAGCCGACCACAGCCCCACATCTTCCACTTTGT CTACAAACGCATCAAGAACGATCCTTATGGCATCATTTTCCAGAACGGGGAAGAAGACCTCACCACCTCCTAGAAGACAGGCGGGACTTC CCAGTGGTGCATCCAAAGGGGAGCTGGAAGCCTTGCCTTCCCGCTTCTACATGCTTGAGCTTGAAAAGCAGTCACCTCCTCGGGGACCCC TCAGTGTAGTGACTAAGCCATCCACAGGCCAACTCGGCCAAGGGCAACTTTAGCCACGCAAGGTAGCTGAGGTTTGTGAAACAGTAGGAT TCTCTTTTGGCAATGGAGAATTGCATCTGATGGTTCAAGTGTCCTGAGATTGTTTGCTACCTACCCCCAGTCAGGTTCTAGGTTGGCTTA CAGGTATGTATATGTGCAGAAGAAACACTTAAGATACAAGTTCTTTTGAATTCAACAGCAGATGCTTGCGATGCAGTGCGTCAGGTGATT CTCACTCCTGTGGATGGCTTCATCCCTGCCTTCCT >17372_17372_6_CLTA-RIN2_CLTA_chr9_36204176_ENST00000470744_RIN2_chr20_19981397_ENST00000440354_length(amino acids)=278AA_BP=165 MPAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQES NGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNSSFSSLTRHGSSWQRT LTLKKSRRSCTADHSPTSSTLSTNASRTILMASFSRTGKKTSPPPRRQAGLPSGASKGELEALPSRFYMLELEKQSPPRGPLSVVTKPST GQLGQGQL -------------------------------------------------------------- >17372_17372_7_CLTA-RIN2_CLTA_chr9_36204176_ENST00000538225_RIN2_chr20_19981397_ENST00000440354_length(transcript)=1281nt_BP=686nt GATTGGTTGTTCCCTTTTCGGCTCTGCAACACCGCCTAGACCGACCGGATACACGGGTAGGGCTTCCGCTTTACCCGTCTCCCTCCTGGC GCTTGTCCTCCTCTCCCAGTCGGCACCACAGCGGTGGCTGCCGGGCGTGGTGTCGGTGGGTCGGTTGGTTTTTGTCTCACCGTTGGTGTC CGTGCCGTTCAGTTGCCCGCCATGGCTGAGCTGGATCCGTTCGGCGCCCCTGCCGGCGCCCCTGGCGGTCCCGCGCTGGGGAACGGAGTG GCCGGCGCCGGCGAAGAAGACCCGGCTGCGGCCTTCTTGGCGCAGCAAGAGAGCGAGATTGCGGGCATCGAGAACGACGAGGCCTTCGCC ATCCTGGACGGCGGCGCCCCCGGGCCCCAGCCGCACGGCGAGCCGCCGGGGGGTCCGGATGCTGTTGATGGAGTAATGAATGGTGAATAC TACCAGGAAAGTAATGGTCCAACAGACAGTTATGCAGCTATTTCACAAGTGGATCGATTGCAGTCAGAGCCTGAAAGTATCCGTAAATGG AGAGAAGAACAAATGGAACGCTTGGAAGCCCTTGATGCCAATTCTCGGAAGCAAGAAGCAGAGTGGAAAGAAAAGGCAATAAAGGAGCTA GAAGAATGGTATGCAAGACAGGACGAGCAGCTACAGAAAACAAAAGCAAACAACAGCTCTTTCTCTTCGTTGACGAGACATGGCAGCAGC TGGCAGAGGACACTTACCCTCAAAAAATCAAGGCGGAGCTGCACAGCCGACCACAGCCCCACATCTTCCACTTTGTCTACAAACGCATCA AGAACGATCCTTATGGCATCATTTTCCAGAACGGGGAAGAAGACCTCACCACCTCCTAGAAGACAGGCGGGACTTCCCAGTGGTGCATCC AAAGGGGAGCTGGAAGCCTTGCCTTCCCGCTTCTACATGCTTGAGCTTGAAAAGCAGTCACCTCCTCGGGGACCCCTCAGTGTAGTGACT AAGCCATCCACAGGCCAACTCGGCCAAGGGCAACTTTAGCCACGCAAGGTAGCTGAGGTTTGTGAAACAGTAGGATTCTCTTTTGGCAAT GGAGAATTGCATCTGATGGTTCAAGTGTCCTGAGATTGTTTGCTACCTACCCCCAGTCAGGTTCTAGGTTGGCTTACAGGTATGTATATG TGCAGAAGAAACACTTAAGATACAAGTTCTTTTGAATTCAACAGCAGATGCTTGCGATGCAGTGCGTCAGGTGATTCTCACTCCTGTGGA TGGCTTCATCCCTGCCTTCCT >17372_17372_7_CLTA-RIN2_CLTA_chr9_36204176_ENST00000538225_RIN2_chr20_19981397_ENST00000440354_length(amino acids)=278AA_BP=165 MPAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDAVDGVMNGEYYQES NGPTDSYAAISQVDRLQSEPESIRKWREEQMERLEALDANSRKQEAEWKEKAIKELEEWYARQDEQLQKTKANNSSFSSLTRHGSSWQRT LTLKKSRRSCTADHSPTSSTLSTNASRTILMASFSRTGKKTSPPPRRQAGLPSGASKGELEALPSRFYMLELEKQSPPRGPLSVVTKPST GQLGQGQL -------------------------------------------------------------- >17372_17372_8_CLTA-RIN2_CLTA_chr9_36204176_ENST00000540080_RIN2_chr20_19981397_ENST00000440354_length(transcript)=1125nt_BP=530nt GATTGGTTGTTCCCTTTTCGGCTCTGCAACACCGCCTAGACCGACCGGATACACGGGTAGGGCTTCCGCTTTACCCGTCTCCCTCCTGGC GCTTGTCCTCCTCTCCCAGTCGGCACCACAGCGGTGGCTGCCGGGCGTGGTGTCGGTGGGTCGGTTGGTTTTTGTCTCACCGTTGGTGTC CGTGCCGTTCAGTTGCCCGCCATGGCTGAGCTGGATCCGTTCGGCGCCCCTGCCGGCGCCCCTGGCGGTCCCGCGCTGGGGAACGGAGTG GCCGGCGCCGGCGAAGAAGACCCGGCTGCGGCCTTCTTGGCGCAGCAAGAGAGCGAGATTGCGGGCATCGAGAACGACGAGGCCTTCGCC ATCCTGGACGGCGGCGCCCCCGGGCCCCAGCCGCACGGCGAGCCGCCGGGGGGTCCGGATGCCAATTCTCGGAAGCAAGAAGCAGAGTGG AAAGAAAAGGCAATAAAGGAGCTAGAAGAATGGTATGCAAGACAGGACGAGCAGCTACAGAAAACAAAAGCAAACAACAGCTCTTTCTCT TCGTTGACGAGACATGGCAGCAGCTGGCAGAGGACACTTACCCTCAAAAAATCAAGGCGGAGCTGCACAGCCGACCACAGCCCCACATCT TCCACTTTGTCTACAAACGCATCAAGAACGATCCTTATGGCATCATTTTCCAGAACGGGGAAGAAGACCTCACCACCTCCTAGAAGACAG GCGGGACTTCCCAGTGGTGCATCCAAAGGGGAGCTGGAAGCCTTGCCTTCCCGCTTCTACATGCTTGAGCTTGAAAAGCAGTCACCTCCT CGGGGACCCCTCAGTGTAGTGACTAAGCCATCCACAGGCCAACTCGGCCAAGGGCAACTTTAGCCACGCAAGGTAGCTGAGGTTTGTGAA ACAGTAGGATTCTCTTTTGGCAATGGAGAATTGCATCTGATGGTTCAAGTGTCCTGAGATTGTTTGCTACCTACCCCCAGTCAGGTTCTA GGTTGGCTTACAGGTATGTATATGTGCAGAAGAAACACTTAAGATACAAGTTCTTTTGAATTCAACAGCAGATGCTTGCGATGCAGTGCG TCAGGTGATTCTCACTCCTGTGGATGGCTTCATCCCTGCCTTCCT >17372_17372_8_CLTA-RIN2_CLTA_chr9_36204176_ENST00000540080_RIN2_chr20_19981397_ENST00000440354_length(amino acids)=226AA_BP=113 MPAMAELDPFGAPAGAPGGPALGNGVAGAGEEDPAAAFLAQQESEIAGIENDEAFAILDGGAPGPQPHGEPPGGPDANSRKQEAEWKEKA IKELEEWYARQDEQLQKTKANNSSFSSLTRHGSSWQRTLTLKKSRRSCTADHSPTSSTLSTNASRTILMASFSRTGKKTSPPPRRQAGLP SGASKGELEALPSRFYMLELEKQSPPRGPLSVVTKPSTGQLGQGQL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CLTA-RIN2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CLTA-RIN2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CLTA-RIN2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C2751321 | Macrocephaly, Alopecia, Cutis Laxa, and Scoliosis | 3 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies