
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AP2A1-NDUFA11 (FusionGDB2 ID:HG160TG126328) |
Fusion Gene Summary for AP2A1-NDUFA11 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AP2A1-NDUFA11 | Fusion gene ID: hg160tg126328 | Hgene | Tgene | Gene symbol | AP2A1 | NDUFA11 | Gene ID | 160 | 126328 |
| Gene name | adaptor related protein complex 2 subunit alpha 1 | NADH:ubiquinone oxidoreductase subunit A11 | |
| Synonyms | ADTAA|AP2-ALPHA|CLAPA1 | B14.7|CI-B14.7|MC1DN14 | |
| Cytomap | ('AP2A1')('NDUFA11') 19q13.33 | 19p13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AP-2 complex subunit alpha-1100 kDa coated vesicle protein Aadapter-related protein complex 2 alpha-1 subunitadapter-related protein complex 2 subunit alpha-1adaptin, alpha Aadaptor protein complex AP-2 subunit alpha-1adaptor related protein complex | NADH dehydrogenase [ubiquinone] 1 alpha subcomplex subunit 11NADH dehydrogenase (ubiquinone) 1 alpha subcomplex, 11, 14.7kDaNADH-ubiquinone oxidoreductase subunit B14.7complex I B14.7 subunit | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q86Y39 | |
| Ensembl transtripts involved in fusion gene | ENST00000600199, ENST00000354293, ENST00000359032, | ||
| Fusion gene scores | * DoF score | 8 X 10 X 7=560 | 3 X 3 X 3=27 |
| # samples | 12 | 4 | |
| ** MAII score | log2(12/560*10)=-2.22239242133645 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/27*10)=0.567040592723894 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: AP2A1 [Title/Abstract] AND NDUFA11 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AP2A1(50270457)-NDUFA11(5897008), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | AP2A1 | GO:0072583 | clathrin-dependent endocytosis | 23676497 |
| Hgene | AP2A1 | GO:1900126 | negative regulation of hyaluronan biosynthetic process | 24251095 |
| Fusion gene breakpoints across AP2A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NDUFA11 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 61N | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
Top |
Fusion Gene ORF analysis for AP2A1-NDUFA11 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000600199 | ENST00000308961 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| 3UTR-3CDS | ENST00000600199 | ENST00000418389 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| 3UTR-3CDS | ENST00000600199 | ENST00000592634 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| 3UTR-intron | ENST00000600199 | ENST00000591160 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| 5CDS-intron | ENST00000354293 | ENST00000591160 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| 5CDS-intron | ENST00000359032 | ENST00000591160 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| In-frame | ENST00000354293 | ENST00000308961 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| In-frame | ENST00000354293 | ENST00000418389 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| In-frame | ENST00000354293 | ENST00000592634 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| In-frame | ENST00000359032 | ENST00000308961 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| In-frame | ENST00000359032 | ENST00000418389 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| In-frame | ENST00000359032 | ENST00000592634 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000354293 | AP2A1 | chr19 | 50270457 | + | ENST00000418389 | NDUFA11 | chr19 | 5897008 | - | 2464 | 233 | 357 | 1415 | 352 |
| ENST00000354293 | AP2A1 | chr19 | 50270457 | + | ENST00000592634 | NDUFA11 | chr19 | 5897008 | - | 2227 | 233 | 1333 | 695 | 212 |
| ENST00000354293 | AP2A1 | chr19 | 50270457 | + | ENST00000308961 | NDUFA11 | chr19 | 5897008 | - | 627 | 233 | 67 | 561 | 164 |
| ENST00000359032 | AP2A1 | chr19 | 50270457 | + | ENST00000418389 | NDUFA11 | chr19 | 5897008 | - | 2298 | 67 | 191 | 1249 | 352 |
| ENST00000359032 | AP2A1 | chr19 | 50270457 | + | ENST00000592634 | NDUFA11 | chr19 | 5897008 | - | 2061 | 67 | 1167 | 529 | 212 |
| ENST00000359032 | AP2A1 | chr19 | 50270457 | + | ENST00000308961 | NDUFA11 | chr19 | 5897008 | - | 461 | 67 | 0 | 395 | 131 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000354293 | ENST00000418389 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - | 0.661541 | 0.33845904 |
| ENST00000354293 | ENST00000592634 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - | 0.6399715 | 0.3600285 |
| ENST00000354293 | ENST00000308961 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - | 0.011990658 | 0.9880093 |
| ENST00000359032 | ENST00000418389 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - | 0.6717169 | 0.3282831 |
| ENST00000359032 | ENST00000592634 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - | 0.9043472 | 0.09565276 |
| ENST00000359032 | ENST00000308961 | AP2A1 | chr19 | 50270457 | + | NDUFA11 | chr19 | 5897008 | - | 0.01640951 | 0.98359054 |
Top |
Fusion Genomic Features for AP2A1-NDUFA11 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
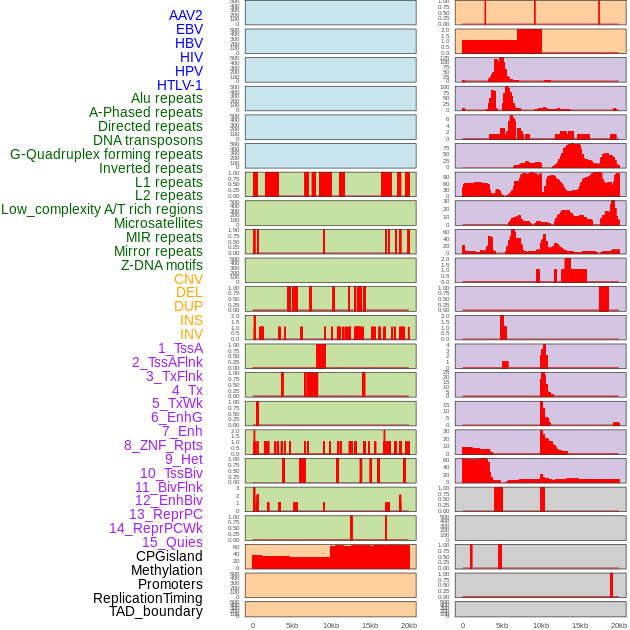 |
Top |
Fusion Protein Features for AP2A1-NDUFA11 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:50270457/chr19:5897008) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | NDUFA11 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Accessory subunit of the mitochondrial membrane respiratory chain NADH dehydrogenase (Complex I), that is believed not to be involved in catalysis. Complex I functions in the transfer of electrons from NADH to the respiratory chain. The immediate electron acceptor for the enzyme is believed to be ubiquinone. {ECO:0000269|PubMed:27626371}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NDUFA11 | chr19:50270457 | chr19:5897008 | ENST00000308961 | 0 | 4 | 58_80 | 32 | 142.0 | Transmembrane | Helical | |
| Tgene | NDUFA11 | chr19:50270457 | chr19:5897008 | ENST00000418389 | 0 | 4 | 58_80 | 32 | 229.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NDUFA11 | chr19:50270457 | chr19:5897008 | ENST00000308961 | 0 | 4 | 21_43 | 32 | 142.0 | Transmembrane | Helical | |
| Tgene | NDUFA11 | chr19:50270457 | chr19:5897008 | ENST00000418389 | 0 | 4 | 21_43 | 32 | 229.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for AP2A1-NDUFA11 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5218_5218_1_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000354293_NDUFA11_chr19_5897008_ENST00000308961_length(transcript)=627nt_BP=233nt GGTGCCACGGCCTGCCAGCCCGCCCGCCCGCCCGCCAGCCAGCCCTCCCCGCGGCCGGCTCGGCTCCTTGGCGCTGCCTGGGGTCCTTTC CGCCCGGTCCCCGCTTGCCAGCCCCCGCTGCTCTGTGCCCTGTCCGGCCAGGCCTGGAGCCGACACCACCGCCATCATGCCGGCCGTGTC CAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGCCTGACCGCCGCTGCCTACAGAGTCACACTCAATCC TCCGGGCACCTTCCTTGAAGGAGTGGCTAAGGTTGGACAATACACGTTCACTGCAGCTGCTGTCGGGGCCGTGTTTGGCCTCACCACCTG CATCAGCGCCCATGTCCGCGAGAAGCCCGACGACCCCCTGAACTACTTCCTCGGTGGCTGCGCCGGAGGCCTGACTCTGGGAGCACGCAC GCACAACTACGGGATTGGCGCCGCCGCCTGCGTGTACTTTGGCATAGCGGCCTCCCTGGTCAAGATGGGCCGGCTGGAGGGCTGGGAGGT GTTTGCAAAACCCAAGGTGTGAGCCCTGTGCCTGCCGGGACCTCCAGCCTGCAGAATGCGTCCAGAAATAAATTCTGTGTCTGTGTG >5218_5218_1_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000354293_NDUFA11_chr19_5897008_ENST00000308961_length(amino acids)=164AA_BP=56 MALPGVLSARSPLASPRCSVPCPARPGADTTAIMPAVSKGDGMRGLAVFISDIRNCLTAAAYRVTLNPPGTFLEGVAKVGQYTFTAAAVG AVFGLTTCISAHVREKPDDPLNYFLGGCAGGLTLGARTHNYGIGAAACVYFGIAASLVKMGRLEGWEVFAKPKV -------------------------------------------------------------- >5218_5218_2_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000354293_NDUFA11_chr19_5897008_ENST00000418389_length(transcript)=2464nt_BP=233nt GGTGCCACGGCCTGCCAGCCCGCCCGCCCGCCCGCCAGCCAGCCCTCCCCGCGGCCGGCTCGGCTCCTTGGCGCTGCCTGGGGTCCTTTC CGCCCGGTCCCCGCTTGCCAGCCCCCGCTGCTCTGTGCCCTGTCCGGCCAGGCCTGGAGCCGACACCACCGCCATCATGCCGGCCGTGTC CAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGCCTGACCGCCGCTGCCTACAGAGTCACACTCAATCC TCCGGGCACCTTCCTTGAAGGAGTGGCTAAGGTTGGACAATACACGTTCACTGCAGCTGCTGTCGGGGCCGTGTTTGGCCTCACCACCTG CATCAGCGCCCATGTCCGCGAGAAGCCCGACGACCCCCTGAACTACTTCCTCGGTGGCTGCGCCGGAGGCCTGACTCTGGGAGCACGCAA GACAGGATCTCACTGTGTTGTGCAGGCTGGTCTCAAACTCCTGGCCTCGAGCAGTCCTCACACCTCAGCCTCCCAGAGTGCTGGGATTAT AGGCATGAGCCACTGTGTACAGAGATTCTGGGTCCCTTCTTCCAGCGCCTGCCTCGAAGTCCTCTCTGGAGAGAGCACAGATGTCCACGC GTGTTCCAGCACAAGGGGGGCATGCAACAGCTCAGGGTCACGTCCACTTCCGGAGCTGGGTGCCCGGGCCTCGGGCTCCCTGAGAAAGGG CGGACACACCCACCCCGCACCCAGAGGGGCAGGGGCCCTGACACCTGTCCAAGCCCTAATAGAGTCATTGTTAAACACTCTGGGTTCGAA CCCCAGAACTTGATTCTTTCCTTGTTCTGTCCTCAGAGGACGGCAGCACCCAGGCCTCAGCTTTCCCACCTGGTAAATGGGAATAAGGGC CCCTCAGAGATGCCCCACAAAGAAAGACGATTCCACCTCCCTGCAGGCATCCCATCCACTCACGGGCATCGCATCCACTCGAGGGCACCG GCCTCTGTCTCTACTGCGGCCGGCAGGGGGCAGCGCCCACCACAGCACGGCCTGCTGGGCAGTGTGGACCCGGGCGGTCATCCCCAGGCC CCCAGCCCCGCGGTGACCACAGGCGTCAGATTCCATCCCTTCCTCCGCACTCCAGGCCTTGTCTGTCCCTCATCCCCCTTCCTTCCCATG CATCCTGCCCACCGCAGCCGGGAAGTGATGGCTTCTAGGAATGGGCAATACAGCCCCAAACCTCCAGCCAAGGACACCGAAGGCTGGACA GGAGGAAAGACTAGTCCACGTCCCCACGACGGTCACCCTCAGCCCTGCACCATGGCCGCTTCTGGGACTGGTTCCACGCAGGCCTCCGCC CCCTGCAAGCCCTTCCCCGGCCCTCCAGGCCCGTGTGCGGCCCAAACCCTGTACCAGATCTCTTAGCCCTCTTCCACGGATGCGCGCGCT GAGGCCCACCCTGGGTAGTGGAGCTTGAAATTTAAAGGCCGCACGCCCCTTCGCACCTCCCAGCCCCAGGTGCCTCCCTGTGTTCAAGGG AGCCGACGGCTCAGACCAGGAGCTGTGCTCGCCGCCCACCCAGCCCATTCCGGGCTAGCCGCCAGGGTTGGCGCAGGCCTGCCAGGCGCC CCCACCTCGCCTGCAGGACGGGCCCCCCAGAATGGAACACGAGGGGGTGGTCTCTTGCTGGGCTCCAGGGAACCCCAAAGCCGAGGCCCC CCGGCCCATAAACATTTACTAGGTTGTGGAGGGCTGACGTCACTCCCACCCCACACACAAGAGGGCCCCCGTCTGGAACATCGGTCCCAG CAGGCTCCCTGAGGGGCTGTGGGGGACCCTTCCTGAGTTTACCTTGAACTTCATGGAGCCCTTCCCAGCCCCAGGCAGTCAGGGCTGGAA CTGAGGAGGGGCAGAGCCTCCCTGGGGAGCTAGGAGGGCTTCCTAGAGGAGGAGGCGGCACAGCAGAGAGGGCCCAAGGATGAAGAGGCT TTTCCATGTGTACCCAGCGGGAGGCTGGTCCAGGCAGAGCACACAGCAACAGCAGAGGCCTGCTGTGAGGGAGAGCAGTGGGCGATCAGG GGCCTCCTGGTCCAGGAGAGGTGCCTGGGGGCTGCAGGGCACACACTTGCTTCCCGAGAATCCATCCCTGGAGACACATCCCCAGCAGAG ACAAGGCTCCAAGAACACCGGCCTGGCCCTGCGCCGTGGCTCAGGCCTGTAATCCCAGTACTTTGGGAGGCCGAGGCTGGGGGATCACTT GAGGTCAGGAGTTTCAGACCACCCTGGCCAACACAGTGAAACCCTGTCTCTACTATACAAAAATAAGCCAGGTGTGGTGGCAGGCACCTG TAATCCCAGCTACTTGGGAGGCTGAGGCATGAGAATCCCTTGAACCTGGGAGGTGGAGGTTGCAGTGAGCCGAGATCATGTCACTGTACT CCAGCCTGGGAGACAGTGAGCGAGACTTTGTATC >5218_5218_2_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000354293_NDUFA11_chr19_5897008_ENST00000418389_length(amino acids)=352AA_BP=31 MHQRPCPREARRPPELLPRWLRRRPDSGSTQDRISLCCAGWSQTPGLEQSSHLSLPECWDYRHEPLCTEILGPFFQRLPRSPLWREHRCP RVFQHKGGMQQLRVTSTSGAGCPGLGLPEKGRTHPPRTQRGRGPDTCPSPNRVIVKHSGFEPQNLILSLFCPQRTAAPRPQLSHLVNGNK GPSEMPHKERRFHLPAGIPSTHGHRIHSRAPASVSTAAGRGQRPPQHGLLGSVDPGGHPQAPSPAVTTGVRFHPFLRTPGLVCPSSPFLP MHPAHRSREVMASRNGQYSPKPPAKDTEGWTGGKTSPRPHDGHPQPCTMAASGTGSTQASAPCKPFPGPPGPCAAQTLYQIS -------------------------------------------------------------- >5218_5218_3_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000354293_NDUFA11_chr19_5897008_ENST00000592634_length(transcript)=2227nt_BP=233nt GGTGCCACGGCCTGCCAGCCCGCCCGCCCGCCCGCCAGCCAGCCCTCCCCGCGGCCGGCTCGGCTCCTTGGCGCTGCCTGGGGTCCTTTC CGCCCGGTCCCCGCTTGCCAGCCCCCGCTGCTCTGTGCCCTGTCCGGCCAGGCCTGGAGCCGACACCACCGCCATCATGCCGGCCGTGTC CAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGCCTGACCGCCGCTGCCTACAGAGTCACACTCAATCC TCCGGGCACCTTCCTTGAAGGAGTGGCTAAGGTTGGACAATACACGTTCACTGCAGCTGCTGTCGGGGCCGTGTTTGGCCTCACCACCTG CATCAGCGCCCATGTCCGCGAGAAGCCCGACGACCCCCTGAACTACTTCCTCGGTGGCTGCGCCGGAGGCCTGACTCTGGGAGCACGCAG TGAGTGGCCCCCTCCCCACCCCCACCCTCCTCCCAGCCTGGCAGAATGACCCCTGACCTCTGCTCATCCTCCACCCTCTCTGTTCCATCC CGGACAAGAAGTAAAGCAGCCTTCTTGAACACCAGCCATTTCAGTCATAGCGACAGCTGCTGCTGCTGCTTAAGCACCTACTGTGGCCCT CCCTGACCTGCCCTGTCCCCTCCCCACCCTCCCCTCCTCACTCTGCTCCAGCCACACGGGCCTCCTCACTGCTCCTCCCACATGCCAGGT ACAGTCCTGCCCCAGGGCCTTTGCATGGGCAGTGCACTGCGTGGAATGCTGTTCCCCTCACTGTCCTGACCACCCTGTGTACAAGCCAGC ATCCCCGCCGCCCTCGCTCTGTGCCGCCTTCCTTCTGTGTGCCTTGTCAGAGGACACAGGTCACCAAGGTCACCCCCTGTCTCTGCCACT GGCCTGTGAGTCAGAGAGGAGGATGGATGGAGTCTCGCCCTGCCATCTCTCTCCCTGCACCTGGAGCCCTGCAGGGGAGCTGCCCCCGCA ACCTTCACTTTACAGAAAAGGGTATTAGGGCTCAGGGAGGGAATTAAGTGGCCCGAGGTCACCTGGAGGAGCAAGTGGCCTTCTTTGCAG CCATCAGAGGGTGCAGCCCTGGTGGAGAAGGCCACGCTTGGCACAGGGGAGCCCGTCTGGAGCATGAGCCAGACATCACTCCTGCCCTCC CATGGGCCCGGGCTCAGCGTCAGTGCCCGCCTGTGCCCCTGGCCTACCCCCAGCCCGCCAAGGCTCGGGCCCTCAGGGCCAGCGGGAGGA GTGAACGAGCCCTCTTGCAGCTCAGCCGCTCTGGCCTGGCATGTTGGGAGTGATGAATGGCAGGTTCCAGGCAGGCAGAGAGGGAGGGTG CGAGGGCAGGGCGTACGCCGTCACTGCTGTCTCTGCGTCAAGACCTTGGGGAGGCCTTGTCCCTCCCCAGCTCCCACTGGAACTGGTCAG AGGTTGCAGGTGGGTTGAGGTCTTGACTGTAGCCCAGCTCAGGCTGGAACTGCTCCCTGTCCCCAAGCCAGCCTCCCTGTCTCTCTTCAA AGAGTGTGAGTCCCTTTAGGTCCTGGTGTGTGGGGACACACCTCCTTCCTCCTCTGGCCCGGAGGCTTCGGAGCAGGAGAGCCTGGAGAA GTGGGGGCACTGTCGGGGCTCCTCGGTACACAGACCACGGGACAGATGCGTGGCCTGGCCCTGGCATCCATGGGCAAAGGAGAGACTGAG ACACACCGATGTGTCACCATGGCCCGGTGCCCAGCCTTGCCCCAGCCCCAGCTGGGGGCAGCACGGTGTCCTCGCAGGGGGAAGTCAGTG TGGGGCGGGATGAGGACCCACAGCCTGGGTTCCTGCTGGGAAGCAACCTGGACTCCGGCCTCCCTCTGTGCATCAGTTTCCACATCTCCA GAGTCTAGGGCCCTCTTCCTGAGTGACTTAATCCCTGAAGAGAGTGTCCTGTCAGGGGTCTCAGTCTGGCTCCCAGGGTGGGCACCGGCC AGGGCGTGGAGCGTCTTGGTCCGGCCGAGCCCCACCCGGGCCTGACATCACCTCCCCACTCCCACAGCGCACAACTACGGGATTGGCGCC GCCGCCTGCGTGTACTTTGGCATAGCGGCCTCCCTGGTCAAGATGGGCCGGCTGGAGGGCTGGGAGGTGTTTGCAAAACCCAAGGTGTGA GCCCTGTGCCTGCCGGGACCTCCAGCCTGCAGAATGCGTCCAGAAATAAATTCTGTGTCTGTGTGTG >5218_5218_3_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000354293_NDUFA11_chr19_5897008_ENST00000592634_length(amino acids)=212AA_BP= MPGTCHSSLPTCQARAAELQEGSFTPPAGPEGPSLGGLGVGQGHRRALTLSPGPWEGRSDVWLMLQTGSPVPSVAFSTRAAPSDGCKEGH LLLQVTSGHLIPSLSPNTLFCKVKVAGAAPLQGSRCRERDGRARLHPSSSLTHRPVAETGGDLGDLCPLTRHTEGRRHRARAAGMLACTQ GGQDSEGNSIPRSALPMQRPWGRTVPGMWEEQ -------------------------------------------------------------- >5218_5218_4_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000359032_NDUFA11_chr19_5897008_ENST00000308961_length(transcript)=461nt_BP=67nt ATGCCGGCCGTGTCCAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGCCTGACCGCCGCTGCCTACAGA GTCACACTCAATCCTCCGGGCACCTTCCTTGAAGGAGTGGCTAAGGTTGGACAATACACGTTCACTGCAGCTGCTGTCGGGGCCGTGTTT GGCCTCACCACCTGCATCAGCGCCCATGTCCGCGAGAAGCCCGACGACCCCCTGAACTACTTCCTCGGTGGCTGCGCCGGAGGCCTGACT CTGGGAGCACGCACGCACAACTACGGGATTGGCGCCGCCGCCTGCGTGTACTTTGGCATAGCGGCCTCCCTGGTCAAGATGGGCCGGCTG GAGGGCTGGGAGGTGTTTGCAAAACCCAAGGTGTGAGCCCTGTGCCTGCCGGGACCTCCAGCCTGCAGAATGCGTCCAGAAATAAATTCT GTGTCTGTGTG >5218_5218_4_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000359032_NDUFA11_chr19_5897008_ENST00000308961_length(amino acids)=131AA_BP=23 MPAVSKGDGMRGLAVFISDIRNCLTAAAYRVTLNPPGTFLEGVAKVGQYTFTAAAVGAVFGLTTCISAHVREKPDDPLNYFLGGCAGGLT LGARTHNYGIGAAACVYFGIAASLVKMGRLEGWEVFAKPKV -------------------------------------------------------------- >5218_5218_5_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000359032_NDUFA11_chr19_5897008_ENST00000418389_length(transcript)=2298nt_BP=67nt ATGCCGGCCGTGTCCAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGCCTGACCGCCGCTGCCTACAGA GTCACACTCAATCCTCCGGGCACCTTCCTTGAAGGAGTGGCTAAGGTTGGACAATACACGTTCACTGCAGCTGCTGTCGGGGCCGTGTTT GGCCTCACCACCTGCATCAGCGCCCATGTCCGCGAGAAGCCCGACGACCCCCTGAACTACTTCCTCGGTGGCTGCGCCGGAGGCCTGACT CTGGGAGCACGCAAGACAGGATCTCACTGTGTTGTGCAGGCTGGTCTCAAACTCCTGGCCTCGAGCAGTCCTCACACCTCAGCCTCCCAG AGTGCTGGGATTATAGGCATGAGCCACTGTGTACAGAGATTCTGGGTCCCTTCTTCCAGCGCCTGCCTCGAAGTCCTCTCTGGAGAGAGC ACAGATGTCCACGCGTGTTCCAGCACAAGGGGGGCATGCAACAGCTCAGGGTCACGTCCACTTCCGGAGCTGGGTGCCCGGGCCTCGGGC TCCCTGAGAAAGGGCGGACACACCCACCCCGCACCCAGAGGGGCAGGGGCCCTGACACCTGTCCAAGCCCTAATAGAGTCATTGTTAAAC ACTCTGGGTTCGAACCCCAGAACTTGATTCTTTCCTTGTTCTGTCCTCAGAGGACGGCAGCACCCAGGCCTCAGCTTTCCCACCTGGTAA ATGGGAATAAGGGCCCCTCAGAGATGCCCCACAAAGAAAGACGATTCCACCTCCCTGCAGGCATCCCATCCACTCACGGGCATCGCATCC ACTCGAGGGCACCGGCCTCTGTCTCTACTGCGGCCGGCAGGGGGCAGCGCCCACCACAGCACGGCCTGCTGGGCAGTGTGGACCCGGGCG GTCATCCCCAGGCCCCCAGCCCCGCGGTGACCACAGGCGTCAGATTCCATCCCTTCCTCCGCACTCCAGGCCTTGTCTGTCCCTCATCCC CCTTCCTTCCCATGCATCCTGCCCACCGCAGCCGGGAAGTGATGGCTTCTAGGAATGGGCAATACAGCCCCAAACCTCCAGCCAAGGACA CCGAAGGCTGGACAGGAGGAAAGACTAGTCCACGTCCCCACGACGGTCACCCTCAGCCCTGCACCATGGCCGCTTCTGGGACTGGTTCCA CGCAGGCCTCCGCCCCCTGCAAGCCCTTCCCCGGCCCTCCAGGCCCGTGTGCGGCCCAAACCCTGTACCAGATCTCTTAGCCCTCTTCCA CGGATGCGCGCGCTGAGGCCCACCCTGGGTAGTGGAGCTTGAAATTTAAAGGCCGCACGCCCCTTCGCACCTCCCAGCCCCAGGTGCCTC CCTGTGTTCAAGGGAGCCGACGGCTCAGACCAGGAGCTGTGCTCGCCGCCCACCCAGCCCATTCCGGGCTAGCCGCCAGGGTTGGCGCAG GCCTGCCAGGCGCCCCCACCTCGCCTGCAGGACGGGCCCCCCAGAATGGAACACGAGGGGGTGGTCTCTTGCTGGGCTCCAGGGAACCCC AAAGCCGAGGCCCCCCGGCCCATAAACATTTACTAGGTTGTGGAGGGCTGACGTCACTCCCACCCCACACACAAGAGGGCCCCCGTCTGG AACATCGGTCCCAGCAGGCTCCCTGAGGGGCTGTGGGGGACCCTTCCTGAGTTTACCTTGAACTTCATGGAGCCCTTCCCAGCCCCAGGC AGTCAGGGCTGGAACTGAGGAGGGGCAGAGCCTCCCTGGGGAGCTAGGAGGGCTTCCTAGAGGAGGAGGCGGCACAGCAGAGAGGGCCCA AGGATGAAGAGGCTTTTCCATGTGTACCCAGCGGGAGGCTGGTCCAGGCAGAGCACACAGCAACAGCAGAGGCCTGCTGTGAGGGAGAGC AGTGGGCGATCAGGGGCCTCCTGGTCCAGGAGAGGTGCCTGGGGGCTGCAGGGCACACACTTGCTTCCCGAGAATCCATCCCTGGAGACA CATCCCCAGCAGAGACAAGGCTCCAAGAACACCGGCCTGGCCCTGCGCCGTGGCTCAGGCCTGTAATCCCAGTACTTTGGGAGGCCGAGG CTGGGGGATCACTTGAGGTCAGGAGTTTCAGACCACCCTGGCCAACACAGTGAAACCCTGTCTCTACTATACAAAAATAAGCCAGGTGTG GTGGCAGGCACCTGTAATCCCAGCTACTTGGGAGGCTGAGGCATGAGAATCCCTTGAACCTGGGAGGTGGAGGTTGCAGTGAGCCGAGAT CATGTCACTGTACTCCAGCCTGGGAGACAGTGAGCGAGACTTTGTATC >5218_5218_5_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000359032_NDUFA11_chr19_5897008_ENST00000418389_length(amino acids)=352AA_BP=31 MHQRPCPREARRPPELLPRWLRRRPDSGSTQDRISLCCAGWSQTPGLEQSSHLSLPECWDYRHEPLCTEILGPFFQRLPRSPLWREHRCP RVFQHKGGMQQLRVTSTSGAGCPGLGLPEKGRTHPPRTQRGRGPDTCPSPNRVIVKHSGFEPQNLILSLFCPQRTAAPRPQLSHLVNGNK GPSEMPHKERRFHLPAGIPSTHGHRIHSRAPASVSTAAGRGQRPPQHGLLGSVDPGGHPQAPSPAVTTGVRFHPFLRTPGLVCPSSPFLP MHPAHRSREVMASRNGQYSPKPPAKDTEGWTGGKTSPRPHDGHPQPCTMAASGTGSTQASAPCKPFPGPPGPCAAQTLYQIS -------------------------------------------------------------- >5218_5218_6_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000359032_NDUFA11_chr19_5897008_ENST00000592634_length(transcript)=2061nt_BP=67nt ATGCCGGCCGTGTCCAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGCCTGACCGCCGCTGCCTACAGA GTCACACTCAATCCTCCGGGCACCTTCCTTGAAGGAGTGGCTAAGGTTGGACAATACACGTTCACTGCAGCTGCTGTCGGGGCCGTGTTT GGCCTCACCACCTGCATCAGCGCCCATGTCCGCGAGAAGCCCGACGACCCCCTGAACTACTTCCTCGGTGGCTGCGCCGGAGGCCTGACT CTGGGAGCACGCAGTGAGTGGCCCCCTCCCCACCCCCACCCTCCTCCCAGCCTGGCAGAATGACCCCTGACCTCTGCTCATCCTCCACCC TCTCTGTTCCATCCCGGACAAGAAGTAAAGCAGCCTTCTTGAACACCAGCCATTTCAGTCATAGCGACAGCTGCTGCTGCTGCTTAAGCA CCTACTGTGGCCCTCCCTGACCTGCCCTGTCCCCTCCCCACCCTCCCCTCCTCACTCTGCTCCAGCCACACGGGCCTCCTCACTGCTCCT CCCACATGCCAGGTACAGTCCTGCCCCAGGGCCTTTGCATGGGCAGTGCACTGCGTGGAATGCTGTTCCCCTCACTGTCCTGACCACCCT GTGTACAAGCCAGCATCCCCGCCGCCCTCGCTCTGTGCCGCCTTCCTTCTGTGTGCCTTGTCAGAGGACACAGGTCACCAAGGTCACCCC CTGTCTCTGCCACTGGCCTGTGAGTCAGAGAGGAGGATGGATGGAGTCTCGCCCTGCCATCTCTCTCCCTGCACCTGGAGCCCTGCAGGG GAGCTGCCCCCGCAACCTTCACTTTACAGAAAAGGGTATTAGGGCTCAGGGAGGGAATTAAGTGGCCCGAGGTCACCTGGAGGAGCAAGT GGCCTTCTTTGCAGCCATCAGAGGGTGCAGCCCTGGTGGAGAAGGCCACGCTTGGCACAGGGGAGCCCGTCTGGAGCATGAGCCAGACAT CACTCCTGCCCTCCCATGGGCCCGGGCTCAGCGTCAGTGCCCGCCTGTGCCCCTGGCCTACCCCCAGCCCGCCAAGGCTCGGGCCCTCAG GGCCAGCGGGAGGAGTGAACGAGCCCTCTTGCAGCTCAGCCGCTCTGGCCTGGCATGTTGGGAGTGATGAATGGCAGGTTCCAGGCAGGC AGAGAGGGAGGGTGCGAGGGCAGGGCGTACGCCGTCACTGCTGTCTCTGCGTCAAGACCTTGGGGAGGCCTTGTCCCTCCCCAGCTCCCA CTGGAACTGGTCAGAGGTTGCAGGTGGGTTGAGGTCTTGACTGTAGCCCAGCTCAGGCTGGAACTGCTCCCTGTCCCCAAGCCAGCCTCC CTGTCTCTCTTCAAAGAGTGTGAGTCCCTTTAGGTCCTGGTGTGTGGGGACACACCTCCTTCCTCCTCTGGCCCGGAGGCTTCGGAGCAG GAGAGCCTGGAGAAGTGGGGGCACTGTCGGGGCTCCTCGGTACACAGACCACGGGACAGATGCGTGGCCTGGCCCTGGCATCCATGGGCA AAGGAGAGACTGAGACACACCGATGTGTCACCATGGCCCGGTGCCCAGCCTTGCCCCAGCCCCAGCTGGGGGCAGCACGGTGTCCTCGCA GGGGGAAGTCAGTGTGGGGCGGGATGAGGACCCACAGCCTGGGTTCCTGCTGGGAAGCAACCTGGACTCCGGCCTCCCTCTGTGCATCAG TTTCCACATCTCCAGAGTCTAGGGCCCTCTTCCTGAGTGACTTAATCCCTGAAGAGAGTGTCCTGTCAGGGGTCTCAGTCTGGCTCCCAG GGTGGGCACCGGCCAGGGCGTGGAGCGTCTTGGTCCGGCCGAGCCCCACCCGGGCCTGACATCACCTCCCCACTCCCACAGCGCACAACT ACGGGATTGGCGCCGCCGCCTGCGTGTACTTTGGCATAGCGGCCTCCCTGGTCAAGATGGGCCGGCTGGAGGGCTGGGAGGTGTTTGCAA AACCCAAGGTGTGAGCCCTGTGCCTGCCGGGACCTCCAGCCTGCAGAATGCGTCCAGAAATAAATTCTGTGTCTGTGTGTG >5218_5218_6_AP2A1-NDUFA11_AP2A1_chr19_50270457_ENST00000359032_NDUFA11_chr19_5897008_ENST00000592634_length(amino acids)=212AA_BP= MPGTCHSSLPTCQARAAELQEGSFTPPAGPEGPSLGGLGVGQGHRRALTLSPGPWEGRSDVWLMLQTGSPVPSVAFSTRAAPSDGCKEGH LLLQVTSGHLIPSLSPNTLFCKVKVAGAAPLQGSRCRERDGRARLHPSSSLTHRPVAETGGDLGDLCPLTRHTEGRRHRARAAGMLACTQ GGQDSEGNSIPRSALPMQRPWGRTVPGMWEEQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AP2A1-NDUFA11 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AP2A1-NDUFA11 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
| Tgene | NDUFA11 | Q86Y39 | DB00157 | NADH | Small molecule | Approved|Nutraceutical |
Top |
Related Diseases for AP2A1-NDUFA11 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C1838979 | MITOCHONDRIAL COMPLEX I DEFICIENCY | 3 | GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C0751651 | Mitochondrial Diseases | 1 | GENOMICS_ENGLAND |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies