
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:COL1A1-THOC6 (FusionGDB2 ID:HG1277TG79228) |
Fusion Gene Summary for COL1A1-THOC6 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: COL1A1-THOC6 | Fusion gene ID: hg1277tg79228 | Hgene | Tgene | Gene symbol | COL1A1 | THOC6 | Gene ID | 1277 | 79228 |
| Gene name | collagen type I alpha 1 chain | THO complex 6 | |
| Synonyms | CAFYD|EDSARTH1|EDSC|OI1|OI2|OI3|OI4 | WDR58|fSAP35 | |
| Cytomap | ('COL1A1')('THOC6') 17q21.33 | 16p13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | collagen alpha-1(I) chainalpha-1 type I collagenalpha1(I) procollagencollagen alpha 1 chain type Icollagen alpha-1(I) chain preproproteincollagen of skin, tendon and bone, alpha-1 chaincollagen, type I, alpha 1pro-alpha-1 collagen type 1type I pro | THO complex subunit 6 homologWD repeat domain 58WD repeat-containing protein 58functional spliceosome-associated protein 35 | |
| Modification date | 20200322 | 20200313 | |
| UniProtAcc | P02452 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000225964, | ||
| Fusion gene scores | * DoF score | 56 X 95 X 16=85120 | 5 X 5 X 4=100 |
| # samples | 86 | 5 | |
| ** MAII score | log2(86/85120*10)=-6.62901768079909 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/100*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: COL1A1 [Title/Abstract] AND THOC6 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | COL1A1(48269835)-THOC6(3076679), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | COL1A1-THOC6 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. COL1A1-THOC6 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. COL1A1-THOC6 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. COL1A1-THOC6 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | COL1A1 | GO:0010718 | positive regulation of epithelial to mesenchymal transition | 20018240 |
| Hgene | COL1A1 | GO:0030335 | positive regulation of cell migration | 20018240 |
| Hgene | COL1A1 | GO:0034504 | protein localization to nucleus | 20018240 |
| Hgene | COL1A1 | GO:0045893 | positive regulation of transcription, DNA-templated | 20018240 |
| Hgene | COL1A1 | GO:0090263 | positive regulation of canonical Wnt signaling pathway | 20018240 |
| Tgene | THOC6 | GO:0006406 | mRNA export from nucleus | 17190602 |
| Tgene | THOC6 | GO:0046784 | viral mRNA export from host cell nucleus | 18974867 |
| Fusion gene breakpoints across COL1A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across THOC6 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
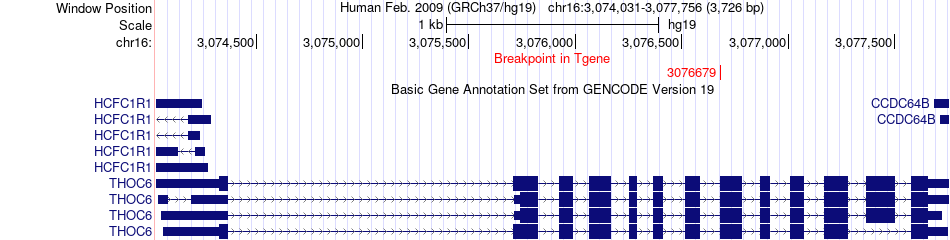 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-CV-7416 | COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + |
Top |
Fusion Gene ORF analysis for COL1A1-THOC6 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000225964 | ENST00000253952 | COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + |
| In-frame | ENST00000225964 | ENST00000326266 | COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + |
| In-frame | ENST00000225964 | ENST00000574549 | COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + |
| In-frame | ENST00000225964 | ENST00000575576 | COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000225964 | COL1A1 | chr17 | 48269835 | - | ENST00000326266 | THOC6 | chr16 | 3076679 | + | 2742 | 2102 | 119 | 2644 | 841 |
| ENST00000225964 | COL1A1 | chr17 | 48269835 | - | ENST00000574549 | THOC6 | chr16 | 3076679 | + | 2743 | 2102 | 119 | 2644 | 841 |
| ENST00000225964 | COL1A1 | chr17 | 48269835 | - | ENST00000575576 | THOC6 | chr16 | 3076679 | + | 2710 | 2102 | 119 | 2644 | 841 |
| ENST00000225964 | COL1A1 | chr17 | 48269835 | - | ENST00000253952 | THOC6 | chr16 | 3076679 | + | 2602 | 2102 | 119 | 2509 | 796 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000225964 | ENST00000326266 | COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + | 0.004212382 | 0.99578756 |
| ENST00000225964 | ENST00000574549 | COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + | 0.0041934 | 0.9958066 |
| ENST00000225964 | ENST00000575576 | COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + | 0.004470956 | 0.995529 |
| ENST00000225964 | ENST00000253952 | COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + | 0.004519245 | 0.9954808 |
Top |
Fusion Genomic Features for COL1A1-THOC6 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + | 0.051783737 | 0.9482163 |
| COL1A1 | chr17 | 48269835 | - | THOC6 | chr16 | 3076679 | + | 0.051783737 | 0.9482163 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
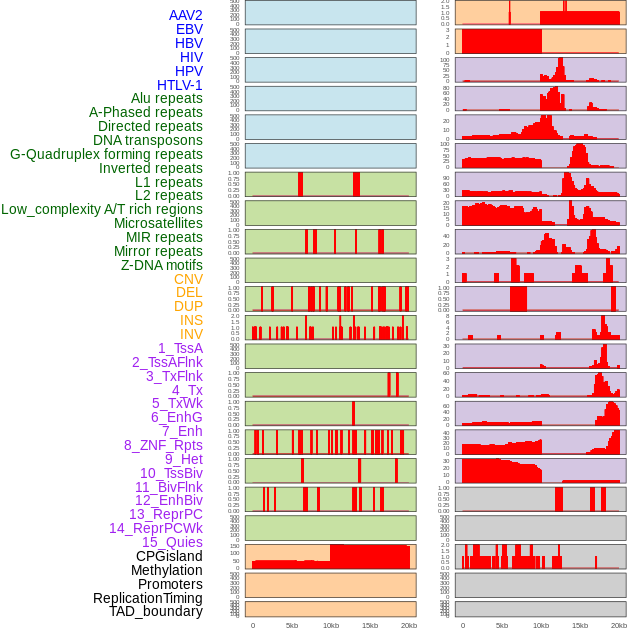 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
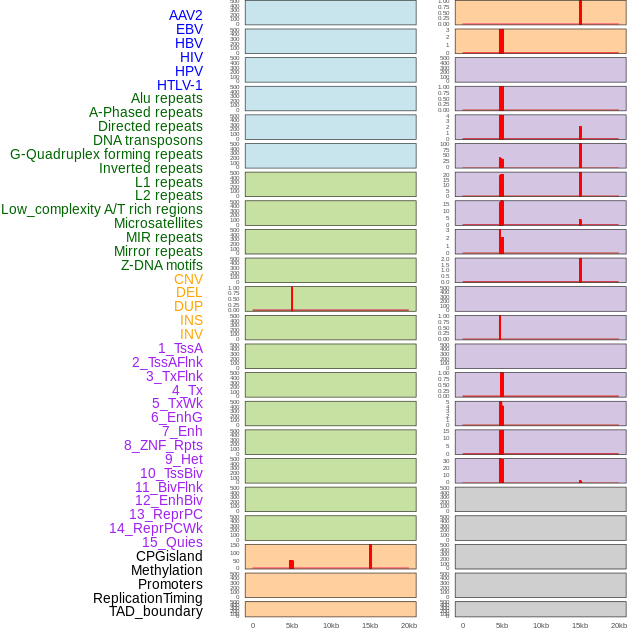 |
Top |
Fusion Protein Features for COL1A1-THOC6 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:48269835/chr16:3076679) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| COL1A1 | . |
| FUNCTION: Type I collagen is a member of group I collagen (fibrillar forming collagen). | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | COL1A1 | chr17:48269835 | chr16:3076679 | ENST00000225964 | - | 29 | 51 | 38_96 | 661 | 1465.0 | Domain | VWFC |
| Hgene | COL1A1 | chr17:48269835 | chr16:3076679 | ENST00000225964 | - | 29 | 51 | 162_178 | 661 | 1465.0 | Region | Note=Nonhelical region (N-terminal) |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000253952 | 6 | 12 | 166_205 | 161 | 297.0 | Repeat | Note=WD 4 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000253952 | 6 | 12 | 215_254 | 161 | 297.0 | Repeat | Note=WD 5 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000253952 | 6 | 12 | 256_293 | 161 | 297.0 | Repeat | Note=WD 6 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000253952 | 6 | 12 | 295_339 | 161 | 297.0 | Repeat | Note=WD 7 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000326266 | 6 | 13 | 166_205 | 161 | 342.0 | Repeat | Note=WD 4 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000326266 | 6 | 13 | 215_254 | 161 | 342.0 | Repeat | Note=WD 5 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000326266 | 6 | 13 | 256_293 | 161 | 342.0 | Repeat | Note=WD 6 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000326266 | 6 | 13 | 295_339 | 161 | 342.0 | Repeat | Note=WD 7 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000574549 | 7 | 14 | 166_205 | 137 | 318.0 | Repeat | Note=WD 4 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000574549 | 7 | 14 | 215_254 | 137 | 318.0 | Repeat | Note=WD 5 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000574549 | 7 | 14 | 256_293 | 137 | 318.0 | Repeat | Note=WD 6 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000574549 | 7 | 14 | 295_339 | 137 | 318.0 | Repeat | Note=WD 7 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000575576 | 6 | 13 | 166_205 | 137 | 318.0 | Repeat | Note=WD 4 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000575576 | 6 | 13 | 215_254 | 137 | 318.0 | Repeat | Note=WD 5 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000575576 | 6 | 13 | 256_293 | 137 | 318.0 | Repeat | Note=WD 6 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000575576 | 6 | 13 | 295_339 | 137 | 318.0 | Repeat | Note=WD 7 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | COL1A1 | chr17:48269835 | chr16:3076679 | ENST00000225964 | - | 29 | 51 | 1229_1464 | 661 | 1465.0 | Domain | Fibrillar collagen NC1 |
| Hgene | COL1A1 | chr17:48269835 | chr16:3076679 | ENST00000225964 | - | 29 | 51 | 1093_1095 | 661 | 1465.0 | Motif | Cell attachment site |
| Hgene | COL1A1 | chr17:48269835 | chr16:3076679 | ENST00000225964 | - | 29 | 51 | 745_747 | 661 | 1465.0 | Motif | Cell attachment site |
| Hgene | COL1A1 | chr17:48269835 | chr16:3076679 | ENST00000225964 | - | 29 | 51 | 1193_1218 | 661 | 1465.0 | Region | Note=Nonhelical region (C-terminal) |
| Hgene | COL1A1 | chr17:48269835 | chr16:3076679 | ENST00000225964 | - | 29 | 51 | 179_1192 | 661 | 1465.0 | Region | Note=Triple-helical region |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000253952 | 6 | 12 | 124_165 | 161 | 297.0 | Repeat | Note=WD 3 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000253952 | 6 | 12 | 22_61 | 161 | 297.0 | Repeat | Note=WD 1 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000253952 | 6 | 12 | 74_112 | 161 | 297.0 | Repeat | Note=WD 2 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000326266 | 6 | 13 | 124_165 | 161 | 342.0 | Repeat | Note=WD 3 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000326266 | 6 | 13 | 22_61 | 161 | 342.0 | Repeat | Note=WD 1 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000326266 | 6 | 13 | 74_112 | 161 | 342.0 | Repeat | Note=WD 2 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000574549 | 7 | 14 | 124_165 | 137 | 318.0 | Repeat | Note=WD 3 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000574549 | 7 | 14 | 22_61 | 137 | 318.0 | Repeat | Note=WD 1 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000574549 | 7 | 14 | 74_112 | 137 | 318.0 | Repeat | Note=WD 2 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000575576 | 6 | 13 | 124_165 | 137 | 318.0 | Repeat | Note=WD 3 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000575576 | 6 | 13 | 22_61 | 137 | 318.0 | Repeat | Note=WD 1 | |
| Tgene | THOC6 | chr17:48269835 | chr16:3076679 | ENST00000575576 | 6 | 13 | 74_112 | 137 | 318.0 | Repeat | Note=WD 2 |
Top |
Fusion Gene Sequence for COL1A1-THOC6 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >18155_18155_1_COL1A1-THOC6_COL1A1_chr17_48269835_ENST00000225964_THOC6_chr16_3076679_ENST00000253952_length(transcript)=2602nt_BP=2102nt AGCAGACGGGAGTTTCTCCTCGGGGTCGGAGCAGGAGGCACGCGGAGTGTGAGGCCACGCATGAGCGGACGCTAACCCCCTCCCCAGCCA CAAAGAGTCTACATGTCTAGGGTCTAGACATGTTCAGCTTTGTGGACCTCCGGCTCCTGCTCCTCTTAGCGGCCACCGCCCTCCTGACGC ACGGCCAAGAGGAAGGCCAAGTCGAGGGCCAAGACGAAGACATCCCACCAATCACCTGCGTACAGAACGGCCTCAGGTACCATGACCGAG ACGTGTGGAAACCCGAGCCCTGCCGGATCTGCGTCTGCGACAACGGCAAGGTGTTGTGCGATGACGTGATCTGTGACGAGACCAAGAACT GCCCCGGCGCCGAAGTCCCCGAGGGCGAGTGCTGTCCCGTCTGCCCCGACGGCTCAGAGTCACCCACCGACCAAGAAACCACCGGCGTCG AGGGACCCAAGGGAGACACTGGCCCCCGAGGCCCAAGGGGACCCGCAGGCCCCCCTGGCCGAGATGGCATCCCTGGACAGCCTGGACTTC CCGGACCCCCCGGACCCCCCGGACCTCCCGGACCCCCTGGCCTCGGAGGAAACTTTGCTCCCCAGCTGTCTTATGGCTATGATGAGAAAT CAACCGGAGGAATTTCCGTGCCTGGCCCCATGGGTCCCTCTGGTCCTCGTGGTCTCCCTGGCCCCCCTGGTGCACCTGGTCCCCAAGGCT TCCAAGGTCCCCCTGGTGAGCCTGGCGAGCCTGGAGCTTCAGGTCCCATGGGTCCCCGAGGTCCCCCAGGTCCCCCTGGAAAGAATGGAG ATGATGGGGAAGCTGGAAAACCTGGTCGTCCTGGTGAGCGTGGGCCTCCTGGGCCTCAGGGTGCTCGAGGATTGCCCGGAACAGCTGGCC TCCCTGGAATGAAGGGACACAGAGGTTTCAGTGGTTTGGATGGTGCCAAGGGAGATGCTGGTCCTGCTGGTCCTAAGGGTGAGCCTGGCA GCCCTGGTGAAAATGGAGCTCCTGGTCAGATGGGCCCCCGTGGCCTGCCTGGTGAGAGAGGTCGCCCTGGAGCCCCTGGCCCTGCTGGTG CTCGTGGAAATGATGGTGCTACTGGTGCTGCCGGGCCCCCTGGTCCCACCGGCCCCGCTGGTCCTCCTGGCTTCCCTGGTGCTGTTGGTG CTAAGGGTGAAGCTGGTCCCCAAGGGCCCCGAGGCTCTGAAGGTCCCCAGGGTGTGCGTGGTGAGCCTGGCCCCCCTGGCCCTGCTGGTG CTGCTGGCCCTGCTGGAAACCCTGGTGCTGATGGACAGCCTGGTGCTAAAGGTGCCAATGGTGCTCCTGGTATTGCTGGTGCTCCTGGCT TCCCTGGTGCCCGAGGCCCCTCTGGACCCCAGGGCCCCGGCGGCCCTCCTGGTCCCAAGGGTAACAGCGGTGAACCTGGTGCTCCTGGCA GCAAAGGAGACACTGGTGCTAAGGGAGAGCCTGGCCCTGTTGGTGTTCAAGGACCCCCTGGCCCTGCTGGAGAGGAAGGAAAGCGAGGAG CTCGAGGTGAACCCGGACCCACTGGCCTGCCCGGACCCCCTGGCGAGCGTGGTGGACCTGGTAGCCGTGGTTTCCCTGGCGCAGATGGTG TTGCTGGTCCCAAGGGTCCCGCTGGTGAACGTGGTTCTCCTGGCCCTGCTGGCCCCAAAGGATCTCCTGGTGAAGCTGGTCGTCCCGGTG AAGCTGGTCTGCCTGGTGCCAAGGGTCTGACTGGAAGCCCTGGCAGCCCTGGTCCTGATGGCAAAACTGGCCCCCCTGGTCCCGCCGGTC AAGATGGTCGCCCCGGACCCCCAGGCCCACCTGGTGCCCGTGGTCAGGCTGGTGTGATGGGATTCCCTGGACCTAAAGGTGCTGCTGGAG AGCCCGGCAAGGCTGGAGAGCGAGGTGTTCCCGGACCCCCTGGCGCTGTCGGTCCTGCTGGCAAAGATGGAGAGGCTGGAGCTCAGGGAC CCCCTGGCCCTGCTGGTCCCGCTGGCGAGAGAGGTGAACAAGGCCCTGCTGGCTCCCCCGGATTCCAGGGTCTCCCTGGTCCTGCTGGTC CTCCAGGTGAAGCAGGCAAACCTGGTGAACAGAGGGTCCTCCGGGGCCACACAGACTACATCCACTGCCTGGCACTGCGGGAAAGGAGCC CAGAGGTGCTGTCAGGTGGCGAGGATGGAGCTGTTCGACTTTGGGACCTGCGCACAGCCAAGGAGGTCCAGACGATCGAGGTCTATAAGC ACGAGGAGTGCTCGAGGCCCCACAATGGGCGCTGGATTGGATGTTTGGCAACTGATTCCGACTGGATGGTCTGTGGAGGGGGCCCAGCCC TCACCCTCTGGCACCTCCGATCCTCCACACCCACCACCATCTTCCCCATCCGGGCGCCACAGAAGCACGTCACCTTCTACCAGGACCTGG TCCTGACAGCTGCAGGCAACAGCTGCCGGGTGGATGTCTTCACCAACCTGGGTTACCGAGCCTTCTCCCTGTCCTTCTGATCTCTGACGA CACCCCCAGCCAGCTCAGGGTTTTAGAGTGTTTTTCATTTTCTTTTTTTTTTTTTTTTTACAATAAAGTTTCAGGCTTTTTT >18155_18155_1_COL1A1-THOC6_COL1A1_chr17_48269835_ENST00000225964_THOC6_chr16_3076679_ENST00000253952_length(amino acids)=796AA_BP=132 MFSFVDLRLLLLLAATALLTHGQEEGQVEGQDEDIPPITCVQNGLRYHDRDVWKPEPCRICVCDNGKVLCDDVICDETKNCPGAEVPEGE CCPVCPDGSESPTDQETTGVEGPKGDTGPRGPRGPAGPPGRDGIPGQPGLPGPPGPPGPPGPPGLGGNFAPQLSYGYDEKSTGGISVPGP MGPSGPRGLPGPPGAPGPQGFQGPPGEPGEPGASGPMGPRGPPGPPGKNGDDGEAGKPGRPGERGPPGPQGARGLPGTAGLPGMKGHRGF SGLDGAKGDAGPAGPKGEPGSPGENGAPGQMGPRGLPGERGRPGAPGPAGARGNDGATGAAGPPGPTGPAGPPGFPGAVGAKGEAGPQGP RGSEGPQGVRGEPGPPGPAGAAGPAGNPGADGQPGAKGANGAPGIAGAPGFPGARGPSGPQGPGGPPGPKGNSGEPGAPGSKGDTGAKGE PGPVGVQGPPGPAGEEGKRGARGEPGPTGLPGPPGERGGPGSRGFPGADGVAGPKGPAGERGSPGPAGPKGSPGEAGRPGEAGLPGAKGL TGSPGSPGPDGKTGPPGPAGQDGRPGPPGPPGARGQAGVMGFPGPKGAAGEPGKAGERGVPGPPGAVGPAGKDGEAGAQGPPGPAGPAGE RGEQGPAGSPGFQGLPGPAGPPGEAGKPGEQRVLRGHTDYIHCLALRERSPEVLSGGEDGAVRLWDLRTAKEVQTIEVYKHEECSRPHNG RWIGCLATDSDWMVCGGGPALTLWHLRSSTPTTIFPIRAPQKHVTFYQDLVLTAAGNSCRVDVFTNLGYRAFSLSF -------------------------------------------------------------- >18155_18155_2_COL1A1-THOC6_COL1A1_chr17_48269835_ENST00000225964_THOC6_chr16_3076679_ENST00000326266_length(transcript)=2742nt_BP=2102nt AGCAGACGGGAGTTTCTCCTCGGGGTCGGAGCAGGAGGCACGCGGAGTGTGAGGCCACGCATGAGCGGACGCTAACCCCCTCCCCAGCCA CAAAGAGTCTACATGTCTAGGGTCTAGACATGTTCAGCTTTGTGGACCTCCGGCTCCTGCTCCTCTTAGCGGCCACCGCCCTCCTGACGC ACGGCCAAGAGGAAGGCCAAGTCGAGGGCCAAGACGAAGACATCCCACCAATCACCTGCGTACAGAACGGCCTCAGGTACCATGACCGAG ACGTGTGGAAACCCGAGCCCTGCCGGATCTGCGTCTGCGACAACGGCAAGGTGTTGTGCGATGACGTGATCTGTGACGAGACCAAGAACT GCCCCGGCGCCGAAGTCCCCGAGGGCGAGTGCTGTCCCGTCTGCCCCGACGGCTCAGAGTCACCCACCGACCAAGAAACCACCGGCGTCG AGGGACCCAAGGGAGACACTGGCCCCCGAGGCCCAAGGGGACCCGCAGGCCCCCCTGGCCGAGATGGCATCCCTGGACAGCCTGGACTTC CCGGACCCCCCGGACCCCCCGGACCTCCCGGACCCCCTGGCCTCGGAGGAAACTTTGCTCCCCAGCTGTCTTATGGCTATGATGAGAAAT CAACCGGAGGAATTTCCGTGCCTGGCCCCATGGGTCCCTCTGGTCCTCGTGGTCTCCCTGGCCCCCCTGGTGCACCTGGTCCCCAAGGCT TCCAAGGTCCCCCTGGTGAGCCTGGCGAGCCTGGAGCTTCAGGTCCCATGGGTCCCCGAGGTCCCCCAGGTCCCCCTGGAAAGAATGGAG ATGATGGGGAAGCTGGAAAACCTGGTCGTCCTGGTGAGCGTGGGCCTCCTGGGCCTCAGGGTGCTCGAGGATTGCCCGGAACAGCTGGCC TCCCTGGAATGAAGGGACACAGAGGTTTCAGTGGTTTGGATGGTGCCAAGGGAGATGCTGGTCCTGCTGGTCCTAAGGGTGAGCCTGGCA GCCCTGGTGAAAATGGAGCTCCTGGTCAGATGGGCCCCCGTGGCCTGCCTGGTGAGAGAGGTCGCCCTGGAGCCCCTGGCCCTGCTGGTG CTCGTGGAAATGATGGTGCTACTGGTGCTGCCGGGCCCCCTGGTCCCACCGGCCCCGCTGGTCCTCCTGGCTTCCCTGGTGCTGTTGGTG CTAAGGGTGAAGCTGGTCCCCAAGGGCCCCGAGGCTCTGAAGGTCCCCAGGGTGTGCGTGGTGAGCCTGGCCCCCCTGGCCCTGCTGGTG CTGCTGGCCCTGCTGGAAACCCTGGTGCTGATGGACAGCCTGGTGCTAAAGGTGCCAATGGTGCTCCTGGTATTGCTGGTGCTCCTGGCT TCCCTGGTGCCCGAGGCCCCTCTGGACCCCAGGGCCCCGGCGGCCCTCCTGGTCCCAAGGGTAACAGCGGTGAACCTGGTGCTCCTGGCA GCAAAGGAGACACTGGTGCTAAGGGAGAGCCTGGCCCTGTTGGTGTTCAAGGACCCCCTGGCCCTGCTGGAGAGGAAGGAAAGCGAGGAG CTCGAGGTGAACCCGGACCCACTGGCCTGCCCGGACCCCCTGGCGAGCGTGGTGGACCTGGTAGCCGTGGTTTCCCTGGCGCAGATGGTG TTGCTGGTCCCAAGGGTCCCGCTGGTGAACGTGGTTCTCCTGGCCCTGCTGGCCCCAAAGGATCTCCTGGTGAAGCTGGTCGTCCCGGTG AAGCTGGTCTGCCTGGTGCCAAGGGTCTGACTGGAAGCCCTGGCAGCCCTGGTCCTGATGGCAAAACTGGCCCCCCTGGTCCCGCCGGTC AAGATGGTCGCCCCGGACCCCCAGGCCCACCTGGTGCCCGTGGTCAGGCTGGTGTGATGGGATTCCCTGGACCTAAAGGTGCTGCTGGAG AGCCCGGCAAGGCTGGAGAGCGAGGTGTTCCCGGACCCCCTGGCGCTGTCGGTCCTGCTGGCAAAGATGGAGAGGCTGGAGCTCAGGGAC CCCCTGGCCCTGCTGGTCCCGCTGGCGAGAGAGGTGAACAAGGCCCTGCTGGCTCCCCCGGATTCCAGGGTCTCCCTGGTCCTGCTGGTC CTCCAGGTGAAGCAGGCAAACCTGGTGAACAGAGGGTCCTCCGGGGCCACACAGACTACATCCACTGCCTGGCACTGCGGGAAAGGAGCC CAGAGGTGCTGTCAGGTGGCGAGGATGGAGCTGTTCGACTTTGGGACCTGCGCACAGCCAAGGAGGTCCAGACGATCGAGGTCTATAAGC ACGAGGAGTGCTCGAGGCCCCACAATGGGCGCTGGATTGGATGTTTGGCAACTGATTCCGACTGGATGGTCTGTGGAGGGGGCCCAGCCC TCACCCTCTGGCACCTCCGATCCTCCACACCCACCACCATCTTCCCCATCCGGGCGCCACAGAAGCACGTCACCTTCTACCAGGACCTGA TTCTGTCAGCTGGCCAGGGCCGCTGCGTCAACCAGTGGCAGCTGAGCGGGGAGCTGAAGGCCCAGGTGCCTGGCTCCTCCCCAGGGCTGC TCAGCCTCAGCCTCAACCAGCAGCCTGCCGCGCCTGAGTGCAAGGTCCTGACAGCTGCAGGCAACAGCTGCCGGGTGGATGTCTTCACCA ACCTGGGTTACCGAGCCTTCTCCCTGTCCTTCTGATCTCTGACGACACCCCCAGCCAGCTCAGGGTTTTAGAGTGTTTTTCATTTTCTTT TTTTTTTTTTTTTTACAATAAAGTTTCAGGCTTTTTTACCAT >18155_18155_2_COL1A1-THOC6_COL1A1_chr17_48269835_ENST00000225964_THOC6_chr16_3076679_ENST00000326266_length(amino acids)=841AA_BP=132 MFSFVDLRLLLLLAATALLTHGQEEGQVEGQDEDIPPITCVQNGLRYHDRDVWKPEPCRICVCDNGKVLCDDVICDETKNCPGAEVPEGE CCPVCPDGSESPTDQETTGVEGPKGDTGPRGPRGPAGPPGRDGIPGQPGLPGPPGPPGPPGPPGLGGNFAPQLSYGYDEKSTGGISVPGP MGPSGPRGLPGPPGAPGPQGFQGPPGEPGEPGASGPMGPRGPPGPPGKNGDDGEAGKPGRPGERGPPGPQGARGLPGTAGLPGMKGHRGF SGLDGAKGDAGPAGPKGEPGSPGENGAPGQMGPRGLPGERGRPGAPGPAGARGNDGATGAAGPPGPTGPAGPPGFPGAVGAKGEAGPQGP RGSEGPQGVRGEPGPPGPAGAAGPAGNPGADGQPGAKGANGAPGIAGAPGFPGARGPSGPQGPGGPPGPKGNSGEPGAPGSKGDTGAKGE PGPVGVQGPPGPAGEEGKRGARGEPGPTGLPGPPGERGGPGSRGFPGADGVAGPKGPAGERGSPGPAGPKGSPGEAGRPGEAGLPGAKGL TGSPGSPGPDGKTGPPGPAGQDGRPGPPGPPGARGQAGVMGFPGPKGAAGEPGKAGERGVPGPPGAVGPAGKDGEAGAQGPPGPAGPAGE RGEQGPAGSPGFQGLPGPAGPPGEAGKPGEQRVLRGHTDYIHCLALRERSPEVLSGGEDGAVRLWDLRTAKEVQTIEVYKHEECSRPHNG RWIGCLATDSDWMVCGGGPALTLWHLRSSTPTTIFPIRAPQKHVTFYQDLILSAGQGRCVNQWQLSGELKAQVPGSSPGLLSLSLNQQPA APECKVLTAAGNSCRVDVFTNLGYRAFSLSF -------------------------------------------------------------- >18155_18155_3_COL1A1-THOC6_COL1A1_chr17_48269835_ENST00000225964_THOC6_chr16_3076679_ENST00000574549_length(transcript)=2743nt_BP=2102nt AGCAGACGGGAGTTTCTCCTCGGGGTCGGAGCAGGAGGCACGCGGAGTGTGAGGCCACGCATGAGCGGACGCTAACCCCCTCCCCAGCCA CAAAGAGTCTACATGTCTAGGGTCTAGACATGTTCAGCTTTGTGGACCTCCGGCTCCTGCTCCTCTTAGCGGCCACCGCCCTCCTGACGC ACGGCCAAGAGGAAGGCCAAGTCGAGGGCCAAGACGAAGACATCCCACCAATCACCTGCGTACAGAACGGCCTCAGGTACCATGACCGAG ACGTGTGGAAACCCGAGCCCTGCCGGATCTGCGTCTGCGACAACGGCAAGGTGTTGTGCGATGACGTGATCTGTGACGAGACCAAGAACT GCCCCGGCGCCGAAGTCCCCGAGGGCGAGTGCTGTCCCGTCTGCCCCGACGGCTCAGAGTCACCCACCGACCAAGAAACCACCGGCGTCG AGGGACCCAAGGGAGACACTGGCCCCCGAGGCCCAAGGGGACCCGCAGGCCCCCCTGGCCGAGATGGCATCCCTGGACAGCCTGGACTTC CCGGACCCCCCGGACCCCCCGGACCTCCCGGACCCCCTGGCCTCGGAGGAAACTTTGCTCCCCAGCTGTCTTATGGCTATGATGAGAAAT CAACCGGAGGAATTTCCGTGCCTGGCCCCATGGGTCCCTCTGGTCCTCGTGGTCTCCCTGGCCCCCCTGGTGCACCTGGTCCCCAAGGCT TCCAAGGTCCCCCTGGTGAGCCTGGCGAGCCTGGAGCTTCAGGTCCCATGGGTCCCCGAGGTCCCCCAGGTCCCCCTGGAAAGAATGGAG ATGATGGGGAAGCTGGAAAACCTGGTCGTCCTGGTGAGCGTGGGCCTCCTGGGCCTCAGGGTGCTCGAGGATTGCCCGGAACAGCTGGCC TCCCTGGAATGAAGGGACACAGAGGTTTCAGTGGTTTGGATGGTGCCAAGGGAGATGCTGGTCCTGCTGGTCCTAAGGGTGAGCCTGGCA GCCCTGGTGAAAATGGAGCTCCTGGTCAGATGGGCCCCCGTGGCCTGCCTGGTGAGAGAGGTCGCCCTGGAGCCCCTGGCCCTGCTGGTG CTCGTGGAAATGATGGTGCTACTGGTGCTGCCGGGCCCCCTGGTCCCACCGGCCCCGCTGGTCCTCCTGGCTTCCCTGGTGCTGTTGGTG CTAAGGGTGAAGCTGGTCCCCAAGGGCCCCGAGGCTCTGAAGGTCCCCAGGGTGTGCGTGGTGAGCCTGGCCCCCCTGGCCCTGCTGGTG CTGCTGGCCCTGCTGGAAACCCTGGTGCTGATGGACAGCCTGGTGCTAAAGGTGCCAATGGTGCTCCTGGTATTGCTGGTGCTCCTGGCT TCCCTGGTGCCCGAGGCCCCTCTGGACCCCAGGGCCCCGGCGGCCCTCCTGGTCCCAAGGGTAACAGCGGTGAACCTGGTGCTCCTGGCA GCAAAGGAGACACTGGTGCTAAGGGAGAGCCTGGCCCTGTTGGTGTTCAAGGACCCCCTGGCCCTGCTGGAGAGGAAGGAAAGCGAGGAG CTCGAGGTGAACCCGGACCCACTGGCCTGCCCGGACCCCCTGGCGAGCGTGGTGGACCTGGTAGCCGTGGTTTCCCTGGCGCAGATGGTG TTGCTGGTCCCAAGGGTCCCGCTGGTGAACGTGGTTCTCCTGGCCCTGCTGGCCCCAAAGGATCTCCTGGTGAAGCTGGTCGTCCCGGTG AAGCTGGTCTGCCTGGTGCCAAGGGTCTGACTGGAAGCCCTGGCAGCCCTGGTCCTGATGGCAAAACTGGCCCCCCTGGTCCCGCCGGTC AAGATGGTCGCCCCGGACCCCCAGGCCCACCTGGTGCCCGTGGTCAGGCTGGTGTGATGGGATTCCCTGGACCTAAAGGTGCTGCTGGAG AGCCCGGCAAGGCTGGAGAGCGAGGTGTTCCCGGACCCCCTGGCGCTGTCGGTCCTGCTGGCAAAGATGGAGAGGCTGGAGCTCAGGGAC CCCCTGGCCCTGCTGGTCCCGCTGGCGAGAGAGGTGAACAAGGCCCTGCTGGCTCCCCCGGATTCCAGGGTCTCCCTGGTCCTGCTGGTC CTCCAGGTGAAGCAGGCAAACCTGGTGAACAGAGGGTCCTCCGGGGCCACACAGACTACATCCACTGCCTGGCACTGCGGGAAAGGAGCC CAGAGGTGCTGTCAGGTGGCGAGGATGGAGCTGTTCGACTTTGGGACCTGCGCACAGCCAAGGAGGTCCAGACGATCGAGGTCTATAAGC ACGAGGAGTGCTCGAGGCCCCACAATGGGCGCTGGATTGGATGTTTGGCAACTGATTCCGACTGGATGGTCTGTGGAGGGGGCCCAGCCC TCACCCTCTGGCACCTCCGATCCTCCACACCCACCACCATCTTCCCCATCCGGGCGCCACAGAAGCACGTCACCTTCTACCAGGACCTGA TTCTGTCAGCTGGCCAGGGCCGCTGCGTCAACCAGTGGCAGCTGAGCGGGGAGCTGAAGGCCCAGGTGCCTGGCTCCTCCCCAGGGCTGC TCAGCCTCAGCCTCAACCAGCAGCCTGCCGCGCCTGAGTGCAAGGTCCTGACAGCTGCAGGCAACAGCTGCCGGGTGGATGTCTTCACCA ACCTGGGTTACCGAGCCTTCTCCCTGTCCTTCTGATCTCTGACGACACCCCCAGCCAGCTCAGGGTTTTAGAGTGTTTTTCATTTTCTTT TTTTTTTTTTTTTTACAATAAAGTTTCAGGCTTTTTTACCATG >18155_18155_3_COL1A1-THOC6_COL1A1_chr17_48269835_ENST00000225964_THOC6_chr16_3076679_ENST00000574549_length(amino acids)=841AA_BP=132 MFSFVDLRLLLLLAATALLTHGQEEGQVEGQDEDIPPITCVQNGLRYHDRDVWKPEPCRICVCDNGKVLCDDVICDETKNCPGAEVPEGE CCPVCPDGSESPTDQETTGVEGPKGDTGPRGPRGPAGPPGRDGIPGQPGLPGPPGPPGPPGPPGLGGNFAPQLSYGYDEKSTGGISVPGP MGPSGPRGLPGPPGAPGPQGFQGPPGEPGEPGASGPMGPRGPPGPPGKNGDDGEAGKPGRPGERGPPGPQGARGLPGTAGLPGMKGHRGF SGLDGAKGDAGPAGPKGEPGSPGENGAPGQMGPRGLPGERGRPGAPGPAGARGNDGATGAAGPPGPTGPAGPPGFPGAVGAKGEAGPQGP RGSEGPQGVRGEPGPPGPAGAAGPAGNPGADGQPGAKGANGAPGIAGAPGFPGARGPSGPQGPGGPPGPKGNSGEPGAPGSKGDTGAKGE PGPVGVQGPPGPAGEEGKRGARGEPGPTGLPGPPGERGGPGSRGFPGADGVAGPKGPAGERGSPGPAGPKGSPGEAGRPGEAGLPGAKGL TGSPGSPGPDGKTGPPGPAGQDGRPGPPGPPGARGQAGVMGFPGPKGAAGEPGKAGERGVPGPPGAVGPAGKDGEAGAQGPPGPAGPAGE RGEQGPAGSPGFQGLPGPAGPPGEAGKPGEQRVLRGHTDYIHCLALRERSPEVLSGGEDGAVRLWDLRTAKEVQTIEVYKHEECSRPHNG RWIGCLATDSDWMVCGGGPALTLWHLRSSTPTTIFPIRAPQKHVTFYQDLILSAGQGRCVNQWQLSGELKAQVPGSSPGLLSLSLNQQPA APECKVLTAAGNSCRVDVFTNLGYRAFSLSF -------------------------------------------------------------- >18155_18155_4_COL1A1-THOC6_COL1A1_chr17_48269835_ENST00000225964_THOC6_chr16_3076679_ENST00000575576_length(transcript)=2710nt_BP=2102nt AGCAGACGGGAGTTTCTCCTCGGGGTCGGAGCAGGAGGCACGCGGAGTGTGAGGCCACGCATGAGCGGACGCTAACCCCCTCCCCAGCCA CAAAGAGTCTACATGTCTAGGGTCTAGACATGTTCAGCTTTGTGGACCTCCGGCTCCTGCTCCTCTTAGCGGCCACCGCCCTCCTGACGC ACGGCCAAGAGGAAGGCCAAGTCGAGGGCCAAGACGAAGACATCCCACCAATCACCTGCGTACAGAACGGCCTCAGGTACCATGACCGAG ACGTGTGGAAACCCGAGCCCTGCCGGATCTGCGTCTGCGACAACGGCAAGGTGTTGTGCGATGACGTGATCTGTGACGAGACCAAGAACT GCCCCGGCGCCGAAGTCCCCGAGGGCGAGTGCTGTCCCGTCTGCCCCGACGGCTCAGAGTCACCCACCGACCAAGAAACCACCGGCGTCG AGGGACCCAAGGGAGACACTGGCCCCCGAGGCCCAAGGGGACCCGCAGGCCCCCCTGGCCGAGATGGCATCCCTGGACAGCCTGGACTTC CCGGACCCCCCGGACCCCCCGGACCTCCCGGACCCCCTGGCCTCGGAGGAAACTTTGCTCCCCAGCTGTCTTATGGCTATGATGAGAAAT CAACCGGAGGAATTTCCGTGCCTGGCCCCATGGGTCCCTCTGGTCCTCGTGGTCTCCCTGGCCCCCCTGGTGCACCTGGTCCCCAAGGCT TCCAAGGTCCCCCTGGTGAGCCTGGCGAGCCTGGAGCTTCAGGTCCCATGGGTCCCCGAGGTCCCCCAGGTCCCCCTGGAAAGAATGGAG ATGATGGGGAAGCTGGAAAACCTGGTCGTCCTGGTGAGCGTGGGCCTCCTGGGCCTCAGGGTGCTCGAGGATTGCCCGGAACAGCTGGCC TCCCTGGAATGAAGGGACACAGAGGTTTCAGTGGTTTGGATGGTGCCAAGGGAGATGCTGGTCCTGCTGGTCCTAAGGGTGAGCCTGGCA GCCCTGGTGAAAATGGAGCTCCTGGTCAGATGGGCCCCCGTGGCCTGCCTGGTGAGAGAGGTCGCCCTGGAGCCCCTGGCCCTGCTGGTG CTCGTGGAAATGATGGTGCTACTGGTGCTGCCGGGCCCCCTGGTCCCACCGGCCCCGCTGGTCCTCCTGGCTTCCCTGGTGCTGTTGGTG CTAAGGGTGAAGCTGGTCCCCAAGGGCCCCGAGGCTCTGAAGGTCCCCAGGGTGTGCGTGGTGAGCCTGGCCCCCCTGGCCCTGCTGGTG CTGCTGGCCCTGCTGGAAACCCTGGTGCTGATGGACAGCCTGGTGCTAAAGGTGCCAATGGTGCTCCTGGTATTGCTGGTGCTCCTGGCT TCCCTGGTGCCCGAGGCCCCTCTGGACCCCAGGGCCCCGGCGGCCCTCCTGGTCCCAAGGGTAACAGCGGTGAACCTGGTGCTCCTGGCA GCAAAGGAGACACTGGTGCTAAGGGAGAGCCTGGCCCTGTTGGTGTTCAAGGACCCCCTGGCCCTGCTGGAGAGGAAGGAAAGCGAGGAG CTCGAGGTGAACCCGGACCCACTGGCCTGCCCGGACCCCCTGGCGAGCGTGGTGGACCTGGTAGCCGTGGTTTCCCTGGCGCAGATGGTG TTGCTGGTCCCAAGGGTCCCGCTGGTGAACGTGGTTCTCCTGGCCCTGCTGGCCCCAAAGGATCTCCTGGTGAAGCTGGTCGTCCCGGTG AAGCTGGTCTGCCTGGTGCCAAGGGTCTGACTGGAAGCCCTGGCAGCCCTGGTCCTGATGGCAAAACTGGCCCCCCTGGTCCCGCCGGTC AAGATGGTCGCCCCGGACCCCCAGGCCCACCTGGTGCCCGTGGTCAGGCTGGTGTGATGGGATTCCCTGGACCTAAAGGTGCTGCTGGAG AGCCCGGCAAGGCTGGAGAGCGAGGTGTTCCCGGACCCCCTGGCGCTGTCGGTCCTGCTGGCAAAGATGGAGAGGCTGGAGCTCAGGGAC CCCCTGGCCCTGCTGGTCCCGCTGGCGAGAGAGGTGAACAAGGCCCTGCTGGCTCCCCCGGATTCCAGGGTCTCCCTGGTCCTGCTGGTC CTCCAGGTGAAGCAGGCAAACCTGGTGAACAGAGGGTCCTCCGGGGCCACACAGACTACATCCACTGCCTGGCACTGCGGGAAAGGAGCC CAGAGGTGCTGTCAGGTGGCGAGGATGGAGCTGTTCGACTTTGGGACCTGCGCACAGCCAAGGAGGTCCAGACGATCGAGGTCTATAAGC ACGAGGAGTGCTCGAGGCCCCACAATGGGCGCTGGATTGGATGTTTGGCAACTGATTCCGACTGGATGGTCTGTGGAGGGGGCCCAGCCC TCACCCTCTGGCACCTCCGATCCTCCACACCCACCACCATCTTCCCCATCCGGGCGCCACAGAAGCACGTCACCTTCTACCAGGACCTGA TTCTGTCAGCTGGCCAGGGCCGCTGCGTCAACCAGTGGCAGCTGAGCGGGGAGCTGAAGGCCCAGGTGCCTGGCTCCTCCCCAGGGCTGC TCAGCCTCAGCCTCAACCAGCAGCCTGCCGCGCCTGAGTGCAAGGTCCTGACAGCTGCAGGCAACAGCTGCCGGGTGGATGTCTTCACCA ACCTGGGTTACCGAGCCTTCTCCCTGTCCTTCTGATCTCTGACGACACCCCCAGCCAGCTCAGGGTTTTAGAGTGTTTTTCATTTTCTTT TTTTTTTTTT >18155_18155_4_COL1A1-THOC6_COL1A1_chr17_48269835_ENST00000225964_THOC6_chr16_3076679_ENST00000575576_length(amino acids)=841AA_BP=132 MFSFVDLRLLLLLAATALLTHGQEEGQVEGQDEDIPPITCVQNGLRYHDRDVWKPEPCRICVCDNGKVLCDDVICDETKNCPGAEVPEGE CCPVCPDGSESPTDQETTGVEGPKGDTGPRGPRGPAGPPGRDGIPGQPGLPGPPGPPGPPGPPGLGGNFAPQLSYGYDEKSTGGISVPGP MGPSGPRGLPGPPGAPGPQGFQGPPGEPGEPGASGPMGPRGPPGPPGKNGDDGEAGKPGRPGERGPPGPQGARGLPGTAGLPGMKGHRGF SGLDGAKGDAGPAGPKGEPGSPGENGAPGQMGPRGLPGERGRPGAPGPAGARGNDGATGAAGPPGPTGPAGPPGFPGAVGAKGEAGPQGP RGSEGPQGVRGEPGPPGPAGAAGPAGNPGADGQPGAKGANGAPGIAGAPGFPGARGPSGPQGPGGPPGPKGNSGEPGAPGSKGDTGAKGE PGPVGVQGPPGPAGEEGKRGARGEPGPTGLPGPPGERGGPGSRGFPGADGVAGPKGPAGERGSPGPAGPKGSPGEAGRPGEAGLPGAKGL TGSPGSPGPDGKTGPPGPAGQDGRPGPPGPPGARGQAGVMGFPGPKGAAGEPGKAGERGVPGPPGAVGPAGKDGEAGAQGPPGPAGPAGE RGEQGPAGSPGFQGLPGPAGPPGEAGKPGEQRVLRGHTDYIHCLALRERSPEVLSGGEDGAVRLWDLRTAKEVQTIEVYKHEECSRPHNG RWIGCLATDSDWMVCGGGPALTLWHLRSSTPTTIFPIRAPQKHVTFYQDLILSAGQGRCVNQWQLSGELKAQVPGSSPGLLSLSLNQQPA APECKVLTAAGNSCRVDVFTNLGYRAFSLSF -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for COL1A1-THOC6 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for COL1A1-THOC6 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
| Hgene | COL1A1 | P02452 | DB00048 | Collagenase clostridium histolyticum | Binder | Biotech | Approved|Investigational |
| Hgene | COL1A1 | P02452 | DB12872 | Vonicog Alfa | Binder | Biotech | Approved|Investigational |
| Hgene | COL1A1 | P02452 | DB13133 | Von Willebrand Factor Human | Binder | Biotech | Approved|Investigational |
| Hgene | COL1A1 | P02452 | DB11338 | Clove oil | Biotech | Approved|Nutraceutical | |
| Hgene | COL1A1 | P02452 | DB04866 | Halofuginone | Small molecule | Investigational|Vet_approved |
Top |
Related Diseases for COL1A1-THOC6 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | COL1A1 | C0268358 | Osteogenesis imperfecta, dominant perinatal lethal | 38 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | COL1A1 | C0268362 | Osteogenesis imperfecta type III (disorder) | 17 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | COL1A1 | C0023931 | Lobstein Disease | 15 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | COL1A1 | C0268363 | Osteogenesis imperfecta type IV (disorder) | 12 | GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | COL1A1 | C0023890 | Liver Cirrhosis | 4 | CTD_human |
| Hgene | COL1A1 | C0239946 | Fibrosis, Liver | 4 | CTD_human |
| Hgene | COL1A1 | C4551623 | EHLERS-DANLOS SYNDROME, ARTHROCHALASIA TYPE, 1 | 4 | CTD_human;GENOMICS_ENGLAND |
| Hgene | COL1A1 | C4552122 | EHLERS-DANLOS SYNDROME, CLASSIC TYPE, 1 | 4 | GENOMICS_ENGLAND;UNIPROT |
| Hgene | COL1A1 | C0020497 | Cortical Congenital Hyperostosis | 3 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Hgene | COL1A1 | C0023893 | Liver Cirrhosis, Experimental | 3 | CTD_human |
| Hgene | COL1A1 | C0268345 | EHLERS-DANLOS SYNDROME, ARTHROCHALASIA TYPE | 2 | ORPHANET |
| Hgene | COL1A1 | C0000786 | Spontaneous abortion | 1 | CTD_human |
| Hgene | COL1A1 | C0000822 | Abortion, Tubal | 1 | CTD_human |
| Hgene | COL1A1 | C0002949 | Aneurysm, Dissecting | 1 | CTD_human |
| Hgene | COL1A1 | C0003504 | Aortic Valve Insufficiency | 1 | CTD_human |
| Hgene | COL1A1 | C0004364 | Autoimmune Diseases | 1 | CTD_human |
| Hgene | COL1A1 | C0005398 | Cholestasis, Extrahepatic | 1 | CTD_human |
| Hgene | COL1A1 | C0005779 | Blood Coagulation Disorders | 1 | GENOMICS_ENGLAND |
| Hgene | COL1A1 | C0006663 | Calcinosis | 1 | CTD_human |
| Hgene | COL1A1 | C0008311 | Cholangitis | 1 | CTD_human |
| Hgene | COL1A1 | C0013720 | Ehlers-Danlos Syndrome | 1 | GENOMICS_ENGLAND |
| Hgene | COL1A1 | C0016059 | Fibrosis | 1 | CTD_human |
| Hgene | COL1A1 | C0018824 | Heart valve disease | 1 | CTD_human |
| Hgene | COL1A1 | C0020538 | Hypertensive disease | 1 | CTD_human |
| Hgene | COL1A1 | C0022548 | Keloid | 1 | CTD_human |
| Hgene | COL1A1 | C0027719 | Nephrosclerosis | 1 | CTD_human |
| Hgene | COL1A1 | C0027726 | Nephrotic Syndrome | 1 | CTD_human |
| Hgene | COL1A1 | C0029172 | Oral Submucous Fibrosis | 1 | CTD_human |
| Hgene | COL1A1 | C0029434 | Osteogenesis Imperfecta | 1 | CTD_human;GENOMICS_ENGLAND |
| Hgene | COL1A1 | C0149721 | Left Ventricular Hypertrophy | 1 | CTD_human |
| Hgene | COL1A1 | C0220679 | Ehlers-Danlos Syndrome, Autosomal Dominant, Type Unspecified | 1 | ORPHANET |
| Hgene | COL1A1 | C0263628 | Tumoral calcinosis | 1 | CTD_human |
| Hgene | COL1A1 | C0340643 | Dissection of aorta | 1 | CTD_human |
| Hgene | COL1A1 | C0521174 | Microcalcification | 1 | CTD_human |
| Hgene | COL1A1 | C1458140 | Bleeding tendency | 1 | GENOMICS_ENGLAND |
| Hgene | COL1A1 | C1619692 | Nephrogenic Fibrosing Dermopathy | 1 | CTD_human |
| Hgene | COL1A1 | C1623038 | Cirrhosis | 1 | CTD_human |
| Hgene | COL1A1 | C1846545 | Autoimmune Lymphoproliferative Syndrome Type 2B | 1 | GENOMICS_ENGLAND |
| Hgene | COL1A1 | C3830362 | Early Pregnancy Loss | 1 | CTD_human |
| Hgene | COL1A1 | C4277533 | Dissection, Blood Vessel | 1 | CTD_human |
| Hgene | COL1A1 | C4552766 | Miscarriage | 1 | CTD_human |
| Tgene | C3150939 | THOC6-related developmental delay-microcephaly-facial dysmorphism syndrome | 2 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies