
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CPS1-MAP2 (FusionGDB2 ID:HG1373TG4133) |
Fusion Gene Summary for CPS1-MAP2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CPS1-MAP2 | Fusion gene ID: hg1373tg4133 | Hgene | Tgene | Gene symbol | CPS1 | MAP2 | Gene ID | 1373 | 4133 |
| Gene name | carbamoyl-phosphate synthase 1 | microtubule associated protein 2 | |
| Synonyms | CPSASE1|PHN | MAP-2|MAP2A|MAP2B|MAP2C | |
| Cytomap | ('CPS1')('MAP2') 2q34 | 2q34 | |
| Type of gene | protein-coding | protein-coding | |
| Description | carbamoyl-phosphate synthase [ammonia], mitochondrialcarbamoyl-phosphate synthase (ammonia)carbamoyl-phosphate synthase 1, mitochondrialcarbamoylphosphate synthetase I | microtubule-associated protein 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P31327 | P11137 | |
| Ensembl transtripts involved in fusion gene | ENST00000233072, ENST00000430249, ENST00000451903, ENST00000497121, | ||
| Fusion gene scores | * DoF score | 10 X 11 X 4=440 | 7 X 8 X 4=224 |
| # samples | 11 | 8 | |
| ** MAII score | log2(11/440*10)=-2 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/224*10)=-1.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CPS1 [Title/Abstract] AND MAP2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CPS1(211454958)-MAP2(210588319), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | CPS1-MAP2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CPS1-MAP2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CPS1-MAP2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CPS1-MAP2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CPS1 | GO:0032496 | response to lipopolysaccharide | 15897806 |
| Hgene | CPS1 | GO:0050667 | homocysteine metabolic process | 20031578 |
| Fusion gene breakpoints across CPS1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MAP2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
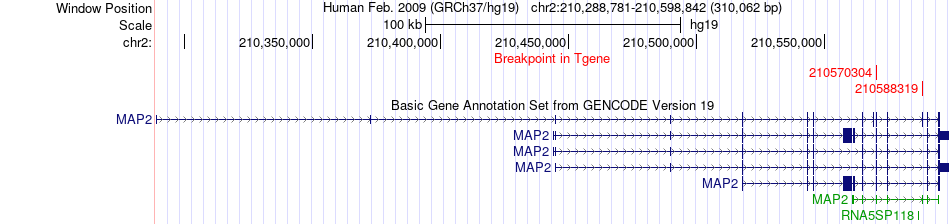 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LIHC | TCGA-2Y-A9H6-01A | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| ChimerDB4 | LIHC | TCGA-MR-A8JO-01A | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
Top |
Fusion Gene ORF analysis for CPS1-MAP2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000233072 | ENST00000475600 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| 5CDS-3UTR | ENST00000233072 | ENST00000475600 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| 5CDS-3UTR | ENST00000430249 | ENST00000475600 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| 5CDS-3UTR | ENST00000430249 | ENST00000475600 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| 5CDS-intron | ENST00000233072 | ENST00000360351 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| 5CDS-intron | ENST00000233072 | ENST00000361559 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| 5CDS-intron | ENST00000233072 | ENST00000392194 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| 5CDS-intron | ENST00000233072 | ENST00000447185 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| 5CDS-intron | ENST00000430249 | ENST00000360351 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| 5CDS-intron | ENST00000430249 | ENST00000361559 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| 5CDS-intron | ENST00000430249 | ENST00000392194 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| 5CDS-intron | ENST00000430249 | ENST00000447185 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| In-frame | ENST00000233072 | ENST00000199940 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| In-frame | ENST00000233072 | ENST00000199940 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| In-frame | ENST00000233072 | ENST00000360351 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| In-frame | ENST00000233072 | ENST00000361559 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| In-frame | ENST00000233072 | ENST00000392194 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| In-frame | ENST00000233072 | ENST00000447185 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| In-frame | ENST00000430249 | ENST00000199940 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| In-frame | ENST00000430249 | ENST00000199940 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| In-frame | ENST00000430249 | ENST00000360351 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| In-frame | ENST00000430249 | ENST00000361559 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| In-frame | ENST00000430249 | ENST00000392194 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| In-frame | ENST00000430249 | ENST00000447185 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000451903 | ENST00000199940 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000451903 | ENST00000199940 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-3CDS | ENST00000451903 | ENST00000360351 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000451903 | ENST00000361559 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000451903 | ENST00000392194 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000451903 | ENST00000447185 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000497121 | ENST00000199940 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000497121 | ENST00000199940 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-3CDS | ENST00000497121 | ENST00000360351 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000497121 | ENST00000361559 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000497121 | ENST00000392194 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3CDS | ENST00000497121 | ENST00000447185 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3UTR | ENST00000451903 | ENST00000475600 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3UTR | ENST00000451903 | ENST00000475600 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-3UTR | ENST00000497121 | ENST00000475600 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + |
| intron-3UTR | ENST00000497121 | ENST00000475600 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-intron | ENST00000451903 | ENST00000360351 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-intron | ENST00000451903 | ENST00000361559 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-intron | ENST00000451903 | ENST00000392194 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-intron | ENST00000451903 | ENST00000447185 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-intron | ENST00000497121 | ENST00000360351 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-intron | ENST00000497121 | ENST00000361559 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-intron | ENST00000497121 | ENST00000392194 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| intron-intron | ENST00000497121 | ENST00000447185 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000430249 | CPS1 | chr2 | 211447433 | + | ENST00000199940 | MAP2 | chr2 | 210570304 | + | 1808 | 694 | 55 | 1686 | 543 |
| ENST00000430249 | CPS1 | chr2 | 211447433 | + | ENST00000360351 | MAP2 | chr2 | 210570304 | + | 5315 | 694 | 55 | 1593 | 512 |
| ENST00000430249 | CPS1 | chr2 | 211447433 | + | ENST00000361559 | MAP2 | chr2 | 210570304 | + | 1720 | 694 | 55 | 1593 | 512 |
| ENST00000430249 | CPS1 | chr2 | 211447433 | + | ENST00000392194 | MAP2 | chr2 | 210570304 | + | 5315 | 694 | 55 | 1593 | 512 |
| ENST00000430249 | CPS1 | chr2 | 211447433 | + | ENST00000447185 | MAP2 | chr2 | 210570304 | + | 1594 | 694 | 55 | 1593 | 513 |
| ENST00000233072 | CPS1 | chr2 | 211447433 | + | ENST00000199940 | MAP2 | chr2 | 210570304 | + | 1931 | 817 | 196 | 1809 | 537 |
| ENST00000233072 | CPS1 | chr2 | 211447433 | + | ENST00000360351 | MAP2 | chr2 | 210570304 | + | 5438 | 817 | 196 | 1716 | 506 |
| ENST00000233072 | CPS1 | chr2 | 211447433 | + | ENST00000361559 | MAP2 | chr2 | 210570304 | + | 1843 | 817 | 196 | 1716 | 506 |
| ENST00000233072 | CPS1 | chr2 | 211447433 | + | ENST00000392194 | MAP2 | chr2 | 210570304 | + | 5438 | 817 | 196 | 1716 | 506 |
| ENST00000233072 | CPS1 | chr2 | 211447433 | + | ENST00000447185 | MAP2 | chr2 | 210570304 | + | 1717 | 817 | 196 | 1716 | 507 |
| ENST00000430249 | CPS1 | chr2 | 211454958 | + | ENST00000199940 | MAP2 | chr2 | 210588319 | + | 1538 | 913 | 55 | 1416 | 453 |
| ENST00000233072 | CPS1 | chr2 | 211454958 | + | ENST00000199940 | MAP2 | chr2 | 210588319 | + | 1661 | 1036 | 196 | 1539 | 447 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000430249 | ENST00000199940 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.001741547 | 0.9982584 |
| ENST00000430249 | ENST00000360351 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.000273916 | 0.9997261 |
| ENST00000430249 | ENST00000361559 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.002157346 | 0.99784267 |
| ENST00000430249 | ENST00000392194 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.000273916 | 0.9997261 |
| ENST00000430249 | ENST00000447185 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.0028263 | 0.99717367 |
| ENST00000233072 | ENST00000199940 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.001397461 | 0.99860257 |
| ENST00000233072 | ENST00000360351 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.000294439 | 0.9997055 |
| ENST00000233072 | ENST00000361559 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.001659118 | 0.99834085 |
| ENST00000233072 | ENST00000392194 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.000294439 | 0.9997055 |
| ENST00000233072 | ENST00000447185 | CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570304 | + | 0.001955906 | 0.99804413 |
| ENST00000430249 | ENST00000199940 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + | 0.000870898 | 0.9991291 |
| ENST00000233072 | ENST00000199940 | CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588319 | + | 0.000617796 | 0.99938214 |
Top |
Fusion Genomic Features for CPS1-MAP2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588318 | + | 0.03721485 | 0.9627851 |
| CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570303 | + | 0.003301424 | 0.99669856 |
| CPS1 | chr2 | 211454958 | + | MAP2 | chr2 | 210588318 | + | 0.03721485 | 0.9627851 |
| CPS1 | chr2 | 211447433 | + | MAP2 | chr2 | 210570303 | + | 0.003301424 | 0.99669856 |
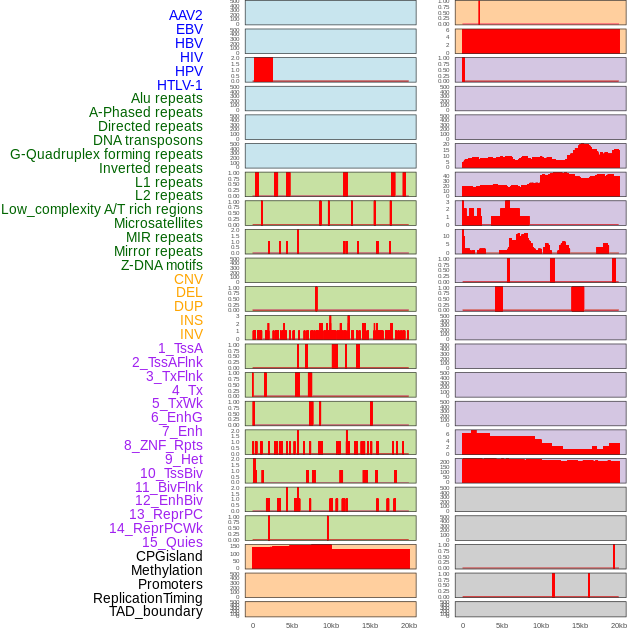
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
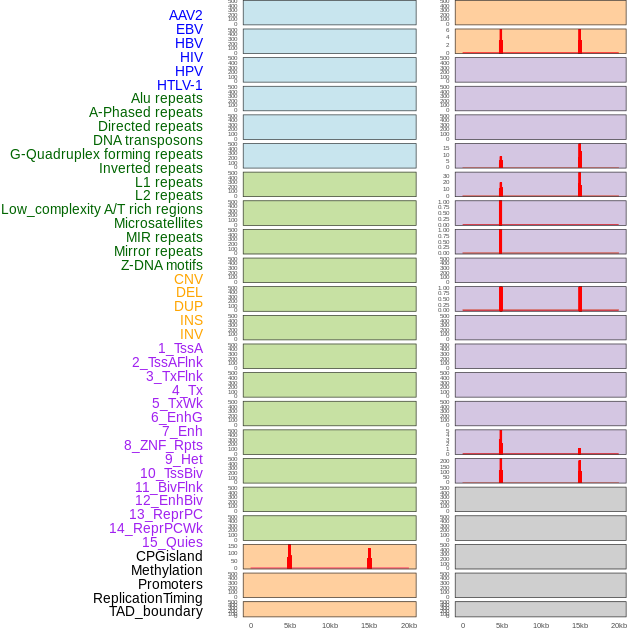
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for CPS1-MAP2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:211454958/chr2:210588319) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CPS1 | MAP2 |
| FUNCTION: Involved in the urea cycle of ureotelic animals where the enzyme plays an important role in removing excess ammonia from the cell. | FUNCTION: The exact function of MAP2 is unknown but MAPs may stabilize the microtubules against depolymerization. They also seem to have a stiffening effect on microtubules. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000233072 | + | 8 | 38 | 39_218 | 280 | 1501.0 | Region | Note=Anthranilate phosphoribosyltransferase homolog |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000430249 | + | 9 | 39 | 39_218 | 286 | 1507.0 | Region | Note=Anthranilate phosphoribosyltransferase homolog |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000199940 | 8 | 15 | 1447_1467 | 229 | 560.0 | Region | Calmodulin-binding | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000361559 | 6 | 12 | 1447_1467 | 172 | 472.0 | Region | Calmodulin-binding | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000392194 | 5 | 11 | 1447_1467 | 172 | 472.0 | Region | Calmodulin-binding | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000199940 | 10 | 15 | 1447_1467 | 392 | 560.0 | Region | Calmodulin-binding | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000360351 | 0 | 15 | 1447_1467 | 0 | 1828.0 | Region | Calmodulin-binding | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000361559 | 0 | 12 | 1447_1467 | 0 | 472.0 | Region | Calmodulin-binding | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000392194 | 0 | 11 | 1447_1467 | 0 | 472.0 | Region | Calmodulin-binding | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000447185 | 0 | 12 | 1447_1467 | 0 | 1824.0 | Region | Calmodulin-binding | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000199940 | 8 | 15 | 1661_1691 | 229 | 560.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000199940 | 8 | 15 | 1692_1722 | 229 | 560.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000199940 | 8 | 15 | 1723_1754 | 229 | 560.0 | Repeat | Note=Tau/MAP 3 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000360351 | 9 | 15 | 1661_1691 | 1528 | 1828.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000360351 | 9 | 15 | 1692_1722 | 1528 | 1828.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000360351 | 9 | 15 | 1723_1754 | 1528 | 1828.0 | Repeat | Note=Tau/MAP 3 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000361559 | 6 | 12 | 1661_1691 | 172 | 472.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000361559 | 6 | 12 | 1692_1722 | 172 | 472.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000361559 | 6 | 12 | 1723_1754 | 172 | 472.0 | Repeat | Note=Tau/MAP 3 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000392194 | 5 | 11 | 1661_1691 | 172 | 472.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000392194 | 5 | 11 | 1692_1722 | 172 | 472.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000392194 | 5 | 11 | 1723_1754 | 172 | 472.0 | Repeat | Note=Tau/MAP 3 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000447185 | 6 | 12 | 1661_1691 | 1524 | 1824.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000447185 | 6 | 12 | 1692_1722 | 1524 | 1824.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000447185 | 6 | 12 | 1723_1754 | 1524 | 1824.0 | Repeat | Note=Tau/MAP 3 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000199940 | 10 | 15 | 1661_1691 | 392 | 560.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000199940 | 10 | 15 | 1692_1722 | 392 | 560.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000199940 | 10 | 15 | 1723_1754 | 392 | 560.0 | Repeat | Note=Tau/MAP 3 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000360351 | 0 | 15 | 1661_1691 | 0 | 1828.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000360351 | 0 | 15 | 1692_1722 | 0 | 1828.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000360351 | 0 | 15 | 1723_1754 | 0 | 1828.0 | Repeat | Note=Tau/MAP 3 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000361559 | 0 | 12 | 1661_1691 | 0 | 472.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000361559 | 0 | 12 | 1692_1722 | 0 | 472.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000361559 | 0 | 12 | 1723_1754 | 0 | 472.0 | Repeat | Note=Tau/MAP 3 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000392194 | 0 | 11 | 1661_1691 | 0 | 472.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000392194 | 0 | 11 | 1692_1722 | 0 | 472.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000392194 | 0 | 11 | 1723_1754 | 0 | 472.0 | Repeat | Note=Tau/MAP 3 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000447185 | 0 | 12 | 1661_1691 | 0 | 1824.0 | Repeat | Note=Tau/MAP 1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000447185 | 0 | 12 | 1692_1722 | 0 | 1824.0 | Repeat | Note=Tau/MAP 2 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000447185 | 0 | 12 | 1723_1754 | 0 | 1824.0 | Repeat | Note=Tau/MAP 3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000233072 | + | 6 | 38 | 1093_1284 | 207 | 1501.0 | Domain | Note=ATP-grasp 2 |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000233072 | + | 6 | 38 | 1355_1500 | 207 | 1501.0 | Domain | MGS-like |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000233072 | + | 6 | 38 | 219_404 | 207 | 1501.0 | Domain | Note=Glutamine amidotransferase type-1 |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000233072 | + | 6 | 38 | 551_743 | 207 | 1501.0 | Domain | Note=ATP-grasp 1 |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000430249 | + | 7 | 39 | 1093_1284 | 213 | 1507.0 | Domain | Note=ATP-grasp 2 |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000430249 | + | 7 | 39 | 1355_1500 | 213 | 1507.0 | Domain | MGS-like |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000430249 | + | 7 | 39 | 219_404 | 213 | 1507.0 | Domain | Note=Glutamine amidotransferase type-1 |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000430249 | + | 7 | 39 | 551_743 | 213 | 1507.0 | Domain | Note=ATP-grasp 1 |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000451903 | + | 1 | 28 | 1093_1284 | 0 | 1050.0 | Domain | Note=ATP-grasp 2 |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000451903 | + | 1 | 28 | 1355_1500 | 0 | 1050.0 | Domain | MGS-like |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000451903 | + | 1 | 28 | 219_404 | 0 | 1050.0 | Domain | Note=Glutamine amidotransferase type-1 |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000451903 | + | 1 | 28 | 551_743 | 0 | 1050.0 | Domain | Note=ATP-grasp 1 |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000233072 | + | 8 | 38 | 1093_1284 | 280 | 1501.0 | Domain | Note=ATP-grasp 2 |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000233072 | + | 8 | 38 | 1355_1500 | 280 | 1501.0 | Domain | MGS-like |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000233072 | + | 8 | 38 | 219_404 | 280 | 1501.0 | Domain | Note=Glutamine amidotransferase type-1 |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000233072 | + | 8 | 38 | 551_743 | 280 | 1501.0 | Domain | Note=ATP-grasp 1 |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000430249 | + | 9 | 39 | 1093_1284 | 286 | 1507.0 | Domain | Note=ATP-grasp 2 |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000430249 | + | 9 | 39 | 1355_1500 | 286 | 1507.0 | Domain | MGS-like |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000430249 | + | 9 | 39 | 219_404 | 286 | 1507.0 | Domain | Note=Glutamine amidotransferase type-1 |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000430249 | + | 9 | 39 | 551_743 | 286 | 1507.0 | Domain | Note=ATP-grasp 1 |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000451903 | + | 1 | 28 | 1093_1284 | 0 | 1050.0 | Domain | Note=ATP-grasp 2 |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000451903 | + | 1 | 28 | 1355_1500 | 0 | 1050.0 | Domain | MGS-like |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000451903 | + | 1 | 28 | 219_404 | 0 | 1050.0 | Domain | Note=Glutamine amidotransferase type-1 |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000451903 | + | 1 | 28 | 551_743 | 0 | 1050.0 | Domain | Note=ATP-grasp 1 |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000233072 | + | 6 | 38 | 39_218 | 207 | 1501.0 | Region | Note=Anthranilate phosphoribosyltransferase homolog |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000430249 | + | 7 | 39 | 39_218 | 213 | 1507.0 | Region | Note=Anthranilate phosphoribosyltransferase homolog |
| Hgene | CPS1 | chr2:211447433 | chr2:210570304 | ENST00000451903 | + | 1 | 28 | 39_218 | 0 | 1050.0 | Region | Note=Anthranilate phosphoribosyltransferase homolog |
| Hgene | CPS1 | chr2:211454958 | chr2:210588319 | ENST00000451903 | + | 1 | 28 | 39_218 | 0 | 1050.0 | Region | Note=Anthranilate phosphoribosyltransferase homolog |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000360351 | 9 | 15 | 1447_1467 | 1528 | 1828.0 | Region | Calmodulin-binding | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000447185 | 6 | 12 | 1447_1467 | 1524 | 1824.0 | Region | Calmodulin-binding |
Top |
Fusion Gene Sequence for CPS1-MAP2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >19092_19092_1_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000199940_length(transcript)=1931nt_BP=817nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGACGGAGTAACCAAGAGCCCAGAAAAGCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGG AGACAGAGATGAGAATTCCTTCTCTCTCAACAGTTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGG GAAGAGTGGTACCTCAACACCCACTACCCCTGGGTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCAC TCCTGGAACCCCTAGCTATCCCAGGACCCCTCACACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCAT CATACGTACTCCTCCAAAATCTCCTGCGACTCCCAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAA AATCGGATCAACAGACAACATCAAATACCAGCCTAAAGGGGGGCAGGTTAGGATTTTAAACAAGAAGATCGATTTTAGCAAAGTTCAGTC CAGATGTGGTTCCAAGGATAACATCAAACATTCGGCTGGGGGCGGAAATGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGAC ATCCAAATGTGGCTCTCTGAAGAACATCCGCCACAGGCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAA GGCCCAAGCTAAAGTTGGTTCTCTTGATAATGCTCATCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAG AGAGCATGCTAAAGCCCGTGTGGACCATGGGGCTGAGATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAG CAATGTCTCCTCGTCTGGAAGCATCAACCTGCTCGAATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCA GGGCTTGTGAATATTTCTCATTTAGCATTGAAATAATAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATT CATTCTTTATAAACCATAAAATAAATAATCTCATCCCCAAA >19092_19092_1_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000199940_length(amino acids)=537AA_BP=207 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRAGKSGTS TPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKSKIGSTD NIKYQPKGGQVRILNKKIDFSKVQSRCGSKDNIKHSAGGGNVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKV GSLDNAHHVPGGGNVKIDSQKLNFREHAKARVDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGL -------------------------------------------------------------- >19092_19092_2_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000360351_length(transcript)=5438nt_BP=817nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGACGGAGTAACCAAGAGCCCAGAAAAGCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGG AGACAGAGATGAGAATTCCTTCTCTCTCAACAGTTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGG GAAGAGTGGTACCTCAACACCCACTACCCCTGGGTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCAC TCCTGGAACCCCTAGCTATCCCAGGACCCCTCACACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCAT CATACGTACTCCTCCAAAATCTCCTGCGACTCCCAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAA AATCGGATCAACAGACAACATCAAATACCAGCCTAAAGGGGGGCAGGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATC CAAATGTGGCTCTCTGAAGAACATCCGCCACAGGCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGC CCAAGCTAAAGTTGGTTCTCTTGATAATGCTCATCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGA GCATGCTAAAGCCCGTGTGGACCATGGGGCTGAGATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAA TGTCTCCTCGTCTGGAAGCATCAACCTGCTCGAATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGG CTTGTGAATATTTCTCATTTAGCATTGAAATAATAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATTCAT TCTTTATAAACCATAAAATAAATAATCTCATCCCCAAACTGTAGTAATTGTTACAATTTTCTATTTAAAAAATGAATAGTACATGCAGAA ATTGACCTGATTTCCATTTGCAACAGGAAGACACTGGCTTTACATGGGTTCAATTGGACAATTATTTTTGCTCTGCTCTGTTTTGCATGG AGTATTATTATTTTAAAAATTGCATTTTTACCTTTCATGTGCCTGAAGGCTATCCACTACATTCTGAAGGCCTTGTTAAAATCCAAGCTG CTCATTTCACTATTCTGTTTCTGAGTGAGAAGATAAAAACTGCCCATTGTAACTTATTTCAGGTTAAATTAAACCAAGGAGTCTGATTGC AGGAAGGGAAGAGCATGTAAGAAATAAGTTTTTTTAAAGTGTTATTTTGTATAAATGGGAAGAAAGATTCAATTAAGTTATTAACATTTG GGACCTGGATAATTATATCAGAGTATGTCAGTCCAATAAATTATTTAACTAATTAAAAAATAGTTGCAAAGCATTTGAGCTGTGGTTGAG GAAGTGGTGTAAAAGTGCATCCATTAGGAATGATGCACTTTCATTAGGATGGACTCGTGTCTGATTAGAATGTCAGTTGATCAGCTAGAT TTGTGTCCACACTACCAGTTTCACACCCCCTTTCCATCTGTTTGATACAGTATTATAGATATAAATATATATATATTTCTCTGTGGCCAT TTGTGATACTTCCTCATATACTTGAATATTATACTTCTTTATTCACAGTATCTGTGTCTCCTGCACCCTTTGGTGTTGCAATTTTAGATA TGTGAAAGTAGATGTTAGCAGGGTTCTCTCCCTATTTAAAAAAAATACATTAAAAAAGACAAAAAATTTTAGCATGAAGTTGCTTTCTGT AACAACTCAAAGCCGTAACCCTGTTTTAGTGCCAGATACAAGTCTCTCCCGTGATGCTAGACAAAAAATTATTTTTCTTTGCTTTCACCA ACATGGAGTTTGTGGGGGTGGGTCCAGTTATACATGAAAGGGTTTACAGATTGTTGGTTTAAGATTATGGATTTATCTCATTTTTAATCA CAGGATAGTTTGGGGTTTATTCCTATTATTATTCATGAAACCGACTTAAGATTTTTTCTTTATTTTTCTTTTTTTTTCCATTTGCTAAAG TTGAAAGTTGAAACTAACTATAATAGTTTGAAACATGTTTTCTCATTTTTCCAAATAGTATCTGTTTATTAAATTCTCTAATAGAAGATG TTTGTCTTTCTTACCCAAAGTAAAGATCCCCTGATCAGAAAGAAAAAATACAATACTTTGGGAAGCTATAGCTATAAAACACTTGAGACA CAGATATCTAAATCAGTTTTTTTCCAAGACTCCAACATTGCACTCTGTAAAGTAACACACTGTGATCTAGTATTATTTATCAGTAGATAA TACTGTTCTGACTGTATATACAGTCTAGAACTCACAAATCAATTAGTTCCTCTCACAAATCATTCATCTTAGACTTACAAATAAGGAATG AAATAGTCAATGGCCTGATTAAGGCAAAGAGCTACCAGGCTAGATGGACACTTTTTAAAAATTTTATCTGTTCTTTTTCTTGCTCAGGGC TGGTAGGTTGGATCTGAACCATTAAAATCAAATGGTCCACTAGGCGTATGATCTCTTTGAGCCAAATCAGTTCCTGAATATAAAGGAGGA AATGATGAGGATGTACTGAGGCAACGGGGAAGTATAGAAACATCCAAGACAAAAGCCAAGGGATGCAAAGGCAGAGACACAGGTGCTTTT TGGTGACCCAGTGGATATGGCAACCAGTGTAACTGCCATACAAGAAACCCTAGGAGCAAACCCACACCACTCATTCTCAGCTAAGAGATT TTACACAGGCAAACGTGTCTTAAACCATCTATAAATCAGTTATTTTATATGACAGTCAAAACCTTAGAAACCTTAGGATCATTATATCTA TTTTCTGCCTATTAATTGCTGTGAGGTTTGATTTGACCAATCTGGGCAATTTATTCATCAGCTTCCCTTGAAGTGCACCAGAAAATAGAA GAAAGGTGTGTGGAGACTTAGGGTATTTTATTACATGTTTTCATAGTCTTAAATAGTGATTAAATTTCTCTAGAAAGAAGTTAACAGCTC ATTAGAAAAGTTTTAACCTGTGAAATAAGTATTTTTCTCAACATTCTTTAAAGTTTTTATATAAGTTAACACTAGGTAAACATTCTGCAT ACTAGAAGTCAGTTTATTACAAATACATGTCAAAAATAAAGATTATACAAGGCACCAAACTACTAGATTTGGCATTAAAACAAATGTTTA TTTCTAATCACAACAAAATTATAATGAATAAATGTTCTTGCTTTGTATGGAAATACAATTCTTTATTAAAGTTAACAGAAAGGAACTGAT CGTTTGTACCAGTAAAAGAGAGAAACACACAGGTTAAATATCTTCTTGTGGGGTTAAGGGGTAGAACCTATCTTGCCTTCACTCTCAAGA TAACGACTCAAATTAAGCTTTTTGAGCACCACTCTTGTGGGGACACACATACGCTGATCTAGGAATGAAATCTTCGTGGTCTCAATTCTA GATCTACTATGCCAGTTTCTCTCTGGCTTTAGCCTTTGAGAACCTGTATAAGAATACGTAAGTAATCCAGAGCTGTGAAGAGTTTAAAGG CCAACTTCTCCAGTGAACTCAACCTCTGGGTCACTTGCAACCAGAAATTGGATACCTCATAATGATGCAGGAAAGACCCGAGTTCATGAT GAGTTTCAAAGGCCACGTTCATTTAGGAACCAACTCTCTCTGGATTTACCTGCTGAGTTCCAGCAGCGTGATGGGCTGACATCCCACCTA CAAGTATGACACCTGTGTAACACCAGCTAGGTACGGCTGGAGAAGGCTGAAGAGAGAATGCCATTAAATGGAAGAATGTACTGATTGTAG TGACCTTCTCCACACACACACACACACACACACACACACACACCTACAGTAATACAGCAAGCGTGGAATAATCAGCCAATATATAACATT CCATCAGTATTTTATTAAGGAAATAACCTGAATGTGGTTGATTTTGACATAGCTGCAATTACAGTTTTCTTCTATTTTTCAAGCCACAAT AAGGAAAATAAACTACTCATGGTCTAAATACTAGAGATAAAGTAGATTCATGGCTTGGTAAGGAAATTTTAAGCATTCCTTCAAAGATTG ACGTGCTAAAATAAGCATTGATGTTTTGAGTTTTTTTACACCTAGGATTTTTAGCTTGGGTGTGTAGGTGAAGGCCAAGACTCTCTGCAG GAAAAAGCTTATTTTCAAACTCAGAAAATAAAATGTCAATCATAAAAATCTACTTCAACTTTAGCAAAAAGAAAAAAAAATCAACAAAAA GTATACTCTGTATGCTGGGATTCCGAGGTTCCAACACACTGTTACAAATCTGTGGGGGGTTTCTTTCTTCTGATAATTCTAGAGCCTGTT ACCATAGAAAGGCATTTCTTCAATGGCTGGTTGTAGTTAGTTCATGTTTTTCAATCAAATTTGCAAATGTATTTGTTGCTGTATAGTGAT TGTTTTGCAAAATAAAATTGCTTGTCACCTAACTGCTA >19092_19092_2_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000360351_length(amino acids)=506AA_BP=207 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRAGKSGTS TPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKSKIGSTD NIKYQPKGGQVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKVGSLDNAHHVPGGGNVKIDSQKLNFREHAKAR VDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGL -------------------------------------------------------------- >19092_19092_3_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000361559_length(transcript)=1843nt_BP=817nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGACGGAGTAACCAAGAGCCCAGAAAAGCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGG AGACAGAGATGAGAATTCCTTCTCTCTCAACAGTTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGG GAAGAGTGGTACCTCAACACCCACTACCCCTGGGTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCAC TCCTGGAACCCCTAGCTATCCCAGGACCCCTCACACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCAT CATACGTACTCCTCCAAAATCTCCTGCGACTCCCAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAA AATCGGATCAACAGACAACATCAAATACCAGCCTAAAGGGGGGCAGGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATC CAAATGTGGCTCTCTGAAGAACATCCGCCACAGGCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGC CCAAGCTAAAGTTGGTTCTCTTGATAATGCTCATCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGA GCATGCTAAAGCCCGTGTGGACCATGGGGCTGAGATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAA TGTCTCCTCGTCTGGAAGCATCAACCTGCTCGAATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGG CTTGTGAATATTTCTCATTTAGCATTGAAATAATAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATTCAT TCTTTATAAACCATAAAATAAATAATCTCATCCCCAAACTGTA >19092_19092_3_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000361559_length(amino acids)=506AA_BP=207 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRAGKSGTS TPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKSKIGSTD NIKYQPKGGQVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKVGSLDNAHHVPGGGNVKIDSQKLNFREHAKAR VDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGL -------------------------------------------------------------- >19092_19092_4_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000392194_length(transcript)=5438nt_BP=817nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGACGGAGTAACCAAGAGCCCAGAAAAGCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGG AGACAGAGATGAGAATTCCTTCTCTCTCAACAGTTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGG GAAGAGTGGTACCTCAACACCCACTACCCCTGGGTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCAC TCCTGGAACCCCTAGCTATCCCAGGACCCCTCACACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCAT CATACGTACTCCTCCAAAATCTCCTGCGACTCCCAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAA AATCGGATCAACAGACAACATCAAATACCAGCCTAAAGGGGGGCAGGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATC CAAATGTGGCTCTCTGAAGAACATCCGCCACAGGCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGC CCAAGCTAAAGTTGGTTCTCTTGATAATGCTCATCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGA GCATGCTAAAGCCCGTGTGGACCATGGGGCTGAGATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAA TGTCTCCTCGTCTGGAAGCATCAACCTGCTCGAATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGG CTTGTGAATATTTCTCATTTAGCATTGAAATAATAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATTCAT TCTTTATAAACCATAAAATAAATAATCTCATCCCCAAACTGTAGTAATTGTTACAATTTTCTATTTAAAAAATGAATAGTACATGCAGAA ATTGACCTGATTTCCATTTGCAACAGGAAGACACTGGCTTTACATGGGTTCAATTGGACAATTATTTTTGCTCTGCTCTGTTTTGCATGG AGTATTATTATTTTAAAAATTGCATTTTTACCTTTCATGTGCCTGAAGGCTATCCACTACATTCTGAAGGCCTTGTTAAAATCCAAGCTG CTCATTTCACTATTCTGTTTCTGAGTGAGAAGATAAAAACTGCCCATTGTAACTTATTTCAGGTTAAATTAAACCAAGGAGTCTGATTGC AGGAAGGGAAGAGCATGTAAGAAATAAGTTTTTTTAAAGTGTTATTTTGTATAAATGGGAAGAAAGATTCAATTAAGTTATTAACATTTG GGACCTGGATAATTATATCAGAGTATGTCAGTCCAATAAATTATTTAACTAATTAAAAAATAGTTGCAAAGCATTTGAGCTGTGGTTGAG GAAGTGGTGTAAAAGTGCATCCATTAGGAATGATGCACTTTCATTAGGATGGACTCGTGTCTGATTAGAATGTCAGTTGATCAGCTAGAT TTGTGTCCACACTACCAGTTTCACACCCCCTTTCCATCTGTTTGATACAGTATTATAGATATAAATATATATATATTTCTCTGTGGCCAT TTGTGATACTTCCTCATATACTTGAATATTATACTTCTTTATTCACAGTATCTGTGTCTCCTGCACCCTTTGGTGTTGCAATTTTAGATA TGTGAAAGTAGATGTTAGCAGGGTTCTCTCCCTATTTAAAAAAAATACATTAAAAAAGACAAAAAATTTTAGCATGAAGTTGCTTTCTGT AACAACTCAAAGCCGTAACCCTGTTTTAGTGCCAGATACAAGTCTCTCCCGTGATGCTAGACAAAAAATTATTTTTCTTTGCTTTCACCA ACATGGAGTTTGTGGGGGTGGGTCCAGTTATACATGAAAGGGTTTACAGATTGTTGGTTTAAGATTATGGATTTATCTCATTTTTAATCA CAGGATAGTTTGGGGTTTATTCCTATTATTATTCATGAAACCGACTTAAGATTTTTTCTTTATTTTTCTTTTTTTTTCCATTTGCTAAAG TTGAAAGTTGAAACTAACTATAATAGTTTGAAACATGTTTTCTCATTTTTCCAAATAGTATCTGTTTATTAAATTCTCTAATAGAAGATG TTTGTCTTTCTTACCCAAAGTAAAGATCCCCTGATCAGAAAGAAAAAATACAATACTTTGGGAAGCTATAGCTATAAAACACTTGAGACA CAGATATCTAAATCAGTTTTTTTCCAAGACTCCAACATTGCACTCTGTAAAGTAACACACTGTGATCTAGTATTATTTATCAGTAGATAA TACTGTTCTGACTGTATATACAGTCTAGAACTCACAAATCAATTAGTTCCTCTCACAAATCATTCATCTTAGACTTACAAATAAGGAATG AAATAGTCAATGGCCTGATTAAGGCAAAGAGCTACCAGGCTAGATGGACACTTTTTAAAAATTTTATCTGTTCTTTTTCTTGCTCAGGGC TGGTAGGTTGGATCTGAACCATTAAAATCAAATGGTCCACTAGGCGTATGATCTCTTTGAGCCAAATCAGTTCCTGAATATAAAGGAGGA AATGATGAGGATGTACTGAGGCAACGGGGAAGTATAGAAACATCCAAGACAAAAGCCAAGGGATGCAAAGGCAGAGACACAGGTGCTTTT TGGTGACCCAGTGGATATGGCAACCAGTGTAACTGCCATACAAGAAACCCTAGGAGCAAACCCACACCACTCATTCTCAGCTAAGAGATT TTACACAGGCAAACGTGTCTTAAACCATCTATAAATCAGTTATTTTATATGACAGTCAAAACCTTAGAAACCTTAGGATCATTATATCTA TTTTCTGCCTATTAATTGCTGTGAGGTTTGATTTGACCAATCTGGGCAATTTATTCATCAGCTTCCCTTGAAGTGCACCAGAAAATAGAA GAAAGGTGTGTGGAGACTTAGGGTATTTTATTACATGTTTTCATAGTCTTAAATAGTGATTAAATTTCTCTAGAAAGAAGTTAACAGCTC ATTAGAAAAGTTTTAACCTGTGAAATAAGTATTTTTCTCAACATTCTTTAAAGTTTTTATATAAGTTAACACTAGGTAAACATTCTGCAT ACTAGAAGTCAGTTTATTACAAATACATGTCAAAAATAAAGATTATACAAGGCACCAAACTACTAGATTTGGCATTAAAACAAATGTTTA TTTCTAATCACAACAAAATTATAATGAATAAATGTTCTTGCTTTGTATGGAAATACAATTCTTTATTAAAGTTAACAGAAAGGAACTGAT CGTTTGTACCAGTAAAAGAGAGAAACACACAGGTTAAATATCTTCTTGTGGGGTTAAGGGGTAGAACCTATCTTGCCTTCACTCTCAAGA TAACGACTCAAATTAAGCTTTTTGAGCACCACTCTTGTGGGGACACACATACGCTGATCTAGGAATGAAATCTTCGTGGTCTCAATTCTA GATCTACTATGCCAGTTTCTCTCTGGCTTTAGCCTTTGAGAACCTGTATAAGAATACGTAAGTAATCCAGAGCTGTGAAGAGTTTAAAGG CCAACTTCTCCAGTGAACTCAACCTCTGGGTCACTTGCAACCAGAAATTGGATACCTCATAATGATGCAGGAAAGACCCGAGTTCATGAT GAGTTTCAAAGGCCACGTTCATTTAGGAACCAACTCTCTCTGGATTTACCTGCTGAGTTCCAGCAGCGTGATGGGCTGACATCCCACCTA CAAGTATGACACCTGTGTAACACCAGCTAGGTACGGCTGGAGAAGGCTGAAGAGAGAATGCCATTAAATGGAAGAATGTACTGATTGTAG TGACCTTCTCCACACACACACACACACACACACACACACACACCTACAGTAATACAGCAAGCGTGGAATAATCAGCCAATATATAACATT CCATCAGTATTTTATTAAGGAAATAACCTGAATGTGGTTGATTTTGACATAGCTGCAATTACAGTTTTCTTCTATTTTTCAAGCCACAAT AAGGAAAATAAACTACTCATGGTCTAAATACTAGAGATAAAGTAGATTCATGGCTTGGTAAGGAAATTTTAAGCATTCCTTCAAAGATTG ACGTGCTAAAATAAGCATTGATGTTTTGAGTTTTTTTACACCTAGGATTTTTAGCTTGGGTGTGTAGGTGAAGGCCAAGACTCTCTGCAG GAAAAAGCTTATTTTCAAACTCAGAAAATAAAATGTCAATCATAAAAATCTACTTCAACTTTAGCAAAAAGAAAAAAAAATCAACAAAAA GTATACTCTGTATGCTGGGATTCCGAGGTTCCAACACACTGTTACAAATCTGTGGGGGGTTTCTTTCTTCTGATAATTCTAGAGCCTGTT ACCATAGAAAGGCATTTCTTCAATGGCTGGTTGTAGTTAGTTCATGTTTTTCAATCAAATTTGCAAATGTATTTGTTGCTGTATAGTGAT TGTTTTGCAAAATAAAATTGCTTGTCACCTAACTGCTA >19092_19092_4_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000392194_length(amino acids)=506AA_BP=207 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRAGKSGTS TPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKSKIGSTD NIKYQPKGGQVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKVGSLDNAHHVPGGGNVKIDSQKLNFREHAKAR VDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGL -------------------------------------------------------------- >19092_19092_5_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000447185_length(transcript)=1717nt_BP=817nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGACGGAGTAACCAAGAGCCCAGAAAAGCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGG AGACAGAGATGAGAATTCCTTCTCTCTCAACAGTTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGG GAAGAGTGGTACCTCAACACCCACTACCCCTGGGTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCAC TCCTGGAACCCCTAGCTATCCCAGGACCCCTCACACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCAT CATACGTACTCCTCCAAAATCTCCTGCGACTCCCAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAA AATCGGATCAACAGACAACATCAAATACCAGCCTAAAGGGGGGCAGGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATC CAAATGTGGCTCTCTGAAGAACATCCGCCACAGGCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGC CCAAGCTAAAGTTGGTTCTCTTGATAATGCTCATCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGA GCATGCTAAAGCCCGTGTGGACCATGGGGCTGAGATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAA TGTCTCCTCGTCTGGAAGCATCAACCTGCTCGAATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGG CTTGTGA >19092_19092_5_CPS1-MAP2_CPS1_chr2_211447433_ENST00000233072_MAP2_chr2_210570304_ENST00000447185_length(amino acids)=507AA_BP=207 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRAGKSGTS TPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKSKIGSTD NIKYQPKGGQVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKVGSLDNAHHVPGGGNVKIDSQKLNFREHAKAR VDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGLX -------------------------------------------------------------- >19092_19092_6_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000199940_length(transcript)=1808nt_BP=694nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGACGGAGTAACCAAGAGCCCAGAAAA GCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGGAGACAGAGATGAGAATTCCTTCTCTCTCAACAG TTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGGGAAGAGTGGTACCTCAACACCCACTACCCCTGG GTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCACTCCTGGAACCCCTAGCTATCCCAGGACCCCTCA CACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCATCATACGTACTCCTCCAAAATCTCCTGCGACTCC CAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAAAATCGGATCAACAGACAACATCAAATACCAGCC TAAAGGGGGGCAGGTTAGGATTTTAAACAAGAAGATCGATTTTAGCAAAGTTCAGTCCAGATGTGGTTCCAAGGATAACATCAAACATTC GGCTGGGGGCGGAAATGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATCCAAATGTGGCTCTCTGAAGAACATCCGCCA CAGGCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGCCCAAGCTAAAGTTGGTTCTCTTGATAATGC TCATCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGAGCATGCTAAAGCCCGTGTGGACCATGGGGC TGAGATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAATGTCTCCTCGTCTGGAAGCATCAACCTGCT CGAATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGGCTTGTGAATATTTCTCATTTAGCATTGAAA TAATAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATTCATTCTTTATAAACCATAAAATAAATAATCTCA TCCCCAAA >19092_19092_6_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000199940_length(amino acids)=543AA_BP=213 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRA GKSGTSTPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKS KIGSTDNIKYQPKGGQVRILNKKIDFSKVQSRCGSKDNIKHSAGGGNVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKE KAQAKVGSLDNAHHVPGGGNVKIDSQKLNFREHAKARVDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAK QGL -------------------------------------------------------------- >19092_19092_7_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000360351_length(transcript)=5315nt_BP=694nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGACGGAGTAACCAAGAGCCCAGAAAA GCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGGAGACAGAGATGAGAATTCCTTCTCTCTCAACAG TTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGGGAAGAGTGGTACCTCAACACCCACTACCCCTGG GTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCACTCCTGGAACCCCTAGCTATCCCAGGACCCCTCA CACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCATCATACGTACTCCTCCAAAATCTCCTGCGACTCC CAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAAAATCGGATCAACAGACAACATCAAATACCAGCC TAAAGGGGGGCAGGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATCCAAATGTGGCTCTCTGAAGAACATCCGCCACAG GCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGCCCAAGCTAAAGTTGGTTCTCTTGATAATGCTCA TCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGAGCATGCTAAAGCCCGTGTGGACCATGGGGCTGA GATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAATGTCTCCTCGTCTGGAAGCATCAACCTGCTCGA ATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGGCTTGTGAATATTTCTCATTTAGCATTGAAATAA TAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATTCATTCTTTATAAACCATAAAATAAATAATCTCATCC CCAAACTGTAGTAATTGTTACAATTTTCTATTTAAAAAATGAATAGTACATGCAGAAATTGACCTGATTTCCATTTGCAACAGGAAGACA CTGGCTTTACATGGGTTCAATTGGACAATTATTTTTGCTCTGCTCTGTTTTGCATGGAGTATTATTATTTTAAAAATTGCATTTTTACCT TTCATGTGCCTGAAGGCTATCCACTACATTCTGAAGGCCTTGTTAAAATCCAAGCTGCTCATTTCACTATTCTGTTTCTGAGTGAGAAGA TAAAAACTGCCCATTGTAACTTATTTCAGGTTAAATTAAACCAAGGAGTCTGATTGCAGGAAGGGAAGAGCATGTAAGAAATAAGTTTTT TTAAAGTGTTATTTTGTATAAATGGGAAGAAAGATTCAATTAAGTTATTAACATTTGGGACCTGGATAATTATATCAGAGTATGTCAGTC CAATAAATTATTTAACTAATTAAAAAATAGTTGCAAAGCATTTGAGCTGTGGTTGAGGAAGTGGTGTAAAAGTGCATCCATTAGGAATGA TGCACTTTCATTAGGATGGACTCGTGTCTGATTAGAATGTCAGTTGATCAGCTAGATTTGTGTCCACACTACCAGTTTCACACCCCCTTT CCATCTGTTTGATACAGTATTATAGATATAAATATATATATATTTCTCTGTGGCCATTTGTGATACTTCCTCATATACTTGAATATTATA CTTCTTTATTCACAGTATCTGTGTCTCCTGCACCCTTTGGTGTTGCAATTTTAGATATGTGAAAGTAGATGTTAGCAGGGTTCTCTCCCT ATTTAAAAAAAATACATTAAAAAAGACAAAAAATTTTAGCATGAAGTTGCTTTCTGTAACAACTCAAAGCCGTAACCCTGTTTTAGTGCC AGATACAAGTCTCTCCCGTGATGCTAGACAAAAAATTATTTTTCTTTGCTTTCACCAACATGGAGTTTGTGGGGGTGGGTCCAGTTATAC ATGAAAGGGTTTACAGATTGTTGGTTTAAGATTATGGATTTATCTCATTTTTAATCACAGGATAGTTTGGGGTTTATTCCTATTATTATT CATGAAACCGACTTAAGATTTTTTCTTTATTTTTCTTTTTTTTTCCATTTGCTAAAGTTGAAAGTTGAAACTAACTATAATAGTTTGAAA CATGTTTTCTCATTTTTCCAAATAGTATCTGTTTATTAAATTCTCTAATAGAAGATGTTTGTCTTTCTTACCCAAAGTAAAGATCCCCTG ATCAGAAAGAAAAAATACAATACTTTGGGAAGCTATAGCTATAAAACACTTGAGACACAGATATCTAAATCAGTTTTTTTCCAAGACTCC AACATTGCACTCTGTAAAGTAACACACTGTGATCTAGTATTATTTATCAGTAGATAATACTGTTCTGACTGTATATACAGTCTAGAACTC ACAAATCAATTAGTTCCTCTCACAAATCATTCATCTTAGACTTACAAATAAGGAATGAAATAGTCAATGGCCTGATTAAGGCAAAGAGCT ACCAGGCTAGATGGACACTTTTTAAAAATTTTATCTGTTCTTTTTCTTGCTCAGGGCTGGTAGGTTGGATCTGAACCATTAAAATCAAAT GGTCCACTAGGCGTATGATCTCTTTGAGCCAAATCAGTTCCTGAATATAAAGGAGGAAATGATGAGGATGTACTGAGGCAACGGGGAAGT ATAGAAACATCCAAGACAAAAGCCAAGGGATGCAAAGGCAGAGACACAGGTGCTTTTTGGTGACCCAGTGGATATGGCAACCAGTGTAAC TGCCATACAAGAAACCCTAGGAGCAAACCCACACCACTCATTCTCAGCTAAGAGATTTTACACAGGCAAACGTGTCTTAAACCATCTATA AATCAGTTATTTTATATGACAGTCAAAACCTTAGAAACCTTAGGATCATTATATCTATTTTCTGCCTATTAATTGCTGTGAGGTTTGATT TGACCAATCTGGGCAATTTATTCATCAGCTTCCCTTGAAGTGCACCAGAAAATAGAAGAAAGGTGTGTGGAGACTTAGGGTATTTTATTA CATGTTTTCATAGTCTTAAATAGTGATTAAATTTCTCTAGAAAGAAGTTAACAGCTCATTAGAAAAGTTTTAACCTGTGAAATAAGTATT TTTCTCAACATTCTTTAAAGTTTTTATATAAGTTAACACTAGGTAAACATTCTGCATACTAGAAGTCAGTTTATTACAAATACATGTCAA AAATAAAGATTATACAAGGCACCAAACTACTAGATTTGGCATTAAAACAAATGTTTATTTCTAATCACAACAAAATTATAATGAATAAAT GTTCTTGCTTTGTATGGAAATACAATTCTTTATTAAAGTTAACAGAAAGGAACTGATCGTTTGTACCAGTAAAAGAGAGAAACACACAGG TTAAATATCTTCTTGTGGGGTTAAGGGGTAGAACCTATCTTGCCTTCACTCTCAAGATAACGACTCAAATTAAGCTTTTTGAGCACCACT CTTGTGGGGACACACATACGCTGATCTAGGAATGAAATCTTCGTGGTCTCAATTCTAGATCTACTATGCCAGTTTCTCTCTGGCTTTAGC CTTTGAGAACCTGTATAAGAATACGTAAGTAATCCAGAGCTGTGAAGAGTTTAAAGGCCAACTTCTCCAGTGAACTCAACCTCTGGGTCA CTTGCAACCAGAAATTGGATACCTCATAATGATGCAGGAAAGACCCGAGTTCATGATGAGTTTCAAAGGCCACGTTCATTTAGGAACCAA CTCTCTCTGGATTTACCTGCTGAGTTCCAGCAGCGTGATGGGCTGACATCCCACCTACAAGTATGACACCTGTGTAACACCAGCTAGGTA CGGCTGGAGAAGGCTGAAGAGAGAATGCCATTAAATGGAAGAATGTACTGATTGTAGTGACCTTCTCCACACACACACACACACACACAC ACACACACACCTACAGTAATACAGCAAGCGTGGAATAATCAGCCAATATATAACATTCCATCAGTATTTTATTAAGGAAATAACCTGAAT GTGGTTGATTTTGACATAGCTGCAATTACAGTTTTCTTCTATTTTTCAAGCCACAATAAGGAAAATAAACTACTCATGGTCTAAATACTA GAGATAAAGTAGATTCATGGCTTGGTAAGGAAATTTTAAGCATTCCTTCAAAGATTGACGTGCTAAAATAAGCATTGATGTTTTGAGTTT TTTTACACCTAGGATTTTTAGCTTGGGTGTGTAGGTGAAGGCCAAGACTCTCTGCAGGAAAAAGCTTATTTTCAAACTCAGAAAATAAAA TGTCAATCATAAAAATCTACTTCAACTTTAGCAAAAAGAAAAAAAAATCAACAAAAAGTATACTCTGTATGCTGGGATTCCGAGGTTCCA ACACACTGTTACAAATCTGTGGGGGGTTTCTTTCTTCTGATAATTCTAGAGCCTGTTACCATAGAAAGGCATTTCTTCAATGGCTGGTTG TAGTTAGTTCATGTTTTTCAATCAAATTTGCAAATGTATTTGTTGCTGTATAGTGATTGTTTTGCAAAATAAAATTGCTTGTCACCTAAC TGCTA >19092_19092_7_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000360351_length(amino acids)=512AA_BP=213 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRA GKSGTSTPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKS KIGSTDNIKYQPKGGQVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKVGSLDNAHHVPGGGNVKIDSQKLNFR EHAKARVDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGL -------------------------------------------------------------- >19092_19092_8_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000361559_length(transcript)=1720nt_BP=694nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGACGGAGTAACCAAGAGCCCAGAAAA GCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGGAGACAGAGATGAGAATTCCTTCTCTCTCAACAG TTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGGGAAGAGTGGTACCTCAACACCCACTACCCCTGG GTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCACTCCTGGAACCCCTAGCTATCCCAGGACCCCTCA CACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCATCATACGTACTCCTCCAAAATCTCCTGCGACTCC CAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAAAATCGGATCAACAGACAACATCAAATACCAGCC TAAAGGGGGGCAGGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATCCAAATGTGGCTCTCTGAAGAACATCCGCCACAG GCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGCCCAAGCTAAAGTTGGTTCTCTTGATAATGCTCA TCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGAGCATGCTAAAGCCCGTGTGGACCATGGGGCTGA GATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAATGTCTCCTCGTCTGGAAGCATCAACCTGCTCGA ATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGGCTTGTGAATATTTCTCATTTAGCATTGAAATAA TAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATTCATTCTTTATAAACCATAAAATAAATAATCTCATCC CCAAACTGTA >19092_19092_8_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000361559_length(amino acids)=512AA_BP=213 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRA GKSGTSTPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKS KIGSTDNIKYQPKGGQVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKVGSLDNAHHVPGGGNVKIDSQKLNFR EHAKARVDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGL -------------------------------------------------------------- >19092_19092_9_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000392194_length(transcript)=5315nt_BP=694nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGACGGAGTAACCAAGAGCCCAGAAAA GCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGGAGACAGAGATGAGAATTCCTTCTCTCTCAACAG TTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGGGAAGAGTGGTACCTCAACACCCACTACCCCTGG GTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCACTCCTGGAACCCCTAGCTATCCCAGGACCCCTCA CACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCATCATACGTACTCCTCCAAAATCTCCTGCGACTCC CAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAAAATCGGATCAACAGACAACATCAAATACCAGCC TAAAGGGGGGCAGGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATCCAAATGTGGCTCTCTGAAGAACATCCGCCACAG GCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGCCCAAGCTAAAGTTGGTTCTCTTGATAATGCTCA TCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGAGCATGCTAAAGCCCGTGTGGACCATGGGGCTGA GATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAATGTCTCCTCGTCTGGAAGCATCAACCTGCTCGA ATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGGCTTGTGAATATTTCTCATTTAGCATTGAAATAA TAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATTCATTCTTTATAAACCATAAAATAAATAATCTCATCC CCAAACTGTAGTAATTGTTACAATTTTCTATTTAAAAAATGAATAGTACATGCAGAAATTGACCTGATTTCCATTTGCAACAGGAAGACA CTGGCTTTACATGGGTTCAATTGGACAATTATTTTTGCTCTGCTCTGTTTTGCATGGAGTATTATTATTTTAAAAATTGCATTTTTACCT TTCATGTGCCTGAAGGCTATCCACTACATTCTGAAGGCCTTGTTAAAATCCAAGCTGCTCATTTCACTATTCTGTTTCTGAGTGAGAAGA TAAAAACTGCCCATTGTAACTTATTTCAGGTTAAATTAAACCAAGGAGTCTGATTGCAGGAAGGGAAGAGCATGTAAGAAATAAGTTTTT TTAAAGTGTTATTTTGTATAAATGGGAAGAAAGATTCAATTAAGTTATTAACATTTGGGACCTGGATAATTATATCAGAGTATGTCAGTC CAATAAATTATTTAACTAATTAAAAAATAGTTGCAAAGCATTTGAGCTGTGGTTGAGGAAGTGGTGTAAAAGTGCATCCATTAGGAATGA TGCACTTTCATTAGGATGGACTCGTGTCTGATTAGAATGTCAGTTGATCAGCTAGATTTGTGTCCACACTACCAGTTTCACACCCCCTTT CCATCTGTTTGATACAGTATTATAGATATAAATATATATATATTTCTCTGTGGCCATTTGTGATACTTCCTCATATACTTGAATATTATA CTTCTTTATTCACAGTATCTGTGTCTCCTGCACCCTTTGGTGTTGCAATTTTAGATATGTGAAAGTAGATGTTAGCAGGGTTCTCTCCCT ATTTAAAAAAAATACATTAAAAAAGACAAAAAATTTTAGCATGAAGTTGCTTTCTGTAACAACTCAAAGCCGTAACCCTGTTTTAGTGCC AGATACAAGTCTCTCCCGTGATGCTAGACAAAAAATTATTTTTCTTTGCTTTCACCAACATGGAGTTTGTGGGGGTGGGTCCAGTTATAC ATGAAAGGGTTTACAGATTGTTGGTTTAAGATTATGGATTTATCTCATTTTTAATCACAGGATAGTTTGGGGTTTATTCCTATTATTATT CATGAAACCGACTTAAGATTTTTTCTTTATTTTTCTTTTTTTTTCCATTTGCTAAAGTTGAAAGTTGAAACTAACTATAATAGTTTGAAA CATGTTTTCTCATTTTTCCAAATAGTATCTGTTTATTAAATTCTCTAATAGAAGATGTTTGTCTTTCTTACCCAAAGTAAAGATCCCCTG ATCAGAAAGAAAAAATACAATACTTTGGGAAGCTATAGCTATAAAACACTTGAGACACAGATATCTAAATCAGTTTTTTTCCAAGACTCC AACATTGCACTCTGTAAAGTAACACACTGTGATCTAGTATTATTTATCAGTAGATAATACTGTTCTGACTGTATATACAGTCTAGAACTC ACAAATCAATTAGTTCCTCTCACAAATCATTCATCTTAGACTTACAAATAAGGAATGAAATAGTCAATGGCCTGATTAAGGCAAAGAGCT ACCAGGCTAGATGGACACTTTTTAAAAATTTTATCTGTTCTTTTTCTTGCTCAGGGCTGGTAGGTTGGATCTGAACCATTAAAATCAAAT GGTCCACTAGGCGTATGATCTCTTTGAGCCAAATCAGTTCCTGAATATAAAGGAGGAAATGATGAGGATGTACTGAGGCAACGGGGAAGT ATAGAAACATCCAAGACAAAAGCCAAGGGATGCAAAGGCAGAGACACAGGTGCTTTTTGGTGACCCAGTGGATATGGCAACCAGTGTAAC TGCCATACAAGAAACCCTAGGAGCAAACCCACACCACTCATTCTCAGCTAAGAGATTTTACACAGGCAAACGTGTCTTAAACCATCTATA AATCAGTTATTTTATATGACAGTCAAAACCTTAGAAACCTTAGGATCATTATATCTATTTTCTGCCTATTAATTGCTGTGAGGTTTGATT TGACCAATCTGGGCAATTTATTCATCAGCTTCCCTTGAAGTGCACCAGAAAATAGAAGAAAGGTGTGTGGAGACTTAGGGTATTTTATTA CATGTTTTCATAGTCTTAAATAGTGATTAAATTTCTCTAGAAAGAAGTTAACAGCTCATTAGAAAAGTTTTAACCTGTGAAATAAGTATT TTTCTCAACATTCTTTAAAGTTTTTATATAAGTTAACACTAGGTAAACATTCTGCATACTAGAAGTCAGTTTATTACAAATACATGTCAA AAATAAAGATTATACAAGGCACCAAACTACTAGATTTGGCATTAAAACAAATGTTTATTTCTAATCACAACAAAATTATAATGAATAAAT GTTCTTGCTTTGTATGGAAATACAATTCTTTATTAAAGTTAACAGAAAGGAACTGATCGTTTGTACCAGTAAAAGAGAGAAACACACAGG TTAAATATCTTCTTGTGGGGTTAAGGGGTAGAACCTATCTTGCCTTCACTCTCAAGATAACGACTCAAATTAAGCTTTTTGAGCACCACT CTTGTGGGGACACACATACGCTGATCTAGGAATGAAATCTTCGTGGTCTCAATTCTAGATCTACTATGCCAGTTTCTCTCTGGCTTTAGC CTTTGAGAACCTGTATAAGAATACGTAAGTAATCCAGAGCTGTGAAGAGTTTAAAGGCCAACTTCTCCAGTGAACTCAACCTCTGGGTCA CTTGCAACCAGAAATTGGATACCTCATAATGATGCAGGAAAGACCCGAGTTCATGATGAGTTTCAAAGGCCACGTTCATTTAGGAACCAA CTCTCTCTGGATTTACCTGCTGAGTTCCAGCAGCGTGATGGGCTGACATCCCACCTACAAGTATGACACCTGTGTAACACCAGCTAGGTA CGGCTGGAGAAGGCTGAAGAGAGAATGCCATTAAATGGAAGAATGTACTGATTGTAGTGACCTTCTCCACACACACACACACACACACAC ACACACACACCTACAGTAATACAGCAAGCGTGGAATAATCAGCCAATATATAACATTCCATCAGTATTTTATTAAGGAAATAACCTGAAT GTGGTTGATTTTGACATAGCTGCAATTACAGTTTTCTTCTATTTTTCAAGCCACAATAAGGAAAATAAACTACTCATGGTCTAAATACTA GAGATAAAGTAGATTCATGGCTTGGTAAGGAAATTTTAAGCATTCCTTCAAAGATTGACGTGCTAAAATAAGCATTGATGTTTTGAGTTT TTTTACACCTAGGATTTTTAGCTTGGGTGTGTAGGTGAAGGCCAAGACTCTCTGCAGGAAAAAGCTTATTTTCAAACTCAGAAAATAAAA TGTCAATCATAAAAATCTACTTCAACTTTAGCAAAAAGAAAAAAAAATCAACAAAAAGTATACTCTGTATGCTGGGATTCCGAGGTTCCA ACACACTGTTACAAATCTGTGGGGGGTTTCTTTCTTCTGATAATTCTAGAGCCTGTTACCATAGAAAGGCATTTCTTCAATGGCTGGTTG TAGTTAGTTCATGTTTTTCAATCAAATTTGCAAATGTATTTGTTGCTGTATAGTGATTGTTTTGCAAAATAAAATTGCTTGTCACCTAAC TGCTA >19092_19092_9_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000392194_length(amino acids)=512AA_BP=213 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRA GKSGTSTPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKS KIGSTDNIKYQPKGGQVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKVGSLDNAHHVPGGGNVKIDSQKLNFR EHAKARVDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGL -------------------------------------------------------------- >19092_19092_10_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000447185_length(transcript)=1594nt_BP=694nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGACGGAGTAACCAAGAGCCCAGAAAA GCGCTCTTCTCTCCCAAGACCTTCCTCCATTCTCCCTCCTCGGCGAGGTGTGTCAGGAGACAGAGATGAGAATTCCTTCTCTCTCAACAG TTCTATCTCTTCTTCAGCACGGCGGACCACCAGGTCAGAGCCAATTCGCAGAGCAGGGAAGAGTGGTACCTCAACACCCACTACCCCTGG GTCTACTGCCATCACTCCTGGCACCCCACCAAGTTATTCTTCACGCACACCAGGCACTCCTGGAACCCCTAGCTATCCCAGGACCCCTCA CACACCAGGAACCCCCAAGTCTGCCATCTTGGTGCCGAGTGAGAAGAAGGTCGCCATCATACGTACTCCTCCAAAATCTCCTGCGACTCC CAAGCAGCTTCGGCTTATTAACCAACCACTGCCAGACCTGAAGAATGTCAAATCCAAAATCGGATCAACAGACAACATCAAATACCAGCC TAAAGGGGGGCAGGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATCCAAATGTGGCTCTCTGAAGAACATCCGCCACAG GCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGCCCAAGCTAAAGTTGGTTCTCTTGATAATGCTCA TCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGAGCATGCTAAAGCCCGTGTGGACCATGGGGCTGA GATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAATGTCTCCTCGTCTGGAAGCATCAACCTGCTCGA ATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGGCTTGTGA >19092_19092_10_CPS1-MAP2_CPS1_chr2_211447433_ENST00000430249_MAP2_chr2_210570304_ENST00000447185_length(amino acids)=513AA_BP=213 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDGVTKSPEKRSSLPRPSSILPPRRGVSGDRDENSFSLNSSISSSARRTTRSEPIRRA GKSGTSTPTTPGSTAITPGTPPSYSSRTPGTPGTPSYPRTPHTPGTPKSAILVPSEKKVAIIRTPPKSPATPKQLRLINQPLPDLKNVKS KIGSTDNIKYQPKGGQVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKVGSLDNAHHVPGGGNVKIDSQKLNFR EHAKARVDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGLX -------------------------------------------------------------- >19092_19092_11_CPS1-MAP2_CPS1_chr2_211454958_ENST00000233072_MAP2_chr2_210588319_ENST00000199940_length(transcript)=1661nt_BP=1036nt GGGGTTAAGAGAAGGAGGAGCTGTGGCTGAAGACATTTAATGGCAGAATGAATGGAAATTCAAAGATCGCTGTGCAGTCAGCCTTAAACA CTGACTGCACCCCTCCCAGATTTCTTTTACATTAACTAAAAAGTCTTATCACACAATCTCATAAAATTTATGTAATTTCATTTAATTTTA GCCACAAATCATCAAAATGACGAGGATTTTGACAGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGC ACACCAAAAATGGAAATTTTCAAGACCTGGCATCAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAA GATGAAAGGTTACTCCTTTGGCCATCCATCCTCTGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTAC TGACCCTGCCTACAAAGGACAGATTCTCACAATGGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACT GGGACTTAGCAAATATTTGGAGTCTAATGGAATCAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGC TACCAAGAGTTTAGGGCAATGGCTACAGGAAGAAAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGA TAAGGGTACCATGCTTGGGAAGATTGAATTTGAAGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTC AACCAAGGATGTCAAAGTGTACGGCAAAGGAAACCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCT AGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCCCTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACC GGGGAACCCAGCTCTTGCAGAACCACTAATTCAGAATGTCAGAAAGGTTAGGATTTTAAACAAGAAGATCGATTTTAGCAAAGTTCAGTC CAGATGTGGTTCCAAGGATAACATCAAACATTCGGCTGGGGGCGGAAATGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGAC ATCCAAATGTGGCTCTCTGAAGAACATCCGCCACAGGCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAA GGCCCAAGCTAAAGTTGGTTCTCTTGATAATGCTCATCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAG AGAGCATGCTAAAGCCCGTGTGGACCATGGGGCTGAGATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAG CAATGTCTCCTCGTCTGGAAGCATCAACCTGCTCGAATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCA GGGCTTGTGAATATTTCTCATTTAGCATTGAAATAATAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATT CATTCTTTATAAACCATAAAATAAATAATCTCATCCCCAAA >19092_19092_11_CPS1-MAP2_CPS1_chr2_211454958_ENST00000233072_MAP2_chr2_210588319_ENST00000199940_length(amino acids)=447AA_BP=280 MTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAITDPAYK GQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIRDKGTML GKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGGPGNPAL AEPLIQNVRKVRILNKKIDFSKVQSRCGSKDNIKHSAGGGNVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKEKAQAKV GSLDNAHHVPGGGNVKIDSQKLNFREHAKARVDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAKQGL -------------------------------------------------------------- >19092_19092_12_CPS1-MAP2_CPS1_chr2_211454958_ENST00000430249_MAP2_chr2_210588319_ENST00000199940_length(transcript)=1538nt_BP=913nt GAAATGTAGTTGCTTTCTTAACCTCATCAAATTCATGAAGATTTAGCCGAGGCCCATGCCACAAATCATCAAAATGACGAGGATTTTGAC AGCTTTCAAAGTGGTGAGGACACTGAAGACTGGTTTTGGCTTTACCAATGTGACTGCACACCAAAAATGGAAATTTTCAAGACCTGGCAT CAGGCTCCTTTCTGTCAAGGCACAGACAGCACACATTGTCCTGGAAGATGGAACTAAGATGAAAGGTTACTCCTTTGGCCATCCATCCTC TGTTGCTGGTGAAGTGGTTTTTAATACTGGCCTGGGAGGGTACCCAGAAGCTATTACTGACCCTGCCTACAAAGGACAGATTCTCACAAT GGCCAACCCTATTATTGGGAATGGTGGAGCTCCTGATACTACTGCTCTGGATGAACTGGGACTTAGCAAATATTTGGAGTCTAATGGAAT CAAGGTTTCAGGTTTGCTGGTGCTGGATTATAGTAAAGACTACAACCACTGGCTGGCTACCAAGAGTTTAGGGCAATGGCTACAGGAAGA AAAGGTTCCTGCAATTTATGGAGTGGACACAAGAATGCTGACTAAAATAATTCGGGATAAGGGTACCATGCTTGGGAAGATTGAATTTGA AGGTCAGCCTGTGGATTTTGTGGATCCAAATAAACAGAATTTGATTGCTGAGGTTTCAACCAAGGATGTCAAAGTGTACGGCAAAGGAAA CCCCACAAAAGTGGTAGCTGTAGACTGTGGGATTAAAAACAATGTAATCCGCCTGCTAGTAAAGCGAGGAGCTGAAGTGCACTTAGTTCC CTGGAACCATGATTTCACCAAGATGGAGTATGATGGGATTTTGATCGCGGGAGGACCGGGGAACCCAGCTCTTGCAGAACCACTAATTCA GAATGTCAGAAAGGTTAGGATTTTAAACAAGAAGATCGATTTTAGCAAAGTTCAGTCCAGATGTGGTTCCAAGGATAACATCAAACATTC GGCTGGGGGCGGAAATGTACAAATTGTTACCAAGAAAATAGACCTAAGCCATGTGACATCCAAATGTGGCTCTCTGAAGAACATCCGCCA CAGGCCAGGTGGCGGACGTGTGAAAATTGAGAGTGTAAAACTAGATTTCAAAGAAAAGGCCCAAGCTAAAGTTGGTTCTCTTGATAATGC TCATCATGTACCTGGAGGTGGTAATGTCAAGATTGACAGCCAAAAGTTGAACTTCAGAGAGCATGCTAAAGCCCGTGTGGACCATGGGGC TGAGATCATTACACAGTCCCCAGGCAGATCCAGCGTGGCATCACCCCGACGACTCAGCAATGTCTCCTCGTCTGGAAGCATCAACCTGCT CGAATCTCCTCAGCTTGCCACTTTGGCTGAGGATGTCACTGCTGCACTCGCTAAGCAGGGCTTGTGAATATTTCTCATTTAGCATTGAAA TAATAATATTTAGGCATGAGCTCTTGGCAGGAGTGGGCTCTGAGCAGTTGTTATATTCATTCTTTATAAACCATAAAATAAATAATCTCA TCCCCAAA >19092_19092_12_CPS1-MAP2_CPS1_chr2_211454958_ENST00000430249_MAP2_chr2_210588319_ENST00000199940_length(amino acids)=453AA_BP=286 MPQIIKMTRILTAFKVVRTLKTGFGFTNVTAHQKWKFSRPGIRLLSVKAQTAHIVLEDGTKMKGYSFGHPSSVAGEVVFNTGLGGYPEAI TDPAYKGQILTMANPIIGNGGAPDTTALDELGLSKYLESNGIKVSGLLVLDYSKDYNHWLATKSLGQWLQEEKVPAIYGVDTRMLTKIIR DKGTMLGKIEFEGQPVDFVDPNKQNLIAEVSTKDVKVYGKGNPTKVVAVDCGIKNNVIRLLVKRGAEVHLVPWNHDFTKMEYDGILIAGG PGNPALAEPLIQNVRKVRILNKKIDFSKVQSRCGSKDNIKHSAGGGNVQIVTKKIDLSHVTSKCGSLKNIRHRPGGGRVKIESVKLDFKE KAQAKVGSLDNAHHVPGGGNVKIDSQKLNFREHAKARVDHGAEIITQSPGRSSVASPRRLSNVSSSGSINLLESPQLATLAEDVTAALAK QGL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CPS1-MAP2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000199940 | 8 | 15 | 701_744 | 229.0 | 560.0 | KNDC1 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000361559 | 6 | 12 | 701_744 | 172.0 | 472.0 | KNDC1 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000392194 | 5 | 11 | 701_744 | 172.0 | 472.0 | KNDC1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000199940 | 10 | 15 | 701_744 | 392.0 | 560.0 | KNDC1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000360351 | 0 | 15 | 701_744 | 0 | 1828.0 | KNDC1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000361559 | 0 | 12 | 701_744 | 0 | 472.0 | KNDC1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000392194 | 0 | 11 | 701_744 | 0 | 472.0 | KNDC1 | |
| Tgene | MAP2 | chr2:211454958 | chr2:210588319 | ENST00000447185 | 0 | 12 | 701_744 | 0.0 | 1824.0 | KNDC1 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000360351 | 9 | 15 | 701_744 | 1528.0 | 1828.0 | KNDC1 | |
| Tgene | MAP2 | chr2:211447433 | chr2:210570304 | ENST00000447185 | 6 | 12 | 701_744 | 1524.0 | 1824.0 | KNDC1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CPS1-MAP2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
| Hgene | CPS1 | P31327 | DB06775 | Carglumic acid | Allosteric modulator | Small molecule | Approved |
| Tgene | MAP2 | P11137 | DB01196 | Estramustine | Antagonist | Small molecule | Approved|Investigational |
| Tgene | MAP2 | P11137 | DB01248 | Docetaxel | Small molecule | Approved|Investigational | |
| Tgene | MAP2 | P11137 | DB01229 | Paclitaxel | Small molecule | Approved|Vet_approved |
Top |
Related Diseases for CPS1-MAP2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | CPS1 | C4082171 | Hyperammonemia Due to Carbamoyl Phosphate Synthetase 1 Deficiency | 19 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Hgene | CPS1 | C0751753 | Carbamoyl-Phosphate Synthase I Deficiency Disease | 13 | CLINGEN;CTD_human;ORPHANET |
| Hgene | CPS1 | C0220994 | Hyperammonemia | 2 | CTD_human |
| Hgene | CPS1 | C4085580 | Carbamoyl Phosphate Synthase 1 Deficiency | 2 | CTD_human |
| Hgene | CPS1 | C0009421 | Comatose | 1 | CTD_human |
| Hgene | CPS1 | C0019193 | Hepatitis, Toxic | 1 | CTD_human |
| Hgene | CPS1 | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human |
| Hgene | CPS1 | C0031190 | Persistent Fetal Circulation Syndrome | 1 | CTD_human |
| Hgene | CPS1 | C0032927 | Precancerous Conditions | 1 | CTD_human |
| Hgene | CPS1 | C0282313 | Condition, Preneoplastic | 1 | CTD_human |
| Hgene | CPS1 | C0376618 | Endotoxemia | 1 | CTD_human |
| Hgene | CPS1 | C0860207 | Drug-Induced Liver Disease | 1 | CTD_human |
| Hgene | CPS1 | C0860634 | Psychogenic coma | 1 | CTD_human |
| Hgene | CPS1 | C1262760 | Hepatitis, Drug-Induced | 1 | CTD_human |
| Hgene | CPS1 | C3658290 | Drug-Induced Acute Liver Injury | 1 | CTD_human |
| Hgene | CPS1 | C4277682 | Chemical and Drug Induced Liver Injury | 1 | CTD_human |
| Hgene | CPS1 | C4279912 | Chemically-Induced Liver Toxicity | 1 | CTD_human |
| Tgene | C0000786 | Spontaneous abortion | 1 | CTD_human | |
| Tgene | C0000822 | Abortion, Tubal | 1 | CTD_human | |
| Tgene | C0005586 | Bipolar Disorder | 1 | PSYGENET | |
| Tgene | C0030567 | Parkinson Disease | 1 | CTD_human | |
| Tgene | C0041696 | Unipolar Depression | 1 | PSYGENET | |
| Tgene | C0087031 | Juvenile-Onset Still Disease | 1 | CTD_human | |
| Tgene | C0525045 | Mood Disorders | 1 | PSYGENET | |
| Tgene | C0752347 | Lewy Body Disease | 1 | CTD_human | |
| Tgene | C1269683 | Major Depressive Disorder | 1 | PSYGENET | |
| Tgene | C3495559 | Juvenile arthritis | 1 | CTD_human | |
| Tgene | C3714758 | Juvenile psoriatic arthritis | 1 | CTD_human | |
| Tgene | C3830362 | Early Pregnancy Loss | 1 | CTD_human | |
| Tgene | C4552091 | Polyarthritis, Juvenile, Rheumatoid Factor Negative | 1 | CTD_human | |
| Tgene | C4552766 | Miscarriage | 1 | CTD_human | |
| Tgene | C4704862 | Polyarthritis, Juvenile, Rheumatoid Factor Positive | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies