
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DNM2-CNN1 (FusionGDB2 ID:HG1785TG1264) |
Fusion Gene Summary for DNM2-CNN1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DNM2-CNN1 | Fusion gene ID: hg1785tg1264 | Hgene | Tgene | Gene symbol | DNM2 | CNN1 | Gene ID | 1785 | 1264 |
| Gene name | dynamin 2 | calponin 1 | |
| Synonyms | CMT2M|CMTDI1|CMTDIB|DI-CMTB|DYN2|DYNII|LCCS5 | HEL-S-14|SMCC|Sm-Calp | |
| Cytomap | ('DNM2')('CNN1') 19p13.2 | 19p13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | dynamin-2dynamin II | calponin-1basic calponincalponin 1, basic, smooth musclecalponin H1, smooth musclecalponins, basicepididymis secretory protein Li 14 | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | . | P51911 | |
| Ensembl transtripts involved in fusion gene | ENST00000314646, ENST00000355667, ENST00000359692, ENST00000389253, ENST00000408974, ENST00000585892, ENST00000591819, | ||
| Fusion gene scores | * DoF score | 36 X 17 X 17=10404 | 4 X 3 X 3=36 |
| # samples | 49 | 5 | |
| ** MAII score | log2(49/10404*10)=-4.40821274494042 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/36*10)=0.473931188332412 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: DNM2 [Title/Abstract] AND CNN1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DNM2(10934575)-CNN1(11649701), # samples:1 DNM2(10934575)-CNN1(11651891), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | DNM2-CNN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DNM2-CNN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DNM2-CNN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. DNM2-CNN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | DNM2 | GO:1903526 | negative regulation of membrane tubulation | 18388313 |
| Fusion gene breakpoints across DNM2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
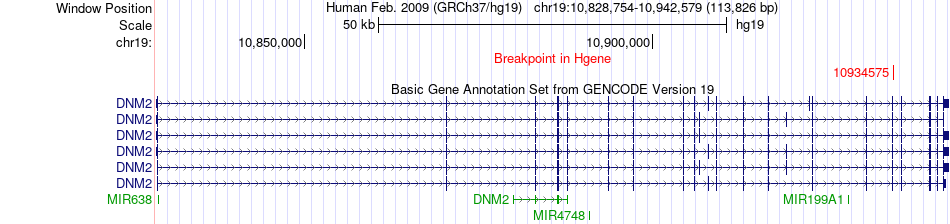 |
| Fusion gene breakpoints across CNN1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | COAD | TCGA-AA-3666-01A | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| ChimerDB4 | COAD | TCGA-AA-3666-01A | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
Top |
Fusion Gene ORF analysis for DNM2-CNN1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000314646 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000314646 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-3UTR | ENST00000314646 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000355667 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000355667 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-3UTR | ENST00000355667 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000359692 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000359692 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-3UTR | ENST00000359692 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000389253 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000389253 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-3UTR | ENST00000389253 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000408974 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000408974 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-3UTR | ENST00000408974 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000585892 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-3UTR | ENST00000585892 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-3UTR | ENST00000585892 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000314646 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000314646 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000314646 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000314646 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000314646 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000355667 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000355667 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000355667 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000355667 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000355667 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000359692 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000359692 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000359692 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000359692 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000359692 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000389253 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000389253 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000389253 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000389253 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000389253 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000408974 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000408974 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000408974 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000408974 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000408974 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000585892 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000585892 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000585892 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-5UTR | ENST00000585892 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-5UTR | ENST00000585892 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| 5CDS-intron | ENST00000314646 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-intron | ENST00000355667 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-intron | ENST00000359692 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-intron | ENST00000389253 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-intron | ENST00000408974 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| 5CDS-intron | ENST00000585892 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| In-frame | ENST00000314646 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| In-frame | ENST00000355667 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| In-frame | ENST00000359692 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| In-frame | ENST00000389253 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| In-frame | ENST00000408974 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| In-frame | ENST00000585892 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| intron-3CDS | ENST00000591819 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| intron-3UTR | ENST00000591819 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| intron-3UTR | ENST00000591819 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| intron-3UTR | ENST00000591819 | ENST00000588468 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| intron-5UTR | ENST00000591819 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| intron-5UTR | ENST00000591819 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| intron-5UTR | ENST00000591819 | ENST00000535659 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| intron-5UTR | ENST00000591819 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| intron-5UTR | ENST00000591819 | ENST00000592923 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + |
| intron-intron | ENST00000591819 | ENST00000544952 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11649701 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000585892 | DNM2 | chr19 | 10934575 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 3416 | 2057 | 164 | 2887 | 907 |
| ENST00000314646 | DNM2 | chr19 | 10934575 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 3416 | 2057 | 164 | 2887 | 907 |
| ENST00000359692 | DNM2 | chr19 | 10934575 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 3390 | 2031 | 150 | 2861 | 903 |
| ENST00000389253 | DNM2 | chr19 | 10934575 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 3364 | 2005 | 112 | 2835 | 907 |
| ENST00000355667 | DNM2 | chr19 | 10934575 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 3332 | 1973 | 80 | 2803 | 907 |
| ENST00000408974 | DNM2 | chr19 | 10934575 | + | ENST00000252456 | CNN1 | chr19 | 11651891 | + | 3275 | 1916 | 35 | 2746 | 903 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000585892 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + | 0.01151712 | 0.9884829 |
| ENST00000314646 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + | 0.011377586 | 0.9886225 |
| ENST00000359692 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + | 0.011337776 | 0.9886622 |
| ENST00000389253 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + | 0.01086522 | 0.9891348 |
| ENST00000355667 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + | 0.011259978 | 0.98874 |
| ENST00000408974 | ENST00000252456 | DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651891 | + | 0.011559702 | 0.9884403 |
Top |
Fusion Genomic Features for DNM2-CNN1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651890 | + | 3.72E-09 | 1 |
| DNM2 | chr19 | 10934575 | + | CNN1 | chr19 | 11651890 | + | 3.72E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
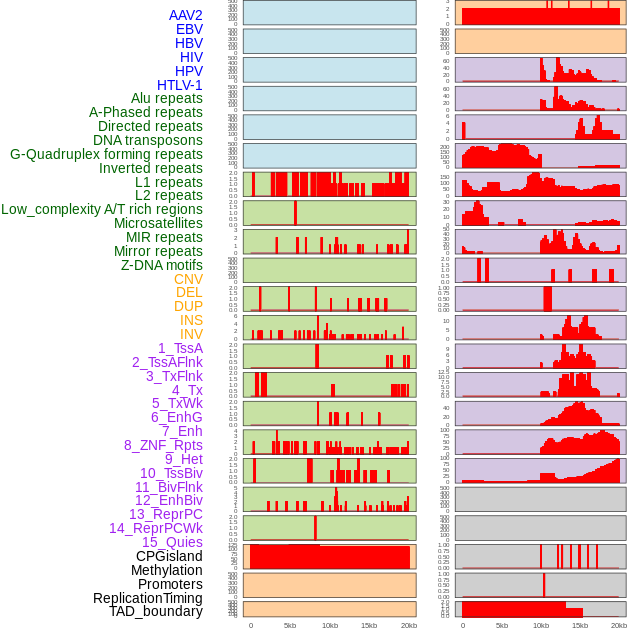 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
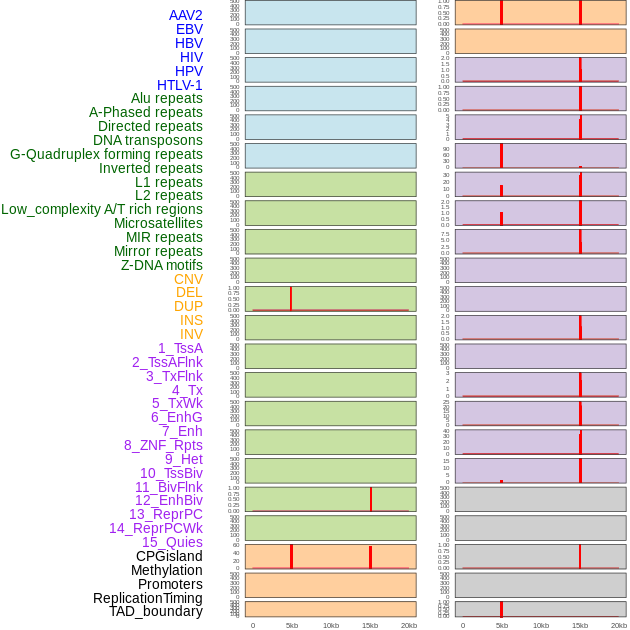 |
Top |
Fusion Protein Features for DNM2-CNN1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:10934575/chr19:11649701) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CNN1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Thin filament-associated protein that is implicated in the regulation and modulation of smooth muscle contraction. It is capable of binding to actin, calmodulin and tropomyosin. The interaction of calponin with actin inhibits the actomyosin Mg-ATPase activity (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 28_294 | 631 | 871.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 519_625 | 631 | 871.0 | Domain | PH |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 28_294 | 627 | 867.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 519_625 | 627 | 867.0 | Domain | PH |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 28_294 | 631 | 871.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 519_625 | 631 | 871.0 | Domain | PH |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 28_294 | 627 | 867.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 519_625 | 627 | 867.0 | Domain | PH |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 28_294 | 631 | 870.0 | Domain | Dynamin-type G |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 519_625 | 631 | 870.0 | Domain | PH |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 205_211 | 631 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 236_239 | 631 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 38_46 | 631 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 205_211 | 627 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 236_239 | 627 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 38_46 | 627 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 205_211 | 631 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 236_239 | 631 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 38_46 | 631 | 871.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 205_211 | 627 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 236_239 | 627 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 38_46 | 627 | 867.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 205_211 | 631 | 870.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 236_239 | 631 | 870.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 38_46 | 631 | 870.0 | Nucleotide binding | GTP |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 136_139 | 631 | 871.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 205_208 | 631 | 871.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 235_238 | 631 | 871.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 38_45 | 631 | 871.0 | Region | G1 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 64_66 | 631 | 871.0 | Region | G2 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 136_139 | 627 | 867.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 205_208 | 627 | 867.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 235_238 | 627 | 867.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 38_45 | 627 | 867.0 | Region | G1 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 64_66 | 627 | 867.0 | Region | G2 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 136_139 | 631 | 871.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 205_208 | 631 | 871.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 235_238 | 631 | 871.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 38_45 | 631 | 871.0 | Region | G1 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 64_66 | 631 | 871.0 | Region | G2 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 136_139 | 627 | 867.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 205_208 | 627 | 867.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 235_238 | 627 | 867.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 38_45 | 627 | 867.0 | Region | G1 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 64_66 | 627 | 867.0 | Region | G2 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 136_139 | 631 | 870.0 | Region | G3 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 205_208 | 631 | 870.0 | Region | G4 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 235_238 | 631 | 870.0 | Region | G5 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 38_45 | 631 | 870.0 | Region | G1 motif |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 64_66 | 631 | 870.0 | Region | G2 motif |
| Tgene | CNN1 | chr19:10934575 | chr19:11651891 | ENST00000252456 | 0 | 7 | 28_131 | 21 | 298.0 | Domain | Calponin-homology (CH) | |
| Tgene | CNN1 | chr19:10934575 | chr19:11651891 | ENST00000252456 | 0 | 7 | 164_189 | 21 | 298.0 | Repeat | Note=Calponin-like 1 | |
| Tgene | CNN1 | chr19:10934575 | chr19:11651891 | ENST00000252456 | 0 | 7 | 204_229 | 21 | 298.0 | Repeat | Note=Calponin-like 2 | |
| Tgene | CNN1 | chr19:10934575 | chr19:11651891 | ENST00000252456 | 0 | 7 | 243_268 | 21 | 298.0 | Repeat | Note=Calponin-like 3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 747_866 | 631 | 871.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 747_866 | 627 | 867.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 747_866 | 631 | 871.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 747_866 | 627 | 867.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 747_866 | 631 | 870.0 | Compositional bias | Note=Pro-rich |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000355667 | + | 17 | 21 | 653_744 | 631 | 871.0 | Domain | GED |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000359692 | + | 16 | 20 | 653_744 | 627 | 867.0 | Domain | GED |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000389253 | + | 17 | 21 | 653_744 | 631 | 871.0 | Domain | GED |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000408974 | + | 16 | 20 | 653_744 | 627 | 867.0 | Domain | GED |
| Hgene | DNM2 | chr19:10934575 | chr19:11651891 | ENST00000585892 | + | 17 | 21 | 653_744 | 631 | 870.0 | Domain | GED |
Top |
Fusion Gene Sequence for DNM2-CNN1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >23639_23639_1_DNM2-CNN1_DNM2_chr19_10934575_ENST00000314646_CNN1_chr19_11651891_ENST00000252456_length(transcript)=3416nt_BP=2057nt GAGAACCGGATGAGGCGGCGACCGTGAGGCCGAGCCGGGAGCGGGCGTCTTGCCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACG CCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGA TGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTG TAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGGACTTCCTTCCCCGCGGTTCAGGAATCGTCACCC GGCGGCCTCTCATTCTGCAGCTCATCTTCTCAAAAACAGAACATGCCGAGTTTTTGCACTGCAAGTCCAAAAAGTTTACAGACTTTGATG AAGTCCGGCAGGAGATTGAAGCAGAGACCGACAGGGTCACGGGGACCAACAAAGGCATCTCCCCAGTGCCCATCAACCTTCGAGTCTACT CGCCACACGTGTTGAACTTGACCCTCATCGACCTCCCGGGTATCACCAAGGTGCCTGTGGGCGACCAGCCTCCAGACATCGAGTACCAGA TCAAGGACATGATCCTGCAGTTCATCAGCCGGGAGAGCAGCCTCATTCTGGCTGTCACGCCCGCCAACATGGACCTGGCCAACTCCGACG CCCTCAAGCTGGCCAAGGAAGTCGATCCCCAAGGCCTACGGACCATCGGTGTCATCACCAAGCTTGACCTGATGGACGAGGGCACCGACG CCAGGGACGTCTTGGAGAACAAGTTGCTCCCGTTGAGAAGAGGCTACATTGGCGTGGTGAACCGCAGCCAGAAGGATATTGAGGGCAAGA AGGACATCCGTGCAGCACTGGCAGCTGAGAGGAAGTTCTTCCTCTCCCACCCGGCCTACCGGCACATGGCCGACCGCATGGGCACGCCAC ATCTGCAGAAGACGCTGAATCAGCAACTGACCAACCACATCCGGGAGTCGCTGCCGGCCCTACGTAGCAAACTACAGAGCCAGCTGCTGT CCCTGGAGAAGGAGGTGGAGGAGTACAAGAACTTTCGGCCCGACGACCCCACCCGCAAAACCAAAGCCCTGCTGCAGATGGTCCAGCAGT TTGGGGTGGATTTTGAGAAGAGGATCGAGGGCTCAGGAGATCAGGTGGACACTCTGGAGCTCTCCGGGGGCGCCCGAATCAATCGCATCT TCCACGAGCGGTTCCCATTTGAGCTGGTGAAGATGGAGTTTGACGAGAAGGACTTACGACGGGAGATCAGCTATGCCATTAAGAACATCC ATGGAGTCAGGACGGGGCTCTTCACCCCCGACATGGCCTTTGAAGCCATTGTGAAAAAACAGATTGTAAAACTCAAAGAGCCGAGTTTGA AGTGTGTTGATCTCGTGGTCTCAGAGCTGGCCACGGTCATAAAAAAGTGTGCCGAGAAGCTCAGTTCCTACCCCCGGTTGCGAGAGGAGA CAGAGCGAATCGTCACCACTTACATCCGGGAACGGGAGGGGAGAACGAAGGACCAGATTCTTCTGCTGATCGACATTGAGCAGTCCTACA TCAACACGAACCATGAGGACTTCATCGGGTTTGCCAATGCCCAGCAGAGGAGCACGCAGCTGAACAAGAAGAGAGCCATCCCCAATCAGC CTGAAACCCTGGTGATCCGCAGGGGCTGGCTGACCATCAACAACATCAGCCTGATGAAAGGCGGCTCCAAGGAGTACTGGTTTGTGCTGA CTGCCGAGTCACTGTCCTGGTACAAGGATGAGGAGGAGAAAGAGAAGAAGTACATGCTGCCTCTGGACAACCTCAAGATCCGTGATGTGG AGAAGGGCTTCATGTCCAACAAGCACGTCTTCGCCATCTTCAACACGGAGCAGAGAAACGTCTACAAGGACCTGCGGCAGATCGAGCTGG CCTGTGACTCCCAGGAAGACGTGGACAGCTGGAAGGCCTCGTTCCTCCGAGCTGGCGTCTACCCCGAGAAGGACCAGCTGGCCCAGAAGT ATGACCACCAGCGGGAGCAGGAGCTGAGAGAGTGGATCGAGGGGGTGACAGGCCGTCGCATCGGCAACAACTTCATGGACGGCCTCAAAG ATGGCATCATTCTTTGCGAATTCATCAATAAGCTGCAGCCAGGCTCCGTGAAGAAGATCAATGAGTCAACCCAAAATTGGCACCAGCTGG AGAACATCGGCAACTTCATCAAGGCCATCACCAAGTATGGGGTGAAGCCCCACGACATTTTTGAGGCCAACGACCTGTTTGAGAACACCA ACCATACACAGGTGCAGTCCACCCTCCTGGCTTTGGCCAGCATGGCGAAGACGAAAGGAAACAAGGTGAACGTGGGAGTGAAGTACGCAG AGAAGCAGGAGCGGAAATTCGAGCCGGGGAAGCTAAGAGAAGGGCGGAACATCATTGGGCTGCAGATGGGCACCAACAAGTTTGCCAGCC AGCAGGGCATGACGGCCTATGGCACCCGGCGCCACCTCTACGACCCCAAGCTGGGCACAGACCAGCCTCTGGACCAGGCGACCATCAGCC TGCAGATGGGCACCAACAAAGGAGCCAGCCAGGCTGGCATGACTGCGCCAGGGACCAAGCGGCAGATCTTCGAGCCGGGGCTGGGCATGG AGCACTGCGACACGCTCAATGTCAGCCTGCAGATGGGCAGCAACAAGGGCGCCTCGCAGCGGGGCATGACGGTGTATGGGCTGCCACGCC AGGTCTACGACCCCAAGTACTGTCTGACTCCCGAGTACCCAGAGCTGGGTGAGCCCGCCCACAACCACCACGCACACAACTACTACAATT CCGCCTAGGGCCACAAGGCCTTCCCTGTTTTCCCCCCAAGGGAGGCTGCTGCTGCTCTTGGCTGGACCCAGCCAGGCCCAGCCGACCCCC TCTCCCTGCATGGCATCCTCCAGCCCCTGTAGAACTCAACCTCTACAGGGTTAGAGTTTGGAGAGAGCAGACTGGCGGGGGGCCCATTGG GGGGAAGGGGACCCTCCGCTCTGTAGTGCTACAGGGTCCAACATAGAGCCGGGTGTCCCCAACAGCGCCCAAAGGACGCACTGAGCAACG CTATTCCAGCTGTCCCCCCACTCCCTCACAAGTGGGTACCCCCAGGACCAGAAGCTCCCCCAGCAAAGCCCCCAGAGCCCAGGCTCGGCC TGCCCCCACCCCATTCCCGCAGTGGGAGCAAACTGCATGCCCAGAGACCCAGCGGACACACGCGGTTTGGTTTGCAGCGACTGGCATACT ATGTGGATGTGACAGTGGCGTTTGTAATGAGAGCACTTTCTTTTTTTTCTATTTCACTGGAGCACAATAAATGGCTGTAAAATCTC >23639_23639_1_DNM2-CNN1_DNM2_chr19_10934575_ENST00000314646_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=907AA_BP=396 MGNRGMEELIPLVNKLQDAFSSIGQSCHLDLPQIAVVGGQSAGKSSVLENFVGRDFLPRGSGIVTRRPLILQLIFSKTEHAEFLHCKSKK FTDFDEVRQEIEAETDRVTGTNKGISPVPINLRVYSPHVLNLTLIDLPGITKVPVGDQPPDIEYQIKDMILQFISRESSLILAVTPANMD LANSDALKLAKEVDPQGLRTIGVITKLDLMDEGTDARDVLENKLLPLRRGYIGVVNRSQKDIEGKKDIRAALAAERKFFLSHPAYRHMAD RMGTPHLQKTLNQQLTNHIRESLPALRSKLQSQLLSLEKEVEEYKNFRPDDPTRKTKALLQMVQQFGVDFEKRIEGSGDQVDTLELSGGA RINRIFHERFPFELVKMEFDEKDLRREISYAIKNIHGVRTGLFTPDMAFEAIVKKQIVKLKEPSLKCVDLVVSELATVIKKCAEKLSSYP RLREETERIVTTYIREREGRTKDQILLLIDIEQSYINTNHEDFIGFANAQQRSTQLNKKRAIPNQPETLVIRRGWLTINNISLMKGGSKE YWFVLTAESLSWYKDEEEKEKKYMLPLDNLKIRDVEKGFMSNKHVFAIFNTEQRNVYKDLRQIELACDSQEDVDSWKASFLRAGVYPEKD QLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEAND LFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLD QATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSLQMGSNKGASQRGMTVYGLPRQVYDPKYCLTPEYPELGEPAHNHHA HNYYNSA -------------------------------------------------------------- >23639_23639_2_DNM2-CNN1_DNM2_chr19_10934575_ENST00000355667_CNN1_chr19_11651891_ENST00000252456_length(transcript)=3332nt_BP=1973nt CAGACGCCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACC GCGGGATGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGA TCGCTGTAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGGACTTCCTTCCCCGCGGTTCAGGAATCG TCACCCGGCGGCCTCTCATTCTGCAGCTCATCTTCTCAAAAACAGAACATGCCGAGTTTTTGCACTGCAAGTCCAAAAAGTTTACAGACT TTGATGAAGTCCGGCAGGAGATTGAAGCAGAGACCGACAGGGTCACGGGGACCAACAAAGGCATCTCCCCAGTGCCCATCAACCTTCGAG TCTACTCGCCACACGTGTTGAACTTGACCCTCATCGACCTCCCGGGTATCACCAAGGTGCCTGTGGGCGACCAGCCTCCAGACATCGAGT ACCAGATCAAGGACATGATCCTGCAGTTCATCAGCCGGGAGAGCAGCCTCATTCTGGCTGTCACGCCCGCCAACATGGACCTGGCCAACT CCGACGCCCTCAAGCTGGCCAAGGAAGTCGATCCCCAAGGCCTACGGACCATCGGTGTCATCACCAAGCTTGACCTGATGGACGAGGGCA CCGACGCCAGGGACGTCTTGGAGAACAAGTTGCTCCCGTTGAGAAGAGGCTACATTGGCGTGGTGAACCGCAGCCAGAAGGATATTGAGG GCAAGAAGGACATCCGTGCAGCACTGGCAGCTGAGAGGAAGTTCTTCCTCTCCCACCCGGCCTACCGGCACATGGCCGACCGCATGGGCA CGCCACATCTGCAGAAGACGCTGAATCAGCAACTGACCAACCACATCCGGGAGTCGCTGCCGGCCCTACGTAGCAAACTACAGAGCCAGC TGCTGTCCCTGGAGAAGGAGGTGGAGGAGTACAAGAACTTTCGGCCCGACGACCCCACCCGCAAAACCAAAGCCCTGCTGCAGATGGTCC AGCAGTTTGGGGTGGATTTTGAGAAGAGGATCGAGGGCTCAGGAGATCAGGTGGACACTCTGGAGCTCTCCGGGGGCGCCCGAATCAATC GCATCTTCCACGAGCGGTTCCCATTTGAGCTGGTGAAGATGGAGTTTGACGAGAAGGACTTACGACGGGAGATCAGCTATGCCATTAAGA ACATCCATGGAGTCAGGACCGGGCTTTTCACCCCGGACTTGGCATTCGAGGCCATTGTGAAAAAGCAGGTCGTCAAGCTGAAAGAGCCCT GTCTGAAATGTGTCGACCTGGTTATCCAGGAGCTAATCAATACAGTTAGGCAGTGTACCAGTAAGCTCAGTTCCTACCCCCGGTTGCGAG AGGAGACAGAGCGAATCGTCACCACTTACATCCGGGAACGGGAGGGGAGAACGAAGGACCAGATTCTTCTGCTGATCGACATTGAGCAGT CCTACATCAACACGAACCATGAGGACTTCATCGGGTTTGCCAATGCCCAGCAGAGGAGCACGCAGCTGAACAAGAAGAGAGCCATCCCCA ATCAGGGGGAGATCCTGGTGATCCGCAGGGGCTGGCTGACCATCAACAACATCAGCCTGATGAAAGGCGGCTCCAAGGAGTACTGGTTTG TGCTGACTGCCGAGTCACTGTCCTGGTACAAGGATGAGGAGGAGAAAGAGAAGAAGTACATGCTGCCTCTGGACAACCTCAAGATCCGTG ATGTGGAGAAGGGCTTCATGTCCAACAAGCACGTCTTCGCCATCTTCAACACGGAGCAGAGAAACGTCTACAAGGACCTGCGGCAGATCG AGCTGGCCTGTGACTCCCAGGAAGACGTGGACAGCTGGAAGGCCTCGTTCCTCCGAGCTGGCGTCTACCCCGAGAAGGACCAGCTGGCCC AGAAGTATGACCACCAGCGGGAGCAGGAGCTGAGAGAGTGGATCGAGGGGGTGACAGGCCGTCGCATCGGCAACAACTTCATGGACGGCC TCAAAGATGGCATCATTCTTTGCGAATTCATCAATAAGCTGCAGCCAGGCTCCGTGAAGAAGATCAATGAGTCAACCCAAAATTGGCACC AGCTGGAGAACATCGGCAACTTCATCAAGGCCATCACCAAGTATGGGGTGAAGCCCCACGACATTTTTGAGGCCAACGACCTGTTTGAGA ACACCAACCATACACAGGTGCAGTCCACCCTCCTGGCTTTGGCCAGCATGGCGAAGACGAAAGGAAACAAGGTGAACGTGGGAGTGAAGT ACGCAGAGAAGCAGGAGCGGAAATTCGAGCCGGGGAAGCTAAGAGAAGGGCGGAACATCATTGGGCTGCAGATGGGCACCAACAAGTTTG CCAGCCAGCAGGGCATGACGGCCTATGGCACCCGGCGCCACCTCTACGACCCCAAGCTGGGCACAGACCAGCCTCTGGACCAGGCGACCA TCAGCCTGCAGATGGGCACCAACAAAGGAGCCAGCCAGGCTGGCATGACTGCGCCAGGGACCAAGCGGCAGATCTTCGAGCCGGGGCTGG GCATGGAGCACTGCGACACGCTCAATGTCAGCCTGCAGATGGGCAGCAACAAGGGCGCCTCGCAGCGGGGCATGACGGTGTATGGGCTGC CACGCCAGGTCTACGACCCCAAGTACTGTCTGACTCCCGAGTACCCAGAGCTGGGTGAGCCCGCCCACAACCACCACGCACACAACTACT ACAATTCCGCCTAGGGCCACAAGGCCTTCCCTGTTTTCCCCCCAAGGGAGGCTGCTGCTGCTCTTGGCTGGACCCAGCCAGGCCCAGCCG ACCCCCTCTCCCTGCATGGCATCCTCCAGCCCCTGTAGAACTCAACCTCTACAGGGTTAGAGTTTGGAGAGAGCAGACTGGCGGGGGGCC CATTGGGGGGAAGGGGACCCTCCGCTCTGTAGTGCTACAGGGTCCAACATAGAGCCGGGTGTCCCCAACAGCGCCCAAAGGACGCACTGA GCAACGCTATTCCAGCTGTCCCCCCACTCCCTCACAAGTGGGTACCCCCAGGACCAGAAGCTCCCCCAGCAAAGCCCCCAGAGCCCAGGC TCGGCCTGCCCCCACCCCATTCCCGCAGTGGGAGCAAACTGCATGCCCAGAGACCCAGCGGACACACGCGGTTTGGTTTGCAGCGACTGG CATACTATGTGGATGTGACAGTGGCGTTTGTAATGAGAGCACTTTCTTTTTTTTCTATTTCACTGGAGCACAATAAATGGCTGTAAAATC TC >23639_23639_2_DNM2-CNN1_DNM2_chr19_10934575_ENST00000355667_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=907AA_BP=398 MGNRGMEELIPLVNKLQDAFSSIGQSCHLDLPQIAVVGGQSAGKSSVLENFVGRDFLPRGSGIVTRRPLILQLIFSKTEHAEFLHCKSKK FTDFDEVRQEIEAETDRVTGTNKGISPVPINLRVYSPHVLNLTLIDLPGITKVPVGDQPPDIEYQIKDMILQFISRESSLILAVTPANMD LANSDALKLAKEVDPQGLRTIGVITKLDLMDEGTDARDVLENKLLPLRRGYIGVVNRSQKDIEGKKDIRAALAAERKFFLSHPAYRHMAD RMGTPHLQKTLNQQLTNHIRESLPALRSKLQSQLLSLEKEVEEYKNFRPDDPTRKTKALLQMVQQFGVDFEKRIEGSGDQVDTLELSGGA RINRIFHERFPFELVKMEFDEKDLRREISYAIKNIHGVRTGLFTPDLAFEAIVKKQVVKLKEPCLKCVDLVIQELINTVRQCTSKLSSYP RLREETERIVTTYIREREGRTKDQILLLIDIEQSYINTNHEDFIGFANAQQRSTQLNKKRAIPNQGEILVIRRGWLTINNISLMKGGSKE YWFVLTAESLSWYKDEEEKEKKYMLPLDNLKIRDVEKGFMSNKHVFAIFNTEQRNVYKDLRQIELACDSQEDVDSWKASFLRAGVYPEKD QLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEAND LFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLD QATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSLQMGSNKGASQRGMTVYGLPRQVYDPKYCLTPEYPELGEPAHNHHA HNYYNSA -------------------------------------------------------------- >23639_23639_3_DNM2-CNN1_DNM2_chr19_10934575_ENST00000359692_CNN1_chr19_11651891_ENST00000252456_length(transcript)=3390nt_BP=2031nt GCGGCGACCGTGAGGCCGAGCCGGGAGCGGGCGTCTTGCCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACGCCGCGGGGCCAGGT CGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGATGGAAGAGCTGATC CCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTGTAGTGGGCGGCCAG AGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGGACTTCCTTCCCCGCGGTTCAGGAATCGTCACCCGGCGGCCTCTCATT CTGCAGCTCATCTTCTCAAAAACAGAACATGCCGAGTTTTTGCACTGCAAGTCCAAAAAGTTTACAGACTTTGATGAAGTCCGGCAGGAG ATTGAAGCAGAGACCGACAGGGTCACGGGGACCAACAAAGGCATCTCCCCAGTGCCCATCAACCTTCGAGTCTACTCGCCACACGTGTTG AACTTGACCCTCATCGACCTCCCGGGTATCACCAAGGTGCCTGTGGGCGACCAGCCTCCAGACATCGAGTACCAGATCAAGGACATGATC CTGCAGTTCATCAGCCGGGAGAGCAGCCTCATTCTGGCTGTCACGCCCGCCAACATGGACCTGGCCAACTCCGACGCCCTCAAGCTGGCC AAGGAAGTCGATCCCCAAGGCCTACGGACCATCGGTGTCATCACCAAGCTTGACCTGATGGACGAGGGCACCGACGCCAGGGACGTCTTG GAGAACAAGTTGCTCCCGTTGAGAAGAGGCTACATTGGCGTGGTGAACCGCAGCCAGAAGGATATTGAGGGCAAGAAGGACATCCGTGCA GCACTGGCAGCTGAGAGGAAGTTCTTCCTCTCCCACCCGGCCTACCGGCACATGGCCGACCGCATGGGCACGCCACATCTGCAGAAGACG CTGAATCAGCAACTGACCAACCACATCCGGGAGTCGCTGCCGGCCCTACGTAGCAAACTACAGAGCCAGCTGCTGTCCCTGGAGAAGGAG GTGGAGGAGTACAAGAACTTTCGGCCCGACGACCCCACCCGCAAAACCAAAGCCCTGCTGCAGATGGTCCAGCAGTTTGGGGTGGATTTT GAGAAGAGGATCGAGGGCTCAGGAGATCAGGTGGACACTCTGGAGCTCTCCGGGGGCGCCCGAATCAATCGCATCTTCCACGAGCGGTTC CCATTTGAGCTGGTGAAGATGGAGTTTGACGAGAAGGACTTACGACGGGAGATCAGCTATGCCATTAAGAACATCCATGGAGTCAGGACC GGGCTTTTCACCCCGGACTTGGCATTCGAGGCCATTGTGAAAAAGCAGGTCGTCAAGCTGAAAGAGCCCTGTCTGAAATGTGTCGACCTG GTTATCCAGGAGCTAATCAATACAGTTAGGCAGTGTACCAGTAAGCTCAGTTCCTACCCCCGGTTGCGAGAGGAGACAGAGCGAATCGTC ACCACTTACATCCGGGAACGGGAGGGGAGAACGAAGGACCAGATTCTTCTGCTGATCGACATTGAGCAGTCCTACATCAACACGAACCAT GAGGACTTCATCGGGTTTGCCAATGCCCAGCAGAGGAGCACGCAGCTGAACAAGAAGAGAGCCATCCCCAATCAGGTGATCCGCAGGGGC TGGCTGACCATCAACAACATCAGCCTGATGAAAGGCGGCTCCAAGGAGTACTGGTTTGTGCTGACTGCCGAGTCACTGTCCTGGTACAAG GATGAGGAGGAGAAAGAGAAGAAGTACATGCTGCCTCTGGACAACCTCAAGATCCGTGATGTGGAGAAGGGCTTCATGTCCAACAAGCAC GTCTTCGCCATCTTCAACACGGAGCAGAGAAACGTCTACAAGGACCTGCGGCAGATCGAGCTGGCCTGTGACTCCCAGGAAGACGTGGAC AGCTGGAAGGCCTCGTTCCTCCGAGCTGGCGTCTACCCCGAGAAGGACCAGCTGGCCCAGAAGTATGACCACCAGCGGGAGCAGGAGCTG AGAGAGTGGATCGAGGGGGTGACAGGCCGTCGCATCGGCAACAACTTCATGGACGGCCTCAAAGATGGCATCATTCTTTGCGAATTCATC AATAAGCTGCAGCCAGGCTCCGTGAAGAAGATCAATGAGTCAACCCAAAATTGGCACCAGCTGGAGAACATCGGCAACTTCATCAAGGCC ATCACCAAGTATGGGGTGAAGCCCCACGACATTTTTGAGGCCAACGACCTGTTTGAGAACACCAACCATACACAGGTGCAGTCCACCCTC CTGGCTTTGGCCAGCATGGCGAAGACGAAAGGAAACAAGGTGAACGTGGGAGTGAAGTACGCAGAGAAGCAGGAGCGGAAATTCGAGCCG GGGAAGCTAAGAGAAGGGCGGAACATCATTGGGCTGCAGATGGGCACCAACAAGTTTGCCAGCCAGCAGGGCATGACGGCCTATGGCACC CGGCGCCACCTCTACGACCCCAAGCTGGGCACAGACCAGCCTCTGGACCAGGCGACCATCAGCCTGCAGATGGGCACCAACAAAGGAGCC AGCCAGGCTGGCATGACTGCGCCAGGGACCAAGCGGCAGATCTTCGAGCCGGGGCTGGGCATGGAGCACTGCGACACGCTCAATGTCAGC CTGCAGATGGGCAGCAACAAGGGCGCCTCGCAGCGGGGCATGACGGTGTATGGGCTGCCACGCCAGGTCTACGACCCCAAGTACTGTCTG ACTCCCGAGTACCCAGAGCTGGGTGAGCCCGCCCACAACCACCACGCACACAACTACTACAATTCCGCCTAGGGCCACAAGGCCTTCCCT GTTTTCCCCCCAAGGGAGGCTGCTGCTGCTCTTGGCTGGACCCAGCCAGGCCCAGCCGACCCCCTCTCCCTGCATGGCATCCTCCAGCCC CTGTAGAACTCAACCTCTACAGGGTTAGAGTTTGGAGAGAGCAGACTGGCGGGGGGCCCATTGGGGGGAAGGGGACCCTCCGCTCTGTAG TGCTACAGGGTCCAACATAGAGCCGGGTGTCCCCAACAGCGCCCAAAGGACGCACTGAGCAACGCTATTCCAGCTGTCCCCCCACTCCCT CACAAGTGGGTACCCCCAGGACCAGAAGCTCCCCCAGCAAAGCCCCCAGAGCCCAGGCTCGGCCTGCCCCCACCCCATTCCCGCAGTGGG AGCAAACTGCATGCCCAGAGACCCAGCGGACACACGCGGTTTGGTTTGCAGCGACTGGCATACTATGTGGATGTGACAGTGGCGTTTGTA ATGAGAGCACTTTCTTTTTTTTCTATTTCACTGGAGCACAATAAATGGCTGTAAAATCTC >23639_23639_3_DNM2-CNN1_DNM2_chr19_10934575_ENST00000359692_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=903AA_BP=398 MGNRGMEELIPLVNKLQDAFSSIGQSCHLDLPQIAVVGGQSAGKSSVLENFVGRDFLPRGSGIVTRRPLILQLIFSKTEHAEFLHCKSKK FTDFDEVRQEIEAETDRVTGTNKGISPVPINLRVYSPHVLNLTLIDLPGITKVPVGDQPPDIEYQIKDMILQFISRESSLILAVTPANMD LANSDALKLAKEVDPQGLRTIGVITKLDLMDEGTDARDVLENKLLPLRRGYIGVVNRSQKDIEGKKDIRAALAAERKFFLSHPAYRHMAD RMGTPHLQKTLNQQLTNHIRESLPALRSKLQSQLLSLEKEVEEYKNFRPDDPTRKTKALLQMVQQFGVDFEKRIEGSGDQVDTLELSGGA RINRIFHERFPFELVKMEFDEKDLRREISYAIKNIHGVRTGLFTPDLAFEAIVKKQVVKLKEPCLKCVDLVIQELINTVRQCTSKLSSYP RLREETERIVTTYIREREGRTKDQILLLIDIEQSYINTNHEDFIGFANAQQRSTQLNKKRAIPNQVIRRGWLTINNISLMKGGSKEYWFV LTAESLSWYKDEEEKEKKYMLPLDNLKIRDVEKGFMSNKHVFAIFNTEQRNVYKDLRQIELACDSQEDVDSWKASFLRAGVYPEKDQLAQ KYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFEN TNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATI SLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSLQMGSNKGASQRGMTVYGLPRQVYDPKYCLTPEYPELGEPAHNHHAHNYY NSA -------------------------------------------------------------- >23639_23639_4_DNM2-CNN1_DNM2_chr19_10934575_ENST00000389253_CNN1_chr19_11651891_ENST00000252456_length(transcript)=3364nt_BP=2005nt CCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACGCCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCT CGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGATGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCAT CGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTGTAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGG CCGGGACTTCCTTCCCCGCGGTTCAGGAATCGTCACCCGGCGGCCTCTCATTCTGCAGCTCATCTTCTCAAAAACAGAACATGCCGAGTT TTTGCACTGCAAGTCCAAAAAGTTTACAGACTTTGATGAAGTCCGGCAGGAGATTGAAGCAGAGACCGACAGGGTCACGGGGACCAACAA AGGCATCTCCCCAGTGCCCATCAACCTTCGAGTCTACTCGCCACACGTGTTGAACTTGACCCTCATCGACCTCCCGGGTATCACCAAGGT GCCTGTGGGCGACCAGCCTCCAGACATCGAGTACCAGATCAAGGACATGATCCTGCAGTTCATCAGCCGGGAGAGCAGCCTCATTCTGGC TGTCACGCCCGCCAACATGGACCTGGCCAACTCCGACGCCCTCAAGCTGGCCAAGGAAGTCGATCCCCAAGGCCTACGGACCATCGGTGT CATCACCAAGCTTGACCTGATGGACGAGGGCACCGACGCCAGGGACGTCTTGGAGAACAAGTTGCTCCCGTTGAGAAGAGGCTACATTGG CGTGGTGAACCGCAGCCAGAAGGATATTGAGGGCAAGAAGGACATCCGTGCAGCACTGGCAGCTGAGAGGAAGTTCTTCCTCTCCCACCC GGCCTACCGGCACATGGCCGACCGCATGGGCACGCCACATCTGCAGAAGACGCTGAATCAGCAACTGACCAACCACATCCGGGAGTCGCT GCCGGCCCTACGTAGCAAACTACAGAGCCAGCTGCTGTCCCTGGAGAAGGAGGTGGAGGAGTACAAGAACTTTCGGCCCGACGACCCCAC CCGCAAAACCAAAGCCCTGCTGCAGATGGTCCAGCAGTTTGGGGTGGATTTTGAGAAGAGGATCGAGGGCTCAGGAGATCAGGTGGACAC TCTGGAGCTCTCCGGGGGCGCCCGAATCAATCGCATCTTCCACGAGCGGTTCCCATTTGAGCTGGTGAAGATGGAGTTTGACGAGAAGGA CTTACGACGGGAGATCAGCTATGCCATTAAGAACATCCATGGAGTCAGGACGGGGCTCTTCACCCCCGACATGGCCTTTGAAGCCATTGT GAAAAAACAGATTGTAAAACTCAAAGAGCCGAGTTTGAAGTGTGTTGATCTCGTGGTCTCAGAGCTGGCCACGGTCATAAAAAAGTGTGC CGAGAAGCTCAGTTCCTACCCCCGGTTGCGAGAGGAGACAGAGCGAATCGTCACCACTTACATCCGGGAACGGGAGGGGAGAACGAAGGA CCAGATTCTTCTGCTGATCGACATTGAGCAGTCCTACATCAACACGAACCATGAGGACTTCATCGGGTTTGCCAATGCCCAGCAGAGGAG CACGCAGCTGAACAAGAAGAGAGCCATCCCCAATCAGGGGGAGATCCTGGTGATCCGCAGGGGCTGGCTGACCATCAACAACATCAGCCT GATGAAAGGCGGCTCCAAGGAGTACTGGTTTGTGCTGACTGCCGAGTCACTGTCCTGGTACAAGGATGAGGAGGAGAAAGAGAAGAAGTA CATGCTGCCTCTGGACAACCTCAAGATCCGTGATGTGGAGAAGGGCTTCATGTCCAACAAGCACGTCTTCGCCATCTTCAACACGGAGCA GAGAAACGTCTACAAGGACCTGCGGCAGATCGAGCTGGCCTGTGACTCCCAGGAAGACGTGGACAGCTGGAAGGCCTCGTTCCTCCGAGC TGGCGTCTACCCCGAGAAGGACCAGCTGGCCCAGAAGTATGACCACCAGCGGGAGCAGGAGCTGAGAGAGTGGATCGAGGGGGTGACAGG CCGTCGCATCGGCAACAACTTCATGGACGGCCTCAAAGATGGCATCATTCTTTGCGAATTCATCAATAAGCTGCAGCCAGGCTCCGTGAA GAAGATCAATGAGTCAACCCAAAATTGGCACCAGCTGGAGAACATCGGCAACTTCATCAAGGCCATCACCAAGTATGGGGTGAAGCCCCA CGACATTTTTGAGGCCAACGACCTGTTTGAGAACACCAACCATACACAGGTGCAGTCCACCCTCCTGGCTTTGGCCAGCATGGCGAAGAC GAAAGGAAACAAGGTGAACGTGGGAGTGAAGTACGCAGAGAAGCAGGAGCGGAAATTCGAGCCGGGGAAGCTAAGAGAAGGGCGGAACAT CATTGGGCTGCAGATGGGCACCAACAAGTTTGCCAGCCAGCAGGGCATGACGGCCTATGGCACCCGGCGCCACCTCTACGACCCCAAGCT GGGCACAGACCAGCCTCTGGACCAGGCGACCATCAGCCTGCAGATGGGCACCAACAAAGGAGCCAGCCAGGCTGGCATGACTGCGCCAGG GACCAAGCGGCAGATCTTCGAGCCGGGGCTGGGCATGGAGCACTGCGACACGCTCAATGTCAGCCTGCAGATGGGCAGCAACAAGGGCGC CTCGCAGCGGGGCATGACGGTGTATGGGCTGCCACGCCAGGTCTACGACCCCAAGTACTGTCTGACTCCCGAGTACCCAGAGCTGGGTGA GCCCGCCCACAACCACCACGCACACAACTACTACAATTCCGCCTAGGGCCACAAGGCCTTCCCTGTTTTCCCCCCAAGGGAGGCTGCTGC TGCTCTTGGCTGGACCCAGCCAGGCCCAGCCGACCCCCTCTCCCTGCATGGCATCCTCCAGCCCCTGTAGAACTCAACCTCTACAGGGTT AGAGTTTGGAGAGAGCAGACTGGCGGGGGGCCCATTGGGGGGAAGGGGACCCTCCGCTCTGTAGTGCTACAGGGTCCAACATAGAGCCGG GTGTCCCCAACAGCGCCCAAAGGACGCACTGAGCAACGCTATTCCAGCTGTCCCCCCACTCCCTCACAAGTGGGTACCCCCAGGACCAGA AGCTCCCCCAGCAAAGCCCCCAGAGCCCAGGCTCGGCCTGCCCCCACCCCATTCCCGCAGTGGGAGCAAACTGCATGCCCAGAGACCCAG CGGACACACGCGGTTTGGTTTGCAGCGACTGGCATACTATGTGGATGTGACAGTGGCGTTTGTAATGAGAGCACTTTCTTTTTTTTCTAT TTCACTGGAGCACAATAAATGGCTGTAAAATCTC >23639_23639_4_DNM2-CNN1_DNM2_chr19_10934575_ENST00000389253_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=907AA_BP=396 MGNRGMEELIPLVNKLQDAFSSIGQSCHLDLPQIAVVGGQSAGKSSVLENFVGRDFLPRGSGIVTRRPLILQLIFSKTEHAEFLHCKSKK FTDFDEVRQEIEAETDRVTGTNKGISPVPINLRVYSPHVLNLTLIDLPGITKVPVGDQPPDIEYQIKDMILQFISRESSLILAVTPANMD LANSDALKLAKEVDPQGLRTIGVITKLDLMDEGTDARDVLENKLLPLRRGYIGVVNRSQKDIEGKKDIRAALAAERKFFLSHPAYRHMAD RMGTPHLQKTLNQQLTNHIRESLPALRSKLQSQLLSLEKEVEEYKNFRPDDPTRKTKALLQMVQQFGVDFEKRIEGSGDQVDTLELSGGA RINRIFHERFPFELVKMEFDEKDLRREISYAIKNIHGVRTGLFTPDMAFEAIVKKQIVKLKEPSLKCVDLVVSELATVIKKCAEKLSSYP RLREETERIVTTYIREREGRTKDQILLLIDIEQSYINTNHEDFIGFANAQQRSTQLNKKRAIPNQGEILVIRRGWLTINNISLMKGGSKE YWFVLTAESLSWYKDEEEKEKKYMLPLDNLKIRDVEKGFMSNKHVFAIFNTEQRNVYKDLRQIELACDSQEDVDSWKASFLRAGVYPEKD QLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEAND LFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLD QATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSLQMGSNKGASQRGMTVYGLPRQVYDPKYCLTPEYPELGEPAHNHHA HNYYNSA -------------------------------------------------------------- >23639_23639_5_DNM2-CNN1_DNM2_chr19_10934575_ENST00000408974_CNN1_chr19_11651891_ENST00000252456_length(transcript)=3275nt_BP=1916nt AGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGATGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACG CCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTGTAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGG AGAACTTCGTGGGCCGGGACTTCCTTCCCCGCGGTTCAGGAATCGTCACCCGGCGGCCTCTCATTCTGCAGCTCATCTTCTCAAAAACAG AACATGCCGAGTTTTTGCACTGCAAGTCCAAAAAGTTTACAGACTTTGATGAAGTCCGGCAGGAGATTGAAGCAGAGACCGACAGGGTCA CGGGGACCAACAAAGGCATCTCCCCAGTGCCCATCAACCTTCGAGTCTACTCGCCACACGTGTTGAACTTGACCCTCATCGACCTCCCGG GTATCACCAAGGTGCCTGTGGGCGACCAGCCTCCAGACATCGAGTACCAGATCAAGGACATGATCCTGCAGTTCATCAGCCGGGAGAGCA GCCTCATTCTGGCTGTCACGCCCGCCAACATGGACCTGGCCAACTCCGACGCCCTCAAGCTGGCCAAGGAAGTCGATCCCCAAGGCCTAC GGACCATCGGTGTCATCACCAAGCTTGACCTGATGGACGAGGGCACCGACGCCAGGGACGTCTTGGAGAACAAGTTGCTCCCGTTGAGAA GAGGCTACATTGGCGTGGTGAACCGCAGCCAGAAGGATATTGAGGGCAAGAAGGACATCCGTGCAGCACTGGCAGCTGAGAGGAAGTTCT TCCTCTCCCACCCGGCCTACCGGCACATGGCCGACCGCATGGGCACGCCACATCTGCAGAAGACGCTGAATCAGCAACTGACCAACCACA TCCGGGAGTCGCTGCCGGCCCTACGTAGCAAACTACAGAGCCAGCTGCTGTCCCTGGAGAAGGAGGTGGAGGAGTACAAGAACTTTCGGC CCGACGACCCCACCCGCAAAACCAAAGCCCTGCTGCAGATGGTCCAGCAGTTTGGGGTGGATTTTGAGAAGAGGATCGAGGGCTCAGGAG ATCAGGTGGACACTCTGGAGCTCTCCGGGGGCGCCCGAATCAATCGCATCTTCCACGAGCGGTTCCCATTTGAGCTGGTGAAGATGGAGT TTGACGAGAAGGACTTACGACGGGAGATCAGCTATGCCATTAAGAACATCCATGGAGTCAGGACGGGGCTCTTCACCCCCGACATGGCCT TTGAAGCCATTGTGAAAAAACAGATTGTAAAACTCAAAGAGCCGAGTTTGAAGTGTGTTGATCTCGTGGTCTCAGAGCTGGCCACGGTCA TAAAAAAGTGTGCCGAGAAGCTCAGTTCCTACCCCCGGTTGCGAGAGGAGACAGAGCGAATCGTCACCACTTACATCCGGGAACGGGAGG GGAGAACGAAGGACCAGATTCTTCTGCTGATCGACATTGAGCAGTCCTACATCAACACGAACCATGAGGACTTCATCGGGTTTGCCAATG CCCAGCAGAGGAGCACGCAGCTGAACAAGAAGAGAGCCATCCCCAATCAGGTGATCCGCAGGGGCTGGCTGACCATCAACAACATCAGCC TGATGAAAGGCGGCTCCAAGGAGTACTGGTTTGTGCTGACTGCCGAGTCACTGTCCTGGTACAAGGATGAGGAGGAGAAAGAGAAGAAGT ACATGCTGCCTCTGGACAACCTCAAGATCCGTGATGTGGAGAAGGGCTTCATGTCCAACAAGCACGTCTTCGCCATCTTCAACACGGAGC AGAGAAACGTCTACAAGGACCTGCGGCAGATCGAGCTGGCCTGTGACTCCCAGGAAGACGTGGACAGCTGGAAGGCCTCGTTCCTCCGAG CTGGCGTCTACCCCGAGAAGGACCAGCTGGCCCAGAAGTATGACCACCAGCGGGAGCAGGAGCTGAGAGAGTGGATCGAGGGGGTGACAG GCCGTCGCATCGGCAACAACTTCATGGACGGCCTCAAAGATGGCATCATTCTTTGCGAATTCATCAATAAGCTGCAGCCAGGCTCCGTGA AGAAGATCAATGAGTCAACCCAAAATTGGCACCAGCTGGAGAACATCGGCAACTTCATCAAGGCCATCACCAAGTATGGGGTGAAGCCCC ACGACATTTTTGAGGCCAACGACCTGTTTGAGAACACCAACCATACACAGGTGCAGTCCACCCTCCTGGCTTTGGCCAGCATGGCGAAGA CGAAAGGAAACAAGGTGAACGTGGGAGTGAAGTACGCAGAGAAGCAGGAGCGGAAATTCGAGCCGGGGAAGCTAAGAGAAGGGCGGAACA TCATTGGGCTGCAGATGGGCACCAACAAGTTTGCCAGCCAGCAGGGCATGACGGCCTATGGCACCCGGCGCCACCTCTACGACCCCAAGC TGGGCACAGACCAGCCTCTGGACCAGGCGACCATCAGCCTGCAGATGGGCACCAACAAAGGAGCCAGCCAGGCTGGCATGACTGCGCCAG GGACCAAGCGGCAGATCTTCGAGCCGGGGCTGGGCATGGAGCACTGCGACACGCTCAATGTCAGCCTGCAGATGGGCAGCAACAAGGGCG CCTCGCAGCGGGGCATGACGGTGTATGGGCTGCCACGCCAGGTCTACGACCCCAAGTACTGTCTGACTCCCGAGTACCCAGAGCTGGGTG AGCCCGCCCACAACCACCACGCACACAACTACTACAATTCCGCCTAGGGCCACAAGGCCTTCCCTGTTTTCCCCCCAAGGGAGGCTGCTG CTGCTCTTGGCTGGACCCAGCCAGGCCCAGCCGACCCCCTCTCCCTGCATGGCATCCTCCAGCCCCTGTAGAACTCAACCTCTACAGGGT TAGAGTTTGGAGAGAGCAGACTGGCGGGGGGCCCATTGGGGGGAAGGGGACCCTCCGCTCTGTAGTGCTACAGGGTCCAACATAGAGCCG GGTGTCCCCAACAGCGCCCAAAGGACGCACTGAGCAACGCTATTCCAGCTGTCCCCCCACTCCCTCACAAGTGGGTACCCCCAGGACCAG AAGCTCCCCCAGCAAAGCCCCCAGAGCCCAGGCTCGGCCTGCCCCCACCCCATTCCCGCAGTGGGAGCAAACTGCATGCCCAGAGACCCA GCGGACACACGCGGTTTGGTTTGCAGCGACTGGCATACTATGTGGATGTGACAGTGGCGTTTGTAATGAGAGCACTTTCTTTTTTTTCTA TTTCACTGGAGCACAATAAATGGCTGTAAAATCTC >23639_23639_5_DNM2-CNN1_DNM2_chr19_10934575_ENST00000408974_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=903AA_BP=396 MGNRGMEELIPLVNKLQDAFSSIGQSCHLDLPQIAVVGGQSAGKSSVLENFVGRDFLPRGSGIVTRRPLILQLIFSKTEHAEFLHCKSKK FTDFDEVRQEIEAETDRVTGTNKGISPVPINLRVYSPHVLNLTLIDLPGITKVPVGDQPPDIEYQIKDMILQFISRESSLILAVTPANMD LANSDALKLAKEVDPQGLRTIGVITKLDLMDEGTDARDVLENKLLPLRRGYIGVVNRSQKDIEGKKDIRAALAAERKFFLSHPAYRHMAD RMGTPHLQKTLNQQLTNHIRESLPALRSKLQSQLLSLEKEVEEYKNFRPDDPTRKTKALLQMVQQFGVDFEKRIEGSGDQVDTLELSGGA RINRIFHERFPFELVKMEFDEKDLRREISYAIKNIHGVRTGLFTPDMAFEAIVKKQIVKLKEPSLKCVDLVVSELATVIKKCAEKLSSYP RLREETERIVTTYIREREGRTKDQILLLIDIEQSYINTNHEDFIGFANAQQRSTQLNKKRAIPNQVIRRGWLTINNISLMKGGSKEYWFV LTAESLSWYKDEEEKEKKYMLPLDNLKIRDVEKGFMSNKHVFAIFNTEQRNVYKDLRQIELACDSQEDVDSWKASFLRAGVYPEKDQLAQ KYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEANDLFEN TNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLDQATI SLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSLQMGSNKGASQRGMTVYGLPRQVYDPKYCLTPEYPELGEPAHNHHAHNYY NSA -------------------------------------------------------------- >23639_23639_6_DNM2-CNN1_DNM2_chr19_10934575_ENST00000585892_CNN1_chr19_11651891_ENST00000252456_length(transcript)=3416nt_BP=2057nt GAGAACCGGATGAGGCGGCGACCGTGAGGCCGAGCCGGGAGCGGGCGTCTTGCCGAGGCCCGGGCGGGCGGGGAGCAACGGCTACAGACG CCGCGGGGCCAGGTCGTTGAGGGTCGGCGGCGGGCGAGGAGCGCAGGGCGCTCGGGCCGGGGGCCGCCGGCGCCATGGGCAACCGCGGGA TGGAAGAGCTGATCCCGCTGGTCAACAAACTGCAGGACGCCTTCAGCTCCATCGGCCAGAGCTGCCACCTGGACCTGCCGCAGATCGCTG TAGTGGGCGGCCAGAGCGCCGGCAAGAGCTCGGTGCTGGAGAACTTCGTGGGCCGGGACTTCCTTCCCCGCGGTTCAGGAATCGTCACCC GGCGGCCTCTCATTCTGCAGCTCATCTTCTCAAAAACAGAACATGCCGAGTTTTTGCACTGCAAGTCCAAAAAGTTTACAGACTTTGATG AAGTCCGGCAGGAGATTGAAGCAGAGACCGACAGGGTCACGGGGACCAACAAAGGCATCTCCCCAGTGCCCATCAACCTTCGAGTCTACT CGCCACACGTGTTGAACTTGACCCTCATCGACCTCCCGGGTATCACCAAGGTGCCTGTGGGCGACCAGCCTCCAGACATCGAGTACCAGA TCAAGGACATGATCCTGCAGTTCATCAGCCGGGAGAGCAGCCTCATTCTGGCTGTCACGCCCGCCAACATGGACCTGGCCAACTCCGACG CCCTCAAGCTGGCCAAGGAAGTCGATCCCCAAGGCCTACGGACCATCGGTGTCATCACCAAGCTTGACCTGATGGACGAGGGCACCGACG CCAGGGACGTCTTGGAGAACAAGTTGCTCCCGTTGAGAAGAGGCTACATTGGCGTGGTGAACCGCAGCCAGAAGGATATTGAGGGCAAGA AGGACATCCGTGCAGCACTGGCAGCTGAGAGGAAGTTCTTCCTCTCCCACCCGGCCTACCGGCACATGGCCGACCGCATGGGCACGCCAC ATCTGCAGAAGACGCTGAATCAGCAACTGACCAACCACATCCGGGAGTCGCTGCCGGCCCTACGTAGCAAACTACAGAGCCAGCTGCTGT CCCTGGAGAAGGAGGTGGAGGAGTACAAGAACTTTCGGCCCGACGACCCCACCCGCAAAACCAAAGCCCTGCTGCAGATGGTCCAGCAGT TTGGGGTGGATTTTGAGAAGAGGATCGAGGGCTCAGGAGATCAGGTGGACACTCTGGAGCTCTCCGGGGGCGCCCGAATCAATCGCATCT TCCACGAGCGGTTCCCATTTGAGCTGGTGAAGATGGAGTTTGACGAGAAGGACTTACGACGGGAGATCAGCTATGCCATTAAGAACATCC ATGGAGTCAGGACCGGGCTTTTCACCCCGGACTTGGCATTCGAGGCCATTGTGAAAAAGCAGGTCGTCAAGCTGAAAGAGCCCTGTCTGA AATGTGTCGACCTGGTTATCCAGGAGCTAATCAATACAGTTAGGCAGTGTACCAGTAAGCTCAGTTCCTACCCCCGGTTGCGAGAGGAGA CAGAGCGAATCGTCACCACTTACATCCGGGAACGGGAGGGGAGAACGAAGGACCAGATTCTTCTGCTGATCGACATTGAGCAGTCCTACA TCAACACGAACCATGAGGACTTCATCGGGTTTGCCAATGCCCAGCAGAGGAGCACGCAGCTGAACAAGAAGAGAGCCATCCCCAATCAGG GGGAGATCCTGGTGATCCGCAGGGGCTGGCTGACCATCAACAACATCAGCCTGATGAAAGGCGGCTCCAAGGAGTACTGGTTTGTGCTGA CTGCCGAGTCACTGTCCTGGTACAAGGATGAGGAGGAGAAAGAGAAGAAGTACATGCTGCCTCTGGACAACCTCAAGATCCGTGATGTGG AGAAGGGCTTCATGTCCAACAAGCACGTCTTCGCCATCTTCAACACGGAGCAGAGAAACGTCTACAAGGACCTGCGGCAGATCGAGCTGG CCTGTGACTCCCAGGAAGACGTGGACAGCTGGAAGGCCTCGTTCCTCCGAGCTGGCGTCTACCCCGAGAAGGACCAGCTGGCCCAGAAGT ATGACCACCAGCGGGAGCAGGAGCTGAGAGAGTGGATCGAGGGGGTGACAGGCCGTCGCATCGGCAACAACTTCATGGACGGCCTCAAAG ATGGCATCATTCTTTGCGAATTCATCAATAAGCTGCAGCCAGGCTCCGTGAAGAAGATCAATGAGTCAACCCAAAATTGGCACCAGCTGG AGAACATCGGCAACTTCATCAAGGCCATCACCAAGTATGGGGTGAAGCCCCACGACATTTTTGAGGCCAACGACCTGTTTGAGAACACCA ACCATACACAGGTGCAGTCCACCCTCCTGGCTTTGGCCAGCATGGCGAAGACGAAAGGAAACAAGGTGAACGTGGGAGTGAAGTACGCAG AGAAGCAGGAGCGGAAATTCGAGCCGGGGAAGCTAAGAGAAGGGCGGAACATCATTGGGCTGCAGATGGGCACCAACAAGTTTGCCAGCC AGCAGGGCATGACGGCCTATGGCACCCGGCGCCACCTCTACGACCCCAAGCTGGGCACAGACCAGCCTCTGGACCAGGCGACCATCAGCC TGCAGATGGGCACCAACAAAGGAGCCAGCCAGGCTGGCATGACTGCGCCAGGGACCAAGCGGCAGATCTTCGAGCCGGGGCTGGGCATGG AGCACTGCGACACGCTCAATGTCAGCCTGCAGATGGGCAGCAACAAGGGCGCCTCGCAGCGGGGCATGACGGTGTATGGGCTGCCACGCC AGGTCTACGACCCCAAGTACTGTCTGACTCCCGAGTACCCAGAGCTGGGTGAGCCCGCCCACAACCACCACGCACACAACTACTACAATT CCGCCTAGGGCCACAAGGCCTTCCCTGTTTTCCCCCCAAGGGAGGCTGCTGCTGCTCTTGGCTGGACCCAGCCAGGCCCAGCCGACCCCC TCTCCCTGCATGGCATCCTCCAGCCCCTGTAGAACTCAACCTCTACAGGGTTAGAGTTTGGAGAGAGCAGACTGGCGGGGGGCCCATTGG GGGGAAGGGGACCCTCCGCTCTGTAGTGCTACAGGGTCCAACATAGAGCCGGGTGTCCCCAACAGCGCCCAAAGGACGCACTGAGCAACG CTATTCCAGCTGTCCCCCCACTCCCTCACAAGTGGGTACCCCCAGGACCAGAAGCTCCCCCAGCAAAGCCCCCAGAGCCCAGGCTCGGCC TGCCCCCACCCCATTCCCGCAGTGGGAGCAAACTGCATGCCCAGAGACCCAGCGGACACACGCGGTTTGGTTTGCAGCGACTGGCATACT ATGTGGATGTGACAGTGGCGTTTGTAATGAGAGCACTTTCTTTTTTTTCTATTTCACTGGAGCACAATAAATGGCTGTAAAATCTC >23639_23639_6_DNM2-CNN1_DNM2_chr19_10934575_ENST00000585892_CNN1_chr19_11651891_ENST00000252456_length(amino acids)=907AA_BP=398 MGNRGMEELIPLVNKLQDAFSSIGQSCHLDLPQIAVVGGQSAGKSSVLENFVGRDFLPRGSGIVTRRPLILQLIFSKTEHAEFLHCKSKK FTDFDEVRQEIEAETDRVTGTNKGISPVPINLRVYSPHVLNLTLIDLPGITKVPVGDQPPDIEYQIKDMILQFISRESSLILAVTPANMD LANSDALKLAKEVDPQGLRTIGVITKLDLMDEGTDARDVLENKLLPLRRGYIGVVNRSQKDIEGKKDIRAALAAERKFFLSHPAYRHMAD RMGTPHLQKTLNQQLTNHIRESLPALRSKLQSQLLSLEKEVEEYKNFRPDDPTRKTKALLQMVQQFGVDFEKRIEGSGDQVDTLELSGGA RINRIFHERFPFELVKMEFDEKDLRREISYAIKNIHGVRTGLFTPDLAFEAIVKKQVVKLKEPCLKCVDLVIQELINTVRQCTSKLSSYP RLREETERIVTTYIREREGRTKDQILLLIDIEQSYINTNHEDFIGFANAQQRSTQLNKKRAIPNQGEILVIRRGWLTINNISLMKGGSKE YWFVLTAESLSWYKDEEEKEKKYMLPLDNLKIRDVEKGFMSNKHVFAIFNTEQRNVYKDLRQIELACDSQEDVDSWKASFLRAGVYPEKD QLAQKYDHQREQELREWIEGVTGRRIGNNFMDGLKDGIILCEFINKLQPGSVKKINESTQNWHQLENIGNFIKAITKYGVKPHDIFEAND LFENTNHTQVQSTLLALASMAKTKGNKVNVGVKYAEKQERKFEPGKLREGRNIIGLQMGTNKFASQQGMTAYGTRRHLYDPKLGTDQPLD QATISLQMGTNKGASQAGMTAPGTKRQIFEPGLGMEHCDTLNVSLQMGSNKGASQRGMTVYGLPRQVYDPKYCLTPEYPELGEPAHNHHA HNYYNSA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DNM2-CNN1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DNM2-CNN1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DNM2-CNN1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | DNM2 | C4551952 | Myopathy, Centronuclear, 1 | 13 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Hgene | DNM2 | C1847902 | CHARCOT-MARIE-TOOTH DISEASE, DOMINANT INTERMEDIATE B (disorder) | 8 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | DNM2 | C1834558 | Myopathy, Centronuclear, Autosomal Dominant | 7 | CLINGEN;CTD_human;ORPHANET |
| Hgene | DNM2 | C0175709 | Centronuclear myopathy | 2 | CTD_human;GENOMICS_ENGLAND |
| Hgene | DNM2 | C3809272 | LETHAL CONGENITAL CONTRACTURE SYNDROME 5 | 2 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | DNM2 | C0410203 | X-linked centronuclear myopathy | 1 | CTD_human |
| Hgene | DNM2 | C0410207 | Tubular Aggregate Myopathy | 1 | CTD_human |
| Hgene | DNM2 | C0546264 | Congenital Fiber Type Disproportion | 1 | CTD_human |
| Hgene | DNM2 | C0752282 | Congenital Structural Myopathy | 1 | CTD_human |
| Hgene | DNM2 | C3645536 | Autosomal Recessive Centronuclear Myopathy | 1 | CTD_human |
| Hgene | DNM2 | C3661489 | Autosomal Dominant Myotubular Myopathy | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies